
Figure 1.
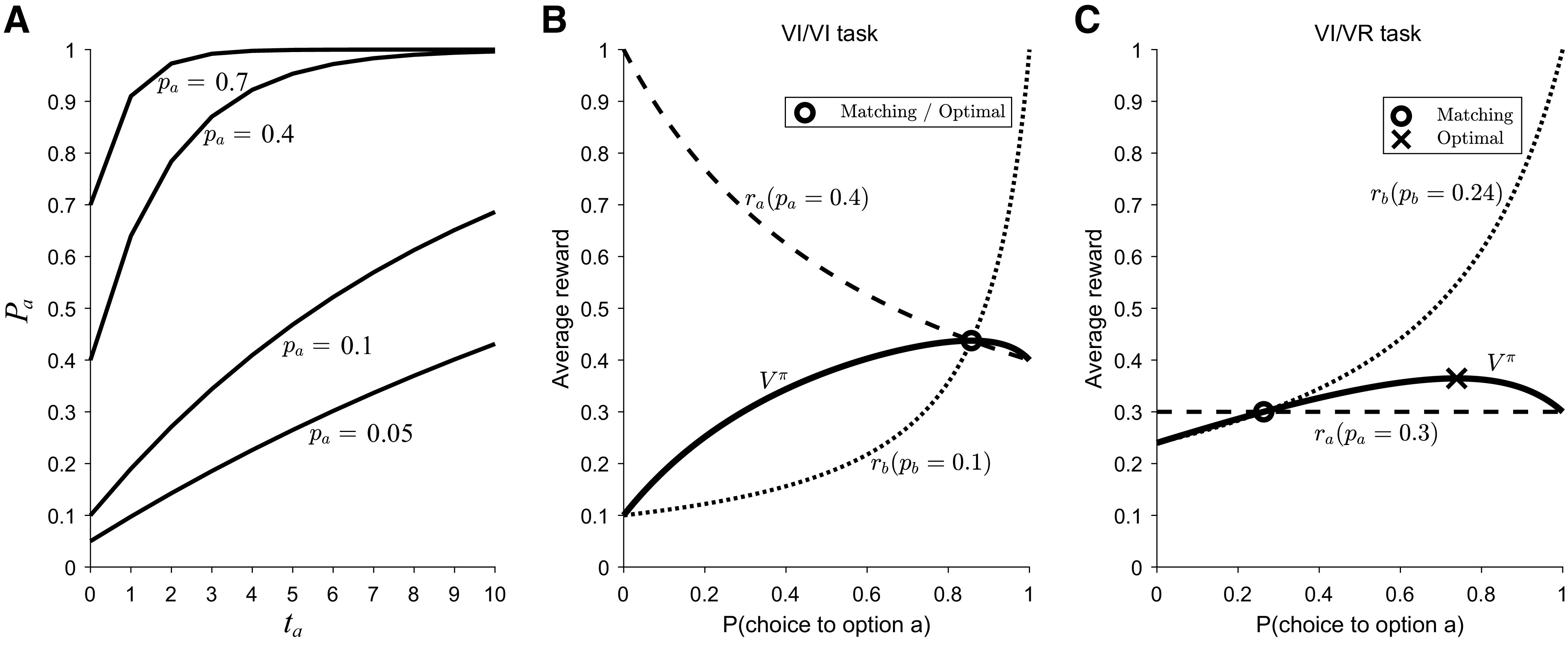
Geometric representation of matching behavior in different task conditions. A, The baiting rule for four different values of pa (base reward probabilities). The x-axis is ta, the number of consecutive choices since that option was last chosen, and the y-axis is pa, the probability of reward. Here, Pa ∈ {0.05, 0.1, 0.4, 0.7}. Adapted from Huh et al. (2009). B, In VI/VI tasks, where both options use the “baiting” rule, matching emerges as the optimal probabilistic policy. Matching occurs where ra = rb (hence they match). C, VI/VR tasks allow us to disambiguate whether animals match or whether they approximate the optimal probabilistic solution. In these task variants, one option (here, option b) follows a VI schedule (i.e., programmed with the baiting rule) and the other option (here, option a) follows a VR schedule (standard probabilistic reward delivery). The matching policy (where ra = rb) differs from the optimal probabilistic policy. Adapted from Bari and Cohen (2021).