
Fig. 1 |. Approach.
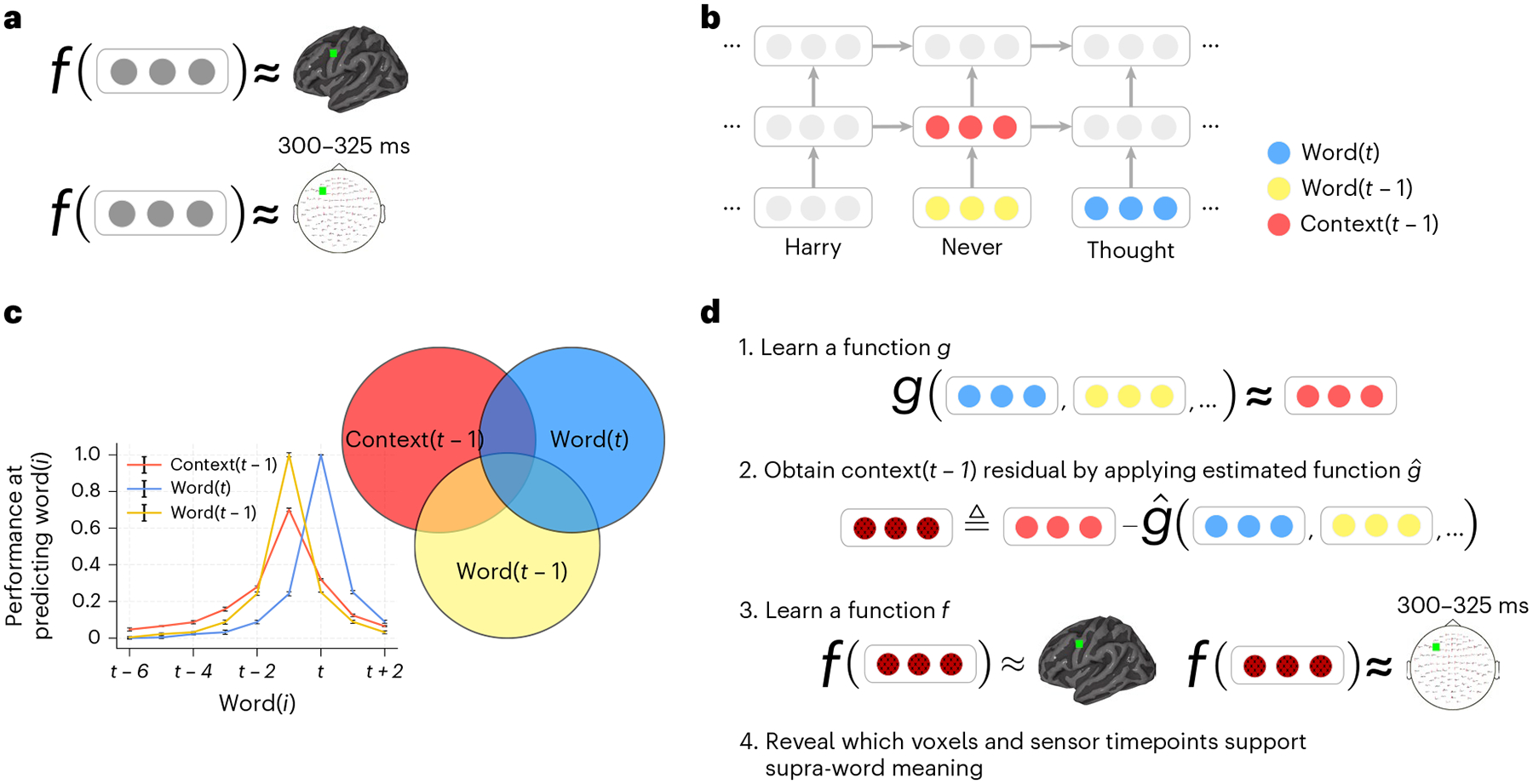
a, An encoding model f learns to predict a brain recording as a function of representations of the text read by a participant during the experiment. A different function is learned for each voxel in fMRI (top) and each sensor timepoint in MEG (bottom). b, Stimulus representations are obtained from an NLP model that has captured language statistics from millions of documents. This model represents words using context-free embeddings (yellow and blue) and context embeddings (red). Context embeddings are obtained by continuously integrating each new word’s context-free embedding with the most recent context embedding. c, Context and word embeddings share information. The performance of the context and word embeddings at predicting the words at surrounding positions is plotted for different positions (the s.e.m. across test instances is shown, n = 5,156). The context embedding contains information about up to six past words, and the word embedding contains information about embeddings of surrounding words. To isolate the representation of supra-word meaning, it is necessary to account for this shared information. d, Supra-word meaning is modelled by obtaining the residual information in the context embeddings after removing information related to the word embeddings. We refer to this residual as the ‘supra-word embedding’ or ‘residual context embedding’. The supra-word embedding is used as an input to an encoding model f, revealing which fMRI voxels and MEG sensor timepoints are modulated by supra-word meaning.