
Figure 6. Rats choose reaction time based on stimulus learnability.
(a) Schematic of experiment: rats trained on stimulus pair 1 were presented with new visible stimulus pair 2 or transparent (alpha = 0, 0.1) stimuli. If rats change their reaction times based on stimulus learnability, they should increase their reaction times for the new visible stimuli to increase learning and future and decrease their reaction time to increase for the transparent stimuli. (b) Learning across normalized sessions in speed-accuracy space for new visible stimuli (, crosses) and transparent stimuli (, squares). Color map indicates time relative to start and end of the experiment. (c) -sensitive threshold model runs with ‘visible’ (crosses) and ‘transparent’ (squares) stimuli (modeled as containing some signal, and no signal) plotted in speed-accuracy space. The crosses are illustrative and do not reflect any uncertainty. Color map indicates time relative to start and end of simulation. (d) Mean change in reaction time across sessions for visible stimuli or transparent stimuli compared to previously known stimuli. Positive change means an increase relative to previous average. Inset: first and second half of first session for transparent stimuli. * denotes in permutation test. (e) Correlation between initial individual mean change in reaction time (quantity in d) and change in signal-to-noise ratio (SNR) (learning speed: slope of linear fit to SNR per session) for first three sessions with new visible stimuli. R2 and from linear regression in d. Error bars reflect standard error of the mean in b and d. (f) Decision time across time engagement time for visible and transparent stimuli runs in model simulation. (g) Instantaneous change in SNR () as a function of initial reaction time (decision time + non-decision time T0) in model simulation.

Figure 6—figure supplement 1. Reaction time analysis of transparent stimuli experiment.

Figure 6—figure supplement 2. Vincentized reaction time distributions throughout learning.

Figure 6—figure supplement 3. Simple drift-diffusion model (DDM) + variable drift rate variability fits for transparent stimuli.
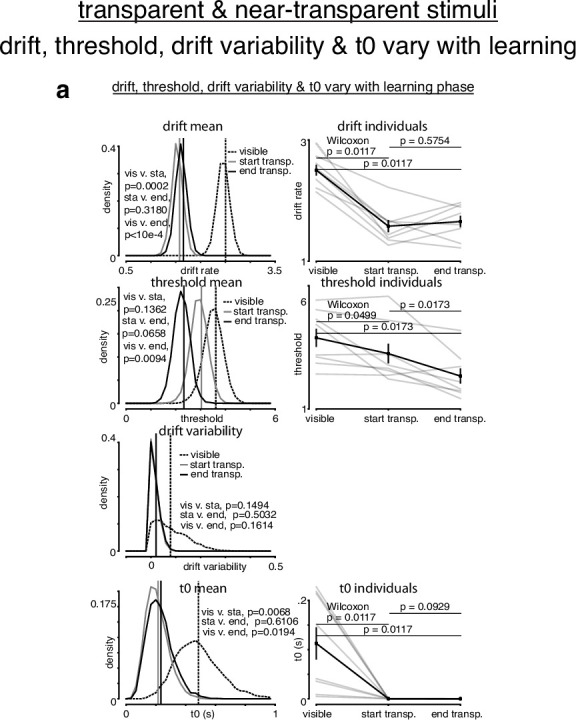
Figure 6—figure supplement 4. Analysis of stimulus-independent strategies for transparent stimuli.

Figure 6—figure supplement 5. Post-error slowing during rat learning dynamics.
