

Abstract
We propose to apply a 2D CNN architecture to 3D MRI image Alzheimer’s disease classification. Training a 3D convolutional neural network (CNN) is time-consuming and computationally expensive. We make use of approximate rank pooling to transform the 3D MRI image volume into a 2D image to use as input to a 2D CNN. We show our proposed CNN model achieves 9.5% better Alzheimer’s disease classification accuracy than the baseline 3D models. We also show that our method allows for efficient training, requiring only 20% of the training time compared to 3D CNN models. The code is available online: https://github.com/UkyVision/alzheimer-project.
Keywords: Dynamic image, 2D CNN, MRI image, Alzheimer’s Disease
1. Introduction
Alzheimer’s disease (AD) is the sixth leading cause of death in the U.S. [1]. It heavily affects the patients’ families and U.S. health care system due to medical payments, social welfare cost, and salary loss. Since AD is irreversible, early stage diagnosis is crucial for helping slow down disease progression. Currently, researchers are using advanced neuroimaging techniques, such as magnetic resonance imaging (MRI), to identify AD. MRI technology produces a 3D image, which has millions of voxels. Figure 1 shows example slices of Cognitive Unimpaired (CU) and Alzheimer’s disease (AD) MRI images.
Fig. 1.
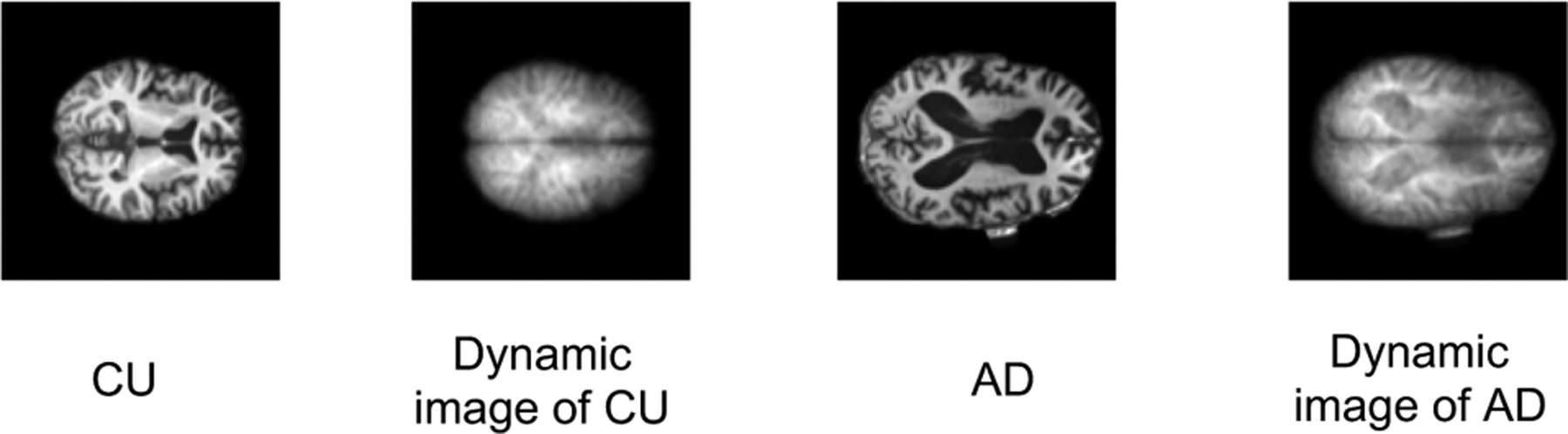
The MRI sample slices of the CU and AD participants and the corresponding dynamic images.
With the promising performance of deep learning in natural image classification, convolutional neural networks (CNNs) show tremendous potential in medical image diagnosis. Due to the volumetric nature of MRI images, the natural deep learning model is a 3D convolutional neural network (3D CNN) [10]. Compared to 2D CNN models, 3D CNN models are more computationally expensive and time consuming to train due to the high dimensionality of the input. Another issue is that most current medical datasets are relatively small. The limited data makes it difficult to train a deep network that generalizes to high accuracy on unseen data. To overcome the problem of limited medical image training data, transfer learning is an attractive approach for feature extraction. However, pre-trained CNN models are mainly trained on 2D image datasets. There are few suitable pre-trained 3D CNN models. In our paper, We propose to apply approximate rank pooling [3] to convert a 3D MRI volume into a 2D image over the height dimension. Thus, we can use a 2D CNN architecture for 3D MRI image classification. The main contributions of our work are following:
We propose to apply a CNN model that transforms the 3D MRI volume image into 2D dynamic image as the input of 2D CNN. Incorporating with an attention mechanism, the proposed model significantly boosts the accuracy of the Alzheimer’s Disease MRI diagnosis.
We analyze the effect of skull MRI images on the approximate rank pooling method, showing that the applied approximate rank pooling method is sensitive to the noise introduced by the skull. Skull striping is necessary before using the dynamic image technology.
2. Related Work
Learning-based Alzheimer’s disease (AD) research can be mainly divided into two branches based on the type of input: (1) manually selected region of interest (ROI) input and (2) whole image input. With ROI models [6] [14], manual region selection is needed to extract the interest region of the original brain image as the input to the CNN model, which is a time consuming task. It is more straightforward and desirable to use the whole image as input. Korolev et al. [11] propose two 3D CNN architectures based on VGGNet and ResNet, which is the first study to prove the manual feature extraction step for Brain MRI image classification is unnecessary. Their 3D models are called 3D-VGG and 3D-ResNet, and are widely used for 3D medical image classification study. Cheng et al. [4] proposes to use multiple 3D CNN models trained on MRI images for AD classification in an ensemble learning strategy. They separate the original MRI 3D images into many patches (n=27), then forward each patch to an independent 3D CNN for feature extraction. Afterward, the extracted features are concatenated for classification. The performance is satisfactory, but the computation cost and training time overhead are very expensive. Yang et al. [18] uses the 3D-CNN models of Korolev et al. [11] as a backbone for studying the explainability of AD classification in MRI images by extending class activation mapping (CAM)[20] and gradient-based CAM[16] on 3D images. In our work, we use the whole brain MRI image as input and use 3D-VGG and 3D-ResNet as our baseline models. Dynamic images where first applied to medical imagery by Liang et al. [13] for breast cancer diagnosis. The authors use the dynamic image method to convert 3D digital breast tomosynthesis images into dynamic images and combined them with 2D mammography images for breast cancer classification. In our work, we propose to combine dynamic images with an attention mechanism for 3D MRI image classification.
3. Approach
We provide a detailed discussion of our method. First, we summarize the high-level network architecture. Second, we provide detailed information about the approximate rank pooling method. Next, we show our classifier structure and attention mechanism. Finally, we discuss the loss function used for training.
3.1. Model Architecture
Figure 2 illustrates the architecture of our model. The 3D MRI image is passed to the approximate rank pooling module to transform the 3D MRI image volume into a 2D dynamic image. We apply transfer learning for feature extraction with the dynamic image as the input. We leveraged a pre-trained CNN as the backbone feature extractor. The feature extraction model is pretrained with the ImageNet dataset [5]. Because we use a lower input resolution than the resolution used for ImageNet training, we use only a portion of the pre-trained CNN. The extracted features are finally sent to a small classifier for diagnosis prediction. The attention mechanism, which is widely used in computer vision community, can boost CNN model performance, so we embed the attention module in our classifier.
Fig. 2.
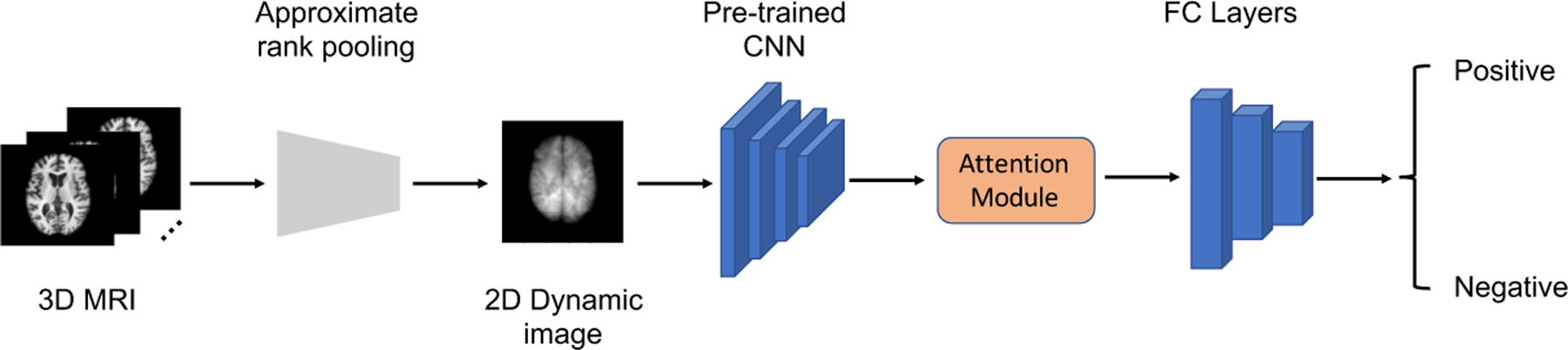
The architecture of our 2D CNN model.
3.2. Dynamic Image
The temporal rank pooling [7] [3] was originally proposed for video action recognition. For a video with T frames , the method compresses the whole video into one frame by temporal rank pooling. The compressed frame is called a dynamic image. The construction of the dynamic image is based on Fernando et al [7]. The authors use a ranking function to represent the video. is a feature representation of the individual frame of the video. is the temporal average of the feature up to time is measured by a ranking score , where is a learned parameter. By accumulating more frames for the average, the later times are associated with larger scores, e.g , which are constraints for the ranking problem. So the whole problem can be formulated as a convex problem using RankSVM:
| (1) |
| (2) |
In Equation (2), the first term is a quadratic regularization used in SVMs, the second term is a hinge-loss counting incorrect rankings for the pairs .
The RankSVM formulation can be used for dynamic image generation, but the operations are computationally expensive. Bilen et al. [3] proposed a fast approximate rank pooling for dynamic images:
| (3) |
where, is the temporal average of frames up to time , and is the coefficient associated to frame . We take this approximate rank pooling strategy in our work for 3D MRI volume to 2D image transformation. In our implementation, the z-dimension of 3D MRI image is equal to temporal dimension of the video.
3.3. Classifier with Attention Mechanism
The classifier is a combination of an attention mechanism module and a basic classifier. Figure 3 depicts the structure of attention mechanism, which includes four 1×1 convolutional layers. The first three activation functions of convolutional layers are ReLU, the last convolutional layer is attached with softmax activation function. The input feature map are passed through the four convolutional layers to calculate attention mask . We apply element-wise multiplication between the attention mask and input feature maps to get the final output feature maps . Our basic classifier contains three fully connected (FC) layers. The output dimensions of the three FC layers are 512, 64, and 2. Dropout layers are used after the first two layers with dropout probability 0.5.
Fig. 3.
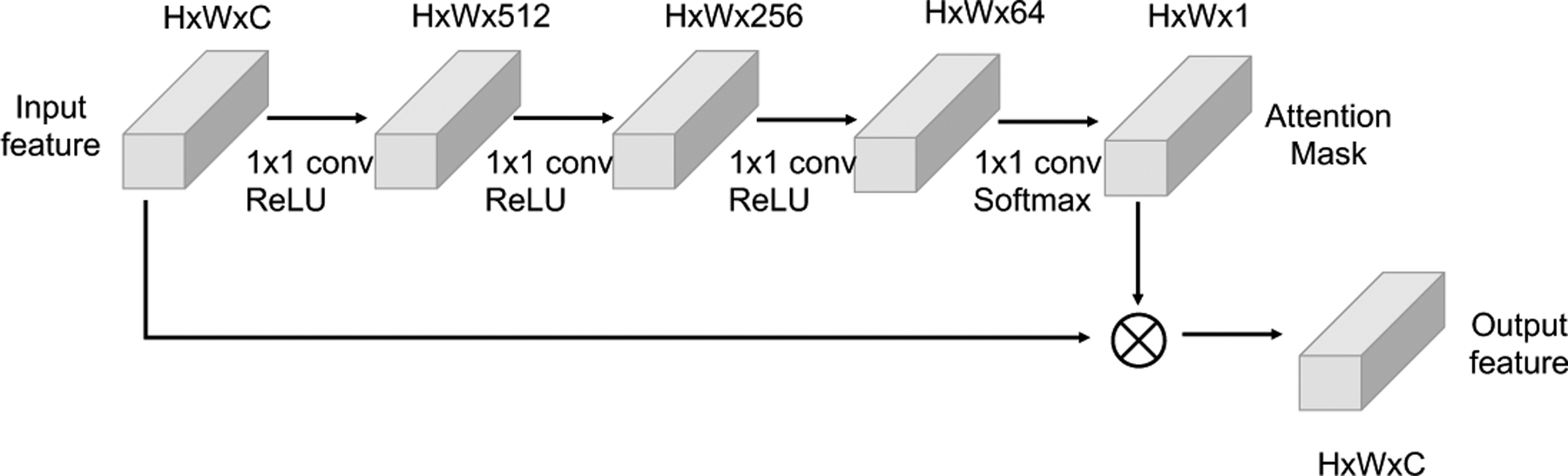
The attention mechanism structure in our CNN model.
3.4. Loss Function
In previous AD classification studies, researchers mainly concentrated on binary classification. In our work, we do the same for ease of comparison. The overall loss function is binary cross-entropy. For a 3D image with label and probability prediction , the loss function is:
| (4) |
where the label indicates a negative sample and indicates a positive sample.
4. Evaluation
We use the publicly available dataset from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) [2] for our work. Specifically, we trained CNNs with the data from the “spatially normalized, masked, and N3-corrected T1 images” category. The brain MRI image size is 110×110×110. Since a subject may have multiple MRI scans in the database, we use the first scan of each subject to avoid data leakage. The total number of data samples is 100, containing 51CU samples and 49 AD samples.
The CNNs are implemented in PyTorch. We use five-fold cross validation to better evaluate model performance. The batch size used for our model is 16. The batch size of the baseline models is 8, which is the maximum batch size of the 3D CNN model trained on the single GTX-1080ti GPU. We use the Adam optimizer with beta and beta . The learning rate is 0.0001. We train for 150 epochs. To evaluate the performance of our model, we use accuracy (Acc), the area under the curve of Receiver Operating Characteristics (ROC), F1 score (F1), Precision, Recall and Average Precision (AP) as our evaluation metrics.
4.1. Quantitative Results
High quality feature extraction is crucial for the final prediction. Different pre-trained CNN models can output different features in terms of size and effective receptive field. We test different pre-trained CNNs to find out which CNN models perform best as our feature extractor. Table 1 shows various CNN models and the corresponding output feature size.
Table 1.
The different pre-trained CNN model as feature extractors and the output feature sizes
Since our dynamic image resolution is 110×110×3, which is much smaller than the ImageNet dataset resolution: 256×256×3, we use only part of the pre-trained CNN as the feature extractor. Directly using the whole pre-trained CNN model as feature extractor will cause the output feature size to be too small, which decreases the classification performance. In the implementation, we get rid of the maxpooling layer of each pre-trained model except for the MobileNet_v2 [15], which contains no maxpooling layer. Also, because there is a domain gap between the natural image and medical image we set the pre-trained CNN models’ parameters trainable, so that we can fine tune the models for better performance.
When analyzing MRI images using computer-aided detectors (CADs), it is common to strip out the skulls from the brain images. Thus, we first test the proposed method using the MRI with the skull stripped. Our proposed model takes dynamic images (Dyn) as input, VGG11 as feature extractor, and a classifier with the attention mechanism: Dyn +VGG11+Att. The whole experiment can be divided into three sections: the backbone and attention section, the baseline model section, and the pooling section. In the backbone and attention section, we use 4 different pre-trained models and test the selected backbone with and without the attention mechanism. Based on the performance shown in Table 2, we choose VGG11 as the backbone model. In the baseline model section, we compare our method with two baselines, namely 3D-VGG and 3D-ResNet. Table 3 shows the performance under different CNN models. The proposed model achieves 9.52% improvement in accuracy and 15.20% better ROC over the 3DResNet. In the pooling section: we construct two baselines by replacing the approximate rank pooling module with the average pooling (Avg.) layer or max pooling (Max.) layer. The pooling layer processes the input 3D image over the z-dimension and outputs the same size as the dynamic image. Comparing with the different 3D-to-2D conversion methods under the same configuration, the dynamic image outperforms the two pooling methods.
Table 2.
The performance results of different backbone models with dynamic image as input
| Model | Acc | ROC | F1 | Precision | Recall | AP |
|---|---|---|---|---|---|---|
| AlexNet | 0.87 | 0.90 | 0.86 | 0.89 | 0.83 | 0.82 |
| ResNet18 | 0.85 | 0.84 | 0.84 | 0.86 | 0.81 | 0.79 |
| MobileNet_v2 | 0.88 | 0.89 | 0.87 | 0.89 | 0.85 | 0.83 |
| VggNet11 | 0.91 | 0.92 | 0.91 | 0.88 | 0.93 | 0.86 |
Table 3.
The performance results of different 2D and 3D CNN models
| Model | Acc | ROC | F1 | Precision | Recall | AP |
|---|---|---|---|---|---|---|
| 3D-VGG [11] | 0.80 | 0.78 | 0.78 | 0.82 | 0.75 | 0.74 |
| 3D-ResNet [11] | 0.84 | 0.82 | 0.82 | 0.86 | 0.79 | 0.78 |
| Max. + VGG11 | 0.80 | 0.77 | 0.80 | 0.78 | 0.81 | 0.73 |
| Avg. + VGG11 | 0.86 | 0.84 | 0.86 | 0.83 | 0.89 | 0.79 |
| Max. + VGG11 + Att | 0.82 | 0.76 | 0.82 | 0.80 | 0.83 | 0.75 |
| Avg. + VGG11 + Att | 0.88 | 0.89 | 0.88 | 0.85 | 0.91 | 0.82 |
| Ours | 0.92 | 0.95 | 0.91 | 0.97 | 0.85 | 0.90 |
4.2. Pre-processing Importance Evaluation
In this section, we show results using the raw MRI image (including skull) as input. We perform experiments on the same patients’ raw brain MRI image with the skull included to test the performance of our model. The raw MRI image category is “MT1,GradWarp,N3m”. The image size of the raw MRI image is 176×256×256 Figure 4 illustrates the dynamic images of different participants’ MRI brain images with the skull. The dynamic images are blurrier than the images under skull striping processing. This is because the skull variance can be treated as noise in the dynamic image. Table 4 shows the significant performance decrease when using 3D Brain MRI images with skull. Figure 4 shows a visual representation of how the dynamic images are affected by including the skull in the image. In this scenario, the model can not sufficiently diagnose the different groups. A potential cause of this decrease in performance is that the approximate rank pooling module is a pre-processing step, and the module is not trainable. We believe an end-to-end, learnable rank pooling module would improve performance.
Fig. 4.
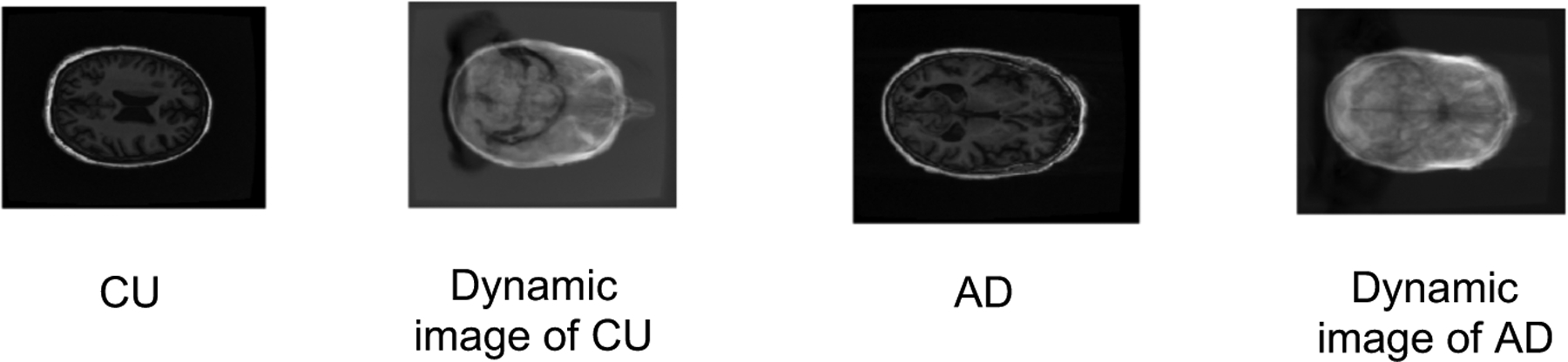
The MRI sample slices with skull of the CU and AD participants and the corresponding dynamic images.
Table 4.
The performance results of different 2D and 3D CNN models on the MRI image with skull.
| Model | Acc | ROC | F1 | Precision | Recall | AP |
|---|---|---|---|---|---|---|
| 3D-VGG [11] | 0.78 | 0.62 | 0.77 | 0.80 | 0.75 | 0.72 |
| Ours | 0.63 | 0.52 | 0.63 | 0.62 | 0.64 | 0.57 |
4.3. Models Training time
Another advantage of the proposed model is faster training. We train all of our CNN models for 150 epochs on the same input dataset. Table 5 shows the total training time of the different 2D and 3D CNN models. Compared with the 3D-CNN networks, the proposed model trains in about 20% of the time. Also, due to the higher dimension of the 3D convolutional layer, the number of parameters of the 3D convolutional layer is naturally higher than the 2D convolutional layer. By applying the MobileNet [9] or ShuffleNet [19] in medical image diagnosis, there is potential for mobile applications. We used MobileNet for our experiments. We used the MobileNet v1 achitecture as the feature extractor and obtained 84.84% accuracy, which is similar in accuracy to the 3D ResNet.
Table 5.
The total 150 epochs training time of different CNN models.
5. Conclusions
We proposed to apply the approximate rank pooling method to convert 3D Brain MRI images into 2D dynamic images as the inputs for a pre-trained 2D CNN. The proposed model outperforms a 3D CNN with much less training time and improves 9.5% better performance than the baselines. We trained and evaluated on MRI brain imagery and found out that brain skull striping pre-processing is useful before applying the approximate rank pooling conversion. We used an offline approximate rank pooling module in our experiments, but we believe it would be interesting to explore a learnable temporal rank pooling module in the future.
Acknowledgement
This work is supported by NIH/NIA R01AG054459.
References
- 1. https://www.nia.nih.gov/
- 2. http://adni.loni.usc.edu/
- 3.Bilen H, Fernando B, Gavves E, Vedaldi A, Gould S: Dynamic image networks for action recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3034–3042 (2016) [Google Scholar]
- 4.Cheng D, Liu M, Fu J, Wang Y: Classification of mr brain images by combination of multi-cnns for ad diagnosis. Proceedings of Ninth International Conference on Digital Image Processing (ICDIP) (2017) [Google Scholar]
- 5.Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L: ImageNet: A Large-Scale Hierarchical Image Database. In: CVPR09 (2009) [Google Scholar]
- 6.Duraisamy B, Venkatraman J, Annamala SJ: Alzheimer disease detection from structural mr images using fcm based weighted probabilistic neural network. Brain imaging and behavior vol. 13,1 (2019): 87–110. (2019) [DOI] [PubMed] [Google Scholar]
- 7.Fernando B, Gavves E, José Oramas M, Ghodrati A, Tuytelaars T: Modeling video evolution for action recognition. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5378–5387 (2015) [Google Scholar]
- 8.He K, Zhang X, Ren S, Sun J: Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385 (2015) [Google Scholar]
- 9.Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, An-dreetto M, Adam H: Mobilenets: Efficient convolutional neural networks for mobile vision applications (2017), http://arxiv.org/abs/1704.04861
- 10.Ji S, Xu W, Yang M, Yu K: 3D convolutional neural networks for human action recognition. (2013) [DOI] [PubMed]
- 11.Korolev S, Safiullin A, Belyaev M, Dodonova Y: Residual and plain convolutional neural networks for 3d brain mri classification. In: 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017). pp. 835–838 (2017) [Google Scholar]
- 12.Krizhevsky A, Sutskever I, Hinton GE: Imagenet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017) [Google Scholar]
- 13.Liang G, Wang X, Zhang Y, Xing X, Blanton H, Salem T, Jacobs N: Joint 2d-3d breast cancer classification. In: 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). pp. 692–696 (2019) [Google Scholar]
- 14.Rondina J, Ferreira L, Duran F, Kubo R, Ono C, Leite C, Smid J, Ni-trini R, Buchpiguel C, Busatto G: Selecting the most relevant brain regions to discriminate alzheimer’s disease patients from healthy controls using multiple kernel learning: A comparison across functional and structural imaging modalities and atlases. NeuroImage: Clinical 17 (2017) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC: Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018) [Google Scholar]
- 16.Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 618–626 (2017) [Google Scholar]
- 17.Simonyan K, Zisserman A: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2015) [Google Scholar]
- 18.Yang C, Rangarajan A, Ranka S: Visual explanations from deep 3d convolutional neural networks for alzheimer’s disease classification. AMIA … Annual Symposium proceedings. AMIA Symposium vol. 2018 1571–1580. (2018) [PMC free article] [PubMed] [Google Scholar]
- 19.Zhang X, Zhou X, Lin M, Sun J: Shufflenet: An extremely efficient convolutional neural network for mobile devices (2017)
- 20.Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A: Learning deep features for discriminative localization. In: Computer Vision and Pattern Recognition (2016) [Google Scholar]