

Introduction
Reinforcement learning formalizes the concept of learning from interactions.1 Broadly, reinforcement learning focuses on a setting in which an agent (decision maker) sequentially interacts with an environment that is partially unknown to them. At each stage, the agent takes an action and receives a reward. The objective of the agent is to maximize rewards accumulated in the long run. There are many situations in health care where decisions are made sequentially for which reinforcement learning approaches could prove useful for decision making. Throughout this article, we consider treatment prescription as an archetypical example to connect reinforcement learning concepts to a health care setting. In this setting, the care provider, the prescribed treatment, and the patients can be viewed as the agent, the action, and the environment, respectively, as depicted in Figure 1.
Figure 1.
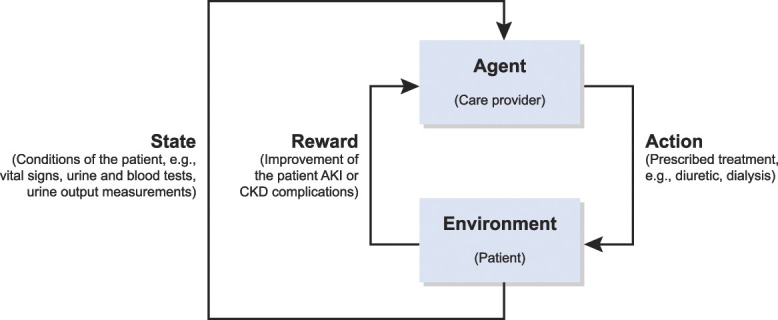
Sequential treatment of AKI or CKD complications modeled as a reinforcement learning problem.
Background
In this section, with the objective of making reinforcement learning literature more accessible to a clinical audience, we briefly introduce related fundamental concepts and approaches. We refer the interested reader to Sutton and Barto1 for a comprehensive introduction to reinforcement learning.
Markov Decision Processes
Markov decision processes (MDPs) are a formalism of the sequential decision-making problem that has been central to the theoretical and practical advancements of reinforcement learning. In each stage of an MDP, the agent observes the state of the environment and takes an action, which, in turn, results in a change of the state. This change of state is assumed to be probabilistic with the next state being determined only by the preceding state, the chosen action, and the transition probability. The agent also receives a reward that is a function of the taken action, the preceding state, and the subsequent state.
In an MDP, the objective of the agent is to maximize the return defined as the reward accumulated over a time horizon. In some applications, it is common to consider the horizon to be infinite, in which case the future rewards are discounted by a factor smaller than one. The selection of action by the agent on the basis of the observed state is known as the policy. More formally, a policy is a probabilistic mapping from states to each possible action. Because the policy and the reward are a function of the state, it is critical to estimate the utility of being in a certain state. More specifically, the value function is defined as the expected return starting from a given state under the chosen policy. Under this formalism, the objective of the agent is to find the optimal policy that maximizes the value function for all states.
Reinforcement Learning Methods
Action-value methods are a class of reinforcement learning methods in which the actions are chosen on the basis of the estimation of their long-term value. A prominent example of an action-value method is Q-learning in which the agent iteratively takes actions with the highest estimated values and updates the action-state value function on the basis of new observations. Policy gradient methods are another class of reinforcement learning methods that seek to optimize the policy directly instead of choosing actions on the basis of their respective estimated value. Such methods could be advantageous in health care applications that entail a large number of possible actions, e.g., when recommending a wide range of drug dosages or treatment options.
Clinical Applications
Reinforcement learning frameworks and methods are broadly applicable to clinical settings in which decisions are made sequentially. A prominent clinical application of reinforcement learning is for treatment recommendation, which has been studied across a variety of diseases and treatments including radiation and chemotherapy for cancer, brain stimulation for epilepsy, and treatment strategies for sepsis.2–5 In such treatment recommendation settings, a policy is commonly known as a dynamic treatment regime. There are various other clinical applications of reinforcement learning including diagnosis, medical imaging, and decision support tools (see refs. 2–5 and the references therein).
Reinforcement Learning in Nephrology
Although there have been recent applications of machine learning in nephrology,6,7 to the best of the authors' knowledge, the application of reinforcement learning to nephrology has been primarily limited to optimizing the erythropoietin dosage in hemodialysis patients.8,9 However, there are other settings where reinforcement learning has the potential to improve patient care in nephrology. For example, reinforcement learning methods can be adopted in the treatment of the complications of AKI or CKD (Figure 1). In this problem, the state models the conditions of the patient (e.g., vital signs, laboratory test results including urine and blood tests, and urine output measurements). The action refers to the treatment options (e.g., the dosage of medications such as sodium polystyrene sulfonate, and hemodialysis). The reward models the improvement in patient conditions. Similarly, reinforcement learning can help automate and optimize the dosage of immunosuppressive drugs in kidney transplants.
Challenges and Opportunities
Despite the success of reinforcement learning in several simplified clinical settings, their large-scale application to patient care faces several open challenges. The complexity of human biology complicates modeling clinical decision making as a reinforcement learning problem. The state space in such settings is often enormous, which could make a purely computational approach infeasible. Moreover, modeling all potential objectives a priori as a reward function may not be feasible. To overcome these challenges and realize the potential of reinforcement learning, clinical insight can play a pivotal role. More specifically, restricting the state space to only include highly relevant clinical variables could greatly reduce the computational complexity. Furthermore, using inverse reinforcement learning,2 relevant reward functions can be learned from retrospective studies assuming the optimality of clinical decisions.
Another critical challenge is addressing moral and ethical concerns. It is imperative to ensure that reinforcement learning methods do not cause harm to the patient. To this end, there exists a need for a thorough validation of such methods before their use in patient care. Hence, there is a need to go beyond retrospective studies that have been used for the proof of concept of most existing reinforcement learning methods in health care applications.2,3 The lessons learned from the success of reinforcement learning in other application areas (e.g., self-driving cars) can help navigate the path to realizing its potential in health care.
Accessible open-source simulation environments that enable researchers to compare various approaches are essential to the field of reinforcement learning. OpenAI Gym is currently the leading toolkit containing a wide range of simulated environments, e.g., surgical robotics.10 The development of high-quality and reliable simulation environments for nephrology and other health care applications can facilitate the development and validation of reinforcement learning methods beyond limited retrospective studies. The adoption of methods validated in such simulation environments in actual clinical settings will require clinicians' oversight. Similar to how self-driving cars require a human driver to ensure collision avoidance, clinicians' oversight is critical to ensure the safety of the patients, especially in the early stages of the adoption of reinforcement learning methods. The data from clinicians' decisions (e.g., overruling the automated treatment recommendation) can be used to improve the reliability of autonomous systems over time and reduce the burden of clinicians' oversight.
Acknowledgments
This article is part of the Artificial Intelligence and Machine Learning in Nephrology series, led by series editor Girish N. Nadkarni.
The content of this article reflects the personal experience and views of the authors and should not be considered medical advice or recommendation. The content does not reflect the views or opinions of the American Society of Nephrology (ASN) or CJASN. Responsibility for the information and views expressed herein lies entirely with the authors.
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Footnotes
Published online ahead of print. Publication date available at www.cjasn.org.
Disclosures
A. Bihorac, T. Ozrazgat-Baslanti, and P. Rashidi report research funding from National Institute of Health (NIH). P. Rashidi also reports ownership interest in Simour.ai and research funding from National Science Foundation (NSF). A. Bihorac, T. Ozrazgat-Baslanti, and P. Rashidi report Method and Apparatus for Prediction of Complications after Surgery, US Patent Application Number 20200161000, filed June 1, 2018; A. Bihorac, T. Ozrazgat-Baslanti, P. Rashidi, and B. Shickel report Systems and Methods for Using Deep Learning to Generate Acuity Scores for Critically Ill or Injured Patients, US patent 20220044809, filed February 21, 2020; and A. Bihorac and P. Rashidi report Method and Apparatus for Pervasive Patient Monitoring, US Patent Number 11424028, patent date Aug. 23, 2022. All remaining authors have nothing to disclose.
Funding
This work was supported by grant AWD09459 from the University of Florida Research.
Author Contributions
A. Bihorac was responsible for resources; A. Bihorac and P. Rashidi provided supervision; K. Khezeli was responsible for investigation and visualization; P. Rashidi was responsible for funding acquisition; K. Khezeli and S. Siegel wrote the original draft; and K. Khezeli, T. Ozrazgat-Baslanti, P. Rashidi, B. Shickel, and S. Siegel reviewed and edited the manuscript.
References
- 1.Sutton RS, Barto AG. Reinforcement Learning: An Introduction. Cambridge, MA, MIT Press; 2018. [Google Scholar]
- 2.Yu C, Liu J, Nemati S, Yin G. Reinforcement learning in healthcare: a survey. ACM Comput Surv. 2021;55(1):1–36. doi: 10.1145/3477600 [DOI] [Google Scholar]
- 3.Coronato A, Naeem M, De Pietro G, Paragliola G. Reinforcement learning for intelligent healthcare applications: a survey. Artif Intelligence Med. 2020;109:101964. doi: 10.1016/j.artmed.2020.101964 [DOI] [PubMed] [Google Scholar]
- 4.Datta S, Li Y, Ruppert MM, et al. Reinforcement learning in surgery. Surgery. 2021;170(1):329–332. doi: 10.1016/j.surg.2020.11.040 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Loftus TJ, Filiberto AC, Li Y, et al. Decision analysis and reinforcement learning in surgical decision-making. Surgery. 2020;168(2):253–266. doi: 10.1016/j.surg.2020.04.049 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Chan L, Vaid A, Nadkarni GN. Applications of machine learning methods in kidney disease: hope or hype? Curr Opin Nephrol Hypertens. 2020;29(3):319–326. doi: 10.1097/mnh.0000000000000604 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Magherini R, Mussi E, Volpe Y, Furferi R, Buonamici F, Servi M. Machine learning for renal pathologies: an updated survey. Sensors (Basel). 2022;22(13):4989. doi: 10.3390/s22134989 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Gaweda AE, Muezzinoglu MK, Aronoff GR, Jacobs AA, Zurada JM, Brier ME. Individualization of pharmacological anemia management using reinforcement learning. Neural Networks. 2005;18(5-6):826–834. doi: 10.1016/j.neunet.2005.06.020 [DOI] [PubMed] [Google Scholar]
- 9.Escandell-Montero P, Chermisi M, Martinez-Martinez JM, et al. Optimization of anemia treatment in hemodialysis patients via reinforcement learning. Artif intelligence Med. 2014;62(1):47–60. doi: 10.1016/j.artmed.2014.07.004 [DOI] [PubMed] [Google Scholar]
- 10.Richter F Orosco RK, and Yip MC. Open-sourced reinforcement learning environments for surgical robotics. arXiv. 2019. doi: 10.48550/arXiv.1903.02090 [DOI] [Google Scholar]