
Fig. 4.
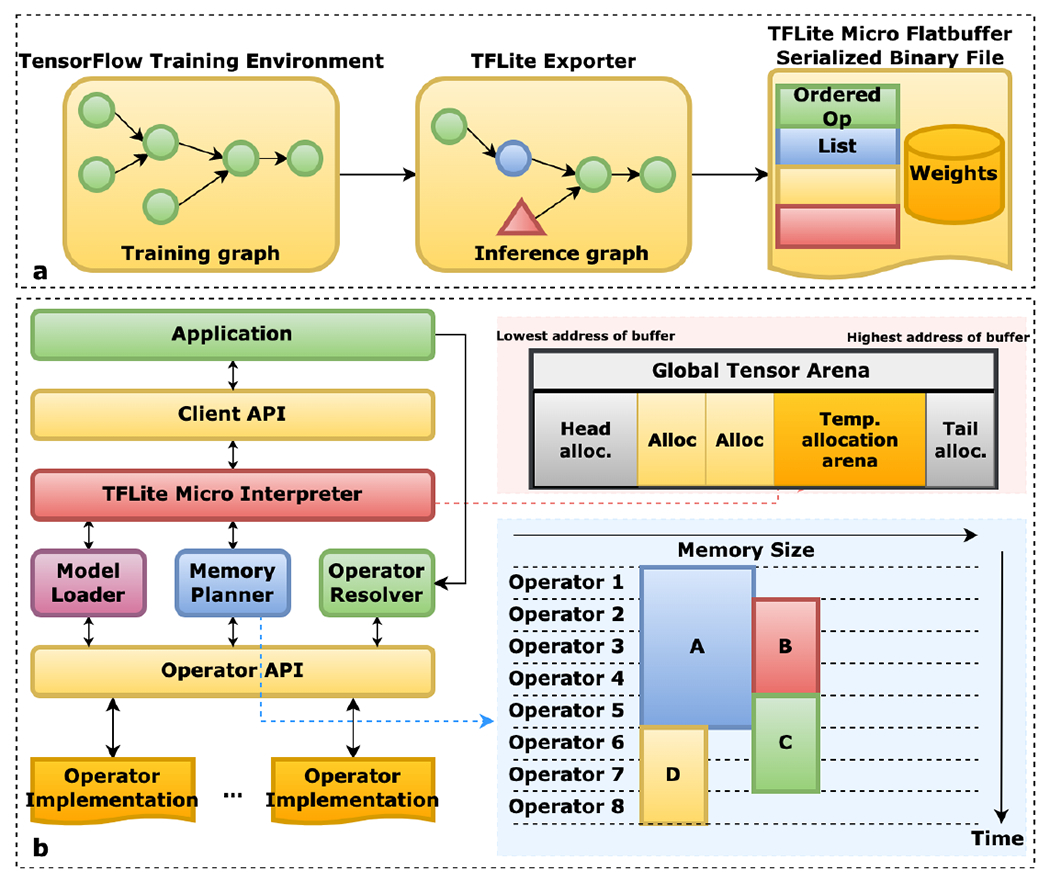
Operation of TensorFlow Lite Micro, an interpreter-based inference engine. (a) The training graph is frozen, optimized and converted to a flatbuffer serialized model schema, suitable for deployment in embedded devices. (b) The TFLM runtime API preallocates a portion of memory in the SRAM (called arena) and performs bin-packing during runtime to optimize memory usage (figure adapted from [167]).