

Abstract
Background:
The importance of robust proton treatment planning to mitigate the impact of uncertainty is well understood. However, its computational cost grows with the number of uncertainty scenarios, prolonging the treatment planning process.
Purpose:
We developed a fast and scalable distributed optimization platform that parallelizes the robust proton treatment plan computation over the uncertainty scenarios.
Methods:
We modeled the robust proton treatment planning problem as a weighted least-squares problem. To solve it, we employed an optimization technique called the Alternating Direction Method of Multipliers with Barzilai-Borwein step size (ADMM-BB). We reformulated the problem in such a way as to split the main problem into smaller subproblems, one for each proton therapy uncertainty scenario. The subproblems can be solved in parallel, allowing the computational load to be distributed across multiple processors (e.g., CPU threads/cores). We evaluated ADMM-BB on four head-and-neck proton therapy patients, each with 13 scenarios accounting for 3 mm setup and 3.5% range uncertainties. We then compared the performance of ADMM-BB with projected gradient descent (PGD) applied to the same problem.
Results:
For each patient, ADMM-BB generated a robust proton treatment plan that satisfied all clinical criteria with comparable or better dosimetric quality than the plan generated by PGD. However, ADMM-BB’s total runtime averaged about 6 to 7 times faster. This speedup increased with the number of scenarios.
Conclusions:
ADMM-BB is a powerful distributed optimization method that leverages parallel processing platforms, such as multi-core CPUs, GPUs, and cloud servers, to accelerate the computationally intensive work of robust proton treatment planning. This results in 1) a shorter treatment planning process and 2) the ability to consider more uncertainty scenarios, which improves plan quality.
I. Introduction
Proton treatment planning has been an active topic of research over the last decade. The sharp dose fall-off of protons, which makes proton therapy an appealing treatment modality, also renders it vulnerable to errors and uncertainties during treatment planning. Consequently, proton plans are usually developed using robust optimization1. The dose distribution for each potential uncertainty scenario (e.g., due to setup or range estimation errors) is computed, then the plan is optimized to fulfill clinical objectives even in these scenarios.
To produce the most robust plan, we would like to consider as many scenarios as possible, covering all potential sources of uncertainty. This presents a number of computational challenges. First, the more scenarios we include in the optimization problem, the longer it will take to solve the problem. This could prolong the treatment planning process and limit the number of parameter adjustments (e.g., objective weights, penalties) that we make, which may result in a suboptimal plan. Second, the memory required to handle all the desired scenarios could exceed the resources available to us, especially on a single computing platform. It is thus of great clinical importance to develop a fast, distributed, and scalable method for robust proton treatment planning.
Given the large size of robust optimization problems in proton therapy, first-order methods like gradient descent have been the de-facto solution technique. In particular, Projected Gradient Descent (PGD) enjoys widespread popularity, as it can handle upper and lower bounds on spot intensities. However, while gradient descent is widely used, it possesses several weaknesses that make it undesirable for solving complex, data-intensive optimization problems. First, it requires the calculation of the gradient, which may be mathematically cumbersome or intractable. Second, its convergence depends heavily on the step size (i.e., the distance moved in the direction of the gradient), which is typically chosen via a line search. This line search is computationally demanding and scales poorly with the size of the problem. Moreover, the very serial format of the line search makes gradient descent unamenable to parallelization. Alternative methods exist for step size selection2,3,4,5, but in general, optimization practitioners turn to the class of distributed algorithms to solve very large problems.
In distributed optimization, multiple agents (e.g., CPUs) collaborate to solve an optimization problem. A typical algorithm will decompose the problem into parts and distribute each part to an agent, which carries out its computation using local information. The agents then combine their results to produce a solution. Due to the use of many agents, these algorithms scale remarkably well: their computational demands increase very modestly with the size and complexity of the problem. Consequently, distributed optimization has been an active topic of research for decades6,7,8,9, and distributed algorithms have been applied in a variety of fields10,11,12,13.
The Alternating Direction Method of Multipliers (ADMM) is a distributed optimization algorithm dating back to the 1970’s14,15,16. It has seen renewed interest over the last few years thanks to its success in solving large-scale optimization problems that arise in data science and machine learning17,18,19,20,21. The key to ADMM’s success is its ability to split a problem into smaller subproblems, which can be solved independently from each other, making it ideal for parallel computation. A clever split can also yield mathematically simple subproblems that permit a closed-form solution. Recently, Zarepisheh, Xing, and Ye22 introduced a new variant of ADMM with improved convergence properties and evaluated its performance on fluence map optimization problems in Intensity Modulated Radiation Therapy (IMRT). They showed that ADMM outperforms other optimization techniques, including an active-set method (FNNLS), a gradient-based method (SBB), and an interior-point solver (CPLEX). This demonstrates the potential of ADMM to efficiently handle large treatment planning problems.
Our paper extends the application of ADMM to robust proton treatment plan optimization. In particular, we exploit the special structure of the robust optimization problem, which enables us to reformulate the problem and split it into smaller subproblems, each corresponding to a separate uncertainty scenario. A major difference between our study and the aforementioned study by Zarepisheh, Xing, and Ye is that we implement a fully parallelized version of ADMM that distributes the workload required to solve these subproblems across multiple CPU threads/cores. This allows us to achieve a greater and more consistent speed advantage over PGD. More importantly, we show that our ADMM algorithm scales well with the number of scenarios, making it possible to include many different sources of uncertainty in the treatment planning process.
II. Methods
II.A. Problem formulation and gradient descent
Suppose we have scenarios, including the nominal scenario, represented by dose-influence matrices for . Here is the number of voxels and is the number of beamlets. Let be row of , corresponding to voxel . The prescribed dose to each voxel is given in the form of a vector , where is equal to the prescription (i.e., a constant scalar ) for target voxels and zero for non-target voxels. Our objective is to find spot intensities that minimize the deviation between the actual and prescribed dose across all scenarios.
Formally, let us define the scenario-specific objective function to be
| (1) |
where is the relative importance weight on voxel . While in principle, different voxels within a structure can admit different weights, in our model, we assign the same weight to all voxels in a structure and only allow weights to vary across structures. Our goal is to solve the optimization problem
| (2) |
with variable . Here we have assumed all scenarios occur with equal probability. It is straightforward to incorporate differing probabilities by replacing with scenario-specific weights , where is the probability of scenario .
PGD starts from an initial estimate of the spots and iteratively computes
where is the step size in iteration , selected using a line search technique such as Armijo23 Section 3.1 to ensure improvement in the objective value. Armijo line search starts from an initial step size and shrinks the step size by a factor of until it produces that satisfies
| (3) |
Here , , and are fixed parameters. PGD proceeds until some stopping criterion is reached, typically when the change in the objective value, , falls below a user-defined cutoff.
The gradient of each scenario’s objective function,
| (4) |
can be computed in parallel, i.e., simultaneously on different processing units (CPUs, GPUs, etc), and summed up to obtain the gradient of the full objective, . However, the Armijo condition 3 must be checked and updated serially, creating a bottleneck in any parallel implementation of PGD.
II.B. Distributed alternating direction method of multipliers
To apply ADMM to problem 2, we must first reformulate it so the objective function is separable. The current objective consists of a sum of scenario-specific objectives , which share the same variable . We will replace with new variables , representing the scenario-specific spots, and a so-called consensus variable . We then introduce a consensus constraint for to ensure the spot intensities are equal. This results in the mathematically equivalent formulation
| (5) |
The objective function in problem 5 is separable across scenarios: the only link between is the requirement that . However, even with the consensus constraint, ADMM is able to split this problem into independent subproblems. The reader is referred to S. Boyd et al. (2011)15 for a detailed description of ADMM.
ADMM starts from an initial estimate of the spot intensity vector , the constant parameter , and the dual variables for . (The value is known as the step size). In each iteration ,
- For , solve for the scenario spot intensities
(6) - Project the average of the scenario spot intensities onto the nonnegative orthant:
- For , update the parameters
(7) Terminate if stopping criterion 9 is satisfied and return as the solution.
Notice that the scenario subproblems 6 can be solved in parallel.
Solving the subproblems.
Subproblem 6 is an unconstrained least-squares problem with a closed-form solution , which can be obtained by solving a system of linear equations of the form , where is an iteration-independent symmetric positive definite matrix and . This system is sometimes referred to as the normal equations. Since the value of remains the same throughout the ADMM loop, we can solve subproblem 6 efficiently by forming the Cholesky factorization of once prior to the start of ADMM and caching it, then using backward substitution to calculate each iteration. This reduces the computational load and ensures our subproblem step is still parallelizable. See the appendix for mathematical details.
ADMM with Barzilai-Borwein step size.
While ADMM will converge for any , the value of often has an effect on the practical convergence rate. In some cases, allowing to vary in each iteration will result in faster convergence. One popular method for selecting a variable step size is the Barzilai-Borwein (BB) method24,25,26. This method has shown great success when combined with ADMM22. The BB step size in iteration is given by
| (8) |
where and . If , we use it in place of in our dual variable update 7. Otherwise, we revert to the user-defined constant .
Note that subproblem 6 always uses the default , since for speed purposes, we do not recompute the Cholesky factorization each iteration. In addition, the BB step size is calculated using simple linear algebra, not the serial loop required by a backtracking line search (e.g., Armijo). As we will see in the results section, this gives ADMM a significant advantage over PGD in terms of runtime and memory efficiency.
Stopping criterion.
The convergence of ADMM with variable step size is still an active topic of research27,28,29. In our algorithm, we employ a stopping criterion based on the optimality conditions of problem 5, which we have observed works well in practice. This translates into checking whether the residuals associated with these conditions,
are close to zero. (Here is referred to as the primal residual and as the dual residual). Thus, a reasonable stopping criterion is
| (9) |
for tolerances and . These tolerances are typically chosen with respect to user-defined cutoffs and using
where and . Intuitively, we want to stop when 1) the scenario-specific spots are approximately equal and 2) the most recent iteration of ADMM yielded little change in the spot intensities . This indicates that the optimality conditions for problem 5 have been fulfilled. We refer the reader to Section 3.3 of S. Boyd et al. (2011)15 for a derivation of the stopping criterion.
II.C. Patient population and computational framework
We tested our ADMM algorithm with BB step size (ADMM-BB) on four head-and-neck cancer patient cases from The Cancer Imaging Archive (TCIA)32,33. For each patient, only the primary clinical target volume (CTV) was considered in the optimization, with a prescribed dose of Gy delivered in 35 fractions of 2 Gy per fraction. Dose calculations were performed in MATLAB using the open-source software MatRad and the pencil beam dose calculation algorithm34,35. The proton spots were placed on a rectangular grid, covering the planning target volume (PTV) region plus 1 mm out from its perimeter with a spot spacing of 5 mm. All patients were planned using two co-planar beams. See table 1 for more details.
Table 1:
Head-and-neck cancer patient information.
| Patient | ||||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Beam Configuration | 40°, 320° | 220°, 320° | 30°, 60° | 30°, 300° |
| CTV volume (cm3) | 91.4 | 2.8 | 72.9 | 59.5 |
| Number of voxels | 98901 | 50728 | 119258 | 126072 |
| Number of spots | 5762 | 707 | 4697 | 3737 |
To create uncertainty scenarios, we simulated range over- and under-shoots by rescaling the stopping power ratio (SPR) image ±3.5% following typical range margin recipes used in proton therapy36,37. We also simulated setup errors by shifting the isocenter ±3 mm in the , , and direction. Combining the range and setup errors gave us a total of 13 scenarios, including the nominal scenario. For each scenario, we computed the dose-influence matrix using a relative biological effectiveness (RBE) of 1.1.
We implemented PGD and ADMM-BB in Python using the built-in multiprocessing library. This library supports parallel computation across multiple CPUs and CPU threads/cores. The algorithms were executed on a server with 2 Intel Xeon Gold 6248 CPUs @ 2.50 GHz / 20 cores and 128 GB RAM. We terminated PGD when the relative change in the objective value was about 10−4 to 10−5. For ADMM-BB, we combined this same criterion with the residual stopping criterion 9 using .
III. Results
III.A. Algorithm runtime comparisons
Figure 1 shows the objective function value over the course of the total runtime of PGD and ADMM-BB, for all four patients. Clearly for all patients, ADMM-BB converges much faster than PGD to approximately the same objective value. On patient 1, a relatively large case, ADMM-BB took 8.3 minutes to converge, whereas PGD required 50 minutes to achieve roughly the same objective. For a smaller case like patient 2, ADMM-BB converged in 31 seconds, while PGD required 241 seconds. Altogether across all patients, ADMM-BB converged on average 6 to 7 times faster than PGD to a very similar objective and spot intensities — a significant speedup.
Figure 1:
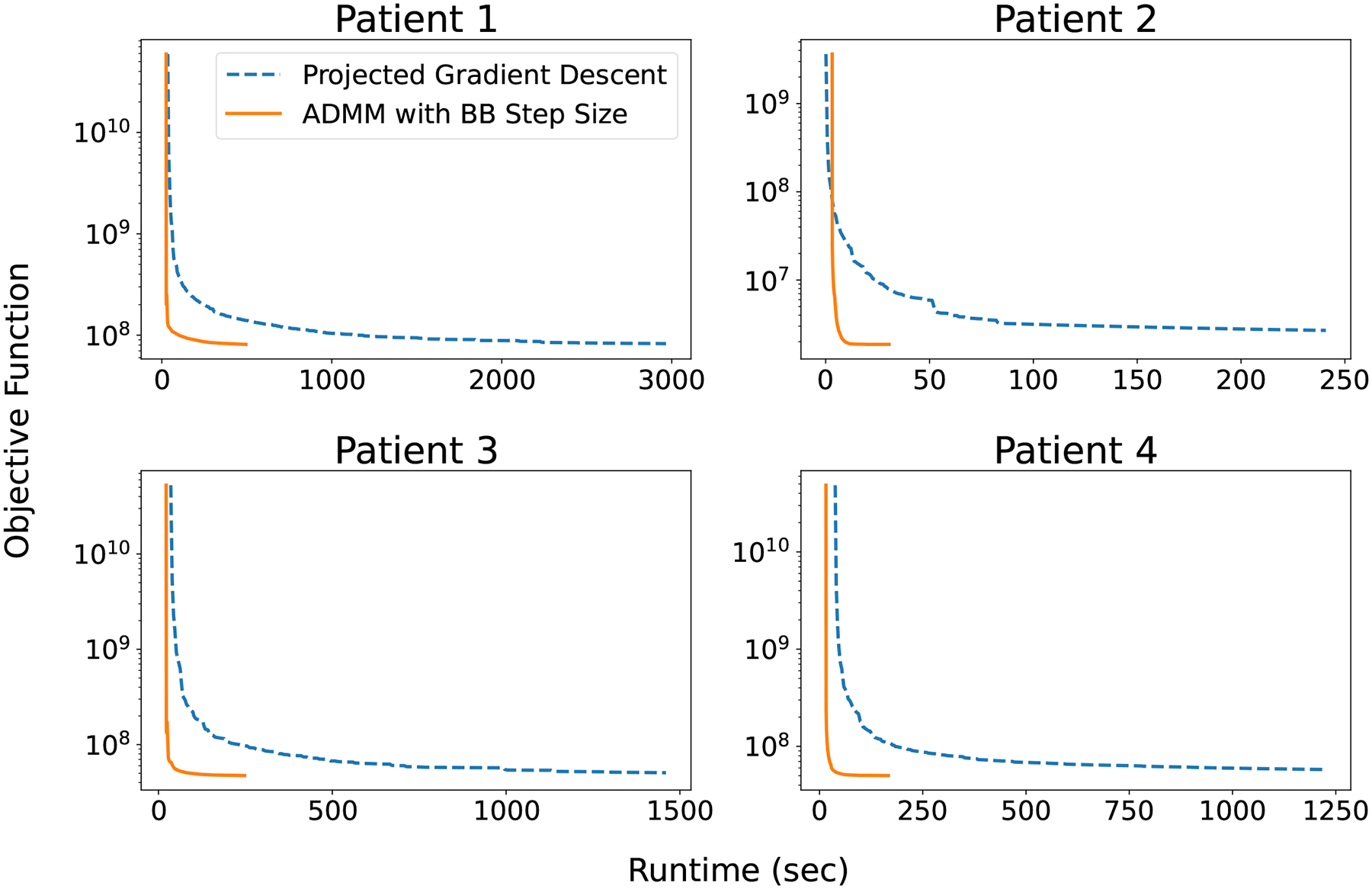
Objective function value versus algorithm runtime (sec) for all patient cases.
III.B. Treatment plan comparisons
Figures 2 and 3 compare the treatment plans produced by PGD and ADMM-BB for patient 2. Figure 2 depicts the DVH bands: each band, color-coded to a particular structure, represents the range of DVH curves across all 13 scenarios, while the corresponding solid curve is the DVH in the nominal scenario. The vertical dotted line marks the prescription Gy. It is clear from an inspection of the figure that PGD and ADMM-BB converge to near-identical DVH bands. The only difference is that ADMM-BB achieves a tighter CTV band around at the expense of a slight increase in the mean dose to the right parotid (Figure 2). Figure 3 shows the box plots of a few dose-volume clinical metrics for this patient. The box plots depict the value of the metric for each of the 13 uncertainty scenarios. The dotted line represents the clinical constraint for the metric; this line is a lower bound for D98% on the CTV and an upper bound for all other metrics. (See table 2 for a full description of the criteria). It is apparent from the plots that both PGD and ADMM-BB produce robust plans that respect the clinical constraints in nearly all scenarios. On the OAR metrics, PGD and ADMM-BB achieve similar performance: the mean doses to the right parotid and the constrictors are nearly identical, while the maximum dose to the mandible is slightly lower for ADMM-BB. However, ADMM-BB outperforms PGD on the CTV metrics.
Figure 2:

Dose-volume histogram (DVH) bands across all scenarios for patient 2.
Figure 3:
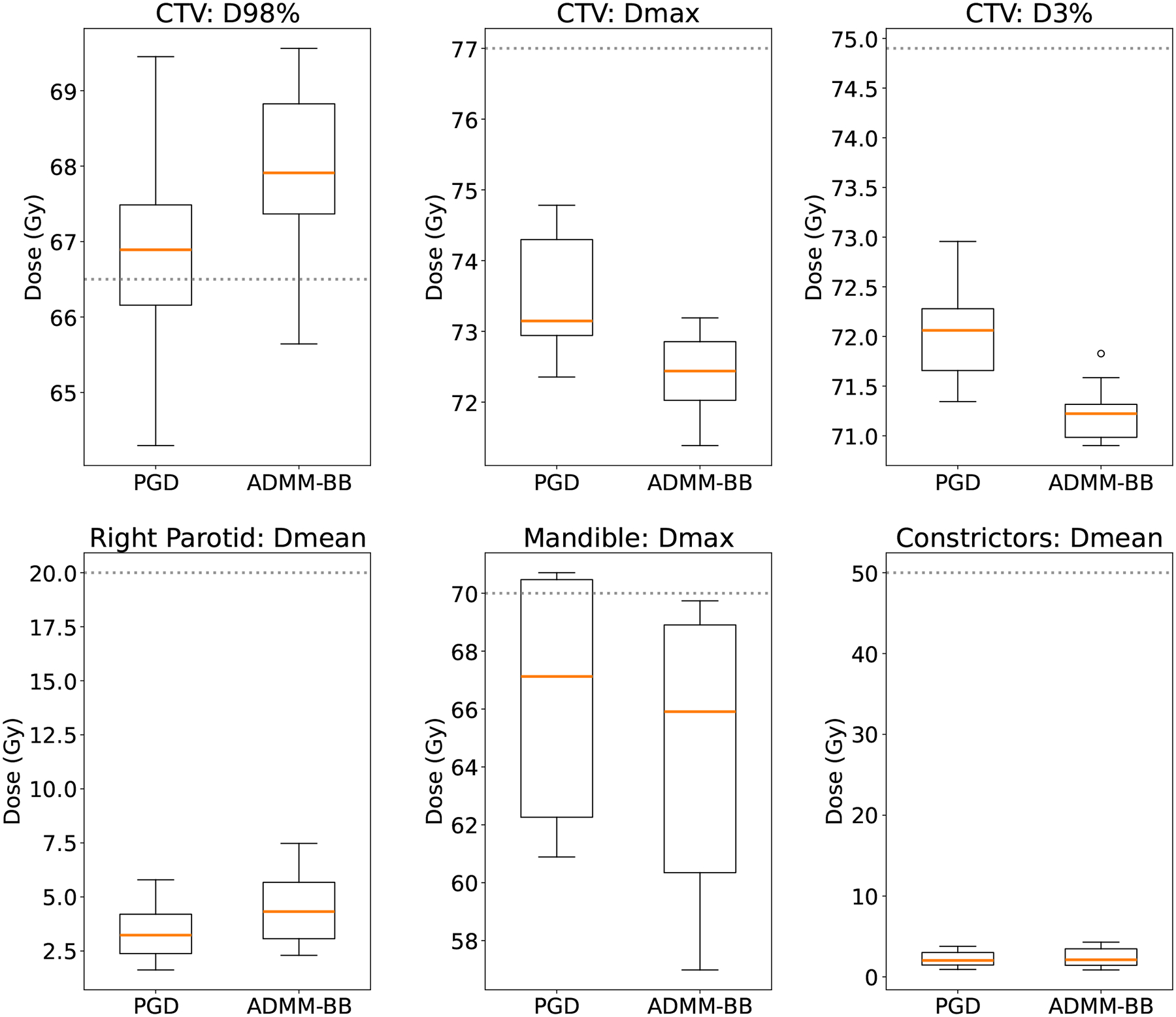
Dose-volume clinical metrics for patient 2. The box plot spans the values over the 13 uncertainty scenarios, with the orange line indicating the median. The dotted lines mark the clinical constraints: higher is better for D98% on the CTV, while lower is better for all other metrics.
Table 2:
Recommended clinical dose bounds for head-and-neck cancer patients38.
| Structure | Dose constraint |
|---|---|
| D98% > 66.5 Gy | |
| CTV | Dmax < 77 Gy |
| D3% < 74.9 Gy | |
| Parotid | Dmean < 20 Gy |
| Mandible | Dmax < 70 Gy |
| Larynx | Dmean < 45 Gy |
| Constrictors | Dmean < 50 Gy |
Figures 4 and 5 depict the DVH bands and clinical metrics for patient 4. Again, the PGD and ADMM-BB treatment plans are nearly identical. ADMM-BB produces a tighter CTV band below 70 Gy, indicating superior robustness, at the expense of a somewhat wider DVH band on the mandible. The box plots of the dose-volume metrics for the ADMM-BB plan are also largely within the desired clinical constraints, and the CTV box plots in particular show an improvement over those of PGD (Figure 4), similar to what we saw in patient 2. The PGD and ADMM-BB treatment plans for other patients reflect the same pattern; we have omitted them here for brevity. Overall, we see that ADMM-BB produces plans identical to or better than the plans produced by PGD, but in a fraction of the runtime.
Figure 4:

Dose-volume histogram (DVH) bands across all scenarios for patient 4.
Figure 5:
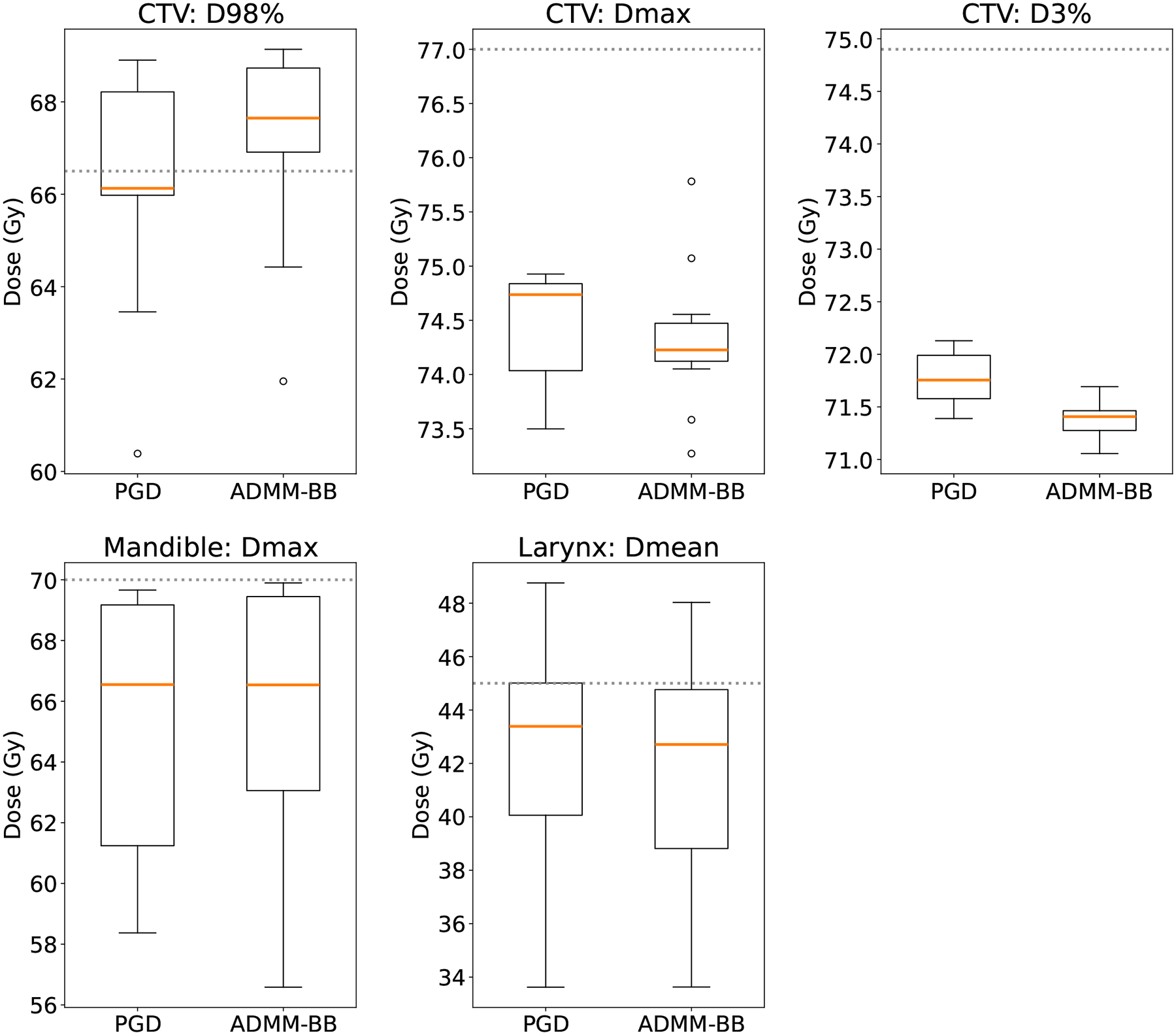
Dose-volume clinical metrics for patient 4. The box plot spans the values over the 13 uncertainty scenarios, with the orange line indicating the median. The dotted lines mark the recommended clinical constraints: higher is better for D98% on the CTV, while lower is better for all other metrics.
III.C. Scalability over multiple scenarios
Not only is ADMM-BB faster than PGD, it also scales better with the number of scenarios. Figure 6 shows the time required by PGD and ADMM-BB to produce a treatment plan for patient 4 for different numbers of scenarios in the optimization problem. Specifically, we solved problem 2 for and recorded the total runtime in each case. Parallelization in ADMM-BB was carried out across the included scenarios. It is clear from the figure that ADMM-BB outperforms PGD by a wide margin. ADMM-BB’s runtime increases modestly from 17.3 seconds at to 111.2 seconds at . By contrast, PGD goes from 273.4 seconds at to 1359.4 seconds at . At its peak, ADMM-BB is over 12 times faster than PGD. This pattern holds true for all the other patients as well.
Figure 6:
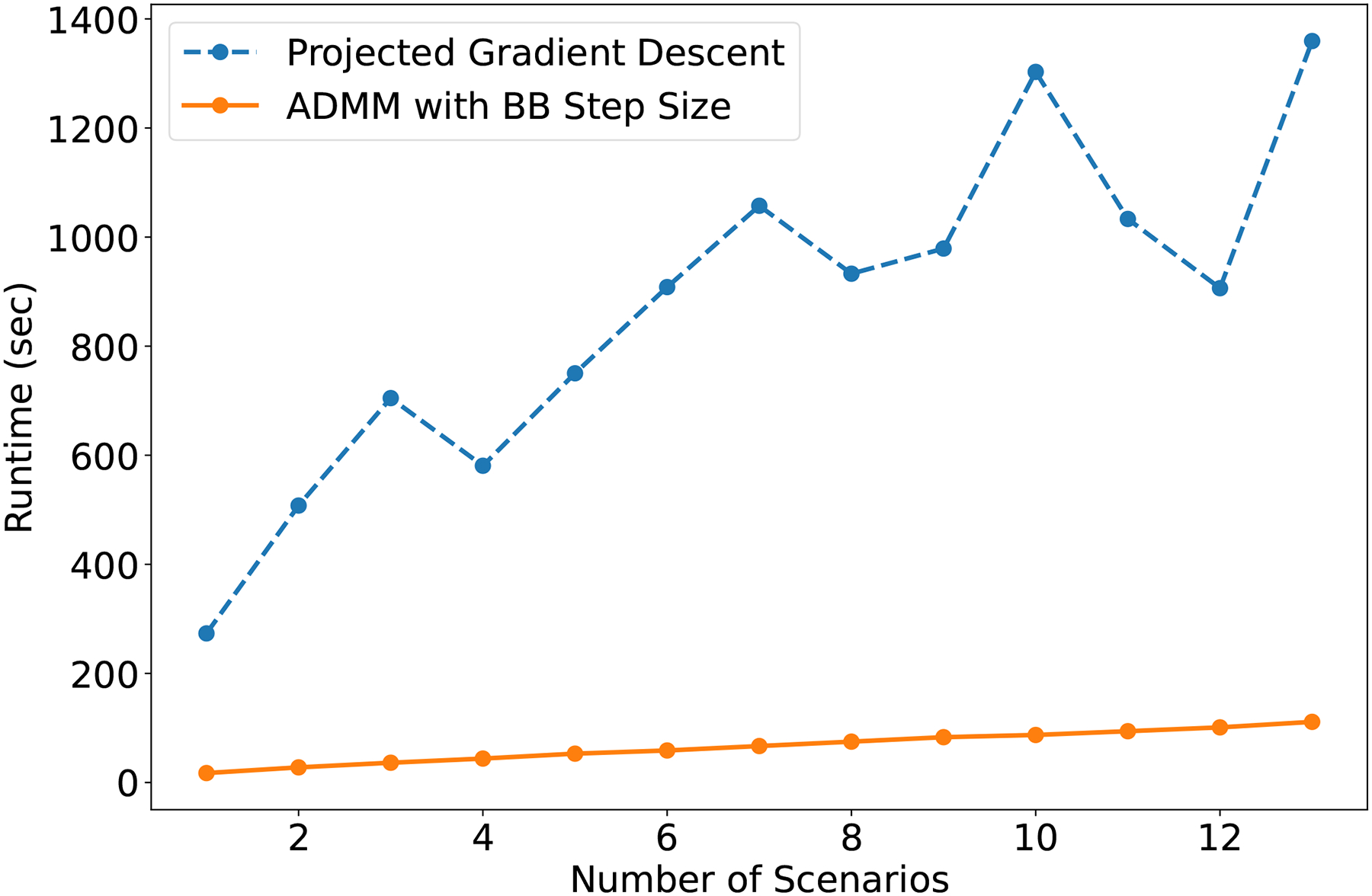
Algorithm runtime (sec) versus number of scenarios (N) for patient 4’s treatment plan.
IV. Discussion
In this study, we presented a distributed optimization method for solving robust proton treatment planning problems. Our method splits the problem into smaller parts, which can be handled on separate machines/processors, allowing us to reduce the overall planning time and overcome the limits (e.g., memory) of single-machine computation. As a result, we can efficiently plan large patient cases with many voxels and spots. We can also consider more uncertainty scenarios for any given patient, enabling us to produce more robust treatment plans.
We have used PGD as our benchmark for comparison because it is commonly employed to solve unconstrained treatment planning problems39,40,41,42. More advanced versions of gradient descent, such as the nonlinear conjugate gradient (CG) method and Nesterov-accelerated gradient descent, can also be applied to problem 2. While these algorithms may work better than PGD, they possess the same dependence on the line search step23,43, which was the main source of computational burden in our experiments. A variant of PGD exists that uses the BB step size44. The removal of line search does speed up PGD, but experiments show that ADMM-BB still generally converges faster in a non-distributed setting22. In sum, both the ADMM subproblem decomposition and the BB step size combine to give ADMM-BB a clear advantage over gradient descent.
Another advantage of ADMM is that it supports a wide variety of constraints. While PGD can only handle box constraints (i.e., upper and lower bounds on the spot intensities), ADMM can easily be modified to handle any type of linear constraint, such as maximum and mean dose constraints. More advanced versions of ADMM can also handle nonlinear constraints45,46,47. Other optimization algorithms exist that support linear/nonlinear constraints (e.g., interior point method48, sequential quadratic programming23), but generally, they require the calculation of the Hessian matrix, which is computationally expensive for robust treatment planning problems.
In our formulation, we have chosen to split problem 6 by scenarios. It is also possible to split the problem by voxels, e.g., create a separate subproblem for each target and organat-risk. Indeed, there are multi-block versions of ADMM that allow arbitrary splitting along rows and columns49,50,51,52, so we can theoretically accommodate any partition of voxels/spots. This is a natural direction for future research.
Finally, we plan to extend the implementation of ADMM-BB to other platforms. Our current software implementation parallelizes computation across multiple CPUs and CPU cores. We intend to add support for parallelization across GPUs, which should produce further speed improvements. With the rise of cloud computing, data storage and processing is increasingly moving to remote high performance computing (HPC) clusters. Our long-term goal is to implement ADMM-BB on these clusters, so that each subproblem (and its corresponding portion of the data) is handled by a separate machine or group of machines in the cluster. This will allow us to solve treatment planning problems of immense size. We foresee ADMM-BB’s application in many data-intensive treatment environments, such as beam angle optimization and volumetric modulated arc therapy (VMAT), as well as more recent treatment planning modalities like 53 and station parameter optimized radiation therapy (SPORT)54
V. Conclusions
We have developed a fast, distributed method for robust proton treatment planning. Our method splits the treatment planning problem into smaller subproblems, which can then be solved in parallel, improving runtime and memory efficiency. Moreover, we showed that the method scales well with the number of uncertainty scenarios. These advantages allow us to 1) shorten the time required by the treatment planning process, 2) incorporate more uncertainty scenarios into the robust optimization problem, and 3) improve plan quality by exploring a larger space of parameters.
Acknowledgments
We thank Joseph O. Deasy for his helpful comments and suggestions on the manuscript. This work was partially supported by MSK Cancer Center Support Grant/Core Grant from the NIH (P30 CA008748).
Appendix
We are interested in solving problem 6 :
with respect to , where , ,and is a parameter. This is an unconstrained least-squares problem. Expand the objective function out to get
where we define
Here is a diagonal matrix with on the diagonal.
By the normal equations, a solution of problem 6 must satisfy
| (10) |
Since is positive definite (because ), such a solution always exists. One way to find is to form the Cholesky decomposition of and apply backward substitution to the triangular matrices. More precisely, we find an upper triangular matrix that satisfies . Then, we solve the system of equations for and for . These two solves can be done very quickly via backward substitution. Notice that need only be computed once at the start of ADMM, as remains the same across iterations, so subsequent solves of problem 6 simply require us to update and solve the two triangular systems of equations.
Footnotes
Conflict of interest statement
The authors have no relevant conflicts of interest to disclose.
References
- 1.Unkelbach J, Alber M, Bangert M, Bokrantz R, Chan TCY, Deasy JO, Fredriksson A, Gorissen BL, van Herk M, Liu W, Mahmoudzadeh H, Nohadani O, Siebers JV, Witte M, and Xu H, Robust Radiotherapy Planning, Phys. Med. Biol 63, 22TR02 (2018). [DOI] [PubMed] [Google Scholar]
- 2.Duchi J, Hazan E, and Singer Y, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, J. Mach. Learn. Res 12, 2121–2159 (2011). [Google Scholar]
- 3.Kingma DP and Ba J, Adam: A Method for Stochastic Optimization, 2014, arXiv:1412.6980 [Google Scholar]
- 4.Tan C, Ma S, Dai Y-H, and Qian Y, Barzilai-Borwein Step Size for Stochastic Gradient Descent, in Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS), volume 29,2016. [Google Scholar]
- 5.Qiao Y, van Lew B, Lelieveldt BPF, and Staring M, Fast Automatic Step Size Estimation for Gradient Descent Optimization of Image Registration, IEEE Trans. Med. Imag 35, 391–403 (2016). [DOI] [PubMed] [Google Scholar]
- 6.Bertsekas DP and Tsitsiklis JN, Parallel and Distributed Computation: Numerical Methods, Prentice-Hall, 1989. [Google Scholar]
- 7.Sayed AH, Adaptation, Learning, and Optimization Over Networks, Found. Trends Mach. Learn 7, 311–801 (2014). [Google Scholar]
- 8.Nedić A and Liu J, Distributed Optimization for Control, Annu. Rev. Control Robot. Auton. Syst 1, 77–103 (2018). [Google Scholar]
- 9.Yang T, Yi X, Wu J, Yuan Y, Wu D, Meng Z, Hong Y, Wang H, Lin Z, and Johansson KH, A Survey of Distributed Optimization, Annu. Rev. Control 47, 278–305 (2019) [Google Scholar]
- 10.Raffard R, Tomlin C, and Boyd S, Distributed Optimization for Cooperative Agents: Application to Formation Flight, in Proceedings of the 43rd IEEE Conference on Decision and Control (CDC), pages 2453–2459, 2004. [Google Scholar]
- 11.Rabbat M and Nowak R, Distributed Optimization in Sensor Networks, in Proceedings of the 3rd International Symposium on Information Processing in Sensor Networks, pages 20–27,2004 [Google Scholar]
- 12.Wang Y, Wang S, and Wu L, Distributed Optimization Approaches for Emerging Power Systems Operation: A Review, Electr. Power Syst. Res 144, 127–135 (2017). [Google Scholar]
- 13.Fu A, Xing L, and Boyd S, Operator Splitting for Adaptive Radiation Therapy with Nonlinear Health Constraints, Optim. Methods Softw, 1–24 (2022), doi: 10.1080/10556788.2022.2078824. [DOI] [Google Scholar]
- 14.Gabay D and Mercier B, A Dual Algorithm for the Solution of Nonlinear Variational Problems via Finite Element Approximations, Comput. Math. Appl 2, 17–40 (1976). [Google Scholar]
- 15.Boyd S, Parikh N, Chu E, Peleato B, and Eckstein J, Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, Found. Trends Mach. Learn 3, 1–122 (2011). [Google Scholar]
- 16.Fang EX, He B, Liu H, and Yuan X, Generalized Alternating Direction Method of Multipliers: New Theoretical Insights and Applications, Math. Program. Comput 7, 149–187(2015) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Huang Z, Hu R, Guo Y, Chan-Tin E, and Gong Y, DP-ADMM: ADMM-Based Distributed Learning with Differential Privacy, IEEE Trans. Inf. Forensics Security 15, 1002–1012 (2019). [Google Scholar]
- 18.Gu Y, Fan J, Kong L, Ma S, and Zou H, ADMM for High-Dimensional Sparse Penalized Quantile Regression, Technometrics 60, 319–331 (2018). [Google Scholar]
- 19.Ramdas A and Tibshirani RJ, Fast and Flexible ADMM Algorithms for Trend Filtering, J. Comput. Graph. Stat 25, 839–858 (2016). [Google Scholar]
- 20.Dhar S, Congrui Y, Ramakrishnan N, and Shah M, ADMM Based Machine Learning on Spark, in IEEE Conference on Big Data, pages 1174–1182, 2015. [Google Scholar]
- 21.Sawatzky A, Xu Q, Schirra CO, and Anastasio MA, Proximal ADMM for Multi-Channel Image Reconstruction in Spectral X-ray CT, IEEE Trans. Med. Imag 33, 1657–1668(2014). [DOI] [PubMed] [Google Scholar]
- 22.Zarepisheh M, Xing L, and Ye Y, A Computation Study on an Integrated Alternating Direction Method of Multipliers for Large Scale Optimization, Optim. Lett 12, 3–15 (2018) [Google Scholar]
- 23.Nocedal J and Wright SJ, Numerical Optimization, Springer-Verlag, 2006. [Google Scholar]
- 24.Barzilai J and Borwein JM, Two-Point Step Size Gradient Methods, IMA J. Numer. Anal 8, 141–148 (1988). [Google Scholar]
- 25.Raydan M, The Barzilai and Borwein Gradient Method for the Large Scale Unconstrained Minimization Problem, SIAM J. Optim 7, 26–33 (1997). [Google Scholar]
- 26.Dai Y and Fletcher R, Projected Barzilai-Borwein Methods for Large-Scale Box-Constrained Quadratic Programming, Numer. Math 100, 21–47 (2005). [Google Scholar]
- 27.Xu Z, Figueiredo M, Yuan X, Studer C, and Goldstein T, Adaptive Relaxed ADMM: Convergence Theory and Practical Implementation, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7389–7398, 2017. [Google Scholar]
- 28.Xu Y, Liu M, Lin Q, and Yang T, ADMM Without a Fixed Penalty Parameter: Faster Convergence with New Adaptive Penalization, in Advances in Neural Information Processing Systems (NIPS), volume 30, 2017. [Google Scholar]
- 29.Bot RI and Csetnek ER, ADMM for Monotone Operations: Convergence Analysis and Rates, Adv. Comput. Math 45, 327–359 (2019). [Google Scholar]
- 30.Eckstein J and Bertsekas DP, On the Douglas-Rachford Splitting Method and the Proximal Point Algorithm for Maximal Monotone Operators, Math. Program 55, 293–318(1992). [Google Scholar]
- 31.Gabay D, Applications of the Method of Multipliers to Variational Inequalities, in Augmented Lagrangian Methods: Applications to the Solution of Boundary-Value Problems, edited by Fortin M and Glowinski R, North-Holland, 1983. [Google Scholar]
- 32.Clark K, Vendt B, Smith K, Freymann J, Kirby J, Koppel P, Moore S, Phillips S, Maffitt D, Pringle M, Tarbox L, and Prior F, The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository, J. Digit. Imaging 26, 1045–1057(2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Nolan T, Head-and-Neck Squamous Cell Carcinoma Patients with CT Taken During Pre-Treatment, Mid-Treatment, and Post-Treatment (HNSCC-3DCT-RT), 10.7937/K9/TCIA.2018.13upr2xf. [DOI]
- 34.Wieser H-P, Cisternas E, Wahl N, Ulrich S, Stadler A, Mescher H, Müller L-R, Klinge T, Gabrys H, Burigo L, Mairani A, Ecker S, Ackermann B, Ellerbrock M, Parodi K, Jäkel O, and Bangert M, Development of the Open-Source Dose Calculation and Optimization Toolkit matRad, Med. Phys 44, 2556–2568 (2017). [DOI] [PubMed] [Google Scholar]
- 35.Wieser H, Wahl N, Gabryś H, Müller L, Pezzano G, Winter J, Ulrich S, Burigo L, Jäkel O, and Bangert M, MatRad – An Open-Source Treatment Planning Toolkit for Educational Purposes, Med. Phys. Int 6, 119–127 (2018). [Google Scholar]
- 36.Taasti VT, Bäumer C, Dahlgren CV, Deisher AJ, Ellerbrock M, Free J, Gora J, Kozera A, Lomax AJ, Marzi LD, Molinelli S, Teo B-KK, Wohlfahrt P, Petersen JBB, Muren LP, Hansen DC, and Richter C, Inter-Centre Variability of CT-Based Stopping-Power Prediction in Particle Therapy: Survey-Based Evaluation, Phys. Imaging Radiat 6, 25–30 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Paganetti H, Range Uncertainties in Proton Therapy and the Role of Monte Carlo Simulations, Phys. Med. Biol 57, R99–R117 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Taasti VT, Hong L, Deasy JO, and Zarepisheh M, Automated Proton Treatment Planning with Robust Optimization using Constrained Hierarchical Optimization, Med. Phys 47, 2779–2790(2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Bortfeld T, Optimized Planning Using Physical Objectives and Constraints, Semin. Radiat. Oncol 9, 20–34 (1999). [DOI] [PubMed] [Google Scholar]
- 40.Hristov D, Stavrev P, Sham E, and Fallone BG, On the Implementation of Dose-Volume Objectives in Gradient Algorithms for Inverse Treatment Planning, Med. Phys 29, 848–856(2002). [DOI] [PubMed] [Google Scholar]
- 41.Ghobadi K, Ghaffari HR, Aleman DM, Jaffray DA, and Ruschin M, Automated Treatment Planning for a Dedicated Multi-Source Intracranial Radiosurgery Treatment Unit Using Projected Gradient and Grassfire Algorithms, Med. Phys 39, 3134–3141 (2012) [DOI] [PubMed] [Google Scholar]
- 42.Yao R, Templeton A, Liao Y, Turian J, Kiel K, and Chu J, Optimization for High-Dose-Rate Brachytherapy of Cervical Cancer with Adaptive Simulated Annealing and Gradient Descent, Brachytherapy 13, 352–360 (2014). [DOI] [PubMed] [Google Scholar]
- 43.Gonzaga CC and Karas EW, Fine Tuning Nesterov’s Steepest Descent Algorithm for Differentiable Convex Programming, Math. Program 138, 141–166 (2013). [Google Scholar]
- 44.Kim D, Sra S, and Dhillon IS, A Non-Monotonic Method for Large-Scale Non-Negative Least Squares, Optim. Methods Softw 28, 1012–1039 (2013). [Google Scholar]
- 45.Gao W, Goldfarb D, and Curtis FE, ADMM for Multiaffine Constrained Optimization, Optim. Methods Softw 35, 257–303 (2020). [Google Scholar]
- 46.Latorre F, Eftekhari A, and Cevher V, Fast and Provable ADMM for Learning with Generative Priors, in Advances in Neural Information Processing Systems (NIPS) 32, 2019. [Google Scholar]
- 47.Benning M, Knoll F, Schonlieb C-B, and Valkonen T, Preconditioned ADMM with Nonlinear Operator Constraint, in IFIP Conference on System Modeling and Optimization, pages 117–126,2015. [Google Scholar]
- 48.Boyd S and Vandenberghe L, Convex Optimization, Cambridge University Press, 2004. [Google Scholar]
- 49.Parikh N and Boyd S, Block Splitting for Distributed Optimization, Math. Program. Comput 6, 77–102 (2014). [Google Scholar]
- 50.Sun R, Luo Z-Q, and Ye Y, On the Expected Convergence of Randomly Permuted ADMM, 2015, arXiv:1503.06387. [Google Scholar]
- 51.Deng W, Lai M-J, Peng Z, and Yin W, Parallel Multi-Block ADMM with o(1/k) Convergence, J. Sci. Comput 71, 712–736 (2017). [Google Scholar]
- 52.Mihić K, Zhu M, and Ye Y, Managing Randomization in the Multi-Block Alternating Direction Method of Multipliers for Quadratic Optimization, Math. Program. Comput 13, 339–413 (2021). [Google Scholar]
- 53.Dong P, Lee P, Ruan D, Long T, Romeijn E, Low DA, Kupelian P, Abraham J, Yang Y, and Sheng K, 4π Noncoplanar Stereotactic Body Radiation Therapy for Centrally Located or Larger Lung Tumors, Int. J. Radiat. Oncol. Biol. Phys 86, 407–413(2013). [DOI] [PubMed] [Google Scholar]
- 54.Zarepisheh M, Li R, Ye Y, and Xing L, Simultaneous Beam Sampling and Aperture Shape Optimization for SPORT, Med. Phys 42, 1012–1022 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]