
Figure 4.
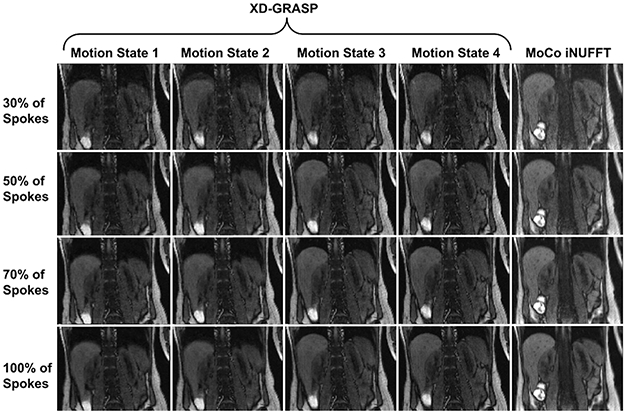
Comparison with XD-GRASP with regularization applied along temporal direction. The proposed method (MoCo NUFFT) uses all of 30%, 50%, 70%, 100% of spokes acquired in each row, respectively, and reconstructs a single motion-corrected image without employing any regularization. Whereas, XD-GRASP bins the spokes into number motion states which essentially reduces the number used to reconstruct each motion state image by the same factor. Here, motion was resolved into four respiratory states. Although increasing the number of motion states could decrease the motion artifacts, it would decrease the image quality as well. Hence, the proposed technique is more efficient compared to XD-GRASP since it uses all of 30%, 50%, 70%, 100% of the spokes in each row. Therefore, 30% of the scan is sufficient for the required image quality using the proposed MoCo.