

Abstract
In recent years, most exciting inputs (MEIs) synthesized from encoding models of neuronal activity have become an established method to study tuning properties of biological and artificial visual systems. However, as we move up the visual hierarchy, the complexity of neuronal computations increases. Consequently, it becomes more challenging to model neuronal activity, requiring more complex models. In this study, we introduce a new attention readout for a convolutional data-driven core for neurons in macaque V4 that outperforms the state-of-the-art task-driven ResNet model in predicting neuronal responses. However, as the predictive network becomes deeper and more complex, synthesizing MEIs via straightforward gradient ascent (GA) can struggle to produce qualitatively good results and overfit to idiosyncrasies of a more complex model, potentially decreasing the MEI’s model-to-brain transferability. To solve this problem, we propose a diffusion-based method for generating MEIs via Energy Guidance (EGG). We show that for models of macaque V4, EGG generates single neuron MEIs that generalize better across architectures than the state-of-the-art GA while preserving the within-architectures activation and requiring 4.7x less compute time. Furthermore, EGG diffusion can be used to generate other neurally exciting images, like most exciting natural images that are on par with a selection of highly activating natural images, or image reconstructions that generalize better across architectures. Finally, EGG is simple to implement, requires no retraining of the diffusion model, and can easily be generalized to provide other characterizations of the visual system, such as invariances. Thus EGG provides a general and flexible framework to study coding properties of the visual system in the context of natural images1
1. Introduction
From the early works of Hubel and Wiesel [1], visual neuroscience has used the preferred stimuli of visual neurons to gain insight into the information processing in the brain. In recent years, deep learning has made big strides in predicting neuronal responses [2–15] enabling in silico stimulus synthesis of non-parametric most exciting inputs (MEIs) [16–18]. MEIs are images that strongly drive a selected neuron and can thus provide insights into its tuning properties. Up until now, they have been successfully used to find novel properties of neurons in various brain areas in mice and macaques [16–23].
However, as we move up the visual hierarchy, such as monkey visual area V4 and IT, the increasing non-linearity of neuronal responses with respect to the visual stimulus makes it more challenging to ❶ obtain models with high predictive performance for single neurons, and ❷ optimize perceptually plausible MEIs, that is, those not corrupted by adversarial high-frequency noise for example. Particularly, area V4 is known to be influenced by attention effects [24], and to be able to shift the location of receptive fields [25]. When models become more complex or units are taken from deeper layers of a network, existing MEI optimization methods based on gradient ascent (GA) can sometimes have difficulties producing qualitatively good results [26] and can overfit to the idiosyncrasies of more complex models, potentially decreasing the MEI’s model-to-brain transferability. Typically, these challenges are addressed by biasing MEIs towards the statistic of natural images, for instance by gradient pre-conditioning [26].
Here, we make two contributions towards the above points: ❶ We introduce a new attention readout for a convolutional data-driven core model for neurons in macaque V4 that outperforms the state-of-the-art robust task-driven ResNet [23, 27] model in predicting neuronal responses. ❷ To improve the quality of MEI synthesis we introduce a novel method for optimizing MEIs via Energy Guided Diffusion (EGG). EGG diffusion guides a pre-trained diffusion model with a learned neuronal encoding model to generate MEIs with a bias towards natural image statistics. Our proposed EGG method is simple to implement and, in contrast to similar approaches [28–30], requires no retraining of the diffusion model. We show that EGG diffusion not only yields MEIs that generalize better across architectures and are thus expected to drive real neurons equally well or better than GA-based MEIs but also provides a significant (4.7×) speed up over the standard GA method enhancing its utility for close-loop experiments such as inception loops [16, 17, 19, 23]. Since optimizing MEIs for thousands of neurons can take weeks [23], such a speed-up directly decreases the energy footprint of this technique. Moreover, we demonstrate that EGG diffusion straightforwardly generalizes to provide other characterizations of the visual system that can be phrased as an inverse problem, such as image reconstructions based on neuronal responses. The flexibility and generality of EGG thus make it a powerful tool for investigating the neural mechanisms underlying visual processing.
2. Attention readout for macaque area V4
Background
Deep network based encoding models have set new standards in predicting neuronal responses to natural images [2–15]. Virtually all architectures of these encoding models consist of at least two parts: a core and a readout. The core is usually implemented via a convolutional network that extracts non-linear features from the visual input and is shared across all neurons to be predicted. It is usually trained through one of two paradigms: i) task-driven, where the core is pre-trained on a different task like object recognition [31, 32] and then only readout is trained to predict the neurons’ responses or ii) data-driven where the model is trained end-to-end to predict the neurons’ responses. The readout is a collection of predictors that map the core’s features to responses of individual neurons. With a few exceptions [33], the readout components and its parameters are neuron-specific and are therefore kept simple. Typically, the readout is implemented by a linear layer with a rectifying non-linearity. Different readouts differ by the constraints they put on the linear layer to reduce the number of parameters [3, 4, 33–35]. One key assumption all current readout designs make is that the readout mechanism does not change with the stimulus. In particular, this means that the location of the receptive field is fixed. While this assumption is reasonable for early visual areas like V1, it is not necessarily true for higher or mid-level areas such as macaque V4, which are known to be affected by attention effects and can even shift the location of the receptive fields [25]. This motivated us to create a more flexible readout mechanism for V4.
State-of-the-art model: robust ResNet with Gaussian readout
In this study, we compare our data-driven model to a task-driven model [23], which is also composed of a core and readout. The core is a pre-trained robust ResNet50 [36, 37]. We use the layers up to layer 3 in the ResNet, providing a 1,024 dimension feature space. Then batch normalization is applied [38], followed by a ReLU non-linearity. The Gaussian readout [33] learns the position of each neuron and extracts a feature vector at this position. During training, the positions are sampled from a 2D Gaussian distribution with means and , during inference the positions are used. Then the extracted features are used in a linear non-linear model to predict neuronal responses.
Proposed model: Data-driven core with attention readout
The predictive model is trained from scratch to predict the neuronal responses in an end-to-end fashion. Following Lurz et al. [33], the architecture is comprised of two main components. First, the core, a four-layer CNN with 64 channels per layer with an architecture identical to Lurz et al. [33]. Secondly, the attention readout, which builds upon the attention mechanism [39, 40] as it is used in the popular transformer architecture [41]. After adding a fixed positional embedding to and normalization through LayerNorm [42] to get , key and value embeddings are extracted from the core representation. This is done by position-wise linear projections and both of which have parameters shared across all neurons. Then, for each neuron a learned query vector is compared with each position’s key embedding using scaled dot-product attention [41].
| (1) |
The result is a spatially normalized attention map that indicates the most important feature locations for a neuron for the input image. Using this attention map to compute a weighted sum of the value embeddings gives us a single feature vector for each neuron. A final neuron-specific affine projection with ELU non-linearity [43] gives rise to the predicted spike rate (Fig. 2A). The model training is performed by minimizing the Poisson loss using the same setup as described in Willeke et al. [23].
Figure 2:

a) Schematic of the Attention Readout. b) Correlation to average scores for 1244 neurons. The data-driven with attention readout (pink) model shows a significant (as per the Wilcoxon signed rank test, p-valu = 6.79 · 10−82) increase in the mean correlation to average in comparison to the task-driven ResNet (blue) model. c) Predictive performance comparison of the two models in a closed-loop MEI evaluation setting. Showing that the data-driven with attention readout model better predicts the in-vivo responses of the MEIs.
Training data
We use the data from Willeke et al. [23] and briefly summarize their data acquisition in the supplementary materials section A.1.
Results
Our attention readout on a CNN core significantly outperforms a state-of-the-art robust ResNet with a Gaussian readout in predicting neuronal responses of macaque V4 cells on unseen natural and model-derived images. We evaluate the model performance by the correlation between the model’s prediction and the averages of actual neuron responses across multiple presentations of a set of test images, as described by Willeke et al. [23]. We compared this predictive performance to a task-driven robust ResNet [37] on 1,244 individual neurons (Fig. 2B). The data-driven attention readout significantly outperforms the task-driven ResNet with Gaussian readout by 12% (Wilcoxon signed-rank test, p-value = 6.79⋅10−82). In addition, we evaluated the new readout on how well it predicts the real neuronal responses to 48 MEIs generated from the task-driven ResNet model [see 23] and 7 control natural images. Our data-driven CNN with the attention readout is better at predicting real neuronal responses, even for MEIs of another architecture (Fig. 2C). Please note that Willeke et al. [23] experimentally verified MEIs in only a subset of neurons and only used the neurons with high functional consistency across different experimental sessions. For that reason, we too can only compare the performance of model-derived MEIs on this subset of neurons.
3. Energy guided diffusion (EGG)
3.1. Algorithm and methods
In this section, we describe our approach to extract tuning properties of neuronal encoding models using a natural image prior as described by a diffusion model. In brief, we use previously established links between diffusion and score-based models and the fact that many tuning properties can be described as inverse problems (most exciting image, image reconstruction from neuronal activity,…) to combine an energy landscape defined by the neuronal encoding model with the energy landscape defined by the diffusion model and synthesize images via energy minimization. We show that this method leads to better generalization of MEIs and image reconstructions across architectures, faster generation, and allows for generating natural-looking stimuli.
Background: diffusion models
Recently, Denoising Diffusion Probabilistic Models (DDPMs) have proved to be successful at generating high-quality images [28, 44–49]. These models can be formalized as a variational autoencoder with a fixed encoder that turns a clean sample into a noisy one by repeated addition of Gaussian noise, and a learned decoder [28], which is often described as inverting a diffusion process [44]. After training, the sampling process is initialized with a standard Normal sample which is iteratively “denoised” for steps until is reached. In the encoding, each step corresponds to a particular noise level such that
| (2) |
where controls the signal strength at time and is independent Gaussian noise. In the decoding step, the diffusion model predicts the noise component at each step of the diffusion process [28]. Then the sampling is performed according to
| (3) |
where .
Several previous works have established a link between diffusion models and energy-based models [50–52]. In particular, the diffusion model can be interpreted as a score function, i.e. the gradient of a log-density or energy w.r.t. the data [53]. This link is particularly useful since combining two density models via a product is equivalent to adding their score functions.
EnerGy Guided Diffusion (EGG)
DDPMs learn to approximate the score of the distribution . The parameterization of diffusion models introduced by Ho et al. [28] only allows for the unconditioned generation of samples. Dhariwal and Nichol [46] introduced a method for sampling from a conditional distribution , with diffusion models using a classifier known as classifier guidance. However, this method requires i) the classifier to be trained on the noisy images, and ii) is limited to conditions for which classification makes sense. At the core, this method relies on computing the score of the posterior distribution.
| (4) |
For classifier-guidance, the gradient of a model with respect to the noisy input is combined with the diffusion model , resulting in samples conditioned on the class . Note that this requires a model that has been trained on noisy samples of the diffusion before. Here we extend this approach to i) use neuronal encoding models, such as the ones described above, to guide the diffusion process and ii) to use a model trained on clean samples only. We achieve i) by defining conditioning as a sum of energies. Specifically, we redefine equation (4) in terms of the output of the diffusion model and an arbitrary energy function E:
| (5) |
where is the energy scale. This takes advantage of the fact that sampling in DDPMs is functionally equivalent to Langevin dynamics Sohl-Dickstein et al. [44]. Langevin dynamics generally define the movement of particles in an energy field and in the special case when , Langevin dynamics generates samples from . For this study, we use a constant value of and normalize the gradient of the energy function to a magnitude of 1.
To achieve ii) we use an approximate clean sample , i.e. the original image, that can be estimated at each time step . This is achieved by a simple trick, used in the code of Dhariwal and Nichol [46], of inverting the forward diffusion process, with the assumption that the predicted is the true noise:
| (6) |
As a result, the energy function receives inputs that are in the domain of at much earlier time steps , and hence makes it feasible to use energy functions only defined on and not , dropping the requirement to provide an energy that can take noisy images. This is particularly relevant in the domain of neural system identification, as encoding models are trained on neuronal responses to natural “clean” images [2–16, 20, 23, 33]. To get an energy that can understand noisy images would require showing the noisy images to the animals in experiments, which would make the use of this method prohibitively more difficult. Therefore, a guidance method that does not require training an additional model on noisy images allows researchers to apply EGG diffusion directly to existing models trained on neuronal responses and extract tuning properties from them.
Related work
Many other methods have been proposed to condition the samples of diffusion processes on additional information. Ho and Salimans [48] provided a method that addressed the second requirement of classifier-guidance by incorporating the condition into the denoiser . However, to introduce a conditioning domain in this classifier-free guidance, the whole diffusion model needs to be retrained. Furthermore, this link between diffusion models and energy-based models allowed several previous works to compose diffusion models to generate outputs that contain multiple desired aspects of a generated image [50–52]. However, these studies focus solely on generalizing the classifier-free guidance to allow guiding diffusion models with other diffusion models. While we were working on this project, Feng et al. [54] published a preprint where they used the score-based definition of diffusion models to introduce an image-based prior for inverse problems where the posterior score function is available. This work is most closely related to our approach. However, they focus on how to obtain samples and likelihoods from the true posterior. For that reason, they need guiding models to be proper score functions. We do not need that constraint and focus on guiding inverse problems defined by a more general energy function and focus particularly on the application to neuronal encoding models.
Image preprocessing for neural models
The neural models used in this study expect 100 × 100 images in grayscale. However, the output of the ImageNet pre-trained Ablated Diffusion Model (ADM) [46] is a 256 × 256 RGB image. We, therefore, use an additional compatibility step that performs i) downsampling from 256 × 256 → 100 × 100 with bilinear interpolation and ii) takes the mean across color channels providing the grayscale image. Each of these preprocessing steps is differentiable and is thus used end-to-end when generating the image.
3.2. Experiments
Most exciting images
We apply EGG diffusion to characterize properties of neurons in macaque area V4. For each of these experiments, we use the pre-trained ADM diffusion model trained on 256 × 256 ImageNet images from Dhariwal and Nichol [46]. In each of our experiments, we consider two paradigms: 1) within architecture, where we use two independently pre-trained ensembles containing 5 models of the same architecture (task-driven ResNet with Gaussian readout or data-driven with attention readout). We generate images on one and evaluate on the other. 2) cross architecture, two independently pre-trained ensembles containing 5 models of different architectures (ResNet and data-driven with attention readout). We demonstrate EGG on three tasks 1) Most Exciting Input (MEI) generation, where the generation method needs to generate an image that maximally excites an individual neuron, 2) Most Exciting Natural Image (MENI) generation, where a natural-looking image is generated that maximizes individual neuron responses, and 3) reconstruction of the input image from predicted neuronal responses. Running the experiments required a total of 7 GPU days. All computations were performed on a single consumer-grade GPU: NVIDIA GeForce RTX 3090 or NVIDIA GeForce RTX 2080 Ti depending on the availability.
MEIs have served as a powerful tool for visualizing features of a network, providing insights and testable predictions [16–20, 22, 55]. For the generation of MEIs, we selected 90 units at random from a subset of all 1,244 for which both ResNet and Attention CNN achieve at least a correlation of 0.5 to the average responses across repeated presentations. We compare our method to a vanilla gradient ascent (GA) method [23] which optimizes the pixels of an input image to obtain the maximal response of the selected neuron. For the GA method, we use Gaussian blur preconditioning of the gradient. The stochastic gradient descent (SGD) optimizer was used with a learning rate of 10 and the image is optimized for 1,000 steps. We define EGG diffusion with the energy function , where is the -th neuron model and is the estimated clean sample. We optimize MEIs for both the ResNet model and the data-driven model with attention readout. We set the energy scale to for the ResNet and for the data-driven model with attention readout. was chosen via a grid search, for more details refer to Fig. 5 B. The diffusion process was run for 100 respaced time steps for the task-driven model and 50 respaced time steps for the data-driven model. For both EGG and GA, we set the norm of the 100 × 100 image to a fixed value of 25. For each of the methods, we chose the best of 3 MEIs optimized from different seeds.
Figure 5:

a) Examples of MENIs optimized using EGG diffusion in the macaque V4 for different neurons and different energy scales . b) Mean and standard error of the normalized activations of neurons across different energy scales. c) Comparison of the MENIs activations to the top-1 most activating ImageNet images per neuron in the cross-architecture domain. Line fit obtained via Huber regression with . Three points at (11, 65), (9, 70), and (16, 120) are not shown for visualization purposes.
We show some examples of MEIs generated with EGG diffusion and GA for the two architectures in figure 3A. For more examples, refer to the supplementary materials figure S1. We find that the EGG-generated MEIs are significantly better (attention readout) or similarly (ResNet) activating within architectures and are significantly better at generalizing across architectures (Fig. 3B). This can also be observed by a significant increase in the mean activation across all units (Table 1). Perceptually, EGG-generated MEIs of the attention readout model looked more complex and natural than the GA-generated MEIs, and more similar to MEIs of the ResNet model trained on image classification.
Figure 3:

a) Examples of MEIs optimized using EGG diffusion and GA for macaque V4 ResNet and ACNN models. b) Comparison of activations for different neurons between EGG diffusion and GA on the Within and Cross Architecture validation paradigms. Line fits obtained via Huber regression with .
Table 1:
Comparison of the average unit activations in response to MEIs in two paradigms 1) within architectures and 2) cross architectures, for two architectures ResNet and Attention CNN.
| Paradigm | Within (ResNet) | Cross (ResNet) | Within (Attention) | Cross (Attention) |
|---|---|---|---|---|
|
| ||||
| Gradient Ascent | 11.43 | 5.51 | 7.59 | 4.42 |
| EGG Diffusion | 11.76 | 6.53 † | 10.56 † | 5.50 † |
Bold marks the method which has higher mean activation, and the † marks the increases which are statistically significant (Wilcoxon signed-rank test, respective p-values: 0.08, 2.87·10−6, 2.84·10−10, 4.39·10−5).
Finally, EGG diffusion is almost 4.7-fold faster than GA, requiring only on average 46s per MEI in comparison to the required 219s for the GA method (Fig. 4) on a single NVIDIA GeForce RTX 3090 across 10 repetitions. This is a substantial gain, as Willeke et al. [23] required approximately 1.25 GPU years to optimize the MEIs presented in their study. With EGG, only approximately 0.25 GPU years would be needed to produce the results of the study, while providing higher quality and higher resolution MEIs. Thus, EGG can provide major savings in time and energy, and improve the quality of MEIs.
Figure 4:
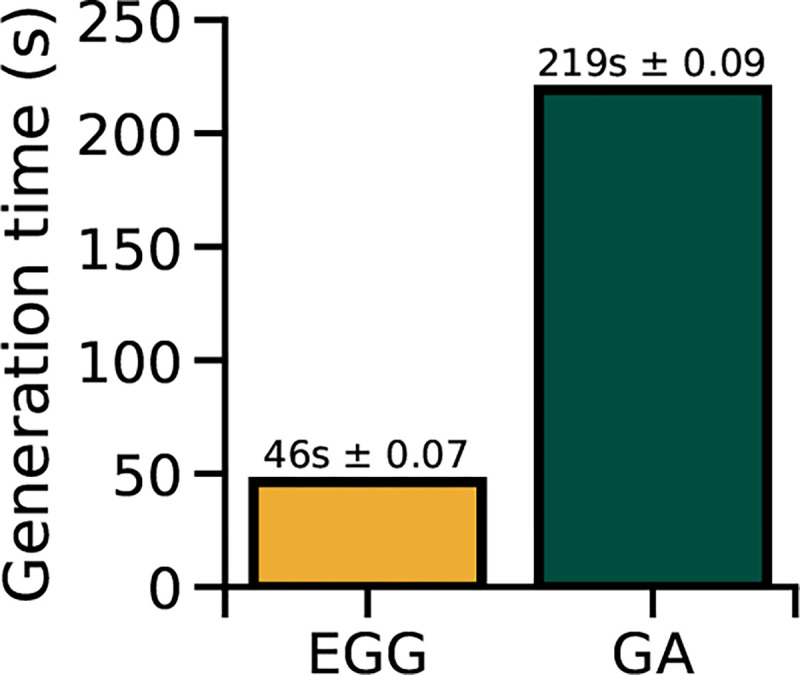
Mean comparison of the generation times between the EGG and GA (errorbars denote standard error).
Controlling the “naturalness” to generate most exciting natural images
Unlike GA, EGG can also be used to synthesize more natural-looking stimuli by controlling the energy scale hyperparameter . Changing the value of trades off the importance of the maximization property of the image and its “naturalness”. To demonstrate this, we generated images for 150 neurons with the highest correlations to the average for the task-driven ResNet model with Gaussian readout. We used energy scales , fixed the 1002 50 steps re-spaced from 1000. Each image was generated using 3 different seeds and the best-performing image on the generator model was selected.
We show examples of the generated images across different energy scales in figure 5A for both the task-driven ResNet with Gaussian readout and the data-driven with attention readout models. For more examples, refer to the supplementary material (Fig. S2] Fig. S3]. Qualitatively, it can be observed that decreasing increases the naturalness of the generated image while preserving the features of the image that the neuron is tuned towards. We subsequently quantified the predicted responses across different values of . We find that increasing increases the predicted responses (Fig. 5B), however, at higher values the responses begin to plateau, or even decrease. Therefore, for generating MEIs with the ResNet model, we use and for the attention readout model.
Finally, we compare the generated MENIs to a standard approach for finding natural images for individual neurons. To that end, we perform a search across 100k images from the ImageNet dataset [56] to find the top-1 most activating image for a particular unit. We then compare the predicted activations of the top-1 ImageNet image and the generated MENIs in the cross-architectures paradigm (Fig. 5C). We find that the generated MENIs drive comparable activation to the top-1 ImageNet images. Like in the MEI generation paradigm, EGG can thus significantly speed up the search for activating natural images, as it does not need to search through millions of images.
Image reconstruction from unit responses
Another application of EGG diffusion is image reconstruction from neuronal responses. A similar task has been attempted with success using diffusion models from human fMRI data [29, 30]. Given that only a small fraction of neurons were recorded, the image is encoded in an under-complete, significantly lower-dimensional space. Therefore, it is to be expected that the reconstructed image will not necessarily be equal to the ground truth image . However, a better reconstruction is one that generalizes across models. Therefore, regardless of the model used, we should get . This is trivially true for but, given the complexity of the model, there are likely other solutions.
We can reconstruct images in the EGG framework by defining the energy function as an distance between the predicted responses to the ground truth image and the predicted responses to a generated image (Fig. 6A) . Note that, instead of f, we could also use recorded neuronal responses. The images are generated from the ResNet model with and 1000 timesteps, with the norm of the100 × 100 image fixed to 60. We compare EGG to a GA method that simply minimizes the L2 distance. The GA uses an AdamW optimizer with a learning rate of 0.05. In GA, at each optimization step the image is Gaussian blurred and the norm is set to 60 before passing it to the neural encoding model. We optimize the GA reconstruction up to the point where the train distance is matched between the GA and the EGG for a fair comparison of the generalization capabilities. We verified that the GA images do not improve qualitatively with more optimization steps (Fig. S5) We find that when generating the reconstruction using EGG diffusion we obtain 1) comparable within-architecture generalization and 2) much better cross-architecture generalization (Fig. 6B). The EGG-generated images produce lower within architecture distances for 84% of the images and for 98% in the cross-architecture case. We show examples of EGG diffusion and GA reconstructions in Fig. 6C. Qualitatively, the images optimized by EGG resemble the ground truth image much more faithfully than the GA images. More examples are available in the supplementary materials (Fig. S4].
Figure 6:

a) Schematic of the reconstruction paradigm. The generated image is compared to the ground truth image via distance in the unit activations space. b) distances in the unit activations space for the Within and Cross architecture domains comparing the EGG and GA generation methods. Shows that the EGG method generalizes better than GA across architectures. c) examples of reconstructions generated by EGG and GA in comparison to the ground truth (GT).
Limitations
While EGG diffusion on average performs better than GA it does come with limitations. Firstly, although the energy scale provides additional flexibility it is an additional hyperparameter that needs to be selected to obtain the desired results. Furthermore, the parameter value does not necessarily represent the same value same across energy functions. Secondly, the maximal number of steps to generate the sample is constricted by the pre-trained diffusion model. Finally, we identified that in 3 out of 90 cases, EGG diffusion failed to provide a satisfactory result with the ResNet model (Fig. 7p, where GA was able to generate an MEI.
Figure 7:

Examples of failure cases in comparison to the gradient ascent method. Text shows predicted response rate by the within-architecture validator.
4. Discussion
In this study, we introduced a new attention readout for a data-driven convolutional core model which provided the first data-driven model that outperformed task-driven models in predicting neurons in macaque V4. Furthermore, we propose a novel method for synthesizing images based on guiding diffusion models via energy functions (EGG). Our results indicate that EGG diffusion produces most exciting inputs (MEIs) which generalize better across architectures than the previous standard gradient ascent (GA) method. In addition, EGG diffusion significantly reduces compute time enabling larger-scale synthesis of visual stimuli. Comparing EGG-based MEIs to the ones found by Willeke et al. [23] using GA, we find that the preferred image feature is usually preserved, but MEIs generated for the attention-readout model are more concentrated than their ResNet counterparts. This is not surprising, since the ResNet model was pre-trained on a large database of natural images. EGG diffusion is not limited to the generation of MEIs and, within the same framework, allows, among other characterizations, to 1) generate most exciting natural images (MENIs) which drive neurons on par with the most activating images in the ImageNet database, and 2) reconstruct images from unit responses, which generalize better across architectures and qualitatively resemble more the original image than images obtained via GA optimization. More generally, EGG can be used whenever the “constraint” on a particular image can be phrased in terms of an energy function. Thus EGG diffusion provides a flexible and powerful framework for studying coding properties of the visual system.
Supplementary Material
Figure 1:

Schematic of the EGG diffusion method with a pre-trained diffusion model. Examples of applications: Left: Most Exciting Inputs for different neurons, Middle: Most Exciting Natural Inputs matched unit-wise to the MEIs. Right: Reconstructions in comparison to the ground truth (top) and gradient descent optimized (bottom).
Acknowledgments
The authors thank the International Max Planck Research School for Intelligent Systems (IMPRS-IS) for supporting Konstantin Willeke and Arne Nix. The authors also thank Mohammad Bashiri and Suhas Shirinvasan for technical support and helpful discussions. The research was funded by the Carl-Zeiss-Stiftung (KW, FHS), the Cyber Valley Research Fund (AN, FHS). FHS is further supported by the German Federal Ministry of Education and Research (BMBF) via the Collaborative Research in Computational Neuroscience (CRCNS) (FKZ 01GQ2107), as well as the Collaborative Research Center (SFB 1233, Robust Vision) and the Cluster of Excellence “Machine Learning – New Perspectives for Science” (EXC 2064/1, project number 390727645). PP is supported by the German Federal Ministry for Economic Affairs and Climate Action (FKZ ZF4076506AW9). We also acknowledge support from the National Institute of Mental Health and National Institute of Neurological Disorders And Stroke under Award Number U19MH114830 and National Eye Institute award numbers R01 EY026927 and Core Grant for Vision Research T32-EY-002520-37 as well as the National Science Foundation Collaborative Research in Computational Neuroscience IIS-2113173.
Footnotes
The code is available at https://github.com/sinzlab/energy-guided-diffusion
References
- [1].Hubel D H and Wiesel T N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol., 148(3):574–591, October 1959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Cadieu Charles F, Hong Ha, Yamins Daniel L K, Pinto Nicolas, Ardila Diego, Solomon Ethan A, Majaj Najib J, and DiCarlo James J. Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Comput. Biol., 10(12):e1003963, December 5014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Yamins Daniel L K, Hong Ha, Cadieu Charles F, Solomon Ethan A, Seibert Darren, and DiCarlo James J. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl. Acad. Sci. U. S. A., 111(23):8619–8624, June 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Cadena Santiago A, Denfield George H, Walker Edgar Y, Gatys Leon A, Tolias Andreas S, Bethge Matthias, and Ecker Alexander S. Deep convolutional models improve predictions of macaque V1 responses to natural images. PLoS Comput. Biol., 15(4):e1006897, April 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Sinz Fabian H, Ecker Alexander S, Fahey Paul G, Walker Edgar Y, Cobos Erick, Froudarakis Emmanouil, Yatsenko Dimitri, Pitkow Xaq, Reimer Jacob, and Tolias Andreas S. Stimulus domain transfer in recurrent models for large scale cortical population prediction on video. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pages 7199–7210, Red Hook, NY, USA, December 2018. Curran Associates Inc. [Google Scholar]
- [6].Zhang Yimeng, Lee Tai Sing, Li Ming, Liu Fang, and Tang Shiming. Convolutional neural network models of V1 responses to complex patterns. J. Comput. Neurosci., 46(1):33–54, February 2019. [DOI] [PubMed] [Google Scholar]
- [7].McIntosh Lane T, Maheswaranathan Niru, Nayebi Aran, Ganguli Surya, and Baccus Stephen A. Deep learning models of the retinal response to natural scenes. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, pages 1369–1377, Red Hook, NY, USA, December 2016. Curran Associates Inc. [PMC free article] [PubMed] [Google Scholar]
- [8].Klindt David A, Ecker Alexander S, Euler Thomas, and Bethge Matthias. Neural system identification for large populations separating “what” and “where”. November 2017.
- [9].Kindel William F, Christensen Elijah D, and Zylberberg Joel. Using deep learning to probe the neural code for images in primary visual cortex. J. Vis., 19(4):29, April 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Ecker Alexander S, Sinz Fabian H, Froudarakis Emmanouil, Fahey Paul G, Cadena Santiago A, Walker Edgar Y, Cobos Erick, Reimer Jacob, Tolias Andreas S, and Bethge Matthias. A rotation-equivariant convolutional neural network model of primary visual cortex. September 2018.
- [11].Cowley Benjamin R and Pillow Jonathan W. High-contrast “gaudy” images improve the training of deep neural network models of visual cortex. June 2020.
- [12].Burg Max F, Cadena Santiago A, Denfield George H, Walker Edgar Y, Tolias Andreas S, Bethge Matthias, and Ecker Alexander S. Learning divisive normalization in primary visual cortex. PLoS Comput. Biol., 17(6):e1009028, June 2021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Batty Eleanor, Merel Josh, Brackbill Nora, Heitman Alexander, Sher Alexander, Litke Alan, Chichilnisky E J, and Paninski Liam. Multilayer recurrent network models of primate retinal ganglion cell responses. July 2022.
- [14].Bashiri Mohammad, Walker Edgar, Lurz Konstantin-Klemens, Jagadish Akshay, Muhammad Taliah, Ding Zhiwei, Ding Zhuokun, Tolias Andreas, and Sinz Fabian. A flow-based latent state generative model of neural population responses to natural images. Adv. Neural Inf. Process. Syst., 34:15801–15815, December 2021. [Google Scholar]
- [15].Antolík Ján, Hofer Sonja B, Bednar James A, and Mrsic-Flogel Thomas D. Model constrained by visual hierarchy improves prediction of neural responses to natural scenes. PLoS Comput. Biol., 12(6):e1004927, June 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Walker Edgar Y, Sinz Fabian H, Cobos Erick, Muhammad Taliah, Froudarakis Emmanouil, Fahey Paul G, Ecker Alexander S, Reimer Jacob, Pitkow Xaq, and Tolias Andreas S. Inception loops discover what excites neurons most using deep predictive models. Nat. Neurosci., 22(12):2060–2065, December 2019. [DOI] [PubMed] [Google Scholar]
- [17].Bashivan Pouya, Kar Kohitij, and DiCarlo James J. Neural population control via deep image synthesis. Science, 364(6439), 2019. [DOI] [PubMed] [Google Scholar]
- [18].Ponce Carlos R, Xiao Will, Schade Peter F, Hartmann Till S, Kreiman Gabriel, and Livingstone Margaret S. Evolving images for visual neurons using a deep generative network reveals coding principles and neuronal preferences. Cell, 177(4):999–1009.e10, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Franke Katrin, Willeke Konstantin F, Ponder Kayla, Galdamez Mario, Zhou Na, Muhammad Taliah, Patel Saumil, Froudarakis Emmanouil, Reimer Jacob, Sinz Fabian H, and Tolias Andreas S. State-dependent pupil dilation rapidly shifts visual feature selectivity. Nature, 610(7930):128–134, October 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Höfling Larissa, Szatko Klaudia P, Behrens Christian, Qiu Yongrong, Klindt David A, Jessen Zachary, Schwartz Gregory W, Bethge Matthias, Berens Philipp, Franke Katrin, Ecker Alexander S, and Euler Thomas. A chromatic feature detector in the retina signals visual context changes. December 2022.
- [21].Fu Jiakun, Shrinivasan Suhas, Ponder Kayla, Muhammad Taliah, Ding Zhuokun, Wang Eric, Ding Zhiwei, Tran Dat T, Fahey Paul G, Papadopoulos Stelios, Patel Saumil, Reimer Jacob, Ecker Alexander S, Pitkow Xaq, Haefner Ralf M, Sinz Fabian H, Franke Katrin, and Tolias Andreas S. Pattern completion and disruption characterize contextual modulation in mouse visual cortex. March 2023.
- [22].Ding Zhiwei, Tran Dat T, Ponder Kayla, Cobos Erick, Ding Zhuokun, Fahey Paul G, Wang Eric, Muhammad Taliah, Fu Jiakun, Cadena Santiago A, Papadopoulos Stelios, Patel Saumil, Franke Katrin, Reimer Jacob, Sinz Fabian H, Ecker Alexander S, Pitkow Xaq, and Tolias Andreas S. Bipartite invariance in mouse primary visual cortex. March 2023.
- [23].Willeke Konstantin F, Restivo Kelli, Franke Katrin, Nix Arne F, Cadena Santiago A, Shinn Tori, Nealley Cate, Rodriguez Gabby, Patel Saumil, Ecker Alexander S, Sinz Fabian H, and Tolias Andreas S. Deep learning-driven characterization of single cell tuning in primate visual area V4 unveils topological organization. May 2023.
- [24].Moore Tirin, Armstrong Katherine M, and Fallah Mazyar. Visuomotor origins of covert spatial attention. Neuron, 40(4):671–683, November 2003. [DOI] [PubMed] [Google Scholar]
- [25].Tolias A S, Moore T, Smirnakis S M, Tehovnik E J, Siapas A G, and Schiller P H. Eye movements modulate visual receptive fields of V4 neurons. Neuron, 29(3):757–767, March 2001. [DOI] [PubMed] [Google Scholar]
- [26].Olah Chris, Mordvintsev Alexander, and Schubert Ludwig. Feature visualization. Distill, 2(11):e7, November 2017. [Google Scholar]
- [27].Ren Yifei and Bashivan Pouya. How well do models of visual cortex generalize to out of distribution samples? May 2023. [DOI] [PMC free article] [PubMed]
- [28].Ho Jonathan, Jain Ajay, and Abbeel Pieter. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst., 33:6840–6851, 2020. [Google Scholar]
- [29].Takagi Yu and Nishimoto Shinji. High-resolution image reconstruction with latent diffusion models from human brain activity. March 2023. [Google Scholar]
- [30].Lu Yizhuo, Du Changde, Wang Dianpeng, and He Huiguang. MindDiffuser: Controlled image reconstruction from human brain activity with semantic and structural diffusion. March 2023.
- [31].Cadena Santiago A, Willeke Konstantin F, Restivo Kelli, Denfield George, Sinz Fabian H, Bethge Matthias, Tolias Andreas S, and Ecker Alexander S. Diverse task-driven modeling of macaque V4 reveals functional specialization towards semantic tasks. May 2022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Yamins Daniel L K and DiCarlo James J. Using goal-driven deep learning models to understand sensory cortex. Nat. Neurosci., 19(3):356–365, March 2016. [DOI] [PubMed] [Google Scholar]
- [33].Lurz Konstantin-Klemens, Bashiri Mohammad, Willeke Konstantin, Jagadish Akshay K, Wang Eric, Walker Edgar Y, Cadena Santiago A, Muhammad Taliah, Cobos Erick, Tolias Andreas S, Ecker Alexander S, and Sinz Fabian H. Generalization in data-driven models of primary visual cortex. April 2021.
- [34].Klindt D A, Ecker A S, Euler T, and Bethge M. Neural system identification for large populations separating “what” and “where”. In Advances in Neural Information Processing Systems, pages 4–6, 2017. [Google Scholar]
- [35].Sinz F, Ecker A S, Fahey P, Walker E, Cobos E, Froudarakis E, Yatsenko D, Pitkow X, Reimer J, and Tolias A. Stimulus domain transfer in recurrent models for large scale cortical population prediction on video. In Advances in Neural Information Processing Systems 31. 2018. [Google Scholar]
- [36].He Kaiming, Zhang Xiangyu, Ren Shaoqing, and Sun Jian. Deep residual learning for image recognition. December 2015.
- [37].Salman Hadi, Ilyas Andrew, Engstrom Logan, Kapoor Ashish, and Madry Aleksander. Do adversarially robust ImageNet models transfer better? July 2020.
- [38].Ioffe Sergey and Szegedy Christian. Batch normalization: Accelerating deep network training by reducing internal covariate shift. February 2015.
- [39].Bahdanau Dzmitry, Cho Kyunghyun, and Bengio Yoshua. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014. [Google Scholar]
- [40].Graves Alex. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013. [Google Scholar]
- [41].Vaswani Ashish, Shazeer Noam, Parmar Niki, Uszkoreit Jakob, Jones Llion, Aidan N Gomez Łukasz Kaiser, and Polosukhin Illia. Attention is all you need. Advances in neural information processing systems, 30, 2017. [Google Scholar]
- [42].Xu Jingjing, Sun Xu, Zhang Zhiyuan, Zhao Guangxiang, and Lin Junyang. Understanding and improving layer normalization. Advances in Neural Information Processing Systems, 32, 2019. [Google Scholar]
- [43].Clevert Djork-Arné, Unterthiner Thomas, and Hochreiter Sepp. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015. [Google Scholar]
- [44].Sohl-Dickstein Jascha, Weiss Eric A, Maheswaranathan Niru, and Ganguli Surya. Deep unsupervised learning using nonequilibrium thermodynamics. March 2015.
- [45].Nichol Alex and Dhariwal Prafulla. Improved denoising diffusion probabilistic models. February 2021.
- [46].Dhariwal Prafulla and Nichol Alex. Diffusion models beat GANs on image synthesis. May 2021.
- [47].Rombach Robin, Blattmann Andreas, Lorenz Dominik, Esser Patrick, and Ommer Björn. High-Resolution image synthesis with latent diffusion models. December 2021.
- [48].Ho Jonathan and Salimans Tim. Classifier-Free diffusion guidance. July 2022.
- [49].Saharia Chitwan, Chan William, Saxena Saurabh, Li Lala, Whang Jay, Denton Emily, Ghasemipour Seyed Kamyar Seyed, Ayan Burcu Karagol, Mahdavi S Sara, Lopes Rapha Gontijo, Salimans Tim, Ho Jonathan, Fleet David J, and Norouzi Mohammad. Photorealistic Text-to-Image diffusion models with deep language understanding. May 2022.
- [50].Liu Nan, Li Shuang, Du Yilun, Tenenbaum Joshua B, and Torralba Antonio. Learning to compose visual relations. November 2021. [Google Scholar]
- [51].Liu Nan, Li Shuang, Du Yilun, Torralba Antonio, and Tenenbaum Joshua B. Compositional visual generation with composable diffusion models. June 2022. [Google Scholar]
- [52].Du Yilun, Durkan Conor, Strudel Robin, Joshua B Tenenbaum Sander Dieleman, Fergus Rob, Sohl-Dickstein Jascha, Doucet Arnaud, and Grathwohl Will. Reduce, reuse, recycle: Compositional generation with Energy-Based diffusion models and MCMC. February 2023.
- [53].Song Yang, Sohl-Dickstein Jascha, Kingma Diederik P, Kumar Abhishek, Ermon Stefano, and Poole Ben. Score-Based generative modeling through stochastic differential equations. November 2020.
- [54].Berthy T Feng Jamie Smith, Rubinstein Michael, Chang Huiwen, Bouman Katherine L, and Freeman William T. Score-Based diffusion models as principled priors for inverse imaging. April 2023.
- [55].Fu Jiakun, Willeke Konstantin F, Pierzchlewicz Pawel A, Muhammad Taliah, Denfield George H, Sinz Fabian Hubert, and Tolias Andreas S. Heterogeneous orientation tuning across Sub-Regions of receptive fields of V1 neurons in mice. February 2022.
- [56].Deng Jia, Dong Wei, Socher Richard, Li Li-Jia, Li Kai, and Fei-Fei Li. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, June 2009. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.