
Fig. 3 |. MEG prediction results at different spatial granularity.
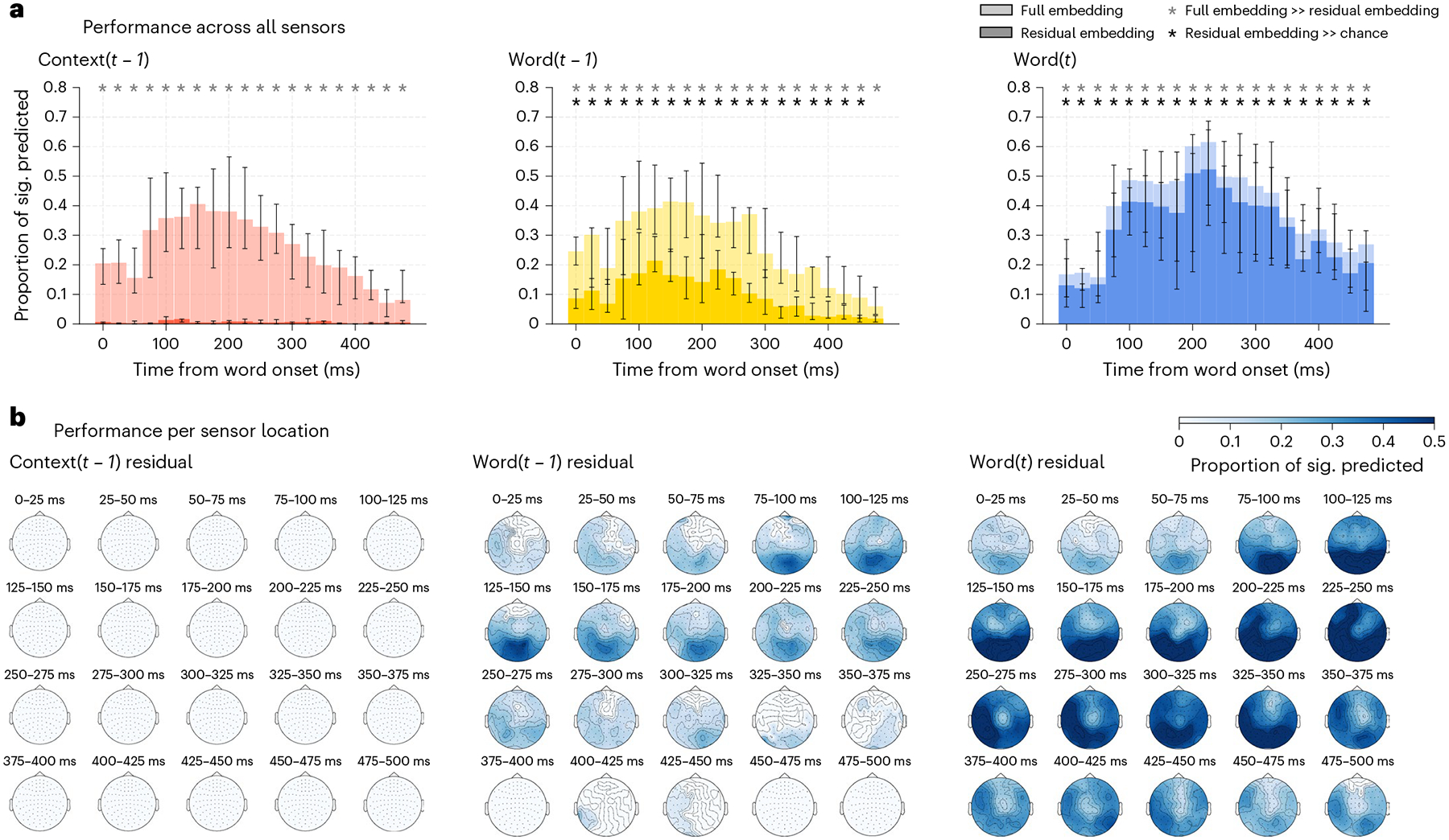
All subplots present the median across all eight participants, and error bars show the 95% confidence interval on the median. a, Proportion of sensors for each timepoint significantly predicted by the full (lighter colours) and residual (darker colours) embeddings. Significant predictions are indicated with an asterisk. Removing the shared information among the full current word, the previous word and the context embeddings results in a significant decrease in performance for all embeddings and lobes (one-sided Wilcoxon signed-rank test, P < 0.05, Benjamini–Hochberg FDR correction). The decrease in performance for the context embedding (left column) is the most drastic, with no time windows being significantly different from chance for the residual context embedding. b, Proportions of sensor neighbourhoods significantly predicted by each residual embedding. Only the significant proportions are displayed (FDR corrected, P < 0.05). Context residuals do not predict any sensor timepoint neighbourhood, while both the previous and the current residual word embedding predict a large subset of sensor timepoints, with performance peaks in occipital and temporal lobes.