
Figure 5:
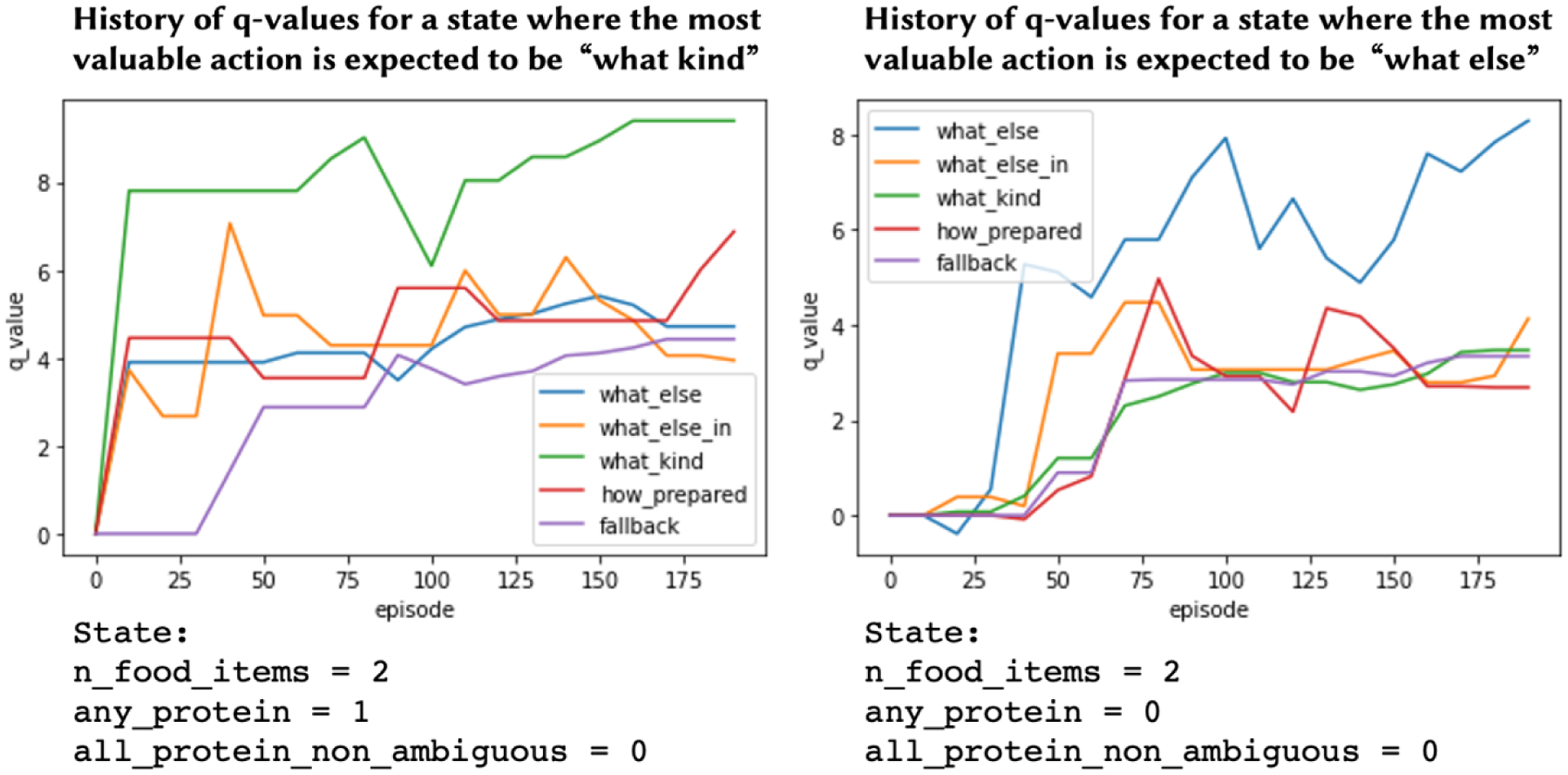
Comparison of change in q-values over training between two different states in offline learning with simulated data. Higher q-values suggest an action will be more valuable in a given state. The only difference between the two states is whether any proteins have been mentioned by the user — any_protein is equal to 1 on the left and 0 on the right. If a protein has been mentioned, then most valuable action per the simulation is to ask “what kind” of protein to determine if it’s fatty or lean. The graph on the left shows that the q-value for “what kind” questions (green) quickly becomes the most valuable after a few dozen training episodes. In contrast, when there are no proteins mentioned yet, as on the right, that question is not valuable and instead asking “what else” to find addition food items that might be proteins should be more valuable. The graph on the right shows that the q-value for “what else” questions quickly and appropriately becomes the most valuable action for that state.