
FIGURE 1.
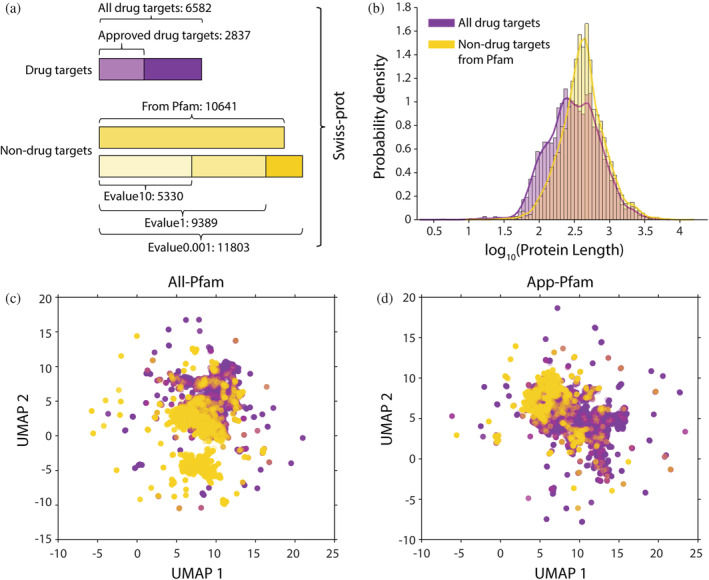
The composition and basic features of the datasets constructed in this study. (a) we utilized two drug‐target datasets: (1) all targets and (2) Food and Drug Administration (FDA)‐approved drug targets, as well as four nondrug‐target datasets, constructed using different extraction methods. (b) Length distribution of all drug‐target proteins and nondrug‐target proteins from Pfam. (c) Dimensionality reduction of protein sequences based on uniform manifold approximation and projection (UMAP). Purple dots represent all drug‐target proteins and yellow dots represent nondrug‐target proteins from Pfam. (d) Data analyzed as in (c), including only FDA‐approved drug targets