

Abstract
Prior studies have shown that the accuracy and efficiency of reaching can be improved using novel sensory interfaces to apply task-specific vibrotactile feedback (VTF) during movement. However, those studies have typically evaluated performance after less than 1 hour of training using VTF. Here we tested the effects of extended training using a specific form of vibrotactile cues – supplemental kinesthetic VTF – on the accuracy and temporal efficiency of goal-directed reaching. Healthy young adults performed planar reaching with a VTF encoding of the moving hand’s instantaneous position, applied to the non-moving arm. We compared target capture errors and movement times before, during, and after approximately 10 hours (20 sessions) of training on the VTF-guided reaching task. Initial performance of VTF-guided reaching showed that people were able to use supplemental VTF to improve reach accuracy. Performance improvements were retained from one training session to the next. After 20 sessions of training, the accuracy and temporal efficiency of VTF-guided reaching were equivalent to or better than reaching performed with only proprioception. However, hand paths during VTF-guided reaching exhibited a persistent strategy where movements were decomposed into discrete sub-movements along the cardinal axes of the VTF display. We also used a dual-task condition to assess the extent to which performance gains in VTF-guided reaching resist dual-task interference. Dual-tasking capability improved over the 20 sessions, such that the primary VTF-guided reaching and a secondary choice reaction time task were performed with increasing concurrency. Thus, VTF-guided reaching is a learnable skill in young adults, who can achieve levels of accuracy and temporal efficiency equaling or exceeding those observed during movements guided only by proprioception. Future studies are warranted to explore learnability in older adults and patients with proprioceptive deficits, who might benefit from using wearable sensory augmentation technologies to enhance control of arm movements.
Keywords: training, sensory augmentation, sensorimotor learning
Introduction
Vibrotactile sensory interfaces show promise for enhancing sensorimotor control by providing supplemental feedback to enhance performance in a variety of tasks. These applications include postural stabilization in patients with vestibular deficits (Sienko et al. 2008; Lee et al. 2011, 2012) and grasp force regulation and hand aperture control in users of myoelectric forearm prostheses (Witteveen et al. 2015). Vibrotactile interfaces have also been used to alert users to an event or sudden change in task condition (Sklar and Sarter 1999; Ferris and Sarter 2011; Li et al. 2012). Although vibrotactile sensory interfaces have been used to train body movements by providing feedback of spatial orientation or by stimulating the moving limb in response to limb configuration, these prior studies have largely been technology demonstrations or feasibility case studies that investigated short-term use of this type of sensory augmentation (Lieberman and Breazeal 2007; Kapur et al. 2009; Weber et al. 2011; De Santis et al. 2014; Afzal et al. 2015; Bark et al. 2015; König et al. 2016).
Cuppone et al. (2016) investigated proprioceptive learning of wrist movements in the absence of vision. They demonstrated that after a 3-day training period where they provided participants with vibrotactile cues when wrist movement errors exceeded certain predetermined limits, neurologically-intact adults had greater wrist proprioceptive acuity. The authors extended this work in a follow up study (Cuppone et al. 2018) of a 5-day training period, where adults trained on wrist movements with vibrotactile cues that indicated errors, in the absence of vision. Results indicated sensorimotor learning of wrist movements occurred within 2 hours of training and that proprioceptive acuity improved after 5 days of training. Importantly, improvements in proprioceptive acuity were retained up to 10 days after training. Thus, short bouts of movement training with discrete vibrotactile error cues can enhance sensorimotor performance well beyond the training period. These studies had a limitation in that the vibrotactile cues were provided discretely as alarms. Cues were only provided when errors exceeded certain limits, unfortunately discrete on/off alarms are not well-suited for augmenting continuous (i.e., moment-by-moment) sensorimotor control of limb posture and movement. There have been very few examinations of the extent to which extended training with continuous, graded vibrotactile cues can facilitate learning of the sensorimotor relationships needed to establish novel closed-loop feedback control of a moving limb [see König et al. (2016) for a study of sensory augmentation training in the context of spatial navigation].
Here, we examined the extent to which extended training with a wearable device that provides continuous, graded supplemental feedback of hand location can promote improved accuracy and efficiency of goal-directed arm movements in a cohort of neurologically intact individuals. The approach uses a non-invasive sensory interface to deliver ongoing, graded feedback of hand location, which can be used to improve the accuracy and efficiency of unseen reaching movements. For this approach to work, the participant must learn a novel mapping between the state of the moving limb and changes in the synthesized feedback delivered by the sensory interface. They must then use that vibrotactile information to control subsequent reaches. Our preliminary studies have demonstrated that within minutes of initial exposure to a novel sensory interface, neurologically intact individuals (Tzorakoleftherakis et al. 2016; Shah et al. 2018; Risi et al. 2019) and some survivors of stroke (Tzorakoleftherakis et al. 2015; Krueger et al. 2017; Ballardini et al. 2021) can rapidly learn to use supplemental feedback of limb configuration and movement to improve the accuracy of reaching actions performed without visual guidance. In the current study, we tested the extent to which extended training can promote skilled use of supplemental VTF to control arm movements performed without ongoing visual feedback. According to classical descriptions, a skill becomes increasingly resistant to dual-task interference as it is learned [cf., Fitts and Posner (1967)]. We hypothesized that extended (10 hours) training with VTF for reaching results in performance improvements that are increasingly automatized, and thus resistant to dual-task interference. We analyzed performance of VTF-guided reaching under single and dual-task conditions before, during, and after extended training. Results demonstrate marked improvements in the accuracy and temporal efficiency of reaching movements guided by supplemental kinesthetic VTF as well as increased dual-task concurrency over the course of the extended training. Our findings have implications for how well VTF-guided reaching can be learned as a skill and provide a foundation for future vibrotactile sensory augmentation applications.
Methods
Fifteen neurologically intact adults (age: 23 to 28 years; eight female) volunteered for this study after providing written informed consent, as approved by Institutional Review Boards serving Marquette University and the University of Genoa in accordance with the Declaration of Helsinki (Protocol Number: HR-3044). All participants were naïve to vibrotactile feedback (VTF) and to the study objectives, and none had known cognitive deficits or tactile deficits of the arm; eleven self-identified as right-handed while four identified as left-handed. They each completed a total of 20 experimental sessions lasting less than 60 minutes each. Sessions were spaced at least 6 hours apart, with no more than 2 sessions per day.
General Experimental Setup
Each participant sat in an adjustable height chair and used their preferred hand to grasp the handle of a passive two-degree-of-freedom planar manipulandum placed such that the device’s entire workspace was comfortably within reach (Fig 1A). The passive manipulandum is comprised of a pantographic linkage with two integrated potentiometers that provide signals uniquely determined by hand position in the horizontal plane [see Ballardini et al. (2018) for full design specifications]. Hand position data were collected at a rate of 50 samples per second using a custom script within the MATLAB computing environment (version R2017a; the MathWorks Inc., Natick MA). A computer monitor (LG Inc, Model: 23EA63V-P, 60 Hz) was placed vertically in front of the participant just beyond the manipulandum (Fig 1A). Visual stimuli were created and displayed in real-time using PsychToolbox-3 for MATLAB (Brainard 1997). The visual stimuli included a set of 25 reaching targets (0.5 cm diameter circles) arranged in a 5x5 grid on the vertical screen. Inter-target distance was 2 cm. The target grid was centered on the vertical screen (Fig 1B). Hand position on the manipulandum was mapped onto the position of a cursor (0.5 cm diameter disk) on the vertical display in a 1:1 ratio, such that 1 cm movement on the manipulandum resulted in a 1 cm movement of the cursor on the monitor. An opaque drape blocked the direct view of the preferred arm and manipulandum. Noise-cancelling headphones and a white noise audio track were used to minimize extraneous auditory cues.
Figure 1:

Experimental setup. Panel A) The participant grasped the handle of a horizontal planar manipulandum with the preferred hand. A vertical monitor was placed behind the manipulandum and displayed the visual reaching targets. The non-moving arm was rested on a rigid support with the vibrotactile interface attached via tape. Panel B) Vibrotactile interface made of four ERM motors (nominal locations indicated by blue markers) attached to the non-moving arm while the moving arm works in a 5x5 grid of reaching targets (black circles). A visual cursor (red symbol) sometimes represented the hand’s location in the workspace (see text for details). Panel C) Illustration of the piecewise mapping between hand displacement and vibration motor activation that defined the VTF interface. Black circles represent the location of three targets arranged horizontally. The circle on the left represents the center target. VTF is not engaged until the hand is 0.6 cm from the middle of the center target. Between 0.6 cm and 4.0 cm vibration intensity increases at a linear rate. Vibration saturates at distances greater than 4.0 cm from the center of the workspace. This pattern was followed for each of the four vibration motors.
The participant’s stationary, non-preferred arm rested on a rigid support structure with the elbow at 90° of flexion and the shoulder at 45° abduction, 0° flexion. We placed the numeric keypad of a standard computer keyboard comfortably under the fingers of this hand. We covered three keycaps of the numeric keypad with colored tape (red, blue, green) such that participants could use their index, middle, and ring fingers to perform a choice reaction time task based on colored visual stimuli, as described below.
A vibrotactile display was implemented at four locations on the non-moving arm to provide supplemental kinesthetic VTF about the moving hand’s location in the workspace (Fig 1A). The display comprised of four eccentric rotating mass vibration motors (ERM; Precision Microdrives Inc, Model: 310-117). The motors were powered and controlled using custom drive circuitry interfaced with a computer running MATLAB. These motors operate in a frequency range of 60–255 Hz and a vibration amplitude range of ~0.02 N to 0.24 N. The frequency and amplitude are coupled and the vibration intensity was controlled through pulse width modulation. Although vibration frequency is coupled with amplitude, in this study we refer to vibration intensity in terms of its operating frequency for simplicity. The motors provided feedback of the moving arm’s hand position relative to the center of the workspace (Krueger et al. 2017; Risi et al. 2019). Motors providing information about position in the left/right dimension were placed on the dermatome C7 and T1 on the forearm (Fig 1B: X+ and X−) and motors providing information about the anterior/posterior dimension were placed on the dorsum of the hand and dermatome C5 on the skin above the lateral biceps muscle (Fig 1B: Y+ and Y−).
The vibrotactile display provided continuous, graded, limb-state feedback about hand position through changes in vibration intensity. The position of the manipulandum’s handle (and thus the position of the hand in the 2D workspace) was converted to vibration intensity in a piecewise linear manner. Vibration was turned off when the cursor was within the boundary of the central target of the workspace; the vibration intensity jumped discontinuously to 120 Hz when the hand moved outside of the central target, and the vibration intensity increased (30 Hz/cm) until it reached an intensity of 245 Hz at 4.5 cm from the center of the display (Fig 1C). The intensity jumped to 255 Hz at distances greater than 4.5 cm, which indicated to the participant that the manipulandum handle was outside the outer most target of the workspace. Note that a 2 cm inter-target distance yields an inter-target change in vibration intensity of 60 Hz, which is greater than the average just noticeable difference in vibration intensity identified for dermatomes of the arm and hand in healthy adults [JND = 37 Hz; c.f., Shah et al. (2019a)]. The 2.0 cm inter-target distance also is below the threshold of limb position acuity (2.5 ± 0.20 cm) derived using joint angular uncertainty values reported by Fuentes and Bastian (2009). We intended these experiment design choices to increase the likelihood that participants would rely on the supplemental VTF rather than intrinsic proprioception to accurately perform the primary reaching task described in the following paragraphs.
Experimental Tasks
Participants performed a primary reaching task and a secondary choice reaction task in blocks of 25 trials each. Both tasks were performed separately (single-task conditions) as well as concurrently in a dual-task context (Table 1). Depending on the session number, different combinations of reaching task blocks, choice reaction task blocks, and dual-task blocks were performed (see Table 1). 125 trials (~30 minutes) of VTF-guided reach training were completed during each of the 20 sessions. We tested VTF-guided reaching performance in the dual-task condition in the 1st, 10th, and 20th sessions.
Table 1:
Block schedule and feedback conditions within each trial block of each session.
| Block | Trials | Task | Feedback | Session | Type |
|---|---|---|---|---|---|
| 1 | 25 | RCH | V+T− | 1 | Visual Reaching (Baseline) |
| 2 | 25 | RCH | V−T− | 1 | Proprioceptive Reaching (Baseline) |
| 3 | ≥25 | CRT | N/A | 1,10,20 | CRT Single-Task |
| 4 | ≥25 | RCH | V+T+ | 1-20 | VTF Familiarization |
| 5 | 25 | RCH+CRT | V−T+ | 1 | Dual-Task Test (Pre-Training) |
| 6-10 | 25/block (125 total) |
RCH | V−T+ | 1-20 | Single-Task Training |
| 11 | 25 | RCH+CRT | V−T+ | 1,10,20 | Dual-Task Test (Post-Training) |
RCH: vibrotactile guided reaching task; CRT: choice reaction task; V+T−: Visual feedback of cursor but no VTF; V−T−: no Visual feedback of cursor and no VTF; V+T+: with Visual feedback and VTF of cursor; V−T+: no Visual feedback but with VTF of cursor. Note: not all trial blocks were performed in each session.
Reaching Task:
during reaching, participants were asked to move the manipulandum’s handle with their preferred hand as quickly and as accurately as possible to capture a visual target presented on the screen (white ring). They verbally indicated when they had reached the target, ending the trial. Reaching could be performed under three different feedback conditions (see Table 1): with concurrent visual feedback of the cursor and no VTF (i.e., V+T−, visual baseline trials); with neither visual cursor feedback nor VTF (V−T−, proprioceptive baseline trials), or with VTF and no visual cursor feedback (V−T+, VTF-guided reaching trials). At the end of each reach, knowledge of results was provided via visual feedback of the onscreen cursor, if it was not already visible. Participants were then to recenter the cursor on the current goal target, which became the starting location for the next reach trial. The visually-guided re-centering served to prevent proprioceptive drift from confounding perception of hand position in the workspace [c.f., Wann and Ibrahim, (1992)]. Visual cursor feedback was removed at the start of every trial in any block labelled V− feedback.
Choice Reaction Task:
during choice reaction trials, participants were to press a button as quickly as possible with their index, middle, or ring finger of the non-preferred hand to indicate a change of the target from a white ring to a filled colored dot (red, blue, or green). When performed alone as a single task on sessions 1, 10, and 20 (block 3), choice reaction trials were cued with colored targets that appeared at pseudorandomly-selected target locations. Inter-trial intervals were defined to be 1400 ± 700 ms.
Dual-Task Test:
during dual-task test trials, VTF-guided reaching and the choice reaction task were to be performed concurrently. At the start of dual-task trials, the onscreen target started as a white ring but changed to a colored dot (red, blue, or green) after a pseudorandom interval ranging from 400 - 1100 ms. Participants were instructed to capture the target as quickly and accurately possible when the white ring target appeared, and to use their index, middle, or ring finger of the non-moving, non-preferred hand to press the appropriate button on a computer keypad as quickly as possible after the target changed colors. They were to continue reaching to the target after pressing the button if they had not yet finished reaching. As described above for single-task VTF-guided reaching trials, participants verbally indicated when they had reached the target, ending the trial. This caused the cursor to re-appear and allowed them to correct any target capture errors by re-centering the cursor on the current target, which served as the starting location for the next trial.
Data Analysis
We computed kinematic measures of movement accuracy and efficiency to assess reach performance. Target capture error (reach accuracy) was defined as the absolute distance between the target location and the final position of the on-screen cursor (i.e., its position at the verbal end-of-trial indication, prior to re-centering the cursor on the target using end-of-trial visual feedback). Target capture time (a temporal measure of reach efficiency) was computed as the time difference between the start of the trial and the point in time when the participant’s hand speed fell below 10% of its maximum hand speed (just prior to their verbal end-of-trial indication). Using these measures, we analyzed performance savings resulting from the consolidation of sensorimotor memory from one session to the next by calculating the percent change across sessions. We also computed Decomposition Index (DI), a unitless scalar measure of efficiency in the spatial domain; DI quantifies the extent to which hand paths move directly to the target vs. whether they move parallel to the cardinal (X, Y) axes of the vibrotactile display [which was aligned with the axes of the 2D workspace; see also the Appendix of Risi et al. (2019)]. DI is calculated as a weighted sum of the current change in X and Y hand position multiplied by the change in current orthogonal velocity (e.g., X position multiplied by Y velocity: Ẏ). This sum was normalized to the total displacement and maximum velocity (e.g., Ẏmax) (Eq 1):
| [1] |
DI values increase when hand trajectories display multiple speed peaks and/or stray from a straight line connecting the start and the endpoint. Risi et al. (2019) showed that a DI value of 0.24 corresponds to straight-line trajectories with bell-shaped (minimum-jerk) velocity profiles. Spatially efficient movements (e.g., straight-line hand movements with single-peaked velocity curves) result in lower Decomposition Index values.
To assess performance on the choice reaction task, we computed choice reaction time as the time difference between the moment of stimulus presentation and the button press. We computed choice accuracy as the percentage of correct color choices. Trials where the participant pressed the button ahead of the cue or did not press the button within the allotted trial time were recorded as errors and the reaction time from these trials was excluded from further analysis. For the dual-task trials we determined the strategy each participant used to combine the reach and button-press tasks by computing the percentage of trials where they pressed the button before the reach started, during the reach, or after the reach had ended; we examined how dual-tasking strategies changed after extended training on VTF-guided reaching.
Statistical Testing
We hypothesized that extended training on VTF-guided reaching would result in performance improvements that are increasingly resistant to dual-task interference (Fitts and Posner 1967). To test that hypothesis, we used repeated measures ANOVA and post hoc, Bonferroni-corrected paired sample t-tests (one-tailed) to compare performances before (session 1), during (session 10), and after extended training on VTF-guided reaching (session 20). Independent variables for the ANOVA included session number and testing condition (single-task, dual-task). Dependent variables included target capture error, target capture time, DI, choice reaction time, and choice accuracy. Each dependent variable was averaged across trials within each session for each participant. All analyses were performed with SPSS 27 (IBM Corp). We used Greenhouse-Geisser correction to mitigate violations of sphericity. Statistical significance was set at a family-wise error rate of α = 0.05.
Results
This study evaluated improvements in the performance of planar goal-directed reaches guided by supplemental vibrotactile feedback of hand position information (VTF) across 20 sessions of training. In the first session, all participants demonstrated that they understood the reaching task, the secondary choice reaction task, and the dual-task instructions. After training, they also demonstrated the capability to use VTF to improve movement accuracy and efficiency in the primary reaching task. Figure 2 shows hand paths from movements made between two targets by a selected participant before and after extended (10 hours) training with VTF-guided reaching. The initial hand location was the same for each movement. The straightest and most accurate reach occurred when visual cursor feedback was provided throughout the movement (Fig 2: solid black line). The least accurate performance occurred when neither visual cursor feedback nor VTF were provided (Fig 2: dashed black line). After brief exposure to VTF (i.e., on training session 1), participants were immediately able to use the supplemental kinesthetic feedback to improve target capture accuracy (Fig 2: solid magenta line). After extended training (session 20), movement accuracy was high, although hand paths exhibited discrete sub-movements along the cardinal axes of the VTF display (Fig 2: dashed magenta line). As described next, performance features highlighted in Figure 2 were characteristic of the sample cohort.
Figure 2:

Selected reach trajectories from a representative participant during reaching under the various feedback conditions. Reaches were made from the blue start position to the red goal target. Black solid trajectory: visually guided reaching. Black dashed trajectory: proprioceptive reaching (V−T− condition). Magenta solid and magenta dashed trajectories: pre- and post-training VTF-guided reaching, respectively. Cyan stars: the end of each reach.
Single-task performance: reaching
We analyzed three aspects of the primary reaching task under single-task conditions. First, we considered how movement accuracy changed as participants trained on making reaches under the guidance of supplemental VTF. Figure 3 presents cohort averages from “Baseline” testing trial blocks of session 1 (data points labeled V and NV), as well as the mean performance in the (V−T+) “Training” blocks performed during sessions 1 through 20. Visually guided reaching (V+T−) produced highly accurate movements with target capture errors averaging about 1 mm (condition labeled “V” in Fig 3A; 0.09 ± 0.03 cm; mean ± SD here and onward). When visual feedback was subsequently removed and participants had to rely solely on intrinsic proprioception (V−T−), target capture errors increased markedly to 1.85 ± 0.37 cm (Fig 3A: “NV”; t14(V-NV) = 18.2, p < 0.001). Repeated measures ANOVA revealed a main effect of training session on target capture error during VTF-guided reaching [F(3.16,44.2) = 20.7, p < 0.001]. On initial exposure to VTF, average target capture error decreased significantly from the V−T− condition to 1.63 ± 0.30 cm in the training block of session 1 (t14(Sess1-NV) = 2.18, p = 0.023). Target capture error decreased further to 1.14 ± 0.36 cm after 10 training sessions (t14(Sess10-NV) = 6.80, p < 0.001) and further still to 0.97 ± 0.25 cm after 20 training sessions (t14(Sess20-NV) = 9.69, p < 0.001). The reduction in error from the 10th to the 20th session was also significant (t14(Sess10-Sess20) = 4.66, p < 0.001). Target capture errors during VTF-guided reaching asymptotically approached the limits of acuity of vibrotactile intensity discrimination (Shah et al. 2019a), as mapped onto the reachable workspace for this study (0.89 ± 0.13 cm; Fig 3A: dashed horizontal black and gray lines).
Figure 3:
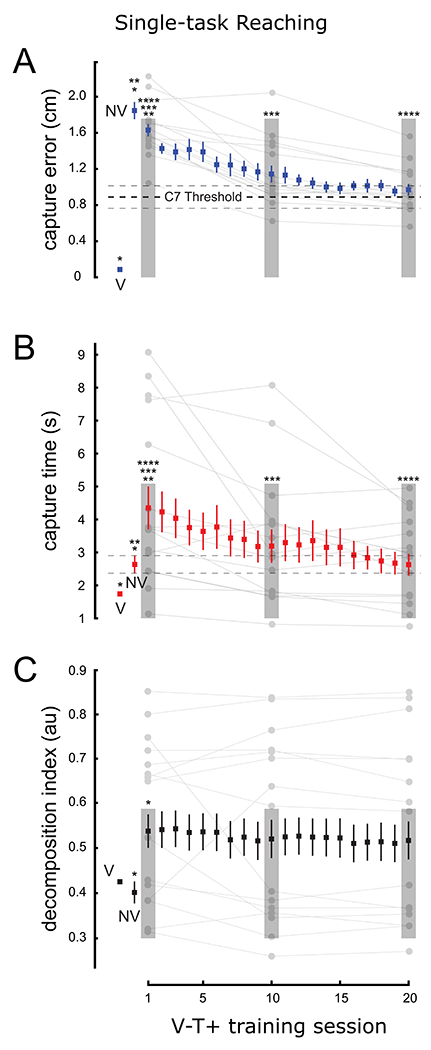
Cohort results: reaching performance under single-task conditions (Error bars = ±1 SEM). Panel A) Target capture error. The thick and thin horizontal dashed lines indicate the average pre-training JND of VTF in dermatome C7 referenced to displacement in the workspace (0.89 ± 0.13 cm). Panel B) Target capture time. Horizontal dashed lines: ±1 SEM of the average cohort performance in the no-vision baseline condition on session 1. Panel C) Decomposition index. In each panel, black asterisks indicate a significant difference between the paired conditions indicated by the different asterisk patterns (eg., * through ****). Gray shaded bars indicate the sessions included in the t-tests described in the text. Light gray markers and lines markers are individual participant averages on 1st, 10th, and 20th training sessions.
We also considered how temporal aspects of reaching efficiency changed as participants trained with supplemental VTF. Visually guided reaches in session 1 were most efficient, requiring the least amount of time to capture the targets (1.88 ± 0.26 s; V+T−; Fig 3B: “V”). Removing visual feedback (V−T−; Fig 3B: “NV”) resulted in longer target capture times relative to visually guided reaching (2.79 ± 1.06 s; t14(V-NV) = 3.85, p = 0.001). Target capture times increased to 4.53 ± 2.57 s on initial exposure to supplemental VTF (V−T+); these capture times were significantly longer than those in the V−T− condition (t14(Sess1-NV) = 3.36, p = 0.002). Target capture times during VTF-guided reaching decreased with extended training [F(3.06,42.8) = 5.08, p = 0.004]. Relative to initial exposure in session 1, target capture times decreased significantly by the 10th training session (3.36 ± 2.00 s; t14(Sess1-Sess20) = 2.53, p = 0.012) such that movement times were no longer statistically different from target capture times observed during proprioceptive reaching (V−T−; t14(Sess10-NV) = 1.10, p = 0.15). Target capture times decreased further by the 20th session (2.78 ± 1.30 s; t14(Sess1-Sess20) = 3.49, p = 0.002); by the end of extended training, average target capture times were indistinguishable from those observed when participants reached using proprioception only (V−T−; t14(Sess20-NV) = 0.013, p = 0.50).
To better understand how performance improvements accrue across training sessions, we computed a measure of “performance savings,” defined as the percentage change in target capture error (or target capture time) between the first training block of one session and the first training block of the next session (Fig 4). Performance savings were most evident in session 2 (target capture error), and savings from session to session rapidly plateaued to a modest level for both target capture error and target capture time. Session-to-session savings averaged 2.05 ± 0.85 % for target capture error and 1.37 ± 0.65 % for target capture time across the 20 sessions.
Figure 4:

Cohort results: percent Δ (change) in target capture errors and target capture times across session (an estimate of performance savings. Panel A) Average percent Δ in target capture errors during single-task VTF-guided reaching. Panel B) Average percent Δ in target capture times during single-task VTF-guided reaching. Error bars = ±1 SEM.
We next considered how spatial aspects of movement efficiency may have changed with training. Although Decomposition Index (DI) was impacted by the introduction of VTF, it did not change substantially over 10 hours of extended training. DI values observed during visually guided reaching averaged 0.42 ± 0.03 (Fig 3C: “V”). DI did not change significantly when visual feedback was removed (V−T− condition; Fig 3C: “NV”; DI = 0.39 ± 0.12; t14(V-NV) = 1.13, p = 0.14). By contrast, the DI increased significantly to 0.57 ± 0.18 during the first session of VTF-guided reaching (t14(Sess1-NV) = 4.58, p < 0.001). This may reflect the tendency of participants to move first along one cardinal axis of the vibrotactile display, then along the other, which is consistent with a previous report of decomposed movements during VTF-guided reaching (Risi et al. 2019). Participants persisted in using this “decomposition strategy” throughout the course of the study [F(1.52,21.3) = 0.70, p = 0.47]. There was no evidence for significant reductions in DI values from the 1st session to the 10th session (DI = 0.55 ± 0.21; t14(Sess1-Sess10) = 0.64, p = 0.27) or between the 1st and 20th sessions (DI = 0.54 ± 0.21; t14(Sess1-Sess20) = 0.74, p = 0.24).
Single-task performance: choice reaction
Participants were equally accurate in performing the choice reaction task during the “CRT Single-Task” block in session 1 (96.7 ± 5.0% correct), session 10 (98.3 ± 3.8% correct), and session 20 (98.9 ± 3.3% correct). Repeated measures ANOVA found no evidence for any systematic difference across these sessions with regards to the accuracy of choice reaction task performance [F(2,28) = 1.49, p = 0.24]. Nevertheless, the choice reaction time decreased significantly from 753 ± 174 ms in session 1, to 647 ± 79 ms in session 10, and to 611 ± 85 ms in session 20 [F(1.19,16.5) = 8.63, p = 0.007].
Dual-task performances
When reaching with VTF under the dual-task condition, decreases in target capture errors paralleled those reported above for single-task conditions (Fig 5A). Target capture errors averaged 1.98 ± 0.53 cm during the 1st session’s first dual-task testing block (block 5) and averaged 1.75 ± 0.43 cm after only one session of VTF-guided reach training. By the 10th session, target capture errors in the dual task testing block decreased to 1.15 ± 0.23 cm and by the 20th session, they averaged 0.98 ± 0.24 cm. We performed two-way repeated measures ANOVA to examine the impact of testing condition (single-task vs. dual-task) and session number (1, 10, and 20) on target capture error in VTF-guided reaching. We found a significant main effect of session number on target capture error [F(1.20,16.9) = 56.8; p < 0.001], and a main effect of testing condition [F(1,14) = 6.72; p = 0.021]. We also observed an interaction between these factors [F(1.36,18.8) = 8.24; p = 0.006] such that the initial impact of dual-tasking on target capture errors in session 1 (pre-training dual-task block vs single-task VTF-guided reaching block; t14 = 3.29; p = 0.003) resolves rapidly (post-training dual-task block vs. single-task VTF-guided reaching block; t14 = 1.34; p = 0.10). For sessions 10 and 20, the difference between single-task and post-training dual-task VTF-guided reaching performance remained non-significant (t14 = 0.024; p = 0.98).
Figure 5:

Dual-task target capture error and target capture time results for sessions 1 (pre- and post-training), 10, and 20. Panel A) Group target capture error for VTF-guided reaching during dual-task blocks. Panel B) Group target capture time for VTF-guided reaching during dual-task blocks. Panel C) Group Decomposition Index for the VTF-guided reaching during dual-task blocks. Error bars = ±1 SEM.
Target capture times for VTF-guided reaching under dual-task conditions showed a similar pattern (Fig 5B). Baseline dual-task target capture times averaged 6.08 ± 3.57 s and remained relatively high after only one session of VTF-guided reach training (5.32 ± 2.68 s). By the 10th session, average dual-task target capture times decreased to 4.12 ± 1.79 s. By the 20th session, they had decreased further to 3.72 ± 1.34 s. A two-way repeated measures ANOVA found significant main effects of testing condition [F(1,14) = 26.5; p < 0.001] and session number [F(1.39,19.4) = 9.28; p = 0.003] on dual-task target capture times. Here, however, we observed no interaction between these factors [F(1.13,15.8) = 2.27; p = 0.15]. The 20th session dual-task target capture times remained significantly higher than single-task VTF-guided reaching target capture times (t14(Sess20Single-Sess20Dual) = 5.23, p < 0.001).
As observed when people performed the reaching task alone, participants persisted in a “decomposition strategy” whenever they were provided supplemental kinesthetic vibrotactile feedback (Fig 5C). DI values averaged 0.54 ± 0.17 during the baseline dual-task test block, 0.56 ± 0.19 after one session of VTF-guided reaching training, 0.55 ± 0.20 after 10 sessions, and 0.55 ± 0.20 after all 20 sessions. Two-way repeated measures ANOVA found no significant main effects of testing condition [F(1,14) = 0.04; p = 0.84] or session number [F(1.07,15) = 0.04; p = 0.86] on DI values, or any interaction between the two factors [F(1.22,17) = 2.67; p = 0.12]. Because there were no changes in decomposition across single- vs. dual-task testing conditions or across training sessions, the results strongly suggest that our sample cohort continued to use the supplemental kinesthetic vibrotactile feedback throughout all 20 testing sessions and did not tend to ignore it over time.
Dual-task reaching had minimal impact on the accuracy of secondary task performance; we performed two-way repeated measures ANOVA to examine the impact of testing condition (single-task vs. dual-task) and session number (1, 10, and 20) on secondary task accuracy. We found no change as a function of testing condition [F(1,14) = 0.08; p = 0.79], no compelling evidence for change as a function of session number [F(2,28) = 3.19; p = 0.06], and no interaction between these factors [F(2,28) = 0.08; p = 0.93]. Participants were equally accurate in pressing the correct target color button during baseline dual-tasking (97.2 ± 4.07% correct), after one session of training (97.2 ± 4.07%), after 10 sessions (98.3 ± 2.64%), and after 20 sessions (98.9 ± 1.91%). By contrast, the impact of dual-tasking on the choice reaction time was large. A two-way repeated measures ANOVA found a significant impact of testing condition (single-task vs. dual-task) on choice reaction time [F(1,14) = 7.27; p = 0.017], but no main effect of session number [F(2,28) = 2.47; p = 0.10], and no interaction between the two factors [F(1.41,19.7) = 0.07; p = 0.88]. During the pre-training dual-task test block (session 1), choice reaction time averaged 1843 ± 956 ms. After one session of training, choice reaction time averaged 1275 ± 709 ms (post-training Dual-Task Test, session 1). In session 10, dual-task choice reaction time averaged 1142 ± 828 ms, while in session 20 they averaged 1154 ± 888 ms. These results are consistent with a speed-accuracy tradeoff in the performance of the dual task, in the sense that button press accuracy was preserved at the cost of a ~500 ms increase in reaction time relative to single task reaction times before, during, and after training on the primary reaching task.
Finally, we assessed the extent to which the primary and secondary tasks were performed serially or in parallel during dual-task trials. Participants could use one of three strategies to coordinate the reaching and the choice reaction tasks based on whether button pressing occurred prior to, during, or after reaching to the target. Before training on single-task VTF-guided reaching, button presses occurred prior to the reach on 46.7% of dual-task trials, during the reach on 33.3% of trials, and after the reach on 20% of trials. After 20 sessions of training on VTF-guided reaching, button presses occurred prior to the reach on 28.9% of trials, during the reach on 49.4% of trials, and after the reach on 21.7% of trials. Across the study population, the percentage of dual-task trials wherein reaching and button pressing occurred concurrently increased significantly over the course of 20 sessions of training (from 33.3% ± 34.1% in session 1 to 49.4% ± 38.2% in session 20; paired t-test: t14 = 1.90, p = 0.04). This result is consistent with the conclusion that over the course of 20 sessions of training, VTF-guided reaching becomes increasingly automatized and resistant to dual-task interference.
Discussion
The long-term goal of our work is to establish non-visual closed-loop control over the movements of one limb by applying supplemental vibrotactile feedback (VTF) of those movements to some other location on the body. Potential applications include mitigation of somatosensory impairments after stroke and the enhancement of movement precision in the manual control of surgical robotics. Prior studies have shown that providing supplemental kinesthetic VTF during reaching and stabilizing movements of the arm can yield measurable improvements in accuracy and efficiency of those actions after less than 1 hour of training in healthy individuals (Krueger et al. 2017; Shah et al. 2018; Risi et al. 2019) and in some survivors of stroke (Tzorakoleftherakis et al. 2015; Ballardini et al. 2021). Motivated by classical descriptions of skill acquisition and automatization (e.g., Fitts and Posner 1967), we tested the hypothesis that extended training on VTF-guided reaching would yield performance improvements that continue to accrue in a manner increasingly resistant to dual-task interference. Our results demonstrate that healthy young adults can learn to use limb-state VTF to supplement intrinsic proprioception, thereby improving the performance of reaching in the absence of concurrent visual feedback. Target capture errors decreased across training sessions such that performance improvements were retained from one session to the next. With extended training, performance of VTF-guided reaching became far more accurate than reaches performed with only proprioception; by the end of training, VTF-guided reach accuracy approached the limits of perceptual acuity within the vibrotactile display [i.e. for vibrotactile intensity discrimination as reported previously (Shah et al. 2019a)]. VTF-guided reaches also improved in temporal aspects of efficiency after 10 hours of training, achieving similar target capture times as reaches guided solely with proprioception. Our results show evidence of sensorimotor memory consolidations in the form of savings in the performance of target capture accuracy; these were most clearly evident within the first 24 hours after initial training [i.e., between sessions 1 and 2; c.f., Brashers-Krug et al. (1996), Shadmehr and Brashers-Krug (1997), Smith et al. (2006), and Cuppone et al.(2018)]. Savings were also reflected in target capture times during single-task VTF-guided reaching. By contrast, spatial aspects of efficiency did not improve with 10 hours of training; VTF-guided reaches remained just as decomposed along the principal axes of the vibrotactile display at the end of the study as they were upon initial exposure.
Reaching performance degraded dramatically in the 1st session when we asked participants to perform a choice reaction task concurrently with the VTF-guided reaching task. But whereas the impact of the choice reaction time task on target capture errors resolved quite rapidly (i.e., by session 10), its impact on target capture times did not resolve by the end of training (by session 20). The choice reaction task had no impact on the spatial efficiency of reaches; decomposition index (DI) values remained high throughout all 20 sessions whether or not the choice reaction time task was required on any given trial. We also assessed the reaching task’s impact on performance of the choice reaction task. Whereas dual-tasking had minimal impact on the accuracy of choice reaction task performance, which remained consistently high from the 1st session to the 20th, the impact of dual-tasking on the choice reaction time was large: choice reaction time in the dual-task condition was effectively twice that observed under single-task testing, even though choice reaction time decreased from session 1 to session 20 in both conditions. Thus, our data reflect a tremendous time cost to preserve accuracy of the choice under these dual-task conditions. Nevertheless, our finding that participants increased concurrency in the performance of the two tasks over the course of the study indicates that 10 hours of training on VTF-guided reaching can confer measurable resistance to dual-task interference consistent with the automatization of that skill.
Our findings support and extend those described by Eversheim and Bock (2001) in their study of dual-task interference during adaptation of a manual tracking task to a visuomotor (up/down) inversion of visual feedback. Healthy human subjects tracked a moving cursor with their finger concurrently with each of four different button-pressing “loading” tasks of varying complexity (i.e., requiring differing demands for neurocomputational resources related to attention, movement preparation, and visuospatial transformations), both before and after inversion of visual feedback for tracking. The authors found a significant interaction between tracking task accuracy and secondary task reaction time for each of the concurrent loading tasks, but only in the presence of the visuomotor inversion. Specifically, target tracking was nearly as accurate in the dual-task conditions as for single-task tracking prior to imposing the up/down inversion, but afterwards, all four loading tasks induced a substantial and persistent accuracy cost relative to single-task tracking performance. This cost decreased with practice for all four loading tasks, albeit with different time courses. Loading tasks that highlighted attention and spatial transformation induced dual-task costs that peaked earlier, whereas the task highlighting movement preparation induced costs that peaked later. Concurrently, each of the loading tasks exhibited dual-task interference in that reaction time increased upon visuomotor inversion and then decreased throughout training. Because dual-task interference effects decreased with different time courses for loading tasks with different neurocomputational demands, the results of Eversheim and Bock (2001) support the interpretation that interference is reduced when demands for competing resources are reduced. The results of the current study are also consistent with this interpretation, and further highlight the three-fold effect of extended training with vibrotactile feedback. These include performance improvements in the primary VTF-guided reaching task (Figs 3A and 3B); a reduction in reaction time for the secondary button pressing task, and an increase of concurrency in the performance of the two tasks. This last observation is remarkable because subjects in our study only experienced the dual task four times (i.e., before VTF training, and then after 1, 10, and 20 days of training). The increase in concurrency indicates therefore that learning of VTF-guided reaching conforms to the skill learning model of Fitts and Posner (1967); whereas the initial stage of learning requires greater cognitive resources that result in a speed-accuracy tradeoff for the secondary task, later in learning (after ~10 hours of training) the demands on cognitive resources are reduced for the primary task, thereby yielding resiliency to dual-task interference.
Exploiting The Skin as a Communications Channel – The Vibrotactile Display
For a vibrotactile display to have utility, vibratory cues must be designed and applied such that encoded information can be easily perceived and interpreted by the user [cf., Elsayed et al. (2020); Bao et al. (2018)]. Factors influencing vibrotactile perception include: surface area of stimulation; the presence or absence of a stable surround; skin temperature; body mass index; alcohol consumption; and advancing age (Verrillo 1980; Stuart et al. 2003; Cholewiak and Collins 2003; Gandhi et al. 2011). For practical applications of vibrotactile sensory augmentation or substitution, it is arguably more relevant to consider the perceptual discrimination of suprathreshold stimuli of different frequencies and/or intensities rather than the detection of small vibrotactile stimuli. Perceptual discrimination also depends on several factors that can impact the rate of information transfer through the skin; these include where the stimuli are presented on the body, the distance between stimulation sites (if multiple sites), the frequency of stimulation, and how task-related information is encoded into the vibrations (Mahns et al. 2006; Krueger et al. 2017; Shah et al. 2019b, a; Elsayed et al. 2020). For example, early experimental work found that a difference of about 20-30% between two constant-frequency sinusoidal stimuli can be detected [see Verrillo (1992) for a review]. Interestingly, Rothenberg and colleagues (1977) reported that the addition of an amplitude cue to the frequency cue, as was the case in this study, improved discrimination performance for each person they tested, with the average difference limen (ΔF/F: i.e., JND / standard stimulus frequency) decreasing from 25% of the center frequency to 17.5%. The results presented in Figure 3A show why constraints on perceptual acuity may be important; the mean accuracy of VTF-guided reaching appears to approach asymptotically the limit of vibrotactile discrimination acuity. Future studies might beneficially explore the extent to which performance of VTF-guided reaching might be enhanced by efforts to learn to improve perception of vibrotactile discrimination.
The Acquisition of VTF-Guided Reaching as a Sensorimotor Skill
Motor skill is characterized by the capability to produce action sequences with minimal outcome uncertainty (Fitts and Posner 1967; Schmidt and Lee 2005; Magill and Anderson 2017). Fitts and Posner (1967) describe three phases of learning thought to be involved in the acquisition of complex skills. These include an early “cognitive” phase wherein the learner tries to understand the task in terms of its fundamental objectives, relationships between perceptual cues and available responses, and how training signals such as knowledge of results may be used to improve performance; an intermediate “associative” phase wherein patterns of coordination among constituent stimulus-response units are formed and re-formed as necessary; and an “autonomous” stage wherein component processes become less subject to cognitive control and less subject to interference from other ongoing activities or environmental distractions. Fitts and Posner note that the distinction between the three stages is rather fluid, and that one phase merges gradually into the next as learning progresses.
There are at least five constituent relationships to be learned when acquiring the use of supplemental kinesthetic VTF to shape ongoing control of goal-directed reaches. The first is perceptual; participants must first discriminate between vibrotactile stimuli of different intensities. Discrimination of vibrotactile stimuli is subject to perceptual learning in that perceptual acuity can increase with practice when trained (Hughes et al. 1990). Second, they must learn a mapping between how the vibrotactile stimuli vary within the vibrotactile display as the hand moves between different target locations across the workspace. Third, they must learn to apply (i.e., to invert) that map to determine what pattern of VTF will correspond to a successful target capture. Fourth, participants must learn how to strategically plan and then execute desired target capture movements based on estimates of current and desired limb states derived from all available sensory sources including VTF [cf., Sober and Sabes (2003)]. Finally, they must use the knowledge of results provided at the end of each reach to determine how best to update each of the constituent relationships to reduce error on the next movement attempt (recall that any target capture error was corrected by re-centering the cursor on the current target in anticipation of the upcoming trial). How much of the performance error on any given trial is due to errors in perception, mapping, planning or execution? How much should participants adjust each aspect of the learned skill from one movement attempt to the next? Exploration of how the brain resolves such “credit assignment” problems is an active area of ongoing research (Fu and Anderson 2008; Dam et al. 2013; McDougle et al. 2016; Rubin et al. 2021).
Although we did not test the extent to which participants improved perceptual acuity of vibrotactile discrimination over the course of their 20 training sessions, the asymptotic limit of target capture errors reported here aligns with the estimate of perceptual acuity obtained from a study of vibrotactile discrimination in dermatomes on the arm and hand [Fig 3A, dashed horizontal lines; c.f. Shah et al. (2019a)]. We conclude therefore that perceptual learning did not contribute substantially to the pattern of results obtained in this study. It is also likely that our cohort did not markedly alter how they used VTF to plan and execute target capture movements, given that most individuals quickly (i.e., within the first few trials) adopted a decomposition strategy that persisted throughout all of testing. Instead, performance improvements over the 20 sessions were likely due to improvements in the capability to infer hand position from the VTF signals, and/or use the map and infer desired VTF signals from newly presented visual targets. A future study could disentangle the extent to which each aspect of mapping improves over the course of training. It would be possible to assess the accuracy of the person’s VTF-to-hand-position map by occasionally asking them to move a cursor via button presses to where they would move their hand to capture a vibrotactile target presented within the vibrotactile display. Likewise, by occasionally asking participants to activate the vibrotactile display via button presses to replicate the stimuli expected for a given hand location, or for a given visual target location, it would be possible to assess the hand-to-VTF and visual-target-to-VTF maps, respectively.
Movement Decomposition Strategy
We next consider reasons why participants might have decomposed VTF-guided reaches along the principal axes of the vibrotactile display. Numerous studies of sensorimotor adaptation have shown that the brain adapts reaching movements to the specific geometry of available sensory feedback (Flanagan and Rao 1995; Wei, et al. 2005; Ghez et al. 2007; Krakauer 2009; Shabbott and Sainburg 2010). For example, Flanagan and Rao (1995) examined horizontal planar reaching movements in which they manipulated the mapping between actual and visually perceived motion such that straight-line hand paths in Cartesian space resulted in curved paths in visually perceived space and vice versa. Individuals in that study learned to make straight line paths in visually perceived space even though the paths of the hand in Cartesian space were markedly curved. By contrast, when the reaches were perceived in Cartesian space, straight line hand paths were observed. The authors concluded that reaching movements are planned in a perceptual frame of reference so as to produce straight lines in perceived space.
In our study, participants generally made no attempt to move their hand so that the projection of its motion onto the vibrotactile display was straight and smooth even after 20 sessions of training. This occurred even though we aligned the vibrotactile display with the Cartesian reference frame of the manipulandum to maximize correspondence between the two reference frames. It is possible that our sample cohort persisted in decomposing their VTF-guided reaches because even after 20 sessions of training, they had not yet formed a useful map (internal representation) of the 2D Euclidean geometry of the space spanned by the vibrotactile display. A future study should explicitly test whether an inability to form an internal representation of vibrotactile space may have caused decomposition by determining the extent to which a learned map acquired through training on a subset of visual targets might generalize to targets not included in the training set. If decomposition persists despite a demonstrated ability to generalize, an alternate explanation would be needed.
Another possible explanation for decomposed movements would be a limitation in the availability of attentional resources as described by “bottleneck” models of attention allocation (Treisman and Gelade 1980; Bonnel and Haftser 1998; Driver and Spence 1998). However, our finding that participants increased concurrency in the performance of the VTF-guided reaching task and the choice reaction task suggests that a limitation of attentional resources is not likely to be the main driver for the persistent decomposition behaviors observed all throughout training. Through training (i.e., by the time of session 20), participants had evidently freed up sufficient attentional resources to increase concurrency during dual-task testing. Consequently, they should have had access to those attentional resources in the single-task reaching blocks of that same session to increase the concurrency of motions along the two cardinal axes of the vibrotactile display if decomposition is the result of an attentional bottleneck. Alternately, it is possible that the strategy to decompose movements was chosen to free up attentional resources for the occasional concurrent performance of the reaching and choice reaction tasks – avoiding a bottleneck altogether – although this seems unlikely because the choice reaction task was only required in sessions 1, 10, and 20, whereas DI values were elevated throughout the entire study. Moreover, elevated DI values were also noted in a prior study of VTF-guided reaching without an explicit dual-task requirement (Risi et al. 2019).
The fact that decomposition has been observed in several prior studies (Shah et al. 2018; Risi et al. 2019) also raises the possibility that VTF-guided reaching should itself be considered a dual-task due to the two-channel design of the VTF interface. We have previously shown that people are better able to discriminate sequentially presented vibrotactile cues than simultaneously presented cues (Shah et al. 2019a). Decomposition might arise due to an unconscious attempt to mitigate a perceptual phenomenon known as masking, whereby the ability to sense one stimulus is degraded by the presence of another stimulus presented simultaneously or very close in time. Masking is a fundamental characteristic of sensory perception and has been observed to apply to auditory, visual, and haptic stimuli (Marcel 1983; Leek et al. 1991; Verrillo 1992; Strait et al. 2010). If masking degrades perceptual acuity in the discrimination of vibrotactile stimuli of varying intensities, participants could obtain more accurate results in VTF-guided reaching if they first moved the hand along one axis of the display to obtain the desired intensity of one vibrator, and then along the other axis to finally capture the target. The potential impact of masking might be large; as shown in (Shah et al. 2019a), simultaneous stimulation caused a 35% increase in the just-noticeable-difference discrimination threshold relative to the sequential stimulation condition when the stimuli were presented across different dermatomes in the arm and a 60% increase for simultaneous stimulation at two sites within the same dermatome. Such results suggest that participants might have compelling motivation to decompose VTF-guided reaches along the cardinal axes of the vibrotactile display to improve accuracy in the presence of masking. In a sense, movement decomposition could be viewed as a simplification of control because the increased cognitive demands associated with discriminating simultaneous vibrotactile stimuli would thereby be avoided. To the extent that moving the hand straight to the target is desirable when using supplemental kinesthetic vibrotactile feedback to guide reaching, future studies should examine how (and to what extent) it may be possible to train users to move with spatial efficiency, as well as with accuracy and temporal efficiency.
Limitations and Future Directions
A limitation of our study pertains to the design of the dual-task testing condition. Although participants were instructed to perform the two tasks as quickly and accurately as possible, we did not otherwise encourage or pressure individuals to perform the two tasks concurrently either through explicit instruction, reward, or penalty. Consequently, the increased concurrency of the two tasks reported here could have underestimated the potential increase in concurrency due to extended training on the reaching task.
We also did not assess the extent to which potential improvements in proprioceptive acuity may have accrued through extended VTF-guided reach training, or how such improvements might have facilitated target capture accuracy and efficiency. In our previous work (Risi et al. 2019), we did find that short-term training on VTF-guided reaching can promote modest improvements in the performance of reaches guided by proprioception alone (26 % reduction in reaching error after 2 days of reach training with VTF), although those performance gains were small relative to the improvements induced by supplemental kinesthetic vibrotactile feedback (74 % reduction in reaching error after 2 days of training with VTF). We cannot confirm those results in the present study because we assessed performance in the V−T− feedback condition (proprioceptive reaching) only once in session 1. Nevertheless, potential improvements in proprioceptive acuity do not likely explain the training-related performance gains because our task space accounts for intrinsic proprioceptive limitations [e.g., target to target distance is well below the limits of proprioceptive acuity reported in the literature; c.f., Fuentes and Bastian (2009)] and because the magnitude of target capture errors later in training asymptotically approach the limits of acuity of vibrotactile stimulus discrimination, as assessed previously with the same ERM vibration motors (Shah et al. 2019a).
Another limitation pertains to our study’s focus solely on horizontal planar reaching movements. For supplemental VTF to be useful in a real-world scenario, movements within a 3D workspace must be considered. Adding a third pair of vibration motors to the display to map a third movement dimension does not pose any real technical challenges. However, the vibratory cues provided by a 3D vibrotactile sensory display may prove difficult for participants to decode in real-time. Relatedly, our study relied on the instrumentation embedded within the planar manipulandum to infer hand location. Practical use of future supplemental VTF systems will require development of wearable limb state estimators using low-cost technology such as inertial measurement units (van der Linden et al. 2009; Lee et al. 2011). In any event, future experimental efforts are warranted to assess the utility and usability of a 3D limb state estimator and vibrotactile sensory display to enhance performance of goal-directed behaviors in 3D, especially those related to key activities of daily living such as eating, dressing, and grooming.
ACKNOWLEDGEMENTS
We thank Dr. Kristy Nielson for helpful comments on the dual-task paradigm, and Giulia Ballardini for development of the manipulandum used in this study.
FUNDING
This work was supported by: National Institutes of Health under award numbers: R15HD093086, and T32AG062728; National Science Foundation under an Individual Research and Development Plan; Marquette University (Research Leaders Fellowship); Whitaker International Fellows and Scholars Program (Whitaker International Program Grant); Ministry of Science and Technology, Israel (Joint Israel-Italy lab in Biorobotics “Artificial Somatosensation for Humans and Humanoids”); EU commission FP7 People: Marie-Curie Actions (334201); Erasmus+ KA 107 action (USA-Italy).
ACRONYMS
- VTF
vibrotactile feedback
- DI
Decomposition Index
Footnotes
STATEMENTS AND DECLARATIONS
On behalf of all authors, the corresponding author states that there are no conflicts of interest.
DATA AVAILABILITY
Data from the current study are available from the corresponding author on reasonable request. All requests will be reviewed by Marquette University.
References
- Afzal MR, Oh M-K, Lee C-H, et al. (2015) A Portable Gait Asymmetry Rehabilitation System for Individuals with Stroke Using a Vibrotactile Feedback. BioMed Res Int 2015:e375638. 10.1155/2015/375638 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ballardini G, Carlini G, Giannoni P, et al. (2018) Tactile-STAR: A Novel Tactile STimulator And Recorder System for Evaluating and Improving Tactile Perception. Front Neurorobotics 12:. 10.3389/fnbot.2018.00012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ballardini G, Krueger A, Giannoni P, et al. (2021) Effect of Short-Term Exposure to Supplemental Vibrotactile Kinesthetic Feedback on Goal-Directed Movements after Stroke: A Proof of Concept Case Series. Sensors 21:1519. 10.3390/s21041519 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bao T, Carender WJ, Kinnaird C, et al. (2018) Effects of long-term balance training with vibrotactile sensory augmentation among community-dwelling healthy older adults: a randomized preliminary study. J NeuroEngineering Rehabil 15:5. 10.1186/s12984-017-0339-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bark K, Hyman E, Tan F, et al. (2015) Effects of Vibrotactile Feedback on Human Learning of Arm Motions. IEEE Trans Neural Syst Rehabil Eng 23:51–63. 10.1109/TNSRE.2014.2327229 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bonnel A-M, Haftser ER (1998) Divided attention between simultaneous auditory and visual signals. Percept Psychophys 60:179–190. 10.3758/BF03206027 [DOI] [PubMed] [Google Scholar]
- Brainard DH (1997) The Psychophysics Toolbox. Spat Vis 10:433–436. 10.1163/156856897X00357 [DOI] [PubMed] [Google Scholar]
- Brashers-Krug T, Shadmehr R, Bizzi E (1996) Consolidation in human motor memory. Nature 382:252–255. 10.1038/382252a0 [DOI] [PubMed] [Google Scholar]
- Cholewiak RW, Collins AA (2003) Vibrotactile localization on the arm: Effects of place, space, and age. Percept Psychophys 65:1058–1077. 10.3758/BF03194834 [DOI] [PubMed] [Google Scholar]
- Cuppone AV, Semprini M, Konczak J (2018) Consolidation of human somatosensory memory during motor learning. Behav Brain Res 347:184–192. 10.1016/j.bbr.2018.03.013 [DOI] [PubMed] [Google Scholar]
- Cuppone AV, Squeri V, Semprini M, et al. (2016) Robot-Assisted Proprioceptive Training with Added Vibro-Tactile Feedback Enhances Somatosensory and Motor Performance. PLOS ONE 11:e0164511. 10.1371/journal.pone.0164511 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dam G, Kording K, Wei K (2013) Credit Assignment during Movement Reinforcement Learning. PLOS ONE 8:e55352. 10.1371/journal.pone.0055352 [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Santis D, Zenzeri J, Casadio M, et al. (2014) Robot-assisted training of the kinesthetic sense: enhancing proprioception after stroke. Front Hum Neurosci 8:1037. 10.3389/fnhum.2014.01037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Driver J, Spence C (1998) Crossmodal attention. Curr Opin Neurobiol 8:245–253. 10.1016/S0959-4388(98)80147-5 [DOI] [PubMed] [Google Scholar]
- Elsayed H, Weigel M, Müller F, et al. (2020) VibroMap: Understanding the Spacing of Vibrotactile Actuators across the Body. Proc ACM Interact Mob Wearable Ubiquitous Technol 4:125:1–125:16. 10.1145/3432189 [DOI] [Google Scholar]
- Eversheim U, Bock O (2001) Evidence for Processing Stages in Skill Acquisition: A Dual-Task Study. Learn Mem 8:183–189. 10.1101/lm.39301 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferris TK, Sarter N (2011) Continuously Informing Vibrotactile Displays in Support of Attention Management and Multitasking in Anesthesiology. Hum Factors 53:600–611. 10.1177/0018720811425043 [DOI] [PubMed] [Google Scholar]
- Fitts PM, Posner MI (1967) Human Performance. Brooks/Cole; Pub, Belmont, CA [Google Scholar]
- Flanagan JR, Rao AK (1995) Trajectory adaptation to a nonlinear visuomotor transformation: evidence of motion planning in visually perceived space. J Neurophysiol 74:2174–2178. 10.1152/jn.1995.74.5.2174 [DOI] [PubMed] [Google Scholar]
- Fu W-T, Anderson JR (2008) Solving the credit assignment problem: explicit and implicit learning of action sequences with probabilistic outcomes. Psychol Res 72:321–330. 10.1007/s00426-007-0113-7 [DOI] [PubMed] [Google Scholar]
- Fuentes CT, Bastian AJ (2009) Where Is Your Arm? Variations in Proprioception Across Space and Tasks. J Neurophysiol 103:164–171. 10.1152/jn.00494.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gandhi MS, Sesek R, Tuckett R, Bamberg SJM (2011) Progress in Vibrotactile Threshold Evaluation Techniques: A Review. J Hand Ther 24:240–256. 10.1016/j.jht.2011.01.001 [DOI] [PubMed] [Google Scholar]
- Ghez C, Scheidt R, Heijink H (2007) Different Learned Coordinate Frames for Planning Trajectories and Final Positions in Reaching. J Neurophysiol 98:3614–3626. 10.1152/jn.00652.2007 [DOI] [PubMed] [Google Scholar]
- Hughes B, Epstein W, Schneider S, Dudock A (1990) An asymmetry in transmodal perceptual learning. Percept Psychophys 48:143–150. 10.3758/BF03207081 [DOI] [PubMed] [Google Scholar]
- Kapur P, Premakumar S, Jax SA, et al. (2009) Vibrotactile feedback system for intuitive upper-limb rehabilitation. In: World Haptics 2009 - Third Joint EuroHaptics conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems. pp 621–622 [Google Scholar]
- König SU, Schumann F, Keyser J, et al. (2016) Learning New Sensorimotor Contingencies: Effects of Long-Term Use of Sensory Augmentation on the Brain and Conscious Perception. PLOS ONE 11:e0166647. 10.1371/journal.pone.0166647 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer JW (2009) Motor Learning and Consolidation: The Case of Visuomotor Rotation. Adv Exp Med Biol 629:405–421. 10.1007/978-0-387-77064-2_21 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krueger AR, Giannoni P, Shah V, et al. (2017) Supplemental vibrotactile feedback control of stabilization and reaching actions of the arm using limb state and position error encodings. J NeuroEngineering Rehabil 14:36. 10.1186/s12984-017-0248-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee B-C, Chen S, Sienko KH (2011) A wearable device for real-time motion error detection and vibrotactile instructional cuing. IEEE Trans Neural Syst Rehabil Eng Publ IEEE Eng Med Biol Soc 19:374–381. 10.1109/TNSRE.2011.2140331 [DOI] [PubMed] [Google Scholar]
- Lee B-C, Kim J, Chen S, Sienko KH (2012) Cell phone based balance trainer. J NeuroEngineering Rehabil 9:10. 10.1186/1743-0003-9-10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Leek MR, Brown ME, Dorman MF (1991) Informational masking and auditory attention. Percept Psychophys 50:205–214. 10.3758/BF03206743 [DOI] [PubMed] [Google Scholar]
- Li H, Sarter NB, Sebok A, Wickens CD (2012) The Design and Evaluation of Visual and Tactile Warnings in Support of Space Teleoperation. Proc Hum Factors Ergon Soc Annu Meet 56:1331–1335. 10.1177/1071181312561384 [DOI] [Google Scholar]
- Lieberman J, Breazeal C (2007) TIKL: Development of a Wearable Vibrotactile Feedback Suit for Improved Human Motor Learning. IEEE Trans Robot 23:919–926. 10.1109/TRO.2007.907481 [DOI] [Google Scholar]
- Magill RA, Anderson D (2017) Motor learning and control: concepts and applications, Eleventh edition. McGraw-Hill Education, New York, NY [Google Scholar]
- Mahns DA, Perkins NM, Sahai V, et al. (2006) Vibrotactile Frequency Discrimination in Human Hairy Skin. J Neurophysiol 95:1442–1450. 10.1152/jn.00483.2005 [DOI] [PubMed] [Google Scholar]
- Marcel AJ (1983) Conscious and unconscious perception: Experiments on visual masking and word recognition. Cognit Psychol 15:197–237. 10.1016/0010-0285(83)90009-9 [DOI] [PubMed] [Google Scholar]
- McDougle SD, Boggess MJ, Crossley MJ, et al. (2016) Credit assignment in movement-dependent reinforcement learning. Proc Natl Acad Sci 113:6797–6802. 10.1073/pnas.1523669113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Risi N, Shah V, Mrotek LA, et al. (2019) Supplemental vibrotactile feedback of real-time limb position enhances precision of goal-directed reaching. J Neurophysiol 122:22–38. 10.1152/jn.00337.2018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rothenberg M, Verrillo RT, Zahorian SA, et al. (1977) Vibrotactile frequency for encoding a speech parameter. J Acoust Soc Am 62:1003–1012. 10.1121/1.381610 [DOI] [PubMed] [Google Scholar]
- Rubin JE, Vich C, Clapp M, et al. (2021) The credit assignment problem in cortico-basal ganglia-thalamic networks: A review, a problem and a possible solution. Eur J Neurosci 53:2234–2253. 10.1111/ejn.14745 [DOI] [PubMed] [Google Scholar]
- Schmidt RA, Lee TD (2005) Motor control and learning: a behavioral emphasis, 4th ed. Human Kinetics, Champaign, IL [Google Scholar]
- Shabbott BA, Sainburg RL (2010) Learning a visuomotor rotation: simultaneous visual and proprioceptive information is crucial for visuomotor remapping. Exp Brain Res 203:75–87. 10.1007/s00221-010-2209-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shadmehr R, Brashers-Krug T (1997) Functional Stages in the Formation of Human Long-Term Motor Memory. J Neurosci 17:409–419. 10.1523/JNEUROSCI.17-01-00409.1997 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shah VA, Casadio M, Scheidt RA, Mrotek LA (2019a) Spatial and temporal influences on discrimination of vibrotactile stimuli on the arm. Exp Brain Res 237:2075–2086. 10.1007/s00221-019-05564-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shah VA, Casadio M, Scheidt RA, Mrotek LA (2019b) Vibration Propagation on the Skin of the Arm. Appl Sci 9:4329. 10.3390/app9204329 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shah VA, Risi N, Ballardini G, et al. (2018) Effect of Dual Tasking on Vibrotactile Feedback Guided Reaching – A Pilot Study. In: Prattichizzo D, Shinoda H, Tan HZ, et al. (eds) Haptics: Science, Technology, and Applications. Springer International Publishing, pp 3–14 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sienko KH, Balkwill MD, Oddsson LIE, Wall C (2008) Effects of multi-directional vibrotactile feedback on vestibular-deficient postural performance during continuous multi-directional support surface perturbations. J Vestib Res Equilib Orientat 18:273–285 [PubMed] [Google Scholar]
- Sklar AE, Sarter NB (1999) Good Vibrations: Tactile Feedback in Support of Attention Allocation and Human-Automation Coordination in Event-Driven Domains. Hum Factors 41:543–552. 10.1518/001872099779656716 [DOI] [PubMed] [Google Scholar]
- Smith MA, Ghazizadeh A, Shadmehr R (2006) Interacting Adaptive Processes with Different Timescales Underlie Short-Term Motor Learning. PLOS Biol 4:e179. 10.1371/journal.pbio.0040179 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sober SJ, Sabes PN (2003) Multisensory Integration during Motor Planning. J Neurosci 23:6982–6992. 10.1523/JNEUROSCI.23-18-06982.2003 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strait DL, Kraus N, Parbery-Clark A, Ashley R (2010) Musical experience shapes top-down auditory mechanisms: Evidence from masking and auditory attention performance. Hear Res 261:22–29. 10.1016/j.heares.2009.12.021 [DOI] [PubMed] [Google Scholar]
- Stuart M, Turman AB, Shaw J, et al. (2003) Effects of aging on vibration detection thresholds at various body regions. BMC Geriatr 3:1. 10.1186/1471-2318-3-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Treisman AM, Gelade G (1980) A feature-integration theory of attention. Cognit Psychol 12:97–136. 10.1016/0010-0285(80)90005-5 [DOI] [PubMed] [Google Scholar]
- Tzorakoleftherakis E, Bengtson MC, Mussa-Ivaldi FA, et al. (2015) Tactile proprioceptive input in robotic rehabilitation after stroke. In: 2015 IEEE International Conference on Robotics and Automation (ICRA). pp 6475–6481 [Google Scholar]
- Tzorakoleftherakis E, Murphey TD, Scheidt RA (2016) Augmenting sensorimotor control using “goal-aware” vibrotactile stimulation during reaching and manipulation behaviors. Exp Brain Res 234:2403–2414. 10.1007/s00221-016-4645-1 [DOI] [PubMed] [Google Scholar]
- van der Linden J, Schoonderwaldt E, Bird J (2009) Good vibrations: Guiding body movements with vibrotactile feedback. Cambridge, UK, pp 13–18 [Google Scholar]
- Verrillo RT (1980) Age Related Changes in the Sensitivity to Vibration. J Gerontol 35:185–193. 10.1093/geronj/35.2.185 [DOI] [PubMed] [Google Scholar]
- Verrillo RT (1992) Vibration Sensation in Humans. Music Percept 9:281–302. 10.2307/40285553 [DOI] [Google Scholar]
- Wann JP, Ibrahim SF (1992) Does limb proprioception drift? Exp Brain Res 91:162–166. 10.1007/BF00230024 [DOI] [PubMed] [Google Scholar]
- Weber B, Schätzle S, Hulin T, et al. (2011) Evaluation of a vibrotactile feedback device for spatial guidance. In: 2011 IEEE World Haptics Conference. pp 349–354 [Google Scholar]
- Wei Y, Bajaj P, Scheidt R, Patton J (2005) Visual error augmentation for enhancing motor learning and rehabilitative relearning. In: 9th International Conference on Rehabilitation Robotics, 2005. ICORR 2005. pp 505–510 [Google Scholar]
- Witteveen HJ, Rietman HS, Veltink PH (2015) Vibrotactile grasping force and hand aperture feedback for myoelectric forearm prosthesis users. Prosthet Orthot Int 39:204–212. 10.1177/0309364614522260 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data from the current study are available from the corresponding author on reasonable request. All requests will be reviewed by Marquette University.