

Abstract
Background and Objective:
Electronic Health Record (EHR) data often include observation records that are unlikely to represent the “truth” about a patient at a given clinical encounter. Due to their high throughput, examples of such implausible observations are frequent in records of laboratory test results and vital signs. Outlier detection methods can offer low-cost solutions to flagging implausible EHR observations. This article evaluates the utility of a semi-supervised encoding approach (super-encoding) for constructing non-linear exemplar data distributions from EHR observation data and detecting non-conforming observations as outliers.
Methods:
Two hypotheses are tested using experimental design and non-parametric hypothesis testing procedures: (1) adding demographic features (e.g., age, gender, race/ethnicity) can increase precision in outlier detection, (2) sampling small subsets of the large EHR data can increase outlier detection by reducing noise-to-signal ratio. The experiments involved applying 492 encoder configurations (involving different input features, architectures, sampling ratios, and error margins) to a set of 30 datasets EHR observations including laboratory tests and vital sign records extracted from the Research Patient Data Registry (RPDR) from Partners HealthCare.
Results:
Results are obtained from (30×492) 14,760 encoders. The semi-supervised encoding approach (super-encoding) outperformed conventional autoencoders in outlier detection. Adding age of the patient at the observation (encounter) to the baseline encoder that only included observation value as the input feature slightly improved outlier detection. Top-nine performing encoders are introduced. The best outlier detection performance was from a semi-supervised encoder, with observation value as the single feature and a single hidden layer, built on one percent of the data and one percent reconstruction error. At least one encoder configurations had a Youden’s J index higher than 0.9999 for all 30 observation types.
Conclusion:
Given the multiplicity of distributions for a single observation in EHR data (i.e., same observation represented with different names or units), as well as non-linearity of human observations, encoding offers huge promises for outlier detection in large-scale data repositories.
Keywords: Neural Networks, Encoding, Semi-supervised Encoding, Outlier Detection, Data Quality, Electronic Health Records
Introduction
Data from Electronic Health Records (EHR) can accelerate real-time translation of evidence-based discoveries in everyday healthcare practice as we strive towards a rapid-learning health care systems.[1,2] However, truthfulness (plausibility) of clinical observations stored in EHRs is can be disputable,[3] as these systems were not initially designed for research and discovery. It is plausible to come across observation in EHRs that are biologically implausible. Examples of such implausible observations can be found in laboratory test results or vital sign records stored in EHRs. For instance, a diastolic blood pressure recorded at 700 or a BMI record of 1,400 are extremely unlikely to represent the “truth” about a patient at a given clinical encounter.
Billions of lab tests are ordered by clinicians every day and recording vital signs are routine in clinical encounters. As a result, very large numbers of labs and vital sign observation data are produced and stored in EHRs. Systematic detection of plausibility issues for labs and vital sign observations in EHR data are difficult for three reasons. First, although there are often gold-standards for high/low “normal” values, global gold-standards are not always available to set cut-off ranges for high/low “implausible” values. Second, even if such global cut-off ranges are available for all types of observation data, they may not fully capture implausible values due to an inherent non-linearity in data representing human biology, as these values are expected to vary from patient to patient, by age, race, and gender. For example, a weight record of 700 lbs. may be plausible for a 50-year-old Male, but certainly not for a 5-month-old. Third, the multiplicity of clinical observations and their representations in EHRs (i.e., same laboratory test represented with different names or measurement units), along with institutional variations in data standards are significant hurdles to systematic implementation of manual procedures to detect plausibility issues. Nevertheless, hard-coding cut-off ranges are the standard approach in many clinical data repositories for identifying implausible values.
With the abundance of unlabeled data (e.g., vital signs) in EHR repositories, unsupervised learning (a.k.a., predictive learning) offers promising applications in characterizing clinical observations into meaningful sub-groups that can embody non-linear properties. In particular, Neural Networks provide low-cost opportunities for constructing adaptive data representations that can be used to evaluate EHR data plausibility. In this paper, we conceptualize implausible values in laboratory test results and vital sign records in EHRs as outliers. We then test the utility of modifying feature learning by auto-encoders for outlier detection in clinical observation data that records of vital signs and laboratory test values.
Background
Outlier detection a rich area of research in data mining – see [4,5] for an extensive survey of outlier detection. There are many algorithms developed to detect outliers based on different approaches to what constitutes an outlier, for which there is no universally agreed definition.[4] Generally, outlier detection refers to the problem of discovering data points in a dataset that do not conform to an expected exemplar.[6] Across different domains, such ‘non-conforming’ observations are referred to as, noise, anomaly, outlier, discordant observation, deviation, novelty, exception, aberration, peculiarity, or contaminant.[4,6]
Outlier detection methods can be characterized into two broad groups of parametric and non-parametric approaches. Parametric methods [7,8] detect outliers by comparing data points to an assumed stochastic distribution model. In contrast, non-parametric (model-free) techniques do not assume a-priori statistical model. Non-parametric methods range in computational and implementation complexity. For example, simple methods such as Grubbs’ method (i.e., Extreme Studentized Deviate) [9] and informal boxplots to visually identify outliers [10] are conveniently used when datasets do not hold complex patterns. Proximity-based methods are popular outlier detection techniques that are often simple to implement. Proximity-based methods are categorized into distance- and density-based techniques. In distance-based methods, an outlier is far away from its nearest neighbors (based on local distance measures).[11,12] Mahalanobis distance and test are popular outlier detection techniques for multivariate data. Distance-based methods can often handle large datasets.[5] Proximity-based methods suffer from computational intensity in highly dimensional data.[4] In addition, identifying the proper distance measure to identify outliers in challenging. In human biological data (e.g., vital signs and labs data), distance-based methods can lead to high false positive rates. Clustering-based outlier detection techniques also apply different clustering methods to identify sparse clusters or data points as outliers. However, clustering-based methods are computationally intensive and do not scale up to large data.
Parametric and non-parametric density-based methods for outlier detection are also popular among researchers. These methods learn generative (stochastic) density models from data and then identify data points with low probabilities as outliers. For example, Gaussian Mixture Models (GMMs) have been applied to anomaly detection problems. A GMM is a parametric unsupervised learning technique for discovering sub-populations in a dataset using Gaussian probability density function, when the data is assumed to encompass multiple different distributions.[13,14] Using the estimated Gaussian densities, data points with low probabilities can represent outliers. The primary issue with using GMMs for outlier detection is the parametric assumptions about the sub-population densities. Human biological data have varying density functions that diminish the utility of using parametric density-based method. Appendix C shows empirical distribution of observation values for a representative sample of lab tests and vital signs in EHRs. Kernel density estimator is a non-parametric density estimation method that have shown utility for outlier detection. After estimating a probability density distribution of the data, the kernel density methods identify outliers by comparing the local density of each data point to the local density of its neighbors.[15] Kernel density methods can address multiplicity of distributions and unusual local trends in labs and vital signs data, however, incorporating contextual information can be challenging. Neural Networks offer possibilities for non-parametric outlier detection in high dimensional EHR data.
Outlier Detection with Autoencoders
Our approach aims to model an exemplar (i.e., inlier) distribution from the data that best represents the underlying patterns in the data, and utilize that distribution to benchmark any other observation, as inliers or outliers. In the context of clinical data, implausible values are examples of observations that do not conform to the exemplar distribution of clinical observations, when massive loads of observation data are available. Our approach takes the view of letting the high-throughput EHR data speak for itself without relying on too many assumptions about what might be plausible or implausible.
We use Neural Networks for this purpose. The primary application of Neural Networks (NNs) is in supervised learning. If provided with the right type of data, deep Neural Networks are powerful learning algorithms with widespread applications across many domains.[16] However, application of supervised learning in general is dependent on presence of labeled input data, which are often manually generated.[17] This dependency limits application of deep Neural Networks in fields where much of the raw data are either still unlabeled or labeled data may not be reliable.
The central idea in Neural Networks is to model outputs as a non-linear function of linearly derived input features,[16] which will enable us to define complex forms of hypothesis , given an activation function , and parameters (or weight) and b (or bias) between units in different layers.[17] NNs have been widely applied to anomaly detection tasks.[4,6,18]
Autoencoders (a.k.a., auto-associative Neural Networks) are unsupervised NN algorithms that automatically learn features from unlabeled data,[17,19] and are efficient for learning both linear and non-linear underlying characteristics of the data without any assumptions or a priori knowledge about input data distribution.[18] Autoencoders can learn non-linear patterns without complex computation.[20] Since their introduction in the 1980s, autoencoders have been successfully applied in the deep architecture approach, dimensionality reduction, image denoising, and information retrieval tasks.[19,21,22]
Suppose we have a vector of unlabeled data, {, , …}, where . An autoencoder applies backpropagation to reconstruct the input values, by setting the target values to be equal to the input values . In other words, the autoencoder aims to learn function that approximates with the least possible amount of distortion from . It compresses the input data into a low dimension latent subspace and decompresses the input data to minimize the reconstruction error,:[20]
Autoencoders often have a multi-layer perceptron feed-forward network architecture in a bottleneck (Figure 1), consisting of an encoder and a decoder that produces as a reconstruction of .[19]
Figure 1.
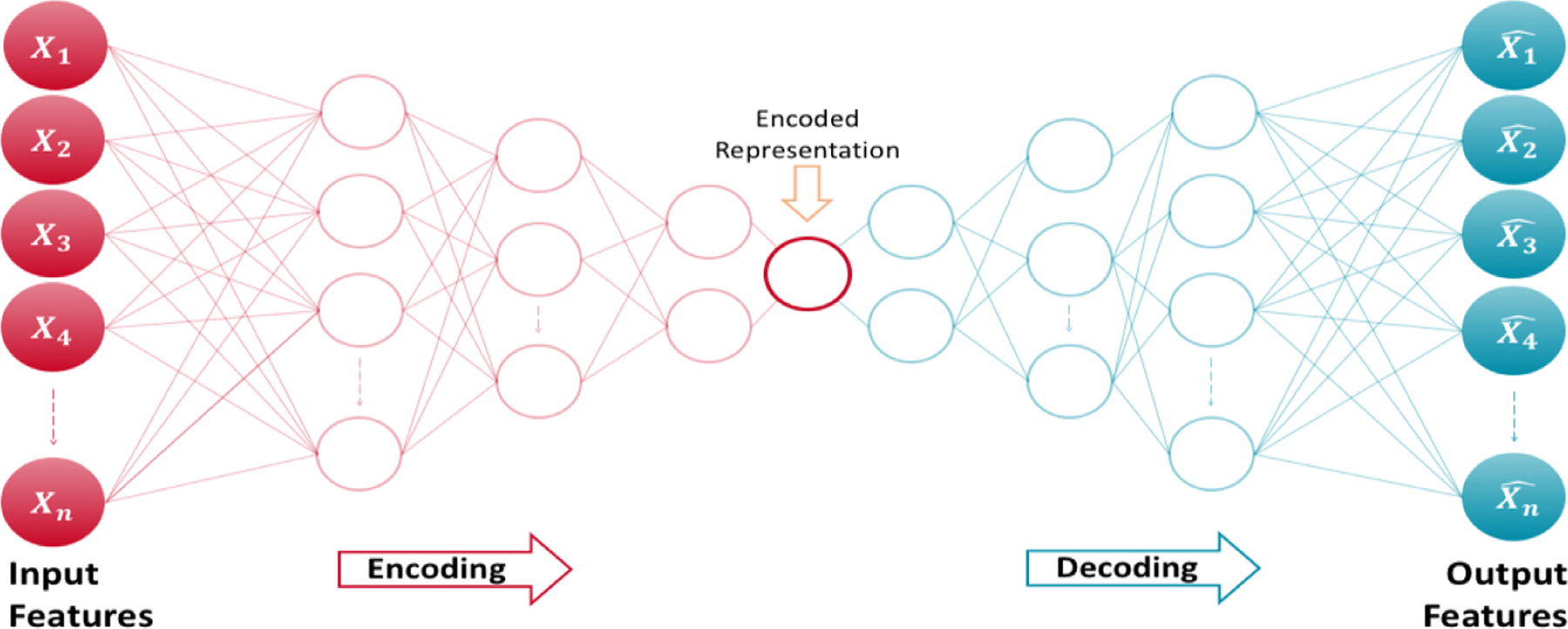
Architecture of an autoencoder
An autoencoder that perfectly reconstructs the input data (i.e.,) is not useful; instead, the goal is that function takes on useful properties from the input data.[19] With this procedure, a worthwhile application of autoencoders is in outlier detection by identifying data points that have high reconstruction errors.[20] For example, Hawkins et al. (2002) used a 3-layer perceptron Neural Networks – also known as Replicator Neural Network (RNNs) – to form a compressed model of data for detecting outliers. [23] In anomaly detection with autoencoders, the reconstruction error is used as the anomaly score, where low reconstruction error values denote normal instances (or inliers) and large reconstruction errors represent anomalous data points (or outliers).[20]
Properly regularized autoencoders outperform Principal Component Analysis (PCA) or K-Means methods in learning practical representations and characterizing data distribution,[24] and are more efficient in detecting “subtle” anomalies than linear PCAs and in computation cost than kernel PCAs.[20,22]
Hypotheses
We conduct experiments to evaluate the utility of encoding for the purpose of detecting outliers in clinical observation data (namely, laboratory test results and vital signs observations) from EHRs. We test two hypotheses. First, we hypothesize that including demographic features stored in EHRs – demographic features in the Informatics for Integrating Biology and the Bedside (i2b2)[25,26] patient dimension – may improve precision learning of the exemplar function and therefore improve outlier detection.
Given the large amount of clinical observation data in EHR repositories and the sheer ability of Neural Networks in learning data representations, we suspect that a conventional implementation of autoencoders – that uses the entire data for compression (i.e., encoding) – may result in a poor outlier detection performance, due to inclusion of noisy data in the learning process. Therefore, our second hypothesis is that training the encoder function on a smaller random sample of data (as a silver-standard distribution) may also result in construction of a more precise “exemplar” representation of the underlying data distribution, and therefore, increased efficiency in outlier detection. We call this implementation semi-supervised encoding, or super-encoding.
Data
To test these hypotheses, we used EHR data on 30 clinical observations, including nearly 200 million records of laboratory test results and vital signs, from Research Patient Data Registry (RPDR) from Partners HealthCare.[27] Empirical distribution of a representative sample of the observations are provided in Appendix C. For these observations, we were able to obtain global gold-/silver-standard cut-off ranges through literature search, and therefor calculate sensitivity and specificity for comparing the encoders (see Appendix A). The number of records for each of the 30 lab and vital sign observations ranged ranging from over 62,000 to less than 16 million, with an average of more than seven million observation records. All observation values are numerical.
For each health record, we calculated patient-specific age at observation. We also created a joint demographic variable from Race and Ethnicity – a list and definition of demographic variables is available in Appendix B.
Design
Although autoencoders are often trained using a single-layer encoder and a single-layer decoder, using deep encoders and decoders offer many advantages, such as exponential reduction in computational cost and amount of training data needed, and better compression.[19] Therefore, we built encoders with different NN architectures to allow for an improved outlier detection performance.
To test our hypotheses, we developed 492 forms of hypotheses per each of the 30 groups of EHR observation data (lab tests and vital signs) from combinations of seven sets of input features, 12 Neural Network architectures (i.e., patterns of connectivity between neurons), four sampling strategies (1%, 5%, 10% for super-encoding, and 100% for autoencoding), and three reconstruction error cut-off points for outlier detection. The following six steps describe the design of our experiments:
-
To test out first hypothesis, a vector of input features is selected from , where,
: observation value (OV) – the baseline feature;
: age at observation (A);
,: gender (G) – male or female; and
: Race/Ethnicity (R/E).
A symmetrical bottleneck Neural Network architecture is selected to extract parameters in . We restricted the choice of NN architecture such that the maximum depth of the network would not exceed the number of input features.
- To test our second hypothesis, a sampling strategy is applied. A random sample of size is drawn from the observation data with size , where,
resulting in a vector of input features , based on the choice made in step 1 – when , then samples between 1–10% construct semi-supervised encoders, and 100% sample construct conventional design of autoencoders. - is trained on , , with the goal of minimizing the reconstruction error for ,:
is used on to reconstruct and calculate .
- Outliers are flagged when , the error margin ratio, where,
through the last step we allow vary by feature, NN architecture, and sampling strategy.
Implementation
We used the autoencoder implementation in H2O [28] and developed functions to run the experiments – functions to run the experiments, results, and analytic code to process the results are available on GitHub (link will be posted after the peer review process). We also used tanh as the activation function. H2O normalizes the data to the compact interval of (−0.5, 0.5) for autoencoding to allow bounded activation functions like tanh to better reconstruct the data.[28]
Performance Indices
Selecting an appropriate cut-off point to evaluate performance of AI algorithms depends on the context.[29] For each of the 492 encoders, we calculated the true-positive rate (TPR), a.k.a. sensitivity (Se) or recall, which represents the probability of truly detecting (Power) outliers, and false-positive rate (FPR) or probability of false alarm (Type I error) – FPR = 1 – specificity (Sp). Minimizing false positive rates while maximizing detection of true outliers are the main evaluation criteria for outlier detection methods.[18] To pick the best overall encoders, we calculated Youden’s J index[30] based on the following formula:
The goal was to maximize the Youden’d J index, and thereby maximize the combined specificity and sensitivity.
Non-parametric hypothesis testing
To evaluate our hypotheses, we used non-parametric and post-hoc tests for comparing and ranking the outlier detection performances a cross the 14,760 encoders (492 encoders × 30 observations). These data points are more than enough for non-parametric hypothesis testing. The goal was to evaluate whether the Youden’d J indices would provide enough statistical evidence that the encoders have different outlier detection performances. Specifically, we applied Friedman post-hoc test,[31] with Bergmann and Hommel’s correction,[32] for comparing and ranking all algorithms.[33,34]
Before performing the Friedman test, we ran Nemenyi’s test to perform an initial ranking, identify the Critical Difference (CD), and create a ranking diagram. The CD diagrams provide effective summarizations of encoder ranking, magnitude of difference between them, and the significance of observed differences. Any two algorithms who have an average performance ranking difference greater that the CD are significantly different.[34]
Results
We compiled results of the 492 encoders on the 30 EHR observation data sets. Figure 2 illustrates the receiver operating characteristic (ROC) plots and Youden’d J indices for each observation – grouped by Logical Observation Identifiers Names and Codes (LOINC). LOINC provides common identifiers, names, and codes for health measurements, observations, and documents. The list of labs, their associated LOINC, and silver-standards cutoff ranges are provided in Appendix A.
Figure 2.
ROC plots and Youden’d J indices for each observation.
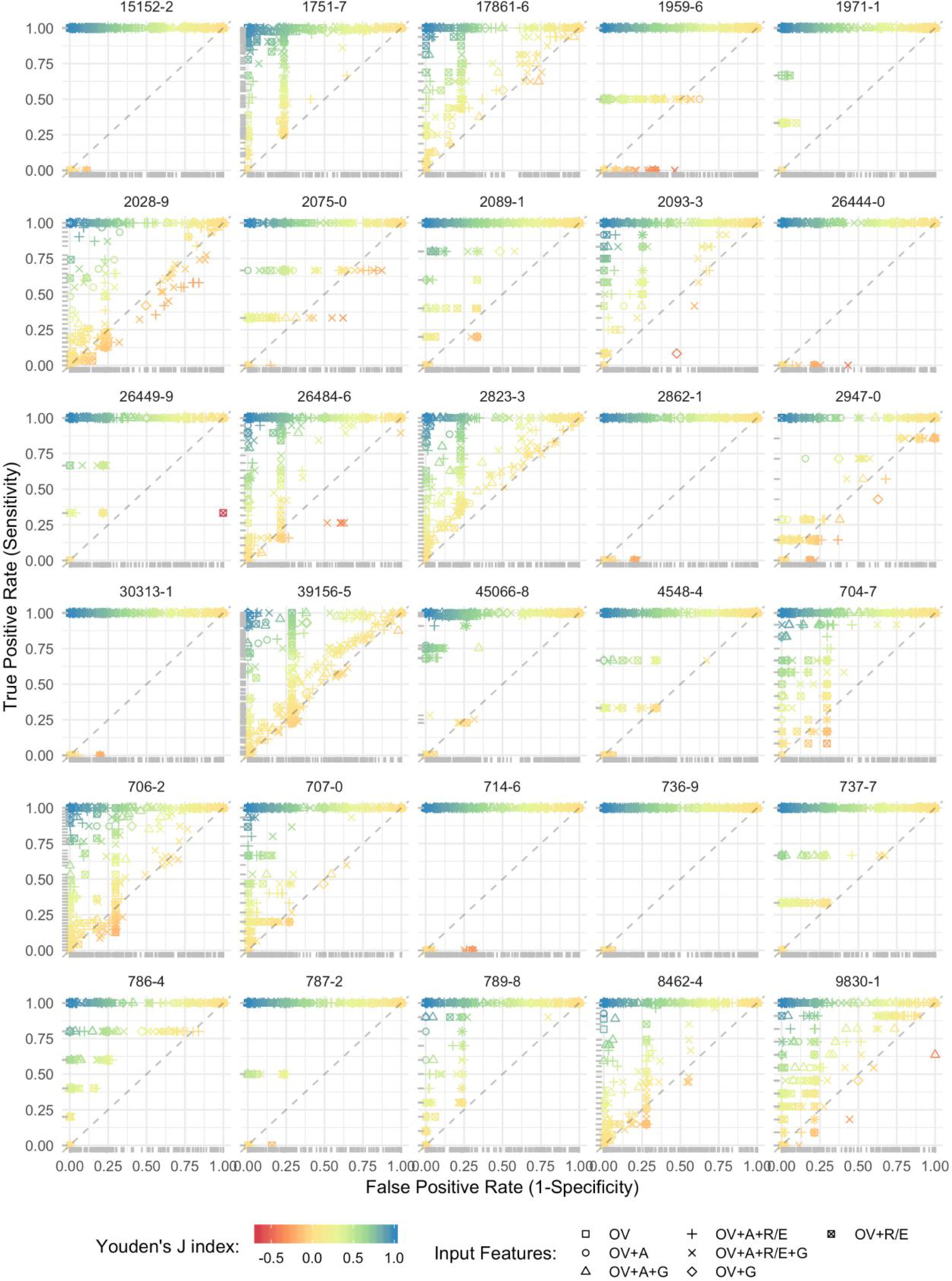
* dots represent results from discrete encoders, so the ROC may not be interpreted as a curve.
** input feature abbreviations = OV: observation value, A: age at observation, G: gender, and R/E: Race/Ethnicity.
Testing the first hypothesis
To evaluate the first hypothesis, we performed non-parametric hypothesis testing on the entire encoders based on the features that formed them. Figure 3 presents the Critical Difference (CD) diagram for encoder features. On the CD diagram, each encoder is placed on the X axis according to its average performance ranking.
Figure 3.
CD diagram of the average encoder performance rankings by features.
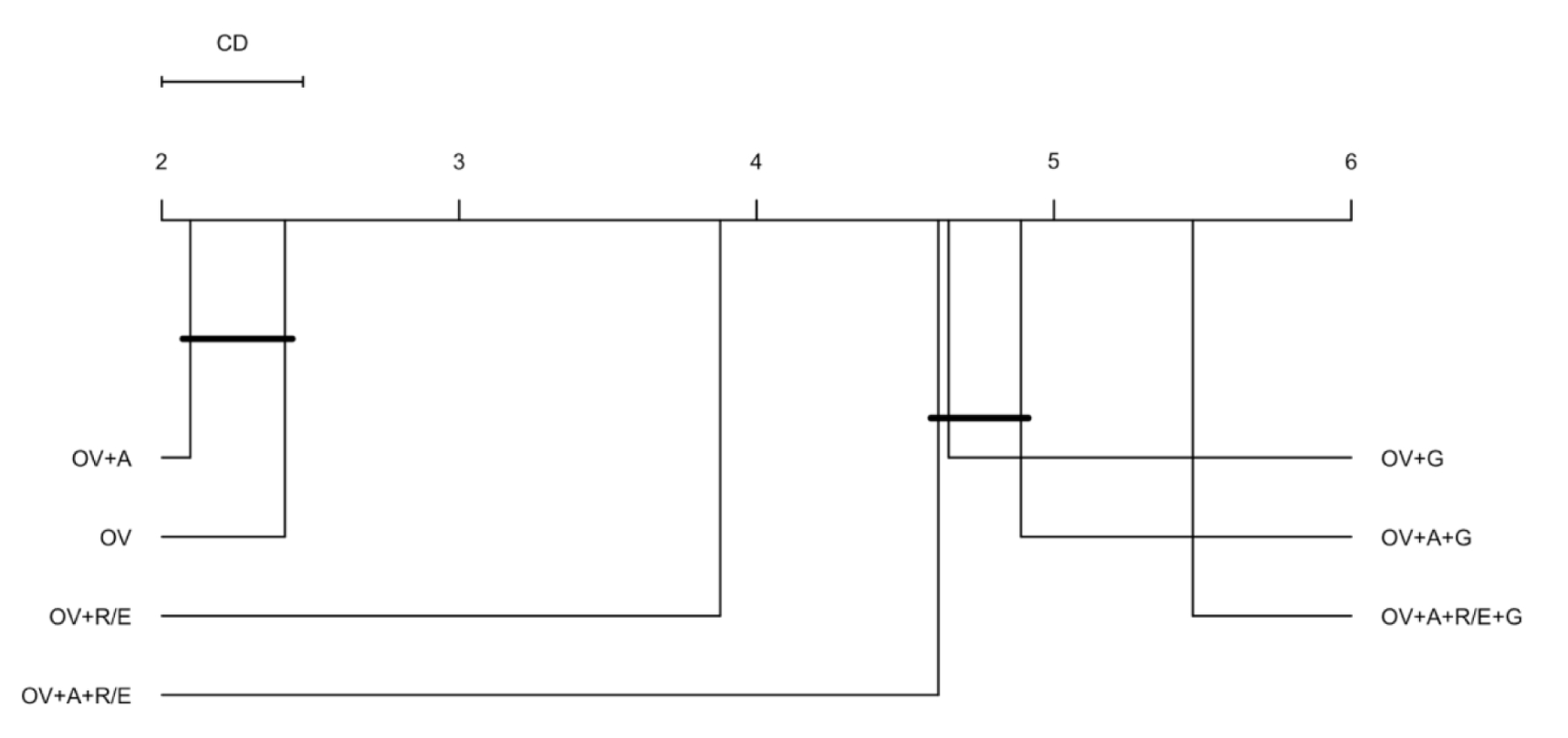
* OV: observation value, A: age at observation, G: gender (male/female), and R/E: Race/Ethnicity (American Indian or Alaska Native, Asian, Black or African American, Native Hawaiian or other Pacific Islander, White Only, Multiple Race/Ethnicity, Hispanic, and unknown).
We obtained a critical difference of 0.475 on 7 different feature compositions and 2,513 degrees of freedom. We found that the encoders with two features, observation value (OV) and age at observation (A) scored the best overall outlier detection performance based on the Youden’d J index. The simplest encoders with only one feature – observation value (OV) – that was the runner up did not have a significant average performance ranking difference with the best encoders, at p-value < 0.05. Adding Race/Ethnicity (R/E) to the baseline encoder produced a better average performance ranking as compared with gender. We also found that the most complex combination of features – with all demographic variables included – performed the worst among all feature compositions. Friedman post-hoc test with Bergmann and Hommel’s correction also confirmed this ranking and significance testing.
So far, our results support our first hypothesis that adding demographic variables that already exist in most EHRs can improve the outlier detection performance – we only found that adding age at observation improves the average performance of our baseline encoders. To further evaluate the hypothesis, we evaluated the encoders by the combination of features and neural network (NN) architectures (Figure 4).
Figure 4.
CD diagram of the average encoder performance rankings by the combination of features and NN architectures.
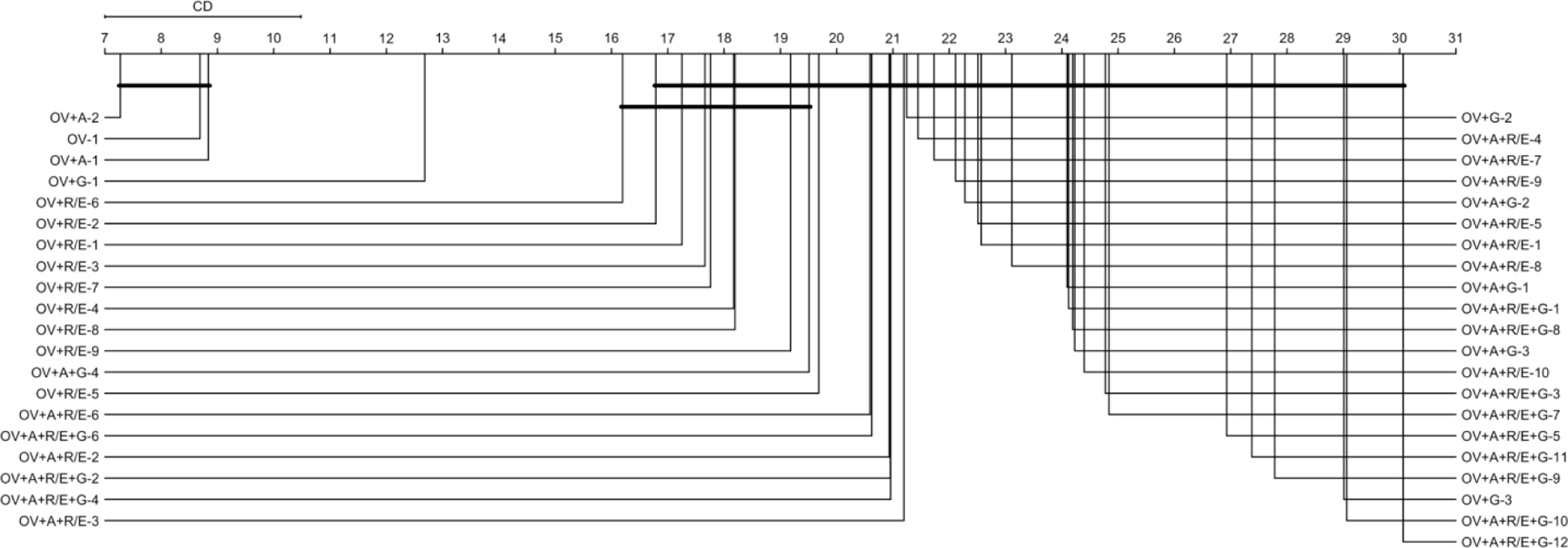
* OV: observation value, A: age at observation, G: gender (male/female), and R/E: Race/Ethnicity (American Indian or Alaska Native, Asian, Black or African American, Native Hawaiian or other Pacific Islander, White Only, Multiple Race/Ethnicity, Hispanic, and unknown). The number after dash represent NN architecture – e.g., OV+A-2: encoder with OV+A as features and a 2➭1➭2 NN architecture.
Critical difference between encoders by the combination of features and NN architectures was 3.482, on 41 distinct feature-NN architecture combinations, and 14,719 degrees of freedom. Similar to what we found previously, still the encoders with two features, observation value (OV) and age at observation (A) scored the best overall outlier detection performance. We also found again that the most complex encoders, with all features and deepest NN architecture (12➭11➭10➭9➭8➭7➭6➭5➭4➭3➭2➭1➭2➭3➭4➭5➭6➭7➭8➭9➭10➭11➭12), produced the worst average outlier detection performance. In general, it appears that outlier detection performance decreased with adding complexity.
Testing the second hypothesis
Each of the 41 distinct feature+NN architecture combinations (in Figure 4), we still have 240 combinations of sampling strategies and error margins. We first compared the average outlier detection performance ranking across the four different sampling strategies – 1%, 5%, 10% for semi-supervised encoders, and 100 percent in conventional autoencoders (Figure 5). With a critical difference of 0.077 and 14,756 degrees of freedom, results unanimously supported our hypothesis that using a sampling strategy would improve outlier detection performance. We found that semi-supervised encoders built on samples of 5 or 10 percent of data equally (at p-value < 0.05) produced the best average performances. The conventional autoencoders had the worst average outlier detection performance among the four sampling strategies. Friedman post-hoc test also confirmed this ranking and significance testing.
Figure 5.
CD diagram of the average encoder performance rankings by the combination of features and NN architectures.
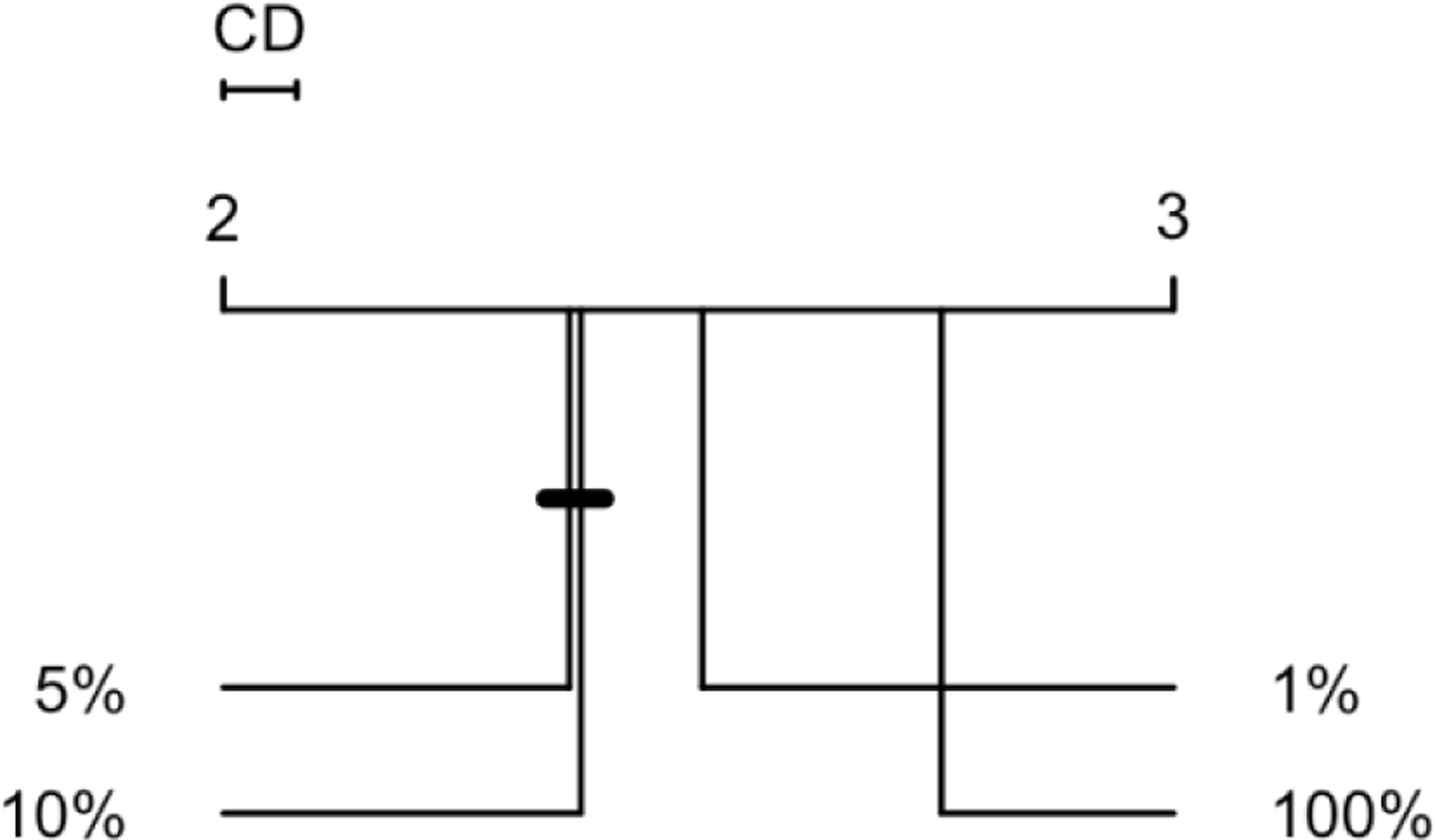
* percentages represent sample-to-data ratio
What is the best outlier detector?
After evaluating our hypotheses with non-parametric tests and calculating average performance rankings, it is taunting to see if an encoder consistently performed outstanding outlier detections across all 30 observations. Results showed that the best encoder performance for each observation has a minimum J index of 0.999 – i.e., there is at least an encoder for each observation that resulted in a J index better than 0.999. As the ROC plots showed (Figure 2), we expected performance variability between the 492 encoders and across the 30 observations. Figure 6 presents a box plot of J indices across all encoders. For the purpose of finding the best encoder, we focused on encoders that had a J index higher than 0.99 of the observations, and more importantly, also had low variability in high performance – such that their first quartile value was higher than 0.9. This left us with seven encoders (Figure 7 – also highlighted on Figure 6).
Figure 6.
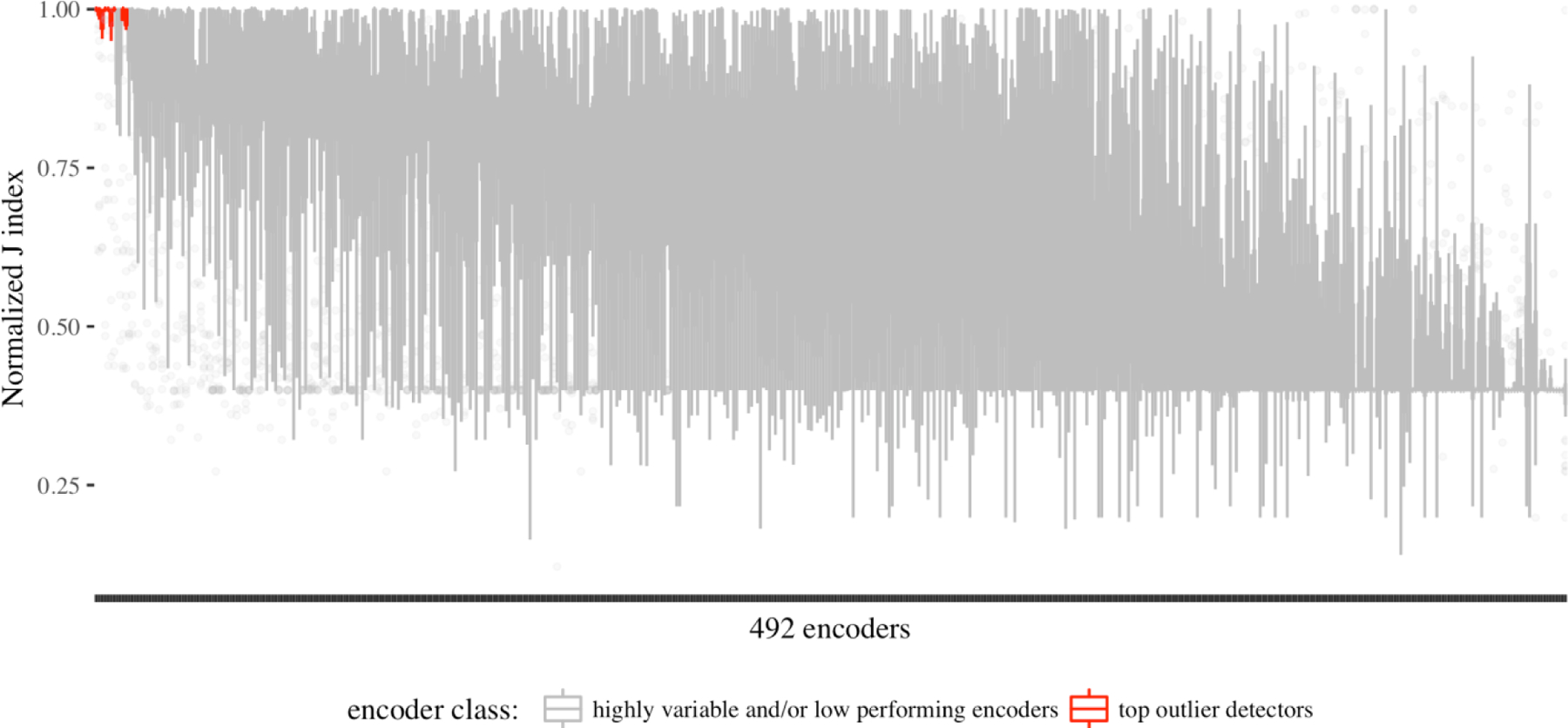
outlier detection performance variability across the 492 encoders.
Figure 7.
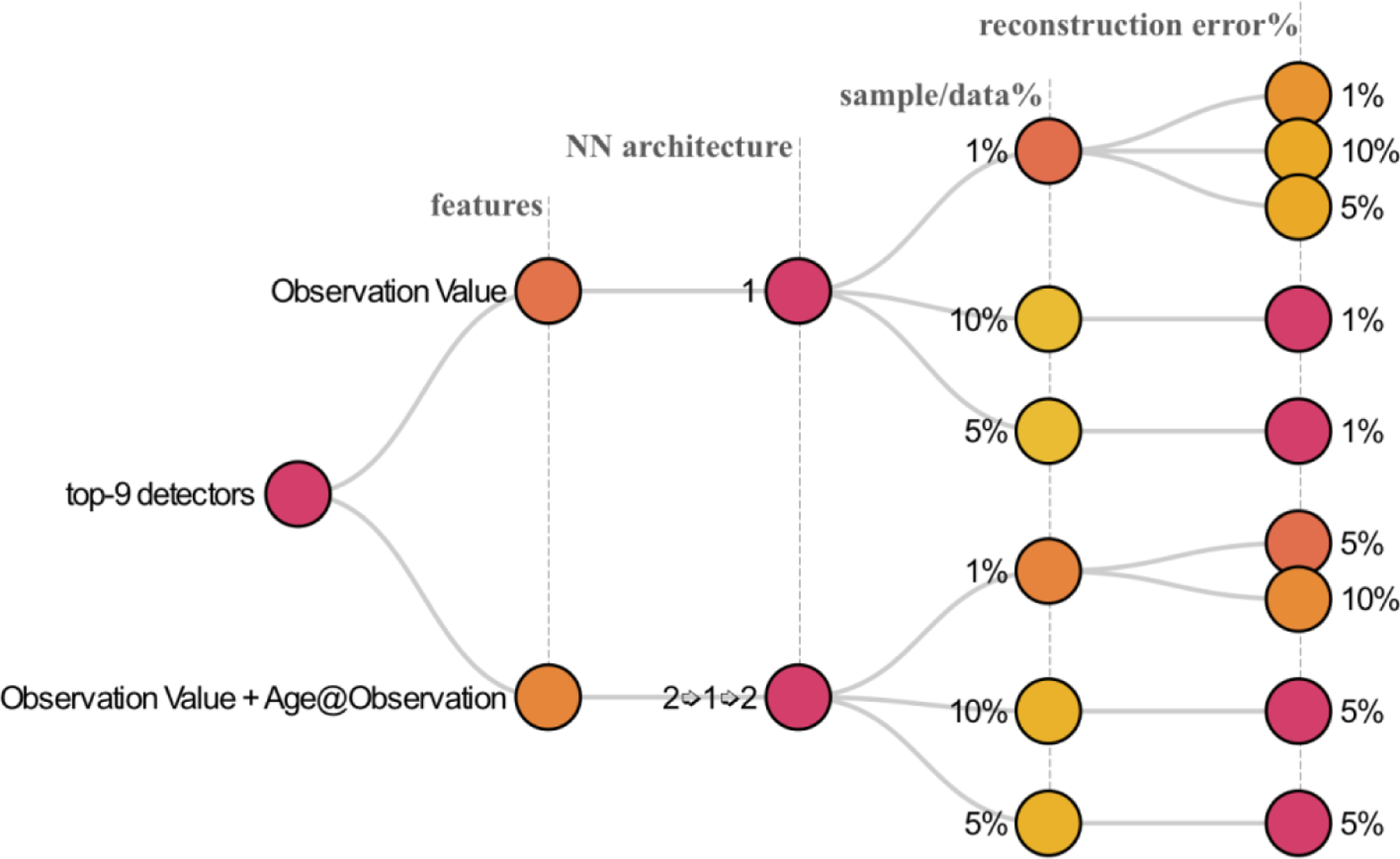
the top-9 outlier detector encoders based on the combination of performance and low variability.
The nine top outlier detector encoders comprised of 270 observations across the 30 observations, allowing us to also observe variability across observations. The box plots in Figure 8 show that while the top performing encoders frequently have reliably high performances across observations, there is only one encoder that performed well for BMI (LOINC 39156–5) and HCO3 (LOINC 1959–6) observations (shown as an outlier point), while most of the top encoders performed poorly for the two observations.
Figure 8.

Variability of outlier detection performance in the top-nine encoders across the 30 observations.
To explore whether there is a common outlier detector encoder among the top-nine encoders that performed well across all observations we broke down J index for each of these encoders by observation. The heatmap on Figure 9 illustrates the normalized J index of the top-nine encoders across the 30 observations. As the figure shows, we found the best all-around encoder in a semi-supervised encoder with one feature – observation value (the baseline feature) – and a single hidden layer, which was built on one percent of the data and identified data points with more than one percent reconstruction error as outliers (OV-1–1%−1%).
Figure 9.
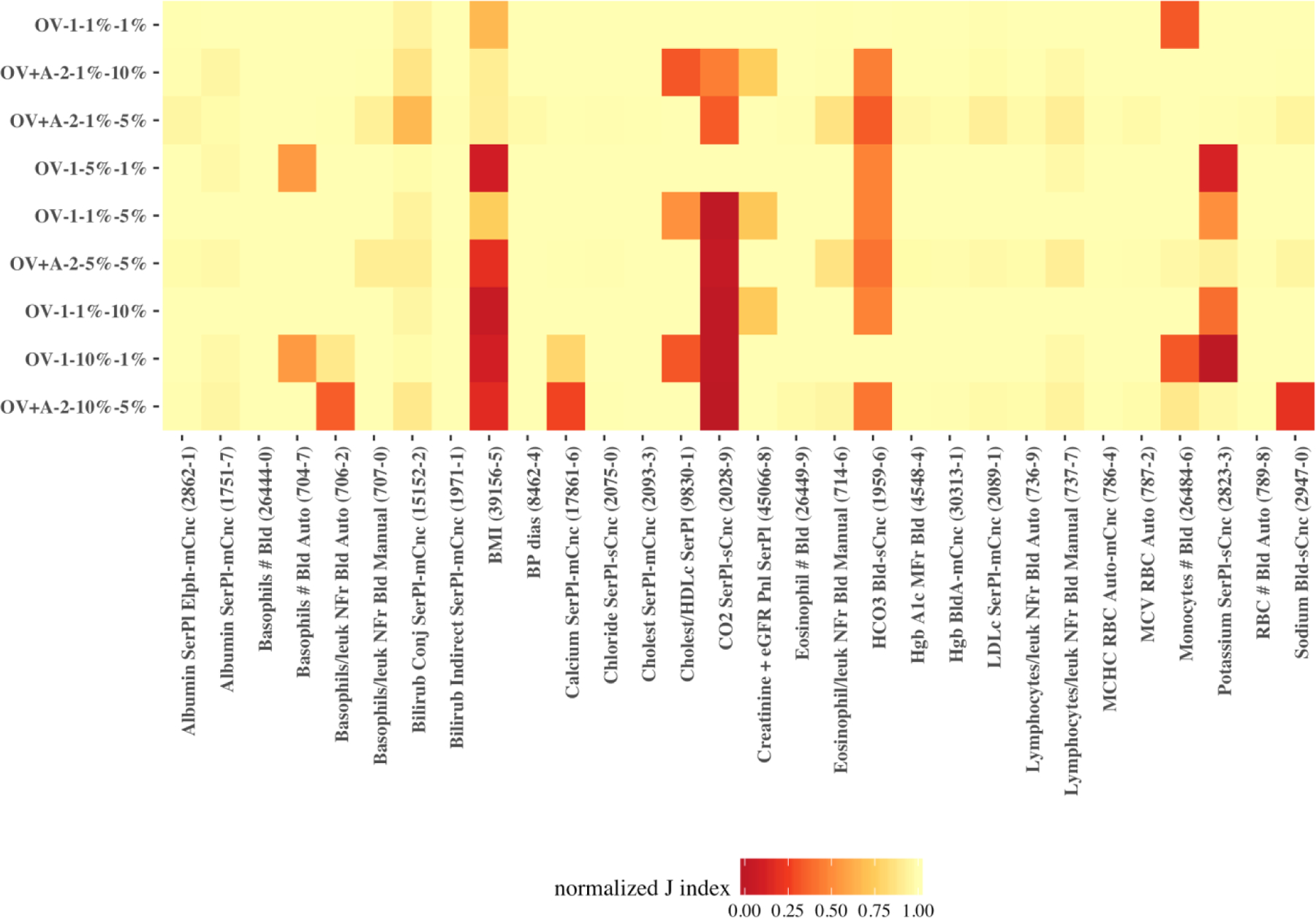
heatmap of the normalized J index for the top-nine encoders across the 30 observations.
To statistically verify these findings, we performed Friedman post-hoc test with Bergmann and Hommel correction on the top-nine encoders (Table 1). Applying Bergmann Hommel correction to the p-values computed in pairwise comparisons of nine algorithms requires checking 54,466 sets of hypotheses. The Friedman post-hoc test shows that the top-performing encoder was not significantly different (at p-value < 0.05) from semi-supervised encoders with similar NN architecture (single hidden layer) and feature (observation value), which applied different sampling strategies and error margins (5% or 10%). The top-performing encoder was also statistically not different from the encoder that used the same sampling strategy (one percent) but had age at observation and observation value as features (OV+A) in a 3-layer (2➭1➭2) NN architecture. Nevertheless, the top encoder’s performance was higher for all 30 observations than the two that generally were not significantly different.
Table 1.
Corrected Friedman post-hoc p-values
|
feature
architecture sample ratio error margin |
OV
1 1% 10% |
OV
1 1% 5% |
OV
1 10% 1% |
OV
1 5% 1% |
OV+A
2 1% 10% |
OV+A
2 1% 5% |
OV+A
2 10% 5% |
OV+A
2 5% 5% |
|---|---|---|---|---|---|---|---|---|
| OV-1-1%−1% | 0.33 | 1.00 | 1.00 | 1.00 | 0.76 | 0.00 | 0.00 | 0.00 |
| OV-1-1%−10% | 1.00 | 0.63 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| OV-1-1%−5% | 1.00 | 1.00 | 0.14 | 0.00 | 0.00 | 0.00 | ||
| OV-1-10%−1% | 1.00 | 0.43 | 0.00 | 0.00 | 0.00 | |||
| OV-1-5%−1% | 0.10 | 0.00 | 0.00 | 0.00 | ||||
| OV+A-2-1%−10% | 0.05 | 0.33 | 0.33 | |||||
| OV+A-2-1%−5% | 1.00 | 1.00 | ||||||
| OV+A-2-10%−5% | 1.00 |
insignificant p-values (>0.05) with Bergmann and Hommel correction are highlighted in Bold for pairwise similarities. The top-performing encoder is highlighted in the first row of the matrix.
The top-nine encoders on average had a J index of 0.9968 for the 30 observations, with a standard deviation of 0.0143. The minimum best performance of the top nine encoders across all observations was 0.9230 – for BMI (LOINC: 39156–5). However, at least one encoder, which may be outside the top-nine encoders had a Youden’s J index higher than 0.9999 for all 30 observations. For example, the top-two performances for BMI had J indices of 0.99998 and 0.99994, respectively from OV+G-1–1%−5% and OV+A-1–1%−5% that were not included to the general top models.
Discussion
Predictive (a.k.a., unsupervised) learning techniques present novel low-cost opportunities for detecting complex patterns in unlabeled clinical data. Given the availability of computing power and large-scale clinical datasets, encoders are effective methods for compressing non-linear representations of clinical data. We demonstrated the utility of semi-supervised encoders (super-encoders) for outlier detection through compressing the data into an exemplar distribution learned from hypothetically less-noisy random samples. In addition to precision, encoders are often very quick in compressing the data. On average, it took 7.034 seconds for the top seven encoders to compress a dataset with an average size of over 7 million rows. Taking into account the multiplicity of distributions for a single observation in EHR data (i.e., same observation represented with different names and/or units), encoding offers huge promises for outlier detection in large scale clinical data repositories.
Generally, we found that simple super-encoders produced outstanding outlier detection performances. We were able to find a super-encoder that performed very well for all 30 observations. The top encoder only used the observation value and a single hidden layer with one neuron to compress and decompress the data – essentially a simple regression model with tanh as the activation function.
While multiple encoders provided high outlier detection performances for most observations, only a single encoder performed outlier detection with high J indices for HCO3 (LOINC 1959–6) and BMI (LOINC 39156–5). We believe such fluctuations in outlier detection performance may be related to distributional differences. Looking at the distribution of values for HCO3 (Appendix C), it appears that the value and frequency of the outliers relative to the range of observation values is small, resulting in most encoders reconstructing the few outlier values with low reconstruction error. In the case of BMI, the distribution in Appendix C suggests an almost opposite situation, where the range of observation values is large and that the distribution is dispersed towards the right. Further research is needed to evaluate distributional variations and their effects on outlier detection using encoders.
We also found that only adding age at observation to the baseline encoder (observation value) improved outlier detection. However, we used a linear cut-off range (based on observation value) to measure the performance of each encoder. Defining ranges in multiple dimensions (which would form a hyperplane) is needed to further evaluate the performance of encoders. Nevertheless, even the linear range definition proved encoding as a feasible alternative for replacing the current manual standard procedures for outliers (i.e., identifying biologically implausible values) in clinical observations data.
We also found that the more complex an encoder gets (i.e., including more demographic features and increasing depth of the NN), the smaller its reconstruction error is. This is in agreement with prior research that holding the number of features constant, a deep autoencoder can produce lower reconstruction error than a shallow architecture.[22] In other words, the compressed data representation produced by a deep NN encoder with all demographic features was very close to the actual data, which included outliers. Increasing the network complexity (input features and architecture) result in extra neurons and better reconstructions of the input features. Therefore, a complex encoder can reconstruct most of the outlier with low errors, making them indistinguishable from normal data points and thus diminishing the outlier detection.
Looking forward, with the availability of state-of-the-art computational resources and increasing amounts of clinical data in today’s healthcare organizations, training generalizable super-encoders for each group (or combination of groups) of clinical observation data seems feasible. Our semi-supervised approach takes the view of letting the data speak for itself and can improve (or at least provide an alternative to) the current rule-based approaches to identification of implausible values that often do not take non-linearities into account.
The experimental work conducted in this research was on 30 observations. Therefore, our comparison and ranking of the algorithms – which resulted in identifying the top encoders – is based on validation results from a limited number of observations. For improving generalizability of these findings further effort is needed to include validation results for a larger set of observations. In addition, we only considered a few operating points for sampling the data (1%, 5%, and 10% vs. 100%) and error margin (1%, 5%, and 10%). Examining more operating points in future may result in finding consistent super-encoders for all type of observation data. Moreover, other activation functions such as rectified linear unit (ReLU) can be tested in future work. We envision the top encoder (or a combination of the top performing encoders) to operate on the data warehouse after each data refresh. Once the outliers are detected and flagged, a workflow that would likely involve context expertise is needed to validate the flagged observations and initiate further actions.
Conclusion
We found a best all-around encoder; a semi-supervised encoder, with observation value as the single feature and a single hidden layer, trained on one percent of the data, identifying outliers as data points with higher than one percent reconstruction error. The top-nine encoders on average had a J index of 0.9968 for the 30 observations. At least one encoder, which may be outside the top-nine encoders had a Youden’s J index higher than 0.9999 for all 30 observations. Due to multiplicity of observation data and their representations in EHRs, detecting outliers (i.e., biologically implausible observations) is challenging. Even in the presence of gold/silver standard implausibility thresholds, non-linearities of human observations are not captured in linear cut-off ranges. We demonstrated the utility of a semi-supervised encoding approach (super-encoding) for outlier detection in clinical observations data. Super-encoder functions and their implementations on i2b2 star schema is available on GitHub (link will be posted after the peer review process). In addition, analytic scripts to perform the experiments and analyze the results in R statistical language are available on GitHub for reproduction of the experiments across other EHR data warehouses.
Supplementary Material
Funding
This work was partially funded through a Patient-Centered Outcomes Research Institute (PCORI) Award (CDRN-1306-04608) for development of the National Patient-Centered Clinical Research Network, known as PCORnet, NIH R01-HG009174, and NLM training grant T15LM007092.
Footnotes
Disclaimer
The statements presented in this publication are solely the responsibility of the author(s) and do not necessarily represent the views of the Patient-Centered Outcomes Research Institute (PCORI), its Board of Governors or Methodology Committee or other participants in PCORnet.
References
- [1].National Research Council, The Learning Healthcare System: Workshop Summary (IOM Roundtable on Evidence-Based Medicine), Washingotn, DC, 2007. [Google Scholar]
- [2].Stewart WF, Shah NR, Selna MJ, Paulus RA, Walker JM, Bridging the inferential gap: The electronic health record and clinical evidence, Health Aff 26 (2007). doi: 10.1377/hlthaff.26.2.w181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Kahn MG, Callahan TJ, Barnard J, Bauck AE, Brown J, Davidson BN, Estiri H, Goerg C, Holve E, Johnson SG, Liaw S-T, Hamilton-Lopez M, Meeker D, Ong TC, Ryan P, Shang N, Weiskopf NG, Weng C, Zozus MN, Schilling L, A Harmonized Data Quality Assessment Terminology and Framework for the Secondary Use of Electronic Health Record Data, EGEMs (Generating Evid. Methods to Improv. Patient Outcomes) 4 (2016). doi: 10.13063/2327-9214.1244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Hodge VJ, Austin J, A survey of outlier detection methodologies, Artif. Intell. Rev 22 (2004) 85–126. doi: 10.1023/B:AIRE.0000045502.10941.a9. [DOI] [Google Scholar]
- [5].Ben-gal I, Outlier Detection, in: Data Min. Knowl. Discov. Handb. A Complet. Guid. Pratitioners Res, 2005. doi: 10.1007/0-387-25465-x_7. [DOI]
- [6].Chandola V, Banerjee A, Kumar V, Anomaly detection: A survey, ACM Comput. Surv 41 (2009) 1–58. doi: 10.1145/1541880.1541882. [DOI] [Google Scholar]
- [7].Beniger JR, Barnett V, Lewis T, Outliers in Statistical Data., Contemp. Sociol (1980). doi: 10.2307/2066277. [DOI]
- [8].Eskin E, Anomaly Detection over Noisy Data using Learned Probability Distributions, in: Proc. Int. Conf. Mach. Learn, 2000. doi: 10.1007/978-1-60327-563-7. [DOI]
- [9].Grubbs FE, Procedures for Detecting Outlying Observations in Samples, Technometrics (1969). doi: 10.1080/00401706.1969.10490657. [DOI]
- [10].Laurikkala J, Juhola M, Kentala E, Lavrac N, Miksch S, Kavsek B, Informal identification of outliers in medical data, Fifth Int. Work. Intell. Data Anal. Med. Pharmacol (2000).
- [11].Aggarwal CC, Yu PS, Outlier detection for high dimensional data, ACM SIGMOD Rec (2001). doi: 10.1145/376284.375668. [DOI]
- [12].Knorr EM, Ng RT, Tucakov V, Distance-based outliers: Algorithms and applications, VLDB J (2000). doi: 10.1007/s007780050006. [DOI]
- [13].Reynolds D, Gaussian Mixture Models, in: Encycl. Biometrics, 2015. doi: 10.1007/978-1-4899-7488-4_196. [DOI]
- [14].Reddy A, Ordway-West M, Lee M, Dugan M, Whitney J, Kahana R, Ford B, Muedsam J, Henslee A, Rao M, Using Gaussian mixture models to detect outliers in seasonal univariate network traffic, in: Proc. - 2017 IEEE Symp. Secur. Priv. Work. SPW 2017, 2017. doi: 10.1109/SPW.2017.9. [DOI]
- [15].Latecki LJ, Lazarevic A, Pokrajac D, Outlier Detection with Kernel Density Functions, in: Mach. Learn. Data Min. Pattern Recognit, 2007. doi: 10.1007/978-3-540-73499-4_6. [DOI] [Google Scholar]
- [16].Hastie T, Tibshirani R, Friedman J, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2009. doi: 10.1007/b94608. [DOI] [Google Scholar]
- [17].Ng A, Sparse autoencoder, in: Lect. Notes; Deep Learn. Unsupervised Featur. Learn, 2011: pp. 1–19. https://web.stanford.edu/class/cs294a/sparseAutoencoder_2011new.pdf.
- [18].Markou M, Singh S, Novelty detection: A review - Part 2:: Neural network based approaches, Signal Processing. 83 (2003) 2499–2521. doi: 10.1016/j.sigpro.2003.07.019. [DOI] [Google Scholar]
- [19].Goodfellow I, Bengio Y, Courville A, Autoencoders, in: Deep Learn, MIT Press, 2016: pp. 502–525. http://www.deeplearningbook.org. [Google Scholar]
- [20].Sakurada M, Yairi T, Anomaly detection using autoencoders with nonlinear dimensionality reduction, Proc. MLSDA 2014 2nd Work. Mach. Learn. Sens. Data Anal (2014) 4. doi: 10.1145/2689746.2689747. [DOI]
- [21].Baldi P, Autoencoders, Unsupervised Learning, and Deep Architectures, ICML Unsupervised Transf. Learn (2012) 37–50. doi: 10.1561/2200000006. [DOI] [Google Scholar]
- [22].Hinton GE, Salakhutdinov RR, Reducing the Dimensionality of, Science 313 (2006) 504–507. doi: 10.1126/science.1127647. [DOI] [PubMed] [Google Scholar]
- [23].Hawkins S, He H, Williams G, Baxter R, Outlier detection using replicator neural networks, Proc. 4th Int. Conf. Data Warehous. Knowl. Discov (2002) 170–180. doi:10.1.1.167.4245. [Google Scholar]
- [24].Zhai S, Cheng Y, Lu W, Zhang Z, Deep Structured Energy Based Models for anomaly detection, 33rd Int. Conf. Mach. Learn 48 (2016). http://arxiv.org/abs/1605.07717. [Google Scholar]
- [25].Murphy SN, Mendis M, Hackett K, Kuttan R, Pan W, Phillips LC, Gainer V, Berkowicz D, Glaser JP, Kohane I, Chueh HC, Architecture of the open-source clinical research chart from Informatics for Integrating Biology and the Bedside., AMIA ... Annu. Symp. Proceedings. AMIA Symp (2007) 548–552. [PMC free article] [PubMed]
- [26].Murphy SN, Weber G, Mendis M, Gainer V, Chueh HC, Churchill S, Kohane I, Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2)., J. Am. Med. Inform. Assoc 17 (2010) 124–130. doi: 10.1136/jamia.2009.000893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Nalichowski R, Keogh D, Chueh HC, Murphy SN, Calculating the benefits of a Research Patient Data Repository., AMIA Annu. Symp. Proc (2006) 1044. [PMC free article] [PubMed] [Google Scholar]
- [28].Candel A, LeDell E, Bartz A, Deep Learning with H2O, n.d. http://docs.h2o.ai/h2o/latest-stable/h2o-docs/booklets/DeepLearningBooklet.pdf. [Google Scholar]
- [29].Habibzadeh F, Habibzadeh P, Yadollahie M, On determining the most appropriate test cut-off value: the case of tests with continuous results, Biochem. Medica 26 (2016) 297–307. doi: 10.11613/BM.2016.034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Youden WJ, Index for rating diagnostic tests, Cancer 3 (1950) 32–35. doi:. [DOI] [PubMed] [Google Scholar]
- [31].Friedman M, The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance, J. Am. Stat. Assoc 32 (1937) 675–701. doi: 10.1080/01621459.1937.10503522. [DOI] [Google Scholar]
- [32].Bergmann B, Hommel G, Improvements of General Multiple Test Procedures for Redundant Systems of Hypotheses, in: Bauer P, Hommel G, Sonnemann E (Eds.), Mult. Hypothesenprüfung / Mult. Hypotheses Test, Springer Berlin Heidelberg, Berlin, Heidelberg, 1988: pp. 100–115. [Google Scholar]
- [33].Calvo B, Santafé G, scmamp: Statistical Comparison of Multiple Algorithms in Multiple Problems, R J. XX (2015) 8. [Google Scholar]
- [34].Demšar J, Statistical Comparisons of Classifiers over Multiple Data Sets, J. Mach. Learn. Res 7 (2006) 1–30. doi: 10.1016/j.jecp.2010.03.005. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.