

Abstract
The extent to which the components of a biological system are (non)linearly regulated determines how amenable they are to therapy and control. To better understand this property termed “regulatory nonlinearity”, we analyzed a suite of 137 published Boolean network models, containing a variety of complex nonlinear regulatory interactions, using a probabilistic generalization of Boolean logic that George Boole himself had proposed. Leveraging the continuous-nature of this formulation, we used Taylor decomposition to approximate the models with various levels of regulatory nonlinearity. A comparison of the resulting series of approximations of the biological models with appropriate random ensembles revealed that biological regulation tends to be less nonlinear than expected, meaning that higher-order interactions among the regulatory inputs tend to be less pronounced. A further categorical analysis of the biological models revealed that the regulatory nonlinearity of cancer and disease networks could not only be sometimes higher than expected but also be relatively more variable. We show that this variation is caused by differences in the apportioning of information among the various orders of regulatory nonlinearity. Our results suggest that there may have been a weak but discernible selection pressure for biological systems to evolve linear regulation on average, but for certain systems such as cancer, on the other hand, to simultaneously evolve more nonlinear rules.
Subject terms: Nonlinear dynamics, Molecular biology
Introduction
How nonlinear is the regulation of the components of biological networks? That is, to what extent do the biochemical components of these networks non-independently interact (Fig. 1) in influencing downstream processes and network behavior. Research on the “nonlinearity” front has hitherto focused on its various manifestations in the dynamics of biological systems, such as chaos, bifurcation, multistability, synchronization, patterning, dissipation, etc.1, but a characterization of regulatory nonlinearity among the components of the underlying systems that give rise to those phenomena is lacking. A more complete understanding of biological regulatory nonlinearity would not only yield insights into their design principles2 but also have theoretical implications ranging from canalization to control3,4 and practical implications for biomedical therapy, synthetic biology, etc.1,5. A good example of this concerns the mapping between molecular or genetic information and the resulting system-level anatomical structure and function of an organism. Advances in regenerative medicine and synthetic morphology require rational control of physiological and anatomical outcomes6, but progress in genetics and molecular biology produce methods and knowledge targeting the lowest-level cellular hardware. There is no one-to-one mapping from genetic information to tissue- and organ-level structure; similarly, ion channels open and close post-translationally, driving physiological dynamics that are not readily inferred from proteomic or transcriptomic data. System-level properties in biology are often highly emergent, with gene-regulatory or bioelectric circuit dynamics connecting initial state information and transition rules to large-scale structure and function. Thus, the difficult inverse problem7 of inferring outcomes and desirable interventions across scales of biology illustrates some of the fundamental questions about the directness or nonlinearity of encodings of information, as well as the importance of this question for practical advances in biomedicine and bioengineering that exploit the plasticity and robustness of cellular collectives. Many deep questions remain about the potential limitations and best strategies to bridge scales for prediction and control in developmental, evolutionary, and cell biology. To that end, we introduce here a formal characterization of the nonlinearity of models of biological regulatory networks, such as those often used to describe relationships between regulatory genes. Specifically, we consider a class of discrete models of biological regulatory systems called “Boolean models” that are known for their relative simplicity and tractability compared to continuous ordinary differential equation-based (ODE) models8.
Fig. 1. An illustration of the concept of regulatory nonlinearity.
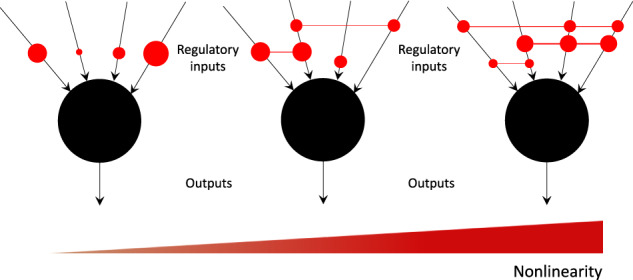
Each black circle represents a generic biochemical component such as a gene, transcription factor, enzyme, etc., regulated by a set of inputs (also biochemical components) and generates a generic output such as concentration level, strength, etc. Non-zero interactions among the inputs are represented by red circles connected by red lines, with the total number of possible interactions for a node with k inputs equal to . The size of the red circles and the width of the connecting lines represents the weight of the interactions. Independent inputs are represented by unconnected red circles. The degree of nonlinearity would thus be expected to increase, though not necessarily linearly, from left to right, as the numbers and the strengths of the regulatory interactions increase. One could also visualize these local interactions in a broader network-context as “hypergraphs”46.
A Boolean network is a discrete network model characterized by the following features. Each node in a Boolean network can only be in one of two states, ON or OFF, which represents the expression or activity of that node. The state of a node depends on the states of other input nodes which are represented as a Boolean rule of these input nodes. Many of the available Boolean network models were created via literature search of the regulatory mechanisms and subsequently validated via experiments9. Some of the publicly available models were generated via network inference methods from time course data3.
Previous studies have found that certain characteristic features of the biological Boolean models, such as the mean in-degree, output bias, sensitivity and canalization, tend to assume an optimal range of values that support optimal function10,11. Here we study a new but generic feature of complex systems termed “regulatory nonlinearity” that we broadly define as the degree to which the inputs to the components of a complex interact. To characterize the regulatory nonlinearity of Boolean networks we formalize an approach to generalizing Boolean logic by casting it as a form of probability, which was originally proposed by George Boole himself12. We leverage the continuous nature of the resulting polynomials to decompose a Boolean function using Taylor-series and reveal the distinct layers of its regulatory nonlinearity (Fig. 5). Various other methods, both discrete and continuous, of decomposing Boolean functions exist, such as Reed-Muller, Walsh spectrum, Fourier, discrete Taylor and fuzzy logic13–16. Our continuous Taylor decomposition method is distinct in that it offers a clear and systematic way to characterize nonlinearity.
Fig. 5. The various approximations of a Boolean function in increasing order of nonlinearity.

The logical OR function is represented as a 2D hypercube (top left) with the coordinate values representing input combinations and the color of the circles representing the corresponding outputs (white = 0, black = 1) and is approximated using Taylor decomposition as the 0th order approximation (top right) showing only the first term, the mean output bias; the 1st order approximation (bottom left) including the linear terms; and finally the 2nd order exact form (bottom right) including all the terms.
Is the regulatory nonlinearity of biological systems special? To that end we specifically ask: (1) how well could biological Boolean models be approximated, that is, faithfully represented with only partial information containing lower levels of nonlinearity relative to that of the original?; (2) is there an optimal level of regulatory nonlinearity, characterized by maximum approximability, that these models may have been selected for by evolution?; and (3) do different classes of biological networks show characteristically different optimal levels of regulatory nonlinearity? To answer these questions, we first approximate the biological models by systematically composing the various nonlinear layers resulting in a sequence of model-approximations with increasing levels of nonlinearity. We then estimate the accuracy of these approximations by comparing the outputs of their simulations with that of the original unapproximated model. We then construct an appropriate random ensemble for each biological model and compare their mean accuracies for fixed levels of approximation. The main idea is that a biological model that is more approximable than expected for a particular level of nonlinearity would mean that the network may have been optimized for that level nonlinearity. Finally, we classify the biological networks into various categories and compare their approximabilities to identify any category-dependent effects.
Results
The regulation of biological models tends to be less nonlinear than expected by chance
The mean approximation error (MAE; see “Methods”) of biological models tends to be less than both the constrained and the unconstrained random ensembles across all approximation orders (Fig. 2a). At the linear order, for example, the mean MAE of biological models is about 0.025, whereas the mean MAE of the constrained ensembles is twice as large at about 0.05 (p < 10−6) and even larger for the unconstrained ensembles at about 0.07 (p < 10−23). This ordering of MAE extends to all approximation orders (Fig. 2a). Even though the mean MAE of the unconstrained ensembles tends to be remarkably low (0.07 at worst), the percentage change in MAE (PMAE; see “Methods”) convey a more accurate sense of approximability. For example, the MAE of the biological models and the constrained ensembles are respectively about 50 and 25% lower than the baseline expectation for the linear order (Fig. 2b). This means that the biological models are about 25% more linearly approximable than expected by chance, an effect that amplifies with higher approximation orders going up to 50% for order 4, since the PMAE of biological models shrinks faster than the constrained ensembles (Fig. 2b).
Fig. 2. Biological models are more approximable than expected by chance.

a The MAE of the biological models and the associated constrained and unconstrained ensembles for approximation orders 1 to 5; MAE values for orders 6 and above are negligible and not shown. b Percentage change in MAE for the biological models and the associated constrained ensembles computed with respect to the MAE of the corresponding unconstrained ensembles. Every point in the distributions corresponding to the random ensembles represents the average MAE of an ensemble of 100 random networks associated with each biological model. The p values indicate the statistical significance of the difference in mean MAEs between sets of random ensembles and the biological models for a given order of nonlinearity. Statistical analysis by Welch’s unequal variances t-test.
A possible explanation for the observed trends is that the Taylor spectrums of the biological models tend to be lopsided and more clustered at the linear ends (see Fig. 4 for an example), dramatically reducing the load on the higher orders and thus resulting in a faster growth of approximability with higher orders. This effect may be less pronounced in constrained ensembles, and even less in unconstrained ensembles, as the apportioning in the corresponding Taylor spectrums may be less lopsided and more uniform in comparison. Based on these observations we hypothesize, but do not conclude, that biological systems may have been subjected to a slight but discernible selection pressure for developing less nonlinear regulatory rules. This hypothesis is further supported by the fact that the approximability systematically increases as more biological constraints are imposed, as one goes from unconstrained to constrained to the biological models (Fig. 2). This has implications not only for the feasibility of biomedical approaches to control emergent somatic complexity or guided self-assembly of novel forms17, but also for models of anatomical homeostasis and evolvability: linearity implies easier control of its own complex processes by any biological system, and more efficient credit assignment during evolution.
Fig. 4. A comparison of the spectrums of the magnitudes of nonlinearity of the models corresponding to the two extreme cases of approximability.
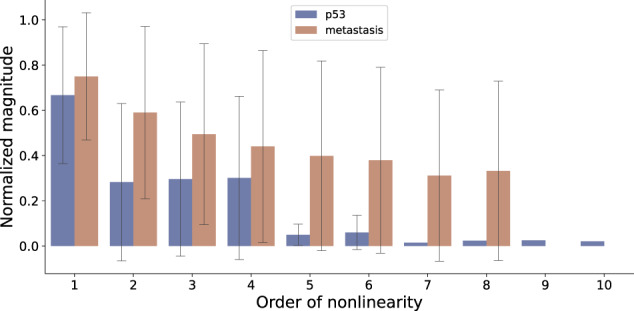
The bars represent the mean absolute value of all the Taylor derivatives of the corresponding order, averaged over all the nodes of the corresponding model containing those terms. The maximum orders (in-degrees) of P53 and Metastasis are respectively 10 and 8. To compare the derivatives from different models they were normalized with respect to the maximum possible absolute value of a Taylor derivative of order ∣α∣ (Eq. (6)) of a Boolean function with output bias p, given by (proof provided in the “Methods” section). The error bars represent the standard deviation and not the confidence intervals of the means since they are not estimates. The errors appear large whenever the corresponding distribution of the magnitudes are bimodal with many values clustered close to 0.
Random models with minimal biological constraints tend to be naturally approximable
The MAE of the unconstrained random ensembles are remarkably low with values averaging around 0.07 and not exceeding 0.17 at the linear order; these values only decrease further with higher approximation orders (Fig. 2a). These observations suggest that even random Boolean models with minimal biological constraints tend to be considerably approximable. In other words, approximability may be a natural property of random Boolean ensembles to some extent and not necessarily a special property of biological models. Furthermore, the MAE has its inflection point at order 2 (Fig. 2a), meaning that the approximability starts saturating at that order. We hypothesize based on these observations that regulatory information beyond the second order may be inconsequential with regards to the statistics of network dynamics in general.
The above hypothesis has an analog in the realm of Boolean Ising models, where it was found that maximum entropy (MaxEnt) models with only pairwise interactions were sufficient to fit random multivariate Ising networks that are densely connected and whose state spaces satisfy certain entropy constraints, features that many biological systems share18. There are however important differences between our results and theirs: (1) even though the Taylor expansions resemble MaxEnt expressions, the latter fit global state-space distributions, whereas our Taylor polynomials are local formulations; and (2) whereas our Taylor polynomials are built on derivatives of the states, MaxEnt models are based on the raw values. Notwithstanding these potentially superficial differences, the analogous results are striking and calls for further research on whether the respective explanations are similar if not fundamentally the same. Besides, the above observations are reminiscent of the concept of model degeneracy or “sloppiness”, where several models (defined by unique sets of parameters) explain the same biological phenomenon due to redundant parameters19. In our case, it’s not the parameters but the higher-order relationships among them that are redundant, as they contribute minimally to the MAE beyond a certain order of approximation (Fig. 2a). Future research will determine whether there’s a deep connection between the sloppiness of the parameters and the orders of relationships among them.
The approximability of a biological model depends on its class, with the cancer family displaying the most variability
Even though the nonlinearity of biological networks is less than expected on average, individual and category-dependent variations were observed. In the following, we focus on the “linear approximability” (PMAE corresponding to the linear order) of the biological models since it’s hypothesized to be the cause of the observed approximabilities in the higher order; values are listed in Supplementary Table 1. First, there are a few networks in almost every category that are more nonlinear than expected, as evidenced by the negative linear approximability values (Fig. 3). Second, the disease networks in C1 and the cancer networks in C2 are the ones with the most linear approximability, with values ≥75% (Fig. 3). In other words, the cancer or disease pathways tend to be more optimized for linearity compared to the other categories. This makes sense since a more linear pathway is more amenable to control, which presumably works in favor of the agents of disease. On the other hand, the disease and cancer networks also display the highest variability in their linear approximability compared to other categories (p < 0.05 in all comparisons for the cancer models), with the PMAE values ranging between −92 and 80% (Fig. 3). In other words, disease and cancer models could be either relatively extremely more linear or nonlinear than expected, depending on the specific cases. Note that about 56% of the disease category comprises of non-cancer networks (31/55), which suggests that the effect is not significantly biased by cancer networks. These observations suggest that regulatory nonlinearity may offer an effective “entry point” to the agents of disease by virtue of its natural heterogeneity that they could leverage to their advantage perhaps as a means to evade treatment since there’s no single level of nonlinearity to target. This heterogeneity may also have a connection to one of the hallmarks of cancer, namely genetic heterogeneity20 where the cancerous cells within an individual display heterogeneous gene expression compared to the homogeneous expression in the healthy cells. In the case of nonlinearity, the heterogeneity manifests at the population level, raising the question of whether it may also be observed at the level of single cells within an individual. In other words, could the heterogeneity of nonlinearity be yet another hallmark of cancer?
Fig. 3. The linear approximabilities of various categories of biological models.

a Classification 1 (C1); b Classification 2 (C2). The categories in either classification are displayed in increasing order of variance. Each box represents the distribution of the linear approximabilities of the corresponding category. The p values indicate the statistical significance of the difference in the variance between pairs of categories; only the p values of significantly different pairs are shown. Statistical analysis by F-test of equality of variances.
The shape of the Taylor spectrum explains the extreme opposite characters of linear approximability of a pair of cancer models
Why are some models more linearly approximable and others less? The answer lies in the organization of the corresponding Taylor decompositions, as described above. To illustrate this in detail, we compared the Taylor decompositions of a pair of models chosen from among the most extreme outliers of linear approximability in either direction (Fig. 3). Those models are respectively the following: a linear model describing the role of the protein p53 in the regulation of cell-cycle arrest in breast cancer21, henceforth referred to as the “P53” model; and a nonlinear model describing the role of mutations in the regulation of metastasis in lung cancer22, henceforth referred to as the “Metastasis” model. P53 has a linear approximability of about 72%, and it consists of 16 nodes with a mean in-degree of 3.8 ± 2.4 and a mean output bias of 0.38 ± 0.14; and, Metastasis has a linear approximability of about −79%, and it consists of 32 nodes with a mean in-degree of 4.9 ± 2.5 and a mean output bias of 0.27 ± 0.26. Thus, while P53 is smaller and sparser than Metastasis, its nodes exhibit more output-uncertainty compared to Metastasis. According to the mean field theory of random Boolean networks23, the opposite characters of the mean in-degree and the output bias of these models means that their dynamical behaviors could be expected to be similar (although with the caution that the theory was originally developed for infinite-sized and homogeneously connected networks, which is not the case here). However, we know that their linear approximabilities, which is another expression of dynamical behavior, are opposites. One explanation for this discrepancy lies in the distinct apportioning of nonlinearity in their respective Taylor decompositions (Fig. 4). Specifically, while the magnitude of nonlinearity, defined as the mean absolute value of the Taylor derivatives for a given order and normalized appropriately (see text of Fig. 4), tends to be clustered around the linear order for P53, they are relatively more spread out for Metastasis. Moreover, while the magnitude of the linear order for P53 is more than twice as large the next largest magnitude at lower orders the corresponding ratios for Metastasis are relatively smaller, thus explaining why P53 is more linearly approximable than Metastasis. This result is consistent with predictions based on a model of scaling of cellular control policies24. A more controllable (linear) network (P53) is optimal for cooperation with other cells toward collective (normal morphogenetic) goals. In contrast, a cell defecting from the collective and reverting to a more unicellular lifestyle (Metastasis) should exhibit a less predictable, controllable network due to pressures from parasites and competitors that independent unicellular organisms face. Methods for calculating controllability (e.g., linearity) are an important addition to recent efforts to solve the conundrum of interpretability of information structures in contexts ranging from machine learning to evolutionary developmental biology25–27.
Discussion
This paper introduces the concept of regulatory nonlinearity as a characteristic of Boolean networks. There are several other related characterizations of Boolean networks such as canalization28, effective connectivity11, symmetry29 and controllability30. It has been previously reported that the levels of canalization (a measure of the extent to which a subset of inputs actually influence the outputs of a Boolean function) and the mean effective connectivity (a measure of collective canalization) are high in biological networks3,11. It has also been found that biological networks need few inputs to reprogram31 and are relatively easier to control4. Our formulation of regulatory nonlinearity is related to these other measures in that more linearity implies more apportioning of influence to individual inputs rather than collective sets of inputs (Fig. 4). Hence, we hypothesize that regulatory nonlinearity may serve the purpose of controllability and epigenetic stability32.
Our results further moot the possibility that regulatory nonlinearity may be a factor underlying more powerful dynamical phenomena such as memory33 and computation, defined as the capacity for adaptive information-processing34. Even though there’s increasing consensus that biological systems contain memory and perform computation, clarity is lacking as to what features of those systems enable it and what general principles underlie it34,35. Our framework of regulatory nonlinearity offers an approach to answering these questions. For example, one could consider a known dynamical model with a capacity for memory33 or universal computation such as the elementary cellular automaton (ECA) driven by rule 11036 and ask if there are unique properties of their Taylor spectrums that confer their respective capabilities. Present approaches to answering this question typically consists of characterization of the dynamical behavior and not the rules33,37,38. A characterization of the rules especially makes sense for ECA39 since the structure is the same (lattice) and the only feature that distinguishes one ECA from the other is the rule.
Looking at such questions from an even broader perspective it becomes evident that they are only instances of the ultimate puzzle of complex systems, namely what connects the structure and the function of a system. Even though recent work has attempted to answer this question from the perspective of the rules or dynamical laws that govern the system11,39,40, more tools are needed41. In that regard, our framework of regulatory nonlinearity could be a novel addition to this burgeoning toolkit in that it could also be applied to continuous differentiable models of biological networks such as those based on differential equations.
The main limitation of our formulation of approximability is that the approximation accuracy will necessarily increase with higher orders of approximation since the Taylor terms would be accumulated with each higher order (the highest order of approximation is exact). However, this does not affect the falsifiability of our framework since it’s possible, for example, to construct networks with XOR-like functions that would be clearly less linearly approximable than the associated ensembles. The Metastasis model is another example in that regard (Fig. 4). Furthermore, though our experiments control for regulatory nonlinearity they don’t offer insights into how it dynamically interacts with other network features such as connectivity in generating the observed approximability. For example, the network structure may be expected to determine which states the network enters into at any given point that in turn determines which parts of the Taylor compositions are actually utilized and how. Moreover, it’s known that certain characteristics of the local regulatory rules, such as “effective connectivity”, dynamically modulate the network structure itself42. Thus, more research is required to investigate the extent to which the structure and output bias facilitates the high approximability of biological networks and vice versa, for which we already have produced preliminary results by way of the constrained models (Fig. 2). Lastly, our conclusions about the linearity of biological regulatory networks may be a reflection of a hidden bias built in the inference methods that produced the models in the first place. We leave it to future work to explore these realms.
Methods
Probabilistic generalization of Boolean logic
Here we provide a continuous-variable formulation of a Boolean function by casting Boolean values as probabilities, thus transforming it into a pseudo-Boolean function43. Consider random variables Xi : {0, 1} → [0, 1], i = 1, …, n, with Bernoulli distributions. That is, pi = Pr(Xi = 1) = 1 − Pr(Xi = 0) = 1 − qi, for i = 1, …, n. Let X = X1 × ⋯ × Xn be the product of random variables and f : X → {0, 1} a Boolean function. Let and . Note that X is a disjoint union of and . Then:
| 1 |
where if xi = 1 and if xi = 0. Let . Thus, is a continuous-variable function. The following theorem shows that is a generalization of f in the sense that for all x ∈ {0, 1}n.
Theorem. For discrete values of xi ∈ {0, 1}, i = 1, …, n, we have .
Proof. Let z = (z1, …, zn) ∈ {0, 1}n. Since each zi is either 0 or 1, we have that pi = 1 if zi = 1 or pi = 0 if zi = 0 for i = 1, …, n. We want to show that . Since , we have that either or . If , then f(z) = 1 and . Moreover, for any other with x ≠ z we have that Pr(x) = 0. Thus, . Now if , then because . Thus, for all x ∈ {0, 1}n.□
Corollary. If pi = 1/2 for all i = 1, …, n, then is the output bias of f.
Proof If pi = 1/2, the qi = 1/2. Then
| 2 |
□
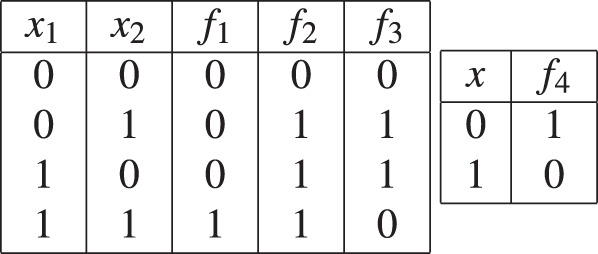
Example. Consider the AND, OR, XOR, and NOT Boolean functions given in Table 1. The continuous-variable generalization of f1, f2, f3, and f4 are: , , , and .
Table 1.
Truth tables of basic Boolean functions.
Note that the above expressions have previously been derived via other (not probability-based) means15,16.
Taylor decomposition of Boolean functions
Since is a continuous-variable function, we can calculate its Taylor expansion. And since is a square-free polynomial, its Taylor expansion is finite and simplified (any term containing multiple derivatives of the same variable is zeroed out), as described in Proposition using the standard multi-index notation. Let α = (α1, …, αn) where αi ∈ {0, 1}. We define:
| 3 |
| 4 |
and
| 5 |
Proposition. For p ∈ [0, 1]n, we have:
| 6 |
Note that in Eq. (6) is the output bias of f as was seen in Corollary. A natural choice for p is p = (1/2, …, 1/2) as it represents an unbiased selection for each variable and it also gives the output bias of the function. Such unbiased choices are not available for the discrete case. Our continuous formulation thus offers such unique advantages over the discrete Taylor decomposition, as it’s a natural generalization of the latter. The Taylor decomposition can be used to approximate a Boolean function by considering a subset of the terms. For example, a linear approximation consists of terms only up to ∣α∣ ≤ 1, a bilinear approximation up to ∣α∣ ≤ 2, etc., up until ∣α∣ ≤ n where it ceases to be an approximation and provides an exact decomposition of . A visual illustration is provided in Fig. 5. The approximation order of a Boolean network could therefore vary between its minimum and maximum in-degrees (number of inputs per node).
Example. Consider the continuous generalizations of the AND, OR, XOR and NOT functions given in Example The corresponding Taylor expansions using Eq. (6) and using the derivatives shown in Table 2with p = (1/2, 1/2) are: , , , and .
Table 2.
Values of partial the derivatives in the Taylor decompositions of the generalizations of basic Boolean functions.
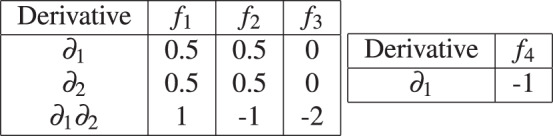
Note that , and in the above equations are the output biases of the AND, OR, XOR, and NOT functions respectively. Also note that both the AND and OR functions contain the linear and the second order terms in their Taylor decomposition while the XOR function only contains the second order term. This difference is because both the AND and OR functions are monotone while XOR is not since it requires both inputs to be known.
Approximability of a model
We considered a suite of Boolean network models of biochemical regulation from two sources, namely the cell collective9 and reference3. This suite consists of 137 networks with the number of nodes ranging from 5 to 321. The mean in-degree of these models ranges from 1.1818 to 4.9375 with the variances ranging between 0.1636 and 9.2941, while the mean output bias is limited to the range [0.1625, 0.65625] with the variances between 0.0070 and 0.0933. For each biological model an ensemble of 100 randomized models was generated each of whose connectivity and output biases were set to be the same as the former, with only the logic rules randomized. This set, referred to as the “constrained ensemble”, facilitates benchmarking the role of regulatory nonlinearity in the biological rules. To accurately assess the differences between the biological models and the constrained ensembles, we considered a baseline set known as the “unconstrained ensemble” relative to which those differences were computed. This ensemble preserved neither the connectivity nor the output bias but had them bootstrap-sampled from the corresponding distributions characterizing the associated biological models. Taylor decomposition was then applied to both the biological models and the random ensembles and all possible nonlinear approximations were computed by considering terms starting from the linear order accumulating up to the maximum possible nonlinear order. Both the biological models and the random ensembles were then simulated using a set of 1000 randomly chosen initial states iterated through 500 update steps for all orders of approximation; the same initial conditions were used for a given biological model and the random ensemble. The states of the variables were restricted to the interval [0,1] at every step during the simulations by simply resetting them to the nearest boundary of the interval whenever they crossed it. The mean approximation error (MAE) of each model is defined as the mean squared error between the exact Boolean states and the approximated probabilistic states at the end of the simulations; for the random ensembles a single average MAE was computed. It varies between 0.0 and 1.0. The “percentage change in MAE” (PMAE) of the biological models and the constrained ensembles is defined as the percentage difference between the respective MAE and the corresponding unconstrained MAE; it can vary between −100.0 and positive infinity. The “approximability” of a biological model is represented by the difference between the PMAE of the corresponding constrained ensemble and that of itself; it can vary between negative infinity and positive infinity. Hence, the more negative the PMAE is for biological models compared to that of constrained ensembles the more approximable they are deemed to be and the more unique their regulatory nonlinearity is. An illustration of how approximability is computed is provided in Fig. 6.
Fig. 6. An illustration of the relationship between nonlinearity and approximability using a simple 3-node Boolean network.

The higher the order of nonlinearity of the network the more approximable it is with respect to the exact dynamics. Left: An example 3-node network utilizing all three 2-input Boolean functions. Right: The network is simulated from a single initial state of (1,1,1). Here the dynamics of the 0th order network (blue) least matches the exact Boolean trajectory (gray), while 1st order network (red) is a slightly better match. The 2nd order network (gray) is exact since it includes all the Taylor terms up to the maximum possible order of 2 (the maximum in-degree of any node). The closer the approximated average dynamics to the exact dynamics, the lower the MAE and the higher the approximability of the former. Notice also that while for node “a” the 0th order network is almost as good as the 1st order network, it is the opposite for node “c” in that its 1st order approximation is as poor as the 0th order; this is because “c” implements the XOR function whose 1st order derivatives are zero.
Classification of biological models
To identify any differences among the approximabilities of different types of biological networks we sought to classify them. Since there are multiple ways to classify biological networks, we chose two classifications so that: (1) they are as orthogonal as possible to each other; and (2) each classification has an appropriate number of (neither too few nor too many) categories. Classification 1 (C1) follows the “pathway ontology” (PW)44 where the networks are grouped into five categories (Fig. 3a), namely biochemical (n = 13), signaling (n = 22), disease (n = 55), metabolic (n = 14) and regulatory (n = 33). According the definitions used in the PW ontology, a “signaling” network comprises mainly of extracellular signal transduction components such as growth factors, kinases, etc. A “regulatory” network, on the other hand, comprises intracellular transcriptional components such as genes, transcription factors, etc. The term “biochemical” here refers to networks that comprises a mix of signaling and regulatory components. “Metabolic” networks consist of components involved in the synthesis and conversion of biomolecules such as enzymes and lipids. Finally, “disease” networks consist of components involved in diseases such as cancer, anemia, pathogenic ailments and disorders such as cell cycle malfunction. Classification 2 was suggested by in-house expertise, where the networks are grouped into four categories (Fig. 3b), namely metazoan (n = 85), cancer (n = 24), primitive (n = 19) and plants (n = 9). The “metazonan” category refers to multicellular organisms and “primitive” refers to unicellular organisms. A given model could naturally belong in multiple categories within a classification but is assigned a unique category for the purpose of simplicity; we chose the categories according to the emphasis laid in the abstracts of the corresponding publications. More details are provided in the Supplementary Material (Supplementary Table 1).
Maximum absolute value of a Taylor derivative
Here we show that .
We begin with the definition of the derivative given by:
| 7 |
Since is a pseudo-Boolean function and hence a multilinear polynomial45, we can compute this as a finite difference; the idea being that the derivative taken over any point on a line is the line itself:
| 8 |
Since multilinear interpolation can be formulated as weighted averaging43, we can further rewrite it as follows (the weights are equal here since the non-binary values are all set to 0.5):
| 9 |
As can be seen, there are a total of 2k terms, with half of them positively signed and half negative. This form of expression generalizes to derivatives taken over two or more variables. For example, the derivative taken over two variables, xi and xj, looks as follows:
| 10 |
Following rearrangement of terms it becomes evident that this expression also contains 2k−1 positive terms and 2k−1 negative terms, with the only difference in the power of the denominator term. It can thus be concluded that any derivative (in multi-index notation) has 2k−1 positive terms and 2k−1 negative terms.
A straightforward way to maximize the value of a derivative expressed in this form is by assigning as many instances of 1 as possible to the positive terms and as few instances of 1 as possible to the negative terms. For a Boolean function with k inputs and output bias p, this can be accomplished by assigning ones and ones respectively. Therefore:
| 11 |
Note that this formula only applies to a specific order of nonlinearity ∣α∣ independent of the other orders within the same Boolean function. In actuality, there are dependencies between the various orders within a Boolean function. That is, if a Boolean function were to be constructed such that the derivative of a particular order ∣α1∣ is maximized then there’s no guarantee that the derivative of another order ∣α2∣ ≠ ∣α1∣ could be simultaneously maximized. This is one of the limitations of the normalization for which the above formula is used.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Supplementary information
Acknowledgements
D.M. was partially supported by a Collaboration grant (850896) from the Simons Foundation. M.L. gratefully acknowledges support via grant TWCF0606 of the Templeton World Charity Foundation. We thank Claus Kadelka for sharing a large repository of Boolean models curated by his group and the accompanying Python code for analyzing it. The authors thank the referees for their insightful comments that have improved the manuscript.
Author contributions
S.M. and D.M. conceived the study; S.M. and K.J. designed code; K.J. performed research and simulations; S.M., K.J. and D.M. analyzed data; M.L. helped bridge the theory to biology. All authors helped in the writing of the manuscript. All authors approved the final version of the manuscript.
Data availability
We used 137 Boolean network models of gene regulation from two sources, namely the cell collective9 and reference3. Subsequently, we categorized these models using two types of classifications C1 and C2 as described in Section. We provide the details of the classification of each model along with their Pubmed ID and their linear approximation score in the Supplementary Information file (SI), Supplementary Table 1.
Code availability
The code that we used for the approximations and the simulations are available through this link: https://gitlab.com/smanicka/boolion.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
These authors contributed equally: Santosh Manicka, Kathleen Johnson.
Supplementary information
The online version contains supplementary material available at 10.1038/s41540-023-00273-w.
References
- 1.Kapitaniak, T. & Jafari, S. Nonlinear Effects in Life Sciences (Springer, 2018).
- 2.Savageau MA. Design principles for elementary gene circuits: elements, methods, and examples. Chaos. 2001;11:142–159. doi: 10.1063/1.1349892. [DOI] [PubMed] [Google Scholar]
- 3.Kadelka, C., Butrie, T.-M., Hilton, E., Kinseth, J. & Serdarevic, H. A meta-analysis of Boolean network models reveals design principles of gene regulatory networks. arXiv10.48550/arXiv.2009.01216 (2020). [DOI] [PMC free article] [PubMed]
- 4.Borriello, E. & Daniels, B. C. The basis of easy controllability in Boolean networks. Nat. Commun.12, 5227 (2021). [DOI] [PMC free article] [PubMed]
- 5.Stoof R, Goñi-Moreno Á. Modelling co-translational dimerization for programmable nonlinearity in synthetic biology. J. R. Soc. Interface. 2020;17:20200561. doi: 10.1098/rsif.2020.0561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Pezzulo G, Levin M. Top-down models in biology: explanation and control of complex living systems above the molecular level. J. R. Soc. Interface. 2016;13:20160555. doi: 10.1098/rsif.2016.0555. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Lobo D, Solano M, Bubenik GA, Levin M. A linear-encoding model explains the variability of the target morphology in regeneration. J. R. Soc. Interface. 2014;11:20130918. doi: 10.1098/rsif.2013.0918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Saadatpour A, Albert R. A comparative study of qualitative and quantitative dynamic models of biological regulatory networks. EPJ Nonlinear Biomed. Phys. 2016;4:1–13. doi: 10.1140/epjnbp/s40366-016-0031-y. [DOI] [Google Scholar]
- 9.Helikar T, Kowal B, Rogers J. A cell simulator platform: the cell collective. Clin. Pharmacol. Ther. 2013;93:393–395. doi: 10.1038/clpt.2013.41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Daniels BC, et al. Criticality distinguishes the ensemble of biological regulatory networks. Phys. Rev. Lett. 2018;121:138102. doi: 10.1103/PhysRevLett.121.138102. [DOI] [PubMed] [Google Scholar]
- 11.Manicka S, Marques-Pita M, Rocha LM. Effective connectivity determines the critical dynamics of biochemical networks. J. R. Soc. Interface. 2022;19:20210659. doi: 10.1098/rsif.2021.0659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Boole, G. Collected Logical Works, Vol. I. Studies in Logic and Probability (ed. Rhees, R.) (Open Court Publishing Company, 1952).
- 13.O’Donnell, R. Analysis of Boolean Functions (Cambridge University Press, 2014).
- 14.Yanushkevich, S. & Shmerko, V. Taylor expansion of logic functions: from conventional to nanoscale design. In Int. TICSP Workshop on Spectral Methods and Multirate Signal Processing (Citeseer, 2004).
- 15.Grieb M, et al. Predicting variabilities in cardiac gene expression with a Boolean network incorporating uncertainty. PLoS ONE. 2015;10:e0131832. doi: 10.1371/journal.pone.0131832. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Betel H, Flocchini P. On the relationship between fuzzy and Boolean cellular automata. The. Comput. Sci. 2011;412:703–713. [Google Scholar]
- 17.Ebrahimkhani MR, Levin M. Synthetic living machines: a new window on life. Iscience. 2021;24:102505. doi: 10.1016/j.isci.2021.102505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Merchan L, Nemenman I. On the sufficiency of pairwise interactions in maximum entropy models of networks. J. Stat. Phys. 2016;162:1294–1308. doi: 10.1007/s10955-016-1456-5. [DOI] [Google Scholar]
- 19.Gutenkunst RN, et al. Universally sloppy parameter sensitivities in systems biology models. PLoS Comput. Biol. 2007;3:e189. doi: 10.1371/journal.pcbi.0030189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hanahan D, Weinberg RA. Hallmarks of cancer: the next generation. Cell. 2011;144:646–674. doi: 10.1016/j.cell.2011.02.013. [DOI] [PubMed] [Google Scholar]
- 21.Choi M, Shi J, Jung SH, Chen X, Cho K-H. Attractor landscape analysis reveals feedback loops in the p53 network that control the cellular response to dna damage. Sci. Signal. 2012;5:ra83–ra83. doi: 10.1126/scisignal.2003363. [DOI] [PubMed] [Google Scholar]
- 22.Cohen DP, et al. Mathematical modelling of molecular pathways enabling tumour cell invasion and migration. PLoS Comput. Biol. 2015;11:e1004571. doi: 10.1371/journal.pcbi.1004571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Derrida B, Pomeau Y. Random networks of automata: a simple annealed approximation. Europhys. Lett. 1986;1:45. doi: 10.1209/0295-5075/1/2/001. [DOI] [Google Scholar]
- 24.Levin M. Bioelectrical approaches to cancer as a problem of the scaling of the cellular self. Prog. Biophys. Mol. Biol. 2021;165:102–113. doi: 10.1016/j.pbiomolbio.2021.04.007. [DOI] [PubMed] [Google Scholar]
- 25.Linardatos P, Papastefanopoulos V, Kotsiantis S. Explainable AI: a review of machine learning interpretability methods. Entropy. 2020;23:18. doi: 10.3390/e23010018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Manicka S, Levin M. Minimal developmental computation: a causal network approach to understand morphogenetic pattern formation. Entropy. 2022;24:107. doi: 10.3390/e24010107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Watson RA, Levin M, Buckley CL. Design for an individual: connectionist approaches to the evolutionary transitions in individuality. Front. Ecol. Evol. 2022;64:64–87. [Google Scholar]
- 28.Kauffman S. The large scale structure and dynamics of gene control circuits: an ensemble approach. J. Theor. Biol. 1974;44:167–190. doi: 10.1016/S0022-5193(74)80037-8. [DOI] [PubMed] [Google Scholar]
- 29.Reichhardt CO, Bassler KE. Canalization and symmetry in Boolean models for genetic regulatory networks. J. Phys. A. 2007;40:4339. doi: 10.1088/1751-8113/40/16/006. [DOI] [Google Scholar]
- 30.Gates AJ, Rocha LM. Control of complex networks requires both structure and dynamics. Sci. Rep. 2016;6:1–11. doi: 10.1038/srep24456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Müller F-J, Schuppert A. Few inputs can reprogram biological networks. Nature. 2011;478:E4–E4. doi: 10.1038/nature10543. [DOI] [PubMed] [Google Scholar]
- 32.Wagner A. Does evolutionary plasticity evolve? Evolution. 1996;50:1008–1023. doi: 10.2307/2410642. [DOI] [PubMed] [Google Scholar]
- 33.Biswas S, Manicka S, Hoel E, Levin M. Gene regulatory networks exhibit several kinds of memory: quantification of memory in biological and random transcriptional networks. Iscience. 2021;24:102131. doi: 10.1016/j.isci.2021.102131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Mitchell M. Ubiquity 2011, 1-7. Ubiquity. 2011;2011:1–7. [Google Scholar]
- 35.Chu, D., Prokopenko, M. & Ray, J. C. J. Computation by natural systems (2018).
- 36.Cook M, et al. Universality in elementary cellular automata. Complex Syst. 2004;15:1–40. [Google Scholar]
- 37.Wolfram S. Statistical mechanics of cellular automata. Rev. Mod. Phys. 1983;55:601. doi: 10.1103/RevModPhys.55.601. [DOI] [Google Scholar]
- 38.Zenil, H. & Riedel, J. Asymptotic intrinsic universality and natural reprogrammability by behavioural emulation. In Advances in Unconventional Computing (ed Adamatzky, A.) 205–220 (Springer, 2017).
- 39.Manicka, S. V. S. The Role of Canalization in the Spreading of Perturbations in Boolean Networks. Ph.D. thesis, Indiana University (2017).
- 40.Marques-Pita M, Rocha LM. Canalization and control in automata networks: body segmentation in drosophila melanogaster. PLoS ONE. 2013;8:e55946. doi: 10.1371/journal.pone.0055946. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Rocha, L. M. On the feasibility of dynamical analysis of network models of biochemical regulation. arXiv10.48550/arXiv.2110.10821 (2021). [DOI] [PMC free article] [PubMed]
- 42.Gates AJ, Brattig Correia R, Wang X, Rocha LM. The effective graph reveals redundancy, canalization, and control pathways in biochemical regulation and signaling. Proc. Natl. Acad. Sci. USA. 2021;118:e2022598118. doi: 10.1073/pnas.2022598118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Press, W. H., Flannery, B. P., Teukolsky, S. A. & Vetterling, W. T. Numeric Recipes in C: The Art of Scientific Computing (Cambridge University Press, 1992).
- 44.Petri V, et al. The pathway ontology–updates and applications. J. Biomed. Semant. 2014;5:1–12. doi: 10.1186/2041-1480-5-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Hammer PL, et al. On the determination of the minima of pseudo-Boolean functions. Studii si Cercetari Matematice. 1963;14:359–364. [Google Scholar]
- 46.Battiston F, et al. The physics of higher-order interactions in complex systems. Nat. Phys. 2021;17:1093–1098. doi: 10.1038/s41567-021-01371-4. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
We used 137 Boolean network models of gene regulation from two sources, namely the cell collective9 and reference3. Subsequently, we categorized these models using two types of classifications C1 and C2 as described in Section. We provide the details of the classification of each model along with their Pubmed ID and their linear approximation score in the Supplementary Information file (SI), Supplementary Table 1.
The code that we used for the approximations and the simulations are available through this link: https://gitlab.com/smanicka/boolion.