

Abstract
Phylodynamics is a set of population genetics tools that aim at reconstructing demographic history of a population based on molecular sequences of individuals sampled from the population of interest. One important task in phylodynamics is to estimate changes in (effective) population size. When applied to infectious disease sequences such estimation of population size trajectories can provide information about changes in the number of infections. To model changes in the number of infected individuals, current phylodynamic methods use non-parametric approaches (e.g., Bayesian curve-fitting based on change-point models or Gaussian process priors), parametric approaches (e.g., based on differential equations), and stochastic modeling in conjunction with likelihood-free Bayesian methods. The first class of methods yields results that are hard to interpret epidemiologically. The second class of methods provides estimates of important epidemiological parameters, such as infection and removal/recovery rates, but ignores variation in the dynamics of infectious disease spread. The third class of methods is the most advantageous statistically, but relies on computationally intensive particle filtering techniques that limits its applications. We propose a Bayesian model that combines phylodynamic inference and stochastic epidemic models, and achieves computational tractability by using a linear noise approximation (LNA) — a technique that allows us to approximate probability densities of stochastic epidemic model trajectories. LNA opens the door for using modern Markov chain Monte Carlo tools to approximate the joint posterior distribution of the disease transmission parameters and of high dimensional vectors describing unobserved changes in the stochastic epidemic model compartment sizes (e.g., numbers of infectious and susceptible individuals). In a simulation study, we show that our method can successfully recover parameters of stochastic epidemic models. We apply our estimation technique to Ebola genealogies estimated using viral genetic data from the 2014 epidemic in Sierra Leone and Liberia.
Keywords: Coalescent, Susceptible-Infectious-Recovered model, state-space model, phylodynamics, Ebola virus
1. Introduction
Phylodynamics is an area at the intersection of phylogenetics and population genetics that studies how epidemiological, immunological, and evolutionary processes affect viral genealogies/phylogenies constructed based on molecular sequences sampled from the population of interest (Grenfell et al., 2004; Volz, Koelle and Bedford, 2013). Phylodynamics is especially useful in infectious disease modeling because genetic data provide a source of information that is complementary to the traditional disease case count data. Here we are interested in inferring parameters governing infectious disease dynamics from the genealogy/phylogeny estimated from infectious disease agent molecular sequences collected during the disease outbreak. Working in a Bayesian framework, we develop an efficient Markov chain Monte Carlo (MCMC) algorithm that allows us to work with stochastic models of infectious disease dynamics, properly accounting for stochastic nature of the dynamics.
Infectious disease phylodynamics methods handle densely and sparsely sampled outbreaks differently (but see (Smith, Ionides and King, 2017; Vaughan et al., 2019) for potentially universal methods). In a densely sampled outbreak scenario, it is possible to simultaneously infer infectious disease dynamics parameters and a transmission network (Ypma, van Ballegooijen and Wallinga, 2013; Jombart et al., 2014; Klinkenberg et al., 2017). When an outbreak is sampled sparsely, a setting we are interested in this paper, it is impossible to determine who infected whom, so additional modeling is needed to connect sampled hosts to the unobserved population dynamics. Currently, learning about population-level infectious disease dynamics from a sparse sample of molecular sequences can be accomplished using three general strategies. The first strategy relies on the coalescent theory — a set of population genetics tools that specify probability models for genealogies relating individuals randomly sampled from the population of interest (Kingman, 1982; Griffiths and Tavaré, 1994; Donnelly and Tavare, 1995). Using a subset of these models (Griffiths and Tavaré, 1994), it is possible to estimate changes in effective population size — the number of breeding individuals in an idealized population that evolves according to a Wright-Fisher model (Wright, 1931). Such reconstruction can be done assuming parametric (Kuhner, Yamato and Felsenstein, 1998; Drummond et al., 2002) or nonparametric (Drummond et al., 2002, 2005; Minin, Bloomquist and Suchard, 2008; Palacios and Minin, 2013; Gill et al., 2013) functional forms of the effective population size trajectory. In the context of infectious disease phylodynamics, nonparametric inference is the norm and the estimated effective population size is often interpreted as the effective number of infections or the effective number of infectious individuals. However, reconstructed effective population size trajectories are not easy to interpret and estimation of parameters of disease dynamics is difficult to accomplish if one wishes to maintain statistical rigor (Pybus et al., 2001; Frost and Volz, 2010).
Another way to learn about infectious disease dynamics from molecular sequences is to model explicitly events that occur during the infectious disease spread and to link these events to the genealogy/phylogeny of sampled individuals using birth-death processes. For example, a Susceptible-Infectious-Removed (SIR) model includes two possible events: infections and removals (e.g., recoveries and deaths), represented by births and deaths in the corresponding birth-death model (Stadler et al., 2013; Kühnert et al., 2014). Other SIR-like models (e.g., SI and SIS models) differ by the number and types of the events that are needed to accurately describe natural history of the infectious disease (Leventhal et al., 2013).
Structured coalescent models provide the third strategy of inferring parameters governing spread of an infectious disease (Volz et al., 2009; Volz, 2012; Dearlove and Wilson, 2013). These models assume infectious disease agent genetic data have been obtained from a random sample of infected individuals, allowing for serial sampling over time. Although similar to the birth-death modeling framework, the structured coalescent models have two advantages. First, one does not have to keep track, analytically or computationally, of extinct and not sampled genetic lineages. Second, the density of the genealogy can be obtained given the population level information about status of individuals: for example, in the SIR model it is sufficient to know the numbers of susceptible, , infectious, , and recovered, , individuals at each time point . The second advantage comes with two caveats: 1) such densities can be obtained only approximately and 2) evaluating densities of genealogies is not straightforward and involves numerical solutions of differential equations. Even in cases when these caveats are manageable, the density of the assumed stochastic epidemic model population trajectory remains computationally intractable. One way around this intractability assumes a deterministic model of infectious disease dynamics (Volz et al., 2009; Volz, 2012; Volz and Pond, 2014), which potentially leads to overconfidence in estimation of model parameters. Particle filter MCMC offers another solution (Rasmussen, Ratmann and Koelle, 2011; Rasmussen, Volz and Koelle, 2014).
In this paper, we develop methods that allow us to bypass particle filter MCMC with the help of a linear noise approximation (LNA). LNA is a low order correction of the deterministic ordinary differential equation describing the asymptotic mean trajectories of compartmental models of population dynamics defined as Markov jump processes (e.g., chemical reaction models and SIR-like models of infectious disease dynamics) (Kurtz, 1970, 1971; Van Kampen and Reinhardt, 1983). LNA can also be viewed as a first order Taylor approximation of Markov population dynamics models represented by stochastic differential equations (Giagos, 2010; Wallace, 2010). A key feature of the LNA method is that it approximates the transition density of a stochastic population model with a Gaussian density (Komorowski et al., 2009).
Inspired by recent applications of LNA to analysis of Google Flu Trends data (Fearnhead, Giagos and Sherlock, 2014) and disease case counts (Buckingham-Jeffery, Isham and House, 2018), we develop a Bayesian framework that combines LNA for stochastic models of infectious disease dynamics with structured coalescent models for genealogies of infectious disease agent genetic samples. Our approach yields a latent Gaussian Markov model that closely resembles a Gaussian state-space model. We use this resemblance to develop an efficient MCMC algorithm that combines high dimensional elliptical slice sampler updates (Murray, Adams and MacKay, 2010) with low dimensional Metropolis-Hastings (MH) moves. Using simulations, we demonstrate that this algorithm can handle reasonably complex models, including an SIR model with a time-varying infection rate. We apply this SIR model to a recent Ebola outbreak in West Africa. Our analysis of data from Liberia and Sierra Leone illuminates significant changes in the Ebola infection rate over time, likely caused by the public health response measures and increased awareness of the outbreak in the population.
2. Methodology
2.1. Genealogy as data
We start with infectious disease agent molecular sequences obtained from infected individuals sampled uniformly at random from the total infected population. Further, we assume that a phylogenetic tree, or genealogy, g relating these sequences has been estimated in such a way that the tree branch lengths respect the known sequence sampling times. Such estimation can be performed with, for example, BEAST — a software package for Bayesian phylogenetic inference (Suchard et al., 2018). The genealogy is represented by a tree structure with its nodes containing two sources of temporal information: coalescent and sampling times. The coalescent times correspond to the internal nodes of the tree, which are defined as the times at which two lineages in the tree are merged into a common ancestor. The sampling times, corresponding to the tips of the tree, are the times at which molecular sequences were sampled. Note that sampling times are observed directly, while coalescent times are estimated from molecular sequences during phylogenetic reconstruction.
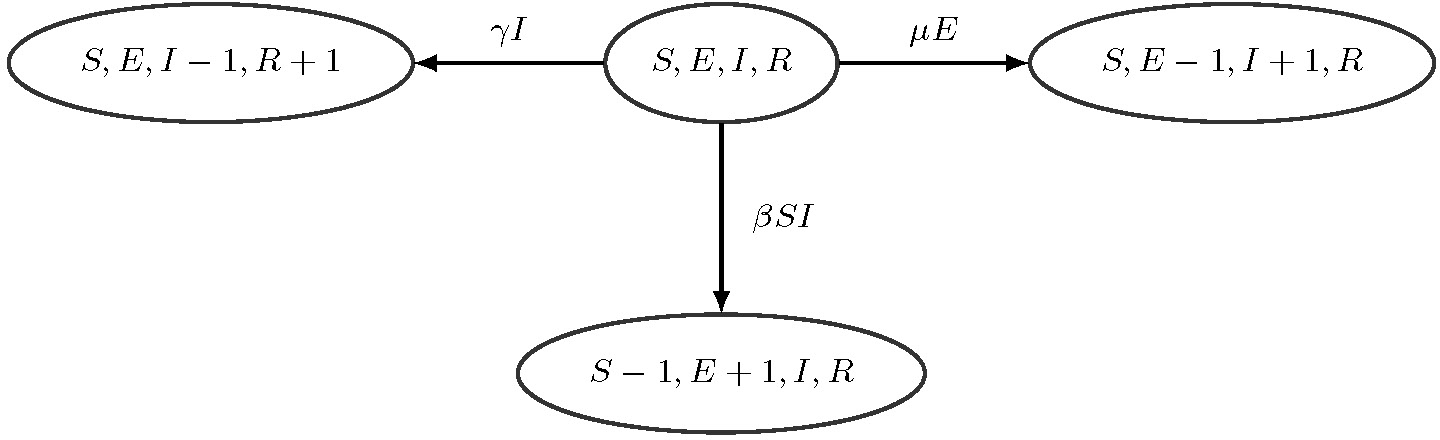
To perform inference about infectious disease dynamics using the above genealogy we need a probability model that relates the genealogy and infectious disease dynamics model parameters. We assume that the infectious disease is spreading through the population according to the SIR model — a canonical compartmental model that at each time point tracks the number of susceptible individuals , number of infected/infectious individuals , and number of removed individuals (Bailey, 1975; Anderson and May, 1992). We assume that the population is closed so for all times , where is the population size that we assume to be known. This constraint implies that vector is sufficient to keep track of the population state at time . We follow common practice and model as a Markov jump process (MJP) with allowable instantaneous jumps shown in Figure 1 (O’Neill and Roberts, 1999). The assumed MJP process is inhomogeneous, because we allow the infection rate and removal rate to be time-varying.
FIGURE 1.

SIR Markov jump process. From the current state with the counts S, I, R, the population can transition to state , (an infection event) with rate or to state , (a removal event) with rate . No other instantaneous transitions are allowed.
The structured coalescent models assume that only coalescent times provide information about the population dynamics. These times are modeled as jumps of an inhomogeneous pure death process with rate , where each “death” event corresponds to coalescence of two lineages and is called a coalescent rate. Then the density of the genealogy, which serves as a likelihood in our work, is written as
where denotes the most recent sequence sampling time. The dependence of coalescent rate on the assumed population dynamics can be complicated and mathematically intractable, but luckily approximations exist for some specific cases. For the SIR model the approximate coalescent rate can be obtained via the following formula:
| (1) |
where is the number of lineages present at time (Rasmussen, Ratmann and Koelle, 2011; Volz, Koelle and Bedford, 2013). The coalescent rate in the SIR model can be interpreted as the rate of infection events between sampled lineages present at time , where is the total infection rate in the population and corresponds to the probability that the infection occurs between lineages present at time . Note that when the number of susceptibles is not changing significantly relative to the total population size (i.e., ) and infection rate is constant (i.e., ), the structured coalescent reduces to the classical Kingman’s coalescent, where we interpret as the effective population size trajectory (Kingman, 1982). It is possible to find approximate coalescence rate for general compartmental models, but closed form expressions exist only for a few models with a low number of compartments (e.g., SI, SIR) (Volz et al., 2009; Volz, 2012; Dearlove and Wilson, 2013).
Since we allow sequences to be sampled at different times , some inter-coalescent times are censored. To deal with this censoring algebraically, each inter-coalesecent interval is partitioned by the sampling events into sub-intervals: . The intervals that start with a coalescent event are defined as , for and . Let the number of lineages in each interval be . Then the number of lineages at each time point can be written as . If the interval ends with a coalescent time, the number of lineages in the next interval will be decreased by 1. If the interval ends with a sampling event , then the number of lineages in the next interval is increased by — the number of sequences sampled at time . Figure 2.1 shows an example of a genealogy with labeled coalescent times, sampling times, number of lineages, and the corresponding intervals.
FIGURE 2.

Example of a genealogy. Black solid lines show the genealogy structure. The colescent times and sampling times are labeled with vertical dashed lines. The number of lineages is given in each intervals .
We are now ready to connect the SIR model and a genealogy with serially sampled tips with the help of a structured coalescent density/likelihood. First we discretize the time interval between the time to the most recent common ancestor (time corresponding to the root of the tree) and the most recent sampling time using a regular grid ( and ) Using this grid, we discretize the latent epidemic trajectory by assuming that , where is a column vector. Similarly, we discretize the infectious disease dynamics parameter vector trajectory so that , where is also a column vector. We collect latent variables and parameters into matrices and respectively. The SIR structured coalescent density/likelihood then becomes
| (2) |
Since , , and are piecewise constant functions, the integrals in the above formula are readily available in closed form and are fast to compute.
2.2. Bayesian data augmentation
2.2.1. Posterior distribution
Given genealogy , our goal is to infer the latent SIR population dynamic and rate parameters over time grid . Let and denote the prior densities for the initial compartment states and the SIR parameters respectively. The posterior distribution for the population trajectory and parameters given observed genealogy is
| (3) |
where is the structured coalescent likelihood introduced in Section 2.1 and is the likelihood function for discrete observations of trajectory given the initial value :
| (4) |
where the factorization comes from the assumed Markov property of the disease dynamics. However, the SIR transition density becomes intractable as population size grows large, making it difficult to perform likelihood-based inference for outbreaks in large populations.
2.2.2. Linear noise approximation
To furnish a feasible computation strategy for large populations, we use a linear noise approximation (LNA) method, in which the computationally intractable transition probability is approximated using a closed form Gaussian transition density (Kurtz, 1970, 1971; Komorowski et al., 2009).
The LNA method replaces the MJP discrete state space with a continuous state space of to approximate the counts of at time , under the following constraints: and . To briefly explain how this approximation is obtained, we will need additional notation.
The SIR MJP instantaneous transitions, depicted in Figure 1, are encoded in an effect matrix
| (5) |
Each row in matrix (5) represents a type of transition event and each column corresponds to a change in the susceptible and infected populations. Next, we define a rate vector and a rate matrix :
| (6) |
The above notation, as well as subsequent developments based on it, can be generalized to other epidemic models and, more generally, to a large class of density dependent stochastic processes, such as chemical reaction and gene regulation models (Wilkinson, 2011). See Section A-1 in the Appendix for more details on this generalization.
Consider a transition from at time to at . Recall that we assume that the SIR rates take constant values in . The LNA represents the value of the next state as , where is a deterministic component and is a stochastic component. The deterministic component can be obtained by solving the standard SIR ODE that in our notation can be written as
| (7) |
The stochastic part corresponds to the solution of the following SDE at time
| (8) |
where is the Jacobian matrix of the deterministic part in (7) evaluated at . The solution of SDE (8), , is a Gaussian process and can be recovered by solving two ordinary differential equations governing the mean function and covariance function :
| (9) |
| (10) |
for . A heuristic derivation of LNA, based on (Wallace, 2010), is given in Section A-2 of the Appendix. Let denote the initial values of , , at time in differential equations (7), (9), and (10) respectively. There are two options for choosing these initial conditions: the non-restarting LNA of Komorowski et al. (2009) and the restarting LNA of Fearnhead, Giagos and Sherlock (2014). In this paper, we will use the non-restarting LNA by Komorowski et al. (2009) since it allows us to isolate the effect of adding stochasticity to the ODE method as the mean population trajectory of the non-restarting LNA is the trajectory from the ODE method. The non-restarting LNA has the following choice of initial conditions:
, where was obtained by solving the ODE (7) using parameter vector over the interval ,
,
.
Solving the system of ODEs (7), (9), (10), we obtain , and . The solution will be a function of the initial value , the interval length and the SIR rates . To make this dependence explicit, we write . Since (9) is a first order homogeneous linear ODE, the solution is a linear function of . Hence, the transition from to follows the following Gaussian distribution:
| (11) |
To summarize, the derived conditional Gaussian densities allow us to compute the density of the latent SIR trajectory (4). As a result, our augmented posterior distribution of and , shown in equation (3), can be computed up to proportionality constant and approximated via “standard” (not particle filter) MCMC approaches.
2.3. Reparameterization, priors, and MCMC algorithm
2.3.1. Reparameterizing SIR rates
We have experimented with multiple parameterizations of our inhomogeneous SIR model and found that the following parameterization works best with our proposed MCMC algorithm for approximating the posterior distribution (3). First, recall that we allow SIR rates to vary with time. Since it is much more likely for the infection rate to be time variable, we are going to assume a constant removal/recovery rate . This leaves us with the following parameters: infection rates on a grid , removal rate , and initial SIR state . Since we are interested in modeling an emerging infectious disease outbreak, we set the initial counts of susceptibles to . Initial counts of infected individuals, , is assumed to be low and treated as an unknown parameter with a lognormal prior distribution. Instead of the time-varying infection rate , we parameterize our SIR model with a time-varying basic reproduction number . The reproduction number is interpreted as the average number of cases that one case generates over its infectious period in a completely susceptible population. Since our infection rate changes in a piecewise manner, the basic reproduction number varies over time in a piecewise manner too:
| (12) |
where is the reproduction number corresponding to the time interval . Let be the initial basic reproductive number and be a normalized log ratio of over two successive time intervals. Then, interval-specific basic reproduction numbers can be written as
| (13) |
where we assume a priori that are independent standard normal random variables.
This construction implies that log-transformed piecewise constant reproduction numbers, s, a priori follow a first order Gaussian Markov random field (GMRF) with standard deviation that controls the a priori smoothness of trajectory (Rue, 2001; Rue and Held, 2005). In addition to speeding MCMC convergence, working with is convenient, because this trajectory is dimensionless and retains its interpretation when one changes the population size . The initial is assigned a lognormal prior. We use a lognormal prior for the inverse of standard deviation .
2.3.2. Grid size and prior for GMRF standard deviation
The number of grid intervals can be thought of as a tuning parameter in our model. Increasing linearly increases complexity of the coalescent likelihood and prior density calculations, suggesting that keeping small is prudent from a computational point of view. However, if the chosen is too small, we may miss large changes of the latent numbers of susceptible and infectious individuals and changes of the basic reproduction number. We recommend choosing large enough to capture these changes, possibly experimenting with multiple grid sizes. We recommend setting the prior distribution for in conjunction with , for example, by controlling the probability that a priori stays within a reasonable range.
2.3.3. Reparameterizing SIR latent trajectories
We reparameterize the latent SIR trajectory with a sequence of independent Gaussian random variables , following a non-centered parameterization framework of Papaspiliopoulos, Roberts and Sköld (2007). According to formula (11), conditional on can be written as
| (14) |
where for and is a identity matrix. In our parameterization, we will treat as random latent variables and the SIR latent trajectory as a deterministic transformation of . More details about our non-centered parameterization of can be found in Section A-3 of the Appendix.
2.3.4. MCMC algorithm
Using our new parameterization, we are now interested in the posterior distribution of the initial number of infected individuals, , removal rate, , the initial basic reproduction number, , standardized vectors, and , and GMRF standard deviation, :
The latent variables and parameter vector are deterministic functions of new parameters , , , , and . We use the following MCMC with block updates to approximate this posterior distribution. We update high dimensional vector using the efficient elliptical slice sampler (Murray, Adams and MacKay, 2010). Vector is updated the same way in a separate step. Initial number of invected individuals and removal rate are updated using univariate Metropolis steps. The full procedure is described in Algorithm 2, which together with details of the elliptical slice sampler can be found in Section A-4.1 of the Appendix. After MCMC is done, we report posterior summaries using natural parameterization. For example, we report posterior medians and 95% Bayesian credible intervals (BCIs) of the piecewise latent reproduction number trajectory, , for , and latent trajectory .
2.3.5. Implementation
Our R package called LNAPhylodyn provides an implementation of our MCMC algorithm. The package code is publicly available at https://github.com/MingweiWilliamTang/LNAphyloDyn. This repository also contains scripts that should allow one to reproduce key numerical results in this manuscript. The PhyDyn simulation example is also included in https://github.com/MingweiWilliamTang/LNAphyloDyn/blob/master/inst/SIR_phydyn_example.xml.
3. Simulation experiments
3.1. Simulations based on single genealogy realizations
In this section, we use simulated genealogies to assess performance of our LNA-based method and to compare it with an ODE-based method, where we replace equation (14) with its simplified version: . Under our assumption of a fixed and known genealogy and constant , our ODE-based method closely resembles previously developed methods by Volz et al. (2009) and Volz and Siveroni (2018). To compare ODE-based and LNA-based models in a Bayesian nonparametric setting, we equip the ODE model with the GMRF prior for time-varying , described in Section 2.3.1. We use the same MCMC algorithm for both LNA-based and ODE-based models, except we do not have a separate step to update latent vector (equivalently, ) in the ODE-based inference. See Algorithm 3 in the Appendix for a more detailed description of the ODE-based MCMC.
The simulation protocol consists of two steps. First, given the population size and pre-specified parameters , and , we simulate one realization of the SIR population trajectory based on the MJP using the Gillespie algorithm (Gillespie, 1977). Next, we generate realistic lineage sampling times and simulate coalescent times from the distribution specified by density (2) using a thinning algorithm by Palacios and Minin (2013). We specified several sampling times spanning the time of the epidemic. The number of sampled sequences at each sampling time in each scenario is set to be approximately proportional to the true prevalence. More details are given in Appendix Section A-5.1.
We test LNA-based and ODE-based methods under three “true” trajectories over the time interval [0, 90]:
Constant (CONST) . for . Recovery rate . Initial counts of infected individuals . Total population size is . The total number of sampled sequences is 1022.
Stepwise decreasing (SD) . , and . Recovery rate . Initial counts of infected individuals . Total population size . The total number of sampled sequences is 342.
Non-monotonic . , and . Recovery rate . Initial counts of infected individuals . Total population size . The total number of sampled sequences is 442.
For all simulations, we use lognormal (1, 1) prior for . The parameters of the lognormal priors for the initial and inverse standard deviation are set to and respectively, in such a way that a priori trajectory stays within a reasonable range of [0, 5] with 0.9 probability. We assign an informative prior for in each simulation scenario, assuming that prior information about this parameter is available: (1) CONST: , (2) SD: , (3) NM: . We set the grid size to , with for . As a result, each scenario has 72 latent variables that keep track of latent numbers of infectious and removed individuals, , and 36 parameters that describe changes in the basic reproduction number, , plus parameters , , and . For both LNA-based and ODE-based methods, we use 1,000,000 MCMC iterations. All MCMC chains appeared to converge (trace plots are shown in Section A-5.4.1 of the Appendix). The effective sample sizes of all unknown quantities were above 400 (See Table A-1 for more details).
The first row of Figure 3 shows point-wise posterior medians and 95% BCIs for the basic reproduction number trajectory, . Our LNA-based method performs well in capturing the continuous dynamics of . Though our approach may not perfectly catch the discontinuous changes in in the SD scenario, the method provides BCIs that are able to capture most of the trajectory. The ODE-based method yields similar results in the CONST case and the case, but underestimates the magnitude of the decrease in toward the end of the epidemic.
FIGURE 3.

Analysis of 3 simulation scenarios. Columns correspond to CONST, SD, and NM simulated trajectories. The first row shows the estimated trajectories for the 3 scenarios, with the black solid lines representing the truth, the red dashed lines depicting the posterior median and the red-shaded area showing the 95% BCIs for the LNA-based method. For the ODE-based method, the posterior median is plotted in blue dotted lines, with blue shading showing the 95% BCIs. The second row corresponds to the estimation for the removal rate γ. Posterior density curves from the LNA are shown in red lines and the posterior density for ODE is plotted in blue lines, compared with prior density curve in green lines. The bottom two figures shows the estimated trajectory of and respectively.
The second row in Figure 3 shows posterior summaries of removal rate . Both LNA-based and ODE-based methods provide good estimates in the CONST scenario, with posterior modes centered at the true value and higher posterior densities at truth when compared with the prior. In the SD and NM scenarios with the time varying , the posterior estimates from the LNA-based method and ODE-based method, though still centered at the truth, do not differ much from the prior distribution.
Posterior summaries of and are depicted in the third and fourth rows of Figure 3. The two methods produce similar results in the CONST and SD scenario, as both of them have narrow BCIs covering the true trajectories. However, in the NM case, while the LNA-based method manages to recover the latent SIR trajectory trend, the BCIs from the ODE-based method fail to cover the true prevalence trajectory in the middle and at the end of the epidemic. Somewhat counterintuitively, LNA-based method produces BCIs for the latent trajectories, and , that are narrower than its ODE counterparts. We suspect this is a result of the ODE-based method poor estimation of the basic reproduction number trajectory at the end of the epidemic.
3.2. Frequentist properties of posterior summaries
In this Section, we design a simulation study based on repeatedly simulating SIR trajectories using MJP with pre-specified parameters. We report simulations based on the non-monotonic trajectory scenario in Section 3.1 with the same parameter setup, except the parameters of the lognormal prior for the initial are set to . Results of repeatedly simulating SIR trajectories with constant and monotonic trajectories are reported in Appendix Section A-5.3. Simulating SIR dynamics under low initial number of infected individuals can end up with low prevalence trajectories that end at the beginning of the epidemic, or trajectories having unrealistically high prevalence, which are less likely to be observed during real infectious disease outbreaks. Therefore, while simulating SIR trajectories we reject such “unreasonable” realizations to arrive at 100 simulated trajectories. The details of the rejection criteria are given in Section A-5.2 of the Appendix. For each simulated SIR trajectory, a realization of a genealogy is generated using the structured coalescent process. We use both LNA-based and ODE-based models to approximate the posterior distribution of model parameters and latent variables for each genealogy. In addition to the informative prior for removal rate , used in Section 3.1, we use a weaker prior to probe prior sensitivity of both LNA-based and ODE-based methods.
We use three metrics to evaluate models based on their estimates of and : average error of point estimates (posterior medians), width of credible intervals, and frequentist coverage of credible intervals. Since the value of is greater than 0 and usually upper-bounded by 20 (i.e, it stays within the same order of magnitude), we will measure accuracy using an unnormalized mean absolute error (MAE):
| (15) |
where is the posterior median of . In contrast, varies from one at the beginning of the epidemic to thousands at the peak, so to evaluate accuracy of prevalence estimation we use the mean relative absolute error (MRAE):
| (16) |
where is the posterior median of . We assess precision of estimation based on the mean credible interval width (MCIW):
| (17) |
where and denote the lower and upper bounds of the 95% BCI for . Similar as our measure of accuracy, precision of estimation is quantified via mean relative credible interval width (MRCIW):
| (18) |
where and specify the lower and upper bounds of the 95% BCI of . In addition, we compute the “envelope” (ENV) — a measure of coverage of BCIs the true trajectory — for and as follows:
Sampling distribution boxplots of posterior summaries are depicted in the left three plots of Figure 4. The LNA-based method yields lower MAE than the ODE-based method under both informative and weakly informative priors for the removal rate . As a trade-off, the MCIWs produced by the LNA-method are generally higher, as expected since the LNA-based method incorporates the stochasticity in the population dynamics. With less bias and wider BCIs, the LNA-based method BCIs result in better coverage than ODE-based BCIs, as shown by the envelope boxplots. Informative prior for the removal rate helps both LNA-based and ODE-based methods to estimate .
FIGURE 4.
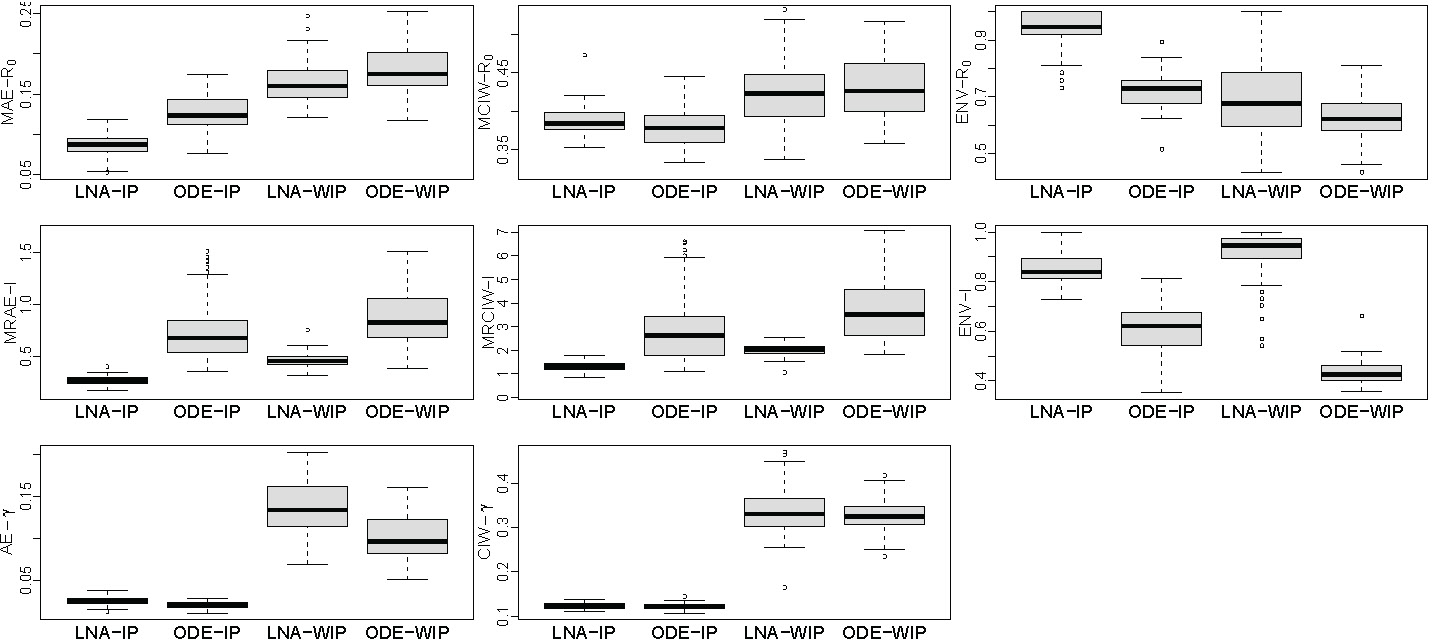
Borplots comparing performance of LNA-based and ODE-based methods using 100 simulated genealogies under informative prior (IP) and weakly informative prior (WIP) for removal rate . The first row shows mean absolute error (MAE), mean credible interval width (MCIW), and enevolope trajectory. The second row depiets mean relative absolute error (MRAE), mean relative credible interval width (MRCIW), and enelope (ENV-1) for (prevalence) trajectory (ENV-I). The last two plots show the absolute error (AE) and Bayesian credible intereval (BCI) width for .
Sampling distribution boxplots of posterior summaries, shown in Figure 4, are similar to the results, with the LNA-based method generally having lower MRAEs, higher MRCIWs and a better coverage/envelope than the ODE-based method. Again, somewhat counterintuitively, the MRCIWs for the LNA-based method are smaller than the ODE counterparts. This is likely caused by significant bias in estimation by the ODE-based method. The contrast between results of informative and weakly informative prior is a little different from estimation results, because the LNA-bnsed method is estimating better than under the weakly informative prior.
We also report the absolute error (AE) and 95% BCI widths for removal rate in Figure 4. The LNA-based method yields slightly higher AEs than the ODE method. Under the informative prior, both LNA-based and ODE-based methods have coverage of 95% BCIs equal to 1.0. However, coverage of LNA-based method drops to 0.65 under the weakly informative prior, while the ODE-based method’s 95% BCI coverage becomes 0.99.
In conclusion, the ODE-based method tends to be biased and overconfident when estimating basic reproduction number and prevalence . By modeling stochasticity of the population trajectory dynamics, our LNA-based method produces more accurate and less precise estimators of and that enjoy good frequentist properties. However, the ODE-based method does better in estimating the recovery rate , which is only weakly identifiable.
3.3. Additional simulations and validation
We perform the same repeated simulations for the constant and stepwise decreasing scenarios under the same parameter setup as in Section 3.1 and report the corresponding frequentist properties of the posterior summaries in Figures A-5 and A-6. Both LNA-based and ODE-based methods results are similar to the results from the non-monotonic simulation scenario, but the differences between LNA-based and ODE-based methods are less pronounced than in the non-monotonic scenario.
Theoretically, both structured coalescent models and LNA are designed to work for epidemics in large populations. We test performance of LNA-based and ODE-based methods in a relatively small population with the size of . For simplicity, we use a constant simulation scenario. Assuming that is constant also allows us to compare our method to the BEAST 2 PhyDyn module that implements the ODE-based approach. PhyDyn can handle a wide range of different compartmental models of infectious disease dynamics, but we use only a simple SIR model in this comparison. This simulation study shows that our implementations of both LNA-based and ODE-based approaches perform reasonably in this small population setting, but PhyDyn does do as well. However, we find that the disagreement between our ODE implementation and PhyDyn is artifact of the small population size setting, which leads to the outbreak to be densely sampled. In Appendix Section A-9, we demonstrate that our ODE-based method implementation agrees with package PhyDynR (a predecessor of BEAST 2 PhyDyn) under a setup with a large population size, but the two implementations disagree under a small population size setting.
4. Analysis of Ebola outbreak in West Africa
We apply our LNA-based method to the Ebola genealogies reconstructed from molecular data collected in Sierra Leone and Liberia during the 2014–2015 epidemic in West Africa (Dudas et al., 2017). We use a Sierra Leone genealogy, depicted in the top left plot of Figure 5, which was estimated from 1010 Ebola virus full genomes sampled from 2014-05-25 to 2015-09-12 in 15 cities. The Liberia genealogy, shown in the top left plot of Figure 6, was estimated from a smaller number of samples: 205 Ebola virus full genomes sampled from 2014-06-20 to 2015-02-14. The original sequence data and the reconstructed genealogies are publicly available at https://github.com/ebov/space-time.
FIGURE 5.

Analysis of the genealogy relating Ebola virus sequences collected in Sierra Leone. Top top left plot depicts the Ebola genealogy. The top right plot shows the estimated , with the red dashed line showing the posterior median and the salmon shaded area showing the 95% BCIs of the LNA-based method. The posterior median based on the ODE-based method is plotted as the blue dotted line with blue shading corresponding to the 95% BCIs. The medium left figure shows prior and posterior densities of the mean infection period . The prior density is shown in green, while the posterior densities based on LNA and ODE are plotted in red and blue respectively. The medium right and the bottom left figures show the estimated trajectory of and , using the same legend as in top right plot. The bottom right plot shows the predicted median and 95% BCIs for weekly reported incidence together with the reported incidence from WHO shown as crosses.
FIGURE 6.

Analysis of the genealogy relating Ebola virus sequences collected in Liberia. See caption in Figure 5 for the explanation of the plots.
When Ebola virus infections were detected in West Africa in mid-Spring of 2014, various intervention measures were proposed and implemented to change behavior of individuals in the populations through which Ebola was spreading. Border closures, encouragement to reduce individual day-to-day mobility, and recommendations on changing burial practices were among the broad spectrum of interventions attempted by multiple countries. It is reasonable to expect that these intervention measures resulted in lowering the contact rates among members of the populations, which in turn reduced the infection rate, or equivalently the basic reproduction number.
When analyzing the Sierra Leone and Liberia genealogies, we rely on conclusions of Dudas et al. (2017) and assume the population in each country to be well mixed. Furthermore, we assume Ebola spread to follow SIR dynamics. For each country, the population size is specified based on its census population size in 2014, with for Sierra Leone and for Liberia. We investigated robustness to population size misspecification in Appendix Section A-8.2 and found that altering population size of Liberia by an order of magnitude in each direction did not appreciably change estimation results. As in our simulation study, we use the lognormal prior for with and and the lognormal prior for the inverse standard deviation with . Recall that this prior setting ensures that a priori stays within a reasonable range of [0, 5] with probability 0.9. For removal rate , we use an informative lognormal prior with mean 3.4 and variance 0.2 based on previous studies (Towers, Patterson-Lomba and Castillo-Chavez, 2014). The parameter , interpreted as the length of the infectious period, is expected to be 8–18 days for each country a priori. The total time span for each genealogy is divided evenly into 40 intervals, which results in grid interval lengths, , to be 12.41 days for Sierra Leone and 6.9 days for Liberia. We experimented with two additional grid sizes for the Liberia analysis in Appendix Section A-7 and found that our results are not too sensitive to the choice of grid size.
We run the MCMC algorithm in Section 2.3 for 2,000,000 iterations with 9 parallel chains for Sierra Leone data and 750,000 iterations for Liberia data using a single chain. The posterior samples are obtained by discarding the first 100,000 iterations and saving every 30th iteration afterward. The trace plots in Section A-5.4.2 of the Appendix indicate the MCMC algorithm has converged and achieved good mixing in each case.
Figures 5 and 6 show results for Sierra Leone and Liberia respectively, with intervention events mapped onto the calendar time on the x-axis. Our LNA-based method estimates the initial in Sierra Leone during 2014–2015 to be 1.66, with 95% BCI of (1.31, 2.15). Similarly, in Liberia during 2014 –2015 has a point estimate 1.67 and a 95% BCI(1.29, 2.24). Our estimate of initial in Sierra Leone is consistent with the estimates of Stadler et al. (2014), who fitted multiple birth-death models to 72 sequences at the early stages of the outbreak. Our LNA-based method yields a slightly smaller estimate of the initial than methods based on susceptible-exposed-infectious-removed (SEIR) models. For example, Volz and Pond (2014) used a SEIR model with a constant and estimated it to be 2.40 (CI: (1.54, 3.87)). Althaus (2014) assumed an exponentially decaying with an estimated initial of 2.52 (CI: (2.41, 2.67))The discrepancies between our and SEIR-based estimates are not unexpected, because SEIR models generally yield higher estimates than SIR models when applied to the same dataset (Wearing, Rohani and Keeling, 2005; Keeling and Rohani, 2011). Our estimated for Liberia is in agreement with results of Althaus (2014), who fitted a SEIR model to incidence data and arrived at an estimated of 1.59 (CI: (1.57, 1.60)).
The dynamics in the two countries share a similar pattern: with (1) a decreasing trend that starts in Spring/Summer of 2014, (2) a stable/constant period until the end of September 2014 and (3) a final decrease below 1.0 (epidemic is contained) around November 2014. Since the number of susceptible individuals did not change significantly over the course of the epidemic, relative to the total population size, the basic and effective reproduction numbers, and , are approximately equal. This allows us to compare our estimation results with previously estimated changes in . Our estimation of early dynamics in Sierra Leone agrees with results of Stadler et al. (2013), who concluded that the effective reproduction number did not significantly decrease until mid June. Our estimated trajectory suggests that later interventions, such as border closures and release of burial guides, may have been helpful in controlling the spread of the disease. The infectious period for Sierra Leone epidemic is estimated to be 10.8 days with a 95% BCI (7.6,15.6). For Liberia, the infection period has a point estimate of 9.8, with a 95% BCI (6.87, 14.05). The posterior median of the total number of infected individuals (final epidemic size) is 7,450 and its 95% BCI is (3495, 15518) for Sierra Leone, which is close to 8,706 total confirmed number of cases reported by (CDC). Liberia had a smaller epidemic than Sierra Leone, with estimated total infected individuals being 2,842 and a 95% BCI of (1296, 6173). These results are also in agreement with 3,163 total confirmed cases from CDC.
We perform an out-of-sample validation by comparing our results with weekly reported confirmed incidence in Sierra Leone and Liberia from the (2016) (WHO). The posterior predictive weekly incidence at time , denoted by , is approximated by
| (19) |
where , and are the posterior estimates of the infection rate, number of susceptible and number of infected individuals at time respectively, and corresponds the time interval of one week. We plot the posterior predictive estimates of weekly incidence together with the corresponding weekly reported confirmed incidence. For both countries, our model-based incidence 95% BCIs cover the reported incidence counts from WHO, suggesting that our time varying SIR model can estimate incidence well from genetic data alone. We note that our estimated latent incidence should be greater than the reported incidence, because not all Ebola cases were reported and recorded. However, the discrepancy between latent and reported incidence should not be large, because Ebola reporting rate was high. For example, Scarpino et al. (2014) estimated that 83% of Ebola cases were reported.
We also report results from the ODE-based method and superimpose these results over LNA-based results on Figures 5 and 6. For the relatively small Liberia genealogy, the ODE-based and LNA-based methods yield similar parameter estimates. However, the larger Sierra Leone genealogy produces substantial differences between ODE-based and LNA-based estimates of the . The ODE-based method captures the decreasing trend of in Spring and Summer of 2014, but provides narrow BCIs with unrealistic short term fluctuations in the basic reproduction number trajectory.
5. Discussion
In this paper, we propose a Bayesian phylodynamic inference method that can fit a stochastic epidemic model to an observed genealogy estimated from infectious disease genetic sequences sampled during an outbreak. Our statistical model can be viewed as semi-parametric: with (1) a parametric SIR model describing the infectious disease dynamics and (2) a non-parametric GMRF-based estimation of the time varying basic reproduction number. To the best of our knowledge, this is the first method combining a Bayesian nonparametric approach with a deterministic or stochastic SIR model for phylodynamic inference (although see (Xu, Kypraios and O’Neill, 2016) for a similar approach applied to more traditional epidemiological data). Our use of LNA allows us to devise an efficient MCMC algorithm to approximate high dimensional posterior distribution of model parameters and latent variables. Our LNA-based method produces posterior summaries with better frequentist properties than the state-of-the-art ODE-based method, underscoring the importance of working with stochastic models even in large populations. We showcase our method by applying it to the Ebola genealogies estimated from viral sequences collected in Sierra Leone and Liberia during the 2014–2015 outbreak. Our nonparametric estimates of in Sierra Lione and Liberia suggest that the basic reproduction number decreased in two-stages, where the second stage brought it below 1.0 — a sign of epidemic containment. The second stage of decrease closely follows in time implementation of interventions, pointing to their effectiveness.
Our method relies on the assumption that population is well-mixed and the population dynamics follow a SIR model. However, it may be desirable to be able to relax these assumptions. For example, in Ebola spread modeling some authors used a SEIR model that assumes a latent period during which an infected individual is not infectious (Althaus, 2014; Volz and Siveroni, 2018). Moreover, adding more compartments should allow us to partially relax the unrealistic assumption of homogeneous mixing. For example, stratifying compartments by age group would allow us to account for different contact rates between these groups. One future direction of this work is to generalize the LNA-based method to fit complicated compartmental epidemic models, including models with multi-stage infections like SEIR model and models with the population stratified by sex, age, geographic location, or other demographic variables. The structured coalescent likelihoods under these models may not have closed-form expressions. However, Volz (2012), Dearlove and Wilson (2013), and Müller, Rasmussen and Stadler (2017) propose several strategies to approximate structured coalescent likelihoods. Our LNA-based methodology is directly portable to these approximate structured coalescent likelihood approaches, but our current implementation lacks this generality. We hope to remedy this in our future work.
The experiments in Section 3.1 indicate that one has to pay close attention to parameter identifiability when fitting SIR models to genealogies or to sequence data directly. Identifiability may not be a problem under an assumption of a constant . However, the removal rate tends to be only weakly identifiable in the scenarios with a time-varying basic reproduction number, in which the estimation can be sensitive to the choice of priors. In Section 3.2 and Appendix Section A-6, we demonstrate that putting a weakly informative prior on the removal rate can cause bias not only in the estimation for removal rate, but also can lead to a failure in recovering the reproduction number and latent population dynamics. Therefore, successful inference of SIR model parameters using genealogical data should rely on a sound informative prior for the removal rate. This constraint is not a big shortcoming in situations where prior information about the removal rate, or mean length of the infectious period is available from patient hospitalization data (WHO Ebola Response Team, 2014).
Since parameter identifiability is a recurring problem in infectious disease modeling, integration of multiple sources of information is of great interest. Using particle filter MCMC, Rasmussen, Ratmann and Koelle (2011) demonstrated that jointly analyzing genealogy and incidence case counts considerably reduces the uncertainty in both estimation of latent population trajectory and SIR model parameters, compared with estimation based on a single source of information. We plan to use our LNA-based framework to perform similar integration of genealogical data and incidence time series. Another possible source of information is the distribution of genetic sequence sampling times. Karcher et al. (2016) proposed a preferential sampling approach that explicitly models dependence of the sampling times distribution on the effective population size. The authors demonstrated that accounting for preferential sampling helps decrease bias and results in more precise effective population size estimation. It would be interesting to incorporate preferential sampling into our LNA-based framework by assuming a probabilistic dependency between sampling times and latent prevalence .
Our method assumes a genealogy/phylogenetic tree is given to us. In reality, genealogies are not directly observed and need to be inferred from molecular sequences. Genealogy estimation remains one of the biggest computational bottlenecks in phylodynamics, with computational burden of such estimation being typically higher than the burden of phylodynamics methods that use the genealogy as input. Ideally, uncertainty in the genealogy should be handled by building a Bayesian hierarchical model and integrating over the space of genealogies using MCMC. In fact, implementations of such Bayesian hierarchical modeling already exist for nonparametric, birth-death, and ODE-based phylodynamic approaches (Drummond et al., 2005; Minin, Bloomquist and Suchard, 2008; Gill et al., 2013; Stadler et al., 2013; Volz and Siveroni, 2018). Therefore, an important future direction will be to extend our LNA framework to fitting stochastic epidemic models to molecular sequences instead of genealogies. Similarly to the structured coalescent model implementation of Volz and Siveroni (2018), the easiest way to achieve this will be integration of our LNA MCMC algorithm into popular open source phylogenetic/phylodynamic software packages, such as BEAST, BEAST2, and RevBayes (Suchard et al., 2018; Bouckaert et al., 2014; Höhna et al., 2016).
Acknowledgements
We thank Jon Fintz for discussing the details of implementing Linear Noise Approximation. We are grateful to Michael Karcher and Julia Palacios for patiently answering questions about nonparametric phylodynamic inference and phylodyn package. M.T and V.N.M. were supported by the NIH grant R01 AI107034. M.T., T.B., and V.N.M. were supported by the NIH grant U54 GM111274. V.N.M. was supported by the NSF grand DMS-1936833. G.D. was supported by the Mahan postdoctoral fellowship from the Fred Hutchinson Cancer Research Center. This work was supported by NIH grant R35 GM119774-01 from the NIGMS to TB. TB is a Pew Biomedical Scholar.
Appendix
for “Fitting stochastic epidemic models to gene genealogies using linear noise approximation”
by Mingwei Tang, Gytis Dudas, Trevor Bedford, Vladimir N. Minin
A-1. A general framework for stochastic kenetic models
A-1.1. Stochastic model generalization
In Section 2, we provide an example of the linear noise approximation (LNA) for the SIR model. The LNA framework can be also generalized to other types of the stochastic kinetic models in Infectious Disease Epidemiology and in Systems Biology. Here, we give a general representation of the stochastic kinetic model by viewing it as a reaction network system. The notation is based on the work of Fearnhead, Giagos and Sherlock (2014).
Let’s start with a reaction system with reactants and reactions. Without loss of generality, each reaction is assumed to have a constant rate parameter for and denotes the rate vector of the system (this framework can be extended to handle stochastic kinetic models with time-varying rates as in Section 2 of the main text). The transition event in the ith reaction has the following form:
| (A-1) |
where and are non-negative integers representing the number of in the ith reaction equation. In a compartmental stochastic epidemic model, the coefficient will be either 0 or 1. The transitions in the reaction system can be encoded in an effect matrix,
| (A-2) |
with each row corresponding to a certain type of reaction event and each column representing the change in the counts of reactants. Let denote counts/population of the at , and the population state at time t can be tracked by vector . Let denote the reaction rate of the th reaction, where can be written as
| (A-3) |
Hence, following the same notation as in Section 2.2.1 of the main text, the rate vector and the rate matrix can be defined as
| (A-4) |
Given the above notation, the deterministic ordinary differential equation model of the reaction system can be written as
| (A-5) |
where is a vector of initial counts of reactants .
FIGURE A-1.
SEIR Markov jump process. From the current state with the counts S, E, I, R, the population can transition to (1) state , , (an infection event) with rate SI or to (2) state , , (an event where infected individual becomes infectious) with rate or to (S) state , , (a removal event) with rate . No other instantaneous transitions are allowed.
A-1.1.1. Example: SEIR model
The above general representation of stochastic kinetic models can be directly applied to stochastic epidemic models. Here, we illustrate this on a Susceptible-Exposed-Infected-Recovery (SEIR) model. SEIR model is an extension of the SIR model that assumes a latent period called “Exposed”, in which an infected individual does not have the ability to infect others. The exposed individual will eventually become infectious with rate . As in the SIR model, an infectious individual has removal/recovery rate . The transition events between different states of the SEIR model are depicted in Figure A-1.
Following the stochastic kinetic model representation, the SEIR model can be viewed as a reaction system of four reactants — susceptible, exposed, infected, and recovered individuals — and the following three “reactions”:
| (A-6) |
| (A-7) |
| (A-8) |
Since the recovered population never interacts with individuals in other compartments, we will only keep track of the counts of susceptible, exposed, and infectious individuals at time , denoted by , , respectively. The effect matrix for the SEIR model can be written as:
| (A-9) |
with columns representing compartments and rows representing reactant changes during reaction events.
If we let denote the state vector at time , then the rate vector for the SEIR model is
| (A-10) |
A-2. Derivation of the linear noise approximation
A-2.1. SDE approximation for MJP
A stochastic way to approximate the MJP model is to use the Stochastic Differential Equation (SDE) approximation, also known as the chemical Langevin equation (CLE) (Gillespie, 2000). The SDE method can be viewed an approximation of the MJP at time , obtained by applying a normal approximation to the Poisson distributed number of state transitions in a small interval of time (Gillespie, 2000; Wallace, 2010). The deterministic part in SDE corresponds to the right hand side of ODE (7) and stochastic part is related to the variance of the system. The SDE for general stochastic kinetic models can be written as
| (A-11) |
where denote a dimensional Wiener process and the square root means the Cholesky triangle of the covariance matrix.
A-2.2. LNA approximation of the SDE
Since in the main text we assume the rate varies in a piecewise constant way, without loss of generality, we use the notation for the rate in a given time interval where the LNA is applied.
Theorem A-2.1
(Linear Noise Approximation for SDE). Let be the solution of ordinary differential equation (7) with initial value . Let be the system size, which is the total number of individuals in the system (In SIR model, will be the total population, i.e , denote the vector of rate parameters in reactions. Then the solution of the SDE (A-11) satisfies the following equation
| (A-12) |
as .
Proof.
The following derivation is based on (Wallace, 2010).
We rescale both the compartment size and reaction rates as follows:
| (A-13) |
| (A-14) |
where is the sum of coeffcients in the left hand side of i-th reaction as in Section A-1. The transformed represents the proportion of individuals/reactants each compartment with respect to the total population size. Then we have and . Hence, the SDE (A-11) becomes
| (A-15) |
Let be the solution of the ODE
| (A-16) |
and we have , where is the solution of the ODE (7). can be viewed as a scaled version solution of ODE (7). Let denote the scaled residual, then the rescaled compartment size vector can be written as
| (A-17) |
After using first order Taylor expansion of and around
, the SDE (A-15) becomes
where is the Jacobian matrix of the deterministic part in (7) at . By subtracting (A-16) and multiplying by on the two ends, the above equation becomes a differential equation with respect to :
| (A-18) |
After multiplying by , the above equation gives us (A-12).
Recall that is the solution of (8) with initial condition . We can use as an approximation of . Based on the local Lipschitz property of with respect to and , can be approximated by with
| (A-19) |
for fixed as system size .
A-2.3. Derivation of equations (9) and (10) in the main text
Lemma A-2.2 (Solution of linear ODE system).
Let and be function of defined on that satisfies the following linear ODE
| (A-20) |
For , the solution of (A-20) can be represented as
| (A-21) |
where is the solution of ordinary differential equation in
| (A-22) |
Lemma (A-2.2) gives the solution of linear ODE. Hence, the solution for the main text linear ODE 9 is on will be
| (A-23) |
where is the initial state at and is the transition matrix by
| (A-24) |
and is the initial value for at time .
Theorem A-2.3.
Let be stochastic process that satisfies the following stochastic differential equation,
| (A-25) |
Then the solution of (A-25) is the Gaussian process
| (A-26) |
with mean process satisfies (10).
Proof.
Define matrix function as (A-24). First we apply the linear transform . Based on Ito’s lemma, (A-25) can be simplified as a SDE of :
| (A-27) |
with solution.
Then the solution of is
| (A-28) |
in (A-28) is a deterministic function of . The integral in (A-28) should be Gaussian random variable with mean 0 since it is a linear combination of the increments of Brownian motion with different variance. Hence, the should be a Gaussian process. By taking the expectation of (A-28), the mean of satisfies
| (A-29) |
which corresponds to the solution of ODE (9).
For the variance process, from (A-28),
| (A-30) |
By differentiation with respect to , (A-30) becomes
which is the result in (10).
A-2.4. Relationship between LNA and other methods
The SDE approach can be viewed as a normal approximation based on a leaping step for the MJP. The LNA can be derived either directly from Taylor expansion of the transition probability of the MJP or the Taylor expansion of the transition density of the SDE. The ODE solution can be considered as a limit of the mean trajectory of the MJP when system size goes to infinity. ODE solution can also be viewed as the deterministic part for SDE (A-11) and the mean process for LNA based on (A-36). Figure A-2.4 depicts relationships between different dynamical system representations as a diagram.
A-3. Non-centered parameterization
In LNA, the latent trajectory is decomposed into the deterministic part plus a stochastic part that follows a multivariate Gaussian distribution with mean 0. However, the population size at the i-th time interval depends on rate parameter and is correlated with other population sizes s in the trajectory, leading to mixing issues for the MCMC chain, especially when we introduce multiple change points for reproduction number .
FIGURE A-2.

The relationship between different dynamical system representations.
Here we take the idea of non-centered parameterization from Papaspiliopoulos, Roberts and Sköld (2007, 2003) and reparameterize the latent trajectrory in terms of residuals for . Given rate parameters , ODE solution , fundamental matrix and variance matrix in (10), the trajectory can be parameterized using standard Gaussian noise based on the following iterative equations:
| (A-31) |
| (A-32) |
Let denote the residual in grid cell . Based on (A-32), the residual process satisfies
| (A-33) |
| (A-34) |
Then can be viewed as a Gaussian Markov random field with mean that follows the Markov property on a chain graph. Let be the abbreviated notation of and . From (A-34), can be written as
Since and are governed by rate parameters and initial value , then we define the transform matrix ,
A linear relationship between and the reparameterized noise can be established with the help of the above transform matrix ,
| (A-36) |
Instead of directly updating , we will apply the above transform and update the Gaussian noise instead. The MCMC approach will focus on sampling parameter , , , , with the posterior likelihood
In summary, the transformation that allows us to move from parameterization in terms of to the parameterization in terms of , , , , are based on the following equations:
- a function of and .
- a function of , and .
- a function of , and .
- a function of and .
.
- a function of , , , and .
A-4. MCMC details
A-4.1. Elliptical slice sampler
FIGURE A-3.

Parameter dependency graph after reparameterization. The root nodes , , , , outside the large box are parameters and latent variables after reparameterization, for which we assign prior distributions. The dash-dotted lines show deterministic relationships and the solid lines show the stochastic dependencies. The grey node denotes the observed data. The figure shows the dependency structure between the transformed parameters and original parameters and .
The elliptical slice sampler, proposed by Murray, Adams and MacKay (2010), aims at sampling from posterior distributions associated with probability models with a latent a priori zero-mean Gaussian random vector with covariance , i.e., . We use to denote the likelihood function for observed data given is
where is the prior distribution for parameter . The goal of elliptical slice sampler is to obtain posterior samples of latent variable from . The proposal step in elliptical sampling consists of two parts: (1) proposing an auxiliary random vector from distribution , (2) proposing a variable as an angle parameter. In elliptical slice sampler, a new state is proposed by rotating the previous state with angle ,
| (A-37) |
| (A-38) |
For any given , this transition leaves the joint prior probability invariant, i.e,
Hence, are considered at the proposed state and the ratio and the propose transition probability from to should equal that from to , i.e
The algorithm for elliptical slice sampler is given in Algorithm 1. Notice that iterations will stop only when a new sample is accepted. Hence, the elliptical slice sampler has acceptance rate 1, meaning that it will always update the latent random vector at each MCMC iteration.
Algorithm 1.
Elliptical slice sampler for posterior distribution
| 1 | Input: Latent variable from the previous iteration . Observed data , previous updated parameter .. |
| 2 | Output Updated latent variable value |
| 3 | Sample ellipse |
| 4 | Compute log-likelihood threshold: sample and let |
| 5 | Sample angle parameter and |
| 6 | |
| 7 | while do |
| 8 | if then |
| 9 | |
| 10 | else |
| 11 | |
| 12 | Sample . |
| 13 | Make new proposal |
| 14 | Return . |
A-4.2. MCMC algorithm for the LNA-based SIR model
In this framework, the observed data are the genealogy g estimated from a sample of sequences from virus hosts. The sufficient statistics for SIR structured coalescent likelihood would be the coalescent times and sampling times . The unknown parameters and the latent variables are
The initial number of infected individuals: . The initial population is parameterized as , suppressing that and that there are no recovered individuals at time 0.
The initial basic reproduction number .
The removal rate .
The hyperparameter that controls the smoothness of trajectory.
-
The parameters modeling the first order differences in .
Note that assuming , the infection rate can be obtained as
The parameter can be obtained from , and .(A-39) Random noise for the population trajectory at , i.e. , with a priori. The latent SIR trajectories can be recovered from and random noise .
The MCMC update for parameters and latent variables is given in Algorithm 2.
Algorithm 2.
Updating rule in the LNA-based MCMC algorithm
| 1: | Input: Parameter values from the previous interation ,,,,, geneology g. Proposal density , for updating the initial number of infected individuals and the removal rate. | |
| 2: | Output Updated parameters values | |
| 3: | Calculate based on ,,,,. | |
| 4: | Propose based on , then will be deterministically updated to according to ,,,,. | |
| 5: | Accept with acceptance probability | |
|
|
||
| 6: | Propose based on , then will be deterministically updated to according to ,,,,. | |
| 7: | Accept with acceptance probability | |
|
|
||
| 8: | Let , then a priori follows a multivariate normal distribution. Use elliptical slice sampler to obtain and get the updated and will be deterministically updated to according to ,,,. | |
| 9: | Since a priori follows a multivariate normal distribution, we use the elliptical slice sampler to obtain will be deterministically updated to according to ,,,,. |
A-4.3. MCMC algorithm for the ODE-based model
The MCMC algorithm for ODE-based method is similar to the LNA-based MCMC except there is no need to update the Gaussian noise in the population trajectory. The MCMC updates of parameters and latent variables is given in Algorithm 3.
Algorithm 3.
Updating rule in the ODE-based MCMC algorithm
| 1: | Input: Parameter values from the previous interation ,,,, geneology g. Proposal density , for updating the initial number of infected individuals and the removal rate. | |
| 2: | Output Updated parameters values | |
| 3: | Calculate based on ,,,. | |
| 4: | Propose based on , then will be deterministically updated to according to ,,, based on ODE integration. | |
| 5: | Accept with acceptance probability | |
|
|
||
| 6: | Propose based on , then will be deterministically updated to according to ,,, | |
| 7: | Accept with acceptance probability | |
|
|
||
| 8: | Let , then a priori follows a multivariate normal distribution. Use elliptical slice sampler of obtain and get the updated and will be deterministically updated to according to ,,, based on ODE integration. |
A-5. Details of the simulation study
A-5.1. Simulation details for Section 3.1 of the main text
Here we provide details for the specified sequence/lineage sampling times and number of samples in each simulation scenario:
CONST Sampling times: , number of samples at each time: .
SD : Sampling times: , number of samples at each time: .
NM Sampling times: , number of samples at each time: .
Table A-1 shows effective sample sizes for the parameter , and in Section 3.1, based on 1,000,000 MCMC iterations.
TABLE A-1.
Effective sample sizes for simulation studies in Section 3.1.
| CONST | SD | NM | ||||
|---|---|---|---|---|---|---|
|
| ||||||
| parameter | LNA.ESS | ODE.ESS | LNA.ESS | ODE.ESS | LNA.ESS | ODE.ESS |
| I 0 | 891 | 1130 | 772 | 1132 | 992 | 1124 |
| R 0 | 677 | 751 | 686 | 730 | 407 | 617 |
| γ | 678 | 1391 | 2375 | 1780 | 705 | 824 |
| σ | 922 | 882 | 807 | 805 | 406 | 594 |
A-5.2. Simulation details for Section 3.2 of the main text
The trajectory in the simulations is set to
| (A-40) |
which is depicted in the left plot of Figure A-4. The initial number of infected individuals is and the removal rate is set to . The population size is fixed to . Epidemic trajectories are simulated using the SIR Markov jump process (MJP) and are accepted/rejected based on the following criteria:
Reject the SIR trajectories that ends before time 90. The number of infected individuals should never drop to 0 for , i.e. .
Reject the SIR trajectories with extremely high maximum prevalence: the maximum prevalence should be less or equal than 12,000, i.e., .
Reject SIR trajectories with extremely low maximum prevalence. The maximum prevalence should be greater or equal than 600, i.e., .
The 100 simulated SIR prevalence trajectories are shown in the right plot of Figure A-4 and the trajectories used in Section 3.1 is highlighted in blue. We also plot the ODE trajectory under the same parameter setting.
A-5.3. Repeated simulations for CONST and SD scenarios
In this Section, we repeat the simulation scenario for CONST and SD scenarios in Section 3.1 100 times. We use the same parameter set up for and . The initial number of infected is se to 3 instead of 1 so that most of the numbers of simulated infectious individuals will not reach 0 before . As in Section A-5.2, we reject trajectories than end before 90. For the SD scenario, we also reject trajectories with and . We run the LNA-based and ODE-based methods assuming the informative prior on . The posterior summary boxplots for CONST and SD scenarios are presented in Figure A-5 and Figure A-6 respectively.
The LNA-based method results in wider BCIs and enjoys better frequentist coverage (envelope) properties than the ODE-based method, although differences between the two methods are less pronounced than their counterparts in the NM scenario. In terms of bias, LNA-based and ODE-based methods perform similarly in these simulations.
FIGURE A-4.

Repeated simulation setup. Left: trajectory under which the population trajectories are simulated. Right: The 100 simulated prevalence trajectories using MJP, the ODE trajectory under the same parameter setup, the MJP trajectory in for simulation in Section 3.1.
FIGURE A-5.

Boxplots comparing performance of LNA-based and ODE-based methods using 100 simulated genealogies in CONST scenario. The first three plots shows mean absolute error (MAE), mean credible interval width (MCIW) and envelope for trajectory. The next three plots depict mean relative absolute error (MRAE), mean relative credible interval width (MRCIW), and envelope for (prevalence) trajectory. The last two plots show the absolute error (AE) and Bayesian credible interval (BCI) width for .
FIGURE A-6.

Boxplots comparing performance of LNA-based and ODE-based methods using 100 simulated genealogies in SD scenario. See caption in Figure A-5 for explanation of the plots.
FIGURE A-7.

MCMC trace plots of the log-posterior in the 3 simulation scenarios. Columns correspond to CONST, SD, and NM simulated trajectories. The first row shows the LNA-based results and the second row shows the ODE-based results.
A-5.4. Trace plots and effective sample sizes
A-5.4.1. Trace plots for simulations from Section 3.1 of the main text
Figure A-7 shows the trace plots of the log-posterior for the LNA-based method and ODE-based method in the three simulation scenarios from Section 3.1. The effective sample sizes (ESSs) for all parameters are above 400.
A-5.4.2. Trace plots for Ebola data
Figures A-8 and A-9 show trace plots of parameters for the LNA-based model and ODE-based model respectively applied to the Sierra Leone genealogy, with each color correspond to a parallel MCMC chain. Figures A-10 and A-11 show the analogous trace plots for the analysis of the Liberia genealogy. We also list posterior medians, 95% BCIs, and ESSs for each parameter in the MCMC algorithm in Table A-2.
FIGURE A-8.

Trace plots for , , and in the LNA-based MCMC runs applied to the Ebola genealogy in Sierra Leone and using 9 parallel chains. Top left: Initial number of infected . Top right: initial basic reproduction number . Bottom left: removal rate . Bottom right: smoothing parameter .
Table A-2 show the effective sample sizes in the MCMC algorithm using genealogy from Sierra Leone and Liberia.
A-6. Prior sensitivity analysis
A-6.1. Simulations based on single genealogy realizations
In Section 3.1, we put informative priors on the removal rate and explore three different simulation scenarios. Although our LNA-based model successfully recovers the dynamics and SIR trajectories, the posterior density of the removal rate is not too different from its prior in the SD and NM scenarios. In this section, we investigate sensitivity of our inferences to changes in the prior of the removal rate . For the same genealogies and parameter settings as in Section 3.1, we assign weakly informative priors to the removal rate
CONST scenario: ,
SD scenario: ,
NM scenario: .
FIGURE A-9.

Trace plots for the ODE-based MCMC algorithm applied to the Ebola genealogy in Sierra Leone. See caption in Figure A-8 for the explanation of the plots.
FIGURE A-10.

Trace plots for the LNA-based MCMC algorithm applied to the Ebola genealogy in Liberia. Top left: Initial number of infected Bottom left: removal rate . Bottom right: smoothing parameter .
FIGURE A-11.

Trace plots for the ODE-based MCMC algorithm applied to the Ebola data in Liberia. See caption in Figure A-10 for the explanation of the plots.
TABLE A-2.
Table for posterior medians, 95% BCIs, and ESSs for MCMC algorithms applied to Ebola data from Sierra Leone and Liberia.
| Sierra Leone | Liberia | |||||||
|---|---|---|---|---|---|---|---|---|
| post med | 95%BCI | ESS | post med | 95%BCI | ESS | |||
|
| ||||||||
| LNA | I 0 | 4.84 | [1.35,13.71] | 1408 | I 0 | 3.49 | [1.03, 9.95] | 1630 |
| R 0 | 1.66 | [1.31.2.15] | 1011 | R 0 | 1.67 | [1.29,2.24] | 942 | |
| γ | 33.61 | [23.44,48.21] | 2160 | γ | 37.21 | [25.98,53.13] | 1704 | |
| ρ | 15.19 | [10.60,21.53] | 953 | ρ | 14.83 | [10.41,20.70] | 870 | |
|
| ||||||||
| ODE | I 0 | 2.63 | [1.09,6.09] | 2085 | I 0 | 4.31 | [1.89,9.27] | 1236 |
| R 0 | 1.64 | [1.29,2.13] | 1253 | R 0 | 1.83 | [1.41.2.44] | 796 | |
| γ | 38.00 | [26.12.55.40] | 2841 | γ | 38.31 | [27.27.53.43] | 1608 | |
| ρ | 12.13 | [8.46,16.40] | 1012 | ρ | 11.79 | [9.78,19.20] | 879 | |
For each scenario, we fit a LNA-based model using 300,000 MCMC iterations. The first row in Figure A-12 shows the point-wise posterior medians and 95% BCIs for the basic reproduction number trajectories, Our LNA-based method performs well in the CONST and SD scenario. However, for NM scenario, the method fails to fully capture the increase and decrease trend at the beginning and the end of the epidemic. The second row in Figure A-12 depicts the prior and posterior densities of the removal rate . The LNA-based method estimates the removal rate with good precision in the CONST scenario. However, for SD and NM scenario, the removal rate posterior densities are similar to the prior densities, but shift to the right from the truth. Posterior summaries of and are given in the third and fourth row of Figure A-12. The LNA-based method performs well in recovering the truth in the CONST and SD scenarios. In the NM scenario, the true trajectories are still covered by the wide BCIs, but the model seems to underestimate the and overestimate .
A-7. Grid sensitivity analysis
The number of grid cells can be viewed as a tuning parameter in our model. Throughout the main text, is set to be around 30 to 40 and with a lognormal (3, 0.2) prior for inverse of smoothing parameter . In this section, we investigate sensitivity to the choice of grid size . We fit our LNA-based method to genealogy data constructed from virus sequences collected from Liberia using the same prior setup as in Section 4 under different choices of grid sizes:
, grid interval length days.
, grid interval length days (The grid setup in Section 4).
, grid interval length days.
For simplicity, we use the same prior setup for each parameter and fit LNA-based method to the Liberia genealogy. We run the MCMC algorithm for 1,000,000 iterations and discard the first 200,000 iterations. Posterior summaries, depicted in Figure A-13, show that the estimation results do change significantly when we change the grid size.
A-8. Performance under population size misspecification
A-8.1. Simulation study
In real applications, the census population size is usually not an accurate estimate of the true population size . Hence, robustness to the misspecification of the population size is desirable. In this section, we repeat the simulation study in Section 3.2 with true population size and fit LNA-based models under different population size misspecifications:
,
,
, true population size used in Section 3.2,
,
.
FIGURE A-12.

Analysis of 3 simulation scenarios using the LNA-based method with weakly informative priors. Columns correspond to CONST, , and NM simulated trajectories. The first row shows the estimated trajectories for the 3 scenarios, with the black solid lines representing the truth, the red depicting the posterior medians and the red-shaded area showing the 95% BCIs for the LNA-based method. The second row corresponds to the estimation of the removal rate . Posterior density curves from the LNA-base method are shown in red lines compared with prior density curve in green lines. The bottom two rows show the estimated trajectories of and respectively.
FIGURE A-13.

Analysis of genealogy relating Ebola sequence data collected in Liberia using LNA-based method under different choices of grid size. Top left: basic reproduction number posterior summaries. Top right: removal rate posterior density. Bottom left: posterior summaries. Bottom right: posterior summaries. The results for in Section 4 are plotted in red. Green color corresponds to the result based on the coarser grid .
FIGURE A-14.

Boxplots comparing the performance of LNA-based method under population size misspecification using 100 simulated genealogies. See caption in Figure 4 for the explanation of the plot.
To evaluate model performance, we use the same metrics defined in Section 3.2 and generate posterior summary boxplots in Figure A-14. The Figure shows that it is safe to overestimate the true population size, but underestimating it leads to poor statistical performance. We note that while basic reproduction number and recovery rate have been shown before to be robust to population size misspecification (Koepke et al., 2016; Fintzi et al., 2017), the latent variables generally do not enjoy such robustness. For example, the number of susceptible individuals does depend on the assumed population size. In our simulation, susceptible individuals do not deplete enough to change estimation of latent prevalence, but in other cases prevalence estimation can be affected by the population size misspecification.
A-8.2. Analysis of Liberia genealogy under different population size assumptions
We repeat LNA-based analysis of the Liberia genealogy under different population size assumptions. Recall that the census population size is used in Section 4. We use our LNA-based method assuming the following population sizes:
,
.
FIGURE A-15.

Analysis of genealogy relating Ebola sequence data collected in Liberia using the LNA-based method under different total population specification. Top left: basic reproduction number posterior summaries. Top right: mean infection period posterior density. Bottom left: Disease prevalence posterior summaries. The results for in Section 4 is plotted in red as, with green color corresponding to the results based on overestimating total population and the blue color plotting posterior summaries under an underestimated total population size .
In conclusion, if the final epidemic size is relatively small compared with the true total population size, estimation results are robust to the misspecification of the population size, if the misspecification is not too severe. Intuitively, this makes sense, because when the number of susceptible individuals is approximately equal to the total population size , the coalescent rate is reduced to
which is invariant to the population size .
A-9. Comparison with PhyDynR package
In this paper, we implement the SIR structured coalescent likelihood based on equation (2) that can be found in (Volz, 2012). We check our implementation of this likelihood by comparing it with the implementation from PhyDynR package (a predecessor of the BEAST 2 PhyDyn module). The comparison protocol consists of two steps. First, a genealogy is simulated under a deterministic ODE SIR population trajectory determined by the pre-specified parameters: and . We assume the constant basic reproduction number. Secondly, the basic reproduction number and removal rate are estimated via the maximum likelihood method. Variances and standard deviations of parameter estimates are obtained from the inverse Hessian of the log-likelihood function. We repeat the experiment 100 times and report absolute errors (AEs) and standard deviation (SDs) for parameters and respectively.
FIGURE A-16.

Comparison of SIR coalescent likelhhood implementations of our ODE method and PhyDynR package in a sparsely sampled outbreak (population size is 10, 000 and the number of sampled sequences is 150). The first row shows the absolute errors (AEs) and estimated standard deviation (SDs) for basic reproduction number . The second row shows the and estimated SDs for removal rate .
We consider two scenarios:
A sparsely sampled outbreak, where the population size is and the number of sampled sequences is 150.
A densely sampled outbreak, where the population size is and the number of sampled sequences is 200.
Figures A-16 and A-17 show the AEs and SDs for parameters in scenarios 1 and 2 respectively, demonstrating that the two likelihood implementations agree in the sparsely sampled outbreak setting, but disagree when outbreaks are densely sampled. Since all coalescent-based methods assume sparse sampling, we do not think that the disagreement between our implementation and PhyDynR is concerning.
Figure A-17.

Comparison of SIR coalescent likelihood implementations of our ODE method and PhyDynR package in a sparsely sampled outbreak (population size is 1, 000 and the number of sampled sequences is 200). The first row shows the absolute errors (AEs) and estimated standard deviation (SDs) for basic reproduction number . The second row shows the AEs and estimated SDs for removal rate .
A-10. Simulations under small population size
A-10.1. Simulations based on single genealogy realization
In this section, we perform simulation studies under a small population size . We simulate an epidemic with constant reproduction number for . The initial number of infected is set to be and the recovery rate the is . First, we simulate one realization of the population trajectory, based on which a sequence of coalescent times are simulated using pre-specified sampling times.
For simplicity, we also assume a constant basic reproduction number in the inference, i.e. fixing . We fit both LNA-based algorithm and ODE-based algorithm to simulated genealogy. Moreover, since the reproduction number is constant, we also use the ODE-based model implementation in PhyDyn package from (Volz and Siveroni, 2018). We use the same prior setup for basic reproduction number and initial number of infected as in Section 3 and an informative prior lognormal is assigned for the recovery rate .
Posterior summaries of the one realization simulation is shown in Figure A-18. Note the there exist differences in the posterior summaries between our ODE-based method and PhyDyn. Such differences are likely to be caused by differences in the grid set up for the coalescent likelihood and different ODE solvers used by the two methods. The top two plots show the posterior densities of and . While both our ODE-based method and PhyDyn posteriors have small shifts from the truth, our LNA-based method yields a more flat density curve that has much higher density at the truth. The bottom two plots depict posterior summaries for the population trajectories. Compared with the results in Section 3.1, the BCIs for LNA based method in small population epidemic lose in coverage of the population trajectory. However, the BCIs and posteriors median generally capture the trend of the population dynamic. Our ODE-based implementation and PhyDyn seem to be over-confident and yield narrow BCIs that miss most of the true trajectories. The inconsistency between our ODE-based inference and BEAST2 PhyDyn results are present only in a densely sampled outbreak settings, as demonstrated in Section A-9 above.
A-10.2. Frequentist properties of posterior summaries
We simulate 100 realizations of the SIR trajectories under the same parameter setup in Section A-10.1. We keep all the simulated trajectories but only reject those ending before . The 100 simulated trajectories are plotted in Figure A-19 in grey lines, with the corresponding ODE curve plotted in black. For each simulated trajectory, we simulate genealogy and apply the LNA-based method, our implementation of ODE-based method, and BEAST2 PhyDyn package to each genealogy under the same prior setup as in Section A-10.1 (Volz and Siveroni, 2018). The estimation and is evaluated by absolute error (AE), BCI width (BCIW) and envelope defined in Section 3.2. We evaluate the estimation of prevalence is based on MRAE, MRICW and ENV-I. Posterior summaries for repeated simulations are depicted in Figure A-20.
FIGURE A-18.
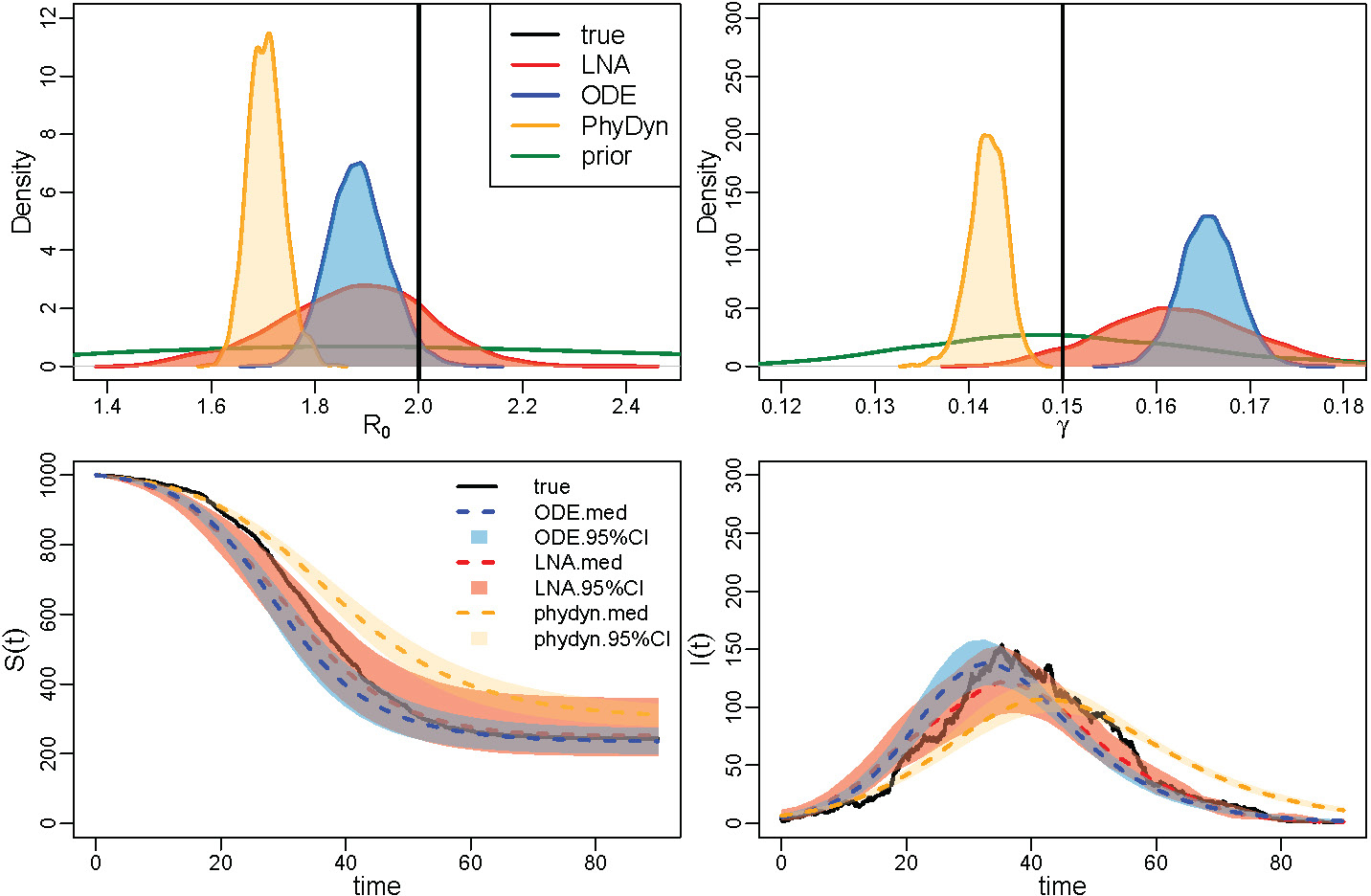
Analysis of LNA-based and ODE-based methods in the small population size setting. The first row shows the estimation results for basic reproduction number R0 and removal rate γ respectively, with posterior density curve for LNA-based method plotted in red, our ODE-based implementation plotted in blue, and PhyDyn results plotted in orange. The second row shows posterior summaries for S(t) and I(t) trajectories with the same color scheme.
FIGURE A-19.

The 100 simulated prevalence trajectories using MJP and the ODE trajectory under the same parameter setup.
FIGURE A-20.
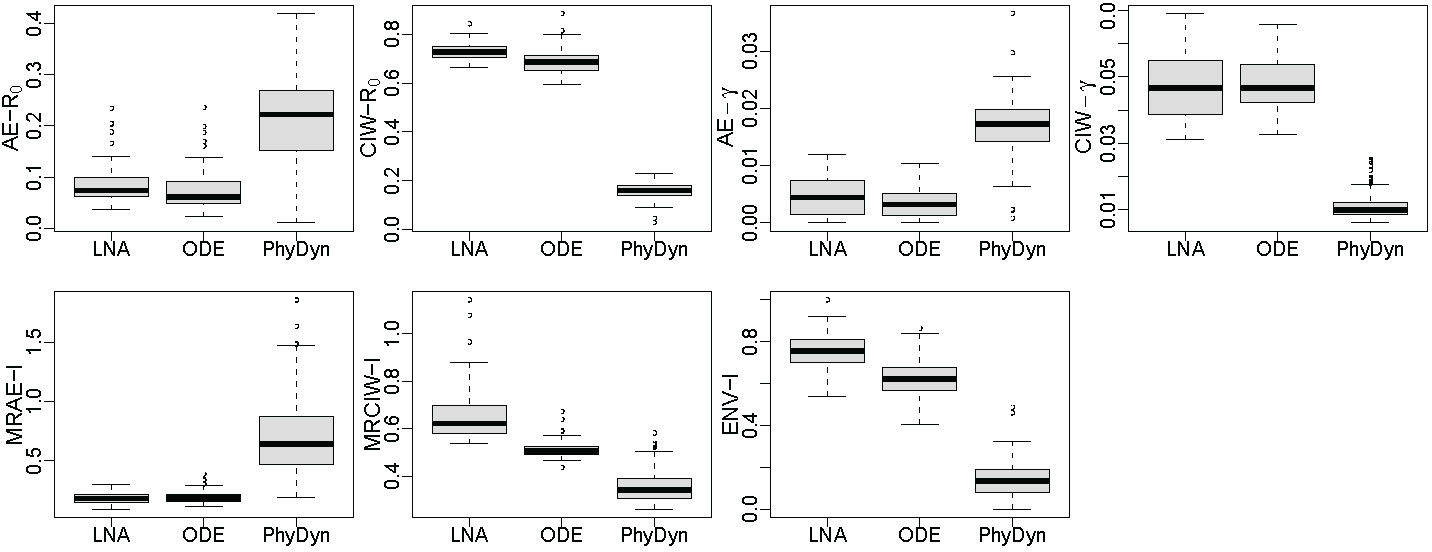
Boxplots comparing the performance of LNA-based, our implementation of the ODE-based method, and BEAST2 PhyDyn package implementation of the ODE-based method under population size and using 100 simulated genealogies. First row: AE, CIW for (left two) AE, CIW for . Second row: MRAE, MRCIW and ENV-I for
References
- ALTHAUS C (2014). Estimating the reproduction number of Ebola virus (EBOV) during the 2014 outbreak in West Africa. PLoS Currents 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- ANDERSON R AND MAY R (1992). Infectious Diseases of Humans: Dynamics and Control 28. Wiley Online Library. [Google Scholar]
- BAILEY N (1975). The Mathematical Theory of Infectious Diseases and Its Applications. Hafner Press/MacMillian Pub. Co. [Google Scholar]
- BOUCKAERT R, HELED J, KÜHNERT D, VAUGHAN T, WU C, XIE D, SUCHARD M, RAMBAUT A and Drummond A (2014). BEAST 2: A Software Platform for Bayesian Evolutionary Analysis. PLoS Computational Biology 10 1–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- BUCKINGHAM-JEFFERY E, ISHAM V and HOUSE T (2018). Gaussian process approximations for fast inference from infectious disease data. Mathematical Biosciences 301. [DOI] [PubMed] [Google Scholar]
- Centers for Disease Control and Prevention. 2014–2016 Ebola outbreak in West Africa. https://www.cdc.gov/vhf/ebola/history/2014-2016-outbreak/index.html. Last accessed: Dec, 15, 2018.
- DEARLOVE B AND WILSON D (2013). Coalescent inference for infectious disease: meta-analysis of hepatitis C. Philosophical Transactions of the Royal Society, Series B 368 20120314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DONNELLY P and TAVARE S (1995). Coalescents and genealogical structure under neutrality. Annual Review of Genetics 29 401–421. [DOI] [PubMed] [Google Scholar]
- DRUMMOND A, NICHOLLS G, RODRIGO A AND SOLOMON W (2002). Estimating mutation parameters, population history and genealogy simultaneously from temporally spaced sequence data. Genetics 161 1307–1320. [DOI] [PMC free article] [PubMed] [Google Scholar]
- DRUMMOND A, RAMBAUT A, SHAPIRO B AND PYBUS O (2005). Bayesian coalescent inference of past population dynamics from molecular sequences. Molecular Biology and Evolution 22 1185–1192. [DOI] [PubMed] [Google Scholar]
- Dudas G, Carvalho L, Bedford T, Tatem A, Baele G, Faria N, Park D, Ladner J, Arias A, Asogun D et al. (2017). Virus genomes reveal factors that spread and sustained the Ebola epidemic. Nature 544 309–315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- FEARNHEAD P, GIAGOS V AND SHERLOCK C (2014). Inference for reaction networks using the linear noise approximation. Biometrics 70 457–466. [DOI] [PubMed] [Google Scholar]
- FINTZI J, CUI X, WAKEFIELD J AND MININ VN (2017). Efficient data augmentation for fitting stochastic epidemic models to prevalence data. Journal of Computational and Graphical Statistics 26 918–929. [DOI] [PMC free article] [PubMed] [Google Scholar]
- FROST SD and VOLZ EM (2010). Viral phylodynamics and the search for an ?effective number of infections? Philosophical Transactions of the Royal Society B: Biological Sciences 365 1879–1890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- GIAGOS V (2010). Inference for Auto-Regulatory Genetic Networks Using Diffusion Process Approximations, PhD thesis, Lancaster University. [Google Scholar]
- GILL M, LEMEY P, FARIA N, RAMBAUT A, SHAPIRO B AND SUCHARD M (2013). Improving Bayesian population dynamics inference: a coalescent-based model for multiple loci. Molecular Biology and Evolution 30 713–724. [DOI] [PMC free article] [PubMed] [Google Scholar]
- GILLESPIE D (1977). Exact stochastic simulation of coupled chemical reactions. The Journal of Physical Chemistry 81 2340–2361. [Google Scholar]
- GILLESPIE D (2000). The chemical Langevin equation. The Journal of Chemical Physics 113 297–306. [Google Scholar]
- GRENFELL B, PYBUS O, GOG J, WOOD J, DALY J, MUMFORD J AND HOLMES E (2004). Unifying the epidemiological and evolutionary dynamics of pathogens. Science 303 327–332. [DOI] [PubMed] [Google Scholar]
- GRIFFITHS R AND TAVARÉ S (1994). Sampling theory for neutral alleles in a varying environment. Philosophical Transactions of the Royal Society of London B: Biological Sciences 344 403–410. [DOI] [PubMed] [Google Scholar]
- HÖHNA S, LANDIS M, HEATH T, BOUSSAU B, LARTILLOT N, MOORE B, HUELSENBECK J AND RONQUIST F (2016). RevBayes: Bayesian Phylogenetic Inference Using Graphical Models and an Interactive Model-Specification Language. Systematic Biology 65 726–736. [DOI] [PMC free article] [PubMed] [Google Scholar]
- JOMBART T, CORI A, DIDELOT X, CAUCHEMEZ S, FRASER C AND FERGUSON N (2014). Bayesian reconstruction of disease outbreaks by combining epidemiologic and genomic data. PLoS Computational Biology 10 e1003457. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KARCHER M, PALACIOS J, BEDFORD T, SUCHARD M AND MININ V (2016). Quantifying and mitigating the effect of preferential sampling on phylodynamic inference. PLoS Computational Biology 12 e1004789. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KEELING M AND ROHANI P (2011). Modeling Infectious Diseases in Humans and Animals. Princeton University Press. [Google Scholar]
- KINGMAN J (1982). The coalescent. Stochastic Processes and their Applications 13 235–248. [Google Scholar]
- KLINKENBERG D, BACKER JA, DIDELOT X, COLIJN C AND WALLINGA J (2017). Simultaneous inference of phylogenetic and transmission trees in infectious disease outbreaks. PLoS Computational Biology 13 e1005495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KOEPKE A, LONGINI JR I, HALLORAN M, WAKEFIELD J and MININ V (2016). Predictive modeling of cholera outbreaks in Bangladesh. The annals of applied statistics 10 575. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KOMOROWSKI M, FINKENSTÄDT B, HARPER C AND RAND D (2009). Bayesian inference of biochemical kinetic parameters using the linear noise approximation. BMC Bioinformatics 10 343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KUHNER M, YAMATO J and FELSENSTEIN J (1998). Maximum likelihood estimation of population growth rates based on the coalescent. Genetics 149 429–434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KÜHNERT D, STADLER T, VAUGHAN T and DRUMMOND A (2014). Simultaneous reconstruction of evolutionary history and epidemiological dynamics from viral sequences with the birth–death SIR model. Journal of the Royal Society Interface 11 20131106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- KURTZ T (1970). Solutions of ordinary differential equations as limits of pure jump Markov processes. Journal of Applied Probability 7 49–58. [Google Scholar]
- KURTZ T (1971). Limit theorems for sequences of jump Markov processes. Journal of Applied Probability 8 344–356. [Google Scholar]
- Leventhal G, Günthard H, Bonhoeffer S and Stadler T (2013). Using an epidemiological model for phylogenetic inference reveals density dependence in HIV transmission. Molecular Biology and Evolution 31 6–17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MININ V, BLOOMQUIST E and SUCHARD M (2008). Smooth skyride through a rough skyline: Bayesian coalescent-based inference of population dynamics. Molecular Biology and Evolution 25 1459–1471. [DOI] [PMC free article] [PubMed] [Google Scholar]
- MÜLLER N, RASMUSSEN D and STADLER T (2017). The Structured Coalescent and its Approximations. Molecular Biology and Evolution 34 2970–2981. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murray I, Adams R and MacKay D. (2010). Elliptical slice sampling. In AISTATS 13 541–548. [Google Scholar]
- O’NEILL P AND ROBERTS G (1999). Bayesian inference for partially observed stochastic epidemics. Journal of the Royal Statistical Society: Series A (Statistics in Society) 162 121–129. [Google Scholar]
- PALACIOS J and MININ V (2013). Gaussian Process-Based Bayesian Non-parametric Inference of Population Size Trajectories from Gene Genealogies. Biometrics 69 8–18. [DOI] [PubMed] [Google Scholar]
- PAPASPILIOPOULOS O, ROBERTS G AND SKÖLD M (2003). Non-centered parameterisations for hierarchical models and data augmentation. In Bayesian Statistics 7: Proceedings of the Seventh Valencia International Meeting (Bernardo JM, Bayarri MJ, Berger JO, Dawid AP, Heck-erman D, Smith AFM AND West D, EDS.) 307 307–326. Oxford University Press, USA. [Google Scholar]
- PAPASPILIOPOULOS O, ROBERTS G AND SKÖLD M (2007). A general framework for the parametrization of hierarchical models. Statistical Science 59–73. [Google Scholar]
- Pybus O, Charleston M, Gupta S, Rambaut A, Holmes E and Harvey P (2001). The epidemic behavior of the hepatitis C virus. Science 292 2323–2325. [DOI] [PubMed] [Google Scholar]
- RASMUSSEN D, RATMANN O AND KOELLE K (2011). Inference for nonlinear epidemiological models using genealogies and time series. PLoS Computational Biology 7 e1002136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- RASMUSSEN D, VOLZ E AND KOELLE K (2014). Phylodynamic inference for structured epidemiological models. PLoS Computational Biology 10 e1003570. [DOI] [PMC free article] [PubMed] [Google Scholar]
- RUE H (2001). Fast sampling of Gaussian Markov random fields. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 63 325–338. [Google Scholar]
- RUE H and HELD L (2005). Gaussian Markov Random Fields: Theory and Applications. CRC press. [Google Scholar]
- SCARPINO S, IAMARINO A, WELLS C, YAMIN D, NDEFFO-MBAH M, WENZEL N, FOX S, NYENSWAH T, ALTICE F, GALVANI A et al. (2014). Epidemiological and viral genomic sequence analysis of the 2014 Ebola outbreak reveals clustered transmission. Clinical Infectious Diseases 60 1079–1082. [DOI] [PMC free article] [PubMed] [Google Scholar]
- SMITH R, IONIDES E and KING A (2017). Infectious disease dynamics inferred from genetic data via sequential Monte Carlo. Molecular Biology and Evolution 34 2065–2084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- STADLER T, KÜHNERT D, BONHOEFFER S AND DRUMMOND A (2013). Birth–death skyline plot reveals temporal changes of epidemic spread in HIV and hepatitis C virus (HCV). Proceedings of the National Academy of Sciences 110 228–233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- STADLER T, KÜHNERT D, RASMUSSEN D AND DU PLESSIS L (2014). Insights into the early epidemic spread of Ebola in Sierra Leone provided by viral sequence data. PLoS Currents 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- SUCHARD M, LEMEY P, BAELE G, AYRES D, DRUMMOND A AND RAMBAUT A (2018). Bayesian phylogenetic and phylodynamic data integration using BEAST 1.10. Virus Evolution 4 vey016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- WHO Ebola Response Team (2014). Ebola virus disease in West Africa — - the first 9 months of the epidemic and forward projections. New England Journal of Medicine 371 1481–1495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- TOWERS S, PATTERSON-LOMBA O and CASTILLO-CHAVEZ C (2014). Temporal variations in the effective reproduction number of the 2014 West Africa Ebola outbreak. PLoS Currents 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VAN KAMPEN N AND REINHARDT W (1983). Stochastic processes in physics and chemistry. [Google Scholar]
- VAUGHAN TG, LEVENTHAL GE, RASMUSSEN DA, DRUMMOND AJ, WELCH D AND STADLER T (2019). Estimating epidemic incidence and prevalence from genomic data. Molecular biology and evolution 36 1804–1816. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Volz E (2012). Complex population dynamics and the coalescent under neutrality. Genetics 190 187–201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VOLZ E, KOELLE K AND BEDFORD T (2013). Viral phylodynamics. PLoS Computational Biology 9 e1002947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VOLZ E and POND S (2014). Phylodynamic analysis of Ebola virus in the 2014 Sierra Leone epidemic. PLoS Currents 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VOLZ E and SIVERONI I (2018). Bayesian phylodynamic inference with complex models. BioRxiv. [DOI] [PMC free article] [PubMed] [Google Scholar]
- VOLZ E, POND S, WARD M, BROWN A AND FROST S (2009). Phylodynamics of infectious disease epidemics. Genetics 183 1421–1430. [DOI] [PMC free article] [PubMed] [Google Scholar]
- WALLACE E (2010). A simplified derivation of the Linear Noise Approximation. Arxiv preprint arXiv:1004.4280. [Google Scholar]
- WEARING H, ROHANI P and KEELING M (2005). Appropriate models for the management of infectious diseases. PLoS Medicine 2 e174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- WILKINSON D (2011). Stochastic Modelling for Systems Biology. CRC press. [Google Scholar]
- (2016). World Health Organization. Ebola data and statistics. http://apps.who.int/gho/data/node.ebola-sitrep.quick-downloads?lang=en. Last accessed: February 28, 2018.
- WRIGHT S (1931). Evolution in Mendelian populations. Genetics 16 97–159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- XU X, KYPRAIOS T and O’NEILL PD (2016). Bayesian non-parametric inference for stochastic epidemic models using Gaussian processes. Biostatistics 17 619–633. [DOI] [PMC free article] [PubMed] [Google Scholar]
- YPMA RJF, VAN BALLEGOOIJEN WM and WALLINGA J (2013). Relating phylogenetic trees to transmission trees of infectious disease outbreaks. Genetics 195 1055–1062. [DOI] [PMC free article] [PubMed] [Google Scholar]