

Abstract
Motivation
The investigation of sets of genes using biological pathways is a common task for researchers and is supported by a wide variety of software tools. This type of analysis generates hypotheses about the biological processes that are active or modulated in a specific experimental context.
Results
The Network Data Exchange Integrated Query (NDEx IQuery) is a new tool for network and pathway-based gene set interpretation that complements or extends existing resources. It combines novel sources of pathways, integration with Cytoscape, and the ability to store and share analysis results. The NDEx IQuery web application performs multiple gene set analyses based on diverse pathways and networks stored in NDEx. These include curated pathways from WikiPathways and SIGNOR, published pathway figures from the last 27 years, machine-assembled networks using the INDRA system, and the new NCI-PID v2.0, an updated version of the popular NCI Pathway Interaction Database. NDEx IQuery’s integration with MSigDB and cBioPortal now provides pathway analysis in the context of these two resources.
Availability and implementation
NDEx IQuery is available at https://www.ndexbio.org/iquery and is implemented in Javascript and Java.
1 Introduction
Investigating sets of proteins and genes of interest using biological pathways and networks is a common task for researchers. Networks describe relationships between genes, proteins, small molecules, and other entities and express the mechanisms associated with a biological process or the function of a cellular component. Pathway resources such as KEGG (Okuda et al. 2008), Reactome (Fabregat et al. 2016), and SIGNOR (Perfetto et al. 2016) go beyond ontology-based enrichment sources (Reimand et al. 2007; Sherman et al. 2007; Kuleshov et al. 2019) by providing information about the relationships in a curated set of genes. Other gene set analysis resources such as STRING (Szklarczyk et al. 2021), GeneMania (Warde-Farley et al. 2010), and IntAct (Del Toro et al. 2022) consult databases of molecular interactions and find relationships involving the queried genes.
This rich landscape of tools serves the biomedical research community well, but unmet needs remain. First, many sources of molecular interaction data are not aggregated and cannot be queried or have limited query interfaces. Second, where network content is aggregated, it is integrated into a single database with a common schema. While this benefits consistency, it nevertheless loses the data's original structure and can obscure qualitative differences between sources. This normalization process also increases the effort to add and update content, slowing the pace at which databases can grow and making community contributions more complex. Third, the diversity of sources poses challenges for the reuse of query results in subsequent analyses, with each source exporting in a different format or accessed via a different API. Last but not least, sharing and publishing the results of network analysis in a computable and editable format is difficult, and most networks are published and presented only as static images in figures. Here, we present Network Data Exchange Integrated Query (NDEx IQuery), a new tool for network and pathway-based gene set interpretation. NDEx IQuery addresses the unmet needs described above, providing functionality that complements or extends existing resources. It combines novel sources of pathways/networks, and its integration with NDEx (Pratt et al. 2015, 2017; Pillich et al. 2021) provides the capability to store and share analysis results.
2 Materials and methods
The NDEx IQuery web user interface is implemented in Javascript by using the React framework. The NDEx IQuery web application is available at https://www.ndexbio.org/iquery accessible through any major web browser. The NDEx IQuery service is implemented in Java; source code and documentation are available on GitHub at https://github.com/ndexbio/iquery. To report a bug, please use the contact form at https://home.ndexbio.org/report-a-bug/.
2.1 Cytoscape Exchange network format
Cytoscape Exchange (CX) is a JSON-based network exchange format, a flexible structure for the transmission of networks. It is designed for flexibility, modularity, and extensibility and as a message payload in common REpresentational State Transfer (REST) protocols. It is not intended as an in-memory data model for use in applications. The flexibility of CX enables straightforward strategies for lossless encoding of potentially any network. At the most basic level, this means that CX imposes very few restrictions: networks can be cyclic or acyclic, and edges are implicitly directed, but networks can use custom annotation schemes to override this. CX does not make any commitment to a single ‘correct’ model of biology or graphic markup scheme. CX is designed to facilitate streaming, potentially reducing the memory footprint burden on applications processing large CX networks. The CX format documentation is available at https://home.ndexbio.org/data-model.
2.2 Methods for ranking query results
NDEx IQuery calculates measures of alignment of a query gene set against a large collection of networks and then returns ranked lists of results. To create this ranking, NDEx IQuery implements three different metrics, each highlighting a different aspect of alignment: similarity, P-value, and overlap.
2.2.1 Similarity: cosine similarity of the query genes and the network genes
This score characterizes the similarity between the query set and the genes in the network while considering that some genes are much more universal than others and will appear in many more networks. The cosine similarity calculation uses values derived from each gene's term frequency-inverse document frequency (TF-IDF) in the query set and the network. Rare genes that are shared between the query set and the network will contribute more to the similarity score than common genes, resulting in a higher similarity score. When sorting by similarity, networks with high similarity are at the top of the list, and networks with low similarity are at the bottom of the list.
2.2.2 P-value: hypergeometric test adjusted for false discovery
This score is the probability that the query set and the network overlap, calculated using the complementary cumulative distribution function of a hypergeometric distribution, where:
The population size (N) is equal to the number of genes in the database (i.e. the total number of unique genes found in all the pathways for any given analysis tab);
The number of success states in the population (K) is equal to the number of genes in the network;
The sample size (n) is equal to the size of the network; and
The number of observed successes (k) is equal to the number of genes that are in both the query set and the network.
The P-values are adjusted to compensate for the high false discovery rate that is an effect of querying a large database of networks. This is done using the Benjamini–Hochberg method, where each P-value is multiplied by the number of networks queried and then divided by its rank relative to other P-values (where low P-values have a low rank and vice versa). When sorting by P-value, networks with a low P-value are at the top of the list, and networks with a high P-value are at the bottom of the list.
2.2.3 Overlap: the number of genes that are in both the query set and the network
When sorting by overlap, networks with a high number of overlapping genes are at the top of the list, and networks with a low number of overlapping genes are at the bottom of the list. Sorting is stable, so sorting by P-value and then by overlap will result in a list where networks are sorted by overlap, and networks that are tied for overlap are sorted by P-value.
2.3 Relationship to other resources
NDEx IQuery is part of the Network Data Exchange (NDEx) infrastructure (https://www.ndexbio.org/). It draws on curated pathway content from WikiPathways (https://www.wikipathways.org/) and the SIGNOR database (https://signor.uniroma2.it/), as well as machine-assembled networks from the INDRA system (https://www.indra.bio/) and published pathway diagrams from the Pathway Figures OCR (https://pfocr.wikipathways.org/) open science project. NDEx IQuery is also integrated with the popular Molecular Signatures Database (MSigDB) (https://gsea-msigdb.org) and cBioPortal for Cancer Genomics (https://www.cbioportal.org/).
2.4 Prior knowledge and limitations
NDEx IQuery v1.4 supports only human gene queries. While we recommend using HGNC-approved gene symbols, synonyms, and aliases are also acceptable and will be normalized to approved symbols. Queries with over 400 gene symbols made on the NDEx IQuery website (https://ndexbio.org/iquery) may become very slow, although we are working to improve response time. Queries made from other websites (e.g. www.cytoscape.org) via an HTTP GET request are limited to roughly 100 gene symbols because larger queries would exceed the maximum size of a URL.
3 Results
The NDEx IQuery interface has several elements, as shown by the colored outlines in Fig. 1, centered on the graphical rendering module that displays the network, identified by the orange outline.
Figure 1.

Pathway figures analysis and user interface elements. An mRNA processing-related gene set (DHX15 GEMIN7 PRP17 SNRNP70 SNRPA1 SNRPC SRRM1 NEF) finds pathway figures from papers specifically focused on the spliceosome. For each query result (bottom left pane, blue outline), matched query genes are shown in red, normalized genes boxed in orange, and invalid genes with a strikethrough. Top bar, red outline: Query input element. Second bar,green outline: Analysis selection element. Bar above the pathway figure, black outline: Toolbar element. Displayed pathway figure, orange outline: Graphical Rendering element. (credit for the pathway figure shown: Kerins, et al. Dev Dyn. ;239(5):1555-1572)
Query input element. The input element(top bar, outlined in red) provides a search box to input query genes, augmented with buttons to clear the query, view it in full, or select one of the available example gene sets. On the right-hand side, the black ‘question mark’ icon lets users access a short tutorial on the interface and its modules.
Analysis selection element. The analysis tabsbelow the query input element (green outline) select between the four currently supported analyses described in the analysis section below.
Results element. The results panel on the bottom left (blue outline) displays the query results of each analysis along with details about the matched query genes.
At the top of the panel, the ‘Sort by’ radio buttons let users choose among three different ordering methods:
Similarity: the cosine similarity of the query genes and the network genes.
P-value: the hypergeometric test adjusted for false discovery.
Overlap: the number of genes that are in both the query set and the network.
Additional details about the three methods are available by clicking the blue info icon next to the ‘Sort by’ controls. Each query result displays the number of matched genes and the number of genes in the network. When selected, the result expands to show all the query genes with matched genes emphasized in red. If the original gene set includes invalid or unofficial gene names, NDEx IQuery will normalize those names and provide details about the normalization performed.
Toolbar element. The toolbar above the displayed network shows the name of the selected query result and provides common controls to perform several actions. The network’s name can be clicked in the toolbar to display a window showing its description, reference, and other attributes. This network information window also includes tabs to browse the network’s nodes and edges in tabular form. The same tabs are also displayed when individual nodes and edges are selected in the graphical rendering to explore their annotations. Annotations are specific to the various types of networks and can include information such as publications supporting an interaction. Other toolbar controls let users change the network's layout, toggle the highlighting of query genes, and display the network’s legend. Finally, two additional dedicated toolbar buttons integrate NDEx IQuery with Cytoscape and NDEx.
Integration with Cytoscape. NDEx IQuery is tightly integrated with Cytoscape (Shannon et al. 2003), the widely used network visualization and analysis application, to enable the immediate use of query results in further analyses. NDEx IQuery results can be seamlessly downloaded to Cytoscape to be edited, used to generate publication-quality images, merged with other networks, annotated with user datasets, or used with any of hundreds of community-developed apps (Lotia et al. 2013).
Integration with NDEx to store and share results. NDEx is the storage and sharing cloud component used by Cytoscape and its umbrella of tools and services. In the NDEx web interface, users can manage their networks in everyday work, make them publicly available, and link to them from publications. NDEx IQuery lets users save query results to their NDEx account, complete with node annotations indicating the query genes.
3.1 Analysis
The NDEx IQuery web application performs four separate gene set analyses based on a diverse range of pathways/networks from NDEx and presents the results in four dedicated tabs: Curated Pathways, Pathway Figures, INDRA GO, and Interactomes.
Curated pathways. This tab aggregates curated pathway content from multiple sources. WikiPathways (Martens et al. 2021) is an open, collaborative, community-driven platform dedicated to the curation of biological pathways. The pathway models were contributed, annotated, and updated by over 700 individuals over the past two decades. Community curators review every edit prior to its inclusion in the official monthly release. NDEx IQuery performs custom gene set analysis on a suite of 675 curated human pathways and 11 cancer hallmark networks, each of which is an aggregation of between 3 and 18 pathway models categorized by the Clinical Proteomic Tumor Analysis Consortium (CPTAC) (https://cptac.wikipathways.org/).
SIGNOR is a repository of manually annotated experimental evidence about causal interactions between proteins and other entities of biological relevance. SIGNOR includes signaling, metabolic, disease, and cancer pathways as well as COVID-19 network hallmarks, providing a total of 90 pathway models.
NCI-PID v2.0 is an updated version of the Pathway Interaction Database (PID) (Schaefer et al. 2009). The PID was created in a collaboration between the US National Cancer Institute and Nature Publishing Group in 2009 and was last updated in 2012. As the maintainers of this popular resource, we are now augmenting the original pathways with machine-generated relationships on an ongoing basis, capturing the latest, up-to-date information. These relationships are assembled using the INDRA system (Gyori et al. 2017) and are annotated with links to detailed summaries of supporting literature evidence, including the specific supporting text. INDRA is described in detail in the INDRA GO analysis section below.
All protein node names are normalized to official gene symbols, but each pathway preserves the semantics and curation approaches intended by the authors. For example, the WikiPathways models retain their diagram format and heterogeneous visual styling features as expected from a community-curated resource, while the SIGNOR pathways keep their causal evidence edge annotations.
Pathway figures. Drawing on the Pathway Figure OCR open science project (Hanspers et al. 2020), NDEx IQuery includes a collection of 32263 gene sets defined by published pathway figures. Using machine learning, they first identified 80000 pathway figures in PMC-indexed articles between 1995 and 2021 and then used optical character recognition (OCR) and named entity recognition (NER) to identify genes, proteins, chemicals, and diseases mentioned in each figure. Altogether, 1.5 million genes (14253 unique genes) were identified in published network and pathway figures, representing more breadth and depth of content than a typical pathway database. The resulting machine-readable gene sets offer a novel means of analyzing published pathway models. The collection is limited to gene sets containing six or more genes to optimize for query similarity, enrichment, and overlap. Each set is represented as an edgeless network and is presented along with the original figure and parent article citation. In NDEx IQuery, this corpus enables users to find pathways specific to individual articles, providing detailed biological and experimental context for interpreting their query results (Fig. 1). Moreover, genes and processes that are not well represented in public curated collections may be found in published pathway figures reflecting recent findings or less-studied topics.
INDRA GO. We used the INDRA system to assemble the output of multiple automated literature mining systems (Valenzuela-Escárcega et al. 2018) (which were run via INDRA on PubMed abstracts and PubMedCentral full-text articles to extract regulation and interaction among biological entities) with the content of structured pathway knowledge bases including Pathway Commons (Rodchenkov et al. 2019). We then used this assembled pathway knowledge base to create networks of interactions and regulations among the set of genes annotated with a given GO term. The INDRA GO tab displays the results of queries against a set of 6295 networks created for small (<200 genes) GO Biological Process terms. Edges between genes in these networks summarize the high-confidence relationships found by INDRA. As in the case of NCI-PID v2.0 described above, the INDRA-derived relationships are up-to-date and have links to detailed summaries of supporting literature evidence, including the specific supporting text (Fig. 2).
Figure 2.

INDRA-GO analysis. The top-ranking INDRA GO network for an input gene set is the GO term for trachea development. The network edges represent interactions or regulations assembled by INDRA among genes annotated with this GO term, including WNT7B and CTNNB1. The evidence supporting the relationship between WNT7B and CTNNB1 can be examined in detail by clicking on the edge, which links to the INDRA Database, where specific evidence sentences and links to source publications are provided
Interactomes. In the Interactomes tab, users can run on-demand queries on selected large interaction networks stored in NDEx (Fig. 3). As of version 1.4, NDEx IQuery uses 20 interactomes derived from public databases or published by researchers. Each interactome is presented with a summary description and a direct link to the original publication in which the dataset is described in full. One of the available interactomes is BioPlex 3 (Huttlin et al. 2021), the latest version of the high-quality network assembled from protein–protein interactions identified in HEK293T and HCT116 cells by affinity purification and mass spectrometry.
Figure 3.
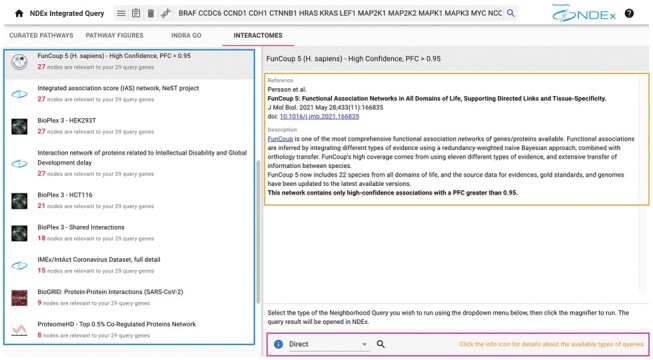
Interactomes analysis. The interactome networks are shown in the results panel on the left (blue outline) and ranked by the total count of nodes relevant to the user’s gene set. Selecting an interactome displays its reference and description on the right-hand side (orange outline). Below, the query control menu lets users choose the type of neighborhood query to run while the blue info button provides a description of each type of query available (purple outline)
Another example is the human protein interaction network from the popular BioGRID database (Oughtred et al. 2021). Both NDEx IQuery and NDEx provide convenient access to these datasets, complementing the single-gene query capability of their own user interfaces. In the cases where the interaction networks are published by researchers, NDEx IQuery allows easy access and use of data that might otherwise be relegated to supplemental materials and not easily accessible by user queries. The type of query and the specific target interaction network to analyze are user-defined, and the analysis is only run if the user decides to do so.
This makes NDEx IQuery fast and efficient while preserving the flexibility to adapt to individual use cases. The query results are opened and displayed in the NDEx web interface using a new browser tab; here, users can refine or modify their query, save their result, or open it in Cytoscape for further analysis.
3.2 Integration
NDEx IQuery has a modular, service-oriented structure in which a primary service aggregates other services. The NDEx IQuery service accepts query strings and returns: (i) lists of networks as query results and (ii) networks in CX format (see Materials and Methods). The integration of NDEx IQuery into a web application is simple. It can be embedded in the application via the ‘IFRAME’ HTML tag and queried via an HTTP “GET’ transaction (Fig. 4A). Alternatively, the application can open NDEx IQuery in a new tab. This method was developed in collaboration with The Molecular Signatures Database (MSigDB) (Liberzon et al. 2015). MSigDB is a widely used and comprehensive database of over 10 000 gene sets for performing gene set enrichment analysis. MSigDB users can now send any gene set to NDEx IQuery for further analysis. A collaboration between The cBioPortal for Cancer Genomics (Gao et al. 2013) and the NDEx project is an excellent example of advanced NDEx IQuery integration.
Figure 4.
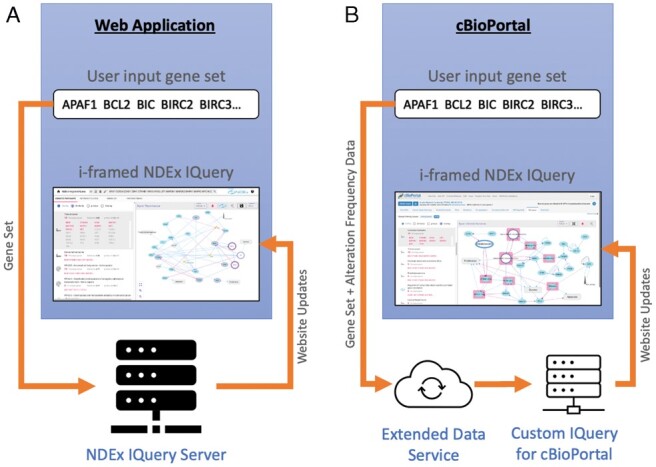
Web application integration of NDEx IQuery. (A) Basic integration. (B) Advanced integration with cBioPortal
cBioPortal provides a web resource for exploring, visualizing, and analyzing multidimensional cancer genomics data. The cBioPortal query interface, combined with customized data storage, enables researchers to interactively explore genetic alterations across samples, genes, and pathways. A customized, cancer-focused version of IQuery was embedded in the cBioPortal interface, enhanced to enable users to view their genes of interest annotated with genetic alteration frequency data from selected datasets (Fig. 4B). The customized IQuery server receives alteration frequency data for each query gene and incorporates that information in the query result networks displayed in the cBioPortal interface.
4 Discussion
Given the diversity of the pathway networks in NDEx IQuery, the values of the scores for a given pathway or its rank in the results should be seen as a general advice, a means of directing the user's attention to potentially relevant mechanisms. Pathways relevant to a given mechanism from different sources reflect alternative choices of genes and may significantly differ in size. This can provide complementary information about the relationships of the genes and proteins within the pathways but can also affect the ranking of those pathways. For example, a gene set related to Apoptosis finds pathways of various sizes from SIGNOR, NCI-PID 2.0, and WikiPathways. A larger pathway may be more informative than a smaller pathway with a better P-value score if it contains more overlapping genes or if the proteins are clustered in a small subnetwork.
4.1 Machine-driven pathway augmentation
With NCI-PID v2.0, we took the first step toward a sophisticated, machine-driven approach to refresh an outdated pathway resource, augmenting the original PID pathways with the addition of up-to-date relationships. However, the proteins, chemicals, and complexes selected for inclusion in each pathway must also be updated to reflect the new research findings generated in the last 10 years. In the next step, we will generate a new pipeline that combines both the INDRA and Pathway Figure OCR technologies to expand the pathways with additional entities relevant to the mechanisms and current members. In this way, the NCI-PID will continue to grow and be maintained as a unique, dynamic reference pathway resource.
4.2 Community-sourced data and application integration
The next steps with NDEx IQuery will focus on (i) expansion via community-sourced pathway and interaction data, (ii) new collaborations in which NDEx IQuery is embedded in applications, (iii) enabling organizations to operate customized IQuery servers focused on their own data, and (iv) enabling users to tailor their IQuery experience.
NDEx IQuery provides collaborators with a simple way to distribute their experimentally derived content and expose it to the community for immediate validation and reuse. Projects that output large datasets, such as BioPlex, HIPPIE (Alanis-Lobato et al. 2017), or ProteomeHD (Kustatscher et al. 2019), can rely on the mature NDEx infrastructure to publish their data rather than developing their own web interface or database.
We will build on the methods developed in our collaboration with cBioPortal to streamline the creation of customized NDEx IQuery instances with alternative sources of pathway data. For example, the cBioPortal uses a selected set of pathways sourced from NCI-PID, WikiPathways, SIGNOR, and NetPath but does not provide access to PFOCR, INDRA GO, and interactome networks.
We will foster new collaborations to enable other projects to integrate NDEx IQuery into their web applications. The methods developed in these collaborations will also enable organizations to deploy private instances of NDEx IQuery and NDEx behind firewalls for use with protected or proprietary pathway data.
Finally, planned extensions of NDEx IQuery will enable users to (i) select among the available public pathway sources to be used for their queries and (ii) include additional sets of pathways/networks stored in their NDEx accounts.
To conclude, NDEx IQuery is a flexible framework for pathway and interaction network-based analysis of gene sets; it encourages collaborations within the research community while providing a channel for researchers to make their network models immediately available and usable by other scientists.
Contributor Information
Rudolf T Pillich, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Jing Chen, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Christopher Churas, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Dylan Fong, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Benjamin M Gyori, Laboratory of Systems Pharmacology, Harvard Medical School, Boston, MA 02115, United States.
Trey Ideker, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Klas Karis, Laboratory of Systems Pharmacology, Harvard Medical School, Boston, MA 02115, United States.
Sophie N Liu, Department of Computer Science, University of Toronto, Toronto, ON M5S 3E1, Canada.
Keiichiro Ono, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Alexander Pico, Institute of Data Science and Biotechnology, Gladstone Institutes, San Francisco, CA 94158, United States.
Dexter Pratt, Department of Medicine, UC San Diego, La Jolla, CA 92093, United States.
Funding
This work was supported by the National Institutes of Health [U24CA184427] and the Defense Advanced Research Projects Agency (DARPA) Young Faculty Award [W911NF-20-1-0255 to B.M.G.].
Conflict of interest
None declared.
Data availability
The data underlying this article (all data sources used by NDEx IQuery) are publicly available in the Network Data Exchange (NDEx) at https://www.ndexbio.org. The following links provide access to the five pathway collections used by NDEx IQuery and the two interactomes mentioned in this article. Other interactomes in NDEx, as with other published networks, can be found in NDEx via search. The URLs below end with the NDEx unique identifier for the networks or collections of networks.
WikiPathways (both the curated pathways and the pathway figure networks): https://www.ndexbio.org/#/user/363f49e0-4cf0-11e9-9f06-0ac135e8bacf
Signor: https://www.ndexbio.org/#/user/0db1f2dc-103f-11e8-b939-0ac135e8bacf
NCI PID v2.0: https://www.ndexbio.org/#/networkset/7bc65b82-2a2f-11ed-ac45-0ac135e8bacf
(and also https://doi.org/10.18119/N93W46)
INDRA GO: https://www.ndexbio.org/#/networkset/bdba6a7a-488a-11ec-b3be-0ac135e8bacf
(and also https://doi.org/10.18119/N9060V)
BioPlex 3.0: https://www.ndexbio.org/#/networkset/ff56527a-aeab-11eb-9e72-0ac135e8bacf
BioGRID: https://www.ndexbio.org/#/user/0edf268f-df15-11e4-951c-000c29cb28fb
References
- Alanis-Lobato G, Andrade-Navarro MA, Schaefer MH. et al. HIPPIE v2.0: enhancing meaningfulness and reliability of protein-protein interaction networks. Nucleic Acids Res 2017;45:D408–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Del Toro N, Shrivastava A, Ragueneau E et al. The IntAct database: efficient access to fine-grained molecular interaction data. Nucleic Acids Res 2022;50:D648–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fabregat A, Sidiropoulos K, Garapati P. et al. The reactome pathway knowledgebase. Nucleic Acids Res 2016;44:D481–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J, Aksoy BA, Dogrusoz U. et al. Integrative analysis of complex cancer genomics and clinical profiles using the cBioPortal. Sci Signal 2013;6:pl1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gyori BM, Bachman JA, Subramanian K. et al. From word models to executable models of signaling networks using automated assembly. Mol Syst Biol 2017;13:954. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanspers K, Riutta A, Summer-Kutmon M. et al. Pathway information extracted from 25 years of pathway figures. Genome Biol 2020;21:273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huttlin EL, Bruckner RJ, Navarrete-Perea J. et al. Dual proteome-scale networks reveal cell-specific remodeling of the human interactome. Cell 2021;184:3022–40.e28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuleshov MV, Diaz JEL, Flamholz ZN. et al. modEnrichr: a suite of gene set enrichment analysis tools for model organisms. Nucleic Acids Res 2019;47:W183–W190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kustatscher G, Grabowski P, Schrader TA. et al. Co-regulation map of the human proteome enables identification of protein functions. Nat Biotechnol 2019;37:1361–71. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberzon A, Birger C, Thorvaldsdóttir H. et al. The Molecular Signatures Database (MSigDB) hallmark gene set collection. Cell Syst 2015;1:417–25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lotia S, Montojo J, Dong Y. et al. Cytoscape app store. Bioinformatics 2013;29:1350–1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martens M, Ammar A, Riutta A. et al. WikiPathways: connecting communities. Nucleic Acids Res 2021;49:D613–21. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Okuda S, Yamada T, Hamajima M. et al. KEGG Atlas mapping for global analysis of metabolic pathways. Nucleic Acids Res 2008;36:W423–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Oughtred R, Rust J, Chang C. et al. The BioGRID database: a comprehensive biomedical resource of curated protein, genetic, and chemical interactions. Protein Sci 2021;30:187–200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perfetto L, Briganti L, Calderone A. et al. SIGNOR: a database of causal relationships between biological entities. Nucleic Acids Res 2016;44:D548–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pillich RT, Chen J, Churas C et al. NDEx: accessing network models and streamlining network biology workflows. Curr Protoc 2021;1:e258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pratt D, Chen J, Welker D. et al. NDEx, the Network Data Exchange. Cell Syst 2015;1:302–5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pratt D, Chen J, Pillich R. et al. NDEx 2.0: a clearinghouse for research on cancer pathways. Cancer Res 2017;77:e58–61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reimand J, Kull M, Peterson H. et al. g:Profiler - a web-based toolset for functional profiling of gene lists from large-scale experiments. Nucleic Acids Res 2007;35:W193–200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rodchenkov I, Babur O, Luna A et al. Pathway Commons 2019 Update: integration, analysis and exploration of pathway data. Nucleic Acids Res 2019;48:D489–97. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schaefer CF, Anthony K, Krupa S. et al. PID: the pathway interaction database. Nucleic Acids Res 2009;37:D674–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shannon P, Markiel A, Ozier O. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res 2003;13:2498–504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sherman BT, Huang DW, Tan Q. et al. DAVID Knowledgebase: a gene-centered database integrating heterogeneous gene annotation resources to facilitate high-throughput gene functional analysis. BMC Bioinformatics 2007;8:426. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Szklarczyk D, Gable AL, Nastou KC. et al. The STRING database in 2021: customizable protein-protein networks, and functional characterization of user-uploaded gene/measurement sets. Nucleic Acids Res 2021;49:D605–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Valenzuela-Escárcega MA, Babur Ö, Hahn-Powell G. et al. Large-scale automated machine reading discovers new cancer-driving mechanisms. Database (Oxford) 2018;2018:bay098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Warde-Farley D, Donaldson SL, Comes O. et al. The GeneMANIA prediction server: biological network integration for gene prioritization and predicting gene function. Nucleic Acids Res 2010;38:W214–20. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data underlying this article (all data sources used by NDEx IQuery) are publicly available in the Network Data Exchange (NDEx) at https://www.ndexbio.org. The following links provide access to the five pathway collections used by NDEx IQuery and the two interactomes mentioned in this article. Other interactomes in NDEx, as with other published networks, can be found in NDEx via search. The URLs below end with the NDEx unique identifier for the networks or collections of networks.
WikiPathways (both the curated pathways and the pathway figure networks): https://www.ndexbio.org/#/user/363f49e0-4cf0-11e9-9f06-0ac135e8bacf
Signor: https://www.ndexbio.org/#/user/0db1f2dc-103f-11e8-b939-0ac135e8bacf
NCI PID v2.0: https://www.ndexbio.org/#/networkset/7bc65b82-2a2f-11ed-ac45-0ac135e8bacf
(and also https://doi.org/10.18119/N93W46)
INDRA GO: https://www.ndexbio.org/#/networkset/bdba6a7a-488a-11ec-b3be-0ac135e8bacf
(and also https://doi.org/10.18119/N9060V)
BioPlex 3.0: https://www.ndexbio.org/#/networkset/ff56527a-aeab-11eb-9e72-0ac135e8bacf
BioGRID: https://www.ndexbio.org/#/user/0edf268f-df15-11e4-951c-000c29cb28fb