

Abstract
Simple Summary
Colorectal cancer (CRC) is a complex disease that has a high mortality rate. This study explored CRC-related core genes (CGs) from multiple microarray gene-expression profiles in the NCBI-GEO database by combining some statistics and bioinformatics techniques. It also disclosed their molecular functions, biological processes, cellular components, signaling pathways, and transcriptional and post-transcriptional regulatory factors by using different online bioinformatics tools and databases. The prognostic power of CGs was investigated from the independent TCGA database by using survival probability curves and box plots of CGs-expressions in different stages (control, Stage 1, Stage 2, Stage 3, and Stage 4) of CRC. Finally, a few CGs-guided drug molecules were suggested for the treatment of CRC by molecular docking and dynamic simulation studies. Therefore, the findings of this study would be useful resources for early diagnosis, prognosis, and therapies of CRC.
Abstract
Colorectal cancer (CRC) is one of the most common cancers with a high mortality rate. Early diagnosis and therapies for CRC may reduce the mortality rate. However, so far, no researchers have yet investigated core genes (CGs) rigorously for early diagnosis, prognosis, and therapies of CRC. Therefore, an attempt was made in this study to explore CRC-related CGs for early diagnosis, prognosis, and therapies. At first, we identified 252 common differentially expressed genes (cDEGs) between CRC and control samples based on three gene-expression datasets. Then, we identified ten cDEGs (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, CKS2, MELK, and TPX2) as the CGs, highlighting their mechanisms in CRC progression. The enrichment analysis of CGs with GO terms and KEGG pathways revealed some crucial biological processes, molecular functions, and signaling pathways that are associated with CRC progression. The survival probability curves and box-plot analyses with the expressions of CGs in different stages of CRC indicated their strong prognostic performance from the earlier stage of the disease. Then, we detected CGs-guided seven candidate drugs (Manzamine A, Cardidigin, Staurosporine, Sitosterol, Benzo[a]pyrene, Nocardiopsis sp., and Riccardin D) by molecular docking. Finally, the binding stability of four top-ranked complexes (TPX2 vs. Manzamine A, CDC20 vs. Cardidigin, MELK vs. Staurosporine, and CDK1 vs. Riccardin D) was investigated by using 100 ns molecular dynamics simulation studies, and their stable performance was observed. Therefore, the output of this study may play a vital role in developing a proper treatment plan at the earlier stages of CRC.
Keywords: colorectal cancer, gene expression profiles, core genes, early diagnosis, prognosis, therapies, integrated statistics and bioinformatics approaches
1. Introduction
Cancer is a complex disease caused by multiple alterations at the genetic and epigenetic levels that increasingly lead to abnormal cell division and cellular transformation [1,2]. Colorectal cancer (CRC) is the third most common solid malignancy and the second deadliest tumor worldwide [3]. The CRC incidence is expected to rise by 60%, with 2.2 million new cases and 1.1 million deaths globally by 2030 [4]. The number of new incidences and mortalities is increasing due to insufficient evidence about diagnostic biomarkers and the molecular mechanism of CRC [4]. Early detection of CRC is associated with lower morbidity and mortality and a higher survival rate compared with late detection. For example, the five-year survival rate increases from 11% (late detection) to 90% at early detection of CRC [5]. However, the survival rate significantly decreases, and the cost of treatment increases, whereas CRC is identified in later stages compared to earlier stages [3,6,7]. Therefore, early diagnosis, prognosis, and therapies leads to reduce CRC-related mortality [7]. Several factors, including excessive alcohol consumption, obesity, unhealthy dietary habits, and an abnormal lifestyle, are all considered non-causal risk factors for CRC development. However, these non-causal risk factors cannot be used for CRC detection at an earlier stage.
Generally, differentially expressed genes (DEGs) between cancer and control samples are considered as the cancer-causing/stimulating genes. A gene may show a differential expression pattern between cancer and control samples for several reasons, including mutation, DNA methylation, and other epigenetic stimulations. The genes that are associated with the development of cancer, are known as oncogenes (upregulated DEGs) and tumour-suppressor genes (down-regulated DEGs) [1,2,8]. Thus, cancer incidence, development, recurrence, and non-recurrence are associated with pathogenetic processes of DEGs [9]. Several studies reported some dysregulating genes in the CRC cases compared to non- CRC cases that are associated with CRC proliferation, differentiation, apoptosis, metastasis, recurrence, and lower survival [10,11,12,13]. Many earlier transcriptomics studies explored the pathogenetic processes of CRC through DEGs [14,15,16,17,18,19,20,21]. However, none of them discussed rigorously about early diagnosis, prognosis, and therapies for CRC. Patil et al. (2021) [22] identified forty CRC-causing/stimulating core DEGs and recommended their application for the early diagnosis of CRC. Though the number 40 is much smaller than the whole genome size, it may also not be suitable for further investigation by the wet-lab researchers, since wet-lab experiments with 40 DEGs might be costly, time-consuming, and laborious. So, a smaller set of core DEGs might be required for further experimental investigation. On the other hand, this study did not provide any recommendations about suggested core DEGs guide any drug molecules for therapies for CRC. Therefore, the present study attempted to discover CRC-causing/stimulating core-DEGs, highlighting their pathogenetic processes for early prognosis, diagnosis, and therapies of CRC. The pipeline of this study is given in Figure 1.
Figure 1.

The pipeline of this study.
2. Materials and Methods
2.1. Data Sources and Descriptions
The necessary datasets that were analyzed in this study are described below.
2.1.1. Collection of Microarray Datasets to Explore CRC-Causing Core Genes
We downloaded three microarray datasets of CRC using the accession IDs GSE106582, GSE110223, and GSE74602 from the NCBI Gene Expression Omnibus (GEO) database. The GPL10558 platform was used for the GSE106582 dataset, which contains 194 samples, including 77 cancer and 117 adjacent tissue samples. The GPL96 platform was used for the GSE110223 dataset, which contains 26 samples, including 13 cancer and 13 adjacent tissue samples. The GPL6104 platform was used for the GSE74602 dataset, which contains 60 samples, including 30 cancer and 30 adjacent tissue samples.
2.1.2. Collection of Drug Molecules Set for Drug Repositioning
For identifying candidate repurposed drugs, we collected target receptor-guided drug molecules from the DSigDB [23] database (Table S1).
2.2. Method for Identification of DEGs
We used the GEO2R web tool [24] based on the LIMMA (linear models for microarray data) approach to identify DEGs between cancer and adjacent tissue samples for each of the three datasets. The LIMMA method uses modified t-statistics to calculate p-values. We used the Benjamini–Hochberg (BH) approach [25] to adjust the p-values. The log2 fold-change (Log2FC) and adjusted p-values were used to separate the up- and down-regulated DEGs by the following cut-offs:
| (1) |
We considered common DEGs (cDEGs) from three datasets to identify core CGs. All DEGs were visualized using a Venn diagram using FunRich 3.1.3 [26].
2.3. Protein-Protein Interaction (PPI) Network Analysis
The protein-protein interaction (PPI) network was utilized to detect core genes (CGs) from cDEGs. We considered the STRING database [27] with a median confidence score (MCS) of 0.4 to produce a PPI network of cDEGs and Cytoscape software for better visualization of the network [28]. The CGs were selected from the PPI network using the CytoHubba plugin in Cytoscape [28,29]. The present study used maximal clique centrality (MCC) topology analysis methods to identify the CGs.
2.4. Association of CGs with Different Stages of CRC Progression
To investigate the association of CGs with the different stages of CRC based on independent databases, we performed box-plot analysis based on their expression levels in different CRC progression stages (Normal status, Stage 1, Stage 2, Stage 3, and Stage 4) through the UALCAN web tool with the TCGA-COAD and TCGA-READ databases [30,31].
2.5. Prognosis Power of CGs
To investigate the prognosis power of CGs by multivariate Kaplan–Meier survival probability curves, we considered the SurvExpress web tool based on the TCGA-COAD and TCGA-READ databases (https://portal.gdc.cancer.gov/exploration, accessed date: 2 January 2022) [30,32]. The log-rank test was used in SurvExpress, and the risk group hazard ratio with a 95% confidence interval was included in the Kaplan-Meier survival plot [32]. The p-value < 0.05 was used as the cut-off.
2.6. CGs-Set Enrichment Analysis
CGs-set enrichment analysis (cGSEA) determines the classes of genes or proteins that are over-represented (enriched) in a predefined large set of genes or proteins that are associated with the terms of interest, including gene ontology (GO), pathways, diseases, chemicals, drugs, biomolecules (miRNA, TFs), and so on. To detect the significantly enriched terms of interest, let Ai be the predefined gene-set in the ith term of interest, and Mi denotes the number of CGs in Ai (i = 1, 2,…, r); T is considered as an enriched gene number that created a combined set A such that and where is considered as the complement-set of Ai. Again, suppose t represents the number of CGs and mi denotes the number of CGs subset of Ai. Table 1 summarizes these results.
Table 1.
Contingency table.
| Predefined Gene-Set | CGs (Proposed) | Not CGs (Proposed) | Marginal Total |
|---|---|---|---|
| ith term of interest (Ai) | mi | Mi − mi | Mi |
| Complement of Ai () | t − mi | T − Mi − t + mi | T − Mi |
| Marginal total | t | T − t | T (Grand total) |
The Enrichr web tool [33] was considered to investigate the association of CGs with terms of interest. This web tool uses the Fisher exact test to examine the significance of the association between CGs and ith term of interest.
2.7. Association of CGs with Different Diseases
We considered the Enrichr web tool [33] to verify the association of CGs with different diseases, including CRC, using the DisGeNET database, which was constructed based on 21,671 genes and 30,170 diseases [34]. It measures the association of a disease with a group of CGs that are overlapped (common) with the reference gene set of that disease (see Table 1). To investigate the pan-cancer role of CGs, we performed the pan-cancer analysis of each CG by the TIMER 2.0 web tool [35] with the TCGA database [36]. In both cases, the p-value < 0.05 was selected as the cut-off for statistical significance.
2.8. Association of CGs with GO Terms and KEGG Pathway
To disclose the pathogenetic processes of CGs, we performed CGs-set enrichment analysis with GO terms and pathways by using the Enrichr web tool [33]. Biological process (BPs), molecular function (MFs), and cellular component (CCs) were investigated to explore potential GO terms and pathways based on the KEGG database as displayed in Table 1. A p-value < 0.001 was used as the cut-off for the statistical significance.
2.9. CGs Regulatory Network Analysis
A gene regulatory network (GRN) provides information about molecular regulators that connect to regulate the gene expression level of mRNA. Transcription factors (TFs) and microRNAs (miRNAs) are considered the major regulators of gene expression. TFs proteins are regarded as the significant contributors to GRN because they bind to a particular region of DNA (enricher/promoter) and influence gene expression at the transcriptional level. A miRNA is a non-coding RNA considered a central post-transcriptional regulator of gene expression. The human genome contains up to 1600 TFs and 1900 miRNAs. A TFs vs. CGs network is considered an undirected graph, where nodes represent TFs or CGs and edges depict interactions between TFs and CGs, respectively. A TF-node is considered the major regulatory factor for CGs if it contains the largest number of interactions with CG nodes. We considered regulatory analysis of CGs (transcription factors (TFs) vs. CGs and micro-RNAs (miRNAs) vs. CGs) through Network Analyst [37] platform-based JASPAR [38] and TarBase [39] databases, respectively, to detect the core transcriptional and post-transcriptional regulators of CGs. For better illustration, we used Cytoscape software [28]. The core regulators were chosen by utilizing degree [40] and betweenness [41] scores.
2.10. Molecular Docking
We conducted molecular docking studies of receptors and drug molecules to explore FDA-approved repurposable drugs for CRC. CGs-mediated proteins and related TFs proteins were considered drug target receptors (p = 14). The online database DSigDB was used to extract CGs-guided drug agents. The 3-dimensional (3D) structures of AURKA, TOP2A, CDK1, PTTG1, CDC20, MAD2L1, CKS2, MELK, TPX2, YY1, and SRF targets were retrieved from the Protein Data Bank (PDB) [42] with IDs 6VPM, 5NNE, 5LQF, 7NJ1, 4GGC, 2V64, 5LQF, 5M5A, 6VPM, 4C5I, and 1HBX, respectively. The remaining targets, FOXC1, CDKN3, and NFIC, were retrieved from the SWISS-MODEL [43] with the Uniport IDs Q12948, P08651, and Q16667, respectively. Using the PubChem database [44], we retrieve the 3D structures of all (q = 158) drug molecules. The visualization of the receptor proteins and co-crystal ligands were performed via the Discovery Studio Visualizer 2019 [27]. The receptor proteins were processed using AutoDock tools [45] and the Swiss PDB viewer by adding the structural charges and reducing the energy of receptors, respectively [45,46]. The docked complexes were analyzed through Discovery Studio Visualizer 2019. Let Bij be the binding affinity (BA) score of ith receptors (i = 1, 2,…, p) and jth drugs (j = 1, 2,..., q). The receptors and drug molecules were sorted by the decreasing order of their average BA score for selecting the top-ordered few potential candidate repurposable drugs.
2.11. Molecular Dynamics (MD) Simulation
We performed MD simulations of the top-orderedprotein–ligand complexes (TPX2–Manzamine A, CDC20–Cardidigin, MELK–Staurosporine, and CDK1–Riccardin D) through the YASARA software (Version: 22.8.22) [47] based on the AMBER14 force field [48]. Prior to simulation, the hydrogen-bonding network of each complex in a simulated cell was optimized using a TIP3P water model [45]. The periodic limit conditions were kept constant at 0.997 gL-1 of solvent concentration. The primary energy was minimized in each simulation by considering the steepest gradient technique with 5000 cycles. The complexes “TPX2–Manzamine A”, “CDC20–Cardidigin”, “MELK–Staurosporine”, and “CDK1–Riccardin D” consist of a total of 56,287, 35,859, 81,347, and 45,153 atoms, respectively. At the Berendsen thermostat [49] and constant pressure, a 100 ns MD simulation was examined. Please see our previous publications for details about the MD simulation strategy [50,51,52,53]. For subsequent analysis, we took snapshots of the trajectories every 250 ps, ran them via the built-in script of YASARA [54] macro, and calculated the binding free energy of the MM-Poisson–Boltzmann surface area (MM-PBSA) by analyzing all the snapshots [55]. To calculate binding-free energy, we used the following formula:
| (2) |
More positive binding energy represents stronger binding.
3. Results
3.1. Identification of DEGs
To identify DEGs from each of three microarray gene-expression datasets, we used the statistical LIMMA approach through the GEO2R web tool, with the cut-off at adjusted p-value < 0.05 and |log2(fold change)| > 1. In the GSE106582 dataset, we identified 594 DEGs, including 213 upregulated and 381 downregulated genes. In the GSE110223 dataset, we identified 625 DEGs that contain 260 upregulated and 365 downregulated genes. In the GSE74602 dataset, we identified 1674 DEGs, including 673 upregulated and 1001 downregulated genes. The Venn diagram in Figure 2 visualizes the common DEGs among the three datasets. The Venn diagram exhibits 252 cDEGs among the three datasets.
Figure 2.

Common differentially expressed genes among GSE110223, GSE106582, and GSE74602 datasets were visualized through a Venn diagram, and 252 genes were found as cDEGs from CRC patients.
3.2. Identification of Core Genes (CGs)
We construct the PPI network of cDEGs and visualize the PPI network to identify the potential genes most significantly associated with the development of CRC. The PPI network contains 216 nodes and 616 edges, with a confidence score of 0.40. Then, the MCC topology analysis method of CytoHubba was performed to calculate the top-ranked CGs within the network. We found the ten top-ranked (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, CKS2, MELK, and TPX2) genes (see Figure 3). These top ten CGs were identified as major controllers of CRC and considered for subsequent analysis.
Figure 3.

Protein-protein interaction network for cDEGs. Edges specify the interconnection between two proteins. The PPI network illustrates 216 nodes and 616 edges. Red color nodes (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, CKS2, MELK, and TPX2) represented the CGs.
3.3. Association of CGs with Different Stages of CRC Progression
The box-plot analysis based on an independent database represents a high difference between normal expression and every CRC progression stage (Stage 1, Stage 2, Stage 3, and Stage 4) expression of all CGs (see Figure 4A and Figure S1). So, our proposed CGs have strong prognostic power to identify CRC at an earlier development stage.
Figure 4.

(A) Box plots for the expressions of CGs with various stages of colon adenocarcinoma (Stage 1, Stage 2, Stage 3, and Stage 4) using the COAD database and comparison with the control stage from the TCGA database. (B) The multivariate Kaplan–Meier survival probability plot of CRC patients with the CGs-expressions using the TCGA-COAD and TCGA-READ databases.
3.4. Prognosis Power of CGs
A survival analysis was performed to examine the prognosis power of CGs. The multivariate Kaplan–Meier survival plot of CGs expressions using the TCGA-COAD and TCGA-READ databases represents a significant difference (p-value < 0.001) between lower-risk and higher-risk groups (see Figure 4B).
3.5. Association of CGs with Different Diseases
The enrichment analysis of the CGs-set with different diseases based on the DisGeNET database showed that the CGs-set is significantly associated with various diseases (p-value < 0.05). Figure 3A and Table S2 show the top-ranked 20 diseases, all of which are different types of cancer, including CRC. We observed that 3 CGs (MELK, CKS2, CDC20) and 2 CGs (MELK, CDC20) do not overlap with the reference gene-sets of colon carcinoma and colorectal carcinoma, respectively (Figure 5A and Figure S2, and Table S2). These results suggested a pan-cancer role for CGs (Figure S3). To investigate the pan-cancer role of CGs, we also performed pan-cancer analysis based on the TCGA database. We selected the top-ranked 20 cancers as displayed in Figure 5B. Figure 5A,B commonly showed that eight cancers (colon adenocarcinoma, bladder urothelial carcinoma, esophageal carcinoma, glioblastoma multiforme, liver hepatocellular carcinoma, lung adenocarcinoma, prostate adenocarcinoma, and stomach adenocarcinoma) are significantly associated with CGs.
Figure 5.

Association of CRC-causing CGs with different diseases. (A) Top 20 diseases associated with CGS obtained by disease-CGs association studies based on the Enrichr web tool with the DisGeNET database, where red and green colors indicate presence and absence, respectively. The red colour text in the column represent CRC-related cancers. (B) Top 20 cancers associated with CGs obtained by pan-cancer analysis based on the TIMER2 web tool with the TCGA database, where red and green colors indicate significant (p-value < 0.05) and insignificant (p-value ≥ 0.05) pairwise gene-disease association, respectively. The red colors text in the column represents CRC-related cancers.
3.6. Association of CGs with GO Terms and KEGG Pathway
Enrichment analysis of the CGs was performed using the Enrichr web tool. Table 2 shows the annotated GO terms in three categories (BPs, CCs, and MFs). In the case of biological processes (BPs), CGs were mainly involved in mitotic cell-cycle phase transition (GO:0044772), anaphase-promoting complex-dependent catabolic process (GO:0031145), regulation of G2/M transition of mitotic cell cycle (GO:0010389), mitotic spindle organization (GO:0007052), regulation of mitotic cell cycle (GO:0007346). In molecular function (MFs), CGs were mainly involved in histone kinase activity (GO:0035173), RNA polymerase II CTD heptapeptide repeat kinase activity (GO:0008353), protein kinase binding (GO:0019901), CXCR chemokine receptor binding (GO:0045236), cyclin-dependent protein kinase activity (GO:0097472), etc. In cellular components (CCs), CGs were mainly involved in the spindle (GO:0005819), cyclin-dependent protein kinase holoenzyme complex (GO:0000307), serine/threonine-protein kinase complex (GO:1902554), intracellular non-membrane-bounded organelle (GO:0043232), mitotic spindle (GO:0072686), etc. The KEGG pathway enrichment analysis results for CGs were also shown in Table 2. The KEGG pathways of CGs were enriched in the cell cycle, bladder cancer, oocyte meiosis, human T-cell leukemia virus one infection, progesterone-mediated oocyte maturation, etc.
Table 2.
List of the top five significantly (p-value < 0.001) annotated GO terms and KEGG pathways by CGs.
| GO ID | GO Term | p-Value | Associated CGs |
|---|---|---|---|
| Biological Process (BPs) | |||
| GO:0044772 | mitotic cell cycle phase transition | 8.50 × 10−10 | MELK;CDK4;MYC;CDK1;AURKA;CDC25B;CDKN3 |
| GO:0031145 | anaphase-promoting complex-dependent catabolic process | 1.71 × 10−8 | CDC20;PTTG1;CDK1;AURKA;MAD2L1 |
| GO:0010389 | regulation of G2/M transition of mitotic cell cycle | 3.04 × 10−7 | TPX2;CDK4;CDK1;AURKA;CDC25B |
| GO:0007052 | mitotic spindle organization | 3.94 × 10−7 | CDC20;TPX2;CENPN;AURKA;MAD2L1 |
| GO:0007346 | regulation of mitotic cell cycle | 7.34 × 10−7 | CDC20;CDK1;CKS2;CDC25B;MAD2L1 |
| Molecular Function (MFs) | |||
| GO:0035173 | histone kinase activity | 2.65 × 10−5 | CDK1;AURKA |
| GO:0008353 | RNA polymerase II CTD heptapeptide repeat kinase activity | 6.23 × 10−5 | CDK4;CDK1 |
| GO:0019901 | protein kinase binding | 1.15 × 10−4 | TOP2A;TPX2;CKS2;AURKA;CDC25B |
| GO:0045236 | CXCR chemokine receptor binding | 1.28 × 10−4 | CXCL8;CXCL12 |
| GO:0097472 | cyclin-dependent protein kinase activity | 2.37 × 10−4 | CDK4;CDK1 |
| Cellular Component (CCs) | |||
| GO:0005819 | Spindle | 1.07 × 10−6 | CDC20;TPX2;CDK1;AURKA;MAD2L1 |
| GO:0000307 | cyclin-dependent protein kinase holoenzyme complex | 3.41 × 10−6 | CDK4;CDK1;CKS2 |
| GO:1902554 | serine/threonine protein kinase complex | 6.50 × 10−6 | CDK4;CDK1;CKS2 |
| GO:0043232 | intracellular non-membrane-bounded organelle | 8.52 × 10−5 | TOP2A;CDC20;TPX2;CDK4;MYC;TRIP13;AURKA |
| GO:0072686 | mitotic spindle | 2.23 × 10−4 | TPX2;CDK1;MAD2L1 |
| Pathways | p-Value | Associated CGs | |
| KEGG Pathway | |||
| Cell cycle | 2.15 × 10−11 | CDC20;PTTG1;CDK4;MYC;CDK1;CDC25B;MAD2L1 | |
| Bladder cancer | 7.19 × 10−8 | CXCL8;MMP1;CDK4;MYC | |
| Oocyte meiosis | 1.48 × 10−7 | CDC20;PTTG1;CDK1;AURKA;MAD2L1 | |
| Human T-cell leukemia virus 1 infection | 2.04 × 10−6 | CDC20;PTTG1;CDK4;MYC;MAD2L1 | |
| Progesterone-mediated oocyte maturation | 2.68 × 10−6 | CDK1;AURKA;CDC25B;MAD2L1 | |
3.7. Identification of Regulatory Factors
TFs proteins and miRNAs play a fundamental role in the modification of gene expression at the transcriptional and post-transcriptional levels, respectively. To explore the major transcriptional regulatory factors of CGs, we constructed a TFs vs. CGs interaction network where round nodes with red color represent the CGs and square nodes with green/purple color represent the TFs (see Figure 6A). TFs proteins vs. CGs regulatory analysis revealed four highest-ranking significant candidate TFs modifiers (NFIC, FOXC1, YY1, and GATA2) that may regulate the expression of CGs at the transcriptional level (see Figure 6A). Similarly, we constructed an undirected interaction network of miRNAs vs. CGs to reveal the post-transcriptional regulator of CGs, where red color nodes represent the CGs and green/blue color nodes illustrate the miRNAs (see Figure 6B). The miRNAs vs. CGs regulatory network analysis revealed six highly interacted non-coding RNAs (miRNAs) such as hsa-mir-147a, hsa-mir-129-2-3p, hsa-mir-124-3p, hsa-mir-34a-5p, hsa-mir-23b-3p, and hsa-mir-16-5p that act as gene expression regulators at the post-transcriptional level (see Figure 6B). So, those identified TFs and miRNAs may influence the gene expression of CGs at the transcriptional and post-transcriptional levels, respectively.
Figure 6.

Regulatory network analysis of CGs. (A) TFs-CGs regulatory network contains 72 nodes and 174 edges. The red node indicates the core genes, whereas purple color nodes represent TFs. Among the TFs, green nodes represent the core TFs. (B) miRNA-CGs interaction network contains 223 nodes and 450 edges. The red node indicates the core genes, whereas blue nodes represent miRNAs. Among the miRNAs, green color represents the core miRNA.
3.8. Drug Repurposing through Molecular Docking Studies
We considered 10 CG-guided proteins and 4 TFs proteins as target-receptor proteins for molecular docking. A structural interaction was carried out between target-receptor proteins and 158 drug agents by molecular docking studies, which computed the receptor-drug binding affinities (BA) for each interaction (see Figure 7).
Figure 7.

Matrix of molecular docking analysis results. The target-receptor proteins are ordered in a row and drug agents are ordered in a column, where red colors represent strong binding affinity. The red colors text in the row represents proposed drug agents.
Manzamine A, Cardidigin, Staurosporine, Sitosterol, Benzo[a]pyrene, Nocardiopsis sp., and Riccardin D were shown to have strong BA against all of the target receptors, and their average BA lies between −9.20 and −8.2 (kcal mol−1). Among those drugs, Manzamine A was shown to have the highest BA against almost every target protein, with an average BA of −9.2 kcal mol−1. Therefore, we proposed those seven drugs (Manzamine A, Cardidigin, Staurosporine, Sitosterol, Benzo[a]pyrene, Nocardiopsis sp., and Riccardin D) as candidate drug agents and displayed them in red color in Figure 7. We also revealed the structural interaction profiles of four top-ordered receptor proteins and drug complexes in Table 3.
Table 3.
The 1st, 2nd, 3rd column show potential targets, 2-dimentional(2d) structure of lead compounds, top ordered binding affinities (kcal mol−1), respectively. The 3-dimension(3d) view of top ranking drug-target complexes is shown in the 4th column. Finally, the last column shows key elements of interacting amino acids, including hydrogen bond, hydrophobic interactions, and electrostatic.
| Potential Targets | Structure of Top Compounds | Binding Affinity Score (kcal mol−1) | 3D Structures of Complex with Interactions | Interacting Amino Acids | ||
|---|---|---|---|---|---|---|
| Hydrogen Bond |
Hydrophobic Interactions |
Electrostatic | ||||
| TPX2 | Manzamine A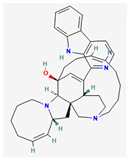
|
−12.4 |
|
- | VAL317 TRP313 HIS366 |
- |
| CDC20 | Cardidigin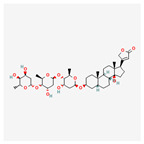
|
−11.0 |
|
TRP317 PRO319 VAL190 LEU449 PRO319 |
LYS236 | - |
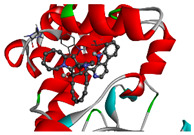
| MELK | Staurosporine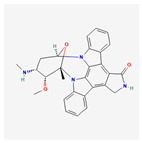
|
−13.4 |
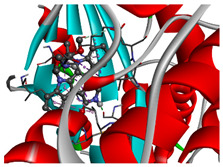
|
GLU87 GLU136 CYS89 ASP150 |
ILE17 VAL25 LEU139 LEU149 ALA38 ILE149 LYS40 |
- |
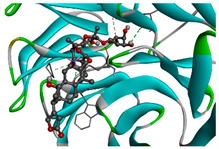
| CDK1 | Riccardin D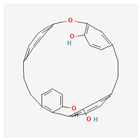
|
−11.3 |
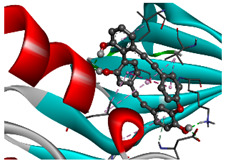
|
LEU83, ASP146, LYS33 |
VAL18 LEU135 ILE10 ALA31 VAL64 |
- |
3.9. Molecular Dynamic (MD) Simulations
TPX2–Manzamine A, CDC20–Cardidigin, MELK–Staurosporine, and CDK1–Riccardin D complexes have shown the highest BA in molecular docking analysis (Table 3). So, we considered those complexes for examining their binding stability through MD simulations. We observed that each protein-ligand complex (TPX2–Manzamine A, CDC20–Cardidigin, MELK–Staurosporine, and CDK1–Riccardin D) showed significant stability in a 100 ns MM-PSSA simulation (see Figure 8A). RMSD values corresponding to each complex were calculated (see Figure 8A). RMSD values showed lower flexibility around 1.5 Å to 3.0 Å for all four complexes. The average RMSD values for TPX2-Manzamine A, CDC20–Cardidigin, MELK–Staurosporine, and CDK1–Riccardin D complexes were 2.592 Å, 1.724 Å, 2.235 Å, and 2.516 Å, respectively. The CDC20–Cardigin complex showed a more substantial structural rigidity than the other three complexes, gained equilibrium at four ns, and displayed good stability after that. MELK–Staurosporine showed a gradual increase in RMSD before 22 ns, and after this time point, the RMSD score of the complex illustrated almost stable movement between 2.2 Å and 2.50 Å for 68 ns. After that, there were irregular fluctuations in the RMSD. On the contrary, CDK1-Riccardin D complexes exhibited instability, and the RMSD displayed an upward trend from 2.0 Å to 3.2 Å over time. Similarly, TPX2–Manzamine A showed irregular oscillation in RMSD between 1.7 Å and 3.3 Å. In addition, the MM-PBSA binding energy for four complexes was also computed. Figure 8B illustrates the binding energies of the complexes. On average, TPX2–Manzamine A, CDC20–Cardidigin, MELK–Staurosporine, and CDK1–Riccardin D complexes produced MM-PBSA binding energies of 84.39 KJ mol−1, −95.07 KJ mol−1, −235.86 KJ mol−1, and 154.39 KJ mol−1, respectively.
Figure 8.

MD simulations of top-ranked complexes. (A) Time evolution of RMSDs for each of top-ranked complexes. (B) Binding stability of top-ranked four complexes by MM-PBSA binding free energy (kJ mol−1) against each ns of simulation; greater positive values show strong binding. Complexes: red color CDC20–Cardidigin, green color MELK–Staurosporine, pink color TPX2–Manzamine A, and blue color CDK1–Riccardin-D.
4. Discussion
To explore core genomic biomarkers and their mechanisms in the CRC progression, firstly, we identified 252 cDEGs between CRC and control samples, out of around 40,000 genes in three gene expression datasets of the NCBI-GEO database with accession numbers GSE106582, GSE110223, and GSE74602. Though the number of DEGs is much smaller than the total number of genes, it may still be a large number for further investigation by wet-lab experiments since it would be laborious, time-consuming, and costly. Therefore, a smaller set of DEGs that are representative of all DEGs is required to reduce time, cost, and labor during further experiments by the wet-lab researchers. Though total DEGs are more informative than any smaller set of DEGs, a smaller representative set of DEGs would be more beneficial from the viewpoints of time, cost, and labor. Therefore, in this study, we proposed 10 top-ranked DEGs (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, CKS2, MELK, and TPX2) as the core genes (CGs) for early diagnosis, prognosis, and therapies of CRC. The survival probability curves and box-plot analyses with the expressions of CGs in different stages (control, Stage 1, Stage 2, Stage 3, and Stage 4) of CRC with the TCGA database indicated their strong prognostic performance from the earlier stages of the disease. It should be mentioned here that Patil et al. (2021) [22] identified CRC-causing 40 CGs for early diagnosis, which might be a large number for further investigation by the wet-lab researchers since it would be laborious, time-consuming, and costly, as mentioned earlier. In our proposed 10 CGs, 9 genes (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, MELK, and TPX2) were overlapped/common with their 40 CGs. In addition, we also investigated the association of our proposed CGs with different diseases. We found they have a strong pan-cancer role, including CRC. The literature review also supported the association of our proposed CGs with CRC. For example, AURKA is considered an oncogene that significantly impacts the proliferation and progression of colorectal carcinoma from colorectal adenoma [56]. Generally, AURKA is overexpressed and amplified in CRCs [57,58,59,60,61,62]. TOP2A is highly expressed during tumor development and responds to drug therapy for CRC [63]. CDK1 is also overexpressed and sensitive to apoptosis in CRC cells [64]. CDKN3 is highly expressed in CRC tissues and remarkably related to patients’ diagnoses [65]. CKS2 overexpression is correlated with aggressive tumor development in CRC, meaning that CKS2 might function as a decent CRC biomarker [66]. CKS2 is a promising biomarker contributing to CRC tumor development [66]. CDC20, PTTG1, and MAD2L1 might be CRC stage-related genes [67]. MELK might play a role as an effective therapeutic target for CRC [68]. TPX2 is highly upregulated in CRC tissues [69].
We identified the top-ranked five GO terms and KEGG pathways of CGs to reveal their molecular mechanisms in CRC progression. The identified GO term ‘cell cycle’ is one of the most important biological processes in the human body [70]. It has four sequential phases. Arguably, the most important phases are the S phase (DNA replication occurs) and the M phase (cell divides into two daughter cells) [71]. The fundamental task of the cell cycle is to ensure that DNA is faithfully replicated once during S phase and that identical chromosomal copies are distributed equally to two daughter cells during M phase. Usually, in adult tissue, there is a delicate balance between cell death and proliferation (cell division), producing a steady state. Disruption of this equilibrium by loss of cell cycle control may eventually lead to tumor development [72], including colorectal cancer [73], colon cancer [74], liver cancer [75], glioblastoma [76], breast cancer [77,78], lung cancer [79,80], gastric cancer [81], etc. So, the cell cycle is considered a vital cancer progression process. TOP2A is related to tumor development and poor survival outcomes by regulating cell proliferation and the CRC cell cycle [82,83]. CDK1 controls the cell cycle and aids in the development of colorectal tumors via an iron-regulated signalling axis [64]. In most CRCs, chromosomal variability resulting in an abnormal chromosome number, aneuploidy, was systematically related to a mitotic checkpoint’s loss of function [84,85]. The GO term ‘mitotic spindle orientation’ can influence tissue organization and control the placement of daughter cells within a tissue. Spindle misorientation greatly affects cancer development and progression [86], including CRC [87]. The top-ranked five MFs (cyclin-dependent protein kinase activity, CXCR chemokine receptor binding, protein kinase binding, RNA polymerase II CTD heptapeptide repeat kinase activity, and histone kinase activity) play a vital role in CRC development and proliferation [12,88,89,90]. Similarly, the enriched five CCs, including the spindle, mitotic spindle, cyclin-dependent protein kinase holoenzyme complex, intracellular non-membrane-bounded organelle, and serine/threonine-protein kinase complex, are strongly related to the progression of CRC [91,92,93,94,95]. Chromosomal instability happens in 80%–85% of CRCs and is considered the most common subtype of CRC [94]. Subsequent research showed that chromosomal instability is caused by mutations in the genes that govern the mitotic spindle checkpoint [93]. The consecutive activation of a group of serine-threonine kinases controls eukaryotic cell-cycle checkpoints [95]. We identified the top 5 enriched common KEGG pathways (cell cycle, bladder cancer [96], oocyte meiosis [22], human T-cell leukemia virus 1 infection, progesterone-mediated oocyte maturation) that are also reported by some other studies [22,96,97].
We also identified key regulators of CGs, such as four TFs (NFIC, FOXC1, YY1, and GATA2) and six miRNAs that played a significant role in CRC development. FOXC1, a member of the forkhead box family, has been connected to the growth and progression of numerous diseases [98,99], particularly CRC [100,101]. YY1 is a multipurpose TF protein that can stimulate or suppress gene expression [102] and plays a significant role in CRC tumor growth [103]. In CRC, the high-level expressions of GATA2 were linked with a poor prognosis and recurrence in solid tumors [104]. Nuclear factor 1 C-type (NFIC) regulates PFKB3 in response to CRC [105].
To find effective repurposable drugs against CRC, we performed molecular docking and computed binding scores among 158 CGs-associated drug agents and CGs-guided receptors. Then we proposed seven top-ordered drugs (Manzamine A, Cardidigin, Staurosporine, Benzo[a]pyren, Sitosterol, Nocardiopsis sp., and Riccardin D) based on binding affinities as the candidate repurposable drug. Manzamine A [106], Cardidigin [107], Staurosporine [108], Benzo[a]pyrene [109], Sitosterol [110], Nocardiopsis sp. [111], and Riccardin D [112] also suggested by some other studies for the treatment of CRC. Finally, the binding stability of top-docked four complexes (TPX2 vs. Manzamine A, CDC20 vs. Cardidigin, MELK vs. Staurosporine, and CDK1 vs. Riccardin D) was investigated by molecular dynamics (MD)-based MM-PBSA simulation and found their performance to be stable [113,114]. Thus, our findings may play a vital role in early diagnosis, prognosis, and therapies for CRC.
5. Conclusions
The present study identified the 10 top-ranked DEGs (AURKA, TOP2A, CDK1, PTTG1, CDKN3, CDC20, MAD2L1, CKS2, MELK, and TPX2) as the core genes (CGs), which showed Strong prognostic performance in the earlier stages of CRC. The CGs-disease and pan-cancer analysis commonly showed that CGs have a robust pan-cancer role, including CRC, bladder urothelial carcinoma, esophageal carcinoma, glioblastoma multiforme, liver hepatocellular carcinoma, lung adenocarcinoma, prostate adenocarcinoma, and stomach adenocarcinoma. The CGs regulatory network analysis detected some essential TFs proteins (NFIC, FOXC1, YY1, and GATA2) and miRNAs (hsa-mir-147a, hsa-mir-129-2-3p, hsa-mir-124-3p, hsa-mir-34a-5p, hsa-mir-23b-3p, and hsa-mir-16-5p) as the transcriptional and post-transcriptional regulators of CGs. The enrichment analysis also revealed some important CRC-causing GO terms and signaling pathways. For example, cell cycle and mitotic spindle pathways have a significant association with CRC progression. Finally, we recommended our proposed CGs-guided 7 candidate drug molecules (Manzamine A, Cardidigin, Staurosporine, Sitosterol, Benzo[a]pyrene, Nocardiopsis sp., and Riccardin D) for the treatment against the CRC by molecular docking analysis. Thus, the findings of this study may be more useful compared to the previous computation study results for early diagnosis, prognosis, and therapies forf CRC.
Acknowledgments
We would like to thank all other members of Bioinformatics Lab, Department of Statistics, University of Rajshahi, Bangladesh, for their excellent cooperation during this work.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/cancers15051369/s1, Figure S1: Box plots for the expressions of KGs with different stages (Stage 1, Stage 2, Stage 3, and Stage 4) of READ (Rectal adenocarcinoma), including the control stage in the TCGA database. Figure S2: Core gene-set enrichment analysis with different diseases. Figure S3: Pan-cancer analysis of core genes (A) AURKA, (B) CDC20, (C) CDK1, (D) CDKN3, (E) CKS2, (F) MAD2L1, (G) MELK, (H) PTTG1, (I) TOP2A, and (J) TPX2. Table S1: Transcriptome-guided 158 meta-drug agents associated with CRC infections collected from the DSigDB online database. Table S2: The list of the top 20 significant (p-value < 0.05) comorbidities associated with CGs.
Author Contributions
M.A.I. and M.N.H.M. conceived the idea of the study. M.A.I. and M.B.H. analyzed the microarray data and drafted the manuscript. M.A.I. and M.A.H. (Md. Abu Horaira) performed molecular docking for drug screening. M.A.I. and M.K.K. performed molecular dynamics simulation. M.A.H. (Md. Alim Hossen) and K.F.T. helped during the data preparation. M.S.R., M.O.F., F.K. and R.A.M. reviewed the manuscript and provided suggestions. M.N.H.M. edited the manuscript and supervised the project. All authors have read and agreed to the published version of the manuscript.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
All data revolved are describe in Section 2.1 (Data Sources and Descriptions).
Conflicts of Interest
The authors declare no conflict of interest.
Funding Statement
The authors declare that no funds, grants, or other support were received during this research work.
Footnotes
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
References
- 1.Hanahan D., Weinberg R.A. Hallmarks of Cancer: The next Generation. Cell. 2011;144:646–674. doi: 10.1016/j.cell.2011.02.013. [DOI] [PubMed] [Google Scholar]
- 2.Gray J.W., Collins C. Genome Changes and Gene Expression in Human Solid Tumors. Carcinogenesis. 2000;21:443–452. doi: 10.1093/carcin/21.3.443. [DOI] [PubMed] [Google Scholar]
- 3.Bray F., Ferlay J., Soerjomataram I., Siegel R.L., Torre L.A., Jemal A. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA. Cancer J. Clin. 2018;68:394–424. doi: 10.3322/caac.21492. [DOI] [PubMed] [Google Scholar]
- 4.Arnold M., Sierra M.S., Laversanne M., Soerjomataram I., Jemal A., Bray F. Global Patterns and Trends in Colorectal Cancer Incidence and Mortality. Gut. 2017;66:683–691. doi: 10.1136/gutjnl-2015-310912. [DOI] [PubMed] [Google Scholar]
- 5.Siegel R.L., Miller K.D., Goding Sauer A., Fedewa S.A., Butterly L.F., Anderson J.C., Cercek A., Smith R.A., Jemal A. Colorectal Cancer Statistics, 2020. CA. Cancer J. Clin. 2020;70:145–164. doi: 10.3322/caac.21601. [DOI] [PubMed] [Google Scholar]
- 6.Joranger P., Nesbakken A., Sorbye H., Hoff G., Oshaug A., Aas E. Survival and Costs of Colorectal Cancer Treatment and Effects of Changing Treatment Strategies: A Model Approach. Eur. J. Health Econ. 2020;21:321–334. doi: 10.1007/s10198-019-01130-6. [DOI] [PubMed] [Google Scholar]
- 7.Mo S., Dai W., Wang H., Lan X., Ma C., Su Z., Xiang W., Han L., Luo W., Zhang L., et al. Early Detection and Prognosis Prediction for Colorectal Cancer by Circulating Tumour DNA Methylation Haplotypes: A Multicentre Cohort Study. eClinicalMedicine. 2023;55:101717. doi: 10.1016/j.eclinm.2022.101717. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Porcu E., Sadler M.C., Lepik K., Auwerx C., Wood A.R., Weihs A., Sleiman M.S.B., Ribeiro D.M., Bandinelli S., Tanaka T., et al. Differentially Expressed Genes Reflect Disease-Induced Rather than Disease-Causing Changes in the Transcriptome. Nat. Commun. 2021;12:5647. doi: 10.1038/s41467-021-25805-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Bogaert J., Prenen H. Molecular Genetics of Colorectal Cancer. Ann. Gastroenterol. 2014;27:9. [PMC free article] [PubMed] [Google Scholar]
- 10.Lu A.G., Feng H., Wang P.X.Z., Han D.P., Chen X.H., Zheng M.H. Emerging Roles of the Ribonucleotide Reductase M2 in Colorectal Cancer and Ultraviolet-Induced DNA Damage Repair. World J. Gastroenterol. 2012;18:4704–4713. doi: 10.3748/wjg.v18.i34.4704. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Liu X., Zhang H., Lai L., Wang X., Loera S., Xue L., He H., Zhang K., Hu S., Huang Y., et al. Ribonucleotide Reductase Small Subunit M2 Serves as a Prognostic Biomarker and Predicts Poor Survival of Colorectal Cancers. Clin. Sci. 2013;124:567–579. doi: 10.1042/CS20120240. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Gan Y., Li Y., Li T., Shu G., Yin G. CCNA2 Acts as a Novel Biomarker in Regulating the Growth and Apoptosis of Colorectal Cancer. Cancer Manag. Res. 2018;10:5113–5124. doi: 10.2147/CMAR.S176833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Branchi V., García S.A., Radhakrishnan P., Győrffy B., Hissa B., Schneider M., Reißfelder C., Schölch S. Prognostic Value of DLGAP5 in Colorectal Cancer. Int. J. Colorectal Dis. 2019;34:1455–1465. doi: 10.1007/s00384-019-03339-6. [DOI] [PubMed] [Google Scholar]
- 14.Hozhabri H., Lashkari A., Razavi S.M., Mohammadian A. Integration of Gene Expression Data Identifies Key Genes and Pathways in Colorectal Cancer. Med. Oncol. 2021;38:1–14. doi: 10.1007/s12032-020-01448-9. [DOI] [PubMed] [Google Scholar]
- 15.Wei F.Z., Mei S.W., Wang Z.J., Chen J.N., Shen H.Y., Zhao F.Q., Li J., Liu Z., Liu Q. Differential Expression Analysis Revealing CLCA1 to Be a Prognostic and Diagnostic Biomarker for Colorectal Cancer. Front. Oncol. 2020;10:573295. doi: 10.3389/fonc.2020.573295. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Xu H., Ma Y., Zhang J., Gu J., Jing X., Lu S., Fu S., Huo J. Identification and Verification of Core Genes in Colorectal Cancer. Biomed Res. Int. 2020;2020:8082697. doi: 10.1155/2020/8082697. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Rahman M.R., Islam T., Gov E., Turanli B., Gulfidan G., Shahjaman M., Banu N.A., Mollah M.N.H., Arga K.Y., Moni M.A. Identification of Prognostic Biomarker Signatures and Candidate Drugs in Colorectal Cancer: Insights from Systems Biology Analysis. Medicina. 2019;55:20. doi: 10.3390/medicina55010020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Yu C., Chen F., Jiang J., Zhang H., Zhou M. Screening Key Genes and Signaling Pathways in Colorectal Cancer by Integrated Bioinformatics Analysis. Mol. Med. Rep. 2019;20:1259–1269. doi: 10.3892/mmr.2019.10336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Chiba M. Bioinformatical Analysis of Gene Expressions and Pathways in Human Colorectal Cancer Tissues. Biomed. Res. 2019;30 doi: 10.35841/biomedicalresearch.30-19-022. [DOI] [Google Scholar]
- 20.Huang Q., Shen Z., Zang R., Fan X., Yang L., Xue M. Identification of Novel Genes and Pathways in Colorectal Cancer Exosomes: A Bioinformatics Study. Transl. Cancer Res. 2018;7:651–658. doi: 10.21037/tcr.2018.05.32. [DOI] [Google Scholar]
- 21.Izadi F. Differential Connectivity in Colorectal Cancer Gene Expression Network. Iran. Biomed. J. 2019;23:34–46. doi: 10.29252/ibj.23.1.34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Patil A.R., Leung M.Y., Roy S. Identification of Hub Genes in Different Stages of Colorectal Cancer through an Integrated Bioinformatics Approach. Int. J. Environ. Res. Public Health. 2021;18:5564. doi: 10.3390/ijerph18115564. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Yoo M., Shin J., Kim J., Ryall K.A., Lee K., Lee S., Jeon M., Kang J., Tan A.C. DSigDB: Drug Signatures Database for Gene Set Analysis. Bioinformatics. 2015;31:3069–3071. doi: 10.1093/bioinformatics/btv313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Smyth G.K. Linear Models and Empirical Bayes Methods for Assessing Differential Expression in Microarray Experiments. Stat. Appl. Genet. Mol. Biol. 2004;3:1–25. doi: 10.2202/1544-6115.1027. [DOI] [PubMed] [Google Scholar]
- 25.Benjamini Y., Hochberg Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B. 1995;57:289–300. doi: 10.1111/j.2517-6161.1995.tb02031.x. [DOI] [Google Scholar]
- 26.Pathan M., Keerthikumar S., Chisanga D., Alessandro R., Ang C.S., Askenase P., Batagov A.O., Benito-Martin A., Camussi G., Clayton A., et al. A Novel Community Driven Software for Functional Enrichment Analysis of Extracellular Vesicles Data. J. Extracell. Vesicles. 2017;6:1321455. doi: 10.1080/20013078.2017.1321455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Szklarczyk D., Franceschini A., Kuhn M., Simonovic M., Roth A., Minguez P., Doerks T., Stark M., Muller J., Bork P., et al. The STRING Database in 2011: Functional Interaction Networks of Proteins, Globally Integrated and Scored. Nucleic Acids Res. 2011;39:D561–D568. doi: 10.1093/nar/gkq973. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Shannon P., Markiel A., Ozier O., Baliga N.S., Wang J.T., Ramage D., Amin N., Schwikowski B., Ideker T. Cytoscape: A Software Environment for Integrated Models of Biomolecular Interaction Networks. Genome Res. 2003;13:2498–2504. doi: 10.1101/gr.1239303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Chin C.H., Chen S.H., Wu H.H., Ho C.W., Ko M.T., Lin C.Y. CytoHubba: Identifying Hub Objects and Sub-Networks from Complex Interactome. BMC Syst. Biol. 2014;8:S11. doi: 10.1186/1752-0509-8-S4-S11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Tomczak K., Czerwińska P., Wiznerowicz M. The Cancer Genome Atlas (TCGA): An Immeasurable Source of Knowledge. Wspolczesna Onkol. 2015;2015:68–77. doi: 10.5114/wo.2014.47136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Chandrashekar D.S., Bashel B., Balasubramanya S.A.H., Creighton C.J., Ponce-Rodriguez I., Chakravarthi B.V.S.K., Varambally S. UALCAN: A Portal for Facilitating Tumor Subgroup Gene Expression and Survival Analyses. Neoplasia. 2017;19:649–658. doi: 10.1016/j.neo.2017.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Aguirre-Gamboa R., Gomez-Rueda H., Martínez-Ledesma E., Martínez-Torteya A., Chacolla-Huaringa R., Rodriguez-Barrientos A., Tamez-Peña J.G., Treviño V. SurvExpress: An Online Biomarker Validation Tool and Database for Cancer Gene Expression Data Using Survival Analysis. PLoS ONE. 2013;8:e74250. doi: 10.1371/journal.pone.0074250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Kuleshov M.V., Jones M.R., Rouillard A.D., Fernandez N.F., Duan Q., Wang Z., Koplev S., Jenkins S.L., Jagodnik K.M., Lachmann A., et al. Enrichr: A Comprehensive Gene Set Enrichment Analysis Web Server 2016 Update. Nucleic Acids Res. 2016;44:W90–W97. doi: 10.1093/nar/gkw377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Piñero J., Ramírez-Anguita J.M., Saüch-Pitarch J., Ronzano F., Centeno E., Sanz F., Furlong L.I. The DisGeNET Knowledge Platform for Disease Genomics: 2019 Update. Nucleic Acids Res. 2020;48:D845–D855. doi: 10.1093/nar/gkz1021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Li T., Fu J., Zeng Z., Cohen D., Li J., Chen Q., Li B., Liu X.S. TIMER2.0 for Analysis of Tumor-Infiltrating Immune Cells. Nucleic Acids Res. 2020;48:W509–W514. doi: 10.1093/nar/gkaa407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.NIH The Cancer Genome Atlas Program—NCI. [(accessed on 10 February 2023)];2022 Available online: https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga.
- 37.Xia J., Gill E.E., Hancock R.E.W. NetworkAnalyst for Statistical, Visual and Network-Based Meta-Analysis of Gene Expression Data. Nat. Protoc. 2015;10:823–844. doi: 10.1038/nprot.2015.052. [DOI] [PubMed] [Google Scholar]
- 38.Khan A., Fornes O., Stigliani A., Gheorghe M., Castro-Mondragon J.A., Van Der Lee R., Bessy A., Chèneby J., Kulkarni S.R., Tan G., et al. JASPAR 2018: Update of the Open-Access Database of Transcription Factor Binding Profiles and Its Web Framework. Nucleic Acids Res. 2018;46:D260–D266. doi: 10.1093/nar/gkx1126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Karagkouni D., Paraskevopoulou M.D., Chatzopoulos S., Vlachos I.S., Tastsoglou S., Kanellos I., Papadimitriou D., Kavakiotis I., Maniou S., Skoufos G., et al. DIANA-TarBase v8: A Decade-Long Collection of Experimentally Supported MiRNA-Gene Interactions. Nucleic Acids Res. 2018;46:D239–D245. doi: 10.1093/nar/gkx1141. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Jeong H., Mason S.P., Barabási A.L., Oltvai Z.N. Lethality and Centrality in Protein Networks. Nature. 2001;411:41–42. doi: 10.1038/35075138. [DOI] [PubMed] [Google Scholar]
- 41.Freeman L.C. A Set of Measures of Centrality Based on Betweenness. Sociometry. 1977;40:35–41. doi: 10.2307/3033543. [DOI] [Google Scholar]
- 42.Berman H.M., Battistuz T., Bhat T.N., Bluhm W.F., Bourne P.E., Burkhardt K., Feng Z., Gilliland G.L., Iype L., Jain S., et al. The Protein Data Bank. Acta Crystallogr. Sect. D Biol. Crystallogr. 2002;58:899–907. doi: 10.1107/S0907444902003451. [DOI] [PubMed] [Google Scholar]
- 43.Waterhouse A., Bertoni M., Bienert S., Studer G., Tauriello G., Gumienny R., Heer F.T., De Beer T.A.P., Rempfer C., Bordoli L., et al. SWISS-MODEL: Homology Modelling of Protein Structures and Complexes. Nucleic Acids Res. 2018;46:W296–W303. doi: 10.1093/nar/gky427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Kim S., Chen J., Cheng T., Gindulyte A., He J., He S., Li Q., Shoemaker B.A., Thiessen P.A., Yu B., et al. PubChem 2019 Update: Improved Access to Chemical Data. Nucleic Acids Res. 2019;47:D1102–D1109. doi: 10.1093/nar/gky1033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Trott O., Olson A.J. AutoDock Vina: Improving the Speed and Accuracy of Docking with a New Scoring Function, Efficient Optimization, and Multithreading. J. Comput. Chem. 2009;31:455–461. doi: 10.1002/jcc.21334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Dallakyan S., Olson A.J. Small-Molecule Library Screening by Docking with PyRx. Methods Mol. Biol. 2015;1263:243–250. doi: 10.1007/978-1-4939-2269-7_19. [DOI] [PubMed] [Google Scholar]
- 47.Krieger E.G.V., Spronk C. YASARA—Yet Another Scientific Artificial Reality Application. YASARA.org. 2013;993:51–78. [Google Scholar]
- 48.Dickson C.J., Madej B.D., Skjevik Å.A., Betz R.M., Teigen K., Gould I.R., Walker R.C. Lipid14: The Amber Lipid Force Field. J. Chem. Theory Comput. 2014;10:865–879. doi: 10.1021/ct4010307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Berendsen H.J.C., Postma J.P.M., Van Gunsteren W.F., Dinola A., Haak J.R. Molecular Dynamics with Coupling to an External Bath. J. Chem. Phys. 1984;81:3684–3690. doi: 10.1063/1.448118. [DOI] [Google Scholar]
- 50.Reza M.S., Hossen M.A., Harun-Or-Roshid M., Siddika M.A., Kabir M.H., Mollah M.N.H. Metadata Analysis to Explore Hub of the Hub-Genes Highlighting Their Functions, Pathways and Regulators for Cervical Cancer Diagnosis and Therapies. Discov. Oncol. 2022;13:1–21. doi: 10.1007/s12672-022-00546-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Reza M.S., Harun-Or-Roshid M., Islam M.A., Hossen M.A., Hossain M.T., Feng S., Xi W., Mollah M.N.H., Wei Y. Bioinformatics Screening of Potential Biomarkers from MRNA Expression Profiles to Discover Drug Targets and Agents for Cervical Cancer. Int. J. Mol. Sci. 2022;23:3968. doi: 10.3390/ijms23073968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Mosharaf M.P., Reza M.S., Kibria M.K., Ahmed F.F., Kabir M.H., Hasan S., Mollah M.N.H. Computational Identification of Host Genomic Biomarkers Highlighting Their Functions, Pathways and Regulators That Influence SARS-CoV-2 Infections and Drug Repurposing. Sci. Rep. 2022;12:4279. doi: 10.1038/s41598-022-08073-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Hossen M.B., Islam M.A., Reza M.S., Kibria M.K., Horaira M.A., Tuly K.F., Faruqe M.O., Kabir F., Mollah M.N.H. Robust Identification of Common Genomic Biomarkers from Multiple Gene Expression Profiles for the Prognosis, Diagnosis, and Therapies of Pancreatic Cancer. Comput. Biol. Med. 2022;152:106411. doi: 10.1016/j.compbiomed.2022.106411. [DOI] [PubMed] [Google Scholar]
- 54.Krieger E., Koraimann G., Vriend G. Increasing the Precision of Comparative Models with YASARA NOVA—A Self-Parameterizing Force Field. Proteins Struct. Funct. Genet. 2002;47:393–402. doi: 10.1002/prot.10104. [DOI] [PubMed] [Google Scholar]
- 55.Mitra S., Dash R. Structural Dynamics and Quantum Mechanical Aspects of Shikonin Derivatives as CREBBP Bromodomain Inhibitors. J. Mol. Graph. Model. 2018;83:42–52. doi: 10.1016/j.jmgm.2018.04.014. [DOI] [PubMed] [Google Scholar]
- 56.Koh H.M., Jang B.G., Hyun C.L., Kim Y.S., Hyun J.W., Chang W.Y., Maeng Y.H. Aurora Kinase A Is a Prognostic Marker in Colorectal Adenocarcinoma. J. Pathol. Transl. Med. 2017;51:32–39. doi: 10.4132/jptm.2016.10.17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Belt E.J.T., Brosens R.P.M., Delis-Van Diemen P.M., Bril H., Tijssen M., Van Essen D.F., Heymans M.W., Beliën J.A.M., Stockmann H.B.A.C., Meijer S., et al. Cell Cycle Proteins Predict Recurrence in Stage II and III Colon Cancer. Ann. Surg. Oncol. 2012;19:682–692. doi: 10.1245/s10434-012-2216-7. [DOI] [PubMed] [Google Scholar]
- 58.Goos J.A.C.M., Coupe V.M.H., Diosdado B., Delis-Van Diemen P.M., Karga C., Beliën J.A.M., Carvalho B., Van Den Tol M.P., Verheul H.M.W., Geldof A.A., et al. Aurora Kinase A (AURKA) Expression in Colorectal Cancer Liver Metastasis Is Associated with Poor Prognosis. Br. J. Cancer. 2013;109:2445–2452. doi: 10.1038/bjc.2013.608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Goktas S., Yildirim M., Suren D., Alikanoglu A.S., Dilli U.D., Bulbuller N., Sezer C., Yildiz M. Prognostic Role of Aurora-A Expression in Metastatic Colorectal Cancer Patients. J. BUON. 2014;19:686–691. [PubMed] [Google Scholar]
- 60.Casorzo L., Dell’Aglio C., Sarotto I., Risio M. Aurora Kinase A Gene Copy Number Is Associated with the Malignant Transformation of Colorectal Adenomas but Not with the Serrated Neoplasia Progression. Hum. Pathol. 2015;46:411–418. doi: 10.1016/j.humpath.2014.11.016. [DOI] [PubMed] [Google Scholar]
- 61.Baba Y., Nosho K., Shima K., Irahara N., Kure S., Toyoda S., Kirkner G.J., Goel A., Fuchs C.S., Ogino S. Aurora-A Expression Is Independently Associated with Chromosomal Instability in Colorectal Cancer. Neoplasia. 2009;11:418–425. doi: 10.1593/neo.09154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Zhang C., Fang Z., Xiong Y., Li J., Liu L., Li M., Zhang W., Wan J. Copy Number Increase of Aurora Kinase A in Colorectal Cancers: A Correlation with Tumor Progression. Acta Biochim. Biophys. Sin. 2010;42:834–838. doi: 10.1093/abbs/gmq088. [DOI] [PubMed] [Google Scholar]
- 63.Coss A., Tosetto M., Fox E.J., Sapetto-Rebow B., Gorman S., Kennedy B.N., Lloyd A.T., Hyland J.M., O’Donoghue D.P., Sheahan K., et al. Increased Topoisomerase IIα Expression in Colorectal Cancer Is Associated with Advanced Disease and Chemotherapeutic Resistance via Inhibition of Apoptosis. Cancer Lett. 2009;276:228–238. doi: 10.1016/j.canlet.2008.11.018. [DOI] [PubMed] [Google Scholar]
- 64.Zhang P., Kawakami H., Liu W., Zeng X., Strebhardt K., Tao K., Huang S., Sinicrope F.A. Targeting CDK1 and MEK/ERK Overcomes Apoptotic Resistance in BRAF-Mutant Human Colorectal Cancer. Mol. Cancer Res. 2018;16:378–389. doi: 10.1158/1541-7786.MCR-17-0404. [DOI] [PubMed] [Google Scholar]
- 65.Li W.H., Zhang L., Wu Y.H. CDKN3 Regulates Cisplatin Resistance to Colorectal Cancer through TIPE1. Eur. Rev. Med. Pharmacol. Sci. 2020;24:3614–3623. doi: 10.26355/eurrev_202004_20823. [DOI] [PubMed] [Google Scholar]
- 66.Yu M.H., Luo Y., Qin S.L., Wang Z.S., Mu Y.F., Zhong M. Up-Regulated CKS2 Promotes Tumor Progression and Predicts a Poor Prognosis in Human Colorectal Cancer. Am. J. Cancer Res. 2015;5:2708–2718. [PMC free article] [PubMed] [Google Scholar]
- 67.Shi G., Wang Y., Zhang C., Zhao Z., Sun X., Zhang S., Fan J., Zhou C., Zhang J., Zhang H., et al. Identification of Genes Involved in the Four Stages of Colorectal Cancer: Gene Expression Profiling. Mol. Cell Probes. 2018;37:39–47. doi: 10.1016/j.mcp.2017.11.004. [DOI] [PubMed] [Google Scholar]
- 68.Liu G., Zhan W., Guo W., Hu F., Qin J., Li R., Liao X. MELK Accelerates the Progression of Colorectal Cancer via Activating the FAK/Src Pathway. Biochem. Genet. 2020;58:771–782. doi: 10.1007/s10528-020-09974-x. [DOI] [PubMed] [Google Scholar]
- 69.Taherdangkoo K., Kazemi N.S.R., Hajjari M.R., Tahmasebi B.M. MiR-485-3p Suppresses Colorectal Cancer via Targeting TPX2. Bratislava Med. J. 2020;121:302–307. doi: 10.4149/BLL_2020_048. [DOI] [PubMed] [Google Scholar]
- 70.Coffman J.A. Cell Cycle Development. Dev. Cell. 2004;6:321–327. doi: 10.1016/S1534-5807(04)00067-X. [DOI] [PubMed] [Google Scholar]
- 71.Williams G.H., Stoeber K. The Cell Cycle and Cancer. J. Pathol. 2012;226:352–364. doi: 10.1002/path.3022. [DOI] [PubMed] [Google Scholar]
- 72.Sherr C.J. Cancer Cell Cycles. Science. 1996;274:1672–1674. doi: 10.1126/science.274.5293.1672. [DOI] [PubMed] [Google Scholar]
- 73.Tominaga O., Nita M.E., Nagawa H., Fujii S., Tsuruo T., Muto T. Expressions of Cell Cycle Regulators in Human Colorectal Cancer Cell Lines. Jpn. J. Cancer Res. 1997;88:855–860. doi: 10.1111/j.1349-7006.1997.tb00461.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Zhang Z., Ji M., Li J., Wu Q., Huang Y., He G., Xu J. Molecular Classification Based on Prognostic and Cell Cycle-Associated Genes in Patients With Colon Cancer. Front. Oncol. 2021;11:636591. doi: 10.3389/fonc.2021.636591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Bisteau X., Caldez M.J., Kaldis P. The Complex Relationship between Liver Cancer and the Cell Cycle: A Story of Multiple Regulations. Cancers. 2014;6:79–111. doi: 10.3390/cancers6010079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Gousias K., Theocharous T., Simon M. Mechanisms of Cell Cycle Arrest and Apoptosis in Glioblastoma. Biomedicines. 2022;10:564. doi: 10.3390/biomedicines10030564. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Caldon C.E., Daly R.J., Sutherland R.L., Musgrove E.A. Cell Cycle Control in Breast Cancer Cells. J. Cell. Biochem. 2006;97:261–274. doi: 10.1002/jcb.20690. [DOI] [PubMed] [Google Scholar]
- 78.Thu K.L., Soria-Bretones I., Mak T.W., Cescon D.W. Targeting the Cell Cycle in Breast Cancer: Towards the next Phase. Cell Cycle. 2018;17:1871–1885. doi: 10.1080/15384101.2018.1502567. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Eymin B., Gazzeri S. Role of Cell Cycle Regulators in Lung Carcinogenesis. Cell Adhes. Migr. 2010;4:114–123. doi: 10.4161/cam.4.1.10977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Vincenzi B., Schiavon G., Silletta M., Santini D., Perrone G., Di Marino M., Angeletti S., Baldi A., Tonini G. Cell Cycle Alterations and Lung Cancer. Histol. Histopathol. 2006;21:423–435. doi: 10.14670/HH-21.423. [DOI] [PubMed] [Google Scholar]
- 81.Fujimoto S., Urushibara O., Watanabe Y., Miyoshi T., Ohkahara K., Adachi M., Watanuki S. Studies on the Cell Cycle of Gastric Cancer Cells. Jpn. J. Surg. 1971;1:32–41. doi: 10.1007/BF02468539. [DOI] [PubMed] [Google Scholar]
- 82.De’angelis G.L., Bottarelli L., Azzoni C., De’angelis N., Leandro G., Di Mario F., Gaiani F., Negri F. Microsatellite Instability in Colorectal Cancer. Acta Biomed. 2018;89:97–101. doi: 10.23750/abm.v89i9-S.7960. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Xiang J., Fang L., Luo Y., Yang Z., Liao Y., Cui J., Huang M., Yang Z., Huang Y., Fan X., et al. Levels of Human Replication Factor C4, a Clamp Loader, Correlate with Tumor Progression and Predict the Prognosis for Colorectal Cancer. J. Transl. Med. 2014;12:320. doi: 10.1186/s12967-014-0320-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Cahill D.P., Lengauer C., Yu J., Riggins G.J., Willson J.K.V., Markowitz S.D., Kinzler K.W., Vogelstein B. Mutations of Mitotic Checkpoint Genes in Human Cancers. Nature. 1998;392:300–303. doi: 10.1038/32688. [DOI] [PubMed] [Google Scholar]
- 85.Dalton W.B., Yang V.W. Mitotic Origins of Chromosomal Instability in Colorectal Cancer. Curr. Colorectal Cancer Rep. 2007;3:59–64. doi: 10.1007/s11888-007-0001-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Pease J.C., Tirnauer J.S. Mitotic Spindle Misorientation in Cancer—Out of Alignment and into the Fire. J. Cell Sci. 2011;124:1007–1016. doi: 10.1242/jcs.081406. [DOI] [PubMed] [Google Scholar]
- 87.Hu Y., Wang L., Li Z., Wan Z., Shao M., Wu S., Wang G. Potential Prognostic and Diagnostic Values of CDC6CDC45, ORC6 and SNHG7 in Colorectal Cancer. Onco. Targets Ther. 2019;12:11609–11621. doi: 10.2147/OTT.S231941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Takahashi Y., Sawada G., Sato T., Kurashige J., Mima K., Matsumura T., Uchi R., Ueo H., Ishibashi M., Takano Y., et al. Microarray Analysis Reveals That High Mobility Group A1 Is Involved in Colorectal Cancer Metastasis. Oncol. Rep. 2013;30:1488–1496. doi: 10.3892/or.2013.2602. [DOI] [PubMed] [Google Scholar]
- 89.Guo Y., Bao Y., Ma M., Yang W. Identification of Key Candidate Genes and Pathways in Colorectal Cancer by Integrated Bioinformatical Analysis. Int. J. Mol. Sci. 2017;18:722. doi: 10.3390/ijms18040722. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Huang W., Tian X., Guan X. The Prognosis Analysis of Rfwd2 Inhibiting the Expression of Etv1 in Colorectal Cancer. Transl. Cancer Res. 2020;9:508–521. doi: 10.21037/tcr.2019.11.35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Wu Z., Liu Z., Ge W., Shou J., You L., Pan H., Han W. Analysis of Potential Genes and Pathways Associated with the Colorectal Normal Mucosa–Adenoma–Carcinoma Sequence. Cancer Med. 2018;7:2555–2566. doi: 10.1002/cam4.1484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Chu X.D., Zhang Y.R., Lin Z.B., Zhao Z., Huangfu S.C., Qiu S.H., Guo Y.G., Ding H., Huang T., Chu X.L., et al. A Network Pharmacology Approach for Investigating the Multitarget Mechanisms of Huangqi in the Treatment of Colorectal Cancer. Transl. Cancer Res. 2021;10:681–693. doi: 10.21037/tcr-20-2596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Lengauer C., Kinzler K.W., Vogelstein B. Genetic Instability in Colorectal Cancers. Nature. 1997;386:623–627. doi: 10.1038/386623a0. [DOI] [PubMed] [Google Scholar]
- 94.Grady W.M., Carethers J.M. Genomic and Epigenetic Instability in Colorectal Cancer Pathogenesis. Gastroenterology. 2008;135:1079–1099. doi: 10.1053/j.gastro.2008.07.076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Cheng X., Zhou D., Wei J., Lin J. Cell-Cycle Arrest at G2/M and Proliferation Inhibition by Adenovirus-Expressed Mitofusin-2 Gene in Human Colorectal Cancer Cell Lines. Neoplasma. 2013;60:620–626. doi: 10.4149/neo_2013_080. [DOI] [PubMed] [Google Scholar]
- 96.Calderwood A.H., Huo D., Rubin D.T. Association between Colorectal Cancer and Urologic Cancers. Arch. Intern. Med. 2008;168:1003–1009. doi: 10.1001/archinte.168.9.1003. [DOI] [PubMed] [Google Scholar]
- 97.Lei M. The MCM Complex: Its Role in DNA Replication and Implications for Cancer Therapy. Curr. Cancer Drug Targets. 2005;5:365–380. doi: 10.2174/1568009054629654. [DOI] [PubMed] [Google Scholar]
- 98.Han B., Bhowmick N., Qu Y., Chung S., Giuliano A.E., Cui X. FOXC1: An Emerging Marker and Therapeutic Target for Cancer. Oncogene. 2017;36:3957–3963. doi: 10.1038/onc.2017.48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Chen X., Deng M., Ma L., Zhou J., Xiao Y., Zhou X., Zhang C., Wu M. Inhibitory Effects of Forkhead Box L1 Gene on Osteosarcoma Growth through the Induction of Cell Cycle Arrest and Apoptosis. Oncol. Rep. 2015;34:265–271. doi: 10.3892/or.2015.3969. [DOI] [PubMed] [Google Scholar]
- 100.Li Q., Wei P., Wu J., Zhang M., Li G., Li Y., Xu Y., Li X., Xie D., Cai S., et al. The FOXC1/FBP1 Signaling Axis Promotes Colorectal Cancer Proliferation by Enhancing the Warburg Effect. Oncogene. 2019;38:483–496. doi: 10.1038/s41388-018-0469-8. [DOI] [PubMed] [Google Scholar]
- 101.Zhang Y., Liao Y., Chen C., Sun W., Sun X., Liu Y., Xu E., Lai M., Zhang H. P38-Regulated FOXC1 Stability Is Required for Colorectal Cancer Metastasis. J. Pathol. 2020;250:217–230. doi: 10.1002/path.5362. [DOI] [PubMed] [Google Scholar]
- 102.Ohtomo T., Horii T., Nomizu M., Suga T., Yamada J. Molecular Cloning of a Structural Homolog of YY1AP, a Coactivator of the Multifunctional Transcription Factor YY1. Amino Acids. 2007;33:645–652. doi: 10.1007/s00726-006-0482-z. [DOI] [PubMed] [Google Scholar]
- 103.Yu J., Wang F., Zhang J., Li J., Chen X., Han G. LINC00667/MiR-449b-5p/YY1 Axis Promotes Cell Proliferation and Migration in Colorectal Cancer. Cancer Cell Int. 2020;20:1–13. doi: 10.1186/s12935-020-01377-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Chen L., Jiang B., Wang Z., Liu M., Ma Y., Yang H., Xing J., Zhang C., Yao Z., Zhang N., et al. Expression and Prognostic Significance of GATA-Binding Protein 2 in Colorectal Cancer. Med. Oncol. 2013;30:498. doi: 10.1007/s12032-013-0498-7. [DOI] [PubMed] [Google Scholar]
- 105.Liu H.Y., Zhang C.J. Identification of Differentially Expressed Genes and Their Upstream Regulators in Colorectal Cancer. Cancer Gene Ther. 2017;24:244–250. doi: 10.1038/cgt.2017.8. [DOI] [PubMed] [Google Scholar]
- 106.Lin L.C., Kuo T.T., Chang H.Y., Liu W.S., Hsia S.M., Huang T.C. Manzamine a Exerts Anticancer Activity against Human Colorectal Cancer Cells. Mar. Drugs. 2018;16:252. doi: 10.3390/md16080252. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Gan H., Qi M., Chan C., Leung P., Ye G., Lei Y., Liu A., Xue F., Liu D., Ye W., et al. Digitoxin Inhibits HeLa Cell Growth through the Induction of G2/M Cell Cycle Arrest and Apoptosis in Vitro and in Vivo. Int. J. Oncol. 2020;57:562–573. doi: 10.3892/ijo.2020.5070. [DOI] [PubMed] [Google Scholar]
- 108.Alsamman K., El-Masry O.S. Staurosporine Alleviates Cisplatin Chemoresistance in Human Cancer Cell Models by Suppressing the Induction of SQSTM1/P62. Oncol. Rep. 2018;40:2157–2162. doi: 10.3892/or.2018.6615. [DOI] [PubMed] [Google Scholar]
- 109.Ajayi B.O., Adedara I.A., Farombi E.O. Benzo(a)Pyrene Induces Oxidative Stress, pro-Inflammatory Cytokines, Expression of Nuclear Factor-Kappa B and Deregulation of Wnt/Beta-Catenin Signaling in Colons of BALB/c Mice. Food Chem. Toxicol. 2016;95:42–51. doi: 10.1016/j.fct.2016.06.019. [DOI] [PubMed] [Google Scholar]
- 110.Baskar A.A., Al Numair K.S., Gabriel Paulraj M., Alsaif M.A., Al Muamar M., Ignacimuthu S. Β-Sitosterol Prevents Lipid Peroxidation and Improves Antioxidant Status and Histoarchitecture in Rats With 1,2-Dimethylhydrazine-Induced Colon Cancer. J. Med. Food. 2012;15:335–343. doi: 10.1089/jmf.2011.1780. [DOI] [PubMed] [Google Scholar]
- 111.Manivasagan P., Alam M.S., Kang K.H., Kwak M., Kim S.K. Extracellular Synthesis of Gold Bionanoparticles by Nocardiopsis Sp. and Evaluation of Its Antimicrobial, Antioxidant and Cytotoxic Activities. Bioprocess Biosyst. Eng. 2015;38:1167–1177. doi: 10.1007/s00449-015-1358-y. [DOI] [PubMed] [Google Scholar]
- 112.Liu H., Li G., Zhang B., Sun D., Wu J., Chen F., Kong F., Luan Y., Jiang W., Wang R., et al. Suppression of the NF-ΚB Signaling Pathway in Colon Cancer Cells by the Natural Compound Riccardin D from Dumortierahirsute. Mol. Med. Rep. 2018;17:5837–5843. doi: 10.3892/mmr.2018.8617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Lovering A.L., Seung S.L., Kim Y.W., Withers S.G., Strynadka N.C.J. Mechanistic and Structural Analysis of a Family 31 α-Glycosidase and Its Glycosyl-Enzyme Intermediate. J. Biol. Chem. 2005;280:2105–2115. doi: 10.1074/jbc.M410468200. [DOI] [PubMed] [Google Scholar]
- 114.Blatt J.M., Weisskopf V.F., Critchfield C.L. Theoretical Nuclear Physics. Am. J. Phys. 1953;21:235–236. doi: 10.1119/1.1933407. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
All data revolved are describe in Section 2.1 (Data Sources and Descriptions).