

Abstract
Early detection of lung cancer is critical for improvement of patient survival. To address the clinical need for efficacious treatments, genetically engineered mouse models (GEMM) have become integral in identifying and evaluating the molecular underpinnings of this complex disease that may be exploited as therapeutic targets. Assessment of GEMM tumor burden on histopathological sections performed by manual inspection is both time consuming and prone to subjective bias. Therefore, an interplay of needs and challenges exists for computer-aided diagnostic tools, for accurate and efficient analysis of these histopathology images. In this paper, we propose a simple machine learning approach called the graph-based sparse principal component analysis (GS-PCA) network, for automated detection of cancerous lesions on histological lung slides stained by hematoxylin and eosin (H&E). Our method comprises four steps: 1) cascaded graph-based sparse PCA, 2) PCA binary hashing, 3) block-wise histograms, and 4) support vector machine (SVM) classification. In our proposed architecture, graph-based sparse PCA is employed to learn the filter banks of the multiple stages of a convolutional network. This is followed by PCA hashing and block histograms for indexing and pooling. The meaningful features extracted from this GS-PCA are then fed to an SVM classifier. We evaluate the performance of the proposed algorithm on H&E slides obtained from an inducible K-ras lung cancer mouse model using precision/recall rates, -score, Tanimoto coefficient, and area under the curve (AUC) of the receiver operator characteristic (ROC) and show that our algorithm is efficient and provides improved detection accuracy compared to existing algorithms.
Keywords: Machine learning, Graph-based sparse PCA, Computational imaging, Cancer lesion detection, Image analysis
Introduction
Lung cancer is the leading cause of cancer-related deaths worldwide, with an estimated 1.6 million deaths each year [1]. Development of novel therapies to battle lung cancer has been greatly aided by the emergence of genetically engineered mouse models (GEMMs) of lung cancer, such as the K-ras; p53 non-small-cell lung carcinoma (NSCLC) model, where the compound effect of conditional mutations in the K-ras oncogene and the p53 tumor suppressor gene leads to development of adenocarcinomas in the mouse lung [2], [3]. Since GEMMs recapitulate certain aspects of the human disease associated with the stroma, vascularity, and immune infiltrate better than other models, it is important to be able to detect, identify and localize the lung tumor lesions seen on the histopathological sections as shown in Fig. 1.
Fig. 1.

An example whole-slide histopathological image from our dataset consisting of many tumor lesions. The high-resolution inset images show the visual features that characterize the tumor (red frame) and normal (blue frame) regions. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of this article.)
Manual assessment of tumor burden (the amount of tumor cells/mass present in a subject’s body) on histopathological mouse lung sections is difficult, time consuming, and a labor-intensive process. This is due to various reasons such as fluctuating intensities [4], color change and morphological variations within structures of the cancer lesions in these images [5], tumor heterogeneity [6] (see Fig. 1), low signal-to-noise-ratio [7], [8], variations in illumination [9], microscopy imaging limitations [10], [11], [12], [13], and the large number of images and the number of lesions per image an expert has to demarcate. Moreover, the task of manual detection of cancer lesions on H&E slides can be subjective, leading to inter-observer variability. Therefore, there is a pressing need for computer-aided diagnostic tools for accurate and efficient quantitative analysis of histopathology images [14], [15], [16], [17].
Tumor detection and classification tools within the commonly available microscopy software are based on feature extraction techniques such as size, shape, and morphological features [8], [14], [15], [16], [18], [19], [20], texture features including local binary pattern (LBP) [21], [22], [23], local Fourier transform [24], co-occurrence matrix and fractal texture features [25], and energy minimization and optimization-based techniques [26], [27], [28], [29]. These techniques suffer considerably due to over-generalization and therefore need extensive customization for the dataset at hand, limiting their use to very simple images obtained/collected in a carefully constrained environment [8]. Tumor detection and grading using size, shape and other morphological features does not work well when the cell population exhibits a variety of sizes and shapes, or when the signal-to-noise (SNR) ratio is poor [30]. Energy minimization and optimization techniques minimize the internal energy within tumor areas for their accurate detection, but may lead to false detections for highly textured and heterogeneous tumor lesions. To overcome these limitations, existing software tools allow user-friendly interfaces to correct the results obtained. This, however, results in losing the benefits of automation such as speed and reproducibility.
There has been much interest in developing algorithmic methods that adapt naturally to the dataset and perform feature discovery. One such popular class of learning or feature discovery methods includes those based on sparse representation-based classification (SRC) [31]. There have been many SRC methods that have been successfully applied to a variety of histopathological image classification problems [32], [33], [34], [35]. These methods are based on finding linear representations in the data. However, linear representations are almost always inadequate for representing non-linear structures of the data which arise in many practical applications. A recent class of learning-based methods involve the design of deep neural networks that can be trained to learn relevant features by themselves. There have been plenty of deep learning methods that have been developed for histopathological image classification [5], [36], [37], [38], [39], [40], [41], [42]. The success of deep learning, however, has been fueled by the availability of generous and clean training data. When the training data is limited and/or noisy, as is often the case in medical imaging, these methods tend to show a performance degradation [43]. Another class of learning-based approaches involve orthogonal transformation of the data such as principal component analysis (PCA) transform to extract relevant features for image classification [30], [44], [45], [46]. These learning-based approaches using orthogonal transformation explore the data distribution to preserve global structures in the data.
In this paper, we present a simple machine learning approach called the graph-based sparse principal component analysis (GS-PCA) network, which combines the local and global structures of all the data and is implemented in a deep learning framework to learn an explicit nonlinear mapping of the data for accurate detection and classification. We use the most basic and easy operations to emulate the processing stages in a typical (convolutional) neural network: First, graph-based sparse PCA filters are used as the data-adapting convolutional filter bank at each stage of the network. Next, we perform a simple binary quantization (hashing) that serves as the nonlinear stage, followed by block-wise histograms of the binary codes as the feature pooling stage to obtain the final output features of the network. Finally, we train a support vector machine (SVM) classifier on the output features of the network to obtain the final classification instead of the regular softmax classifier, as the softmax classifier is known to overfit [44]. For ease of reference, we call this data-processing network a Graph-Based Sparse PCA Network (GS-PCANet). The key contributions of this paper are as follows:
-
•
Feature Extraction Using Graph-Based Sparse PCA: Unlike other histopathology image classification methods, in this work we propose a baseline neural network method called GS-PCANet, which is different from prior methods [30], [44], [45], [46] in two aspects. 1) We include an additional sparsity promoting term in the PCA transformation so as to select more interpretable features from the image patches. 2) We include a graph regularization term in the objective function to recover the low-dimensional manifold structure from high-dimensional sampled data.
-
•
Computationally Efficient Approach: Our proposed GS-PCANet is computationally efficient in comparison to other deep learning methods in two aspects. 1) We show that a simple two-stage network is good enough to extract all the relevant features for classifying the tumor versus healthy lung regions. 2) We do not need to learn the filter weights at each stage of the network.
We evaluate the proposed method and seven state-of-the-art algorithms developed for histopathology image classification on a dataset of 67 images provided by the Stefanie Galban Lab, at the University of Michigan. The dataset consists of microscopy images of murine H&E stained lung sections and are divided into two categories: images of non-tumor-bearing control mice and images of mice with visible tumor.
Principal Component Analysis
Let denote an matrix of rows and columns of rank , where is the number of data samples, and is the number of features/variables in each data sample. Let for denote a row of the matrix , assumed to have a zero mean. Let denote the covariance matrix of , where is a positive definite matrix of size , which can be decomposed as
| (1) |
where is the largest eigenvalue of and is its associated eigenvector. PCA reduces the dimensionality of the data from to by replacing the original features/variables with linear combinations of the form known as the principal components (PCs), which are obtained by maximizing their variance:
and
where is the principal loading vector and the projection of the data is the principal component and the operator denotes the (estimated) variance of a random variable.
Generally, PCA is computed using singular value decomposition (SVD) of as
| (2) |
where the columns of are the PCs, and the columns of are the corresponding principal loading vectors (also known as basis vectors) [47]. The matrix is a diagonal matrix of ordered singular values and the columns of and are orthonormal such that . If is low rank, it is possible to significantly reduce its dimensionality by using the most significant basis vectors. The projection of the data upon the first basis vectors gives the PCs.
An alternative formulation for PCA can be derived on the projection framework [44], where the PC loading matrix also known as the PCA basis (defined as the matrix containing the principal loading vectors) can be estimated by solving the following least squares optimization problem:
| (3) |
where is the Frobenius norm, is a matrix whose columns form an orthonormal basis , and is an identity matrix of size . The columns of that minimize (3) are referred to as the PCA basis . The minimization is solved by formulating it as a least absolute shrinkage and selection operator (LASSO) problem [48]. Each principal component is derived from a linear combination of all features, consequently making non-sparse. We use this alternative formulation for PCA feature extraction in this work.
Proposed Method
Based on the PCA methodology, we propose a simple and efficient machine learning method for histopathology image classification. First, we obtain graph-based sparse PCA filters (i.e., the PCs) from the training images as the data adaptive convolutional filter bank for the various stages of a convolutional neural network. Then we perform a simple binary quantization (hashing), which serves as a nonlinear stage. Next, we use block-wise histograms of the binary codes obtained from the quantization process to get the output features of the network. Finally, we train a SVM classifier using the output features to obtain the final classification. The proposed GS-PCANet model is shown in Fig. 2, illustrating each of the above steps involved in our algorithm.
Fig. 2.

An outline of the proposed (two-stage) GS-PCANet.
Graph‐Based Sparse PCA
From the analysis of PCA in Section II, we can obtain a sparse PCA basis by including a regularization term in (3). Inclusion of a sparsity penalty reduces the number of features involved in each linear combination for obtaining the PCs. One way to extend (3) to obtain sparse basis vectors is by imposing -norm and -norm penalty constraints upon the regression coefficients (basis vectors) [48]:
| (4) |
where the same (the regularization parameter of the -norm) is used for all components, different (the regularization parameters of the -norm) are allowed for penalizing the loadings of different PCs. The corresponds to the required sparse basis . The -norm and -norm regularization terms penalize the number of non-zero coefficients in , whereas the loss term simultaneously minimizes the reconstruction error . If and the are zero, the problem reduces to finding the ordinary PCA basis vectors, equivalent to (3). When some coefficients of are forced to zero, resulting in sparsity.
The sparse PCA defined in (4) preserves the global structures in the data, but does not retain intrinsic geometric structure within input data, thereby missing mutual influences in the data. In addition to preserving the global structures, we are interested in preserving the local structures, i.e., nearest neighbor (NN) preservation of each data sample , as they help in identifying local features in the data (See Section IV-F for more details). The idea of a graph-Laplacian from manifold learning theory is to recover low-dimensional manifold structure from high-dimensional sampled data [49]. This provides a motivation to embed a Laplacian to PCA to help preserve the local features in the data. Let the vertices correspond to data samples , respectively. We define a symmetric weight matrix , where is the weight of the edge connecting vertices and . The value of is set as follows:
| (5) |
where the set is the set of nearest neighbors of . Let us suppose that = is the embedding coordinates of the data and define as the diagonal matrix with . Thus, with weight matrix , we can formulate a graph regularization term as
| (6) |
where is the graph Laplacian matrix computed as and is the trace of a matrix. Simply put, in the case of maintaining the local adjacency relationship of the graph, the graph can be transformed from the high-dimensional space to a low-dimensional space. Minimizing the graph regularization term in (6) helps to preserve the low-dimensional manifold structure in the data [49]. Combining the sparse PCA from (4) and the graph regularization from (6), we propose a graph-based sparse PCA model,
| (7) |
where is a graph regularization parameter. To solve (7), we perform the following steps: first solve an ordinary PCA problem to fix , then formulate an elastic net with the fixed and solve for , then perform SVD to update , and repeat these steps until convergence, finally obtaining the solution as .
Architecture of GS‐PCA Network
Suppose there are training images of size , and assume that PCA filter size is (formed by reshaping a basis vector of length ) at all stages of the network. The sparse PCA filters are learned from these training images. We describe each component of the network in detail below (see Fig. 2).
1) First stage (GS‐PCA)
For each training image , around each pixel we take an image patch of size and denote all the overlapping image patches in the image as , where denotes the vectorized image patch in , , . We then subtract the image patch mean from each of the image patches and obtain the centralized matrix of as , where and . By constructing a similar centralized matrix for each training image , we obtain
| (8) |
Assuming that we have PCA filters in stage , sparse PCA minimizes the reconstruction error within a family of orthonormal filters using (7), where is an identity matrix of size . The solution to the minimization problem in (7) are the principal eigenvectors of [44]. The PCA filters can therefore be expressed as
| (9) |
where is an operator that reshapes a column vector to a matrix and denotes the principal eigenvector of . The principal eigenvectors capture the main variation of the centralized image patches in the training data. Similar to a convolutional neural network we stack multiple stages of the sparse PCA filters to extract higher level features.
2) Second stage (GS‐PCA)
We repeat the same process as in first stage. Let the filter output of first stage be
| (10) |
where denotes 2D convolution and boundary of the images are zero padded before convolution. Similar to the first stage we collect all the overlapping image patches of the convolved image , subtract the patch mean from each patch and obtain the centralized matrix , where is the mean subtracted image patch in . We define as the matrix containing all the mean subtracted patches of the filter output and concatenate for all filter outputs as
| (11) |
Once again we solve (7) with as the input. The solution to the minimization problem in (7) are the principal eigenvectors of . The sparse PCA filters of the second stage are then obtained as
| (12) |
For each input image of the second stage, there will be output images of size generated as
| (13) |
After the second stage we will obtain output images. It is easy to repeat the above process to build more (sparse PCA) stages if a deeper architecture is needed.
3) Binary quantization (hashing)
For each of the input images presented to the second stage we obtain real-valued output images . We binarize these outputs and obtain , where is a Heaviside step (like) function, which has a value of 1 for positive entries and zero otherwise. Around each pixel, we view the vector of binary bits as a decimal number, thus converting the outputs in into a single integer-valued “image”
| (14) |
which has pixel values in the range .
4) Block‐wise histograms
We partition each of the “images” into distinct blocks, compute the histogram (with bins) of the decimal values in each block and concatenate all histograms into a single vector denoting it as . After such an encoding process the “feature” of the input image is then defined to be the set of block-wise histograms, i.e.,
| (15) |
We use overlapping blocks to build the feature vector for each input image as it helps in retaining most amount of the information.
We train a linear support vector machine (SVM) classifier [50] using the feature vector obtained for each input image from the GS-PCANet in order to classify cancer lesions versus normal tissues on H&E stained histological lung slides.
Classifying Color Images
There are several options to extend the proposed GS-PCANet method to be able to extract features for classifying color images. In this work, we follow the approach described in Gurcan et al. [14], Chan et al. [44] and apply the proposed GS-PCANet to each of the red, blue, and green channels to obtain multichannel sparse PCA filters, that are then used to extract features for classifying the color images.
Experiments and Results
In this section we evaluate our proposed GS-PCANet image classification algorithm with other open-source histopathology image classification methods: SpPCANet method for image classification [46], multiple clustered instance learning (MCIL) for histopathology image classification [51], saliency-based dictionary learning (SDL) [34], analysis-synthesis learning with shared features (ASLF) [35], patch-based convolutional neural network (PCNN) [36], encoded local projections (ELP) for histopathology image classification [20], and weakly supervised deep learning (WSDL) for whole slide tissue classification [40]. We evaluate these seven methods using commonly used detection/classification measures: precision (P), recall (R), detection accuracy, -score, Tanimoto coefficient (T), and the receiver operating characteristic (ROC) curves along with the area under the curve (AUC).
The Precision P and recall R (a.k.a. true positive rate or sensitivity) are given by
| (16) |
where TP is the number of true positive classifications, FP is the number of false positive classifications, and FN is the number of false negative classifications. The false positive rate (a.k.a. complement of specificity) is defined as . An ROC curve is a plot of the true positive rate versus the false positive rate. The detection accuracy is defined as (.
The -score is defined by
| (17) |
We use (i.e., ) as this is the most common choice for this type of evaluation [8].
Tanimoto coefficient, also known as Tanimoto distance in statistics, is defined as
| (18) |
where M is the number of detected individual tumors by an automated algorithm and N is the actual number of individual tumors in the image.
The AUC is the average of precision over the interval (), where is a function of recall R. It is given by
| (19) |
The best detection algorithm among several alternatives is commonly defined as the one that maximizes the Tanimoto coefficient, AUC, and the -score.
Dataset
The proposed method was mainly developed with the goal of identifying individual tumors in H&E stained whole slide histopathology lung images obtained from an inducible K-ras lung cancer model. The images were produced using a digital slide scanner (Super COOLSCAN 5000 ED Digital Slide Scanner; Nikon Corporation) with a objective lens (level-0 pixel size: 0.52 µm 0.52 µm). In our experiments, the size of each image acquired is approximately pixels. Our dataset consists of a total of 67 whole slide histopathology lung images obtained from 32 non-tumor-bearing mice and 35 mice with visible tumors. All animals were maintained in accordance with the University of Michigan’s Institutional Animal Care and Use Committee guidelines approved protocol (UCUCA PRO00008646). A careful manual delineation of the borders of the individual tumors within the 35 images was performed by an expert and considered as ground truth for subsequent analysis. We divide each image in our dataset into non-overlapping image patches of size pixels consisting of a total of 52,487 cancer lesion patches and 1,455,023 normal patches.
Experimental Setup
We used a total of 15 non-tumor-bearing mice images and 15 images with visible tumors for training the compared algorithms, consisting of a total of 21,934 cancer lesion patches and 653,092 normal patches. Our test dataset consists of 17 non-tumor-bearing mice images and 20 images with visible tumors consisting of a total of 30,553 cancer lesion patches and 801,931 normal patches. The hyper-parameters of the GS-PCANet algorithm include the filter size (), the number of stages, the number of filters in each stage (), and the block size for the local histograms in the output stage. The optimal values for these parameters were automatically selected on a validation set (randomly chosen from within the training data), using the ROC curves by varying one parameter at a time while keeping the others fixed and choosing that value of the parameter that maximizes the AUC of the ROC curve. The parameters of the GS-PCANet were set to , , , and, a histogram block size of .
Qualitative Results
Fig. 3 shows the qualitative detection results for an example image containing visible tumors from our test dataset. Fig. 3(a) shows that the proposed GS-PCANet method detects most of tumor regions correctly with very few false positives and false negatives. Fig. 3(e) shows that the ASLF method is also able to identify the tumor regions well, but detects more false positives than the GS-PCANet method. The SpPCANet, MCIL, and WSDL methods have many misclassifications (with blood vessels being identified as tumors) as shown in Fig. 3(b), (c) and (h), respectively. The ELP method splits a single tumor into three tumors (see Fig. 3(g) row 3), with many false positives. The SDL, PCNN, and ELP methods miss large parts of individual tumors, i.e., have many false negatives as shown in Fig. 3(d), (f), and (g), respectively. Visually it is clear that the proposed GS-PCANet method accurately detects both large and small individual tumors within the whole slide image with very few false positives and false negatives. This is of great significance for those studying oncogenesis, progression, and metastasis because the robustness of the algorithm to the size of the tumor reduces the likelihood that the algorithm will mislabel cases containing only small tumors.
Fig. 3.

Detection results on a representative image containing visible tumors in our test dataset using: (a) GS-PCANet, (b) SpPCANet, (c) MCIL, (d) SDL, (e) ASLF, (f) PCNN, (g) ELP, and (h) WSDL. The true borders delineated by an expert of each individual tumor in the image are shown in blue, the true positives patches identified by each method are shown in green and the false positives of each method are bordered in red in the color version of this paper. False negatives are those regions within the blue-bordered individual tumors that are not shaded in green. Results on the entire image are shown in row 1, and two zoomed regions are shown in rows 2 and 3.
Quantitative Results
We compared the quantitative performance of the automated methods at the image patch level and for the task of individual tumor detection within an entire image as well. Fig. 4 shows the ROC curves of all automated methods at the image patch level on the test dataset. From Fig. 4, we observe that our proposed GS-PCANet method exhibits the most favorable trade-off in terms of accurate detection while maintaining low false positive rate in comparison to the other automated methods. Table 1 shows the quantitative performance of the compared methods for the task of individual tumor detection within the histopathology images in the test dataset. Table 1 shows that the detection accuracy of the proposed GS-PCANet method is much higher than the other competing algorithms. From Table 1, we also observe that the -score, and Tanimoto coefficient (T) of the proposed method are the highest among the compared algorithms. Table 1 also provides the AUC values and their 95% confidence intervals corresponding to the ROC curves in Fig. 4 for each method. We observe from the AUC values that the GS-PCANet method outperforms the alternatives. In addition to the metrics in Table 1, we also computed the free receiver operating characteristics curves (FROC) [8] for all the compared algorithms. Fig. 5 shows that the proposed GS-PCANet method has better tumor detection sensitivity compared to the other automated methods at all points along the FROC curve. This shows that the proposed method detects the individual tumors within these images better than the other compared methods.
Fig. 4.

ROC curve of image patch classification as cancerous or healthy for different methods.
Table 1.
Mean performance (and standard deviation) for various algorithms.
| Method | Precision (P) | Recall (R) | -score | Tanimoto coefficient (T) | Detection accuracy | AUC |
|---|---|---|---|---|---|---|
| GS-PCANet | 0.872 (0.013) | 0.955 (0.019) | 0.912 (0.015) | 0.903 (0.010) | 0.908 (0.008) | 0.9510.011 |
| SpPCANet[46] | 0.841 (0.019) | 0.870 (0.025) | 0.855 (0.022) | 0.836 (0.014) | 0.853 (0.015) | 0.907 0.017 |
| MCIL[51] | 0.719 (0.022) | 0.780 (0.015) | 0.748 (0.031) | 0.762 (0.019) | 0.738 (0.026) | 0.821 0.013 |
| SDL[34] | 0.752 (0.024) | 0.850 (0.031) | 0.798 (0.025) | 0.801 (0.017) | 0.785 (0.011) | 0.849 0.021 |
| ASLF[35] | 0.811 (0.028) | 0.900 (0.019) | 0.853 (0.021) | 0.829 (0.030) | 0.845 (0.018) | 0.903 0.022 |
| PCNN[36] | 0.807 (0.039) | 0.815 (0.031) | 0.811 (0.032) | 0.796 (0.023) | 0.810 (0.024) | 0.871 0.039 |
| ELP[20] | 0.761 (0.023) | 0.750 (0.018) | 0.756 (0.021) | 0.739 (0.027) | 0.758 (0.023) | 0.844 0.014 |
| WSDL[40] | 0.798 (0.030) | 0.785 (0.028) | 0.823 (0.031) | 0.821 (0.035) | 0.818 (0.028) | 0.882 0.041 |
Fig. 5.

FROC curve of different methods for the individual tumor detection task within an entire image.
The confusion matrix corresponding to competing methods for our test dataset is provided in Table 2. From Table 2, we observe that our proposed GS-PCANet method outperforms competing dictionary learning methods as well as deep learning methods. This could be due to the fact that our proposed GS-PCANet method uses a complete basis representation whereas dictionary learning or deep learning methods use an overcomplete basis to represent the features associated with both normal and cancerous regions within the images.
Table 2.
Confusion matrix (%).
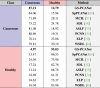 |
1) Impact of the number of stages
The impact of the number of GS-PCANet stages for our data is studied here. Specifically, we are interested in the impact on the performance of GS-PCANet when we merge the two stages into one stage that has the equal number of sparse PCA filters and receptive field size defined as the size of the region of the input image that produces the feature. We built a single-stage GS-PCANet (GS-PCANet-1) with filters of size and compare it with the two-stage GS-PCANet (GS-PCANet-2) described in Section III-B. The parameters for both networks are set to , , , and a histogram block size of . The detection accuracy and the AUC values of both networks for our test data are reported in Table 3. From Table 3 we observe that the two-stage GS-PCANet outperforms the single-stage GS-PCANet. One explanation behind this could be that in comparison to the PCA filters learned by GS-PCANet-1, the PCA filters of GS-PCANet-2 essentially have a low-rank factorization, resulting in a lower chance of over-fitting the data. Also, from a computational perspective, GS-PCANet-1 requires learning filters with variables, whereas GS-PCANet-2 only learns filters with a total of variables, confirming the need for a multiple-stage network structure. Another benefit of GS-PCANet-2 is the larger receptive field, which leads to observing image regions with a bigger context around the objects of interest, as well as its learning invariance [44] which can capture more semantic information.
Table 3.
Mean performance (and standard deviation) for various stages of GS-PCANet. Here and .
| Method | Detection accuracy | AUC |
|---|---|---|
| GS-PCANet-1 () | 0.815 (0.019) | 0.842 0.014 |
| GS-PCANet-2 | 0.908 (0.008) | 0.9510.011 |
Statistical Analysis
To investigate the robustness of training or selection bias for each automated method, we obtain the detection performance for 10 different choices of training image patches (the number of training images were fixed), using the rest of the image patches as test image patches. The detection accuracy for each training run was fit to a Gaussian probability density function (pdf) and plotted in Fig. 6. From Fig. 6, we observe that the mean our proposed GS-PCANet curve is much higher than the competing methods indicating superior average detection accuracy. Even more crucial is the spread/variance of our GS-PCANet curve is smaller than its alternatives indicating highly desirable robustness to the particular choice of training image patches.
Fig. 6.

Selection bias plot showing the distribution of detection accuracy over ten different training choices of image patches for the compared methods.
We also performed a balanced two-way analysis of variance (ANOVA) [52] on the detection accuracies in the selection-bias experiment for all the methods. Fig. 7 shows these comparisons using a post-hoc Tukey range test [52]. Fig. 7 shows that the performance of the GS-PCANet method is significantly separated from its competing alternatives. -values of the proposed GS-PCANet method compared with other state-of-the-art methods are observed to be much less than , emphasizing the fact that the GS-PCANet method is more effective.
Fig. 7.

Comparison of the proposed GS-PCANet method and other state-of-the-art alternatives by a two-way ANOVA. Values reported by ANOVA (using MATLAB function anova2) across the methods are , indicating that the improved accuracy of the proposed GS-PCANet method is statistically significant. The intervals shown represent 95% confidence intervals of the detection accuracies for the proposed method (blue) and the competing methods (red). (For interpretation of the references to color in this figure legend, the reader is referred to the web version of this article.)
Comparison of PCA, Sparse PCA, and GS‐PCA
It has been shown in the literature that performing a PCA or a sparse PCA analysis preserves the global structures in the data [53], whereas manifold learning-based feature extraction methods are effective for dealing with high-dimensional data as they preserve the local structures in the data via manifold learning [54]. In our GS-PCANet method, we find it reasonable to combine both types of structure-preserving approaches as they strengthen the performance of the image classification task due to providing complementary information. For example, the global structure preservation can improve generalization ability. In this section, we show results of constructing a neural network architecture using the PCA, sparse PCA, and the proposed GS-PCA method. The comparison of the top nine PCs (a.k.a. the filters) of the final stage of the network and the covariance matrix of the PCs for each method are shown in Fig. 8. Different colors in Fig. 8(a)–(c) represent negative (blue), positive (red), and zero-valued (white) coefficients. From Fig. 8(a) to (c), we observe that the GS-PCANet method has more sparse filters as compared to SpPCANet [46] and PCANet [44] methods. Looking at the covariance matrices in Fig. 8(d) to (f), we observe that the PCs for the PCANet are most orthogonal, and that the GS-PCANet method has PCs more orthogonal than those found by SpPCANet method. Additionally, for comparison we present the scatter plots of the top three PCs for each method on image patches from our test dataset in Fig. 9. From Fig. 9, we observe that the GS-PCANet method achieves better separation for the healthy versus the cancerous test image patches in comparison to SpPCANet and PCANet methods. In addition, we computed the mean silhouette score, the Calinski–Harabasz (C–H) index [55], and Davies–Bouldin (D–B) index [56] on these scatter plots and report these values in Table 4. The silhouette score is calculated using the mean intra-cluster distance and the mean nearest cluster distance for each data point. The C–H index (also known as the variance ratio criterion) is defined as the ratio between the within-cluster dispersion and the between-cluster dispersion. The D–B index is defined as the average similarity measure of each cluster with its most similar cluster. The method that has the highest mean silhouette score and C–H index and the lowest D–B index would have the best separation for healthy and cancerous test image patches. From Table 4, we observe that the GS-PCANet method has the highest mean silhouette score and C–H index, and the lowest D–B index among the three methods. These results show that addition of the graph regularization term in the GS-PCANet method leads to a better separation between the image classes in comparison to SpPCANet and PCANet methods.
Fig. 8.

Comparison of the filters of the final stage learned on our dataset. Red color are positive values, blue color are negative values, and white color is zero. (a) PCANet filters, (b) SpPCANet filters, (c) GS-PCANet filters. Also shown are the covariance matrix of the components. (d) PCANet covariance matrix, (e) SpPCANet covariance matrix, (f) GS-PCANet covariance matrix.
Fig. 9.

Scatter plots of the test image patches of our dataset based on the first three principal components by (a) PCANet method, (b) SpPCANet method, (c) GS-PCANet method.
Table 4.
Performance metrics for various PCA methods.
| Method | Silhouette score | C–H Index | D–B index |
|---|---|---|---|
| PCANet | 0.56 | 185.62 | 1.04 |
| SpPCANet | 0.62 | 318.24 | 0.71 |
| GS-PCANet | 0.74 | 362.45 | 0.54 |
Computational Complexity
Here we show computational complexity of the GS-PCANet method by considering a two stage network. For each stage in the GS-PCANet, forming the mean subtracted image patch matrix has a computational complexity of ; the inner product in (9) has a complexity of ; the computational complexity of the eigen decomposition with graph-regularization is . The sparse PCA filter convolution has a complexity of at stage . The block-wise histogram computation has a complexity of . With , , and assuming , the overall complexity of GS-PCANet is
| (20) |
The computational complexity in (20) applies to both the training and testing phase of GS-PCANet because the extra computation burden during training is the eigen decomposition, which can be ignored when .
We compared the mean inference run time, namely, the time required to classify all the image patches in a single test image for each of the competing algorithms. Table 5 shows the mean and standard deviation of the run time each method takes to classify an entire image. From Table 5, we observe that the proposed GS-PCANet method runs 0.83 seconds slower than the WSDL method, but is on average faster than all the other methods. The SDL and ASLF methods classify the test image patch by reconstructing them from the learned dictionaries and thus take more time to execute at test time. The ELP algorithm finds the Radon transformation of each test image patch at various orientations, thereby taking more time to classify each test image patch. The MCIL method integrates the clustering of multiple subtypes of a single class into the MIL classification framework, thus requiring more run time compared to the other methods, except for the ELP method. In Table 5 we also report the training time required to train each of the competing algorithms. From Table 5, we observe that the proposed GS-PCANet method and the SpPCANet method take roughly about 21 min to train, whereas the other methods take about 3 to 62 times more time to train a good model. The small training time of the GS-PCANet method is attributed to the low computational complexity of the method.
Table 5.
Mean run time (and standard deviation).
| Method | Training time (HH:MM:SS) | Run time (Std. Dev.) in Sec. |
|---|---|---|
| GS-PCANet | 00:21:09 | 11.14 (3.09) |
| SpPCANet[46] | 00:20:53 | 15.21 (1.41) |
| MCIL[51] | 18:25:06 | 66.35 (14.36) |
| SDL[34] | 01:22:41 | 46.11 (4.51) |
| ASLF[35] | 01:49:27 | 19.39 (5.15) |
| PCNN[36] | 19:27:55 | 39.47 (15.22) |
| ELP[20] | 04:38:03 | 71.44 (9.40) |
| WSDL[40] | 21:44:17 | 10.31 (6.02) |
Impact on Number of Training Images
In this section, we show the practicality and applicability of the proposed GS-PCANet method in medical imaging tasks where we have very few data to learn from. Whereas in all other experiments we trained on 15 images from each class, in this experiment we varied the number of training images (from 1 to 20) for all the competing methods and computed detection accuracy of these methods. Fig. 10 shows the detection accuracy of all the competing algorithms on the test dataset of 27 images (12 non-tumor images and 15 images with visible tumors). From Fig. 10, we observe that the proposed GS-PCANet method trained with as few as 8 images achieves a high detection accuracy of 91%, whereas the other methods are able to achieve a maximum detection accuracy of only about 89% and also require as much as 20 training images. This shows that the proposed GS-PCANet method can produce a good model for image classification with less training data.
Fig. 10.

Detection accuracy as a function of the number of training images for the competing methods.
Discussion and Conclusion
Tumor burden in histopathological sections is difficult to assess by manual evaluation, as well as by prior automated tumor detection algorithms. To solve this problem, our proposed machine learning algorithm uses a cascaded graph-based sparse PCA transform followed by PCA binary hashing and block-wise histograms to obtain features within image patches. These features are then used to classify an image patch as cancerous or healthy using a linear SVM classifier. Our approach differs from earlier learning-based methods based on deep learning [36], [40], instance learning [20], [51] or dictionary learning [34], [35] for histopathology image classification. Like many deep learning methods, the network parameters, such as the number of stages, the filter size, and the number of filters, need to be optimized and fixed for our GS-PCANet method. Once these parameters are fixed, training the GS-PCANet is extremely simple and efficient because the filter learning in GS-PCANet does not require regularized parameters or require numerical optimization solvers. Moreover, the GS-PCANet consists of only linear operations at each stage with a non-linearity applied only at the output stage, which makes the method more interpretable than other deep learning methodologies.
The GS-PCANet method was first validated with respect to detection accuracy using ROC curves and the AUC of the ROC curve. Second, the algorithm was validated with respect to detection accuracy using the precision, recall, -score, Tanimoto coefficient, FROC curves, and the confusion matrix. Tables 1 and 2 show that the proposed GS-PCANet method performs the best among the compared methods for histopathology image classification. Fig. 3 shows that the proposed GS-PCANet method qualitatively performs the best in comparison to the other methods. Further, Fig. 6 shows that the GS-PCANet method has superior average detection accuracy and is more robust to the choice of training images compared to the other methods. We also show the low computational complexity of the GS-PCANet method and compare the training and inference run times for all the methods. Table 4 shows that the GS-PCANet method is relatively very fast to learn a good model in comparison to other methods. Finally, Fig. 10 shows that the proposed method requires less data to learn a good model.
Next, we present some inherent limitations of the automated methods for tumor detection. Fig. 11 shows an example case of an image containing individual tumors where all algorithms including our algorithm fail to produce optimum detection results. In Fig. 11 we observe that even though the algorithm has detected all the individual tumors, i.e., the true positive image patches shown in green color, it has also detected many false positive image patches shown in red color. On close examination, we see that the false positive image patches within the image look very similar to cancerous image patches. This could be due to the fact that there is not enough resolution in this image to differentiate between the cancerous and healthy image patches, or this histopathology section was captured when some of the underlying cells were transitioning from healthy to being cancerous.
Fig. 11.

Example of detection errors produced by all algorithms on an image with visible tumors. The true borders delineated by an expert of each individual tumor in the image are shown in blue, the true positive and the false positive image patches are shown in green and red, respectively, in the color version of this paper (the image is better viewed in zoomed mode). (For interpretation of the references to color in this figure legend, the reader is referred to the web version of this article.)
The proposed detection algorithm uses all the image patches in the training data for obtaining the local structures within the data when computing the graph-based term in (6) and (7). This adds to the time complexity and results in noise and outlier image patches still being included. However, the algorithm can be modified by linearly clustering the image patches into subgroups and taking these cluster centers to compute the graph regularization term in (7). Making this change could further reduce detection errors and also accelerate the algorithm, making it more accurate and efficient at the same time.
CRediT authorship contribution statement
Sundaresh Ram: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. Wenfei Tang: Formal analysis, Methodology, Software, Validation, Writing – review & editing. Alexander J. Bell: Data curation, Project administration, Validation, Visualization, Writing – review & editing. Ravi Pal: Data curation, Validation, Visualization, Writing – review & editing. Cara Spencer: Data curation, Writing – review & editing. Alexander Buschhaus: Data curation, Writing – review & editing. Charles R. Hatt: Formal analysis, Investigation, Project administration, Supervision, Writing – review & editing. Marina Pasca diMagliano: Resources, Supervision, Writing – review & editing. Alnawaz Rehemtulla: Project administration, Supervision, Writing – review & editing. Jeffrey J. Rodríguez: Conceptualization, Investigation, Methodology, Project administration, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. Stefanie Galban: Data curation, Funding acquisition, Project administration, Resources, Supervision, Writing – review & editing. Craig J. Galban: Conceptualization, Funding acquisition, Investigation, Project administration, Supervision, Validation, Visualization, Writing – review & editing.
Declaration of Competing Interest
The authors declare the following financial interests/personal relationships which may be considered as potential competing interests:
Dr. Charles Hatt is employed by and has stock options in Imbio, Inc. Dr. Craig Galban is co-inventor of Parametric Response Mapping, which the University of Michigan has licensed to Imbio, Inc., and has a financial interest in Imbio, Inc.
Footnotes
This work was supported in part by the National Heart, Lung, and Blood Institute of the National Institute of Health under Grant R01HL139690 and in part by grant support awarded to Dr. Stefanie Galban by the Rogel Cancer Center at the University of Michigan.
References
- 1.Cruz C.S.D., Tanoue L.T., Matthay R.A. Lung cancer: epidemiology, etiology, and prevention. Clin. Chest Med. 2011;32(4):605–644. doi: 10.1016/j.ccm.2011.09.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Walrath J.C., Hawes J.J., Van Dyke T., Reilly K.M. Advances in Cancer Research. vol. 106. Academic Press; 2010. Genetically engineered mouse models in cancer research; pp. 113–164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Barck K.H., Bou-Reslan H., Rastogi U., Sakhuja T., Long J.E., Molina R., Lima A., Hamilton P., Junttila M.R., Johnson L., Carano R.A.D. Quantification of tumor burden in a genetically engineered mouse model of lung cancer by micro-CT and automated analysis. Transl. Oncol. 2015;8(2):126–135. doi: 10.1016/j.tranon.2015.03.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ram S., Rodriguez J.J. 2013 IEEE Intl. Conf. Acoustics Speech Signal Process. (ICASSP) IEEE; 2013. Symmetry-based detection of nuclei in microscopy images; pp. 1128–1132. [Google Scholar]
- 5.Lin H., Chen H., Graham S., Dou Q., Rajpoot N., Heng P.-A. Fast scannet: fast and dense analysis of multi-gigapixel whole-slide images for cancer metastasis detection. IEEE Trans. Med. Imaging. 2019;38(8):1948–1958. doi: 10.1109/TMI.2019.2891305. [DOI] [PubMed] [Google Scholar]
- 6.Junttila M.R., de Sauvage F.J. Influence of tumour micro-environment heterogeneity on therapeutic response. Nature. 2013;501(7467):346–354. doi: 10.1038/nature12626. [DOI] [PubMed] [Google Scholar]
- 7.Ram S., Rodriguez J.J., Bosco G. 2010 IEEE Southwest Symp. Image Anal. Interp. (SSIAI) IEEE; 2010. Segmentation and classification of 3-D spots in FISH images; pp. 101–104. [Google Scholar]
- 8.Ram S., Rodriguez J.J. Size-invariant detection of cell nuclei in microscopy images. IEEE Trans. Med. Imaging. 2016;35(7):1753–1764. doi: 10.1109/TMI.2016.2527740. [DOI] [PubMed] [Google Scholar]
- 9.Ram S., Danford F., Howerton S., Rodriguez J.J., Geest J.P.V. Three-dimensional segmentation of the ex-vivo anterior lamina cribrosa from second-harmonic imaging microscopy. IEEE Trans. Biomed. Eng. 2018;65(7):1617–1629. doi: 10.1109/TBME.2017.2674521. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Ram S., Rodriguez J.J., Bosco G. 2012 IEEE Southwest Symp. Image Anal. Interp. (SSIAI) IEEE; 2012. Size-invariant cell nucleus segmentation in 3-D microscopy; pp. 37–40. [Google Scholar]
- 11.Ram S. Sparse Representations and Nonlinear Image Processing for Inverse Imaging Solutions. Department of Electrical and Computer Engineering, The University of Arizona, Tucson, AZ; 2017. Ph.D. dissertation. [Google Scholar]
- 12.Ram S., Majdi M.S., Rodriguez J.J., Gao Y., Brooks H.L. 2018 IEEE Southwest Symp. Image Anal. Interp. (SSIAI) IEEE; 2018. Classification of primary cilia in microscopy images using convolutional neural random forests; pp. 89–92. [Google Scholar]
- 13.Ram S., Nguyen V.T., Limesand K.H., Rodriguez J.J., Bosco G. 2020 IEEE Southwest Symp. Image Anal. Interp. (SSIAI) IEEE; 2010. Combined detection and segmentation of cell nuclei in microscopy images using deep learning; pp. 26–29. [Google Scholar]
- 14.Gurcan M.N., Boucheron L.E., Can A., Madabhushi A., Rajpoot N.M., Yener B. Histopathological image analysis: a review. IEEE Rev. Biomed. Eng. 2009;2:147–171. doi: 10.1109/RBME.2009.2034865. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Veta M., Pluim J.P.W., van Diest P.J., Viergever M.A. Breast cancer histopathology image analysis: a review. IEEE Trans. Biomed. Eng. 2014;61(5):1400–1411. doi: 10.1109/TBME.2014.2303852. [DOI] [PubMed] [Google Scholar]
- 16.Xing F., Yang L. Robust nucleus/cell detection and segmentation in digital pathology and microscopy images: a comprehensive review. IEEE Rev. Biomed. Eng. 2016;9:234–263. doi: 10.1109/RBME.2016.2515127. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Ram S., Tang W., Bell A.J., Spenser C., Buschhuas A., Hatt C.R., di Magliano M.P., Galban S., Galban C. Proc. AACR Virtual Spl. Conf. Artif. Intell. Diag. and Imag. AACR; 2021. Detection of cancer lesions in histopathological lung images using a sparse PCA network. [Google Scholar]; Clin Cancer Res 2021; 27(5–Suppl): Abstract nr PO–086
- 18.Basavanhally A., Ganesan S., Feldman M., Shih N., Mies C., Tomaszewski J., Madabhushi A. Multi-field-of-view framework for distinguishing tumor grade in ER+ breast cancer from entire histopathology slides. IEEE Trans. Biomed. Eng. 2013;60(8):2089–2099. doi: 10.1109/TBME.2013.2245129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Gorelick L., Veksler O., Gaed M., Gömez J.A., Moussa M., Bauman G., Fenster A., Ward A.D. Prostate histopathology: learning tissue component histograms for cancer detection and classification. IEEE Trans. Med. Imaging. 2013;32(10):1804–1818. doi: 10.1109/TMI.2013.2265334. [DOI] [PubMed] [Google Scholar]
- 20.Tizhoosh H.R. Representing medical images with encoded local projections. IEEE Trans. Biomed. Eng. 2018;65(10):2267–2277. doi: 10.1109/TBME.2018.2791567. [DOI] [PubMed] [Google Scholar]
- 21.Reis S., Gazinska P., Hipwell J.H., Mertzanidou T., Naidoo K., Williams N., Pinder S., Hawkes D.J. Automated classification of breast cancer stroma maturity from histological images. IEEE Trans. Biomed. Eng. 2017;64(10):2344–2352. doi: 10.1109/TBME.2017.2665602. [DOI] [PubMed] [Google Scholar]
- 22.Wan S., Lee H.-C., Huang X., Xu T., Xu T., Zeng X., Zhang Z., Sheikine Y., Connolly J.L., Fujimoto J.G., Zhou C. Integrated local binary pattern texture features for classification of breast tissue imaged by optical coherence microscopy. Med. Imaging Anal. 2017;38:104–116. doi: 10.1016/j.media.2017.03.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Simon O., Yacoub R., Jain S., Tomaszewski J.E., Sarder P. Multi-radial LBP features as a tool for rapid glomerular detection and assessment in whole slide histopathology images. Sci. Rep. 2018;8(1):1–11. doi: 10.1038/s41598-018-20453-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Kong H., Gurcan M., Belkacem-Boussaid K. Partitioning histopathological images: an integrated framework for supervised color-texture segmentation and cell splitting. IEEE Trans. Med. Imaging. 2011;30(9):1661–1677. doi: 10.1109/TMI.2011.2141674. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Alinsaif S., Jochen L. Partitioning histopathological images: an integrated framework for supervised color-texture segmentation and cell splitting. BMC Med. Inform. Decis. Mak. 2020;20(14):1–19. [Google Scholar]
- 26.Tosun A.B., Gunduz-Demir C. Graph run-length matrices for histopathological image segmentation. IEEE Trans. Med. Imaging. 2011;30(3):721–732. doi: 10.1109/TMI.2010.2094200. [DOI] [PubMed] [Google Scholar]
- 27.Ozdemir E., Gunduz-Demir C. A hybrid classification model for digital pathology using structural and statistical pattern recognition. IEEE Trans. Med. Imaging. 2013;32(2):474–483. doi: 10.1109/TMI.2012.2230186. [DOI] [PubMed] [Google Scholar]
- 28.Bejnordi B.E., Balkenhol M., Litjens G., Holland R., Bult P., Karssemeijer N., van der Laak J.A.W.M. Automated detection of DCIS in whole-slide H&E stained breast histopathology images. IEEE Trans. Med. Imaging. 2016;35(9):2141–2150. doi: 10.1109/TMI.2016.2550620. [DOI] [PubMed] [Google Scholar]
- 29.Javed S., Mahmood A., Werghi N., Benes K., Rajpoot N. Multiplex cellular communities in multi-gigapixel colorectal cancer histology images for tissue phenotyping. IEEE Trans. Image Process. 2020;29:9204–9219. doi: 10.1109/TIP.2020.3023795. [DOI] [PubMed] [Google Scholar]
- 30.Shi J., Wu J., Li Y., Zhang Q., Ying S. Histopathological image classification with color pattern random binary hashing-based PCANet and matrix-form classifier. IEEE J. Biomed. Health Inform. 2017;21(5):1327–1337. doi: 10.1109/JBHI.2016.2602823. [DOI] [PubMed] [Google Scholar]
- 31.Wright J., Yang A.Y., Ganesh A., Sastry S.S., Ma Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009;31(2):210–227. doi: 10.1109/TPAMI.2008.79. [DOI] [PubMed] [Google Scholar]
- 32.Srinivas U., Mousavi H.S., Monga V., Hattel A., Jayarao B. Simultaneous sparsity model for histopathological image representation and classification. IEEE Trans. Med. Imaging. 2014;33(5):1163–1179. doi: 10.1109/TMI.2014.2306173. [DOI] [PubMed] [Google Scholar]
- 33.Vu T.H., Mousavi H.S., Monga V., Rao G., Rao U.K.A. Histopathological image classification using discriminative feature-oriented dictionary learning. IEEE Trans. Med. Imaging. 2016;35(3):738–751. doi: 10.1109/TMI.2015.2493530. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Sarkar R., Acton S.T. SDL: saliency-based dictionary learning framework for image similarity. IEEE Trans. Image Process. 2018;27(2):749–763. doi: 10.1109/TIP.2017.2763829. [DOI] [PubMed] [Google Scholar]
- 35.Li X., Monga V., Rao U.K.A. Analysis-synthesis learning with shared features: algorithms for histology image classification. IEEE Trans. Biomed. Eng. 2020;67(4):1061–1073. doi: 10.1109/TBME.2019.2928997. [DOI] [PubMed] [Google Scholar]
- 36.Hou L., Samaras D., Kurc T.M., Gao Y., Davis J.E., Saltz J.H. 2016 IEEE Conf. Computer Vis. Pattern Recognit. (CVPR) IEEE; 2016. Patch-based convolutional neural network for whole slide tissue image classification; pp. 2424–2433. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Xu Y., Jia Z., Wang L.-B., Ai Y., Zhang F., Lai M., Chang E.I.-C. Large scale tissue histopathology image classification, segmentation, and visualization via deep convolutional activation features. BMC Bioinform. 2017;18(1):1–17. doi: 10.1186/s12859-017-1685-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Tellez D., Balkenhol M., Otte-Holler I., van de Loo R., Vogels R., Bult P., Wauters C., Vreuls W., Mol S., Karssemeijer N., Litjens G., van der Laak J., Ciompi F. Whole-slide mitosis detection in H&E breast histology using PHH3 as a reference to train distilled stain-invariant convolutional networks. IEEE Trans. Med. Imaging. 2018;37(9):2126–2136. doi: 10.1109/TMI.2018.2820199. [DOI] [PubMed] [Google Scholar]
- 39.Xing F., Cornish T.C., Bennett T., Ghosh D., Yang L. Pixel-to-pixel learning with weak supervision for single-stage nucleus recognition in KI67 images. IEEE Trans. Biomed. Eng. 2019;66(11):3088–3097. doi: 10.1109/TBME.2019.2900378. [DOI] [PubMed] [Google Scholar]
- 40.Campanella G., Hanna M.G., Geneslaw L., Miraflor A., Silva V.W.K., Busam K.J., Brogi E., Reuter V.E., Klimstra D.S., Fuchs T.J. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nat. Med. 2019;25(8):1301–1309. doi: 10.1038/s41591-019-0508-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Wei J.W., Tafe L.J., Linnik Y.A., Vaickus L.J., Tomita N., Hassanpour S. Pathologist-level classification of histologic patterns on resected lung adenocarcinoma slides with deep neural networks. Sci. Rep. 2019;9(1):1–8. doi: 10.1038/s41598-019-40041-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Valkonen M., Isola J., Ylinen O., Muhonen V., Saxlin A., Tolonen T., Nykter M., Ruusuvuori P. Cytokeratin-supervised deep learning for automatic recognition of epithelial cells in breast cancers stained for ER, PR, and ki-67. IEEE Trans. Med. Imaging. 2020;39(2):534–542. doi: 10.1109/TMI.2019.2933656. [DOI] [PubMed] [Google Scholar]
- 43.Goodfellow I., Bengio Y., Courville A. MIT Press; 2016. Deep Learning. [Google Scholar]; http://www.deeplearningbook.org
- 44.Chan T.-H., Jia K., Gao S., Lu J., Zeng Z., Ma Y. PCANet: a simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015;24(12):5017–5032. doi: 10.1109/TIP.2015.2475625. [DOI] [PubMed] [Google Scholar]
- 45.Bruna J., Mallat S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013;35(8):1872–1886. doi: 10.1109/TPAMI.2012.230. [DOI] [PubMed] [Google Scholar]
- 46.Dutta K., Bhattacharjee D., Nasipuri M. SpPCANet: a simple deep learning-based feature extraction approach for 3D face recognition. Multimed. Tools Appl. 2020;79(41):31329–31352. [Google Scholar]
- 47.Malladi S.R.S.P., Ram S., Rodriguez J.J. Image denoising using superpixel-based PCA. IEEE Trans. Multimed. 2020;23:2297–2309. [Google Scholar]
- 48.Zou H., Hastie T., Tibshirani R. Sparse principal component analysis. J. Comput. Graph. Stat. 2006;15(2):265–286. [Google Scholar]
- 49.Chung F.R. vol. 92. American Mathematical Soc.; 1997. Spectral Graph Theory. [Google Scholar]
- 50.Cortes C., Vapnik V. Support vector networks. Mach. Learn. 1995;20(3):273–297. [Google Scholar]
- 51.Xu Y., Zhu J.-Y., Chang E.I.-C., Lai M., Tu Z. Weakly supervised histopathology cancer image segmentation and classification. Med. Imaging Anal. 2014;18(3):591–604. doi: 10.1016/j.media.2014.01.010. [DOI] [PubMed] [Google Scholar]
- 52.Hogg R.V., Ledolter J. Macmillan Publishing Company; 1987. Engineering Statistics. [Google Scholar]
- 53.Zhu X., Zhang L., Huang Z. A sparse embedding and least variance encoding approach to hashing. IEEE Trans. Image Process. 2014;23(9):3737–3750. doi: 10.1109/TIP.2014.2332764. [DOI] [PubMed] [Google Scholar]
- 54.Zhu X., Li X., Zhang S., Ju C., Wu X. Robust joint graph sparse coding for unsupervised spectral feature selection. IEEE Trans. Neural Netw. 2017;28(6):1263–1275. doi: 10.1109/TNNLS.2016.2521602. [DOI] [PubMed] [Google Scholar]
- 55.Caliński T., Harabasz J. A dendrite method for cluster analysis. Commun. Stat. 1974;3(1):1–27. [Google Scholar]
- 56.Davies D.L., Bouldin D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979;PAMI-1(2):224–227. [PubMed] [Google Scholar]