

Abstract
Since the number of drugs based on natural products (NPs) represents a large source of novel pharmacological entities, NPs have acquired significance in drug discovery. Peru is considered a megadiverse country with many endemic species of plants, terrestrial, and marine animals, and microorganisms. NPs databases have a major impact on drug discovery development. For this reason, several countries such as Mexico, Brazil, India, and China have initiatives to assemble and maintain NPs databases that are representative of their diversity and ethnopharmacological usage. We describe the assembly, curation, and chemoinformatic evaluation of the content and coverage in chemical space, as well as the physicochemical attributes and chemical diversity of the initial version of the Peruvian Natural Products Database (PeruNPDB), which contains 280 natural products. Access to PeruNPDB is available for free (https://perunpdb.com.pe/). The PeruNPDB’s collection is intended to be used in a variety of tasks, such as virtual screening campaigns against various disease targets or biological endpoints. This emphasizes the significance of biodiversity protection both directly and indirectly on human health.
Subject terms: Chemical biology, Computational biology and bioinformatics, Drug discovery
Introduction
Biodiversity is the variety of all life forms, including the morphological diversity of individuals and populations within a species, the taxonomic diversity of species within a community or ecosystem, the functional diversity of groups of species within an ecosystem, and the diversity of ecosystems themselves1. While the total number of species in every taxonomic group has been predicted for all kingdoms of life on earth at approximately 8.7 million2,3, it is remarkable that the distribution of that vast number of species is highly concentrated in specific areas. These regions are particularly important for biodiversity conservation and are called biodiversity hotspots4, although: Bolivia, Brazil, China, Colombia, Costa Rica, the Democratic Republic of Congo, Ecuador, India, Indonesia, Kenya, Madagascar, Malaysia, Mexico, Peru, Philippines, South Africa, and Venezuela are considered megadiverse countries5. Peru occupies the seventh place in this group, as it possesses 28 of the 32 existing climates in the world and 84 of the 103 life zones known on earth. This is evidenced by considering that the country has 25,000 plant species or 10% of the entire number of species worldwide, whereas 30% are endemic, and endemic animal species such as 115 birds, 109 mammals, and 185 amphibians species, which represent 6, 27.5 and 48.5% of the total number worldwide, respectively6,7.
Biodiversity conservation is important since plants, animals, and other life forms such as bacteria, archaea, protozoa, and fungi, are used directly or indirectly to produce pharmaceuticals, and for their scientific value, among other resources8. The number of drugs derived from natural products (NP) that were introduced to the market over forty years represented a significant source of new pharmacological entities9. Whilst the Peruvian population uses approximately 5000 Peruvian plants for 49 purposes or applications, where about 1400 species are described as medicinal10–13. The contribution from traditional Peruvian medicine can be embodied by Quinine, a component of the bark of the cinchona tree (Cinchona officinalis), employed in the treatment of Malaria14. Additionally, two other valuable contributions to modern pharmacopeias such as the coca plant (Erythroxylum coca), from which cocaine was first isolated and later led to local anesthetics15, and the balsam of Peru (Myroxylon balsamum), which was used wide-reaching for the treatment of wounds16, can be mentioned. However, the potential of Peruvian NPs remains underexploited since most of these useful native species can be domesticated or semi-domesticated17. Also, the amount and nature of experimental evidence published on active NPs are still limited18, and most of the current studies reported crude medicinal activities, while potentially active NPs have been isolated only from a few numbers of plants19.
Computer-aided drug design (CADD), one of the key approaches to modern pre-clinical drug discovery, can be defined as computational methods that are applied to discover, develop, and analyze drugs and active molecules20. Among the key approaches that comprise CADD, virtual screening is one of the major contributors to CADD since it stands as a contemporary approach to the experimental in vitro high-throughput screening (HTS) for hit identification and optimization21. Integrating CADD approaches to curated databases, which are described as a well-organized collection of data in any field, the drug development process may be sped up and cost reduced22. Considering this, large databases containing NPs from various data sources have been released, such as the COlleCtion of Open Natural prodUcTs (COCONUT), which contains 406,076 unique “flat” NPs, and a total of 730,441 NPs where stereochemistry has been preserved23; and the LOTUS initiative, which has 750,000 referenced structure-organism pairs24. Also, several NPs compound databases from particular geographical locations have been assembled, such as the Traditional Chinese Medicine (TCM) Database@Taiwan database containing approximately 58,000 molecules25; the Indian Medicinal Plants, Phytochemistry and Therapeutics 2.0 (IMPPAT 2.0) which contains more than 10,000 phytochemicals26; and the AfroDB which is composed of around 1000 NPs27. Likewise, some countries in Latin America have published their own public NPs databases such as NuBBEDB which contains more than 2000 NPs28, and SistematX which contains more than 2500 NPs29, both from Brazil, and BIOFACQUIM from Mexico, which contains a total of 531 molecules30. Furthermore, NPs databases had been used as a repository to identify several promising candidates to be considered for further development for the treatment of diseases31, such as Chagas disease32,33, Tuberculosis34, Leishmaniasis35,36, Schistosomiasis37, and COVID-1938. The present work introduces the first version of the Peruvian Natural Products Database (PeruNPDB), describing its assembly, curation, and chemoinformatic characterization of molecular diversity and coverage in chemical space. The database is freely available at the web-interface PeruNPDB Explorer (https://perunpdb.com.pe/). We anticipate that the PeruNPDB will make it possible to conduct additional virtual screening tests to create innovative pharmacological entities and other biotechnological approaches and serve as a resource for information on conservation guidelines.
Methods
Search strategy, study selection, and data extraction
A systematic review search strategy to examine the literature for studies describing NP from Peruvian sources was adapted from39. Whereas PubMed, the main database for the health sciences, maintained by the National Center for Biotechnology Information (NCBI) at the National Library of Medicine (NLM), is a database that contains about 32 million citations, belonging to more than 5300 journals currently indexed in MEDLINE40; it provides uniform indexing of biomedical literature, the Medical Subject Headings (MeSH terms), which form a controlled vocabulary or specific set of terms that describe the topic of a paper consistently and uniformly41. Firstly, to find terms associated in the literature with Peruvian NPs, the MeSH terms “Peru” AND the “Natural Products” were employed in a search carried out at the PubMed database (https://pubmed.ncbi.nlm.nih.gov/), (last searched on 10 June 2022), though the results were plotted into a network map of the co-occurrence of MeSH terms in the VOSviewer software (version 1.6.17)42, which employs a modularity-based method algorithm to measure the strength of clusters43. The resultant cluster content was analyzed to select relevant studies associated with Peruvian NPs. Three phases went into selecting the studies. First, papers written in languages other than English, copies of articles, reviews, and meta-analyses were disregarded. The highly relevant full studies were then retrieved and separated from the papers with a title or abstract that did not provide enough information to be included. Next, the titles and abstracts of the publications chosen through the search approach were visually evaluated. The data supplied from each investigation contained the NP’s characterization as well as details on the genus and species of the sources from which the NP were isolated. Additionally, the information from the bibliographic reference was extracted, even if all research that discussed chemicals derived from Peruvian natural sources was already considered.
PeruNPDB assemble and molecular properties calculation
The simplified molecular-input line-entry system (SMILES)44 of compounds previously described in the NPs selected in the previous step were searched and retrieved from PubChem45, DrugBank46, or ChEMBL47 servers, while for unavailable NPs the ChemDraw tool48 was employed to generate the SMILE notation. Moreover, the Osiris DataWarrior v05.02.01 software49 was employed to generate the dataset’s structure data files (SDFs). This followed the uploading to the Konstanz information miner (KNIME) Analytics Platform50, where the “Molecular Type Cast”, and the “RDKit Structure Normalizer” KNIME nodes were employed to curate the chemical structures on the dataset. Moreover, for every compound in the dataset, the classification system for describing small molecule structures is described based on NP Classifier51, which employs a biosynthetic ontology that is specific to natural products; or ClassyFire52 which is a general classification system for small molecules that are based on the ChemOnt ontology, was employed. The KNIME’s “RKDit Descriptor Calculator” node was employed to calculate six physicochemical properties of therapeutic interest, namely: molecular weight (MW), octanol/water partition coefficient (clogP), topological surface area (TPSA), aqueous solubility (clogS), number of H-bond donor atoms (HBD) and number of H-bond acceptor atoms (HBA) of the PeruNPDB, while the statistical analysis was done within the GraphPad Prism software version 9.4.0 for Windows, GraphPad Software, San Diego, California USA, http://www.graphpad.com, by calculating the mean, median, standard deviation, and the coefficient of variation of the calculated properties. Box-and-whisker plots showing, the maximum and minimum values were generated for visualization, and the One-way ANOVA followed by Dunnett correction for multiple comparisons test was employed to evaluate the differences between the datasets. The results were considered statistically significant when p<0.05.
Visual representation of chemical space
To generate a visual representation of the chemical space of the PeruNPDB, two visualization methods, for the auto-scaled six properties of pharmaceutical interest, namely: MW, ClogP, TPSA, clogS, HBD, and HBA, were employed: principal component analysis (PCA), which reduces data dimensions by geometrically projecting them onto lower dimensions called principal components (PCs)53 calculated by the “PCA” KNIME node. The second technique was the t-distributed stochastic neighbor embedding (t-SNE), which is a nonlinear dimension reduction in which Gaussian probability distributions over high-dimensional space are constructed and used to optimize a student t-distribution in low-dimensional space54, calculated by the t-SNE (L. Jonsson) KNIME node. Three and two-dimensional scatter-plot representations were generated for PCA and t-SNE, respectively with the Plotly KNIME node. Additionally, the Tanimoto similarity score was calculated for clustering the compounds, while the atom-pair-based fingerprints of the NPs were obtained using the “ChemmineR” package55 in the R programming environment (version 4.0.3)56, a heatmap was generated for visualization. The same procedure was employed in the reference datasets: AfroDB27, BIOFAQUIM30, and NUBBEDB28 retrieved from the ZINC20 database57.
Global diversity: consensus diversity analysis
Since chemical diversity strongly depends on the structure representation, it is reasonable to consider multiple representations for a complete global assessment. The consensus diversity (CD) plots have been proposed as simple two-dimensional graphs that enable the comparison of the diversity of compound data sets using four sets of structural representations: the molecular fingerprints, scaffolds, molecular properties, and the number of NPs58. The multiple-variable plot was generated by GraphPad Prism software version 9.4.0, whereas the y-axis represents the area under the cyclic system recovery curve59, the x-axis, represents the median of the fingerprint-based diversity computed with Molecular Access System (MACCS) keys (166-bits) and the Tanimoto coefficient60, the bubble color represents the molecular properties of pharmaceutical interest, and the bubble size represents the number of NPs for each database.
Drug-likeness
The Osiris DataWarrior v05.02.01 software61 was employed to calculate the drug-likeness score of the compounds from the PeruNPDB; the calculation is based on a library of 5300 substructure fragments and their associated drug-likeness scores. This library was prepared by fragmenting 3300 commercial drugs as well as 15,000 commercial non-drug-like Fluka NPs61. Frequency distribution of the obtained scores was performed at GraphPad Prism software version 9.4.0 for Windows, GraphPad Software, San Diego, California USA (http://www.graphpad.com), and plotted into stacked bar plots. Furthermore, the Lipinski Rule-of-5 (Ro5) is a set of four rules (logP, MW, and H-bond donor and acceptor cut-offs) for drug-likeness and oral bioavailability derived from a subset of 2245 drugs62. For this Lipinski’s Ro5 KNIME node was employed to assess the number of violations to the rule for each compound on the PeruNPDB and plotted into pie charts. The US Food and Drug Administration (FDA)-approved drugs dataset57, was employed as a reference, whereas the same procedures were applied to their compounds. Also, the chemical space representation was analyzed, and the procedures were the same as described earlier.
Results
PeruNPDB assemble
In the present study, the assembly of the PeruNPDB, followed by its chemoinformatic characterization on molecular diversity and coverage of the chemical space was performed; to select the studies from which the NPs will further retrieve, a search with the MeSH Terms “Peru” AND “Natural Products” was performed in the Pubmed database, followed by the construction of a network map of the co-occurrence of MeSH terms. The workflow proposed in Fig. 1 was considered. The search resulted in 399 published papers between 1950-2021, whereas establishing the value of five as the minimum number of occurrences of keywords, a map with 194 keywords that reaches the threshold was constructed (Fig. 2A). In the analysis of the map, it is shown that six main clusters were formed, while terms such as “Plant Extracts”, “Plants, medicinal”, “Phytotherapy”, “Ethnopharmacology”, “Ethnobotany”, “Plants stems”, “Plants bark”, and “Seeds”, which are associated with NPs were observed in the first cluster (red color). Also, terms such as “Peru”, “Humans”, “Animals”, and “Male”, were recurrent terms. Although using the eligibility criterion established, 47 articles were selected which showed a 2000-2021-year range, and terms such as “Flavonoids”, “Sesquiterpenes”, and “Anthocyanins”, were recurrent terms (Fig. 2B). Also, bibliographic data extracted from the selected articles analyzed: the “Journal of Agricultural and Food Chemistry”, the “Journal of Ethnopharmacology”, “Phytochemistry”, and “Planta Medica” where the main peer-reviewed journals were the studies describing compounds extracted from Peruvian NPs were published (Fig. 2C). Furthermore, while retrieving the SMILES of the compounds from PubChem, DrugBank, and ChEMBL, it was observed that 242 structures were found in the repositories and that 38 needed to be generated in the ChemDraw tool. Ninety-five and five percent of the compounds were retrieved from plant or animal sources, respectively (Fig. 3A). The genus from which most of the compounds were extracted were Uncaria and Lepidium, with 11 and 10 percent, respectively (Fig. 3B). When analyzing the structure of the compounds with a classification system for small molecule structures, it is shown that 76 classes of NPs were found among the 280 NPs of the PeruNPDB, whereas anthocyanidins (N=25), aporphine alkaloids (N=11), cinnamic acids and derivatives (N=17), germacrane sesquiterpenoids (N=13), stigmastane steroids (N=10), and unsaturated fatty acids (N=22) were the most predicted classes of NPs (Fig. 4).
Figure 1.
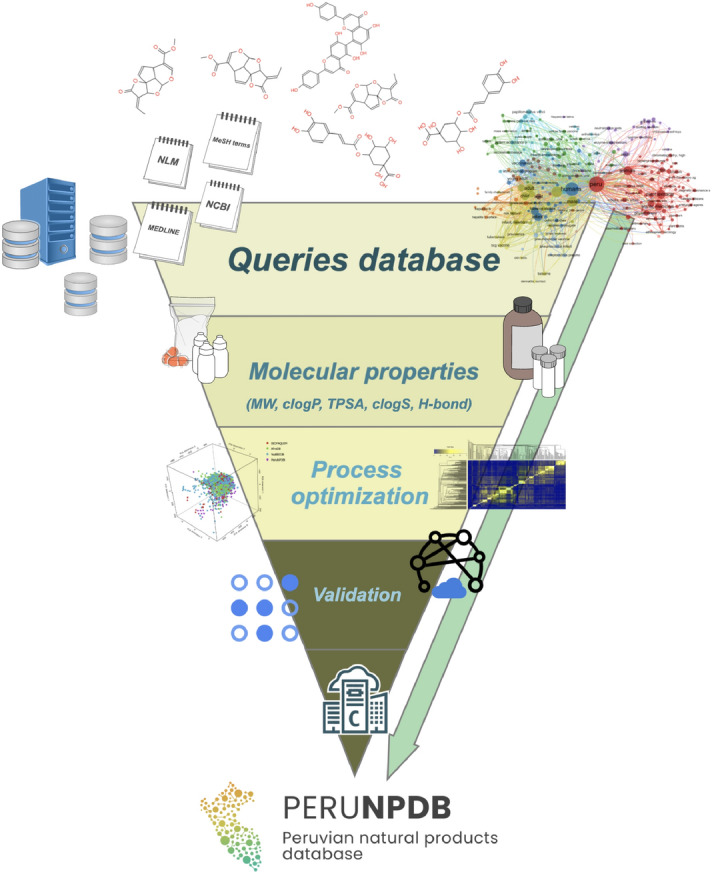
General workflow to generate and curate the first version of the Peruvian natural product database. The graph was edited in SmartDraw 2023 Software, LLC (Accessed April 14, 2023).
Figure 2.

Bibliographic search for studies describing the characterization of Peruvian natural products. (A) Network map of the co-occurrence of MeSH terms. (B) Network map of articles selected from 2000 to 2021-year. (C) Bibliographic data extracted from selected articles that describe compounds extracted from Peruvian NPs.
Figure 3.

Dot plots showing the kingdom and genus of the species studied. (A) Compounds of Peruvian NPs found in PubChem, DrugBank, and ChEMBL databases. (B) Dot plot of the genus of the Peruvian NPs compounds obtained from the databases.
Figure 4.

Dot plots showing the natural products classification.
Molecular properties
Six physicochemical properties were calculated for all compounds in PeruNPDB and plotted into box plots, which include the distribution of the same properties of the three reference datasets, retrieved from the ZINC20 database (Fig. 5). To compare the results of the datasets, the coefficient of variation (CV) was calculated, which represents the ratio of the standard deviation to the mean and is considered a useful tool to statistically compare the degree of variation from one dataset to another54. Besides the results of the HBA, in which NuBBEDB obtain the highest CV (123.2%), the PeruNPDB showed the highest CV in MW, clogP, TPSA, clogS, and HBD with 46.58%, 84.49%, 112.8%, 50.08%, and 83.84%, respectively. Still, the results from TPSA, clogP, clogS, and HBD showed high statistical differences compared to AfroDB, BIOFAQUIM, and NuBBEDB, while showed no statistical difference in HBA results compared to the AfroNP database (Fig. 5).
Figure 5.

Box plots for the physicochemical properties of PeruNPDB and reference datasets.
Visualization of the chemical space
The chemical space visualization of PeruNPDB was conducted using PCA and t-SNE. Though the visual analysis of 3D-PCA shows that molecules in PeruNPDB share the chemical space roughly with NuBBEDB. Whereas in some regions the molecules of PeruNPDB are predominant (Fig. 6A). While the explained variance percentage of PC1, PC2, and PC3 was 50.24, 39.94, and 6.72, respectively. PeruNPDB, BIOFAQUIM, and NuBBEDB chemicals overlap in most of the chemical space represented, according to the 2D-t-SNE visual analysis (Fig. 6B).
Figure 6.

Visual representation of the chemical space of the PeruNPDB and reference datasets. (A) PeruNPDB 3D-PCA chemical space. (B) 2D-t-SNE visual analysis of the compounds PeruNPDB, AfroNP, BIOFAQUIM, and NuBBEDB. (C) Heatmap generated with Tanimoto scoring matrix of similar structures among compounds between PeruNPDB and control data sets.
Diversity analysis
The heatmap generated using the Tanimoto score matrix and the atom-pair-based fingerprints show that there is a similarity between the structures of the compounds of the PeruNPDB, AfroDB, BIOFAQUIM, and NuBBEDB (Fig. 6C). Also, a consensus diversity plot was used to evaluate the diversity of the PeruNPDB dataset, based on molecular fingerprints, scaffolds, and physicochemical properties. The Euclidean distance of the scaled properties was used to compute the property-based diversity of the PeruNPDB, AfroDB, BIOFAQUIM, and NuBBEDB databases. Data points on a continuous color scale are used to represent the values on the color CD plot. Darker colors signify less diversity, but brighter colors signify more diversity. Finally, different point sizes are used to illustrate how large or tiny the databases are, with smaller data points indicating databases with fewer molecules. The results showed that the diversity of compounds found in the PeruNPDB was the largest since it was found in the area where the highest diversity in scaffold and fingerprints should are found (Fig. 7), which is consistent with the results shown in the box plots (Fig. 6).
Figure 7.
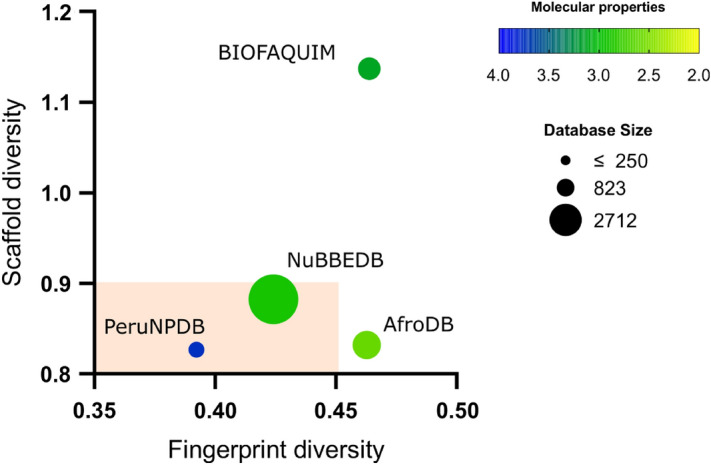
Consensus diversity plot comparing the global diversity of PeruNPDB with the reference data sets.
Drug-likeness
Druglikeness assesses qualitatively the chance for a molecule to become an oral drug concerning bioavailability and is established from structural or physicochemical inspections of development compounds advanced enough to be considered oral drug candidates63. To assess the “drug-like” profile of the compounds from the PeruNPDB two approaches were performed; firstly, the frequency distribution of the drug-likeness score was analyzed, and the results showed that besides the differences in the number of compounds compared in both datasets a similar distribution among the compounds is observed (Fig. 8A). In the second approach, the number of violations to Lipinski’s Ro5 was analyzed and the results showed that compounds with at least one violation represent the 85.82 and 76.35% of the FDA and PeruNPDB datasets, respectively (Fig. 8B). Also, the visual representation of the chemical space as PCAs (Fig. 8C) and t-SNE (Fig. 8D) indicates that some of the NPs are distributed in the same space as the already approved drugs. Whereas the explained variance percentage of PC1, PC2, and PC3 was 52.38, 37.64, and 5.54, respectively. The findings imply that because the compounds in PeruNPDB have chemical structures like those of approved medications, they can be used in virtual screening to find possible lead compounds or points for further optimization.
Figure 8.

Druglikeness analysis of the PeruNPDB and the reference datasets. (A) The similar distribution between FDA compounds and PeruNPDB. (B) Lipinski’s five rules from the FDA and PeruNPDB data sets. (C) Visual 3D representation of the chemical space as PCAs from the FDA and PeruNPDB data sets. (D) Representation t-SNE of FDA and PeruNPDB data sets.
Discussion
Peru has exceptionally high biodiversity, with numerous endemic species of mammals, reptiles, amphibians, flowering plants, and ferns, which is why has been described as a “megadiverse” country64,65, but worldwide hotspot analysis for potential conflict between food security and biodiversity conservation points out Peru as a region that is especially at risk of biodiversity loss due to agricultural expansion66. Thus, the conservancy of biodiversity can be considered important since historically NPs have played a key role in drug discovery, especially for illnesses such as cancer, cardiovascular and infectious diseases67, while the growing interest in NPs and their application is evidenced by a growth of the number of published databases of NPs, and collections of structures from various organisms, geographical locations, targeted diseases, and traditional applications68. Currently, several NPs or NPs-derived molecules are employed in the treatment of distinct diseases, such as the antibiotic penicillin originally obtained from the fungi Penicillium spp.69; the analgesic aspirin, which is the most used drug in the world, derived from salicin extracted from the bark of the willow trees Salix alba70; and the immunosuppressant tacrolimus employed in the prevention of the rejection organ after transplants, obtained from bacteria Streptomyces tsukubaensis71, are some examples. Besides, NPs and their derivatives have been considered promising options to improve treatment efficiency in cancer patients and decrease adverse reactions72, whereas vinca alkaloids73, taxane diterpenoids74, camptothecin derivatives75, and epipodophyllotoxin76, are NPs-derived anticancer compounds clinically used as chemotherapeutics; while an example of the importance of biodiversity conservation is exemplified by the tree Taxus brevifolia, from which the chemotherapeutic drug paclitaxel was originally extracted, that was put on the list of endangered species77,78. According to the data, there are fewer compounds identified in the PeruNPDB than in AfroDB, BIOFAQUIM, and NuBBEDB, but the chemical diversity is also higher. Of the 280 compounds characterized, 95% came from plant sources, and 5% came from animal sources. But in the BIOFACQUIM and NuBBE databases as well as plant sources, compounds derived from fungi, propolis, bacteria, and marine organisms are also described. This partially explains the difference in the TPSA results of the PeruNPDB, since it has been reported that natural products from the animal kingdom have the highest TPSA due to the number of hydrogen bond donors and acceptors79. Furthermore, the Peruvian marine biodiversity hotspot located on the northern coast has been predicted to hold 501 species, 270 genera, and 193 families80, as marine natural products have shown an interesting array of diverse and novel chemical structures with potent biological activities81, which includes: Cephalosporin C an antibiotic derived from marine fungi Cephalosporium82, Eribulin an anticancer drug derived from halichondrin B from the natural Japanese marine sponge Halichondria okada83 and the antiviral, isolated from sponge Tethya crypta, nucleoside Ara-A84. Also, Peru is considered a diverse country that has a very broad microbial diversity richness, however, remains slightly studied and exploited85,86. Fungi, the eukaryotic microorganisms, produce a tremendous number of NPs with diverse chemical structures and biological activities87, such as lovastatin, the first statin approved as a hypercholesterolemic medication by the FDA, most frequently produced by Aspergillus terreus88, and cyclosporine A, a potent immunosuppressant that was initially used to prevent organ rejection, isolated from the fungal species Tolypocladium inflatum gams89. Besides that no current drug has been developed from propolis, it is considered a very rich and complex chemical composition, while about 300 different chemicals components isolated from it, and which composition fluctuates according to parameters such as plant source, seasons harvesting, geography, type of bee flora, climate changes, and honeybee species90,91; highlighting Artepillin C, extracted from Brazilian green propolis, that showed in vitro92 and in vivo93 anti-inflammatory potential. These emphasize the urgency to promote and enhance the study of Peruvian NPs quantitatively and qualitatively. Compounds from Peruvian medicinal plants have been evaluated for their antidiabetic94, anticancer95, antiviral96, antibiotic97, and antiparasitic activities98; however, most of the studies in the literature were in vitro performed over plants extracts, and little information about the potential of single compounds on these activities is described, while these promising results can be explained by synergistic interaction or multi-factorial effects between compounds present in the plant extracts studied99. While pharmacodynamic synergy involves multiple substances acting on various receptor targets to enhance the overall therapeutic effect, and pharmacokinetic synergy involves substances with little to no activity helping the main active principle to reach the target by improving bioavailability or by reducing metabolism and excretion, this type of assay can hide the true potential of single molecules activity between different constituents of plant extracts100. Thus, the concerted effort of experimental NPs research with CADD is continuously increasing; and recently, NPs from the Peruvian native plants Smallanthus sonchilofolius, Lepidium meyenii (40 compounds)39, and Uncaria tomentosa (26 compounds)101 were in silico analyzed for their antiviral activity against SARS-CoV-2. Also, the in silico polypharmaceutical potential of 84 NPs from S. sonchifolius, L. meyenii, Croton lechleri, U. tomentosa, Minthostachys mollis, and Physalis peruvianus was analyzed against Alzheimer’s disease102.
Conclusion
Here we present the first version of PeruNPDB, a compound database of NPs from Peru that includes 280 compounds from plant and animal sources. PeruNPDB was constructed curated, and maintained by the Computational Biology and Chemistry Research Group from the Universidad Catolica de Santa Maria, and it is freely accessible through the website https://perunpdb.com.pe/. The PeruNPDB was envisioned as a tool for virtual screening, identifying promising compounds, serving as a springboard for further biotechnological products, and providing suggestions for conservation policies. The chemoinformatic characterization and analysis of the coverage and diversity of PeruNPDB in chemical space suggest broad coverage, overlapping with regions in the drug-like chemical space. The database contains an identification code (ID), the chemical name, bibliographic reference (name of the journal, year of publication, and DOI number), kingdom, genus, and species of the natural product, SMILES notation, and classification of the natural product. In the future, we want to launch the PeruNPDB version 2 with new computed molecular descriptors, NP stereochemical data, and the possibility to download several structures at once. The web-based user interface will also be improved and kept, and new NPs from various taxonomic ranks that aren’t included in the current edition will be added. Additionally, as we increase the quantity of NPs, we anticipate comparing the PeruNPDB with larger, more varied free datasets that are available in the literature. The complete PeruNPDB dataset for research purposes is available upon request and may be directed to and will be fulfilled by the lead contact Miguel Angel Chavez Fumagalli (mchavezf@ucsm.edu.pe).
Author contributions
Conceptualization: J.L.M.F. and M.A.C-F.; data curation: H.L.B-C., L.G.R., and M.A.C-F.; formal analysis: J.L.M.F. and M.A.C-F.; funding acquisition: G.D.D-C. and M.A.C-F.; investigation H.L.B-C., L.G.R., M.A.C-P., E.G.C-R., A.E.C-L.; methodology: J.L.M.F. and M.A.C-F.; writing—review and editing: H.L.B-C., L.G.R., G.D.D-C., J.L.M.F., and M.A.C-F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Universidad Catolica de Santa Maria (grants 27499-R-2020, 27574-R-2020, 7309-CU-2020, and 28048-R-2021) and by the Research Management Office from the Universidad Catolica de Santa Maria.
Data availibility
The datasets generated and/or analyzed during the current study are available in the PeruNPDB repository, https://perunpdb.com.pe/.
Competing interests
The authors declare no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Hanley N, Perrings C, et al. The economic value of biodiversity. Annu. Rev. Resour. Econ. 2019;11:355–375. doi: 10.1146/annurev-resource-100518-093946. [DOI] [Google Scholar]
- 2.Mora C, Tittensor DP, Adl S, Simpson AG, Worm B. How many species are there on earth and in the ocean? PLoS Biol. 2011;9:e1001127. doi: 10.1371/journal.pbio.1001127. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Sweetlove L. Number of species on earth tagged at 8.7 million. Nature. 2011;23:1. [Google Scholar]
- 4.Myers N, Mittermeier RA, Mittermeier CG, Da Fonseca GA, Kent J. Biodiversity hotspots for conservation priorities. Nature. 2000;403:853–858. doi: 10.1038/35002501. [DOI] [PubMed] [Google Scholar]
- 5.Mittermeier, R. A., Turner, W. R., Larsen, F. W., Brooks, T. M. & Gascon, C. Global biodiversity conservation: The critical role of hotspots. In Biodiversity Hotspots, 3–22 (Springer, 2011).
- 6.Fajardo J, Lessmann J, Bonaccorso E, Devenish C, Munoz J. Combined use of systematic conservation planning, species distribution modelling, and connectivity analysis reveals severe conservation gaps in a megadiverse country (peru) PLoS ONE. 2014;9:e114367. doi: 10.1371/journal.pone.0114367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Shanee S, et al. Protected area coverage of threatened vertebrates and ecoregions in Peru: Comparison of communal, private and state reserves. J. Environ. Manag. 2017;202:12–20. doi: 10.1016/j.jenvman.2017.07.023. [DOI] [PubMed] [Google Scholar]
- 8.Institute WR. Ecosystems and Human Well-being: Biodiversity Synthesis. World Resources Institute; 2005. [Google Scholar]
- 9.Newman DJ, Cragg GM. Natural products as sources of new drugs over the nearly four decades from 01/1981 to 09/2019. J. Nat. Prod. 2020;83:770–803. doi: 10.1021/acs.jnatprod.9b01285. [DOI] [PubMed] [Google Scholar]
- 10.Rai M, Bhattarai S, Feitosa CM. Ethnopharmacology of Wild Plants. CRC Press; 2021. [Google Scholar]
- 11.Tresca G, Marcus O, Politi M. Evaluating herbal medicine preparation from a traditional perspective: Insights from an ethnopharmaceutical survey in the Peruvian Amazon. Anthropol. Med. 2020;27:268–284. doi: 10.1080/13648470.2019.1669939. [DOI] [PubMed] [Google Scholar]
- 12.Bussmann RW, Sharon D. Plantas medicinales de los andes y la amazonía-la flora mágica y medicinal del norte del perú. Ethnobotany Res. Appl. 2016;15:1–293. [Google Scholar]
- 13.de Salud Convenio Hipólito Unanue, O. A. Plantas medicinales de la subregión andina (2014).
- 14.Achan J, et al. Quinine, an old anti-malarial drug in a modern world: Role in the treatment of malaria. Malar. J. 2011;10:1–12. doi: 10.1186/1475-2875-10-144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Calatayud J, González Á. History of the development and evolution of local anesthesia since the coca leaf. J. Am. Soc. Anesthesiol. 2003;98:1503–1508. doi: 10.1097/00000542-200306000-00031. [DOI] [PubMed] [Google Scholar]
- 16.Schottenhammer A. “Peruvian balsam”: An example of transoceanic transfer of medicinal knowledge. J. Ethnobiol. Ethnomed. 2020;16:1–20. doi: 10.1186/s13002-020-00407-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Lock O, Perez E, Villar M, Flores D, Rojas R. Bioactive compounds from plants used in Peruvian traditional medicine. Nat. Prod. Commun. 2016;11:315–37. [PubMed] [Google Scholar]
- 18.Gonzales GF, Valerio LG. Medicinal plants from Peru: A review of plants as potential agents against cancer. Anti-Cancer Agents Med. Chem. (Formerly Current Medicinal Chemistry-Anti-Cancer Agents) 2006;6:429–444. doi: 10.2174/187152006778226486. [DOI] [PubMed] [Google Scholar]
- 19.Bussmann RW. The globalization of traditional medicine in northern perú: from shamanism to molecules. Evid.-based Complement. Altern. Med. 2013;2013:291903. doi: 10.1155/2013/291903. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sabe VT, et al. Current trends in computer aided drug design and a highlight of drugs discovered via computational techniques: A review. Eur. J. Med. Chem. 2021;224:113705. doi: 10.1016/j.ejmech.2021.113705. [DOI] [PubMed] [Google Scholar]
- 21.Gimeno A, et al. The light and dark sides of virtual screening: What is there to know? Int. J. Mol. Sci. 2019;20:1375. doi: 10.3390/ijms20061375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Masic I, Ferhatovica A. Review of most important biomedical databases for searching of biomedical scientific literature. DSJUOG. 2012;6:343–61. doi: 10.5005/jp-journals-10009-1258. [DOI] [Google Scholar]
- 23.Sorokina M, Merseburger P, Rajan K, Yirik MA, Steinbeck C. Coconut online: Collection of open natural products database. J. Cheminform. 2021;13:1–13. doi: 10.1186/s13321-020-00478-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Rutz A, et al. The lotus initiative for open knowledge management in natural products research. Elife. 2022;11:e70780. doi: 10.7554/eLife.70780. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Chen CY-C. TCM database@ Taiwan: The world’s largest traditional Chinese medicine database for drug screening in silico. PLoS ONE. 2011;6:e15939. doi: 10.1371/journal.pone.0015939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Mohanraj K, et al. IMPPAT: A curated database of Indian medicinal plants, phytochemistry and therapeutics. Sci. Rep. 2018;8:1–17. doi: 10.1038/s41598-018-22631-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Ntie-Kang F, et al. AfroDb: A select highly potent and diverse natural product library from African medicinal plants. PLoS ONE. 2013;8:e78085. doi: 10.1371/journal.pone.0078085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Pilon AC, et al. NuBBEDB: An updated database to uncover chemical and biological information from Brazilian biodiversity. Sci. Rep. 2017;7:1–12. doi: 10.1038/s41598-017-07451-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Scotti MT, et al. SistematX, an online web-based cheminformatics tool for data management of secondary metabolites. Molecules. 2018;23:103. doi: 10.3390/molecules23010103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Pilón-Jiménez BA, Saldívar-González FI, Díaz-Eufracio BI, Medina-Franco JL. BIOFACQUIM: A Mexican compound database of natural products. Biomolecules. 2019;9:31. doi: 10.3390/biom9010031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Gómez-García A, Medina-Franco JL. Progress and impact of Latin American natural product databases. Biomolecules. 2022;12:1202. doi: 10.3390/biom12091202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Acevedo CH, Scotti L, Scotti MT. In silico studies designed to select sesquiterpene lactones with potential antichagasic activity from an in-house asteraceae database. ChemMedChem. 2018;13:634–645. doi: 10.1002/cmdc.201700743. [DOI] [PubMed] [Google Scholar]
- 33.do Carmo Santos N, da Paixão VG, da Rocha Pita SS. New Trypanosoma cruzi trypanothione reductase inhibitors identification using the virtual screening in database of nucleus bioassay, biosynthesis and ecophysiology (NuBBE) Anti-Infect. Agents. 2019;17:138–149. doi: 10.2174/2211352516666180928130031. [DOI] [Google Scholar]
- 34.Antunes SS, Rabelo VW-H, Romeiro NC. Natural products from Brazilian biodiversity identified as potential inhibitors of PknA and PknB of M. tuberculosis using molecular modeling tools. Comput. Biol. Med. 2021;136:104694. doi: 10.1016/j.compbiomed.2021.104694. [DOI] [PubMed] [Google Scholar]
- 35.Herrera-Acevedo C, et al. Selection of antileishmanial sesquiterpene lactones from SistematX database using a combined ligand-/structure-based virtual screening approach. Mol. Divers. 2021;25:2411–2427. doi: 10.1007/s11030-020-10139-6. [DOI] [PubMed] [Google Scholar]
- 36.Ccahuana, H. L. B. et al. In silico-based screening for natural products structural analogs as new drugs candidate against leishmaniasis. bioRxiv (2022).
- 37.Menezes RPBD, Viana JDO, Muratov E, Scotti L, Scotti MT. Computer-assisted discovery of alkaloids with schistosomicidal activity. Curr. Issues Mol. Biol. 2022;44:383–408. doi: 10.3390/cimb44010028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Rodrigues G, et al. Ligand and structure-based virtual screening of lamiaceae diterpenes with potential activity against a novel coronavirus (2019-NCOV) Curr. Top. Med. Chem. 2020;20:2126–2145. doi: 10.2174/1568026620666200716114546. [DOI] [PubMed] [Google Scholar]
- 39.Goyzueta-Mamani LD, Barazorda-Ccahuana HL, Mena-Ulecia K, Chávez-Fumagalli MA. Antiviral activity of metabolites from Peruvian plants against SARS-CoV-2: An in silico approach. Molecules. 2021 doi: 10.3390/molecules26133882. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.White J. Pubmed 2.0. Med. Ref. Serv. Q. 2020;39:382–387. doi: 10.1080/02763869.2020.1826228. [DOI] [PubMed] [Google Scholar]
- 41.Rogers FB. Medical subject headings. Bull. Med. Lib. Assoc. 1963;51:114–116. [PMC free article] [PubMed] [Google Scholar]
- 42.Van Eck NJ, Waltman L. Citation-based clustering of publications using CitNetExplorer and VOSviewer. Scientometrics. 2017;111:1053–1070. doi: 10.1007/s11192-017-2300-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Waltman L, Van Eck NJ. A new methodology for constructing a publication-level classification system of science. J. Am. Soc. Inf. Sci. Technol. 2012;63:2378–2392. doi: 10.1002/asi.22748. [DOI] [Google Scholar]
- 44.Weininger D. Smiles, a chemical language and information system. 1. Introduction to methodology and encoding rules. J. Chem. Inf. Comput. Sci. 1988;28:31–36. doi: 10.1021/ci00057a005. [DOI] [Google Scholar]
- 45.Kim S, et al. Pubchem 2019 update: Improved access to chemical data. Nucl. Acids Res. 2019;47:D1102–D1109. doi: 10.1093/nar/gky1033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Wishart DS, et al. Drugbank 5.0: A major update to the DrugBank database for 2018. Nucl. Acids Res. 2018;46:D1074–D1082. doi: 10.1093/nar/gkx1037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Mendez D, et al. ChEMBL: Towards direct deposition of bioassay data. Nucl. Acids Res. 2019;47:D930–D940. doi: 10.1093/nar/gky1075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Evans DA. History of the Harvard ChemDraw project. Angew. Chem. Int. Ed. 2014;53:11140–11145. doi: 10.1002/anie.201405820. [DOI] [PubMed] [Google Scholar]
- 49.Sander T, Freyss J, von Korff M, Rufener C. DataWarrior: An open-source program for chemistry aware data visualization and analysis. J. Chem. Inf. Model. 2015;55:460–473. doi: 10.1021/ci500588j. [DOI] [PubMed] [Google Scholar]
- 50.Fillbrunn A, et al. KNIME for reproducible cross-domain analysis of life science data. J. Biotechnol. 2017;261:149–156. doi: 10.1016/j.jbiotec.2017.07.028. [DOI] [PubMed] [Google Scholar]
- 51.Kim HW, et al. NPClassifier: A deep neural network-based structural classification tool for natural products. J. Nat. Prod. 2021;84:2795–2807. doi: 10.1021/acs.jnatprod.1c00399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Djoumbou Feunang Y, et al. ClassyFire: Automated chemical classification with a comprehensive, computable taxonomy. J. Cheminform. 2016;8:1–20. doi: 10.1186/s13321-016-0174-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Bro R, Smilde AK. Principal component analysis. Anal. Methods. 2014;6:2812–2831. doi: 10.1039/C3AY41907J. [DOI] [Google Scholar]
- 54.Probst D, Reymond J-L. Visualization of very large high-dimensional data sets as minimum spanning trees. J. Cheminform. 2020;12:1–13. doi: 10.1186/s13321-020-0416-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Cao Y, Charisi A, Cheng L-C, Jiang T, Girke T. ChemmineR: A compound mining framework for R. Bioinformatics. 2008;24:1733–1734. doi: 10.1093/bioinformatics/btn307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Team, R. C. R: A Language and Environment for Statistical Computing. http://www.R-project.org/ (R Foundation for Statistical Computing, 2013).
- 57.Irwin JJ, et al. ZINC20—a free ultralarge-scale chemical database for ligand discovery. J. Chem. Inf. Model. 2020;60:6065–6073. doi: 10.1021/acs.jcim.0c00675. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.González-Medina M, Prieto-Martínez FD, Owen JR, Medina-Franco JL. Consensus diversity plots: A global diversity analysis of chemical libraries. J. Cheminform. 2016;8:1–11. doi: 10.1186/s13321-016-0176-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Medina-Franco JL, Martínez-Mayorga K, Bender A, Scior T. Scaffold diversity analysis of compound data sets using an entropy-based measure. QSAR Combinatorial Sci. 2009;28:1551–1560. doi: 10.1002/qsar.200960069. [DOI] [Google Scholar]
- 60.Kuwahara H, Gao X. Analysis of the effects of related fingerprints on molecular similarity using an eigenvalue entropy approach. J. Cheminform. 2021;13:1–12. doi: 10.1186/s13321-021-00506-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.López-López E, Naveja JJ, Medina-Franco JL. DataWarrior: An evaluation of the open-source drug discovery tool. Expert Opin. Drug Discov. 2019;14:335–341. doi: 10.1080/17460441.2019.1581170. [DOI] [PubMed] [Google Scholar]
- 62.Kralj S, Jukič M, Bren U. Comparative analyses of medicinal chemistry and cheminformatics filters with accessible implementation in Konstanz information miner (KNIME) Int. J. Mol. Sci. 2022;23:5727. doi: 10.3390/ijms23105727. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Daina A, Michielin O, Zoete V. SwissABME: A free web tool to evaluate pharmacokinetics, drug-likeness and medicinal chemistry friendliness of small molecules. Sci. Rep. 2017;7:1–13. doi: 10.1038/srep42717. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Rodríguez LO, Young KR. Biological diversity of Peru: Determining priority areas for conservation. AMBIO J. Hum. Environ. 2000;29:329–337. doi: 10.1579/0044-7447-29.6.329. [DOI] [Google Scholar]
- 65.McNeely JA, et al. Conserving the World’s Biological Diversity. International Union for Conservation of Nature and Natural Resources; 1990. [Google Scholar]
- 66.Molotoks A, Kuhnert M, Dawson TP, Smith P. Global hotspots of conflict risk between food security and biodiversity conservation. Land. 2017;6:67. doi: 10.3390/land6040067. [DOI] [Google Scholar]
- 67.Atanasov AG, Zotchev SB, Dirsch VM, Supuran CT. Natural products in drug discovery: Advances and opportunities. Nat. Rev. Drug Discov. 2021;20:200–216. doi: 10.1038/s41573-020-00114-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Sorokina M, Steinbeck C. Review on natural products databases: Where to find data in 2020. J. Cheminform. 2020;12:1–51. doi: 10.1186/s13321-020-00424-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Gaynes R. The discovery of penicillin-new insights after more than 75 years of clinical use. Emerg. Infect. Dis. 2017;23:849. doi: 10.3201/eid2305.161556. [DOI] [Google Scholar]
- 70.Montinari MR, Minelli S, De Caterina R. The first 3500 years of aspirin history from its roots—A concise summary. Vasc. Pharmacol. 2019;113:1–8. doi: 10.1016/j.vph.2018.10.008. [DOI] [PubMed] [Google Scholar]
- 71.Tanaka H, Nakahara K, Hatanaka H, Inamura N, Kuroda A. Discovery and development of a novel immunosuppressant, tacrolimus hydrate. Yakugaku Zasshi J. Pharm. Soc. Jpn. 1997;117:542–554. doi: 10.1248/yakushi1947.117.8_542. [DOI] [PubMed] [Google Scholar]
- 72.Choudhari AS, Mandave PC, Deshpande M, Ranjekar P, Prakash O. Phytochemicals in cancer treatment: From preclinical studies to clinical practice. Front. Pharmacol. 2020;10:1614. doi: 10.3389/fphar.2019.01614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Martino E, et al. Vinca alkaloids and analogues as anti-cancer agents: Looking back, peering ahead. Bioorganic Med. Chem. Lett. 2018;28:2816–2826. doi: 10.1016/j.bmcl.2018.06.044. [DOI] [PubMed] [Google Scholar]
- 74.Oudard S, et al. Cabazitaxel versus docetaxel as first-line therapy for patients with metastatic castration-resistant prostate cancer: A randomized phase iii trial-firstana. J. Clin. Oncol. 2017;35:3189–3197. doi: 10.1200/JCO.2016.72.1068. [DOI] [PubMed] [Google Scholar]
- 75.Hertzberg RP, Caranfa MJ, Hecht SM. On the mechanism of topoisomerase i inhibition by camptothecin: Evidence for binding to an enzyme-DNA complex. Biochemistry. 1989;28:4629–4638. doi: 10.1021/bi00437a018. [DOI] [PubMed] [Google Scholar]
- 76.Cao B, et al. Cip-36, a novel topoisomerase II-targeting agent, induces the apoptosis of multidrug-resistant cancer cells in vitro. Int. J. Mol. Med. 2015;35:771–776. doi: 10.3892/ijmm.2015.2068. [DOI] [PubMed] [Google Scholar]
- 77.Mayor, S. Tree that provides paclitaxel is put on list of endangered species (2011). [DOI] [PubMed]
- 78.Murage P, Batalha HR, Lino S, Sterniczuk K. From drug discovery to coronaviruses: Why restoring natural habitats is good for human health. BMJ. 2021;375:n2329. doi: 10.1136/bmj.n2329. [DOI] [PubMed] [Google Scholar]
- 79.Pilkington LI. A chemometric analysis of deep-sea natural products. Molecules. 2019;24:3942. doi: 10.3390/molecules24213942. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Miloslavich P, et al. Marine biodiversity in the Atlantic and Pacific coasts of South America: Knowledge and gaps. PLoS ONE. 2011;6:e14631. doi: 10.1371/journal.pone.0014631. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Jeong G-J, Khan S, Tabassum N, Khan F, Kim Y-M. Marine-bioinspired nanoparticles as potential drugs for multiple biological roles. Mar. Drugs. 2022;20:527. doi: 10.3390/md20080527. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Silber J, Kramer A, Labes A, Tasdemir D. From discovery to production: Biotechnology of marine fungi for the production of new antibiotics. Mar. Drugs. 2016;14:137. doi: 10.3390/md14070137. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Swami U, Shah U, Goel S. Eribulin in cancer treatment. Mar. Drugs. 2015;13:5016–5058. doi: 10.3390/md13085016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Sagar S, Kaur M, Minneman KP. Antiviral lead compounds from marine sponges. Mar. drugs. 2010;8:2619–2638. doi: 10.3390/md8102619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Vega K, et al. Production of alkaline cellulase by fungi isolated from an undisturbed rain forest of peru. Biotechnol. Res.Int. 2012;2012:934325. doi: 10.1155/2012/934325. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Plata ER, Lücking R. High diversity of graphidaceae (lichenized ascomycota: Ostropales) in Amazonian Perú. Fungal Divers. 2013;58:13–32. doi: 10.1007/s13225-012-0172-y. [DOI] [Google Scholar]
- 87.Du L, Li S. Compartmentalized biosynthesis of fungal natural products. Curr. Opin. Biotechnol. 2021;69:128–135. doi: 10.1016/j.copbio.2020.12.006. [DOI] [PubMed] [Google Scholar]
- 88.Al-Saman MA, et al. Optimization of lovastatin production by Aspergillus terreus ATCC 10020 using solid-state fermentation and its pharmacological applications. Biocatal. Agric. Biotechnol. 2021;31:101906. doi: 10.1016/j.bcab.2021.101906. [DOI] [Google Scholar]
- 89.Colombo D, Ammirati E. Cyclosporine in transplantation—A history of converging timelines. J. Biol. Regul. Homeost. Agents. 2011;25:493–504. [PubMed] [Google Scholar]
- 90.Hossain R, et al. Propolis: An update on its chemistry and pharmacological applications. Chin. Med. 2022;17:1–60. doi: 10.1186/s13020-022-00651-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Silva-Carvalho R, Baltazar F, Almeida-Aguiar C. Propolis: a complex natural product with a plethora of biological activities that can be explored for drug development. Evidence-Based Complementary Altern. Medicine. 2015;2015:206439. doi: 10.1155/2015/206439. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Paulino N, et al. Anti-inflammatory effects of a bioavailable compound, artepillin c, in Brazilian propolis. Eur. J. Pharmacol. 2008;587:296–301. doi: 10.1016/j.ejphar.2008.02.067. [DOI] [PubMed] [Google Scholar]
- 93.Moura SALD, et al. Aqueous extract of brazilian green propolis: primary components, evaluation of inflammation and wound healing by using subcutaneous implanted sponges. Evidence-Based Complementary Altern. Medicine. 2011;2011:748283. doi: 10.1093/ecam/nep112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Guillen Quispe YN, Hwang SH, Wang Z, Zuo G, Lim SS. Screening in vitro targets related to diabetes in herbal extracts from Peru: Identification of active compounds in Hypericum laricifolium Juss. by offline high-performance liquid chromatography. Int. J. Mol. Sci. 2017;18:2512. doi: 10.3390/ijms18122512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Bautista-Flores A, Mayor PNA, Arellano AAL. Cytotoxic effect of hydroalcoholic extract of annona muricata against a human cell line of gastric adenocarcinoma. Vitae. 2022;29:1–9. doi: 10.17533/udea.vitae.v29n1a348194. [DOI] [Google Scholar]
- 96.Roumy V, et al. Viral hepatitis in the Peruvian Amazon: Ethnomedical context and phytomedical resource. J. Ethnopharmacol. 2020;255:112735. doi: 10.1016/j.jep.2020.112735. [DOI] [PubMed] [Google Scholar]
- 97.Roumy V, et al. In vitro antimicrobial activity of traditional plant used in mestizo shamanism from the Peruvian amazon in case of infectious diseases. Pharmacogn. Mag. 2015;11:S625. doi: 10.4103/0973-1296.172975. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Céline V, et al. Medicinal plants from the Yanesha (Peru): Evaluation of the leishmanicidal and antimalarial activity of selected extracts. J. Ethnopharmacol. 2009;123:413–422. doi: 10.1016/j.jep.2009.03.041. [DOI] [PubMed] [Google Scholar]
- 99.Williamson EM. Synergy and other interactions in phytomedicines. Phytomedicine. 2001;8:401–409. doi: 10.1078/0944-7113-00060. [DOI] [PubMed] [Google Scholar]
- 100.Rasoanaivo P, Wright CW, Willcox ML, Gilbert B. Whole plant extracts versus single compounds for the treatment of malaria: Synergy and positive interactions. Malar. J. 2011;10:1–12. doi: 10.1186/1475-2875-10-S1-S4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Yepes-Pérez AF, Herrera-Calderon O, Quintero-Saumeth J. Uncaria tomentosa (cat’s claw): A promising herbal medicine against SARS-CoV-2/ACE-2 junction and SARS-CoV-2 spike protein based on molecular modeling. J. Biomol. Struct. Dyn. 2022;40:2227–2243. doi: 10.1080/07391102.2020.1837676. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Goyzueta-Mamani LD, et al. In silico analysis of metabolites from Peruvian native plants as potential therapeutics against Alzheimer’s disease. Molecules. 2022;27:918. doi: 10.3390/molecules27030918. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets generated and/or analyzed during the current study are available in the PeruNPDB repository, https://perunpdb.com.pe/.