
Figure 3.
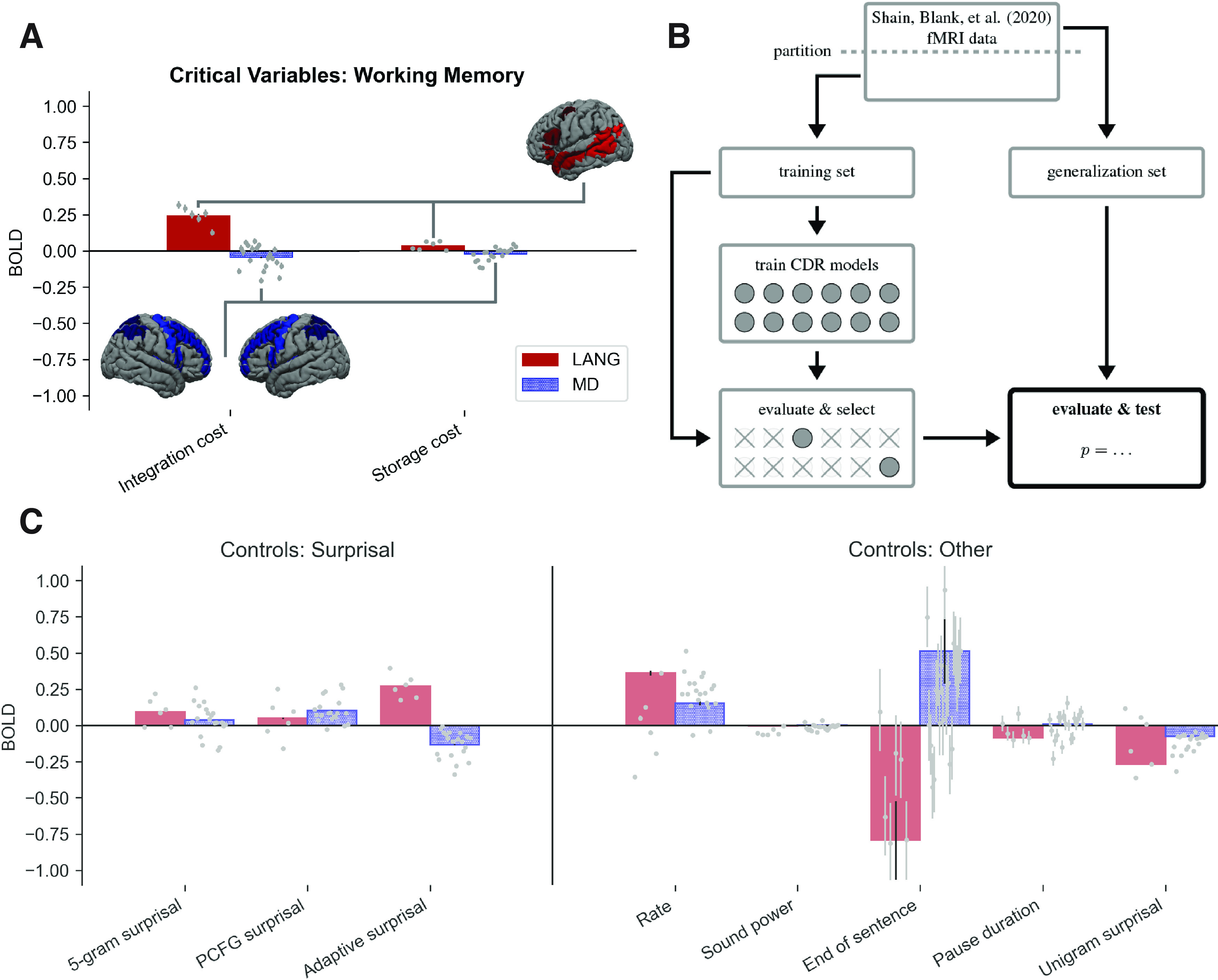
A, C, The critical working memory result (A), with reference estimates for surprisal variables and other controls shown in C. The LANG network shows a large positive estimate for integration cost (DLT-VCM, comparable to or larger than the surprisal effect) and a weak positive estimate for storage (DLT-S). The MD network estimates for both variables are weakly negative. fROIs individually replicate the critical DLT pattern and are plotted as points left-to-right in the following order (individual subplots by fROI are available on OSF: https://osf.io/ah429/): LANG: LIFGorb, LIFG, LMFG, LAntTemp, LPostTemp, LAngG; MD: LMFGorb, LMFG, LSFG, LIFGop, LPrecG, LmPFC, LInsula, LAntPar, LMidPar, LPostPar, RMFGorb, RMFG, RSFG, RIFGop, RPrecG, RmPFC, RInsula, RAntPar, RMidPar, and RpostPar (where L is left, R is right). (Note that estimates for the surprisal controls differ from those reported in the study by Shain et al. (2020). This is because models contain additional controls, especially adaptive surprisal, which overlaps with both of the other surprisal estimates and competes with them for variance. Surprisal effects are not tested because they are not relevant to our core claim.) Error bars show 95% Monte Carlo estimated variational Bayesian credible intervals. For reference, the group masks bounding the extent of the LANG and MD fROIs are shown projected onto the cortical surface. As explained in Materials and Methods, a small subset (10%) of voxels within each of these masks is selected in each participant based on the relevant localizer contrast. B, Schematic of analysis pipeline. fMRI data from the Study by Shain et al. (2020) are partitioned into training and generalization sets. The training set is used to train multiple CDR models, two for each of the memory variables explored in this study (a full model that contains the variable as a fixed effect and an ablated model that lacks it). Variables whose full model (1) contains estimates that go in the predicted direction and (2) significantly outperforms the ablated model on the training set are selected for the critical evaluation, which deploys the pretrained models to predict unseen responses in the generalization set and statistically evaluates the contribution of the selected variable to generalization performance.