
FIG. 6.
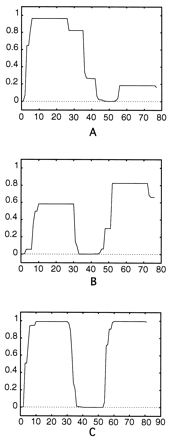
Coiled-coil prediction in the consensus sequence for the repeats of Emb (A), EF* (B), and the uncharacterized protein of S. pyogenes (C). The consensus sequence for the various repeats was analyzed with COILS 2.2 to predict the probability that they could assume a coiled-coil conformation. The amino acids number is shown on the x axis; the probability that a region might assume a coiled-coil conformation is shown on the y axis. The calculation was done with the MTIDK matrix, considering a 21-residue scanning window (13).