

Abstract
Background:
Idiopathic pulmonary fibrosis (IPF) is a progressive, irreversible, and usually fatal lung disease of unknown reasons, generally affecting the elderly population. Early diagnosis of IPF is crucial for triaging patients’ treatment planning into anti-fibrotic treatment or treatments for other causes of pulmonary fibrosis. However, current IPF diagnosis workflow is complicated and time-consuming, which involves collaborative efforts from radiologists, pathologists, and clinicians and it is largely subject to inter-observer variability.
Purpose:
The purpose of this work is to develop a deep learning-based automated system that can diagnose subjects with IPF among subjects with interstitial lung disease (ILD) using an axial chest computed tomography (CT) scan. This work can potentially enable timely diagnosis decisions and reduce inter-observer variability.
Methods:
Our dataset contains CT scans from 349 IPF patients and 529 non-IPF ILD patients. We used 80% of the dataset for training and validation purposes and 20% as the holdout test set. We proposed a two-stage model: at stage one, we built a multi-scale, domain knowledge-guided attention model (MSGA) that encouraged the model to focus on specific areas of interest to enhance model explainability, including both high- and medium-resolution attentions; at stage two, we collected the output from MSGA and constructed a random forest (RF) classifier for patient-level diagnosis, to further boost model accuracy. RF classifier is utilized as a final decision stage since it is interpretable, computationally fast, and can handle correlated variables. Model utility was examined by (1) accuracy, represented by the area under the receiver operating characteristic curve (AUC) with standard deviation (SD), and (2) explainability, illustrated by the visual examination of the estimated attention maps which showed the important areas for model diagnostics.
Results:
During the training and validation stage, we observe that when we provide no guidance from domain knowledge, the IPF diagnosis model reaches acceptable performance (AUC±SD = 0.93±0.07),but lacks explainability; when including only guided high- or medium-resolution attention, the learned attention maps are not satisfactory; when including both high- and medium-resolution attention, under certain hyperparameter settings, the model reaches the highest AUC among all experiments (AUC±SD = 0.99±0.01) and the estimated attention maps concentrate on the regions of interests for this task. Three best-performing hyperparameter selections according to MSGA were applied to the holdout test set and reached comparable model performance to that of the validation set.
Conclusions:
Our results suggest that, for a task with only scan-level labels available, MSGA+RF can utilize the population-level domain knowledge to guide the training of the network, which increases both model accuracy and explainability.
Keywords: attention models, computed tomography, deep learning, domain knowledge, idiopathic pulmonary fibrosis, machine learning, medical imaging
1. INTRODUCTION
Idiopathic pulmonary fibrosis (IPF) is a specific form of chronic, progressive, irreversible, and usually lethal lung disease of unknown causes with an estimated median survival of 3–5 years since the initial diagnosis.1 In clinical settings, making a correct, rapid, and reliable IPF diagnosis is critical to triage patients’ treatment planning into anti-fibrotic treatment or other causes of pulmonary fibrosis treatment, and even lung transplantation registry.2
According to the official clinical guideline,2 computed tomography (CT) has become an integral part of the diagnosis of IPF. Radiological patterns of usual interstitial pneumonia (UIP) are the hallmark of IPF.2 Specifically, several CT features are frequently observed in UIP patterns, including honeycombing, subpleural reticulation, and traction bronchiectasis in a lower lobe subpleural distribution.2 The diagnosis of IPF involves the collaboration of multi-disciplinary discussion from specialists: clinicians, radiologists, and pathologists.2 In more detail, patients suspected to have IPF should undergo an in-depth evaluation of potential causes or associated conditions, such as hypersensitivity pneumonitis, connective tissue disease, etc. If there is no potential cause identified, the chest CT patterns of the patient are evaluated. Despite the existence of these guidelines,2 the evaluation of these radiological patterns is a difficult task and needs a multidisciplinary team of experts in interstitial lung disease (ILD) with subject to inter-observer variability.3,4 The average time from the referral to multidisciplinary diagnosis is a year.
To this end, this research aims to develop a deep learning-based automated diagnosis system to distinguish IPF from non-IPF among subjects with ILD based on chest CT scans. This diagnostic system is a stand-alone system without requiring additional efforts from imaging analysts and radiologists, such as lung segmentation, contouring, or other disease assessment. The clinical meaning of this research area is to (1) reduce inter-observer variability in the IPF diagnosis task, (2) enable timely and reliable IPF diagnosis, and (3) enable early anti-fibrosis treatment which may prolong patients’ survival time in the long term.5
Several machine learning and deep learning approaches have been developed to provide diagnostic support for IPF.6,7 For example, Walsh et al. trained a deep learning-based method to classify fibrotic lung disease into UIP, possible UIP, or inconsistent with UIP based on four CT slice combinations.8 Similarly, Christe et al. developed a pipeline for the automatic classification of CT images into several UIP patterns.9 The diagnostic pipeline involves lung segmentation and voxel-level tissue characterization. The development and maintenance of these techniques usually involve extensive collaborative efforts from radiologists, imaging analysts, software engineers, data scientists, which are not as desirable taking time and resource considerations into account.10
Moreover, some work in this area takes several CT slices as training or testing samples8,11; whereas our work takes 3D CT volumes as input to utilize more information across the lungs.
In recent years, numerous deep learning-based algorithms have achieved great success in various medical imaging tasks, such as segmentation, diagnosis, detection, etc.12,13 The successful application of deep learning systems in clinical practice relies on these three prerequisites: (1) the availability of well-labeled fine-scale data, which are usually at a pixel, regions of interests (RoI), or image slice level; (2) the extent of explainability on where and how the deep learning-based system makes the decision; and (3) the ability to generalize well to a new dataset.
Attention mechanisms, which originated from natural language processing, have gained substantial interests in research problems that deal with label scarcity, strengthen model generalizability to a new dataset, and encourage long-range dependencies in computer vision.14–16 Attention mechanisms are one way to explain which region of the image the network’s decision depends on and can enhance the explainability of deep learning-based systems.17 Attention mechanisms have recently become popular in the medical imaging domain to solve the research question of segmentation18–20 classification,21,22 detection,23 and so on. Notably, attention mechanisms are usually incorporated at multiple resolution scales, to encourage a more effective feature connection.24,25 In this work, guided attention modules of multiple scales are implemented to encourage the deep learning-based system to focus on the areas of interests, which are lung parenchyma, especially the peripheral lung areas, based on the provided population-level domain knowledge (DK) acquired from prior studies.
The goal of this study is to develop an automated diagnosis system using deep learning that meets explainability and adequate model performance using chest high-resolution CT (HRCT) scans to distinguish IPF from non-IPF among subjects with ILDs.
1 |. MATERIALS AND METHODS
1.1 |. Datasets
Lung CT images in this research were collected from multi-center studies and the UCLA computer vision and imaging biomarkers (CVIB) Laboratory served as the imaging core facility. Only subjects with clinical diagnoses of ILD were included. A total number of 878 volumetric non-contrast HRCT scans were retrospectively collected IPF (N = 349, 39.7%) and non-IPF ILD cohorts (N = 529, 60.3%). In more detail, non-IPF subjects were clinically diagnosed as systemic sclerosis ILD (N = 230), rheumatoid arthritis (RA) ILD (N = 103), myositis ILD (N = 81), hypersensitivity pneumonitis ILD (N = 74), and Sjogren syndrome ILD (N = 41). CT images were collected from May 1997 to May 2018. We applied the stratified random sampling of IPF and non-IPF subjects: the training and validation set (N = 702, 80.0%, IPF% = 39.7%) and the testing set (N = 176, 20.0%, IPF% = 39.8%), as illustrated in Figure 1. As a result, the training, validation, and testing set are composed of CT scans collected from multi-center studies. A five-fold cross-validation was employed to the training and validation with stratification of IPF and non-IPF subjects: four subsets were used to construct the model and one subset was used to evaluate the model performance (shown as “Val” in Figure 1).
FIGURE 1.

The overall separation of the dataset. Val: validation, which is the subset that is used to evaluate the model performance at a specific fold
1.2 |. Image processing
HRCT scans underwent preprocessing (see Supporting information A for details). Each CT scan was standardized to the dimension 256 × 256 × 128, and further resampled a fixed number of 3D-volumes, with dimension 128 × 128 × 64 to boost sample size and reduce the data dimension. We use subject index and resample index ; for example, is the th sampled CT volume from subject (see Supporting information B and Table S1 for the key notations). The total number of resampling was chosen after the evaluation of balance in model performance and computational time (see the details of in Supporting information C.1 and Figure S1).
1.3 |. Elements of two-staged multi-scale guided attention and random forest model
During the model training stage, the input of the system contains three components: and the expected output contains two parts: . Specifically, is the patient-level CT scan collected from subject is the ground truth indicating whether the subject is clinically diagnosed as IPF or non-IPF ILD , which is used to compute the loss function for model training; is the number of subjects in the study; is a standardized quantitative measure of population-level DK collected from previous IPF studies, indicating which regions in lung parenchyma are typically prevalent in pulmonary fibrosis. is the predicted label for scan and . is the estimated attention maps for scan and sample , highlighting the regions that are closed to image. We implemented two attention multi-scale modules at a high- and medium-resolution level, then , where and are the estimated attention map at a high- and medium-resolution for a subject’s scan and sample , respectively. During the model testing stage, only patient-level CT scans are required as model input and model output includes scan-level predictions (IPF vs. non-IPF, ,) and estimated attention maps .
The dimension of information is: (a) is usually of dimension 512 × 512 × number of CT slices, where 512 is the number of voxels in the -and -dimension for each CT slice; (b) standardized domain knowledge is a multi-dimensional array of dimension 256 × 256 × 128 as an input image. It is down sampled to high- and medium-resolutions, as represented by and , which are dimension 64 × 64 × 32 and 16 × 16 × 8, respectively (Figure 2); (c) for the estimated attention maps, the dimensions of and are 64 × 64 × 32 and 16 × 16 × 8, respectively. The image dimension is represented as throughout this paper, where the depth dimension is the dimension along the patient’s body from apex to base and height–width plane is the axial plane of each CT slice. The dimension of intermediate features generated by 3D-convolutions is , where -dimension is the channel dimension.
FIGURE 2.
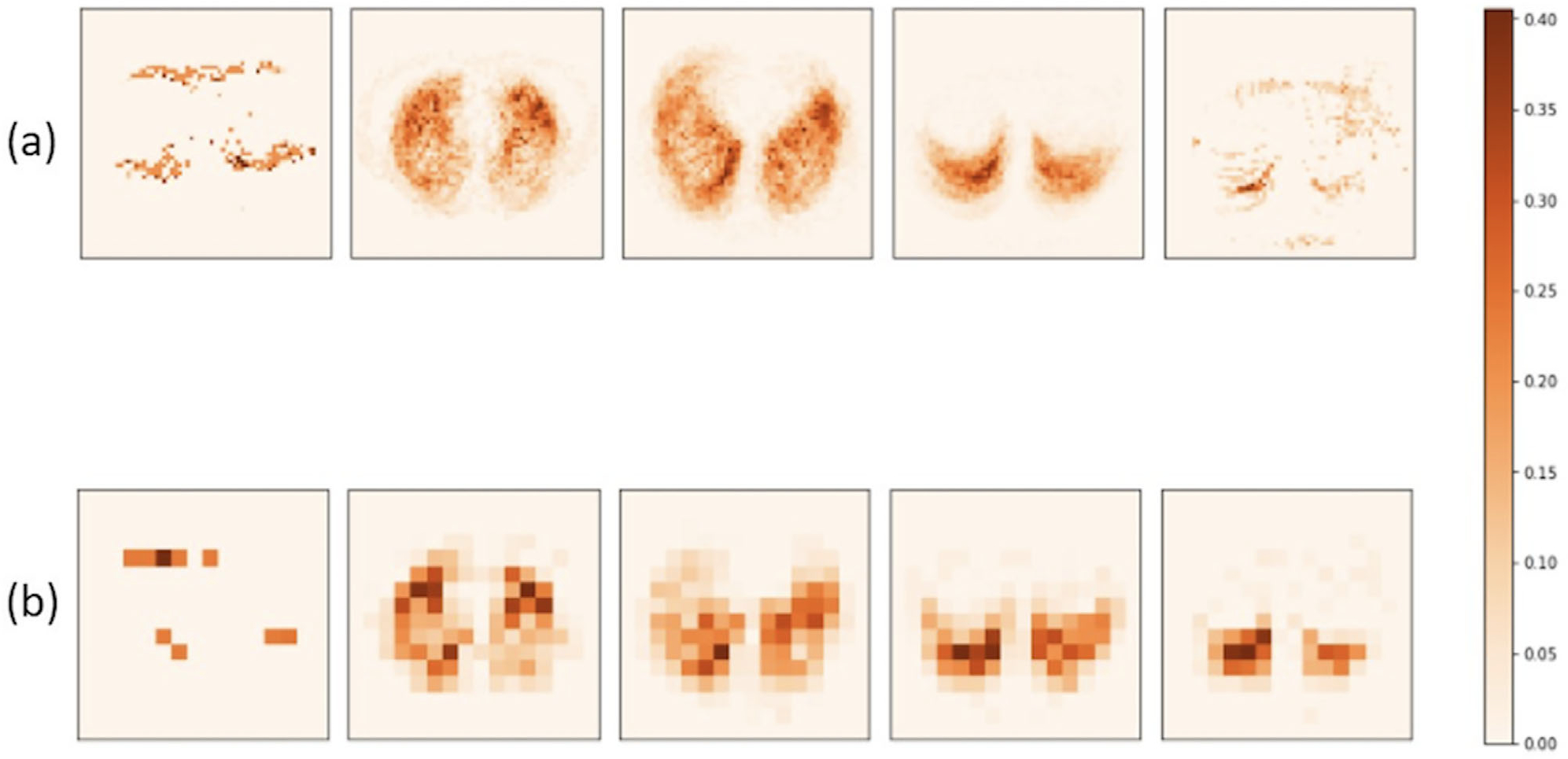
Population-level domain knowledge at high (a) and medium (b) resolutions. Subplots (a) are produced at the 3%, 28%, 53%, 78%, 97% position along the depth D-axis; subplots (b) are produced at the 13%, 38%, 63%, 75%, 88% position along the D-axis
1.4 |. Population-level domain knowledge
1.4.1 |. Explainability
In the past 10 years, quantitative CT imaging biomarkers have been developed and evaluated as clinical studies among patients with ILD.26 These developed measures are spatially traceable and can be used as DK to guide the training of IPF diagnosis model.
Quantitative lung fibrosis (QLF) is a well-developed automated algorithm to classify CT voxels into different types, including normal, lung fibrosis, ground glass opacity, honeycombing etc.27 In this study, QLF score is used to provide a DK map, which is defined as a marginal probability map that serves as a general guidance on where disease patterns usually locate, especially for IPF subjects. Therefore, DK is calculated before the training of the IPF diagnosis models and is not dependent on the training and testing procedure of the IPF diagnosis model.
DK is acquired as follows: (1) Voxel-level prediction: using the QLF algorithm to predict the CT scans from the 102 eligible IPF subjects on a voxel-level. We define or 0 indicating if the scan for subject at voxel location is predicted as lung fibrosis; (2) Population-level sum and standardization: after acquiring the voxel-level prediction for all 102 subjects, we sum over all subjects for each voxel location by , and then standardize to a scale of [0, 1]: . By definition, ranges from 0 to 1.
Domain knowledge is later downsampled to two resolution scales: 64 × 64 × 32 and 16 × 16 × 8, as shown in Figure 2. A 3D representation of the DK map is provided in Supporting information D and Figure S2. Higher intensity values (more orange) in Figure 2 represent a greater value of , which concentrates on the Rol for this IPF diagnosis task. Lung areas, especially peripheral lungs, are highlighted in Figure 2, which agrees with IPF-related CT features. In the future sections, we will discuss how DK is incorporated as an integral part of the loss function during training to encourage the model to focus on IPF disease patterns.
1.5 |. Attention gates
We provide a schematic of the proposed guided attention gates in Figure 3. The attention gates take intermediate feature maps , and population-level domain knowledge as input and produce two outputs: (1) a feature map with the same dimension as the input , and (2) an estimated attention map . For simplicity, is represented as throughout the paper. Theoretically, attention gates can be incorporated in any layer of any existing architecture. In this work, we focus on the attention gates that are suitable for 3D-CNN architectures, which generate intermediate feature maps of four dimensions, including height, width, depth, and channel.
FIGURE 3.
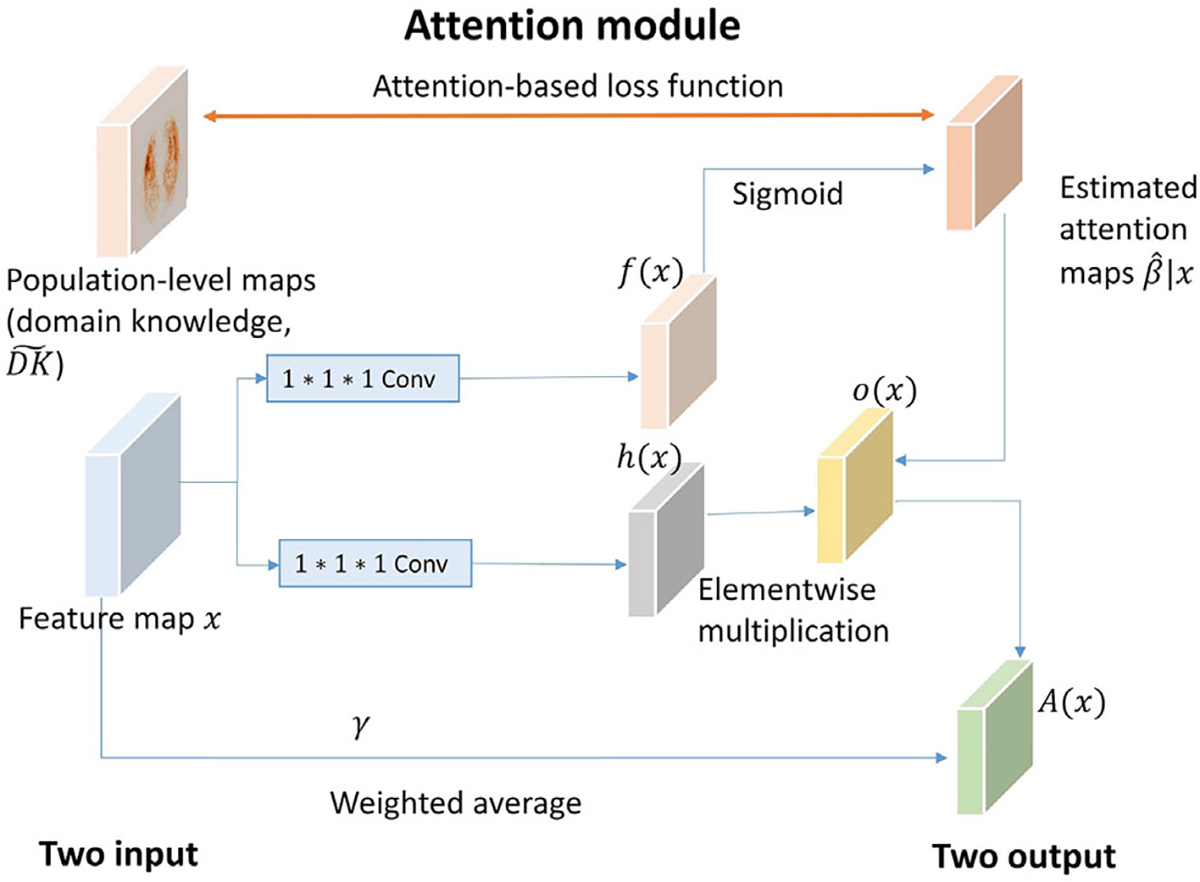
Attention gate (AG) modules
Suppose the attention gates are implemented at the layer and takes the intermediate feature maps that are generated at the previous layer, that is, layer, as input. For 3D-CNN architectures, is a four-dimensional tensor with , where are the height, weight, depth, the number of channels at the layer, respectively. For simplicity, we omit the subject index and sample index throughout this section . The intermediate feature maps are first transformed into two feature spaces and using 1 × 1 × 1 convolutions: where
A sigmoid function is applied to the feature space to calculate the attention scores (i.e., estimated attention maps) at layer at a three-dimensional voxel location , where . Here, is a scalar, and . The dimension of is decided by the choice of layers , where the attention module is implemented in. In our example, let the model layers where the attention modules are incorporated be and , which represent the high and medium attention, respectively. Based on our design, h is a three-dimensional tensor with and .
We further calculate the element-wise multiplication of and the estimated attention maps across each channel: , where is the cth channel of the intermediate feature maps is the cth channel of , and is the elementwise multiplication operation.
The final output of the attention gate is a weighted average of the input intermediate feature maps and , where is a trainable scalar parameter initialized at zero.
1.6 |. Multi-scale guided-attention model
1.6.1 |. Loss function
We use the voxel-wise mean absolute error as the attention-based loss to measure the similarity between the estimated map of each sample with the provided population-level maps where is the estimated attention maps for subject and sample at layer is the rescaled domain knowledge map at layer that has the same dimension as , and is the grand average of all elements from a tensor .
During training, the attention-based loss function is calculated by averaging all the samples: . In this work, we introduced two attention modules at high- and medium-resolution scales; therefore, attention-based loss is incorporated into the overall loss function under two forms: and , where and represent high and medium.
1.6.2 |. Explainability
The overall schematic diagram of MSGA is provided in Figure 4b. 3D-residual blocks are used as building blocks for our model, which is shown as RB1, RB2, and RB3 in Figure 4b). Detailed implementations of 3D-residual blocks, including layer name, hyperparameters, and output size, are provided in Supporting information E and Table S2. For each scan , we first produce number of 3D samples for each scan, indexed by . During the model training procedure, the system includes three types of input: the processed CT scans , the population-level domain knowledge maps at two resolution scales ( and ), and the patient-level clinical ground truth . MSGA takes each sample as a training or testing unit and produces three types of output for each input sample: the sample-level predicted score of being IPF the learned attention map at different resolution scales ( and ) and the estimated attention-based loss values at two resolution scales and ). The attention gates are incorporated into the training of the IPF diagnosis model in an end-to-end manner, at two resolution scales, shown as AG1 and AG2.
FIGURE 4.
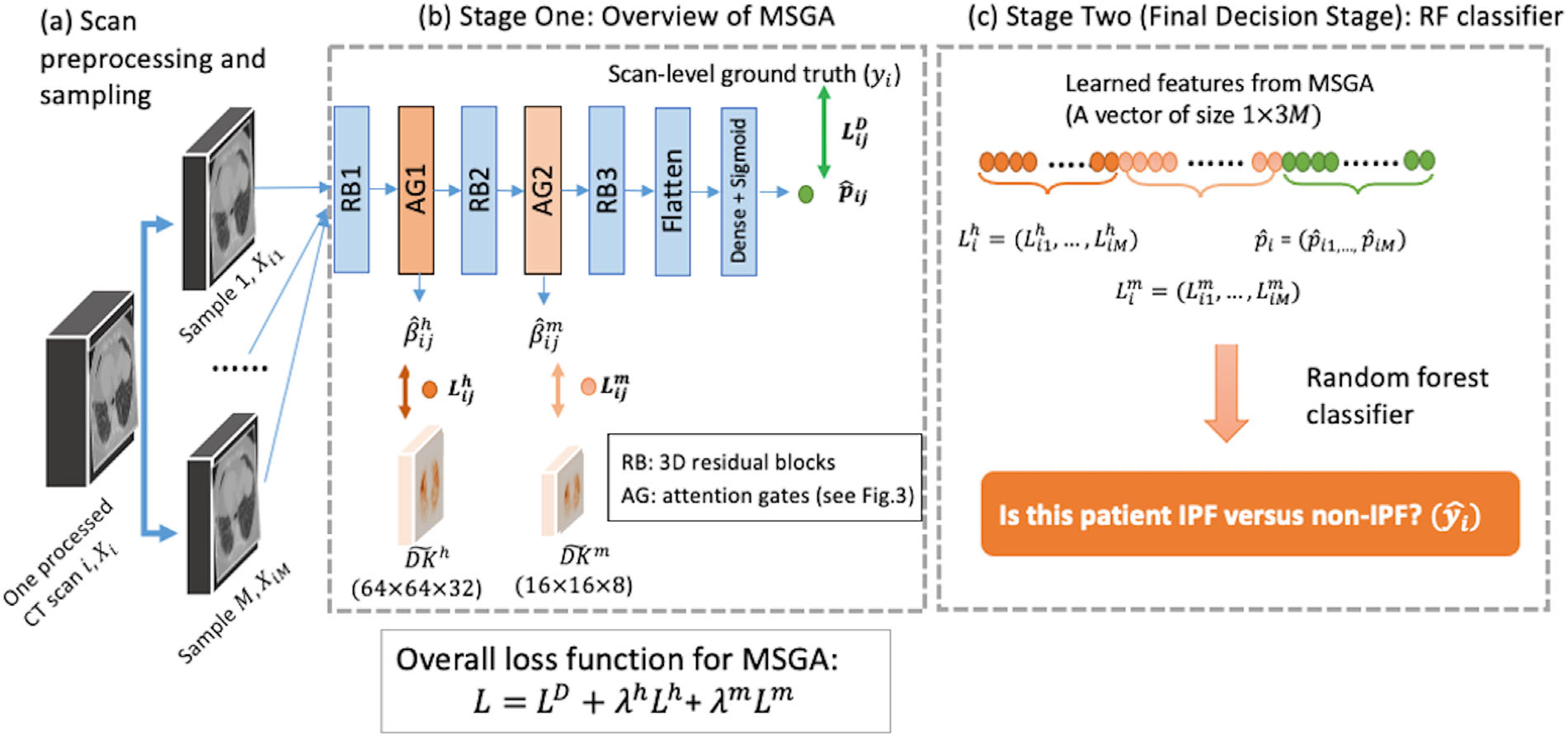
Schematic of the overall system. First, a total number of Msamples are generated from one processed computed tomography (CT) scan . The samples are presented as , where . Multi-scale, domain knowledge-guided attention (MSGA) takes each function at a high- and medium- , and the estimated attention maps at a high- and medium- resolutions. The overall loss function for MSGA is a weighted average of three loss function components: overall IPF diagnosis loss (), attention-based loss at a high- () and medium- resolution. At the final decision stage, random forest (RF) takes the output from MSGA from all M samples and produces a patient-level diagnosis. RB: 3D residual blocks; AG: attention gates (see Figure 3 for the details)
Binary cross-entropy loss is used for the IPF diagnosis task:
where if the subject is clinically diagnosed as non-IPF or IPF, respectively, and is the predicted probability of subject , sample being IPF at the last layer of MSGA.
The overall loss function of the system is composed of a weighted average of two attention-based losses and one diagnosis-based loss:
where is the binary cross-entropy for IPF diagnosis, is the attention-based loss at a high resolution, is the attention-based loss at a medium resolution. and are the relative task importance for the high- and medium-resolution attention models, respectively, with and . We note that when setting and , this represents a scenario where both attention modules are unguided with population-level maps (see Figure 5 for IPF and Figure S3 for non-IPF examples of the estimated AG1 and AG2).
FIGURE 5.
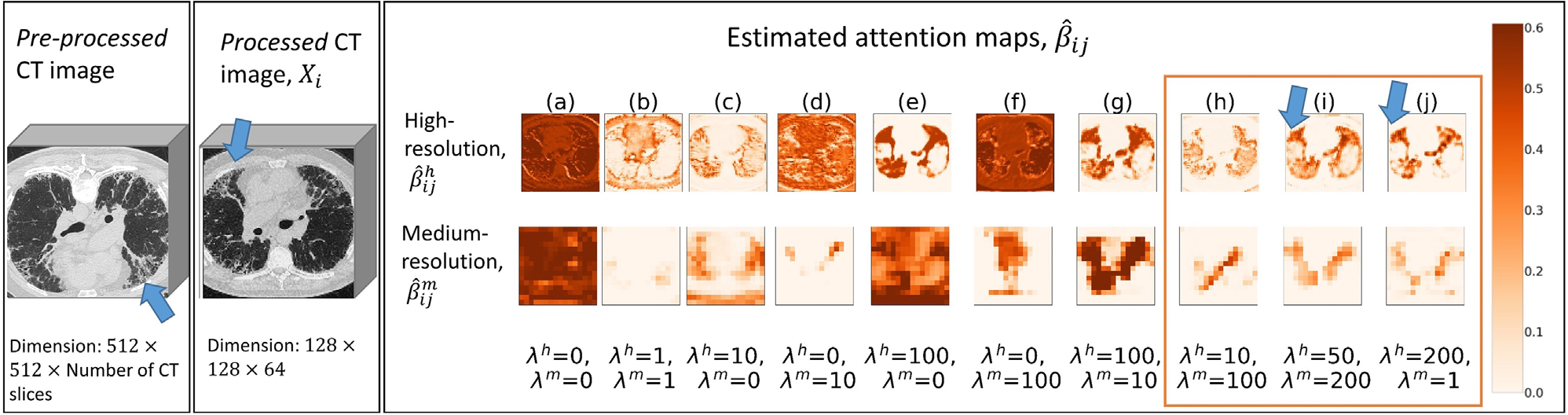
Estimated attention map for an idiopathic pulmonary fibrosis (IPF) subject with 10 different hyperparameters. One representative computed tomography (CT) slice (slice number = 153; in total 309 slices for this scan) of the pre-processed image is provided. One processed CT image is plotted at D = 33 out of 64. The estimated attention maps for high- and medium-resolutions are plotted at D = 17 out of 32 and D = 5 out of 8, respectively. Key CT features of usual interstitial pneumonia (UIP) are highlighted as arrows. Three top performing combinations based on multi-scale, domain knowledge-guided attention (MSGA) are highlighted as an orange rectangle. The models that used this scan as validation samples were selected for plotting. For all ten hyperparameter collections (𝝀h and 𝝀m), both MSGA and MSGA+RF successfully classify this scan as IPF (true positives)
1.6.3 |. Evaluation of explainability
We provide both qualitative and quantitative methods to examine the extent of explainability in this research. Qualitatively, the scan-level estimated attention maps at both high- and medium-resolution can be viewed to see if highlighted areas correspond to disease-specific regions (Figure S4). This method can shed some light on what specific regions are critical for this IPF diagnosis task.
From a quantitative perspective, previous research has shown that histogram analysis of the segmented lung areas is associated with the disease progression of IPF subjects.28 Specifically, a low kurtosis of lung regions is found to be associated with a higher risk of mortality. In this study, we use kurtosis from the estimated attention maps as an explainability index to identify patients with IPF from other causes of pulmonary fibrosis. More technical details are provided in the Supporting information G and Table S3.
1.7 |. Random forest classifier
1.7.1 |. Enhanced improvement
Random forest (RF) is a popular supervised machine learning approach, where the model output is decided based on majority voting of multiple decision trees.29 For a classification task, such as patient-level IPF diagnosis, RF outputs the mode of the classes (IPF vs. non-IPF) predicted by individual decision trees. It has been widely used in medical fields due to its high accuracies, robustness to outliers, explainable nature, and a possibility of parallel processing.30 RF is chosen as the final stage classifier for this research since (1) it is easy to implement and computationally fast; (2) it can handle correlated variables, for example, in our case, the estimated attention loss from M samples; and (3) it is a relatively interpretable algorithm where the variable importance can be used to empirically understand the model decision process.
The intuition of adding RF in the final decision stage is that the high magnitude of attention-based loss ( and ) in the training model can also play a role in the feedback loop of improving the classification of IPF and non-IPF, where the hyperparameters are not close to optimal (Figure S5 for the variable importance in RF). We provide a figure (Figure S6), which shows the distribution of the estimated attention loss values is visually different for IPF and non-IPF subjects. The estimated attention-based loss depicts how each processed CT scan differs from the population-level IPF information. Therefore, we utilize the information of difference of the processed CT scan from the population-level IPF information (i.e., , and ) as well as the predicted probability (i.e., ) for IPF diagnosis.
For each CT scan , we leverage these three types of information acquired from all samples, including the estimated high- and medium- resolution attention loss and the predicted probability of being , to build an RF model that classifies whether a given CT scan is from an IPF subject or a non-IPF ILD subject. For each scan, the designed MSGA produces a vector of size for , respectively, representing the estimated high-, medium attention-based loss function and the predicted IPF score from the samples. This is later combined into a vector of size , in our case, , as the input for the RF model, as shown in Figure 4c).
After the training process of the MSGA is completed, we continue to build an RF-based classifier for each hyperparameter selection ( and ) and for each fold. At each fold, we construct an RF using training samples only. For simplicity, we fix the hyperparameters during the training of RF for each model: RF classifier was consistently configured to use 90 decision trees with a maximum depth of 4.
1.8 |. Overall proposed method: multi-scale, domain knowledge-guided attention +random forest
We propose a two-stage model for scan-level IPF diagnosis.
1.8.1 |. Stage one (multi-scale, domain knowledge-guided attention)
For each CT scan , MSGA provides (1) two estimated attention maps at high- and medium- resolutions and (2) three outputs, including the loss function for high- and medium- attention gates, and the binary cross-entropy loss for IPF diagnosis . The training process of stage one is end-to-end. For each hyperparameter selection, we constructed five MSGA models, leaving one fold of data as the validation set as a time.
1.8.2 |. Stage two (random forest)
For each CT scan, RF takes the features produced by MSGA as input and produces the final probability of being IPF for each scan. We then built an RF model for each MSGA model using the training cases in that fold only. The mean and standard deviations (SDs) across five folds for both MSGA and MSGA+RF were reported as validation set performance. Based on the validation set performance, we further selected the best performing hyperparameter combination as our final model to apply to the test set. Test set performance was reported as the mean and SD across five-fold models.
1.9 |. Model implementation details
For model training, we used Adam optimizer with an initial learning rate of 10−4, followed by an exponential decay after 20 epochs of decay rate 0.05. The batch size was set to be 5 and the model trained after 200 epochs was saved for evaluation. The hardware of Tesla V100-SXM2–32GB and GeForce RTX 2080 Ti and Keras framework were used.31 Sensitivity analysis of epoch numbers is included in Supporting information C.
2 |. RESULTS
2.1 |. Model results: multi-scale, domain knowledge-guided attention (validation set performance)
We report the performance of MSGA from two perspectives of accuracy and explainability. Accuracy was assessed by the area under the curve (AUC) from an ROC analysis. The other assessment is done to visually examine explainability, which is characterized by reviewing the estimated attention maps.
2.1.1 |. Multi-scale, domain knowledge-guided attention model accuracy: idiopathic pulmonary fibrosis diagnosis
Regarding the sample-level IPF diagnosis, Table 1 summarizes the AUC values of MSGA with mean and SD across folds under the validation set, with different selections of hyperparameters ( and ). Both and are selected from a range of values: 0, 1, 10, 50, 100, 200. This range of hyperparameter searching was selected by examining the empirical values of each loss function component. Also, similar work which optimizes a multi-objective loss function utilizes hyperparameters within this range.17,21
TABLE 1.
Area under curve (AUC) mean and standard deviation values of multi-scale, domain knowledge-guided attention (MSGA) performance on validation set for various λh and λm (task importance) parameters
|
λm
|
|||||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 10 | 50 | 100 | 200 | ||
|
| |||||||
| λh | 200 | 0.87 (0.14) | 0.98 (0.02) | 0.88 (0.21) | 0.89 (0.18) | 0.87 (0.21) | 0.97 (0.02) |
| 100 | 0.85 (0.20) | 0.96 (0.04) | 0.86 (0.20) | 0.90 (0.10) | 0.84 (0.21) | 0.97 (0.03) | |
| 50 | 0.83 (0.20) | 0.88 (0.09) | 0.89 (0.22) | 0.84 (0.22) | 0.97 (0.01) | 0.98 (0.02) | |
| 10 | 0.87 (0.21) | 0.92 (0.09) | 0.84 (0.17) | 0.85 (0.21) | 0.99 (0.01) | 0.81 (0.23) | |
| 1 | 0.87 (0.18) | 0.84 (0.21) | 0.95 (0.07) | 0.89 (0.08) | 0.89 (0.12) | 0.76 (0.23) | |
| 0 | 0.93 (0.07) | 0.93 (0.07) | 0.93 (0.09) | 0.86 (0.15) | 0.94 (0.04) | 0.85 (0.21) | |
Note: λh and λm are the relative task importance parameters in the overall loss function, representing high- and medium-resolution attentions, respectively. Three top performing combinations (λh = 200 and λm = 1; λh = 50 and λm = 200; λh = 10 and λm = 100) are in bold font.
As shown in Table 1, without including guided attention by attention-based loss function ( and ), the IPF diagnosis model reached an AUC of ). In most cases (9 out of 10 hyperparameter combinations), only incorporating guided high- and or medium-resolution attention and ) decreased the performance of IPF diagnosis, compared to without guided attention in the loss function ( and ). Under one hyperparameter setting and , the average AUC across five folds is 0.94, which is slightly higher than that of the unguided model (average AUC).
Our proposal, which included both high- and medium-resolution attentions, was able to reach the highest AUC (± SD) value of for all of the experiments, under certain hyperparameter selections ( and ). Three top performing hyperparameter combinations are (1) and (2) and (3) and . Notably, model performance is sensitive to the selection of relative task importance. For example, under certain hyperparameter combinations, that is, and , the AUC (± SD) decreased to .
2.1.2 |. Model explainability: estimated attention maps
We explored the model explainability by plotting the estimated attention maps at both high- and medium-resolutions using one randomly sampled IPF as an example, shown in Figure 5. We also provided one non-IPF ILD subject in Supporting information F and Figure S3. We note that without guided attention models (Figure 5, column a), the observed attention maps are uninformative and lack explainability.
When we provide guidance from population-level DK in constructing the overall loss function, the estimated attention maps begin to focus on the lung parenchyma. Specifically, when the relative task importance is low (column b), the attention maps begin to concentrate on the lungs, but it is not clear. When we add solely the high-resolution guided attention in the loss function (Figure 5, columns c and e), visual examinations indicate that high-resolution attention maps can characterize the lungs, while the medium-resolution attention maps are less informative. On the other hand, when only medium-resolution guidance is added (Figure 5, columns d and f), both high- and medium-resolution attention maps do not concentrate on the lung parenchyma.
Finally, when we provide guidance on both high- and medium-resolution attentions with considerable relative task importance (Figure 5, columns g, h, i, and j), the estimated attention maps become instructive, focus on the lung parenchyma, and suppress irrelevant background areas. Under certain hyperparameter collection (columns h, i, and j), both the estimated attention map and a high- and medium-resolution can focus on peripheral lungs, which are the key regions for making a correct IPF diagnosis. These highlighted areas are critical for this task of IPF diagnosis and are incorporated into the training of deep learning systems.
2.2 |. Model results: multi-scale, domain knowledge-guided attention +random forest (validation set performance)
Table 2 summarizes the model performance using MSGA+RF with mean and SE across five folds under the validation set, under different selections of hyperparameters and . Top three hyperparameter selections based on MSGA remained one of the best performing hyperparameter groups for MSGA+RF (average ); therefore, these three models were selected as best performing models and were used as the final models for this task (see Table S4 for the each fold).
TABLE 2.
Area under curve (AUC) mean and standard deviation values of multi-scale, domain knowledge-guided attention + random forest (MSGA+RF performance on validation set for various λh and λm (task importance) parameters
|
λm
|
|||||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 10 | 50 | 100 | 200 | ||
|
| |||||||
| λh | 200 | 0.95 (0.04) | 0.98 (0.01) | 0.99 (0.01) | 0.97 (0.01) | 0.97 (0.04) | 0.98 (0.02) |
| 100 | 0.97 (0.03) | 0.98 (0.02) | 0.97 (0.03) | 0.95 (0.06) | 0.96 (0.04) | 0.97 (0.02) | |
| 50 | 0.97 (0.03) | 0.96 (0.03) | 0.97 (0.03) | 0.94 (0.05) | 0.97 (0.02) | 0.98 (0.02) | |
| 10 | 0.95 (0.06) | 0.98 (0.02) | 0.97 (0.03) | 0.95 (0.05) | 0.99 (0) | 0.96 (0.02) | |
| 1 | 0.99 (0.02) | 0.98 (0.02) | 0.97 (0.05) | 0.94 (0.05) | 0.97 (0.03) | 0.92 (0.08) | |
| 0 | 0.97 (0.03) | 0.98 (0.01) | 0.99 (0.01) | 0.94 (0.04) | 0.95 (0.03) | 0.95 (0.06) | |
Note: λh and λm are the relative task importance parameters in the overall loss function, representing high- and medium-resolution attentions, respectively. Three top performing combinations based on MSGA (λh = 200 and λm = 1; λh = 50 and λm = 200; = 10 and = 100) are in bold font.
We also calculated and plotted the variable importance for the constructed RF using the normalized total reduction of Gini impurity brought by each feature (as shown in Supporting information H). Variable importance plots show that when MSGA can perform well (Figure S5a), RF mostly leveraged information from the predicted probability of IPF generated in the last layer of MSGA for the final classification; when MSGA performs unsatisfactorily (Figure S5c), attention-based loss values play a role in the final classification of MSGA+RF and boosted the model performance.
2.3 |. Test set performance
Based on the validation set performance and the estimated attention maps, we applied the three best performing models to the holdout test set . The three best performing models (i.e., (1) 200 and ; (2) and ; (3) 10 and ) had the AUC (± SD) values 0.987 (±0.007), 0.975 (±0.011), and 0.980 (±0.018), respectively.
3 |. DISCUSSIONS AND CONCLUSIONS
We presented a two-stage model for automated IPF diagnosis among subjects with ILD based on chest HRCT images. The model combines an MSGA, for explainability and an RF model for enhancing accuracy in the final decision. MSGA+RF is well-suited for other weakly supervised tasks in medical imaging domains, where population-level DK is available. Several advantages can be addressed using MSGA+RF.First,population-level DK from the prior studies was utilized, which may overcome the black-box approaches of deep learning and the time and expert-dependent labeling of machine learning. Guided with population-level DK at various resolution scales, we can accomplish satisfactory model performance only using the clinical information of IPF diagnosis in subjects with ILD.
Second, using attention models at various resolution scales increase model explainability, which is a crucial step for transparency in AI for medical applications. Over the past decade, there have been extensive discussions regarding enhancing the explainability of deep learning-based systems, especially in clinical settings.32 Building explainable deep learning models can increase trust in models and it is a critical step for model diagnostics. Saliency maps,33 and class activation mapping34 are effective post hoc methods for visualizing deep learning models; attention mechanisms, on the other hand, can encourage the network to focus on specific areas of interest (in our case, lung parenchyma) in a trainable and end-to-end manner. Furthermore, using attention models at different resolution scales can effectively capture more useful information for this diagnosis task and improve model performance. For example, low-resolution attention gates can focus more on the overall disease distribution, whereas high-resolution attention gates are able to capture more detailed disease characteristics. Previous research also found that combining multi-scale features can improve model performance.20,35
The third advantage is in accuracy. To boost model performance, traditional machine learning models tend to increase model accuracy by adding model features in a classifier.36 We borrowed a similar idea here by adding RF classifiers using the feature sets learned from the estimated loss function of learning from MSGA, as the final decision stage. This is necessary since we note that results on the validation set are sensitive to the selection of relative task importance (i.e., λh and λm). For example, in Table 1, 36 hyperparameter combinations,7 out of 36 combinations have a mean AUC less than 0.85 using stratified five-fold cross-validation on the validation sets. However, after adding the RF classifier, as results shown in Table 2, all 36 combinations have a mean AUC greater than 0.92. Therefore, in our example, having a two-stage model increases the model’s robustness against changes regarding relative task importance. Overall, RF can boost the performance of the worst-performing models, but it does not aid the best-performing models. The ceiling effect may be one reason since the three best-performing models have achieved an AUC of greater than 0.98 without RF, leaving limited room for improvement.
Based on our understanding, it is infeasible to compare our results with other literature since little research has been concentrated on developing automated software for a scan-level IPF diagnosis. On a similar note, Walsh et al. developed an algorithm to classify several CT slices into different UIP patterns and reported an accuracy of 76.4% on the test set.8 Christe et al. built an automated UIP classification model that includes lung segmentation, tissue characterization, and quantification. This algorithm can perform on par with radiologists with a reported accuracy of 81%.9 The novelty of this study is to utilize the DK and multi-scale attention gated model. The DK of the expected spatial location in ILD patterns in the lung serves as indirect lung segmentation. Multi-scale attention models increase the explainability of this model, increase model performance, and lead to reliable measurements.
Most of the criticism in deep learning models is that model accuracy does not guarantee satisfactory model explainability on the validation set in deep learning. To overcome this issue, we designed a two-stage model that combines explainability achieved by a deep learning approach, MSGA, and accuracy by a machine learning technique, RF. Strengthened by the combined benefit of a transparent model decision process and boosted diagnostic performance, the proposed method serves as an important step for clinical applications.
Certain limitations exist in this work: (1) the current MSGA setup requires population-level DK acquired from prior studies; (2) only volumetric CT scans with consistent slice spacing were included in the training and testing sets, which limited the applicability of this trained model to other non-volumetric CT scans; (3) the selections of relative task importance requires extensive computational time and resources in hyperparameter selections. (4) It is worth investigating the model performance when applying to datasets from different institutions, which may contain CT scans collected from different non-IPF disease types, disease severity, and various CT imaging protocols. Although some research works demonstrated the superior generalizability of attention models to unseen datasets,16 the evaluation of our proposed model to independent datasets is underway and is out of the scope of this paper.
In this paper, we have developed an automated IPF diagnosis using CT images and demonstrated a promising method of attention maps for both enhancing explainability and increasing performance. Future work includes examining the trained MSGA+RF on independent cohort and prospective studies.
Supplementary Material
ACKNOWLEDGMENTS
This research is supported by NIH, NHLBI-R21-HL140465. Hua Zhou is supported by grants from the National Human Genome Research Institute (HG006139), the National Institute of General Medical Sciences (GM053275), and the National Science Foundation (DMS-2054253).
Footnotes
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest that could be perceived as prejudicing the impartiality of the research reported.
SUPPORTING INFORMATION
Additional supporting information can be found online in the Supporting Information section at the end of this article.
DATA AVAILABILITY STATEMENT
Raw data were generated from UCLA. Derived data from HRCT images supporting the findings of this study are available from the corresponding author GK on reasonable request.
REFERENCES
- 1.King TE Jr, Pardo A, Selman M. Idiopathic pulmonary fibrosis. Lancet North Am Ed. 2011;378(9807):1949–1961. [DOI] [PubMed] [Google Scholar]
- 2.Raghu G, Remy-Jardin M, Myers JL, et al. Diagnosis of idiopathic pulmonary fibrosis: an official ATS/ERS/JRS/ALAT clinical practice guideline. Am J Respir Crit Care Med. 2018;198(5): e44–e68. [DOI] [PubMed] [Google Scholar]
- 3.Walsh SL, Calandriello L, Sverzellati N, Wells AU, Hansell DM. Interobserver agreement for the ATS/ERS/JRS/ALAT criteria for a UIP pattern on CT. Thorax. 2016;71(1):45–51. [DOI] [PubMed] [Google Scholar]
- 4.Widell J, Lidén M. Interobserver variability in high-resolution CT of the lungs. Eur J Radiol Open. 2020;7:100228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Daniels CE, Lasky JA, Limper AH, Mieras K, Gabor E, Schroeder DR.Imatinib treatment for idiopathic pulmonary fibrosis:randomized placebo-controlled trial results. Am J Respir Crit Care Med. 2010;181(6):604–610. [DOI] [PubMed] [Google Scholar]
- 6.Yu W, Zhou H, Choi Y, Goldin JG, Teng P, Kim GHJ, An automatic diagnosis of idiopathic pulmonary fibrosis (IPF) using domain knowledge-guided attention models in HRCT images. Medical Imaging 2021: Computer-Aided Diagnosis. Vol. 11597. SPIE; 2021:458–463. [Google Scholar]
- 7.Yu W, Zhou H, Choi Y, Goldin JG, Kim GHJ, Mga-Net: multi-scale guided attention models for an automated diagnosis of idiopathic pulmonary fibrosis (IPF). IEEE 18th International Symposium on Biomedical Imaging (ISBI). IEEE; 2021:1777–1780. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Walsh SL, Calandriello L, Silva M, Sverzellati N. Deep learning for classifying fibrotic lung disease on high-resolution computed tomography: a case–cohort study. Lancet Respir Med. 2018;6(11):837–845. [DOI] [PubMed] [Google Scholar]
- 9.Christe A,Peters AA,Drakopoulos D, et al. Computer-aided diagnosis of pulmonary fibrosis using deep learning and CT images. Invest Radiol. 2019;54(10):627. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Zhou ZH.A brief introduction to weakly supervised learning. Natl Sci Rev. 2018;5(1):44–53. [Google Scholar]
- 11.Yu W, Zhou H, Goldin JG, Wong WK, Kim GHJ. End-to-end domain knowledge assisted automatic diagnosis of idiopathic pulmonary fibrosis (IPF) using computed tomography (CT). Med Phys. 2021;48(5):2458–2467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Ker J,Wang L,Rao J,Lim T.Deep learning applications in medical image analysis. IEEE Access. 2017;6:9375–9389. [Google Scholar]
- 13.Lee H, Yune S, Mansouri M, et al. An explainable deep-learning algorithm for the detection of acute intracranial haemorrhage from small datasets. Nat Biomed Eng. 2019;3(3):173. [DOI] [PubMed] [Google Scholar]
- 14.Luong MT, Pham H, Manning CD, Effective approaches to attention-based neural machine translation. Conference proceedings-EMNLP 2015. Conference on Empirical Methods in Natural Language Processing 2015:1412–1421. [Google Scholar]
- 15.Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in Neural Information Processing Systems.2017:5998–6008. [Google Scholar]
- 16.Jetley S, Lord NA, Lee N, Torr PH, Learn to pay attention. International Conference on Learning Representations (ICLR), ICLR 2018. [Google Scholar]
- 17.Li K, Wu Z, Peng KC, Ernst J, Fu Y, Tell me where to look: guided attention inference network.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2018:9215–9223. [Google Scholar]
- 18.Schlemper J, Oktay O, Schaap M, et al. Attention gated networks: learning to leverage salient regions in medical images. Med Image Anal. 2019;53:197–207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Lei Y, Dong X, Tian Z, et al. CT prostate segmentation based on synthetic MRI-aided deep attention fully convolution network. Med Phys. 2020;47(2):530–540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sinha A, Dolz J. Multi-scale self-guided attention for medical image segmentation. IEEE J Biomed Health Inform. 2021;25(1):121–130. [DOI] [PubMed] [Google Scholar]
- 21.Yang H,Kim JY,Kim H,Adhikari SP.Guided soft attention network for classification of breast cancer histopathology images. IEEE Trans Med Imaging. 2019;39(5):1306–1315. [DOI] [PubMed] [Google Scholar]
- 22.Wang J, Liu C, Wang X, Liu Y, Yao L, Zhang H. Automated ECG classification using a non-local convolutional block attention module. Comput Methods Programs Biomed. 2021;203:106006. [DOI] [PubMed] [Google Scholar]
- 23.Zlocha M, Dou Q, Glocker B. Improving retinanet for CT lesion detection with dense masks from weak recist labels. International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2019:402–410. [Google Scholar]
- 24.Wang Y, Zhao Z, Hu S, Chang F. CLCU-Net: cross-level connected U-shaped network with selective feature aggregation attention module for brain tumor segmentation. Comput Methods Programs Biomed. 2021;207:106154. [DOI] [PubMed] [Google Scholar]
- 25.Cui H, Yuwen C, Jiang L, Xia Y, Zhang Y. Multiscale attention guided U-Net architecture for cardiac segmentation in short-axis MRI images. Comput Methods Programs Biomed. 2021;206:106142. [DOI] [PubMed] [Google Scholar]
- 26.Wu X, Kim GH, Salisbury ML, et al. Computed tomographic biomarkers in idiopathic pulmonary fibrosis: the future of quantitative analysis. Am J Respir Crit Care Med. 2019;199(1):12–21. [DOI] [PubMed] [Google Scholar]
- 27.Kim H, Tashkin D, Clements P, et al. A computer-aided diagnosis system for quantitative scoring of extent of lung fibrosis in scleroderma patients. Clin Exp Rheumatol. 2010;28:S26. [PMC free article] [PubMed] [Google Scholar]
- 28.Best AC, Meng J, Lynch AM, et al. Idiopathic pulmonary fibrosis: physiologic tests, quantitative CT indexes, and CT visual scores as predictors of mortality. Radiology. 2008;246(3):935–940. [DOI] [PubMed] [Google Scholar]
- 29.Breiman L. Random forests. Mach Learn. 2001;45(1):5–32. [Google Scholar]
- 30.Lebedev A, Westman E, Van Westen G, et al. Random forest ensembles for detection and prediction of Alzheimer’s disease with a good between-cohort robustness. NeuroImage: Clinical. 2014;6:115–125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Chollet F. Keras. GitHub; 2015. Accessed September 12, 2020. http://github.com/fchollet/keras [Google Scholar]
- 32.Longo L, Goebel R, Lecue F, Kieseberg P, Holzinger A, Explainable artificial intelligence: concepts, applications, research challenges and visions. International Cross-Domain Conference for Machine Learning and Knowledge Extraction. Springer; 2020:1–16. [Google Scholar]
- 33.Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: visualising image classification models and saliency maps. Proceedings of the International Conference on Learning Representations (ICLR), ICLR 2014:1–8. [Google Scholar]
- 34.Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2016:2921–2929. [Google Scholar]
- 35.Zhao H, Shi J, Qi X, Wang X, Jia J. Pyramid scene parsing network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE; 2017:2881–2890. [Google Scholar]
- 36.Hastie T, Tibshirani R, Friedman J. The elements of statistical learning: data mining, inference, and prediction. Springer; 2009. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Raw data were generated from UCLA. Derived data from HRCT images supporting the findings of this study are available from the corresponding author GK on reasonable request.