

Summary
Sex differences in complex traits are suspected to be in part due to widespread gene-by-sex interactions (GxSex), but empirical evidence has been elusive. Here, we infer the mixture of ways in which polygenic effects on physiological traits covary between males and females. We find that GxSex is pervasive but acts primarily through systematic sex differences in the magnitude of many genetic effects (“amplification”) rather than in the identity of causal variants. Amplification patterns account for sex differences in trait variance. In some cases, testosterone may mediate amplification. Finally, we develop a population-genetic test linking GxSex to contemporary natural selection and find evidence of sexually antagonistic selection on variants affecting testosterone levels. Our results suggest that amplification of polygenic effects is a common mode of GxSex that may contribute to sex differences and fuel their evolution.
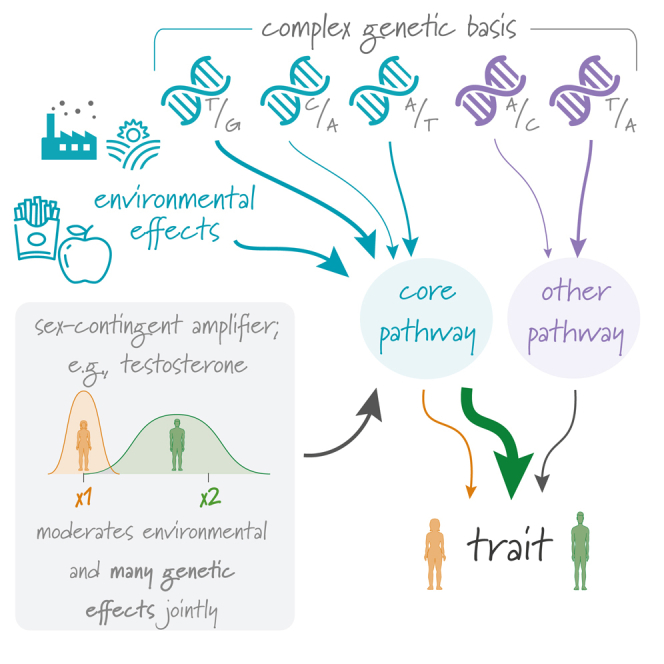
Graphical abstract
Highlights
-
•
Genetic effects on physiology often depend on sex in an underappreciated way
-
•
Amplification: differences in magnitude shared by many genetic effects
-
•
Amplification may act jointly on co-moderated environmental and genetic effects
-
•
Polygenic scores that incorporate amplification improve phenotypic prediction
Zhu et al. estimate the ways in which genetic effects on anthropometric measurements and biomarkers depend on sex. They find pervasive sex contingency acting not through differences in genetic basis but largely through “amplification”—systematic differences in the magnitude of numerous genetic effects. They show that amplification explains trait variance differences between the sexes and that it may be consequential for sex-specific natural selection.
Introduction
Genetic effects can depend on context. If the distribution of contexts differs between groups of people, as it does for males and females, so should the average genetic effects on traits.1,2 In particular, such gene-by-sex interaction (GxSex) may be a result of sex differences in bodily, environmental, and social contexts or epistatic interaction with sex chromosomes.3,4,5,6,7,8,9 Sex differences in genetic effects on complex traits are clearly of high evolutionary8,10,11,12,13,14 and translational9,15,16,17,18,19,20,21,22 importance. However, with the exception of testosterone levels,23,24,25,26 the basis of sexual dimorphism in complex traits is not well understood.19 To date, empirical evidence of GxSex in genome-wide association study (GWAS) data—whether focused on identifying large GxSex effects at individual loci or by estimating genetic correlations between the sexes for polygenic traits—has been lacking.
Here, we set out to study governing principles of GxSex in complex human traits and explain why current approaches for characterizing GxSex may be lacking for this goal. We then suggest a mode of GxSex that may have gone largely underappreciated: a shared difference in the magnitude of effect of many variants between the sexes, which we refer to as “amplification.”27 Amplification can happen for a large set of variants regulating a specific pathway if the pathway responds to a sex-contingent cue.28,29,30,31 In classic hypothesis-testing approaches that test for a GxSex effect separately in each variant, the signal of amplification may be crushed under the multiple-hypotheses burden. On the other hand, even state-of-the-art tools designed with complex traits in mind may miss amplification signals. They often treat genetic correlation (between GWAS estimates based on samples from two contexts, such as males and females) as a litmus test for whether effects are the same in the two contexts,32,33,34,35,36 but correlations are scaleless and thus may entirely miss amplification signals.
We developed a new approach for flexibly estimating male-female genetic covariance relationships and applied it to 27 complex physiological traits in the UK Biobank. We found that amplification is pervasive across traits. The inferred polygenic covariance structure explains sex differences in trait variance remarkably well and, in most cases, helps improve phenotypic prediction. Finally, we consider an implication of polygenic GxSex for sexually antagonistic selection. We develop a model that demonstrates how variants that affect traits may be subject to sexually antagonistic selection when male and female trait optima are very different or, surprisingly, even when the trait optima are very similar. We developed a novel test for sexually antagonistic polygenic selection that connects GxSex to signals of contemporary viability selection. Using this test, we find subtle evidence of sexually antagonistic selection on variants affecting testosterone levels.
Results
The limited scope of single-locus analysis
We conducted GWASs stratified by sex chromosome karyotype for 27 continuous physiological traits in the UK Biobank (UKB) using a sample of ∼150,000 individuals with two X chromosomes, another sample of ∼150,000 individuals with XY, and a combined sample that included the XX and XY samples. We chose to analyze traits with SNP heritabilities over 7.5% in the combined sample to have higher statistical power. While there is not a strict one-to-one relationship between sex chromosome karyotype and biological sex, we label XX individuals as females and XY individuals as males and view these labels as capturing group differences in distributions of contexts for autosomal effects rather than as a dichotomy.9,22,37 Throughout, we analyze GWASs on the raw measurement units as provided by the UKB. (See the note on the rationale behind this choice under Flexible model of sex-specific genetic effects as arising from a mixture of covariance relationships).
Among the 27 traits, we observed substantial discordance between males and females in associations with the trait only for testosterone and waist:hip ratio (whether or not it is adjusted for BMI; Figure S1). For testosterone, as noted in previous analyses, associated genes are often in separate pathways in males and females.23,25 This is reflected in the small overlap of genes neighboring top associations in our GWAS. For example, in females, the gene CYP3A7 is involved in hydroxylation of testosterone, resulting in its inactivation. In males, FKBP4 plays a role in the downstream signaling of testosterone in the hypothalamus. Both genes, to our knowledge, do not affect testosterone levels in the other sex.
For waist:hip ratio, we saw multiple associations in females only, such as variants near ADAMTS9, a gene involved in insulin sensitivity.38 As a previous work established,23,25,26 testosterone and waist:hip ratio are the exception, not the rule; most traits did not display many sex differences in top associations. For instance, arm fat-free mass, a highly heritable dimorphic trait, showed near-perfect concordance in significant loci (Figure S1). A previous study26 examining the concordance in top associations between males and females found few uniquely associated SNPs (<20) across the 84 continuous traits they studied; waist:hip ratio was an exception with 100 associations unique to one sex. Considering the evidence of the polygenicity of additive genetic variation affecting many complex traits,39,40,41 it stands to reason that looking beyond lead associations, through a polygenic prism, may aid characterization of non-additive effects (such as GxSex) as well.
The limited scope of analyzing GxSex via heritability differences and genetic correlations
We turned to consider the polygenic nature of GxSex, first by employing commonly used approaches: comparing sex-specific SNP heritabilities and examining genetic correlations. We used linkage disequilibrium score regression (LDSC)36,42 to estimate these for each trait. In most traits (17 of 27), males and females had a genetic correlation greater than 0.9. Testosterone had the lowest genetic correlation of 0.01, which suggests very little sharing of signals between males and females (see similar results by Flynn et al.25 and Sinnott-Armstrong et al.23).
For the majority of traits (18 of 27), male and female heritabilities were greater than the heritability in a sample that included both sexes. For instance, in arm fat-free mass (right), the heritability in the both-sex sample was 0.232 (±0.009), while the heritabilities for male and female were 0.279 (±0.012) and 0.255 (±0.011), respectively. In particular, all body mass-related traits, excluding BMI-adjusted waist:hip ratio, had greater sex-specific heritabilities (Figures 1A and 1B).
Figure 1.

Heritabilities and genetic correlations cannot fully distinguish models of GxSex
(A) Genetic correlations between males and females, estimated using bivariate LDSC, are shown in descending order.
(B) The x axis represents the relative heritability (i.e., the SNP heritability divided by the SNP heritability) estimated in the sample with both sexes combined. Red asterisks indicate body mass-related traits with greater heritability in both sex-specific samples compared with the sample combining both sexes. Error bars represent ± 1 SE.
(C) Polygenic models of GxSex. We examine different models of the nature of GxSex in complex traits that link to previous studies and motivations. Each model leads to different expectations from the analysis of heritability and genetic correlations (A and B). The illustrations in the third column depict examples of directions and magnitudes of genetic effects corresponding to each model. , , and denote narrow-sense heritabilities in males, females, and a combined sample, respectively.
In addition, we noticed a trend where, as the genetic correlation decreased, the difference between the heritabilities within each sex and in the sample combining both sexes tended to become larger (Pearson r = −0.88, paired t test p = 10−10; Figures 1A and 1B). Nonetheless, several traits with genetic correlation above 0.9 also present relatively large sex differences in heritability. For example, diastolic blood pressure and arm fat-free mass (left) had differences of 5.2% (two-sample t test p = ) and 3.4% (two-sample t test p = 0.04), respectively. These examples are incompatible with a model of pervasive uncorrelated genetic effects driving sex-specific genetic contributions to variation in the trait (Figure 1C, second model).
We therefore considered two other alternative hypotheses under a simple additive model of variance in a trait. Differences in heritability are due to sex differences in genetic variance, in environmental variance, or both. If genetic effects are similar, then differences in environmental variance alone could cause heritability differences (Figure 1C, first model). But as we show in the STAR Methods, under such a model, the heritability in the combined sample cannot be smaller than both sex-specific heritabilities.
Therefore, the observation of higher sex-specific heritabilities for most traits suggests that the genetic variance must differ between males and females. Given the random segregation of autosomal alleles, independent of an individual’s sex chromosome karyotype, and assuming, further, that there is little to no interaction of sex and genotype affecting participation in the UKB,43 allele frequencies in males and females are expected to be very similar. Thus, this observation suggests that causal genetic effects differ between males and females for most traits analyzed.
A last hypothesis that might tie together many of the observations summarized in Figure 1 is a less appreciated mode of GxSex, amplification, where the identity and direction of effects are largely shared between sexes (leading to high genetic correlation), but the magnitude of genetic effects differs—e.g., larger genetic effects on blood pressure in females—which, in turn, leads to differences in genetic variance (Figure 1C, third model).
We can test the hypothesis that amplification acts systematically—across a large fraction of causal variants—by examining the effects of polygenic scores (PGSs), genetic predictors of a complex trait. Under this hypothesis, regardless of whether the PGS is estimated in a sample of males, females, or a combined sample of both males and females, it should be predictive in both sexes because the causal variants and the direction of their effects are shared, and the magnitude is correlated (Figure 1C, third model). At the same time, in the sex for which genetic effects are larger, the effect of the PGS is expected to be larger. To evaluate evidence of the systematic amplification model, we estimated PGSs based on our sex-specific GWASs and examined their effect in both sexes. For some traits, like albumin and lymphocyte percentage, the effects of the same PGS on trait value in males and females were statistically indistinguishable (Figures 2A, 2E, 2I, and 2J). In a few other traits, such as diastolic blood pressure, the result was contingent on the sample in which the PGS was estimated (Figures 2C, 2G, 2I, and 2J). However, for roughly half of the traits examined, regardless of the sample from which the PGS was derived, the effect of the PGS was predictive in both sexes but significantly larger in one of the sexes (17 of 27 traits with t test p <0.05 using the PGS derived from the males sample; 13 of 27 using the PGS derived from the females sample; Figures 2B, 2D, 2F, 2H, 2I, and 2J). These observations are consistent with systematic amplification.
Figure 2.

Evaluating evidence of systematic amplification
(A–D) We regressed trait values in males (green) and separately in females (orange) on a PGS estimated in an independent sample of males. Points show mean values in one decile of the PGS; the fitted line and associated effect estimate and correspond to regressions on the raw, non-binned data. In some traits, like albumin (A), the PGS has a similar effect on the trait in both sexes. In other traits (B and D), the estimated effect of the PGS differs significantly, consistent with a substantial difference in the magnitude of genetic effects of sites included in the PGS.
(E–H) Same analysis as in (A)–(D) but with a PGS pre-estimated in an independent sample of females.
(I and J) Summary of the ratio of the effect of the PGS on the trait (±2 SE) in males to the effect in females across physiological traits. See results for other traits in Figure S11.
The results presented in Figures 1 and 2 suggested to us that various modes of polygenic GxSex ought to be jointly evaluated. None of the hypothesized rules of thumb (Figure 1C) for interpreting genetic correlations and sex differences in heritability worked across all traits (see also a relevant discussion in Khramtsova et al.9). This motivated us to directly estimate the covariance between genetic effects in males and females. Another reason to treat covariance of genetic effects themselves as the estimand of interest is that multiple, distinct GxSex patterns may exist across subsets of genetic factors affecting a trait, depending on the pathways through which the subset acts, and whether and how the pathways are sex contingent (Figure 1C, fourth model).
Flexible model of sex-specific genetic effects as arising from a mixture of covariance relationships
We set to directly infer the mixture of covariance relationships of genetic effects among the sexes. We analyzed all traits in their raw measurement units as provided by the UKB. In particular, we did not normalize or standardize phenotypes within each sex before performing the sex-stratified GWAS because sex differences in trait variance may be partly due to amplification. Standardization would have therefore resulted in masking amplification signals that may exist in the data. In some cases, this is indeed the purpose of standardization.44 More generally, while each scaling choice has it merits, we view the measurement of genetic effects in their raw units as the most biologically interpretable.
We used multivariate adaptive shrinkage (mash),45 a tool that allows inference of genome-wide frequencies of genetic covariance relationships. We model the marginal SNP effect estimates as sampled (with SNP-specific, sex-specific noise) from a mixture of zero-centered normal distributions with various pre-specified covariance relationships (2 × 2 variance-covariance matrices for male and female effects; Equation 1 in Urbut et al.45). Our pre-specified covariance matrices (“hypothesis matrices”) span a wide array of amplification and correlation relationships and use mash to estimate the mixture weights. Loosely, these weights can be interpreted as the proportion of variants that follow the pattern specified by the covariance matrix (Figure 3A). Our covariance matrices ranged from −1 to 1 in between-sex correlation and 10 levels of relative magnitude in females relative to males, including matrices corresponding to no effect in one or both sexes (Figure S2).
Figure 3.

Polygenic covariance structure between males and females
(A) Our analysis of the polygenic covariance between males and females is based on sex-stratified GWASs. We modeled the sex-stratified GWAS estimates as sampled with error from true effects arising from a mixture of possible covariance relationships between female and male genetic effects. As an example, shown are illustrations for three possible relationships of the same qualitative nature—perfectly correlated effects that are also larger in females—and the mixture weights estimated for each in the case of diastolic blood pressure.
(B–F) Each box shows the sum of weights placed on all covariance relationships of the same qualitative nature, as specified by relative magnitude (horizontal axis) and correlation (vertical axis) between male and female effects. The full set of pre-specified covariance matrices is shown in Figure S2, and the weights placed on each of them for each trait are shown in Data S1–27. All weights shown are percentages of non-null weights; i.e., the weight divided by the sum of all weights except for the one corresponding to no effect in either sex.
We first focus on testosterone, for which previous research sets the expectation for polygenic male-female covariance. In terms of magnitude, the vast majority of effects should have much greater effect in males. In terms of correlation, we expect a class of genetic effects acting through largely independent and uncorrelated pathways alongside a class of effects via shared pathways.23 Independent pathways include the role of the hypothalamic-pituitary-gonadal axis in male testosterone regulation and the contrasting role of the adrenal gland in female testosterone production. Shared pathways involve sex hormone-binding globulin (SHBG), which decreases the amount of bioavailable testosterone in males and females. As expected, we found that mixture weights for testosterone concentrated on greater magnitudes in males and largely uncorrelated effects. Of the 32% total weights on matrices with an effect in at least one sex, 98% of the weights were placed on matrices representing larger effects in males, including 20.4% (±0.7%) having male-specific effects (Figures 3 and S5).
Amplification of genetic effects is the primary mode of GxSex
The only trait of the 27 where a large fraction ( 10%) of non-zero effects was negatively correlated was testosterone (17%). Most effects were instead perfectly or near-perfectly correlated. For example, diastolic blood pressure and eosinophil percentage had 66% (Figure 3B) and 68% (Data S8) of effects being perfectly correlated, respectively. Overall, the low weights on matrices representing negative correlation do not support opposite directions of effects being a major mode of GxSex (Figure S7).
In some traits, such as hemoglobin A1C or diastolic blood pressure, previously considered non-sex specific because of high genetic correlations between sexes and a concordance in top GWAS hits, we find evidence of substantial GxSex through amplification (Figures 3B and 3F).25,26 Furthermore, about half (13 of 27) of the traits analyzed had the majority of weights placed on greater effects in just one of the sexes (x axis in Figure 4A). For instance, 92% of effects on BMI-adjusted waist:hip ratio were greater in females, and 92% of effects on (right) arm fat-free mass were greater in males. Both traits had mixture weights concentrated on highly correlated effects (Figure 3). We confirmed, using a simulation study, that this summary of sex-biased amplification indeed captures sex differences in the magnitude of genetic effects and that it is not due to differences in the extent of estimation noise (e.g., variation in environmental factors independent of genetic effects; Figures S5 and S6; STAR Methods).
Figure 4.

Consequences of amplification for trait variance and polygenic score predictive utility
(A) Phenotypic variance strongly correlates with amplification. “Sex-biased amplification” on the x axis is calculated by taking the difference between the sum of mixture weights on covariance matrices with male effects greater in magnitude than female effects (M > F) and the sum of weights of M < F matrices. The solid gray line shows a linear fit across traits, excluding testosterone as an outlier, with correlation summaries in gray in the top left corner.
(B) Utility of the polygenic GxSex model for trait prediction. The x axis shows the relative prediction accuracy estimated from the incremental R2 ratio of a GxSex model informed by polygenic covariance patterns and an additive model. For each trait, smaller points show relative prediction accuracies across 20 cross-validation folds, and larger points show the average across the 20 folds. The phenotypes are ordered by the mean relative prediction accuracy. The color of each point corresponds to the degree of sex-biased amplification as described in (A).
Across traits, the difference between the fraction of male-larger effects and the fraction of female-larger effects correlates strongly with male-to-female phenotypic variance ratio (Pearson r = 0.873, p = 6 10−9 after removing testosterone as an outlier; Figure 4A). This observation is consistent with our hypothesis of amplification leading to differences in genetic variance between sexes, thereby contributing substantially to sex differences in phenotypic variance. Together, these observations point to amplification, rather than uncorrelated effects, as a primary mode of polygenic GxSex.
Another important question about the implication of pervasive amplification is whether it is a major driver of mean phenotypic differences. The ratio between male and female phenotypic means is correlated with the difference between male-larger and female-larger amplification (Pearson r = 0.75, p = after removing testosterone and BMI-adjusted waist:hip ratio as outliers). Although this correlation is intriguing, within-sex GWAS aims to explain individual differences from the mean of the sex, and such GWAS results do not dictate the values of the sex means. Further, the ratio of mean trait values between sexes and the difference in amplification are strongly correlated with phenotypic variance ratios (Figure 4A; Figure S8; see also Karp et al.8), and many different causal accounts could explain these correlations.
Finally, the pervasiveness of GxSex, alongside the mixture of covariance relationships across the genome for many traits, may be important to consider in phenotypic prediction. We compared the prediction accuracy of PGSs that consider the polygenic covariance structure with that of additive models that ignore GxSex as well as models that include GxSex but do not consider the polygenic covariance structure (supplemental information; Figure S12). Indeed, for most traits (20 of 27 traits; Figure 4B), models that consider the polygenic covariance structure outperform all other models evaluated. Traits that showed better prediction accuracy using the model that considered polygenic covariance structure included many body mass-related traits, such as BMI and whole body fat mass, that also tended to have higher sex-based amplification (Figure 4B; Pearson between sex-biased amplification and prediction accuracy ratio). These results point to the utility of considering polygenic covariance structure in PGS prediction.
Testosterone as an amplifier
Thus far, we treated the genetic interaction as discretely mediated by biological sex. One mechanism that may underlie GxSex is a cue or exposure that modulates the magnitude (and less often the direction) of genetic effects and varies in its distribution between the sexes. As an example of such a cue, we considered testosterone. Testosterone may be a plausible instigator because the hormone is present in distinctive pathways and levels between the sexes and is a known contributor to the development of male secondary characteristics and therefore could modulate genetic causes on sex-differentiated traits.
To test this idea, we first binned individuals of each sex by their testosterone levels. Then, for each trait and within the bin, we quantified the magnitude of total genetic effect as the linear regression coefficient of trait values to a PGS for the trait (STAR Methods; see Figure S14 for results obtained using sex-specific PGSs). For BMI, testosterone (mean per bin) and the magnitude of genetic effect were correlated for males and females (Pearson p < 0.05; Figure 5A). For all body mass-related traits, there was a negative correlation between the magnitude of genetic effect and testosterone levels for males and a positive correlation for females (Figure 5B). Because the relationship with testosterone remains contingent on sex, a model of testosterone as the sole driver of the observed sex specificity would be invalid. These observations may help explain previous reports of positive correlations between obesity and free testosterone in women and negative correlations in men.46 We conclude that, in body mass-related traits, testosterone may be modulating genetic effects in a sexually antagonistic manner.
Figure 5.

Amplification of total genetic effect in relation to testosterone levels
(A) The relationship between testosterone level bins and estimated magnitude of genetic effect on traits is shown for three traits. The magnitude of genetic effect is estimated using the slope of the regression of phenotypic values to PGSs in that bin. The units on the y axis are effect per standard deviation (SD) of the PGSs across all individuals in all bins. The hollow data points are bins with overlapping testosterone ranges between males and females; these are based on fewer individuals (∼800 compared with ∼2,200 in other bins) and not included in the regression. Figure S13 show all other traits analyzed.
(B) The correlation for each sex (90% CI) are shown for all 27 traits. Traits are ordered in descending order of male-female differences in Pearson correlation.
We performed two additional analyses designed to control for possible caveats to the association of testosterone and the magnitude of polygenic effect. First, a test that controls for possible confounding with age (Figure S16). Second, a test that mitigates confounding with other variables or reverse causality (where the magnitude of genetic effect affecting the focal trait causally affecting testosterone levels; Figure S15). The evidence of an effect of testosterone on the magnitude of polygenic effect did not remain statistically significant in either of these tests. It is possible, however, that this was due to the low statistical power of these more conservative analyses (STAR Methods).
Are polygenic and environmental effects jointly amplified?
Our results thus far suggest that polygenic amplification across sexes is pervasive across traits and that the ratio of phenotypic variance scales with amplification (Figure 4A). An immediate question of interest is whether the same modulators that act on the magnitude of genetic effects act on environmental effects as well (see also a relevant discussion by Domingue et al.47). Consider the example of human skeletal muscle. The impact of resistance exercise varies between males and females. Resistance exercise can be considered an environmental effect because it upregulates multiple skeletal muscle genes present in males and females, such as insulin growth factor 1 (IGF-1), which, in turn, is involved in muscle growth.48 However, after resistance exercises at similar intensities, upregulation of such genes is sustained in males, while levels return sooner to the resting state in females (Figure S17). It is plausible that modulators of the effect of IGF-1, such as insulin49 or sex hormones,50,51 drive a difference in the magnitude of effect of core genes such as IGF-1 in a sex-specific manner. To express this intuition with a model: if amplification mechanisms are shared, then amplification may be modeled as having the same scalar multiplier effect on genetic and environmental effects (Figure 6A). In the STAR Methods, we specify the details of a null model of joint amplification, which yields the prediction that the male-female ratio of genetic variances should equal the respective ratio of environmental variances (blue line in Figure 6B). As we explain in the supplemental information, this expectation is qualitatively different from those of two long-standing “rule of thumb” predictions for sex differences in trait variance52: the “greater male variability” and “estrus-mediated variability” models, which provide a poor fit across the 27 physiological traits analyzed (Figure S18B).
Figure 6.

Testing a model of pervasive, joint amplification of environmental and polygenic effects
(A) A model of equal amplification of genetic (G) and environmental (E) effect that produces the sex differences in the distribution of the phenotype, Y. G and E act through a core pathway that is amplified in a sex-specific manner.
(B) The blue 1:1 line depicts the theoretical expectation under a simple model of equal amplification of G and E effects in males compared with females. Error bars show 90% confidence intervals. Traits in blue are consistent (within their 90% CI) with the theoretical prediction. Figure S18 shows the same data alongside the predictions under other theoretical models of male-female variance ratios.
We tested the fit of the theoretical prediction under pervasive joint amplification across traits. We used our estimates of sex-specific phenotypic variance and SNP heritabilities to estimate the ratios of genetic and environmental variances. We note that environmental variance is proxied here by all trait variance not due to additive genetic effects, and caution is advised with interpretation of this proxy. Twenty of the 27 traits were consistent with the null model of pervasive joint amplification (within 90% confidence interval [CI]; Figure 6B). This finding may suggest a sharing of pathways between polygenic and environmental effects for these traits (Figure 6A). Interesting exceptions include diastolic blood pressure, which was the strongest outlier (p = , single-sample z test), excluding testosterone.
Sexually antagonistic selection
A hypothesized cause of sexual dimorphism is sexually antagonistic selection, in which some alleles are beneficial in one sex but deleterious in the other.11,12,14,53,54 Sexually antagonistic selection is difficult to study using traditional population genetics methods because Mendelian inheritance equalizes autosomal allele frequencies between the sexes at conception, thereby erasing informative signals. One way around this limitation is to examine allele frequency differences between the sexes in the current generation, known as “selection in real time.”14,55,56 In this section, we consider a model of sexually antagonistic selection acting on a polygenic trait and use it to estimate the strength of contemporary viability selection acting on the 27 traits we analyzed.
Most theoretical models of sexually antagonistic selection on a trait under stabilizing selection usually posit either highly distinct male and female fitness optima or genetic variants affecting traits antagonistically. Our findings on pervasive amplification suggest that variant effects on traits tend to have concordant signs. However, under pervasive amplification, a somewhat surprising intuition arises. Alleles affecting a trait may frequently experience sexually antagonistic selection in the case in which trait optima for males and females are very distinct (Figure 7B) and for the case in which they are similar (Figure 7A).
Figure 7.

Testing for sexually antagonistic selection
(A and B) A model of sexually antagonistic selection. Selection coefficients, and , are linear with the additive effect on the trait in each sex. Sexually antagonistic selection acts so that . The model yields the prediction of Equation 1. While in (A), trait optima are close to each other and in (B) they are far apart, in both cases alleles will tend to be antagonistically selected.
(C) Two examples of the weighted least-squares linear regression performed to estimate the strength of sexually antagonistic selection on variants associated with a trait ( in A and Equation 1). Each point shows one SNP. Size is proportional to each point’s regression weight.
(D) Z scores (90% non-parametric bootstrap CI) estimated through 1,000 resampling iterations of the weighted linear regression of (B) for each trait. The two colored estimates correspond to the examples in (B) and (C).
We developed a theoretical model of sexually antagonistic viability selection on a single trait that builds on this intuition. The model relates sex-specific effects on a complex trait to the divergence in allele frequency between males and females (measured as 57,58) because of viability selection “in real time”; i.e., acting in the current generation between conception and the time of sampling. We derive the expected relationship for each site ,
| (Equation 1) |
where
and and are the allele frequency of an allele at site , its effect on the trait in males, and its effect in females, respectively. is a constant parameter shared across all variants and can therefore be interpreted as the effect of sexually antagonistic selection on male-female divergence at variants associated with the trait (STAR Methods). We estimated for all sites across subsamples of various ancestry groups in the gnomAD dataset.59 To estimate at each site and for each trait, we used our sex-stratified GWAS results. Because there is large heterogeneity in uncertainty of GxSex-genetic variance estimates, we use a variance-weighted linear regression to estimate A (see STAR Methods for the derivation of the variance of estimates and supplemental information for further details).
Recent work has shown that apparent sex differences in autosomal allele frequencies within a sample are often due to a bioinformatic artifact: mismapping of sequencing reads from autosomes to sex chromosomes or vice versa.53,60,61 We identified and excluded sites that are potentially vulnerable to this artifact (supplemental information). In Figure 7D, we only show results for gnomAD subsamples that are the closest in their genetic ancestry to our UKB sample62 (results for other subsamples are shown in Figures S19 and S20). Furthermore, given the concerns of study recruitment biases,43,60 we place higher confidence in results that replicate qualitatively across different subsamples, even though we note that subsample-specific selection signals may be real because sexually antagonistic selection may act heterogeneously across groups.
With these conservative criteria considered, we only find evidence of sexually antagonistic polygenic selection on testosterone. In the non-Finnish sample, the largest of the three samples, the null hypothesis in Equation 1 is rejected (p < 0.05) only for testosterone (Z score = 2.2). Testosterone is among the three strongest signals in the two other samples as well, although none of the traits are statistically significant in these samples.
Discussion
Departing from previous studies that sought GxSex through single loci or heritability analyses, we modeled GxSex as a mixture of polygenic relationships across the genome. Our analysis supports pervasive context dependency of genetic effects on complex traits, acting largely through amplification. Surprisingly, even for some traits such as red blood cell count, previously considered non-sex specific because of high genetic correlations between sexes and a concordance in top GWAS hits, we find evidence of substantial GxSex. The strong relationships we find between amplification, environmental variance, and phenotypic variance further point to its potential importance for sex differences.
We have shown that considering the polygenic covariance structure, including amplification signals, improves phenotypic prediction for most traits. Its incorporation in PGSs is straightforward. We therefore recommend its broad application and further building on our approach to improve clinical risk stratification and other applications of PGSs.
Our findings may seem at odds with previous reports of GxSex primarily consisting of sex-limited effects (i.e., no effect in one of the sexes) or antagonistic effects (differences in sign).63 In the supplemental information and Table S6, we illustrate that these apparent discrepancies may be rooted in ascertainment biases. Therefore, limiting analyses to variants with outsized sex differences provides a clouded picture of polygenic GxSex.
Localization of GxSex signals can provide clues regarding the modulators underlying amplification. Here, we proposed one such modulator, testosterone, and found a correlation between testosterone levels and the magnitude of genetic effect on whole body fat mass. The opposite signs of these correlations in females and males may reflect the discrepant relationship between testosterone and these traits at the phenotypic level.
Our approach for studying GxSex in complex physiological traits can be adopted to study the moderation of polygenic effects by other environments. Starting out with sex as an environmental variable offers a methodological advantage. The study of context dependency in humans is often complicated by study participation biases, leading to a genetic ancestry structure that confounds genotype-phenotype associations,43,64,65,66 reverse causality between the phenotype and environment variable, collider bias, gene-by-environment correlation, and other problems.67,68,69 Focusing on sex as a case study circumvents many of these “usual suspect” problems; for example, problems involving the phenotype causally affecting sex are unlikely. This is an important benchmark for future studies of environmental modulation because of the methodological advantage of sex as an environmental variable and because sex is almost always measured; so insight into sex differences in genetic effects can be incorporated straightforwardly in future studies and in clinical risk prediction. Here, we showed that, for most of the traits considered, modeling polygenic GxSex (as opposed to individually estimating sex-specific effects at each site; Figure S12) yields sex-specific predictors that outperform standard additive PGSs.
Finally, we developed a model—the first to our knowledge—that considers how GxSex may fuel sexually antagonistic selection on complex traits. Over long evolutionary timescales, the two scenarios depicted in Figures 7A and 7B may lead to different predictions about the long-term maintenance of GxSex genetic variance. Regardless, in both cases, alleles that underlie GxSex may experience sexually antagonistic selection.
We found suggestive signals of sexually antagonistic selection on variation associated with testosterone levels (also see related results by Ruzicka et al.56). The signal for our inference of selection is systematic allele frequency differences between adult males and females, which are consistent with contemporary viability selection. The severity, age of onset, and prevalence of nearly all diseases are sexually dimorphic.70 These signals may therefore point to a related disease that differentially affects lifespan in the two sexes, such as immune system suppression, diabetes, cancers, and hypertension.71,72,73,74 Recently, high testosterone levels have been linked to increased rates of mortality and cancer in women but decreased rates in men.75,76 However, the testosterone result is also consistent with other accounts, such as testosterone having opposing effects on the propensity to participate in a study in the two sexes. Further validation is therefore required to better test hypotheses of sexually antagonistic selection; for example, in studies with no recruitment biases (or at least distinct recruitment biases).
In this work, we have shown that amplification of the magnitude of polygenic effects may be important to consider as a driver of sex differences and their evolution. Our approach included the flexible modeling of genetic effect covariance among the sexes, as well as various subsequent analyses exploring the implications of these covariance structures. We hope this study can inform future work on the context specificity of genetic effects on complex traits.
Limitations of the study
Study participation in large biobanks like the UKB differs by sex,77 and work by Pirastu et al.60 further argued that allele frequency differences between males and females may reflect sex-specific recruitment biases. However, a recent study by Benonisdottir and Kong43 found no evidence of sex-specific genetic associations with UKB participation, and another by Kasimatis et al.53 showed that many apparent associations of autosomal genotypes and biological sex in the UKB were instead primarily due to a bioinformatic artifact: mis-hybridization of autosomal genotyping probes with sex chromosomes. Even still, subtle recruitment biases affecting male and female participation differently remains a possible caveat to our conclusions. For the analysis of natural selection, the replication of signals of selection in multiple samples may lend some credence to our inference. Nevertheless, in medical datasets based on recruitment of participants via referring physicians, recruitment biases may still plausibly be shared across studies.
Another limitation of the study is the inability to directly test the hypothesis about pervasive, joint amplification of genetic and environmental effects. While the data available to us are consistent with the hypothesis (Figures 6 and S19), they are also consistent with other possible explanations and susceptible to caveats. For example, our proxy for environmental variance includes, to an unknown extent, genetic variance, which is not well tagged by the UKB genotype array. Further study is required to robustly test this hypothesis, but it may require detailed data on environmental effects on a complex trait in females and males.
STAR★Methods
Key resources table
| REAGENT or RESOURCE | SOURCE | IDENTIFIER |
|---|---|---|
| Deposited data | ||
| Genotype and phenotype files and minor allele frequencies from UK Biobank | Bycroft et al., 201878 | https://www.ukbiobank.ac.uk/ |
| 1000 Genomes phase 3 (build 37) | Auton et al., 2015 | https://www.cog-genomics.org/plink/2.0/resources#phase3_1kg |
| Sex-specific summary statistics | This paper | https://doi.org/10.5281/zenodo.7222725 |
| Both-sex summary statistics | This paper | https://doi.org/10.5281/zenodo.7508246 |
| LD Scores and weights | Bulik-Sullivan et al., 201536 | https://alkesgroup.broadinstitute.org/LDSCORE/ |
| LD blocks | Berisa and Pickrell, 201679 | https://doi.org/10.1093/bioinformatics/btv546 |
| Allele frequency data from gnomAD v3.1.2 | Karczewski et al., 202059 | https://gnomad.broadinstitute.org/ |
| Software and algorithms | ||
| R | R Core Team | https://www.R-project.org |
| plink v1.90 beta | Purcell and Chang, 2021 | https://www.cog-genomics.org/plink/ |
| Plink v2.00 alpha | Purcell and Chang, 2020 | https://www.cog-genomics.org/plink/2.0/ |
| LD Score Regression v1.0.1 | Bulik-Sullivan et al. 201542 | https://github.com/bulik/ldsc |
| Ensembl command line variant effect predictor (VEP) v106 | McLaren et al., 2016 | https://github.com/Ensembl/ensembl-vep.git |
| mashr: Multivariate Adaptive Shrinkage in R | Urbut et al., 201945 | https://github.com/stephenslab/mashr |
| VCFTools | Danecek et al., 2011 | https://vcftools.github.io/downloads.html |
| BLAST | Camacho et al., 2009 | https://blast.ncbi.nlm.nih.gov/Blast.cgi |
| LiftOver | Kent et al., 2002 | https://genome.ucsc.edu/cgi-bin/hgLiftOver |
| BLAT | Kent, 2002 | http://genome.ucsc.edu/cgi-bin/hgBlat |
| Custom code | This study | https://doi.org/10.5281/zenodo.7765067 |
Resource availability
Lead contact
Further information and requests for resources should be directed to and will be fulfilled by the lead contact, Arbel Harpak (arbelharpak@utexas.edu).
Materials availability
This study did not generate new unique reagents.
Method details
UK Biobank sample characteristics
The UK Biobank is an extensive database that contains a wide variety of phenotypic and genotypic information of around half a million participants aged 40-69 at recruitment.78
In this study, we considered 337,111 individuals who passed quality control (QC) checks, which included the removal of samples identified by the UK Biobank with sex chromosome aneuploidy or self-reported sex differing from sex determined from genotyping analysis. We excluded related individuals (3rd-degree relatives or closer) as identified by the UK Biobank in data field 22020. To reduce potential population structure confounding, we further limited our sample to individuals identified by the UK Biobank as “White British” in data field 22006. These are individuals who both self-identified as White and as British and were additionally very tightly clustered in the genetic principal component space.78,80 Individuals who had withdrawn from the UK Biobank by the time of this study were removed. For each phenotype, we also removed individuals who had missing data for the specified phenotype. These procedures left us with between 255,426 to 336,551 individuals in the analysis for each trait.
Expectations for sex-specific heritabilities with no GxSex
In the section “The limited scope of analyzing GxSex via heritability differences and genetic correlations,” we report our observation that, for most traits examined, sex-specific heritabilities (i.e., estimated independently from sex-stratified GWAS) were both higher than the heritability in the combined sample. Here, we explain why this observation is inconsistent with a simple model in which genetic effects are the same across the sexes.
Under a simple additive model of variance in a trait within each sex ,
| (Equation 2) |
where represent the trait value, additive effect, and environmental effect (including all non-genetic context aside from sex), respectively. Under this model, the sex-specific heritability is
| (Equation 3) |
Therefore, sex differences in heritability are either due to sex differences in genetic variance, in environmental variance, or both. If genetic effects are equal, differences in environmental variance alone could cause heritability differences (Figure 1C, first model). But as we show below, the heritability in the combined sample cannot be smaller than both sex-specific heritabilities.
We assume as before that allele frequencies are highly similar between males and females. Since genetic effects are equal, this implies
For the environmental variance, we have that
| (Equation 4) |
The first equality follows from the law of total variance. In the second equality, we have assumed that there are no mean sex differences in the environmental effects (or, in practice in our analysis and as routine in other analyses, that mean phenotypic sex differences have been subtracted out), giving
Equation 4 shows that the combined environmental variance cannot be greater than the larger of the two sex-specific environmental variances. It follows that if the genetic variance is equal in both sexes, then the heritability in the combined sample cannot be smaller than both of the sex-specific heritabilities,
| (Equation 5) |
Multivariate adaptive shrinkage (mash)
We used multivariate adaptive shrinkage (mash) to examine correlation and differences in magnitude of SNP effects between males and females.45 mash is an adaptive shrinkage method81 that improves upon previous methods of estimating and comparing effects across multiple conditions by flexibly allowing for a mixture of effect covariance patterns between conditions and requiring only summary statistics from each condition (including a point estimate of the effect and corresponding standard error for each SNP and condition). The method adapts to patterns of sparsity, sharing, and correlation among the conditions to compute improved effect estimates.
In this study, we set two conditions, male and female, and provided effect estimates and corresponding standard errors from our male-specific and female-specific GWAS. mash learns from the data by estimating mixture proportions of various predefined covariance matrices representing different patterns in effects. Using maximum likelihood, mash assigns low weights to matrices that capture fewer patterns in the data, and higher weights to those that capture more.
Mixture weights for covariance structure between male and female effects
To interpret patterns of SNP effects between males and females, we inputted 66 hypothesis-based covariance matrices (Figure S2) spanning a range of correlations and relative magnitudes of effects between males and females. We used a random subset of all SNPs for mash to learn the covariance mixture weights. In order for the random subset to contain approximately independent SNPs and capture the weight of SNPs with no effect (Figure S2), we created a subset of SNPs for each trait by taking a random SNP from each of 1703 approximately independent LD blocks estimated for Europeans.79 mash can also generate data-driven covariance matrices that capture SNP effects in the data, but we did not use this feature since the data-driven matrices had negligible differences from our hypothesized matrices (in terms of 2 norm) and were less interpretable.
For each trait, we repeat this weight-learning step 100 times, sampling the SNPs from the 1703 LD blocks without replacement to fit the mash model and generate mixture proportions. We then take the average proportion for each covariance matrix as an estimate of its weight, effectively treating each of the 100 samples as i.i.d. draws.
Choice of SNPs used to estimate male-female effect covariance
We examined the effect of using a random subset taken from different p-value thresholds [1, 5e-2, 1e-5, 5e-8] while selecting from LD blocks. By doing so, we can examine differences in the distribution of weights across the p-value thresholds. We performed this test on height, BMI, testosterone, and BMI-adjusted waist:hip ratio. For each trait, weight placed on the no-effect matrix decreased as we reduced the p-value threshold (Figure S4A). Patterns of weights for non-null effect matrices varied across the traits (Figures S4B and S4C). Since mash considers the proportion of null effects and sex-specific, SNP-specific noise; together with the fact that for complex traits, less significant associations may still reflect valuable signal, we decided on using the whole set of SNPs to sample from when estimating mixture proportions.
Simulating equal genetic effects and heterogeneous estimation noise among the sexes
To ensure that mash was not mistaking sex differences in estimation noise (e.g. via differences in the extent of environmental variance) to be differences in the magnitude of genetic effects, we performed a simulation study. In short, samples of males and females were generated under the model given by Equation 2. Genetic effects were set as equal, but the environmental variance differed among the sexes. We then perform a GWAS on both samples and input the simulated GWAS results into mash, and test whether the estimated mixture weights spuriously suggest the presence of GxSex. We performed this simulation on a grid of parameters, including heritabilities in males set to either 5% or 50%, female to male environmental variance ratio of 1, 1.5 or 5; and 100, 1,000 or 10,000 causal SNPs.
First, we created a sample of 300K individuals with randomly assigned sex. We then sampled genotypes for all individuals consisting of 20K SNPs by sampling from the observed distribution of allele frequencies from UK Biobank’s imputed data,82 assuming linkage equilibrium. From the 20K SNPs, we portioned out the predetermined number of causal SNPs and assigned effect sizes by sampling from a Standard Normal distribution. We set the environmental variance for males using the equation
| (Equation 6) |
where is the simulated environmental variance for males, is the genetic effect in a male, is the heritability in males and and are the effect size and allele frequency at site , which are equal for males and females. We multiplied by the predetermined environmental variance ratio to obtain the environmental variance for females . Afterwards, for each individual with sex , we sampled the environmental effect as
Phenotypes were then set using the following additive model,
| (Equation 7) |
where is the phenotypic value for individual and is the number of effect allele copies at the causal SNP for the individual. With the phenotype, genotype and environmental effect set, we obtained the estimated effect sizes, , using least squares simple linear regression for all 20K SNPs and used the estimated effect sizes and corresponding standard errors as input into mash.
For nearly all parameters, out of the weights on matrices other than the null matrix, the vast majority was placed on the matrix for perfect correlation, equal magnitude (Figure S5). As the number of causal SNPs increased, the weight on the no-effect covariance matrix decreased accordingly. These results suggest that mash was not grossly mistaking differences in environmental variance as amplification.
Simulating sex-biased amplification
To evaluate whether mash accurately captures sex-biased amplification of genetic effects (a measure we have used in the x-axis of Figures 4A and 4B), we followed the same simulation procedure described in the Section “Simulating equal genetic effects and heterogeneous estimation noise among the sexes”. However, instead of using equal genetic effects in males and females, we sampled genetic effects from pre-specified covariance matrices (Figure S6 left-hand panel). We set the female to male environmental variance ratio as 1.2 and the heritability as 0.5. We generated data from (A) a model in which all genetic effects are sampled from a matrix where male and female effects are equal, (B) a model in which 86% of the genetic effects are sampled from a matrix where effects between the sexes are equal, and 14% of the effects are sampled from a matrix where the female effect size magnitude is 4 times that of males, and (C) a model in which 86% of effects are sampled from a matrix where effects between sexes are equal, and 14% of effects are sampled from a matrix of only female-specific effects. After simulating sex-specific GWAS on the three models, we input the results into mash to estimate mixture weights. We repeated this simulation procedure 100 times for each model.
For model (A), the equal effect matrix received 78% of the weight, and the difference between male-larger and female-larger magnitude was 1% (Figure S6). For model (B), 67% of the weight was placed on the matrix for equal effects. The weight difference between male-larger and female-larger magnitude was 13%. In model (C), 69% of the weight was on the matrix for equal effects, and the difference between male-larger and female-larger magnitude was 16%. These simulation results therefore suggest some overestimation of the proportion of SNPs with magnitude differences. However, the measure of “sex-biased amplification” matched that of the pre-specified generative models up to an error of 2%. Therefore, the simulations suggest that “sex-biased amplification” is measured accurately in our estimation procedure.
Testosterone as an amplifier
We tested a model of testosterone as a modulator of magnitude differences in males and females. We first split individuals by sex and for each sex, created 10 bins of testosterone levels. We adjusted one of the 10 bins to have testosterone levels overlap between males and females. The overlapping testosterone bin was based on fewer individuals (∼800) compared to the other bins (∼2200). For each trait, each of the sexes, and within each bin, we performed a simple linear regression of trait values to the PGS for the trait (using a PGS based on both-sex summary statistics (supplemental information)). We interpret the estimated coefficient for the effect of the PGS as a proxy for the magnitude of polygenic effect. Finally, we summarized the relationship between testosterone level and magnitude of polygenic effect across bins using the Pearson correlation between the two.
To mitigate the possible effects of confounding (of testosterone and magnitude of polygenic effect) or reverse causation (the magnitude of polygenic effect on the focal trait causally affecting testosterone levels) we employed a version of Mendelian Randomization83,84 of the same analysis (Figure S15). Namely, we replaced testosterone levels of each individual with their PGS for testosterone. Here, given the near-zero genetic correlation between males and females, we used our sex-specific PGS for each sex; otherwise, the analysis is unchanged.
We also examined whether participants’ age may have confounded the relationship between testosterone and polygenic effect. In this analysis, instead of using the polygenic effect as the response variable across bins, we used the polygenic effect residualized for mean age in the bin and examined the effect of an individual’s polygenic score on the residual (Figure S16).
Model of shared amplification
Here, we suggest a null model in which amplification is shared between genetic and environmental effects. We then suggest a prediction that the model yields and explain how we tested this prediction across traits (Figure 6).
If an amplifier is shared, it may be modeled as having the same scalar multiplier effect on genetic and environmental effects. Consider the within-sex additive model of Equation 1 in the section “The limited scope of analyzing GxSex via heritability differences and genetic correlations” above. For a phenotype value in sex
| (Equation 8) |
Where c is a constant, is the environmental effect and
| (Equation 9) |
is the polygenic effect where is the effect of an allele at site (say the minor allele) in sex and is the number of copies of the allele. We assume here for simplicity that male genetic effects relate to female effects solely through a shared polygenic amplification constant, α,
| (Equation 10) |
Allele frequencies are once again assumed to be close to equal between males and females, since due to random segregation of alleles during meiosis, genotype frequencies at autosomal sites are independent of sex; and further assuming no substantial interaction between genotype and sex affecting participation in UKB.43 Consequently, differences in polygenic effect distributions between males and females are solely based on GxSex, and thus:
| (Equation 11) |
The model we would like to test is one where the amplification of environmental effects can also be simplified to the same scalar multiplier,
| (Equation 12) |
Hence, with equal amplification,
| (Equation 13) |
To test the model of shared amplification between environmental and polygenic effects (Equation 8) we obtained the genetic and environmental variance for males and females based on the following relationships,
| (Equation 14) |
and
| (Equation 15) |
where , and are the additive genetic, environmental, and phenotype variances, respectively. Estimates of the sex-specific heritabilities, , were obtained from previous estimates using LD Score Regression (supplemental information).
Representing male genetic or environmental variance as , and the corresponding female variance as , we derived standard errors for the ratio of male to female variance using the 2nd-order Taylor approximation for the standard error of a ratio of estimators of and ,
| (Equation 16) |
assuming independence between and since they are statistics of independent sampling distributions (independent samples of males and females). The standard errors of the genetic and environmental variance were estimated using the law of total variance for a product of two random variables. For and , unbiased estimators of the two parameters and , respectively, we get
Plugging in the point estimate for and the point estimate for ,
| (Equation 17) |
In this case, represents the phenotypic variance for a sex, and represents either for estimation of genetic variance or for estimation of environmental variance. Lastly, to obtain the standard error of the phenotypic variance, we used 100 bootstrapped samples of estimates of the phenotypic variance in sex ,
Finally, for each trait, we estimated , the ratio of the two male-female ratios (environmental and genetic, y and x axes in Figure 6, respectively), and its standard error, , using the same method as in Equation 16. Under the null hypothesis of equal environmental and genetic amplification (Equation 8),
| (Equation 18) |
where
In Figure 6, we approximated 90% confidence intervals on by treating it as a Z score, i.e., further treating as a Standard Normal.
A model of sexually antagonistic selection
We developed a model relating sex differences in additive effects on a trait at a biallelic locus ( and ) and divergence in allele frequencies. Our model resembles that of Cheng and Kirkpatrick14 who developed a similar model relating allele-frequency differences and sex bias in gene expression. In short, we modeled sexually antagonistic, post-conception viability selection on a focal complex trait. We assumed allele frequencies in adult males, , and adult females, , are at equilibrium, i.e. do not change in consecutive generations. Under these conditions, we derive the relationship
where 57 is the fixation index with respect to the male and female subpopulations, i.e., the proportion of heterozygosity in the population that is due to allelic divergence between the sexes. is defined as
| (Equation 19) |
where is the allele frequency in zygotes. is a parameter that, importantly, is shared across all variants affecting the trait and can be thought of as the intensity of sexually antagonistic selection acting on genetic variation for the trait in question.
In our model, allele frequencies at the autosomal locus are assumed to be equal in males and female zygotes. at adulthood takes the form
| (Equation 20) |
where
If we further assume a near-1:1 sex ratio such that ,
| (Equation 21) |
Sexually antagonistic selection acting on viability will cause divergence in allele frequencies between adult males and females. We write the relative viabilities of the homozygote for the reference allele, the heterozygote and the homozygote for the effect allele as for each sex . The selection coefficient and dominance coefficient can be frequency-dependent, in which case these coefficients take their values at equilibrium. We can write the additive selection coefficient of the effect allele as
| (Equation 22) |
Assuming that zygotes are at Hardy-Weinberg equilibrium, the allele frequency in each sex at adulthood is
| (Equation 23) |
where we neglected terms of order 85. Plugging Equation 23 into Equation 21, the divergence between males and females post-selection is
| (Equation 24) |
We model the strength of viability selection acting on males and females as linear with the additive effect on a focal trait in each sex,
| (Equation 25) |
and recalling the simplifying assumption that allele frequencies are at equilibrium under sexually antagonistic viability selection at the locus, such that selection favoring an allele in one sex is balanced by selection against that allele in the other sex,
| (Equation 26) |
If , then Equation 24 simplifies to
| (Equation 27) |
where
| (Equation 28) |
is the additive genetic variance. However, when does not strictly equal , Equation 25, 26 together imply
| (Equation 29) |
Finally, using Equation 25,
| (Equation 30) |
which together with Equation 29 gives
| (Equation 31) |
We denote the heritability due to GxSex at the locus as and the parameter relating this contribution to the differentiation in allele frequencies as
| (Equation 32) |
and plugging Equation 31 into Equation 24, we get
| (Equation 33) |
as given by Equation 1 in the section “sexually antagonistic selection.”
Estimating the potential for sexually antagonistic selection on standing variation ()
For each trait and gnomAD subsample (supplemental information), we estimated using weighted least squares linear regression of our estimate of ( to our estimate of (), with weight inversely proportional to our site-specific estimate of noise in the estimate of ,
| (Equation 34) |
To simplify the estimation of we treated the allele frequency as perfectly estimated, and as independent of the allele frequency in the GWAS sample—as different data are used in the GWAS (UK Biobank) and in the allele frequency estimation (gnomAD). Under these assumptions,
| (Equation 35) |
and thus the task at hand is estimating . Using the law of total variance,
| (Equation 36) |
We begin with the argument of the first term,
| (Equation 37) |
where we denote
| (Equation 38) |
for each sex Plugging Equation 37 into the first term of Equation 36,
| (Equation 39) |
where the first and second step follow from the fact that is a constant. We can take note of the fact that is Normally distributed around , and in particular that it has no skewness. Therefore,
| (Equation 40) |
where is the skewness of . We can also note that
| (Equation 41) |
where we defined
and therefore is a Standard Normal and therefore is Chi-squared with one degree of freedom. Equation 41 now gives
| (Equation 42) |
Plugging Equations 40 and 42 into Equation 39, we find
| (Equation 43) |
We now turn to the second term of Equation 36. First,
| (Equation 44) |
Equations 40 and 42 again give us
| (Equation 45) |
which then gives
| (Equation 46) |
Plugging Equations 43 and 46 into Equation 36, we obtain
| (Equation 47) |
Finally, we estimate with the GWAS-derived point estimate of the effect and with its standard error, . Plugging back into Equation 35, we obtain
| (Equation 48) |
Using Equation 33, we estimate with the estimator
| (Equation 49) |
where
| (Equation 50) |
and noting that
| (Equation 51) |
where in the first equality we approximated the expectation of a ratio with the ratio of expectations. Therefore, Equation 49 provides an approximately unbiased estimator of despite the absence of genotype frequencies.
To perform this estimation of A on the GWAS and data, we used paired and points for all sites which passed all previous stages of filtering. Weights were set by Equation 34 and follow Equation 48 where and are the GWAS effect estimates as above, and and are the GWAS standard errors (SE) estimates for the effect size of each site per trait.
To minimize the possibility of LD between sites used in the analysis as much as possible, we used the approximately independent LD blocks in Europeans79 as in Section “Mixture weights for covariance structure between male and female effects”. Namely, we subdivided the genome into 1703 approximately independent LD blocks as before. We iterated over the 1703 blocks and sampling one site per block in a given iteration, using a sample of (up to) 1703 post-filtering sites to perform the weighted linear regression of on The slope of this regression was used as an estimate of . We perform this estimation procedure 1,000 times and take an average of scores (slope point estimates divided by their SE) as the final estimate of . In each replicate, we sample with replacement m LD blocks from the m LD blocks which had at least one site within them post-filtering (supplemental information); we then sample one site per resampled block. In Figure 7D, each point is the mean of the 1,000 samples of one site per LD block and 90% confidence intervals show the range between the 5th and 95th percentile of 10,000 bootstrap re-samplings of 1,000 samples, calculating a new mean for each bootstrap.
In the main text, we focus on the results performed this estimation for Ashkenazi Jewish, Finnish, and Non-Finnish European populations as the other ancestry group-stratified subsamples in gnomAD are further diverged from the UKB White British sample and therefore our GWAS estimates are expected to be less portable.62,86 We also performed a similar analysis using UKB data to measure differentiation in allele frequencies between males and females, rather than an independent dataset (gnomAD) as in the main text. Since individual level data was available in this case, we replaced with , a measure developed by Ruzicka et al.56 can be thought of as site-specific controlled for major axes of population structure differentiating males and females (Figure S20).
Acknowledgments
We thank the Harpak Lab and Edge Lab members Ziyue Gao, Tom Juenger, Jonathan Pritchard, Molly Przeworski, Guy Sella, Jeff Spence, and Elliot Tucker-Drob for helpful comments on the manuscript. We also thank Brian Dilkes, Andrés Bendesky, and Jim Fleet for insightful discussions. We thank Abin Abraham and Tony Capra for help with implementing code from Kasimatis et al.53 and Michelle Traglia and Lauren Weiss for useful discussions of the relationship between the results reported here and Traglia et al.63 This work was supported by NIH GM116853-07 (to M.K.) and NIH GM137758 (to M.D.E.). This study was conducted using the UK Biobank resource under application 61666, as approved by the University of Texas at Austin institutional review board (protocol 2019-02-0125).
Author contributions
C.Z., M.J.M., and A.H. designed the experiments. C.Z. and M.J.M. performed the experiments. C.Z. and A.H. wrote the paper with assistance from all authors. J.M.C., M.D.E., and M.K. provided expertise and feedback.
Declaration of interests
The authors declare no competing interests.
Published: April 6, 2023
Footnotes
Supplemental information can be found online at https://doi.org/10.1016/j.xgen.2023.100297.
Supplemental information
Data and code availability
This study used genotype and phenotype data from the UK Biobank https://www.ukbiobank.ac.uk/.
Sex-specific and additive GWAS summary statistics are available at Zenodo: https://doi.org/10.5281/zenodo.7222725 and https://doi.org/10.5281/zenodo.7508246 respectively, and are publicly available as of the data of publication. DOIs are listed in the key resources table.
All original code has been deposited at https://github.com/harpak-lab/amplification_gxsex and Zenodo: https://doi.org/10.5281/zenodo.7765067, and is publicly available as of the date of publication. DOIs are listed in the key resources table.
Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
References
- 1.van Doorn G.S. Intralocus sexual conflict. Ann. N. Y. Acad. Sci. 2009;1168:52–71. doi: 10.1111/j.1749-6632.2009.04573.x. [DOI] [PubMed] [Google Scholar]
- 2.Arnqvist G., Rowe L. Princeton University Press; 2005. Sexual Conflict. [DOI] [Google Scholar]
- 3.Camus M.F., Piper M.D., Reuter M. Sex-specific transcriptomic responses to changes in the nutritional environment. Elife. 2019;8 doi: 10.7554/eLife.47262. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bayer E.A., Stecky R.C., Neal L., Katsamba P.S., Ahlsen G., Balaji V., Hoppe T., Shapiro L., Oren-Suissa M., Hobert O. Ubiquitin-dependent regulation of a conserved DMRT protein controls sexually dimorphic synaptic connectivity and behavior. Elife. 2020;9 doi: 10.7554/eLife.59614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Baar E.L., Carbajal K.A., Ong I.M., Lamming D.W. Sex- and tissue-specific changes in mTOR signaling with age in C57 BL/6J mice. Aging Cell. 2016;15:155–166. doi: 10.1111/acel.12425. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Wat L.W., Chao C., Bartlett R., Buchanan J.L., Millington J.W., Chih H.J., Chowdhury Z.S., Biswas P., Huang V., Shin L.J., et al. A role for triglyceride lipase brummer in the regulation of sex differences in Drosophila fat storage and breakdown. PLoS Biol. 2020;18 doi: 10.1371/journal.pbio.3000595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Wat L.W., Chowdhury Z.S., Millington J.W., Biswas P., Rideout E.J. Sex determination gene transformer regulates the male-female difference in Drosophila fat storage via the adipokinetic hormone pathway. Elife. 2021;10 doi: 10.7554/eLife.72350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Karp N.A., Mason J., Beaudet A.L., Benjamini Y., Bower L., Braun R.E., Brown S.D.M., Chesler E.J., Dickinson M.E., Flenniken A.M., et al. Prevalence of sexual dimorphism in mammalian phenotypic traits. Nat. Commun. 2017;8 doi: 10.1038/ncomms15475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Khramtsova E.A., Davis L.K., Stranger B.E. The role of sex in the genomics of human complex traits. Nat. Rev. Genet. 2019;20:173–190. doi: 10.1038/s41576-018-0083-1. [DOI] [PubMed] [Google Scholar]
- 10.Barson N.J., Aykanat T., Hindar K., Baranski M., Bolstad G.H., Fiske P., Jacq C., Jensen A.J., Johnston S.E., Karlsson S., et al. Sex-dependent dominance at a single locus maintains variation in age at maturity in salmon. Nature. 2015;528:405–408. doi: 10.1038/nature16062. [DOI] [PubMed] [Google Scholar]
- 11.Kidwell J.F., Clegg M.T., Stewart F.M., Prout T. Regions of stable equilibria for models of differential selection in the two sexes under random mating. Genetics. 1977;85:171–183. doi: 10.1093/genetics/85.1.171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Connallon T., Cox R.M., Calsbeek R. Fitness consequences of sex-specific selection. Evolution. 2010;64:1671–1682. doi: 10.1111/j.1558-5646.2009.00934.x. [DOI] [PubMed] [Google Scholar]
- 13.Harrison P.W., Wright A.E., Zimmer F., Dean R., Montgomery S.H., Pointer M.A., Mank J.E. Sexual selection drives evolution and rapid turnover of male gene expression. Proc. Natl. Acad. Sci. USA. 2015;112:4393–4398. doi: 10.1073/pnas.1501339112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Cheng C., Kirkpatrick M. Sex-specific selection and sex-biased gene expression in humans and flies. PLoS Genet. 2016;12 doi: 10.1371/journal.pgen.1006170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Schroderus E., Jokinen I., Koivula M., Koskela E., Mappes T., Mills S.C., Oksanen T.A., Poikonen T., Ketterson A.E.E.D., McPeek E.M.A. Intra- and intersexual trade-offs between testosterone and immune system: implications for sexual and sexually antagonistic selection. Am. Nat. 2010;176:E90–E97. doi: 10.1086/656264. [DOI] [PubMed] [Google Scholar]
- 16.Power R.A., Kyaga S., Uher R., MacCabe J.H., Långström N., Landen M., McGuffin P., Lewis C.M., Lichtenstein P., Svensson A.C. Fecundity of patients with schizophrenia, autism, bipolar disorder, depression, anorexia nervosa, or substance abuse vs their unaffected siblings. JAMA Psychiatr. 2013;70:22–30. doi: 10.1001/jamapsychiatry.2013.268. [DOI] [PubMed] [Google Scholar]
- 17.Mokkonen M., Crespi B.J. Genomic conflicts and sexual antagonism in human health: insights from oxytocin and testosterone. Evol. Appl. 2015;8:307–325. doi: 10.1111/eva.12244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Harper J.A., Janicke T., Morrow E.H. Systematic review reveals multiple sexually antagonistic polymorphisms affecting human disease and complex traits. Evolution. 2021;75:3087–3097. doi: 10.1111/evo.14394. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Oliva M., Muñoz-Aguirre M., Kim-Hellmuth S., Wucher V., Gewirtz A.D.H., Cotter D.J., Parsana P., Kasela S., Balliu B., Viñuela A., et al. The impact of sex on gene expression across human tissues. Science. 2020;369:eaba3066. doi: 10.1126/science.aba3066. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Clayton J.A., Collins F.S. Policy: NIH to balance sex in cell and animal studies. Nature. 2014;509:282–283. doi: 10.1038/509282a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Clayton J.A. Studying both sexes: a guiding principle for biomedicine. FASEB J. 2016;30:519–524. doi: 10.1096/fj.15-279554. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Nature journals raise the bar on sex and gender reporting in research. Nature. 2022;605:396. doi: 10.1038/d41586-022-01218-9. [DOI] [PubMed] [Google Scholar]
- 23.Sinnott-Armstrong N., Naqvi S., Rivas M., Pritchard J.K. Gwas of three molecular traits highlights core genes and pathways alongside a highly polygenic background. Elife. 2021;10:e58615–e58635. doi: 10.7554/eLife.58615. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Hooven C. Henry Holt and Co.; 2021. T: The Story of Testosterone, the Hormone that Dominates and Divides Us. [Google Scholar]
- 25.Flynn E., Tanigawa Y., Rodriguez F., Altman R.B., Sinnott-Armstrong N., Rivas M.A. Sex-specific genetic effects across biomarkers. Eur. J. Hum. Genet. 2021;29:154–163. doi: 10.1038/s41431-020-00712-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Bernabeu E., Canela-Xandri O., Rawlik K., Talenti A., Prendergast J., Tenesa A. Sex differences in genetic architecture in the UK Biobank. Nat. Genet. 2021;53:1283–1289. doi: 10.1038/s41588-021-00912-0. [DOI] [PubMed] [Google Scholar]
- 27.Muir W., Nyquist W.E., Xu S. Alternative partitioning of the genotype-by-environment interaction. Theor. Appl. Genet. 1992;84:193–200. doi: 10.1007/BF00224000. [DOI] [PubMed] [Google Scholar]
- 28.Robertson A. The sampling variance of the genetic correlation coefficient. Biometrics. 1959;15:469. doi: 10.2307/2527750. [DOI] [Google Scholar]
- 29.Falconer D.S. The problem of environment and selection. Am. Nat. 1952;86:293–298. [Google Scholar]
- 30.Fry J.D. The mixed-model analysis of variance applied to quantitative genetics: biological meaning of the parameters. Evolution. 1992;46:540–550. doi: 10.2307/2409870. [DOI] [PubMed] [Google Scholar]
- 31.Yamada Y. Genotype by environment interaction and genetic correlation of the same trait under different environments. Jpn. J. Genet. 1962;37:498–509. doi: 10.1266/jjg.37.498. [DOI] [PubMed] [Google Scholar]
- 32.Brown B.C., Asian Genetic Epidemiology Network Type 2 Diabetes Consortium. Ye C.J., Price A.L., Zaitlen N. Transethnic genetic-correlation estimates from summary statistics. Am. J. Hum. Genet. 2016;99:76–88. doi: 10.1016/j.ajhg.2016.05.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Galinsky K.J., Reshef Y.A., Finucane H.K., Loh P.-R., Zaitlen N., Patterson N.J., Brown B.C., Price A.L. Estimating cross-population genetic correlations of causal effect sizes. Genet. Epidemiol. 2019;43:180–188. doi: 10.1002/gepi.22173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Ni G., Moser G., Schizophrenia Working Group of the Psychiatric Genomics Consortium. Wray N.R., Lee S.H. Estimation of genetic correlation via linkage disequilibrium score regression and genomic restricted maximum likelihood. Am. J. Hum. Genet. 2018;102:1185–1194. doi: 10.1016/j.ajhg.2018.03.021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Shi H., Mancuso N., Spendlove S., Pasaniuc B. Local genetic correlation gives insights into the shared genetic architecture of complex traits. Am. J. Hum. Genet. 2017;101:737–751. doi: 10.1016/j.ajhg.2017.09.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Bulik-Sullivan B., Finucane H.K., Anttila V., Gusev A., Day F.R., Loh P.-R., ReproGen Consortium. Psychiatric Genomics Consortium. Genetic Consortium for Anorexia Nervosa of the Wellcome Trust Case Control Consortium 3. Duncan L., et al. An atlas of genetic correlations across human diseases and traits. Nat. Genet. 2015;47:1236–1241. doi: 10.1038/ng.3406. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.DiMarco M., Zhao H., Boulicault M., Richardson S.S. Why “sex as a biological variable” conflicts with precision medicine initiatives. Cell Rep. Med. 2022;3 doi: 10.1016/j.xcrm.2022.100550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Lumish H.S., O’Reilly M., Reilly M.P. Sex differences in genomic drivers of adipose distribution and related cardiometabolic disorders: opportunities for precision medicine. Arterioscler. Thromb. Vasc. Biol. 2020;40:45–60. doi: 10.1161/ATVBAHA.119.313154. [DOI] [PubMed] [Google Scholar]
- 39.Boyle E.A., Li Y.I., Pritchard J.K. An expanded view of complex traits: from polygenic to omnigenic. Cell. 2017;169:1177–1186. doi: 10.1016/j.cell.2017.05.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Shi H., Kichaev G., Pasaniuc B. Contrasting the genetic architecture of 30 complex traits from summary association data. Am. J. Hum. Genet. 2016;99:139–153. doi: 10.1016/j.ajhg.2016.05.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Sella G., Barton N.H. Thinking about the evolution of complex traits in the era of genome-wide association studies. Annu. Rev. Genomics Hum. Genet. 2019;20:461–493. doi: 10.1146/annurev-genom-083115-022316. [DOI] [PubMed] [Google Scholar]
- 42.Bulik-Sullivan B.K., Loh P.-R., Finucane H.K., Ripke S., Yang J., Schizophrenia Working Group of the Psychiatric Genomics Consortium. Patterson N., Daly M.J., Price A.L., Neale B.M. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 2015;47:291–295. doi: 10.1038/ng.3211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Benonisdottir S., Kong A. The genetics of participation: method and analysis. bioRxiv. 2022 doi: 10.1101/2022.02.11.480067. Preprint at. [DOI] [Google Scholar]
- 44.Lynch M., Walsh B. 1st ed. Sinauer Associates; 1998. Genetics and Analysis of Quantitative Traits. [Google Scholar]
- 45.Urbut S.M., Wang G., Carbonetto P., Stephens M. Flexible statistical methods for estimating and testing effects in genomic studies with multiple conditions. Nat. Genet. 2019;51:187–195. doi: 10.1038/s41588-018-0268-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Pasquali R. Obesity and androgens: facts and perspectives. Fertil. Steril. 2006;85:1319–1340. doi: 10.1016/j.fertnstert.2005.10.054. [DOI] [PubMed] [Google Scholar]
- 47.Domingue B.W., Kanopka K., Mallard T.T., Trejo S., Tucker-Drob E.M. Modeling interaction and dispersion effects in the analysis of gene-by-environment interaction. Behav. Genet. 2022;52:56–64. doi: 10.1007/s10519-021-10090-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Liu D., Sartor M.A., Nader G.A., Gutmann L., Treutelaar M.K., Pistilli E.E., Iglayreger H.B., Burant C.F., Hoffman E.P., Gordon P.M. Skeletal muscle gene expression in response to resistance exercise: sex specific regulation. BMC Genom. 2010;11:659. doi: 10.1186/1471-2164-11-659. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Lutz S.Z., Wagner R., Fritsche L., Peter A., Rettig I., Willmann C., Fehlert E., Martus P., Todenhöfer T., Stefan N., et al. Sex-specific associations of testosterone with metabolic traits. Front. Endocrinol. 2019;10:90. doi: 10.3389/fendo.2019.00090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Kraemer W.J., Ratamess N.A., Nindl B.C. Recovery responses of testosterone, growth hormone, and IGF-1 after resistance exercise. J. Appl. Physiol. 2017;122:549–558. doi: 10.1152/japplphysiol.00599.2016. [DOI] [PubMed] [Google Scholar]
- 51.Roberts B.M., Nuckols G., Krieger J.W. Sex differences in resistance training: a systematic review and meta-analysis. J. Strength Cond. Res. 2020;34:1448–1460. doi: 10.1519/JSC.0000000000003521. [DOI] [PubMed] [Google Scholar]
- 52.Zajitschek S.R., Zajitschek F., Bonduriansky R., Brooks R.C., Cornwell W., Falster D.S., Lagisz M., Mason J., Senior A.M., Noble D.W., Nakagawa S. Sexual dimorphism in trait variability and its eco-evolutionary and statistical implications. Elife. 2020;9 doi: 10.7554/eLife.63170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Kasimatis K.R., Abraham A., Ralph P.L., Kern A.D., Capra J.A., Phillips P.C. Evaluating human autosomal loci for sexually antagonistic viability selection in two large biobanks. Genetics. 2021;217:1–10. doi: 10.1093/genetics/iyaa015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Ryan M. 1st ed. Routledge; 2020. The Genetics of Political Behavior. [Google Scholar]
- 55.Ruzicka F., Holman L., Connallon T. Polygenic signals of sexually antagonistic selection in contemporary human genomes. bioRxiv. 2021 doi: 10.1101/2021.09.20.461171. Preprint at. [DOI] [Google Scholar]
- 56.Ruzicka F., Dutoit L., Czuppon P., Jordan C.Y., Li X.Y., Olito C., Runemark A., Svensson E.I., Yazdi H.P., Connallon T. The search for sexually antagonistic genes: practical insights from studies of local adaptation and statistical genomics. Evol. Lett. 2020;4:398–415. doi: 10.1002/evl3.192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Wright S. The genetical structure of populations. Ann. Eugen. 1951;15:323–354. doi: 10.1111/j.1469-1809.1949.tb02451.x. [DOI] [PubMed] [Google Scholar]
- 58.Weir B.S., Cockerham C.C. Estimating F-statistics for the analysis of population structure. Evolution. 1984;38:1358–1370. doi: 10.2307/2408641. [DOI] [PubMed] [Google Scholar]
- 59.Karczewski K.J., Francioli L.C., Tiao G., Cummings B.B., Alföldi J., Wang Q., Collins R.L., Laricchia K.M., Ganna A., Birnbaum D.P., et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature. 2020;581:434–443. doi: 10.1038/s41586-020-2308-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Pirastu N., Cordioli M., Nandakumar P., Mignogna G., Abdellaoui A., Hollis B., Kanai M., Rajagopal V.M., Parolo P.D.B., Baya N., et al. Genetic analyses identify widespread sex-differential participation bias. Nat. Genet. 2021;53:663–671. doi: 10.1038/s41588-021-00846-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Bissegger M., Laurentino T.G., Roesti M., Berner D. Widespread intersex differentiation across the stickleback genome – the signature of sexually antagonistic selection? Mol. Ecol. 2020;29:262–271. doi: 10.1111/mec.15255. [DOI] [PubMed] [Google Scholar]
- 62.Privé F., Aschard H., Carmi S., Folkersen L., Hoggart C., O’Reilly P.F., Vilhjálmsson B.J. Portability of 245 polygenic scores when derived from the UK Biobank and applied to 9 ancestry groups from the same cohort. Am. J. Hum. Genet. 2022;109:12–23. doi: 10.1016/j.ajhg.2021.11.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Traglia M., Bout M., Weiss L.A. Sex-heterogeneous SNPs disproportionately influence gene expression and health. PLoS Genet. 2022;18 doi: 10.1371/journal.pgen.1010147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Berg J.J., Harpak A., Sinnott-Armstrong N., Joergensen A.M., Mostafavi H., Field Y., Boyle E.A., Zhang X., Racimo F., Pritchard J.K., Coop G. Reduced signal for polygenic adaptation of height in UK Biobank. Elife. 2019;8 doi: 10.7554/eLife.39725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Sohail M., Maier R.M., Ganna A., Bloemendal A., Martin A.R., Turchin M.C., Chiang C.W., Hirschhorn J., Daly M.J., Patterson N., et al. Polygenic adaptation on height is overestimated due to uncorrected stratification in genome-wide association studies. Elife. 2019;8 doi: 10.7554/eLife.39702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Young A.I., Benonisdottir S., Przeworski M., Kong A. Deconstructing the sources of genotype-phenotype associations in humans. Science. 2019;365:1396–1400. doi: 10.1126/science.aax3710. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Coop G., Przeworski M. Lottery, luck, or legacy. A review of “The Genetic Lottery: why DNA matters for social equality”. Evolution. 2022;76:846–853. doi: 10.1111/evo.14449. [DOI] [Google Scholar]
- 68.Mills M.C., Tropf F.C. Sociology, genetics, and the coming of age of sociogenomics. Annu. Rev. Sociol. 2020;46:553–581. doi: 10.1146/annurev-soc-121919-054756. [DOI] [Google Scholar]
- 69.Coop G. (2019). Reading Tea Leaves? Polygenic Scores and Differences in Traits Among Groups. 10.48550/arXiv.1909.00892. [DOI]
- 70.Ober C., Loisel D.A., Gilad Y. Sex-specific genetic architecture of human disease. Nat. Rev. Genet. 2008;9:911–922. doi: 10.1038/nrg2415. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Khan S.S., Ning H., Wilkins J.T., Allen N., Carnethon M., Berry J.D., Sweis R.N., Lloyd-Jones D.M. Association of body mass index with lifetime risk of cardiovascular disease and compression of morbidity. JAMA Cardiol. 2018;3:280–287. doi: 10.1001/jamacardio.2018.0022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Vazquez G., Duval S., Jacobs D.R., Silventoinen K. Comparison of body mass index, waist circumference, and waist/hip ratio in predicting incident diabetes: a meta-analysis. Epidemiol. Rev. 2007;29:115–128. doi: 10.1093/epirev/mxm008. [DOI] [PubMed] [Google Scholar]
- 73.Ning Y., Wang L., Giovannucci E.L. A quantitative analysis of body mass index and colorectal cancer: findings from 56 observational studies. Obes. Rev. 2010;11:19–30. doi: 10.1111/j.1467-789X.2009.00613.x. [DOI] [PubMed] [Google Scholar]
- 74.Brown C.D., Higgins M., Donato K.A., Rohde F.C., Garrison R., Obarzanek E., Ernst N.D., Horan M. Body mass index and the prevalence of hypertension and dyslipidemia. Obes. Res. 2000;8:605–619. doi: 10.1038/oby.2000.79. [DOI] [PubMed] [Google Scholar]
- 75.Arthur R.S., Dannenberg A.J., Rohan T.E. The association of prediagnostic circulating levels of cardiometabolic markers, testosterone and sex hormone-binding globulin with risk of breast cancer among normal weight postmenopausal women in the UK Biobank. Int. J. Cancer. 2021;149:42–57. doi: 10.1002/ijc.33508. [DOI] [PubMed] [Google Scholar]
- 76.Wang J., Fan X., Yang M., Song M., Wang K., Giovannucci E., Ma H., Jin G., Hu Z., Shen H., Hang D. Sex-specific associations of circulating testosterone levels with all-cause and cause-specific mortality. Eur. J. Endocrinol. 2021;184:723–732. doi: 10.1530/EJE-20-1253. [DOI] [PubMed] [Google Scholar]
- 77.Fry A., Littlejohns T.J., Sudlow C., Doherty N., Adamska L., Sprosen T., Collins R., Allen N.E. Comparison of sociodemographic and health-related characteristics of UK biobank participants with those of the general population. Am. J. Epidemiol. 2017;186:1026–1034. doi: 10.1093/aje/kwx246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Bycroft C., Freeman C., Petkova D., Band G., Elliott L.T., Sharp K., Motyer A., Vukcevic D., Delaneau O., O’Connell J., et al. The UK Biobank resource with deep phenotyping and genomic data. Nature. 2018;562:203–209. doi: 10.1038/s41586-018-0579-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Berisa T., Pickrell J.K. Approximately independent linkage disequilibrium blocks in human populations. Bioinformatics. 2016;32:283–285. doi: 10.1093/bioinformatics/btv546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Haworth S., Mitchell R., Corbin L., Wade K.H., Dudding T., Budu-Aggrey A., Carslake D., Hemani G., Paternoster L., Smith G.D., et al. Apparent latent structure within the UK Biobank sample has implications for epidemiological analysis. Nat. Commun. 2019;10:333. doi: 10.1038/s41467-018-08219-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Stephens M. False discovery rates: a new deal. Biostatistics. 2017;18:275–294. doi: 10.1093/biostatistics/kxw041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Sudlow C., Gallacher J., Allen N., Beral V., Burton P., Danesh J., Downey P., Elliott P., Green J., Landray M., et al. UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 2015;12 doi: 10.1371/journal.pmed.1001779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Davies N.M., Holmes M. v, Davey Smith G. Reading Mendelian randomisation studies: a guide, glossary, and checklist for clinicians. BMJ. 2018;362:k601. doi: 10.1136/bmj.k601. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Smith G.D., Ebrahim S. ‘Mendelian randomization’: can genetic epidemiology contribute to understanding environmental determinants of disease? Int. J. Epidemiol. 2003;32:1–22. doi: 10.1093/ije/dyg070. [DOI] [PubMed] [Google Scholar]
- 85.Gillespie J.H. 2nd ed. Johns Hopkins University Press; 2004. Population Genetics: A Concise Guide. [Google Scholar]
- 86.Wang Y., Guo J., Ni G., Yang J., Visscher P.M., Yengo L. Theoretical and empirical quantification of the accuracy of polygenic scores in ancestry divergent populations. Nat. Commun. 2020;11:3865. doi: 10.1038/s41467-020-17719-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
This study used genotype and phenotype data from the UK Biobank https://www.ukbiobank.ac.uk/.
Sex-specific and additive GWAS summary statistics are available at Zenodo: https://doi.org/10.5281/zenodo.7222725 and https://doi.org/10.5281/zenodo.7508246 respectively, and are publicly available as of the data of publication. DOIs are listed in the key resources table.
All original code has been deposited at https://github.com/harpak-lab/amplification_gxsex and Zenodo: https://doi.org/10.5281/zenodo.7765067, and is publicly available as of the date of publication. DOIs are listed in the key resources table.
Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.