
Figure 2. B-KinD, an approach for keypoint discovery from spatiotemporal difference reconstruction.
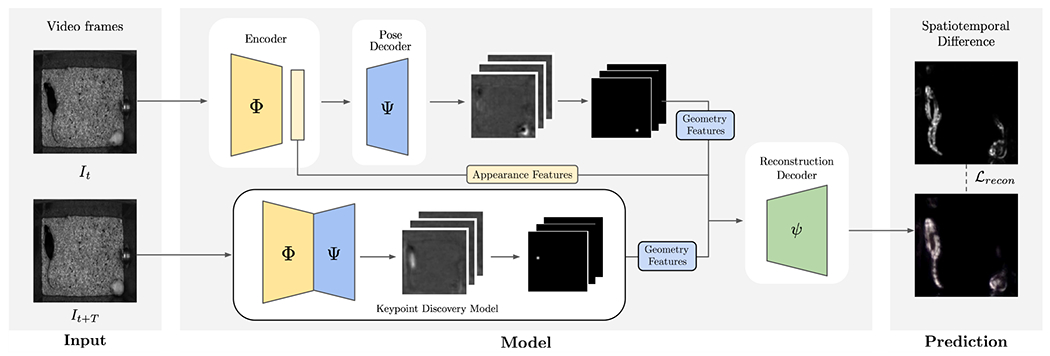
It and It+T are video frames at time t and t + T. Both frame It and frame It+T are fed to an appearance encoder Φ and a pose decoder Ψ. Given the appearance feature from It and geometry features from both It and It+T (Sec 3.1), our model reconstructs the spatiotemporal difference (Sec 3.2.1) computed from two frames using the reconstruction decoder ψ.