

Key Points
Question
In response to patient questions about cancer on an online forum, how do conversational artificial intelligence chatbots compare with licensed physicians across measures of empathy, response quality, and readability?
Findings
In this equivalence trial, after controlling for response length to 200 patient questions, 6 oncology physician evaluators consistently rated chatbot responses higher in response empathy, quality, and readability based on style of writing. The mean reading grade level of physician responses was lower than those from 2 of 3 chatbots, suggesting that chatbot responses may be more difficult to read based on word and sentence length.
Meaning
The results of this study may motivate future development of physician-chatbot collaborations in clinical practice to expand access to care for more patients and decrease physician burnout, wherein chatbots may provide empathetic response templates for physicians to edit for medical accuracy using their expertise and clinical judgment.
Abstract
Importance
Artificial intelligence (AI) chatbots pose the opportunity to draft template responses to patient questions. However, the ability of chatbots to generate responses based on domain-specific knowledge of cancer remains to be tested.
Objective
To evaluate the competency of AI chatbots (GPT-3.5 [chatbot 1], GPT-4 [chatbot 2], and Claude AI [chatbot 3]) to generate high-quality, empathetic, and readable responses to patient questions about cancer.
Design, Setting, and Participants
This equivalence study compared the AI chatbot responses and responses by 6 verified oncologists to 200 patient questions about cancer from a public online forum. Data were collected on May 31, 2023.
Exposures
Random sample of 200 patient questions related to cancer from a public online forum (Reddit r/AskDocs) spanning from January 1, 2018, to May 31, 2023, was posed to 3 AI chatbots.
Main Outcomes and Measures
The primary outcomes were pilot ratings of the quality, empathy, and readability on a Likert scale from 1 (very poor) to 5 (very good). Two teams of attending oncology specialists evaluated each response based on pilot measures of quality, empathy, and readability in triplicate. The secondary outcome was readability assessed using Flesch-Kincaid Grade Level.
Results
Responses to 200 questions generated by chatbot 3, the best-performing AI chatbot, were rated consistently higher in overall measures of quality (mean, 3.56 [95% CI, 3.48-3.63] vs 3.00 [95% CI, 2.91-3.09]; P < .001), empathy (mean, 3.62 [95% CI, 3.53-3.70] vs 2.43 [95% CI, 2.32-2.53]; P < .001), and readability (mean, 3.79 [95% CI, 3.72-3.87] vs 3.07 [95% CI, 3.00-3.15]; P < .001) compared with physician responses. The mean Flesch-Kincaid Grade Level of physician responses (mean, 10.11 [95% CI, 9.21-11.03]) was not significantly different from chatbot 3 responses (mean, 10.31 [95% CI, 9.89-10.72]; P > .99) but was lower than those from chatbot 1 (mean, 12.33 [95% CI, 11.84-12.83]; P < .001) and chatbot 2 (mean, 11.32 [95% CI, 11.05-11.79]; P = .01).
Conclusions and Relevance
The findings of this study suggest that chatbots can generate quality, empathetic, and readable responses to patient questions comparable to physician responses sourced from an online forum. Further research is required to assess the scope, process integration, and patient and physician outcomes of chatbot-facilitated interactions.
This equivalence study compared the use of oncologist vs chatbot responses to patient questions regarding cancer in an online forum.
Introduction
The integration of digital solutions in oncology shows great potential to reduce costs, workflow inefficiencies, and physician burnout while improving patient outcomes and quality of life.1 The application of artificial intelligence (AI) has made substantial strides in medicine and health care delivery.2 In particular, conversational AI chatbots have been successfully piloted to educate patients with cancer about various aspects of clinical diagnostics and treatment approaches.3,4,5
There is major interest in applying these technologies in a patient-facing capacity; however, their performance with respect to competencies such as medical accuracy, conveying empathy, and enhancing readability are unclear. In a recent study, chatbot responses were found to be more empathetic than physician responses for general medicine patient questions on online forums.6 To further benchmark the competence of chatbots in responding to oncology-related patient questions, we evaluated multiple state-of-the-art chatbots using pilot metrics of response quality, empathy, and readability.
Methods
In this equivalence trial, after obtaining approval from the University Health Network Research Ethics Board, we collected a random sample of 200 unique public patient questions related to cancer and corresponding verified physician responses posted on Reddit r/AskDocs7 from January 1, 2018, to May 31, 2023. Data were collected on May 31, 2023. We generated responses from 3 AI chatbots (GPT-3.5 [chatbot 1], GPT-4 [chatbot 2], and Claude AI [chatbot 3]) to each patient question with an additional prompt to limit the word length of the chatbot response to the mean physician response word count (mean, 125). Responses were blinded and randomly ordered for each question.
First, the readability of each response was measured using the Flesch-Kincaid Grade Level (FKGL), Automated Readability Index, and Gunning-Fog Index. Second, 2 measures of cognitive load for reading comprehension—mean dependency distance for syntactic complexity and measure of textual lexical diversity for lexical diversity—were examined. Third, responses were rated based on overall measures of quality, empathy, and readability by attending physicians from radiation oncology (n = 2), medical oncology (n = 2), and palliative and supportive care (n = 2) (eTable 1 and eMethods in Supplement 1). The primary outcomes were pilot ratings of the quality, empathy, and readability on a Likert scale, ranging from 1 to 5 (1: very poor, 2: poor, 3: acceptable, 4: good, and 5: very good). Each metric was independently rated by 3 evaluators (2 teams: A.H., B.H., F.-F.L., and E.M., L.E., N.F.-R.) and averaged to determine a consensus score.
Using 1-way analysis of variance with a post hoc Tukey honestly significantly difference test (paired, 2-sided test with significance level at P < .05), we compared each rating of readability, quality, and empathy (n = 200) and readability metrics (n = 90) between responses generated by chatbots and physicians. Correlations between metrics were analyzed using Pearson correlation coefficient. Statistical analyses were conducted with Python, version 3.8.9 (Python Software Foundation) using scipy 1.11.3.
Results
Responses generated by chatbot 1, chatbot 2, and chatbot 3 were rated consistently higher in mean component measures of response quality, including medical accuracy, completeness, and focus, as well as overall quality compared with physician responses (Figure 1A; eFigure 1 in Supplement 1). Likewise, both the overall and the component measures of empathy of chatbot responses were rated higher than physician responses (Figure 1B; eFigure 2 in Supplement 1). The detailed statistical results are provided in the Table and eTable 2 in Supplement 1. The best-performing AI chatbot, chatbot 3, was rated higher in overall measures of quality (mean, 3.56 [95% CI, 3.48-3.63] vs 3.00 [95% CI, 2.91-3.09]; P < .001), empathy (mean, 3.62 [95% CI, 3.53-3.70] vs 2.43 [95% CI, 2.32-2.53]; P < .001), and readability (mean, 3.79 [95% CI, 3.72-3.87] vs 3.07 [3.00-3.15]; P < .001) compared with physician responses.
Figure 1. Overall Median and Distribution of Physician Rater Evaluations of Physician and Chatbot Responses to Patient Questions.

Quality (A), empathy (B), and readability (C) of physician and chatbot responses to patient questions. Chatbot 1 indicates GPT-3.5; chatbot 2, GPT-4; and chatbot 3, Claude AI. The midline indicates the median (50% percentile); the box, 25% and 75% percentile; whiskers, 5% and 95% percentile; and the density distribution plot represents the probability density of the response score distribution.
Table. Quality, Empathy, and Readability Scores of Physician and Chatbot Responses to Patient Questionsa.
| Evaluation category and metric | Response, mean (95% CI)b | |||
|---|---|---|---|---|
| Physician | Chatbot 1 | Chatbot 2 | Chatbot 3 | |
| Rater-evaluated quality score | ||||
| Medical accuracy | 3.16 (3.08-3.23) | 3.31 (3.23-2.29) | 3.57 (3.50-3.64)c | 3.55 (3.47-3.64)c |
| Completeness | 2.89 (2.78-2.99) | 3.21 (3.13-3.28)c | 3.53 (3.45-3.60)c | 3.66 (3.57-3.75)c |
| Focus | 3.08 (3.00-3.16) | 3.32 (3.24-3.39)c | 3.57 (3.51-3.63)c | 3.56 (3.48-3.64)c |
| Quality overall score | 3.00 (2.91-3.09) | 3.25 (3.18-3.32)c | 3.52 (3.46-3.59)c | 3.56 (3.48-3.63)c |
| Rater-evaluated empathy score | ||||
| Emotional empathy | 2.36 (2.25-2.48) | 3.18 (3.10-3.26)c | 3.22 (3.13-3.30)c | 3.63 (3.53-3.72)c |
| Cognitive empathy | 2.46 (2.35-2.57) | 3.12 (3.04-3.20)c | 3.22 (3.15-3.28)c | 3.49 (3.41-3.58)c |
| Empathy overall score | 2.43 (2.32-2.53) | 3.17 (3.10-3.24)c | 3.28 (3.20-3.36)c | 3.62 (3.53-3.70)c |
| Rater-evaluated readability score | ||||
| Readability overall score | 3.07 (3.00-3.15) | 3.42 (3.34-3.50)c | 3.77 (3.71-3.82)c | 3.79 (3.72-3.87)c |
| Readability metric | ||||
| Word count | 125 (108-142) | 136 (133-139) | 140 (139-142) | 198 (193-204)c |
| Flesch-Kincaid Grade Level | 10.11 (9.21-11.03) | 12.33 (11.84-12.83)c | 11.32 (11.05-11.79) | 10.31 (9.89-10.72) |
Rater-evaluated quality, empathy, and readability of chatbot responses were only compared to physician responses. Rater evaluation of the quality, empathy, and readability of patient questions was not conducted.
Chatbot 1 indicates GPT-3.5; chatbot 2, GPT-4; and chatbot 3, Claude AI.
Mean metric of chatbot responses was significantly different compared with mean metric of physician response (α < .05).
Mean word count of the chatbot 3 responses (mean, 198.16 [95% CI, 192.61-203.71]; P < .001) was increased compared with physician responses (mean, 125.19 [95% CI, 108.13-142.24]), while the chatbot 1 (mean, 135.87 [95% CI, 132.78-138.96]; P = .37) and chatbot 2 (mean, 140.15 [95% CI, 138.66-141.62]; P = .11) responses were not significantly different. Despite attempting to control for word count, only chatbot 3 responses had higher mean word count than physician responses (Figure 2A). Physician responses tended to score lower in terms of FKGL, indicating a higher level of calculated readability, compared with chatbot responses (Figure 2B; eFigure 3 in Supplement 1). Both chatbot 1 (mean, 12.33 [95% CI, 11.84-12.83]; P < .001) and chatbot 2 (mean, 11.42 [95% CI, 11.05-11.79]; P = .01) responses had significantly higher mean FKGL compared with physician responses (mean, 10.12 [95% CI, 9.21-11.03]), whereas chatbot 3 responses (mean, 10.31 [95% CI, 9.89-10.72]; P = .97) were on par with physicians. However, physician responses were rated 18.9% lower in mean overall readability (mean, 3.07 [95% CI, 3.00-3.15]) compared with the highest-rated chatbot, chatbot 3 (mean, 3.79 [95% CI, 3.72-3.87]; P < .001).
Figure 2. Measures of Cognitive Load of Patient Questions, Physician Responses, and Chatbot Responses.
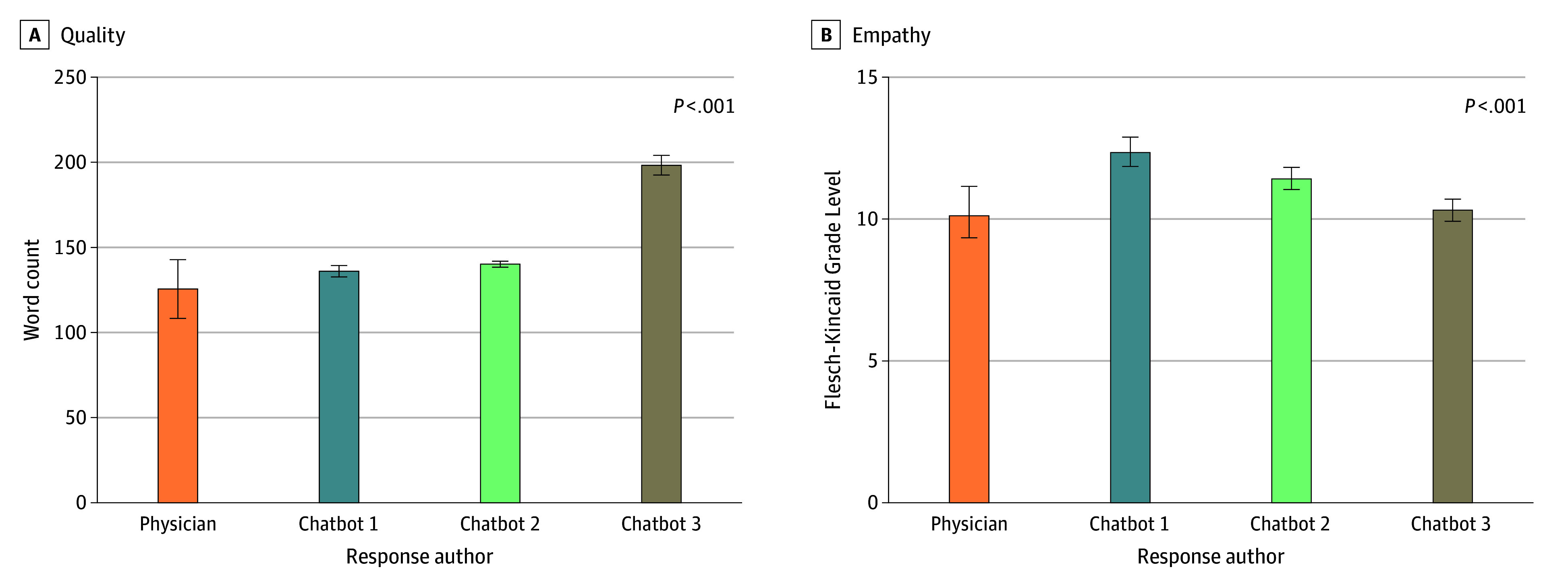
Means and 95% CIs are shown for word count (A). Flesch-Kincaid Grade Level of readability (B). Chatbot 1 indicates GPT-3.5; chatbot 2, GPT-4; and chatbot 3, Claude AI.
Word count was positively correlated with measures of response quality generated by physicians, chatbot 1, and chatbot 2 and positively correlated with measures of empathy for physician and chatbot 3 responses only (eFigure 4 in Supplement 1).
Discussion
Study benchmarks observed that chatbot 1, chatbot 2, and chatbot 3 can provide quality, empathetic, and readable responses to patients’ cancer questions compared with physician responses in a public online forum; this result is consistent with previous findings in the general medicine setting.6 We speculate that the higher variance of physician response scores in quality, empathy, and readability may be related to differences in the amount of effort and commitment to patient care between an anonymous online forum and real physician-patient relationships.
The superior empathy of chatbot responses may encourage future investigation of physician-chatbot collaborations in clinical practice with the hope that chatbots can provide empathetic response templates for physicians to edit for medical accuracy. We hypothesize that the lower reading grade level and lower readability ratings of physician responses compared with chatbot responses may be due to the use of shorter sentences in place of fewer but longer sentences coupled with natural variation in grammar, spelling, and informal tone of communication on an online forum. Patient preferences of the reading grade level of medical advice remains unclear.8 Thus, we recommend that the use of template responses to patient questions generated by chatbots should remain under the oversight of a supervising clinician to ensure content quality and readability while tailoring its use based on the complexity and acuity of the patient scenario.9
Future development of specialized chatbots trained with large corpora of domain-specific medical text may provide supportive emotional care to patients with cancer while also being fine-tuned for the nuanced medical and psychosocial considerations of oncology care.8,10 In addition, if carefully deployed, chatbots can serve as a useful point-of-care tool for providing digital health care and information to vulnerably situated populations without accessible clinical care due to geography and financial considerations or lack of social integration.
Future benchmarks of conversational AI chatbots should be conducted in carefully designed randomized clinical trials in clinical settings to inform their implementation into clinical workflow, with considerations for appropriate oversight and limitations in scope, as well as outcomes for physicians and patients.
Limitations
The primary limitations of this study include the use of isolated textual exchanges on an online forum to model physician-patient interactions and the lack of patient raters to measure response empathy from a patient perspective. The attempt to limit word count saw mixed results: chatbot 1 and chatbot 2 generally abided by the limit, while chatbot 3 routinely exceeded the limit by 60 to 70 words, thereby potentially introducing a confounding factor. Other limitations include the fact that the pilot summary measures of quality and empathy were not validated, chatbots were trained on date-limited public data without access to peer-reviewed medical literature, the sample size of physician ratings for each response was limited (n = 3), physician raters were not matched to rate responses within their oncology subspecialty domain, patient questions generally fell inside the scope of generalist physicians, and differences of patient-physician interactions on forums compared with longitudinal patient-physician relationships are possible.
Conclusions
The findings of this equivalence trial suggest the potential for conversational AI chatbots to generate high-quality, empathetic, and readable responses to patient questions compared with physicians. Further research is required to investigate the implementation of AI chatbots into clinical workflows with consideration of chatbot scope, data security, and content accuracy in the age of digital health care.
eFigure 1. Rater Evaluations of Physician and Chatbot Responses to Patient Questions Using Pilot Component Measures of Response Quality
eFigure 2. Rater Evaluations of Physician and Chatbot Responses to Patient Questions Using Pilot Component Measures of Empathy
eFigure 3. Readability of Physician and Chatbot Responses to Patient Questions
eFigure 4. Correlation Heatmap of Physician-Evaluated Component and Overall Measures of Response Quality, Empathy, Readability, and Word Count
eTable 1. Definitions of Component and Overall Measures of Quality, Empathy, and Readability Used for Response Evaluation
eTable 2. Mean Scores of Readability (ARI, GFI), Syntactic Complexity (MDD), and Lexical Diversity (MLTD) of Physician Responses and Chatbot Responses to Patient Questions
eMethods. Instructions to Physician Raters
Data Sharing Statement
References
- 1.Garg S, Williams NL, Ip A, Dicker AP. Clinical integration of digital solutions in health care: an overview of the current landscape of digital technologies in cancer care. JCO Clin Cancer Inform. 2018;2:1-9. doi: 10.1200/CCI.17.00159 [DOI] [PubMed] [Google Scholar]
- 2.Haug CJ, Drazen JM. Artificial intelligence and machine learning in clinical medicine, 2023. N Engl J Med. 2023;388(13):1201-1208. doi: 10.1056/NEJMra2302038 [DOI] [PubMed] [Google Scholar]
- 3.Siglen E, Vetti HH, Lunde ABF, et al. Ask Rosa—the making of a digital genetic conversation tool, a chatbot, about hereditary breast and ovarian cancer. Patient Educ Couns. 2022;105(6):1488-1494. doi: 10.1016/j.pec.2021.09.027 [DOI] [PubMed] [Google Scholar]
- 4.Görtz M, Baumgärtner K, Schmid T, et al. An artificial intelligence–based chatbot for prostate cancer education: design and patient evaluation study. Digit Health. 2023;9:20552076231173304. doi: 10.1177/20552076231173304 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Chaix B, Bibault JE, Pienkowski A, et al. When chatbots meet patients: one-year prospective study of conversations between patients with breast cancer and a chatbot. JMIR Cancer. 2019;5(1):e12856. doi: 10.2196/12856 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Ayers JW, Poliak A, Dredze M, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med. 2023;183(6):589-596. doi: 10.1001/jamainternmed.2023.1838 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ask Docs . Reddit. Accessed April 2022. https://reddit.com/r/AskDocs/
- 8.Au Yeung J, Kraljevic Z, Luintel A, et al. AI chatbots not yet ready for clinical use. Front Digit Health. 2023;5:1161098. doi: 10.3389/fdgth.2023.1161098 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Morrow GR, Hoagland AC, Carpenter PJ. Improving physician-patient communications in cancer treatment. J Psychosoc Oncol. 1983;1(2):93-101. doi: 10.1300/J077v01n02_07 [DOI] [Google Scholar]
- 10.Greer S, Ramo D, Chang YJ, Fu M, Moskowitz J, Haritatos J. Use of the chatbot “vivibot” to deliver positive psychology skills and promote well-being among young people after cancer treatment: randomized controlled feasibility trial. JMIR Mhealth Uhealth. 2019;7(10):e15018. doi: 10.2196/15018 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
eFigure 1. Rater Evaluations of Physician and Chatbot Responses to Patient Questions Using Pilot Component Measures of Response Quality
eFigure 2. Rater Evaluations of Physician and Chatbot Responses to Patient Questions Using Pilot Component Measures of Empathy
eFigure 3. Readability of Physician and Chatbot Responses to Patient Questions
eFigure 4. Correlation Heatmap of Physician-Evaluated Component and Overall Measures of Response Quality, Empathy, Readability, and Word Count
eTable 1. Definitions of Component and Overall Measures of Quality, Empathy, and Readability Used for Response Evaluation
eTable 2. Mean Scores of Readability (ARI, GFI), Syntactic Complexity (MDD), and Lexical Diversity (MLTD) of Physician Responses and Chatbot Responses to Patient Questions
eMethods. Instructions to Physician Raters
Data Sharing Statement