

Abstract
We propose neural network layers that explicitly combine frequency and image feature representations and show that they can be used as a versatile building block for reconstruction from frequency space data. Our work is motivated by the challenges arising in MRI acquisition where the signal is a corrupted Fourier transform of the desired image. The proposed joint learning schemes enable both correction of artifacts native to the frequency space and manipulation of image space representations to reconstruct coherent image structures at every layer of the network. This is in contrast to most current deep learning approaches for image reconstruction that treat frequency and image space features separately and often operate exclusively in one of the two spaces. We demonstrate the advantages of joint convolutional learning for a variety of tasks, including motion correction, denoising, reconstruction from undersampled acquisitions, and combined undersampling and motion correction on simulated and real world multicoil MRI data. The joint models produce consistently high quality output images across all tasks and datasets. When integrated into a state of the art unrolled optimization network with physics-inspired data consistency constraints for undersampled reconstruction, the proposed architectures significantly improve the optimization landscape, which yields an order of magnitude reduction of training time. This result suggests that joint representations are particularly well suited for MRI signals in deep learning networks. Our code and pretrained models are publicly available at https://github.com/nalinimsingh/interlacer.
1. Introduction
Magnetic resonance imaging (MRI) (Lauterbur, 1973) acquires frequency space data and converts these measurements to images for visualization and downstream analysis. Practical imaging considerations often affect the data acquisition process. For example, motion occurs during acquisition (Andre et al., 2015), noise affects sensor readings (Macovski, 1996), and sub-Nyquist undersampling is routinely used to speed up data acquisition (Lustig et al., 2008). Traditionally, the acquired frequency space signals are converted to image space reconstructions via an inverse Fourier transform, with each individual frequency space measurement contributing to all output pixels in the image space. As a result, local changes in the acquired frequency space data induce global effects on the entire output image. To produce accurate image reconstructions, modeling tools for Fourier imaging must correct these global artifacts in addition to performing fine-scale image space processing.
Recently, neural networks have emerged as an alternative approach for MRI reconstruction (Aggarwal et al., 2018; Hammernik et al., 2018; Hyun et al., 2018; Lee et al., 2017; Putzky and Welling, 2019; Quan et al., 2018; Schlemper et al., 2017; Sun et al., 2016; Yang et al., 2017; Aggarwal et al., 2018; Hammernik et al., 2018; Cheng et al., 2018; Han et al., 2019; Zhu et al., 2018; Duffy et al., 2021; Haskell et al., 2019; Johnson and Drangova, 2019; Küstner et al., 2019; Pawar et al., 2018; Shaw et al., 2020; Oksuz et al., 2019; Usman et al., 2020; Benou et al., 2017; Jiang et al., 2018; Manjón and Coupe, 2018). Most existing architectures are based on purely frequency space representations or purely image space representations. Here, we propose and demonstrate joint frequency-image space representations that enable networks to learn a wide set of tasks including and beyond the extensively studied undersampled reconstruction. To motivate our approach, we examine the correlation structure for frequency and image space representations in Fig. 1. Local neighborhoods around a pixel exhibit strong correlations, suggesting that local convolution operations, which are widely successful on image space computer vision tasks, might also be useful when applied to frequency space data to capture this local structure. Convolutional operations in frequency space promise to enable direct correction of local frequency space artifacts corresponding to global image space effects, while convolutional image space processing facilitates complementary correction of artifacts that are best captured in the image domain.
Figure 1:
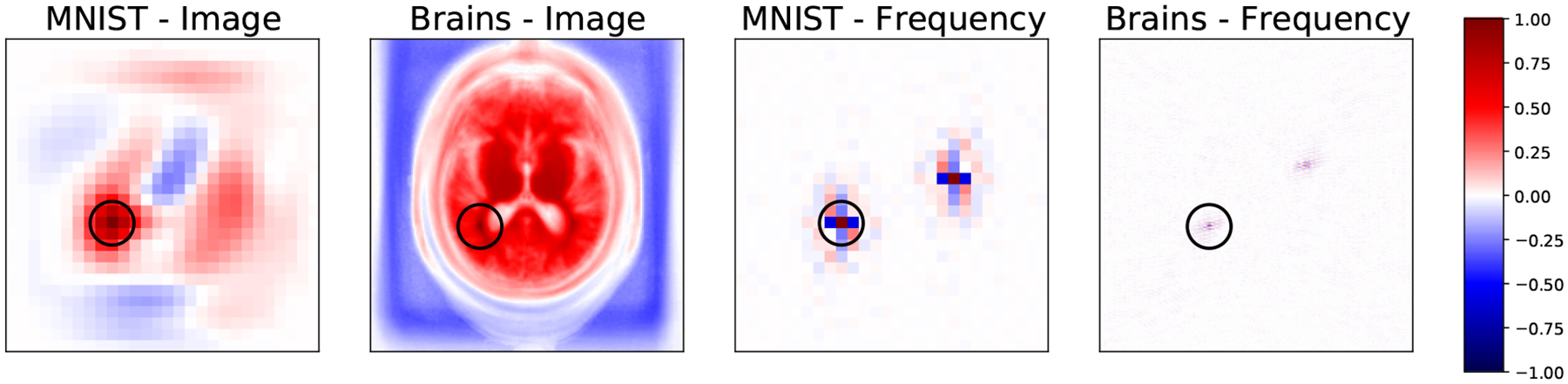
Maps of correlation coefficients between a single pixel (center of circle) and all other pixels in image (left two panels) and frequency space (right two panels) representations of MNIST and a brain MRI dataset. All maps show strong local correlations useful for inferring missing or corrupted data in both spaces. Frequency space correlations also display conjugate symmetry characteristic of Fourier transforms of real images.
1.1. Prior Work
We study joint representations in the context of three corruption processes that arise during the imaging process.
Motion.
Previous retrospective motion correction strategies (Batchelor et al., 2005; Haskell et al., 2018) are cast as large, non-convex optimization problems with iterative solutions that are slow to compute. Deep learning methods (Duffy et al., 2021; Haskell et al., 2019; Johnson and Drangova, 2019; Küstner et al., 2019; Pawar et al., 2018; Shaw et al., 2020; Usman et al., 2020) solve the motion correction problem with a neural network operating purely in the image space, even though motion artifacts are induced directly in the frequency space during data acquisition. An alternative approach has been demonstrated recently that detects motion directly on frequency space data, followed by motion correction via an image space network (Oksuz et al., 2019).
Noise.
Previous work on MRI denoising applies classical signal processing techniques including filtering (Manjón et al., 2008) and wavelet-based methods (Anand and Sahambi, 2010; Nowak, 1999). Deep learning methods employ convolutional networks solely on image space data (Benou et al., 2017; Jiang et al., 2018; Manjón and Coupe, 2018).
Undersampling.
Classical undersampled reconstruction techniques either construct the output image as a least-squares estimate from the acquired frequency space data (Pruessmann et al., 1999) or combine convolutional filters in the frequency space with an inverse Fourier transform (Griswold et al., 2002; Lustig and Pauly, 2010). Many deep learning methods apply convolutions to image space reconstructions of the acquired undersampled frequency data (Aggarwal et al., 2018; Hammernik et al., 2018; Hyun et al., 2018; Lee et al., 2017; Putzky and Welling, 2019; Quan et al., 2018; Schlemper et al., 2017; Sun et al., 2016; Yang et al., 2017). To improve the quality and fidelity of the reconstruction, the convolutional layers can be combined into an architecture that emulates unrolled optimization, with a convolutional regularizer coupled with a physics-inspired data consistency constraint that is enforced after each iteration (Aggarwal et al., 2018; Hammernik et al., 2018). Alternatively, the convolutional architectures can act directly on the frequency space data (Akçakaya et al., 2019; Cheng et al., 2018; Han et al., 2019). The notably different AUTOMAP architecture uses fully-connected layers to convert frequency space data to the image space and then applies further image space convolutions (Zhu et al., 2018), incurring prohibitive memory complexity of 𝒪(N4) for a N × N image.
More recently, solutions that combine frequency and image space convolutions have been demonstrated in the context of undersampled reconstruction. One approach is to combine separately trained pure frequency and pure image space networks into a common architecture (Eo et al., 2018; Souza and Frayne, 2019; Wang et al., 2019). The most closely related work to ours integrates frequency and image space blocks within the same network (Zhou and Zhou, 2020), effectively implementing one of the two variants we consider in this paper. Here we propose an additional layer architecture that also tightly couples frequency and image space representations and evaluate both variants on a wide variety of tasks, well beyond the undersampled reconstruction scenario for which the previously combined architectures have been proposed.
In our experiments, a basic network that simply concatenates joint layers outperforms its pure frequency and image counterparts across a large set of artifacts and reconstruction quality metrics. To investigate how the joint layer architecture interacts with the data consistency constraints often used in undersampled reconstruction, we train the basic network with such a constraint and observe that it compares favorably with the state of the art task-specific undersampled reconstruction networks (Eo et al., 2018; Schlemper et al., 2017) that also incorporate a data consistency constraint. Moreover, we probe the relationship between the proposed joint layers and the widely used unrolled optimization architectures by replacing image convolutional layers with our joint layers in a state of the art unrolled optimization network, MoDL (Aggarwal et al., 2018). Using the proposed joint layers improves the training landscape and reduces training time by about an order of magnitude.
To summarize, our contributions are as follows:
We define two task-independent convolutional layer architectures that tightly couple frequency and image representations of an input image that can be used in conjunction with unrolled optimization, data consistency constraints, and other sophisticated strategies for building and training reconstruction neural networks.
We demonstrate in simulation experiments that joint networks outperform pure image or pure frequency space networks for reconstructing high quality images in the presence of (i) extreme motion, (ii) heavy noise, and (iii) combination of artifacts, such as motion and undersampling.
We demonstrate that the proposed joint learning strategy is compatible with a data consistency constraint and performs favorably relative to state-of-the-art networks specifically designed for the undersampled reconstruction task.
We demonstrate on complex-valued, multicoil, real world data that incorporating joint layers into unrolled optimization networks results in more effective training and an order of magnitude decrease of training time, suggesting that the proposed architectures are particularly well suited for image representation in MRI reconstruction networks.
This paper is organized as follows. In the next section, we define the proposed layer and network architectures. Section 3 provides the implementation details and describes our ablation studies. Section 4 reports experimental results, followed by the discussion of the proposed layers, their limitations, and conclusions in Section 5.
2. Joint Networks
MRI acquires Fourier transform measurements, referred to as k-space data. We assume a 2D multislice MRI acquisition. For each slice in this setup, the goal of image reconstruction is to generate an image I from the acquired Fourier transform measurements F = ℱ{I}. Classically, this reconstruction is computed via a 2D inverse Fourier transform, producing an estimated image . In practice, corrupted and possibly undersampled measurements are acquired instead of F, and the goal is to estimate the desired image I from the corrupted signal . Many strategies exist for selecting which measurements to acquire in frequency space. Here we consider Cartesian sampling, where measurement coordinates kx and ky are evenly sampled across the 2D Fourier plane, but our method can be generalized to other acquisition schemes. In this section, we define two neural network layer variants that combine image and frequency space convolutional features, referred to as Interleaved and Alternating, specify the network architectures, and describe the learning procedure.
2.1. Joint Layer Structures
Fig. 2 illustrates the layer structures of the two joint networks. We use un to denote the frequency space input and vn to denote the image space input of layer n. Thus, and v0 = ℱ−1{u0} represent the frequency space and image space inputs to the network.
Figure 2:
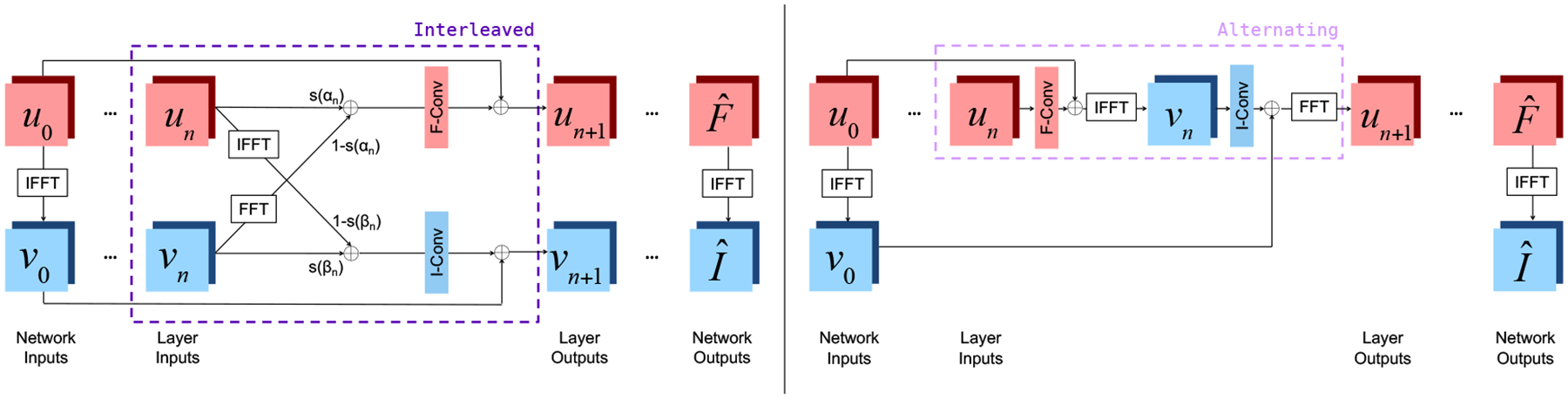
The Interleaved (left) and Alternating (right) layers, embedded within full network architectures. Each ‘F-Conv’ or ‘I-Conv’ block applies Batch Normalization (BN), a convolution, and an activation function in the frequency or image space, respectively.
In the Interleaved setup, layer inputs are combined via learned, layer-specific mixing parameters αn and βn that parameterize the sigmoid function s(x) = (1+e−x)−1 to constrain the mixing coefficients to (0,1):
| (1) |
Real and imaginary parts of inputs are represented as separate channels at each layer and are joined appropriately to form complex numbers when computing the Fourier transform ℱ {·} or its inverse. Next, the layer applies batch normalization (BN), a convolution, and an activation function with a skip connection to produce the outputs:
| (2) |
where (wn, bn) are learned frequency space convolution weights and biases, are learned image space convolution weights and biases, and σ(·) and σ′(·) are activation functions specific to the frequency space and image space network components, described later in this section.
This layer architecture is a generalization of networks that operate purely in frequency space, obtained by choosing s(αn) = 1 and s(βn) = 0, and of networks that operate purely in image space, that arise when s(αn) = 0 and s(βn) = 1. When 0 < s(αn) < 1 and 0 < s(βn) < 1, this layer represents a function that cannot be expressed solely via pure image or frequency space convolutional layers that do not invoke the Fourier transform or its inverse. Note that the frequency output un of layer n is not required to be the Fourier transform of the layer’s image output vn, only that the mixing is applied to either two frequency space outputs or two image space outputs. This additional flexibility ensures that un and vn are not entirely redundant and the network learns the right features to capture MRI structure based on the input data and the task at hand.
In the Alternating setup, each layer sequentially incorporates frequency and image space convolutions with the appropriate batch normalization and activation function:
| (3) |
i.e., the reconstruction alternates between convolutions in the frequency and image space. A version of this architecture was previously introduced as part of a task-specific network for undersampled reconstruction (Zhou and Zhou, 2020).
For both joint architectures, the frequency space convolutions represent element-wise multiplications in the image space. Since the convolution kernels have limited width, the learned convolutions cannot represent all such element-wise multiplications, but instead parameterize the subset whose 2D Fourier transform is zero outside of a central region. Coupled with nonlinearities in the frequency space, these operations enable the network to use global, spatially varying operations not captured by image space convolutions.
Although both of these layers explicitly include the Fourier transform and its inverse, no parameters are associated with those transforms. Thus, we learn only convolutional weights, biases, and possibly mixing coefficients. Since our networks incorporate Fourier transforms, they have an overall 𝒪(N2 logN) space complexity for N × N images.
2.2. Activation Functions
Adopting the standard practice of using the ReLU nonlinearity for image data, we define σ′(x) = ReLU(x) for all convolutions in the image space. This operation is applied separately to real and imaginary channels of each image space convolution output (Trabelsi et al, 2018). However, the zero-gradient of this nonlinearity for negative values is ill-suited for networks that operate on frequency space data, as individual inputs can take on a large range of positive and negative values. We introduce an alternative nonlinear activation function that we apply to both the real and imaginary channels of each frequency space convolution output:
| (4) |
This nonlinearity’s magnitude increases with that of the input everywhere, while preserving the distinction between positive and negative inputs. We found that networks using this nonlinearity consistently outperformed networks that employed ReLU activation functions on frequency space convolution outputs.
2.3. Learning
The networks evaluated in this paper can be trained with any differentiable loss function ℒ. In our experiments, we investigate a wide variety of loss functions. We train the joint network f(·; θf, θi) for image reconstruction by optimizing a set of frequency space parameters θf and a set of image space parameters θi over the training dataset using stochastic gradient descent-based strategies to obtain
| (5) |
where θf and θi depend on the setup of the joint layer.
3. Implementation Details and Ablation Architectures
We construct each joint network to contain 10 joint frequency and image space layers. We performed a hyperparameter sweep and observed that the accuracy of reconstruction on the validation set stopped improving for networks that included more than 10 joint layers. A single 2D convolutional layer acts on the frequency space output u10 of the final joint layer to produce the final 2-channel complex output . The estimated image is the inverse Fourier transform of the network’s output, i.e., . All convolution blocks within both types of joint layers have kernel size 3×3 and 64 output features, resulting in a total of 670,622 parameters for the Interleaved network and 706,438 parameters for the Alternating network.
To evaluate the utility of combined frequency and image space layers as a network building block for manipulating Fourier imaging data, we compare performance of the Interleaved and Alternating architectures to two similarly structured baseline architectures with only frequency or only image space operations.
First, we create an architecture Frequency that performs convolutions only on frequency space data and train the network g(·; θf) to identify frequency space parameters
| (6) |
The network contains 20 convolution layer to match the joint networks’ 10 pairs of 2 convolution layers. As in the Interleaved and Alternating networks, each convolution layer has kernel size 3×3 and 64 output features, followed by the final, two-feature 2D convolutional layer, resulting in 706,438 parameters. This network captures the convolution strategy used in (Akçakaya et al., 2019; Han et al., 2019; Kim et al., 2019), which incorporate frequency space convolutions in the context of other task-specific architectures and loss choices.
We also implement an image space network Image. The network g(·; θi) is trained by optimizing
| (7) |
This network’s architecture is identical to that of Frequency and also contains 706,438 parameters, but it operates on image space data. This network captures the convolution strategy used in prior work that incorporates image space convolutions with task-specific architectures and loss function choices, e.g., unrolled optimization and data consistency constraints (Aggarwal et al., 2018; Hammernik et al., 2018; Haskell et al., 2019; Hyun et al., 2018; Küstner et al., 2019; Lee et al., 2017; Manjón and Coupe, 2018; Pawar et al., 2018; Putzky and Welling, 2019; Quan et al., 2018; Schlemper et al., 2017; Sun et al., 2016; Yang et al., 2017).
We initialize all convolution weights using the He normal initializer (He et al., 2015) and use the Adam optimizer (Kingma and Ba, 2014) (learning rate 0.001) until convergence. We initialize s(α) and s(β) to 0.5. Training each model requires one day on an NVIDIA RTX 2080 Ti GPU. Our code and pre-trained models for each of these networks is available at https://github.com/nalinimsingh/interlacer.
4. Experiments
In this section, we evaluate the proposed joint layers in a set of experiments that progress from simulated data and basic networks to real world complex-valued multicoil MRI measurements and unrolled optimization frameworks with physics-inspired data consistency constraints. The experiments in this section are performed on brain MRIs from multiple datasets. Additional experiments on FastMRI single coil knee MRI, including comparisons with the top methods on FastMRI leaderboard, are provided in Appendix A.
4.1. No Data Consistency
In this section, we present experiments where no data consistency contraint is employed in training our networks. These experiments directly compare the performance of the different layer types described in Sections 2 and 3. These experiments are particularly useful for understanding the relative performance of these methods in settings where direct data consistency may not be desirable because the acquired data is corrupted by an artifact.
Data.
In this experiment, we simulate artifacts of interest in a set of 6,276 T1-weighted brain MRI images from patients aged 55–90 collected as part of the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (Mueller et al., 2005). We select the central 2D axial image of each volume for training and evaluation. To simulate acquired data, we apply the 2D Fourier transform to each image. After simulating the artifacts as described below, we normalize each input and output training pair by dividing by the maximum value in the corrupted image. The k-space data were zero-padded in this dataset during the original image reconstruction process, prior to our simulations. As a result, the quantitative results from these experiments do not represent model performance when deployed on raw, acquired k-space data (Shimron et al., 2022). Instead, these experiments probe the relative performance of competing methods on tasks for which large datasets of raw k-space are not readily available, such as motion correction and denoising. Subsequent experiments with raw, acquired frequency space data that have not been padded demonstrate that the proposed joint layers can also handle non-padded data. We split the dataset into 4,115 training images, 2,061 validation images, and 100 test images such that no subjects are shared across the training, validation, and test sets. Preliminary experiments and hyper-parameters are evaluated on the validation dataset; the test set is only used for computing the performance statistics.
Training Loss and Evaluation Metric.
We train Frequency, Image, Interleaved, and Alternating networks described in Section 3 using L1 loss on the real and imaginary components of the output and employ the SSIM scores (Wang et al., 2004) between the ground truth and reconstructed magnitude images to evaluate the quality of reconstruction on the test set.
4.1.1. Experimental Setup
Motion.
Imaging subjects may move as measurements are being acquired at different points in the Fourier space. In practice, all points within a single line F(·, ky) in frequency space are acquired rapidly together. Thus, it is commonly assumed that no motion occurs during acquisition of a single frequency space line. In this work, we use a rigid-body motion model for motion that occurs between acquisitions of successive lines.
If the imaged subject is affected by a rotation about the origin, a horizontal translation , and a vertical translation during acquisition of line ky, the acquired signal corresponds to the rigidly transformed image
| (8) |
Eq. (8) forms a translated and rotated version of the desired image I. A pure translation without rotation in the image space corresponds to a phase shift in the frequency space:
| (9) |
for a N ×N image. A pure rotation about the center of the image space without translation corresponds to a rotation by the same angle in the frequency space:
| (10) |
To simulate motion artifacts during image acquisition as described in Eq. (8), we sample three motion parameters at various lines in frequency space: a horizontal translation Δx, vertical translation Δy, and rotation ϕ. We report results for the case when the fraction γm of the total number of lines at which motion occurs is 0.03, though the trends in our results hold for several different values of this parameter. We apply the sampled motion parameters to contiguous lines in frequency space between consecutive motion line samples. Translation parameter values are drawn uniformly from the range [−8px, 8px], corresponding to physical translations on the range [−8mm, 8mm]. Rotation parameter values are drawn uniformly from the range [−11°, 11°]. These parameter ranges are chosen to include extreme motion at the upper limit of what might be expected in a typical MRI scan. For a Cartesian, fully-sampled acquisition, the resulting combined frequency space data represents the signal acquired when the imaging subject shifts according to the sampled motion parameters at each of the randomly sampled lines in frequency space.
Noise.
Noisy MRI data can be modeled via an additive i.i.d. complex Gaussian distribution:
| (11) |
where 𝒩(μ, Σ) represents the Gaussian distribution with mean μ and covariance Σ. This noise distribution gives rise to the standard Rician distribution on MRI image space pixel magnitudes (Cárdenas-Blanco et al., 2008).
To simulate noisy acquisitions as described in Eq. (11), we sample pixelwise independent noise from a zero-mean Gaussian distribution. We report results in the case where this noise has standard deviation γn of 10,000, though our observed trends are consistent for both smaller and larger values of this parameter. This value was chosen because it visually results in an aggressive noise corruption on the magnitude image; the average resulting magnitude image has SNR≈1.5.
Undersampling.
To speed up image acquisition, a common approach is to only acquire data at a subset Sy of discrete “lines,” i.e., values of ky ∈ Sy:
| (12) |
We simulate undersampling as described in Eq. (12) with sampling frequency γs = 25% (equivalent to an acceleration factor of 4), where the selected line indices Sy are sampled at random. These lines are selected without a bias toward the low-frequency lines at the center of the Fourier plane of each image, independently of the sampling pattern in all other images. This challenging undersampling pattern measures how well different layer architectures perform under non-traditional acquisition schemes, for example, when using scan-specific acquisition patterns (Bahadir et al., 2020). Our subsequent experiments evaluate the proposed layers with more conventional undersampling schemes. As an aside, the ground truth data in this experiment has conjugate symmetry in the frequency space, so in the hypothetical case of γs=50% with our random sampling scheme it is possible that all of the data required to perfectly reconstruct the image is present in the input. This is impossible for the acceleration factor of γs=25% in this study.
Undersampling with Motion.
Undersampling reduces scan time and thus is commonly used to limit the time during which motion can occur. We analyze the setting where both motion corruption and undersampling occur simultaneously (Fig. 3), forcing the reconstruction algorithms to correct both types of artifacts. As in the pure motion experiments, for each slice, we set the fraction of lines γm = 0.03. For each line affected by motion, we sample three parameters of motion: Δxi, Δyi, and ϕi, corresponding respectively to a horizontal translation, vertical translation, and counterclockwise rotation about the slice origin. We simulate the corresponding motion-corrupted frequency space as described in Eq. (8). We then sample the full center 8% of ky-lines and sample the remainder of the line indices from a uniform distribution to achieve an overall 4x acceleration factor.
Figure 3:
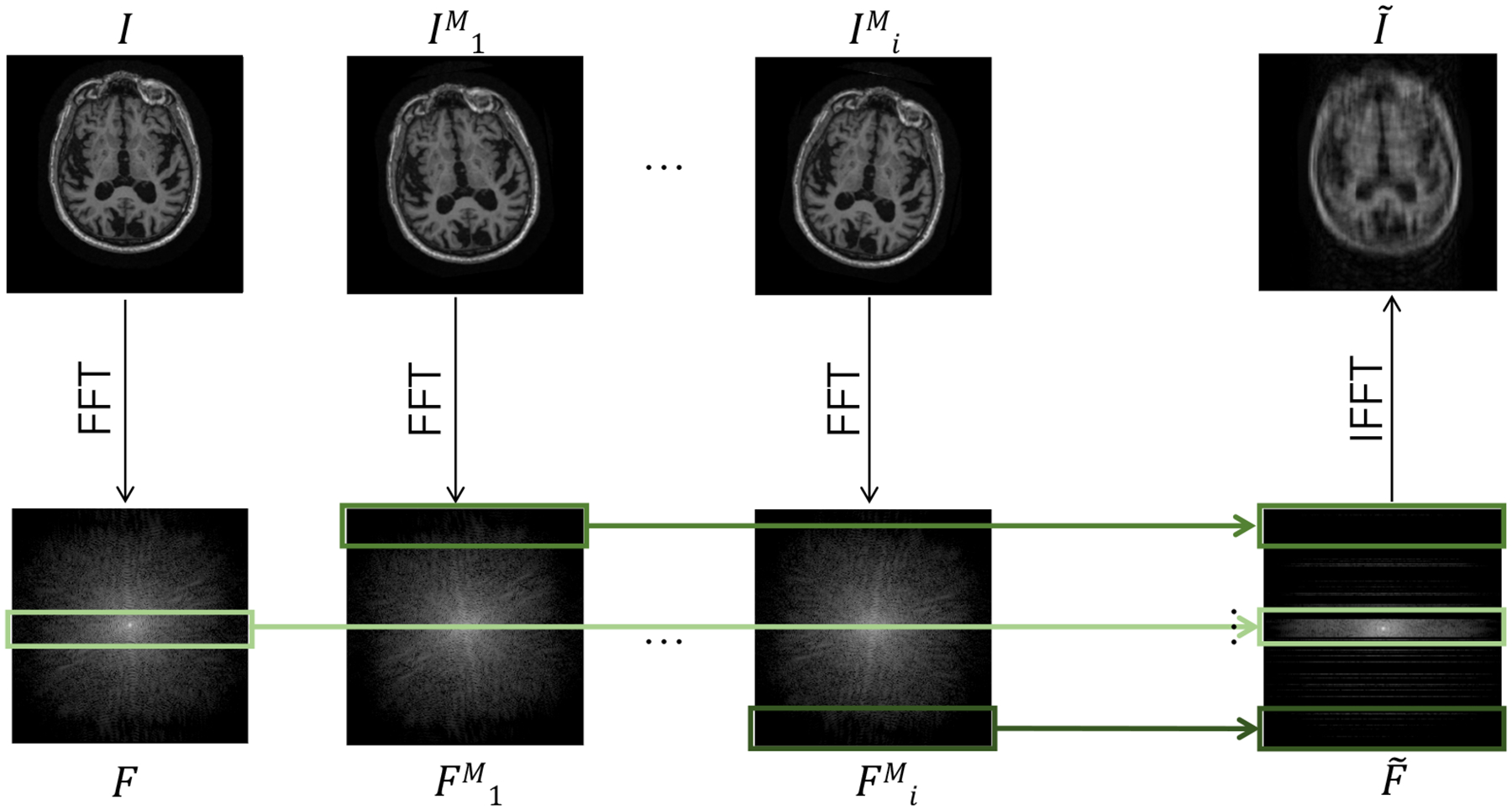
Data generation procedure for undersampling in the presence of motion. At line Li in frequency space, the original image I is rotated and translated to form . Lines from the corresponding Fourier transforms F and are mixed and undersampled to generate motion-corrupted frequency space data that would have been acquired under the illustrated motion pattern. A similar method is used to simulate pure motion corruption without undersampling, where all frequency space lines are maintained to generate .
4.1.2. Results
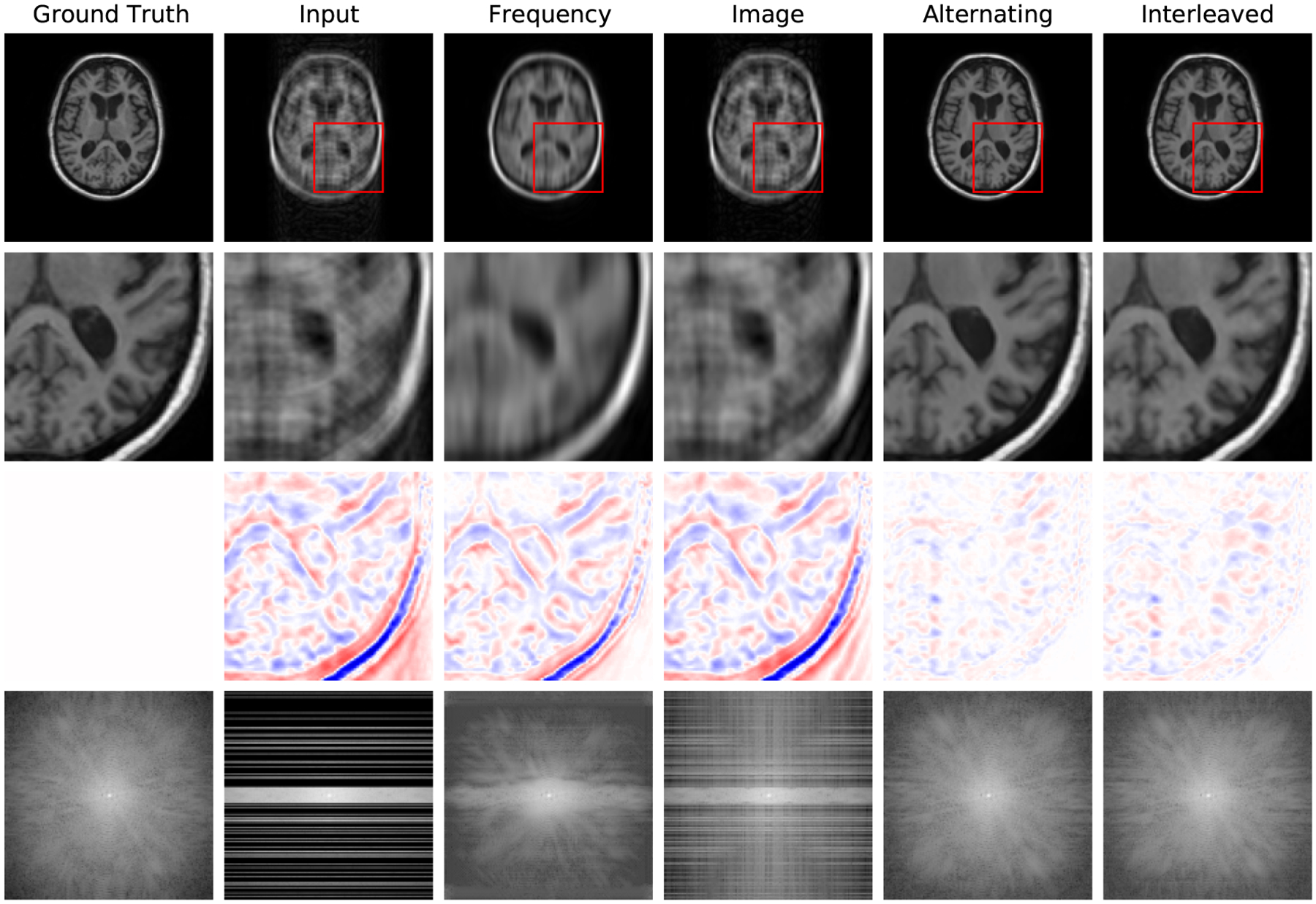
Fig. 4 reports reconstruction quality statistics for all four types of simulations described in Section 4.1.1: motion, noise, undersampling, and motion combined with undersampling. The Interleaved and Alternating architectures outperform the baseline architectures for nearly every task and subject. Across all tasks and nearly all subjects, the Interleaved and Alternating architectures are quite similar in numerical performance. Sample image reconstructions for the motion, motion with undersampling and denoising tasks are shown in Figs. 5–7. Qualitatively, for each task, the Frequency network provides a blurry version of the ground truth image. The Image network provides a reconstruction which effectively removes ‘background’ effects but has limited success in correcting these artifacts within the image. In contrast, the Interleaved and Alternating networks provide sharper, high-quality reconstructions across all tasks. Further, the frequency space reconstructions provided by those networks appear the most faithful to the ground truth frequency data.
Figure 4:
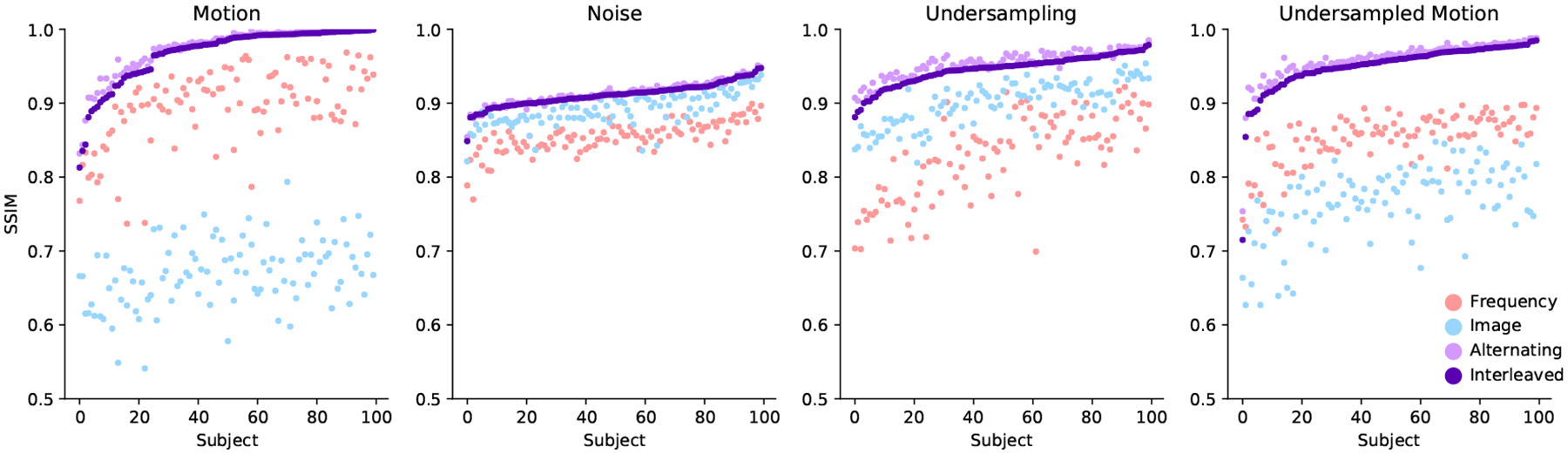
Subjectwise SSIM comparison for all brain MRI tasks without data consistency constraints. Subjects are sorted by performance of the Interleaved network. For all tasks, networks combining frequency and image space convolutions outperform single-domain networks.
Figure 5:
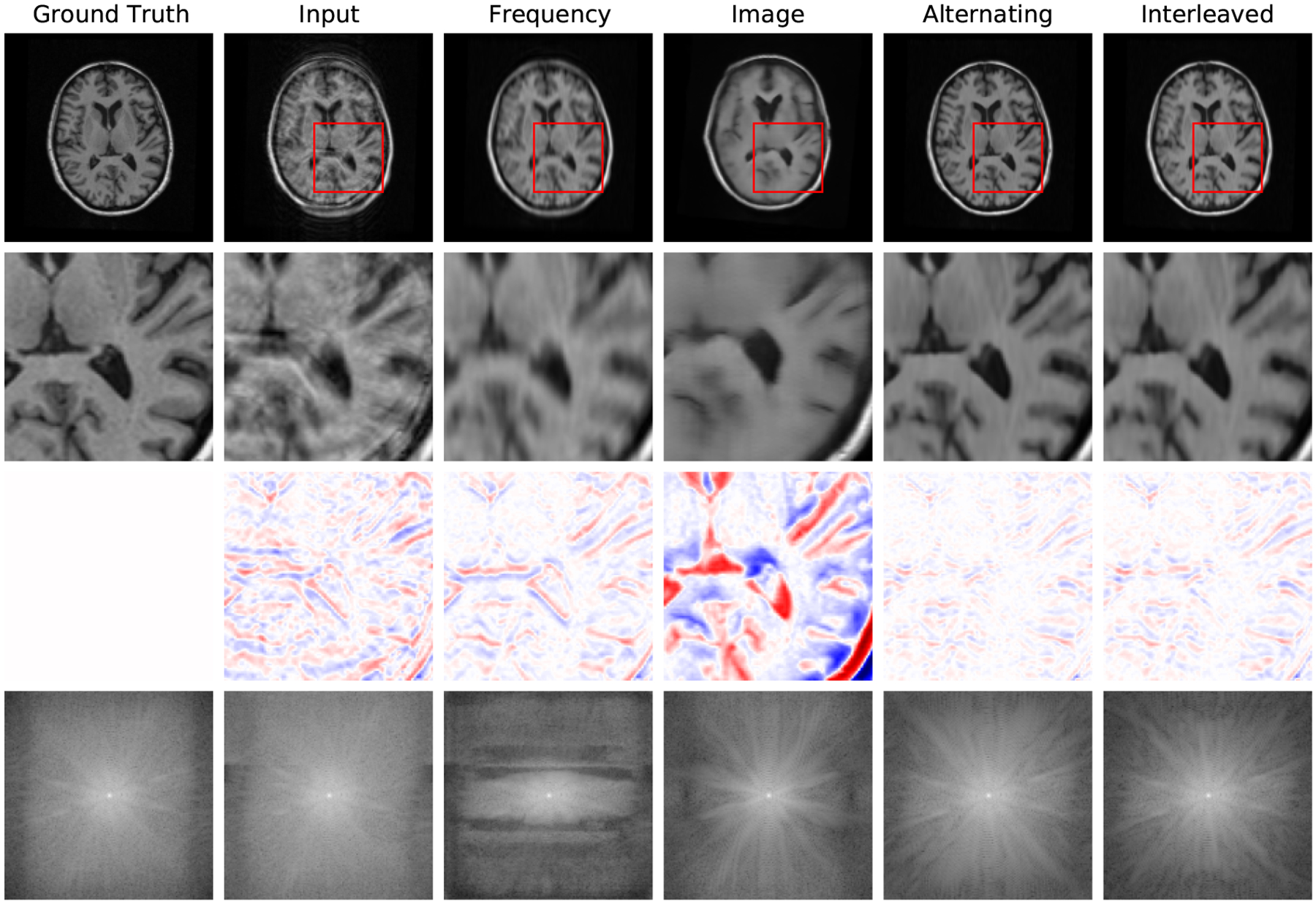
Example reconstructions with motion at 3% of scanning lines, zoomed-in image patches, difference patches between reconstructions and ground truth images, and frequency space reconstructions. The log values are taken of the frequency space data to better visualize its dynamic range. In the patch difference, red pixels have a higher value in the reconstruction than in the ground truth, while blue pixels have a lower value in the reconstruction than in the ground truth. The Interleaved and Alternating architectures more accurately eliminate the ‘shadow’ of the moved brain and the induced blurring compared to the single-domain networks.
Figure 7:
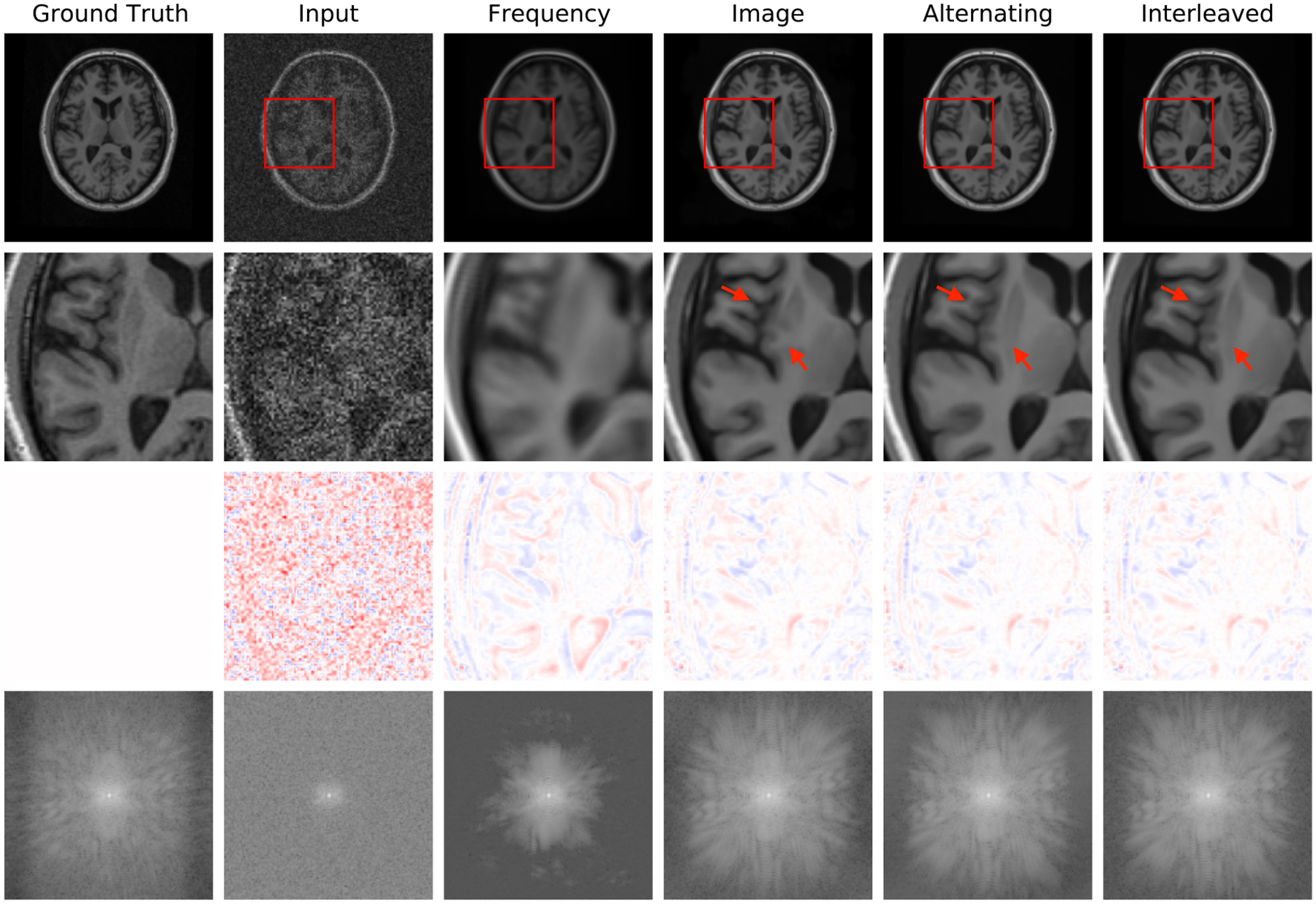
Example reconstructions with noise of standard deviation 10,000. The Interleaved and Alternating reconstructions remove the pixelated noise effect without over-smoothing, in contrast to the single-domain networks.
4.2. Hard Data Consistency Constraint
Deep learning for undersampled reconstruction is an active area of research and several state of the art methods have emerged for this task. In this experiment, we compare Interleaved and Alternating networks to such methods on ADNI data introduced in Section 4.1.
Undersampling is fundamentally different from motion and noise corruption, because the acquired data for lines ky ∈ Sy are the correct, desired outputs of the reconstruction algorithm at those frequency space locations. Data consistency can be enforced at test time and at intermediate layers of the network by substituting the appropriate k-space lines into the k-space representations of the image (final or intermediate) produced by the network. We enforce data consistency in Interleaved and Alternating networks by copying the acquired frequency space data into the network output.
We compare Interleaved and Alternating networks to a U-Net (Falk et al., 2019), the CascadeNet (Schlemper et al., 2017), which combines image space convolutions with forced data consistency at each layer of the network, and, most similar to our method, the KIKI network (Eo et al., 2018), which includes two separate image and frequency space networks. The KIKI-net architecture incorporates four networks operating in the frequency, image, frequency, and image spaces, respectively. This is in contrast to our networks, where every layer contains convolutions in both spaces and uses a custom nonlinearity for the frequency space layers. Moreover, the KIKI-net architecture imposes a data consistency constraint after each k-space subnetwork. For tasks other than undersampled image reconstruction, the data consistency constraints in CascadeNet and KIKI-net would incorrectly force the acquired k-space lines to be maintained in the final reconstruction; thus, we restrict comparisons with CascadeNet and KIKI-net to the undersampled reconstruction case.
We use implementations of the baseline methods available at https://github.com/zaccharieramzi/fastmri-reproducible-benchmark (Ramzi et al., 2020). We scale each network to have roughly 800,000 parameters for fair comparison with our joint architectures. We use an L1 loss function to train the networks and SSIM scores to evaluate their performance on the test set.
Undersampling patterns.
In addition to the random sampling scheme in Section 4.1, we simulate two traditional undersampling patterns: (i) the central 8% of lines are fully sampled while every fourth line of the outer regions of k-space is sampled and (ii) the central 4% of lines are fully sampled while every eighth line of the outer regions of k-space is sampled.
4.2.1. Results
Fig. 8 reports statistics for U-Net, CascadeNet, KIKI-net, Joint and Alternating networks. Fig. 9 provides sample image reconstructions. Interleaved and Alternating networks perform comparably to other state of the art methods on the simpler uniform undersampling tasks and outperform the state of the art methods on the more complex random undersampling task.
Figure 8:
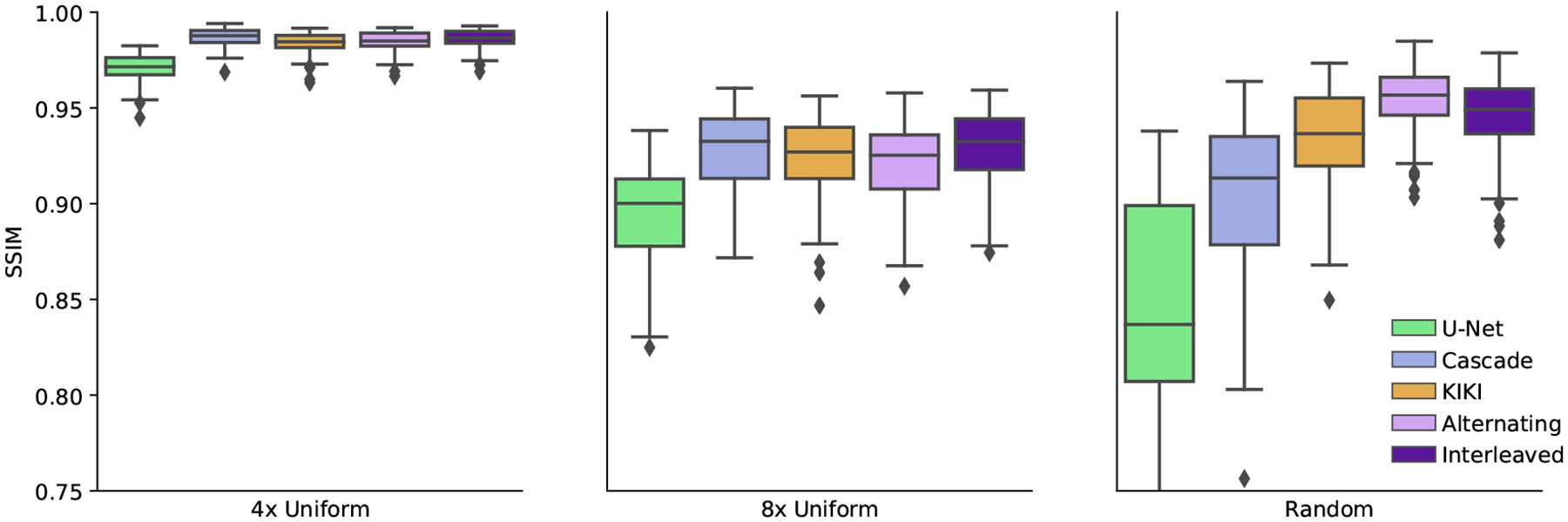
SSIM comparison of the joint networks with the state of the art undersampled reconstruction approaches on ADNI data. Results are reported for three undersampling patterns: 4x uniform undersampling with a fully-sampled central region (left), 8x uniform undersampling with a fully-sampled central region (middle), and 4x undersampling at random (right). In all cases, simple networks composed of repeated copies of our joint layers perform at least as well as other state of the art networks, and in the difficult case of a random sampling pattern, outperform the baseline networks.
Figure 9:
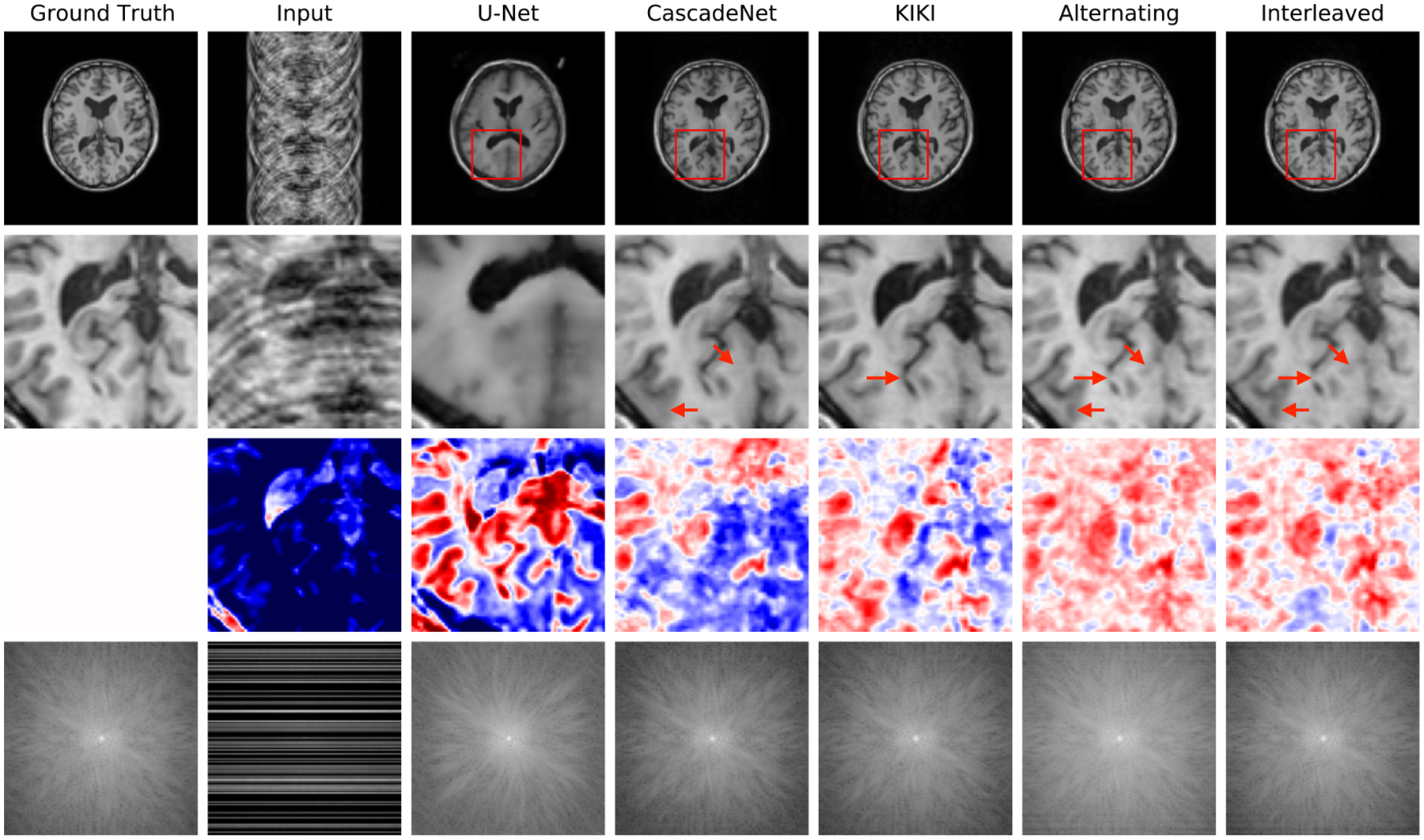
Example reconstructions from 4x undersampled data, with lines selected at random. The Interleaved and Alternating architectures provide more accurate reconstructions of the ground truth images, better eliminating ‘ringing’ and blurring artifacts.
4.3. Unrolled Optimization
Finally, we evaluate the performance of the proposed joint layers in the setting of an unrolled optimization architecture on real world multicoil MRI data. In this experiment, we replace the image space convolutional layers with our Interleaved layers in the MoDL framework (Aggarwal et al., 2018) for unrolled optimization. We use the authors’ publicly available implementation of MoDL at https://github.com/hkaggarwal/modl. Each iteration of the MoDL network first passes the input through convolutional layers that serve as a data-driven regularizer and then applies an analytical update based on the data consistency term. To keep the total number of convolutions comparable, we train the baseline MoDL network with 10 image convolutional layers in each iteration and the joint MoDL network with 5 Interleaved layers in each iteration. We set K = 5 iterations for both networks. The authors use the strategy of first training a one-iteration MoDL network and using its weights to initialize the training of a multi-iteration MoDL network. This process speeds up training of the larger unrolled optimization network and avoids instabilities. We found that pre-training of a one-iteration model was unnecessary when using the joint layers, and train both the one-iteration and the five-iteration joint MoDL networks using random initializations. For consistency with the original MoDL training approach, we train all networks using L2 loss.
Data.
We use the data from the original MoDL study (Aggarwal et al., 2018). This dataset contains raw k-space data from 3D T2 CUBE acquisitions with Cartesian readouts using a 12-channel head coil. The dataset contains 360 training slices from 4 training subjects and a single, separate test subject. We exclude some edge slices in this test volume and use the central 90 slices for our evaluations to match the training distribution. We train all networks using a variable density 6x undersampling mask as specified in the original paper.
4.3.1. Results
Figure 10 presents the training curves, validation SSIM, and sample reconstructions for all versions of the MoDL architecture. All networks attain similar validation SSIM values, but MoDL networks with joint layers achieve high reconstruction quality in roughly a third as many epochs as image space networks. Further, using our joint layers removes the need to pretrain a one-iteration network. The five-iteration network with joint layers trains successfully from random initializations. The resulting differences in wall clock training times are summarized in Table 1.
Figure 10:
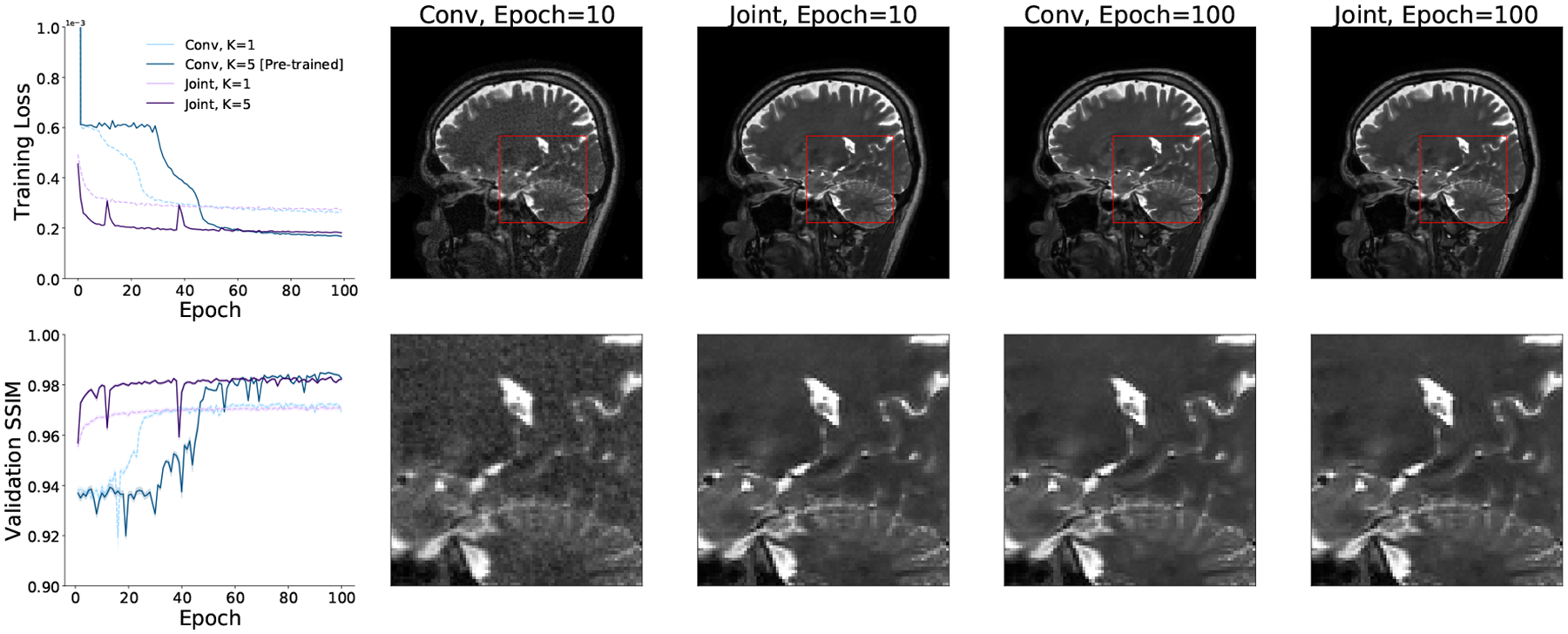
Example training loss and validation SSIM curves (left) and sample reconstructions and patches for MoDL networks with K = 1, 5 iterations trained with image convolutional layers and with the proposed joint (Interleaved) layers. MoDL networks with image convolutional layers do not converge if trained directly with K = 5. Instead, a K = 1 MoDL network must be trained and used to initialize the weights of a K = 5 MoDL network. MoDL networks trained with joint layers do not require pre-training and achieve the same loss and validation SSIM values as networks trained with image convolutions in significantly less time.
Table 1:
Training times for the full (K = 5) versions of the MoDL architecture to achieve validation SSIM≥ 0.98. For stable training, MoDL with image space convolutions must be initialized using the weights learned for a K = 1 MoDL network. MoDL architectures trained with our joint layers require no pre-training. In total, using joint layers results in roughly an 8x speed-up over the pure image space approach.
| MoDL Layer | Pre-Training (Hrs) | Training (Hrs) | Total (Hrs) |
|---|---|---|---|
| Image Convolution | 19 | 12 | 31 |
| Joint Layer | 0 | 4 | 4 |
5. Discussion and Conclusions
We demonstrate the advantages of joint image and frequency space learning strategies for correcting corrupted MRI data. For tasks where data consistency constraints cannot be readily applied, our joint networks produce sharper reconstructions than the more blurry, artifacted versions generated by single space networks. For the well-studied task of undersampled reconstruction, where data consistency constraints can be imposed easily, we show that networks comprising joint layers can be trained with such constraints and compare favorably to other strategies that incorporate data consistency constraints to improve the quality of single space network reconstructions. For unrolled architectures that iteratively perform the steps of an optimization procedure to produce high quality reconstructions, the joint layers can straightforwardly replace image convolutional layers to improve training landscape and convergence. These results point to joint layers as a useful building block when designing neural network architectures for correcting frequency space artifacts.
While we demonstrate our method in a diverse set of acquisition scenarios, our analysis does not exhaustively cover all possible imaging artifacts. For example, we do not analyze the effects of interslice motion, which may occur in addition to the intraslice motion studied in this work and introduces new image content from an adjacent slice into the slice being imaged. Further, while we analyze extremely aggressive versions of motion, noise, and undersampling to demonstrate the effectiveness of our method in the most challenging scenarios, future versions of this method could tune these parameters to more closely match the statistics of the patient population being scanned. For example, empirically measured motion trajectories could be used to characterize the rate and severity of the induced motion artifacts.
In the future, we aim to develop additional strategies for applications where direct consistency with acquired data is not necessarily desirable, such as motion correction. We also plan to investigate local operations beyond convolutions that more directly capitalize on properties and symmetries of frequency space data for use in joint architectures. Local convolutions in the frequency space represent a subset of all possible element-wise multiplications in the image space. Thus, future work could perform these operations in the image space, saving the computational overhead of performing an FFT within each layer, or could take advantage of additional element-wise image space multiplications whose Fourier transforms are not bandlimited to the size of our filter kernels. The combination of these advances promises to significantly improve reconstruction and analysis of MRI data in the face of widely varying acquisition challenges and downstream applications.
Figure 6:
Example reconstructions from 4x undersampled, motion-corrupted data data, zoomed-in image patches, difference patches between reconstructions and ground truth images, and frequency space reconstructions. As in the motion corruption and undersampling examples, the Interleaved and Alternating architectures provide more accurate reconstructions of the ground truth images and reconstructing a more coherent k-space.
Acknowledgments
The authors thank members of the Medical Vision Group at MIT CSAIL for useful discussions. This research was supported by NIBIB, NICHD, NIA, and NINDS of the National Institutes of Health under award numbers 5T32EB1680, P41EB015902, R01EB017337, R01HD100009, R01EB032708, 1R01AG064027-01A1, 5R01NS105820-02, 1R01AG070988-01 and 1RF1MH123195-01, by the European Research Council Starting Grant 677697, project “BUNGEE-TOOLS,” by Alzheimer’s Research UK (ARUK-IRG2019A-003), by an NSF Graduate Research Fellowship, and by a Google PhD Fellowship.
Appendix A. FastMRI Experiments
We compare the Interleaved and Alternating networks with Frequency and Image baseline methods, as well as the top three methods submitted to the single coil track of the FastMRI challenge at https://fastmri.org.
A.1. Data
We train and evaluate all networks on the proton density knee MRI frequency space data from the single coil FastMRI Dataset (Zbontar et al., 2018). We train separate networks for signals acquired with and without fat suppression. We apply the FastMRI 4x undersampling scheme at both training and test time. The 4x undersampling scheme acquires all of the central 8% of lines and samples lines outside of the central region from a uniform distribution such that 25% of all lines are sampled in total. After undersampling the signals, we normalize each input and output training pair by dividing by the maximum value in the corrupted image. We use the standard FastMRI split of 34,742 training slices from 973 volumes and 7,135 validation slices from 199 volumes. No subjects are shared across these sets. We treat the FastMRI validation set as our test set and use it only for evaluation by comparing the network’s output to the high quality fully sampled images provided as part of the FastMRI dataset.
A.2. Training Loss and Evaluation Metrics
We evaluate and compare the networks trained with a variety of loss functions and assess reconstruction quality via different quality metrics. We train Frequency, Image, Interleaved and Alternating networks with seven loss functions: image space L1 error, frequency space L1 error, a joint L1 metric summing image and frequency L1 errors, SSIM (Wang et al., 2004), multiscale SSIM (Wang et al., 2003), and PSNR (Huynh-Thu and Ghanbari, 2008). The joint L1 metric weighs the frequency space L1 error by 0.1 relative to the image space L1 error to account for differences in the error magnitudes. The SSIM and multiscale SSIM scores are computed with window size 7 × 7 and constants k1 = 0.01, k2 = 0.03.
We also compare the joint networks with top single coil methods on the FastMRI benchmark. For these experiments, we use a larger version of the Interleaved network comprised of 6 joint layers with two frequency space and two image space convolutions per layer, yielding roughly 3 million parameters total.
A.3. Results
Our results on the knee undersampled reconstruction task replicate the trends observed in the brain undersampled reconstruction task. Joint networks outperform single-domain networks, as reported in Table 2. This suggests that our joint layers can successfully process acquired, complex-valued MRI data. Further, Table 2 confirms that the success of joint learning is not specific to a certain loss landscape. Qualitative examples of reconstructions from networks trained with various loss functions are shown in Fig. 11.
Table 2:
Image reconstruction evaluation metrics (columns) for networks trained with varying loss functions (rows) on images acquired without fat suppression. Similar trends hold for images with fat suppression. MS SSIM stands for multiscale SSIM. For metrics labeled ↓, smaller values are better; for metrics labeled ↑, larger values are better. Across nearly every training loss function and metric, the Interleaved network performs best. In almost every case, the Alternating network architecture performs similarly or only slightly worse than the Interleaved network. This is particularly true in the case of SSIM-based loss functions, which provide the best overall quantitative results across all evaluation metrics.
| Loss | Architecture | Freq L1 (↓) | Image L1 (↓) | Joint L1 (↓) | SSIM (↑) | MS SSIM (↑) | PSNR (↑) |
|---|---|---|---|---|---|---|---|
| Freq L1 | Frequency | 5.2 ± 1.4 | 0.089 ± 0.063 | 0.61 ± 0.19 | 0.60 ± 0.12 | 0.76 ± 0.06 | 19.8 ± 2.4 |
| Image | 8.9 ± 3.4 | 0.079 ± 0.060 | 0.97 ± 0.40 | 0.70 ± 0.14 | 0.88 ± 0.06 | 22.4 ± 3.3 | |
| Interleaved | 3.9 ± 1.5 | 0.040 ± 0.018 | 0.43 ± 0.16 | 0.73 ± 0.11 | 0.91 ± 0.05 | 26.6 ± 2.4 | |
| Alternating | 4.1 ± 1.5 | 0.095 ± 0.023 | 0.51 ± 0.16 | 0.58 ± 0.10 | 0.77 ± 0.09 | 20.3 ± 1.9 | |
| Image L1 | Frequency | 7.9 ± 2.5 | 0.040 ± 0.015 | 0.83 ± 0.27 | 0.69 ± 0.12 | 0.88 ± 0.06 | 26.8 ± 2.2 |
| Image | 21.9 ± 8.2 | 0.054 ± 0.034 | 2.24 ± 0.85 | 0.59 ± 0.14 | 0.85 ± 0.09 | 24.9 ± 2.7 | |
| Interleaved | 6.9 ± 2.7 | 0.031 ± 0.018 | 0.72 ± 0.28 | 0.78 ± 0.12 | 0.92 ± 0.06 | 28.9 ± 2.5 | |
| Alternating | 7.5 ± 2.9 | 0.032 ± 0.013 | 0.78 ± 0.31 | 0.76 ± 0.12 | 0.91 ± 0.06 | 28.5 ± 2.4 | |
| Joint L1 | Frequency | 5.2 ± 1.7 | 0.062 ± 0.068 | 0.58 ± 0.23 | 0.66 ± 0.15 | 0.86 ± 0.06 | 23.1 ± 3.1 |
| Image | 8.9 ± 3.4 | 0.055 ± 0.060 | 0.95 ± 0.39 | 0.70 ± 0.14 | 0.88 ± 0.06 | 25.4 ± 3.4 | |
| Interleaved | 3.9 ± 1.5 | 0.032 ± 0.019 | 0.43 ± 0.17 | 0.77 ± 0.12 | 0.92 ± 0.05 | 27.8 ± 2.4 | |
| Alternating | 4.1 ± 1.5 | 0.035 ± 0.020 | 0.44 ± 0.17 | 0.75 ± 0.12 | 0.91 ± 0.05 | 26.8 ± 2.5 | |
| -SSIM | Frequency | 7.3 ± 1.8 | 0.039 ± 0.018 | 0.76 ± 0.20 | 0.73 ± 0.12 | 0.90 ± 0.05 | 26.5 ± 2.4 |
| Image | 12.0 ± 4.3 | 0.058 ± 0.059 | 1.25 ± 0.49 | 0.69 ± 0.14 | 0.87 ± 0.07 | 24.7 ± 3.3 | |
| Interleaved | 6.4 ± 2.4 | 0.029 ± 0.015 | 0.67 ± 0.25 | 0.80 ± 0.12 | 0.94 ± 0.05 | 29.0 ± 2.3 | |
| Alternating | 7.4 ± 2.8 | 0.031 ± 0.012 | 0.77 ± 0.29 | 0.79 ± 0.13 | 0.93 ± 0.06 | 27.7 ± 2.1 | |
| -MS SSIM | Frequency | 9.3 ± 1.5 | 0.043 ± 0.023 | 0.98 ± 0.16 | 0.69 ± 0.14 | 0.91 ± 0.05 | 25.3 ± 2.0 |
| Image | 15.6 ± 7.7 | 0.061 ± 0.045 | 1.63 ± 0.81 | 0.61 ± 0.13 | 0.86 ± 0.07 | 24.0 ± 3.5 | |
| Interleaved | 8.6 ± 1.8 | 0.030 ± 0.017 | 0.89 ± 0.19 | 0.79 ± 0.12 | 0.94 ± 0.05 | 27.5 ± 1.9 | |
| Alternating | 15.0 ± 4.3 | 0.031 ± 0.014 | 1.54 ± 0.44 | 0.79 ± 0.12 | 0.94 ± 0.05 | 23.8 ± 1.8 | |
| -PSNR | Frequency | 8.0 ± 2.5 | 0.038 ± 0.012 | 0.84 ± 0.26 | 0.70 ± 0.12 | 0.89 ± 0.06 | 27.4 ± 2.2 |
| Image | 15.3 ± 7.1 | 0.058 ± 0.043 | 1.59 ± 0.75 | 0.64 ± 0.13 | 0.85 ± 0.07 | 24.0 ± 2.6 | |
| Interleaved | 7.3 ± 2.8 | 0.031 ± 0.012 | 0.76 ± 0.29 | 0.77 ± 0.12 | 0.92 ± 0.06 | 29.1 ± 2.2 | |
| Alternating | 9.1 ± 4.7 | 0.037 ± 0.016 | 0.95 ± 0.49 | 0.70 ± 0.13 | 0.89 ± 0.08 | 27.6 ± 2.4 |
Figure 11:

Typical image reconstruction results for all architectures (rows) and loss functions (columns) on FastMRI images without fat suppression. The Interleaved and Alternating networks provide the sharpest reconstructions for all loss functions. Amongst these, both SSIM-based loss functions most sharply reconstruct high frequency structures within the zoomed-in patch. Similar results are observed in images with fat suppression.
The reconstructed images produced by the larger Interleaved network are qualitatively similar to those produced by the top three methods on the FastMRI leaderboard (Fig. 12). Table 3 reports reconstruction quality measures for Interleaved network and the top single-slice methods on the FastMRI benchmark. Interleaved network achieves results that are close to the state of the art architectures specifically tuned for this task. We emphasize that our goal is not to attain state of the art performance on the FastMRI benchmark, but rather to show that simple layers comprised of both frequency and image space convolutions achieve reasonable performance on this benchmark while offering flexibility for correcting a wide range of other artifacts, and for correcting multiple artifacts present simultaneously.
Figure 12:
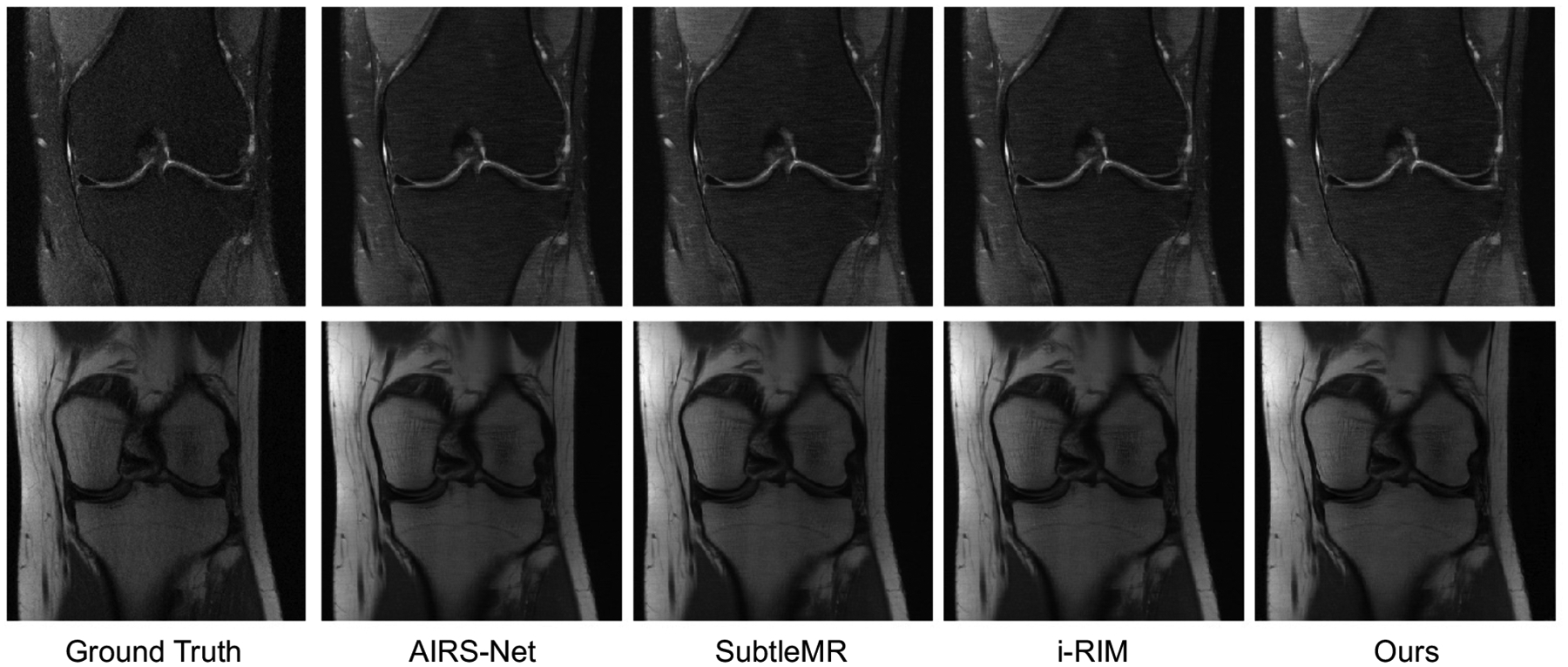
Comparison of the Interleaved reconstruction results with the top methods on the FastMRI single coil knee reconstruction challenge. All images were taken from the FastMRI online submission website. Our method produces a reconstruction qualitatively similar to those of the top three methods on the leaderboard.
Table 3:
Reconstruction quality statistics on the FastMRI leaderboard test dataset, at 4x undersampling. The FastMRI dataset contains images both with and without fat suppression. Simple Interleaved network comprised of joint layers is comparable to the three top models on the FastMRI leaderboard, yielding reconstructions with SSIM within 3% of the leading methods.
| Method | MAE | SSIM | PSNR |
|---|---|---|---|
| Interleaved (Ours) | 0.0296 | 0.768 | 32.9 |
| AIRS-Net | 0.0266 | 0.784 | 33.8 |
| SubtleMR | 0.0270 | 0.781 | 33.7 |
| i-RIM | 0.0271 | 0.781 | 33.7 |
Footnotes
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
Contributor Information
Nalini M. Singh, Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA, USA Dept. of Health Sciences & Technology, MIT, Cambridge, MA, USA.
Juan Eugenio Iglesias, A. A. Martinos Center, Massachusetts General Hospital, Boston, MA, USA; Harvard Medical School, Cambridge, MA, USA; Centre for Medical Image Computing, UCL, London, UK; Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA, USA.
Elfar Adalsteinsson, Research Laboratory of Electronics, MIT, Cambridge, MA, USA; Dept. of Electrical Engineering & Computer Science, MIT, Cambridge, MA, USA.
Adrian V. Dalca, A. A. Martinos Center, Massachusetts General Hospital, Boston, MA, USA Harvard Medical School, Cambridge, MA, USA; Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA, USA.
Polina Golland, Computer Science and Artificial Intelligence Laboratory, MIT, Cambridge, MA, USA; Dept. of Electrical Engineering & Computer Science, MIT, Cambridge, MA, USA.
References
- Aggarwal Hemant K, Mani Merry P, and Jacob Mathews. MoDL: Model-based deep learning architecture for inverse problems. IEEE Transactions on Medical Imaging, 38(2): 394–405, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Akçakaya Mehmet, Moeller Steen, Weingärtner Sebastian, and Uğurbil Kâmil. Scanspecific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: Database-free deep learning for fast imaging. Magnetic Resonance in Medicine, 81(1): 439–453, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anand C Shyam and Sahambi Jyotinder S. Wavelet domain non-linear filtering for MRI denoising. Magnetic Resonance Imaging, 28(6):842–861, 2010. [DOI] [PubMed] [Google Scholar]
- Andre Jalal B, Bresnahan Brian W, Mossa-Basha Mahmud, Hoff Michael N, Smith C Patrick, Anzai Yoshimi, and Cohen Wendy A. Toward quantifying the prevalence, severity, and cost associated with patient motion during clinical MR examinations. Journal of the American College of Radiology, 12(7):689–695, 2015. [DOI] [PubMed] [Google Scholar]
- Bahadir Cagla D, Wang Alan Q, Dalca Adrian V, and Sabuncu Mert R. Deep-learning-based optimization of the under-sampling pattern in MRI. IEEE Transactions on Computational Imaging, 6:1139–1152, 2020. [Google Scholar]
- Batchelor PG, Atkinson D, Irarrazaval P, Hill DLG, Hajnal J, and Larkman D. Matrix description of general motion correction applied to multishot images. Magnetic Resonance in Medicine, 54(5):1273–1280, 2005. [DOI] [PubMed] [Google Scholar]
- Benou Ariel, Veksler Ronel, Friedman Alon, and Raviv Tammy Riklin. Ensemble of expert deep neural networks for spatio-temporal denoising of contrast-enhanced MRI sequences. Medical Image Analysis, 42:145–159, 2017. [DOI] [PubMed] [Google Scholar]
- Cárdenas-Blanco Arturo, Tejos Cristian, Irarrazaval Pablo, and Cameron Ian. Noise in magnitude magnetic resonance images. Concepts in Magnetic Resonance Part A: An Educational Journal, 32(6):409–416, 2008. [Google Scholar]
- Cheng Joseph Y, Mardani Morteza, Alley Marcus T, Pauly John M, and Vasanawala SS. DeepSPIRiT: Generalized parallel imaging using deep convolutional neural networks. In Proc. 26th Annual Meeting of the ISMRM, Paris, France, 2018. [Google Scholar]
- Duffy Ben A, Zhao Lu, Sepehrband Farshid, Min Joyce, Wang Danny JJ, Shi Yonggang, Toga Arthur W, Kim Hosung, Alzheimer’s Disease Neuroimaging Initiative, et al. Retrospective motion artifact correction of structural MRI images using deep learning improves the quality of cortical surface reconstructions. Neuroimage, 230:117756, 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eo Taejoon, Jun Yohan, Kim Taeseong, Jang Jinseong, Lee Ho-Joon, and Hwang Dosik. KIKI-net: Cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images. Magnetic resonance in medicine, 80(5):2188–2201, 2018. [DOI] [PubMed] [Google Scholar]
- Falk Thorsten, Mai Dominic, Bensch Robert, Çiçek Özgün, Abdulkadir Ahmed, Marrakchi Yassine, Böhm Anton, Deubner Jan, Jäckel Zoe, Seiwald Katharina, et al. U-net: Deep learning for cell counting, detection, and morphometry. Nature methods, 16(1): 67–70, 2019. [DOI] [PubMed] [Google Scholar]
- Griswold Mark A, Jakob Peter M, Heidemann Robin M, Nittka Mathias, Jellus Vladimir, Wang Jianmin, Kiefer Berthold, and Haase Axel. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magnetic Resonance in Medicine, 47(6):1202–1210, 2002. [DOI] [PubMed] [Google Scholar]
- Hammernik Kerstin, Klatzer Teresa, Kobler Erich, Recht Michael P, Sodickson Daniel K, Pock Thomas, and Knoll Florian. Learning a variational network for reconstruction of accelerated MRI data. Magnetic Resonance in Medicine, 79(6):3055–3071, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han Yoseob, Sunwoo Leonard, and Ye Jong Chul. k-space deep learning for accelerated MRI. IEEE Transactions on Medical Imaging, 2019. [DOI] [PubMed] [Google Scholar]
- Haskell Melissa W, Cauley Stephen F, and Wald Lawrence L. TArgeted Motion Estimation and Reduction (TAMER): Data consistency based motion mitigation for MRI using a reduced model joint optimization. IEEE Transactions on Medical Imaging, 37(5):1253–1265, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haskell Melissa W, Cauley Stephen F, Bilgic Berkin, Hossbach Julian, Splitthoff Daniel N, Pfeuffer Josef, Setsompop Kawin, and Wald Lawrence L. Network Accelerated Motion Estimation and Reduction (NAMER): Convolutional neural network guided retrospective motion correction using a separable motion model. Magnetic Resonance in Medicine, 82 (4):1452–1461, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- He Kaiming, Zhang Xiangyu, Ren Shaoqing, and Sun Jian. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision, pages 1026–1034, 2015. [Google Scholar]
- Huynh-Thu Quan and Ghanbari Mohammed. Scope of validity of PSNR in image/video quality assessment. Electronics letters, 44(13):800–801, 2008. [Google Scholar]
- Hyun Chang Min, Kim Hwa Pyung, Lee Sung Min, Lee Sungchul, and Seo Jin Keun. Deep learning for undersampled MRI reconstruction. Physics in Medicine & Biology, 63(13): 135007, 2018. [DOI] [PubMed] [Google Scholar]
- Jiang Dongsheng, Dou Weiqiang, Vosters Luc, Xu Xiayu, Sun Yue, and Tan Tao. Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network. Japanese Journal of Radiology, 36(9):566–574, 2018. [DOI] [PubMed] [Google Scholar]
- Johnson Patricia M and Drangova Maria. Conditional generative adversarial network for 3D rigid-body motion correction in MRI. Magnetic Resonance in Medicine, 82(3):901–910, 2019. [DOI] [PubMed] [Google Scholar]
- Kim Tae Hyung, Garg Pratyush, and Haldar Justin P. LORAKI: Autocalibrated recurrent neural networks for autoregressive MRI reconstruction in k-space. arXiv preprint arXiv:1904.09390, 2019. [Google Scholar]
- Kingma Diederik P and Ba Jimmy. Adam: A method for stochastic optimization. In International Conference on Machine Learning, 2014. [Google Scholar]
- Küstner Thomas, Armanious Karim, Yang Jiahuan, Yang Bin, Schick Fritz, and Gatidis Sergios. Retrospective correction of motion-affected MR images using deep learning frameworks. Magnetic Resonance in Medicine, 82(4):1527–1540, 2019. [DOI] [PubMed] [Google Scholar]
- Lauterbur Paul C. Image formation by induced local interactions: Examples employing nuclear magnetic resonance. Nature, 242(5394):190–191, 1973. [PubMed] [Google Scholar]
- Lee Dongwook, Yoo Jaejun, and Ye Jong Chul. Deep residual learning for compressed sensing MRI. In 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), pages 15–18. IEEE, 2017. [Google Scholar]
- Lustig Michael and Pauly John M. SPIRiT: Iterative self-consistent parallel imaging reconstruction from arbitrary k-space. Magnetic resonance in medicine, 64(2):457–471, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lustig Michael, Donoho David L, Santos Juan M, and Pauly John M. Compressed sensing MRI. IEEE Signal Processing Magazine, 25(2):72–82, 2008. [Google Scholar]
- Macovski Albert. Noise in MRI. Magnetic Resonance in Medicine, 36(3):494–497, 1996. [DOI] [PubMed] [Google Scholar]
- Manjón José V and Coupe Pierrick. MRI denoising using deep learning. In International Workshop on Patch-based Techniques in Medical Imaging, pages 12–19. Springer, 2018. [Google Scholar]
- Manjón José V, Carbonell-Caballero José, Lull Juan J, García-Martí Gracián, Martí-Bonmatí Luís, and Robles Montserrat. MRI denoising using non-local means. Medical Image Analysis, 12(4):514–523, 2008. [DOI] [PubMed] [Google Scholar]
- Mueller Susanne G, Weiner Michael W, Thal Leon J, Petersen Ronald C, Jack Clifford, Jagust William, Trojanowski John Q, Toga Arthur W, and Beckett Laurel. The Alzheimer’s Disease Neuroimaging Initiative. Neuroimaging Clinics, 15(4):869–877, 2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nowak Robert D. Wavelet-based Rician noise removal for magnetic resonance imaging. IEEE Transactions on Image Processing, 8(10):1408–1419, 1999. [DOI] [PubMed] [Google Scholar]
- Oksuz Ilkay, Clough James, Ruijsink Bram, Puyol-Antón Esther, Bustin Aurelien, Cruz Gastao, Prieto Claudia, Rueckert Daniel, King Andrew P, and Schnabel Julia A. Detection and correction of cardiac MRI motion artefacts during reconstruction from k-space. In International conference on medical image computing and computer-assisted intervention, pages 695–703. Springer, 2019. [Google Scholar]
- Pawar Kamlesh, Chen Zhaolin, Shah N Jon, and Egan Gary F. MoCoNet: Motion correction in 3D MPRAGE images using a convolutional neural network approach. arXiv preprint arXiv:1807.10831, 2018. [Google Scholar]
- Pruessmann Klaas P, Weiger Markus, Scheidegger Markus B, and Boesiger Peter. SENSE: Sensitivity encoding for fast MRI. Magnetic Resonance in Medicine, 42(5):952–962, 1999. [PubMed] [Google Scholar]
- Putzky Patrick and Welling Max. Invert to learn to invert. In Advances in Neural Information Processing Systems, pages 446–456, 2019. [Google Scholar]
- Quan Tran Minh, Nguyen-Duc Thanh, and Jeong Won-Ki. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE Transactions on Medical Imaging, 37(6):1488–1497, 2018. [DOI] [PubMed] [Google Scholar]
- Ramzi Zaccharie, Ciuciu Philippe, and Starck Jean-Luc. Benchmarking MRI reconstruction neural networks on large public datasets. Applied Sciences, 10(5):1816, 2020. [Google Scholar]
- Schlemper Jo, Caballero Jose, Hajnal Joseph V, Price Anthony N, and Rueckert Daniel. A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Transactions on Medical Imaging, 37(2):491–503, 2017. [DOI] [PubMed] [Google Scholar]
- Shaw Richard, Sudre Carole H, Varsavsky Thomas, Ourselin Sébastien, and Cardoso M Jorge. A k-space model of movement artefacts: Application to segmentation augmentation and artefact removal. IEEE transactions on medical imaging, 39(9):2881–2892, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shimron Efrat, Tamir Jonathan I, Wang Ke, and Lustig Michael. Implicit data crimes: Machine learning bias arising from misuse of public data. Proceedings of the National Academy of Sciences, 119(13):e2117203119, 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Souza Roberto and Frayne Richard. A hybrid frequency-domain/image-domain deep network for magnetic resonance image reconstruction. In 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), pages 257–264. IEEE, 2019. [Google Scholar]
- Sun Jian, Li Huibin, Xu Zongben, et al. Deep ADMM-Net for compressive sensing MRI. In Advances in Neural Information Processing Systems, pages 10–18, 2016. [Google Scholar]
- Usman Muhammad, Latif Siddique, Asim Muhammad, Lee Byoung-Dai, and Qadir Junaid. Retrospective motion correction in multishot MRI using generative adversarial network. Scientific Reports, 10(1):1–11, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Guanhua, Gong Enhao, Banerjee Suchandrima, Pauly John, and Zaharchuk Greg. Accelerated MRI reconstruction with dual-domain generative adversarial network. In International Workshop on Machine Learning for Medical Image Reconstruction, pages 47–57. Springer, 2019. [Google Scholar]
- Wang Zhou, Simoncelli Eero P, and Bovik Alan C. Multiscale structural similarity for image quality assessment. In The Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pages 1398–1402. IEEE, 2003. [Google Scholar]
- Wang Zhou, Bovik Alan C, Sheikh Hamid R, and Simoncelli Eero P. Image quality assessment: From error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004. [DOI] [PubMed] [Google Scholar]
- Yang Guang, Yu Simiao, Dong Hao, Slabaugh Greg, Dragotti Pier Luigi, Ye Xujiong, Liu Fangde, Arridge Simon, Keegan Jennifer, Guo Yike, et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Transactions on Medical Imaging, 37(6):1310–1321, 2017. [DOI] [PubMed] [Google Scholar]
- Zbontar Jure, Knoll Florian, Sriram Anuroop, Muckley Matthew J, Bruno Mary, Defazio Aaron, Parente Marc, Geras Krzysztof J, Katsnelson Joe, Chandarana Hersh, et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:1811.08839, 2018. [Google Scholar]
- Zhou Bo and Zhou S Kevin. DuDoRNet: Learning a dual-domain recurrent network for fast MRI reconstruction with deep T1 prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4273–4282, 2020. [Google Scholar]
- Zhu Bo, Liu Jeremiah Z, Cauley Stephen F, Rosen Bruce R, and Rosen Matthew S. Image reconstruction by domain-transform manifold learning. Nature, 555(7697):487–492, 2018. [DOI] [PubMed] [Google Scholar]