

Abstract
Dichotomization is often used on clinical and diagnostic settings to simplify interpretation. For example, a person with systolic and diastolic blood pressure above 140 over 90 may be prescribed medication. Blood pressure as well as other factors such as age and cholesterol and their interactions may lead to increased risk of certain diseases. When using a dichotomized variable to determine a diagnosis, if the interactions with other variables are not considered, then an incorrect threshold for the continuous variable may be selected. In this paper, we compare single dichotomization with joint dichotomization; the process of simultaneously optimizing cutpoints for multiple variables. A simulation study shows that simultaneous dichotomization of continuous variables is more accurate in recovering both ‘true’ thresholds given they exist.
1. Introduction
Dichotomization of continuous predictors to discriminate binary outcomes is widely used in clinical settings. The practice of dichotomization provides clinicians with easily implementable decision rules in diagnoses, treatment options, and prognoses. Although dichotomization of continuous predictors is heavily criticized by the statistical community because it leads to loss of information, the benefit of clinical utility may outweigh the drawbacks.
Also, a growing body of evidence suggests that complex diseases, may be influenced by the interactions between multiple genetic, clinical, and environmental variables ([10, 11, 8]). For example, a clinical determination of kidney disease requires a patient to exhibit both an estimated glomerular filtration rate of < 60mg/min and albumin 30 mg/g creatinine. [2] Another example is in cardiovascular disease (CVD). The Score2 model is an algorithm used to predict 10-year risk of first-onset of CVD. This model dichotomizes continuous variables in order to determine risk categories for individuals. According to model, a 50-year-old man with systolic blood pressure of 140 mHg, total cholesterol of 5.5 mmol/L and HDL of 1.3 is in the high risk category [14]. If disease risk, progression, or response to therapy are influenced by the interaction of two or more factors rather than by each factor independently, then dichotomizing these factors separately may result in less than optimal choices of threshold for both factors. Also, if continuous factors are interacting with other variables yet are dichotomized separately, their interaction with each other and with disease outcome may never be identified. If the factors of interest are continuous and must be dichotomized for clinical or statistical reasons, they should also be dichotomized simultaneously (jointly) in order to preserve their association with each other and the outcome.
There are many methods for finding an optimal threshold to dichotomize a single continuous variable for discriminating a binary outcome such as odds ratio [7], Youden’s statistic [19], ROC curve [5, 3, 6], relative risk [5], Gini Index [15], median [17] sensitivity and specificity [9] among others [1, 18, 4]. Relative risk can be considered when there is a cohort study design in which the sample is designed to mimic disease distribution in the population. However, there is limited methodology described in the literature to simultaneously optimize the thresholds for two or more interacting variables to discriminate a binary outcome[17]. There are no methods that address joint dichotomization when interactions have a larger impact on probability of disease in the absence of main effects.Decision tree methods such as Classification and Regression Trees (CART) have the ability to identify thresholds (“cut-points”) for more than one continuous variable but these dichotomization processes are done sequentially rather than simultaneously.
In this paper, we describe an interaction in which only the presence of two or more variables lead to increased risk of disease and not any single variable alone. We also describe an algorithm for jointly dichotomizing those variables to discriminate a binary outcome. Section 2 of this paper describes the framework for an interaction term and gives numerical justification for joint dichotomization. In Section 3, we will provide theoretical proof that maximizing the statistics identified in the paper “An evaluation of common methods for dichotomization of continuous variables to discriminate disease status” by Prince-Nelson et al. finds the true threshold given that one exists. Section 4 describes the algorithm for joint thresholding. Section 5 presents the results of a simulation study designed to evaluate the impact of the location of the true thresholds, sample size, and strength of association between the binary outcome and the interaction on the ability of the methods described by Prince-Nelson et al. to correctly estimate the threshold. The simulation study shows that there is less variability and bias in the selection of thresholds when they are chosen jointly rather than individually for the statistics identified by [12]. In section 6, we will discuss the implications of the simulation results.
2. Case for Joint Dichotomization
This section provides an empirical and theoretical comparison of six methods for selecting thresholds to dichotomize two continuous variables, , to discriminate a binary outcome, , by jointly or singly selecting the thresholds, , for each variable when is associated with and through their interaction. The threshold for a continuous variable or set of variables can be selected by maximizing or minimizing specific statistics, which can estimated from a contingency table for the binary outcome and dichotomized .
Prince-Nelson et al [12] showed that when a true threshold for a continuous variable that discriminates a binary outcome exists, dichotomization based on maximizing the odds ratio, relative risk, Youden’s statistic, chisquare statistic, Gini Index or kappa statistic theoretically recovers the true threshold given the relationship between and a single continuous variable has the relationship defined by:
| (1) |
where and is the true threshold for .
For this paper, we extend this definition to include two variables, and and leave it for future work to determine which of the six methods are preferable under other specific scenarios. We describe the interaction between them as:
| (2) |
where
and
The probabilities corresponding to a contingency table for the joint condition of and or 0 are summarized in Table 1. Here, is associated with and through an interaction, and thus is larger when the interaction is present. If is associated with through an interaction, then is larger when in the presence of the interaction. For this paper, an interaction between two or more variables means that there is an increased risk of when both or all variables are present.
Table 1:
The contingency table for continuous variables and and dichotomous outcome where and are jointly thresholded at and respectively
2.1. Numeric Investigation of Single and Joint Thresholding
This section provides an empirical examination of the ability of joint and singly thresholding to correctly identify a true thresholds, , in the case where two continuous variables and are associated with a binary outcome through the relationship defined in Equation 2. Variable is singly dichotomized if the threshold for , is selected by choosing the value of that maximizes one of the six statistics in Table 2 without considering the joint impact with . Joint dichotomization is defined as selecting the thresholds, and , for and such that one of the six statistics in Table 2 is maximized based on , and defined in Table 2.
Table 2:
Formulas for statistics for selecting a threshold for a continuous variable to discriminate a binary outcome based on the probabilities in a standard contingency table.
| Odds Ratio | Youden’s Statistic | Chi-Square |
|---|---|---|
| Kappa Statistic | Relative Risk* | Gini Index |
For cohort study designs only
Consider the case where , , and . Probabilities for the cells from Table 2 under joint thresholding and the corresponding values of the six statistics shown in Table 1 at each combination of values for and in the interval in increments of 0.001 and including and are calculated.
Single thresholding finds the threshold for without considering the value of or vice versa. To calculate the six statistics in Table 2 under single thresholding for different possible thresholds of , three cases must be considered: (1) , (2) , and (3) . The cell probabilities for a 2 table based on single thresholding of for these three cases are shown below where and .
(3) (4) (5)
Similar to joint thresholding, for single thresholding the statistics in Table 2 are calculated over the range of thresholds for in the interval in increments of 0.001. To examine the rate of convergence, numeric derivations of the statistics in Table 2 are calculated using the formula where
Figure 1 shows the value of the six statistics for every value of considered in the interval . The dashed line represents statistic for the single threshold and the solid line represents the joint threshold for when . In Figure 2, the numeric derivatives are plotted in a similar manner for each statistic under single and joint thresholding. The plots in Figure 1 confirm, the true threshold for occurs at the maximum for these statistics under single and joint thresholding. Additionally, Figure 1 shows that the maximum value for each statistic is smaller when singly thresholding relative to joint thresholding when the association between , and conforms to Equation 2.
Figure 1:
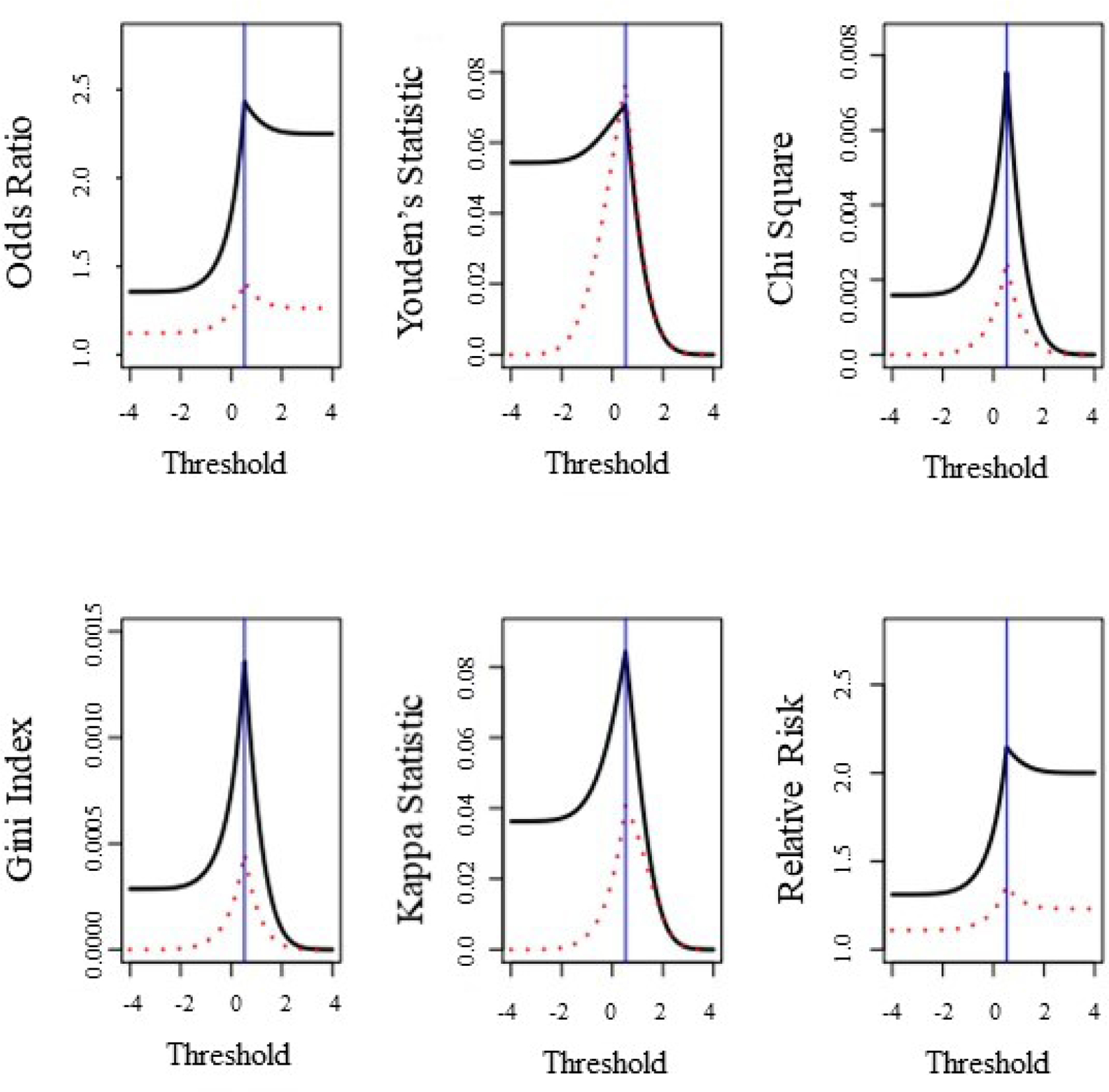
Values of statistics from Table 2 for different thresholds, ; for under single or joint thresholding in the case where two continuous variables and are associated with a binary outcome the relationship in the Equation 2. Here , , and . The solid line represents the value of each statistic for values of in under joint thresholding where . The dashed line represents the values of each statistic for values of under single thresholding. The vertical line occurs at the true threshold for .
Figure 2:
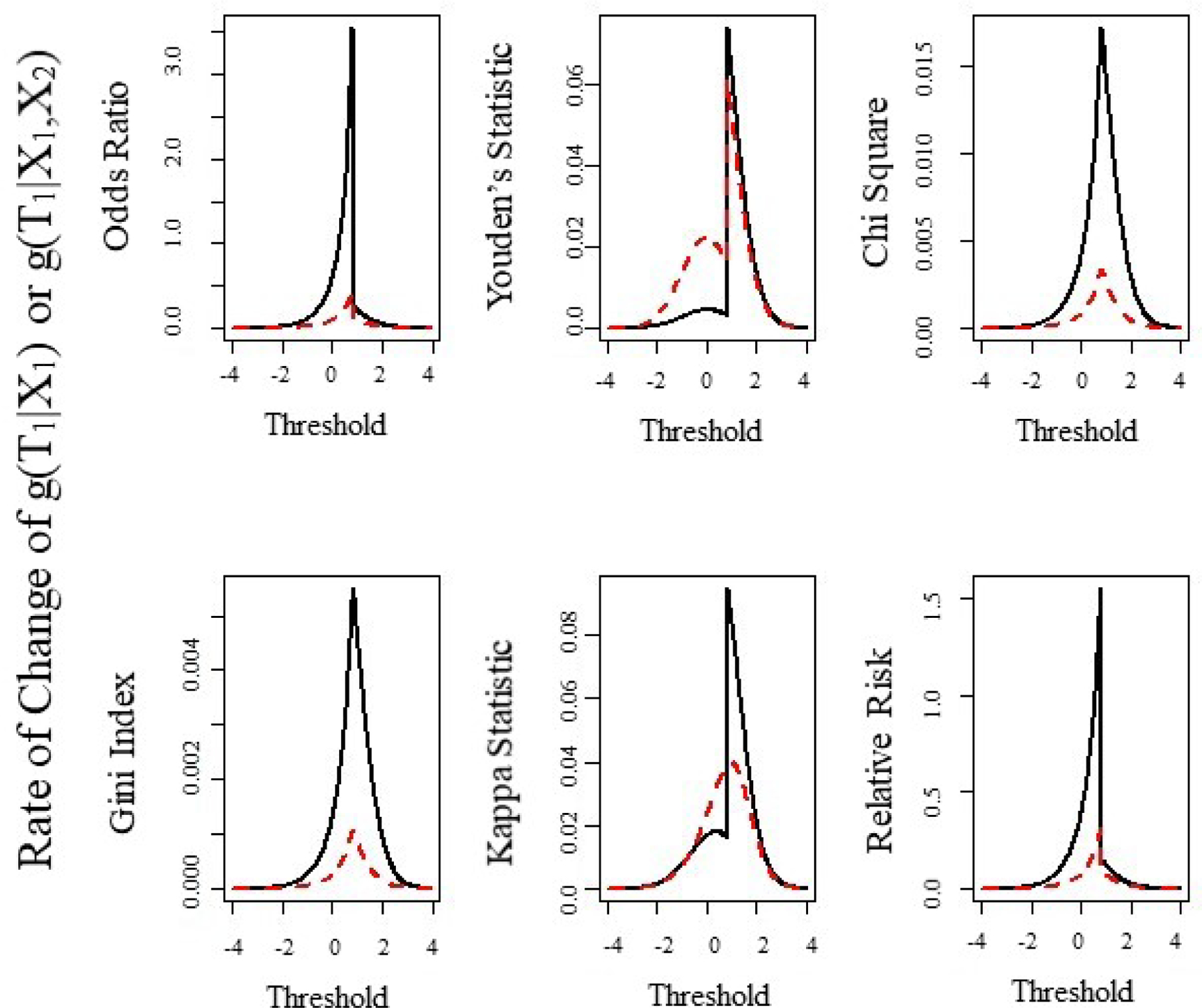
Numeric estimation of the first derivative of the six statistics from Table 2 for different values of threshold, for continuous variable under single or joint dichotomization. Here and . Under joint dichotomization we assume that varies while
In Figure 2, we examine the rate of change in and at for small changes in . The rate of change is calculated for single thresholding as and for joint thresholding as for over the range . The solid line is the rate of change under joint thresholding and the dashed line is the rate of change under single thresholding. For all six statistics in Table 2, the rate of change near is faster for joint thresholding relative to single thresholding. The plots of the derivatives (Figure 2) suggest, the rate of convergence to is faster for the odds ratio, relative risk, chi-square statistic, and gini index. With respect to the Youden’s and kappa statistics, the right convergence in faster to for joint versus single thresholding; however the left convergence is faster for single versus joint thresholding. We will comment about how this plays a role in estimating a threshold in our simulations.
3. Theoretical confirmation
Our previous work [12] demonstrated that dichotomization of a single variable based on the six statistics identify the correct threshold given one exists. Here we extend this work to the case of two continuous variables to discriminate a binary outcome . Consider two continuous variables and where the relationship between and with a dichotomous outcome is defined by Equation 1. Define and as the functions for odds ratio, relative risk, chi-square statistic, gini index, Youden’s statistic, and kappa statistic under marginal thresholding of and respectively and as the function for odds ratio, relative risk, chi-square statistic, gini index, Youden’s statistic, and kappa statistic for the threshold under joint thresholding of and . Motivated by the numeric results in Section 2, we conjecture and prove the following theorems. Theorem 1 generalizes the results in Figure 1.
Theorem 1: For continuous variables and and a dichotomous variable with prevalence and thresholds and such that , (equation(1)), the inequality for any holds where is any of the six statistics defined in Table 2. To consider the case where true thresholds exist, we assume for any that the conditional probability is a step function at and .
We demonstrate the proof where is the odds ratio and provide this proof in the supplemental material. The proof is under the assumption that and the complement in the statement of the theorem are constant.
Next Theorem 2 generalizes the results of Figure 2 for any continuous for odds ratio, relative risk, chi-square statistic, and gini index.
Theorem 2: For continuous variables and and a dichotomous variable with prevalence and thresholds and such that (Equation 2), the rate of convergence to is faster under joint compared to single thresholding. That is,
when is one of statistics 1–4 in Table 2. This theorem can be stated in terms of as well.
This proof of Theorem 2 becomes trivial given the following lemma. Lemma 1 is also motivated by the results in Figure 1.
Lemma 1: For continuous variables and and a dichotomous variable with prevalence and thresholds and such that then for functions defined earlier, where is defined under joint thresholding using cell probabilities in Table 1 and is defined under single thresholding using the cell probabilities in a standard contingency table. We conjecture that this Lemma will extend to the case of continuous variables where the variables are associated with dichotomous outcome through their interaction. This proof can be shown through induction.
Proof:
For the case where is the odds ratio, the statement of the lemma is equivalent to the claim that
where are defined by the probabilities defined in a standard contingency table for the single thresholding case and are the cell probabilities for the joint thresholding case defined in Table 1 for the given thresholds and . To prove the lemma, consider the inequality and multiply both sides by and which yields
Now adding to both sides and factoring and simplifying yields
Multiply both sides by
Rearranging the terms and recognizing the factors yields
Thus,
Theorem 1 and Lemma 1 are also confirmed by the numeric findings shown in Figure 1. The proofs for Theorem 1 and Lemma 1 for Relative Risk, chi square, Kappa, Youden’s, and Gini Index can be found in Appendix B. Lemma 1 demonstrated that for or 2 and for all fixing . Therefore, the proof of Theorem 2 follows. We demonstrate Theorem 2 further using a numeric approach shown in Figure 2. In Figure 2, we examine the rate of change in and at for small changes in . The rate of change is calculated for single thresholding as and for joint thresholding as for over the range . The solid line is the rate of change under joint thresholding and the dashed line is the rate of change under single thresholding. For all six statistics in Table 2, the rate of change near is faster for joint thresholding relative to single thresholding.
4. Joint thresholding algorithm
We propose an algorithm to jointly identify the best combination of thresholds and for and to discriminate a binary outcome . The proposed algorithm is shown in the box below.
In application it was noted that the six statistics were not stable when cell counts in the table were zero or small. Thus constraints on thresholds were applied. Specifically only values with 2 standard deviations of the means for and were considered for both the single and joint dichotomization algorithms.
5. Simulation Study
In sections 2 and 3, we demonstrated that the six statistics defined in Table 2 are maximized at the true threshold when response is associated with the continuous variables and through the relationship defined by Equation 2 whether and are dichotomized singly or jointly. Furthermore, we showed that joint dichotomization should converge to faster than single dichotomization for all six statistics if the relationship in Equation 2 is true. However, it is not generally known in advance whether or not is associated with two continuous variables independently or through their interaction. Therefore, we investigate the ability of joint and single thresholding to recover the true thresholds, and , for two continuous variables, and , to discriminate a binary outcome when and are associated with when sampling from a population. A simulation study was conducted to evaluate the ability of the six statistics to correctly find and under different scenarios arising from combinations of (1) the relationship between and (independent or interaction), (2) strength of association between the predictors in and response as defined by an odds ratio, and (3) value of the true thresholds and .
Independent Case:
We set , the odds ratio for , and the odds ratio for . In the case where the interaction, , is independently associated with , the OR is the product of and . Continuous variables and are generated from and and are defined based on and . The four probabilities, can be calculated based on the set values of and . Response is generated from based on the observed values of and . For the independent case, we consider the scenarios outlined in Table 3 where probabilities and of 0.05, 0.2, and 0.5 yield thresholds of 1.645, 0.84, and 0 respectively.
Table 3:
Simulation Scenarios
| OR | Scenario | ||
|---|---|---|---|
| 1.5 | 0.05 | 0.2 | a |
| 0.2 | 0.2 | b | |
| 0.5 | 0.2 | c | |
| 3 | 0.05 | 0.2 | d |
| 0.2 | 0.2 | e | |
| 0.5 | 0.2 | f | |
| 6 | 0.05 | 0.2 | g |
| 0.2 | 0.2 | h | |
| 0.5 | 0.2 | i |
Joint case:
We set , and the OR for condition and . Continuous variables and are generated from and the true thresholds and are set as the inverse normal values of and . Two probabilities and are calculated from the set values of and ,. Response is generated from based on the observed values of and . For the joint case, we consider the scenarios outlined in Table 3 where probabilities of 0.05, 0.2, and 0.5 yield thresholds of 1.645, 0.84, and 0 respectively.
For each simulation scenario outlined in Table 3, we generated 500 datasets of sample size , and 500. The threshold for each method was estimated using the single and joint thresholding algorithms described in Section 3. The ability of each method to recover the true thresholds, and , was evaluated by examining the mean squared error and the bias squared for the estimated threshold across all simulated datasets for all scenarios. All simulations were conducted in R v. 3.2.1 [13].
5.1. Simulation Results
Figures 3 and 4 show the results for thresholding singly and jointly. Each graph shows the mean squared error (MSE) by bias squared for all statistics described in Table 2 for the different values of and and strength of association with . The columns show the impact of increasing values for and and the rows show the impact of increasing strength of association with . Filled circles represent joint thresholding while open circles represent single. The columns in Figure 4 show the impact of increasing values for and and the rows show the impact of increasing strength of association with . Filled circles represent joint thresholding while open circles represent single thresholding. The results for thresholding were similar.
Figure 3:

The results from the simulation study comparing joint and single dichotomization of independent continuous variables. Each plot shows MSE by bias squared for the different values of and and strength of association with .
Figure 4:
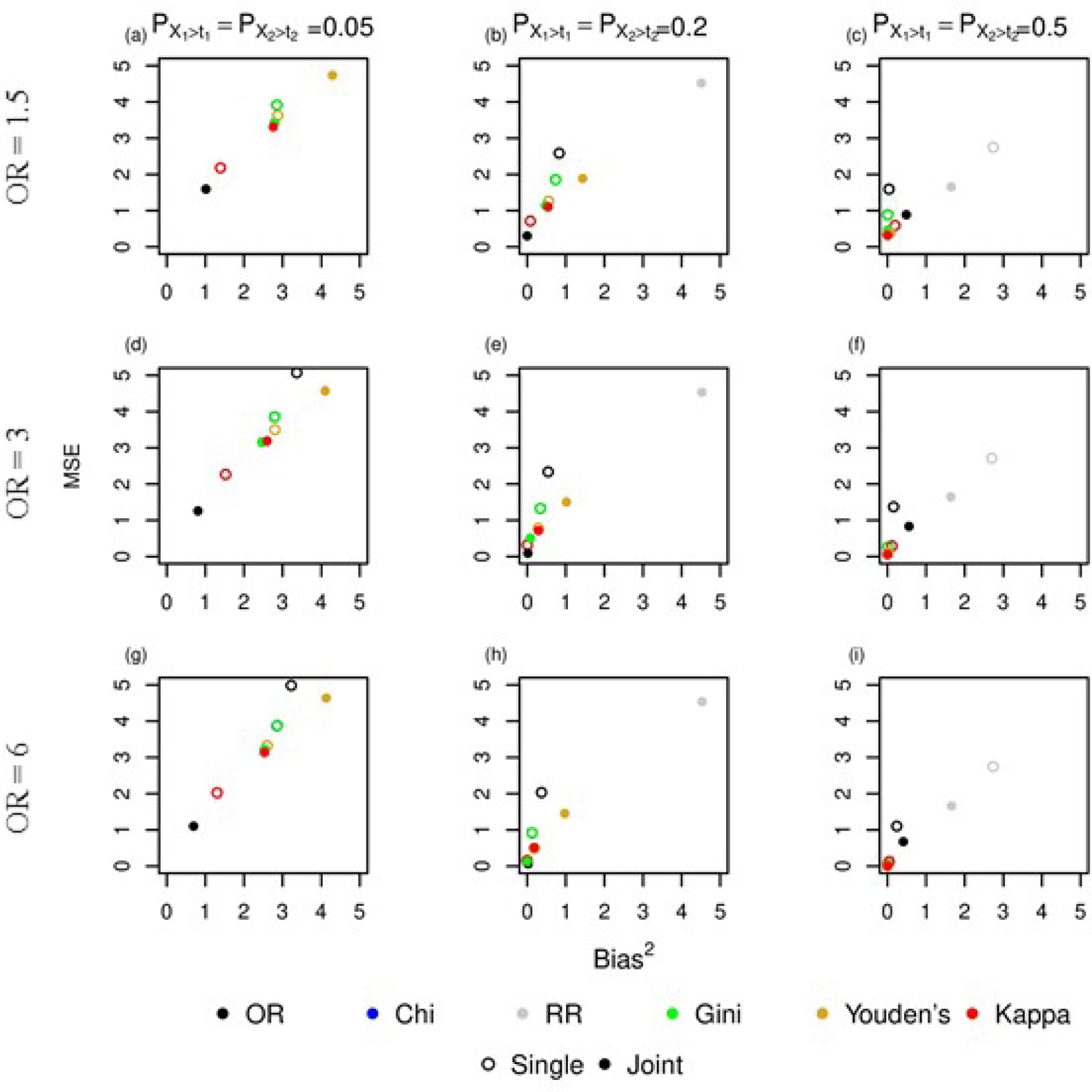
The results from the simulation study comparing joint and single dichotomization of interacting continuous variables. Each plot shows MSE by bias squared for the different values of and and strength of association with .
5.2. Independent case
In the independent case, as the strength of association between and increases ( to ), both joint and single thresholding exhibit smaller MSE for the estimated threshold for all methods and bias decreases slightly suggesting that the estimated threshold is less variable and biased as the strength of association between and increases. When the strength of association is , single thresholding is better for all methods except odds ratio and relative risk. Joint thresholding for kappa statistic has a lower MSE and bias than single thresholding for kappa when and increases to 0.5.
Holding odds ratio constant, as the probabilities and increase, both joint and single thresholding show a reduction in bias. At the lowest odds ratio as and increase, the threshold estimated jointly using odds ratio, Gini Index, or relative risk has lower MSE and bias relative to the threshold selected using single thresholding. However, the jointly estimated threshold using Youden’s statistic or kappa statistic has higher bias and MSE than the threshold selected using single thresholding. When and (Figure 4c), selecting a threshold jointly based on kappa improves relative to single thresholding. Relative risk has the highest MSE and bias for both joint and single thresholding. Relative risk is not shown for plots 4a,d, and g due to the magnitude of the MSE and bias.
5.3. Joint Case
In the joint case, as the probability of observing values of and increase, both joint and single thresholding show a reduction in MSE and bias. As was seen in the independent case, selecting a threshold jointly using odds ratio, Gini Index, or relative risk result in a lower MSE and bias than single thresholding. However, the jointly estimated threshold using Youden’s statistic or kappa statistic has a higher MSE and bias than the threshold selected using single thresholding. When and or 0.2, selecting a threshold singly using kappa has a lower MSE and bias than jointly. But as the probability increases to and , selecting a threshold jointly using kappa improves relative to single thresholding (Figures 4c,f, and i). When and , single and joint thresholding using Youden’s statistic results in an MSE and bias approximately zero.
As the strength of association between and increases ( to ), both joint and single thresholding exhibit a reduction in MSE and bias decreases slightly suggesting that the estimated threshold is less variable and biased as the strength of association increases. Selecting a threshold jointly using odds ratio results in the lowest MSE and bias of all the methods except when and . At this highest probability, selecting a threshold jointly and singly using chi square, gini index, Youden’s statistic and Kappa statistic result in a lower MSE and bias relative to joint thresholding using odds ratio. Single thresholding using relative risk results in the highest MSE and bias of all the methods.
5.4. Summary of Results
When and are independently associated with , single thresholding results in a lower MSE and bias when there is a weak association and small probability of observing values above a threshold. As that association and probability increase, joint thresholding performs similarly or better than single thresholding. When and are associated with described by an interaction as described by Equation 2, joint thresholding with the odds ratio method results in the lowest MSE and bias when there is a weak or modest association with response variable . When there is a strong association and a high probability of observing values above a certain threshold, all of the methods except relative risk yield a low MSE and bias for the estimated thresholds. Results were similar across all sample sizes though MSE and bias increased with decreasing sample size (See Supplemental Material).
6. Conclusion
Previous research has shown that six of the common dichotomization methods work well in recovering a true threshold given our framework. This paper used those six dichotomization methods to recover the true threshold of two interacting variables. Identifying interactions that lead to increased risk of disease is an important step in understanding disease etiology. If two or more variables are dichotomized independently, their association with the outcome may never be identified. Thus, if continuous variables must be dichotomized and there is a suspected interaction, joint dichotomization is ideal. Even when two variables are independently associated with the outcome, joint dichotomization, particularly using the odds ratio, performs similarly or better than single dichotomization. Joint dichotomization is a first step in optimizing thresholds for 2 or more clinical predictors. Once the thresholds are selected, one could construct a hierarchical model using the selected thresholds to evaluate whether an interaction is statistically meaningful.
This paper provided mathematical and numeric proof that if and are associated with outcome through an interaction, joint dichotomization (1) yields a larger statistic for odds ratio, relative risk, chi square, Youden’s, Kappa and (2) converges more quickly to a true threshold than single thresholding. Through a simulation study, we showed that when a binary outcome is associated with two continuous variables through an interaction, dichotomizing them jointly to discriminate recovers the true threshold with less variability than dichotomizing singly. Of the six statistics investigated, simulations showed that maximizing the odds ratio provided the most improvement when dichotomizing jointly instead of singly. In the proposed method, the region defined by the predictors is separated into two regions defined by the selected thresholds and therefore could easily be extended to more than two variables or cases where one predictor was continuous and another was binary.
In situations where interactions between variables are suspected and there is a need to dichotomize the continuous variables, these variables should be dichotomized jointly. However, our simulations showed that even in the independent case when and were associated with the outcome, joint thresholding was still shown to be effective in recovering a true threshold. In the case of the odds ratio statistic, joint thresholding performs better whether there is an interaction or not.
There are limitations to the method for joint dichotmization presented here. For example, we considered the case where true thresholds for the predictors exist. This is possible when disease outcome can be described by a mixture of normal distributions meaning disease negative has one distribution and disease positive has another distribution. However, dichotomies defined as in equation 2 are likely rare in real applications. Despite the ubiquitous use of dichotomization in clinical settings, statistical issues are well documented in the literature (Altman1994, MacCallum2002, Altman2006, Naggara2011). Specifically dichotomization can result in loss compromising power in testing hypotheses regarding the association of these predictors with the outcome (Metze2008). It may also lead to these associations being measured incorrectly (Hunter1990). Therefore, justification for dichotomizing needs to be addressed and we are exploring this in a subsequent paper. Additionally, the method assumes a continuous predictor has a dichotomous association with an outcome that is also dependent on another predictor, which should be verified.
7. Software
Software in the form of R code, together with a sample input data set and complete documentation is available on request from the corresponding author (sprincenelson@wlu.edu) and at Github
Supplementary Material
Box: Algorithm for jointly thresholding .
Order the values for each variable in , to yield which is the matrix with values for and sorted in ascending order
Remove values that are not within two standard deviations of the mean.
- For each pair where , calculate the cell counts for a contingency table as follows:
(6) - Select the pair that maximizes the statistic , where is one of the six statistics in Table 2. For example,
Acknowledgments
This project was supported in part by the South Carolina Clinical and Translational Research Institute, Medical University of South Carolina’s CTSA, NIH/NCATS Grant Number UL1TR000062.
References
- [1].Aoki K, Misumi J, Kimura T, Zhao W, Xie T, “Evaluation of Cutoff Levels for Screening of Gastric Cancer Using Serum Pepsinogens and Distributions of Levels of Serum Pepsinogen I, II and of PG I / PG II Ratios in a Gastric Cancer Case-Control Study”, Journal of Epidemiology volume 7, number 3, pages 143–151, (1997), DOI: 10.2188/jea.7.143 [DOI] [PubMed] [Google Scholar]
- [2].Benjamin O, Lappin SL “End-Stage Renal Disease”, StatPearls[Internet], 2021. Sep 16. Treasure Island (FL): StatPearls Publishing; 2021 Jan–. [PubMed] [Google Scholar]
- [3].Boehning D, Holling H, Patilea V, “ A limitation of the diagnostic-odds ratio in determining an optimal cut-off value for a continuous diagnostic test”, Statistical Methods in Medical Research, volume 20, number 5, pages 541–550, (2011) [DOI] [PubMed] [Google Scholar]
- [4].Breiman L, Friedman J, Stone CJ, Olshen RA, “ Classification and regression trees”, CRC press; (1984) [Google Scholar]
- [5].Greiner M, Pfeiffer D, Smith R.D.t, “ Principles and practical application of the receiver operating characteristic analysis for diagnostic tests”, Preventive Veterinary Medicine volume 45, pages 23–41, (2000) [DOI] [PubMed] [Google Scholar]
- [6].Greiner M, “Two-graph receiver operating characteristic (TG-ROC): a Microsoft-EXCEL template for the selection of cut-off values in diagnostic tests”, Journal of Immunological Methods, volume 185, number 1, pages 145–146, (1995) [DOI] [PubMed] [Google Scholar]
- [7].Kraemer HC, “ Risk ratios, odds ratio, and the test QROC. In: Evaluating medical tests”, pages 103–113, (1992), Newbury Park, CA: SAGE Publications, Inc [Google Scholar]
- [8].Lobo I, “Epistasis: Gene Interaction and the Phenotypic Expression of Complex Diseases Like Alzheimer’s,” Nature Education, 2008. 1(1):180. [Google Scholar]
- [9].Lopez-Raton M, Rodriguez-Alvarez MX, Cardosa-Suarez C, Gude-Sampedro F, “ OptimalCutpoints: An R package for selecting optimal cutpoints in diagnostic testing”, Journal of Statistical Software, volume 61, number 8, pages 1–36 (2014) [Google Scholar]
- [10].Manolio TA, Collins FS, “Genes, Enviornment, Health and Disease: Facing Up to Complexity”, Hum Hered 2007;63(2):63–6. doi: 10.1159/000099178 [DOI] [PubMed] [Google Scholar]
- [11].McKinney BA, Reif DM, Ritchie MD, Moore JH “Machine Learning for Detecting Gene-Gene Interactions” Applied Bioinformatics, 2006;5(2):77–88. doi: 10.2165/00822942-200605020-00002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].PrinceNelson SL, Ramakrishnan V, Nietert PJ, Kamen DL,Ramos PS, Wolf BJ, “An Evaluation of Common Methods for Dichotomization of Continuous Variables to Discriminate Disease Status,” Communication in Statistics, 2017; 46(21): 10823–10834 doi: 10.1080/03610926.2016.1248783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].R Core Team, “R:A Language and Environment for Statistical Computing”, R Foundation for Statistical Computing, 2013. Vienna, Austria. [Google Scholar]
- [14].SCORE2 working group and ESC Cardiovascular risk collaboration, “SCORE2 risk prediction algorithms: new models to estimate 10-year risk of cardiovascular disease in Europe,” European Heart Journal, volume 42, number 25, pages 2439–2454 (2021); doi: 10.1093/eurheartj/ehab309 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Strobl C, Boulesteix AL, Augustin T, “ Unbiased split selection for classification trees based on the Gini Index”, Computational Statistics and Data Analysis, volume 52, pages 483–501, (2007) [Google Scholar]
- [16].Tabor HK, Risch NJ, Myers RM, “Candidate-Gene Approaches for Studying Complex Genetic Traits: Practical Considerations”, Nature Reviews Genetics volume 3, pages391–397 (2002) 10.1038/nrg796 [DOI] [PubMed] [Google Scholar]
- [17].Vargha A, Rudas T,Delaney HD, Maxwell SE, “ Dichotomization, Partial Correlation, and Conditional Independence”, Journal of Educational and Behavioral Statistics, volume 21, number 3, pp. 264–282 (1996) 10.2307/1165272 [DOI] [Google Scholar]
- [18].Vermont J, Bosson JL, Francois P, Robert C, Rueff A, Demongeot J, “ Strategies for graphical threshold determination”, Computer Methods and Programs in Biomedicine, volume 35, pages 141–150, (1991) [DOI] [PubMed] [Google Scholar]
- [19].Youden WJ, “Index for rating diagnostic tests “, Cancer volume 3, number 1, pages 32–35 (1950) 10.1002/1097-0142(1950)3:1¡32::AID-CNCR2820030106¿3.0.CO;2-3 [DOI] [PubMed] [Google Scholar]
- [20].Altman DG, Lausen B, Sauerbrei W, Schumacher M, “Dangers of using “optimal” cutpoints in the evaluation of prognostic factors”, Journal of the National Cancer Institute, volume 86, number 11, pages 829–35,(1994). [DOI] [PubMed] [Google Scholar]
- [21].MacCallum R, Zhang S, Preacher K, “On the Practice of Dichotomization of Quantitative Variables”, Psychological Methods, volume 7, number 1, pages 19–40, (2002). [DOI] [PubMed] [Google Scholar]
- [22].Altman D, Royston P, “The cost of dichotomizing continuous variables”, British Medical Journal, volume 332, number 7549, pages 1080, (2006) [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Naggara O, Raymond J, Guilbert F, Weill A, Altman DG, “Analysis by categorizing or dichotomizing continuous variables is inadvisable: an example from the natural history of unruptured aneurysms”, American Journal of Neuroradiology, volume 32, number 3, pages 437–40, (2011) [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Metze K, “Dichotomization of continuous data– a pitfall in prognostic factor studies”, Pathology Research and Practice, volume 204, number 3, pages 213–214,(2008). [DOI] [PubMed] [Google Scholar]
- [25].Hunter J, Schmidt F, “Dichotomization of Continuous Variables: The Implications for Meta-Analysis”, Journal of Applied Psychology, volume 75, number 3, pages 334–49, (1990). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.