

Abstract
Despite decades of costly research, we still cannot accurately predict individual differences in cognition from task-based functional magnetic resonance imaging (fMRI). Moreover, aiming for methods with higher prediction is not sufficient. To understand brain-cognition relationships, we need to explain how these methods draw brain information to make the prediction. Here we applied an explainable machine-learning (ML) framework to predict cognition from task-based fMRI during the n-back working-memory task, using data from the Adolescent Brain Cognitive Development (n = 3,989). We compared 9 predictive algorithms in their ability to predict 12 cognitive abilities. We found better out-of-sample prediction from ML algorithms over the mass-univariate and ordinary least squares (OLS) multiple regression. Among ML algorithms, Elastic Net, a linear and additive algorithm, performed either similar to or better than nonlinear and interactive algorithms. We explained how these algorithms drew information, using SHapley Additive explanation, eNetXplorer, Accumulated Local Effects, and Friedman’s H-statistic. These explainers demonstrated benefits of ML over the OLS multiple regression. For example, ML provided some consistency in variable importance with a previous study and consistency with the mass-univariate approach in the directionality of brain-cognition relationships at different regions. Accordingly, our explainable-ML framework predicted cognition from task-based fMRI with boosted prediction and explainability over standard methodologies.
Keywords: Adolescent Brain Cognitive Development, explainers, predictive modeling, task-based fMRI, working memory
Introduction
Task-based functional magnetic resonance imaging (fMRI) has been a prominent tool for neuroscientists since the early 90s (Kwong et al. 1992). One goal of task-based fMRI is to derive brain-based predictive measures of individual differences in cognitive abilities (Gabrieli et al. 2015; Dubois and Adolphs 2016). Yet, the goal of obtaining a robust, predictable brain-cognition relationship from task-based fMRI remains largely unattained (Elliott et al. 2020). Moreover, obtaining a method with a higher predictive ability may not be sufficient if we cannot explain how such a method draws information from different brain regions to make a prediction. Using an explainable machine-learning (ML) framework (Molnar 2019; Belle and Papantonis 2021), we aim at (i) choosing algorithms that extract information across brain regions to predict individual differences in cognition from task-based fMRI data with higher predictive ability and (ii) explaining how these algorithms draw information to make the prediction. Ultimately, this explainable, predictive model can potentially be used in future studies that collect task-based fMRI to predict individual differences in cognitive abilities, especially if the model is built from well-powered data. This is similar to the use of polygenic scores in genetics studies (Torkamani et al. 2018).
Conventionally, to learn about which brain regions are associated with individual differences, neuroscientists use the mass-univariate approach (Friston 2007). Here, researchers first test many univariate associations between (i) the fMRI blood-oxygen-level-dependent (BOLD) signal at each brain region that varies as a function of task conditions (e.g. high vs. low working memory load) and (ii) an individual-difference variable of interest (e.g. cognitive abilities). They then apply multiple comparison corrections, such as Benjamini-Hochberg’s false discovery rate (FDR) (Benjamini et al. 2001) or Bonferroni, to control for false conclusions based on multiple testing (Friston 2007). Accordingly, the mass univariate analyses allow for easy interpretation of the brain-cognition association at each brain region. However, this simplicity may come at a price. Recent findings have challenged the ability of the mass univariate approach in predicting individual differences (Kragel et al. 2021; Marek et al. 2022). For instance, in the context of resting-state fMRI and structural MRI, Marek et al. (2022), showed that mass univariate analyses had a much poorer ability in predicting individual differences in cognition, compared to multivariate analyses, or the techniques involving drawing information across different brain regions simultaneously in one model. Additionally, having separate tests for different brain regions in a mass-univariate fashion rests on the assumption that these regions are statistically independent of each other, which seems unrealistic given what is known about brain function. This focus on “marginal importance” (i.e. the contribution from each brain region at a time, ignoring other regions), as opposed to “partial importance”(i.e. the contribution from multiple regions in the same model), further constrains our ability to achieve a holistic understanding of the relationship between the brain and individual differences (Chen et al. 2019; Debeer and Strobl 2020).
Multivariate analyses have been suggested as a potential solution to improve prediction and avoid the use of multiple comparison corrections (Chen et al. 2019; Kragel et al. 2020). The ordinary least squares (OLS) multiple regression is arguably the most widespread method for predicting a response variable from multiple explanatory variables simultaneously. For task-based fMRI, this means simultaneously having all brain regions as explanatory variables to predict a response variable of individual differences. In gist, the OLS multiple regression fits a plane to the data that minimizes the squared distance between itself and the data points (James et al. 2013; Kuhn and Johnson 2013). With uncorrelated explanatory variables, the OLS multiple regression has the benefit of being readily interpretable—each explanatory variable’s slope represents an additive effect on the response variable (Kuhn and Johnson 2013).
However, in a situation where strongly correlated explanatory variables are present, known as multicollinearity, the OLS multiple regression may misrepresent the nature of the relationship between brain activity and individual differences. For instance, with high multicollinearity, the OLS multiple regression can give very unstable estimates of coefficients and extremely high estimates of model uncertainty (reflected in large standard errors [SE]) (Graham 2003; Alin 2010; Monti 2011; Vatcheva et al. 2016). Moreover, the direction of an explanatory variable’s coefficient may also depend on its relationship with other explanatory variables thus leading to sign flips (Courville and Thompson 2001; Beckstead 2012; Ray-Mukherjee et al. 2014). For example, when an explanatory variable has a strong, positive correlation with other explanatory variables and by itself has a weak, positive correlation with the response variable, the OLS multiple regression can unintentionally show a negative weight for this explanatory variable. Accordingly, it is crucial to examine this “suppression” by comparing the directionality of the relationship estimated from the OLS multiple regression with those from the mass-univariate analyses (Conger 1974; Ray-Mukherjee et al. 2014).
To improve out-of-sample prediction and to, a certain extent, mitigate multicollinearity, many researchers have exchanged the classical OLS multiple regression for ML algorithms (Dormann et al. 2013). Yet, it is still unclear how much improvement in prediction ML algorithms may lead to. ML algorithms include, but are not limited to, algorithms based on penalized regression (Kuhn and Johnson 2013), tree-based regression (Breiman et al. 2017), and Support Vector Machine (SVM) (Cortes and Vapnik 1995), such as Elastic Net (Zou and Hastie 2005), Random Forest (Breiman 2001), XGBoost (Chen and Guestrin 2016), and SVM with different kernels (Cortes and Vapnik 1995; Drucker et al. 1996). These algorithms usually require hyperparameters that can be estimated through a cross-validation (James et al. 2013). The algorithms differ in how the relationships between explanatory and response variables as well as among explanatory variables are modeled. Some algorithms, such as Random Forest, XGBoost, and SVM with certain kernels (e.g. polynomial and Radial Basis Function, RBF) (Cortes and Vapnik 1995; Drucker et al. 1996) allow for nonlinearity in the relationship between explanatory and response variables as well as interaction among different explanatory variables. Elastic Net, on the other hand, extends directly from the linear OLS multiple regression, but with an added ability to regularize the contribution of explanatory variables (James et al. 2013; Kuhn and Johnson 2013). Accordingly, Elastic Net is linear (i.e. assuming the relationship between explanatory and response variables to be linear) and additive (i.e. not automatically modeling interactions among explanatory variables). It is still unclear whether nonlinear and interactive algorithms improve the predictive ability of task-based fMRI over linear and additive algorithms as well as over the OLS multiple regression and mass-univariate analyses. Therefore, it is important to compare the predictive performance across algorithms.
A major drawback of ML algorithms used in the task-based fMRI (Kragel et al. 2020) is the difficulty to explain how each algorithm draws information from different brain regions in making predictions. Fortunately, recent developments in the explainable ML framework have provided techniques that can improve explainability for many algorithms (Molnar 2019). Here we focused on four aspects of explainability. The first aspect is “variable importance,” or the relative contribution from each brain region when an algorithm makes a prediction. Linear and additive algorithms, such as Elastic Net and the OLS multiple regression, usually make a prediction based on a weighted sum of features. Accordingly, an explanatory variable with a higher coefficient magnitude has a higher weight in prediction, and thus the coefficient magnitude can readily be used as a measure of variable importance. For nonlinear and interactive algorithms, such as Random Forest, XGBoost, and SVM with polynomial and RBF kernels, the prediction is not made based on a weighted sum of features, and thus we need an additional “explainer” to compute variable importance. SHapley Additive exPlanation (SHAP) (Lundberg and Lee 2017) is a newly developed algorithm-agnostic technique for variable importance. SHAP is designed to explain the contribution of each explanatory variable via Shapley values (Roth 1988). Based on Cooperative Game Theory, a Shapley value quantifies a fair distribution of compensation to each player based on his/her contribution in all possible coalitions where each coalition includes a different subset of players. When applying Shapley values to machine learning, researchers treat each explanatory variable as a player in a game, a predicted value as compensation and subsets of explanatory variables as coalitions. Shapley values reflect the weighted differences in a predicted value when each explanatory variable is included vs. not included in all possible subsets of explanatory variables. SHAP offers a computationally efficient approach for estimating Shapley values (Lundberg and Lee 2017). Using these measures of variable importance, one is able to demonstrate the similarity in contribution from each brain region based on different algorithms. Importantly, we would also be able to examine the consistency in variable importance across studies with similar fMRI tasks and individual difference variables.
The second aspect of explainability is “variable selection” (Heinze et al. 2018). There are existing statistical methods that could assist us further in selecting explanatory variables based on their variable importance and uncertainty around the variable importance, at least for some algorithms. For instance, for mass univariate analyses and the OLS multiple regression, a conventional P-value associated with each coefficient is often used for variable selection. For Elastic Net, a permutation-based approach called eNetXplorer (Candia and Tsang 2019) has recently been proposed. The central idea behind eNetXplorer is to fit 2 different sets of Elastic Net models, each set consisting of many realizations of n-fold cross-validated models. In the first set, Elastic Net models are fitted to predict the true response variable (target models), whereas in the second set, the models are fitted to predict a randomly permuted response variable (null models). For example, if the observations are participants in a study, then the target models will try to predict one participant’s response from the same participant’s set of explanatory variables (e.g. brain regions), whereas the null models will try to predict one participant’s response from another participant’s explanatory variable. Both the null and the target models are tuned and assessed via repeated cross-validation. Given that there is no relationship between the shuffled response and the predictors in the null models, any non-null predictive accuracy and coefficient estimates in the null models have to be spurious. Comparisons of the magnitude of the coefficient estimates in target models to null models, as well as of the frequency of feature selection in target models to null models, allow for near-exact inference for each individual explanatory variable (via the permutation tests) (Winkler et al. 2014; Helwig 2019). While eNetXplorer use cases were originally demonstrated for cellular and molecular “omics” data, this approach is widely applicable to many other scenarios aimed at uncovering predictors in a multivariable setting. Indeed, there is a considerable overlap in the challenges faced in the analysis of omics and fMRI data (Antonelli et al. 2019), and as such, eNetXplorer may prove a valuable tool in the latter as well. With eNetXplorer, we can compare and contrast variable selection between the OLS multiple regression and Elastic Net with regards to Elastic Net hyperparameters, the uncertainty of the coefficients, coefficient magnitude after regularization, and multicollinearity.
In addition to demonstrating relative contribution from different brain regions, the third aspect of explainability is to understand the extent to which predictive values from each algorithm change as a function of fMRI activity at these regions—in terms of the pattern (i.e. linearity vs. nonlinearity) and directionality (i.e. positive vs. negative) of the relationship with the response variable. It is straightforward to examine the pattern and directionality of the univariate relationship for mass-univariate analyses. For instance, a “univariate effects” plot (Fox and Weisberg 2018) can show a linear fitted line between fMRI activity at each different region and their associated predicted values of the response variable. For multivariate algorithms, we need to consider the collinearity among explanatory variables that could distort the pattern and directionality of the influences from each explanatory variable (Molnar 2019). Accumulated local effects (ALE), a newly developed algorithm-agnostic explainer, is designed to help visualize how each explanatory variable in each algorithm impacts a predictive value on average (Apley and Zhu 2020). Importantly, ALE is specifically designed to handle data with moderate collinearity. With univariate effects and ALE plots, we could examine the similarity in pattern and directionality across algorithms. This can potentially reveal “suppression,” allowing us to check whether multivariate algorithms provide a similar directionality to the univariate algorithm.
The fourth aspect is to demonstrate the extent to which the variation of the prediction from these algorithms depends on the interaction of the explanatory variables. Some algorithms, including Random Forest, XGBoost, and SVM with RBF and polynomial kernels, allow for interactions among explanatory variables. Friedman’s H-statistic (Friedman and Popescu 2008) is a metric of the interaction strength between each brain region and all other brain regions in predicting individual differences. In the case that interactive algorithms have higher predictive performance than additive algorithms, Friedman’s H-statistic can reveal interaction from certain brain regions that may account for the boost in prediction.
Our study used a large task-based fMRI dataset in children from the Adolescent Brain Cognitive Development (ABCD) study (Casey et al. 2018). We treated task-based fMRI activity during the working-memory “n-back” task (Barch et al. 2013; Casey et al. 2018) as our explanatory variables. fMRI activity during the n-back task has been shown to correlate well with the performance of cognitive tasks in children and adults (Rosenberg et al. 2020; Sripada et al. 2020). For our response variables, we used individual differences in behavioral performance from 11 cognitive tasks and the g-factor, or the latent variable that captured the shared variance of behavioral performance across different cognitive tasks. Using the explainable ML framework (Molnar 2019), we first identified algorithms that could achieve good accuracy in predicting individual differences from task-based fMRI data. Here we compared widely used 9 algorithms: the mass univariate with the FDR and Bonferroni corrections, OLS multiple regression, Elastic Net, Random Forest, XGBoost, and SVM with linear, polynomial, and RBF kernels. We especially aimed to compare the predictive ability of linear and additive multivariate algorithms, including the OLS multiple regression and Elastic Net, against mass-univariate analyses and nonlinear and interactive multivariate algorithms. We then applied various explainers (such as SHAP, eNetXplorer, ALE, and Friedman’s H-statistic) to explain the extent to which these algorithms drew information from each brain region in making a prediction in four aspects: variable importance, variable selection, pattern and directionality and interaction. We focused on explaining the models predicting the g-factor, so that we could (i) examine if our framework can capture individual differences in cognitive abilities in general (i.e. not confined to specific cognitive tasks) and (ii) compare variable importance in our study with that of a previous study (Sripada et al. 2020).
Materials and methods
Data
We used the data from the ABCD Study Curated Annual Release 2.01 (Yang and Jernigan 2019). Our participants were 9–10-year-old children scanned with 3T MRI systems at 21 sites across the United States, recruited as reported previously (Garavan et al. 2018). Following exclusion (see below), there were 3989 children (1968 females). The ethical oversight of this study is detailed elsewhere (Charness 2018). The ABCD Study provided detailed data acquisition procedures and fMRI image processing that are also outlined in previous publications (Casey et al. 2018; Hagler et al. 2019).
Explanatory variables
The ABCD study applied Freesurfer to parcellate the brain based on Destrieux (Destrieux et al. 2010) and ASEG (Fischl et al. 2002) atlases. The parcellation resulted in data showing fMRI activity at 167 gray-matter (148 cortical surface and 19 subcortical volumetric) regions. We used fMRI activity at these 167 regions during the n-back task (Barch et al. 2013; Casey et al. 2018) as our explanatory variables. In this n-back task, children saw pictures featuring houses and faces with different emotions. Depending on the trial blocks, children needed to report whether the picture matched either: (i) a picture shown 2 trials earlier (2-back condition), or (ii) a picture shown at the beginning of the block (0-back condition). We used fMRI measures derived from the [2-back vs. 0-back] linear contrast (i.e. high vs. low working memory load), averaged across two runs.
Response variables
We tested the ability of fMRI during the n-back task to predict individual differences in cognitive abilities across all variables available in the dataset. First is the behavioral performance collected from the n-back task during the fMRI scan. Specifically, we used the accuracy of the 2-back condition as it is correlated well with the behavioral performance of other cognitive tasks collected outside of the scanner (Rosenberg et al. 2020). Nonetheless, predicting behavioral performance collected from the same fMRI task may have captured idiosyncratic variance that is specific to the task and session, not necessarily capturing individual differences in cognitive abilities per se. Thus, we also used behavioral performance from 10 cognitive tasks (Luciana et al. 2018; Thompson et al. 2019) collected outside of the fMRI session, as additional response variables.
Children completed the 10 “out-of-scanner” cognitive tasks on an iPad during a 70-min in-person visit. A detailed description of these out-of-scanner cognitive tasks was provided elsewhere (Luciana et al. 2018). First, the Flanker task measured inhibitory control (Eriksen and Eriksen 1974). Second, the Card Sort task measured the cognitive flexibility (Zelazo et al. 2013). Third, the Pattern Comparison Processing task measured the processing speed (Carlozzi et al. 2013). Fourth, the Picture Vocabulary task measured language and vocabulary comprehension (Gershon et al. 2014). Fifth, the Oral Reading Recognition task measured language decoding and reading (Bleck et al. 2013). Sixth, the Picture Sequence Memory task measured the episodic memory (Bauer et al. 2013). Seventh, the Rey-Auditory Verbal Learning task measured auditory learning, recall, and recognition (Daniel and Wahlstrom 2014). Eight, the List Sorting Working Memory task measured the working-memory (Bleck et al. 2013). Ninth, the Little Man task measured visuospatial processing via mental rotation (Acker and Acker 1982). Tenth, the Matrix Reasoning task measured visuospatial problem solving and inductive reasoning (Daniel and Wahlstrom 2014).
Lastly, in addition to these 11 response variables, we also derived a general factor of cognitive abilities, called the g-factor, from out-of-scanner cognitive tasks. Similar to previous work on fMRI and individual differences in cognitive abilities in adults and children (Dubois et al. 2018; Ang et al. 2020; Sripada et al. 2020), we applied a bifactor model of the g-factor using confirmatory factor analysis (CFA). Here we treated the g-factor as the general latent variable underlying performance across out-of-scanner cognitive tasks that is orthogonal to the three specific factors: language reasoning (capturing the Picture Vocabulary, Oral Reading Recognition, List Sorting Working Memory, and Matrix Reasoning tasks), cognitive flexibility (capturing the Flanker, Card Sort and Pattern Comparison Processing tasks), and memory recall (capturing the Picture Sequence Memory and Rey Auditory Verbal Learning tasks). We applied robust maximum likelihood estimation (MLR) with robust (Huber-White) SEs and scaled test statistics. To demonstrate model fit, we used scaled and robust comparative fit index (CFI), Tucker-Lewis Index (TLI), root-mean-squared error of approximation (RMSEA) with 90% CI of the g-factor. To implement the CFA, we used lavaan (Rosseel 2012) (version = 0.6–9) and semPlot (Epskamp 2015).
Exclusion criteria
We followed the exclusion criteria recommended by the ABCD study (Jernigan 2019). We excluded data with structure MRI T1 images that were flagged as needing clinical referrals, having incidental findings (e.g. hydrocephalus and herniation) or not passing quality controls (including IQC_T1_OK_SER and FSQC_QC fields). Second, we excluded data with fMRI T2* images that did not pass quality controls or had excessive movement (dof > 200). Third, we excluded data flagged with unacceptable behavioral performance during the n-back task. Fourth, we removed all data from a Philips scanner due to a postprocessing error in Release 2.01. Lastly, we identified outliers of the contrast estimates for each of the 167 regions using the 3 IQR rule and applied listwise deletion to remove observations with outliers in any region.
Modeling pipeline
We first split the data into training (75%) and test (25%) sets. For ML-based algorithms that needed hyperparameter tuning (see below), we implemented a grid search via 10-fold cross-validation within the training set. Here each algorithm created model candidates with a different combination of hyperparameters, and we considered the candidate model with the lowest RMSE as the best model for each algorithm. To prevent data leakage, we fitted the CFA model of the g-factor to the observations in the training set and later applied this fitted model to the test set. Similarly, we separately applied the 3 IQR rule and data standardization on the training and test sets.
To evaluate predictive performance, we used the test set and examined the similarity between predicted and observed (i.e. real) values of each response variable. To reveal different aspects of the model’s predictive ability, we used multiple out-of-sample prediction metrics (Poldrack et al. 2020).
The first metric is Pearson’s correlation, which was defined as
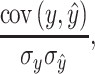 |
(1) |
where cov is the covariance, σ is the standard deviation, y is the observed value, and ŷ is the predicted value. Pearson’s correlation ranges from −1 to 1. The high positive Pearson’s correlation reflects high predictive accuracy, regardless of scale. Negative Pearson’s correlation reflects poor predictive information in the model.
Second, we used traditional r square defined using the sum-of-squared formulation:
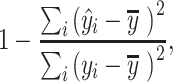 |
(2) |
where 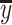 is the mean of the observed value. Traditional r square is often interpreted as variance explained, with the value closer to 1 reflecting high predictive accuracy. Like Pearson’s correlation, traditional r square can be negative in case of no predictive information in the model.
is the mean of the observed value. Traditional r square is often interpreted as variance explained, with the value closer to 1 reflecting high predictive accuracy. Like Pearson’s correlation, traditional r square can be negative in case of no predictive information in the model.
Third, we defined the mean absolute error (MAE) as
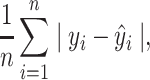 |
(3) |
MAE measures how far the predicted value is from the observed value in absolute terms. Unlike Pearson’s correlation and traditional r square, MAE does not scale the data, rendering it more sensitive to scaling. Lower MAE reflects high predictive accuracy.
Forth, we defined the RMSE as
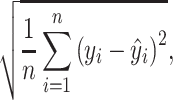 |
(4) |
Similar to MAE, RMSE measures how far the predicted value is from the observed value but uses the square root of the average of squared differences, as opposed to the absolute differences. Lower RMSE reflects high predictive accuracy.
To demonstrate the distribution of the predictive performance across algorithms, we bootstrapped these out-of-sample prediction metrics on the test set 5,000 times, resulting in bootstrap distributions of each prediction metric for each algorithm. To compare predictive performance, we also created bootstrap distributions of the differences in the predictive performance between each pair of algorithms. If the 95% confidence interval of the bootstrap distribution of the differences did not include zero, we concluded that the 2 algorithms were significantly different from each other. We used “tidymodels” (www.tidymodels.org) for this pipeline.
Modeling algorithms
We tested the predictive performance of 9 algorithms. The first algorithm was the mass univariate analyses with the FDR correction. Here we used the simple linear regression with each of 167 regions as the only explanatory variable in each model, resulting in 167 different models in the form of:
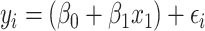 |
(5) |
where x is the explanatory variable, β is the coefficient, and 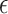 is the error term. β is estimated based on the minimization of the sum of squared errors following:
is the error term. β is estimated based on the minimization of the sum of squared errors following:
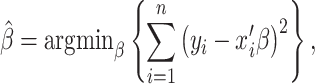 |
(6) |
where n is the number of observations (i.e. participants) in the training set. The FDR (Benjamini and Hochberg 1995) corrects for multiple comparisons following:
 |
(7) |
where 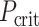 indicates a criterion in which P-value needs to be below, rank is the rank of P-values of one model compared with other models whereas the smallest P-value leads to rank = 1, n_models is the number of models, which equals 167 brain regions in our case, and α_level is the overall type-I error rate, set at 0.05. We then used the test set to examine the prediction of the models that passed the FDR correction in the training set at
indicates a criterion in which P-value needs to be below, rank is the rank of P-values of one model compared with other models whereas the smallest P-value leads to rank = 1, n_models is the number of models, which equals 167 brain regions in our case, and α_level is the overall type-I error rate, set at 0.05. We then used the test set to examine the prediction of the models that passed the FDR correction in the training set at 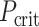 .
.
The second algorithm was the mass univariate analyses with the Bonferroni correction. The Bonferroni correction is usually considered more conservative than the FDR correction (Moran 2003). We used the same simple regression with the first algorithm, except that here we applied the Bonferroni correction instead of the FDR correction. The Bonferroni correction defines 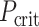 as
as
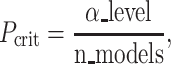 |
(8) |
Note, only the first 2 algorithms were univariate algorithms, using separate models for each explanatory variable. Other algorithms were multivariate algorithms that included all brain regions as explanatory variables in one model. Accordingly, when creating bootstrap distributions of each prediction metric for univariate algorithms in the test set, we included multiple predicted values per testing participant based on the number of brain regions that survived each multiple comparison correction in the training set. By contrast, bootstrap distributions of each prediction metric for multivariate algorithms in the test set were based on one predictive value per testing participant for each algorithm.
The third algorithm was the OLS multiple regression. Here, similar to the mass univariate analyses, the OLS multiple regression uses the same minimization of the sum of squared errors as the first 2 algorithms. However, the OLS multiple regression used all brain regions as explanatory variables in one linear regression model in the form of
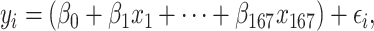 |
(9) |
Note, all other algorithms below beyond the first 3 were ML based that required hyperparameter tuning via cross-validation.
The fourth algorithm was Elastic Net (Zou and Hastie 2005). Here, apart from minimizing the sum of squared errors done in the previous 3 algorithms (see equation (6)), Elastic Net simultaneously minimizes the weighted sum of the explanatory variables’ coefficients (Zou and Hastie 2005; James et al. 2013; Kuhn and Johnson 2013). As a result, Elastic Net shrinks the contribution of some explanatory variables closer toward zero (or set it to zero exactly). The degree of penalty to the sum of the explanatory variable’s coefficients is determined by a “penalty” hyperparameter denoted by λ. The greater the penalty, the stronger shirking the explanatory variable’s coefficient is, and the more regularized the model becomes. In addition to the “penalty” hyperparameter, Elastic Net also includes a “mixture” hyperparameter denoted by α, which determines the degree to which the sum of either the squared (known as “Ridge”) or absolute (known as “LASSO”) coefficients is penalized. The estimates from Elastic Net are defined by
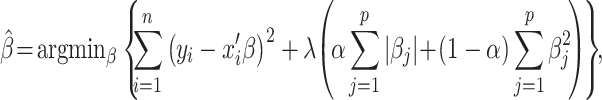 |
(10) |
where p is the number of parameters. In our hyperparameter-turning grid, we used 200 levels of penalty from 10–10 to 10, equally spaced on the logarithmic-10 scale and 11 levels of the mixture from 0 to 1 on the linear scale.
The fifth algorithm is Random Forest (Breiman 2001). Random Forest creates several regression trees by bootstrapping observations and including a random subset of explainable variables at each split of tree building. To make a prediction, Random Forest applies “bagging,” or aggregating predicted values across bootstrapped trees. Unlike the above algorithms, Random Forest allows for (i) nonlinearity (i.e. the relationship between explanatory and response variables does not constrain to be linear) and (ii) interaction (i.e. different explanatory variables can interact with each other). Here we used 500 trees and tuned 2 hyperparameters: “mtry” and “min_n.” “mtry” is the number of explainable variables that are randomly sampled at each split. Here we used the integers between 1 and 167 (i.e. the maximum number of brain regions) in our grid. “min_n” is the minimum number of observations to allow for a split of a node. In other words, min_n puts a limit on how trees grow. We used the integers between 2 and 2000 for min_n in our grid.
The 6th algorithm is XGBoost (Chen and Guestrin 2016). XGBoost is another regression-tree based algorithm. Like Random Forest, XGBoost also allows for nonlinearity and interaction. Unlike “bagging” used in Random Forest that builds multiple independent trees, “boosting” used in XGBoost creates sequential trees where a current tree adapts from previous trees. Accordingly, XGBoost has “learning rate” as a hyperparameter, denoted by η, to control for the speed of the adaptation. Here we sampled “learning rate” from exponentiation with a base of 10 and 3,000 exponents ranging linearly from −10 to −1. XGBoost’s trees are also different from regular regression trees in many aspects. They, for instance, require a “loss reduction” hyperparameter, denoted by γ, to control for the conservativeness in tree pruning. We sampled “loss reduction” from exponentiation with a base of 10 and 3,000 exponents ranging linearly from −10 to 1.5. We also tuned “tree_dept,” or the maximum splits possible using integers from 1 to 15. Additionally, we tuned “sample_size” or the proportion of observations exposed to the fitting routine, using 3,000 numbers ranging from 0.1 to 0.99 on the linear scale. Similar to Random Forest, here we used 500 trees and tuned “mtry” from 1 to 167 and “min_n” from 2 to 1,000. To cope with many hyperparameters, we used a Latin hypercube grid with a size of 3,000.
The 7th to 9th algorithms are SVM for regression, also known as Support Vector Regression, with 3 different kernels: linear, polynomial, and RBF (Cortes and Vapnik 1995; Drucker et al. 1996). SVM includes a “margin of tolerance” hyperparameter, denoted by ε. The “margin of tolerance” signifies an area around a hyperplane where no penalty is given to errors following:
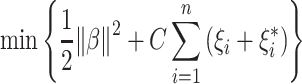 |
with constraints:
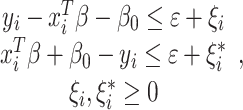 |
(11) |
where ξ are nonzero slack variables that are allowed to be above (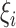 ) and below (
) and below (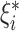 ) the margin of tolerance, and C is a “cost” hyperparameter. A higher “cost” indicates higher tolerance to data points outside of the “margin of tolerance”. Here we sampled the “margin of tolerance” using 30 numbers from 0 to 0.2 on the linear scale. As for the “cost,” we sampled it from exponentiation with a base of 10 and 15 exponents ranging linearly from −3 to 1.5. To allow for nonlinearity and interaction, researchers can apply kernel tricks to transform the data into a higher-dimensional space. Accordingly, in addition to using a linear kernel, we also applied polynomial and RBF kernels. For the polynomial kernel, we needed to tune 2 additional hyperparameters: “degree” and “scale factor”. We sampled “degree” from the numbers 1, 2, and 3 and “scale factor” from exponentiation with a base of 10 and 10 exponents, ranging linearly from −10 to −1. As for the RBF kernel, we sampled another hyperparameter “RBF sigma” from exponentiation with a base of 10 and 10 exponents, ranging linearly from −10 to 0.
) the margin of tolerance, and C is a “cost” hyperparameter. A higher “cost” indicates higher tolerance to data points outside of the “margin of tolerance”. Here we sampled the “margin of tolerance” using 30 numbers from 0 to 0.2 on the linear scale. As for the “cost,” we sampled it from exponentiation with a base of 10 and 15 exponents ranging linearly from −3 to 1.5. To allow for nonlinearity and interaction, researchers can apply kernel tricks to transform the data into a higher-dimensional space. Accordingly, in addition to using a linear kernel, we also applied polynomial and RBF kernels. For the polynomial kernel, we needed to tune 2 additional hyperparameters: “degree” and “scale factor”. We sampled “degree” from the numbers 1, 2, and 3 and “scale factor” from exponentiation with a base of 10 and 10 exponents, ranging linearly from −10 to −1. As for the RBF kernel, we sampled another hyperparameter “RBF sigma” from exponentiation with a base of 10 and 10 exponents, ranging linearly from −10 to 0.
Explaining the algorithms
We applied different methods to help explain how each algorithm drew information from 167 brain regions when making predictions (Molnar 2019). We focused our analyses on the g-factor, so that we can compare our modeling explanation with prior findings with a similar exploratory and response variable in adults (Sripada et al. 2020).
Variable importance: coefficients and SHapley Additive exPlanation
Variable importance refers to the relative contribution of each explanatory variable (i.e. brain region) in making a prediction. To better understand the similarity in contribution from each brain region based on different algorithms, we calculated Spearman’s correlation between variable importance of different algorithms. For the mass univariate analyses, the OLS multiple regression and Elastic Net, we used the coefficient magnitude as a measure for variable importance. Note for the mass univariate analyses, we did not apply any multiple-comparison correction when examining Spearman’s correlations in variable importance with other algorithms, so that the number of explanatory variables stayed the same across algorithms. For Random Forest, XGBoost and SVM, we applied SHapley Additive exPlanation (SHAP) (Lundberg and Lee 2017), to compute variable importance. We implemented SHAP using the fastshap package (https://bgreenwell.github.io/fastshap/).
In addition to examining the similarity in variable importance across algorithms, we also tested how variable importance found in the current study was in line with prior findings (Sripada et al. 2020). Sripada et al. (2020) have recently used young adult data from the Human Connectome Project (HCP) dataset and examined the multivariate relationship between task-fMRI from the similar n-back task and the g-factor. They used an algorithm based on the Principal Component Regression (PCR) and regressed the g-factor on the first 75 principal components (PCs). To explain the regions that were related to the g-factor, they projected all PCs back to the brain space, weighted by the magnitude of the regression. Fortunately, Sripada et al. (2020) uploaded this weighted, PCR brain map on https://balsa.wustl.edu/study/v0D7.
We downloaded and parcellated Sripada et al.’s (2020) brain map using Destrieux’s for cortical surface and ASEG for subcortical regions. We then examined Spearman’s correlations between our variable importance from different algorithms and Sripada et al.’s (2020) weighted, PCR brain map. Given the differences in the age of ABCD vs. HCP participants and the superiority of cortical surface in brain registration across ages (Ghosh et al. 2010), we separately computed Spearman’s correlations on the cortical surface alone and on the whole brain (including both cortical surface and subcortical volume).
Variable selection for variable importance: conventional P-value and eNetXplorer
Here, we only focused on variable selection methods designed for algorithms based upon the general linear model, including mass univariate analyses, the OLS multiple regression, and Elastic Net. We examined the variable selection of these algorithms using the training set. With the mass univariate analyses, we determined brain regions that were significantly associated with the g-factor using FDR and/or Bonferroni corrections (α-level = 0.05). With the OLS multiple regression, we defined significant regions as those with a P-value < 0.05 coefficient.
With Elastic Net, we selected the best mixture hyperparameters from the previously run grid search and applied eNetXplorer (Candia and Tsang 2019) to fit 2 sets of many Elastic Net models. In one set, the models were fitted to predict the true response variable (the g-factor; target models), while in the other set the models were fitted to predict the same response variable randomly permuted (null permuted models). We split the data into 10 folds 100 times (100 runs; eNetXplorer default), and then in each run, the target models were repeatedly trained on 9 folds and tested on the leftover fold. Additionally, for each cross-validation run of the target models, there were 25 permutations of the null permuted models (eNetXplorer default). We defined the explanatory variables’ (brain regions) coefficient for each run, β′, as the average of nonzero model coefficients across all folds in a given run. Across runs, we used an average of a model coefficient weighted by the frequency of obtaining a nonzero model coefficient per run. See the detailed implementation of eNetXplorer in Candia and Tsang (2019). Formally, we defined an empirical P-value as:
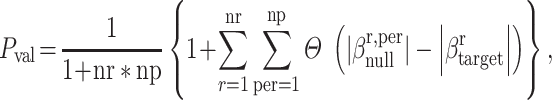 |
(12) |
where Pval is an empirical P-value, r is a run index, nr is the number of runs, per is a permutation index, np is the number of permutations, Θ is the right-continuous Heaviside step function and |β| is the magnitude of an explanatory variable’s coefficient. That is, eNetXplorer uses the proportion of runs in which the null models performed better than the target models to establish statistical significance for each explanatory variable’s coefficient. We implemented eNetXplorer using the eNetXplorer package version 1.1.2 (https://github.com/cran/eNetXplorer).
To demonstrate the differences in variable selection of the OLS multiple regression and eNetXplorer, we created plots to visualize coefficient magnitude and uncertainty estimates as a function of hyperparameters of Elastic Net and multicollinearity. For uncertainty estimates, we used SE of the coefficients for the OLS multiple regression and standard deviation (SD) of the permuted null coefficients from eNetXplorer for Elastic Net. As for hyperparameters of Elastic Net, we created 3 plots with different solutions: full Elastic Net (i.e. tuning both the “mixture” (α) and “penalty” (λ) hyperparameters), Ridge (i.e. fixing the mixture at 0 and tuning the penalty) and LASSO (i.e. fixing the mixture at 1 and turning the penalty). Lastly, we quantified multicollinearity of the brain regions using variance inflation factors (VIF) calculated from the model fit of the unregularized model (i.e. the OLS multiple regression).
Prediction pattern and directionality: univariate effects and accumulated local effects
Here we demonstrated the pattern (i.e. linearity vs. nonlinearity) and directionality (i.e. positive vs. negative) of the relationship between task-based fMRI activity at different brain regions and the g-factor based on different algorithms. For mass-univariate analyses, we plotted a “univariate effect,” a fitted line between fMRI activity at each different region and their associated predicted values of the g-factor, using the “effects” package (Fox and Weisberg 2018). For multivariate algorithms, we plotted ALE (Apley and Zhu 2020). ALE is defined as follows:
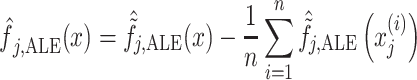 |
where
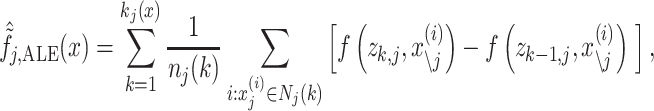 |
(13) |
First, ALE creates a grid, z, that splits the values of an explanatory variable, j, into small windows. The difference between predicted values of xj at the two edges of each window is the “effect.” The summation of the effects across data points within the same window, k, is the “local effect.” The accumulation of local effects from the first window to the last window then constitutes “accumulated local effects, ALE”. Finally, the value of ALE is mean centered, such that the main effect of the explanatory variable at a certain value is compared to the average prediction (Molnar 2019). Accordingly, with ALE, we could plot a line to show how a brain region impacted the prediction of each algorithm on average. We computed ALE with a grid size of 20 using the FeatureEffect command from the iml package (https://christophm.github.io/iml/).
With univariate effects and ALE, we examined the similarity in the pattern and directionality across algorithms. We picked the top 30 regions with the highest variable importance across algorithms. More specifically, we were interested to see which multivariate algorithms provided the pattern and directionality similar to those of univariate algorithms.
Interaction: Friedman’s H statistic
Some algorithms, including Random Forest, XGBoost, and SVM with RBF and polynomial kernels, allow for interactions among explanatory variables. Here, we used Friedman’s H-statistic (Friedman and Popescu 2008) to reveal interaction strength from different brain regions. Friedman’s H-statistic relies on a partial dependent (PD) function (Friedman 2001):
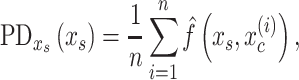 |
(14) |
where 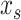 is the explanatory variable of interest, and
is the explanatory variable of interest, and 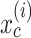 are actual values for all other explanatory variables. Accordingly, PD indicates the average marginal effect for a given value of the explanatory variable
are actual values for all other explanatory variables. Accordingly, PD indicates the average marginal effect for a given value of the explanatory variable 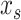 (Molnar 2019). Friedman’s H-statistic, in turn, is estimated from
(Molnar 2019). Friedman’s H-statistic, in turn, is estimated from
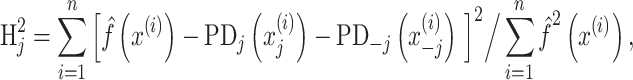 |
(15) |
where H is the Friedman’s H-statistic. Here 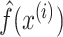 is the prediction function with all explanatory variables included.
is the prediction function with all explanatory variables included. 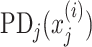 and
and 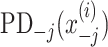 are PD for an explanatory variable j, and for those without the explanatory variable j, respectively. In the case of no interaction,
are PD for an explanatory variable j, and for those without the explanatory variable j, respectively. In the case of no interaction, 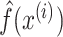 is the same with the sum of
is the same with the sum of 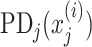 and
and 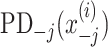 , which results in Friedman’s H-statistic of 0. Friedman’s H-statistic of 1 means that the variation of the prediction is only due to interaction. Accordingly, a higher Friedman’s H-statistic indicates a higher interaction strength from a certain explanatory variable. We computed Friedman’s H-statistic using the Interaction$new() command from the iml package (https://christophm.github.io/iml/) and plotted 20 brain regions with the highest Friedman’s H-statistic from each algorithm.
, which results in Friedman’s H-statistic of 0. Friedman’s H-statistic of 1 means that the variation of the prediction is only due to interaction. Accordingly, a higher Friedman’s H-statistic indicates a higher interaction strength from a certain explanatory variable. We computed Friedman’s H-statistic using the Interaction$new() command from the iml package (https://christophm.github.io/iml/) and plotted 20 brain regions with the highest Friedman’s H-statistic from each algorithm.
Please see our Github page for our scripts and detailed outputs: https://narunpat.github.io/TaskFMRIEnetABCD/ExplainableMachineLearningForTaskBasedfMRI.html.
Results
The g-factor
Figure 1 shows the CFA of the g-factor. The bifactor model of the g-factor shows a good fit: scaled, robust CFI = 0.992, TLI = 0.983, and RMSE = 0.028 (90% CI = 0.021–0.035).
Fig. 1.
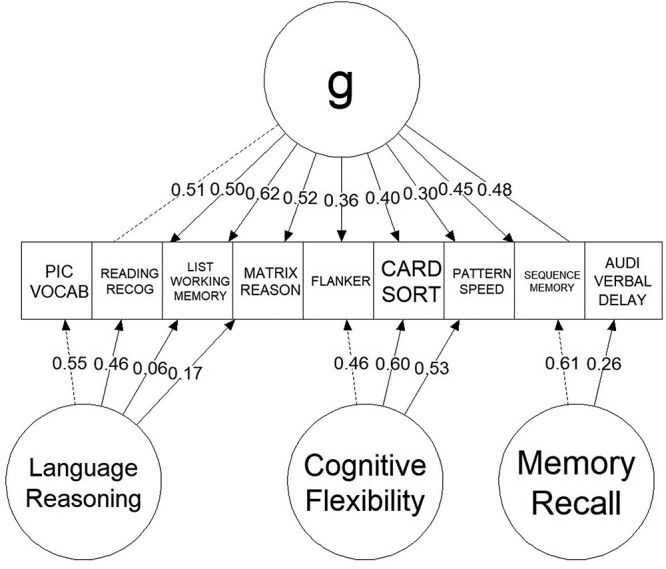
CFA of the bifactor model of the g-factor. The number in each line reflects the magnitude of standardized parameter estimates. The dotted lines indicate marker variables that were fixed to 1. Pic Vocab = Picture Vocabulary; Reading Recog = Oral Reading Recognition; Pattern Speed = Pattern Comparison Processing task.
Predictive performance
Figure 2 shows the bootstrap distributions of predictive performance across algorithms and response variables. Overall, the mass univariate analyses, with either the FDR or the Bonferroni correction, consistently performed worse than multivariate algorithms across response variables and prediction matrices. To statistically compare the predictive ability of linear and additive multivariate algorithms against nonlinear and interactive multivariate algorithms along with mass-univariate analyses, we created the bootstrap distributions of the differences in predictive performance by subtracting the performance of the OLS multiple regression (Fig. 3, Supplementary Fig. 1) and Elastic Net (Fig. 4, Supplementary Fig. 2) from other algorithms. Note to highlight the differences between linear and additive vs. nonlinear and interactive multivariate algorithms, we created Supplementary Figures 1 and 2 the comparisons without mass univariate analyses. These comparisons revealed problems with the OLS multiple regression. For most response variables, the predictive performance of the OLS multiple regression was significantly worse than most of the ML algorithms. Moreover, when the response variables were not-well predicted (e.g. sequential memory, Flanker, auditory-verbal, and pattern speed), the predictive performance of the OLS multiple regression was even worse than that of mass univariate analyses. By contrast, across the response variables, the performance of Elastic Net was either on par with or better than other algorithms. Lastly, fMRI during the n-back task predicted the g-factor well, compared to other out-of-scanner cognitive tasks, especially with multivariate algorithms.
Fig. 2.
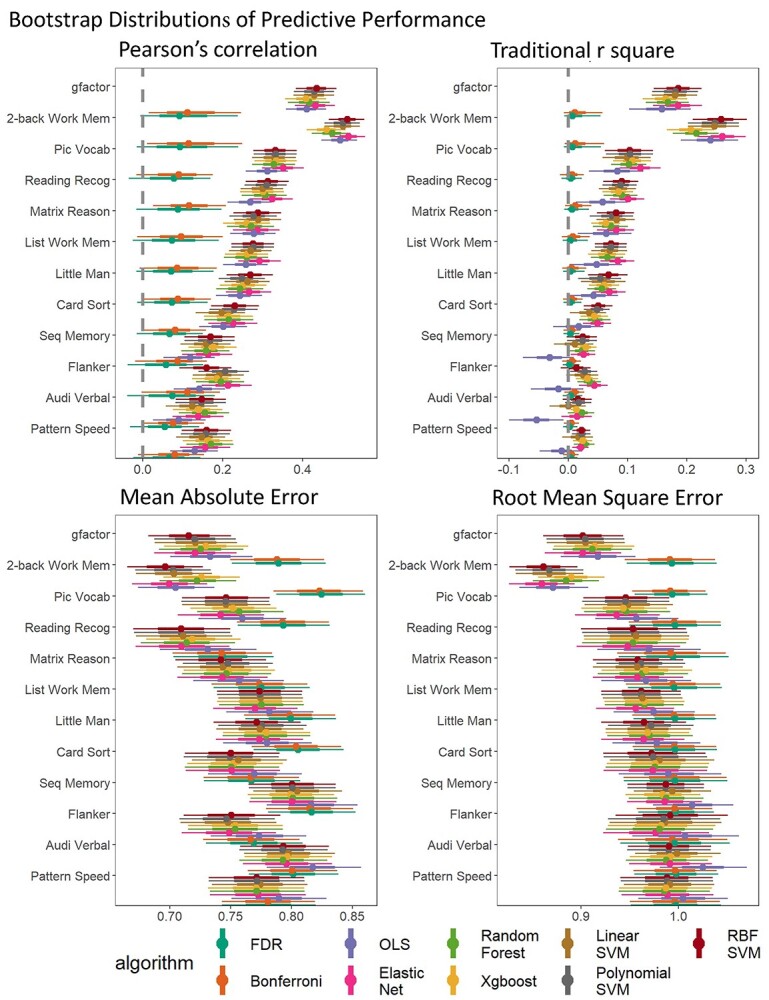
Bootstrap distributions of predictive performance across algorithms and response variables. The thicker lines reflect 65% bootstrap confidence intervals and the thinner lines reflect 95% confidence intervals. MAE = the mean absolute error; RMSE = root-mean-square error.
Fig. 3.

Bootstrap distributions of the differences in predictive performance between the OLS multiple regression and other algorithms. For Pearson’s correlation and traditional r square, values lower than zero indicates lower performance than the OLS multiple regression. For MAE and RMSE, values higher than zero indicates lower performance than the OLS multiple regression. The thicker lines reflect 65% bootstrap confidence intervals and the thinner lines reflect 95% confidence intervals. MAE = mean absolute error; RMSE = root-mean-square error.
Fig. 4.

Bootstrap distributions of the differences in predictive performance between Elastic Net and other algorithms. For Pearson’s correlation and traditional r square, values lower than zero indicates lower performance than Elastic Net. For MAE and RMSE, values higher than zero indicates lower performance than Elastic Net. The thicker lines reflect 65% bootstrap confidence intervals and the thinner lines reflect 95% confidence intervals. MAE = mean absolute error; RMSE = root-mean-square error.
Explaining the algorithms
Variable importance: coefficients and SHAP
Figure 5 shows the variable importance of models predicting the g-factor across all algorithms. Figure 6 shows Spearman’s correlations in variable importance among the algorithms. The variable importance of different algorithms appear to be significantly related (i.e. ρ with P-value < 0.05), but in varying degrees. For instance, the variable importance of Elastic Net was more similar to that of SVM of different kernels (ρ ~ 0.7) than that of mass-univariate algorithm (ρ ~ 0.2). On the other hand, the variable importance of mass-univariate algorithms seemed more closely related to that of Random Forest and XGBoost (ρ ~ 0.5–0.6) than other algorithms. Accordingly, this shows that different algorithms drew information from areas across the brain differently.
Fig. 5.
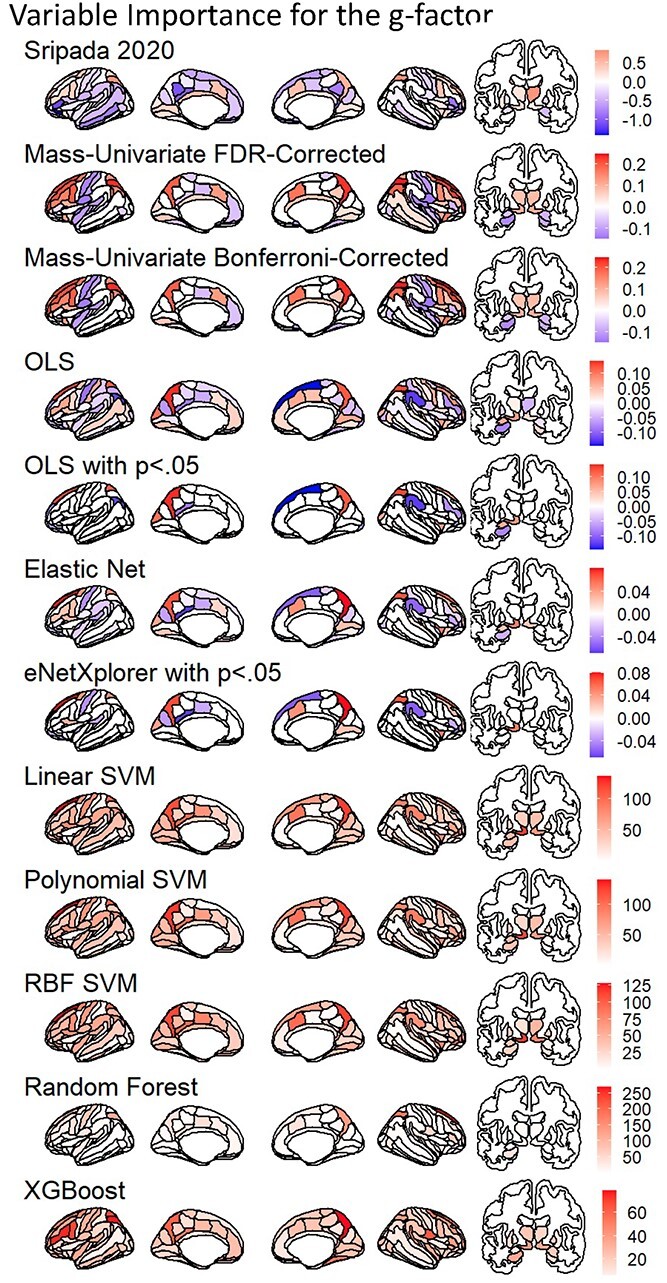
Variable importance of models predicting the g-factor across all algorithms. Variable importance for Sripada et al. (2020) is based on a weighted, PCR. Variable importance for Mass Univariate Analyses, OLS multiple regression, and Elastic Net is the coefficient values while variable importance for SVM, Random Forest, XGBoost is the absolute value of SHAP. We plotted variable importance on the brain using ggseg (Mowinckel and Vidal-Piñeiro 2019).
Fig. 6.
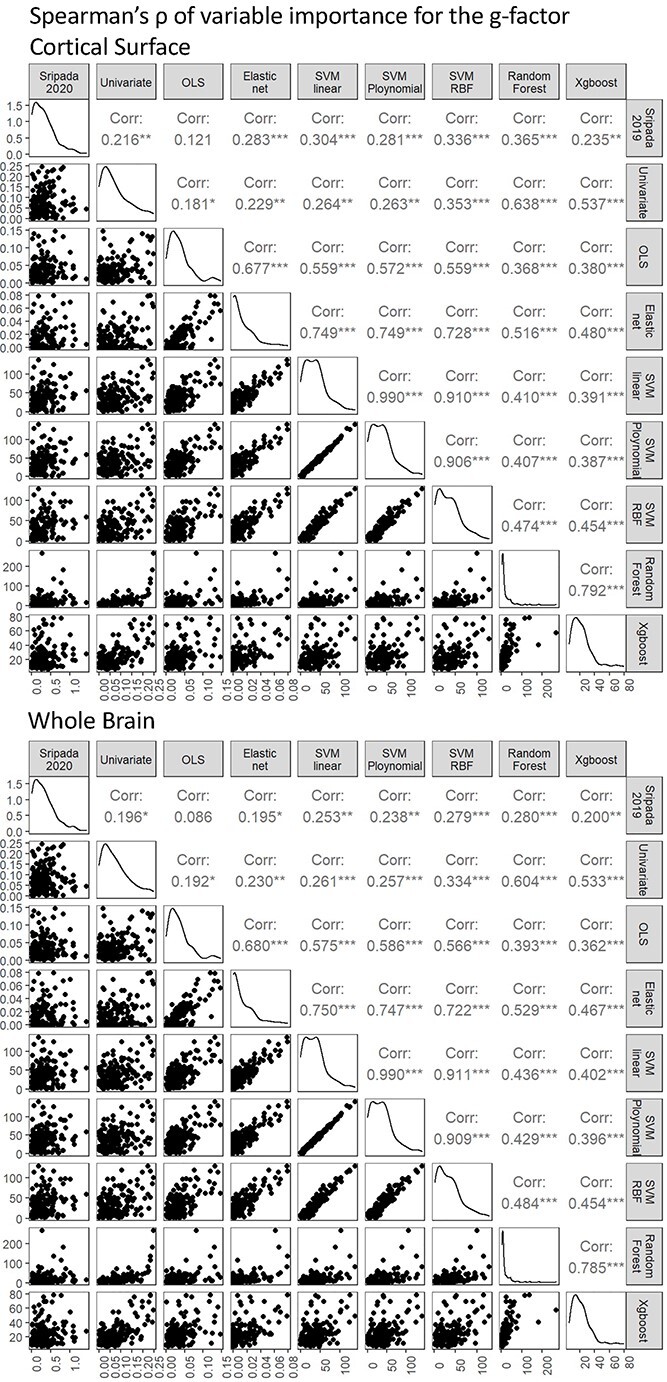
Spearman’s correlations in variable importance between algorithms. We calculated variable importance for models predicting the g-factor. Variable importance for Sripada et al. (2020) is based on a weighted, PCR. Variable importance for mass univariate analyses, OLS multiple regression, and Elastic Net is the coefficient magnitude (i.e. the absolute value of the coefficients). Variable importance for SVM, Random Forest, XGBoost is the absolute value of SHAP.
As for the similarity with Sripada et al.’s (2020) findings, we found significant Spearman’s correlations (P-value < 0.05) across all but one algorithm, the OLS multiple regression. These significant correlations were small in magnitude (ρ ~ 0.2–0.3 on the cortical surface and ρ ~ 0.2 on the whole brain). Still, the OLS multiple regression seemed to be the only algorithm that yielded inconsistent results with Sripada et al.’ (2020) findings.
Variable selection for variable importance: conventional P-value and eNetXplorer
Figure 5 plots variable selection for the variable importance of models predicting the g-factor on the brain. These plots include mass univariate analyses with FDR and Bonferroni corrections, the OLS multiple regression, and Elastic Net with eNetXplorer. Figure 7 plots variable selection for the OLS multiple regression and Elastic Net to highlight the differences between the OLS multiple regression and eNetXplorer in coefficient magnitude and uncertainty estimates as a function of hyperparameters of Elastic Net and multicollinearity. The OLS multiple regression selected 23 regions while eNetXplorer selected 27, 32, and 21 regions for full Elastic Net, Ridge, and LASSO, respectively (Figs. 7 and 8). Of these selected regions, only 14 regions were the same regions among the OLS multiple regression, full Elastic Net, Ridge, and LASSO, and 20 regions were the same among Elastic Net, Ridge, and LASSO. Compared to Elastic Net (penalty at 0.13) and LASSO (penalty at 0.01), Ridge led to the highest penalty at 0.36, resulting in the smallest coefficient magnitude. As for uncertainty estimated, we found that, for the OLS multiple regression, the coefficient SE linearly increased as a function of the VIF. In contrast, for eNetXplorer, the changes in the permuted null coefficient SD as a function of the VIF were less pronounced.
Fig. 7.

Variable selection for the variable importance of the OLS multiple regression (A) and Elastic Net (via eNetXplorer) (B) predicting the g-factor. We only plotted regions with P < 0.05.
Fig. 8.
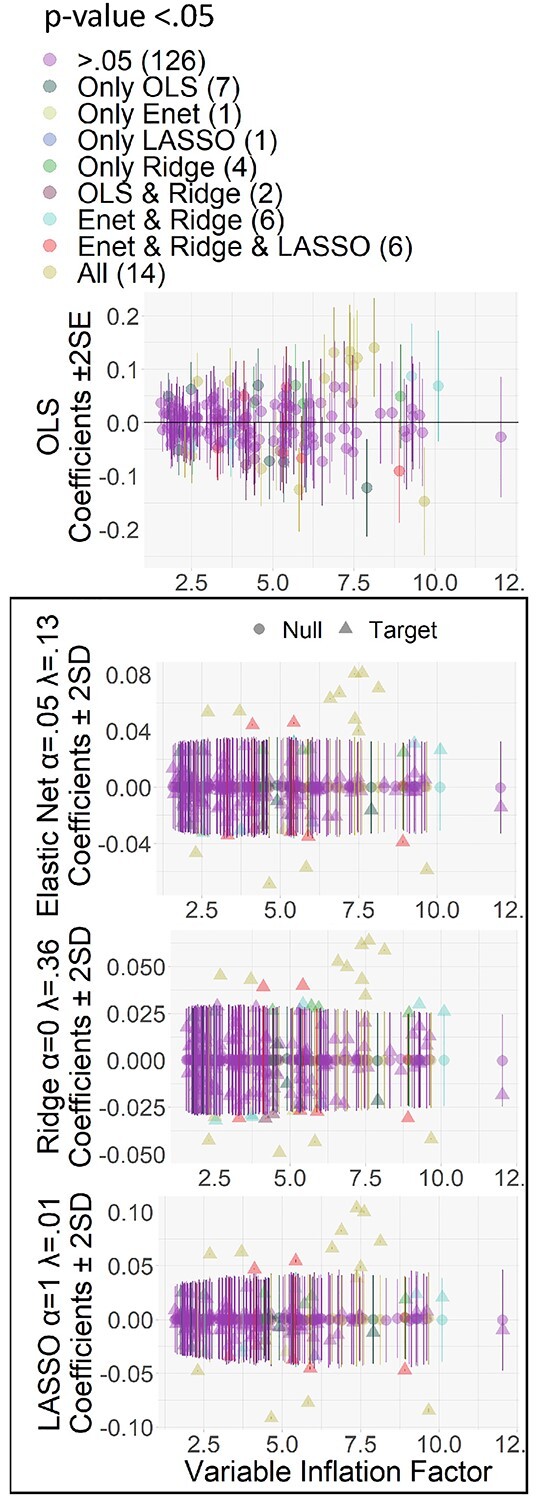
Uncertainty estimates of explanatory variables (brain regions) as a function of VIF for the OLS multiple regression, Elastic Net, Ridge, and LASSO predicting the g-factor. We calculated the VIF based on the OLS multiple regression. For the OLS multiple regression, confidence intervals are the coefficients ±2 multiplied by coefficient’s SE. For the Elastic Net, Ridge, and LASSO, confidence intervals are the permuted null coefficients ±2 multiplied by the permuted null SD.
Prediction pattern and directionality: univariate effects and accumulated local effects
Figure 9 plots univariate effects and ALE of models predicting the g-factor across all algorithms. They show the prediction pattern and directionality of the relationship between predictive values of the g-factor based on different algorithms and fMRI activity at each brain region. Across brain regions, most of the multivariate algorithms, apart from the OLS multiple regression, had a similar pattern and direction (i) with each other and (ii) with the univariate effects. ALE of the OLS multiple regression deviated from that of other multivariate algorithms in many regions. Moreover, ALE of the OLS multiple regression demonstrated a relationship in an opposite direction to univariate effects in several regions, such as the left intra-transverse parietal sulcus, left middle frontal gyrus, left and right middle frontal sulcus, right supplementary precentral sulcus, left angular gyrus, right post ramus of the lateral sulcus, and right superior parietal gyrus.
Fig. 9.
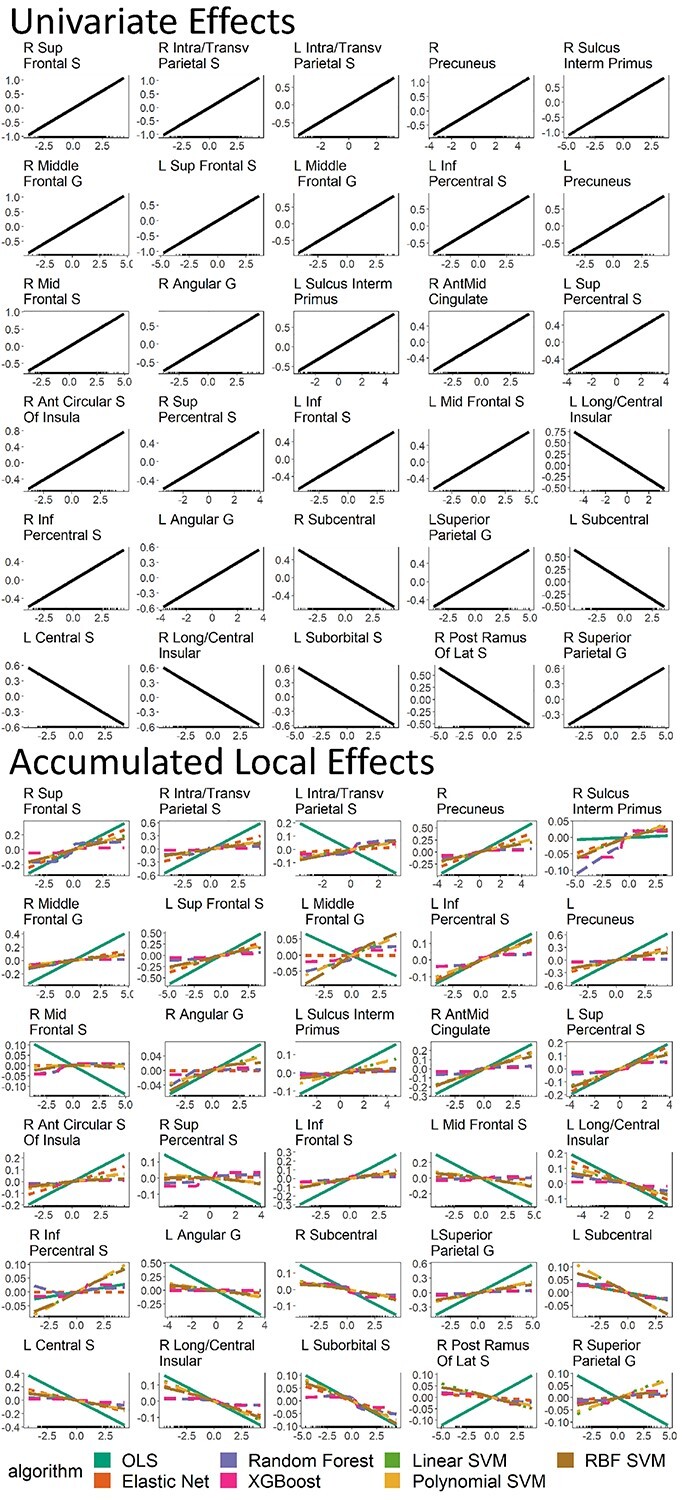
Univariate effects and ALE of models predicting the g-factor across all algorithms. These plots show the prediction pattern and directionality of the relationship between predictive values of the g-factor from different algorithms and fMRI activity at each brain region. We plotted the top 30 brain regions with the highest variable importance across algorithms.
Interaction: Friedman’s H statistic
Figure 10 shows interaction plots based on Friedman’s H-statistic. They show the interaction strength between each brain region and all other brain regions for 4 interactive algorithms predicting the g-factor, including Random Forest, XGBoost, and SVM with RBF and polynomial kernels. The interaction strength between brain regions for XGBoost and SVM with polynomial and RBF kernels accounted for less than 6% of variance explained per region. Random forest, on the other hand, had 2 explanatory variables that accounted for 15% and 20% of variance explained per region.
Fig. 10.

Interaction plots based on Friedman’s H-statistic. H-statistic here indicates the interaction strength between each brain region and all other brain regions for different algorithms predicting the g-factor. Higher values indicate higher strength of the interaction from a particular brain region. Here we plotted the top 20 brain regions with the highest Friedman’s H-statistic at each algorithm.
Discussion
We applied the explainable ML framework (Molnar 2019; Belle and Papantonis 2021) to predict children’s cognition from task-based fMRI during the n-back task, using the ABCD dataset (Casey et al. 2018). We first compared the performance of nine algorithms in their ability to predict individual differences in cognitive abilities across 12 response variables and found better predictive performance from ML algorithms, compared to the conventional mass-univariate analyses and the OLS multiple regression. Despite being a linear and additive algorithm, Elastic Net came up among the top-performing algorithm. We then implemented various explainers to explain how these algorithms drew information from task-based fMRI to predict the g-factor. With these explainers, we found (i) some similarity in variable importance across algorithms and studies, (ii) differences in variable selection between the OLS multiple regression and Elastic Net, (iii) similar directionality in the relationship with the g-factor between ML and mass-univariate algorithms, and (iv) interaction from certain brain regions as captured by interactive algorithms. These explainers also showed potential problems of the OLS multiple regression, including having lower consistency in variable importance with a prior study (Sripada et al. 2020) and having a relationship with the g-factor in the opposite direction with the mass-univariate algorithms at many regions, suggesting the presence of suppression (Ray-Mukherjee et al. 2014).
For predictive performance, the conventional mass-univariate algorithms, either with the FDR or the more-conservative Bonferroni correction, showed worse performance than most multivariate algorithms across most response variables of individual differences in cognitive abilities. Our findings using task-based fMRI are consistent with recent work that compared the performance between mass-univariate and multivariate algorithms (via SVM with the RBF kernel) to predict individual differences in cognition from resting-state fMRI and structural MRI (Marek et al. 2022). Accordingly, across different MRI modalities, using multivariate algorithms appear to be a more promising approach than the mass-univariate algorithms to ensure reproducibility of the brain-cognition relationship and to use MRI as a predictive tool for individual differences.
Nonetheless, simply including all brain regions as explanatory variables in an OLS multiple regression model may not be ideal for prediction. The OLS multiple regression had poorer predictive performance than ML algorithms for most response variables. More importantly, its predictive performance for response variables that were hard to predict across algorithms (e.g. sequential memory, Flanker, auditory-verbal, and pattern speed) was very poor, indicated by negative traditional r square and lowest RMSE, even when compared to the mass-univariate algorithms. By contrast, adding regularization to the OLS multiple regression algorithm in the form of Elastic Net (Zou and Hastie 2005) appeared to boost predictive performance across response variables. In fact, the performance of Elastic Net, despite being a less complex ML algorithm given its constraints on linearity and additivity, was on par with, and in many cases better than, many nonlinear and interactive algorithms, including Random Forest, XGBoost, and SVM of different kernels. This finding is consistent with work on resting-state fMRI, showing that a penalized regression-based algorithm, such as Elastic Net, performed just as well as other algorithms (Dadi et al. 2019). Given that Elastic Net is readily interpretable, it can be considered a parsimonious choice for future task-based fMRI studies.
We observed variability in the level of predictive performance among the 12 response variables of individual differences in cognitive abilities, especially with multivariate algorithms. It is not surprising to see the highest predictive performance from the behavioral performance during the n-back fMRI task. Given that the fMRI and behavioral data were collected at the same time, our predictive models may capture idiosyncratic variation due to the task and session itself (e.g. arousal, attention and other processes). As for out-of-scanner tasks, our predictive models performed better for some cognitive tasks (e.g. picture vocabulary, reading recognition and matrix reasoning) than others (e.g. sequential memory, Flanker, auditory-verbal, and pattern speed). More importantly, capturing the shared variance of behavioral performance across different tasks using the latent variable, the g-factor, led to higher predictive performance than any individual task. This suggests that our framework can be used to build predictive models for individual differences in cognitive abilities in general, and is not confined to specific tasks or processes.
Our implementation of various explainers allowed us to better understand how each algorithm made a prediction of the g-factor. First, variable importance enabled us to move beyond simply estimating the contribution from each separate brain region (i.e. marginal importance), commonly done in mass-univariate analyses. Instead, with variable importance, we could investigate the contribution from multiple regions in the same model (i.e. partial importance; Chen et al. 2019; Debeer and Strobl 2020). Here, we found different degrees of similarity in variable importance across algorithms. On the one hand, the variable importance of mass-univariate algorithms, which are the dominant approach for explaining the brain-cognition associations in the neuroimaging community (Friston 2007), were more closely related to tree-based algorithms, Random Forest, and XGBoost, than other algorithms. On the other hand, the top two algorithms that predicted the g-factor well in the current study, Elastic Net and SVM with the RBF kernel, had variable importance that was correlated well with each other (ρ > 0.7). This suggests that the brain information similarly drawn by Elastic Net and SVM with the RBF kernel in our study allowed us to capture individual differences in the g-factor relatively well.
More importantly, we also tested the similarity in variable importance found in the current study with Sripada et al.’s (2020). Variable importance from all algorithms, except for the OLS multiple regression, was significantly correlated with that of Sripada et al. (2020). While significant, these correlations were small in magnitude, perhaps due to many different characteristics between Sripada et al.’s (2020) and our study. For instance, Sripada et al. (2020) built a predictive model from adults’ data (as opposed to children’s data), applied principle component regression on nonparcellated regions (as opposed to different univariate and multivariate algorithms on parcellated regions) and used a slightly different variation of the n-back task (Barch et al. 2013; Casey et al. 2018) and of the response variables for individual differences in cognitive abilities. Additionally, we also saw more similarity in variable importance with Sripada et al. (2020) on the cortical surface, compared to the whole brain. This might be due to the superiority of cortical surface in brain registration across ages, compared to the subcortical volumetric regions used in the whole brain (Ghosh et al. 2010). Altogether, this suggests some degree of consistency in variable importance across studies for most of the algorithms examined here, apart from the OLS regression.
We showed variable selection for different algorithms: mass univariate analyses with FDR and Bonferroni corrections, the OLS multiple regression, and Elastic Net with eNetXplorer (Candia and Tsang 2019). Being able to explain and select brain regions that exhibited an above-chance-level contribution to the prediction of Elastic Net via eNetXplorer was of great importance, given that Elastic Net had high predictive performance in the current study. Variable selection for the OLS multiple regression and eNetXplorer relies on 2 factors: coefficient magnitudes and uncertainty estimates. Accordingly, we created Figure 8 to investigate coefficient magnitudes and uncertainty estimates at different levels of the mixture hyperparameter, including tuned (Elastic Net) or fixed at either 0 (Ridge) or 1 (LASSO), and multicollinearity. For coefficient magnitudes, we saw lower coefficient magnitude from an algorithm with higher regularization: ranking from Ridge, (penalty (λ) = 0.36), Elastic Net (penalty = 0.13), LASSO (penalty = 0.01) to the OLS multiple regression, which could be viewed as having penalty at 0. As for uncertainty estimates, we saw 2 behaviors of eNetXplorer. First, in our data, the permutation used in eNetXplorer showed more consistency in uncertainty estimates across the different levels of multicollinearity (as reflected by VIF), as compared to the OLS multiple regression. Second, a higher regularization, indicated by the penalty, led to not only a smaller coefficient magnitude of the target model, but also a smaller standard deviation (SD) of the permuted null model, which is the uncertainty estimate for eNetXplorer. This is because eNetXplorer used the same hyperparameters for both the target and permuted null models, which were based on the hyperparameters associated with the best predictive performance for the target model during cross-validation. eNetXplorer then tested which of the brain regions contributed to the prediction of regularized regression higher than chance by comparing regularized coefficients of the target models against regularized coefficients of the permuted null models. Thus, a higher reduction in coefficient magnitude based on the penalty hyperparameter does not necessarily mean a smaller number of regions selected. To illustrate this, in our case, Ridge led to the highest penalty, which resulted in the smallest coefficient magnitude, but had the highest number of regions selected. Altogether, as a result of Elastic Net hyperparameters and multicollinearity, some of the regions with high VIF had high SE and were not selected by the OLS multiple regression, but were selected by eNetXplorer. In contrast, some of the regions that were selected by the OLS multiple regression had smaller relative magnitude and were not selected by eNetXplorer. Thus, eNetXplorer allowed us to explain and select variables that contributed to the prediction given the combination of Elastic Net hyperparameters estimated (Candia and Tsang 2019).
Next, to reveal the pattern and directionality of the relationship between task-based fMRI activity and the g-factor based on different algorithms at different brain regions, we used univariate effects and ALE. For the pattern, ALE revealed the expected pattern from each algorithm. For instance, ALE showed a linear pattern from linear algorithms, such as the OLS multiple regression and Elastic Net. Similarly, ALE also showed a nonlinear pattern from nonlinear algorithms, such as Random Forest and XGBoost. As for the directionality, we saw inconsistency in the directionality between ALE from the OLS multiple regression and univariate effects from mass-univariate analyses. For example, there were many brain regions that were shown to have a positive relationship according to univariate effects, but have a negative relationship according to ALE from the OLS multiple regression. Some of these regions included the left intra/transverse parietal sulcus, left middle frontal gyrus, left and right middle frontal sulcus, right supplementary precentral sulcus, left angular gyrus and right superior parietal gyrus. Accordingly, adding multiple brain regions into an OLS multiple-regression model appeared to change the directionality of the relationship each of the regions had when considered by itself. This may indicate the “suppression” effect whereby the directionality of an explanatory variable depends on its relationship with other explanatory variables (Courville and Thompson 2001; Beckstead 2012; Ray-Mukherjee et al. 2014). Fortunately, all of the ML algorithms we tested did not show this inconsistency. Indeed, regularizing the coefficients in the OLS multiple regression as implemented by Elastic Net appeared to keep the directionality of the relationship in line with that of mass-univariate analyses.
Finally, using Friedman’s H-statistic (Friedman and Popescu 2008), we also demonstrated the interactions among brain regions that were captured by each of the four interactive algorithms: Random Forest, XGBoost and SVM with polynomial and RBF kernels. The interaction strength between brain regions for XGBoost and SVM with polynomial and RBF kernels was quite weak, accounting for less than 6% of variance explained per region. Random forest, on the other hand, had 2 brain regions, the right superior frontal sulcus and right intraparietal sulcus, that accounted for 15% and 20% of variance explained per region. Nonetheless, these 4 algorithms that allowed for interactions generally did not perform well over noninteractive Elastic Net in terms of predictive performance for the g-factor. This means that not accounting for interactions may be parsimonious enough for the current data.
Given the emergence of large-scale, task-based fMRI studies (Van Horn and Toga 2014), one potential use of the explainable ML framework (Molnar 2019; Belle and Papantonis 2021) is to build explainable, predictive models for future studies. This is similar to polygenic scores in genomics (Torkamani et al. 2018), where geneticists use large discovery datasets to build models that reflect the influences of SNPs across the genome on certain phenotypes of interest in the form of polygenic scores. Polygenic scores improve the replicability of genetics studies, compared to the classical “candidate-gene” approach (Bogdan et al. 2018). Polygenic scores are explainable based on the influences of each SNP associated with phenotypes in the discovery dataset (Torkamani et al. 2018). Here we suggest that neuroimagers can take a similar approach to build a predictive model based on task-based fMRI from large-scale studies. In fact, our predictive performance for the g-factor from just one fMRI n-back task (r square ~ 0.2) was considerably higher than that from a polygenic score (r square < 0.1) (Allegrini et al. 2019). This encourages the potential use of task-based fMRI for individual differences in cognition.
To build predictive models for individual differences in cognition from task-based fMRI, there are existing toolboxes, particularly designed for neuroimaging, such as PRoNTO (Schrouff et al. 2013), pyMVPA (Hanke et al. 2009), and Neurominer (Hanke et al. 2009). Here, we took a more general ML approach using the tidymodels (Kuhn et al. 2020) and other R packages. Given the availability of a number of algorithms in tidymodels and the versatility of the R language, our approach is more flexible and readily scalable. Moreover, unlike the neuroimaging toolboxes, using the R language allowed us to integrate the predictive modeling framework with modern explainers, such as SHAP (Lundberg and Lee 2017), eNetXplorer (Candia and Tsang 2019), ALE (Apley and Zhu 2020), and Friedman’s H-statistic (Friedman and Popescu 2008). These explainers are not likely to be available in the purposefully built toolboxes for neuroimaging.
Our study has limitations. While the ABCD dataset is one of the largest datasets with task-based fMRI available (Casey et al. 2018), its sample as of 2020 has, by design, a narrow age range. The predictive model built from our study may only be generalized to children aged 9–10 years old. However, given that the study will trace the participants until they are 19–20 years old, future studies will be able to use a similar approach to ours and expand the age range. Next, our method shown relied on Freesurfer’s parcellation (Fischl et al. 2002; Destrieux et al. 2010), which is the only parcellation available postprocessed from the ABCD release 2.0.1 (Yang and Jernigan 2019). This commonly used parcellation is based on subject-specific anatomical landmarks, but its regions are relatively large. Future studies may need to demonstrate predictive ability with smaller parcels, which will lead to more regions, and in turn, more explanatory variables, but might also result in higher inconsistencies in identifying areas across participants. Lastly, there were many large outliers in the data that we dealt with via listwise deletion. Many of our algorithms tested, including the mass univariate, OLS multiple regression, and Elastic Net, all rely on minimizing the sum of the squared errors, which can be disproportionately influenced by outliers (Maronna 2011; Rousselet et al. 2017). In the future, it may be useful to test the workflow that mitigates the influences of outliers without using the listwise deletion (Lawrence and Marsh 1984; Maronna 2011).
To conclude, applying the explainable ML framework (Molnar 2019; Belle and Papantonis 2021) to task-based fMRI from a large-scale study, we demonstrated poorer predictive ability from the conventional mass-univariate approach and the OLS multiple regression. Drawing information from multiple brain areas across the whole brain via different mL algorithms appeared to improve predictive ability. Elastic Net, a linear and additive algorithm, provides predictive performance on par with, if not better than, other algorithms. Using different explainers allowed us to explain different aspects of the predictive models: variable importance, variable selection, pattern and directionality and interaction. This in turn enabled us to pinpoint problems with the OLS multiple regression. We believe our approach should enhance the scientific understanding and replicability of task-based fMRI signals, similar to what polygenic scores have done for genetics.
Supplementary Material
Acknowledgments
Data used in the preparation of this article were obtained from the Adolescent Brain Cognitive Development (ABCD) Study (https://abcdstudy.org), held in the NIMH Data Archive (NDA). This is a multisite, longitudinal study designed to recruit more than 10,000 children age 9–10 and follow them over 10 years into early adulthood. The ABCD Study is supported by the National Institutes of Health and additional federal partners under award numbers U01DA041022, U01DA041028, U01DA041048, U01DA041089, U01DA041106, U01DA041117, U01DA0411 20, U01DA041134, U01DA041148, U01DA041156, U01DA0 41174, U24DA041123, U24DA041147, U01DA041093, and U01DA041025. A full list of supporters is available at https://abcdstudy.org/federal-partners.html. A listing of participating sites and a complete listing of the study investigators can be found at https://abcdstudy.org/scientists/workgroups/. ABCD consortium investigators designed and implemented the study and/or provided data but did not necessarily participate in analysis or writing of this report. This manuscript reflects the views of the authors and may not reflect the opinions or views of the NIH or ABCD consortium investigators. The authors also thank developers who have maintained R packages used here, including but not limited to eNetXplorer (Candia and Tsang 2019), ggseg (Mowinckel and Vidal-Piñeiro 2019), tidyverse (Wickham et al. 2019), and tidymodels (Kuhn et al. 2020).
Contributor Information
Narun Pat, Department of Psychology, University of Otago, William James Building, 275 Leith Walk, Dunedin 9016, New Zealand.
Yue Wang, Department of Psychology, University of Otago, William James Building, 275 Leith Walk, Dunedin 9016, New Zealand.
Adam Bartonicek, Department of Psychology, University of Otago, William James Building, 275 Leith Walk, Dunedin 9016, New Zealand.
Julián Candia, Longitudinal Studies Section, Translational Gerontology National Institute on Aging, National Institute of Health, Branch, 251 Bayview Boulevard, Rm 05B113A, Biomedical Research Center, Baltimore, MD 21224, USA.
Argyris Stringaris, Division of Psychiatry and Department of Clinical, Educational – Health Psychology, University College London, 1-19 Torrington Pl, London WC1E 7HB, United Kingdom; Department of Psychiatry, National and Kapodistrian University of Athens, Medical School, Mikras Asias 75, Athina 115 27, Greece.
Funding
NP and YW were supported by Health Research Council of New Zealand (award number: 21/618) and by the University of Otago, New Zealand. JC was supported by the Intramural Research Program of the National Institute on Aging, National Institutes of Health, Baltimore, MD, USA (award number: 1ZIAAG000995-07). NP and AS were supported by the Intramural Research Program of the National Institute of Mental Health, National Institutes of Health, Bathesda, MD, USA (award number: ZIA-MH002957). This support of the Intramural Research Program of the National Institute of Mental Health to NP and AS was from 2019 to 2021, prior to the support by the Health Research Council of New Zealand and by the University of Otago, New Zealand in 2022.
Conflict of interest statement: The authors declare no competing interests.
References
- Acker WL, Acker C. Bexley Maudsley automated psychological screening and Bexley Maudsley category sorting test manual. NFER-Nelson, for the Institute of Psychiatry; 1982 [Google Scholar]
- Alin A. Multicollinearity: multicollinearity. Wiley Interdiscip Rev Comput Stat. 2010:2(3):370–374. [Google Scholar]
- Allegrini AG, Selzam S, Rimfeld K, von Stumm S, Pingault JB, Plomin R. Genomic prediction of cognitive traits in childhood and adolescence. Mol Psychiatry. 2019:24(6):819–827. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ang Y-S, Frontero N, Belleau E, Pizzagalli DA. Disentangling vulnerability, state and trait features of neurocognitive impairments in depression. Brain. 2020:awaa314. 10.1093/brain/awaa314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Antonelli L, Guarracino MR, Maddalena L, Sangiovanni M. Integrating imaging and omics data: a review. Biomed Signal Process Control. 2019:52:264–280. [Google Scholar]
- Apley DW, Zhu J. Visualizing the effects of predictor variables in black box supervised learning models. J R Stat Soc B. 2020:82(4):1059–1086. [Google Scholar]
- Barch DM, Burgess GC, Harms MP, Petersen SE, Schlaggar BL, Corbetta M, Glasser MF, Curtiss S, Dixit S, Feldt C, et al. Function in the human connectome: task-fMRI and individual differences in behavior. NeuroImage. 2013:80:169–189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bauer PJ, Dikmen SS, Heaton RK, Mungas D, Slotkin J, Beaumont JL. Iii. Nih Toolbox Cognition Battery (cb): measuring episodic memory. Monogr Soc Res Child Dev. 2013:78(4):34–48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beckstead JW. Isolating and examining sources of suppression and multicollinearity in multiple linear regression. Multivar Behav Res. 2012:47(2):224–246. [DOI] [PubMed] [Google Scholar]
- Belle V, Papantonis I. Principles and practice of explainable machine learning. Front Big Data. 2021:4:688969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc Ser B Methodol. 1995:57(1):289–300. [Google Scholar]
- Benjamini Y, Drai D, Elmer G, Kafkafi N, Golani I. Controlling the false discovery rate in behavior genetics research. Behav Brain Res. 2001:125(1–2):279–284. [DOI] [PubMed] [Google Scholar]
- Bleck TP, Nowinski CJ, Gershon R, Koroshetz WJ. What is the NIH Toolbox, and what will it mean to neurology? Neurology. 2013:80(10):874–875. [DOI] [PubMed] [Google Scholar]
- Bogdan R, Baranger DAA, Agrawal A. Polygenic risk scores in clinical psychology: bridging genomic risk to individual differences. Annu Rev Clin Psychol. 2018:14(1):119–157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breiman L. Random forests. Mach Lang. 2001:45:5–32. 10.1023/A:1010933404324. [DOI] [Google Scholar]
- Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and regression trees. 1st ed. Routledge; 2017 [Google Scholar]
- Candia J, Tsang JS. eNetXplorer: an R package for the quantitative exploration of elastic net families for generalized linear models. BMC Bioinformatics. 2019:20(1):189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carlozzi NE, Tulsky DS, Kail RV, Beaumont JL. Vi. Nih Toolbox Cognition Battery (cb): measuring processing speed. Monogr Soc Res Child Dev. 2013:78(4):88–102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Casey BJ, Cannonier T, Conley MI, Cohen AO, Barch DM, Heitzeg MM, Soules ME, Teslovich T, Dellarco DV, Garavan H, et al. The Adolescent Brain Cognitive Development (ABCD) study: imaging acquisition across 21 sites. Dev Cogn Neurosci. 2018:32:43–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Charness ME. The Adolescent Brain Cognitive Development Study external advisory board. Dev Cogn Neurosci. 2018:32:155–160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Presented at the KDD ‘16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, CA, USA: ACM. 2016: 785–794. [Google Scholar]
- Chen G, Xiao Y, Taylor PA, Rajendra JK, Riggins T, Geng F, Redcay E, Cox RW. Handling multiplicity in neuroimaging through bayesian lenses with multilevel modeling. Neuroinformatics. 2019:17(4):515–545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Conger AJ. A revised definition for suppressor variables: a guide to their identification and interpretation. Educ Psychol Meas. 1974:34(1):35–46. [Google Scholar]
- Cortes C, Vapnik V. Support-vector networks. Mach Learn. 1995:20(3):273–297. [Google Scholar]
- Courville T, Thompson B. Use of structure coefficients in published multiple regression articles: β is not enough. Educ Psychol Meas. 2001:61(2):229–248. [Google Scholar]
- Dadi K, Rahim M, Abraham A, Chyzhyk D, Milham M, Thirion B, Varoquaux G. Benchmarking functional connectome-based predictive models for resting-state fMRI. NeuroImage. 2019:192:115–134. [DOI] [PubMed] [Google Scholar]
- Daniel MH, Wahlstrom D. Equivalence of Q-interactive™ and paper administrations of cognitive tasks: WISC®–V. 13. 2014. https://www.pearsonclinical.com.au/files/830351450329565.pdf.
- Debeer D, Strobl C. Conditional permutation importance revisited. BMC Bioinformatics. 2020:21(1):307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Destrieux C, Fischl B, Dale A, Halgren E. Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature. NeuroImage. 2010:53(1):1–15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dormann CF, Elith J, Bacher S, Buchmann C, Carl G, Carré G, Marquéz JRG, Gruber B, Lafourcade B, Leitão PJ, et al. Collinearity: a review of methods to deal with it and a simulation study evaluating their performance. Ecography. 2013:36(1):27–46. [Google Scholar]
- Drucker H, Burges CJC, Kaufman L, Smola A, Vapnik V. 1996. Support vector regression machines. In: Proceedings of the 9th International Conference on Neural Information Processing Systems. NIPS’96. Cambridge, MA, USA: MIT Press. p. 155–161. [Google Scholar]
- Dubois J, Adolphs R. Building a science of individual differences from fMRI. Trends Cogn Sci. 2016:20(6):425–443. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dubois J, Galdi P, Paul LK, Adolphs R. A distributed brain network predicts general intelligence from resting-state human neuroimaging data. Philos Trans R Soc B. 2018:373(1756):20170284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott ML, Knodt AR, Ireland D, Morris ML, Poulton R, Ramrakha S, Sison ML, Moffitt TE, Caspi A, Hariri AR. What is the test-retest reliability of common task-fMRI measures? New empirical evidence and a meta-analysis. Neuroscience. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott ML, Knodt AR, Ireland D, Morris ML, Poulton R, Ramrakha S, Sison ML, Moffitt TE, Caspi A, Hariri AR. What is the test-retest reliability of common task-functional MRI measures? New empirical evidence and a meta-analysis. Psychol Sci. 2020:31(7):792–806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epskamp S. semPlot: unified visualizations of structural equation models. Struct Equ Modeling. 2015:22(3):474–483. [Google Scholar]
- Eriksen BA, Eriksen CW. Effects of noise letters upon the identification of a target letter in a nonsearch task. Percept Psychophys. 1974:16(1):143–149. [Google Scholar]
- Fischl B, Salat DH, Busa E, Albert M, Dieterich M, Haselgrove C, van der Kouwe A, Killiany R, Kennedy D, Klaveness S, et al. Whole brain segmentation. Neuron. 2002:33(3):341–355. [DOI] [PubMed] [Google Scholar]
- Fox J, Weisberg S. Visualizing fit and lack of fit in complex regression models with predictor effect plots and partial residuals. J Stat Softw. 2018:87(9):1–27. [Google Scholar]
- Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Stat. 2001:29(5):1189–1232. [Google Scholar]
- Friedman JH, Popescu BE. Predictive learning via rule ensembles. Ann Appl Stat. 2008:2:916–954. [Google Scholar]
- Friston KJ, editors. Statistical parametric mapping: the analysis of funtional brain images. 1st ed. Amsterdam, Boston: Elsevier/Academic Press; 2007 [Google Scholar]
- Gabrieli JDE, Ghosh SS, Whitfield-Gabrieli S. Prediction as a humanitarian and pragmatic contribution from human cognitive neuroscience. Neuron. 2015:85(1):11–26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garavan H, Bartsch H, Conway K, Decastro A, Goldstein RZ, Heeringa S, Jernigan T, Potter A, Thompson W, Zahs D. Recruiting the ABCD sample: design considerations and procedures. Dev Cogn Neurosci. 2018:32:16–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gershon RC, Cook KF, Mungas D, Manly JJ, Slotkin J, Beaumont JL, Weintraub S. Language measures of the NIH toolbox cognition battery. J Int Neuropsychol Soc. 2014:20(6):642–651. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghosh SS, Kakunoori S, Augustinack J, Nieto-Castanon A, Kovelman I, Gaab N, Christodoulou JA, Triantafyllou C, Gabrieli JDE, Fischl B. Evaluating the validity of volume-based and surface-based brain image registration for developmental cognitive neuroscience studies in children 4 to 11years of age. NeuroImage. 2010:53(1):85–93. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Graham MH. Confronting multicollinearity in ecological multiple regression. Ecology. 2003:84(11):2809–2815. [Google Scholar]
- Hagler DJ, SeanN H, Cornejo MD, Makowski C, Fair DA, Dick AS, Sutherland MT, Casey BJ, Barch DM, Harms MP, et al. Image processing and analysis methods for the Adolescent Brain Cognitive Development Study. NeuroImage. 2019:202:116091. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanke M, Halchenko YO, Sederberg PB, Hanson SJ, Haxby JV, Pollmann S. PyMVPA: a Python toolbox for multivariate pattern analysis of fMRI data. Neuroinformatics. 2009:7(1):37–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heinze G, Wallisch C, Dunkler D. Variable selection—a review and recommendations for the practicing statistician. Biom J. 2018:60(3):431–449. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helwig NE. Statistical nonparametric mapping: multivariate permutation tests for location, correlation, and regression problems in neuroimaging. Wiley Interdiscip Rev Comput Stat. 2019:11(2):1–24. [Google Scholar]
- James G, Witten D, Hastie T, Tibshirani R. An introduction to statistical learning. Springer US: Springer Texts in Statistics; 2013. 10.1007/978-1-0716-1418-1. [DOI] [Google Scholar]
- Jernigan TL. Adolescent Brain Cognitive Development Study (ABCD)—annual release 2.0; 2019.
- Kragel PA, Han X, Kraynak TE, Gianaros PJ, Wager TD. fMRI can be highly reliable, but it depends on what you measure. 2020. [DOI] [PMC free article] [PubMed]
- Kragel PA, Han X, Kraynak TE, Gianaros PJ, Wager TD. Functional MRI can be highly reliable, but it depends on what you measure: a commentary on Elliott et al. (2020). Psychol Sci. 2021:32(4):622–626. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuhn M, Johnson K. Applied predictive modeling. Vol. 26. New York: Springer; 2013 [Google Scholar]
- Kuhn M, Wickham H, RStudio . Tidymodels: easily install and load the “Tidymodels” packages. 2020
- Kwong KK, Belliveau JW, Chesler DA, Goldberg IE, Weisskoff RM, Poncelet BP, Kennedy DN, Hoppel BE, Cohen MS, Turner R. Dynamic magnetic resonance imaging of human brain activity during primary sensory stimulation. Proc Natl Acad Sci. 1992:89(12):5675–5679. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawrence KD, Marsh LC. Robust ridge estimation methods for predicting US coal mining fatalities. Commun Stat-Theory Methods. 1984:13(2):139–149. [Google Scholar]
- Luciana M, Bjork JM, Nagel BJ, Barch DM, Gonzalez R, Nixon SJ, Banich MT. Adolescent neurocognitive development and impacts of substance use: overview of the adolescent brain cognitive development (ABCD) baseline neurocognition battery. Dev Cogn Neurosci. 2018:32:67–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R, editors. Advances in neural information processing systems. Curran Associates, Inc.; 2017 [Google Scholar]
- Marek S, Tervo-Clemmens B, Calabro FJ, Montez DF, Kay BP, Hatoum AS, Donohue MR, Foran W, Miller RL, Hendrickson TJ, et al. Reproducible brain-wide association studies require thousands of individuals. Nature. 2022:1–7. 10.1038/s41586-022-04692-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maronna RA. Robust ridge regression for high-dimensional data. Technometrics. 2011:53(1):44–53. [Google Scholar]
- Molnar C. Interpretable machine learning. In: A guide for making black box models explainable; 2019.
- Monti M. Statistical analysis of fMRI time-series: a critical review of the GLM approach. Front Hum Neurosci. 2011:5:28. 10.3389/fnhum.2011.00028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moran MD. Arguments for rejecting the sequential Bonferroni in ecological studies. Oikos. 2003:100(2):403–405. [Google Scholar]
- Mowinckel AM, Vidal-Piñeiro D. Visualization of Brain Statistics With R Packages ggseg and ggseg3d. Advances in Methods and Practices in Psychological Science. 2020:3(4):466–483. 10.1177/2515245920928009. [DOI] [Google Scholar]
- Poldrack RA, Huckins G, Varoquaux G. Establishment of best practices for evidence for prediction: a review. JAMA Psychiat. 2020:77(5):534–540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ray-Mukherjee J, Nimon K, Mukherjee S, Morris DW, Slotow R, Hamer M. Using commonality analysis in multiple regressions: a tool to decompose regression effects in the face of multicollinearity. Methods Ecol Evol. 2014:5(4):320–328. [Google Scholar]
- Rosenberg MD, Martinez SA, Rapuano KM, Conley MI, Cohen AO, Cornejo MD, Hagler DJ, Meredith WJ, Anderson KM, Wager TD, et al. Behavioral and neural signatures of working memory in childhood. J Neurosci. 2020:40(26):5090–5104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rosseel Y. lavaan: an R package for structural equation modeling. J Stat Softw. 2012:48(2):1–36. 10.18637/jss.v048.i02. [DOI] [Google Scholar]
- Roth AE, editors. The Shapley value: essays in honor of Lloyd S. Shapley. Cambridge: Cambridge University Press; 1988 [Google Scholar]
- Rousselet GA, Pernet CR, Wilcox RR. Beyond differences in means: robust graphical methods to compare two groups in neuroscience. Eur J Neurosci. 2017:46(2):1738–1748. [DOI] [PubMed] [Google Scholar]
- Schrouff J, Rosa MJ, Rondina JM, Marquand AF, Chu C, Ashburner J, Phillips C, Richiardi J, Mourão-Miranda J. PRoNTo: pattern recognition for neuroimaging toolbox. Neuroinformatics. 2013:11(3):319–337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sripada C, Angstadt M, Rutherford S, Taxali A, Shedden K. Toward a “treadmill test” for cognition: improved prediction of general cognitive ability from the task activated brain. Hum Brain Mapp. 2020:41(12):3186–3197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson WK, Barch DM, Bjork JM, Gonzalez R, Nagel BJ, Nixon SJ, Luciana M. The structure of cognition in 9 and 10 year-old children and associations with problem behaviors: findings from the ABCD study’s baseline neurocognitive battery. Dev Cogn Neurosci. 2019:36:100606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Torkamani A, Wineinger NE, Topol EJ. The personal and clinical utility of polygenic risk scores. Nat Rev Genet. 2018:19(9):581–590. [DOI] [PubMed] [Google Scholar]
- Van Horn JD, Toga AW. Human neuroimaging as a “Big Data” science. Brain Imaging Behav. 2014:8(2):323–331. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vatcheva KP, Lee M, McCormick JB, Rahbar MH. Multicollinearity in regression analyses conducted in epidemiologic studies. Epidemiology (Sunnyvale). 2016:6(2):227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wickham H, Averick M, Bryan J, Chang W, McGowan LD, François R, Grolemund G, Hayes A, Henry L, Hester J, et al. Welcome to the Tidyverse. J Open Source Softw. 2019:4(43):1686. [Google Scholar]
- Winkler AM, Ridgway GR, Webster MA, Smith SM, Nichols TE. Permutation inference for the general linear model. NeuroImage. 2014:92:381–397. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang R, Jernigan TL. Adolescent Brain Cognitive Development Study (ABCD) 2.0.1 release [Data set]. NIMH Data Repositories. 2019. 10.15154/1504041. [DOI]
- Zelazo PD, Anderson JE, Richler J, Wallner-Allen K, Beaumont JL, Weintraub S. II. Nih toolbox cognition battery (CB): measuring executive function and attention: Nih toolbox cognition battery (CB). Monogr Soc Res Child Dev. 2013:78(4):16–33. [DOI] [PubMed] [Google Scholar]
- Zou H, Hastie T. Regularization and variable selection via the elastic net. J Royal Statistical Soc B. 2005:67(2):301–320. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.