

Abstract
Making effective decisions during approach-avoidance conflict is critical in daily life. Aberrant decision-making during approach-avoidance conflict is evident in a range of psychological disorders, including anxiety, depression, trauma-related disorders, substance use disorders, and alcohol use disorders. To help clarify etiological pathways and reveal novel intervention targets, clinical research into decision-making is increasingly adopting a computational psychopathology approach. This approach uses mathematical models that can identify specific decision-making related processes that are altered in mental health disorders. In our review, we highlight foundational approach-avoidance conflict research, followed by more in-depth discussion of computational approaches that have been used to model behavior in these tasks. Specifically, we describe the computational models that have been applied to approach-avoidance conflict (e.g., drift-diffusion, active inference, and reinforcement learning models), and provide resources to guide clinical researchers who may be interested in applying computational modeling. Finally, we identify notable gaps in the current literature and potential future directions for computational approaches aimed at identifying mechanisms of approach-avoidance conflict in psychopathology.
Keywords: approach-avoidance conflict, decision-making, computational modeling
Introduction
Decision-making is a fundamental aspect of human behavior. Broadly, it is a set of processes through which individuals select among potential choice options (e.g., deciding whether to go out and spend time with friends or stay home; for a discussion of decision-making systems, see Walters & Redish, 2018). According to the value-based theory of decision-making (Rangel et al., 2008), individuals make decisions by following a policy that tries to maximize an objective function, such as average reward. Possible decisions are weighed based on expected values of outcomes from the decisions, and a decision is selected that adheres with a given policy. The expected values of possible outcomes reflect outcome magnitude and likelihoods (i.e., probabilities and costs) and are determined from prior experiences of the decision maker, indirect experiences (e.g., via direct observation and/or hearing about others’ experiences), and individual differences in orientation toward and/or away from reward/harm.
Prima facie, making decisions that lead to “good” outcomes seems as simple as following a policy that attempts to maximize an objective function; however, individuals do not always make optimal decisions. Though not necessarily problematic on occasion, suboptimal decisions could negatively impact functioning in daily life. Notably, aberrant decision-making has been observed in mental health disorders (Sripada & Weigard, 2021). Difficulties with decision-making in the context of approach-avoidance conflict may be especially relevant for psychopathology, as difficulties with decision-making during approach-avoidance conflict is evident in multiple psychopathologies, including anxiety disorders, posttraumatic stress disorder (PTSD), alcohol use disorder, and substance use disorders (for reviews, see Aupperle & Paulus, 2010; Loijen et al., 2020).
The concept of approach-avoidance conflict was coined by Lewin (1935), who identified that stress can arise when individuals work toward a goal that has the potential to result in both pleasant and unpleasant outcomes; one of which an individual wants to approach and the other that the individual wants to avoids. For example, in PTSD, approach-avoidance conflict can emerge when an individual wants to spend time with friends (pleasant outcome that they want to approach; approach-reward), but also wants to avoid places that remind them of their trauma (unpleasant outcome they want to avoid; avoid-harm).1 Relatedly, in social anxiety disorder (SAD), conflict can emerge in which an individual wants to spend time with friends (pleasant outcome that they want to approach; approach-reward), but also wants to avoid social situations that elicit anxiety (unpleasant outcome they want to avoid; avoid-harm). For both PTSD and SAD, choosing to spend time with friends has the potential for both reward and emotional pain; choosing not to spend time with friends will result in avoiding perceived potential harm, but also in the loss of potential reward.
Several processes have been proposed to contribute to impaired decision-making during approach-avoidance conflict in psychopathology (Aupperle & Paulus, 2010; Barker et al., 2019; Corr & McNaughton, 2012; Livermore et al., 2021; McNally, 2022; Pastor & Medina, 2021). For example, Aupperle and Paulus (2010) proposed that individuals with anxiety disorders have difficulties with approach-avoidance conflict as a result of overrepresentation of potential harm, under- or overrepresentation of reward valuation, aberrant information integration, and/or impaired decision arbitration. For example, overrepresentation can bias individuals to pay attention to threat-related information and/or weigh potential harm outcomes to a greater degree than potential reward, resulting in reduced approach behavior. Although a large body of research has examined decision-making during approach-avoidance conflict, the specific mechanisms of these impairments have remained elusive. One promising approach is the application of computational modeling to approach-avoidance conflict in humans. Below we provide an overview of decision-making during approach-avoidance conflict and relevant literature, followed by a review of approach-avoidance conflict studies that have included computational modeling and summarize the results of this work.
Review of Approach-Avoidance Conflict and Computational Modeling
To provide an introduction and background information about approach-avoidance conflict research, we searched for “approach AND avoidance” and “approach AND avoidance AND conflict” via the PubMed and Web of Science databases, screened for relevancy by title, then by abstract, with additional sources added as they were discovered. Because there are in-depth reviews of approach-avoidance conflict available (Kirlic et al., 2017; Loijen et al., 2020), we focused on providing a foundational overview and identifying recent studies that had not been included in previous reviews. For our review of computational modeling studies of approach-avoidance conflict, initial sources were found using the search term “approach AND avoidance AND conflict AND comput*” via the PubMed and Web of Science databases, screened for relevancy by title, then by abstract, with additional sources added as they were discovered. Criteria for inclusion required a human subject study with a task that included the potential for both pleasant and unpleasant outcomes (discussed below).
Assessing Decision-Making during Approach-Avoidance Conflict
There is a rich literature for researchers interested in decision-making during approach-avoidance conflict, including several recent studies that are not included the aforementioned reviews (Boschet et al., 2022; Bravo-Rivera et al., 2021; Chu et al., 2021; Hulsman et al., 2021; Klaassen et al., 2021; Lake et al., 2021; Pittig & Scherbaum, 2020; Weaver et al., 2020; Zech et al., 2021). Critically, decision-making during approach-avoidance conflict generalizes many traditional decision-making scenarios for which a decision’s outcome is represented one-dimensionally, generally as a single number with larger numbers representing outcomes that are more desirable and smaller numbers representing outcomes that are less desirable. Although approach and avoidance conflict may be activated when a choice option can lead to either pleasant or unpleasant outcomes, the potential for simultaneous (or, temporally successive) pleasant and unpleasant (two-dimensional) outcomes is the defining feature of approach-avoidance conflict.
While approach-avoidance conflict tasks build on studies that assess pure threat or reward, these tasks assess more than the constituent components. As discussed by (Kirlic et al., 2017), animal studies have identified divergent reward-seeking behavior in the context of reward only versus the context of potential reward and harm (see Orsini et al., 2015). Similarly, human studies have identified aberrant behavioral and neural responses during high, but not low, approach-avoidance conflict (e.g., Aupperle et al., 2015; Weaver et al., 2020), even when the potential for one of the outcomes during the low conflict was relatively high. For example, Weaver et al. (2020) found that women with PTSD only exhibited impaired reward acquisition when the potential for reward and threat were directly in conflict. However, when the potential for harm was high but not in conflict with the potential for reward, participants did not accrue fewer points than controls. Critically, the conflict that emerges directly as a result of the two-dimensional outcomes (harm and reward) can alter behavior in ways are not evident during tasks that purely assess threat or reward.
As discussed by Aupperle and Paulus (2010), to date, most of the approach-avoidance conflict research has focused on decision-making during reward (e.g., winning money or points) and punishment (e.g., physical or physical emotional harm). In human studies, the reward is frequently a monetary outcome, and the punishment is often physical discomfort (electrotactile stimulation [“shock”], eye puff; Garcia-Guerrero et al., 2023; Moughrabi et al., 2022; Talmi et al., 2009), or an unpleasant image (Aupperle et al., 2011, 2015; Weaver et al., 2020). Loss has also been incorporated in some approach-avoidance tasks, such that individuals have the potential to win money and lose money (e.g., during approach-avoidance foraging tasks; Korn et al., 2017). However, for these tasks, the outcomes can be represented one-dimensionally as the net change in money (either you win money or lose all money if caught by a predator).
Task design is essential for the assessment of approach-avoidance conflict; the mechanisms that can be tested are highly dependent on task features. Several tasks have been developed that meet one of the fundamental aspects of approach-avoidance conflict – choices have the potential to deliver simultaneous multidimensional outcomes. Consider, for example, the Approach-Avoidance Conflict (AAC) task developed in animal research (e.g., Amemori & Graybiel, 2012) and modified for human studies in Pedersen et al. (2021) and Rolle et al. (2022; see Figure 1A), and the Avoidance–Reward Conflict (ARC) task developed by Sierra-Mercado et al. (2015) and modified by Zorowitz et al. (2019). These tasks ask participants to choose between two options that vary the degree of reward (money) and the likelihood of punishment (electrotactile stimulation; negative images). They are designed to investigate individual preferences between the two options, but not how individuals learn about the outcomes from their decisions. During the AAC task used by Pedersen et al. (2021) and Rolle et al. (2022), participants must either select a “safe” or a “risky” option; the risky choice has a higher likelihood of delivering more money than the safe option, but also has a higher likelihood of delivering the aversive outcome. On each trial, participants must decide whether to approach, and receive both punishment and reward, or avoid, and receive neither punishment nor reward.
Figure 1.
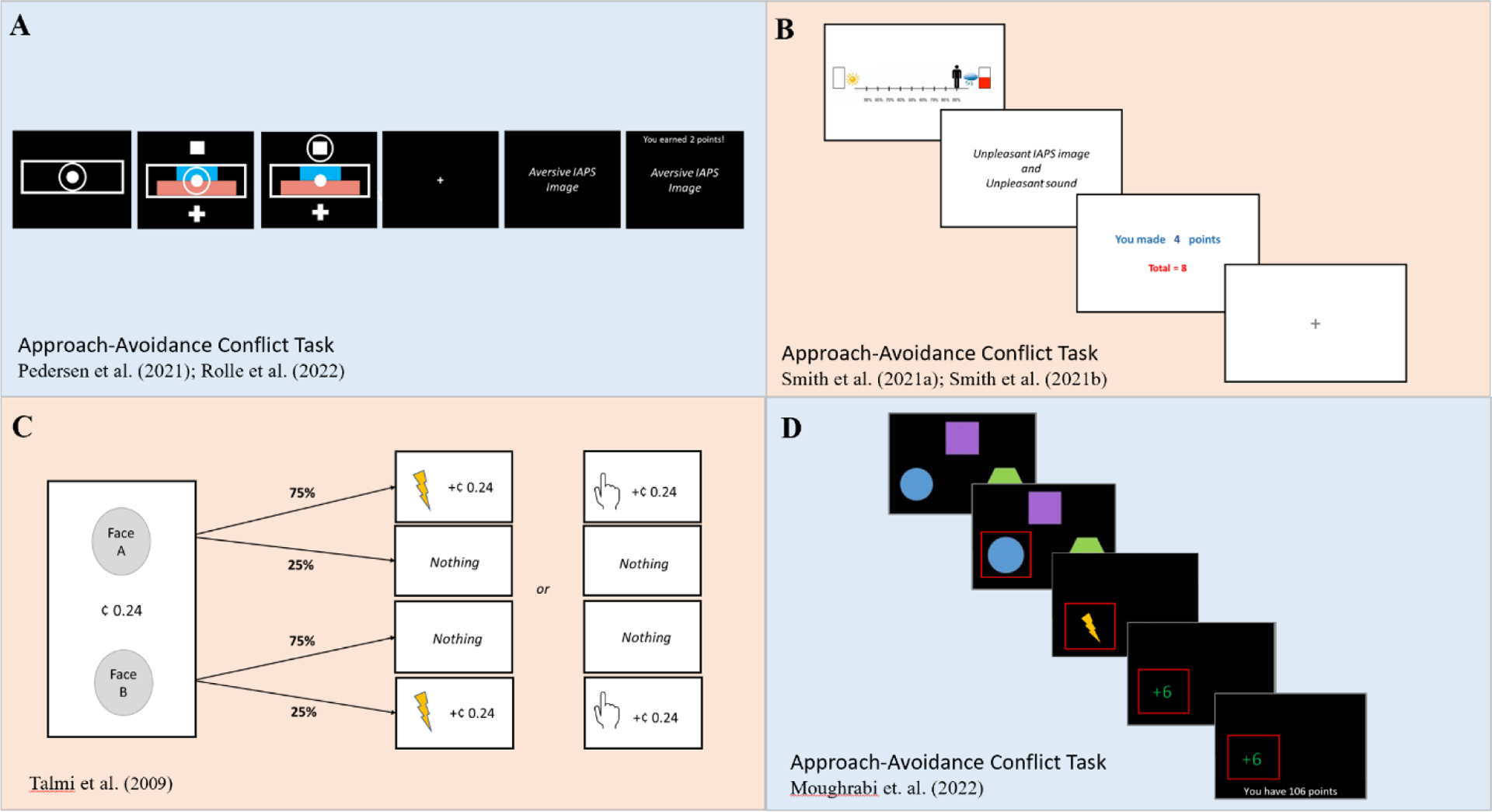
Graphical depiction of tasks that have been used to assess approach-avoidance conflict, which were reproduced from the original manuscripts. The tasks included below included a computational approach to model participants’ behavior: (A) Participants choose to approach or avoid an offer of a potential reward and punishment by moving a circle located at the center either upward or downward. Punishment intensity is scaled from 1 to 5, using the normative negative valence rating for a picture from the International Affective Picture Series. Reward intensity was also scaled from 1 to 5, given by points. (B) Participants move an avatar along a runway closer or further away from an anchor. The closer a participant moves toward one of the anchors, the more likely that the outcome closest to that anchor will occur (and the less likely that the other outcome will occur). (C) Participants choose between two faces, which probabilistically led to either a painful or mild stimulation or nothing. If stimulation occurs, participants also gain (or lose) a previously displayed amount of money. Approach resulted in points and punishment, whereas avoidance resulted in neither. (D) Participants choose one of three geometric shapes, each of which has a different (independent) likelihood of delivering an electrotactile stimulation (shock) and points. The task includes a baseline period, followed by alternating blocks of high and low conflict. During high conflict, the shape that is most likely to deliver a shock is also most likely to deliver points. During low conflict, the shape that is most likely to deliver a shock is also least likely to deliver points.
Another task that has been used to assess approach-avoidance conflict is the Approach-Avoidance Conflict Task developed by Aupperle et al. (2011, 2015; see Figure 1B). In this task, individuals move an avatar along a runway to a (relatively) preferred position under conditions of conflict. During conflict trials, each end of the runway is anchored by two competing choices: (1) a positive affective stimulus and no points or (2) a negative image/sound and points (an alternative version of this task includes money instead of points; McDermott et al., 2022). The closer that an individual moves toward one anchor, the greater the probability that the outcome that is closest to that anchor will occur (90% at either anchor, with a 10% chance of the other [father away] outcome occurring), whereas there is 50% chance of either outcome occurring in the middle of the runway. Notably, this task assesses approach-avoidance preferences that affect decision-making; it was designed in a manner that the participant does not have to learn the outcome probabilities. See Enkhtaivan et al. (2023) for a related discussion regarding limitations of current approach-avoidance tasks to distinguish between decision-makers based on Pareto-optimal performance (i.e., performance that cannot be improved upon in terms of yielding both greater rewards and less harm), as well as task recommendations and relevant code (https://github.com/eza0107/Multi-Objective-RL-and-Human-Decision-Making).
In contrast with the AAC task, some approach-avoidance conflict tasks have included a learning component, such as the approach-avoidance conflict task used by Talmi et al. (2009), the Trauma-related Approach-Avoidance Conflict task (trAAC; Weaver et al., 2020), and a variant of the trAAC task that does not include trauma-related stimuli (AACT; Moughrabi et al., 2022). For example, in the study by Talmi et al. (2009), learning occurred during pre-study conditioning training followed by an experimental phase that included an assessment of decision-making. During the task, participants were shown faces that had a different (high [75%] versus low [25%]) likelihood of delivering money and delivering a painful electrotactile stimulation (or a mild touch in the control condition) versus receiving no money or an electrotactile stimulation (see Figure 1C). The experimental phase did not explicitly test learning, as the probabilities were already known to the participants. By contrast, learning is explicitly assessed during the trAAC and AACT tasks (see Figure 1D). During these tasks, participants are presented with three different cues, each of which is associated with a different reward likelihood of 80%, 50%, or 20% for winning points and an independent threat likelihood of 80%, 50%, or 20% for being presented with a negative assaultive trauma-related image for the trAAC task or receiving a shock during the AACT task. To capture dynamic changes in decision-making, the reward and threat likelihoods change during different blocks (congruent, incongruent) of the task.
Neural Correlates of Approach-Avoidance Conflict
Broadly, several brain regions are activated during reward and punishment (aversive) decision-making and instrumental learning, including dlPFC, orbitofrontal cortex (OFC), ventromedial PFC (vmPFC), dorsal anterior cingulate cortex (dACC), insula, parietal cortex, amygdala, ventral striatum (which includes the nucleus accumbens), and dorsal striatum (for reviews, see Garrison et al., 2013, Gupta et al., 2021, Montague et al., 2006, and Pastor & Medina, 2021). For both reward and punishment, goal-oriented decision-making is associated with activation of the dlPFC, with left dlPFC related to approach goals and right dlPFC to avoidance goals (Spielberg et al., 2011, 2013). Reward and punishment valuation are associated with the OFC, dorsal striatum, and ventral striatum, and the linking of somatic information to expected values with the insula. Conflict identification and prediction errors (PEs) are associated with the dACC, dorsal striatum, and ventral striatum activation, while salience detection is related to activation of the insula and amygdala. Although there are overlapping regions and circuits that are implicated in reward and punishment learning (e.g., some portions of the OFC, Kahnt et al., 2014), there is also evidence of divergence: the ventral striatum typically exhibits greater activation during reward than punishment learning, whereas the dorsal striatum and insula typically exhibit greater activation during punishment than reward learning (Palminteri et al., 2012; Von Siebenthal et al., 2020).
Several studies have examined the neural processes involved in decision-making during approach-avoidance conflict (Aupperle et al., 2015; Chrysikou et al., 2017; Ironside et al., 2015; McDermott et al., 2022). Many have identified similar brain regions to those activated during more general decision-making and learning (e.g., dACC, dlPFC, insula, striatum, hippocampus, and amygdala). For example, during the AAC task, healthy controls exhibited greater activation within right dlPFC, bilateral insula, and right dACC during conflict trials than non-conflict trials (i.e., avoid-threat and approach-reward trials; Aupperle et al., 2015). Furthermore, greater activation within the right caudate during conflict trials predicted less approach behavior (Aupperle et al., 2015). Among individuals with high anxiety sensitivity, approach behavior was reduced during conflict trials after enhancing right dlPFC activity via transcranial magnetic stimulation (TMS; Chrysikou et al., 2017). In a study of adults with either clinical anxiety or depression, there was evidence of altered activation of the amygdala and striatum during the ACC task (McDermott et al., 2022). Specifically, patients had blunted amygdala activation and reduced striatal activation in response to reward, along with enhanced striatal activation in response to affective stimuli (i.e., the positive or negative image and sound outcomes). Across participants, approach behavior during conflict was negatively correlated with activation of the striatum in response to affective stimuli, but was positively associated with reward-related activation of the striatum during feedback.
Zorowitz et al. (2019) examined which brain regions support deliberation versus conflict more specifically during approach-avoidance conflict decision-making. Whereas deliberation processes were related to activation of ACC, dmPFC, anterior insula, dlPFC, striatum, and hippocampus, conflict predicted activation in bilateral inferior frontal gyrus (IFG), right dlPFC, right dmPFC, and right pre-supplementary motor area (SMA). In animal studies, research has identified a role of the hippocampus in decision-making during approach-avoidance conflict (for reviews, see Bryant & Barker, 2020, Ito & Lee, 2016, and Rusconi et al., 2022). Specifically, during threat, the ventral hippocampus activation is theorized to support avoidance behavior by blocking approach responses. In humans, there is evidence that a homologous anterior region of the hippocampus blocks approach behavior during threat (Bach et al., 2014). However, it should be noted that Chu et al. (2021) found that the perirhinal cortex, not the anterior hippocampus, was associated with approach-avoidance conflict resolution.
Computational Modeling of Approach-Avoidance Conflict
Computational models can quantify distinct decision-making processes with greater precision than traditional approaches by estimating parameters that capture separate decision-making components (Haynos et al., 2022; Redish, 2004; Redish et al., 2022). Computational modeling has been applied in animal research to decision-making during approach-avoidance conflict. It has similarly been applied in human research with healthy controls (Rolle et al., 2022; Talmi et al., 2009), major depressive disorder (MDD; Pedersen et al., 2021; Smith et al., 2021a, 2021b), substance use disorders (Smith et al., 2021a, 2021b), and anxiety disorders (Smith et al., 2021a, 2021b; for a review, see Yamamori & Robinson, 2022). Several different types of computational models have been applied, including drift-diffusion models (DDM; Pedersen et al., 2021; Rolle et al., 2022), active inference frameworks (Smith et al., 2021a, 2021b), and reinforcement learning models (e.g., Q-learning; Moughrabi et al., 2022; Talmi et al., 2009). Below we discuss computational approaches that have been used to model decision-making in the context of approach-avoidance conflict tasks, results of these studies, and, when available, resources (e.g., source code) for these modeling approaches.
Drift-Diffusion Models
The drift-diffusion model (DDM) was developed to capture different cognitive processes that are theorized to underlie decision-making and is applied to tasks that require participants to choose between two options (Karalunas & Huang-Pollock, 2013; Ratcliff et al., 2018; Weigard et al., 2020). In the model, choice options are represented as upper and lower boundaries. On a given trial, evidence drifts toward or away from these boundaries. Once enough evidence has accumulated in favor of one of the options, the corresponding boundary is crossed and the response for that option is enacted. Several parameters estimated by DDM capture separate decision-making related processes, including boundary separation, bias, drift-rate, and non-decision time (see Figure 2). The boundary separation parameter (a) represents the distance between the two response option boundaries and reflects the degree of speed-accuracy tradeoff – the greater the distance between the boundaries, the more time is needed for evidence to accumulate and the slower (though more accurate) the responses will be. The bias parameter (z) captures an individuals’ starting position between the boundaries and reflects the tendency for individuals to make one response over the other. The drift-rate parameter (v) reflects how quickly evidence accumulates in favor of a particular response, with larger values reflecting a faster rate of evidence accumulation. Finally, the non-decision time parameter (t) captures the duration of “non-decision” processes, such as the time needed for visual processing, motor preparation, and response execution, with larger values reflecting greater non-decision processing time.
Figure 2.
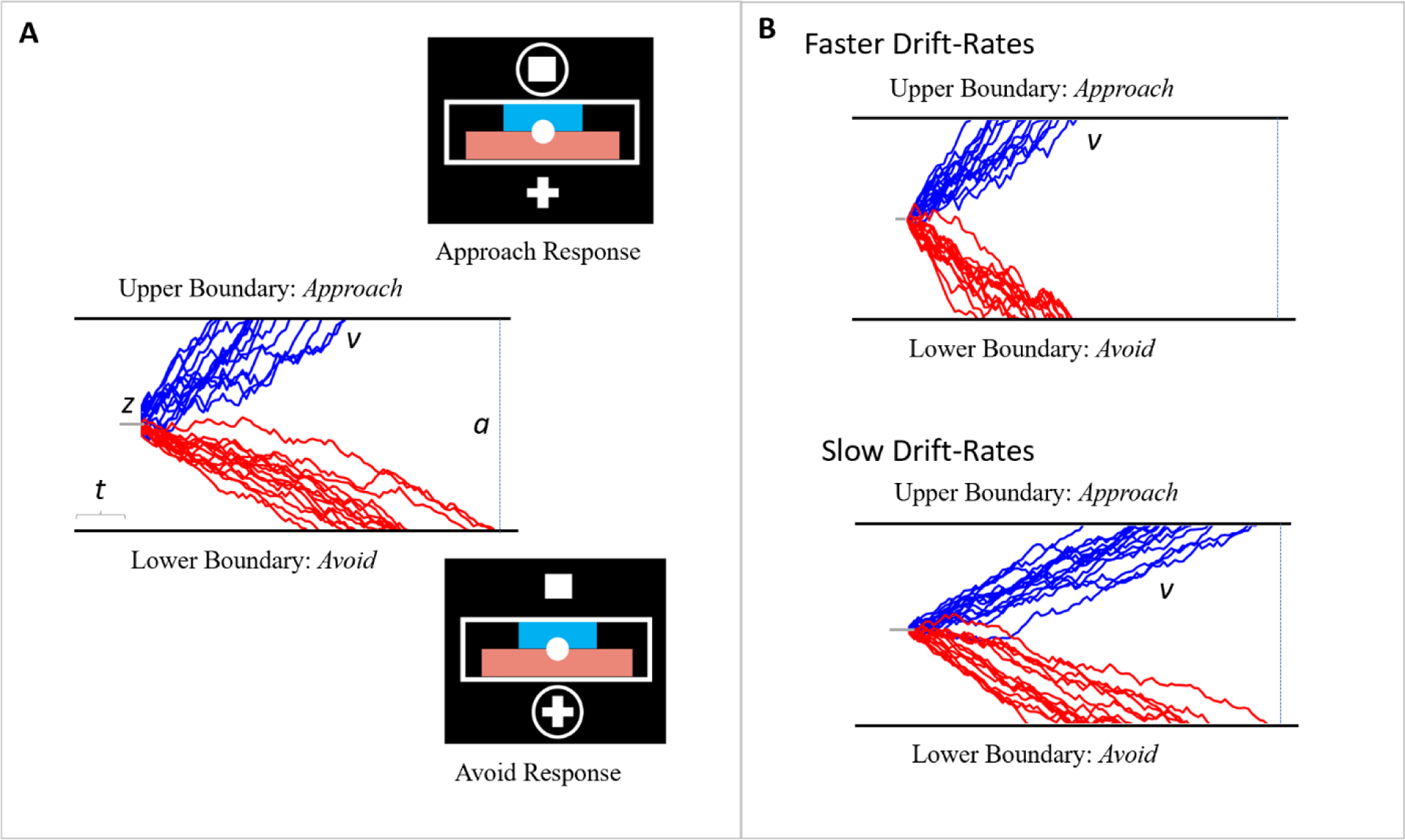
(A) Depiction of the modeling parameters (v, a, z, and t) that are captured by the Drift-Diffusion Model. The upper and lower boundaries are defined by approach and avoidance behavior, respectively, and the drift-rates were simulated. Example responses for these boundaries are represented by the task responses included in Pedersen et al. (2021) and Rolle et al. (2022). (B) Simulated drift-rates representing faster and slower drift rates, respectively.
Whereas a number of studies have examined decision-making using DDM (e.g., Karalunas & Huang-Pollock, 2013; Weigard et al., 2020), we identified only a few that have applied DDM to approach-avoidance conflict behavior. Pedersen et al. (2021), for example, found an effect of major depressive disorder (MDD) on the bias parameter, with a lower starting position (bias parameter, z) relative to controls (i.e., a bias away from the approach boundary). Drift rates were also estimated for the decision to approach versus avoid, and a reduced impact of reward values on the drift rate (v) in the direction of the approach boundary was identified for the MDD group relative to controls, with no group differences for the changes in aversive values on the drift rate toward the avoid boundary. Taken together, these results indicate that MDD is characterized by undervaluation of potential reward.
In healthy controls, Rolle et al. (2022) used transcranial magnetic stimulation (TMS) to disrupt the right dorsolateral prefrontal cortex (dlPFC) during approach-avoidance conflict decision-making. They found that trial-wise changes on the drift rate were blunted in response to reward during conflict; in other words, right dlPFC deactivation contributed to decreased reward sensitivity. Although increased left dlPFC activation is typically implicated in approach/reward motivation (both of which are blunted in depression; Engels et al., 2010; Herrington et al., 2010) and increased right dlPFC in avoidance motivation (Spielberg et al., 2011, 2013), this study suggests that altered right dlPFC activation may also contribute to atypical reward sensitivity in MDD. Notably, atypical right dlPFC activation is evident in depression, characterized by a pattern of blunted activation that emerges when co-occurring anxiety is taken into account (Engels et al., 2010; Herrington et al., 2010).
DDM decision-making models can be applied using publicly available scripts and packages that can be implemented with software such as R, Matlab, and Python. Available packages include fast-dm (Voss et al., 2015), EZ-Diffusion (Wagenmakers et al., 2007, 2008), PyDDM (https://github.com/murraylab/PyDDM; Shinn et al., 2020), hBayesDM (an R package that is integrated with R Stan: https://ccs-lab.github.io/hBayesDM; Ahn et al., 2017), and Hierarchical Drift-Diffusion Model (HDDM) Toolbox (http://github.com/hddm-devs/hddm; Wiecki et al., 2013). The HDDM toolbox offers several advantages, including flexible model building, online documentation that is regularly updated, and a Bayesian estimation approach that yields reliable estimates with fewer trials than maximum likelihood-based approaches (Lerche et al., 2017). Furthermore, several approach-avoidance conflict studies have used the HDDM package to estimate decision-making parameters (e.g., Pedersen et al., 2021; Rolle et al., 2022). For researchers who are relatively new to DDM and computational modeling, the hBayesDM package is a very user-friendly package that provides candidate models for many commonly used decision-making tasks and models and extensive online documentation/support (https://ccs-lab.github.io/hBayesDM/index.html). For further information about and a comparison of several of these DDM packages, see Lerche et al. (2017) and Shinn et al. (2020).
(Partially Observable) Markov Decision Process
Broadly, Markov Decision Process (MDP) is a mathematical framework for modeling situations when decisions are made sequentially over time in the presence of uncertainty. MDPs are defined by: S, A, P, R, γ, which are the set of possible states (S), set of possible actions (A), matrix of state transition probabilities (P), reward distribution (R), and discount factor γ which captures the extent to which the decision-maker’s objective is to maximize current rewards versus future rewards. States define the current conditions for the decision-maker (or “agent”) – i.e., what the current environment is – and influence the consequent rewards and states of a decision. With MDPs, states are directly observable; in other words, the decision-maker knows their current state.
A generalization of this is Partially Observable Markov Decision Processes (POMDP), in which state information is only partially available and states are inferred from available, but incomplete, information. POMDPs are defined by: S, A, P, R, γ, Ω, O, which, similar to MDPs, includes the set of possible states, set of possible actions, matrix of transition probabilities, reward function, and discount factor, but also includes a set of observations (Ω) and a set of observation probabilities (O). In the case of POMDPs, the true current state is unknown (i.e., the states are hidden), and observations provide information about the unknown state. The decision-maker’s (un)certainty regarding their current state can be incorporated by reformulating the POMDP as an MDP, called the belief MDP, whose state space includes the decision-maker’s beliefs about states (i.e., the decision-maker’s estimate for the probability of being in a particular state given their observations). MDPs and POMDPs can be solved using several different classes of models and algorithms, including active inference.
Active Inference
Active inference is an approach to modeling behavior that follows the assumption that individuals make choices by seeking to minimize “surprise.” Surprise is formalized in terms of the predicted likelihood of observations according to some generative probability model of the decision-maker for how observations are generated. Minimizing surprise is equivalent to maximizing this predicted likelihood and is thought to be cast by the decision-maker as a problem of Bayesian inference; i.e., trying to infer the “correct” generative model for the observations. This approach incorporates Bayes’ theorem (Friston et al., 2017a, b; Smith et al., 2020), which decomposes the probability p(a|b) of event a conditional on event b in terms of the probability p(b|a) of event b conditional on event a, the probability p(a) of event a, and the probability p(b) of event b, provided these probabilities are defined:
Within the context of a POMDP, Bayes’ theorem can invert a decision-maker’s generative model to compute the posterior likelihood of the decision-maker being in an unknown state based on prior information and new information that is observed. For example, given an unknown state s, all the known information o currently available to a person, and a generative model m (e.g., transitions probabilities between states; for additional information, see Smith et al., 2022), then Bayes’ theorem gives:
In other words, Bayes’ theorem relates, according to model m, the probability p(s|o, m) of being in a state given available information to the likelihood p(o|s, m) of this information given the state along with the probability p(s|m) of being in the state and the probability p(o|m) of the information.
Bayesian inference can be computationally intractable. Active inference proposes that a decision-maker uses approximate Bayesian inference to infer a generative model for observations, where, instead of surprise, the decision-maker minimizes an upper bound of surprise called variational free energy. Importantly, minimizing variational free energy is an easier problem for the decision-maker to perform. A decision-maker’s policy on whether to approach or avoid is chosen to minimize variational free energy. Preference towards approaching reward and minimizing harm is accounted for with a generative model that assumes a prior probability of future observations that favors more rewarding and less harmful outcomes.
As stated previously, the Approach-Avoidance Conflict Task developed by Aupperle et al. (2011, 2015) assesses preferences without a reinforcement learning component. To model behavior, Smith et al. (2021a, 2021b) used active inference to solve a POMDP model that included states (runway positions [10 including the starting position] and trial types: Avoid-Threat, Approach-Reward, Conflict+2 points, Conflict+4 points, Conflict+6 points [5 total]), participants’ actions (i.e., choice of runway position), observable task stimuli (runway cues, trial type cues, affective stimuli, points; see Figure 3), and matrices that link the probability that different states (positions on the runway and trial type) will lead to particular outcomes following particular actions given participants’ aversion/preference for the task stimuli. The model also captured beliefs about current states and a parameter (β) that affected the degree to which policies were deterministic. Parameters were estimated using Variational Bayes, which approximates Bayesian estimation (given that intractable integrals can arise in Bayesian inference). Smith et al. (2021a, 2021b) provide links to their Matlab code in the appendix of their 2021a paper and additional code in the supplement of their 2021b paper, which utilizes software developed by Karl Friston https://www.fil.ion.ucl.ac.uk/spm. Additionally, Smith et al. (2022) provide a step-by-step tutorial on building active inference models and Matlab code for running simulations and fitting models to data.
Figure 3.
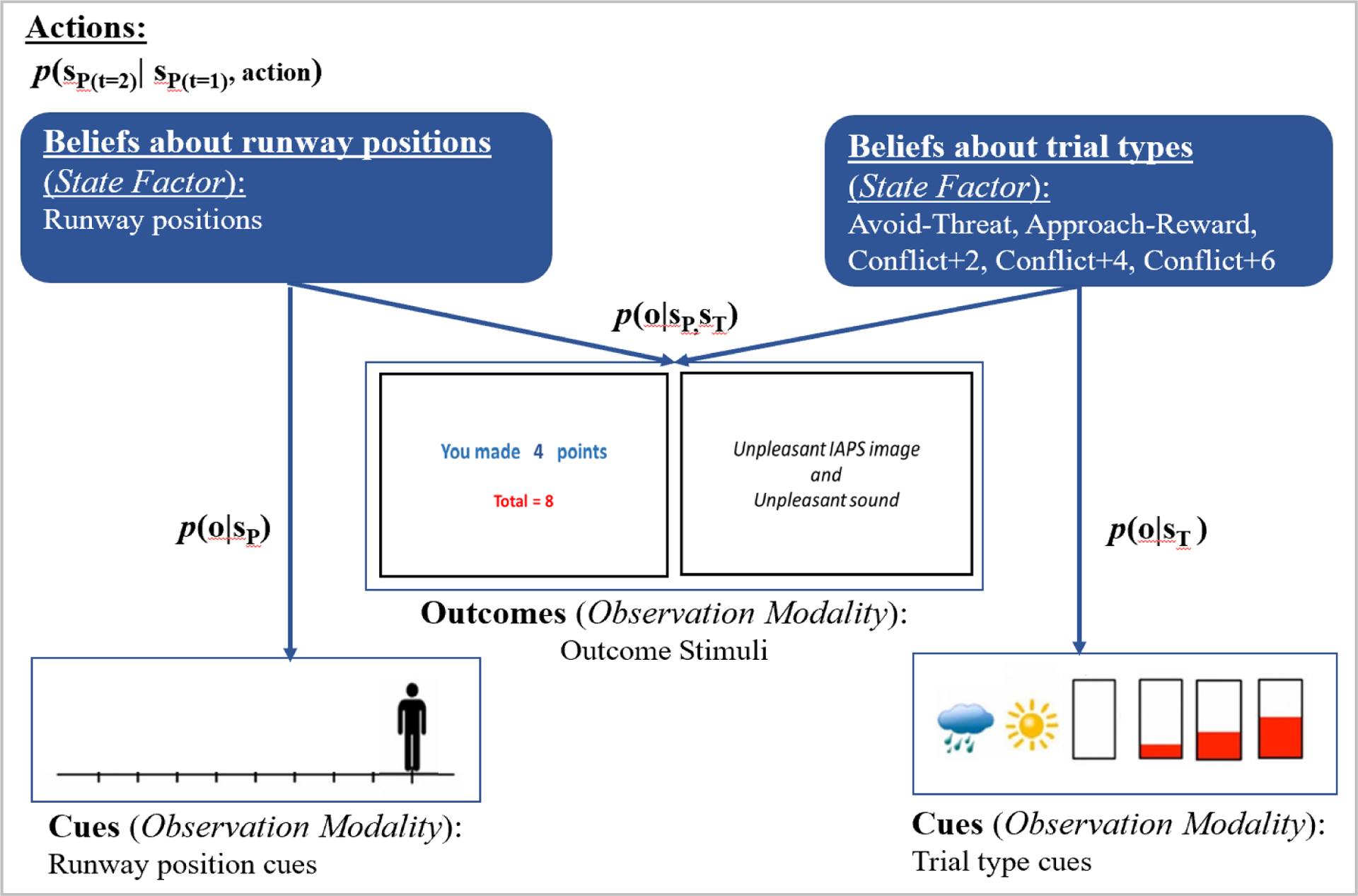
Modified representation of the Generative Model for the Approach-Avoidance Conflict (AAC) Task from Smith et al. (2021a, 2021b). Participants use available (observable) information to generate beliefs about current states to inform their choices (actions). In the AAC task, observations include task stimuli (runway position cues and trial type cues) and the outcome stimuli (points, aversive stimuli). Beliefs are generated from the likelihood of observing the runway position cue given a particular runway position, stateP: p(o|sP), the likelihood of observing a trial cue given a particular trial type, stateT: p(o|sT), and the likelihood of observing the outcome stimuli given the interaction between a particular position and trial type: p(o|sP,sT).
The analyses performed by Smith et al. (2021a, 2021b) focused on two parameters that were estimated by their model: (1) an “emotional conflict” (EC) parameter that captured the degree to which participants preferred the positive outcome (point values) relative to the aversive outcome (negative stimuli), such that higher EC values reflected a greater tendency to avoid negative outcomes (which were negative images/sounds in this task) and (2) β, which reflected decision uncertainty; higher values reflected less consistent choices within the trial types (i.e., less deterministic action selection). Results revealed that, for emotional conflict, self-reported anxiety during the task was positively correlated with the EC parameter (i.e., greater anxiety was associated with a greater tendency to avoid negative outcomes) and that individuals with substance use disorders exhibited (marginally) lower EC values than healthy controls (Smith et al., 2021a). For decision uncertainty, self-reported difficulty making decisions was positively associated with β values. In addition, individuals with an anxiety disorder and/or depression without substance use disorders and individuals with substance use disorders exhibited greater decision uncertainty (higher β values) relative to healthy controls (Smith et al., 2021a).
Importantly, there is evidence that the modeling parameters are reliable over time. In a follow-up study, the EC and β parameters were found to have moderate stability across one year. Additionally, one-year later, individuals with substance use disorders continued to exhibit less emotional conflict than healthy controls, and those with anxiety disorders and/or depression and substance use disorders continued to exhibit more decision uncertainty than healthy controls (Smith et al., 2021b). Surprisingly, patients with clinical anxiety disorders and/or depression had less emotional conflict than healthy controls; although this did not reach the level of significance at baseline as it did at the one-year follow-up assessment.
Model-Free Reinforcement Learning Models
Model-free reinforcement learning (RL) models capture processes that are involved in learning cue-outcome associations through iterative trial-and-error. These models are considered model-free in the sense that they do not involve the internal representation of, or beliefs about, the likelihood of the environment changing from one state to another (Beierholm et al. 2011; Gläscher et al. 2010). Model-free RL can be framed as algorithms for solving an MDP that do not represent state transition probabilities explicitly. This type of learning is advantageous during novel or unstructured conditions. For example, during a task in which individuals are presented with cues that are associated with different reward and punishment likelihoods that are unknown to the decision-makers, trial-and-error can help them learn the expected rewards and punishments that are associated with each cue, so that they can identify which choice yields greater expected reward and less expected punishment.
There are several different types of models that are subsumed under the umbrella of model-free RL models. Temporal difference learning models, which include Q-learning (the Rescorla-Wagner model represents a simple version of this model) and State-Action-State-Reward-Action (SARSA) algorithms, are frequently used in computational decision-making and reinforcement learning research, including psychopathology-related decision-making research (e.g., Huys et al., 2013; Letkiewicz et al., 2022a–c; Ross et al., 2018). Broadly, temporal difference learning models involve placing a value on each state-action pair (s,a) and updating these values after a decision by weighting the decision’s outcome, the current value of the decision, and future values. An in-depth discussion of temporal difference learning and the Q-learning and SARSA algorithms (which are off and on-policy, respectively) is beyond the scope of paper; however, below we describe Q-learning, which unlike SARSA (and other model-free RL models, such as actor-critic models) has previously been applied to decision-making during approach-avoidance conflict (Talmi et al, 2009).
Broadly, Q-learning includes Q-values for state-action (s,a) pairs – in other words, it captures the quality (Q, or value) of action a in state s. As shown in the formula below, Q-values are compared to each other in order to identify an action that is expected to yield the greatest value. The Q-values are updated based on the outcome that follows the selected action a:
The latter portion of the formula that is in brackets is called the prediction error (PE). The PE reflects the difference between what happened on the trial (O=outcome) plus a discounted optimal expected future value for that action (γ reflects how much individuals discount future rewards) versus what the current prediction of future expected discounted rewards, Q(a, s), reflects the current prediction in state s if action a is selected). The learning rate (α) scales the PE (i.e., how much individuals’ weigh PE) and can be conceptualized as a refresh rate – larger values of α update new Q-values to a greater extent than smaller values.
With the inclusion of a decision-making model, Q-learning can formalize value-based decision-making. Typically, decision-making is modeled by a softmax function (as opposed to a “hard” or absolute maximum); Q-values are transformed with a softmax function to capture the probability of selecting a given action, such that choices with higher Q-values having a higher likelihood of being chosen. The softmax function also typically includes a “temperature” parameter (τ). The temperature parameter controls how “soft” the softmax transformation is for each individual. That is, the parameter characterizes individuals’ tendency towards exploration (testing out new actions) versus exploitation (choosing an action that is known to yield a reward). At lower values of τ, actions associated with higher Q-values have a greater likelihood of being selected (i.e., the individual is more likely to exploit high-value choices), with k representing the total number of actions:
In Talmi et al. (2009) approach-avoidance conflict decision-making was examined in healthy controls using a Q-learning model, focusing on reward and physical pain. During a pre-study (conditioning) session, participants were presented with a pair of faces, one of which was associated with a 75% likelihood of delivering a painful electrotactile stimulation and a monetary outcome versus a 25% likelihood of delivering nothing, and the other of which was associated with a 75% likelihood of delivering nothing versus a 25% likelihood of delivering a painful electrotactile stimulation and a monetary outcome. Participants were also presented with control faces, which were associated with a 75% (or 25%) likelihood of delivering a touch stimulation and a monetary outcome versus 25% (75%) likelihood of delivering nothing. Following the pre-study phase (i.e., after participants had learned the cue-outcome associations), they completed a test phase that examined how reward and pain information is integrated when individuals make decisions.
In another study with healthy control participants, Moughrabi et al. (2022) used a modified three-armed Bandit task to examine how individuals make choices during low versus high approach-avoidance conflict. Participants selected from three cues (geometric shapes) each of which had a different likelihood of delivering a shock and points. Points ranged from −10 to +10, and hence, participants could lose points. During high conflict, the cue that was most likely to deliver a reward (e.g., 80% likelihood) was also most likely to lead to harm (e.g., 80% likelihood). During low conflict, the cue that was most likely to deliver a reward (e.g., 80% likelihood) was least likely to lead to harm (e.g., 20% likelihood). Three variants of a standard Rescorla-Wagner model were fit to participants behavior, and the winning model included separate value estimates for reward (VR) and threat (VT), a single learning rate for reward and threat. Utilizing the common Rescorla-Wagner model notation, Q’s are replaced with V’s. The value estimates for each cue are updated from one trial (t) to the next (t+1), such that the value expectation on the next trial will be equivalent to the value estimate on the current trial (e.g., VRt) added to the prediction error (δR = outcome – VRt) scaled by the learning rate (α):
The separate reward and threat value expectations were combined (VC), with the reward and threat values scaled by a parameter that captured individual preferences for threat versus reward, π, as follows:
The value expectations were transformed by a softmax function, which included an exploration-exploitation parameter (β, akin to a temperature parameter). Notably, the threat-weight preference parameter (π) was strongly related to participants’ decisions to either approach or avoid during high conflict, such that higher values were associated with in less approach relative to avoidance behavior.
As stated previously potential outcomes for choice options are two-dimensional in approach-avoidance conflict tasks (e.g., reward and threat). As shown in Figure 4, Q-learning models (and other learning/decision-making models) can capture two-dimensional outcomes, such that Q-values for different choice options will include estimates of both reward and threat. One way that the reward and threat information can be integrated is using an additive approach, such as by assigning the threat-related outcome a negative weight and taking a linear combination of the outcomes. For example, if reward is assigned a value of 1 and threat −1, then the occurrence of both would sum to zero. Notably, however, Talmi et al. (2009) found that participants integrated reward and threat values differently depending on the condition. Specifically, reward values were significantly attenuated in the presence of potential physical pain, but not touch; hence, an interactive model better explained how participants integrated reward and threat values than an additive model. Further highlighting the importance of examining alternative approaches to integrating reward and threat expectations during approach-avoidance conflict (i.e., not merely taking a combined average of reward and threat values), Moughrabi et al. (2022) identified that participants combined reward and threat values that were weighted by participants’ preferences for threat versus reward.
Figure 4.
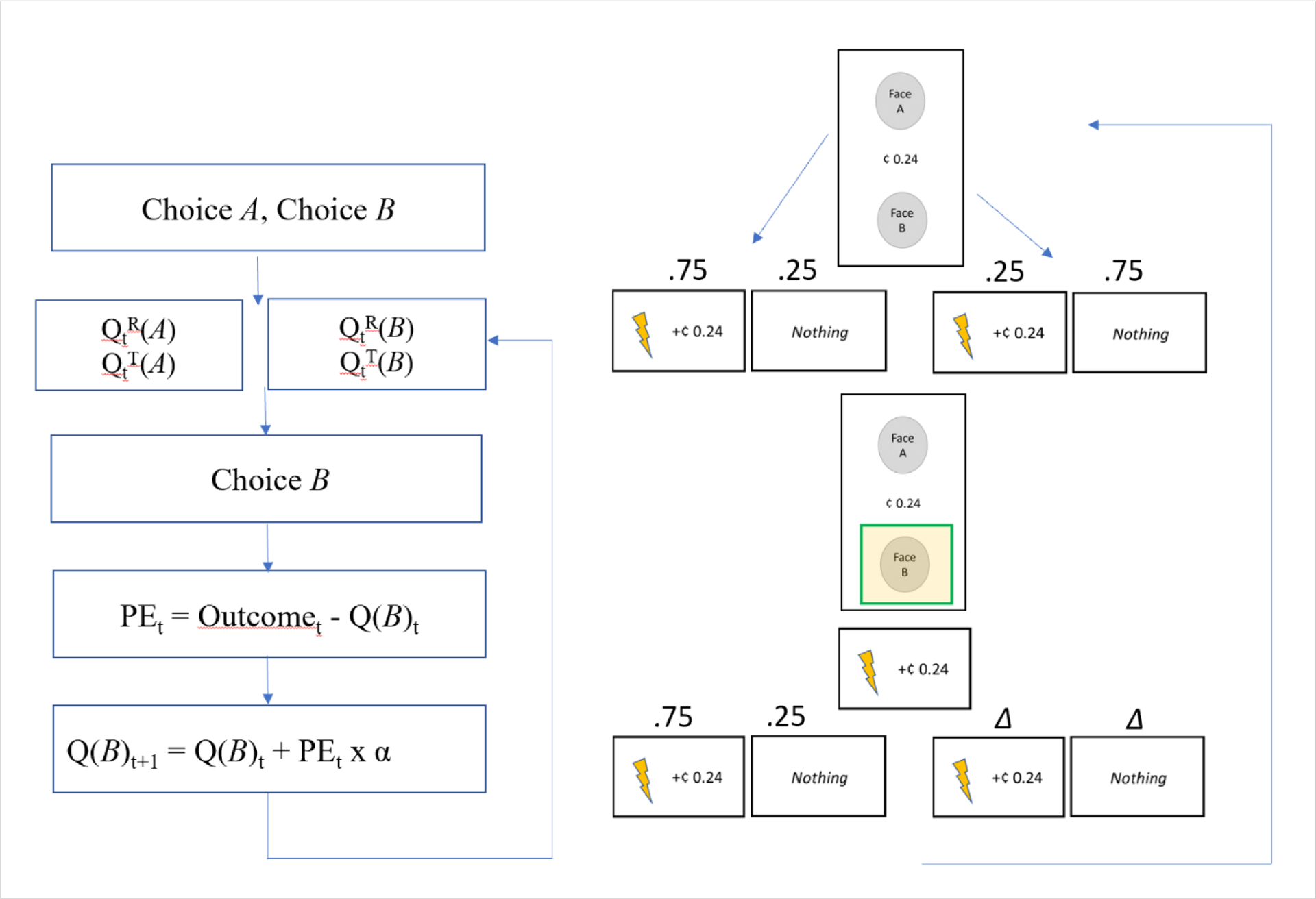
Representation of the Q-learning model included in Talmi et al. (2009). On the left, the flow of learning/decision-making is outlined. On the right, corresponding portions of the approach-avoidance task are depicted. During the task, participants must choose between option A (face A) and option B (face B). Each of the options are evaluated based on prior learning history. The values of threat and reward for each cue (Q-values) are compared and integrated to inform participant choices (modeled using a softmax function). One of the cues is selected and based on the outcome, Q-values are updated (depicted by the delta, or change, symbol) to inform future decision-making.
Assessing RL in future studies could help to clarify whether specific learning and/or decision-making processes contribute to difficulties with approach-avoidance conflict (e.g., impaired PE updating, altered learning rates). Indeed, value estimates are assigned not only based on current information provided about cues during the choice phase of a task (e.g., a symbol indicating that a given option has a high and low likelihood of reward and threat) and individual differences in sensitivity toward/away from potential reward and/or threat (Corr & McNaughton, 2012), but on prior experience (i.e., learning and related processes, such as stimulus generalization). Hence, learning deficits can contribute to later difficulties with decision-making, even if a task does not explicitly assess learning. Finally, although we did not identify any approach-avoidance conflict studies that used the following approach, RL models can be combined with DDM (e.g., Pedersen et al., 2017; Pedersen & Frank, 2020). A combination of reinforcement learning (RL) and DDM models can be applied using the HDDMrl module of the Hierarchical Drift-Diffusion Model Toolbox (http://github.com/hddm-devs/hddm).
Model-Based Reinforcement Learning Models
In contrast with model-free RL, model-based RL is an inference-based learning strategy that involves building cognitive maps, i.e., representations, rules, and contextual information about the environment (Daw et al., 2011; Daw et al., 2005; Doll et al., 2016; Lee et al., 2014). For example, model-based RL could involve building an explicit representation of transition probabilities between states in a decision-making task. Rather than relying on trial-and-error to learn the expected outcomes of a decision (which can be sampling inefficient), model-based RL can often be a more efficient learning strategy, in terms of requiring fewer observations to identify what actions are optimal under which condition.
One task that has been used to assess model-based RL and to separate model-free from model-based RL is the two-stage Markov task (Daw et al., 2011; Doll et al., 2012; Eppinger et al., 2013; Gläscher et al., 2010). In the two-stage Markov task, individuals must learn which of two choices (e.g., picture A or B) in the first stage (i.e., the first state) are likely to lead to a particular set of choice options in the second stage (i.e., the second state; e.g., either pictures C and D or pictures E and F). The likelihood that the first stage choices will lead to the second stage options is fixed throughout the task - for example, there is a 75% probability that picture A will lead to pictures C and D, and 25% probability that it will lead to pictures E and F (the likelihoods are reversed for picture B). Participants must also keep track of which choices in the second stage are currently most rewarding – the reward likelihoods in this task are (typically) designed to change over time with a random walk (Eppinger et al., 2013). A participant who has developed a cognitive map of state transition probabilities will recognize that if they won money when they selected picture E or F given an initial picture A, they should switch to selecting picture B on the next trial, because picture B is most likely to lead them back to pictures E and F. In short, this task includes more than one state - the choice in the first stage leads to one of two second states (Daw et al., 2011; Eppinger et al., 2013), with the trial’s outcome depending on both of the (sequential) decisions.
Reversal learning tasks also include elements of model-based RL – after learning cue-outcome associations in block 1 and new cue-outcome associations in block 2, in block 3 the block 1 cue-outcome likelihoods are shown again. An individual that is utilizing model-based RL will be able to recall that they were previously in a state (i.e., state 1) where they learned relevant “rules” that they can now apply. By contrast, an individual using model-free RL will not recall the similarity of block 3 to block 1 and will engage in trial-and-error learning to update their current expectations of the cue-outcome associations. Indeed, Cochran and Cisler (2019) identified that a model-based RL model (the latent state model) that captures beliefs about hidden (latent) states provided a better fit to simulated reversal-learning task data than model-free. Broadly, the latent-state model assumes that Q-values are tracked for different latent states and are combined across latent states to specify the expectation of choice options. Specifically, Q-values are combined at the start of a trial (t) by taking a weighted average of the Q-values for each choice option (c) across l latent states, with weights (p) given by prior beliefs in the latent state:
Although the use of tasks that capture model-based RL seems promising for testing computational mechanisms of approach-avoidance conflict, we did not identify any peer-reviewed papers that examined this. As an example, the two-stage Markov task could be revised to include both potential reward and punishment outcomes in the second stage. Different reward and punishment likelihoods could be implemented to help to identify at what point increases in the potential for punishment relative to reward disrupts model-based RL (i.e., inference-based learning) and whether this varies as a function of psychopathology. Notably, model-based RL is associated with, and may depend upon, cognitive control processes (or, “executive” functions), including updating working memory. It is also associated with activation in brain regions that are associated with cognitive control, including inferior frontal gyrus, dorsolateral prefrontal cortex, and anterior prefrontal cortex (Alvarez & Emory, 2006; Doll et al., 2016). Prior research has documented deficits in cognitive control processes in many forms of psychopathology (e.g., Leskin & White, 2007; Snyder, 2013); hence, studying model-based RL during approach-avoidance conflict could identify whether top-down cognitive control impairments contribute to difficulties with more complex, inference-based decision-making.
Modeling Approach-Avoidance Conflict: One-Dimensional Outcomes
Although there are additional studies available that have applied computational modeling to approach-avoidance-related behavior, these were not included above because they do not include two-dimensional outcomes (i.e., participants either only win or lose). These studies have included several of the computational modeling approaches identified above, including DDM and Q-learning (e.g., Carl Aberg et al., 2017; Grèzes et al. 2021; Klaassen et al., 2021; Krypotos et al., 2015; Mennella et al., 2020; Rutledge et al., 2016). For example, Klaassen et al. (2021) developed a value-based decision-making model to identify the role of anticipatory freezing behavior in the decision to either approach or avoid during a Passive-active Approach-avoidance Task (PAT). In each trial, participants are presented with an indicator of potential money and shock amounts, and they choose to approach or avoid a target (using an active or passive response, depending on the action context) as it moves towards or away from an icon representing the player. At the end of each trial, participants receive either shocks, money, or no outcome. The best-fitting model for participants’ choices (to approach or avoid) included subjective outcome value (V), an index of bradycardia (indicative of freezing), an action context parameter, and the interaction between the subjective value and action context. When participants had to act in a manner that was incongruent with their response tendency (either active or passive action), higher levels of bradycardia reduced the impact of subjective value on choices. Future studies could consider extending these studies by incorporating two-dimensional outcomes.
Neural Correlates of Computational Modeling Parameters of Approach-Avoidance Conflict
Despite the potential for identifying computational biomarkers of approach-avoidance conflict, relatively few studies have examined neural correlates of decision-making during approach-avoidance conflict using a computational approach (e.g., Moughrabi et al., 2022; Pedersen et al., 2021; Rolle et al., 2022; Talmi et al., 2009;). As stated previously, Rolle et al. (2022) also identified a role of right dlPFC in approach-avoidance conflict decision-making in healthy controls. Specifically, they found that disrupting right dlPFC reduced the impact of changes in reward on the drift rate. In healthy controls, Talmi et al. (2009) identified Q-value signals in the NAcc and ACC and PE signals in the ventral striatum, right hippocampus, bilateral insula, posterior cingulate cortex, and vmPFC, and extended to the OFC and ACC. Additionally, increases in pain reduced the correlation between reward Q-values and activation in the NAcc and ACC, suggesting that the NAcc and ACC are both involved in integrating pain and reward information as part of a cost-benefit analysis. Using psychophysiological interaction (PPI), the insula was found to modulate the relation between reward values and activation in the OFC, such that a greater (pain) signal from the insula dampened the correlation between the reward value representation and OFC activation.
Also in healthy controls, Moughrabi et al. (2022) found that value signals and PEs for reward and threat were differentially encoded within several networks, including the lateral PFC, medial prefrontal cortex, inferior frontal cortex, and salience networks. For example, the salience network, which included the ACC and anterior insula, was related to enhanced encoding of threat versus reward values during the anticipation phase of the task and to threat versus reward PEs following outcomes. Finally, the left frontoparietal network was the only network that was found to encode conflict between reward versus threat values during the choice phase.
In individuals with MDD, Pedersen et al. (2021) found that greater NAcc activation predicted more of a bias toward the avoid boundary (away from approach). By contrast, greater activation of the NAcc predicted a greater bias toward the approach boundary in controls. Although the MDD group exhibited a reduced impact of reward on drift-rates relative to controls (i.e., reduced reward sensitivity), this finding was unrelated to activation of the basal ganglia (caudate or NAcc). There was evidence, however, that greater ACC activation was associated faster drift rates toward approach among the MDD group only. Notably, including the neural correlates of the starting point bias and drift rate parameters (NAcc and ACC, respectively) as predictors of diagnostic status led to the correct classification of participants at a level that was above chance.
Discussion
Aberrant decision-making during approach-avoidance conflict is evident in many forms of psychopathology. In contrast with decision-making scenarios that represent outcomes one-dimensionally (e.g., individuals make choices that lead them to either win or lose money), approach-avoidance conflict includes the potential for the simultaneous occurrence of both pleasant and unpleasant outcomes, and, hence, can only be fully represented with a two-dimensional outcome space for each option. Building on animal research, several approach-avoidance tasks have been developed to help capture the decision-making processes that are disrupted during approach-avoidance conflict.
Computational modeling is increasingly being used to model behavior during these tasks, with the goal of increasing the specificity and precision in our ability to identify mechanisms of atypical decision-making during approach avoidance conflict. Different types of computational models have been applied to approach-avoidance conflict tasks, including drift-diffusion models, active inference models, and reinforcement learning models (e.g., Q-learning models), some of which have been applied to patient populations. As theorized, results of these studies indicate that under/over valuation of reward/threat; for example, changes in rewards did not increase drift-rates toward approach decisions in MDD (indicative of reward undervaluation/insensitivity) and patients with substance use disorders exhibited less emotional conflict (likely reflecting overvaluation of reward and undervaluation of threat). Additionally, decision-related uncertainty has been found to be a contributing factor across several disorders, as patients with anxiety and/or depression (without co-occurring substance use disorders) and those with substance use disorders exhibited greater decision-related uncertainty.
Though these results are informative, we cannot draw strong conclusions as there are a limited number of available studies that have applied computational modeling to approach-avoidance conflict. Hence, more work is needed to clarify mechanisms of impairment in psychopathology during approach-avoidance conflict, utilizing both transdiagnostic and disorder-specific approaches. Whereas some aspects of decision-making may be impaired across different disorders (as found in Smith et al. 2021a and 2021b), other impairments may be specific to disorders or psychopathology dimensions. For example, although PTSD and SAD are both characterized by overrepresentation of potential harm (i.e., shared contributing factors; Abramowitz & Blakey, 2020), they may have distinct contributing factors that uniquely affect decision-making, as the types of threats that are overestimated may differ between SAD and PTSD vary by disorder (e.g., Peschard & Philippot, 2017; White et al., 2008). Additionally, PTSD is often characterized by symptoms of anhedonia, such as difficulties experiencing pleasure and loss of interest, and reduced reward sensitivity (Pessin et al., 2021; for a review, see Nawijn et al., 2015). Thus, for individuals with PTSD, the valuation of potential reward and harm may be affected by both the overrepresentation of potential harm and underrepresentation of potential reward.
In addition to modeling approach-avoidance conflict, it will be important to integrate this work with neuroimaging (e.g., fMRI). Using a Q-learning model, for example, Q-values and PEs, which are revised throughout a task, are recoverable at the trial level. The drift-diffusion model can also be used to capture trial-wise changes in drift-rate (or other parameters, including boundary separation). These values can be used to identify distinct neural substrates of the separate decision-making processes that are involved in approach-avoidance conflict and identify neural mechanisms of unique and shared impairments in psychopathology. Critically, neuroimaging can detect differences in how information is processed that may not be evident through behavioral measures, such as when two individuals exhibit similar performance on a task. Neuroimaging can also identify whether similar patterns of brain activation manifest in different behavior – for example, Pedersen et al. (2021) identified that increased NAcc activation predicted divergent behavior in individuals with MDD and controls. Furthermore, the inclusion of computational biomarkers as predictors of diagnostic status led to more accurate classification than the DDM parameters alone. Thus, integrating computational modeling and neuroimaging may help to identify computational biomarkers that have potential clinical utility beyond computational parameters and regional activation alone.
Approach-avoidance conflict has been examined almost exclusively in the context of receiving rewards (“approach-reward”) and receiving physical/emotional harm (positive punishment, “avoid-harm”). From the perspective of behavior change and reinforcement, however, behaviors are influenced via additional routes that have not been extensively examined, including not losing something desired (“avoid-loss”) and having something that is not desired taken away (“approach-relief”). Whereas the loss of money is frequently examined in decision-making research, choice options typically include one-dimensional outcomes (i.e., you can win or lose), not two-dimensional outcomes (i.e., you can win and lose). Studies have also not extensively examined conflict in the context of approaching relief, which is likely relevant for alcohol use, substance use, and chronic pain (e.g., Burnette et al., 2021; Glöckner-Rist et al., 2013; Navratilova & Porreca, 2014). And, although physical pain and emotional harm-related negative outcomes are well-suited for studying decision-making in the context of some disorders (e.g., anxiety, trauma), that which is experienced as “conflicting” by the decision-maker may differ across disorders. As stated previously, trauma-specific negative outcomes (e.g., images) may be more conflicting than general negative outcomes for PTSD. In depression, perceptions of (physical or mental) effort may be more relevant than unpleasant images.
For everyday decisions, individuals often do not have complete information about potential outcomes – we try to estimate potential outcomes based on the information (prior and present) that is available. However, whether decision-makers can engage in effective decision-making with (relatively) more complete information available may illuminate the ways in which real-world decisions go awry. Clarifying the processes through which atypical decision-making occurs during approach-avoidance conflict can help to identify both transdiagnostic and specific treatment targets to inform the development of treatment approaches that can help to enhance or optimize decision-making in psychopathology.
Acknowledgments
This work was supported, in part, by the National Institutes of Health’s National Center for Advancing Translational Sciences TL1 TR001423 and National Institute of Mental Health K23 MH129607 grants awarded to Dr. Letkiewicz, the National Institute of Mental Health grant R01 MH118741 awarded to Dr. Shankman, and the National Institute of Mental Health grant K01 MH112876 awarded to Dr. Cochran. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Declarations of interest: None
The use of terms “positive” and “negative” outcomes above is intended to illustrate a general valenced attribution on the part of the decision-maker, not to positive or negative reinforcement learning processes.
References
- Abramowitz JS, & Blakey SM (2020). Overestimation of threat. In Abramowitz JS & Blakey SM (Eds.), Clinical Handbook of Fear and Anxiety: Maintenance Processes and Treatment Mechanisms (pp. 7–25). American Psychological Association. [Google Scholar]
- Ahn WY, Haines N, & Zhang L (2017). Revealing neurocomputational mechanisms of reinforcement learning and decision-making with the hBayesDM package. Computational Psychiatry, 1, 24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Alvarez JA, & Emory E (2006). Executive function and the frontal lobes: a meta-analytic review. Neuropsychology review, 16(1), 17–42. [DOI] [PubMed] [Google Scholar]
- Amemori KI, & Graybiel AM (2012). Localized microstimulation of primate pregenual cingulate cortex induces negative decision-making. Nature Neuroscience, 15(5), 776–785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aupperle RL, Melrose AJ, Francisco A, Paulus MP, & Stein MB (2015). Neural substrates of approach-avoidance conflict decision-making. Human Brain Mapping, 36(2), 449–462. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aupperle RL, & Paulus MP (2010). Neural systems underlying approach and avoidance in anxiety disorders. Dialogues in Clinical Neuroscience,12(4), 517–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aupperle RL, Sullivan S, Melrose AJ, Paulus MP, & Stein MB (2011). A reverse translational approach to quantify approach-avoidance conflict in humans. Behavioural Brain Research, 225(2), 455–463. 10.1016/j.bbr.2011.08.003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bach DR, Guitart-Masip M, Packard PA, Miró J, Falip M, Fuentemilla L, & Dolan RJ (2014). Human hippocampus arbitrates approach-avoidance conflict. Current Biology, 24(5), 541–547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barker TV, Buzzell GA, & Fox NA (2019). Approach, avoidance, and the detection of conflict in the development of behavioral inhibition. New Ideas in Psychology, 53, 2–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Beierholm UR, Anen C, Quartz S, & Bossaerts P (2011). Separate encoding of model-based and model-free valuations in the human brain. Neuroimage, 58(3), 955–962. [DOI] [PubMed] [Google Scholar]
- Boschet JM, Scherbaum S, & Pittig A (2022). Costly avoidance of Pavlovian fear stimuli and the temporal dynamics of its decision process. Scientific Reports, 12(1), 1–13. 10.1038/s41598-022-09931-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bravo-Rivera H, Rubio Arzola P, Caban-Murillo A, Vélez-Avilés AN, Ayala-Rosario SN, & Quirk GJ (2021). Characterizing different strategies for resolving approach-avoidance conflict. Frontiers in Neuroscience, 15, 608922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bryant KG, & Barker JM (2020). Arbitration of approach-avoidance conflict by ventral hippocampus. Frontiers in Neuroscience, 14, 615337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burnette EM, Grodin EN, Schacht JP, & Ray LA (2021). Clinical and neural correlates of reward and relief drinking. Alcoholism: Clinical and Experimental Research, 45(1), 194–203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carl Aberg K, Doell KC, & Schwartz S (2016). Linking individual learning styles to approach-avoidance motivational traits and computational aspects of reinforcement learning. PloS one, 11(11), e0166675. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chrysikou EG, Gorey C, & Aupperle RL (2017). Anodal transcranial direct current stimulation over right dorsolateral prefrontal cortex alters decision making during approach-avoidance conflict. Social Cognitive and Affective Neuroscience, 12(3), 468–475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chu S, Margerison M, Thavabalasingam S, O’Neil EB, Zhao YF, Ito R, & Lee AC (2021). Perirhinal Cortex is Involved in the Resolution of Learned Approach–Avoidance Conflict Associated with Discrete Objects. Cerebral Cortex, 31(5), 2701–2719. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cochran AL, & Cisler JM (2019). A flexible and generalizable model of online latent-state learning. PLoS Computational Biology, 15(9), e1007331. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Corr PJ, & McNaughton N (2012). Neuroscience and approach/avoidance personality traits: A two stage (valuation–motivation) approach. Neuroscience & Biobehavioral Reviews, 36(10), 2339–2354. [DOI] [PubMed] [Google Scholar]
- Daw ND, Gershman SJ, Seymour B, Dayan P, & Dolan RJ (2011). Model-based influences on humans’ choices and striatal prediction errors. Neuron, 69(6), 1204–1215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Daw ND, Niv Y, & Dayan P (2005). Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature Neuroscience, 8(12), 1704–1711. [DOI] [PubMed] [Google Scholar]
- Doll BB, Simon DA, & Daw ND (2012). The ubiquity of model-based reinforcement learning. Current Opinion in Neurobiology, 22(6), 1075–1081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Doll BB, Bath KG, Daw ND, & Frank MJ (2016). Variability in dopamine genes dissociates model-based and model-free reinforcement learning. Journal of Neuroscience, 36(4), 1211–1222. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Engels AS, Heller W, Spielberg JM, Warren SL, Sutton BP, Banich MT, & Miller GA (2010). Co-occurring anxiety influences patterns of brain activity in depression. Cognitive, Affective, & Behavioral Neuroscience, 10(1), 141–156. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Enkhtaivan E, Nishimura J, & Cochran AL (2023). Placing approach-avoidance conflict within the framework of multi-objective reinforcement learning. bioRxiv, 2023–01 [Preprint]. [DOI] [PubMed] [Google Scholar]
- Eppinger B, Walter M, Heekeren HR, & Li SC (2013). Of goals and habits: age-related and individual differences in goal-directed decision-making. Frontiers in Neuroscience, 7, 253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston K, FitzGerald T, Rigoli F, Schwartenbeck P, & Pezzulo G (2017a). Active inference: a process theory. Neural Computation, 29(1), 1–49. [DOI] [PubMed] [Google Scholar]
- Friston K, Lin M, Frith C, Pezzulo G, Hobson J, and Ondobaka S (2017b). Active inference, curiosity and insight. Neural Computation, 29, 2633–2683. doi: 10.1162/neco_a_00999 [DOI] [PubMed] [Google Scholar]
- Garcia-Guerrero S, O’Hora D, Zgonnikov A, & Scherbaum S (2023). The action dynamics of approach-avoidance conflict during decision-making. Quarterly Journal of Experimental Psychology, 76(1), 160–179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garrison J, Erdeniz B, & Done J (2013). Prediction error in reinforcement learning: a meta-analysis of neuroimaging studies. Neuroscience & Biobehavioral Reviews, 37(7), 1297–1310. [DOI] [PubMed] [Google Scholar]
- Gläscher J, Daw N, Dayan P, & O’Doherty JP (2010). States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement learning. Neuron, 66(4), 585–595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glöckner-Rist A, Lémenager T, Mann K, & PREDICT Study Research Group. (2013). Reward and relief craving tendencies in patients with alcohol use disorders: results from the PREDICT study. Addictive Behaviors, 38(2), 1532–1540. [DOI] [PubMed] [Google Scholar]
- Grèzes J, Erblang M, Vilarem E, Quiquempoix M, Van Beers P, Guillard M, Sauvet F, Mennella R, & Rabat A (2021). Impact of total sleep deprivation and related mood changes on approach-avoidance decisions to threat-related facial displays. Sleep, 44(12), zsab186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gupta A, Bansal R, Alashwal H, Kacar AS, Balci F, & Moustafa AA (2021). Neural Substrates of the Drift-Diffusion Model in Brain Disorders. Frontiers in Computational Neuroscience, 15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haynos AF, Widge AS, Anderson LM, & Redish AD (2022). Beyond Description and Deficits: How Computational Psychiatry Can Enhance an Understanding of Decision-Making in Anorexia Nervosa. Current Psychiatry Reports, 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Herrington JD, Heller W, Mohanty A, Engels AS, Banich MT, Webb AG, & Miller GA (2010). Localization of asymmetric brain function in emotion and depression. Psychophysiology, 47(3), 442–454. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hulsman AM, Kaldewaij R, Hashemi MM, Zhang W, Koch SB, Figner B, Roelofs K, & Klumpers F (2021). Individual differences in costly fearful avoidance and the relation to psychophysiology. Behaviour Research and Therapy, 137, 103788. [DOI] [PubMed] [Google Scholar]
- Huys QJ, Pizzagalli DA, Bogdan R, & Dayan P (2013). Mapping anhedonia onto reinforcement learning: a behavioural meta-analysis. Biology of Mood & Anxiety Disorders, 3(1), 1–16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ironside M, Amemori K-i., McGrath CL, Pedersen ML, Kang MS, Amemori S, Frank MJ, Graybiel AM, & Pizzagalli DA (2020). Approach-avoidance conflict in major depressive disorder: Congruent neural findings in humans and nonhuman primates. Biological Psychiatry, 87(5), 399–408. 10.1016/j.biopsych.2019.08.022 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ito R, & Lee AC (2016). The role of the hippocampus in approach-avoidance conflict decision-making: evidence from rodent and human studies. Behavioural Brain Research, 313, 345–357. [DOI] [PubMed] [Google Scholar]
- Kahnt T, Park SQ, Haynes JD, & Tobler PN (2014). Disentangling neural representations of value and salience in the human brain. Proceedings of the National Academy of Sciences, 111(13), 5000–5005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karalunas SL, & Huang-Pollock CL (2013). Integrating impairments in reaction time and executive function using a diffusion model framework. Journal of Abnormal Child Psychology, 41(5), 837–850. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kirlic N, Young J, & Aupperle RL (2017). Animal to human translational paradigms relevant for approach avoidance conflict decision making. Behaviour Research and Therapy, 96, 14–29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klaassen FH, Held L, Figner B, O’Reilly JX, Klumpers F, de Voogd LD, & Roelofs K (2021). Defensive freezing and its relation to approach-avoidance decision-making under threat. Scientific Reports, 11(1), 12030. doi: 10.1038/s41598-021-90968-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- Korn CW, Vunder J, Miró J, Fuentemilla L, Hurlemann R, & Bach DR (2017). Amygdala lesions reduce anxiety-like behavior in a human benzodiazepine-sensitive approach–avoidance conflict test. Biological Psychiatry, 82(7), 522–531. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krypotos AM, Beckers T, Kindt M, & Wagenmakers EJ (2015). A Bayesian hierarchical diffusion model decomposition of performance in Approach–Avoidance Tasks. Cognition and Emotion, 29(8), 1424–1444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lake AJ, Finn PR, & James TW (2021). Neural Modulation in Approach-Avoidance Conflicts in Externalizing Psychopathology. Brain Imaging and Behavior, 15(2), 1007–1024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee SW, Shimojo S, & O’Doherty JP (2014). Neural computations underlying arbitration between model-based and model-free learning. Neuron, 81(3), 687–699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lerche V, Voss A, & Nagler M (2017). How many trials are required for parameter estimation in diffusion modeling? A comparison of different optimization criteria. Behavior Research Methods, 49(2), 513–537. [DOI] [PubMed] [Google Scholar]
- Leskin LP, & White PM (2007). Attentional networks reveal executive function deficits in posttraumatic stress disorder. Neuropsychology, 21(3), 275. [DOI] [PubMed] [Google Scholar]
- Letkiewicz AM, Cochran AL, & Cisler JM (2022a). Frontoparietal network activity during model-based reinforcement learning updates is reduced among adolescents with severe sexual abuse. Journal of Psychiatric Research, 145, 256–262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Letkiewicz AM, Cochran AL, Mittal VA, Walther S, & Shankman SA (2022b). Reward-based reinforcement learning is altered among individuals with a history of major depressive disorder and psychomotor retardation symptoms. Journal of Psychiatric Research, 152, 175–181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Letkiewicz AM, Cochran AL, Privratsky AA, James GA, & Cisler JM (2022c). Value estimation and latent-state update-related neural activity during fear conditioning predict posttraumatic stress disorder symptom severity. Cognitive, Affective, & Behavioral Neuroscience, 22(1), 199–213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lewin K (1935). A Dynamic Theory of Personality. New York: McGraw-Hill. [Google Scholar]
- Livermore JJ, Klaassen FH, Bramson B, Hulsman AM, Meijer SW, Held L, … & Roelofs K (2021). Approach-avoidance decisions under threat: the role of autonomic psychophysiological states. Frontiers in Neuroscience, 15, 621517. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loijen A, Vrijsen JN, Egger JI, Becker ES, & Rinck M (2020). Biased approach-avoidance tendencies in psychopathology: A systematic review of their assessment and modification. Clinical psychology review, 77, 101825. [DOI] [PubMed] [Google Scholar]
- McDermott TJ, Berg H, Touthang J, Akeman E, Cannon MJ, Santiago J, Cosgrove KT, Clausen AN, Kirlic N, Smith R, Craske MG, Abelson JL, Paulus MP, & Aupperle RL (2022). Striatal reactivity during emotion and reward relates to approach–avoidance conflict behaviour and is altered in adults with anxiety or depression. Journal of Psychiatry and Neuroscience, 47(5), E311–E322. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McNally GP (2021). Motivational competition and the paraventricular thalamus. Neuroscience & Biobehavioral Reviews, 125, 193–207. [DOI] [PubMed] [Google Scholar]
- Montague PR, King-Casas B, & Cohen JD (2006). Imaging valuation models in human choice. Annual Review of Neuroscience, 29(1), 417–448. [DOI] [PubMed] [Google Scholar]
- Moughrabi N, Botsford C, Gruichich TS, Azar A, Heilicher M, Hiser J, Crombie KM, Dunsmoor JE, Stowe Z, & Cisler JM (2022). Large-scale neural network computations and multivariate representations during approach-avoidance conflict decision-making. NeuroImage, 264, 119709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Navratilova E, & Porreca F (2014). Reward and motivation in pain and pain relief. Nature Neuroscience, 17(10), 1304–1312. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nawijn L, van Zuiden M, Frijling JL, Koch SB, Veltman DJ, & Olff M (2015). Reward functioning in PTSD: a systematic review exploring the mechanisms underlying anhedonia. Neuroscience & Biobehavioral Reviews, 51, 189–204. [DOI] [PubMed] [Google Scholar]
- Orsini CA, Moorman DE, Young JW, Setlow B, & Floresco SB (2015). Neural mechanisms regulating different forms of risk-related decision-making: Insights from animal models. Neuroscience & Biobehavioral Reviews, 58, 147–167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palminteri S, Justo D, Jauffret C, Pavlicek B, Dauta A, Delmaire C, Czernecki V, Karachi C, Capelle L, Durr A, & Pessiglione M (2012). Critical roles for anterior insula and dorsal striatum in punishment-based avoidance learning. Neuron, 76(5), 998–1009. [DOI] [PubMed] [Google Scholar]
- Pastor V, & Medina JH (2021). Medial prefrontal cortical control of reward-and aversion-based behavioral output: Bottom-up modulation. European Journal of Neuroscience, 53, 3039–3062. [DOI] [PubMed] [Google Scholar]
- Pedersen ML, & Frank MJ (2020). Simultaneous hierarchical bayesian parameter estimation for reinforcement learning and drift diffusion models: A tutorial and links to neural data. Computational Brain & Behavior, 3(4), 458–471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedersen ML, Frank MJ, & Biele G (2017). The drift diffusion model as the choice rule in reinforcement learning. Psychonomic Bulletin & Review, 24(4), 1234–1251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedersen ML, Ironside M, Amemori KI, McGrath CL, Kang MS, Graybiel AM, Pizzagalli DA, & Frank MJ (2021). Computational phenotyping of brain-behavior dynamics underlying approach-avoidance conflict in major depressive disorder. PLoS Computational Biology, 17(5), e1008955. 10.1371/journal.pcbi.1008955 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peschard V, & Philippot P (2017). Overestimation of threat from neutral faces and voices in social anxiety. Journal of Behavior Therapy and Experimental Psychiatry, 57, 206–211. [DOI] [PubMed] [Google Scholar]
- Pessin S, Philippi CL, Reyna L, Buggar N, & Bruce SE (2021). Influence of anhedonic symptom severity on reward circuit connectivity in PTSD. Behavioural Brain Research, 407, 113258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pittig A, & Scherbaum S (2020). Costly avoidance in anxious individuals: Elevated threat avoidance in anxious individuals under high, but not low competing rewards. Journal of Behavior Therapy and Experimental Psychiatry, 66, 101524. [DOI] [PubMed] [Google Scholar]
- Rangel A, Camerer C, & Montague PR (2008). A framework for studying the neurobiology of value-based decision making. Nature Reviews Neuroscience, 9(7), 545–556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ratcliff R, Voskuilen C, & Teodorescu A (2018). Modeling 2-alternative forced-choice tasks: Accounting for both magnitude and difference effects. Cognitive Psychology, 103, 1–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Redish AD (2004). Addiction as a computational process gone awry. Science, 306(5703), 1944–1947. [DOI] [PubMed] [Google Scholar]
- Redish AD, Kepecs A, Anderson LM, Calvin OL, Grissom NM, Haynos AF,AF, Heilbronner SR, Herman AB, Jacob S, Ma S & Vilares I (2022). Computational validity: Using computation to translate behaviours across species. Philosophical Transactions of the Royal Society B, 377(1844), 20200525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rolle CE, Pedersen ML, Johnson N, Amemori KI, Ironside M, Graybiel AM, Pizzagalli DA, & Etkin A (2022). The role of the dorsal–lateral prefrontal cortex in reward sensitivity during approach–avoidance conflict. Cerebral Cortex, 32(6), 1269–1285. 10.1093/cercor/bhab292 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ross MC, Lenow JK, Kilts CD, & Cisler JM (2018). Altered neural encoding of prediction errors in assault-related posttraumatic stress disorder. Journal of Psychiatric Research, 103, 83–90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rusconi F, Rossetti MG, Forastieri C, Tritto V, Bellani M, & Battaglioli E (2022). Preclinical and clinical evidence on the approach-avoidance conflict evaluation as an integrative tool for psychopathology. Epidemiology and Psychiatric Sciences, 31, e90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rutledge RB, Smittenaar P, Zeidman P, Brown HR, Adams RA, Lindenberger U, Dayan P, & Dolan RJ (2016). Risk taking for potential reward decreases across the lifespan. Current Biology, 26(12), 1634–1639. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shinn M, Lam NH, & Murray JD (2020). A flexible framework for simulating and fitting generalized drift-diffusion models. ELife, 9, e56938. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sierra-Mercado D, Deckersbach T, Arulpragasam AR, Chou T, Rodman AM, Duffy A, McDonald EJ, Eckhardt CA, Corse AK, Kaur N, & Dougherty DD (2015). Decision making in avoidance–reward conflict: a paradigm for non-human primates and humans. Brain Structure and Function, 220(5), 2509–2517. 10.1007/s00429-014-0796-7 [DOI] [PubMed] [Google Scholar]
- Smith R, Schwartenbeck P, Parr T, & Friston KJ (2020). An active inference approach to modeling structure learning: Concept learning as an example case. Frontiers in computational neuroscience, 14, 41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith R, Kirlic N, Stewart JL, Touthang J, Kuplicki R, Khalsa SS, Feinstein J, Paulus MP, & Aupperle RL (2021a). Greater decision uncertainty characterizes a transdiagnostic patient sample during approach-avoidance conflict: a computational modelling approach. Journal of Psychiatry and Neuroscience, 46(1), E74–E87. 10.1503/jpn.200032 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith R, Kirlic N, Stewart JL, Touthang J, Kuplicki R, McDermott TJ, Taylor S, Khalsa SS, Paulus MP, & Aupperle RL (2021b). Long-term stability of computational parameters during approach-avoidance conflict in a transdiagnostic psychiatric patient sample. Scientific Reports, 11(1), 1–13. doi: 10.1038/s41598-021-91308-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith R, Friston KJ, & Whyte CJ (2022). A step-by-step tutorial on active inference and its application to empirical data. Journal of Mathematical Psychology, 107, 102632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Snyder HR (2013). Major depressive disorder is associated with broad impairments on neuropsychological measures of executive function: a meta-analysis and review. Psychological Bulletin, 139(1), 81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spielberg JM, Miller GA, Engels AS, Herrington JD, Sutton BP, Banich MT, & Heller W (2011b). Trait approach and avoidance motivation: lateralized neural activity associated with executive function. NeuroImage, 54(1), 661–670. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Spielberg JM, Heller W, & Miller GA (2013). Hierarchical brain networks active in approach and avoidance goal pursuit. Frontiers in human neuroscience, 7, 284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sripada C, & Weigard A (2021). Impaired evidence accumulation as a transdiagnostic vulnerability factor in psychopathology. Frontiers in psychiatry, 12, 627179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Talmi D, Dayan P, Kiebel SJ, Frith CD, & Dolan RJ (2009). How humans integrate the prospects of pain and reward during choice. Journal of Neuroscience, 29(46), 14617–14626. 10.1523/JNEUROSCI.2026-09.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Von Siebenthal Z, Boucher O, Lazzouni L, Taylor V, Martinu K, Roy M, Rainville P, Lepore F, & Nguyen DK (2020). Expected value and sensitivity to punishment modulate insular cortex activity during risky decision making. Scientific Reports, 10(1), 1–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Voss A, Voss J, & Lerche V (2015). Assessing cognitive processes with diffusion model analyses: A tutorial based on fast-dm-30. Frontiers in Psychology, 6, 336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagenmakers EJ, Van Der Maas HL, & Grasman RP (2007). An EZ-diffusion model for response time and accuracy. Psychonomic Bulletin & Review, 14(1), 3–22. [DOI] [PubMed] [Google Scholar]
- Wagenmakers EJ, van der Maas HL, Dolan CV, & Grasman RP (2008). EZ does it! Extensions of the EZ-diffusion model. Psychonomic Bulletin & Review, 15(6), 1229–1235. [DOI] [PubMed] [Google Scholar]
- Walters CJ, & Redish AD (2018). A case study in computational psychiatry: Addiction as failure modes of the decision-making system. In Computational Psychiatry (pp. 199–217). Academic Press. [Google Scholar]
- Walters CJ, Jubran J, Sheehan A, Erickson MT, & Redish AD (2019). Avoid-approach conflict behaviors differentially affected by anxiolytics: implications for a computational model of risky decision-making. Psychopharmacology, 236(8), 2513–2525. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weaver SS, Kroska EB, Ross MC, Sartin-Tarm A, Sellnow KA, Schaumberg K, Kiehl KA, Koenigs M, & Cisler JM (2020). Sacrificing reward to avoid threat: Characterizing PTSD in the context of a trauma-related approach–avoidance conflict task. Journal of Abnormal Psychology, 129(5), 457–468. 10.1037/abn000052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- White M, McManus F, & Ehlers A (2008). An investigation of whether patients with post-traumatic stress disorder overestimate the probability and cost of future negative events. Journal of Anxiety Disorders, 22(7), 1244–1254. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiecki TV, Sofer I, & Frank MJ (2013). HDDM: Hierarchical Bayesian estimation of the drift-diffusion model in Python. Frontiers in Neuroinformatics, 14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yamamori Y, & Robinson OJ (2022). Computational perspectives on human fear and anxiety. Neuroscience & Biobehavioral Reviews, 104959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zech HG, Rotteveel M, van Dijk WW, & van Dillen LF (2020). A mobile approach-avoidance task. Behavior Research Methods, 52(5), 2085–2097. 10.3758/s13428-020-01379 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zorowitz S, Rockhill AP, Ellard KK, Link KE, Herrington T, Pizzagalli DA, Widge AS, Deckersbach T, & Dougherty DD (2019). The neural basis of approach-avoidance conflict: A model based analysis. Eneuro, 6(4). 10.1523/ENEURO.0115-19.2019 [DOI] [PMC free article] [PubMed] [Google Scholar]