
Figure 2.
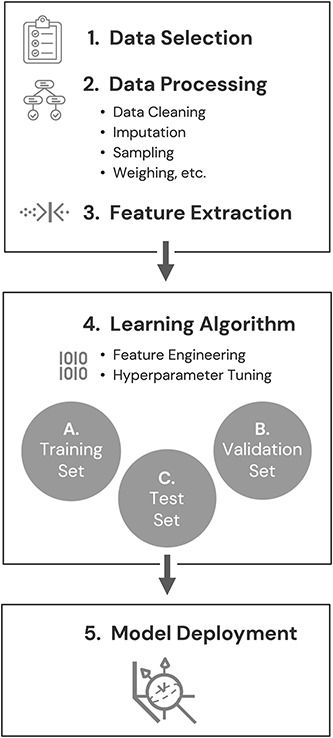
(1) Data are selected based on the type of prediction task to be undertaken. (2) Data are processed to prepare them for use and to address any inadequacies such as missing or biased data or incorrectly formatted data fields. (3) Features expected to contain the information most relevant to the prediction task are selected or formulated and extracted from the full feature set. (4) The data set is split into training and validation sets. Before model deployment, if sufficient data exist, a third “test set” may also be used to test the model's performance with novel data. (5) After iterative improvement, the model is deployed in real-world scenarios.