

Abstract
Recent advances in single-cell technologies have enabled high-throughput molecular profiling of cells across modalities and locations. Single-cell transcriptomics data can now be complemented by chromatin accessibility, surface protein expression, adaptive immune receptor repertoire profiling and spatial information. The increasing availability of single-cell data across modalities has motivated the development of novel computational methods to help analysts derive biological insights. As the field grows, it becomes increasingly difficult to navigate the vast landscape of tools and analysis steps. Here, we summarize independent benchmarking studies of unimodal and multimodal single-cell analysis across modalities to suggest comprehensive best-practice workflows for the most common analysis steps. Where independent benchmarks are not available, we review and contrast popular methods. Our article serves as an entry point for novices in the field of single-cell (multi-)omic analysis and guides advanced users to the most recent best practices.
Subject terms: Software, RNA sequencing, Functional genomics, Machine learning
Practitioners in the field of single-cell omics are now faced with diverse options for analytical tools to process and integrate data from various molecular modalities. In an Expert Recommendation article, the authors provide guidance on robust single-cell data analysis, including choices of best-performing tools from benchmarking studies.
Introduction
Single-cell RNA sequencing (scRNA-seq) technologies have revolutionized molecular biology by enabling the measurement of transcriptome profiles at unprecedented scale and resolution. Advancements in experimental technology have motivated large-scale innovation in computational methods, leading to more than 1,400 tools currently being available to analyse scRNA-seq data1. Computational frameworks and software repositories, such as Bioconductor2, Seurat3 and Scanpy4, complemented by method benchmarks and best-practice workflows2,5,6 have allowed data analysts to navigate this space and build analysis pipelines. This interplay of experimental and computational innovation has enabled biological landmark discoveries that uncover tissue cellular heterogeneity7,8.
However, scRNA-seq captures only one layer of the complex regulatory machinery that governs cellular function and signalling. To complement this, considerable efforts have been made to measure other modalities at single-cell resolution, including chromatin accessibility9, surface proteins10, T cell receptor (TCR)/B cell receptor (BCR) repertoires11 and spatial location12, enabling findings such as type 2 diabetes mellitus regulatory signatures13, dysregulated response of the innate14 and adaptive15 immune system against severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) and better understanding of immunosuppressive effects of the tumour microenvironment at spatial resolution16. Experimental innovation has led to the development of many new computational tools for various single-cell omic modalities, yet a lack of best-practice workflows makes navigation of the vast landscape of novel tools challenging. Moreover, although computational best practices and tool recommendations have previously been outlined for scRNA-seq2,5,6,17, they are either outdated or incomplete.
Here, we guide the reader through the various steps of unimodal as well as multimodal single-cell data analysis and discuss analysis pitfalls and recommendations (Fig. 1). Where best practices cannot be determined owing to the novelty of tools or lack of independent benchmarks, we list popular tools and community recommendations. We organize the article into modality-specific sections and groups of analysis steps instead of a single workflow, which in modern single-cell analysis rarely exists anymore owing to the diversity of tasks. For further reading, we provide a more extensive and regularly updated (but not peer-reviewed) Single-Cell Best Practices online book with more than 50 chapters including detailed code examples, analysis templates as well as an assessment of computational requirements.
Fig. 1. Single-cell analysis across modalities.

Cellular state is characterized by various modalities, including, but not limited to, RNA transcription, chromatin accessibility, surface proteins including T cell receptors (TCRs) and B cell receptors (BCRs), as well as spatial location. Various frameworks covering the most important analysis steps have been developed. Transcriptomics data can be analysed with Scanpy4, Seurat36 and Bioconductor-based SingleCellExperiment2; chromatin accessibility measurements with muon150, ArchR140, snapATAC135 and Signac143; TCR and BCR repertoire analysis with Scirpy164, Dandelion14 and scRepertoire166; surface protein expression with muon150, Seurat36 and CiteFuse163; spatially resolved single-cell data sets with frameworks such as Squidpy209, Seurat36, Giotto244 and Bioconductor-based SpatialExperiment211. These frameworks are complemented with a myriad of additional tools for specific subsequent analysis tasks.
Transcriptome
scRNA-seq measures the abundance of mRNA molecules per cell. Extracted biological tissue samples constitute the input for single-cell experiments. Tissues are digested during single-cell dissociation, followed by single-cell isolation to profile the mRNA per cell separately. Plate-based protocols isolate cells into wells on a plate, whereas droplet-based methods capture cells in microfluidic droplets18. In this article, we focus on droplet-based assays owing to their popularity.
The obtained mRNA sequence reads are mapped to genes and cells of origin in raw data processing pipelines that use either cellular barcodes or unique molecular identifiers (UMIs) and a reference genome to produce a count matrix of cells by genes (Fig. 2a). For a detailed comparison of various raw data processing tools, we refer to Lafzi et al.19 and consider count matrices as the starting point for our analysis workflow of unimodal scRNA-seq data.
Fig. 2. Overview of unimodal analysis steps for scRNA-seq.

a, Count matrices of cells by genes are obtained from raw data processing pipelines. To ensure that only high-quality cells are captured, count matrices are corrected for cell-free ambient RNA and filtered for doublets and low-quality or dying cells. The latter is done by removing outliers with respect to quality control metrics (the number of counts per barcode, called count depth or library size, the number of genes per barcode and the fraction of counts from mitochondrial genes per barcode (percentage mito.)). All counts represent successful capture, reverse transcription and sequencing of an mRNA molecule. These steps vary across cells, and therefore count depths for identical cells can differ. Hence, when comparing gene expression between cells, differences may originate solely from sampling effects. This is addressed by normalization to obtain correct relative gene abundances between cells. Single-cell RNA sequencing (scRNA-seq) data sets can contain counts for up to 30,000 genes for humans. However, most genes are not informative, with many genes having no observed expression. Therefore, the most variably expressed genes are selected. Different batches of data are integrated to obtain a corrected data matrix across samples. To ease computational burden and to reduce noise, dimensionality reduction techniques are commonly applied. This further allows for the low-dimensional embedding of the transcriptomics data for visualization purposes. b, The corrected space can then be organized into clusters, which represent groups of cells with similar gene expression profiles, annotated by labels of interest such as cell type. The annotation can be conducted manually using prior knowledge or with automatic annotation approaches. Continuous processes, such as transitions between cell identities during differentiation or reprogramming, can be inferred to describe cellular diversity that does not fit into discrete classes. c, Depending on the question of interest and experimental set-up, conditions in the data set can be tested for upregulated or downregulated genes (differential expression analysis), effects on pathways (gene set enrichment) and changes in cell-type composition. Perturbation modelling enables the assessment of the effect of induced perturbations and the prediction of unmeasured perturbations. Expression patterns of ligands and receptors can reveal altered cell–cell communication. Transcriptomics data further enable the recovery of gene regulatory networks. q, q value.
From raw count matrices to high-quality cellular data
Advances in scRNA-seq led to high-quality runs with high throughputs. However, scRNA-seq data sets contain systematic and random noise (such as from poor-quality cells) that obscures the biological signal. Preprocessing of scRNA-seq data attempts to remove these confounding sources of variation. This involves quality control, normalization, data correction and feature selection (Fig. 2a).
Filtering low-quality cells and noise correction
Most analysis tasks assume that each droplet contains RNA from an intact single cell. This assumption is commonly violated through low-quality cells, contamination from cell-free RNA or the capture of multiple cells (Fig. 2a). Cells with a low number of detected genes, a low count depth and a high fraction of mitochondrial counts are typically termed low-quality cells as they can represent dying cells with broken membranes. Low-quality cells are identified and filtered by manually setting thresholds as recommended in a previous guide5 or sample-wise automatic filtering based on the number of median absolute deviations20. These metrics are considered jointly to prevent the misinterpretation of cellular signals5. Quality control is performed at the sample level as thresholds can vary substantially between samples.
Cell-free RNA can be present in the cell solution and will be assigned to a cell’s native RNA during library construction. Ambient RNA contamination can lead to cell-type-specific marker gene transcripts being detectable also in other cell populations, which can blend different cell populations together21. Popular methods such as SoupX estimate the cell-specific contamination fraction on the basis of the expression profiles of otherwise ‘empty’ droplets and cell clusters in the data set21. CellBender formulates the removal of ambient RNA as an unsupervised Bayesian model that requires no prior knowledge of cell-type-specific gene expression profiles22. Even in the absence of a systematic benchmark, one should consider removing ambient RNA as an initial analysis step in quality control to improve downstream analyses for many tissues21–23.
Empty droplets and doublets (droplets containing two cells) violate the assumption that each droplet contains a single cell. Doublets formed by different cell types (heterotypic doublets) are hard to annotate and can lead to wrong cell-type labels. Common doublet detection methods generate artificial doublets by combining two randomly sampled cells and comparing them against measured cells. scDblFinder24 leverages this idea and can additionally be combined with prior knowledge on known doublets. Several benchmarks have highlighted that scDblFinder outperforms other methods in terms of doublet detection accuracy and computational efficiency25–27. Additionally, it can be beneficial to apply multiple doublet detection methods and compare the results to increase the accuracy of doublet detection27.
The selected quality control strategy often needs to be reassessed during downstream analysis when low-quality cells and doublets cluster together. We therefore recommend setting permissive thresholds initially and potentially removing more cells as necessary during (re-)analysis.
Normalization and variance stabilization
Cells can have different numbers of gene counts owing to differences in mRNA-containing volume (cell size) or purely randomly during sequencing. Count normalization makes cellular profiles comparable. Subsequent variance stabilization ensures that outlier profiles have limited effect on the overall data structure28 (Fig. 2a). A recent benchmark compared 22 transformations for single-cell data based on the K nearest-neighbours graph (KNN graph) overlap with the ground truth29. The shifted logarithm transformation with size factor s performs well but should not be used with counts per million as an input, as it reflects an unrealistically large overdispersion. By scaling all genes by a common factor, one assumes that differences in count depth due to cell size are negligible. However, for heterogeneous scRNA-seq data sets, defining a per-gene statistic might not be accurate if the data set is composed of various different cell types with non-identical cell properties. Scran30 normalization aims to minimize this issue by pooling cells with similar count depth and estimating pool-based size factors using a linear regression over genes. An approach that was shown to perform similarly well in the aforementioned benchmark29 is the analytical approximation of Pearson residuals, which fits a generalized linear model with sequencing depth as a covariate to obtain transformed count matrices31. We agree with previous studies that the normalization method should be chosen carefully and based on the subsequent analysis task5,32,33. The shifted logarithm was shown to work better for stabilizing variance for subsequent dimensionality reduction33, Scran performs well for batch correction tasks34,35, and analytical Pearson residuals are better suited for selection of biologically variable genes and identification of rare cell identities31.
Removing confounding sources of variation
Confounding sources of variation can be separated into technical as well as biological covariates and should be treated separately as they describe different effects and challenges.
Data sets that contain multiple samples may be confounded by batch effects that reflect technical variation. Batch effects can be observable after clustering and visualization and should be removed to ensure that they are not mistaken as actual biological insight5. Data integration methods address batch effects between samples in the same experimental setting. A recent benchmark compared 16 integration methods based on 14 metrics on the basis of batch correction as well as biological variance conservation35. Linear-embedding models such as canonical correlation analysis36 and Harmony37 were shown to perform well for batch correction on simpler integration tasks with distinct batch structures38,39. scANVI40 can incorporate the cell-type labels, which is favourable as it can help to conserve biological variation35. Depending on the complexity of the integration tasks, such as atlas integration, deep-learning approaches such as scANVI40, scVI41 and scGen42 as well as linear-embedding models such as Scanorama43 performed best, whereas for less complex integration tasks, Harmony37 is the preferred method35. The package scIB can be used to evaluate the integration using the aforementioned benchmark’s evaluation metrics35.
Besides count sampling effects, scRNA-seq data may contain biological confounding factors such as cell cycle effects, whereby differences between cells might be due to different cell cycle states rather than cell types44. Removing such effects from the data set can be favourable for downstream analysis; however, knowing whether cells are cycling may provide valuable insights into the underlying biology5. A recent benchmark44 recommends using the built-in cell cycle labelling and correction functions in Scanpy4 or Seurat45 as a baseline, which compare the mean expression values to a reference signature. Subsequently, a more complex method such as Tricycle46 should be applied, which maps the data set to an embedding that represents the cell cycle46. Tricycle was shown to perform well for data sets with high cell-type heterogeneity44.
Selecting informative features and reducing dimensionality
To ensure that analysis focuses only on biologically meaningful genes and to deal with large data sets, the count matrix can be reduced to the most informative features. Feature selection methods should ideally select genes that explain the biological variation in a data set by prioritizing those that vary between subpopulations rather than within one subpopulation, without affecting the identifiability of small subpopulations20. Deviance identifies highly informative genes by fitting a gene-wise model that assumes constant expression across all cells and quantifying which genes violate this assumption47. It performed favourably for identifying genes with high variance across subpopulations and thus for selecting informative genes, as shown in an independent comparison20. Additionally, ranking genes by deviance is performed on raw counts and is therefore not sensitive to normalization. After feature selection, the dimensions of the data set can be further reduced by dimensionality reduction algorithms such as principal component analysis (PCA) (Fig. 2a). Dimensionality reduction techniques can be used for either visualization or summarization of the underlying data topology. On the basis of other studies, PCA can be used for data summarization and t-SNE, UMAP and PHATE for more flexible visualization of scRNA-seq data5,48. Notably, a recent study showed that relying only on 2D embeddings can lead to misinterpretation of the relationships between cells, and results should not be formulated only on the basis of visual inspection of these representations, but should be combined with quantitative assessments49.
From clusters to cell identities
After preprocessing, unwanted effects have been removed from the data set and the signal-to-noise ratio improved. Thus, one can now start asking biologically relevant questions. As a next analysis milestone, different cellular populations can be identified to further guide and structure the analysis (Fig. 2b).
From single cells to clusters
The first step towards identifying cellular populations is to cluster cells into groups with similar expression profiles that explain the heterogeneity in the data. Independent benchmarks5,50,51 showed that community detection based on graph modularity optimization via the Louvain algorithm works best for cluster identification. However, the Louvain algorithm can lead to arbitrarily poorly connected communities52. Louvain’s successor Leiden circumvents this issue by yielding guaranteed connected communities and is computationally more efficient52. Both methods are applied to the KNN graph computed on a low-dimensional representation of the data and can be run at different resolutions to control the number of identified clusters. We recommend using the Leiden algorithm at different resolutions to obtain an ideal clustering for annotating cells5.
Mapping cell clusters to cell identities
Annotation is the process of giving detected cell clusters a biological interpretation such as cell type (Fig. 2b). It can be performed with manual or automatic approaches. A three-step approach is recommended that leverages automated annotation, followed by expert manual annotation and a last step of verification to obtain the ideal annotation result53. The first step, automated cell-type annotation, can be separated into classifier-based methods and reference mapping. Annotation results obtained with pre-trained classifiers are strongly affected by the classifier type and the quality of the training data used to create the classifier54,55. Furthermore, it can be difficult to assess the resulting annotation without additionally inspecting individual markers. Examples of classifiers that are trained on previously annotated data sets or atlases and that consider a large set of genes are CellTypist56 and Clustifyr57. The second group of automated annotation approaches is mapping to existing, annotated single-cell references and performing label transfer on the resulting joint embedding. References can be either individual samples of the data set or, ideally, well-curated existing atlases. Query-to-reference mapping can then be performed with methods such as scArches58, Symphony59 or Azimuth3. Similar to classifier-based approaches, the quality of the transferred annotations depends on the quality of the reference data, the model and the suitability to the data set. The second step, manual annotation, leverages gene signatures of each cluster to annotate cell clusters. These gene signatures are commonly known as marker genes and can be identified using simple differential expression testing approaches such as t-tests or Wilcoxon rank-sum tests. The statistical test is applied to two groups of clusters to find genes that are upregulated or downregulated in a cluster of interest. For this purpose, Wilcoxon rank-sum tests performed best, but owing to the nature of clustering, P values can be inflated and might lead to false discoveries, as the same data are used to define the labels that we test for differences between60,61. The obtained markers are then compared with marker genes from well-annotated references to annotate cell clusters. As a last step, the annotation should be verified by experts, especially for data sets with high complexity or studies that involve rare cell subpopulations for which references might not be available53.
From discrete states to continuous processes
In non-stationary, biological processes such as differentiation, cells traverse a continuous space of cellular states. Using single-cell data to understand cell fate — and genes regulating it in this landscape — is challenging as measurements are only snapshots. The underlying trajectories can be cyclic, linear, a tree or, most generally, a graph. Models that order cells along a trajectory based on similarities in their expression patterns are known as trajectory inference or pseudotime analysis methods. The performance of trajectory inference approaches depends on the type of trajectory present in the data set. Although Slingshot62 performed better for simple topologies, PAGA63 and RaceID/StemID64 scored better for complex trajectories65. We therefore recommend using dynguidelines to select an applicable method65. When the expected topology is unknown, trajectories and downstream hypotheses should be confirmed by multiple trajectory inference methods using different underlying assumptions. Inferred trajectories might not necessarily have biological meaning5. Incorporating more complex methods and sources of information through, for example, RNA velocity measurements, can be beneficial to recover further evidence of actual biological processes.
To infer dynamic, directed information, velocyto66 and scVelo67 model splicing kinetics using unspliced and spliced reads to infer RNA velocity: if a gene is being activated, unspliced RNA precedes the spliced RNA, which can be visualized in the phase portrait67. Obtained RNA velocity fields serve as input for CellRank68 to estimate cellular fates. RNA velocity inference assumes gene independence and constant rates of transcription, splicing and degradation. Under the assumption of constant rates, phase portraits form an almond shape with induction (upper half/arc) and repression (lower half/arc) phases. We therefore recommend checking whether the model assumptions hold by examining phase portraits of genes with high likelihoods determined by the dynamic model of scVelo. If phase portraits lack the expected shape, RNA velocity may be inferred incorrectly. Moreover, if a gene includes multiple, pronounced kinetics, lineage-specific models are more appropriate69. Cases in which RNA velocity is inferred incorrectly include the presence of transcriptional bursts70,71. Additionally, steady-state populations pose further challenges where RNA velocity infers erroneous directions between independent, terminal cell populations70,71.
Although pseudotime-based methods do not have any timescale limitations as long as the process is covered in sufficiently fine-grained steps, RNA velocity cannot cover all time scales. As it is splicing kinetics that are modelled, the observed process must also occur during this time frame70.
Retrospective experimental lineage tracing approaches use variability observed in cells, such as naturally occurring genetic mutations, to infer a model of their lineage, summarizing the cell division history in a clonal population. Analysis of lineage tracing data can be conducted with Cassiopeia72, which implements several reconstruction algorithms including classic approaches such as UPGMA73 or neighbour joining74 as well as newer approaches for CRISPR–Cas9 lineage tracing data. Reconstruction performance of algorithms is difficult to assess, as they might highlight different parts of the lineages well75. We therefore recommend applying several algorithms for performance comparisons. In addition, dedicated tools are introduced for the analysis of more complicated lineage tracing studies that include time course information. Among them are LineageOT76, an optimal transport-based framework suitable for evolving CRISPR–Cas9-based settings77, and CoSpar78 for static barcode lineage tracing.
Revealing mechanisms
Having obtained confident annotations on high-quality data, the analysis space becomes diverse, and many mechanisms of interest can be investigated. The choice and order of the following analysis steps are dependent on the question of interest and experimental design (Fig. 2c).
Differential gene expression analysis
The negative binomially distributed scRNA-seq data can be tested for genes that are differentially expressed to identify marker genes or genes that are upregulated or downregulated in specific conditions. Differential gene expression (DGE) analysis is currently approached from two viewpoints. The sample-level view aggregates counts per sample–label combination to create pseudobulks, which are analysed with packages originally designed for bulk expression analysis, such as edgeR79, DEseq2 (ref. 80) or limma81. Alternatively, the cell-level view models cells individually using generalized mixed effect models, such as MAST82. The consensus and robustness between DGE tools is low83,84, but methods designed for bulk RNA-seq data perform favourably84–86. Single-cell-specific methods were found to systematically underestimate the variance of gene expression and to be prone to wrongly labelling highly expressed genes as differentially expressed86.
Current methods for DGE analysis still show a trade-off between true positive rate (TPR) and precision. High TPR results in low precision because of a high number of false positives, whereas high precision leads to low TPR owing to a lack of identified differentially expressed genes83. Pseudoreplication leads to an inflated false discovery rate (FDR) as DGE methods do not account for the inherent correlation of replicates (cells from the same individual)86–88. Within-sample correlation should be accounted for by aggregating cell-type-specific counts within an individual before DGE analysis87. Generally, pseudobulk methods with sum aggregation and mixed models such as MAST with random effect setting were found to be superior to naive methods, such as the popular Wilcoxon rank-sum test, which does not account for within-sample correlation88.
The validity of DGE results strongly depends on the capture of the major axis of variation in the statistical model. Intermediate data exploration steps, such as PCA on pseudobulk samples, help to identify sources of variation and thus can guide the construction of corresponding design and contrast matrices for modelling the data89. Failing to account for multiple sources of biological variability for experiments will inflate the FDR90,91. We therefore recommend flexible methods such as limma, edgeR or DESeq2 that allow for complex experimental designs. P values obtained with DGE tests over conditions must be corrected for multiple testing5,92 to obtain q values.
Gene set enrichment analysis
The high-throughput nature of scRNA-seq data makes them hard to interpret. Gene set enrichment analysis allows the summarization of many molecular insights into interpretable terms such as pathways, defined as gene sets known to be involved through previous studies. Common databases include MSigDB93, Gene Ontology94, KEGG95 or Reactome96. An extension to this concept are weighted gene sets, including PROGENy97 for signalling pathways and DoRothEA98 for transcription factors (TFs). Common methods for enrichment include hypergeometric tests, GSEA99,100 or GSVA101, which can be applied after DGE analysis or at the individual cell level. Gene set enrichment analysis was found to be more sensitive to the choice of gene sets rather than statistical methods102; therefore, we recommend selecting the database carefully to ensure that potential gene sets are covered. To this end, enrichment frameworks such as decoupleR103 provide access to different databases and methods in a single tool. Enrichment methods developed for bulk transcriptomics can be applied to scRNA-seq102, but some single-cell-based methods, namely Pagoda2 (ref. 104), might outperform them105.
Deciphering changes in cell composition
Compositional analysis addresses conditional changes not in the gene expression profile of a cell but instead in the relative abundance of different cell types in the form of compositional data. Changes in composition are frequently observed in development106 and disease107, yet methods for compositional analysis lack an independent benchmark. Univariate statistical models, which analyse change in abundance for each cell type individually, such as Poisson regression or Wilcoxon rank-sum tests, may perceive some cell-type population shifts as statistically sound effects, although they are purely a statistical artefact caused by the compositionality of the data108, leading to an elevated FDR. Tests specifically designed for single-cell data that make use of cell-type counts include scDC109, scCODA108 and tascCODA, which can incorporate hierarchical cell-type information110.
For developmental data, sharp clustering boundaries might be deceptive, and determination of compositional changes based on known annotations may not be appropriate. DA-seq111 and MILO112 use KNN graphs to define subpopulations that are tested for differential abundance between experimental conditions. KNN-based methods are sensitive to a loss of information if the conditions of interest and confounding sources of variation are strongly correlated. Reducing K for the KNN graph or constructing a graph on particular lineages mitigates this issue112. If large differences are apparent in large clusters by visualization, KNN graph-based methods might be ill-suited, and a more direct analysis with tools that use known cell-type counts might be more appropriate.
Inferring perturbation effects
Advances in single-cell experimental protocols have enabled massively multiplexed experiments to measure cells under thousands of unique conditions, commonly termed ‘perturbations’113. Recent technologies such as perturb-seq114 or CROP-seq115 allow for profiling CRISPR–Cas9 screens with multimodal readouts116, genome-wide perturbations117 and combinatorial perturbations118. Analysing these complex conditions is known as perturbation modelling119, for which tools have not yet been independently benchmarked.
One area of perturbation modelling tries to differentiate successfully from unsuccessfully targeted cells for experimental set-ups in which this assignment is unknown and to assess the perturbation effect. Mixscape116 and MUSIC120 first remove confounding sources of variation, then dissect successfully from unsuccessfully perturbed cells, to finally visualize and score perturbation effects. Augur121,122 and MELD123 cover only the third step and rank cell types according to the degree of perturbation response to identify cell populations that were most affected by a perturbation.
A second area of perturbation modelling concerns perturbations that are not experimentally measured. Latent space learning models such as scGen42, CPA124 and CellBox125 aim to predict responses for unseen perturbations, combinations or drug doses. Such models generally work well for highly expressed genes but may struggle with lowly expressed genes owing to a lack of variance.
Communication events across cells
Cells are in constant interaction with each other for organismal development and homeostasis. If this interaction is impaired, disease ensues. Cell–cell communication inference methods commonly use repositories of ligands, receptors and their interactions to predict interactions between annotated clusters. These databases were found to be biased towards specific pathways, functional categories and tissue-enriched proteins126. The choice of method and interaction database has a strong effect on the predicted interactions126. CellChat127 and CellPhoneDB128, which also consider heteromeric interaction complexes, and SingleCellSignalR129 were found to be robust to both data and resource noise126. Owing to the lack of consensus between tools, we recommend using LIANA, which provides an overall ranking for several combinations of method and database126. Moreover, tools such as Nichenet130 or Cytotalk131, which provide complementary estimates of intracellular activities, such as induced gene expression changes or spatial information, can be used to increase the confidence in predicted interactions.
Chromatin accessibility
Analysing regulatory elements is essential for deciphering cellular diversity and understanding cell decision-making. Gene expression is controlled by a complex interplay of regulatory mechanisms, including epigenetics and chromatin accessibility132. To gain insights into the dynamics of chromatin state at the single-cell level, single-cell assay for transposase-accessible chromatin sequencing (scATAC-seq) measures genome-wide chromatin accessibility in individual cells133,134 (Fig. 3).
Fig. 3. Overview of scATAC-seq analysis steps.

a, Single-cell assay for transposase-accessible chromatin sequencing (scATAC-seq) measures single-cell chromatin accessibility. The data can be represented in several distinct ways. The two most common options are cell-by-peak and cell-by-bin matrices. Peak-calling algorithms find regions of high accessibility compared with background noise, whereas binning algorithms capture Tn5 transposition events in equally sized bins. b, To ensure that subsequent analyses focus on biologically meaningful features and not noise, the feature matrix is subject to quality control. The data need to be controlled for the total number of fragments per cell (representing cellular sequencing depth) and several other tests for relevant signal: the number of peaks with non-zero counts per cell, the transcription start site (TSS) enrichment score, the nucleosome signal reflecting the ratio of mononucleosome to nucleosome-free fragments and finally the ratio of reads in genomic regions that have been associated with artefactual signals. The sparsely distributed scATAC-seq features are then corrected through normalization. The subsequent preprocessing and visualization workflow closely follows the steps of a typical RNA analysis. c, scATAC-seq data can be annotated with cell types based on known differentially accessible regions, often by coupling to nearby or annotated coding DNA regions. The annotated cells can be leveraged to analyse continuous processes through trajectory inference. d, Depending on the question of interest, the data can now be investigated for co-accessibility to identify cis-regulatory interactions, differentially accessible regions to understand changes between conditions, transcription factor (TF) activity to identify key regulators and motif discovery to identify DNA sequence patterns serving as TF binding sites, amongst others.
Feature definition and quality control
Compared with the clearly defined gene features used for scRNA-seq data, scATAC-seq data lack a standardized feature set due to the genome-wide nature of the data. Most workflows use a cell-by-peak or cell-by-bin matrix as a basis for analysis, which performs better than matrices of gene or TF motif features135 (Fig. 3a). Bins are uniformly sized windows across the genome that capture all Tn5 transposition events, whereas peaks refer to variable regions of open chromatin with enrichment of Tn5 transposition events over background noise. Notably, the cell-by-peak matrix is even more sparse than scRNA-seq data, with only 1–10% of peaks called in each cell owing to the presence of only two copies of assayable chromatin in cells of a diploid organism135. Identifying peaks requires a sufficient number of cells and therefore may fail in rare cell types136. The sensitivity of peak detection can be improved by calling them within clusters, which reduces the risk of missing peaks in rare cell types masked by the noise of other highly abundant cell types. For this approach, cell-by-bin matrices that do not rule out genomic regions serve as a basis for clustering136.
The most common entry point of scATAC-seq quality control is fragment files that contain all sequenced DNA fragments generated by two adjacent Tn5 transposition events. These are used to calculate a set of scATAC-seq-specific quality metrics to determine low-quality cells (Fig. 3b). Comparable to sequencing depth in scRNA-seq data, the total number of sequenced fragments per cell, the log total number of fragments and the transcription start site (TSS) enrichment score (a metric that captures the signal-to-noise ratio in each cell based on generally more open promoter regions compared with non-promoter regions) are examined. Low-quality cells often form a cluster combining low counts and low TSS enrichment scores that should be removed137. Additionally, the nucleosome signal is used to evaluate the fragment length distribution137. It is further recommended to verify the ratio of reads mapped to genomic regions associated with artefactual signals138. After peak calling, the number of detected features per cell is controlled with data set-dependent minimum thresholds. Moreover, low numbers of reads in peak versus non-peak regions are indicators for low signal-to-noise ratios similar to TSS scores9.
To score doublets, we suggest following the recommendation by Germain et al.24 to use two orthogonal methods specifically designed for scATAC-seq data and consider both scores in downstream analysis. The first method is an adjustment of scDblFinder that reduces correlated features into a small set to use the complete information while making count data more continuous24. The second, AMULET139, leverages the diploidy of the chromosomes and scores cells with an unexpectedly high number of positions with more than two counts as a doublet, which can further capture homotypic doublets139.
Learning a low-dimensional representation
The sparse scATAC-seq data require normalization, analogous to scRNA-seq. In scATAC-seq data, the most common normalization strategy is binarization of peaks136,140,141. However, this may also remove biological information and therefore modelling of scATAC counts directly has been suggested142. Dimensionality reduction methods based on latent semantic indexing (ArchR140 and Signac143), latent Dirichlet allocation (cisTopic141) and spectral embedding (snapATAC136) were shown to perform best for downstream clustering and cell annotation135. Concerning batch correction, LIGER was shown to perform best for scATAC-seq data35. Recently, deep-learning models such as PeakVI144 or MultiVI145 have been proposed for scATAC-seq data as combined dimensionality reduction and batch correction methods. After a corrected low-dimensional representation is obtained, we recommend Leiden clustering based on its good performance in scRNA-seq-derived representations.
Annotating cell identities based on accessible regions
Annotation of cell clusters can be performed on the basis of differentially accessible regions (DARs) and gene activity scores (Fig. 3c). DARs can be obtained by differential testing methods similar to scRNA-seq. Analogous differences in sequencing depth need to be accounted for by treating total counts as a confounder143 or by selecting a comparative group of bias-matched cells with respect to total count and potentially other quality control metrics such as the TSS score140. Although the performance on scATAC-seq data has not been benchmarked yet, existing benchmarks on bulk ATAC-seq data recommend edgeR for the determination of DARs when sample size is limited and DESeq2 in the case of large sample sizes146. DARs might contain informative sequence patterns such as known cis-regulatory elements (CREs) or can be linked to proximal genes, which is leveraged in functional enrichment analysis tools such as GREAT147, LOLA148 or GIGGLE149. Chromatin accessibility of CREs associated with a gene can be summarized into an estimate of gene expression (gene activity scores). This can be achieved by summing up counts within genes and a certain distance upstream of the TSS136,143,150. More complex models additionally integrate signals from distal regions either in a weighting-by-distance scheme140 or by integrating co-accessibility networks151 (Fig. 3d). To guide cell-type annotation, simple models are often sufficient, and visualization can be enhanced by smoothing gene activity scores among neighbouring cells, which is often performed using MAGIC152.
Unravelling identities with TF motifs and footprinting
TF-motif enrichment facilitates the characterization of cell identity and can be conducted on a cluster level using a hypergeometric test on cluster-specific DARs140. To obtain enrichment scores per cell, chromVAR can be used to calculate the deviation of accessibility across all motif-containing peaks per cell while correcting for the insertion bias of the Tn5 transposase, which emerges from sequence binding preferences of the transposase153. The TF markers facilitate cluster annotation and represent top candidates for regulatory proteins determining cell state. Once TFs of interest have been identified, scATAC-seq data allow for additional validation of the TF impact through footprinting, which indicates whether the TF is binding in the given cell cluster. To perform this analysis, cluster-wise pseudobulks are generated to reduce sparsity, and the number of Tn5 insertions around the motif of interest is plotted140. In the case of active binding of the TF in the given cell cluster, the binding site itself is protected from Tn5 transposition events while the nucleosomes in close proximity are displaced, resulting in a peak–valley–peak accessibility profile. As this profile is also affected by the Tn5 insertion bias, current footprinting tools often correct for this bias using a k-mer model that estimates the bias by the number of cleavage sites within each k-mer relative to the number of genome-wide occurrences140,143,154.
Linking single-cell chromatin accessibility and transcriptomics
Assays such as the proprietary 10x Multiome, sci-CAR155 or scCAT-seq156 allow joint profiling of gene expression and chromatin accessibility. Current workflows use established methods for unimodal quality control and take the intersection of high-quality cells of all modalities for integrative analysis136,140,143. Once high-quality cells are selected, a joint representation of cells capturing the variability of both modalities can be learned whereby confounding sources of variation are removed (Box 1). As no optimal method for this integration has been identified, we recommend performing unimodal analysis including cell-type annotation first. This enables evaluation of the joint representation by comparing updated clustering results with cell-type labels of the unimodal analysis. A high-quality multimodal representation then serves as input for most unimodal analysis methods including cell-type annotation, differential testing and trajectory analysis.
Paired scRNA-seq and scATAC-seq data also enable the use of new joint methods to identify regulators of gene expression and cell states. To identify potential CREs, correlation-based methods are used to link peaks to genes within clusters of cells140,143,156. This approach can be extended by inferring active TFs using SCENIC followed by matching the corresponding motifs with peak regions to add additional interpretability156. To gain insights into whether the local or global chromatin landscape influences the expression of a gene in a specific cell state, the predictability of expression based on the local neighbourhood and the genome-wide chromatin states can be compared157. Methods to infer gene regulatory networks leveraging both modalities, such as FigR154 or Pando158, are currently being developed (Fig. 3d).
Box 1 Data integration across modalities.
Holistic representations of cells can be obtained only with analyses across modalities245, whereby several modalities of the same cells are jointly examined. Although advancements in experimental assays allow for the paired measurements of many modality combinations246, different modalities are still commonly measured independently, resulting in unpaired data247. These data sets need to be properly integrated to obtain an informative low-dimensional embedding that can be used to visualize properties of interest.
Combining jointly measured modalities: paired integration
For paired measurements, cells serve as the integration anchor (see the figure, part a). Paired integration can be conducted with linear approaches such as factor analysis implemented in MOFA+248 to obtain a joint, interpretable latent space. This approach requires size factor normalization to ensure that the first factors are not dominated by differences in total expression per sample. Alternatively, weighted nearest-neighbour (WNN)3 analysis learns cell-specific modality weights that reflect the modality information content to determine the importance of modalities in downstream analyses in the form of a neighbour graph. This graph can be reused for the calculation of embeddings or distance metrics.
Integrating disjoint measurements: unpaired integration
The main difficulty in integrating unpaired multi-omic data (diagonal integration; see the figure, part b) lies in the distinct feature spaces. Initial approaches that map multimodal data into a common feature space based on prior knowledge — such as assay for transposase-accessible chromatin (ATAC) regions to nearby transcripts — with subsequent application of single-cell data integration methods have been shown to result in information loss135. Nonlinear manifold alignment approaches such as optimal transport-based methods such as SCOT249 or UnionCom250 do not require prior knowledge and could therefore reduce the inter-modality information loss. GLUE models cell states as low-dimensional embeddings learned through modality-specific variational autoencoders that use probabilistic generative modelling based on a guidance graph incorporating prior knowledge251. It has been shown to work well for the integration of more than two modalities and is the winner of the NeurIPS 2021 multimodal single-cell data integration challenge252.
Integrating joint and disjoint measurements: mosaic integration
Capture of several modalities from the same cell simultaneously is still challenging despite advancements in experimental assays. Profiling individual modalities on different populations of cells from the same biological sample is more common, leading to completely missing data matrices245. The integration of data in such set-ups is known as ‘mosaic integration’, for which tools recently started to emerge (see the figure, part c). Although totalVI and MultiVI can also be used for mosaic integration, they are both applicable only to CITE-seq and Multiome data, respectively. Alternative methods for all modality combinations are Stabmap253, which traverses the shortest path along the mosaic topology by projecting all cells onto reference coordinates, and Multigrate254, which leverages transfer learning to impute missing modalities.
Query-to-reference mapping in a multimodal scenario
A recent development in the field is the advent of multi-omic reference data sets and therefore the possibility for unimodal and multimodal queries against multimodal references (see the figure, part d). By applying supervised principal components analysis (PCA)255 to references built with WNN, single-cell RNA sequencing (scRNA-seq) query cells can be mapped onto multimodal references, visualized and annotated3. Alternatively, Multigrate learns a joint latent space of paired and unpaired measurements. Combined with transfer learning, Multigrate can map unimodal and multimodal query data sets to multi-omic references while imputing missing modalities254. The imputed modalities may pose further important sources of information. Bridge integration poses a third option that uses a multi-omic data set as a molecular bridge to create a dictionary of cells that is used to reconstruct unimodal data sets that get transformed into a shared embedding256. Although flexible, a disadvantage of bridge integration is the requirement for the bridge data set, which may not always be available.
Surface protein expression
Transcription and chromatin accessibility are proxies for cellular state, activity and regulation. The actual generated products, the proteins, take on either intracellular or extracellular tasks, and a subset of proteins are presented on the cell surface. Surface protein expression helps with the identification of cell types such as haematopoietic cells of the immune system, the annotation of which is based on markers that are usually used in flow cytometry or mass cytometry experiments. They can be further used to validate specific genetically knocked-out genes using, for example, the aforementioned Mixscape pipeline. The most widely used protocols for combined scRNA-seq and surface protein profiling are CITE-seq10 and REAP-seq159, with the main difference being the antibody-derived tags (ADTs) that are used to quantify surface protein expression levels (Fig. 4a).
Fig. 4. Overview of CITE-seq data processing.
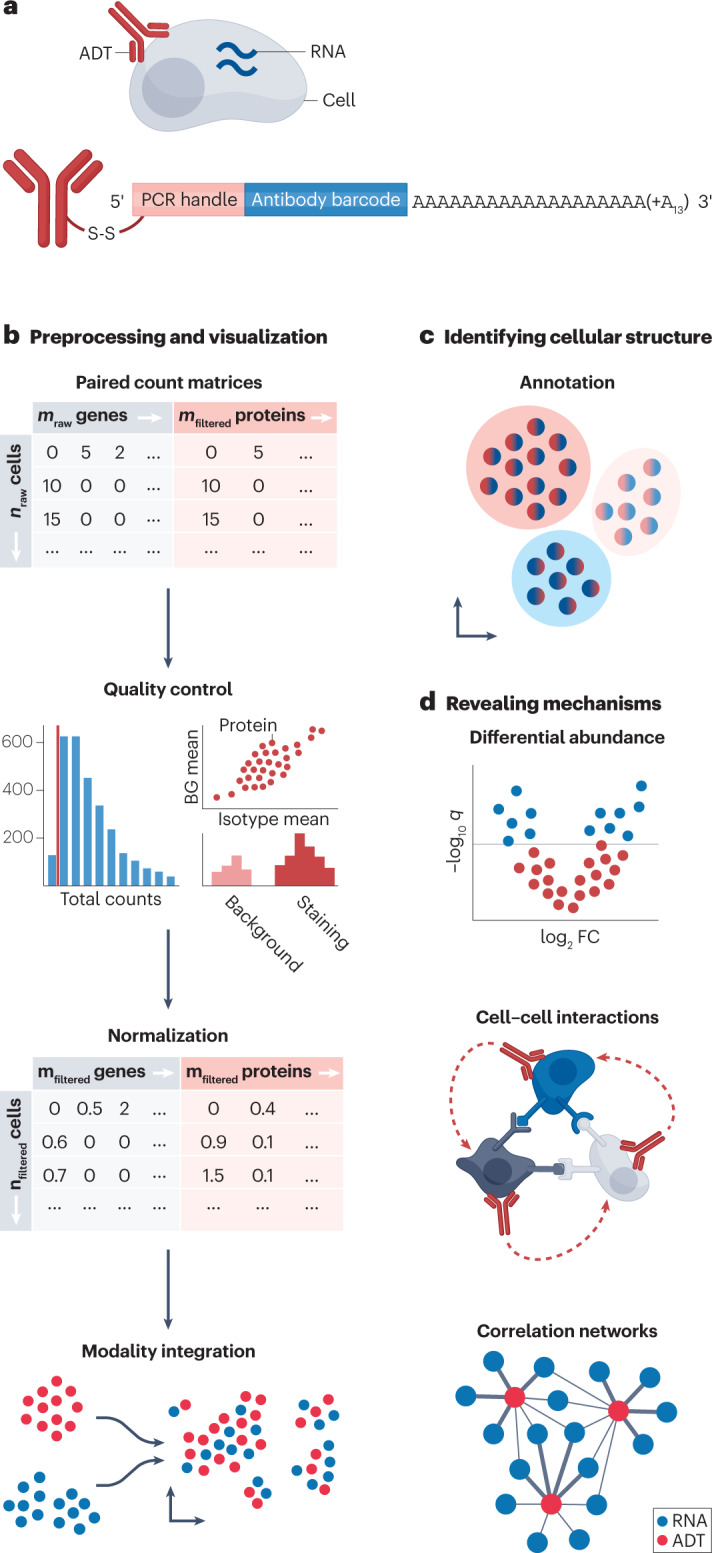
a, Antibody-derived tags (ADTs) are antibody clones with unique barcodes attached to poly(A) sequences and a PCR handle that is specifically amplified in subsequent library processing steps. The antibody binds to surface proteins, and the sequenced ADT counts represent the expression level of those proteins. b, Although ADT data can be unimodally analysed, it is rarely measured alone, but more commonly in conjunction with matching gene expression data. Such paired count matrices of gene expression and ADTs are subject to individual quality control and normalization followed by individual or jointly visualized embeddings. c, The annotation of CITE-seq data can happen at the level of either the transcriptomics data, the ADT data or jointly by matching clusters to both marker gene and marker ADTs. d, To learn about biological mechanisms, ADT data can be tested for differential abundance, cell–cell communication can be inferred and correlation networks of RNA and ADT information can be constructed. q, q value.
Correcting ADT counts
Contrary to the negative binomial distribution of gene counts, ADT data are less sparse. For droplet-based assays, non-zero counts are commonly observed for ADTs owing to ambient contamination and nonspecific antibody binding. Most markers exhibit a bimodal distribution with a ‘negative’ (low count) peak for nonspecific antibody binding and a ‘positive’ peak that resembles enrichment of cell-surface proteins in specific cell types160. Libraries with zero counts for all or most of the antibody panel should be removed; however, removing cells with a low total ADT count may remove cell types that do not express a specific set of proteins or express only a few2. CITE-seq experiments can also contain isotype controls, which are non-target-specific antibodies that are used to measure nonspecific binding per cell (such as antibody aggregates). Large isotype counts can be detected in outlier cells, which should then be removed. Owing to these considerations, careful evaluation of individual quality control metrics should be carried out in the ADT modality, and joint measurements of RNA and ADTs should be quality controlled separately. As antibody efficacy is variable, the integration of ADT data across several studies can lead to strong batch effects that should be corrected for160.
Accounting for ADT composition biases
Cell characteristics can lead to heterogeneous capture efficiency that causes cell composition biases. Only cells expressing the targeted proteins result in increases in the tag count, which are possibly only particular cell types2. This can be accounted for by normalizing using the centred log-ratio (CLR) transformation10 or denoised and scaled by background (DSB)161. DSB uses background droplets that represent protein background noise to correct values in cells while removing cell-to-cell variation by combining isotype control levels with the specific background level of the respective cell. The authors of DSB found that this approach removes more noise owing to the availability of the background distribution in the raw counts161.
Jointly analysing transcriptomics and ADT data
The unimodal downstream analysis of the ADT data follows a similar pipeline to unimodal RNA analysis where annotated clusters can be tested for differential abundance (Figs. 2b and 4b). However, ADT data provide the most insight when analysed jointly with other modalities such as transcriptomics measurements. After the respective preprocessing, joint embedding can be obtained with generally applicable multimodal integration tooling (Box 1) or the CITE-seq specific, deep-learning-based totalVI162, which learns a joint probabilistic representation of paired measurements that also accounts for noise and technical biases, including batch effects per modality. An alternative approach is to use CiteFuse163, which normalizes ADTs using CLR and combines both modality matrices with a similarity network fusion algorithm. The joint embedding can then be clustered using Leiden and annotated based on differentially expressed RNA and ADT using Wilcoxon rank-sum tests by comparing clusters against all other clusters163 (Fig. 4c). Both modalities can be used for downstream tasks such as the investigation of cell–cell communication in which the RNA expression of the ligand cluster and the protein expression of the receptor cluster are considered, or RNA and ADT correlation analysis (Fig. 4d) using CiteFuse. The obtained results are visualized on the joint embedding.
Adaptive immune receptor repertoires
TCRs and BCRs are transmembrane surface protein complexes that constitute the adaptive immune receptor repertoire (AIRR) (Fig. 5a). Both types of receptor detect pathogen- and tumour-specific antigens, but interact in different ways. Whereas BCRs directly recognize soluble or membrane-bound epitopes, TCRs interact with linear peptides bound to cell-surface major histocompatibility complex (MHC) molecules. Activated B and T cells perform various functions such as effector immunity, forming memory by proliferation or regulating further immune responses. The specificity of individual B and T cells is defined by the AIR sequence. To capture the vast range of antigens, somatic V(D)J recombination generates highly diverse AIR sequences across the population of B and T cells in an individual (Fig. 5a). The commercial 10x Chromium Single Cell Immune Profiling and BD Rhapsody TCR/BCR Multiomic assays enable the generation of paired transcriptomics and AIRR data. Immune receptor analysis can be conducted with frameworks such as scirpy164, Dandelion165 or scRepertoire166.
Fig. 5. Overview of the adaptive immune receptor analysis.

a, Structure of T cell receptors (TCRs) and B cell receptors (BCRs). The diverse adaptive immune receptor (AIR) repertoire is generated through V(D)J recombination, whereby variable (V) and joining (J) gene segments are randomly rearranged for the TCR α-chain and BCR light chain, and further diversity (D) regions are incorporated for the TCR β-chain and BCR heavy chain. b, The generated TCR/BCR raw sequencing data are first mapped against TCR/BCR reference sequences to obtain continuous sequences assembled from mapped reads (contigs). In a process known as contig alignment, the contigs are annotated by V(D)J gene usage and complementarity-determining region (CDR) 1, 2 and 3 amino acid sequences. After cell alignment, the obtained measurements need to be matched to ideally unique full AIR chains. Cells with multiple matching AIRs, missing chains or doublets can influence downstream processing and should be marked. c, The investigation of over-represented V(D)J sequences through spectratyping, motif discovery and gene usage enables insight into preferential sequence selection. d, Clonotypes can be identified to reconstruct recent immune responses through clonotype composition analysis and lineage reconstruction. e, The construction of clonotype similarity networks, database queries and epitope prediction provide insight into the targets recognized by B and T cells.
Decoding AIRR sequence characteristics
AIRR sequences can be deciphered with V(D)J sequencing followed by alignments and chain pairing (Fig. 5b). Although no benchmarks exist for TCR sequence reconstruction, MiXCR167 and TRUST4 (ref. 168) are frequently used. BALDR169, BASIC170 and BraCer171 were shown to robustly recover BCR sequences172 but are no longer maintained. We therefore encourage analysts to consider the more recent MiXCR and TRUST4 also for BCR sequences. Overexpressed combinations of V, D and J genes provide valuable information on how the various genes are combined to create VJ and VDJ chains. The recombination of V(D)J gene segments and the imprecise junction of V and J segments produce the CDR3 region in VJ and VDJ chains that is mainly responsible for AIR–antigen binding. Germinal B cells further generate immunoglobulin variants during somatic hypermutation, in which immunoglobulin genes rapidly mutate within productively rearranged V, D and J segments. AIRR sequence analysis (Fig. 5b) highlights preferentially selected gene segments for AIR arrangements that relate to biological function. For spectratyping, the CDR3 length profiles are observed under multiple conditions, which may indicate an antigen-specific shift in the AIRR composition. Sequence motifs reveal conserved and differing amino acids over the CDR3 positions in clusters of AIRs via frequency analysis (Fig. 5c). These analyses capture protein sequence characteristics to infer specificity and enable AIR design. These approaches are available in Scirpy, Dandelion and scRepertoire.
Filtering for functional adaptive immune receptors
Not all generated AIR chains produced during allelic rearrangements form a functional AIR. Incomplete AIRs with cells assigned to only a VJ or VDJ chain are regularly detected and represent valid cells, but cannot be used for all downstream processes that expect complete AIRs. Lymphocytes can express dual AIRs173 with ~10% expressing multiple VJ chains paired with a single VDJ chain. Lymphocytes that express dual VDJ chains are even more rare (1%) and should be treated with caution. However, cells with more than two assignments for either VJ or VDJ chains are always indicative of doublets. Associating the AIR state with chain pairing information and receptor type enables task-specific AIR selection during downstream analysis to ensure that as much data as possible are used (Fig. 5b). For example, orphan VDJ chains can still be used for database queries based on CDR3-VDJ chains, but not for queries based on the full AIR. The distribution of chain pairings and receptor types can be visualized over groups such as samples or conditions, and outlier clusters with excessive quality issues should be removed.
Identifying and classifying clonotypes
Groups of T or B cells that are descended from the same ancestral cell form a clonotype and are generally in a dormant state until receiving an external signal or stimulation from autocrine agents. Hence, the specific cells proliferate dramatically to fulfil their respective predefined defence response during clonal expansion174. The persistence of clonally expanded T or B cells serves as a biomarker of recent immune response. Clonotypes can be identified by identical V gene and identical nucleic acid sequences for VJ and VDJ CDR3 for TCRs or based on distance as implemented in the analysis frameworks for lineage reconstruction of BCRs accounting for somatic hypermutation (Fig. 5d).
During analysis, the requirement to match V genes may be omitted, and cells with orphan chains may be assigned to related clonotypes. Owing to somatic hypermutation, B cells from clonal lineages are typically grouped with a Hamming distance-based homology of more than 80% in their CDR3 amino acid sequence175. Public clonotypes appear in more than one donor and can represent shared immunological response. By contrast, private clonotypes represent patient-specific clonal responses that might be valuable for personalized medicine. The sample-wise abundance of clonotypes can be further used to compare AIRRs through Jaccard distances, diversity measurements or hierarchical clustering (Fig. 5d).
Determining cell specificity
The most influencing positions of the AIR–antigen interaction, reflecting specificity, are contained in the CDR3 of the VDJ chain and to a lesser degree the CDR3 in the VJ chain176. Antigen specificity in T cells is driven by an epitope sequence and the entire AIR–epitope complex. Although AIR specificity can be experimentally determined using barcoded antigens177,178, several approaches attempt to infer it computationally (Fig. 5e). First, the sequences can be queried against databases that contain AIR–epitope pairs from existing studies directly or through Scirpy or immunarch179. Commonly used databases are IEDB180, PIRD181, vdjDB182 (TCRs only) or SAbDab (BCRs only). Similarly to clonotype assignment, database queries can be conducted with varying strictness by considering either the VDJ CDR3 sequence alone, or additionally the VJ CDR3 sequence, which decreases the FDR. A second approach compares AIRs using distance metrics applied to the CDR3 sequences directly or an embedding of the sequences, as AIRs with similar sequences are likely to have common specificity183. Although the Hamming distance is often used for BCRs because it mimics somatic hypermutation, specialized methods are more commonly employed for TCRs, such as TCRdist, which compares all CDR3 sequences of two TCRs via transformation cost and gap penalties184, or TCRmatch, which uses k-mers to compare the overlap in motifs based on their CDR3β sequences185. As a third strategy, recent approaches directly predict binding between AIRs and an epitope using machine learning tools such as ERGO-II176. All three approaches suffer from reliance on public databases that contain data primarily from commonly researched diseases and a lack of information on MHCs to decipher T cell antigen specificity.
Integrating adaptive immunoreceptors with transcriptomic measurements
AIRR sequencing is typically combined with other omics layers such as surface protein and transcriptomics measurements, enabling a detailed view of cell fate following infection or vaccination165. The presence of AIRs can guide cell-type annotation by separating immune cell clusters and facilitating detailed T cell annotations. For paired data (Box 1), phenotypic AIRR analysis can be performed on AIR conditions such as specificity or clonotype networks using cell-type clusters with Scirpy and scRepertoire. Owing to inherent structural differences of the modalities, novel approaches such as TESSA186, mvTCR187 or Conga188 for TCR data and Benisse189 for BCR data aim to integrate both modalities for easier joint annotations and visualizations.
Single-cell data resolved in space
Up to this point, all discussed modalities were dissociation-based single-cell omics technologies that characterize cellular identities and tissue states. However, in multicellular organisms cells interact and form spatially structured microenvironments that can vary across samples and conditions. Cellular organization bridges the gap between tissue biology and pathology, which enables the discovery of new cellular functionalities and creates new computational challenges for which distinct analysis methods are required190–192. Spatial omics resolves features and cellular identities by adding two additional modalities to single-cell genomics: histological imaging and spatial profiling measurements. Spatial localization of individual cells helps to disentangle tissue microenvironments and their functional dependencies. Beyond leveraging the spatial coordinates of cells to generate a better understanding of tissue structures, one can also use the non-molecular features of the histological image. Adding information extracted from the imaging data can enhance, for example, cell identification193,194 or the resolution of the molecular features195, or can help to identify spatial patterns of variation196. Technologies developed for gene expression profiling in space vary in spatial resolution (subcellular versus barcode region, where features are aggregated across regions), detection efficiency, throughput192,197 and the modality resolved in space198–200. Most analysis methods developed so far are tailored to spatial transcriptomics and we therefore focus our recommendations on these measurements. The two major spatial molecular profiling technologies are array-based201,202 (Fig. 6a) and image-based approaches203–205 (Fig. 6b). Various reviews provide a detailed overview of different experimental techniques192,206–208. Analysing spatial data sets requires analysis tools specifically tailored to this modality, which can be conducted with frameworks such as Squidpy209, Giotto210, Seurat45 or SpatialExperiment211.
Fig. 6. Overview of spatial transcriptomics preprocessing and downstream analysis steps.

a, Array-based spatial transcriptomics technologies quantify gene expression in predefined barcoded (BC) regions with regions spanning areas between 10 μm and 200 μm. BC regions contain measurements from multiple cells, resulting in count matrices and spatial coordinates where each observation is a BC region. Cell-type deconvolution methods decompose the cellular composition of individual BC regions to obtain count matrices and spatial coordinates where each observation is a single cell. Further preprocessing can be performed analogously to analysis of single-cell RNA sequencing (scRNA-seq) data sets. b, Image-based spatial transcriptomics, such as fluorescent in situ hybridization (FISH) and in situ sequencing (ISS) technologies, capture individual locations of transcripts in multiple sequential hybridization rounds. Transcript locations can be aggregated to obtain count matrices and spatial coordinates at single-cell level. Subsequent processing is again performed in a similar manner to scRNA-seq. c, Cellular structure in spatial transcriptomics can be identified at the resolution of single cells or BC regions. Limitations of small feature space in image-based spatial transcriptomics (owing to only the targeted subset of transcripts being measured) can be resolved using spatial mapping, which imputes unmeasured transcripts onto spatial coordinates. d, Mechanisms in spatial transcriptomics can be analysed with respect to spatial positions of cells by identifying genes that vary across space, analysing neighbourhoods of cells and inferring communication events based on receptors and ligands, tight junctions, mechanical effects or indirect mechanisms.
Obtaining count matrices and spatial coordinates of cells
Both array-based and image-based spatial transcriptomics require specific tools to assign measured molecules to single cells. As array-based assays do not capture single-cell resolution, the gene expression profile of spots reflects cell-type composition rather than distinct cell types. Various methods have been proposed to decompose gene expression profiles in array-based gene expression profiles. Cell2location212, SpatialDWLS213 and RCTD214 estimates the cell-type composition per spot based on the gene expression profile of the cell populations in a single-cell-resolved reference. For simulated data sets, cell2location outperformed other approaches for cell-type deconvolution, but requires more computational resources, whereas for real data sets, SpatialDWLS and RCTD performed best in terms of the overall accuracy score based on four different accuracy metrics215,216.
For image-based assays such as fluorescence in situ hybridization (FISH) and in situ sequencing (ISS), cell count matrices and spatial coordinates are obtained with cell segmentation217–220. Owing to the complexity of spatial transcriptomics data (in terms of the assay used, resolution and tissue variation) these tools often require manual fine-tuning to obtain valuable segmentation results. Processing pipelines such as Giotto and squidpy allow the addition of tailored segmentation methods to the analysis pipeline, which simplifies the comparison, choice and evaluation of the chosen method. Additionally, the localization of transcripts can be used in segmentation-free methods such as SSAM221 or Baysor222, which directly assign cell labels to spatially proximal pixels. Baysor222 additionally incorporates cell-shape information obtained through the histological image to enhance segmentation results. These tools can be a useful alternative to segmentation-based approaches.
Gene expression matrices obtained by array-based spatial transcriptomics followed by cell-type deconvolution, or by image-based spatial transcriptomics followed by segmentation, can be filtered, normalized and visualized in a similar way to scRNA-seq data.
Characterization of cell identity and cellular microenvironments
For imaging-based spatial transcriptomics data at single-cell resolution, cells can be annotated similarly to scRNA-seq data (Fig. 6c). These technologies commonly read out only a predefined set of transcripts. Genes are typically selected on the basis of prior biological knowledge obtained from scRNA-seq (probe selection) and might not be suited to the identification of rare cell subpopulations, which results in bias towards known cell types223. Alignment of standard spatially naive scRNA-seq data and targeted spatially resolved data enables imputation of the whole transcriptome (measured in standard scRNA-seq) in a spatially resolved manner and attempts to resolve the limitations of targeted feature spaces. This approach generates transcriptome-wide single-cell-resolved spatial transcriptomics data. Tangram224 imputes undetected transcripts in spatial samples by optimizing the gene-wise similarity between spatial and scRNA-seq data. It was shown to outperform other imputation methods such as gimVI225 and SpaGE226 with respect to various accuracy metrics and scalability215.
Beyond annotating cells based solely on their gene expression profiles, one can also leverage the spatial location to identify cellular identities. Tools such as BayesSpace227, stLearn228 and spaGCN229 identify so-called spatial domains by accounting for both gene expression commonalities and spatial neighbourhood structures. The labels obtained can be used to identify regions in the tissue that have similar expression profiles and might correspond to the overall morphology of the data set.
The identification of cellular microenvironments across different samples can be hindered by differences with respect to image orientation. Images might not always be perfectly aligned throughout the data set and comparing findings across different fields of view might be challenging. Tangram224, GridNet230 and eggplant231 generate common coordinate frameworks across samples to mitigate this issue232.
Identification of spatial patterns linked to cellular organization and tissue structure
Cellular microenvironments generate new insight into mechanisms that drive tissue states and can be analysed in multiple ways (Fig. 6d). Analysis of gene expression differences is widely explored for scRNA-seq in terms of identifying highly variable genes and DGE analysis. For spatial transcriptomics data, this is complemented by identification of spatially variable genes (SVGs). Methods for this purpose vary broadly with respect to their assumptions and their definition of SVGs, and there is no consensus on how to best identify SVGs. SPARK233 and SpatialDE234, for example, leverage spatial correlation testing, BayesSpace227 uses Markov random fields, spaGCN229 uses graph neural networks to integrate gene expression data, spatial information and histology images, and sepal235 utilizes diffusion-based modelling to identify genes with spatial patterns.
Spatially dependent communication events across cells
In tissue, cells have direct contact and can interact through surface-bound ligands and receptors, long-range paracrine effects, bio-mechanical forces and indirect mechanisms such as metabolite exchange. These events are commonly referred to as extrinsic effects on gene expression variation and should be taken into consideration in efforts to describe cellular organization and tissue niches236. Cell communication events can be identified in dissociated scRNA-seq data as described above. Nevertheless, these methods often neglect the spatial organization of the underlying tissue, which can result in false-positive discoveries. Methods for spatial cell–cell communication typically compare gene expression patterns based on the surrounding neighbouring cells. GCNG237, Misty238 and NCEM236 formulate this task in terms of spatial graphs of cells and graph neural networks, SpaOTsc239 uses optimal transport, and SVCA240 quantifies the effect of cell–cell communication events on gene expression profiles with spatial variance component analysis.
Conclusions and future perspectives
We here review the steps of typical unimodal and multimodal analyses of transcriptomics, chromatin accessibility, surface protein, AIRR and spatially resolved single-cell data. Our work represents an entry point for newcomers into the field, while updating experienced analysts on recent analytical best practices. All recommendations are based on independent benchmarks, which inevitably lag behind the latest method developments. With further published benchmarks, the individual tool recommendations might change and require regular updates to ensure best-practice single-cell analysis. Therefore, we refer to our Single-Cell Best Practices online book, which provides detailed method descriptions, demonstrates how to put our recommendations into practice and serves as an analysis template. Our online book will incorporate regular updates and serve as a flexible and up-to-date guideline for newcomers and experts in the field of multi-omic single-cell analysis. Nevertheless, we expect that the outlined analysis workflows in this article will largely remain valid and correspond to the most widely used analysis workflows.
Beyond the growing number of methods, the number of generated single-cell data sets is also increasing, and we expect that learning from large-scale data sets such as integrated atlases will become even more important. Large-scale data sets enable the development of models that describe cellular and individual heterogeneity through, for example, latent space embeddings. Latent representations, as learned by frameworks such as single-cell variational inference41, can be used for batch correction, clustering, visualization and DGE analysis. They simplify the analysis of single-cell data by skipping manual quality control steps. Models built on these latent spaces become predictive with query-to-reference mapping approaches, which will create a shift from the unsupervised, exploratory analysis approach to single-cell analysis complemented by supervised predictions. Constructing multimodal reference atlases will further enable the characterization of cell states on several layers at the same time to provide multimodal insights even for unimodal queries.
Understanding the effects of perturbations on these multi-omic cellular states will become increasingly important. Highly parallel perturbation screens, such as genome-scale Perturb-seq117, already measure genome-wide perturbation effects. Coupling genome-scale Perturb-seq with further modalities enables the systematic exploration of the genetic landscape to unveil context-specific gene regulatory networks. This further extends single-cell genomics to pharmacological applications such as drug target screens. We expect more analysis methods to be introduced that dissect successful and failed perturbations and infer gene regulatory networks from multimodal data, such as CellOracle241 or SCENIC+242 (Fig. 2c). Moreover, new molecular measurements are becoming available such as the young and fast-evolving field of single-cell proteomics243. Methods for the analysis of these measurements are sparse, selectively benchmarked, and best practices have yet to be developed.
For single-cell multi-omics to have a strong clinical impact, the inclusion of patient covariates from, for example, electronic health records can prove vital. Tools for their exploratory analysis, the integration with omics data sets and the mapping of omics measurements to phenotype information are lacking, and we expect further developments in this direction. We foresee such integrative workflows to build upon the foundation that we have established for multimodal single-cell analysis.
Acknowledgements
The authors acknowledge Y. Chen for editing the single-cell RNA-sequencing discussions, Y. Ji for editing the perturbation modelling discussions, A. McKenna for editing the lineage tracing discussions, C. N. Talavera Lopez for providing helpful suggestions for the adaptive immune receptor repertoire discussion, L. B. Kuemmerle for editing the spatial omics discussions, and all members of the Theis group for reviews and helpful discussion. This work was supported by the German Federal Ministry of Education and Research (BMBF) under grant no. 01IS18053A, by the Bavarian Ministry of Science and the Arts in the framework of the Bavarian Research Association “ForInter” (Interaction of human brain cells), by the Wellcome Trust grant 108413/A/15/D and by the Helmholtz Association’s Initiative and Networking Fund through Helmholtz AI (grant number: ZT-I-PF-5-01). Main author list, individual acknowledgements: F.D. is supported by the Helmholtz Association under the joint research school Munich School for Data Science and by the Joachim Herz Stiftung. F.C. acknowledges support from a German Research Foundation (DFG) (SFB-TRR 338/1 2021-452881907), Bavarian Ministry of Science and the Arts in the framework of the Bavarian Research Association “ForInter” (Interaction of human brain cells) and by the Deutsche Forschungsgemeinschaft. A.C.S., F.C. and L.Z. acknowledge support from the Bavarian Ministry of Science and the Arts in the framework of the Bavarian Research Association “ForInter” (Interaction of human brain cells). C.L. is supported by the Helmholtz Association under the joint research school Munich School for Data Science. Single-cell Best Practices Consortium, individual acknowledgements: G.P. and L.D. are supported by the Joachim Herz Stiftung. G.P. is supported by the Helmholtz Association under the joint research school Munich School for Data Science. R.P. acknowledges funding from US NIH (R01 HG009937) and US National Science Foundation (CCF-1750472, and CNS-1763680). L. Hetzel and L.D.M. are supported by the Helmholtz Association under the joint research school Munich School for Data Science. B.S. acknowledges funding from (DFG, German Research Foundation) Projektnummer 490846870-TRR355/1 TPZ02.
Glossary
- Adaptive immune receptor
(AIR). Transmembrane complex of proteins expressed on T and B cells that is key for the recognition of potential hazardous antigens and pathogens invading the body.
- Ambient RNA
mRNA counts that originate from other lysed cells in the input solution and do not belong to the cell captured in the droplet itself.
- Antibody-derived tags
(ADTs). Antibodies (also known as soluble immunoglobulins) are Y-shaped proteins used by the immune system to identify and neutralize pathogens by recognizing antigens. ADTs are directly conjugated DNA-barcode oligonucleotides that can be used to recover expressed surface proteins.
- Antigens
Substances recognized as non-self that induce an immune response and lead to the production of antibodies.
- Barcodes
Unique known nucleic acid sequences of fixed length used to label individual cells to enable tracking through space and time.
- Batch effects
Confounding effects that result from technical differences in data generation across different batches, such as samples obtained through different experimental set-ups or from different laboratories.
- CDR3
Whereas complementarity-determining region 1 (CDR1) and CDR2 are encoded in the germline V genes, CDR3 loops are assembled from V(D)J segments, giving rise to the variability of adaptive immune receptors.
- Cell fate
A cell’s final cell type that is established by corresponding, specific transcriptional programmes.
- Cell–cell communication
Interactions of cells through secreted ligands and plasma membrane receptors, secreted enzymes, extracellular matrix proteins or cell–cell adhesion proteins and gap junctions.
- Cell-type deconvolution
Decomposing the cell-type composition of individual barcode regions based on a reference data set to obtain abundances or proportions of individual cells within a barcode region.
- Cell segmentation
Processing of microscopic image domains into segments that represent individual cells.
- Chain pairing
Assignment of cells to V(D)J chain types such as orphans, single pair, extra VJ/VDJ or multichains.
- Cis-regulatory elements
(CREs). Regions of non-coding DNA — such as promoters, enhancers and silencers — that control the transcription of nearby genes.
- Clonotype
Collection of T or B cells that descended from an antecedent cell, have the same adaptive immune receptors and henceforth recognize the same epitopes.
- Compositional data
Comprises multi-dimensional data points (for example, cell-type composition) in which each component (or part) carries only proportional or relative abundance information about some whole.
- Confounding sources of variation
Technical artefacts that arise from library preparation and sequencing, and biological confounders such as cell cycle status, which cause systematic bias and may distort biological findings.
- Differential gene expression
(DGE). The inference of statistically significant differences in expression between groups such as healthy and diseased.
- Epitopes
The parts of antigens that are recognized by antibodies, B cells or T cells to potentially stimulate immune responses.
- Gene set enrichment
Grouping genes with shared characteristics together and testing for over-representation.
- Graph neural networks
A deep-learning approach to do inference on input data represented in the form of a graph. For example, in spatial transcriptomics, cells are typically represented as nodes in graphs obtained through spatial proximity.
- Highly variable genes
A measure to identify genes that vary in terms of gene expression across all cells present in the data set.
- K nearest-neighbours graph
(KNN graph). A computational data structure in which cells are represented as nodes in a graph. Based on distance metrics such as the Euclidean distance on a principal-component reduced expression, cells are connected to their K most similar cells. K is commonly set to be between 5 and 100 depending on the data set.
- Latent semantic indexing
(LSI). A dimension reduction method that uses term frequency inverse document frequency transformation (TFIDF) followed by singular value decomposition (SVD).
- Lineage tracing
Tracking physiological or pathological changes by exogenous or endogenous cell markers such as DNA mutations.
- Major histocompatibility complex
(MHC). Surface proteins that display or ‘present’ small peptides (epitopes) on the cell surface for T and B cells to potentially react to. Presented endogenous self-antigens prevent the immune system from targeting its own cells, whereas presented pathogen-derived peptides alarm nearby immune cells.
- Nucleosome signal
The ratio of long fragments resulting from one or multiple histones bound between the Tn5 transposition sites and short nucleosome-free fragments; the ratio is small in high-quality single-cell assay for transposase-accessible chromatin sequencing (scATAC-seq) data.
- Optimal transport
Mathematical framework to estimate the optimal transport plan of mass between two (discrete) distributions.
- Phase portrait
For any given gene, the phase portrait visualizes splicing kinetics as a parametric curve (with time as a parameter).
- Pseudobulks
Aggregated cells within a biological replicate whereby the data from every single cell is combined via sum or mean of counts into a single pseudo-sample to resemble a bulk RNA experiment.
- Pseudoreplication
Also known as subsampling. Pseudoreplication occurs when replicates are not statistically independent, but are treated as if they were, such as cell samples from a single individual.
- Reference mapping
The process of leveraging and transferring information from a reference data set to a query.
- RNA velocity
Ratios of spliced mRNA, unspliced mRNA and mRNA degradation. Positive ratios (velocities) indicate recent increases in unspliced transcripts followed by upregulation of spliced transcripts. Negative velocities indicate downregulation. Examining velocities across genes can provide insight into future states of individual cells.
- Scaling
Normalization of gene expression levels that scales gene counts to zero mean and unit variance.
- Somatic hypermutation
Mechanism of B cell receptors to allow the immune system to adapt its response to unseen threats. Somatic hypermutation is triggered when B cells engage antigens, which results in the introduction of point mutations in the variable regions of the V(D)J genes. Cells harbouring mutagenized antibodies with a high affinity for the antigen proliferate preferentially (known as affinity maturation).
- Spatially variable genes
(SVGs). Genes with variable expression levels between individual locations in the spatial transcriptomics data set.
- Spectratyping
Measuring the heterogeneity of complementarity-determining region 3 (CDR3) regions by their length diversity across different cell types or conditions.
- Trajectory inference
Also known as pseudotime analysis. Ordering of cells along a trajectory based on gene expression similarity.
- Transcription factor motif
(TF motif). DNA sequence pattern that is specifically recognized by a sequence-specific TF. It is commonly represented as a logo diagram representing the most informative DNA positions by height.
- Variational autoencoders
A generative artificial neural network architecture that allows for statistical inference. Input data are sampled from a parameterized distribution (prior), and an encoder and decoder are trained jointly to minimize the reconstruction error between the updated prior probability (posterior) and its parametric approximation (variational posterior).
- V(D)J recombination
Somatic recombination in developing lymphocytes whereby variable (V), diversity (D) and joining (J) segments are randomly selected and joined to form the V region of a full-length receptor.
- V(D)J sequencing
Determination of protein sequence of the adaptive immune receptor (AIR) for both chains, from which the variable (V), diversity (D), joining (J) and constant (C) sequences are determined in addition to the complementarity-determining region (CDR) sequences.
Author contributions
Main author list: A.C.S., L. Heumos and F.J.T. conceived the project. L. Heumos and A.C.S. contributed equally and have the right to list their name first in their curriculum vitae. A.C.S., L. Heumos, C.L. and F.D. wrote the manuscript. L.Z. and M.D.L. provided expertise for the discussion on transcriptomics; C.L. on chromatin accessibility; D.C.S. on surface protein expression; F.D., J.H. and F.C. on adaptive immune receptor repertoire analysis; and A.L. and F.C. on multimodal data integration. F.J.T. and H.B.S. supervised the work. Single-cell Best Practices Consortium: A.F., H.A., I.L.I., L.D., L.S., M.B., M.L., P.W., S.H.-z., Z.P., M.G.J., A.S., H.S., D.H., E.D., J.O., I.V., D.D., R.P., C.L.M., J.S.-R., J.H., P.B.M. and M.N. provided expertise for the discussion on transcriptomics; L.D.M. and I.L.I. on chromatin accessibility; C.R.-S. on surface protein expression; B.S. on adaptive immune receptor repertoire analysis; and G.P., L. Hetzel, J.T. and J.S.-R. on single-cell data resolved in space. M.A. contributed to the figure design. All authors read, edited and approved the final manuscript.
Peer review
Peer review information
Nature Reviews Genetics thanks Francesca Finotello, Jong-Eun Park and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Competing interests
Main author list: M.D.L. has received speaker’s honoraria from Pfizer and Janssen, and received consulting fees from Chan-Zuckerberg Initiative. F.J.T. consults for Immunai Inc., Singularity Bio B.V., CytoReason Ltd and Omniscope Ltd, and has ownership interest in Dermagnostix GmbH and Cellarity. M.G.J. consults for and has ownership interests in Vevo Therapeutics. L. Heumos has received speaker’s honorarium from Vesalius Therapeutics. Single-Cell Best Practices Consortium: M.G.J. consults for and has ownership interests in Vevo Therapeutics. R.P. is co-founder of Ocean Genomics, Inc. The other authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Related links
Single-Cell Best Practices online book: https://sc-best-practices.org
These authors contributed equally: Lukas Heumos, Anna C. Schaar.
A list of authors and their affiliations appears at the end of the paper.
Contributor Information
Fabian J. Theis, Email: fabian.theis@helmholtz-muenchen.de
Single-cell Best Practices Consortium:
Hananeh Aliee, Meshal Ansari, Pau Badia-i-Mompel, Maren Büttner, Emma Dann, Daniel Dimitrov, Leander Dony, Amit Frishberg, Dongze He, Soroor Hediyeh-zadeh, Leon Hetzel, Ignacio L. Ibarra, Matthew G. Jones, Mohammad Lotfollahi, Laura D. Martens, Christian L. Müller, Mor Nitzan, Johannes Ostner, Giovanni Palla, Rob Patro, Zoe Piran, Ciro Ramírez-Suástegui, Julio Saez-Rodriguez, Hirak Sarkar, Benjamin Schubert, Lisa Sikkema, Avi Srivastava, Jovan Tanevski, Isaac Virshup, and Philipp Weiler
References
- 1.Zappia L, Theis FJ. Over 1000 tools reveal trends in the single-cell RNA-seq analysis landscape. Genome Biol. 2021;22:301. doi: 10.1186/s13059-021-02519-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Amezquita RA, et al. Orchestrating single-cell analysis with bioconductor. Nat. Methods. 2020;17:137–145. doi: 10.1038/s41592-019-0654-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Hao Y, et al. Integrated analysis of multimodal single-cell data. Cell. 2021;184:3573–3587.e29. doi: 10.1016/j.cell.2021.04.048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Wolf FA, Angerer P, Theis FJ. SCANPY: large-scale single-cell gene expression data analysis. Genome Biol. 2018;19:15. doi: 10.1186/s13059-017-1382-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Luecken MD, Theis FJ. Current best practices in single-cell RNA-seq analysis: a tutorial. Mol. Syst. Biol. 2019;15:e8746. doi: 10.15252/msb.20188746. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Kharchenko PV. The triumphs and limitations of computational methods for scRNA-seq. Nat. Methods. 2021;18:723–732. doi: 10.1038/s41592-021-01171-x. [DOI] [PubMed] [Google Scholar]
- 7.Sikkema L, et al. An integrated cell atlas of the human lung in health and disease. bioRxiv. 2022 doi: 10.1101/2022.03.10.483747. [DOI] [Google Scholar]
- 8.Eraslan G, et al. Single-nucleus cross-tissue molecular reference maps toward understanding disease gene function. Science. 2022;376:eabl4290. doi: 10.1126/science.abl4290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Baek S, Lee I. Single-cell ATAC sequencing analysis: from data preprocessing to hypothesis generation. Comput. Struct. Biotechnol. J. 2020;18:1429–1439. doi: 10.1016/j.csbj.2020.06.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Stoeckius M, et al. Simultaneous epitope and transcriptome measurement in single cells. Nat. Methods. 2017;14:865–868. doi: 10.1038/nmeth.4380. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Han A, Glanville J, Hansmann L, Davis MM. Linking T-cell receptor sequence to functional phenotype at the single-cell level. Nat. Biotechnol. 2014;32:684–692. doi: 10.1038/nbt.2938. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Larsson L, Frisén J, Lundeberg J. Spatially resolved transcriptomics adds a new dimension to genomics. Nat. Methods. 2021;18:15–18. doi: 10.1038/s41592-020-01038-7. [DOI] [PubMed] [Google Scholar]
- 13.Rai V, et al. Single-cell ATAC-seq in human pancreatic islets and deep learning upscaling of rare cells reveals cell-specific type 2 diabetes regulatory signatures. Mol. Metab. 2020;32:109–121. doi: 10.1016/j.molmet.2019.12.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Unterman A, et al. Single-cell multi-omics reveals dyssynchrony of the innate and adaptive immune system in progressive COVID-19. Nat. Commun. 2022;13:440. doi: 10.1038/s41467-021-27716-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Gangaev A, et al. Identification and characterization of a SARS-CoV-2 specific CD8+ T cell response with immunodominant features. Nat. Commun. 2021;12:2593. doi: 10.1038/s41467-021-22811-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Dhainaut M, et al. Spatial CRISPR genomics identifies regulators of the tumor microenvironment. Cell. 2022;185:1223–1239.e20. doi: 10.1016/j.cell.2022.02.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Stuart T, Satija R. Integrative single-cell analysis. Nat. Rev. Genet. 2019;20:257–272. doi: 10.1038/s41576-019-0093-7. [DOI] [PubMed] [Google Scholar]
- 18.Mereu E, et al. Benchmarking single-cell RNA-sequencing protocols for cell atlas projects. Nat. Biotechnol. 2020;38:747–755. doi: 10.1038/s41587-020-0469-4. [DOI] [PubMed] [Google Scholar]
- 19.Lafzi A, Moutinho C, Picelli S, Heyn H. Tutorial: guidelines for the experimental design of single-cell RNA sequencing studies. Nat. Protoc. 2018;13:2742–2757. doi: 10.1038/s41596-018-0073-y. [DOI] [PubMed] [Google Scholar]
- 20.Germain P-L, Sonrel A, Robinson MD. pipeComp, a general framework for the evaluation of computational pipelines, reveals performant single cell RNA-seq preprocessing tools. Genome Biol. 2020;21:227. doi: 10.1186/s13059-020-02136-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Young MD, Behjati S. SoupX removes ambient RNA contamination from droplet-based single-cell RNA sequencing data. Gigascience. 2020;9:giaa151. doi: 10.1093/gigascience/giaa151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Fleming SJ, et al. Unsupervised removal of systematic background noise from droplet-based single-cell experiments using CellBender. bioRxiv. 2022 doi: 10.1101/791699. [DOI] [PubMed] [Google Scholar]
- 23.Yang S, et al. Decontamination of ambient RNA in single-cell RNA-seq with DecontX. Genome Biol. 2020;21:57. doi: 10.1186/s13059-020-1950-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Germain P-L, Lun A, Garcia Meixide C, Macnair W, Robinson MD. Doublet identification in single-cell sequencing data using scDblFinder. F1000Res. 2021;10:979. doi: 10.12688/f1000research.73600.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Xi NM, Li JJ. Protocol for executing and benchmarking eight computational doublet-detection methods in single-cell RNA sequencing data analysis. Star. Protoc. 2021;2:100699. doi: 10.1016/j.xpro.2021.100699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Xi NM, Li JJ. Benchmarking computational doublet-detection methods for single-cell RNA sequencing data. Cell Syst. 2021;12:176–194.e6. doi: 10.1016/j.cels.2020.11.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Neavin D, et al. Demuxafy: improvement in droplet assignment by integrating multiple single-cell demultiplexing and doublet detection methods. bioRxiv. 2022 doi: 10.1101/2022.03.07.483367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Vallejos CA, Risso D, Scialdone A, Dudoit S, Marioni JC. Normalizing single-cell RNA sequencing data: challenges and opportunities. Nat. Methods. 2017;14:565–571. doi: 10.1038/nmeth.4292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Ahlmann-Eltze C, Huber W. Comparison of transformations for single-cell RNA-seq data. bioRxiv. 2022 doi: 10.1101/2021.06.24.449781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Lun ATL, Bach K, Marioni JC. Pooling across cells to normalize single-cell RNA sequencing data with many zero counts. Genome Biol. 2016;17:75. doi: 10.1186/s13059-016-0947-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Lause J, Berens P, Kobak D. Analytic Pearson residuals for normalization of single-cell RNA-seq UMI data. Genome Biol. 2021;22:258. doi: 10.1186/s13059-021-02451-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Ahlmann-Eltze C, Huber W. Comparison of transformations for single-cell RNA-seq data. bioRxiv. 2022 doi: 10.1101/2021.06.24.449781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Sina Booeshaghi A, Hallgrímsdóttir IB, Gálvez-Merchán Á, Pachter L. Depth normalization for single-cell genomics count data. bioRxiv. 2022 doi: 10.1101/2022.05.06.490859. [DOI] [Google Scholar]
- 34.Vieth B, Parekh S, Ziegenhain C, Enard W, Hellmann I. A systematic evaluation of single cell RNA-seq analysis pipelines. Nat. Commun. 2019;10:4667. doi: 10.1038/s41467-019-12266-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Luecken MD, et al. Benchmarking atlas-level data integration in single-cell genomics. Nat. Methods. 2022;19:41–50. doi: 10.1038/s41592-021-01336-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Butler A, Hoffman P, Smibert P, Papalexi E, Satija R. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat. Biotechnol. 2018;36:411–420. doi: 10.1038/nbt.4096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Korsunsky I, et al. Fast, sensitive and accurate integration of single-cell data with Harmony. Nat. Methods. 2019;16:1289–1296. doi: 10.1038/s41592-019-0619-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Tran HTN, et al. A benchmark of batch-effect correction methods for single-cell RNA sequencing data. Genome Biol. 2020;21:12. doi: 10.1186/s13059-019-1850-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Chazarra-Gil R, van Dongen S, Kiselev VY, Hemberg M. Flexible comparison of batch correction methods for single-cell RNA-seq using BatchBench. Nucleic Acids Res. 2021;49:e42. doi: 10.1093/nar/gkab004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Xu C, et al. Probabilistic harmonization and annotation of single-cell transcriptomics data with deep generative models. Mol. Syst. Biol. 2021;17:e9620. doi: 10.15252/msb.20209620. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Lopez R, Regier J, Cole MB, Jordan MI, Yosef N. Deep generative modeling for single-cell transcriptomics. Nat. Methods. 2018;15:1053–1058. doi: 10.1038/s41592-018-0229-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Lotfollahi M, Wolf FA, Theis FJ. scGen predicts single-cell perturbation responses. Nat. Methods. 2019;16:715–721. doi: 10.1038/s41592-019-0494-8. [DOI] [PubMed] [Google Scholar]
- 43.Hie B, Bryson B, Berger B. Efficient integration of heterogeneous single-cell transcriptomes using Scanorama. Nat. Biotechnol. 2019;37:685–691. doi: 10.1038/s41587-019-0113-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Chervov A, Zinovyev A. Computational challenges of cell cycle analysis using single cell transcriptomics. arXiv. 2022 doi: 10.48550/arXiv.2208.05229. [DOI] [Google Scholar]
- 45.Hafemeister C, Satija R. Normalization and variance stabilization of single-cell RNA-seq data using regularized negative binomial regression. Genome Biol. 2019;20:296. doi: 10.1186/s13059-019-1874-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Zheng SC, et al. Universal prediction of cell-cycle position using transfer learning. Genome Biol. 2022;23:41. doi: 10.1186/s13059-021-02581-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Townes FW, Hicks SC, Aryee MJ, Irizarry RA. Feature selection and dimension reduction for single-cell RNA-seq based on a multinomial model. Genome Biol. 2019;20:295. doi: 10.1186/s13059-019-1861-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Moon KR, et al. Visualizing structure and transitions in high-dimensional biological data. Nat. Biotechnol. 2019;37:1482–1492. doi: 10.1038/s41587-019-0336-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Chari T, Banerjee J, Pachter L. The specious art of single-cell genomics. bioRxiv. 2022 doi: 10.1101/2021.08.25.457696. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Duò A, Robinson MD, Soneson C. A systematic performance evaluation of clustering methods for single-cell RNA-seq data. F1000Res. 2018;7:1141. doi: 10.12688/f1000research.15666.2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Freytag S, Tian L, Lönnstedt I, Ng M, Bahlo M. Comparison of clustering tools in R for medium-sized 10x Genomics single-cell RNA-sequencing data. F1000Res. 2018;7:1297. doi: 10.12688/f1000research.15809.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Traag VA, Waltman L, van Eck NJ. From Louvain to Leiden: guaranteeing well-connected communities. Sci. Rep. 2019;9:5233. doi: 10.1038/s41598-019-41695-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Clarke ZA, et al. Tutorial: guidelines for annotating single-cell transcriptomic maps using automated and manual methods. Nat. Protoc. 2021;16:2749–2764. doi: 10.1038/s41596-021-00534-0. [DOI] [PubMed] [Google Scholar]
- 54.Abdelaal T, et al. A comparison of automatic cell identification methods for single-cell RNA sequencing data. Genome Biol. 2019;20:194. doi: 10.1186/s13059-019-1795-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Pasquini G, Rojo Arias JE, Schäfer P, Busskamp V. Automated methods for cell type annotation on scRNA-seq data. Comput. Struct. Biotechnol. J. 2021;19:961–969. doi: 10.1016/j.csbj.2021.01.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Domínguez Conde C, et al. Cross-tissue immune cell analysis reveals tissue-specific features in humans. Science. 2022;376:eabl5197. doi: 10.1126/science.abl5197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Fu R, et al. clustifyr: an R package for automated single-cell RNA sequencing cluster classification. F1000Research. 2020;9:223. doi: 10.12688/f1000research.22969.2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Lotfollahi M, Naghipourfar M, Luecken MD. Mapping single-cell data to reference atlases by transfer learning. Nat Biotechnol. 2022;40:121–130. doi: 10.1038/s41587-021-01001-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Kang JB, et al. Efficient and precise single-cell reference atlas mapping with Symphony. Nat. Commun. 2021;12:5890. doi: 10.1038/s41467-021-25957-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Pullin JM, McCarthy DJ. A comparison of marker gene selection methods for single-cell RNA sequencing data. bioRxiv. 2022 doi: 10.1101/2022.05.09.490241. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Zhang JM, Kamath GM, Tse DN. Valid post-clustering differential analysis for single-cell RNA-seq. Cell Syst. 2019;9:383–392.e6. doi: 10.1016/j.cels.2019.07.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Street K, et al. Slingshot: cell lineage and pseudotime inference for single-cell transcriptomics. BMC Genomics. 2018;19:477. doi: 10.1186/s12864-018-4772-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Wolf FA, et al. PAGA: graph abstraction reconciles clustering with trajectory inference through a topology preserving map of single cells. Genome Biol. 2019;20:59. doi: 10.1186/s13059-019-1663-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Grün D, et al. De novo prediction of stem cell identity using single-cell transcriptome data. Cell Stem Cell. 2016;19:266–277. doi: 10.1016/j.stem.2016.05.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Saelens W, Cannoodt R, Todorov H, Saeys Y. A comparison of single-cell trajectory inference methods: towards more accurate and robust tools. Nat. Biotechnol. 2019;37:547–554. doi: 10.1038/s41587-019-0071-9. [DOI] [PubMed] [Google Scholar]
- 66.La Manno G, et al. RNA velocity of single cells. Nature. 2018;560:494–498. doi: 10.1038/s41586-018-0414-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Bergen V, Lange M, Peidli S, Wolf FA, Theis FJ. Generalizing RNA velocity to transient cell states through dynamical modeling. Nat. Biotechnol. 2020;38:1408–1414. doi: 10.1038/s41587-020-0591-3. [DOI] [PubMed] [Google Scholar]
- 68.Lange M, et al. CellRank for directed single-cell fate mapping. Nat. Methods. 2022;19:159–170. doi: 10.1038/s41592-021-01346-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Weiler P, Van den Berge K, Street K, Tiberi S. A guide to trajectory inference and RNA velocity. Methods Mol. Biol. 2023;2584:269–292. doi: 10.1007/978-1-0716-2756-3_14. [DOI] [PubMed] [Google Scholar]
- 70.Bergen V, Soldatov RA, Kharchenko PV, Theis FJ. RNA velocity-current challenges and future perspectives. Mol. Syst. Biol. 2021;17:e10282. doi: 10.15252/msb.202110282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Gorin G, Fang M, Chari T, Pachter L. RNA velocity unraveled. PLoS Comput. Biol. 2022;18:e1010492. doi: 10.1371/journal.pcbi.1010492. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Jones MG, et al. Inference of single-cell phylogenies from lineage tracing data using Cassiopeia. Genome Biol. 2020;21:92. doi: 10.1186/s13059-020-02000-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Sokal R, Michener C. A statistical method for evaluating systematic relationships. Univ. Kans., Sci. Bull. 1958;38:1409–1438. [Google Scholar]
- 74.Saitou N, Nei M. The neighbor-joining method: a new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987;4:406–425. doi: 10.1093/oxfordjournals.molbev.a040454. [DOI] [PubMed] [Google Scholar]
- 75.Gong W, et al. Benchmarked approaches for reconstruction of in vitro cell lineages and in silico models of C. elegans and M. musculus developmental trees. Cell Syst. 2021;12:810–826.e4. doi: 10.1016/j.cels.2021.05.008. [DOI] [PubMed] [Google Scholar]
- 76.Forrow A, Schiebinger G. LineageOT is a unified framework for lineage tracing and trajectory inference. Nat. Commun. 2021;12:4940. doi: 10.1038/s41467-021-25133-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.McKenna A, Gagnon JA. Recording development with single cell dynamic lineage tracing. Development. 2019;146:dev169730. doi: 10.1242/dev.169730. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Wang S-W, Herriges MJ, Hurley K, Kotton DN, Klein AM. CoSpar identifies early cell fate biases from single-cell transcriptomic and lineage information. Nat. Biotechnol. 2022;40:1066–1074. doi: 10.1038/s41587-022-01209-1. [DOI] [PubMed] [Google Scholar]
- 79.Robinson MD, McCarthy DJ, Smyth GK. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics. 2010;26:139–140. doi: 10.1093/bioinformatics/btp616. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Love MI, Huber W, Anders S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014;15:550. doi: 10.1186/s13059-014-0550-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Ritchie ME, et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015;43:e47. doi: 10.1093/nar/gkv007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Finak G, et al. MAST: a flexible statistical framework for assessing transcriptional changes and characterizing heterogeneity in single-cell RNA sequencing data. Genome Biol. 2015;16:278. doi: 10.1186/s13059-015-0844-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Wang T, Li B, Nelson CE, Nabavi S. Comparative analysis of differential gene expression analysis tools for single-cell RNA sequencing data. BMC Bioinformatics. 2019;20:40. doi: 10.1186/s12859-019-2599-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Das S, Rai A, Merchant ML, Cave MC, Rai SN. A comprehensive survey of statistical approaches for differential expression analysis in single-cell RNA sequencing studies. Genes. 2021;12:1947. doi: 10.3390/genes12121947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Soneson C, Robinson MD. Bias, robustness and scalability in single-cell differential expression analysis. Nat. Methods. 2018;15:255–261. doi: 10.1038/nmeth.4612. [DOI] [PubMed] [Google Scholar]
- 86.Squair JW, et al. Confronting false discoveries in single-cell differential expression. Nat. Commun. 2021;12:5692. doi: 10.1038/s41467-021-25960-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Zimmerman KD, Espeland MA, Langefeld CD. A practical solution to pseudoreplication bias in single-cell studies. Nat. Commun. 2021;12:738. doi: 10.1038/s41467-021-21038-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Junttila S, Smolander J, Elo LL. Benchmarking methods for detecting differential states between conditions from multi-subject single-cell RNA-seq data. Brief. Bioinform. 2022;23:bbac286. doi: 10.1093/bib/bbac286. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Law CW, et al. A guide to creating design matrices for gene expression experiments. F1000Res. 2020;9:1444. doi: 10.12688/f1000research.27893.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Thurman AL, Ratcliff JA, Chimenti MS, Pezzulo AA. Differential gene expression analysis for multi-subject single cell RNA sequencing studies with aggregateBioVar. Bioinformatics. 2021;37:3243–3251. doi: 10.1093/bioinformatics/btab337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Lähnemann D, et al. Eleven grand challenges in single-cell data science. Genome Biol. 2020;21:31. doi: 10.1186/s13059-020-1926-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Stat. Methodol. 1995;57:289–300. [Google Scholar]
- 93.Liberzon A, et al. Molecular signatures database (MSigDB) 3.0. Bioinformatics. 2011;27:1739–1740. doi: 10.1093/bioinformatics/btr260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Ashburner M, et al. Gene ontology: tool for the unification of biology. Nat. Genet. 2000;25:25–29. doi: 10.1038/75556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Kanehisa M, Furumichi M, Tanabe M, Sato Y, Morishima K. KEGG: new perspectives on genomes, pathways, diseases and drugs. Nucleic Acids Res. 2017;45:D353–D361. doi: 10.1093/nar/gkw1092. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96.Gillespie M, et al. The reactome pathway knowledgebase 2022. Nucleic Acids Res. 2022;50:D687–D692. doi: 10.1093/nar/gkab1028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Schubert, et al. Perturbation-response genes reveal signaling footprints in cancer gene expression. Nat. Commun. 2018;9:20. doi: 10.1038/s41467-017-02391-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Garcia-Alonso L, Holland CH, Ibrahim MM, Turei D, Saez-Rodriguez J. Benchmark and integration of resources for the estimation of human transcription factor activities. Genome Res. 2019;29:1363–1375. doi: 10.1101/gr.240663.118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Korotkevich G, et al. Fast gene set enrichment analysis. bioRxiv. 2021 doi: 10.1101/060012. [DOI] [Google Scholar]
- 100.Subramanian A, et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl Acad. Sci. USA. 2005;102:15545–15550. doi: 10.1073/pnas.0506580102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Hänzelmann S, Castelo R, Guinney J. GSVA: gene set variation analysis for microarray and RNA-seq data. BMC Bioinformatics. 2013;14:7. doi: 10.1186/1471-2105-14-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Holland CH, et al. Robustness and applicability of transcription factor and pathway analysis tools on single-cell RNA-seq data. Genome Biol. 2020;21:36. doi: 10.1186/s13059-020-1949-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Badia-i-Mompel P, et al. decoupleR: ensemble of computational methods to infer biological activities from omics data. Bioinform. Adv. 2022;2:vbac016. doi: 10.1093/bioadv/vbac016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Barkas, N., Pethukov, V., Kharchenko, P. and Biederstedt, E. pagoda2: Single Cell Analysis and Differential Expression, https://github.com/kharchenkolab/pagoda2 (2021).
- 105.Zhang Y, et al. Benchmarking algorithms for pathway activity transformation of single-cell RNA-seq data. Comput. Struct. Biotechnol. J. 2020;18:2953–2961. doi: 10.1016/j.csbj.2020.10.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Pijuan-Sala B, et al. A single-cell molecular map of mouse gastrulation and early organogenesis. Nature. 2019;566:490–495. doi: 10.1038/s41586-019-0933-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 107.Smillie CS, et al. Intra- and inter-cellular rewiring of the human colon during ulcerative colitis. Cell. 2019;178:714–730.e22. doi: 10.1016/j.cell.2019.06.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 108.Büttner M, Ostner J, Müller CL, Theis FJ, Schubert B. scCODA is a Bayesian model for compositional single-cell data analysis. Nat. Commun. 2021;12:6876. doi: 10.1038/s41467-021-27150-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 109.Cao Y, et al. scDC: single cell differential composition analysis. BMC Bioinformatics. 2019;20(Suppl. 19):721. doi: 10.1186/s12859-019-3211-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Ostner J, Carcy S, Müller CL. tascCODA: Bayesian tree-aggregated analysis of compositional amplicon and single-cell data. Front. Genet. 2021;12:766405. doi: 10.3389/fgene.2021.766405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 111.Zhao J, et al. Detection of differentially abundant cell subpopulations in scRNA-seq data. Proc. Natl Acad. Sci. USA. 2021;118:e2100293118. doi: 10.1073/pnas.2100293118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Dann E, Henderson NC, Teichmann SA, Morgan MD, Marioni JC. Differential abundance testing on single-cell data using k-nearest neighbor graphs. Nat. Biotechnol. 2022;40:245–253. doi: 10.1038/s41587-021-01033-z. [DOI] [PubMed] [Google Scholar]
- 113.Srivatsan SR, et al. Massively multiplex chemical transcriptomics at single-cell resolution. Science. 2020;367:45–51. doi: 10.1126/science.aax6234. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Dixit A, et al. Perturb-seq: dissecting molecular circuits with scalable single-cell RNA profiling of pooled genetic screens. Cell. 2016;167:1853–1866.e17. doi: 10.1016/j.cell.2016.11.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 115.Datlinger P, et al. Ultra-high-throughput single-cell RNA sequencing and perturbation screening with combinatorial fluidic indexing. Nat. Methods. 2021;18:635–642. doi: 10.1038/s41592-021-01153-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 116.Papalexi E, et al. Characterizing the molecular regulation of inhibitory immune checkpoints with multimodal single-cell screens. Nat. Genet. 2021;53:322–331. doi: 10.1038/s41588-021-00778-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 117.Replogle JM, et al. Mapping information-rich genotype–phenotype landscapes with genome-scale Perturb-seq. Cell. 2022;185:2559–2575.e28. doi: 10.1016/j.cell.2022.05.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 118.Wessels H-H, et al. Efficient combinatorial targeting of RNA transcripts in single cells with Cas13 RNA Perturb-seq. Nat. Methods. 2023;20:86–94. doi: 10.1038/s41592-022-01705-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Ji Y, Lotfollahi M, Wolf FA, Theis FJ. Machine learning for perturbational single-cell omics. Cell Syst. 2021;12:522–537. doi: 10.1016/j.cels.2021.05.016. [DOI] [PubMed] [Google Scholar]
- 120.Duan B, et al. Model-based understanding of single-cell CRISPR screening. Nat. Commun. 2019;10:2233. doi: 10.1038/s41467-019-10216-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 121.Squair JW, Skinnider MA, Gautier M, Foster LJ, Courtine G. Prioritization of cell types responsive to biological perturbations in single-cell data with Augur. Nat. Protoc. 2021;16:3836–3873. doi: 10.1038/s41596-021-00561-x. [DOI] [PubMed] [Google Scholar]
- 122.Skinnider MA, et al. Cell type prioritization in single-cell data. Nat. Biotechnol. 2021;39:30–34. doi: 10.1038/s41587-020-0605-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 123.Burkhardt DB, et al. Quantifying the effect of experimental perturbations at single-cell resolution. Nat. Biotechnol. 2021;39:619–629. doi: 10.1038/s41587-020-00803-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 124.Lotfollahi M, et al. Learning interpretable cellular responses to complex perturbations in high-throughput screens. bioRxiv. 2021 doi: 10.1101/2021.04.14.439903. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 125.Yuan B, et al. CellBox: interpretable machine learning for perturbation biology with application to the design of cancer combination therapy. Cell Syst. 2021;12:128–140.e4. doi: 10.1016/j.cels.2020.11.013. [DOI] [PubMed] [Google Scholar]
- 126.Dimitrov D, et al. Comparison of methods and resources for cell-cell communication inference from single-cell RNA-seq data. Nat. Commun. 2022;13:3224. doi: 10.1038/s41467-022-30755-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 127.Jin S, et al. Inference and analysis of cell-cell communication using CellChat. Nat. Commun. 2021;12:1088. doi: 10.1038/s41467-021-21246-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 128.Efremova M, Vento-Tormo M, Teichmann SA, Vento-Tormo R. CellPhoneDB: inferring cell–cell communication from combined expression of multi-subunit ligand–receptor complexes. Nat. Protoc. 2020;15:1484–1506. doi: 10.1038/s41596-020-0292-x. [DOI] [PubMed] [Google Scholar]
- 129.Cabello-Aguilar S, et al. SingleCellSignalR: inference of intercellular networks from single-cell transcriptomics. Nucleic Acids Res. 2020;48:e55. doi: 10.1093/nar/gkaa183. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.Browaeys R, Saelens W, Saeys Y. NicheNet: modeling intercellular communication by linking ligands to target genes. Nat. Methods. 2020;17:159–162. doi: 10.1038/s41592-019-0667-5. [DOI] [PubMed] [Google Scholar]
- 131.Hu Y, Peng T, Gao L, Tan K. CytoTalk: de novo construction of signal transduction networks using single-cell transcriptomic data. Sci. Adv. 2021;7:eabf1356. doi: 10.1126/sciadv.abf1356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 132.Isbel L, Grand RS, Schübeler D. Generating specificity in genome regulation through transcription factor sensitivity to chromatin. Nat. Rev. Genet. 2022;23:728–740. doi: 10.1038/s41576-022-00512-6. [DOI] [PubMed] [Google Scholar]
- 133.Cusanovich DA, et al. Multiplex single-cell profiling of chromatin accessibility by combinatorial cellular indexing. Science. 2015;348:910–914. doi: 10.1126/science.aab1601. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 134.Buenrostro JD, et al. Single-cell chromatin accessibility reveals principles of regulatory variation. Nature. 2015;523:486–490. doi: 10.1038/nature14590. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 135.Chen H, et al. Assessment of computational methods for the analysis of single-cell ATAC-seq data. Genome Biol. 2019;20:241. doi: 10.1186/s13059-019-1854-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 136.Fang R, et al. Comprehensive analysis of single cell ATAC-seq data with SnapATAC. Nat. Commun. 2021;12:1337. doi: 10.1038/s41467-021-21583-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 137.Ou J, et al. ATACseqQC: a Bioconductor package for post-alignment quality assessment of ATAC-seq data. BMC Genomics. 2018;19:169. doi: 10.1186/s12864-018-4559-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 138.Amemiya HM, Kundaje A, Boyle AP. The ENCODE blacklist: identification of problematic regions of the genome. Sci. Rep. 2019;9:9354. doi: 10.1038/s41598-019-45839-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 139.Thibodeau A, et al. AMULET: a novel read count-based method for effective multiplet detection from single nucleus ATAC-seq data. Genome Biol. 2021;22:252. doi: 10.1186/s13059-021-02469-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 140.Granja JM, et al. ArchR is a scalable software package for integrative single-cell chromatin accessibility analysis. Nat. Genet. 2021;53:403–411. doi: 10.1038/s41588-021-00790-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 141.Bravo González-Blas C, et al. cisTopic: cis-regulatory topic modeling on single-cell ATAC-seq data. Nat. Methods. 2019;16:397–400. doi: 10.1038/s41592-019-0367-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 142.Martens LD, Fischer DS, Theis FJ, Gagneur J. Modeling fragment counts improves single-cell ATAC-seq analysis. bioRxiv. 2022 doi: 10.1101/2022.05.04.490536. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 143.Stuart T, Srivastava A, Madad S, Lareau CA, Satija R. Single-cell chromatin state analysis with Signac. Nat. Methods. 2021;18:1333–1341. doi: 10.1038/s41592-021-01282-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 144.Ashuach T, Reidenbach DA, Gayoso A, Yosef N. PeakVI: a deep generative model for single-cell chromatin accessibility analysis. Cell Rep. Methods. 2022;2:100182. doi: 10.1016/j.crmeth.2022.100182. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 145.Ashuach, T., Gabitto, M. I., Jordan, M. I. & Yosef, N. MultiVI: deep generative model for the integration of multi-modal data. Preprint at 10.1101/2021.08.20.457057. [DOI] [PMC free article] [PubMed]
- 146.Gontarz P, et al. Comparison of differential accessibility analysis strategies for ATAC-seq data. Sci. Rep. 2020;10:10150. doi: 10.1038/s41598-020-66998-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 147.McLean CY, et al. GREAT improves functional interpretation of cis-regulatory regions. Nat. Biotechnol. 2010;28:495–501. doi: 10.1038/nbt.1630. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 148.Sheffield NC, Bock C. LOLA: enrichment analysis for genomic region sets and regulatory elements in R and Bioconductor. Bioinformatics. 2016;32:587–589. doi: 10.1093/bioinformatics/btv612. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 149.Layer RM, et al. GIGGLE: a search engine for large-scale integrated genome analysis. Nat. Methods. 2018;15:123–126. doi: 10.1038/nmeth.4556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 150.Bredikhin D, Kats I, Stegle O. MUON: multimodal omics analysis framework. Genome Biol. 2022;23:42. doi: 10.1186/s13059-021-02577-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 151.Pliner HA, et al. Cicero predicts cis-regulatory DNA interactions from single-cell chromatin accessibility data. Mol. Cell. 2018;71:858–871.e8. doi: 10.1016/j.molcel.2018.06.044. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 152.van Dijk D, et al. Recovering gene interactions from single-cell data using data diffusion. Cell. 2018;174:716–729.e27. doi: 10.1016/j.cell.2018.05.061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 153.Schep AN, Wu B, Buenrostro JD, Greenleaf WJ. chromVAR: inferring transcription-factor-associated accessibility from single-cell epigenomic data. Nat. Methods. 2017;14:975–978. doi: 10.1038/nmeth.4401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 154.Kartha VK, et al. Functional inference of gene regulation using single-cell multi-omics. Cell Genom. 2022;2:100166. doi: 10.1016/j.xgen.2022.100166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 155.Cao J, et al. Joint profiling of chromatin accessibility and gene expression in thousands of single cells. Science. 2018;361:1380–1385. doi: 10.1126/science.aau0730. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156.Liu L, et al. Deconvolution of single-cell multi-omics layers reveals regulatory heterogeneity. Nat. Commun. 2019;10:470. doi: 10.1038/s41467-018-08205-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 157.Lynch AW, Theodoris CV, Long HW. MIRA: joint regulatory modeling of multimodal expression and chromatin accessibility in single cells. Nat. Methods. 2022;19:1097–1108. doi: 10.1038/s41592-022-01595-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 158.Fleck JS, et al. Inferring and perturbing cell fate regulomes in human brain organoids. Nature. 2022 doi: 10.1038/s41586-022-05279-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159.Peterson VM, et al. Multiplexed quantification of proteins and transcripts in single cells. Nat. Biotechnol. 2017;35:936–939. doi: 10.1038/nbt.3973. [DOI] [PubMed] [Google Scholar]
- 160.Zheng, Y., Jun, S.-H., Tian, Y., Florian, M. & Gottardo, R. Robust normalization and integration of single-cell protein expression across CITE-seq datasets. Preprint at 10.1101/2022.04.29.489989.
- 161.Mulè MP, Martins AJ, Tsang JS. Normalizing and denoising protein expression data from droplet-based single cell profiling. Nat. Commun. 2022;13:2099. doi: 10.1038/s41467-022-29356-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 162.Gayoso A, et al. Joint probabilistic modeling of single-cell multi-omic data with totalVI. Nat. Methods. 2021;18:272–282. doi: 10.1038/s41592-020-01050-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 163.Kim HJ, Lin Y, Geddes TA, Yang JYH, Yang P. CiteFuse enables multi-modal analysis of CITE-seq data. Bioinformatics. 2020;36:4137–4143. doi: 10.1093/bioinformatics/btaa282. [DOI] [PubMed] [Google Scholar]
- 164.Sturm G, et al. Scirpy: a Scanpy extension for analyzing single-cell T-cell receptor-sequencing data. Bioinformatics. 2020;36:4817–4818. doi: 10.1093/bioinformatics/btaa611. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 165.Stephenson E, et al. Single-cell multi-omics analysis of the immune response in COVID-19. Nat. Med. 2021;27:904–916. doi: 10.1038/s41591-021-01329-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 166.Borcherding N, Bormann NL, Kraus G. scRepertoire: an R-based toolkit for single-cell immune receptor analysis. F1000Res. 2020;9:47. doi: 10.12688/f1000research.22139.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 167.Bolotin DA, et al. MiXCR: software for comprehensive adaptive immunity profiling. Nat. Methods. 2015;12:380–381. doi: 10.1038/nmeth.3364. [DOI] [PubMed] [Google Scholar]
- 168.Song L, et al. TRUST4: immune repertoire reconstruction from bulk and single-cell RNA-seq data. Nat. Methods. 2021;18:627–630. doi: 10.1038/s41592-021-01142-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 169.Upadhyay AA, et al. BALDR: a computational pipeline for paired heavy and light chain immunoglobulin reconstruction in single-cell RNA-seq data. Genome Med. 2018;10:20. doi: 10.1186/s13073-018-0528-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 170.Canzar S, Neu KE, Tang Q, Wilson PC, Khan AA. BASIC: BCR assembly from single cells. Bioinformatics. 2017;33:425–427. doi: 10.1093/bioinformatics/btw631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 171.Lindeman I, et al. BraCeR: B-cell-receptor reconstruction and clonality inference from single-cell RNA-seq. Nat. Methods. 2018;15:563–565. doi: 10.1038/s41592-018-0082-3. [DOI] [PubMed] [Google Scholar]
- 172.Andreani T, et al. Benchmarking computational methods for B-cell receptor reconstruction from single-cell RNA-seq data. NAR Genom. Bioinform. 2022;4:lqac049. doi: 10.1093/nargab/lqac049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 173.Schuldt NJ, Binstadt BA. Dual TCR T cells: identity crisis or multitaskers? J. Immunol. 2019;202:637–644. doi: 10.4049/jimmunol.1800904. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 174.Polonsky M, Chain B, Friedman N. Clonal expansion under the microscope: studying lymphocyte activation and differentiation using live-cell imaging. Immunol. Cell Biol. 2016;94:242–249. doi: 10.1038/icb.2015.104. [DOI] [PubMed] [Google Scholar]
- 175.Greiff V, Miho E, Menzel U, Reddy ST. Bioinformatic and statistical analysis of adaptive immune repertoires. Trends Immunol. 2015;36:738–749. doi: 10.1016/j.it.2015.09.006. [DOI] [PubMed] [Google Scholar]
- 176.Springer I, Tickotsky N, Louzoun Y. Contribution of T cell receptor alpha and beta CDR3, MHC typing, V and J genes to peptide binding prediction. Front. Immunol. 2021;12:664514. doi: 10.3389/fimmu.2021.664514. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 177.Setliff I, et al. High-throughput mapping of B cell receptor sequences to antigen specificity. Cell. 2019;179:1636–1646.e15. doi: 10.1016/j.cell.2019.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 178.Zhang S-Q, et al. High-throughput determination of the antigen specificities of T cell receptors in single cells. Nat. Biotechnol. 2018 doi: 10.1038/nbt.4282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 179.Nazarov, V. I. et al. immunarch: bioinformatics analysis of T-cell and B-cell immune repertoires (immunarch, 2022).
- 180.Fleri W, et al. The immune epitope database and analysis resource in epitope discovery and synthetic vaccine design. Front. Immunol. 2017;8:278. doi: 10.3389/fimmu.2017.00278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 181.Zhang W, et al. PIRD: pan immune repertoire database. Bioinformatics. 2020;36:897–903. doi: 10.1093/bioinformatics/btz614. [DOI] [PubMed] [Google Scholar]
- 182.Shugay M, et al. VDJdb: a curated database of T-cell receptor sequences with known antigen specificity. Nucleic Acids Res. 2018;46:D419–D427. doi: 10.1093/nar/gkx760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 183.Glanville J, et al. Identifying specificity groups in the T cell receptor repertoire. Nature. 2017;547:94–98. doi: 10.1038/nature22976. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 184.Dash P, et al. Quantifiable predictive features define epitope-specific T cell receptor repertoires. Nature. 2017;547:89–93. doi: 10.1038/nature22383. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 185.Chronister WD, et al. TCRMatch: predicting T-cell receptor specificity based on sequence similarity to previously characterized receptors. Front. Immunol. 2021;12:640725. doi: 10.3389/fimmu.2021.640725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 186.Zhang Z, Xiong D, Wang X, Liu H, Wang T. Mapping the functional landscape of T cell receptor repertoires by single-T cell transcriptomics. Nat. Methods. 2021;18:92–99. doi: 10.1038/s41592-020-01020-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 187.An, Y., Drost, F., Theis, F., Schubert, B. & Lotfollahi, M. Jointly learning T-cell receptor and transcriptomic information to decipher the immune response. Preprint at 10.1101/2021.06.24.449733.
- 188.Schattgen SA, et al. Integrating T cell receptor sequences and transcriptional profiles by clonotype neighbor graph analysis (CoNGA) Nat. Biotechnol. 2022;40:54–63. doi: 10.1038/s41587-021-00989-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Zhang Z, et al. Interpreting the B-cell receptor repertoire with single-cell gene expression using Benisse. Nat. Mach. Intell. 2022;4:596–604. doi: 10.1038/s42256-022-00492-6. [DOI] [Google Scholar]
- 190.Palla G, Fischer DS, Regev A, Theis FJ. Spatial components of molecular tissue biology. Nat. Biotechnol. 2022;40:308–318. doi: 10.1038/s41587-021-01182-1. [DOI] [PubMed] [Google Scholar]
- 191.Dries R, et al. Advances in spatial transcriptomic data analysis. Genome Res. 2021;31:1706–1718. doi: 10.1101/gr.275224.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 192.Asp M, Bergenstråhle J, Lundeberg J. Spatially resolved transcriptomes-next generation tools for tissue exploration. Bioessays. 2020;42:e1900221. doi: 10.1002/bies.201900221. [DOI] [PubMed] [Google Scholar]
- 193.Tan X, Su A, Tran M, Nguyen Q. SpaCell: integrating tissue morphology and spatial gene expression to predict disease cells. Bioinformatics. 2020;36:2293–2294. doi: 10.1093/bioinformatics/btz914. [DOI] [PubMed] [Google Scholar]
- 194.He B, et al. Integrating spatial gene expression and breast tumour morphology via deep learning. Nat. Biomed. Eng. 2020;4:827–834. doi: 10.1038/s41551-020-0578-x. [DOI] [PubMed] [Google Scholar]
- 195.Bergenstråhle L, et al. Super-resolved spatial transcriptomics by deep data fusion. Nat. Biotechnol. 2022;40:476–479. doi: 10.1038/s41587-021-01075-3. [DOI] [PubMed] [Google Scholar]
- 196.Velten B, et al. Identifying temporal and spatial patterns of variation from multimodal data using MEFISTO. Nat. Methods. 2022;19:179–186. doi: 10.1038/s41592-021-01343-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 197.Liao J, Lu X, Shao X, Zhu L, Fan X. Uncovering an organ’s molecular architecture at single-cell resolution by spatially resolved transcriptomics. Trends Biotechnol. 2021;39:43–58. doi: 10.1016/j.tibtech.2020.05.006. [DOI] [PubMed] [Google Scholar]
- 198.Deng Y, et al. Spatial profiling of chromatin accessibility in mouse and human tissues. Nature. 2022;609:375–383. doi: 10.1038/s41586-022-05094-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 199.Liu S, et al. Spatial maps of T cell receptors and transcriptomes reveal distinct immune niches and interactions in the adaptive immune response. Immunity. 2022;55:1940–1952.e5. doi: 10.1016/j.immuni.2022.09.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 200.Lundberg E, Borner GHH. Spatial proteomics: a powerful discovery tool for cell biology. Nat. Rev. Mol. Cell Biol. 2019;20:285–302. doi: 10.1038/s41580-018-0094-y. [DOI] [PubMed] [Google Scholar]
- 201.Ståhl PL, et al. Visualization and analysis of gene expression in tissue sections by spatial transcriptomics. Science. 2016;353:78–82. doi: 10.1126/science.aaf2403. [DOI] [PubMed] [Google Scholar]
- 202.Rodriques SG, et al. Slide-seq: a scalable technology for measuring genome-wide expression at high spatial resolution. Science. 2019;363:1463–1467. doi: 10.1126/science.aaw1219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 203.Lubeck E, Coskun AF, Zhiyentayev T, Ahmad M, Cai L. Single-cell in situ RNA profiling by sequential hybridization. Nat. Methods. 2014;11:360–361. doi: 10.1038/nmeth.2892. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 204.Chen KH, Boettiger AN, Moffitt JR, Wang S, Zhuang X. RNA imaging. Spatially resolved, highly multiplexed RNA profiling in single cells. Science. 2015;348:aaa6090. doi: 10.1126/science.aaa6090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 205.Ke R, et al. In situ sequencing for RNA analysis in preserved tissue and cells. Nat. Methods. 2013;10:857–860. doi: 10.1038/nmeth.2563. [DOI] [PubMed] [Google Scholar]
- 206.Crosetto N, Bienko M, van Oudenaarden A. Spatially resolved transcriptomics and beyond. Nat. Rev. Genet. 2015;16:57–66. doi: 10.1038/nrg3832. [DOI] [PubMed] [Google Scholar]
- 207.Zhang M, et al. Spatial molecular profiling: platforms, applications and analysis tools. Brief. Bioinform. 2021;22:bbaa145. doi: 10.1093/bib/bbaa145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 208.Zhuang X. Spatially resolved single-cell genomics and transcriptomics by imaging. Nat. Methods. 2021;18:18–22. doi: 10.1038/s41592-020-01037-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 209.Palla G, et al. Squidpy: a scalable framework for spatial omics analysis. Nat. Methods. 2022;19:171–178. doi: 10.1038/s41592-021-01358-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 210.Dries R, et al. Giotto: a toolbox for integrative analysis and visualization of spatial expression data. Genome Biol. 2021;22:78. doi: 10.1186/s13059-021-02286-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 211.Righelli D, et al. SpatialExperiment: infrastructure for spatially resolved transcriptomics data in R using Bioconductor. Bioinformatics. 2022;38:3128–3131. doi: 10.1093/bioinformatics/btac299. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 212.Kleshchevnikov V, et al. Cell2location maps fine-grained cell types in spatial transcriptomics. Nat. Biotechnol. 2022;40:661–671. doi: 10.1038/s41587-021-01139-4. [DOI] [PubMed] [Google Scholar]
- 213.Dong R, Yuan G-C. SpatialDWLS: accurate deconvolution of spatial transcriptomic data. Genome Biol. 2021;22:145. doi: 10.1186/s13059-021-02362-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 214.Cable DM, et al. Robust decomposition of cell type mixtures in spatial transcriptomics. Nat. Biotechnol. 2022;40:517–526. doi: 10.1038/s41587-021-00830-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 215.Li B, et al. Benchmarking spatial and single-cell transcriptomics integration methods for transcript distribution prediction and cell type deconvolution. Nat. Methods. 2022;19:662–670. doi: 10.1038/s41592-022-01480-9. [DOI] [PubMed] [Google Scholar]
- 216.Yan L, Sun X. Benchmarking and integration of methods for deconvoluting spatial transcriptomic data. Bioinformatics. 2023;39:btac805. doi: 10.1093/bioinformatics/btac805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 217.Schindelin J, et al. Fiji: an open-source platform for biological-image analysis. Nat. Methods. 2012;9:676–682. doi: 10.1038/nmeth.2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 218.McQuin C, et al. CellProfiler 3.0: Next-generation image processing for biology. PLoS Biol. 2018;16:e2005970. doi: 10.1371/journal.pbio.2005970. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 219.Berg S, et al. ilastik: interactive machine learning for (bio)image analysis. Nat. Methods. 2019;16:1226–1232. doi: 10.1038/s41592-019-0582-9. [DOI] [PubMed] [Google Scholar]
- 220.Stringer C, Wang T, Michaelos M, Pachitariu M. Cellpose: a generalist algorithm for cellular segmentation. Nat. Methods. 2021;18:100–106. doi: 10.1038/s41592-020-01018-x. [DOI] [PubMed] [Google Scholar]
- 221.Park J, et al. Cell segmentation-free inference of cell types from in situ transcriptomics data. Nat. Commun. 2021;12:3545. doi: 10.1038/s41467-021-23807-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 222.Petukhov V, et al. Cell segmentation in imaging-based spatial transcriptomics. Nat. Biotechnol. 2022;40:345–354. doi: 10.1038/s41587-021-01044-w. [DOI] [PubMed] [Google Scholar]
- 223.Kuemmerle, L. B. et al. Probe set selection for targeted spatial transcriptomics. Preprint at 10.1101/2022.08.16.504115.
- 224.Biancalani T, et al. Deep learning and alignment of spatially resolved single-cell transcriptomes with Tangram. Nat. Methods. 2021;18:1352–1362. doi: 10.1038/s41592-021-01264-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 225.Lopez R, et al. A joint model of unpaired data from scRNA-seq and spatial transcriptomics for imputing missing gene expression measurements. arXiv. 2019 doi: 10.48550/arXiv.1905.02269. [DOI] [Google Scholar]
- 226.Abdelaal T, Mourragui S, Mahfouz A, Reinders MJT. SpaGE: spatial gene enhancement using scRNA-seq. Nucleic Acids Res. 2020;48:e107. doi: 10.1093/nar/gkaa740. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 227.Zhao E, et al. Spatial transcriptomics at subspot resolution with BayesSpace. Nat. Biotechnol. 2021;39:1375–1384. doi: 10.1038/s41587-021-00935-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 228.Pham D, et al. stLearn: integrating spatial location, tissue morphology and gene expression to find cell types, cell-cell interactions and spatial trajectories within undissociated tissues. bioRxiv. 2020 doi: 10.1101/2020.05.31.125658. [DOI] [Google Scholar]
- 229.Hu J, et al. SpaGCN: integrating gene expression, spatial location and histology to identify spatial domains and spatially variable genes by graph convolutional network. Nat. Methods. 2021;18:1342–1351. doi: 10.1038/s41592-021-01255-8. [DOI] [PubMed] [Google Scholar]
- 230.Daly AC, Geras KJ, Bonneau RA. A convolutional neural network for common coordinate registration of high-resolution histology images. Bioinformatics. 2021;37:4216–4226. doi: 10.1093/bioinformatics/btab447. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 231.Andersson A, et al. A landmark-based common coordinate framework for spatial transcriptomics data. bioRxiv. 2021 doi: 10.1101/2021.11.11.468178. [DOI] [Google Scholar]
- 232.Rood JE, et al. Toward a common coordinate framework for the human body. Cell. 2019;179:1455–1467. doi: 10.1016/j.cell.2019.11.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 233.Sun S, Zhu J, Zhou X. Statistical analysis of spatial expression patterns for spatially resolved transcriptomic studies. Nat. Methods. 2020;17:193–200. doi: 10.1038/s41592-019-0701-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 234.Svensson V, Teichmann SA, Stegle O. SpatialDE: identification of spatially variable genes. Nat. Methods. 2018;15:343–346. doi: 10.1038/nmeth.4636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 235.Anderson A, Lundeberg J. sepal: identifying transcript profiles with spatial patterns by diffusion-based modeling. Bioinformatics. 2021;37:2644–2650. doi: 10.1093/bioinformatics/btab164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 236.Fischer DS, Schaar AC, Theis FJ. Modeling intercellular communication in tissues using spatial graphs of cells. Nat. Biotechnol. 2022 doi: 10.1038/s41587-022-01467-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 237.Yuan Y, Bar-Joseph Z. GCNG: graph convolutional networks for inferring gene interaction from spatial transcriptomics data. Genome Biol. 2020;21:300. doi: 10.1186/s13059-020-02214-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 238.Tanevski J, Flores ROR, Gabor A, Schapiro D, Saez-Rodriguez J. Explainable multiview framework for dissecting spatial relationships from highly multiplexed data. Genome Biol. 2022;23:97. doi: 10.1186/s13059-022-02663-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 239.Cang Z, Nie Q. Inferring spatial and signaling relationships between cells from single cell transcriptomic data. Nat. Commun. 2020;11:2084. doi: 10.1038/s41467-020-15968-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 240.Arnol D, Schapiro D, Bodenmiller B, Saez-Rodriguez J, Stegle O. Modeling cell-cell interactions from spatial molecular data with spatial variance component analysis. Cell Rep. 2019;29:202–211.e6. doi: 10.1016/j.celrep.2019.08.077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 241.Kamimoto K, Stringa B, Hoffmann CM. Dissecting cell identity via network inference and in silico gene perturbation. Nature. 2022;614:742–751. doi: 10.1038/s41586-022-05688-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 242.González-Blas CB, et al. SCENIC+: single-cell multiomic inference of enhancers and gene regulatory networks. bioRxiv. 2022 doi: 10.1101/2022.08.19.504505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 243.Brunner A-D, et al. Ultra-high sensitivity mass spectrometry quantifies single-cell proteome changes upon perturbation. Mol. Syst. Biol. 2022;18:e10798. doi: 10.15252/msb.202110798. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 244.Del Rossi N, Chen JG, Yuan G-C, Dries R. Analyzing spatial transcriptomics data using Giotto. Curr. Protoc. 2022;2:e405. doi: 10.1002/cpz1.405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 245.Argelaguet R, Cuomo ASE, Stegle O, Marioni JC. Computational principles and challenges in single-cell data integration. Nat. Biotechnol. 2021;39:1202–1215. doi: 10.1038/s41587-021-00895-7. [DOI] [PubMed] [Google Scholar]
- 246.Mimitou EP, et al. Scalable, multimodal profiling of chromatin accessibility, gene expression and protein levels in single cells. Nat. Biotechnol. 2021;39:1246–1258. doi: 10.1038/s41587-021-00927-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 247.Lake BB, et al. Integrative single-cell analysis of transcriptional and epigenetic states in the human adult brain. Nat. Biotechnol. 2018;36:70–80. doi: 10.1038/nbt.4038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 248.Argelaguet R, et al. MOFA+: a statistical framework for comprehensive integration of multi-modal single-cell data. Genome Biol. 2020;21:111. doi: 10.1186/s13059-020-02015-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 249.Demetci P, Santorella R, Sandstede B, Noble WS, Singh R. SCOT: single-cell multi-omics alignment with optimal transport. J. Comput. Biol. 2022;29:3–18. doi: 10.1089/cmb.2021.0446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 250.Cao K, Bai X, Hong Y, Wan L. Unsupervised topological alignment for single-cell multi-omics integration. Bioinformatics. 2020;36:i48–i56. doi: 10.1093/bioinformatics/btaa443. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 251.Cao ZJ, Gao G. Multi-omics single-cell data integration and regulatory inference with graph-linked embedding. Nat. Biotechnol. 2022;40:1458–1466. doi: 10.1038/s41587-022-01284-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 252.Lance, C. et al. Multimodal single cell data integration challenge: results and lessons learned. in Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track (eds Kiela, D., Ciccone, M. & Caputo, B.) vol. 176 162–176 (PMLR, 2022).
- 253.Ghazanfar S, Guibentif C, Marioni JC. StabMap: mosaic single cell data integration using non-overlapping features. bioRxiv. 2022 doi: 10.1101/2022.02.24.481823. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 254.Lotfollahi M, Litinetskaya A, Theis FJ. Multigrate: single-cell multi-omic data integration. bioRxiv. 2022 doi: 10.1101/2022.03.16.484643. [DOI] [Google Scholar]
- 255.Barshan E, Ghodsi A, Azimifar Z, Zolghadri Jahromi M. Supervised principal component analysis: visualization, classification and regression on subspaces and submanifolds. Pattern Recognit. 2011;44:1357–1371. doi: 10.1016/j.patcog.2010.12.015. [DOI] [Google Scholar]
- 256.Hao Y, et al. Dictionary learning for integrative, multimodal, and scalable single-cell analysis. bioRxiv. 2022 doi: 10.1101/2022.02.24.481684. [DOI] [PMC free article] [PubMed] [Google Scholar]