

Summary
The joint modeling of longitudinal and time-to-event data is an active area in biostatistics research. The focus of this article is on developing a modeling framework for these joint models when the longitudinal and time-to-event data do not have a meaningful time-zero. The motivating example is the study of a longitudinal assessment of station during child labor and it’s relationship to time-to-delivery. A good predictor of delivery type and timing would help obstetricians better manage the end of pregnancy and better facilitate delivery. One measure of labor progression is station, a measure of the position of the fetus’ head in relation to the pelvis of the pregnant women, may be a good marker for delivery time and type. However, women enter the hospital, where their station is closely monitored, at arbitrary points in their labor process, resulting in no clear time zero. In addition, since delivery may be of various types, the competing risks due to type need to be accounted for. We develop a joint model of longitudinal and time-to-event data for this situation. The model is formulated through shared random effects between the survival and longitudinal processes, and parameter estimation is conducted through a Bayesian approach. The model is illustrated with longitudinal data on station where the relationship between station and event-time is studied and the model is used to assess the ability of longitudinal measures of station to predict the type and timing of pregnancy. We illustrate the methodology with longitudinal data taken during labor.
Keywords: Competing risk, longitudinal data, prediction, random effects, station, time-to-event
1. Introduction
Understanding the relationship between longitudinal biomarkers and time-to-event has been an important area for methodological research (Rizopoulos (2012), for example). These methods have been used for both characterizing the relationship between features of the longitudinal biomarker and the event-time distribution as well as to develop dynamic predictors of clinical outcome from the repeated biomarker. This article proposes new statistical methodology for the situation where the longitudinal and survival processes have no clearly defined time zero and where there are competing risks for the time-to-event outcome. We present a shared random parameter model where the longitudinal process is linked to the event process through a series of random effects. Competing risks are incorporated by separately modeling the type and timing of the clinical event given these shared random effects.
The application of interest is on understanding the relationship between a longitudinal assessment of labor progression and the type and timing of delivery in women at the end of pregnancy. Specifically, researchers are interested in assessing the relationship between station, defined as the position of the fetuses in their mother’s pelvis, and eventual delivery type and timing. Studying this relationship would provide useful information to the obstetrician about monitoring pregnant women for station during labor. The station in labor describes the descent of the fetus into the pelvis and is often measured on a to scale in centimeters, where the reference point of zero refers to the point where the head crosses the midpelvis (halfway out). Since women start getting measured for station once they come to the hospital in labor, there is no clear time zero relative to their start of followup. Instead, using the point where the station value crosses zero is a natural reference point. There are different ways that a fetus can be delivered, and labor progression may influence each delivery type differently. To account for this type of competing risk, we model delivery type using a polychotomous logistic regression model and then the time-to-delivery given the delivery type. The three delivery types are spontaneous which requires no intervention, C-section, and those requiring vacuum assistance.
Figure 1 shows a series of individual profiles for women who eventually have a spontaneous delivery. The figure demonstrates that the monitoring of station begins at different points in labor. Further, the longitudinal profile appears different before and after a station value of zero.
Figure 1:
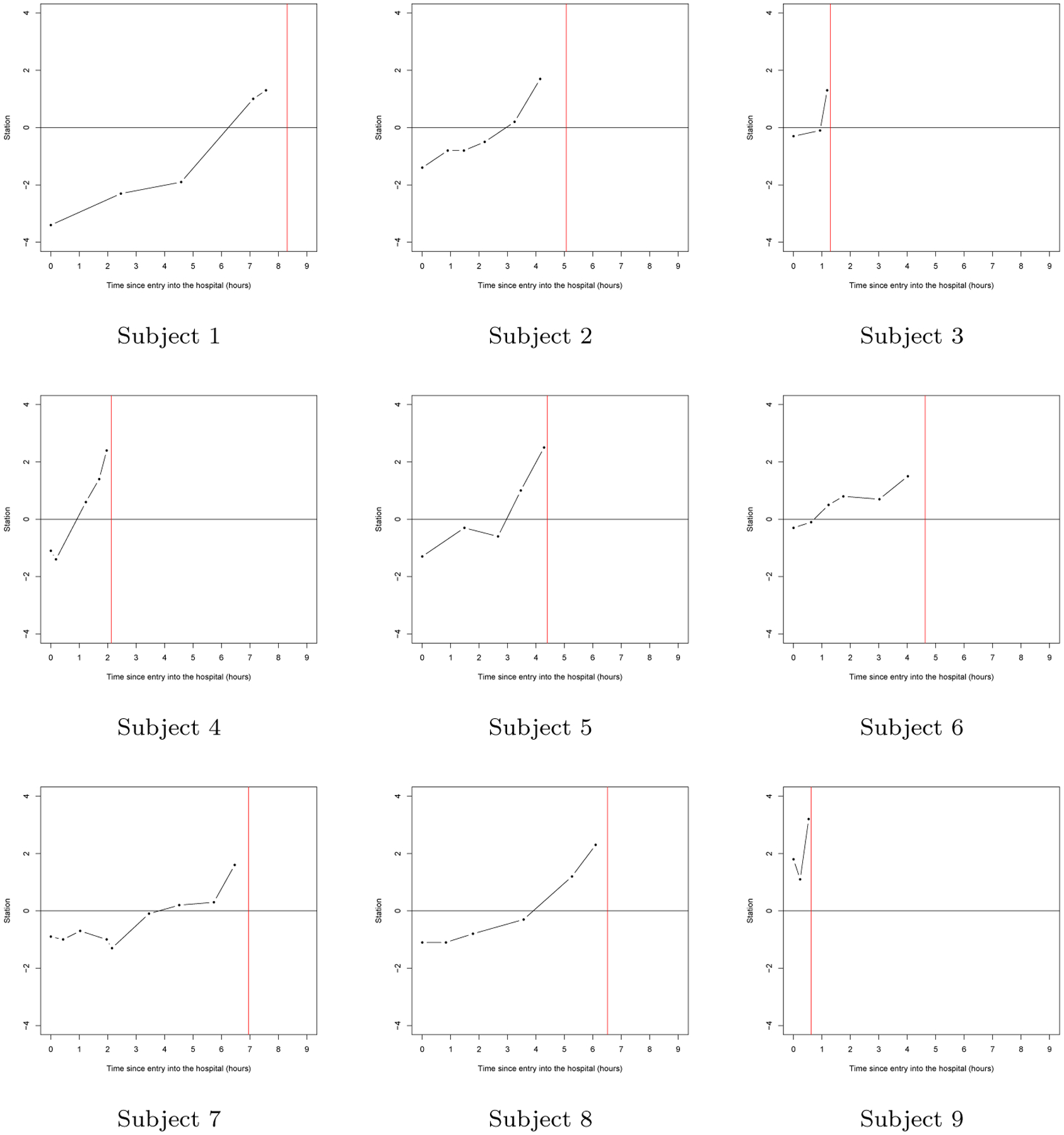
Representative station measurement trajectories resulting in a spontaneous delivery as a function of time from study entry (in hours). The red line represents the time of the spontaneous delivery.
McLain and Albert (2014) proposed a model for longitudinal data with a random change point and no-time zero that was motivated by repeat labor dilation data. The methodology was used to characterize the relationship between key demographic factors and labor progression as assessed by repeated measures of a woman’s cervical dilation. Further, this modeling strategy was used to predict future dilation measurements as well as the time to full dilation for a pregnant women based on prior dilation measurements. The current article asks a different, and perhaps the more important question of whether a repeated measure of labor progression affects the timing and type of pregnancy outcome.
In this article, we propose a joint model for longitudinal assessments of station with a random landmark and time to delivery and mode of delivery as a competing risk. We consider a shared random parameter model that links together model components for the longitudinal station process (with no time-zero) and both the time and type of delivery. Specifically, each model component includes random effects that are shared between these three components, inducing realistic dependence between these three model components. To this end, we develop an efficient Bayesian computational method for fitting this joint model via several modified collapsed Gibbs samplers (Chen et al. 2000; Liu 1994). In addition, we derive the deviance information criterion (DIC) for comparing several variations of the proposed joint models, which is a modified DIC measure when mixtures of distributions or latent variables are present.
The rest of this paper is organized as follows. In Section 2, we provide the methodological development of a flexible class of joint models for the longitudinal station measurements and the time to delivery as well as the model of delivery. This includes specifying a skewed generalized -distribution for the time to delivery. In Section 3, we discuss the prediction of both the timing and type of delivery from repeated station measurements taken at various time points that can be irregularly spaced across individuals. The prior and posterior distributions, the Markov chain Monte Carlo (MCMC) sampling algorithm, and the Bayesian model comparison criteria are presented in Sections 4.1, 4.2, and 4.3, respectively. In Section 5, we apply the methodology to longitudinal labor data in order to study the association between labor dynamics and delivery time. Finally, we conclude the article with some discussion for future research in Section 6.
2. Joint Models
Suppose that denotes individual and denotes time point . We assume that each measurement is taken at repeated time points, which are potentially irregularly spaced times in the delivery. Further, we assume that there are individuals in the study, each contributing time points, where denotes the number of repeated time points on the th individual. Let and denote the vectors of fixed effect covariates, where may share common components with . Also let and denote the corresponding regression vectors for model components of the time to delivery and the mode of delivery, respectively. In addition, denotes the vector of regression parameters for the longitudinal measurements. Furthermore, we assume that denotes the time for the individual after arriving at the hospital, where (arriving time). Note that, since the application has three types of delivery (spontaneous, vacuum, and C-section), for ease of notation, the model is specified with three competing risks.
Let denote the longitudinal station measurement, denotes the mode of delivery such as spontaneous, vacuum, or C-section, and denotes the time to delivery from entry into the hospital for the individual, separatively. Note that each individual enter the hospital with different station measurement so that there is no known time zero when labor starts. Furthermore, station measurements were taken on each woman from time of entry into the hospital to a few hours before giving birth, resulting in no clear time zero for use as a reference point for valid statistical inferences and predictions. Therefore, we re-scale the and such that time zero is the time when a woman’s station is zero (i.e. when a fetus is said to be engaged in the pelvis). We consider the joint models with shared random effects for the longitudinal measurements, time to delivery, and delivery type. First, we propose the following random effects regression model for the longitudinal measurements as
| (2.1) |
where is the mean station when is the re-scaled time for the station measurement on the woman with the mean time re-scaling factor and random effect allowing for heterogeneity, and are random variables for the error distributions. A station value of zero, the point at which the head of the fetus crosses the mid-pelvis, is a natural reference choice; thus, . Furthermore, , and are individual-level random effects, characterizing heterogeneity in the station process across women. Let and . In (2.1), we assume that (i) and are independent; (ii) follows a normal distribution with mean 0 and variance ; and (iii) the shared random effect follows a multivariate normal distribution mean and unstructured variance-covariance matrix for and . Furthermore, we assume quadratic trend after station zero and a linear form before and set . Let , and . Also let denote the observed data. Given and , the likelihood function of for longitudinal station measurements is given by
| (2.2) |
where for and for . Note that denotes a normal distribution with mean and variance .
For time to delivery, we propose the following flexible regression model as
| (2.3) |
where is the re-scaled time to delivery for the woman, are shared parameters accounting for correlation between , and which is dichotomized. We assume that and are independent, and are random variables for the flexible error distributions that will allow for long-tailed and skewed distributions. In this paper, we propose to use long-tailed and skewed distributions to accomplish this goal. We model
| (2.4) |
where the first and second terms in (2.4) characterize skewness and long tails, respectively. Similar to Kim et al. (2008), we assume that (i) and are independent; (ii) are each independent, where is the cumulative density function (cdf) of a skewed distribution defined on ; and (iii) follows a symmetric distribution. Also in (2.4), is a skewness parameter, where reflects a symmetric distribution. Following Chen et al. (1999) and Kim et al. (2008), we assume that has a known cdfs in order to ensure model identifiability. In this paper, we first specify several different distributions for , and use the DIC (Spiegelhalter et al. (2002)) to determine which fits the data best. We consider the following distributions for (a) is degenerated at 0, denoted by , yielding a symmetric distribution; (b) is a standard exponential distribution with probability density function (pdf) if and 0 otherwise; and (c) is a half normal with pdf if and 0 otherwise. Thus given , the model (2.4) yields a skewed distribution. Furthermore, we propose a skewed generalized model for , which is motivated by Kim et al. (2008) for a binary response data in a generalized linear model. Let denote the pdf of a generalized -distribution (Abranowitz and Stegun (1972)) that is given by
| (2.5) |
where is a shape (or degrees of freedom) and is a scale parameter. Let , then for and for . To ensure identifiability, we assume to be 1 (Kim et al. 2008). We note that based on (2.5), in (2.4) leads to a skewed generalized -distribution for . The models defined in (2.3), (2.4), and (2.5) are general and flexible, which includes the normal and skewed models as special cases. Figure 2 illustrates the skewed generalized -distribution for positive, negative, and no skewness.
Figure 2:
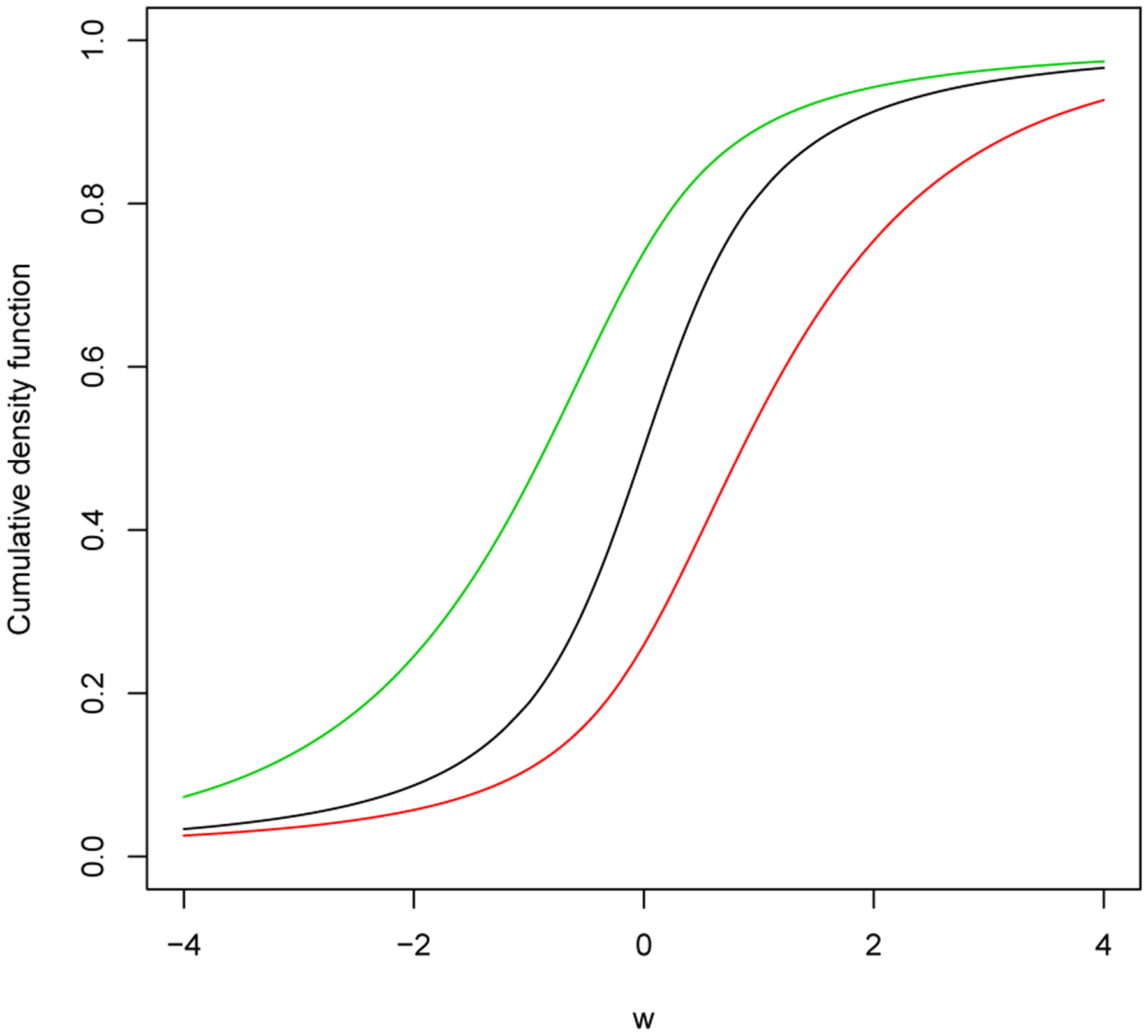
CDF plots of the skewed generalized -distribution. Black line: symmetric, Red line: positive skewed, and Green line: negative skewed.
Let , and . Also let denote the observed data. Given and , the likelihood function of for time to delivery is given by
| (2.6) |
where . Note that denotes a pdf of generalized -distribution with mean , variance and .
For the mode of delivery, we assume the multinomial logistic regression model as
| (2.7) |
where are shared parameters accounting for correlation between , and . Note that . Let , , and . Also let denote observed data. Given and , the likelihood function of for time to delivery is given by
| (2.8) |
where is given in (2.7) and is an indicator function, which is defined as of is true and 0 otherwise.
The observed joint likelihood function of is
| (2.9) |
where , and are given in (2.2), (2.6), and (2.8), respectively. Since it is not easy to work directly with the observed joint likelihood function of in (2.9), we develop an efficient MCMC algorithm using the fact that the generalized -distribution can be represented as a gamma mixture of normal distributions for as described in Section 4.2.
3. Predicting the time to delivery and delivery type
The joint model in (2.1), (2.3), and (2.7) relates the longitudinal station patterns to the probability of a delivery type and time to delivery through an individual’s predicted station measurement, and can be used to develop a predictor of the timing and delivery type using individualized longitudinal assessments of station. To predict the time to delivery and mode of delivery at birth using the longitudinal station measurements, we let denote the longitudinal station measurement taken at time points , where is the number of repeated measurements in the predictor. Furthermore, let and denote the time to delivery and mode of delivery we wish to predict. Also let . Then the posterior predictive probability for and posterior predictive distribution for based on longitudinal measurements can be given by
| (3.1) |
where is a multivariate random effects and is the posterior distribution for and based on . To obtain the posterior predictive probability for and posterior predictive distribution for in (3.1), we sample from joint posterior distribution based on test set data (with parameter estimates using training dataset). Specifically, to evaluate the prediction accuracy, we divide the data into a training and test set data. Note that mode of delivery is treated as a competing risk for predicting .
4. Posterior inference
4.1. Prior and posterior distributions
We assume that , and are independent a priori. The priors that we assume have as weak information as possible so that the data can dominate the posterior computation. Specifically, we assume that, , and , where , , and , are the prespecified hyperparameters. Note that Gamma is a Gamma distribution with mean is an Inverse-gamma distribution with mean , and denotes a Wishart prior distribution with degrees of freedom and mean . The hyperparameters of the prior were specified as , and in the analysis. These choices of hyperparameters lead to noninformative priors. Let . Based on the prior distributions specified above, the joint posterior distribution of , and is thus given by
| (4.1) |
where is defined in (2.9). We can generate a sample from this joint posterior distribution using Gibbs sampler and make appropriate inference of the various model parameters. A description of the MCMC algorithm is given in Section 4.2.
4.2. Computational Developments
The analytical evaluation of the posterior distribution of given in (4.1) is not available. However, we can develop an efficient MCMC sampling algorithm to sample from (4.1). For ease of presentation, we consider the standard exponential distribution for only as the MCMC sampling algorithms for other choices of are similar. Since it is difficult to work directly with the observed joint likelihood function of in (2.9), we use the complete data joint likelihood function of using the fact that the generalized -distribution can be represented as a gamma mixture of normal distributions for and , where is a mixing variable. Let and . Also let denote complete data set. The joint posterior distribution of based on the complete data joint likelihood function can be written as
| (4.2) |
where , and are given in (2.2), (2.6), and (4.1), respectively. From (4.2), the algorithm requires sampling the following parameters in turn from their respective full conditional distributions: (I) ; (III) and (IV) . Let , and . For (I), observed that
| (4.3) |
where and for . For (II), we observe that
| (4.4) |
For (III), the conditional posterior densities for do not have closed form. Therefore, we use the Metropolis-Hastings algorithm (Hastings (1970)) to sample from their conditional posterior distributions. For (IV), we apply the collapsed Gibbs technique of Liu (1994) via the following identity:
That is, we sample , and after collapsing out and . Observe that
| (4.5) |
where is given in (2.2). We also observe that
| (4.6) |
where and are given in (2.3). The conditional posterior densities for , and do not have closed form. Therefore, we use the Metropolis-Hastings algorithm (Hastings (1970)) to sample , and from their conditional posterior distributions.
4.3. Model Comparison
To assess the goodness of fit of the models for different choices of the distributions for and in (2.4), we use the DIC proposed by Celeux et al. (2006) without integrating out analytically in (2.1), (2.3), and (2.7). Although certain numerical integration or Monte Carlo methods may be used for evaluating those analytically intractable integrals, those methods are computationally intensive to carry out due to the large size of the data. Following the suggestions of Celeux et al. (2006), we use the , which is a modified DIC measure when mixtures of distributions or latent variables are present. The measure DIC4 makes use of the complete-data likelihood in the presence of latent variables, which is given by
| (4.7) |
where and are defined in (2.5) and (2.7), and denote a pdf of normal distribution with mean and variance , and multivariate normal distribution with mean and variance-covariance matrix , respectively. Then can be written as
| (4.8) |
where the integration for is evaluated numerically. The smaller the DIC value, the better the model fits the data. The other properties of the DIC can be found in Spiegelhalter et al. (2002) and Celeux et al. (2006).
5. Analysis of the Labor Data
In this section, we used the proposed joint model in (2.1) - (2.7) to analyze data from the cohort study introduced in Section 1. The outcome variables were , and , which were defined as a station measurement at the th time point, time to delivery, and the mode of delivery for the th individual. , and 3 correspond to spontaneous, vacuum, and C-section, respectively. The time point is the th time (hours) from time of entry into the hospital for the th individual . We considered two covariates: Age (years) and the delivery type. Delivery type was dichotomized for spontaneous, (1, 0) for vacuum, and (0, 1) for C-section). In total, we had and , the range of the maximum number of repeated station measurements. In addition, 18.4%, 15.3%, and 66.3% of the women delivered through vacuum, C-section, and spontaneous, respectively. The medium delivery times since entry into the hospital were 6.27 hours for vacuum, 5.97 hours for C-section, and 4.6 hours for spontaneous, respectively. In addition, we divide the whole data into two data sets randomly with a 70% and 30% split of the sample into a training and test set, respectively (i.e., 446 in the training set and 191 in the test set). We used the training set data to develop the predictor, while test set data was used to validate the predictor with different accuracy measures. We fitted the proposed joint model in (2.1) - (2.7) and estimated all parameters using the training-set data.
To help the numerical stability and to improve convergence for the MCMC sampling algorithm, we standardized two covariates. The means and standard deviations were (28.7, 5.04) for age, (0.16, 0.37) for , and (0.15, 0.35) for , respectively. In all the Bayesian computations, we used 20,000 Gibbs samples, which were taken from every 5th iteration, after a burn-in of 6,000 iterations, to compute all the posterior estimates, including means (Estimates), SDs, 95% HPD intervals, as well as the DICs. The computer programs were written in FORTRAN 95 using IMSL subroutines with double precision accuracy. The convergence of the MCMC sampling algorithm for all the parameters was checked based on the recommendations of Cowles and Carlin (1996). All trace and autocorrelation plots showed good convergence and mixing of the MCMC sampling algorithm.
We are interested in investigating how the goodness of fit might be affected by the choices of for joint model in (2.1) - (2.7) using the DIC discussed in Section 4.3. We considered the following distributions for and (1) Normal and generalized for , and for . Table 1 shows the DIC values for the six models under consideration, with the smallest value for DIC (3612.15) corresponding to skewed generalized -distribution with the for , which fits training data the best among all models considered. This affirms the need for considering the skewed heavy tail distributions. In addition, the models with symmetric distributions for had the larger DIC value, suggesting that these models fit data worse than the skewed models, demonstrating the importance of including skewness for the model of the time to delivery in (2.1).
Table 1:
DIC Values
| Normal | GT | |
|---|---|---|
| 4278.64 | 4174.57 | |
| 4081.16 | 3612.15 | |
| 4140.03 | 3818.06 |
The posterior estimates, including the posterior means, posterior standard deviations (SDs), and 95% highest posterior density (HPD) intervals of the parameters under the best model based on the training set are reported in Tables 2 and 3. We define a posterior estimate to be “statistically significant at a significance level of 0.05” if the corresponding 95% HPD interval does not contain 0. The results shown in Table 3 indicate that the fixed effects parameters , and are all statistically significant with the slope before reaching a station value of zero being gradual as compared to the much larger increases after reaching this reference time. The estimated mean scaling factor, , is −2.61, suggesting that the typical fetus reaches a zero reference approximately 2.6 hours after entering the hospital in labor. Time to delivery (from a zero station) decreases with age (−0.176 hours per year) and this time for vacuum assisted and C-section deliveries is 0.152 longer and −0.296 shorter, respectively, relative to a spontaneous delivery. For a women at the average age of 28.7 years who has a spontaneous delivery, the median time to delivery relative to reaching a station value of zero is hours (this was computed based on on the standardized scale and with the random effects and mode of delivery effects set to zero). The shared random effects , and demonstrate that increases in the slopes before and after the zero station value are associated with a decreased time to delivery, with this association being substantially stronger for the slope after the zero value. Table 3 shows the relationship between longitudinal station measurements and the type of delivery. An increased subject-specific rate of change before and after the zero station value was associated with a decreased risk of a C-section compared with the reference category of a spontaneous delivery. There was no effect of the dynamics of labor progression on the risk of a vacuum assisted delivery as compared to this reference category.
Table 2:
Posterior estimates under the best model
| Parameter | Posterior Mean | Posterior SD | 95% HPD Interval | |
|---|---|---|---|---|
| Longitudinal Measurements | −0.792 | 0.025 | (−0.840, −0.743) | |
| 0.137 | 0.007 | (0.125, 0.150) | ||
| 1.687 | 0.294 | (1.153, 2.355) | ||
| 0.158 | 0.008 | (0.143, 0.174) | ||
| −2.610 | 0.193 | (−2.987, −2.253) | ||
| Time to Delivery | 7.830 | 0.216 | (7.408, 8.257) | |
| −0.176 | 0.068 | (−0.304, −0.040) | ||
| −5.367 | 0.736 | (−6.834, −3.912) | ||
| −48.766 | 3.099 | (−54.667,−42.536) | ||
| −0.091 | 0.616 | (−1.337, 1.224) | ||
| 0.152 | 0.070 | (0.010, 0.286) | ||
| −0.296 | 0.114 | (−0.538, −0.079) | ||
| 1.101 | 0.125 | (0.863, 1.353) | ||
| 0.664 | 0.517 | (0.114, 1.643) | ||
| 13.857 | 9.866 | (2.195, 34.350) |
Table 3:
Posterior estimates under the best model
| Parameter | Posterior Mean |
Posterior SD |
95% HPD Interval | |
|---|---|---|---|---|
| Mode of delivery | −1.509 | 0.142 | (−1.784,−1.230) | |
| −0.133 | 0.138 | (−0.401, 0.139) | ||
| −2.118 | 0.467 | (−2.979,−1.468) | ||
| 0.337 | 0.180 | (−0.010, 0.692) | ||
| 0.310 | 0.813 | (−1.298, 1.915) | ||
| −4.148 | 3.159 | (−10.223, 2.136) | ||
| −0.155 | 0.574 | (−1.309, 1.008) | ||
| −3.831 | 2.228 | (−8.348,−0.018) | ||
| −16.161 | 4.405 | (−24.730, −7.532) | ||
| −3.910 | 2.453 | (−9.329,−0.800) | ||
| Variance of the random effects | 0.109 | 0.016 | (0.080, 0.141) | |
| −0.005 | 0.002 | (−0.009,−0.002) | ||
| −0.109 | 0.031 | (−0.170,−0.053) | ||
| 0.538 | 0.103 | (0.341, 0.738) | ||
| 0.004 | 0.001 | (0.003, 0.005) | ||
| −0.003 | 0.004 | (−0.012, 0.004) | ||
| 0.027 | 0.016 | (−0.003, 0.059) | ||
| 0.276 | 0.134 | (0.068, 0.547) | ||
| −1.210 | 0.339 | (−1.893, −0.596) | ||
| 6.846 | 0.997 | (5.072, 8.905) |
We fitted the model with the training-set data and evaluated it’s performance on the test-set data. Figure 3 shows a plot of deciles of the predicted probabilities versus the corresponding sample proportions corresponding to those deciles for each delivery type. The plot shows that for spontaneous deliveries (the type that is not controlled by the obstetrician), the predictive model is well calibrated. Further the predictive probabilities range from a lower decile of 0.55 to an upper decile of 0.9, showing a large amount of potential discrimination. Figure 4 shows the predicted versus the observed delivery times for spontaneous deliveries. The figure demonstrates that for predicted values less than 2 hours, the model prediction is accurate (all subjects with predictive values less 2 hours had an observed delivery time of < 2 hours). However, the predicted delivery time is not as accurate when the predicted values are greater than 2 hours.
Figure 3:
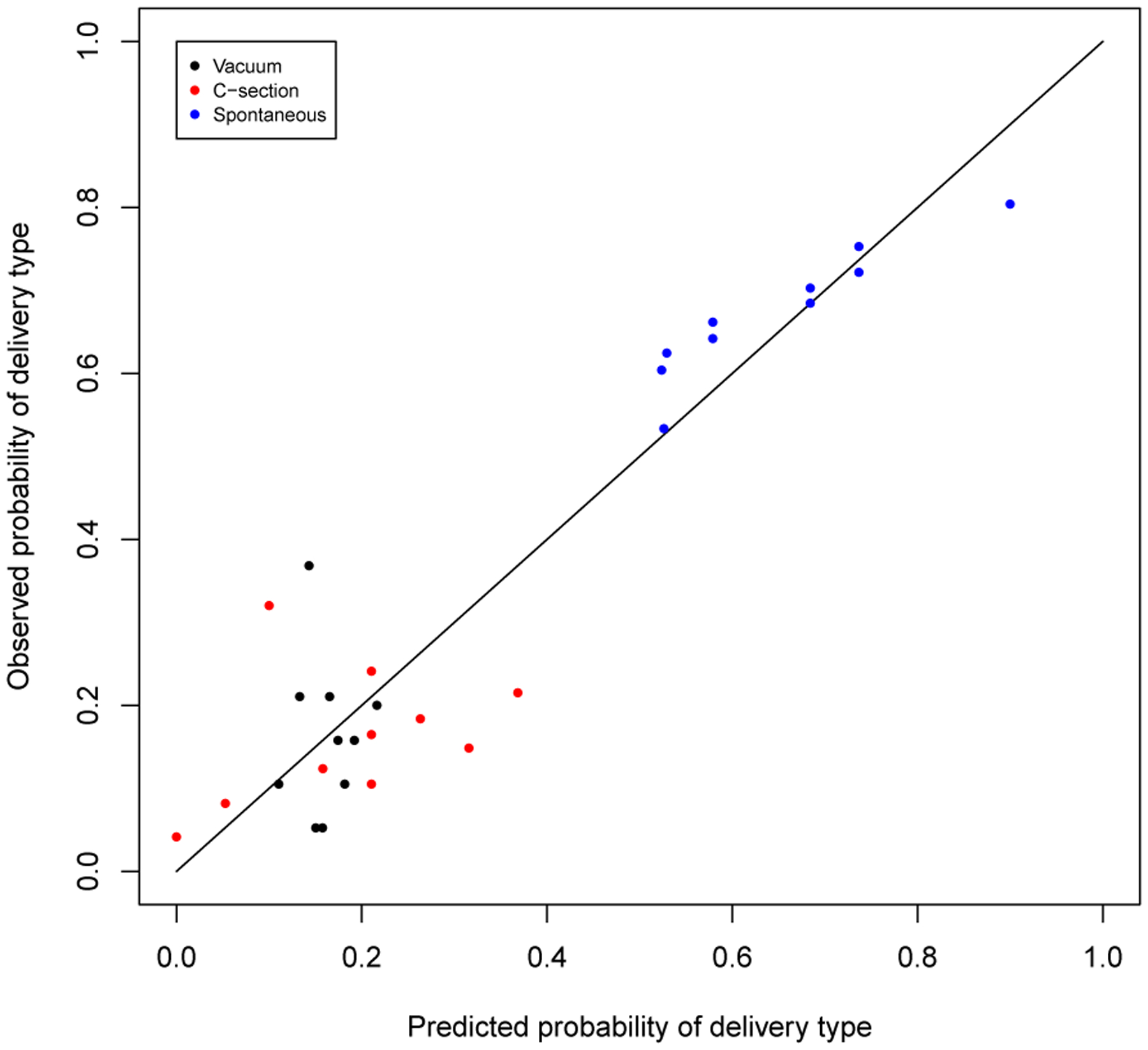
Decile plots of the predicted probability versus the corresponding observed proportions.
Figure 4:
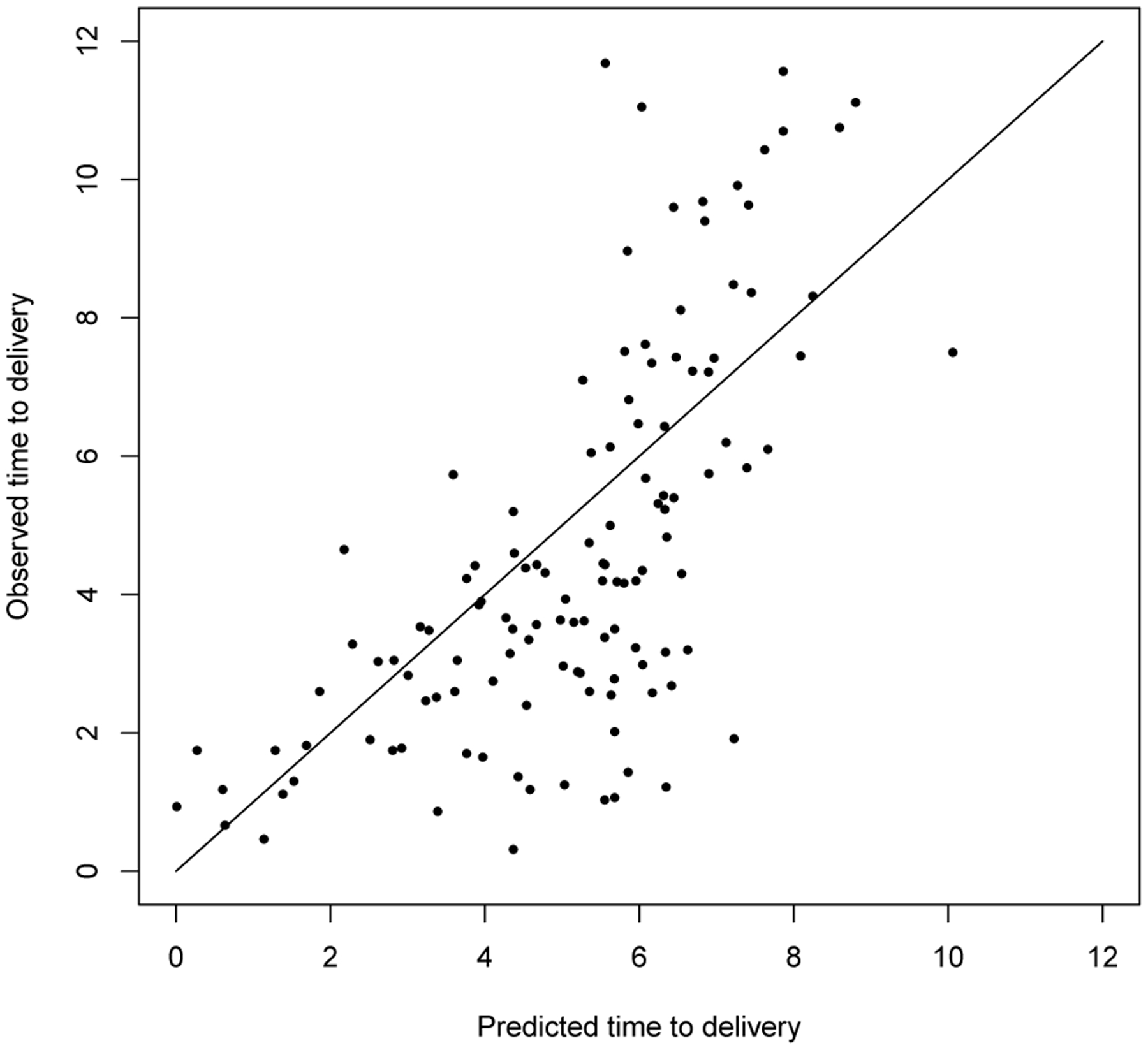
Plots of predicted time to delivery from last observed station value
6. Discussion
This article proposed a joint model of longitudinal and time-to-event data when there is no natural time zero and when there are competing risks. For the labor example, station values are measured longitudinally and the time of study entry is not a natural reference point since expecting mothers come to the hospital at different points in their late pregnancy. The competing risk aspects need to be considered since delivery type is an important component of the endpoint and time-to-delivery may be influenced by the type of delivery. The model led to important scientific observations. First, the dynamics in labor (longitudinal station process) is associated with delivery time such that the time to delivery is shorter when the velocity of station is higher. This is particularly pronounced in the later stage of labor (after the station value crosses zero). The type of delivery is also associated with station velocity. Most notably, a C-section is much more likely when the velocity (before and after a station value of zero) is delayed relative to the typical profile. This later observation is consistent with clinical experience.
For the labor progression application, the reference time (time zero) used is the time from when the station value is zero. The proposed approach allows us to use all the subjects’ data to estimate, including those who started the observation process before and after having reached time zero. In our application, we had such data. The model may be only weakly identifiable in situations where the observation process begins after a dilation value of zero. In this latter case, we recommend that the model not be used.
Although, the model is useful for understanding etiology through a close examination of the model parameters, the prediction of delivery times was not that good in some situations. Our prediction results demonstrated that prediction was accurate when the time to delivery was less than approximately 2 hours, while it was less accurate for longer range predictions. Although this is a bit disappointing, it is not surprising that a single longitudinal biomarker would be able to accurately predict delivery time among spontaneous pregnancies. The model can be extended to incorporate multiple longitudinal biomarkers in the future. Plots of the deciles of risk shows that there is a fairly large range in predictive probabilities and that the predictive model is well calibrated. Thus, the model may be very useful for predicting an individual woman’s risk of a spontaneous delivery.
The proposed modeling framework addresses the issue of relating a longitudinal biomarker to survival when there is no clearly defined time zero. Although this was motivated by a study of labor progression where women come to the hospital at different times during their labor process, the methodology would apply to any study of the effect of a disease severity score on survival where subjects are enrolled at varying levels of initial disease severity. Another example comes from studying the relationship between disability and survival in multiple sclerosis. Disease severity in multiple sclerosis is often characterized using the expanded disability status scale (EDSS) which ranges between 0 and 10 in 0.5 increments. The proposed method may be used to assess the relationship between changes in EDSS and survival in a population where subjects enroll in the study at different levels of disability.
Acknowledgments
This research of Drs. Kim and Albert was supported by the intramural research program of National Cancer Institute.
References
- Abranowitz M and Stegun IA (1972). Handbook of mathematical functions with formulas, graphs, and mathematical tables. New York, Dover Publications, Inc. [Google Scholar]
- Celeux G, Forbes F, Robert CP, and D. M. Titterington D (2006). Deviance information criteria for missing data models. Bayesian Analysis, 1:651–674. [Google Scholar]
- Chen M-H, Dey DK, and Shao Q-M (1999). A new skewed link model for dichotomous quantal response data. Journal of the American Statistical Association, 94:1172–1186. [Google Scholar]
- Chen M-H, Shao OM, and Ibrahim JG (2000). Monte Carlo Methods in Bayesian Computation. New York, Springer-Verlag. [Google Scholar]
- Cowles C and Carlin BP (1996). Markov chain monte carlo convergence diagnostics: a comparative review. Journal of the American Statistical Association, 91:883–904. [Google Scholar]
- Hastings WK (1970). Monte carlo sampling methods using markov chains and their applications. Biometrika, 57:97–109. [Google Scholar]
- Kim S, Chen M-H, and Dey DK (2008). Flexible generalized t-link models for binary response data. Biometrika, 95:93–106. [Google Scholar]
- Liu JS (1994). The collapsed gibbs sampler in bayesian computations with applications to a gene regulation problem. Journal of the American Statistical Association, 89:958–66. [Google Scholar]
- McLain AC and Albert PS (2014). Modeling longitudinal data with a random change point and no time-zero: applications to inference and prediction of the labor curve. Biometrics, 70:1052–1060. [DOI] [PubMed] [Google Scholar]
- Rizopoulos D (2012). Joint models for longitudinal and time-to-event data: with applications in R. Boca Raton: Chapman & Hall/CRC. [Google Scholar]
- Spiegelhalter DJ, Best NG, Carlin BP, and van der Linde A (2002). Bayesian measures of model complexity and fit (with discussion). Journal of Royal Statistical Society, B, 64:583–639. [Google Scholar]