
Fig. 4 |. Direct comparisons of prediction performance of different meaning embeddings.
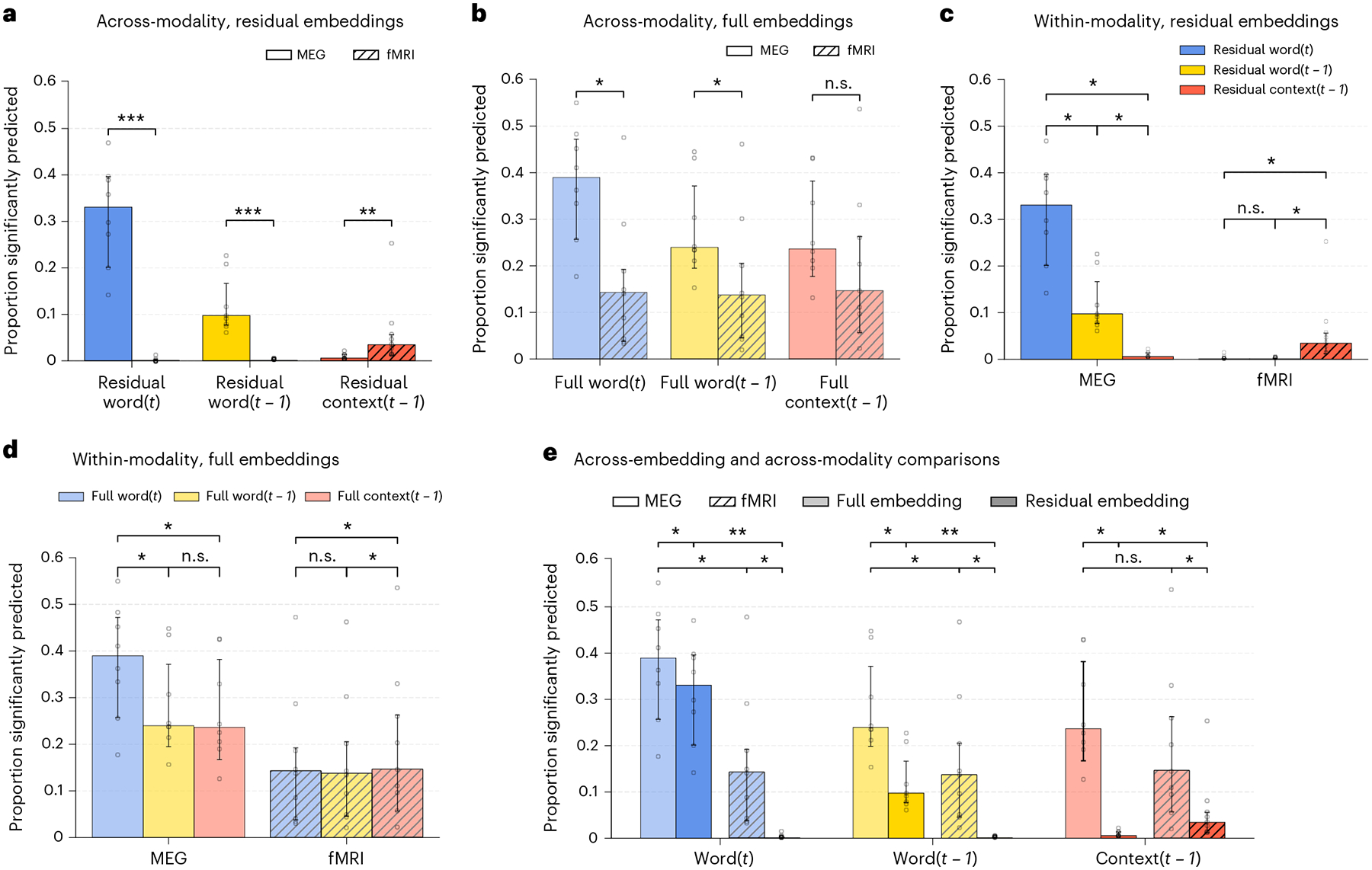
Median proportions across participants and the 95% confidence intervals on the median (nfMRI = 9, nMEG = 8). The proportions for individual participants are marked with open circles. Differences between modalities are tested for significance using a one-sided Wilcoxon rank-sum test. Differences within modality are tested using a one-sided Wilcoxon signed-rank test. All P values are adjusted for multiple comparisons with the Holm–Bonferroni procedure at level 0.05. Significant differences are indicated with asterisks according to their P value (***P < 0.001, **P < 0.01, *P < 0.05). a, Residual previous word, context and current word embeddings predict fMRI and MEG with significant differences. b, Full context embeddings do not predict fMRI and MEG with significant differences, while the full current word and previous word embeddings predict MEG significantly better than fMRI. c, MEG and fMRI display a contrasting pattern of prediction by the residual embeddings. The current residual word embedding best predicts MEG activity, significantly better than the previous residual word embedding, which in turns predicts MEG significantly more than the residual context. In contrast, the residual context significantly predicts fMRI activity better than the previous and current residual word embedding. d, Full previous word and context embeddings do not predict MEG significantly differently. e, All full embeddings predict both fMRI and MEG significantly better than the corresponding residual embeddings.