
Figure 3. A CRISPR base editor screen for protein abundance.
(A) Schematic overview of the screen. (B) Network representing all identified gene-protein relationships. In yellow are the eleven proteins and in blue-red are all the gene perturbations that affect at least one of the proteins significantly (FDR<0.05). On the outer circle are gene perturbations that affect only a single protein, whereas on the inside are those that affect two or more proteins. Node sizes correlate with the number of proteins affected. Colors indicate whether a perturbation (predominantly) increases (red) or decreases (blue) the protein(s). The figure was created with Cytoscape (Shannon et al., 2003). (C) For each protein, the number of gene perturbations that cause a significant increase (positive vertical axis) or decrease (negative vertical axis) (FDR<0.05). The darker shade indicates gene perturbations that affect only one or two of the eleven proteins (‘specific’), whereas the lighter shade indicates gene perturbations that affect three or more of the eleven proteins (‘nonspecific’). (D) Same as in (C) but the darker shade indicates perturbations of essential genes, whereas the lighter shade indicates perturbations of nonessential genes. (E) Same as in (C) but the different shades reflect different types of expected mutations introduced by the particular gRNA. (F) Effect sizes (log2 fold changes) of gRNAs that cause a significant change in protein abundance grouped by the type of expected mutation introduced by each gRNA (FDR<0.05).

Figure 3—figure supplement 1. Correlation between replicates and among gRNAs targeting the same mutation.

Figure 3—figure supplement 2. Correlation between the effect of genetic perturbations on mRNA and protein abundances.
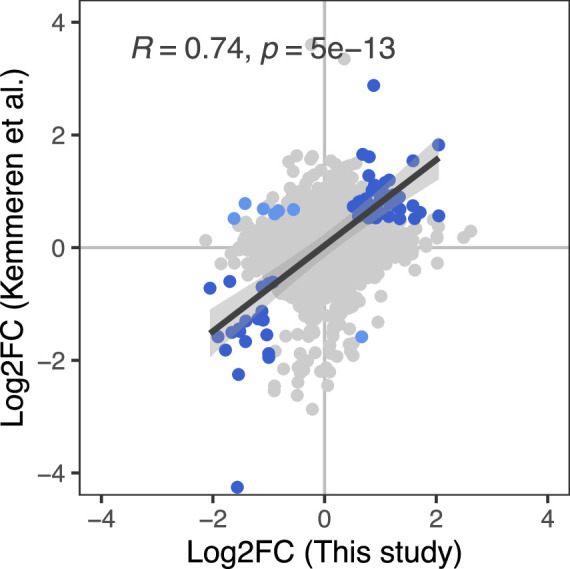
Figure 3—figure supplement 3. Correlation between the number of gene perturbations significantly affecting a protein and the absolute abundance of that protein.

Figure 3—figure supplement 4. Correlation between number and effect size of perturbations with significant effects and their target site across the gene.
