

Abstract
In this paper, we lay out the basic elements of Bayesian sample size determination (SSD) for the Bayesian design of a two-arm superiority clinical trial. We develop a flowchart of the Bayesian SSD that highlights the critical components of a Bayesian design and provides a practically useful roadmap for designing a Bayesian clinical trial in real world applications. We empirically examine the amount of borrowing, the choice of noninformative priors, and the impact of model misspecification on the Bayesian type I error and power. A formal and statistically rigorous formulation of conditional borrowing within the decision rule framework is developed. Moreover, by extending the partial borrowing power priors, a new borrowing-by-parts power prior for incorporating historical data is proposed. Computational algorithms are also developed to calculate the Bayesian type I error and power. Extensive simulation studies are carried out to explore the operating characteristics of the proposed Bayesian design of a superiority trial.
Keywords: Borrowing-by-Parts Power Prior, Conditional Borrowing, Sample Size Determination, Power Prior
1. Introduction
Complex Innovative Trial Design (CID) Pilot Meeting Program was initiated by the U.S. Food and Drug Administration (FDA) in 2018 to support the goal of facilitating and advancing the use of complex adaptive, Bayesian, and other novel clinical trial designs (U.S. Food and Drug Administration, 2018). The first study ever selected by the FDA for the CID Pilot Meeting Program is the DYSTANCE 51 clinical trial sponsored by Wave Life Sciences, which is a global Phase 2/3, multicenter, randomized, double-blind, placebo-controlled clinical trial that evaluates the efficacy and safety of suvodirsen in ambulatory boys who are between 5 and 12 years of age (inclusive) with a genetically confirmed diagnosis of Duchenne muscular dystrophy (DMD) amenable to exon 51 skipping (Lake et al., 2021). DMD is a rapidly progressive form of muscular dystrophy that occurs primarily in males and manifests prior to the age of six years, affecting approximately 1 in 3,600 to 9,300 male births worldwide (Mah et al., 2014). From the experience with the CID Pilot Meeting Program shared by Wave Life Sciences, the DYSTANCE 51 clinical trial incorporates the capability to augment the placebo arm with historical data using Bayesian methods (Lake et al., 2021). Natural history studies can be used to support the development of safe and effective drugs and biological products for rare diseases. There has been a joint effort from the DMD communities and worldwide regulatory agencies to access the appropriateness of natural history data to supplement clinical development programs. The suitability in borrowing historical data of DMD has also been supported by studies (Goemans et al., 2020).
The literature on Bayesian sample size determination (SSD) has been growing recently due to recent advances in Bayesian computation and Markov chain Monte Carlo sampling. Joseph et al. (1995); Lindley (1997); Rubin and Stern (1998); Katsis and Toman (1999); and Inoue et al. (2005) are the Bayesian SSD articles cited in the FDA guidance for the use of Bayesian statistics in medical device clinical trials (U.S. Food and Drug Administration, 2010). The early literature on Bayesian SSD includes Rahme and Joseph (1998); Simon (1999); Wang and Gelfand (2002); Spiegelhalter et al. (2004); De Santis (2004, 2007); M’Lan et al. (2006); M’lan et al. (2008); Lee and Liu (2008); and Reyes and Ghosh (2013). Campbell (2011) and Berry et al. (2010) provided a list of Bayesian papers up to 2011. Gamalo-Siebers et al. (2016) gave an excellent review of Bayesian methods for the design and analysis of non-inferiority trials. Chen et al. (2011) developed a new Bayesian design methodology with a focus on controlling the type I error and power for non-inferiority trials. Chen et al. (2014) extended the methodology of Chen et al. (2011) to the Bayesian design of superiority clinical trials for recurrent events data. Li et al. (2015) developed the Bayesian design of non-inferiority clinical trials with co-primary endpoints and multiple dose comparison, and Li et al. (2018) proposed a Bayesian design via Bayes Factor. Bayesian methods for incorporating historical data include the power prior (Ibrahim and Chen, 2000; Ibrahim et al., 2015), the hierarchical prior (Chen et al., 2011), the commensurate prior (Hobbs et al., 2011, 2012), the meta-analytic-predictive (MAP) prior (Neuenschwander et al., 2010), the robust MAP prior (Schmidli et al., 2014), the covariate-adjusted hierarchical model-based prior (Han et al., 2017), and their respective variations. Recent review papers of these methods include Schmidli et al. (2020); Hall et al. (2021); Ghadessi et al. (2020); and van Rosmalen et al. (2018).
Motivated by the DYSTANCE 51 clinical trial, we explore different aspects in borrowing historical data within the Bayesian framework. Using the DMD natural history aggregate data, we develop a formal formulation of conditional borrowing of Allocco et al. (2010) via the decision rule. By extending the partial borrowing power priors (Ibrahim et al., 2012; Chen et al., 2014; Ibrahim et al., 2015), we propose a new borrowing-by-parts power prior for incorporating historical data. In this paper, we also address several critical issues in Bayesian SSD, namely, the amount of borrowing from the historical data, the choice of noninformative priors, and the impact of model misspecification on the Bayesian type I error and power.
The remaining part of the manuscript is organized as follows. In Section 2, we present the critical elements and necessary steps including the computational algorithm of a Bayesian design of a superiority trial and develop a flowchart of Bayesian SSD. In Section 3, we analytically examine the properties of the Bayesian type I error and the power when the variances are known and empirically investigate the choice of noninformative priors and the impact of model misspecification on the Bayesian type I error and power. Section 4 presents a comprehensive treatment of leveraging historical data in Bayesian SSD. In this section, we first introduce the DMD natural history aggregate data, then present two commonly used priors, namely, the power prior and the robust mixture prior, to leverage the historical data, and further investigate the impact of the amount of borrowing on the Bayesian type I error and power. In this very same section, the formal and statistically rigorous formulations of conditional borrowing and the borrowing-by-parts power prior are developed, and extensive simulation studies are conducted to examine the empirical performance of the proposed methodology. We conclude the paper with a brief discussion in Section 5.
2. Bayesian Design of a Superiority Trial
We consider designing a randomized, double-blind, placebo-controlled clinical trial to evaluate the superiority of a drug candidate over placebo with a continuous primary endpoint. Given the large amount of historical data available, we also consider borrowing the historical data to augment the placebo control in the clinical trial design. Let and be the primary endpoint data of test drug and placebo control, with sample sizes nt and nc, respectively. We assume and are independent, , and . The parameter of interest is the expectation of difference in the effects of the test drug and the placebo control, namely, . The hypotheses of the superiority trial are versus , equivalently, versus .
Let . We also consider two special cases: (i) when the variances are known and (ii) when the variances are equal but unknown, where . Let and . The joint distribution of and θ is written as
where is the conditional distribution of y(n) given θ, which is the product of the normal densities corresponding to and , respectively, and π (θ) denotes a prior distribution. Denote the fitting prior as and the sampling prior as , where the fitting prior is used to fit the model and the sampling prior is used to generate the data (Wang and Gelfand, 2002). Then, the posterior is given by
| (2.1) |
Let the null parameter space corresponding to the null hypothesis and the alternative parameter space corresponding to the alternative hypothesis. The sampling priors and , which are used to generate the data, are defined on and such that for .
Let be a test statistic. We define a decision rule based on to reject H0 as
| (2.2) |
where T0 is a critical value, which only depends on the study design, not on the data . We define the Bayesian power function as
| (2.3) |
where the expectation is taken with respect to the marginal distribution of y(n) under the sampling prior . Based on the approach by (Chen et al., 2011), we take
| (2.4) |
where the probability is computed with respect to the posterior distribution given the data and the fitting prior . Let be a Bayesian credible level, where 0 < γ < 1. Then the Bayesian power function in (2.3) reduces to
| (2.5) |
where the indicator function takes a value of “1” if A is true and “0” otherwise.
The analytical evaluation of (2.3) or (2.5) is often not available. The following computational algorithm can be used for :
Step 0. Set nt, nc, γ, and N (the number of simulated datasets);
Step 1. Generate ;
Step 2. Generate ;
Step 3. Calculate ;
Step 4. Check whether or not;
Step 5. Repeat Steps 1-4 N times;
Step 6. Compute the proportion of in these N runs, which gives an estimate of in (2.3) or (2.5).
The Bayesian type I error is with in (2.5) while the Bayesian power is with . The maximum Bayesian type I error is . For given and , we compute and . The Bayesian sample size is then given by . Common choices of α0 and α1 are and . With the Bayesian sample size of nB, the type I error rate is intended to be less than or equal to 0.025 and the power is intended to be at least 0.80.
We summarize the above Bayesian SSD process in Figure 1. Every Bayesian SSD starts with the trial specification, which primarily consists of the type of trial (superiority, or non-inferiority, or equivalence) based on the objective of a study, the number of treatment arms, and the sample size allocation in each arm. The next step of Bayesian SSD shown in Figure 1 includes the specification of a statistical model for the current data, the derivation of the corresponding likelihood, and the mathematical formulation of scientific hypotheses according to the chosen model. According to (2.1), the next step in the flowchart is to specify a fitting prior and then to derive the posterior. One of the key components in Bayesian SSD is to construct a test statistic in (2.2), which leads to the formulation of a decision rule. The key design quantity, i.e., the Bayesian power function in (2.3), can be evaluated either analytically or numerically via a Monte Carlo method, under a given sampling prior , which eventually leads to the final determination of Bayesian sample size. One additional component in Figure 1 is the historical data when available, which can be incorporated in the fitting priors via the decision rule. The inclusion of the historical data typically leads to a reduction of the Bayesian sample size while at the same time, it may increase the type I error. The technical details and potential issues in using a noninformative fitting prior or an informative prior by leveraging historical data are discussed in details in the next two sections.
Fig. 1.
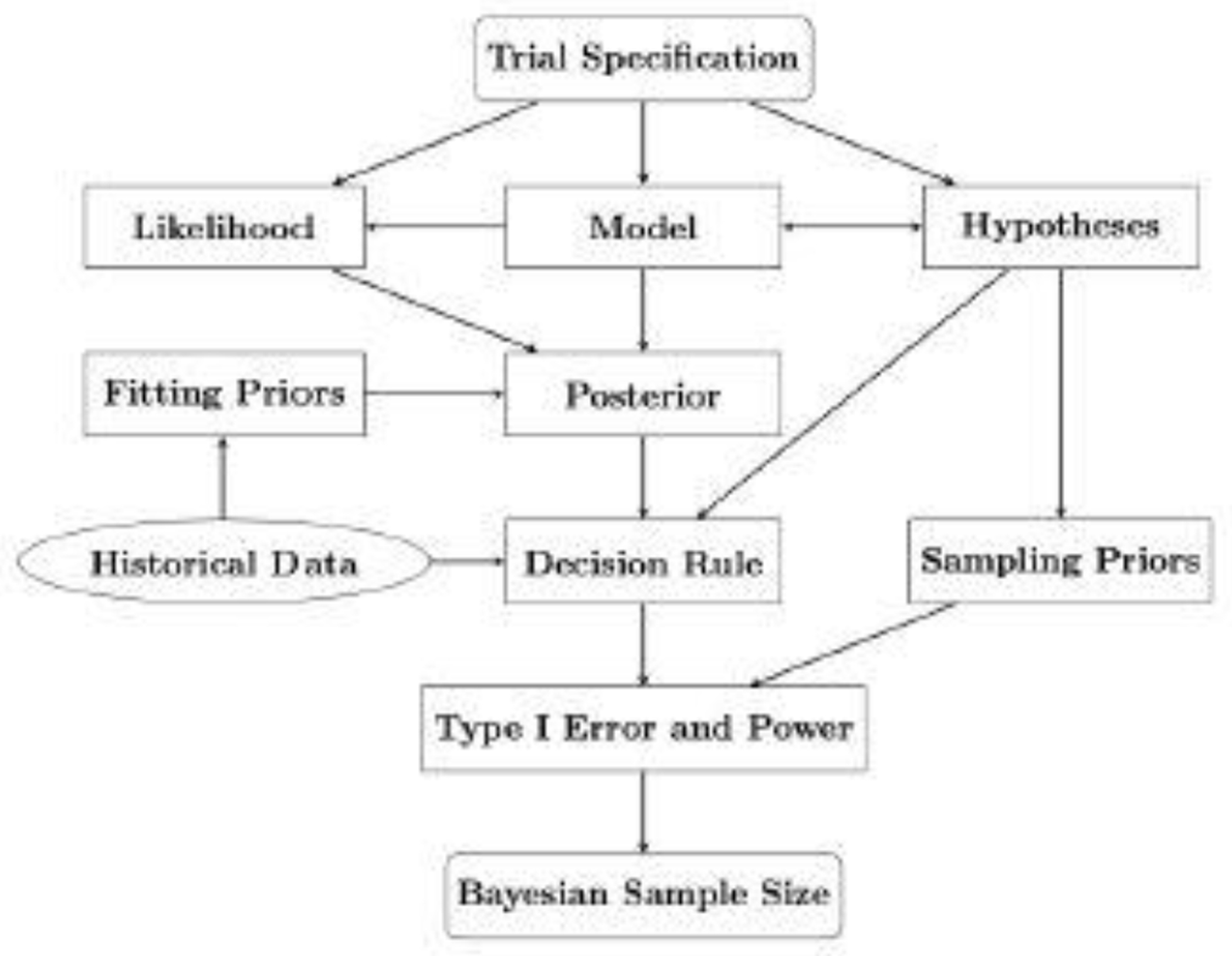
Flowchart of Bayesian SSD.
3. Bayesian SSD with Noninformative Priors
3.1. Theoretical Properties of the Bayesian Power Function with Known Variances
In this subsection, we assume the variances, i.e., and are known. Under this assumption, we have . The null parameter space is and the alternative parameter space is . We assume a noninformative uniform prior for the fitting prior, namely, . Then, the joint distribution of is given by
From (2.1), the posterior distribution takes the form
where and . The test statistic in (2.4) is expressed as
where Φ is the standard normal N(0, 1) cumulative distribution function (cdf). The decision rule in (2.2) is to reject H0 if
| (3.1) |
Taking , which is the inverse function of Φ, from both sides of (3.1) gives
| (3.2) |
where . Using (3.2), the critical function in (2.2) reduces to
| (3.3) |
Assume the sampling prior such that and . Since , using (3.3), the Bayesian power function (2.5) then becomes
| (3.4) |
Taking such that , using (3.4), the Bayesian type I error is given by
It is easy to show that
| (3.5) |
It is easy to see that the maximum type I error is attained at the boundary by specifying the sampling prior as a degenerate distribution at δ = 0, denoted by , i.e., . Furthermore, we take a point mass sampling prior
| (3.6) |
which is a degenerate distribution at δ = δ1, where δ1 > 0. Using (3.4) and (3.6), the Bayesian power is given by
| (3.7) |
We have the following results for the Bayesian type I error and power.
Result 1. The maximum Bayesian type I error is 1 − γ and is attained at the boundary of the parameter space corresponding to the null hypothesis.
Result 2. Using the point mass sampling prior in (3.6), for any choice of δ ∈ Θ1 , the Bayesian power is equal to the frequentist power given by
| (3.8) |
where 0 < α0 < 1 is the type I error.
Suppose we specify the maximum type I error at α0 = 0.025 , the power at 1 − α1 = 0.8, and the randomization ratio with nt : nc = 2 : 1. Assume that , and δ1 = 3.5. Solving
gives . Thus, the required sample sizes are nt = 50 and nc = 25.
3.2. Choice of Noninformative Priors and Model Misspecification
Under the unequal variances assumption, , while under the equal variances assumption, with . For each case, the fitting prior is specified as and , respectively, where m = 0 corresponds to a uniform prior, m = 1 corresponds to a reference prior, and m = 3/2 corresponds to a Jeffreys’s prior. The detailed derivation of the Bayesian power function in (2.5) under each of these priors is given in Appendix A. We set nt = 50, nc = 25, and N = 106 in the computational algorithm in Section 2 for calculating in the following calculations.
The Bayesian type I errors and powers with three noninformative fitting priors are given in Tables 1 and 2 under the models assuming unequal and equal variances, respectively. Several interesting observations are seen from these two tables. First, we see from the right block labeled with “Assuming Equal Variances” of Table 1 that (i) when (or ), the type I errors are 0.0281, 0.0325, and 0.0275 (or 0.0195, 0.0164, and 0.0199) under the uniform prior; (ii) when , the type I errors are 0.0236, 0.0235 and 0.0236, respectively, under the uniform prior; and (iii) the similar results are obtained under the reference prior and the Jeffreys’s prior, respectively. Thus, when the fitted model is misspecified, the type I errors are greater than 0.025 when one arm (“control”) has a smaller sample size coupled with a larger variance than another arm (“test”). On the contrary, the type I errors are less than 0.025 when one arm (“test”) has a larger sample size coupled with a larger variance than another arm (“control”). Second, we see from the left block labeled with “Assuming Unequal Variances” of Table 1 that the type I errors are smaller than, slightly smaller than, and almost at 0.025 under the uniform prior, the reference prior, and the Jeffreys’s prior, respectively, when we fit the model with unequal variances while the true model has equal variances. For example, the type I errors are 0.0195, 0.0235, and 0.0257 under these three priors, respectively, when we fit the model with unequal variances while the true model has .
Table 1.
Bayesian type I errors with noninformative fitting priors.
| Assuming Unequal Variances | Assuming Equal Variances | |||||
|---|---|---|---|---|---|---|
| 16 | 20.25 | 25 | 16 | 20.25 | 25 | |
| Uniform Prior (m = 0) | ||||||
| 16 | 0.0196 | 0.0196 | 0.0195 | 0.0236 | 0.0195 | 0.0164 |
| 20.25 | 0.0196 | 0.0195 | 0.0197 | 0.0281 | 0.0235 | 0.0199 |
| 25 | 0.0196 | 0.0196 | 0.0196 | 0.0325 | 0.0275 | 0.0236 |
| Reference Prior (m = 1) | ||||||
| 16 | 0.0231 | 0.0233 | 0.0232 | 0.0247 | 0.0207 | 0.0176 |
| 20.25 | 0.0234 | 0.0235 | 0.0234 | 0.0299 | 0.0250 | 0.0213 |
| 25 | 0.0235 | 0.0237 | 0.0234 | 0.0340 | 0.0293 | 0.0249 |
| Jeffreys’s Prior (m = 3/2) | ||||||
| 16 | 0.0252 | 0.0253 | 0.0248 | 0.0257 | 0.0216 | 0.0180 |
| 20.25 | 0.0257 | 0.0257 | 0.0252 | 0.0307 | 0.0259 | 0.0220 |
| 25 | 0.0257 | 0.0257 | 0.0254 | 0.0349 | 0.0302 | 0.0259 |
Note that the sampling prior is used in all calculations.
Table 2.
Bayesian powers with noninformative fitting priors.
| Assuming Unequal Variances | Assuming Equal Variances | |||||
|---|---|---|---|---|---|---|
| 16 | 20.25 | 25 | 16 | 20.25 | 25 | |
| Uniform Prior (m = 0) | ||||||
| 16 | 92.31% | 90.17% | 87.59% | 93.79% | 90.48% | 86.22% |
| 20.25 | 87.42% | 85.07% | 82.37% | 90.98% | 87.38% | 83.01% |
| 25 | 81.62% | 79.30% | 76.63% | 87.80% | 84.05% | 79.70% |
| Reference Prior (m = 1) | ||||||
| 16 | 93.46% | 91.51% | 89.09% | 94.13% | 90.99% | 86.92% |
| 20.25 | 89.10% | 86.90% | 84.36% | 91.40% | 87.96% | 83.71% |
| 25 | 83.83% | 81.58% | 79.10% | 88.25% | 84.68% | 80.50% |
| Jeffreys’s Prior (m = 3/2) | ||||||
| 16 | 93.90% | 92.01% | 89.71% | 94.27% | 91.19% | 87.18% |
| 20.25 | 89.75% | 87.65% | 85.24% | 91.58% | 88.25% | 84.14% |
| 25 | 84.73% | 82.62% | 80.17% | 88.50% | 85.02% | 80.87% |
Note that the sampling prior is used in all calculations.
With noninformative priors, a decreased type I error typically corresponds to a lower power, while an increased type I error is associated with a higher power. Tables 1 and 2 exactly show these patterns. For example, the powers are 87.80%, 88.25%, and 88.50% under the uniform prior, the reference prior, and the Jeffreys’s prior, respectively, when we fit the model with equal variances while the true model has and . For and , the powers are 81.62%, 83.83%, and 84.73%, respectively, under these three priors when we fit the model with unequal variances, which are lower than those when we fit the model with equal variances. Note that in this case, the model assuming equal variances lead to increased type I errors, as discussed earlier. Thus, when the true variances are unequal, the misspecified model assuming equal variances could lead to a substantial decrease or increase of the type I error and power, depending on whether or . Moreover, the different noninformative priors lead to different type I errors and powers. From Tables 1 and 2, we see that the type I errors and powers under the uniform prior and the reference prior are lower than those under the Jeffreys’s prior, even when the fitted model is correctly specified. Furthermore, the type I errors and powers under the Jeffreys’s prior are very close to those under the frequentist method. Therefore, the Jeffreys’s prior is a more desirable noninformative prior than the other two noninformative priors we consider. Subsequently, the Jeffreys’s prior will be used as a default noninformative initial prior in constructing the informative priors.
Using the frequentist method, we use simulation to calculate type I error and power under the models with equal and unequal variances. We first introduce the following notation: let and denote the sample standard deviations, respectively, for the control and test arms. Also let and denote the standard errors, respectively, under the models with equal and unequal variances, where and are defined in Section 3.1. Denote the critical value by such that , where is the cdf of a central-t distribution with degrees of freedom df, which is taken as nt + nc − 2 or for the model with equal or unequal variances.
Using the corresponding df and for the model assuming equal variances or the model assuming unequal variances, the simulation algorithm is given as follows:
Step 1. Generate random samples yc from and yt from for the type I error or for the power;
Step 2. Calculate , Sc, , St, and for the corresponding model;
Step 3. Calculate test statistic and its corresponding degrees of freedom df; Compare T* with for the corresponding model;
Step 4. Repeat Steps 1-3 for 107 times. The type I error or power is the proportion of .
For the case of , , nc = 25, μc = 0, , and δ = 3.5 , Figure 2 (a) shows the type I error under the model assuming equal variances. When the true is different from , the type I error is increased in when and is decreased when under the wrong model. The type I errors under the model assuming unequal variances stay at 0.025 since the model is correctly specified. Figure 2 (b) shows the power under the model assuming equal variances and unequal variances. Compared with the powers under the model with unequal variances (cyan line), the powers under the model with equal variances (red line) are increased when and decreased when . Thus, the misspecified model may increase or decrease the frequentist type I error and power, which is similar to the Bayesian framework.
Fig. 2.
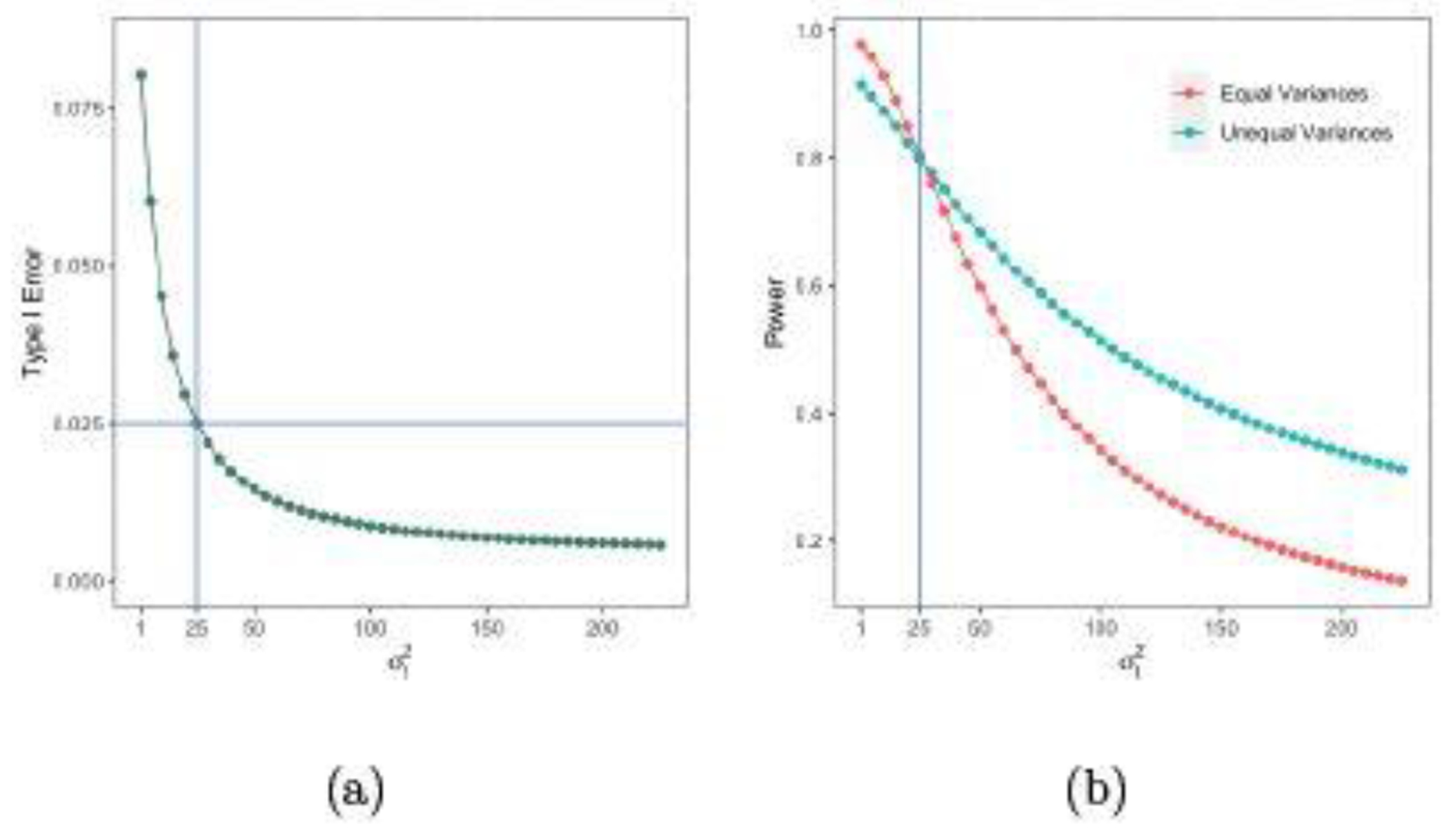
Plots of frequentist type I errors and powers versus σt.
4. Bayesian SSD with Informative Priors
4.1. Leveraging Historical Data
Historical data makes its impact on the fitting priors by various ways, including but not limited to full borrowing (Ibrahim and Chen, 2000), partial borrowing (Ibrahim et al., 2012; Chen et al., 2014; Ibrahim et al., 2015), dynamic borrowing (Viele et al., 2014; Pan et al., 2017; Lim et al., 2018), conditional borrowing (Allocco et al., 2010), and propensity score matching (Wang et al., 2019). Suppose that the historical data from a natural history study consists of the sample size of 44, the sample mean of −0.18, and the sample standard deviation of 3.38 for the primary endpoint. We next discuss how to leverage the historical data in Bayesian SSD via informative priors.
We first examine the effect of the amount of borrowing of the historical data on the gain in power within the frequentist SSD framework. For a randomized controlled trial, suppose the starting sample size ratio of the test arm versus the concurrent control arm is 2 : 1. When the concurrent control is augmented using historical data by 50% or 100% of the concurrent control sample size, the augmented sample size ratios of the test arm versus the concurrent control arm are then 2 : 1.5 or 2 : 2, respectively. Set δ = 3.5 and . Table 3 show the frequentist powers for , 16, 20.25 and 25; nt = 32, 40, 44, and 52; and , and nt : nc = 2 : 2. We notice that we assume (i) all random samples for the control arm in Table 3 are from the same normal distribution and (ii) the model with unequal variances is used in all power calculations. From Table 3, we observe that (i) when , the powers are 79.8%, 86.5%, and 89.7% for nt : nc = 2 : 1, nt : nc, = 2 : 1.5, and nt : nc = 2 : 2, respectively, and the gains in power are 6.7% and 3.2% when the sample sizes on the control arm increase from 16 to 24 and 24 to 32, respectively; and (ii) the results remain similar for the other three values of . Thus, in all of these four cases, the most gain in power is achieved at the first 50% increase in sample size on the control arm, i.e., when nt : nc = 2 : 1 increases to nt : nc = 2 : 1.5.
Table 3.
Frequentist powers with different amounts of borrowing .
| nt : nc = 2 : 1 | nt : nc = 2 : 1.5 | nt : nc = 2 : 2 | ||||
|---|---|---|---|---|---|---|
| N | Power | N | Power | N | Power | |
| 11.42 | 32 + 16 = 48 | 79.8% | 32 + 24 = 56 | 86.5% | 32 + 32 = 64 | 89.7% |
| 16 | 40 + 20 = 60 | 81.9% | 40 + 30 = 70 | 89.4% | 40 + 40 = 80 | 92.7% |
| 20.25 | 44 + 22 = 66 | 80.2% | 44 + 33 = 77 | 88.8% | 44 + 44 = 88 | 92.7% |
| 25 | 52 + 26 = 78 | 82.1% | 52 + 39 = 91 | 90.5% | 52 + 52 = 104 | 94.2% |
We next explore the amount of borrowing within the Bayesian framework. The power prior and the robust mixture prior are considered to leverage the historical data. Let be the historical data with sample size of n0 from the control arm, and assume . Let and denote the sample mean and the sample variance of y0. Write the historical data as . Denote the likelihood of the historical data by . Under the unequal variances assumption, . The power prior (Ibrahim and Chen, 2000) is given by
| (4.1) |
where is an initial prior and 0 ≤ a0 ≤ 1 is the discounting parameter, which determines the amount of borrowing. The robust mixture prior (Greenhouse and Waserman, 1995; Ye et al., 2020) given p0 is defined by
| (4.2) |
where with which is the power prior in (4.1) with a0 = 1 and the weight determines the amount of borrowing. In (4.2), the skeptical prior when p0 = 0 is specified as , where and , which correspond to the normal distribution and the inverse gamma distribution IG (0.001, 0.001). We further assume that and are independent a priori. Thus, we have . Since the historical data are available only for the control arm, is taken as the robust mixture prior given in (4.2) and a non-informative prior, , is specified for .
Figure 3 (a) and (b) show the type I errors and the powers for different μc’s using the power prior given in (4.1) with a0 = 0 (red lines), a0 = 0.18 (green lines) and a0 = 0.36 (blue lines) when nt = 32, nc = 16, , and δ = 3.5. Comparing the power gain from a0 = 0 to a0 = 8 / 44 = 0.18, and the power gain from a0 = 8 / 44 = 0.18 to a0 = 16 / 44 = 0.36, we see from Figure 3 (b) most gain in Bayesian power is achieved at the first 50% increase in sample size on the concurrent control arm, i.e., when a0 = 0 increases to a0 = 0.18. Specifically, the powers with a0 = 0, 0.18, and 0.36 are 79.78%, 85.92%, and 88.73%, respectively, at μc = −0.51; 79.79%, 87.99%, and 91.51%, respectively, at μc = −0.18; and 79.76%, 91.59%, and 95.63%, respectively, at μc = 0.52. Thus, the power gains from a0 = 0 to a0 = 0.18 are 6.14%, 8.20%, and 11.83%, respectively, at μc = −0.51, −0.18, and 0.52 while the power gains from a0 = 0.18 to a0 = 0.36 are 2.81%, 3.52%, and 4.04%, respectively, at μc = −0.51, −0.18, and 0.52. Note that the type I errors with a0 = 0, 0.18, and 0.36 are 0.025, 0.013, and 0.011, respectively, at μc = −0.51; 0.025, 0.018, and 0.017, respectively, at μc = −0.18; and 0.025, 0.030, and 0.038, respectively, at μc = 0.52. In the above discussion, we consider μc = −0.51, −0.18 and 0.52, since these values of μc lead to a negative bias, no bias, and a positive bias, respectively, compared with the historical mean. In Figure 3 (a), the maximum values of μc so that the type I error is less than 0.025 are 0.27 and 0.15, respectively, for a0 = 0.18 and 0.36. These results indicate that (i) borrowing the historical data may lead to a gain in power and a reduction in type I error at the same time and an example for this scenario is that the power increases but the type I error decreases in a0 when μc = −0.51; (ii) borrowing the historical data may lead to a gain in power and an increase in type I error and, for example, both the power and type I error increase in a0 when μc = 0.52; (iii) the type I error can still be less than 0.025 (a prespecified significance level) even when the historical data and the data from the concurrent control arm are not similar, for example, the type I errors are less than 0.025 when μc < 0.27 when a0 = 0.18; and (iv) when a0 = 0 , the type I errors are around 0.025 and the powers are about 0.80, which may be due to the fact that a noninformative prior is specified as the initial prior.
Fig. 3.
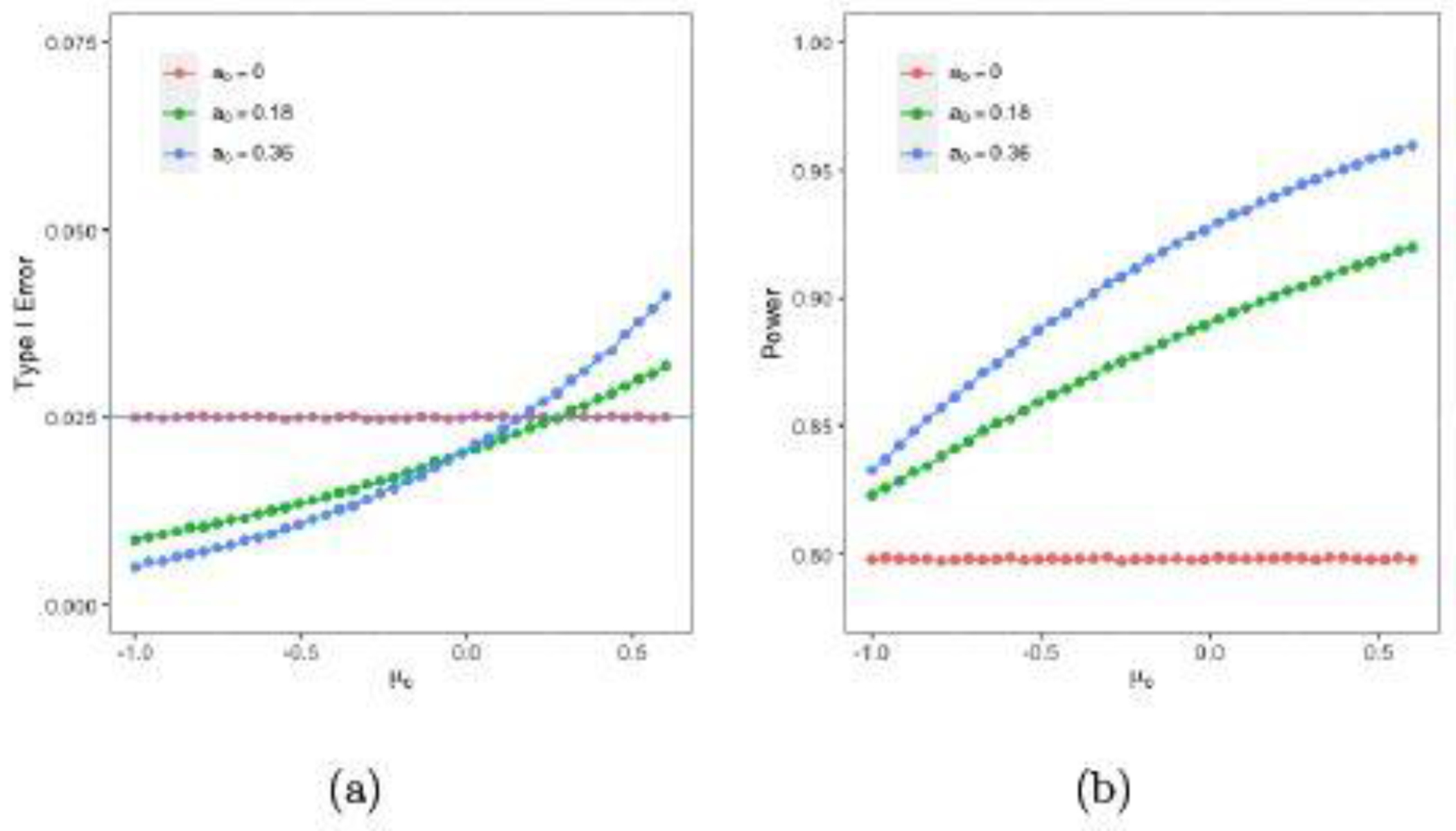
Plots of Bayesian type I errors and powers with the power prior versus μc.
Figure 4 (a) and (b) show the plots of the type I error and power using the robust mixture prior in (4.2) for p0 = 0 , 0.18, 0.36, 0.5, and 1. The type I errors for p0 = 0 , 0.18, 0.36, 0.5, and 1 are 0.025, 0.022, 0.019, 0.017, and 0.009, respectively, at μc = −0.51; 0.025, 0.024, 0.022, 0.022, and 0.018, respectively, at μc = −0.18; and 0.025, 0.031, 0.038, 0.043, and 0.060, respectively, at μc = 0.52. The powers for p0 = 0 , 0.18, 0.36, 0.5, and 1 are 79.82%, 81.92%, 84.13%, 85.83%, and 91.82%, respectively, at μ = −0.51; 79.79%, 82.56%, 85.29%, 87.39%, and 95.08%, respectively, at μ = −0.18; and 79.79%, 83.13%, 86.52%, 89.14% and 98.59%, respectively, at μc = 0.52. Compared to those using the power prior, (i) the robust mixture prior leads to less gain in power when p0 = a0 <= 0.36; (ii) the powers using the robust mixture prior with p0 = 0.5 are lower than those using the power prior with a0 = 0.36 ; (iii) the type I errors are closer to 0.025 using the robust mixture prior than the power prior when p0 = a0 <= 0.36 ; and (iv) the skeptical prior given in (4.2) is quite noninformative in the sense that the type I errors are around 0.025 and the powers remain around 80% for all μc.
Fig. 4.
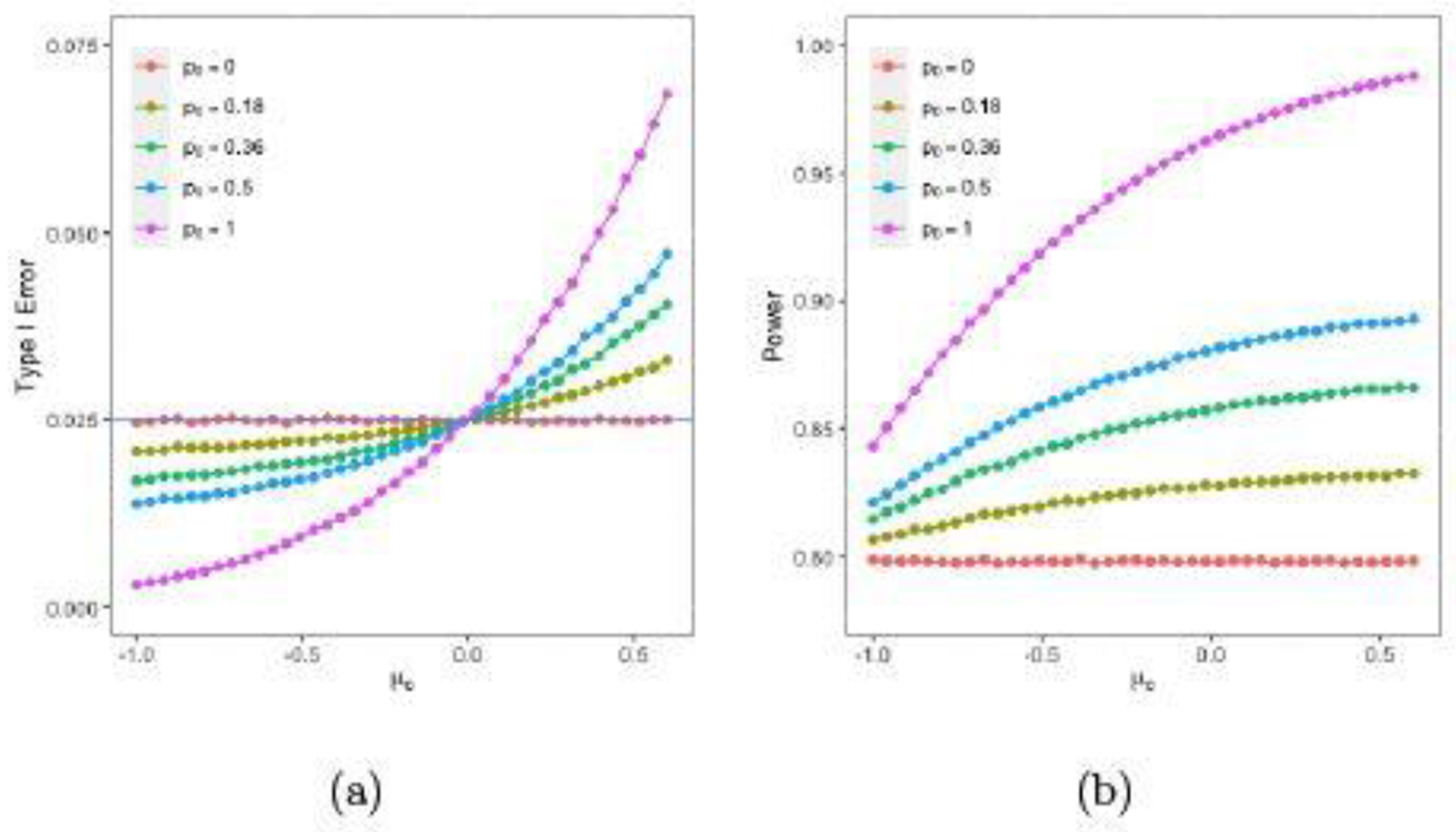
Plots of Bayesian type I errors and powers with the robust mixture prior versus μc.
4.2. Conditional Borrowing
Under the assumption of compatibility between the natural history data and the concurrent control data, the conditions on the primary end point can be further imposed in borrowing the historical data. We take
| (4.3) |
where and are two fitting priors, A denotes a subset of the sample space induced by y(n) , and AC is the complement of A. We let T0 = γ , where 0 < γ < 1 is a Bayesian credible level. Thus the Bayesian power function is
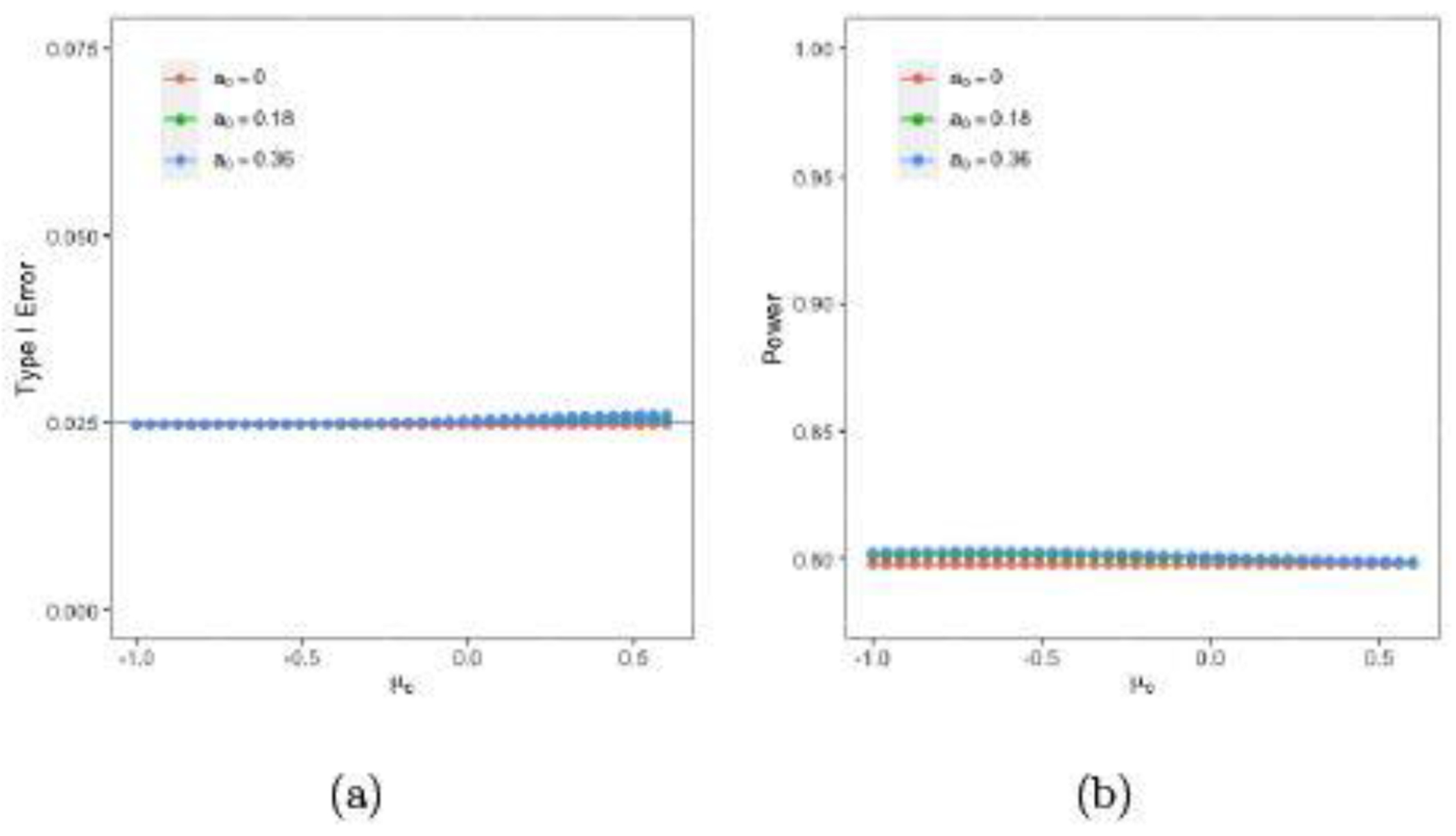
Suppose we impose a conditional borrowing region of for the mean and for the standard deviation of the concurrent control. Thus, . Using the historical data in Section 4.1, . In (4.3), we specify the power prior in (4.1) for and the Jeffreys’s prior for . Figure 5 plots the type I errors and powers versus μc for a0 = 0, 0.18, and 0.36 with conditional borrowing when nt = 32, nc = 16, , , , , , and δ = 3.5.
Fig. 5.
Plots of Bayesian type I errors and powers with conditional borrowing versus μc.
Note that the powers with a0 = 0, 0.18, and 0.36 are 79.79%, 80.11%, and 80.25%, respectively, at μc = −0.51; 79.79%, 80.04%, and 80.13%, respectively, at μc = −0.18; and 79.79%, 79.84%, and 79.86%, respectively, at μc = 0.52. Thus, the power gains from a0 = 0 to a0 = 0.18 are 0.32%, 0.25%, and 0.05%, respectively, at μc = −0.51, −0.18, and 0.52 while the power gains from a0 = 0.18 to a0 = 0.36 are close to 0 at μc = −0.51, −0.18, and 0.52. Also note that the type I errors with a0 = 0 , 0.18, and 0.36 are 0.025, 0.025, and 0.025, respectively, at μc = −0.51; 0.025, 0.025, and 0.025, respectively, at μc = −0.18; and 0.025, 0.025, and 0.026, respectively, at μc = 0.52. Compared with those obtained using the power prior and the robust mixture prior shown in Figures 3 and 4, (i) the type I errors shown in Figure 5 are better controlled with a small increase toward larger μc; and (ii) the powers shown in Figure 5 are lower than those under unconditional borrowing.
4.3. Borrowing-by-Parts Power Priors
Let denote the current data, where and are the sample means and and are the sample variances, respectively, for the concurrent control and the test arm. In (4.1), the historical data is borrowed all together via the power prior. A new variation of the power prior is the borrowing-by-parts power prior via distinct discounting parameters a01 and a02, given by
| (4.4) |
where . In (4.4), the distinct discounting parameters a01 and a02 are used in borrowing the mean and the variance, respectively. In the case when the mean of the concurrent control is consistent with that of the historical data, however the variance of the concurrent control is not consistent with that of the historical data, a01 > 0 and a02 = 0 can be specified for borrowing the mean part but not borrowing the variance part. Compared with full borrowing, where a01 = a02 > 0 , borrowing only the mean part where a01 > 0 and a02 = 0 allows for achieving a desirable power while controlling the type I error at the same time.
Table 4 reports the type I errors and powers using the borrowing-by-parts power prior with consistent and inconsistent variances of the concurrent control compared with that of the historical control for nt = 32, nc = 16, , and Jeffreys’s prior. When , we see from Table 4 that (i) the type I error decreases and the power increases in a01 when a02 = 0; (ii) both the type I error and the power increase in a02 when a01 = 0; and (iii) the type I errors are less than 0.025 but the power increases considerably when a01 = a02 gets larger. When and , we also see from Table 4 that (i) the type I errors are controlled at 0.025 and the powers under various values of a01 and a02 such that a01 + a02 > 0 (borrowing) are greater than those under a01 = a02 = 0 (no borrowing); (ii) the gain in the power is incremental when a02 > 0 and a01 = 0. These results indicate that borrowing the mean part of the historical data only or the whole historical data is more effective in increasing the power than borrowing the variance part of the historical data only. The results with μc = −1 and μc = 1 are given in Appendix C. Figure 6(a) plots the type I error against a01 and a02 and Figure 6(b) plots the type I error against for . When , the type I error stays at or below 0.025 as a0 increases. When a02 = 0 , the type I error first decreases and then increases slightly as a01 increases. When a01 = 0 , the type I error increases as a02 increases.
Table 4.
Bayesian type I errors and powers using the borrowing-by-parts power prior.
| a 01 | a 02 | Type I Error | Power | ||
|---|---|---|---|---|---|
| δ = 3.5 | δ = 4 | δ = 4.5 | |||
| 0.00 | 0.00 | 0.0255 | 60.44% | 71.93% | 81.50% |
| 0.18 | 0.00 | 0.0162 | 74.71% | 85.46% | 92.60% |
| 0.36 | 0.00 | 0.0143 | 83.01% | 91.82% | 96.62% |
| 0.00 | 0.18 | 0.0329 | 65.78% | 76.67% | 85.27% |
| 0.00 | 0.36 | 0.0376 | 68.42% | 78.88% | 86.99% |
| 0.18 | 0.18 | 0.0213 | 78.97% | 88.55% | 94.50% |
| 0.36 | 0.36 | 0.0212 | 87.43% | 94.44% | 97.93% |
| a 01 | a 02 | Type I Error | Power | ||
| δ = 3.5 | δ = 4 | δ = 4.5 | |||
| 0.00 | 0.00 | 0.0247 | 79.79% | 89.11% | 94.84% |
| 0.18 | 0.00 | 0.0202 | 88.68% | 95.25% | 98.33% |
| 0.36 | 0.00 | 0.0205 | 92.40% | 97.30% | 99.21% |
| 0.00 | 0.18 | 0.0243 | 80.24% | 89.49% | 95.09% |
| 0.00 | 0.36 | 0.0242 | 80.45% | 89.64% | 95.18% |
| 0.18 | 0.18 | 0.0202 | 89.03% | 95.47% | 98.45% |
| 0.36 | 0.36 | 0.0206 | 92.72% | 97.47% | 99.29% |
Fig. 6.
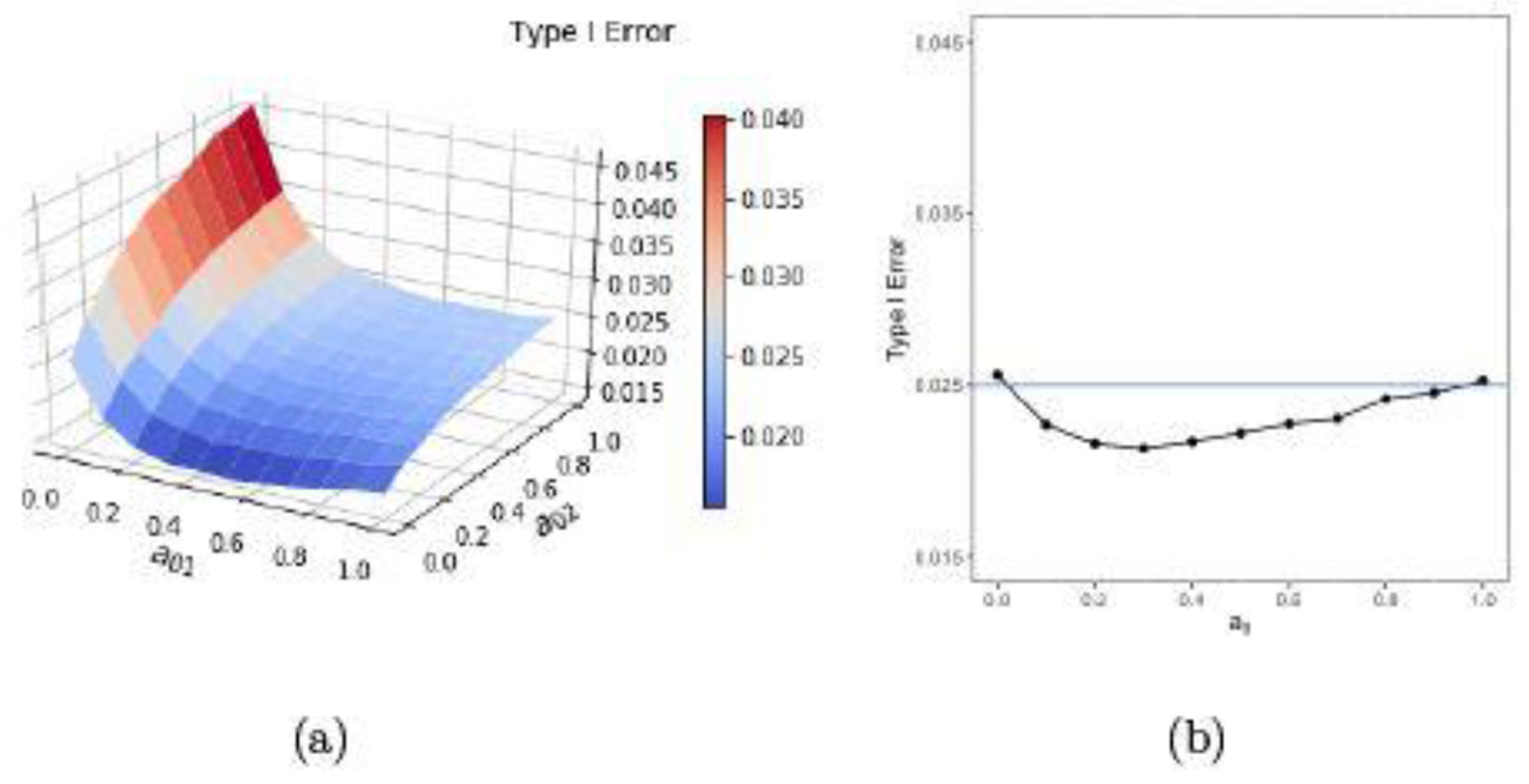
Bayesian type I errors with borrowing mean and/or variance as a function of (a) and (b).
5. Discussion
In this paper, we develop a roadmap of Bayesian SSD as shown in Figure 1. We analytically explore the properties of the Bayesian type I error and power with noninformative priors when the variances are known. We also examine the impact of model misspecification and the choice of noninformative priors on the Bayesian type I error and power. For misspecified models, although it is a common practice that the variances for the test group and the control group are assumed to be equal under the normal distributions for a superiority trial, we empirically show that the type I error and power can be increased or decreased depending on the relationship of and . The consequences of model misspecification are consistent for both frequentist and Bayesian methods. Also the choice of the priors matters even with noninformative priors.
For a 2 : 1 randomized controlled trial, we show that the first half in the amount of borrowing leads to more power gain than the second half in the amount of borrowing for both frequentist and Bayesian methods. This would be worth of consideration for both economical and practical point of view. We further demonstrate the risks and benefits of conditional borrowing. The type I error can be protected by the conditional borrowing, however, the power is lowered at the same time. We note that the conditional borrowing approach can be extended to the case in which multiple historical data sets are available (see the detailed elaboration in Appendix D of the Supplementary Materials).
We develop borrowing-by-parts power priors for incorporating the historical data in Bayesian SSD. The likelihood function is partitioned into the part of the parameter of primary interest and the part of the nuisance parameter, which are the mean and the variance, respectively, in the normal distribution case. By using separate discounting parameters a01 and a02, the historical data can be borrowed by either the mean part, or the variance part, or both. Although the borrowing-by-parts power priors are developed under the normal models, these priors can also be constructed under more general normal regression models or even more complex joint longitudinal and survival models such as those considered in Zhang et al. (2014, 2017); and Sheikh et al. (2021). As shown in Figure 3 and Table 4, borrowing the historical data can lead to inflation of type I errors when the concurrent control mean is greater than the sample mean of the historical data in certain magnitude or the variance of the future outcomes in the concurrent control arm quite differs from the sample variance of the historical data. The conditional borrowing approach discussed in Section 4.2 is quite effective in preventing inflation of type I errors, however, this approach also leads to much smaller gain in the power. Embedding the robust mixture prior and the borrowing-by-parts power priors into the conditional borrowing framework may yield a more promising approach which has a better control of the type I error and at the same time results in more gain in the power.
Although we assume that the historical data are available from the control arm, the proposed methodology can be extended to a more general case, in which the historical data are available for both the investigated product and control arms as considered in Chen et al. (2014). In this case, the borrowing-by-parts power priors may be even more attractive, which allows us to leverage different parts of the historical data within and between the investigated product arm and the control arm. When the historical effect such as the mean of the historical control is different from the mean of the concurrent control, the proposed conditional borrowing approach automatically takes this into consideration by essentially leveraging less amount of the historical data. Recently, the empirical profile approach (Wu et al., 2020) and the scale transformed power prior (Nifong et al., 2021) may be potentially more effective in dealing with different effects for the history control comparing with the concurrent control. These approaches can be integrated into our proposed borrowing-by-parts power priors and the conditional borrowing framework, which is another useful extension for the future research.
Supplementary Material
Contributor Information
Wenlin Yuan, Department of Statistics, University of Connecticut at Storrs, CT 06269.
Ming-Hui Chen, Department of Statistics, University of Connecticut at Storrs, CT 06269.
John Zhong, REGENXBIO Inc., 9804 Medical Center Drive, Rockville, MD 20850.
References
- Allocco DJ, Cannon LA, Britt A, Heil JE, Nersesov A, Wehrenberg S, Dawkins KD, and Kereiakes DJ (2010). A prospective evaluation of the safety and efficacy of the taxus element paclitaxel-eluting coronary stent system for the treatment of de novo coronary artery lesions: design and statistical methods of the perseus clinical program. Trials 11 (1), 1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berry SM, Carlin BP, Lee JJ, and Muller P (2010). Bayesian adaptive methods for clinical trials. CRC Press. [Google Scholar]
- Campbell G (2011). Bayesian statistics in medical devices: innovation sparked by the fda. Journal of Biopharmaceutical Statistics 21 (5), 871–887. [DOI] [PubMed] [Google Scholar]
- Chen M-H, Ibrahim JG, Lam P, Yu A, and Zhang Y (2011). Bayesian design of noninferiority trials for medical devices using historical data. Biometrics 67(3), 1163–1170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen M-H, Ibrahim JG, Zeng D, Hu K, and Jia C (2014). Bayesian design of superiority clinical trials for recurrent events data with applications to bleeding and transfusion events in myelodyplastic syndrome. Biometrics 70 (4), 1003–1013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Santis F (2004). Statistical evidence and sample size determination for Bayesian hypothesis testing. Journal of Statistical Planning and Inference 124 (1), 121–144. [Google Scholar]
- De Santis F (2007). Using historical data for Bayesian sample size determination. Journal of the Royal Statistical Society: Series A (Statistics in Society) 170 (1), 95–113. [Google Scholar]
- Gamalo-Siebers M, Gao A, Lakshminarayanan M, Liu G, Natanegara F, Railkar R, Schmidli H, and Song G (2016). Bayesian methods for the design and analysis of noninferiority trials. Journal of Biopharmaceutical Statistics 26 (5), 823–841. [DOI] [PubMed] [Google Scholar]
- Ghadessi M, Tang R, Zhou J, Liu R, Wang C, Toyoizumi K, Mei C, Zhang L, Deng C, and Beckman RA (2020). A roadmap to using historical controls in clinical trials–by drug information association adaptive design scientific working group (diaadswg). Orphanet Journal of Rare Diseases 15 (1), 1–19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goemans N, Signorovitch J, Sajeev G, Yao Z, Gordish-Dressman H, McDonald CM, Vandenborne K, Miller D, Ward SJ, Mercuri E, et al. (2020). Suitability of external controls for drug evaluation in duchenne muscular dystrophy. Neurology 95 (10), e1381–e1391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greenhouse JB and Waserman L (1995). Robust Bayesian methods for monitoring clinical trials. Statistics in Medicine 14 (12), 1379–1391. [DOI] [PubMed] [Google Scholar]
- Hall KT, Vase L, Tobias DK, Dashti HT, Vollert J, Kaptchuk TJ, and Cook NR (2021). Historical controls in randomized clinical trials: opportunities and challenges. Clinical Pharmacology & Therapeutics 109 (2), 343–351. [DOI] [PubMed] [Google Scholar]
- Han B, Zhan J, John Zhong Z, Liu D, and Lindborg S (2017). Covariate-adjusted borrowing of historical control data in randomized clinical trials. Pharmaceutical Statistics 16 (4), 296–308. [DOI] [PubMed] [Google Scholar]
- Hobbs BP, Carlin BP, Mandrekar SJ, and Sargent DJ (2011). Hierarchical commensurate and power prior models for adaptive incorporation of historical information in clinical trials. Biometrics 67 (3), 1047–1056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hobbs BP, Sargent DJ, and Carlin BP (2012). Commensurate priors for incorporating historical information in clinical trials using general and generalized linear models. Bayesian Analysis 7 (3), 639. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ibrahim JG and Chen M-H (2000). Power prior distributions for regression models. Statistical Science 15 (1), 46–60. [Google Scholar]
- Ibrahim JG, Chen M-H, Gwon Y, and Chen F (2015). The power prior: theory and applications. Statistics in Medicine 34 (28), 3724–3749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ibrahim JG, Chen M-H, Xia HA, and Liu T (2012). Bayesian meta-experimental design: evaluating cardiovascular risk in new antidiabetic therapies to treat type 2 diabetes. Biometrics 68 (2), 578–586. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Inoue LY, Berry DA, and Parmigiani G (2005). Relationship between Bayesian and frequentist sample size determination. The American Statistician 59 (1), 79–87. [Google Scholar]
- Joseph L, Wolfson DB, and Berger RD (1995). Sample size calculations for binomial proportions via highest posterior density intervals. Journal of the Royal Statistical Society: Series D (The Statistician) 44 (2), 143–154. [Google Scholar]
- Katsis A and Toman B (1999). Bayesian sample size calculations for binomial experiments. Journal of Statistical Planning and Inference 81 (2), 349–362. [Google Scholar]
- Lake SL, Quintana MA, Broglio K, Panagoulias J, Berry SM, and Panzara MA (2021). Bayesian adaptive design for clinical trials in duchenne muscular dystrophy. Statistics in Medicine 40 (19), 4167–4184. [DOI] [PubMed] [Google Scholar]
- Lee JJ and Liu DD (2008). A predictive probability design for phase ii cancer clinical trials. Clinical Trials 5 (2), 93–106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li W, Chen M-H, Tan H, and Dey DK (2015). Bayesian design of noninferiority clinical trials with co-primary endpoints and multiple dose comparison. In Applied Statistics in Biomedicine and Clinical Trials Design, pp. 17–33. Springer. [Google Scholar]
- Li W, Chen M-H, Wang X, and Dey DK (2018). Bayesian design of noninferiority clinical trials via the bayes factor. Statistics in Biosciences 10 (2), 439–459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lim J, Walley R, Yuan J, Liu J, Dabral A, Best N, Grieve A, Hampson L, Wolfram J, Woodward P, et al. (2018). Minimizing patient burden through the use of historical subject-level data in innovative confirmatory clinical trials: review of methods and opportunities. Therapeutic Innovation & Regulatory Science 52 (5), 546–559. [DOI] [PubMed] [Google Scholar]
- Lindley DV (1997). The choice of sample size. Journal of the Royal Statistical Society: Series D (The Statistician) 46 (2), 129–138. [Google Scholar]
- Mah JK, Korngut L, Dykeman J, Day L, Pringsheim T, and Jette N (2014). A systematic review and meta-analysis on the epidemiology of duchenne and becker muscular dystrophy. Neuromuscular Disorders 24 (6), 482–491. [DOI] [PubMed] [Google Scholar]
- M’Lan CE, Joseph L, and Wolfson DB (2006). Bayesian sample size determination for case-control studies. Journal of the American Statistical Association 101 (474), 760–772. [Google Scholar]
- M’lan CE, Joseph L, Wolfson DB, et al. (2008). Bayesian sample size determination for binomial proportions. Bayesian Analysis 3 (2), 269–296. [Google Scholar]
- Neuenschwander B, Capkun-Niggli G, Branson M, and Spiegelhalter DJ (2010). Summarizing historical information on controls in clinical trials. Clinical Trials 7(1), 5–18. [DOI] [PubMed] [Google Scholar]
- Nifong B, Psioda MA, and Ibrahim JG (2021). The scale transformed power prior for use with historical data from a different outcome model. arXiv preprint arXiv:2105.05157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pan H, Yuan Y, and Xia J (2017). A calibrated power prior approach to borrow information from historical data with application to biosimilar clinical trials. Journal of the Royal Statistical Society: Series C (Applied Statistics) 66 (5), 979–996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rahme E and Joseph L (1998). Exact sample size determination for binomial experiments. Journal of Statistical Planning and Inference 66 (1), 83–93. [Google Scholar]
- Reyes EM and Ghosh SK (2013). Bayesian average error-based approach to sample size calculations for hypothesis testing. Journal of Biopharmaceutical Statistics 23 (3), 569–588. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rubin DB and Stern HS (1998). Sample size determination using posterior predictive distributions. Sankhyā: The Indian Journal of Statistics, Series B 60 (1), 161–175. [Google Scholar]
- Schmidli H, Gsteiger S, Roychoudhury S, O’Hagan A, Spiegelhalter D, and Neuenschwander B (2014). Robust meta-analytic-predictive priors in clinical trials with historical control information. Biometrics 70 (4), 1023–1032. [DOI] [PubMed] [Google Scholar]
- Schmidli H, Häring DA, Thomas M, Cassidy A, Weber S, and Bretz F (2020). Beyond randomized clinical trials: use of external controls. Clinical Pharmacology & Therapeutics 107 (4), 806–816. [DOI] [PubMed] [Google Scholar]
- Sheikh MT, Ibrahim JG, Gelfond JA, Sun W, and Chen M-H (2021). Joint modelling of longitudinal and survival data in the presence of competing risks with applications to prostate cancer data. Statistical Modelling 21 (1-2), 72–94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simon R (1999). Bayesian design and analysis of active control clinical trials. Biometrics 55 (2), 484–487. [DOI] [PubMed] [Google Scholar]
- Spiegelhalter DJ, Abrams KR, and Myles JP (2004). Bayesian approaches to clinical trials and health-care evaluation, Volume 13. John Wiley & Sons. [Google Scholar]
- U.S. Food and Drug Administration (2010). Guidance for the Use of Bayesian Statistics in Medical Device Clinical Trials. https://www.fda.gov/regulatory-information/search-fda-guidance-documents/guidance-use-bayesian-statistics-medical-device-clinical-trials. Accessed December 2020.
- U.S. Food and Drug Administration (2018). Complex Innovative Trial Designs Pilot Program. https://www.fda.gov/drugs/development-resources/complex-innovative-trial-designs-pilot-program. Accessed November 2020.
- van Rosmalen J, Dejardin D, van Norden Y, Löwenberg B, and Lesaffre E (2018). Including historical data in the analysis of clinical trials: Is it worth the effort? Statistical Methods in Medical Research 27 (10), 3167–3182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Viele K, Berry S, Neuenschwander B, Amzal B, Chen F, Enas N, Hobbs B, Ibrahim JG, Kinnersley N, Lindborg S, et al. (2014). Use of historical control data for assessing treatment effects in clinical trials. Pharmaceutical Statistics 13 (1), 41–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang C, Li H, Chen W-C, Lu N, Tiwari R, Xu Y, and Yue LQ (2019). Propensity score-integrated power prior approach for incorporating real-world evidence in single-arm clinical studies. Journal of Biopharmaceutical Statistics 29 (5), 731–748. [DOI] [PubMed] [Google Scholar]
- Wang F and Gelfand AE (2002). A simulation-based approach to Bayesian sample size determination for performance under a given model and for separating models. Statistical Science 17 (2), 193–208. [Google Scholar]
- Wu Y, Hui J, and Deng Q (2020). Empirical profile Bayesian estimation for extrapolation of historical adult data to pediatric drug development. Pharmaceutical Statistics 19 (6), 787–802. [DOI] [PubMed] [Google Scholar]
- Ye J, Reaman G, De Claro RA, and Sridhara R (2020). A Bayesian approach in design and analysis of pediatric cancer clinical trials. Pharmaceutical Statistics 19 (6), 814–826. [DOI] [PubMed] [Google Scholar]
- Zhang D, Chen M-H, Ibrahim JG, Boye ME, and Shen W (2017). Bayesian model assessment in joint modeling of longitudinal and survival data with applications to cancer clinical trials. Journal of Computational and Graphical Statistics 26 (1), 121–133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang D, Chen M-H, Ibrahim JG, Boye ME, Wang P, and Shen W (2014). Assessing model fit in joint models of longitudinal and survival data with applications to cancer clinical trials. Statistics in Medicine 33 (27), 4715–4733. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.