
Figure 6.
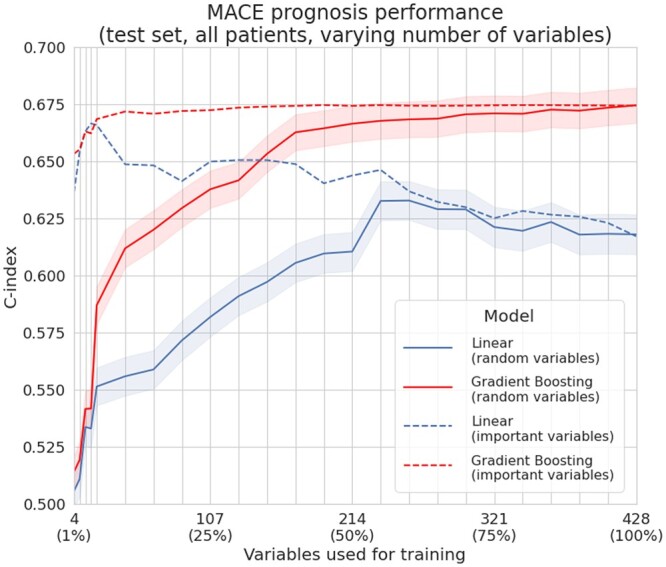
Performances depending on the number of used variables. When randomly sampling variables from the data (right, full lines), even if some of the selected subsets might lack some common prognostic variables and not convey much useful information, we again observed that gradient boosting requires less variables than linear models to achieve similar performance. When selecting variables by order of decreasing importance (right, dashed lines)—using their univariate c-index to the outcome for linear models and their SHAP values for gradient boosting models—both models achieve better performance (compared to random variables sampling) in lower dimension regimes by having access to more prognostic variables. The performance of linear models peaks with few variables,16 while gradient boosting slightly but consistently improves when more are provided.