

Abstract
To deal with situations involving uncertainty, Fermatean fuzzy sets are more effective than Pythagorean fuzzy sets, intuitionistic fuzzy sets, and fuzzy sets. Applications for fuzzy similarity measures can be found in a wide range of fields, including clustering analysis, classification issues, medical diagnosis, etc. The computation of the weights of the criteria in a multi-criteria decision-making problem heavily relies on fuzzy entropy measurements. In this paper, we employ t-conorms to suggest various Fermatean fuzzy similarity measures. We have also discussed all of their interesting characteristics. Using the suggested similarity measurements, we have created some new entropy measures for Fermatean fuzzy sets. By using numerical comparison and linguistic hedging, we have established the superiority of the suggested similarity metrics and entropy measures over the existing measures in the Fermatean fuzzy environment. The usefulness of the proposed Fermatean fuzzy similarity measurements is shown by pattern analysis. Last but not least, a novel multi-attribute decision-making approach is described that tackles a significant flaw in the order preference by similarity to the ideal solution, a conventional approach to decision-making, in a Fermatean fuzzy environment.
Keywords: Fuzzy set, Fermatean fuzzy set, t-Conorm, Similarity measure, Entropy measure, Multi-attribute decision-making
Introduction
To solve problems involving uncertainty more precisely, a new notion known as the Pythagorean fuzzy set (PFS) was put forward by Yager (2013). PFS is a generalized version of fuzzy (Zadeh 1965) and intuitionistic fuzzy sets (Atanassov 1986) (IFSs). A membership and a non-membership degree whose maximum square sum is one is assigned to each element in a PFS. The Pythagorean fuzzy number and the technique for order of preference by similarity to the ideal solution (TOPSIS) in a Pythagorean fuzzy (PF) environment were proposed by Zhang and Xu (2014). Yager (2014) provided several PF aggregating functions and their usefulness in decision-making. Wei and Lu (2018) developed some PF power aggregation functions. Garg (2016) suggested some new aggregating functions for the PF environment utilizing Einstein operations. Wei (2017) proposed many PF interaction aggregation functions and discussed their applicability to multi-attribute decision-making (MADM). The literature has numerous studies (Garg 2017; Lu et al. 2017; Wei et al. 2017; Wei and Lu 2017) on the PF aggregating functions and their applicability. The TODIM (multi-criteria decision-making in Portuguese) in the PF setting was developed by Ren et al. (2016). Many PF measures of information were proposed by Peng et al. (2017). A new PF distance metric was proposed by Peng and Dai (2017). Singh and Ganie (2020) developed a few PF metrics of correlation with their utility. PFSs have been examined and implemented by numerous researchers (Garg 2019a, b; Khan et al. 2019a, b; Akram and Ali 2020; Ejegwa 2020a, b; Rahman et al. 2020; Zhang et al. 2021; Olgun et al. 2021; Mishra et al. 2021; Zeb et al. 2022; Wang et al. 2022; Ganie 2022, 2023; Ganie et al. 2022; Akram and Bibi 2023; Ejegwa et al. 2023; Aldring and Ajay 2023; Kirişci 2023; Akram et al. 2023b; Akram et al. 2023a, c) in various uncertain situations. Chen and Chiou (2015) and Zeng et al. (2020) discussed the applicability of interval-valued IFSs to MADM problems. Although PFSs have many uses in a variety of domains, they are unable to handle circumstances where . For instance, if and , then . Senapati and Yager’s (2020) concept of Fermatean fuzzy sets was thus proposed (FFSs). We have in a Fermatean fuzzy set (FFS). FFSs are more robust and effective than FSs, IFSs, and PFSs because these all fall in the space of FFSs. Senapati and Yager (2019) provided a list of FFS aggregation operators and their potential applications in decision-making. Mishra and Rani (2021) proposed the weighted aggregated sum product assessment (WASPAS) method in the Fermatean fuzzy (FF) environment. Keshavarz-Ghorabaee et al. (2020) presented an innovative FF decision-making approach. Garg et al. (2020) demonstrated the use of FF aggregating functions in the COVID-19 testing facility. The continuities and derivatives of FF functions were researched by Yang et al. (2021). Sergi and Sari (2021) suggested a few FF capital budgeting strategies. Sahoo (2021a, b) suggested a few score functions for FFSs and discussed their use in solving transportation-related problems and making decisions. Aydemir and Yilmaz (2020) introduced the FF TOPSIS technique. Some FF aggregating functions based on Einstein’s norm were proposed by Akram et al. (2020). There are some investigations of FFSs and their real-world applications in the literature (Salsabeela and John 2021; Aydın 2021; Gul et al. 2021; Hadi et al. 2021; Shit and Ghorai 2021; Rani and Mishra 2021; Akram et al. 2022, 2023d; Mishra et al. 2022a, b, 2023; Ali and Ansari 2022; Zhou et al. 2022; Luqman and Shahzadi 2023). The creation of several FF similarity and entropy measurements is discussed in this study.
Based on the content of equality, two things can be compared very effectively using similarity measurements. Zhang (2016) introduced a PF metric of similarity and applied it to a decision-making problem. Many novel PF measurements of distance and similarity were given by Peng (2019). Based on the cosine function, some PF measurements of similarity were proposed by Wei and Wei (2018). Mohd and Abdullah (2018) created several innovative PF similarity metrics by fusing the Euclidean distance measure with cosine similarity measures. By considering all three membership grades Ejegwa (2020a) presented many PF metrics of similarity and distance. The applicability of some PF metrics of similarity and distance in MADM was shown by Zeng et al. (2018). A Hausdorff PF similarity metric was suggested by Hussain and Yang (2019). Zhang et al. (2019) developed some exponential PF similarity metrics and showed how they may be used for pattern identification, MADM, and medical diagnostics. Li and Lu (2019) provided a few complement-based, matching function-based, and set theoretic-based PF similarity measurements. Wang et al. (2019) provided some PF Dice similarity measures with applications in decision-making. Some trigonometric function-based PF metrics of similarity were created by Verma and Merigo (2019). Peng and Garg (2019) highlighted how several multi-parametric PF measures of similarity can be used in classification challenges.
A PFS’s ambiguous content determines its entropy. In a MADM problem involving PF information, the attribute weights are computed using entropy measures. Xue et al. (2018) defined the entropy function for PFSs and its usage in decision-making. Yang and Hussain (2018) provided some probabilistic and nonprobabilistic PF entropy measurements. Thao and Smarandache (2019) introduced the CORPAS MADM approach in the PF environment with the use of a new PF entropy measure. Five FF entropy measurements were introduced by Mishra and Rani (2021).
The following are the main causes that motivated us to carry out this study.
Several domains, including clustering, decision-making, pattern detection, etc., use fuzzy sets' similarity metrics and their various extensions. The FFS similarity measures, however, have not yet been properly investigated.
The majority of the proposed formula-level fuzzy similarity metrics, both standard and non-standard, do not adhere to the axiomatic requirements. Thus, there is no technique that can be applied repeatedly to assess similarity.
The five FF entropy measurements (Olgun et al. 2021) are worthless from the standpoint of linguistic hedging, and there is no standard method for creating the FF entropy measurements.
The conventional MADM technique i.e., TOPSIS provides a compromise solution that is most similar to the PIS (positive ideal solution), but not the least similar to the NIS (negative ideal solution). So, a new decision-making method is desirable.
The contribution of this paper is given below:
We suggest four metrics of similarity for FFSs along with their weighted equivalents.
We suggest four metrics of entropy for FFSs using the suggested FF metrics of similarity.
We contrast the performance of the proposed FF information measures with the available measures.
We apply the FF similarity metrics in classification problems.
We introduce an innovative decision-making method in the FF setting.
Section 2 of the paper is preliminary. Section 3 lists many unique FF similarity measurements along with desirable characteristics. A few similarity-based FF entropy measurements are introduced in Sect. 4. Section 5 displays a comparison of the proposed FF entropy and similarity metrics with the current FF/PF compatibility metrics. The use of the suggested similarity measures in pattern identification is illustrated in Sect. 6. In Sect. 7, a new MADM technique for the FF environment is proposed. The benefits and implications of the suggested FF similarity metrics, entropy measures, and the new MADM method are covered in Sect. 8. Section 9 provides the conclusion and recommendations for further research.
Preliminaries
Let denote the collection of all FFSs of the universal set .
Definition 1
(Yager 2013) A PFS in is defined as
Here, is the grade of membership and is the grade of non-membership of the element in with the conditions that and . Further, is the grade of the hesitancy of the element in .
An example of a PFS is Here, we see that but .
Definition 2
(Senapati and Yager 2020) An FFS in is defined as
Here, is the grade of membership and is the grade of non-membership of the element in with the conditions that and . Further, is the grade of the hesitancy of the element in .
An example of an FFS is . Here, we see that , but .
Definition 3
(Senapati and Yager 2020) Let , then some operations are listed below.
iff and .
For example, consider the two FFSs given as
Then,
because and .
Definition 4
(Peng et al. 2017) A PF similarity measure is a function such that and ,
.
.
iff .
iff is a crisp set, where denotes the complement.
If , then and .
An example of a PF similarity measure is given below:
Definition 5
(Peng et al. 2017) A PF distance measure is a function such that and ,
.
.
iff .
iff is a crisp set, where denotes the complement.
If , then and .
An example of a PF similarity measure is given below:
Definition 6
(Mishra and Rani 2021) An FF entropy measure is a function such that and ,
iff is a crisp set.
iff .
where denotes the complement.
, if or .
An example of FF entropy is given below:
Definition 7
(Weber 1983) A t-conorm is a function if
.
whenever and .
.
.
An example of a t-conorm is .
We offer some innovative similarity measures for FFSs along with their characteristics in the following section.
New Fermatean fuzzy similarity measures
Here, we suggest a few FF similarity measurements. A similarity metric is first defined in the FF environment.
Definition 8
An FF similarity measure is a function such that and :
.
.
iff .
iff is a crisp set, where denotes the complement.
If , then and .
We now present a novel technique for deriving FF similarity metrics from t-conorms.
Definition 9
For let be a function defined as
| 1 |
Here, is a t-conorm.
Theorem 1
in Eq. ( 1 ) is a valid measure of similarity for FFSs.
Proof
We will establish that satisfies the characteristic of a metric of similarity for FFSs listed in Definition 8.
(SM1) It is obvious.
(SM2) follows from the definition of .
(SM3) and , and , .
(SM4) and , , and or and and or and is a crisp set.
(SM5) Let , then and . Then, we have
and
So, and
Thus and . Hence, is a similarity measure for FFSs.
Theorem 2
The measure of similarity in Eq. (1) possesses the following characteristics.
.
.
if and only if .
, for every .
, for every .
Proof 1.
2.
3.
and
4. .
Now, there are the following cases:
- When and , then
- When and , then
- When and , then
- When and , then
5. .
Now, there are the following cases:
- When and , then
- When and , then
- When and , then
- When and , then
Example 1
Table 1 provides some examples of FF similarity measurements.
Table 1.
FF similarity measurements
| t-Conorms | FF similarity measures |
|---|---|
Next, we construct the weighted metrics of similarity for FFSs.
Definition 10
For let the function be defined as
| 2 |
where is a t-conorm.
Theorem 2
given in Eq. (1) is a valid weighted measure of similarity for FFSs.
Proof
Same as Theorem 1.
Example 2
Table 2 provides some examples of weighted FF similarity measurements.
Table 2.
Some examples of weighted FF similarity measurements
| t-Conorms | FF-weighted similarity measures |
|---|---|
Some similarity-based metrics of entropy for FFSs are given in the next section.
Entropy measures based on FF similarity measures
The degree of ambiguity in an FFS is determined using the entropy measures. In this section, we present a technique for creating FF entropy measurements using FF similarity measures.
Definition 11
For , let the function be defined as
| 3 |
with a similarity measure of FFSs.
Theorem 3
in Eq. (3) is a valid measure of entropy for FFSs.
Proof
We demonstrate that the function has the characteristics of an FF measure of entropy listed in Definition 6.
(EM1) It is obvious as .
(EM2) is a crisp set.
(EM3) .
(EM4) follows by the definition of .
(EM5) Consider to be less fuzzy than , i.e., or
When , we have . So,
Thus, .
Similarly, for , we have . Hence, in Eq. (3) is a valid measure of entropy for FFSs.
Some FF measurements of entropy are provided in Table 3 below using Eq. (3) and the recommended FF measures of similarity.
Table 3.
Some examples of FF entropy measures
| Recommended FF similarity measures | FF entropy measures |
|---|---|
Now, we contrast several existing PF/FF measures of information with the suggested FF measures of similarity and entropy.
Comparative analysis
In this part, we demonstrate that the proposed FF measures of similarity and entropy outperform the majority of existing PF/FF measures of information in terms of accuracy.
Comparability of the proposed metrics of similarity for FFSs with the several available metrics
For comparability, we first recall the available metrics of distance and similarity. These are shown in Tables 4 and 5 respectively.
Table 4.
Some existing PF measures of similarity (Peng et al. 2017)
| Similarity measure | Expression |
|---|---|
Table 5.
Some existing PF measures of distance (Peng et al. 2017)
| Distance measures | Expression |
|---|---|
Now, we examine three distinct FFS situations, each of which consists of two distinct FFSs. Table 6 displays the values of comparability.
Table 6.
Values of comparability
| Compatibility measure | Case I |
Case I |
Case I |
|---|---|---|---|
| 0.9100 | 0.9100 | 0.5000 | |
| 0.9550 | 0.9300 | 1 | |
| 0.8650 | 0.8150 | 0.7500 | |
| 0.9100 | 0.9100 | 0.7500 | |
| 0.8349 | 0.8349 | 0.6000 | |
| 0.8349 | 0.8349 | 0.6000 | |
| − 0.5080 | − 0.1191 | 0 | |
| − 0.5080 | − 0.1191 | 0 | |
| 0.6400 | 0.6400 | 0 | |
| 0.6400 | 0.6400 | 0 | |
| 0.9224 | 0.8843 | 0.6000 | |
| 0.9224 | 0.8843 | 0.6000 | |
| 0.0900 | 0.0900 | 0.5000 | |
| 0.0450 | 0.0700 | 0 | |
| 0.1350 | 0.1850 | 0.2500 | |
| 0.0900 | 0.0900 | 0.2500 | |
| 0.1651 | 0.1651 | 0.4000 | |
| 0.1651 | 0.1651 | 0.4000 | |
| 0.1080 | 0.4969 | 1 | |
| 0.1080 | 0.4969 | 1 | |
| 0.3600 | 0.3600 | 1 | |
| 0.3600 | 0.3600 | 1 | |
| 0.0776 | 0.1157 | 0.4000 | |
| 0.0776 | 0.1157 | 0.4000 | |
| 0.9390 | 0.9222 | 0.7778 | |
| 0.9390 | 0.9212 | 0.7656 | |
| 0.9390 | 0.9200 | 0.7500 | |
| 0.9390 | 0.9201 | 0.7538 |
Unreasonable results are indicated by bold values
From Table 6, we observe
The similarity metrics and distance metrics consider the FFSs (Case I) and (Case II) to be the same, which is unreasonable.
The similarity metric gives 1 as the similarity level between the FFSs (Case III), which is unreasonable as .
The level of similarity between the FFSs (Case I and Case II) comes out to be negative by the similarity metrics and thus violates the non-negativity property of a similarity metric.
The similarity metrics , and gives 0 as the similarity level between the FFSs (Case III), which is unreasonable as is not a complement of .
The distance metrics , and gives 1 as the similarity level between the FFSs (Case III), which is unreasonable as is not a complement of .
The suggested metrics of similarity produce satisfactory results in all three cases.
Thus, we conclude that most of the available compatibility measures produce unreasonable results as shown by bold values, whereas the newly suggested measures of similarity give satisfactory results in all three cases. This establishes the effectiveness of the suggested similarity measures.
Next, we contrast the proposed FF entropy measures with the existing PF/FF entropy metrics.
Comparison of the proposed FF entropy measurements with the existing PF/FF entropy measures
For comparability, we first enumerate the available metrics of entropy for FFSs/PFSs as shown in Table 7.
Table 7.
Some existing PF/FF measures of entropy (Xue et al. 2018; Yang and Hussain 2018; Thao and Smarandache 2019; Senapati and Yager 2020; Mishra and Rani 2021)
| Entropy measure | Expression |
|---|---|
Now, we demonstrate the usefulness of the recommended FF measurements of entropy using linguistic hedges.
Definition 12
(Senapati and Yager 2020) The modifier of an FFS is given by
| 4 |
Now, we consider the following FFSs:
LARGE: , very LARGE: , quite very LARGE: , very very LARGE: , more or less LARGE: .
, the entropy must meet the following criteria since it computes the ambiguity content in an FFS.
| 5 |
We now take a look at an illustration of how the aforementioned FFSs compute ambiguity.
Example 3
Consider as
We form the FFSs , and with the aid of Definition 12. Table 8 displays the amount of ambiguity present in these FFSs.
Table 8.
Computed values of several measures of entropy concerning Example 3
| 0.5229 | 0.6056 | 0.7101 | 0.8650 | 0.8455 | |
| 0.1422 | 0.1598 | 0.1782 | 0.1919 | 0.1829 | |
| 0.6867 | 0.7717 | 0.8602 | 0.9266 | 0.8831 | |
| 0.6867 | 0.7717 | 0.8602 | 0.9266 | 0.8831 | |
| 0.2731 | 0.3612 | 0.4943 | 0.6880 | 0.6248 | |
| 0.3155 | 0.4224 | 0.5296 | 0.6782 | 0.6670 | |
| 1.5283 | 1.4081 | 1.2429 | 0.9902 | 0.8592 | |
| 0.3640 | 0.4785 | 0.5750 | 0.7412 | 0.7209 | |
| 0.3640 | 0.4785 | 0.5750 | 0.7412 | 0.7209 | |
| 12.0414 | 12.0963 | 12.1659 | 12.2385 | 12.2186 | |
| 1.2769 | 1.2909 | 1.3087 | 1.3275 | 1.3222 | |
| 0.0836 | 0.1677 | 0.1497 | 0.3864 | 0.4849 | |
| 0.3155 | 0.4260 | 0.5296 | 0.7311 | 0.7176 | |
| 0.1873 | 0.2706 | 0.3602 | 0.5762 | 0.5596 | |
| 0.3050 | 0.4183 | 0.5062 | 0.6900 | 0.6761 | |
| 0.3849 | 0.4778 | 0.5188 | 0.6659 | 0.6692 | |
| 0.3241 | 0.4210 | 0.4680 | 0.6339 | 0.6404 | |
| 0.2212 | 0.3082 | 0.3731 | 0.5636 | 0.6046 | |
| 0.2939 | 0.3890 | 0.4325 | 0.6094 | 0.6238 |
From Table 8, we observe that
Therefore, it follows that none of the PF/FF measurements of entropy that are currently available satisfy the condition stated in Eq. (5). All of our FF entropy metrics , however, adhere to the specification outlined in Eq. (5). This demonstrates that the recommended measurements of entropy are more reliable than the ones that are already available from the perspective of a linguistic hedge.
The applicability of the proposed similarity metrics in pattern identification
Here, we demonstrate how the suggested FF measures of similarity can be applied to address pattern classification-related issues. In pattern analysis, an unidentified pattern is categorized into one of the recognized patterns by applying several compatibility criteria, such as “similarity”, “distance”, “correlation”, etc. We also compare our findings to the various similarity metrics.
Now, using the examples below, we will solve several pattern analysis-related issues.
Example 4
(Jiang et al. 2019) Consider , and representing patterns in terms of FFSs.
The challenge is to determine which pattern shares the most similarities with . We use the existing metrics of similarity with the recommended FF similarity measurements for this aim. Table 9 displays the computed results. Table 9 makes it obvious that should be assigned to based on the majority of similarity metrics, including the specified FF metrics.
Table 9.
Computed values of several similarity metrics about Example 4
| Similarity measure | Result | |||
|---|---|---|---|---|
| 0.9824 | 0.9829 | 0.9792 | ||
| 0.9851 | 0.9869 | 0.9833 | ||
| 0.9837 | 0.9849 | 0.9813 | ||
| 0.9824 | 0.9829 | 0.9792 | ||
| 0.9655 | 0.9665 | 0.9595 | ||
| 0.0173 | 0.0168 | 0.0204 | ||
| 0.8431 | 0.8560 | 0.8242 | ||
| 0.7237 | 0.7152 | 0.7494 | ||
| 0.5639 | 0.5503 | 0.5923 | ||
| 0.8348 | 0.8547 | 0.8188 | ||
| 0.9694 | 0.9719 | 0.9643 | ||
| 0.9690 | 0.9728 | 0.9654 | ||
| 0.9854 | 0.9872 | 0.9827 | ||
| 0.9854 | 0.9872 | 0.9826 | ||
| 0.9853 | 0.9872 | 0.9825 | ||
| 0.9853 | 0.9872 | 0.9825 |
Example 5
Consider , and representing patterns in terms of FFSs.
The challenge is to determine which pattern shares the most similarities with . We use the existing metrics of similarity with the recommended FF similarity measurements for this aim. Table 10 and Fig. 1 both display the computed results. As can be seen from Table 10, the majority of the measures indicate that should be assigned to .
Table 10.
Computed values of several similarity metrics concerning Example 5
| Similarity measure | Result | |||
|---|---|---|---|---|
| 0.7840 | 0.8000 | 0.8860 | ||
| 0.8590 | 0.9030 | 0.9280 | ||
| 0.8215 | 0.8515 | 0.9070 | ||
| 0.7940 | 0.8260 | 0.8860 | ||
| 0.6868 | 0.7291 | 0.8075 | ||
| 0.1708 | 0.1482 | 0.1023 | ||
| 0.3429 | 0.3147 | 0.6027 | ||
| 0.4036 | 0.3094 | 0.4911 | ||
| 0.3749 | 0.4024 | 0.6498 | ||
| 0.3041 | 0.3627 | 0.6418 | ||
| 0.7707 | 0.8130 | 0.8870 | ||
| 0.7545 | 0.8026 | 0.8873 | ||
| 0.8321 | 0.8619 | 0.9096 | ||
| 0.8257 | 0.8585 | 0.9083 | ||
| 0.8158 | 0.8534 | 0.9068 | ||
| 0.8197 | 0.8552 | 0.9070 |
Fig. 1.
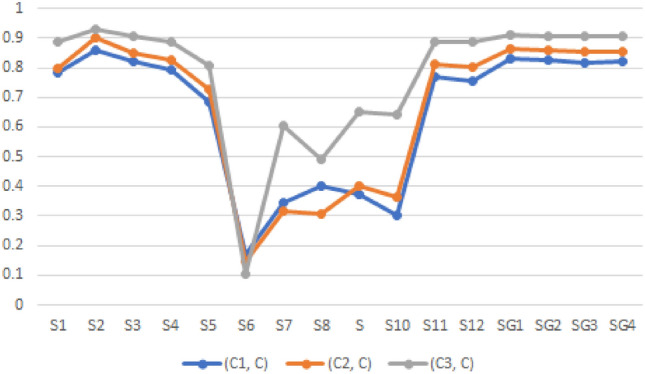
Similarity values regarding Example 5
From examples 4 and 5, we conclude that the recommended similarity metrics of FFSs are compatible with the current similarity metrics in terms of pattern recognition.
We now demonstrate the usefulness of the FF entropy and similarity measurements in decision-making.
An innovative Fermatean fuzzy MADM approach
In this section, we first go over the shortcomings of the conventional Fermatean fuzzy TOPSIS method. Then, under the FF circumstances, we present a novel MADM approach that is similar to TOPSIS.
Flaws of Fermatean fuzzy TOPSIS method
One of the most popular and efficient approaches for solving MADM problems is the methodology for order preference by similarity to ideal solution (TOPSIS), which was first put out by Hwang and Yoon (1981) and then extended to the fuzzy environment by Chen (2000). The TOPSIS method is predicated on the notion that the best choice should be the one that is farthest from the NIS and closest to the PIS. The selected alternative should have the lowest similarity to NIS and the highest similarity to PIS if we use the similarity metric in TOPSIS rather than the distance measure. The TOPSIS-selected alternative, however, does not have a minimum similarity to NIS, as can be shown in the examples below.
Example 6
Take into consideration a FF decision matrix with three options , and two characteristics .
Then, PIS and NIS are and . Table 11 and Fig. 2 display how similar each alternative is to i.e., and i.e., and their closeness coefficient The same Table 11 also displays the alternatives’ final rankings. Table 11 makes it evident that there is no minimum similarity between the best alternative and the NIS as .
Table 11.
Computed values related to Example 6
| Alternative | Ranking | |||
|---|---|---|---|---|
| 0.8085 | 0.8620 | 0.5160 | 2 | |
| 0.9198 | 0.7954 | 0.4637 | 3 | |
| 0.8232 | 0.8037 | 0.5205 | 1 |
Fig. 2.
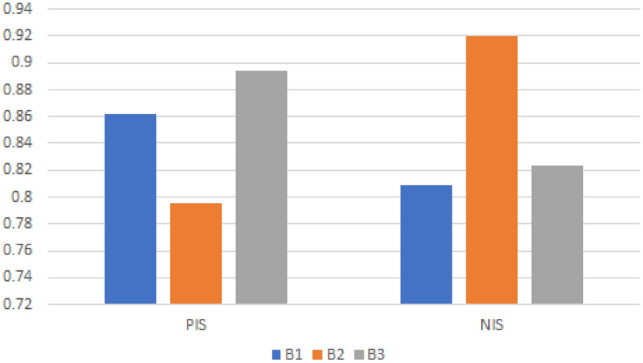
Alternatives’ similarity with PIS and NIS concerning Example 6
Example 7
Take into consideration an FF decision matrix with three options , and two characteristics .
Then PIS and NIS are and . Table 12 and Fig. 3 display how similar each alternative is to i.e., and i.e., and their closeness coefficient The same Table 12 also displays the alternatives’ final rankings. Table 12 makes it evident that there is no minimum similarity between the best alternative and the NIS as .
Table 12.
Computed values related to Example 7
| Alternative | Ranking | |||
|---|---|---|---|---|
| 0.8051 | 0.8378 | 0.5099 | 3 | |
| 0.7531 | 0.8460 | 0.5291 | 1 | |
| 0.7202 | 0.7814 | 0.5204 | 2 |
Fig. 3.
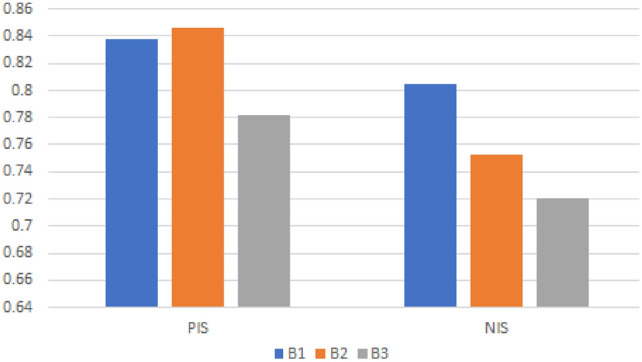
Alternatives’ similarity with PIS and NIS concerning Example 7
The ideal TOPSIS alternative does not possess low similarity with NIS, as seen in Examples 6 and 7. To overcome this severe issue, we suggest the inferior ratio method in the FF environment known as the Fermatean fuzzy inferior ratio (FFIR) method. This is based on the same principle as that of TOPSIS.
Fermatean fuzzy inferior ratio (FFIR) method
Our suggested method produces an alternative that is the least identical to NIS and the most similar to PIS. The algorithm for solving an MCDM problem with choices and criteria and as criteria weights, where and is given below.
Algorithm
Step 1: Create the decision matrix to convey information about the options concerning the criteria.
Step 2: Create the normalized decision matrix with
Step 3: Find the criteria weights using the FF entropy measure as , with being a FF measure of entropy.
Step 4: Find the PIS
and the NIS
where , and ,
Step 5: Determine the similarity of each alternative with the PIS and NIS with the help of the newly introduced FF-weighted measures of similarity, i.e., find and and
Step 6: Determine , where and so if , the alternative has maximum similarity with PIS.
Step 7: Determine , where and so if , the alternative has minimum similarity with NIS.
Step 8: Determine It is obvious that represents the amount to which an option has the least and greatest similarity with NIS and PIS, respectively, at the same time. The option for which is the best choice.
Step 9: Compute the FFIR .
Step 10: In the increasing order of the values of , we rank the alternatives.
In the example that follows, we apply the suggested FFIR approach to resolve a MADM issue with FF data.
Example 8
(Singh and Ganie 2022) Consider the issue of choosing a home among the five homes . Take into account the following factors: : Ventilation, : Purchase price, : Location, : Design, : Ceiling height. The decision matrix below illustrates how the information regarding the five houses in relation to the five aforementioned criteria is expressed as FFSs.
Given that the criteria is a cost attribute, the normalized decision matrix is provided below using Step 2:
We acquire the following criteria weights using Step 3 and the suggested entropy measure presented in Table 3: and .
The FF PIS and FF NIS are then provided using Step 4.
Then using the suggested similarity measure we calculate the similarity values of each alternative with the FF PIS and FF NIS . Then we get and
Then for each alternative, we determine and . Finally, we rank the alternatives in increasing order of the values of . All these computations are listed in Table 13 and shown in Fig. 4. Table 13 also provides the ranking results for the other there suggested weighted similarity measures .
Table 13.
Computed values for Example 8 based on the suggested FF similarity measure
| Similarity measure | Alternative | Ranking | |||
|---|---|---|---|---|---|
| (proposed) | 0.9414 | 0.9472 | − 0.0243 | 2 | |
| 0.9307 | 0.9594 | 0 | 1 | ||
| 0.9595 | 0.9216 | − 0.0703 | 5 | ||
| 0.9571 | 0.9304 | − 0.0586 | 3 | ||
| 0.9610 | 0.9260 | − 0.0674 | 4 | ||
| (proposed) | 0.9365 | 0.9438 | − 0.0248 | 2 | |
| 0.9255 | 0.9562 | 0 | 1 | ||
| 0.9594 | 0.9165 | − 0.0781 | 5 | ||
| 0.9551 | 0.9249 | − 0.0648 | 3 | ||
| 0.9590 | 0.9210 | − 0.0730 | 4 | ||
| (proposed) | 0.9256 | 0.9374 | − 0.0285 | 2 | |
| 0.9128 | 0.9512 | 0 | 1 | ||
| 0.9592 | 0.9047 | − 0.0998 | 3 | ||
| 0.9515 | 0.9115 | − 0.0842 | 4 | ||
| 0.9559 | 0.9047 | − 0.0932 | 5 | ||
| (proposed) | 0.9325 | 0.9409 | − 0.0520 | 2 | |
| 0.9216 | 0.9534 | 0 | 1 | ||
| 0.9593 | 0.9125 | − 0.0838 | 5 | ||
| 0.9535 | 0.9208 | − 0.0688 | 3 | ||
| 0.9573 | 0.9174 | − 0.0765 | 4 |
Fig. 4.
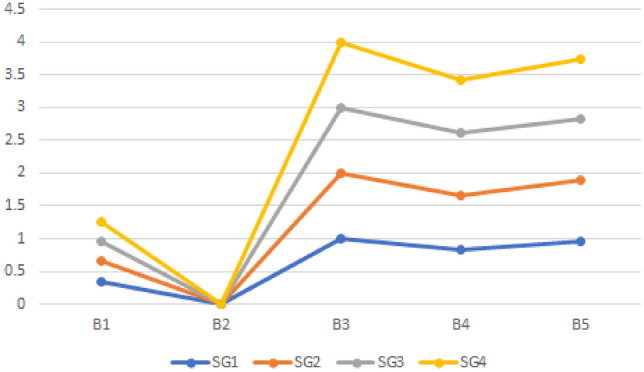
FFIR values corresponding to the proposed four FF similarity measures
We conclude from Table 13 and Figs. 5, 6, 7 and 8 that is the most practical choice because all recommended FF similarity measures show the same results. We can see from Table 13 and Figs. 5, 6, 7 and 8 that the optimal alternative is most similar to PIS while being least similar to NIS .
Fig. 5.
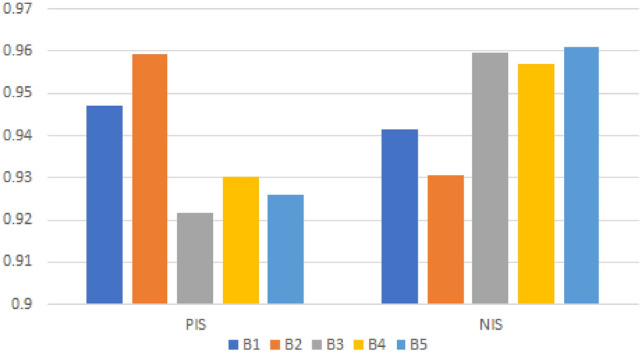
Alternatives’ similarity using
Fig. 6.
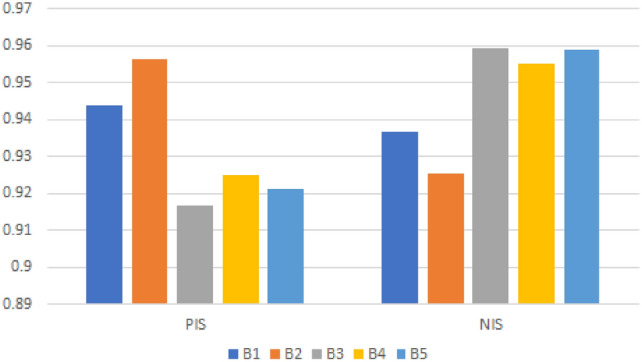
Alternatives’ similarity using
Fig. 7.
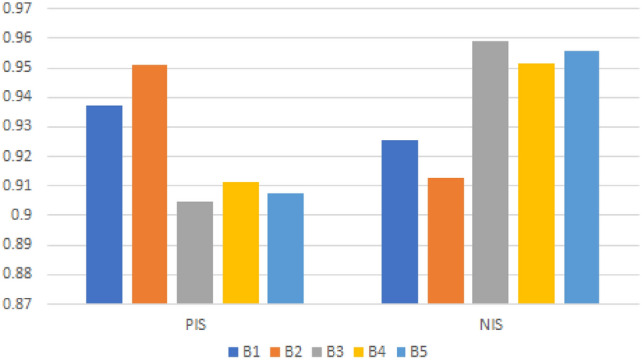
Alternatives’ similarity using
Fig. 8.
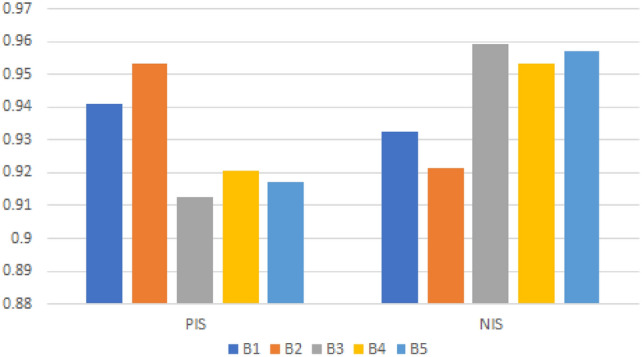
Alternatives’ similarity using
Discussion and comparative analysis
In the vast quantity of studies on the topic, applications for fuzzy and non-standard fuzzy information measures can be found in MADM, pattern recognition, clustering analysis, picture segmentation, etc. In a certain situation, both activities appear to have the same outcome. Yet, it could provide a variety of results. For instance, in a MADM situation, the ranks of the alternatives may vary depending on the fuzzy entropy or fuzzy knowledge metrics used. When evaluating the compatibility of two fuzzy sets, we may obtain different results with alternate fuzzy similarity/distance/accuracy metrics. This seems to be due to the fuzzy/non-standard fuzzy information measure's failure to accurately represent the ambiguity or precision present in the fuzzy/non-standard fuzzy sets under consideration. As a result, when modeling a specific fuzzy system, we must carefully assess the fuzzy/non-standard fuzzy information measurements. There are many reasons given in the literature for picking a fuzzy information/compatibility measure in a certain situation. The noteworthy ones involve computations for weight, similarity/distance, and linguistic hedging, among other things. The significance of our recommended similarity and entropy metrics are then justified.
We have devised a method for creating the FF similarity measures from t-conorms in Sect. 3 . In Theorem 2, we went through a few of their fresh features. By computing the similarity between several FFSs, we have demonstrated in Sect. 5 that the suggested similarity metrics are preferable. Table 6 has three different FFS situations, each of which consists of two different FFSs. In these three circumstances, while calculating the degree of similarity between the FFSs, we found that the majority of the existing distance and similarity metrics did not produce the desired results, and some of them even failed to meet the necessary axiomatic requirements. Nonetheless, the suggested similarity measures handled all three scenarios correctly and without creating any illogical circumstances. We have demonstrated in Sect. 6 how the recommended similarity measures can be applied to the classification problems and we have also noted that the suggested similarity metrics produce satisfactory results.
With the suggested FF similarity measures, we have demonstrated how to create several innovative FF entropy measures in Sect. 4. Additionally, we have proven that these entropy measurements meet all axiomatic constraints for FF entropy measures. We used linguistic hedges in Sect. 5.2 to demonstrate how the suggested entropy metrics outperform the current entropy measures. Only the suggested entropy measures are found to perform in accordance with the desired condition stated in Eq. (5) in the numerical example studied in this Sect. 5.2. Also, we've shown how to use them to calculate attribute weights in a MADM problem in Sect. 7.2 (Step 3 of Algorithm).
Finding the best option out of all those that are offered is the ultimate goal of a MADM technique. The alternative that is most similar to the positive ideal solution (PIS) and least similar to the negative ideal solution is the ideal alternative (NIS). In contrast, we have demonstrated in Examples 6 and 7 that the optimal option resulting from TOPSIS has maximum similarity to PIS but not least resemblance to NIS. However, the suggested FFIR method gives us the optimal option that is close to PIS and at the same time is far from the NIS as can be seen in Table 13.
The benefits of the novel MADM technique, the suggested entropy metrics, and similarity measures are outlined below.
The suggested method of obtaining the new similarity measures from t-conorms can be used in many recent generalizations of fuzzy sets.
Since the present entropy methods yield inaccurate results, the ambiguity content of FFSs can be calculated using similarity-based entropy measurements.
The suggested similarity metrics can be used for image processing, identifying construction materials, and bidirectional approximate reasoning, among other things.
The TOPSIS method has a significant flaw that causes it to provide irrational results, hence the newly developed MADM approach, the FFIR method, can be used in its substitute.
In addition to the benefits already described, one drawback of the suggested methods is that they are challenging to implement in real-world situations with the crisp data found in repositories and other websites that are similar to them. The suggested actions can be put into practice by either developing a linguistic database or applying certain conversion procedures.
Conclusion
This article presents a novel method for the creation of various similarity metrics and entropy measures for FFSs. First, four new similarity measures were created, and then utilizing the suggested similarity measurements, four new entropy measures were established. The proposed measures of similarity outperform the majority of the PF distance/similarity metrics reported in the literature in terms of the distance or degree of similarity between different PFSs/FFSs. The suggested entropy metrics for FFSs are also more dependable than the existing PF/FF entropy measures from the linguistic hedge standpoint. The suggested FF similarity measurements have achieved satisfactory results in pattern analysis. A compromise solution that has the most similarity to PIS and the least similarity to NIS was created using the recently proposed MADM methodology, commonly known as the FFIR method.
We will further present examples of clustering and medical diagnostics using the proposed FFS similarity metrics. Additionally, we will add some more recent generalizations of FSs, such as picture fuzzy sets (Cuong and Kreinovich 2013), spherical fuzzy sets (Mahmood et al. 2019), complex fuzzy sets (Ramot et al. 2002), etc., into the suggested method for calculating similarity and entropy measurements. We will also extend the newly introduced MADM method to the recent extensions of fuzzy sets.
Acknowledgements
The authors extend their appreciation to the editor and anonymous reviewers for their valuable suggestions to bring this paper to the present form.
Author contributions
All authors contributed equally.
Data availability
All data generated or analyzed during this study are included in this published article.
Declarations
Conflict of interest
The authors declare that they do not have any conflict of interest.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Reham A. Alahmadi, Email: r.alhmadi@seu.edu.sa
Abdul Haseeb Ganie, Email: ahg110605@gmail.com.
Yousef Al-Qudah, Email: y.alqudah@aau.edu.jo, Email: alquyousef82@gmail.com.
Mohammed M. Khalaf, Email: khalfmohammed2003@yahoo.com
Abdul Hamid Ganie, Email: a.ganie@seu.edu.sa.
References
- Akram M, Ali G. Hybrid models for decision-making based on rough Pythagorean fuzzy bipolar soft information. Granul Comput. 2020;5:1–15. doi: 10.1007/s41066-018-0132-3. [DOI] [Google Scholar]
- Akram M, Bibi R. Multi-criteria group decision-making based on an integrated PROMETHEE approach with 2-tuple linguistic Fermatean fuzzy sets. Granul Comput. 2023 doi: 10.1007/s41066-022-00359-6. [DOI] [Google Scholar]
- Akram M, Shahzadi G, Ahmadini AAH. Decision-making framework for an effective sanitizer to reduce COVID-19 under Fermatean fuzzy environment. J Math. 2020;2020:1–19. doi: 10.1155/2020/3263407. [DOI] [Google Scholar]
- Akram M, Muhiuddin G, Santos-García G. An enhanced VIKOR method for multi-criteria group decision-making with complex Fermatean fuzzy sets. Math Biosci Eng. 2022;19:7201–7231. doi: 10.3934/mbe.2022340. [DOI] [PubMed] [Google Scholar]
- Akram M, Khan A, Ahmad U. Extended MULTIMOORA method based on 2-tuple linguistic Pythagorean fuzzy sets for multi-attribute group decision-making. Granul Comput. 2023;8:311–332. doi: 10.1007/s41066-022-00330-5. [DOI] [Google Scholar]
- Akram M, Muhammad G, Ahmad D. Analytical solution of the Atangana–Baleanu–Caputo fractional differential equations using Pythagorean fuzzy sets. Granul Comput. 2023 doi: 10.1007/s41066-023-00364-3. [DOI] [Google Scholar]
- Akram M, Nawaz HS, Kahraman C. Rough Pythagorean fuzzy approximations with neighborhood systems and information granulation. Expert Syst Appl. 2023;218:119603. doi: 10.1016/j.eswa.2023.119603. [DOI] [Google Scholar]
- Akram M, Shahzadi G, Davvaz B. Decision-making model for internet finance soft power and sportswear brands based on sine-trigonometric Fermatean fuzzy information. Soft Comput. 2023;27:1971–1983. doi: 10.1007/s00500-022-07060-5. [DOI] [Google Scholar]
- Aldring J, Ajay D. Multicriteria group decision making based on projection measures on complex Pythagorean fuzzy sets. Granul Comput. 2023;8:137–155. doi: 10.1007/s41066-022-00321-6. [DOI] [Google Scholar]
- Ali G, Ansari MN. Multiattribute decision-making under Fermatean fuzzy bipolar soft framework. Granul Comput. 2022;7:337–352. doi: 10.1007/s41066-021-00270-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Atanassov KT. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986;20:87–96. doi: 10.1016/S0165-0114(86)80034-3. [DOI] [Google Scholar]
- Aydemir SB, Yilmaz SG. Fermatean fuzzy TOPSIS method with Dombi aggregation operators and its application in multi-criteria decision making. J Intell Fuzzy Syst. 2020;39:851–869. doi: 10.3233/JIFS-191763. [DOI] [Google Scholar]
- Aydın S. A fuzzy MCDM method based on new Fermatean fuzzy theories. Int J Inf Technol Decis Mak. 2021;20:881–902. doi: 10.1142/S021962202150019X. [DOI] [Google Scholar]
- Chen C-T. Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets Syst. 2000;114:1–9. doi: 10.1016/S0165-0114(97)00377-1. [DOI] [Google Scholar]
- Chen S-M, Chiou C-H. Multiattribute decision making based on interval-valued intuitionistic fuzzy sets, PSO techniques, and evidential reasoning methodology. IEEE Trans Fuzzy Syst. 2015;23:1905–1916. doi: 10.1109/TFUZZ.2014.2370675. [DOI] [Google Scholar]
- Cuong BC, Kreinovich V (2013) Picture fuzzy sets—a new concept for computational intelligence problems. In: 2013 third world congress on information and communication technologies (WICT 2013). IEEE, pp 1–6
- Ejegwa PA. Distance and similarity measures for Pythagorean fuzzy sets. Granul Comput. 2020;5:225–238. doi: 10.1007/s41066-018-00149-z. [DOI] [Google Scholar]
- Ejegwa PA. Improved composite relation for Pythagorean fuzzy sets and its application to medical diagnosis. Granul Comput. 2020;5:277–286. doi: 10.1007/s41066-019-00156-8. [DOI] [Google Scholar]
- Ejegwa PA, Wen S, Feng Y, et al. A three-way Pythagorean fuzzy correlation coefficient approach and its applications in deciding some real-life problems. Appl Intell. 2023;53:226–237. doi: 10.1007/s10489-022-03415-5. [DOI] [Google Scholar]
- Ganie AH. Applicability of a novel Pythagorean fuzzy correlation coefficient in medical diagnosis, clustering, and classification problems. Comput Appl Math. 2022;41:410. doi: 10.1007/s40314-022-02108-6. [DOI] [Google Scholar]
- Ganie AH. Some t-conorm-based distance measures and knowledge measures for Pythagorean fuzzy sets with their application in decision-making. Complex Intell Syst. 2023;9:515–535. doi: 10.1007/s40747-022-00804-8. [DOI] [Google Scholar]
- Ganie AH, Singh S, Khalaf MM, Al-Shamiri MMA. On some measures of similarity and entropy for Pythagorean fuzzy sets with their applications. Comput Appl Math. 2022;41:420. doi: 10.1007/s40314-022-02103-x. [DOI] [Google Scholar]
- Garg H. A new generalized Pythagorean fuzzy information aggregation using Einstein operations and its application to decision making. Int J Intell Syst. 2016;31:886–920. doi: 10.1002/int.21809. [DOI] [Google Scholar]
- Garg H. Generalized Pythagorean fuzzy geometric aggregation operators using Einstein t -norm and t -conorm for multicriteria decision-making process. Int J Intell Syst. 2017;32:597–630. doi: 10.1002/int.21860. [DOI] [Google Scholar]
- Garg H. Hesitant Pythagorean fuzzy Maclaurin symmetric mean operators and its applications to multiattribute decision-making process. Int J Intell Syst. 2019;34:601–626. doi: 10.1002/int.22067. [DOI] [Google Scholar]
- Garg H. New logarithmic operational laws and their aggregation operators for Pythagorean fuzzy set and their applications. Int J Intell Syst. 2019;34:82–106. doi: 10.1002/int.22043. [DOI] [Google Scholar]
- Garg H, Shahzadi G, Akram M. Decision-making analysis based on Fermatean fuzzy Yager aggregation operators with application in COVID-19 testing facility. Math Probl Eng. 2020;2020:1–16. doi: 10.1155/2020/7279027. [DOI] [Google Scholar]
- Gul M, Lo H-W, Yucesan M. Fermatean fuzzy TOPSIS-based approach for occupational risk assessment in manufacturing. Complex Intell Syst. 2021;7:2635–2653. doi: 10.1007/s40747-021-00417-7. [DOI] [Google Scholar]
- Hadi A, Khan W, Khan A. A novel approach to MADM problems using Fermatean fuzzy Hamacher aggregation operators. Int J Intell Syst. 2021;36:3464–3499. doi: 10.1002/int.22423. [DOI] [Google Scholar]
- Hussain Z, Yang M. Distance and similarity measures of Pythagorean fuzzy sets based on the Hausdorff metric with application to fuzzy TOPSIS. Int J Intell Syst. 2019;34:2633–2654. doi: 10.1002/int.22169. [DOI] [Google Scholar]
- Hwang C-L, Yoon K. Multiple attribute decision making methods and applications a state-of-the-art survey. Berlin: Springer; 1981. [Google Scholar]
- Jiang Q, Jin X, Lee S-J, Yao S. A new similarity/distance measure between intuitionistic fuzzy sets based on the transformed isosceles triangles and its applications to pattern recognition. Expert Syst Appl. 2019;116:439–453. doi: 10.1016/j.eswa.2018.08.046. [DOI] [Google Scholar]
- Keshavarz-Ghorabaee M, Amiri M, Hashemi-Tabatabaei M, et al. A new decision-making approach based on Fermatean fuzzy sets and WASPAS for green construction supplier evaluation. Mathematics. 2020;8:2202. doi: 10.3390/math8122202. [DOI] [Google Scholar]
- Khan MSA, Abdullah S, Ali A, Amin F. An extension of VIKOR method for multi-attribute decision-making under Pythagorean hesitant fuzzy setting. Granul Comput. 2019;4:421–434. doi: 10.1007/s41066-018-0102-9. [DOI] [Google Scholar]
- Khan MSA, Abdullah S, Ali A, Amin F. Pythagorean fuzzy prioritized aggregation operators and their application to multi-attribute group decision making. Granul Comput. 2019;4:249–263. doi: 10.1007/s41066-018-0093-6. [DOI] [Google Scholar]
- Kirişci M. New cosine similarity and distance measures for Fermatean fuzzy sets and TOPSIS approach. Knowl Inf Syst. 2023;65:855–868. doi: 10.1007/s10115-022-01776-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Z, Lu M. Some novel similarity and distance measures of Pythagorean fuzzy sets and their applications. J Intell Fuzzy Syst. 2019;37:1781–1799. doi: 10.3233/JIFS-179241. [DOI] [Google Scholar]
- Lu M, Wei G, Alsaadi FE, et al. Hesitant pythagorean fuzzy hamacher aggregation operators and their application to multiple attribute decision making. J Intell Fuzzy Syst. 2017;33:1105–1117. doi: 10.3233/JIFS-16554. [DOI] [Google Scholar]
- Luqman A, Shahzadi G. Multi-attribute decision-making for electronic waste recycling using interval-valued Fermatean fuzzy Hamacher aggregation operators. Granul Comput. 2023 doi: 10.1007/s41066-023-00363-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mahmood T, Ullah K, Khan Q, Jan N. An approach toward decision-making and medical diagnosis problems using the concept of spherical fuzzy sets. Neural Comput Appl. 2019;31:7041–7053. doi: 10.1007/s00521-018-3521-2. [DOI] [Google Scholar]
- Mishra AR, Rani P. Multi-criteria healthcare waste disposal location selection based on Fermatean fuzzy WASPAS method. Complex Intell Syst. 2021;7:2469–2484. doi: 10.1007/s40747-021-00407-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mishra AR, Garg AK, Purwar H, et al. An extended intuitionistic fuzzy multi-attributive border approximation area comparison approach for smartphone selection using discrimination measures. Informatica. 2021;32:119–143. doi: 10.15388/20-INFOR430. [DOI] [Google Scholar]
- Mishra AR, Chen S-M, Rani P. Multiattribute decision making based on Fermatean hesitant fuzzy sets and modified VIKOR method. Inf Sci (NY) 2022;607:1532–1549. doi: 10.1016/j.ins.2022.06.037. [DOI] [Google Scholar]
- Mishra AR, Rani P, Pandey K. Fermatean fuzzy CRITIC-EDAS approach for the selection of sustainable third-party reverse logistics providers using improved generalized score function. J Ambient Intell Humaniz Comput. 2022;13:295–311. doi: 10.1007/s12652-021-02902-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mishra AR, Chen S-M, Rani P. Multicriteria decision making based on novel score function of Fermatean fuzzy numbers, the CRITIC method, and the GLDS method. Inf Sci (NY) 2023;623:915–931. doi: 10.1016/j.ins.2022.12.031. [DOI] [Google Scholar]
- Mohd WRW, Abdullah L (2018) Similarity measures of Pythagorean fuzzy sets based on combination of cosine similarity measure and Euclidean distance measure. In: AIP conference proceedings. AIP Publishing LLC, p 030017
- Olgun M, Türkarslan E, Ünver M, Ye J. A cosine similarity measure based on the choquet integral for intuitionistic fuzzy sets and its applications to pattern recognition. Informatica. 2021;32:849–864. doi: 10.15388/21-INFOR460. [DOI] [Google Scholar]
- Peng X. New similarity measure and distance measure for Pythagorean fuzzy set. Complex Intell Syst. 2019;5:101–111. doi: 10.1007/s40747-018-0084-x. [DOI] [Google Scholar]
- Peng X, Dai J. Approaches to Pythagorean fuzzy stochastic multi-criteria decision making based on prospect theory and regret theory with new distance measure and score function. Int J Intell Syst. 2017;32:1187–1214. doi: 10.1002/int.21896. [DOI] [Google Scholar]
- Peng X, Garg H. Multiparametric similarity measures on Pythagorean fuzzy sets with applications to pattern recognition. Appl Intell. 2019;49:4058–4096. doi: 10.1007/s10489-019-01445-0. [DOI] [Google Scholar]
- Peng X, Yuan H, Yang Y. Pythagorean fuzzy information measures and their applications. Int J Intell Syst. 2017;32:991–1029. doi: 10.1002/int.21880. [DOI] [Google Scholar]
- Rahman K, Ali A, Abdullah S. Multiattribute group decision making based on interval-valued Pythagorean fuzzy Einstein geometric aggregation operators. Granul Comput. 2020;5:361–372. doi: 10.1007/s41066-019-00154-w. [DOI] [Google Scholar]
- Ramot D, Milo R, Friedman M, Kandel A. Complex fuzzy sets. IEEE Trans Fuzzy Syst. 2002;10:171–186. doi: 10.1109/91.995119. [DOI] [Google Scholar]
- Rani P, Mishra AR. Fermatean fuzzy Einstein aggregation operators-based MULTIMOORA method for electric vehicle charging station selection. Expert Syst Appl. 2021;182:115267. doi: 10.1016/j.eswa.2021.115267. [DOI] [Google Scholar]
- Ren P, Xu Z, Gou X. Pythagorean fuzzy TODIM approach to multi-criteria decision making. Appl Soft Comput. 2016;42:246–259. doi: 10.1016/j.asoc.2015.12.020. [DOI] [Google Scholar]
- Sahoo L. A new score function based Fermatean fuzzy transportation problem. Results Control Optim. 2021;4:100040. doi: 10.1016/j.rico.2021.100040. [DOI] [Google Scholar]
- Sahoo L. Some score functions on Fermatean fuzzy sets and its application to bride selection based on TOPSIS method. Int J Fuzzy Syst Appl. 2021;10:18–29. doi: 10.4018/IJFSA.2021070102. [DOI] [Google Scholar]
- Salsabeela V, John SJ (2021) TOPSIS techniques on fermatean fuzzy soft sets. In: AIP conference proceedings 2336, p 040022
- Senapati T, Yager RR. Fermatean fuzzy weighted averaging/geometric operators and its application in multi-criteria decision-making methods. Eng Appl Artif Intell. 2019;85:112–121. doi: 10.1016/j.engappai.2019.05.012. [DOI] [Google Scholar]
- Senapati T, Yager RR. Fermatean fuzzy sets. J Ambient Intell Humaniz Comput. 2020;11:663–674. doi: 10.1007/s12652-019-01377-0. [DOI] [Google Scholar]
- Sergi D, Sari IU (2021) Fuzzy capital budgeting using Fermatean fuzzy sets. In: intelligent and fuzzy techniques: smart and innovative solutions: proceedings of the infus 2020 conference, Istanbul, Turkey, July 21–23, 2020. Springer, pp 448–456
- Shit C, Ghorai G. Multiple attribute decision-making based on different types of Dombi aggregation operators under Fermatean fuzzy information. Soft Comput. 2021;25:13869–13880. doi: 10.1007/s00500-021-06252-9. [DOI] [Google Scholar]
- Singh S, Ganie AH. On some correlation coefficients in Pythagorean fuzzy environment with applications. Int J Intell Syst. 2020;35:682–717. doi: 10.1002/int.22222. [DOI] [Google Scholar]
- Singh S, Ganie AH. Some novel q-rung orthopair fuzzy correlation coefficients based on the statistical viewpoint with their applications. J Ambient Intell Humaniz Comput. 2022;13:2227–2252. doi: 10.1007/s12652-021-02983-7. [DOI] [Google Scholar]
- Thao NX, Smarandache F. A new fuzzy entropy on Pythagorean fuzzy sets. J Intell Fuzzy Syst. 2019;37:1065–1074. doi: 10.3233/JIFS-182540. [DOI] [Google Scholar]
- Verma R, Merigó JM. On generalized similarity measures for Pythagorean fuzzy sets and their applications to multiple attribute decision-making. Int J Intell Syst. 2019;34:2556–2583. doi: 10.1002/int.22160. [DOI] [Google Scholar]
- Wang J, Gao H, Wei G. The generalized Dice similarity measures for Pythagorean fuzzy multiple attribute group decision making. Int J Intell Syst. 2019;34:1158–1183. doi: 10.1002/int.22090. [DOI] [Google Scholar]
- Wang Z, Xiao F, Cao Z. Uncertainty measurements for Pythagorean fuzzy set and their applications in multiple-criteria decision making. Soft Comput. 2022;26:9937–9952. doi: 10.1007/s00500-022-07361-9. [DOI] [Google Scholar]
- Weber S. A general concept of fuzzy connectives, negations and implications based on t-norms and t-conorms. Fuzzy Sets Syst. 1983;11:115–134. doi: 10.1016/S0165-0114(83)80073-6. [DOI] [Google Scholar]
- Wei G. Pythagorean fuzzy interaction aggregation operators and their application to multiple attribute decision making. J Intell Fuzzy Syst. 2017;33:2119–2132. doi: 10.3233/JIFS-162030. [DOI] [Google Scholar]
- Wei G, Lu M. Dual hesitant pythagorean fuzzy Hamacher aggregation operators in multiple attribute decision making. Arch Control Sci. 2017;27:365–395. doi: 10.1515/acsc-2017-0024. [DOI] [Google Scholar]
- Wei G, Lu M. Pythagorean fuzzy power aggregation operators in multiple attribute decision making. Int J Intell Syst. 2018;33:169–186. doi: 10.1002/int.21946. [DOI] [Google Scholar]
- Wei G, Wei Y. Similarity measures of Pythagorean fuzzy sets based on the cosine function and their applications. Int J Intell Syst. 2018;33:634–652. doi: 10.1002/int.21965. [DOI] [Google Scholar]
- Wei G, Lu M, Alsaadi FE, et al. Pythagorean 2-tuple linguistic aggregation operators in multiple attribute decision making. J Intell Fuzzy Syst. 2017;33:1129–1142. doi: 10.3233/JIFS-16715. [DOI] [Google Scholar]
- Xue W, Xu Z, Zhang X, Tian X. Pythagorean Fuzzy LINMAP Method Based on the Entropy Theory for Railway Project Investment Decision Making. Int J Intell Syst. 2018;33:93–125. doi: 10.1002/int.21941. [DOI] [Google Scholar]
- Yager RR (2013) Pythagorean fuzzy subsets. In: 2013 joint IFSA world congress and NAFIPS annual meeting (IFSA/NAFIPS). IEEE, pp 57–61
- Yager RR. Pythagorean membership grades in multicriteria decision making. IEEE Trans Fuzzy Syst. 2014;22:958–965. doi: 10.1109/TFUZZ.2013.2278989. [DOI] [Google Scholar]
- Yang M-S, Hussain Z. Fuzzy entropy for Pythagorean fuzzy sets with application to multicriterion decision making. Complexity. 2018;2018:1–14. doi: 10.1155/2018/2832839. [DOI] [Google Scholar]
- Yang Z, Garg H, Li X. Differential calculus of Fermatean fuzzy functions: continuities, derivatives, and differentials. Int J Comput Intell Syst. 2021;14:282–294. doi: 10.2991/ijcis.d.201215.001. [DOI] [Google Scholar]
- Zadeh LA. Fuzzy sets. Inf Control. 1965;8:338–353. doi: 10.1016/S0019-9958(65)90241-X. [DOI] [Google Scholar]
- Zeb A, Khan A, Fayaz M, Izhar M. Aggregation operators of Pythagorean fuzzy bi-polar soft sets with application in multiple attribute decision making. Granul Comput. 2022;7:931–950. doi: 10.1007/s41066-021-00307-w. [DOI] [Google Scholar]
- Zeng W, Li D, Yin Q. Distance and similarity measures of Pythagorean fuzzy sets and their applications to multiple criteria group decision making. Int J Intell Syst. 2018;33:2236–2254. doi: 10.1002/int.22027. [DOI] [Google Scholar]
- Zeng S, Chen S-M, Fan K-Y. Interval-valued intuitionistic fuzzy multiple attribute decision making based on nonlinear programming methodology and TOPSIS method. Inf Sci (NY) 2020;506:424–442. doi: 10.1016/j.ins.2019.08.027. [DOI] [Google Scholar]
- Zhang X. A novel approach based on similarity measure for Pythagorean fuzzy multiple criteria group decision making. Int J Intell Syst. 2016;31:593–611. doi: 10.1002/int.21796. [DOI] [Google Scholar]
- Zhang X, Xu Z. Extension of TOPSIS to multiple criteria decision making with Pythagorean fuzzy sets. Int J Intell Syst. 2014;29:1061–1078. doi: 10.1002/int.21676. [DOI] [Google Scholar]
- Zhang Q, Hu J, Feng J, et al. New similarity measures of Pythagorean fuzzy sets and their applications. IEEE Access. 2019;7:138192–138202. doi: 10.1109/ACCESS.2019.2942766. [DOI] [Google Scholar]
- Zhang S, Tang J, Meng F, Yuan R. A group decision making method with interval-valued intuitionistic fuzzy preference relations and its application in the selection of cloud computing vendors for SMEs. Informatica. 2021;32:163–193. doi: 10.15388/20-INFOR416. [DOI] [Google Scholar]
- Zhou L-P, Wan S-P, Dong J-Y. A Fermatean fuzzy ELECTRE method for multi-criteria group decision-making. Informatica. 2022;33:181–224. doi: 10.15388/21-INFOR463. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.