

Abstract
As one of the key methods of Traditional Chinese Medicine inspection, tongue diagnosis manifests the advantages of simplicity and directness. Sublingual veins can provide essential information about human health. In order to automate tongue diagnosis, sublingual veins segmentation has become one important issue in the field of Chinese medicine medical image processing. At present, the primary methods for sublingual veins segmentation are traditional feature engineering methods and the feature representation methods represented by deep learning. The former, which mainly based on colour space, belongs to unsupervised classification method. The latter, which includes U-Net and other deep neural network models, belongs to supervised classification method. Current feature engineering methods can only capture low dimensional information, which makes it difficult to extract efficient features for sublingual veins. On the other hand, current deep learning methods use down-sampling structures, which manifest weak robustness and low accuracy. So, it is difficult for current segmentation approaches to recognize tiny branches of sublingual veins. To overcome the above limits, this paper proposes a novel two-stage semantic segmentation method for sublingual veins. In the first stage, a fully convolutional network without down-sampling is used to realize the accurate segmentation of the tongue that includes the sublingual veins to be segmented in the next stage. During the tongue segmentation, the proposed networks can effectively reduce the loss of medical images spatial feature information. At the same time, in order to expand the receptive field, the dilated convolution has been introduced to the proposed networks, which can capture multi-scale information of segmentation images. In the second stage, another fully convolutional network has been used to segment the sublingual veins on the base of the results from the first stage. In this model, proper dilated convolutional rates have been selected to avoid gridding issue. In order to keep the quality of the images to be segmented, several particular data pre-processing and post-processing have been used, which includes specular highlight removal, data augmentation, erosion and dilation. Finally, in order to evaluate the performance of the proposed model, segmentation results have been compared with the state-of-the-art methods on the base of the dataset from Shanghai University of Traditional Chinese Medicine. The effectiveness of sublingual veins segmentation has been proved.
Keywords: Traditional Chinese Medicine, Medical image semantic segmentation, Sublingual veins, Fully convolutional networks, Dilated convolution
Introduction
As one of the key methods of Traditional Chinese Medicine (TCM) inspection, the analysis based on sublingual veins is one of the important issues in the field of TCM image processing. Various diseases can be recognized by the features of the sublingual veins, which includes brain tumours, brain stroke, coronary atherosclerotic heart disease [1–4], etc. The level of diseases can also be judged by observing the colour, shape, length, width, and the ecchymosis presence of the sublingual veins. However, there are many tiny branches of sublingual veins, so it is difficult for the doctor to observe them directly from original images. Therefore, an intelligent medical image processing method is required for automatic sublingual veins segmentation.
Current state-of-the-art methods mainly focuse on tongue segmentation [5–8], and There is almost no research on sublingual veins segmentation. Now there are two types of segmentation methodologies for sublingual veins segmentation. The first one is the feature engineering methods. It realizes the segmentation based on the extracted colour space features of the image utilizing prior knowledge. The other one, it realizes the segmentation based on the feature representation methods represented by deep learning. The typical ones include U-Net [9] and modified U-Net [10].
The feature engineering methods first extract useful features from the analyzed images. To realize the object segmentation, There are several representative achievements. Yan et al. [11] have focused on the pixel-based adaptive sublingual vein segmentation algorithm for sublingual images with low contrast. Besides, they proposed a sublingual vein segmentation method combining LUV colour space and HSI colour space [12]. Li et al. [13] propose hyperspectral imaging systems which could capture hyperspectral images with both the spectral and spatial information of sublingual veins. The spectra extracted from the hyperspectral image could use a hidden Markov model (HMM) to segment sublingual veins. Sun et al. [14] segmented sublingual veins based on feature clustering. The current image segmentation methods based on feature engineering manifests the advantages of model simplicity, fast training speed, and no requirements for expert annotation. However, for the actual application, high-quality images are required. Poor robustness and low segmentation accuracy need to be addressed.
Deep learning methods have achieved great success in the field of medical image processing. This kind of supervised learning methods requires experts to label the datasets. Especially for semantic segmentation, deep neural networks are used to learn features from the medical images to be processed. Long et al. [15] proposed fully convolutional networks (FCN) for semantic segmentation, and the original terminal fully connected layer is removed in convolutional neural networks. This model is the originator of the semantic segmentation in deep learning. This model architecture has been widely utilized in subsequent semantic segmentation models. In the proposed FCN, the pooling layer has been used to enlarge the receptive field. Up-sampling has been used to expand the image size. In 2015, Ronneberger et al. [9] proposed a model called U-Net, which applied the pooling layer results in the decoding process and introduced more coding information. U-Net is a very famous medical image segmentation model that can be trained with a small amount of data, which is the panel feature of medical image datasets. Yang et al. [10] modified the U-Net model and retrained it with a dataset of the limited number of labels. With the prior knowledge of tongue segmentation, the loss of the trained model converged quickly. Zhao et al. [16] proposed a pyramid scene analysis network that used a large core pooling layer to expand the receptive field of the model. He et al. [17] proposed mask R-CNN, a convolutional network based on the faster R-CNN architecture [18]. This network realizes high-quality semantic segmentation while performing target detection. Chen et al. [19] proposed atrous spatial pyramid pooling (ASPP), which could combine information on different scales. In the proposed model, the fully connected CRF has been used for post-processing. Peng et al. [20] used large kernel convolutions for the encoder–decoder architecture, which has a residual network called boundary refinement, that improves the semantic segmentation performance. The encoder used ResNet [21]. The decoder used deconvolution and graph convolutional networks (GCN). In 2019, Kirillov et al. [22] subtly considered the image segmentation problem as a rendering problem and proposed PointRend, which can be incorporated into popular meta-architectures for semantic segmentation. The deep learning has shown the following disadvantages. The model is relatively complex. The training time is long. The dataset needs experts to label. However, this type of methods owns high robustness and high segmentation accuracy to different images.
In the field of image semantic segmentation, data pre-processing and post-processing are conventional techniques to improve the segmentation performance of the model. Data augmentation is a typical technique to extend datasets, which could benefit the training in general. It can also speed up convergence or act as a regularizer, thus avoiding overfitting and increasing generalization capabilities [23]. Common transformations in data augmentation that can be applied: translation, rotation, warping, scaling, colour space shifts, crops, etc. Besides, another prominent technology is data generation based on GANs, which directly generates new data without modifying the original data. GANs based augmentation techniques for segmentation can improve the robustness of the model and have been applied for a wide variety of problems [24]. One typical post-processing method for refining the output of the segmentation network is Conditional Random Field (CRF). CRF enables the combination of low-level image information with the output of multi-class inference systems that produce per-pixel class scores [25]. In summary, pre-processing and post-processing can effectively improve the performance of the model.
To overcome the shortcomings of the current methods, this paper proposes a two-stage compact fully convolutional networks for image segmentation, which aims to achieve highly accurate segmentation of sublingual veins. Firstly, the data pre-processing methods of specular highlight removal and data augmentation are conducted to preserve the quality and quantity and reduce the cost of labelling data by experts. In order to achieve the effective segmentation of the tongue, we propose a fully convolutional network in the first stage that does not include down-sampling. This structure effectively reduces the loss of spatial feature information of medical pictures. At the same time, this paper introduces the dilated convolution into the fully convolutional networks to expand the receptive field and capture multi-scale context information. In the second stage, a fully convolutional network has been used to segment the sublingual veins on the base of the results from the first stage. The segmentation model uses the fully convolutional networks that consistent with the first stage and sets different dilated convolution rates to avoid gridding issue effectively. In the data post-processing stage, edge erosion and dilation are used to smooth the edges to improve the accuracy and visual effect of segmentation. Two-stage sublingual veins segmentation of the proposed method has been evaluated on the dataset, which contains 322 groups of tongue images collected by Shanghai University of Traditional Chinese Medicine. The experiment results show that the proposed method is significantly better than the state-of-the-art ones. Figure 1 illustrates the proposed two-stage sublingual veins segmentation strategy in this paper.
Fig. 1.
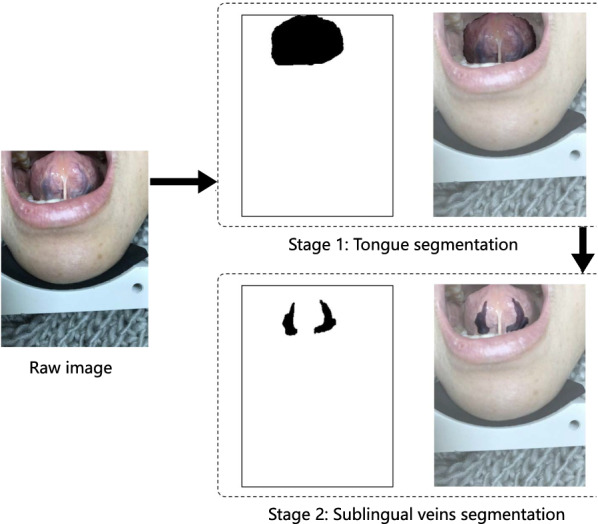
Illustration of sublingual veins segmentation in two stages
The rest of this paper is organized as follows. In Sect. 2, current related studies are introduced. In Sect. 3, the proposed method is discussed in details. Section 4 evaluates the proposed method and discusses the experiment results. Finally, important conclusion has been given in Sect. 5.
Related work
In the two-stage sublingual veins semantic segmentation model studied in this paper, we use compact fully convolutional networks and improved dilated convolution and other structures to achieve the best results. Compared with the traditional network architecture, compact fully convolutional networks can reduce the loss of spatial information. Dilated convolution can expand the receptive field of the network. At the same time, we use a series of dilated rates to improve the traditional dilated convolution to avoid gridding issue. The details are as follows.
In the pixel-wise semantic segmentation task, as mentioned above, most of these existing network architectures follow the fully convolutional networks of encoder-decoder. Instead, Li et al. [26] proposed a novel 3D architecture that incorporated high spatial resolution feature maps throughout the layers. They designed a compact network architecture without down-sampling for the segmentation of volumetric images. This architecture uses dilated convolution to expand the receptive field instead of the pooling layer.
Dilated convolution Dilated convolution maintains image resolution and computes with a high spatial resolution by inserting “holes” between pixels in convolutional kernels. The apparent advantage of dilated convolution is that it enlarges the size of the receptive field. Chen et al. [19] used dilated convolution with up-sampled kernels for semantic image segmentation. Yu and Koltun [27] used dilated convolution with increasing rates to aggregate multi-scale context. Dilated convolution can be used to produce accurate dense predictions and detailed segmentation maps along object boundaries. Furthermore, it has been applied to a broader range of tasks, such as optical flow [28], and audio generation [29].
Gridding The standard dilated convolution has a fundamental problem, gridding. When we use the standard dilated convolution, the receptive field covers an area with non-zero values. The dilated convolution can be regarded as the standard convolution on different feature maps. If the pixels of each feature map have no further interaction, it will cause discontinuity of pixel connection. Besides, repeated stacking would further aggravate the gridding issue. In the dilated convolution kernel with a large rate, the receptive field is too sparse to cover any information. Wang et al. [30] alleviated this issue by using a range of dilated rates instead of the same dilated rates. They reported that the gridding issue would still exist if a series of dilated rates have a common factor relationship (such as 2,4,8, etc.). Proper dilated rates can increase the receptive field effectively.
Methodology
As shown in Fig. 2, that is the overall segmentation process framework for sublingual veins. In this framework, our proposed method can be divided into three steps: data pre-processing, two-stage semantic segmentation, and data post-processing. In the data pre-processing step, we use the technique of specular highlight removal and data augmentation. Among them, the removal of reflective dots can improve the quality of data, and the augmentation of data can extend the current dataset. In the semantic segmentation network, we divide the sublingual veins segmentation into two stages. In the first stage, we use a compact fully convolutional network to segment the tongue from the image to be processed. In the second stage, the sublingual veins are recognized from the segmented tongue images. Finally, in the data post-processing step, we adopt erosion and dilation methods to smooth the edges of the segmented region. The specific implementation details of each step are illustrated below.
Fig. 2.

The framework of two-stage sublingual veins segmentation method proposed in this paper
Data preprocessing
In this section, the data pre-processing methods for sublingual veins segmentation are proposed, which includes specular highlight removal and data augmentation. The actual effect of the data pre-processing methods are analyzed at last.
Specular highlight removal
Images that contain sublingual veins usually exhibits specular highlights caused by sharp reflections of light off the saliva on its surface. To overcome the influence of reflective points on the sublingual veins segmentation, we propose a specular highlight removal algorithm based on the work of Tan and Ikeuchi [31]. The diffuse reflection coefficient of all specular reflection is obtained by the non-linear function relationships between the pixels’ colour and the maximum diffuse chromaticity. We use a new method to estimate diffuse chromaticity instead of [31] and design a simplified algorithm. According to the dichromatic reflection model, the reflected lights can be divided into diffuse reflection and specular reflection following Eq. (1).
| 1 |
where represents the colour vector of the raw images. r, g, b represent three channels: red, green and blue. represents the coordinates of the pixel. represent the diffuse reflection and specular reflection of the pixel. respectively represent the weight factors of diffuse reflection and specular reflection of the pixel.
And we define chromaticity as the following.
| 2 |
| 3 |
| 4 |
where is the chromaticity associated with the pixels’ color. means diffuse chromaticity. means specular reflection chromaticity.
Tan [31] proposed that the diffuse reflection of each pixel in the image could be calculated as the following.
| 5 |
where . means the weight factors of diffuse reflection. represents the max . Thus images without specular reflection can be obtained according to the maximum diffuse reflection chromaticity . How to estimate becomes the key to solve the problem. We use to estimate as Eq. (6).
| 6 |
where . represents the max . The maximum estimated diffuse reflection chromaticity is calculated by Eq. (7).
| 7 |
There is a linear relationship between the maximum estimated diffuse reflection chromaticity and the maximum true diffuse reflection chromaticity [32], which is defined as the following.
| 8 |
where a and b are coefficients of the linear model. In the set w, their values are constant. To find a and b, we need to minimize the energy equation as shown in Eq. (9).
| 9 |
where means regularization parameter to prevent the value of a from being too large. By means of linear regression [33], the solution of Eq. (9) can be obtained.
| 10 |
| 11 |
where and is the mean and variance of in the set w. means the cardinality of the set w. In our dataset, the value of a is 1 and the value of b is 0.5. We calculate the maximum true diffuse reflection chromaticity using Eq. (8), and obtain the corresponding images after specular highlight removal.
Data augmentation
Training a well-performing network commonly requires a large amount of data, but the size of the dataset in the medical field is generally small. Due to the small dataset, there are usually overfitting phenomena happening in the trained model. So, data augmentation is used to extend the corresponding medical image dataset to ensure model training performance. Since the segmentation should not destroy the complete structure of sublingual veins, the data augmentation methods, such as random cropping and warping, are not considered. Because the segmentation should not affect the shape of sublingual veins, data augmentation methods like stretching and scaling, should not still be considered. For each image in the training dataset, three data augmentation methods are used, which includes horizontal flip, vertical flip and horizontal flip with vertical flip. Figure 3 illustrates the dataset extension results of three different data augmentation methods used in this paper.
Fig. 3.

Data augmentation results. (H - Horizontal, V - Vertical)
Two-stage segmentation strategy
In the current medical image dataset, the ratio of the number of sublingual veins images is too low to get good segmentation results. Further, even the images contain the sublingual veins, and their pixels are still very imbalanced. That is to say, sublingual veins belong to small segmentation targets. In order to get an excellent semantic segmentation result, two-stage segmentation strategy is used. In the first stage (stage 1), we segment the tongue from the image as foreground regions of interest (RoI). At the same time, the background is removed, and the difficulty of semantic segmentation for small targets is reduced. The process is illustrated in Fig. 4. We train our proposed compact fully convolutional networks with tongue labels in stage 1, instead of directly training them with sublingual veins labels. Then the segmentation result of the tongue is used as the network input of sublingual vein segmentation in Stage 2. This progressive two-stage semantic segmentation method can gradually extract effective image features and help improve the segmentation performance of the model. The specific network structure and loss function settings are shown below.
Fig. 4.

Two-stage sublingual veins segmentation strategy
Compact fully convolutional networks
In every stage, the fully convolutional network is used to realize the semantic segmentation. In the second stage (stage 2), we encountered some difficulties when segmenting the sublingual veins. The sublingual veins are small and contain many tiny bifurcations. That leads to uneven of the segmented samples. It is difficult for the network to converge. Therefore, to segment the sublingual veins which own many tiny branches, we need to ensure the accuracy of the semantic segmentation. However, the encoder–decoder structure commonly used in deep learning will inevitably lose some spatial information of the images to be analyzed. So it is challenging to extract effective features and reconstruct small objects in sublingual veins images because of the limitation of down-sampling and up-sampling.
To overcome the difficulties mentioned above, we propose a compact fully convolutional network on the base of state-of-the-art research [26]. The architecture is depicted in Fig. 5. We adopt a compact eight-layer convolutional neural network. In the first layer, we adopt 5 5 pixel convolutions without dilated convolution. A convolutional kernel with 5 5 pixel convolution gives the same receptive field as stacking two layers of 3 3 pixel convolution. The layer 2 uses a batch normalization operation [34]. The layer 1 and layer 2 are designed to learn the low-level features of the input images. In layer 3–6, dilated convolution is added to the network for expanding the receptive field and capturing multi-scale context information. The kernels are dilated by the different candidate rates, which do not have the common factor relationship in the subsequent four convolutional layers. Proper rates can effectively expand the receptive filed and avoid the gridding issue [30]. To merge the features at multiple scales, the rates of dilated convolution are gradually increased as the depth of the network increases. In the first stage and the second stage, we use this type of compact fully convolutional networks to realize the tongue segmentation and sublingual veins segmentation respectively. For different characteristics of the tongue and sublingual veins, such as size, we fine-tune the network parameters separately and optimize the dilated convolution rates. The dilated convolution rates corresponding to the tongue are 2,5,7,9, and the sublingual veins’ rates are 2,3,5,7. The layer 7 and layer 8 give binary classification labels for every pixel utilizing 1 1 convolutional layer (Table 1).
Fig. 5.

The architecture of compact fully convoluted networks that we proposed
Table 1.
The detailed experimental parameters in proposed compact fully convolutional networks
| Layer | Num of Kernel | Kernel size | Activation | Dilationrate veins | Dilationrate tongue |
|---|---|---|---|---|---|
| 1 | 32 | 5 5 | ReLU | – | – |
| 2 | 32 | 5 5 | ReLU | – | – |
| 3 | 32 | 5 5 | ReLU | (2, 2) | (2, 2) |
| 4 | 32 | 5 5 | ReLU | (3, 3) | (5, 5) |
| 5 | 32 | 5 5 | ReLU | (5, 5) | (7, 7) |
| 6 | 32 | 5 5 | ReLU | (7, 7) | (9, 9) |
| 7 | 32 | 1 1 | ReLU | – | – |
| 8 | 1 | 1 1 | – | – | – |
Loss function
In the proposed compact fully convolutional networks, the loss function is used to evaluate the segmentation effect of the model. On the one hand, the loss function can evaluate the segmentation effect of the model. On the other hand, it can optimize the model parameters by backpropagation. A proper loss function can help the model converge faster and converge to the optimal solution. In order to get a better segmentation result for the sublingual veins of TCM, we use a hinge loss function with pre-set weight which is inspired by support vector machine (SVM) soft margin classification [35]. The original hinge loss function is defined as Eq. (12).
| 12 |
where denotes the true target value, and y denotes the predicted values.
Usually, medical-related datasets always manifest the characteristic of data imbalance, which is also a typical problem often encountered in medical image segmentation. The loss function above may lead to a strongly biased estimation towards the majority class, which is the non-vein region. To handle the potential problems above, a pre-set weight has been introduced into the loss function, which can balance the training effect. The loss function with corresponding weight is defined as follows.
| 13 |
When the weight , the network will be more inclined to obtain the segmentation target, and its parameters will be optimized more actively. The introduction of weight can break the prediction bias of the proposed compact FCN due to the imbalance of the training dataset, and allow the proposed compact FCN to implement the semantic segmentation task without any biases. We will discuss the impact of weight on bias in details in the subsequent experiments (see Sect. “Experiment results”).
Data post-processing
To handle with the problems encountered in segmented images, this paper adopts different data post-processing methods in the two-stage image segmentation. In the first stage, the method of removing small connected regions is applied to segmented tongue images. In the second stage, the technique of erosion and dilation is used to segmented sublingual veins images. The details are illustrated below.
Small connected regions removal
After the first stage of semantic segmentation, the stray points outside the tongue images and holes inside the tongue images may affect the subsequent sublingual veins segmentation. So small connected regions removal is used as the data post-processing method in the first stage. We look for the connected regions of binary tongue images segmented by the networks and retain the relatively larger connected regions. The actual small connected regions removal is conducted based on Eq. (14). Figure 6 has illustrated the small connected regions removal.
| 14 |
where A represents the tongue segmentation. represents the rest background. CR represents the connected regions and .
Fig. 6.

An example of the small connected regions removal
Erosion and dilation of segmentation edges
For the edges of sublingual veins are jagged in the binary images in the second stage, we perform erosion and dilation as post-processing on them to remove the glitches on the edges. Erosion and dilation and are mathematical morphology transformations [36].
To smooth edges, researchers usually employ erosion and dilation in pairs. Erosion allows the target to shrink inwards and eliminates small, meaningless objects. Besides, dilation merges the background points of the target connection into the target to fill the hole in the image. Therefore, in this paper, dilation followed by erosion of images eliminates the small holes and fills the gaps of the sublingual veins edges, which smoothes them well.
Experiments
We perform sublingual veins segmentation experiments to verify the proposed method on the dataset collected by ourselves. To present the experiment results clearly, this section introduces the data collection process, the dataset statistic, and other experimental conditions firstly. Secondly, we introduced the evaluation metrics adopted in the process of verifying the two-stage segmentation. Finally, we discuss tongue segmentation results and sublingual veins segmentation results based on the compact fully convolutional networks proposed in this paper. According to the experiment results, we conducted an in-depth discussion on the effectiveness of the method.
Experiment condition
To verify the effect of our sublingual veins segmentation algorithm, Shanghai University of Traditional Chinese Medicine has specially developed a device for collecting images of the tongue and sublingual veins, as shown in Fig. 7. Using this instrument, we have collected high-definition images. The image resolution is 3024 4032. Finally, we collected 322 sets of images for algorithm verification. The authors have obtained an ethical approval from the Shanghai University of Traditional Chinese Medicine (ethical review approval No: 2021-1039-114-01).
Fig. 7.
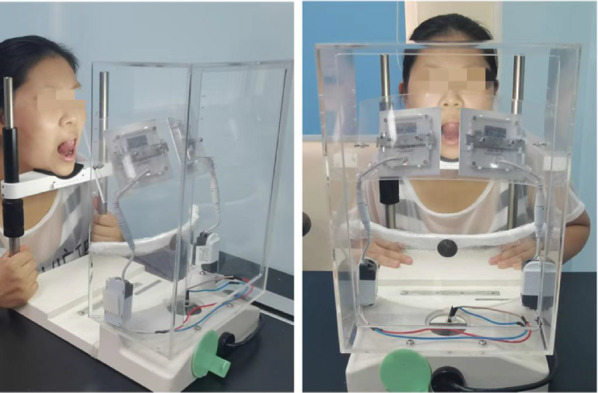
Image acquisition equipment
Manual calibration and dataset division have been conducted on sublingual veins dataset to prepare for the next phase of algorithm verification. Two experts calibrated the tongue and sublingual veins, forming a labelled high-quality dataset based on the professional knowledge of Traditional Chinese Medicine. After that, we divide it into two datasets. One is for tongue segmentation, and the other is for sublingual veins segmentation. The ratios of the training set and the testing set of the two types of datasets are both set to 8:2. The models of tongue segmentation and sublingual veins segmentation are trained respectively.
In this paper, the experiments are performed on the following hardware platform: Intel Core i7 processor at 3.4 GHz, NVIDIA GeForce GTX 2070 GPU with Ubuntu 18.04. The epochs of tongue segmentation are 380, and the epochs of sublingual veins segmentation are 500. The learning rate is set to 0.0001 in all experiments.
Evaluation metrics
To evaluate the semantic segmentation effect of the tongue and sublingual veins, we adopt five evaluation indicators such as precision, recall, F1-score, AUC, and mIoU [37]. In the segmentation process, it is a binary classification problem for each pixel of the image. In this experiment, the specific evaluation metrics are defined as follows. Some abbreviations appear in the following formula. P is positive. N is Negative. TP means that the label is P and the classification result is P. TN means that the label is N and the classification result is N. FN means that the label is P and the classification result is N. FP means that the label is N and the classification result is P.
Experiment results
The proposed segmentation method is a two-stage method. Therefore, in the discussion part of the experiment results, we respectively introduce and discuss the two-stage experiment results. First, we present the preliminary results of tongue segmentation, and then we present the results of sublingual veins segmentation. Finally, we compare our proposed method with U-Net [9], Modified U-Net [10], and Colour Space method [12].
Tongue segmentation experiment results
In this part, we discuss the experiment results of the compact fully convolutional networks for tongue segmentation under different parameter settings. The relevant parameters we focus on include the weight setting in the loss function, whether to use dilated convolution, different dilated convolution rate settings and a series of experimental settings for data pre-processing and post-processing.
As shown in Fig. 8, when the weight of the loss function is different, the loss value of the model changes in different epochs. From Fig. 8, it can be observed that the convergence speed of the loss function is the fastest when , and the convergence value is the smallest.
Fig. 8.

Experiment results of different weights for the loss function
In the experiment part of the tongue segmentation, we have conducted eight different experiments, as shown in Table 2. The experiment results under different conditions are shown in Table 3.
Table 2.
Details of the methods used by different tongue segmentation strategies (TSS)
| Strategy | LW | DC | DR | DR | DR | GI | RSH | DA | RSCR |
|---|---|---|---|---|---|---|---|---|---|
| (2,4,6,8) | (2,3,5,7) | (2,5,7,9) | |||||||
| TSS-1 | |||||||||
| TSS-2 | |||||||||
| TSS-3 | |||||||||
| TSS-4 | |||||||||
| TSS-5 | |||||||||
| TSS-6 | |||||||||
| TSS-7 | |||||||||
| TSS-8 |
chosen method in the strategy, abandoned method in the strategy, LW loss weight , DC dilated convolution, DR dilated rates, GI grdding issue, RSH removing specular highlights, DA data augmentation, RSCR removing small connected regions
Table 3.
Experiment results for tongue segmentation strategies (TSS)
| Strategy | Evaluation metrics | ||||
|---|---|---|---|---|---|
| F1-score | Precision | Recall | AUC | mIoU | |
| TSS-1 | 0.8825 | 0.9014 | 0.8644 | 0.9735 | 0.7897 |
| TSS-2 | 0.8979 | 0.9288 | 0.8689 | 0.9788 | 0.8146 |
| TSS-3 | 0.9026 | 0.9302 | 0.8766 | 0.9766 | 0.8225 |
| TSS-4 | 0.9063 | 0.9355 | 0.8790 | 0.9844 | 0.8288 |
| TSS-5 | 0.9104 | 0.9426 | 0.8804 | 0.9853 | 0.8356 |
| TSS-6 | 0.9141 | 0.9324 | 0.8965 | 0.9896 | 0.8418 |
| TSS-7 | 0.9473 | 0.9559 | 0.9390 | 0.9979 | 0.9000 |
| TSS-8 | 0.9506 | 0.9608 | 0.9406 | 0.9926 | 0.9058 |
The best performance is highlighted in boldface
In Table 3, eight different experiment results have been compared. The ablation experiments prove that the weight of loss function and the setting of dilated convolution rates (2,5,7,9) are effective. Table 3 clearly shows that the network architecture has excellent semantic segmentation performance of the tongue without any data processing. And It indicates that the best tongue segmentation effect can be obtained under the conditions of using TSS-. As shown in the Table 3, the compact fully convolutional networks proposed in this paper can effectively segment tongues. The segmentation accuracy of the model can be improved by data augmentation and specular highlight removal. The F1-score of the model performance can reach 0.9506, and the mIoU of the model performance can reach 0.9058. In the post-processing stage, the experiment of removing small connection regions shows that we can get a clear segmented tongue region, as shown in Fig. 9. RSCR can improve the segmentation results and provide high-quality data for the subsequent sublingual veins segmentation.
Fig. 9.

Tongue post-processing. (RSCR removing small connected regions)
Sublingual veins segmentation experiment results
According to the segmentation results from the first stage, we conducted sublingual veins segmentation in the second stage. In this experiment, we have designed nine different combinations of conditions, as shown in Table 4. The experiment results under different conditions are shown in Table 5.
Table 4.
Details of the methods used by different sublingual veins segmentation strategies (SVSS)
| Strategy | LW | DC | DR | DR | DR | GI | RSH | TSR | DA | EED |
|---|---|---|---|---|---|---|---|---|---|---|
| (2,4,6,8) | (2,3,5,7) | (2,5,7,9) | ||||||||
| SVSS-1 | ||||||||||
| SVSS-2 | ||||||||||
| SVSS-3 | ||||||||||
| SVSS-4 | ||||||||||
| SVSS-5 | ||||||||||
| SVSS-6 | ||||||||||
| SVSS-7 | ||||||||||
| SVSS-8 | ||||||||||
| SVSS-9 |
chosen method in the strategy, abandoned method in the strategy, LW loss weight , DC dilated convolution, DR dilated rates, GI grdding issue, RSH removing specular highlights, TSR two-stage segmentation strategy, DA data augmentation, EED edge erosion and dilation
Table 5.
Experiment results for sublingual veins segmentation strategies (SVSS)
| Strategy | Evaluation metrics | ||||
|---|---|---|---|---|---|
| F1-score | Precision | Recall | AUC | mIoU | |
| SVSS-1 | 0.6641 | 0.7321 | 0.6076 | 0.9789 | 0.4951 |
| SVSS-2 | 0.6738 | 0.7456 | 0.6146 | 0.9800 | 0.5081 |
| SVSS-3 | 0.6821 | 0.7500 | 0.6254 | 0.9791 | 0.5175 |
| SVSS-4 | 0.6907 | 0.7544 | 0.6370 | 0.9821 | 0.5276 |
| SVSS-5 | 0.6941 | 0.7628 | 0.6368 | 0.9811 | 0.5315 |
| SVSS-6 | 0.7013 | 0.7532 | 0.6561 | 0.9802 | 0.5400 |
| SVSS-7 | 0.7131 | 0.7693 | 0.6646 | 0.9872 | 0.5542 |
| SVSS-8 | 0.7376 | 0.7888 | 0.6926 | 0.9893 | 0.5843 |
| SVSS-9 | 0.7603 | 0.8104 | 0.7160 | 0.9901 | 0.6133 |
The best performance is highlighted in boldface
The experiments are shown in Table 5. According to the comparative analysis results of our proposed sublingual veins segmentation method under different experimental conditions, it can be seen that the best effect can be obtained by combining the five evaluation indicators which is SVSS-9. With this method, F1-score can reach 0.7603, and mIoU can reach 0.6133. The final experiment results show that the data processing methods we adopt for data augmentation, specular highlight removal, and edge erosion and dilation are conducive to the improvement of experiment results. As shown in Fig. 10, this is a comparison of the images before and after removing the specular highlight. Images that contain sublingual veins usually exhibits specular highlights caused by sharp reflections of light off the saliva on its surface. For example, the highlight at the circle of figure (a) was processed by RSH to get figure (b). Obviously, the highlight was effectively removed, thus improving the quality of data. As shown in Fig. 11, this is a comparison of whether erosion and dilation are used for smoothing edges. Therefore, after edges are smoothed by erosion and dilation, the segmented images are not only closer to the real annotated images, but also have a better visualization effect., that make the results look clear and complete.
Fig. 10.
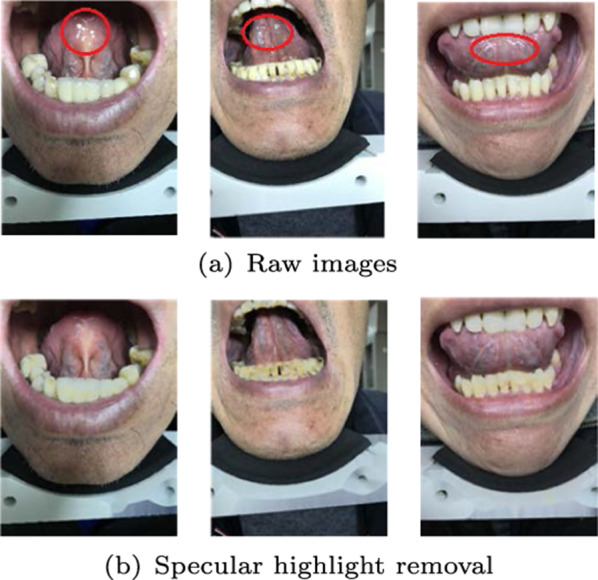
An example of specular highlight removal
Fig. 11.

Sublingual veins post-processing. (EED edge erosion and dilation)
As shown in Fig. 11, we perform erosion and dilation as post-processing on the sublingual veins jagged edges. This processing method fills the gaps between the sublingual veins’ edges and improves the performance of segmentation.
Next, we compare the SVSS-5 and SVSS-9 with the current state-of-the-art (Colour Space method [12], U-Net [9], Modified U-Net [10]). In the comparison process, the parameters used by other networks come from their original papers. For the fairness of the experiment, we set the same experimental parameters and the corresponding experimental dataset division. The final experiment results are shown in Table 6.
Table 6.
Experiment results comparison for sublingual veins segmentation among SVSS-5, SVSS-9, and approaches of [9, 10, 12]
| Model | Evaluation metrics | ||||
|---|---|---|---|---|---|
| F1-score | Precision | Recall | AUC | mIoU | |
| Colour Space [12] | 0.5970 | 0.5066 | 0.7267 | – | 0.4255 |
| U-Net [9] | 0.6573 | 0.6972 | 0.6217 | 0.9735 | 0.4895 |
| Modified U-Net [10] | 0.6832 | 0.7445 | 0.6313 | 0.9813 | 0.5189 |
| SVSS-5 | 0.6941 | 0.7628 | 0.6368 | 0.9811 | 0.5315 |
| SVSS-9 | 0.7603 | 0.8104 | 0.7160 | 0.9901 | 0.6133 |
The best performance is highlighted in boldface
According to the results in Table 6, the model proposed in this paper is significantly better than the current state-of-the-art models (Colour Space method, Classic U-Net and Modified U-Net). This proves the practical effectiveness of our proposed method.
The method based on colour features has high requirements for image acquisition. It cannot segment well for images with little difference in colour features between RoI and surrounding pixels. In Table 6, a series of colour space evaluation metrics are lower than other methods, except for recall. The reason for the high recall of the colour space method is that this method can segment most of the pixels labelled as true, so FN is low and TP is high. However, this method segments a large number of non-vein pixels as veins, so FP is high, which leads to low precision. The colour space method is not sufficient and suitable for sublingual vein segmentation, since F1-score, mIoU and other metrics are low.
Discussion
In terms of semantic segmentation of medical images, data pre-processing, such as specular highlight removal and data augmentation, can effectively improve the effect of semantic segmentation of medical images. First of all, image pre-processing can effectively improve the quality and quantity of the dataset. The method of specular highlight removal can remove the noise of data collection. Data augmentation can effectively augment the dataset and avoid the high cost of expert annotation. Secondly, the ablation experiment proves that the data pre-processing method can effectively improve the segmentation effect of the model in both stages. Therefore, appropriate data pre-processing method is the key to improve the model performance.
It can be seen from the experiments in this paper that the compact fully convolution networks achieved good segmentation effect in tongue segmentation and sublingual veins segmentation. As can be seen in Table 6, even without any data processing methods, the compact fully convolutional networks proposed by us still get the best results compared with those of the traditional colour space method, U-Net, and modified U-Net. Firstly, the compact fully convolutional networks use dilated convolution to enlarge the receptive field and set different dilated convolution rates to avoid the gridding issue. Secondly, the networks do not adopt any down-sampling method, which can completely retain the high resolution of images. Finally, a two-stage segmentation method is used to extract the sublingual veins gradually. Such a network architecture can overcome the difficulties in feature extraction caused by the tiny branches of sublingual veins.
In the field of image semantic segmentation, data post-processing can make up for the defects of the segmentation model through prior knowledge. In this paper, different methods of data post-processing are used in two stages of the segmentation model. In the first stage of tongue segmentation, a post-processing method is used to remove the small connected regions and the cavity. Experiments show that this post-processing method can improve the segmentation results and provide high-quality data for the subsequent sublingual veins segmentation. In the second stage, which is sublingual veins segmentation, erosion and dilation are used to smooth the edges to achieve good visual effect and segmentation results. The results of ablation experiments also show that the methods of data post-processing dramatically improves the segmentation results of the original model (Figs. 12, 13).
Fig. 12.

The tongue segmentation: a Raw images, b Labeled binary images, c Modified U-Net, d TSS-8, e Visualization of segmentation using TSS-8 and raw images overlay
Fig. 13.

The sublingual vein segmentation: a Raw images, b Labeled binary images, c Colour Space, d Modified U-Net, e SVSS-9, f Visualization of segmentation using SVSS-9 and raw images overlay
To sum up, TSS-8, which integrates all processing methods, achieves the best tongue segmentation results. Based on tongue segmentation, SVSS-9 achieves the best sublingual segmentation results compare to the state-of-the-art. These prove the validity of the proposed two-stage compact fully convolutional networks and the data processing methods.
Conclusions
In this paper, a two-stage sublingual veins segmentation method based on compact fully convolutional networks is proposed. It contains a series of data pre-processing and post-processing techniques.
The feature of the proposed method is that it can achieve accurate segmentation of small targets. Experiments show that the two-stage semantic segmentation method of medical images, which combines data pre-processing and post-processing, can achieve the best semantic segmentation results compared with state-of-the-art methods. However, we achieved the best results with the dataset calibrated by Traditional Chinese Medicine experts. The trained model needs to be improved in the following aspects in the future. On the one hand, it is the Generalization Performance of the model. Although the current model can get good segmentation results on sublingual veins, the performance of this model is yet to be verified in the face of new semantic segmentation problems in the future. On the other hand, it is the robustness of the model. Both data pre-processing and post-processing methods are proposed to enhance model robustness for small-scale datasets. However, in the future, how to improve robustness in large-scale datasets to achieve better segmentation effect is also a problem that needs to be studied.
In the future, we need to consider expanding the research from the following three aspects to address the above deficiencies. Firstly, we need to discuss how to improve the quality and quantity of datasets by using data augmentation and data selection methods to improve the segmentation accuracy of the model. Secondly, How to make the model train a larger dataset. Last but not least, based on the existing manual calibration dataset and sublingual veins segmentation model, how to transfer the learning strategy to the broader medical image segmentation problem, to improve the model generalization ability.
Acknowledgements
A heartfelt thanks to all those who participated in this paper (Lijuan Wang, Huadong Li, Fanyang Meng, Wenmeng Yu, Junhui Deng, Yingyan Hou).
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 62173195); and the National Key R &D Program Projects of China (Grant No: 2018YFC1707605).
Declarations
Conflict of interest
The authors confirm that there are no conflict of interest.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Hua Xu, Email: xuhua@tsinghua.edu.cn.
Peng Qian, Email: qqpp2000439@126.com.
References
- 1.Li N, Zhang D, Wang K. Tongue diagnostics. Beijing: Xueyuan Press; 2006. [Google Scholar]
- 2.Li N. The handbook of Chinese tongue diagnosis. Beijing: Xueyuan Press; 1994. [Google Scholar]
- 3.Wang FW, Liu Y, Lin M-X. Observation and analysis of 112 cases on subglossal collateral vessels of coronary heart disease patients. Chin J Inf Tradit Chin Med. 2004;4:323–324. [Google Scholar]
- 4.Yang Y, Qian J, Zhan Y, Wang Y, Xu H, Yang W. Observation and characteristics analysis of sublingual veins of diabetic vascular disease. J Nanjing Univ Tradit Chin Med. 2008;24(06):370–372. [Google Scholar]
- 5.Pang B, Zhang D, Li N, Wang K. Computerized tongue diagnosis based on Bayesian networks. IEEE Trans Biomed Eng. 2004;51(10):1803–1810. doi: 10.1109/TBME.2004.831534. [DOI] [PubMed] [Google Scholar]
- 6.Zhang D, Pang B, Li N, Wang K, Zhang H. Computerized diagnosis from tongue appearance using quantitative feature classification. Am J Chin Med. 2005;33(06):859–866. doi: 10.1142/S0192415X05003466. [DOI] [PubMed] [Google Scholar]
- 7.Lin H-J, Chen Y-J, Damdinsuren N, Tan T-H, Liu T-Y, Chiang JY. Automatic sublingual vein feature extraction system. In: Proceedings of international conference on medical biometrics. IEEE; 2014. p. 55–62.
- 8.Ma J, Wen G, Wang C, Jiang L. Complexity perception classification method for tongue constitution recognition. Artif Intell Med. 2019;96:123–133. doi: 10.1016/j.artmed.2019.03.008. [DOI] [PubMed] [Google Scholar]
- 9.Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of international conference on medical image computing and computer-assisted intervention. Springer; 2015. p. 234–41.
- 10.Yang T, Yoshimura Y, Morita A, Namiki T, Nakaguchi T. Fully automatic segmentation of sublingual veins from retrained u-net model for few near infrared images. 2018. http://arxiv.org/abs/1812.09477.
- 11.Yan Z, Wang K, Li N. Sublingual vein segmentation from near infrared sublingual images. In: Proceedings of the 8th IEEE international conference on bioinformatics and bioengineering, BIBE; 2008. October 8–10, Athens, Greece.
- 12.Yan Z, Wang K, Li N. Computerized feature quantification of sublingual veins from color sublingual images. Comput Methods Programs Biomed. 2009;93(2):192–205. doi: 10.1016/j.cmpb.2008.09.006. [DOI] [PubMed] [Google Scholar]
- 13.Li Q, Wang Y, Liu H, Guan Y, Xu L. Sublingual vein extraction algorithm based on hyperspectral tongue imaging technology. Comput Med Imaging Graph. 2011;35(3):179–185. doi: 10.1016/j.compmedimag.2010.10.001. [DOI] [PubMed] [Google Scholar]
- 14.Sun D, Wu J, Zhang Y, Bai J, Weng W, Wu Y. Sublingual veins automatic extraction method based on feature clustering. Chin J Biomed Eng. 2008;27(02):265–269. [Google Scholar]
- 15.Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015. p. 3431–40. [DOI] [PubMed]
- 16.Zhao H, Shi J, Qi X, Wang X, Jia J. Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2017. p. 2881–90.
- 17.He K, Gkioxari G, Dollár P, Girshick R. Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision; 2017. p. 2961–69.
- 18.Ren S, He K, Girshick R, Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell. 2015;39(6). [DOI] [PubMed]
- 19.Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS. IEEE Trans Pattern Anal Mach Intell. 2017;40(4):834–848. doi: 10.1109/TPAMI.2017.2699184. [DOI] [PubMed] [Google Scholar]
- 20.Peng C, Zhang X, Yu G, Luo G, Sun J. Large kernel matters–improve semantic segmentation by global convolutional network. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2017. p. 4353–61.
- 21.Szegedy C, Ioffe S, Vanhoucke V, Alemi AA. Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of thirty-first AAAI conference on artificial intelligence; 2017.
- 22.Kirillov A, Wu Y, He K, Girshick R. Pointrend: image segmentation as rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 2020. p. 9799–08.
- 23.Wong SC, Gatt A, Stamatescu V, McDonnell MD. Understanding data augmentation for classification: when to warp? In: Proceedings of international conference on digital image computing: techniques and applications (DICTA). IEEE; 2016. p. 1–6.
- 24.Taghanaki SA, Abhishek K, Cohen JP, Cohen-Adad J, Hamarneh G. Deep semantic segmentation of natural and medical images: a review. Artif Intell Rev. 2020;54:1–42. [Google Scholar]
- 25.Chen L-C, Papandreou G, Kokkinos I, Murphy K, Yuille AL. Semantic image segmentation with deep convolutional nets and fully connected crfs. 2014. http://arxiv.org/abs/1412.7062. [DOI] [PubMed]
- 26.Li W, Wang G, Fidon L, Ourselin S, Cardoso MJ, Vercauteren T. On the compactness, efficiency, and representation of 3d convolutional networks: brain parcellation as a pretext task. In: Proceedings of international conference on information processing in medical imaging. Springer; 2017. p. 348–60.
- 27.Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. 2015. http://arxiv.org/abs/1511.07122.
- 28.Sevilla-Lara L, Sun D, Jampani V, Black MJ. Optical flow with semantic segmentation and localized layers. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016. p. 3889–98.
- 29.Oord Avd, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, Kalchbrenner N, Senior A, Kavukcuoglu K. Wavenet: a generative model for raw audio. 2016. http://arxiv.org/abs/1609.03499.
- 30.Wang P, Chen P, Yuan Y, Liu D, Huang Z, Hou X, Cottrell G. Understanding convolution for semantic segmentation. In: 2018 IEEE winter conference on applications of computer vision (WACV). IEEE; 2018. p. 1451–60.
- 31.Tan RT, Ikeuchi K. Separating reflection components of textured surfaces using a single image. In: Ikeuchi K, Miyazaki D, editors. Digitally archiving cultural objects. New York: Springer; 2008. pp. 353–384. [Google Scholar]
- 32.He K, Sun J, Tang X. Single image haze removal using dark channel prior. IEEE Trans Pattern Anal Mach Intell. 2010;33(12):2341–2353. doi: 10.1109/TPAMI.2010.168. [DOI] [PubMed] [Google Scholar]
- 33.He K, Sun J, Tang X. Guided image filtering. IEEE Trans Pattern Anal Mach Intell. 2012;35(6):1397–1409. doi: 10.1109/TPAMI.2012.213. [DOI] [PubMed] [Google Scholar]
- 34.Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd international conference on international conference on machine learning; 2015. p. 448–56.
- 35.Tang Y. Deep learning using linear support vector machines. 2013. http://arxiv.org/abs/1306.0239.
- 36.Haralick RM, Sternberg SR, Zhuang X. Image analysis using mathematical morphology. IEEE Trans Pattern Anal Mach Intell. 1987;4:532–550. doi: 10.1109/TPAMI.1987.4767941. [DOI] [PubMed] [Google Scholar]
- 37.Fawcett T. An introduction to roc analysis. Pattern Recogn Lett. 2006;27(8):861–874. doi: 10.1016/j.patrec.2005.10.010. [DOI] [Google Scholar]