

Abstract
In pathological studies, subjective assays, especially companion diagnostic tests, can dramatically affect treatment of cancer. Binary diagnostic test results (ie, positive vs negative) may vary between pathologists or observers who read the tumor slides. Some tests have clearly defined criteria resulting in highly concordant outcomes, even with minimal training. Other tests are more challenging. Observers may achieve poor concordance even with training. While there are many statistically rigorous methods for measuring concordance between observers, we are unaware of a method that can identify how many observers are needed to determine whether a test can reach an acceptable concordance, if at all. Here we introduce a statistical approach to the assessment of test performance when the test is read by multiple observers, as would occur in the real world. By plotting the number of observers against the estimated overall agreement proportion, we can obtain a curve that plateaus to the average observer concordance. Diagnostic tests that are well-defined and easily judged show high concordance and plateau with few interobserver comparisons. More challenging tests do not plateau until many interobserver comparisons are made, and typically reach a lower plateau or even 0. We further propose a statistical test of whether the overall agreement proportion will drop to 0 with a large number of pathologists. The proposed analytical framework can be used to evaluate the difficulty in the interpretation of pathological test criteria and platforms, and to determine how pathology-based subjective tests will perform in the real world. The method could also be used outside of pathology, where concordance of a diagnosis or decision point relies on the subjective application of multiple criteria. We apply this method in two recent PD-L1 studies to test whether the curve of overall agreement proportion will converge to 0 and determine the minimal sufficient number of observers required to estimate the concordance plateau of their reads.
Keywords: Binomial distribution, concordance, inflated binomial distribution, overall agreement proportion, pathological tests
1 |. INTRODUCTION
Therapeutic decisions made in medicine are commonly aided by review and consideration of test results of biomarkers. Due to the importance of accurate results, multiple pathologists can be required to read laboratory results to ensure the validity. While many of these pathology tests are delivered as continuous values, anatomic pathology tests often are provided as categorical findings of “positive” or “negative.” This categorization of findings demonstrates varying levels of subjectivity, relying on the pathologist’s opinion to establish an overall interpretation. Subjectivity in pathology can occur in categorizing tumor subtypes and assigning grades to malignant neoplasms, but often involves the interpretation or quantification of immunohistochemical staining. While most of the stains used in pathology are interpreted simply as the presence or absence of chromogen staining, some, particularly those that guide the selection of therapeutic drugs, require semiquantitative assessment of the extent (eg, on a scale from 0 to 5), and pattern of staining as the percentage of cells at each intensity. If a test requires the human eye for quantitative assessment, some level of interobserver variability is typically present depending on the subtly of the categorical differences.1–4
The best tests to optimize patient management would be objective and accurate, with high sensitivity and specificity. Ideally these pathology tests should have high levels of inter and intraobserver concordances ensuring that patients receive equal treatment irrespective of the interpreting observer, and the concordant values should be associated with clinical outcomes. In the real world, however, tests are subjective and thus a “gold” standard is unavailable. Tests may show low concordance levels, making the interpretation hard to reproduce.5 As an example, the SP142 assay used for the IMpassion 130 trial6 showed significant association between the Programmed death-ligand 1 (PD-L1) expression and disease outcomes, but a similar test in lung cancer showed low or poor reproducibility.7,8 Reisenbichler et al5 collected cases to determine the reproducibility of the assay in a real world-type pathology practice, where multiple observers/pathologists examine SP263 and SP142 assays for triple negative breast cancer (TNBC). The level of concordance in this test was progressively worse, with the test interpretation dropping to below 50% when there were ten or more observers.
Specifically, Figure 1 illustrates the proportions of positive evaluation (on the y-axis) among the pathologists from two studies about the PD-L1 expression in breast cancer and lung cancer, where the x-axis is the number of tumor sample cases ranging from small to large proportion. A proportion of “0” (or “1”) of a case indicates that the case is interpreted negative (or positive) by all pathologists in the study, whereas a proportion between 0 and 1 indicates some level of discordance among the pathologists. Panel (A) is a bar chart of the SP263 assay reads of the PD-L1 evaluation for stromal cells in patients with TNBC,5 labeled as “SP263 TNBC,” where the cut-off value for being positive was 1%, and 76 cases were evaluated by 18 pathologists. More than 50% of the 76 cases had discordant reads. Panel (B) is a bar chart of the 22c3 assay reads of tumor cells in a study for PD-L1 expression in non-small cell lung cancer (NSCLC) from,7 labeled “22c3 tumor NSCLC,” where the cut-off value for being positive was 50%, and 90 cases were evaluated by 13 pathologists. Among the 90 cases, 20 (or 22%) had discordant reads. The concordance in Figure 1B looks higher than that in Figure 1A. With two or three pathologists reaching an agreement for a case in Figure 1A, it is quite possible that additional pathologists will view the case differently. Intuitively, this possibility would be lower for cases in Figure 1B.
FIGURE 1.
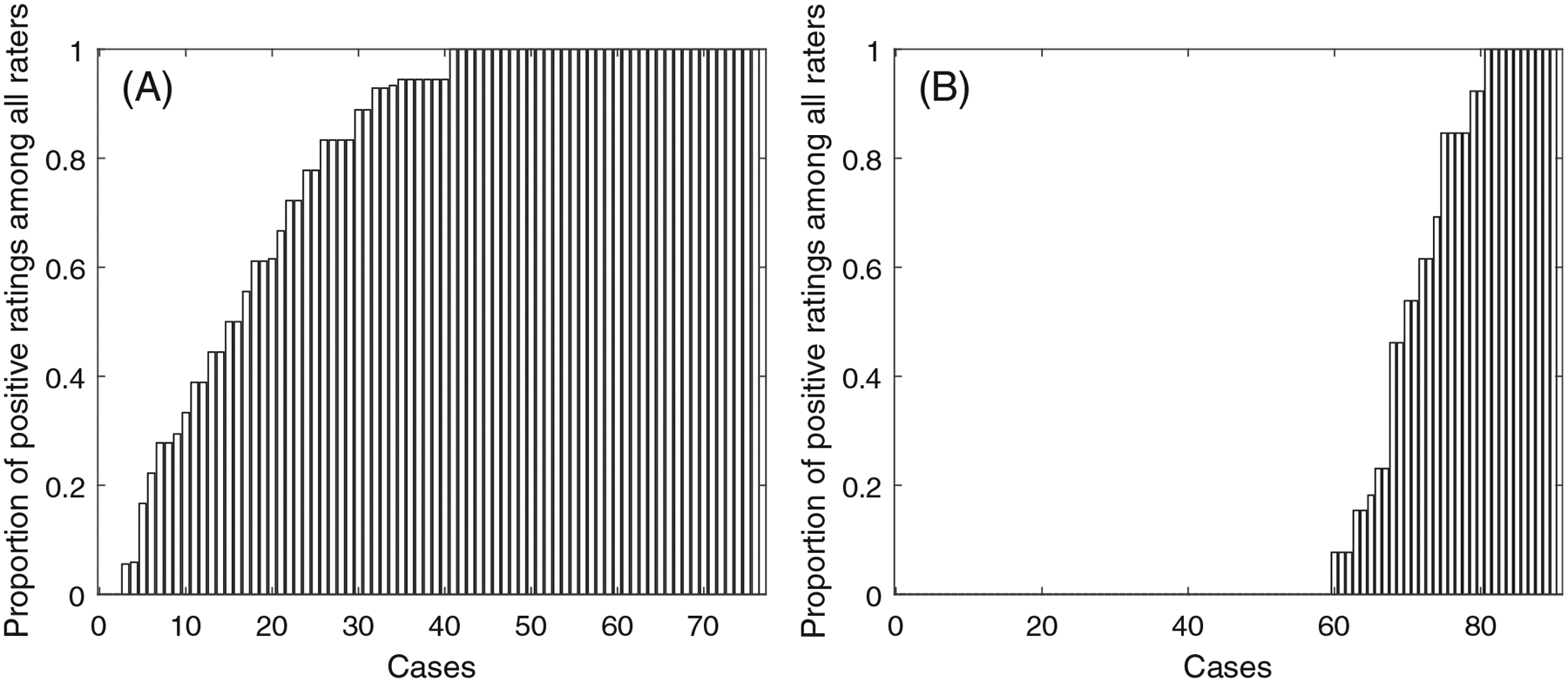
Bar charts of the PD-L1 expression agreement percentage of (A) SP263 TNBC data set, and (B) 22c3 tumor NSCLC data set
In reality, the utilization of a pathology test may eventually result in thousands of different observers worldwide interpreting the given test. For an essay in Figure 1 to read the PD-L1 expression, no statistical test has been developed to evaluate if the overall agreement will eventually drop to 0 when the number of pathologists continue to increase. If the agreement proportion will plateau to a positive number, analysis of concordance of an assay should reflect the sufficient number of observers that will be performing the interpretations. This number may be hard to estimate because pathologists could take pride in their observational skills and two or three pathologists can often reach an agreement. Once the scoring methods for a test are determined, there needs to be a determination of how the test will perform with more (eg, tens or hundreds of) observers. In this article, we propose and describe a novel statistical method that we have called the observers needed for evaluation of subjective tests (ONEST) method. This method tests if a nonzero overall agreement can be reached at any large number of observers, and identifies the number of observers needed to reach a stable estimate of the concordance in their pathological reads. This method could be utilized by test creators and regulatory agencies to evaluate the concordance of a newly proposed subjective laboratory test at different numbers of pathologists, which can ensure that the test will perform reproducibly in real-world settings.
The rest of this article is laid out in the following sections: In Section 2, we review existing methods for quantifying multiple observers’ agreement. The proposed exploratory analysis, statistical model, statistical test, and inference procedure are introduced in Section 3. In Section 4, we demonstrate the ONEST analysis of two data sets in Figure 1. Discussion and concluding remarks are giving in Section 5.
In our discussion, the term “observers” is referred to as pathologists, readers, or raters reading the tissue samples, and the term “cases” is referred to as tissue samples. The binary reads can be saved in a data matrix, where each row corresponds to one case and each column corresponds to one observer. We use the term “overall agreement proportion” (or “agreement proportion”) to quantify the concordance among all the observers in the proposed method. The term “concordance” or “total concordance” in our discussion implies multiple observers all agree on a case being rated positive or negative in the binary rating.
2 |. EXISTING METHODS
Several methods for quantifying multiple observers’ concordance or agreement can be found from the statistical literature. The most commonly used measures for categorical and continuous data are the weighted Cohen’s kappa statistic,9 and the intra-class correlation (ICC),10 respectively. They each have extensions based on the data type. For example, Fleiss’ Kappa11 is suitable for data of three or more observers with ordinal/nominal scale. Kendall’s W statistic relies on nonparametric method for ranks, and can include multiple observers with either continuous or ordinal data.12,13 Lin’s CCC can quantify agreement between pairs of continuous data given a gold standard.14–18 Lin et al19 proposed a unified approach to quantifying concordance for different data types with two or more observers. In addition to the above methods, measurements of agreement from two observers were defined in the U.S. Food and Drug Administration (FDA)-approved companion test to determine patient eligibility for atezolizumab therapy.20,21 In Appendix A we provide greater details about these measurements including positive percent agreement, negative percent agreement, average positive agreement, average negative agreement, and overall percent agreement.
To our knowledge, none of the existing methods can test if overall agreement will converge to 0 if the number of observers converges to infinity. And none of the existing methods has been used to define the minimum sufficient number of observers needed to mimic real-world test performance. Although the aforementioned methods are appropriate to use, determining the concordance from subjective reads, as has been the case for PD-L1 assays, is challenging for at least three reasons. One is that some of the existing methods are limited to two observers where a “consensus” is common, but the concordance for more than two observers is important in the practical use of an assay where hundreds or thousands of observers will perform the assays and determine the test outcome for patient care. Another challenge is that the interpretations of different methods could differ. For example, Fleiss’ kappa may return low values compared with ICC even when agreement is high. Among the FDA criteria, an overall measurement of the positive percent agreement can be hard to define, especially since test positive is not the same as outcome positive. Last but not least, a gold standard is commonly unavailable. In the subjective assessment of tissue, such as in immunohistochemistry (IHC) assays, experts often fail to predict the correct outcome, showing the expert opinion should not be used as a gold standard.
3 |. THE PROPOSED METHOD
Subjective assessment can be highly variable and hard to train, depending on the subtilty of the scoring criteria and the number of categories in the scoring system. Since IHC can only have expert opinion, but not a physical standard, a greater number of observers will lead to more discordance between observations. Thus a plot of identical reads percentage (the overall agreement proportion) against the number of observers should start high, dip down, and then plateau at a point that is indicative of the difficulty of reproducibility of the assay. Since reproducibility is critical for pathology IHC assays, we propose a method to quantify the concordance for any number of observers from which we can estimate the minimum sufficient number of pathologists for the curve to reach a plateau. The plateau value of overall agreement proportion reflects the reproducibility of the test in real world settings. Named “ONEST” for the number of Observers Needed for Evaluation of Subjective Tests, this method is has two major components. The first is the exploratory analysis. We can visualize the agreement at different numbers of observers, and quantify an empirical confidence interval of the agreement at any fixed number of observers. Details of the exploratory analysis are given in Section 3.1. The second component is to develop a statistical model about the overall agreement proportion at different numbers of observers (details in Section 3.2). The statistical model will lead to the discussion in Sections 3.3 and 3.4 about 1) testing whether the proportion will converge to 0 with a large number of observers, and 2) estimating the minimum sufficient number of raters so that the agreement will remain in a small, negligible margin such as 0.1% with high probability (eg, ≥ 95%) after including additional raters.5
3.1 |. Exploratory analysis
The original pathological rating could be a percentage of positive tumor cells, where the positive status is defined as the signal intensity above a detection threshold, for example, greater or equal to 1% in the NSCLC data.7 We calculate the overall agreement proportion at any number of the observers as the proportion of cases having identical reads from all the observers. This agreement proportion estimate at different numbers of observers reflects the heterogeneity from the observers. For example, with 20 observers there are possibly 190 (20 choose 2) and 184 000 (20 choose 10) different estimates of the agreement proportions for 2 and 10 observers, respectively. We choose a sufficiently large number of random permutations to gauge the uncertainty in the overall agreement proportion estimates, and make a plot to visualize the estimate. Specifically, let denote the number of cases and the number of observers. There are a total of ! (ie, factorial) permutations of the observers, which can be millions (if ) or billions (if ), making inclusion of all permutations computationally difficult. So we randomly sample (for example, 100 to 1000) permutations of the observers. For each permutation, we compute the agreement proportions for observers. For example, with 3 pathologists the agreement proportion is the proportion of cases having 3 identical reads among all n cases. We plot the percentage against the number of observers to show a trajectory from 2 to raters for each permutation. By repeating this process for each of the randomly selected permutations, the plot of multiple trajectories can illustrate a plateau as shown in Figures 2A and 3A.
FIGURE 2.
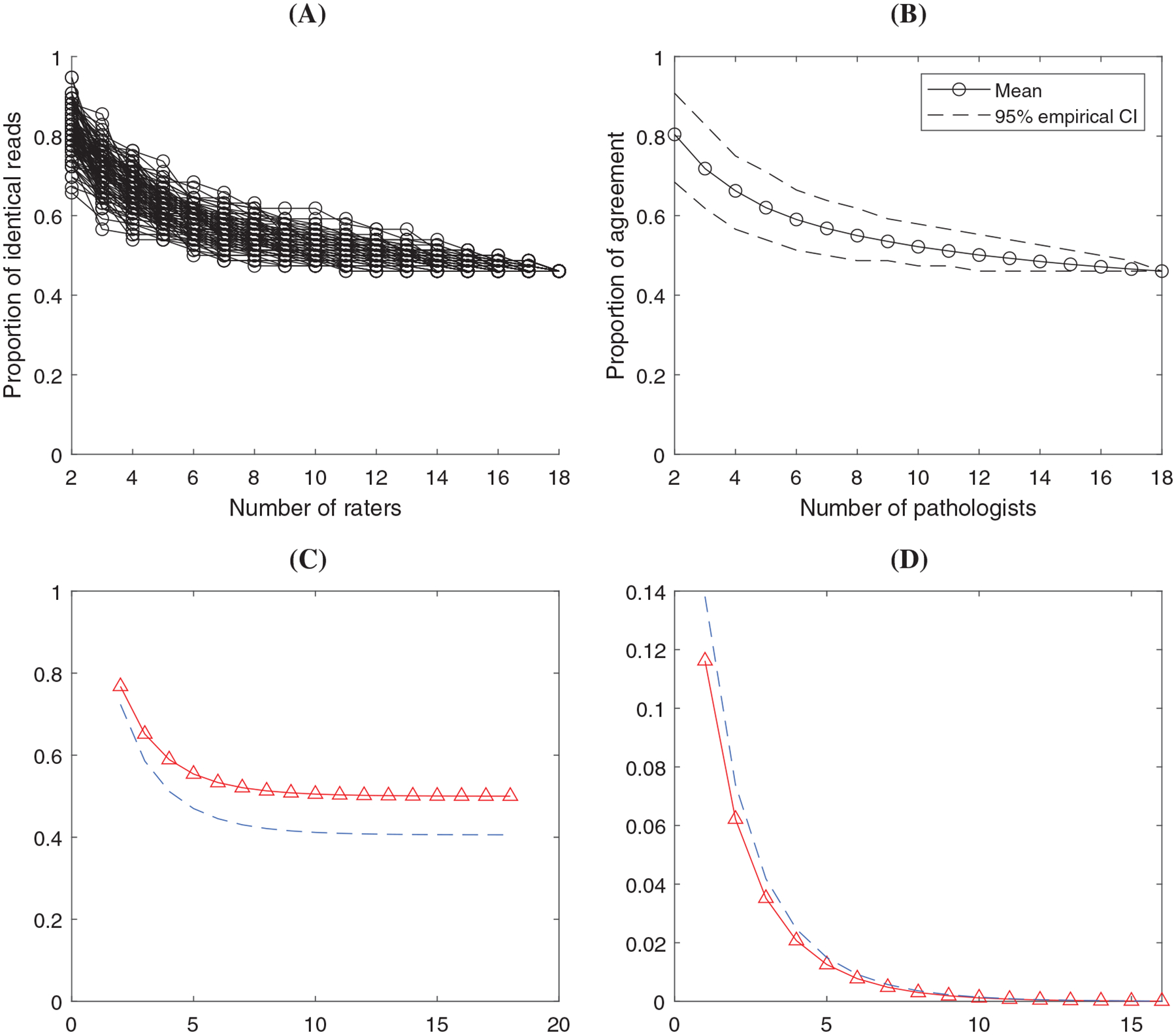
Results in the analysis of SP263 TNBC data set. (A) ONEST plot from 100 random permutations of the raters; (B) ONEST empirical estimate of the mean and 95% CI using the 100 permutations; (C) ONEST inference about agreement percentage (solid curve with triangles) and the 95% lower bound (dashed curve) at different number of raters; (D) ONEST inference about the change of percentage agreement (solid curve with triangles) with 95% upper bound (dashed curve)
FIGURE 3.
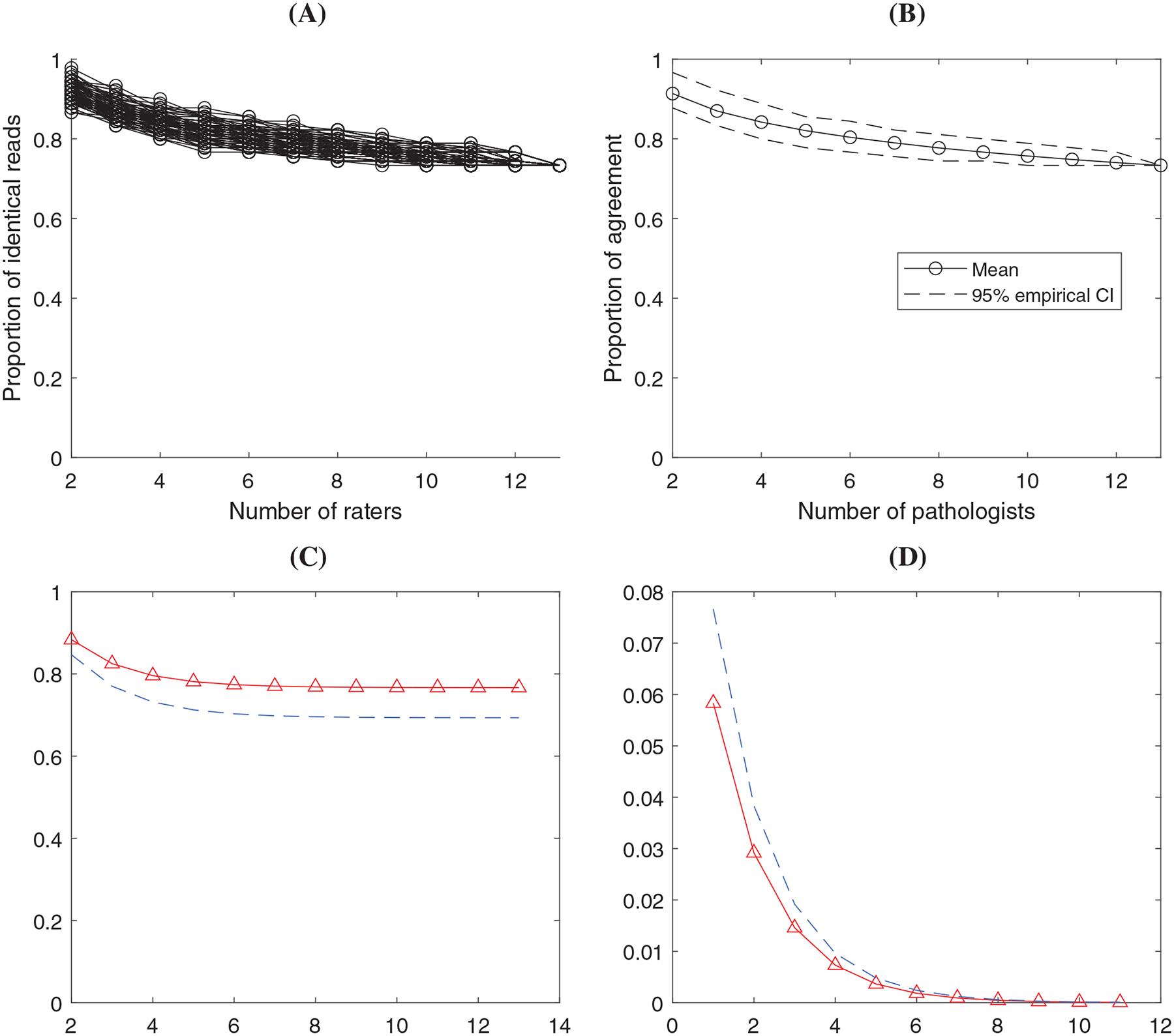
Results in the analysis of 22c3 tumor NSCLC data set. (A) ONEST plot from 100 random permutations of the raters; (B) ONEST empirical estimate of the mean and 95% CI using the 100 permutations; (C) ONEST inference about agreement percentage (solid curve with triangles) and the 95% lower bound (dashed curve) at different number of raters; (D) ONEST inference about the change of percentage agreement (solid curve with triangles) with 95% upper bound (dashed curve)
Furthermore, we can empirically estimate the overall trend and confidence interval (CI) of the agreement proportion, and plot a confidence band of the agreement for different numbers of raters. At a certain number of observers, the empirical point estimate of the agreement proportion can be the average of all the percentages from the randomly selected permutations. We calculate the 2.5th and 97.5th percentiles from the randomly selected permutations as an empirical 95% CI of the agreement proportion. By plotting the estimates and the 2.5th and 97.5th percentiles of agreement proportions from 2 to k observers, we can visualize an empirical trend estimate and a 95% confidence band as illustrated in Figures 2B and 3B.
3.2 |. The proposed statistical model
We develop a statistical model to describe the probabilities that a case will be rated positive by 0 to observers. This model can be used to estimate agreement proportion and the associated uncertainty with any number of observers. We let denote the proportion of identical reads among a set of raters for . The value of decreases as , the number of raters, increases. The estimate of will be more accurate if the number of cases (ie, sample size) increases. We assume (1) each observer independently provides positive or negative assessments, and (2) a certain proportion of the cases will always be read positive and a proportion will be read negative for any number of observers. Among the proportion of cases that could be rated either positive or negative, each case has the probability of being rated positive for any observer. The proportion of consistent reads among observers can be written as
| (1) |
We let denote the number of positive reads for case , where . So are identically and independently distributed (i.i.d.) observations taking values in with the probabilities
| (2) |
where is the probability mass function (pmf) of binomial distribution
This distribution in (2) is named inflated binomial in that the probabilities of being 0 and are inflated by and respectively. The inflated binomial distribution in (2) is an extension of the mixture distribution proposed in Reference 22, which had but not .
We next define the minimal sufficient number of observers needed to reach a stable estimate of . We let “ “ denote the minimal sufficient number defined to be the minimum integer value of to meet the criteria
| (3) |
with a prespecified confidence level or probability, for example, 95%. Here is a threshold of the change in the agreement proportion due to including one additional rater, and is defined based on the clinical considerations. For example, if a change of less than 1% in the proportion of consistent reads is negligible in clinical practice, then can be set to 1%. If the condition (3) is met, adding one more observer will not change the clinical interpretation of the agreement proportion.
3.3 |. Testing if the agreement proportion will converge to 0 with an increasing number of observers
Let , the null and alternative hypotheses are
| (4) |
Similar to the score test used in the zero-inflated Poisson distribution,23 at the score test statistics can be derived as
| (5) |
where is the first order derivative of the log-likelihood function (in the order of , and ), and is the corresponding Fisher information matrix with and . We let denote the maximum likelihood estimate (MLE) of given .
Specifically,
where and are the observed numbers of cases having all positive and negative reads from the observers, respectively. Details about the derivations of the test statistic are given in Appendix B.
3.4 |. Estimation of the model parameters
Estimation of the model parameters , and is based on the joint likelihood function from the model (2). The data is for . The likelihood function can be written as
| (6) |
where denote the number of cases having positive reads from the observers for . So .22 proposed using Newton iteration to estimate the parameters in their mixture model, which essentially is the model in (2) with . The estimation of in (2) can also be based on Newton iteration. The inverse matrix of the negative second partial derivatives evaluated at the MLEs is an estimate of the asymptotic covariance matrix of the parameter estimates.
The above calculation of the first and second order derivatives is computationally heavy and may not be easily carried out in practice. We next derive a reasonable approximation. First of all, after taking the first order derivatives of the following equation can hold
| (7) |
If is sufficiently large or is close to 0.5, then . Second, under the condition that is sufficiently large, it is also asymptotically true that . So and . Given the values of and , maximizing the log likelihood in (6) is asymptotically equivalent to maximizing
By setting the first order derivative to 0, the estimate , which is the proportion of being positive among the cases.
We can estimate by plugging in the estimates of in Equation (1). To determine the minimal sufficient number of raters, we define the objective function as
| (8) |
Using 95% as the probability threshold, the smallest integer “” satisfying with probability 95% is the minimal sufficient number. The variation of the estimate of the objective function depends on: 1) the variation from the estimate of “,” and (2) the variation from the estimate of “.” For (1), the estimate of can be viewed as the binomial mean with the sample size being the product of and , which can be relatively large making the estimate of “” stable. For 2), the approximated estimation of is . Based on the central limit theorem, the asymptotic 95% lower bound of is
By plugging in this lower bound of in (8), we can compute the upper bound of with 95% confidence level. According to Section 3.2, the minimum sufficient number is the smallest number to meet the criteria in (3), for example, the 95% upper bound of is less than .
Last but not least, in Appendix C we show that for and the aforementioned approximated estimation is reasonable. We also verify that the proposed estimation is able to account for the cluster effect of cases using the framework of Reference 24.
4 |. RESULTS
Here we illustrate the analysis using two data sets shown in Figure 1. Figures 2 and 3 illustrate four types of plots from the ONEST analysis regarding the two data sets. In both Figure 2 and 3, panel (A) depicts the plot of empirical agreement percentage from 2 to raters based on 100 random permutations. Panel (B) shows the average (mean) percentage agreement and the empirical 95% confidence band based on the data in (A). Panel (C) is a plot of the estimated agreement percentage trajectory with the 95% lower bound from the ONEST statistical inference. Corresponding to panel (C), panel (D) shows the estimated change of agreement percentage (when including one more rater) and its 95% upper bound. In addition to the figures, we list the estimated model parameters “” with the numbers of cases and observers in Table 1. Table 2 shows the estimated agreement proportion and the 95% lower bound by the number of observers from the statistical inference. We can use the change of the values in this table to determine the sufficient number of observers.
TABLE 1.
Estimated ONEST model parameters in the two real examples
| SP263 TNBC | 22c3 tumor NSCLC | |
|---|---|---|
| 76 | 90 | |
| 18 | 13 | |
| 0.633 | 0.495 | |
| 0.474 | 0.111 | |
| 0.026 | 0.656 |
Abbreviations: , number of cases; , number of raters; , estimated proportion of positive reads when raters do not agree; , estimated proportion of cases all raters rate positive; , estimated proportion of cases all raters rate negative.
TABLE 2.
Estimated agreement proportion with [the 95% lower bound] from the ONEST inference
| Number of observers | SP263 TNBC | 22c3 tumor NSCLC |
|---|---|---|
| 2 observers | 0.768 [0.724] | 0.883 [0.847] |
| 3 observers | 0.651 [0.589] | 0.825 [0.770] |
| 4 observers | 0.589 [0.512] | 0.796 [0.732] |
| 5 observers | 0.554 [0.470] | 0.781 [0.713] |
| 6 observers | 0.533 [0.445] | 0.774 [0.703] |
| 7 observers | 0.521 [0.430] | 0.770 [0.698] |
| 8 observers | 0.513 [0.421] | 0.769 [0.696] |
| 9 observers | 0.508 [0.415] | 0.767 [0.694] |
| 10 observers | 0.505 [0.412] | 0.767 [0.694 |
| 11 observers | 0.503 [0.410] | 0.767 [0.694] |
| 12 observers | 0.502 [0.408] | 0.767 [0.694] |
| 13 observers | 0.501 [0.407] | 0.767 [0.693] |
Note: The two columns correspond to the two data sets. Each number of raters (from 2 to 13) is in one row.
-values from the score test in Section 3.3 are less than 0.0001 for both data sets, indicating significant evidence that and are not both 0 and the ONEST plot is unlikely to drop to 0 with any number of observers. The ONEST analysis of data “SP263 TNBC” indicated that 45% and 3% of the cases were unanimously positive and negative, respectively, as shown in Table 1 ( and ). The chance of being evaluated positive for the cases with discordant ratings is about 65% (Table 1, ). Variation in the agreement percentage estimate is shown clearly in the empirical ONEST plots, Figure 2A–B, with a plateau around 0.5 when reaching 8 to 10 observers. This is consistent with results from the ONEST model’s inference in Figure 2C and Table 2. Table 2 also indicated that the lower bound of total agreement will not be less than 38% with 95% probability. Table 2 and Figure 2D can be used to estimate the sufficient number of observers to ensure a stable estimate of the agreement percentage. Assuming that a change of less than 0.5% of the agreement percentage is clinically insignificant, we define the threshold in the change of agreement percentage to be (or 0.5%). Table 2 indicates that if there are 10 observers, adding one additional observer will lead to a change of no more than 0.5% with probability of at least 95%. We conclude that at least 10 observers is sufficient to estimate the agreement percentage at 95% confidence level with a threshold .
Comparing the “SP263 TNBC” data with “22c3 tumor NSCLC” using panels (A to C) in Figure 2 vs Figure 3 and the two columns in Table 2, the agreement proportion of 22c3 assay will converge to 76.7%, about 30% higher than that of SP263. The last column of Table 1 indicates that the higher agreement among the observers was from higher proportion of complete negative reads, that is, . The proportion of complete positive reads was . If we assume the same threshold in the change of agreement proportion to be , Table 2 and Figure 3D indicates that six observers is sufficient to estimate the agreement proportion at the 95% confidence level. As a result, the number of observers required in the 22c3 assay for tumor is 40% lower (ie, 6 vs 10) than the number of observers required in the SP263 assay for stroma to reach a stable estimate of the agreement proportion.
In Supplementary Materials, part one, we presented the analysis of additional SP142 assay in three other PD-L1 expression data sets, including stromal cells from patients with TNBC,5 and tumor and stromal cells of nonsmall cell lung cancer in Reference 7. Using the same threshold as in Figures 2 and 3, we identified that the minimal sufficient numbers for those three SP142 assay data sets ranged from 8 and 9.
5 |. DISCUSSION
The proposed method can be used to evaluate an assay by determining whether the multiple observers are concordant, which could also help evaluate whether the assay is inherently unreliable due to the lack of clear differences between positive and negative conclusions. We determine the number of observers required to evaluate a subjective test by finding the minimal sufficient number of observers after which the inclusion of additional observers will not meaningfully change the clinical interpretation of the agreement proportion. As an extension of the mixture distribution from Farewell et al,22 we develop a new distribution named the inflated binomial distribution to describe the binary reads from observers for cases. We also propose a statistical test to determine if the agreement proportion may converge to 0 for a large number of observers. A small -value from this score test indicates significant evidence that the observers’ agreement will converge to a nonzero proportion. In practice, one can implement this method by running a free software program that we have developed. Details about the access to the software through the GitHub and CRAN websites are given in Appendix D. The software can be applied to data sets with three or more observers. With a less number of observers (five as an example), the curves in Figures 2C and 3C would not reach a plateau.
Future work is necessary to expand the current ONEST method for at least three more complicated scenarios. First, mixed-effects models could be used to accommodate multiple evaluations or repeated measurements. Second, Bayesian methods may incorporate additional prior information to account for observers’ difference or similarity, for example, by imposing a conjugate beta prior on . Third, development is underway to extend the ONEST method for outcomes with more than two levels.
It is worthwhile to note that binary data from multiple observers can also be analyzed using the framework of Lin’s concordance.19 The difference between Lin’s concordance and the ONEST method lies in that the concordance measures in Reference 19 do not decrease with the number of observers, but the agreement proportion estimate from the ONEST method would decrease and reach a plateau. In part two of Supplementary Materials, we demonstrate the Lin’s concordance with the SP142 assay reads of the TNBC cases in Reisenbichler et al,5 as well as the two data sets in Figure 1. The Lin’s concordance coefficients were estimated to be 0.49 and 0.78 for the SP263 TNBC and 22c3 tumor NSCLC data sets, respectively. The higher concordance in the 22c3 tumor NSCLC data is consistent with the estimated agreement percentages in Figures 2 and 3. Incorporating the precision (variability) and accuracy (bias) factors, Lin’s concordance indices can provide an overall measure of the concordance. The ONEST method, on the other hand, can help clinicians understand the agreement proportion at different numbers of the observers. We believe the two methods are both useful and can supplement each other.
Supplementary Material
ACKNOWLEDGEMENTS
This research was partly funded by Bristol-Myers Squibb in collaboration with the National Comprehensive Cancer Network Oncology Research Program (Gang Han, David L.Rimm), the Yale SPORE in Lung Cancer P50 CA196530 (David L.Rimm), and the Yale Cancer Center Support Grant P30 CA016359 (David L.Rimm). The authors thank the reviewer and the associate editor for their valuable and constructive comments, which have significantly improved the research and writing of this article.
Abbreviations:
- PD-L1
Programmed death-ligand 1
- TNBC
Triple-negative breast cancer
- ONEST
Observers needed for evaluation of subjective tests
- ICC
Intra-class correlation
- CCC
Concordance correlation coefficient
- IHC
Immunohistochemistry
- FDA
Food and drug administration
- MLE
Maximum likelihood estimate
- NSCLC
Non-small cell lung cancer
- CI
Confidence interval
APPENDIX A. FDA APPROVED MEASURES OF TWO RATERS AGREEMENT
Based on Table A1, the positive percent agreement (PPA) is defined as . The negative percent agreement (NPA) is . The overall percent agreement (OPA) is . The average positive agreement (APA) is . The average negative agreement (ANA) is . The overall percent agreement (OPA) is . The above definition can make the interpretation of average agreement difficult. For example, we investigate the proportion of positive agreement in two ways. The first is using PPA, which can be defined as if rater A is the reference, or as if B is the reference. By taking the average, we have a measure of the positive agreement . The second way to define positive agreement is . Note that the difference is greater than or equal to 0, where the equal sign holds only if . The two definitions and are both meaningful but they can be different.
TABLE A1.
Percent of agreement of two raters used by FDA
| Observer 1, positive | Observer 1, negative | |
|---|---|---|
| Observer 2, positive | ||
| Observer 2, negative |
APPENDIX B. DERIVING THE SCORE TEST STATISTIC
With , the MLE of is the proportion of positive reads, . Under the null hypothesis (4), the expected value of can be derived as
As a result, and .
Under the null hypothesis in (4) that , the derivation of each element in and , using the likelihood function in (6), is given below
Similarly,
With , the MLE under the null hypothesis in (4), the first order derivative with respect to should be 0,
The Fisher information matrix can be derived as
APPENDIX C. ONEST INFERENCE CAN ACCOUNT FOR THE CLUSTER EFFECT
Given the exact value of can be calculated using Equation (7). The approximation, on the other hand, is . If the approximation and exact estimates of are reasonably close, we can conclude the approximation is reasonable. In Figure C1 we plot the estimates of in two settings. The two panels indicate that for and the approximation and exact estimates are nearly identical.
The sufficient number of observers depend on the proportion of agreement in the data as well as the sample size (the number of cases and the number of pathologists). In practice, reads for the same case could be more similar than for different cases, which is commonly referred to as the cluster effect. Here we discuss the proposed method with the presence of this cluster effect. If we arrange the data in an by matrix , where observation is for case and observer, where . We let indicate the status whether all pathologists read the same for the case. According to the proposed model, the distribution of is , where is the probability that all observers gave the same reading. Conditional on is either a point mass or of a binomial distribution, that is, , and is or with probability 1. By the likelihood principle,25 unconditional on , each follows a binomial distribution, , where . If we can show the estimation of is the same with or without the cluster effect then the proposed model is valid for accounting the cluster effect in the point estimation. For binomial data, a natural estimator “” is the summation of all ones divided by the number of total observations. Define , where is the sum of all ones for the th case. Let . Then can be written as . According to Reference 26, the asymptotic variance can be calculated as
The asymptotic distribution of given cluster effects can be written as
Define the variance inflation rate due to clustering (or the design effect) to be
Then the effective sample size can be estimated using the design effect , and the effective total number of ones can be written as . We can estimate the proportion after account for the design effect as
So is valid given cluster effects. According to Reference 24, we claim the estimation with the current model is valid given cluster effects from cases.
FIGURE C1.
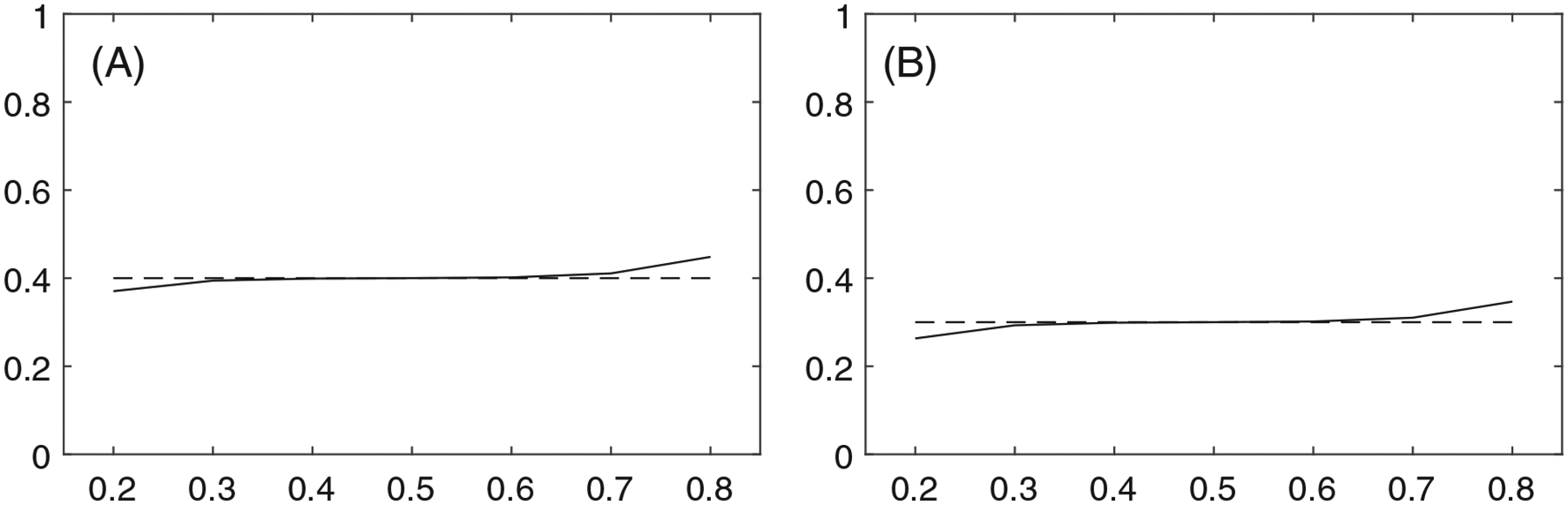
Plots of the value of on the x-axis against the exact (solid line “——”) and approximate (dashed line “– – –”) estimates of on the y-axis for (A): ; (B):
APPENDIX D. ACCESSING THE ONEST SOFTWARE PACKAGE IN R AND GITHUB
This ONEST software can be downloaded from two websites. The first is R library: https://cran.r-project.org/web/packages/ONEST/index.html. It can also be installed directly in R using the code: install.packages (“ONEST”). The second is GitHub: https://github.com/hangangtrue/ONEST. Running this program requires R software. After the installation, the tutorial file (Vignettes) of this software can be obtained by running the code: browseVignettes (“ONEST”), which is also available at https://cran.r-project.org/web/packages/ONEST/vignettes/ONEST.html.
Footnotes
SUPPORTING INFORMATION
Additional supporting information may be found online in the Supporting Information section at the end of this article.
DATA AVAILABILITY STATEMENT
The data that support the findings of this artilce are available from the corresponding author upon reasonable request.
REFERENCES
- 1.Diaz LK, Sahin A, Sneige N. Interobserver agreement for estrogen receptor immunohistochemical analysis in breast cancer: a comparison of manual and computer-assisted scoring methods. Ann Diagn Pathol. 2004;8(1):23–27. [DOI] [PubMed] [Google Scholar]
- 2.Leung SC, Nielsen TO, Zabaglo LA, et al. Analytical validation of a standardised scoring protocol for Ki67 immunohistochemistry on breast cancer excision whole sections: an international multicentre collaboration. Histopathology. 2019;75(2):225–235. [DOI] [PubMed] [Google Scholar]
- 3.Maranta AF, Broder S, Fritzsche C, et al. Do YOU know the Ki-67 index of your breast cancer patients? knowledge of your institution’s Ki-67 index distribution and its robustness is essential for decision-making in early breast cancer. Breast. 2020;51:120–126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Rexhepaj E, Brennan DJ, Holloway P, et al. Novel image analysis approach for quantifying expression of nuclear proteins assessed by immunohistochemistry: application to measurement of Oestrogen and progesterone receptor levels in breast cancer. Breast Cancer Res. 2008;10(5):1–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Reisenbichler ES, Han G, Bellizzi A, et al. Prospective multi-institutional evaluation of pathologist assessment of PD-L1 assays for patient selection in triple negative breast cancer. Mod Pathol. 2020;33(9):1746–1752. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Schmid P, Adams S, Rugo HS, et al. Atezolizumab and nab-paclitaxel in advanced triple-negative breast cancer. N Engl J Med. 2018;379(22):2108–2121. [DOI] [PubMed] [Google Scholar]
- 7.Rimm DL, Han G, Taube JM, et al. A prospective, multi-institutional, pathologist-based assessment of 4 immunohistochemistry assays for PD-L1 expression in non-small cell lung cancer. JAMA Oncol. 2017;3(8):1051–1058. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Tsao MS, Kerr KM, Kockx M, et al. PD-L1 immunohistochemistry comparability study in real-life clinical samples: results of blueprint phase 2 project. J Thorac Oncol. 2018;13(9):1302–1311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Cohen J Weighted kappa: nominal scale agreement provision for scaled disagreement or partial credit. Psychol Bull. 1968;70(4):213. [DOI] [PubMed] [Google Scholar]
- 10.Harris JA. On the calculation of intra-class and inter-class coefficients of correlation from class moments when the number of possible combinations is large. Biometrika. 1913;9(3/4):446–472. [Google Scholar]
- 11.Fleiss JL, Cohen J. The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability. Educ Psychol Meas. 1973;33(3):613–619. [Google Scholar]
- 12.Kendall MG, Smith BB. The problem of m rankings. Ann Math Stat. 1939;10(3):275–287. [Google Scholar]
- 13.Kendall MG. Rank Correlation Methods. London, UK: Griffin; 1948. [Google Scholar]
- 14.Lin LI. A concordance correlation coefficient to evaluate reproducibility. Biometrics. 1989;45(1):255–268. [PubMed] [Google Scholar]
- 15.Lin LI. Assay validation using the concordance correlation coefficient. Biometrics. 1992;48(2):599–604. [Google Scholar]
- 16.Lin LI. A note on the concordance correlation coefficient. Biometrics. 2000;56(1):324–325. [Google Scholar]
- 17.Lin LI, Hedayat A, Sinha B, Yang M. Statistical methods in assessing agreement: models, issues, and tools. J Am Stat Assoc. 2002;97(457):257–270. [Google Scholar]
- 18.Lin LI, Hedayat A, Wu W. Statistical Tools for Measuring Agreement. Berlin, Germany: Springer Science & Business Media; 2012. [Google Scholar]
- 19.Lin L, Hedayat A, Wu W. A unified approach for assessing agreement for continuous and categorical data. J Biopharm Stat. 2007;17(4):629–652. [DOI] [PubMed] [Google Scholar]
- 20.FDA. Summary of Safety and Effectiveness Data (SSED) PMA P160046; 2017. https://www.accessdata.fda.gov/cdrh_docs/pdf16/P160046B.pdf.
- 21.FDA. Summary of safety and effectiveness data (SSED) PMA P160002/S009; 2019. https://www.accessdata.fda.gov/cdrh_docs/pdf16/p160002s009b.pdf.
- 22.Farewell VT, Sprott D. The use of a mixture model in the analysis of count data. Biometrics. 1988;44(4):1191–1194. [PubMed] [Google Scholar]
- 23.van der Broek J A score test for zero inflation in a Poisson distribution. Biometrics. 1995;51(2):738–743. [PubMed] [Google Scholar]
- 24.Rao J, Scott A. A simple method for the analysis of clustered binary data. Biometrics. 1992;48(2):577–585. [PubMed] [Google Scholar]
- 25.Birnbaum A On the foundations of statistical inference. J Am Stat Assoc. 1962;57(298):269–306. [Google Scholar]
- 26.Cochran WG. Sampling Techniques. 3rd ed. Hoboken, NJ: John Wiley & Sons; 1977. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The data that support the findings of this artilce are available from the corresponding author upon reasonable request.