

Abstract
Avoiding overfitting is a central challenge in machine learning, yet many large neural networks readily achieve zero training loss. This puzzling contradiction necessitates new approaches to the study of overfitting. Here we quantify overfitting via residual information, defined as the bits in fitted models that encode noise in training data. Information efficient learning algorithms minimize residual information while maximizing the relevant bits, which are predictive of the unknown generative models. We solve this optimization to obtain the information content of optimal algorithms for a linear regression problem and compare it to that of randomized ridge regression. Our results demonstrate the fundamental trade-off between residual and relevant information and characterize the relative information efficiency of randomized regression with respect to optimal algorithms. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil information-theoretic analogs of double and multiple descent phenomena.
1. Information bottleneck
Conventional wisdom identifies overfitting as being detrimental to generalization performance, yet modern machine learning is dominated by models that perfectly fit training data. Recent attempts to resolve this dilemma have offered much needed insight into the generalization properties of perfectly fitted models [1, 2]. However investigations of overfitting beyond generalization error have received less attention. In this work we present a quantitative analysis of overfitting based on information theory and, in particular, the information bottleneck (IB) method [3].
The essence of learning is the ability to find useful and generalizable representations of training data. An example of such a representation is a fitted model which may capture statistical correlations between two variables (regression and pattern recognition) or the relative likelihood of random variables (density estimation). While what makes a representation useful is problem specific, a good model generalizes well—that is, it is consistent with test data even though they are not used at training.
Achieving good generalization requires information about the unknown data generating process. Maximizing this information is an intuitive strategy, yet extracting too many bits from the training data hurts generalization [4, 5]. This fundamental trade-off underpins the IB principle, which formalizes the notion of a maximally efficient representation as an optimization problem [3]1
| (1) |
Here W denotes the data generating process. The conditional distribution QT|S denotes a learning algorithm which defines a stochastic mapping from the training data S to the hypothesis or fitted model T (Fig 1a). The relevant information, I(T; W), is the bits in T that are informative of the generative model W. On the other hand, the residual information, I(S;T | W), is the bits in T that are specific to each realization of the training data S and thus are not informative of W. In other words the residual bits measure the degree of overfitting. The parameter γ controls the trade-off between these two informations.
Figure 1: Information optimal algorithm—

a A learning algorithm QT|Y is a mapping from training data Y to fitted models T. Information optimal algorithms minimize residual bits I(T; Y | W)—which are uninformative of the unknown generative model W—at fixed relevance level μ, defined as the ratio between the encoded and available relevant bits, I(T; W) and I(Y; W). b–d The information content of optimal algorithms for learning a linear map (Sec 1.1) at various measurement densities N/P (see color bar). b Optimal algorithms cannot increase the relevance level without encoding more residual bits. Increasing N/P reduces the residual bits per sample but only when N ≲ P. This results from the change in sample size dependence of relevant bits in the data from linear to logarithmic around N ≈ P (inset). That is, available relevant bits in each sample become redundant around N ≈ P and increasingly so as N increases further. Learning algorithms use this redundancy to better distinguish signals from noise, thereby requiring fewer residual bits per sample. c-d The IB frontiers in (b) are parametrized by a spectral cutoff ψc [see Eqs (8–9)]. Here we set ω2/σ2 = 1 and let P, N → ∞ at the same rate such that the ratio N/P remains fixed and finite. The empirical spectral distribution FΨ follows the standard Marchenko-Pastur law (see Sec 4).
The IB method has found success in a diverse array of applications, from neural coding [6, 7], developmental biology [8] and statistical physics [9–11] to clustering [12], deep learning [13–15] and reinforcement learning [16].
Indeed the IB principle has emerged as a potential candidate for a unifying framework for understanding learning phenomena [15, 17–19] and a number of recent works have explored deep connections between information-theoretic quantities and generalization properties [4, 5,20–28]. However a direct application of information theory to practical learning algorithms is often limited by the difficulty in estimating information, especially in high dimensions. While recent advances in characterizing variational bounds of mutual information have enabled a great deal of scalable, information-theory inspired learning methods [13, 29, 30], these bounds are generally loose and may not reflect the true behaviors of information.
To this end we consider a tractable problem of learning a linear map. We show that the level of overfitting, as measured by the encoded residual bits, is nonmonotonic in sample size, exhibiting a maximum near the crossover between under- and overparametrized regimes. We also demonstrate that additional maxima can develop under anisotropic covariates. As the residual information bounds the generalization gap [4, 5], its nonmonotonicity can be viewed as an information-theoretic analog of (sample-wise) multiple descent—the existence of disjoint regions in which more data hurt generalization (see, e.g., Refs [31, 32]). Using an IB optimal representation as a baseline, we show that the information efficiency of a randomized least squares regression estimator exhibits sample-wise nonmonotonicity with a minimum near the residual information peak. Finally we discuss how redundant coding of relevant information in the data gives rise to the nonmonotonicity of the encoded residual bits and how additional maxima emerge from covariate anisotropy (Sec 4).
1.1. Generative model
Linear map—
We consider training data of N iid samples, S = {(x1, y1), …, (xN, yN)}, each of which is a pair of P dimensional input vector and scalar response for i ∈ {1, …, N}. We assume a linear relation between the input and response,
| (2) |
where denotes the unknown linear map and ϵi a scalar Gaussian noise with mean zero and variance σ2. In other words the responses and the inputs are related via a Gaussian channel
| (3) |
where we define and .
Fixed design—
We adopt the fixed design setting in which the inputs (design matrix) X are deterministic and only the responses Y are random variables (see, e.g., Ref [33, Ch 3]). As a result, the mutual information between the training data S and any random variable A is given by I(A; S) = I(A; X, Y) = I(A; Y). In the following analyses, we use S and Y interchangeably.
Random effects—
In addition we work in the random effects setting (see, e.g., [34, 35] for recent applications of this setting) in which the true regression parameter W is a Gaussian vector,
| (4) |
Here we define the covariance such that the signal strength, , is independent of P.
1.2. Information optimal algorithm
The data generating process above results in training data Y and true parameters W that are Gaussian correlated (under the fixed design setting). In this case the IB optimization—minimizing residual information I(T; Y | W) while maximizing relevant information I(T; W)—admits an exact solution [36], characterized by the eigenmodes of the normalized regression matrix,
| (5) |
where λ* denotes the scaled noise-to-signal ratio. The relevant and residual informations of an optimal representation read [36]
| (6) |
| (7) |
where vi denote the eigenvalues of and γ parametrizes the IB trade-off2 [see Eq (1)]. In our setting it is convenient to recast the summations above as integrals (see Appendix A for derivation),
| (8) |
| (9) |
where Ψ = XX⊤/N and FΨ denote the empirical covariance and its cumulative spectral distribution, respectively.3 In addition we introduce the parameter ψc = λ*/(γ – 1) which controls the number and the weights of eigenmodes used in constructing the optimal representation . In the limit ψc →0+, the residual information diverges logarithmically (Fig 1d) and the relevant information converges to the available relevant information in the data (Fig 1c),
| (10) |
Increasing ψc from zero decreases both residual and relevant informations, tracing out the optimal frontier until the lower spectral cutoff ψc reaches the upper spectral edge at which both informations vanish (Fig 1b) and beyond which no informative solution exists [36–38].
1.3. Information efficiency
The exact characterization of the IB frontier provides a useful benchmark for information-theoretic analyses of learning algorithms, not least because it allows a precise definition of information efficiency. That is, we can now ask how many more residual bits a given algorithm needs to encode, compared to the IB optimal algorithm, in order to achieve the same level of relevant information. Here we define the information efficiency ημ as the ratio between the residual bits encoded in the outputs of the IB optimal algorithm and the algorithm of interest— and T, respectively—at some fixed relevance level μ, i.e.,
| (11) |
Since the optimal representation minimizes residual bits at fixed μ (Fig 1a), the information efficiency ranges from zero to one, 0 ≤ ημ ≤ 1. In addition we have 0 < μ ≤ 1, resulting from the data processing inequality I(T; W) ≤ I(Y; W) for the Markov constraint T↔Y↔W (see, e.g., Ref [39]).
2. Gibbs-posterior least squares regression
We consider one of the best-known learning algorithms: least squares linear regression. Not only is this algorithm widely used in practice, it has also proved a particularly well-suited setting for analyzing learning in the overparametrized regime [40–47]. Indeed it exhibits some of the most intriguing features of overparametrized learning, including benign overfitting and double descent which describe the surprisingly good generalization performance of overparametrized models and its nonmonotonic dependence on model complexity and sample size [31,42, 48].
Inferring a model from data generally requires an assumption on a class of models, which defines the hypothesis space, as well as a learning algorithm, which outputs a hypothesis according to some criteria that rank how well each hypothesis explains the data. Linear regression restricts the model class to a linear map, parametrized by , between an input xi and a predicted response ,
| (12) |
Minimizing the mean squared error yields a closed form solution for the estimated regressor, T* = (XX⊤)−1XY. However, this requires XX⊤ to be invertible and thus does not work in the overparametrized regime in which the sample covariance is not full rank and infinitely many models have vanishing mean squared error.
There are several approaches to break this degeneracy but perhaps the simplest and most studied is the ridge regularization which adds to the mean squared error the preference for model parameters with small L2 norm, resulting in the regularized loss function
| (13) |
where λ > 0 controls the regularization strength. Minimizing this loss function leads to a unique solution even when N < P.
Gibbs posterior—
While ridge regression works in the overparametrized regime, it is a deterministic algorithm which does not readily lend itself to information-theoretic analyses because the mutual information between two deterministically related continuous random variables diverges. Instead we consider the Gibbs posterior (or Gibbs algorithm) which becomes a Gaussian channel when defined with the ridge regularized loss in Eq (13),
| (14) |
Here β denotes the inverse temperature. In the zero temperature limit β →∞, this algorithm returns the usual ridge regression estimate (the mean of the above normal distribution) with probability approaching one. Whilst randomized ridge regression needs not take the form above, Gibbs posteriors are attractive, not least because they naturally emerge, for example, from information-regularized risk minimization [5] (see also Ref [27] for a recent discussion).
Markov constraint—
The generative model PY|W, true parameter distribution PW and learning algorithm QT|Y [Eqs (3–4) & (14)] completely describe the relationship between all random variables of interest through the Markov factorization of their joint distribution (Fig 1a),
| (15) |
Note that PY|W = PY|X,W and QT|Y = QT|X,Y in the fixed design setting (see Sec 1.1).
3. Information content of Gibbs regression
We now turn to the relevant and residual informations of the models that result from the Gibbs regression algorithm [Eq (14)]. Since all distributions appearing on the rhs of Eq (15) are Gaussian, the relevant and residual informations are given by
| (16) |
Here we use the fact that ΣT|W,Y = ΣT|Y due to the Markov constraint [Eq (15)]. The covariance ΣT|Y is defined by the learning algorithm in Eq (14). To obtain ΣT|W and ΣT, we marginalize out Y and W in order from PT,Y,W [Eqs (3–4) & (14–15)] and obtain
| (17) |
| (18) |
Substituting the covariance matrices above into Eq (16) yields (see Appendix B for derivation)
| (19) |
| (20) |
The integration domains are restricted to positive real numbers since the eigenvalues of a covariance matrix are non-negative and the integrands vanish at ψ = 0.
In the zero temperature limit β → ∞, the residual information diverges (as expected from a deterministic algorithm [23, 24]; see also Fig 2c) whereas the relevant information approaches the mutual information between the data Y and the true parameter W,
| (21) |
Relevant and residual informations decrease with β until they vanish as β → 0+ at which Gibbs posteriors become completely random (Fig 2a–c).
Figure 2: Gibbs regression—
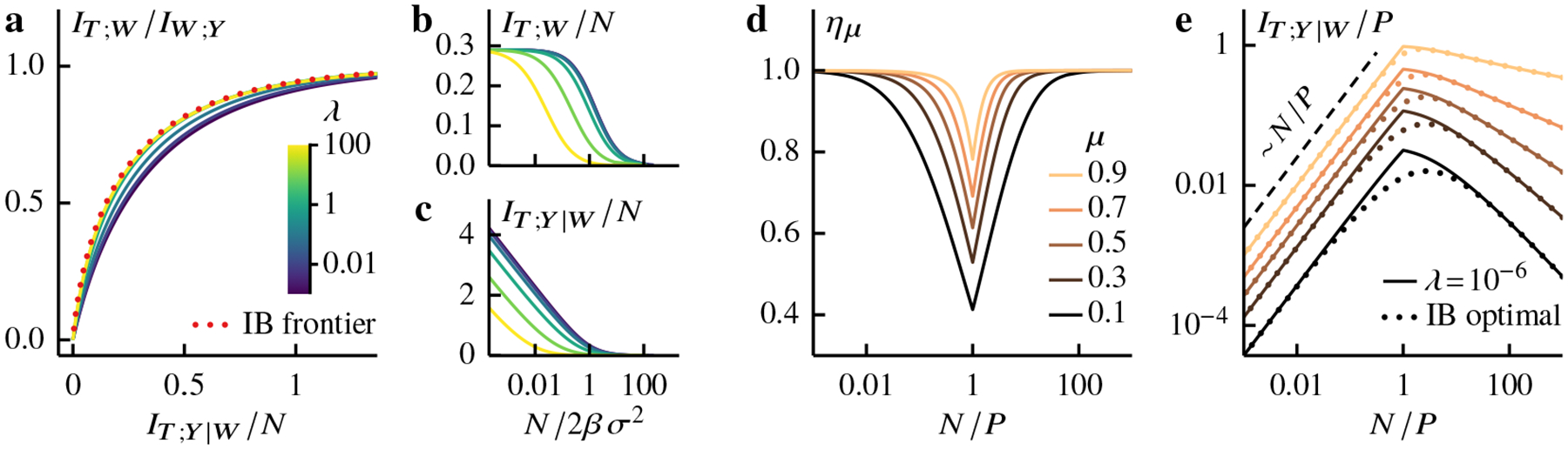
a-c The information content of Gibbs regression [Eq (14)] at N/P = 1 and various regularization strengths λ (see color bar). a The information curves of Gibbs regression are bounded by the IB frontier (dotted curve). b-c The inverse temperature β controls the stochasticity of Gibbs posteriors [Eqs (19–20)]. Both relevant and residual bits decrease with temperature and vanish in the limit β → 0 where Gibbs posteriors become completely random. d-e Information efficiency [Eq (11)] and residual information of Gibbs regression with λ = 10−6 vs measurement ratio at various relevance levels μ (see legend). d Gibbs regression approaches optimality in the limits, N ≫ P and N ≪ P, and becomes least efficient at N/P = 1. e Residual bits of Gibbs regression and optimal algorithm (dotted) grow linearly with N when N ≲ P. This growth is similar to that of the available relevant bits (Fig 1b inset). But while the available relevant bits always increase with N, the residual bits decrease as N exceeds P. Here we set ω2/σ2 = 1 and let P, N → ∞ at the same rate such that the ratio N/P remains fixed and finite. The eigenvalues of the sample covariance follow the standard Marchenko-Pastur law (see Sec 4).
3.1. Zero temperature limit
At first sight it appears that our analyses are not applicable in the high-information limit since the residual information diverges for both the optimal algorithm and Gibbs regression (see Figs 1d&2c). However the rates of divergence differ. Here we use this difference to characterize the efficiency of Gibbs regression in the zero temperature limit β → ∞.
We first analyze the limiting behaviors of relevant information. From Eq (10), we see that the relevant information ratio of the IB solution approaches one at ψc = 0. Perturbing ψc in Eq (8) away from zero results in a linear correction to the relevant information,
| (22) |
Keeping only the leading correction and recalling that [Eq (11)], we obtain
| (23) |
Similarly expanding the relevant information of Gibbs regression [Eq (19)] around β → ∞ yields
| (24) |
As a result, the correspondence between the low-temperature and high-information limits reads
| (25) |
We turn to the residual bits. Expanding Eq (9) around ψc = 0 and Eq (20) around β−1 = 0 leads to
| (26) |
| (27) |
From Eqs (23) & (25), we see that the residual informations above have the same logarithmic singularity, ln(1 – μ), at μ = 1. Therefore their difference remains finite even as μ → 1. Combining Eqs (23) & (25–27) and recalling our definition of information efficiency [Eq (11)] gives
| (28) |
Note that Jensen’s inequality guarantees that the terms in the parentheses sum to a non-negative value.
It is worth pointing out that, at λ = λ*, the correction term in Eq (28) vanishes and the efficiency of deterministic Gibbs regression becomes minimally sensitive to algorithmic noise. Incidentally, this value of λ also minimizes the L2 prediction error of ridge regression in the asymptotic limit [40].
4. High dimensional limit
To place our results in the context of high dimensional learning, we specialize to the thermodynamic limit in which sample size and input dimension tend to infinity at a fixed ratio—that is, N, P → ∞ at N/P = n ∈ (0, ∞). While it is easy to grow the dimension of the true parameter W (Sec 1.1), we have so far not specified how the design matrix X, and thus the training data Y, should scale in this limit.
To this end, we consider a setting in which the design matrix is generated from X = Σ1/2Z where is a matrix with iid entries drawn from a distribution with zero mean and unit variance, and is a covariance matrix.4 If Σ admits a limiting spectral density as P → ∞, then the empirical spectral distribution FΨ becomes deterministic [49, 50].
To aid interpretation of our results, we frame all of the following discussions from the perspective that the input dimension P is held fixed and a change in measurement density n = N/P results only from a change in sample size N.
4.1. Isotropic covariates
For Σ = IP, the empirical spectral distribution converges to to the standard Marchenko-Pastur law [49]
| (29) |
where and FΨ (0) = max(0,1 – n). We use this spectral distribution in Figs 1–2.
Optimal algorithm—
In Fig 1b, the IB optimal frontiers illustrate the fundamental trade-off; optimal algorithms cannot encode fewer residual bits without becoming less relevant. Figure 1c–d shows that encoded relevant and residual bits go down as ψc increases and fewer eigenmodes contribute to the IB optimal representation [Eqs (8–9)]. However relevant and residual informations exhibit different behaviors at high information; as ψc → 0, relevant information plateaus whereas residual information diverges logarithmically [see also Eq (26)].
Gibbs regression—
Figure 2a depicts the information content of Gibbs regression at different regularization strengths [Eqs (19–20)] and illustrates the fundamental trade-off, similarly to the IB frontier (dotted) but at a lower relevance level. Here the information curves are parametrized by the inverse temperature β which controls the algorithmic stochasticity; Gibbs posteriors become deterministic as β → ∞ and completely random at β = 0 [Eq (14)]. In Fig 2b–c, we see that Gibbs regression encodes fewer relevant and residual bits as temperature goes up. Decreasing Gibbs temperature results in an increase in encoded information. In the zero-temperature limit, the relevant bits saturate while the residual bits grow logarithmically (cf. Fig 1c–d; see Sec 3.1 for a detailed analysis of this limit). The amount of encoded information depends also on the regularization strength λ. Figure 2b–c shows that, at a fixed temperature, an increase in λ leads to less information extracted. However this does not necessarily mean that a larger λ hurts information efficiency. Indeed a lower temperature can compensate for the decrease in information. In Fig 2a, we see that the information curves can be closer to the optimal frontier as λ increases. In general the maximum efficiency occurs at an intermediate regularization strength that depends on data structure and measurement density (see also Sec 4.2).
Efficiency—
Figure 2d displays the information efficiency of Gibbs regression at different relevant information levels (see Sec 1.3). We see that the efficiency approaches optimality (ημ= 1) in the limits n → 0 and n → ∞. Away from these limits, Gibbs regression requires more residual bits than the optimal algorithm to achieve the same level of relevance with an efficiency minimum around n = 1. We also see that the efficiency of Gibbs regression decreases with relevance level (see also Supplementary Figure in Appendix D).
Extensivity—
Learning is qualitatively different in the over- and underparametrized regimes. In Fig 2e we see that both optimal algorithms and Gibbs regression exhibit nonmonotonic dependence on sample size. In the overparametrized regime n < 1, the residual information is extensive in sample size, i.e., it grows linearly with N. This scaling behavior mirrors that of the relevant bits in the data (Fig 1b inset). But unlike the available relevant bits which continue to grow in the data-abundant regime, albeit sublinearly—the encoded residual bits decrease with sample size in this limit (see also Supplementary Figure in Appendix D). The resulting maximum is an information-theoretic analog of double descent—the decrease in overfitting level (test error) as the number of parameters exceeds sample size (decreasing n) [31,48].
Redundancy—
Indeed we could have anticipated the extensive behavior of the residual bits in the overparametrized regime (Fig 2e). In this limit, the extensivity of available relevant bits implies that the data encode relevant information with no redundancy. In other words, the relevant bits in one observation do not overlap with that in another. As a result, the dominant learning strategy is to treat each sample separately and extract the same amount of information from each of them, thus resulting in extensive residual information. In the data-abundant regime, on the other hand, the coding of relevant bits in the data becomes increasingly redundant (Fig 1b inset). Learning algorithms exploit this redundancy to better distinguish signals from noise, thereby encoding fewer residual bits.
4.2. Anisotropic covariates
To explore the effects of anisotropy, we consider a two-scale model in which the population spectral distribution FΣ is an equal mixture of two point masses at s+ and s−. We normalize the trace of the population covariance such that the signal variance, and thus the signal-to-noise ratio, does not depend on FΣ—i.e., we set tr Σ/P = (s+ + s−)/2 = 1 such that . As a result the anisotropy in our two-scale model is parametrized completely by the eigenvalue ratio r ≡ s−/s+.
Unlike the isotropic case, the limiting empirical spectral distribution does not admit a closed form expression. We obtain FΨ by solving the Silverstein equation and inverting the resulting Stieltjes transform [51] (see Appendix C). Figure 3c depicts the spectral density at various anisotropy ratios and measurement densities. At high measurement densities n ≳ 1, anisotropy splits the continuum part of the spectrum into two bands, corresponding to the two modes of the population covariance. These bands broaden as n decreases and eventually merge into one in the overparametrized limit.
Figure 3: Multiple descent under anisotropic covariates—
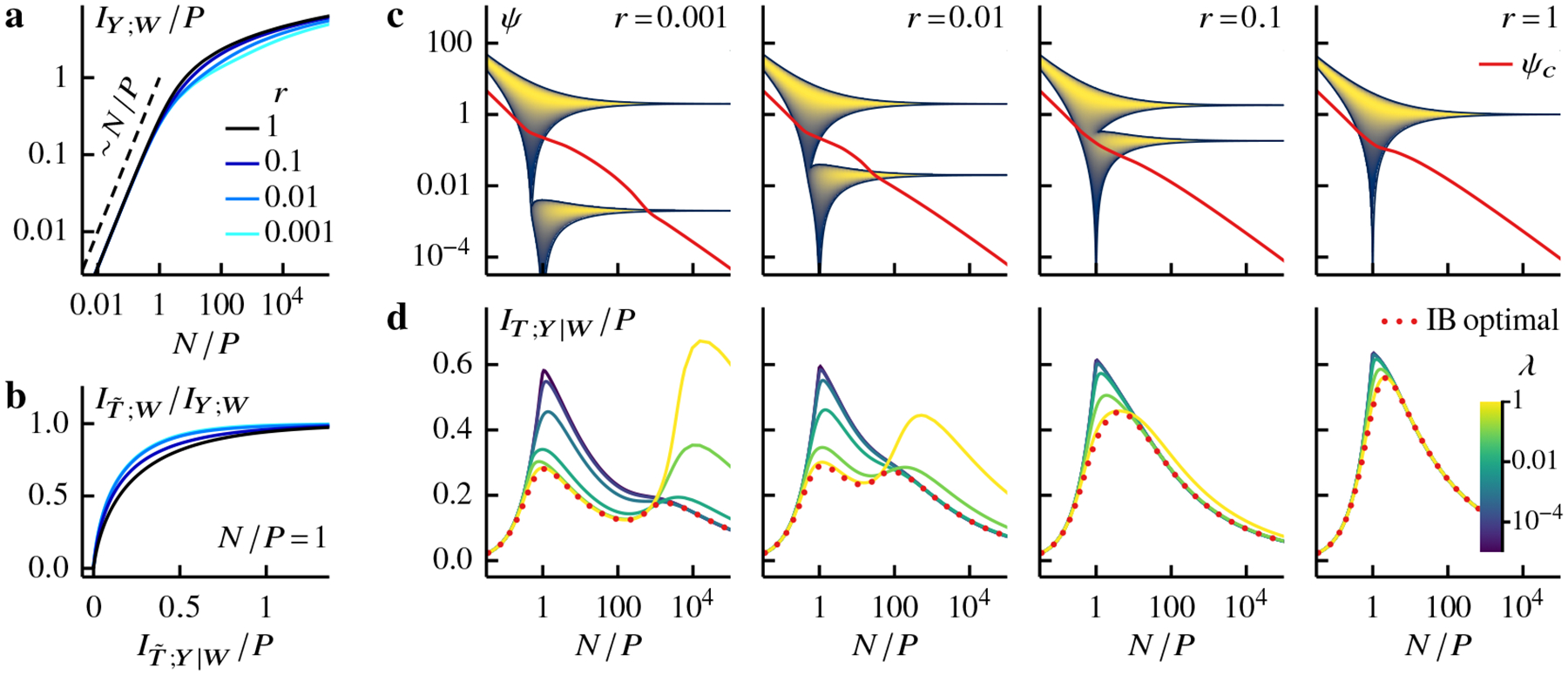
a The relevant bits in the data decreases slightly as the anisotropy ratio r departs from one (see legend). When n ≲ 0, the available relevant information grow linearly with N. Strong anisotropy sees this growth start becoming sublinear at smaller N/P. b The IB frontiers at N/P = 1. We see that while less relevant information is available in the anisotropic case, it takes fewer residual bits to achieve the same relevance level as the isotropic case (see legend in a). c The empirical spectral density of the sample covariance at different anisotropy ratios (see labels). Each vertical line is normalized by its maximum. We see that anisotropy splits the spectral continuum into two bands which merge into one as N/P decreases. The solid line depicts the IB cutoff ψc [Eqs (8–9)] for the relevance level μ = 0.8. e The residual information of optimal algorithms (dotted) and Gibbs regression at various regularization strengths (see color bar) for μ = 0.8 and different anisotropy ratios (same labels as in c). Here we set ω2/σ2 = 1 and let P, N → ∞ at the same rate such that the ratio N/P remains fixed and finite. The eigenvalues of the sample covariance follows the general Marchenko-Pastur theorem (see Sec 4.2).
Available information—
In Fig 3a, we see that anisotropy decreases the relevant information in the data, but does not affect its qualitative behaviors: the available relevant bits are extensive in the overparametrized regime and subextensive in the data-abundant regime. Although fewer relevant bits are available, learning needs not be less information efficient. Indeed the IB frontiers in Fig 3b illustrate that it takes fewer residual bits in the anisotropic case to reach the same level of relevance as in the isotropic case. This behavior is also apparent in Fig 3d (dotted) as we increase anisotropy levels (from right to left panels).
Anisotropy effects—
Anisotropy affects optimal algorithms via the different scales in the population covariance. The signals along high-variance (easy) directions are stronger and, as a result, the coding of relevant bits in these directions becomes subextensive and redundant around n ≈ 1/2 (the proportion of easy directions) instead of at one (Fig 3a). This earlier onset of redundancy allows for more effective signal-noise discrimination in the anisotropic case (Fig 3b & d). In the data-abundant limit, however, low-variance (hard) directions become important as learning algorithms already encode most of the relevant bits along the easy directions. Indeed the hard directions are harder for more anisotropic inputs and thus the required residual bits increase with anisotropy in the limit n → ∞ (Fig 3d).
Triple descent—
Perhaps the most striking effect of anisotropy is the emergence of an information-theoretic analog of (sample-wise) multiple descent, which describes disjoint regions where more data makes overfitting worse (larger test error) [32, 52]. In Fig 3d, we see that an additional residual information maximum emerges at large n. This behavior is a consequence of the separation of scales. The first maximum at n ~ 1 originates from easy directions and the other maximum at higher n from hard directions. In fact the IB cutoff ψc in Fig 3c demonstrates that the residual information maxima roughly coincide with the inclusion of all high-variance modes around n ~ 1 and low-variance modes at higher n.5 In addition we note that for optimal algorithms the first maximum shifts to a lower n as the anisotropy level increases. This observation is consistent with the fact that the onset of redundancy of relevant bits in the data occurs at smaller n in the anisotropic case (Fig 3a).
Gibbs regression—
Anisotropy makes Gibbs regression depend more strongly on regularization strengths, see Fig 3. In particular the information efficiency decreases with λ near the first residual information minimum around n ~ 1 but this dependence reverses near the second maximum and at larger n. This behavior is expected. Inductive bias from strong regularization helps prevent noise from poisoning the models at small n. But when the data become abundant, regularization is unnecessary.
5. Conclusion & Outlook
We use the information bottleneck theory to analyze linear regression problems and illustrate the fundamental trade-off between relevant bits, which are informative of the unknown generative processes, and residual bits, which measure overfitting. We derive the information content of optimal algorithms and Gibbs posterior regression, thus enabling a quantitative investigation of information efficiency. In addition our analytical results on the zero temperature limit of the Gibbs posterior offer a glimpse of a connection between information efficiency and optimally tuned ridge regression. Finally, using results from random matrix theory, we reveal the information complexity of learning a linear map in high dimensions and unveil an information-theoretic analog of multiple descent phenomena. Since residual information is an upper bound on the generalization gap [4, 5], we believe that this information nonmonotonicity could be connected to the original double descent phenomena. But it remains to be seen how deep this connection is.
Our work paves the way for a number of different avenues for future research. While we only focus on isotropic regularization here, it would be interesting to understand how structured regularization affects information extraction. Information-efficiency analyses of different algorithms, such as Bayesian regression, and other classes of learning problems, e.g., classification and density estimation, are also in order. An investigation of information efficiency based on other f -divergence could lead to new insights into generalization. In particular an exact relationship exists between residual Jeffreys information and generalization error of Gibbs posteriors [27]. Finally exploring how coding redundancy in training data quantitatively affects learning phenomena in general would make for an exciting research direction (see, e.g., Refs [17, 19]).
Acknowledgments and Disclosure of Funding
This work was supported in part by the National Institutes of Health BRAIN initiative (R01EB026943), the National Science Foundation, through the Center for the Physics of Biological Function (PHY-1734030), the Simons Foundation and the Sloan Foundation.
A. Information content of maximally efficient algorithms
Consider an IB problem where we are interested in an information efficient representation of Y that is predictive of W (Fig 1a). When Y and W are Gaussian correlated, the central object in constructing an IB solution is the normalized regression matrix ; in particular, its eigenvalues completely characterize the information content of the IB optimal representation via (see Ref [36] for a derivation)
| (30) |
| (31) |
where N is the dimension of Y and γ parametrizes the IB trade-off [Eq (1)].
Our work focuses on the following generative model for W and Y (see Sec 1.1)
| (32) |
Marginalizing out W yields
| (33) |
As a result, the normalized regression matrix reads
| (34) |
Substituting Eq (34) into Eqs (30–31) gives
| (35) |
| (36) |
where ϕi [X⊤X/N] denote the eigenvalues of X⊤X/N. Since the eigenvalues of X⊤X/N and the sample covariance Ψ = X⊤X/N are identical except for the zero modes which do not contribute to information, we can recast the above equations as
| (37) |
| (38) |
where ψi are the eigenvalues of Ψ and the summation limits change to P, the number of eigenvalues of Ψ. Introducing the cumulative spectral distribution FΨ and replacing the summations with integrals results in
| (39) |
| (40) |
We see that the contributions to the integrals come from the logarithms but only when they are positive. This condition can be recast into integration limits (note that γ > 0 and λ* > 0)
| (41) |
| (42) |
Finally we define the lower cutoff ψc ≡ λ*/(γ − 1) and use the above limits to rewrite the expressions for relevant and residual informations,
| (43) |
| (44) |
These equations are identical to Eqs (8–9) in the main text.
B. Information content of Gibbs-posterior regression
To compute the information content of Gibbs regression [Eq (14)], we first recall that the mutual information between two Gaussian correlated variables, A and B, is given by
| (45) |
where ΣA is the covariance of A, and ΣA|B of A | B.
We now write down the relevant information, using the covariances Σt|W and Σt from Eqs (17–18),
| (46) |
| (47) |
| (48) |
| (49) |
| (50) |
| (51) |
where λ* = Pσ2/Nω2. In the above, we use the identity Indet H = tr ln H which holds for any positive-definite Hermitian matrix H, let ψi denote the eigenvalues of the sample covariance Ψ and introduce FΨ, the cumulative distribution of eigenvalues. We also assume that λ and β are finite and positive. Note that the integral is limited to positive real numbers because the eigenvalues of a covariance matrix is non-negative and the integrand vanishes for ψ = 0.
Following the same logical steps as above and noting that the Markov constraint W ↔ Y ↔ T implies ΣT|Y,W = ΣT|Y, we write down the residual information,
| (52) |
| (53) |
| (54) |
| (55) |
where we use the covariance matrices ΣT|W and ΣT|W from Eqs (17) & (14).
C. Marchenko-Pastur law
Consider X = Σ1/2Z where is a matrix with iid entries drawn from a distribution with zero mean and unit variance, and is a covariance matrix. In addition we take the asymptotic limit N → ∞, N → ∞ and P/N → α ∈ (0, ∞). If the population spectral distribution FΣ converges to a limiting distribution, the spectral distribution of the sample covariance Ψ = XX⊤/N becomes deterministic [49]. The density, fΨ (ψ) = dfΨ(ψ)/dψ, is related to its Stieltjes transform m(z) via
| (56) |
We can obtain fΨ by solving the Silverstein equation for the companion Stieltjes transform v(z) [51],
| (57) |
and using the relation
| (58) |
Here denotes the upper half of the complex plane.
D. Supplementary figure
Figure 4:

Gibbs ridge regression is least information efficient around N/P = 1. a Residual information I(T; Y | W) of the IB optimal algorithm over a range of sample densities N/P (horizontal axis) and given extracted relevant bits I(T; W) (vertical axis). The extracted relevant bits are bounded by the available relevant bits in the data (black curve), i.e., the data processing inequality implies I(T; W) ≤ I(Y; W). b Same as (a) but for Gibbs regression with λ = 10−6. Holding other things equal, Gibbs regression estimators encode more residual bits than optimal representations. c Information efficiency, the ratio between residual bits in optimal representations (a) and Gibbs estimator (b), is minimum around N/P = 1. Here we set ω2/σ2 = 1 and let P, N → ∞ at the same rate such that the ratio N/P remains fixed and finite. The eigenvalues of the sample covariance follow the standard Marchenko-Pastur law (see Sec 4).
Footnotes
36th Conference on Neural Information Processing Systems (NeurIPS 2022).
Note that this minimization is identical to that of the original IB method since I(S; T|W) = I(S; T)−I(T; W) under the Markov constraint T ↔ S ↔ W.
The arguments of the logarithms in Eqs (6–7) are always nonnegative since the data processing inequality means that the IB problem is well-defined only for γ > 1, and the eigenvalues of a normalized regression matrix always range from zero to one [36].
Note that the eigenvalues of XX⊤ and X⊤X are identical except for the number of zero modes.
This prescription includes the case where input vectors are drawn iid from xi ~ N(0, Σ) for i ∈ {1, …, N}.
Note that Fig 3c does not show the zero modes which are present at n < 1. The fact that the spectral continuum appears to be above the IB cutoff at small n does not mean all eigenmodes are used in the IB solution.
References
- [1].Belkin M, Hsu DJ, and Mitra P, Overfitting or perfect fitting? Risk bounds for classification and regression rules that interpolate, in Advances in Neural Information Processing Systems, Vol. 31, edited by Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Curran Associates, Inc., 2018). [Google Scholar]
- [2].Belkin M, Rakhlin A, and Tsybakov AB, Does data interpolation contradict statistical optimality?, in Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 89, edited by Chaudhuri K and Sugiyama M (PMLR, 2019) pp. 1611–1619. [Google Scholar]
- [3].Tishby N, Pereira FCN, and Bialek W, The information bottleneck method, in 37th Allerton Conference on Communication, Control and Computing, edited by Hajek B and Sreenivas RS (University of Illinois, 1999) pp. 368–377. [Google Scholar]
- [4].Russo D and Zou J, Controlling Bias in Adaptive Data Analysis Using Information Theory, in Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Vol. 51, edited by Gretton A and Robert CC (PMLR, 2016) pp. 1232–1240. [Google Scholar]
- [5].Xu A and Raginsky M, Information-theoretic analysis of generalization capability of learning algorithms, in Advances in Neural Information Processing Systems, Vol. 30, edited by Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Curran Associates, Inc., 2017). [Google Scholar]
- [6].Palmer SE, Marre O, Berry MJ, and Bialek W, Predictive information in a sensory population, Proceedings of the National Academy of Sciences 112, 6908 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Wang S, Segev I, Borst A, and Palmer S, Maximally efficient prediction in the early fly visual system may support evasive flight maneuvers, PLOS Computational Biology 17, e1008965 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Bauer M, Petkova MD, Gregor T, Wieschaus EF, and Bialek W, Trading bits in the readout from a genetic network, Proceedings of the National Academy of Sciences 118, e2109011118 (2021). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Still S, Sivak DA, Bell AJ, and Crooks GE, Thermodynamics of Prediction, Physical Review Letters 109, 120604 (2012). [DOI] [PubMed] [Google Scholar]
- [10].Gordon A, Banerjee A, Koch-Janusz M, and Ringel Z, Relevance in the Renormalization Group and in Information Theory, Physical Review Letters 126, 240601 (2021). [DOI] [PubMed] [Google Scholar]
- [11].Kline AG and Palmer SE, Gaussian information bottleneck and the non-perturbative renormalization group, New Journal of Physics 24, 033007 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Strouse D and Schwab DJ, The Information Bottleneck and Geometric Clustering, Neural Computation 31, 596 (2019). [DOI] [PubMed] [Google Scholar]
- [13].Alemi AA, Fischer I, Dillon JV, and Murphy K, Deep Variational Information Bottleneck, in International Conference on Learning Representations (2017). [Google Scholar]
- [14].Achille A and Soatto S, Information Dropout: Learning Optimal Representations Through Noisy Computation, IEEE Transactions on Pattern Analysis and Machine Intelligence 40, 2897 (2018). [DOI] [PubMed] [Google Scholar]
- [15].Achille A and Soatto S, Emergence of Invariance and Disentanglement in Deep Representations, Journal of Machine Learning Research 19, 1 (2018). [Google Scholar]
- [16].Goyal A, Islam R, Strouse D, Ahmed Z, Larochelle H, Botvinick M, Levine S, and Bengio Y, Transfer and Exploration via the Information Bottleneck, in International Conference on Learning Representations (2019). [Google Scholar]
- [17].Bialek W, Nemenman I, and Tishby N, Predictability, Complexity, and Learning, Neural Computation 13, 2409 (2001). [DOI] [PubMed] [Google Scholar]
- [18].Shamir O, Sabato S, and Tishby N, Learning and generalization with the information bottleneck, Theoretical Computer Science 411, 2696 (2010), Algorithmic Learning Theory (ALT 2008). [Google Scholar]
- [19].Bialek W, Palmer SE, and Schwab DJ, What makes it possible to learn probability distributions in the natural world? (2020). [Google Scholar]
- [20].Alabdulmohsin I, An Information-Theoretic Route from Generalization in Expectation to Generalization in Probability, in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 54, edited by Singh A and Zhu J (PMLR, 2017) pp. 92–100. [Google Scholar]
- [21].Nachum I and Yehudayoff A, Average-Case Information Complexity of Learning, in Proceedings of the 30th International Conference on Algorithmic Learning Theory, Proceedings of Machine Learning Research, Vol. 98, edited by Garivier A and Kale S (PMLR, 2019) pp. 633–646. [Google Scholar]
- [22].Negrea J, Haghifam M, Dziugaite GK, Khisti A, and Roy DM, Information-Theoretic Generalization Bounds for SGLD via Data-Dependent Estimates, in Advances in Neural Information Processing Systems, Vol. 32, edited by Wallach H, Larochelle H, Beygelzimer A, d’Alchd-Buc F, Fox E, and Garnett R (Curran Associates, Inc., 2019). [Google Scholar]
- [23].Bu Y, Zou S, and Veeravalli VV, Tightening Mutual Information-Based Bounds on Generalization Error, IEEE Journal on Selected Areas in Information Theory 1, 121 (2020). [Google Scholar]
- [24].Steinke T and Zakynthinou L, Reasoning About Generalization via Conditional Mutual Information, in Proceedings of Thirty Third Conference on Learning Theory, Proceedings of Machine Learning Research, Vol. 125, edited by Abernethy J and Agarwal S (PMLR, 2020) pp. 3437–3452. [Google Scholar]
- [25].Haghifam M, Negrea J, Khisti A, Roy DM, and Dziugaite GK, Sharpened Generalization Bounds based on Conditional Mutual Information and an Application to Noisy, Iterative Algorithms, in Advances in Neural Information Processing Systems, Vol. 33, edited by Larochelle H, Ranzato M, Hadsell R, Balcan M, and Lin H (Curran Associates, Inc., 2020) pp. 9925–9935. [Google Scholar]
- [26].Neu G, Dziugaite GK, Haghifam M, and Roy DM, Information-Theoretic Generalization Bounds for Stochastic Gradient Descent, in Proceedings of Thirty Fourth Conference on Learning Theory, Proceedings of Machine Learning Research, Vol. 134, edited by Belkin M and Kpotufe S (PMLR, 2021) pp. 3526–3545. [Google Scholar]
- [27].Aminian G, Bu Y, Toni L, Rodrigues M, and Wornell G, An Exact Characterization of the Generalization Error for the Gibbs Algorithm, in Advances in Neural Information Processing Systems, Vol. 34, edited by Ranzato M, Beygelzimer A, Dauphin Y, Liang P, and Vaughan JW (Curran Associates, Inc., 2021) pp. 8106–8118. [Google Scholar]
- [28].Chen Q, Shui C, and Marchand M, Generalization Bounds For Meta-Learning: An Information-Theoretic Analysis, in Advances inNeural Information Processing Systems, Vol. 34, edited by Ranzato M, Beygelzimer A, Dauphin Y, Liang P, and Vaughan JW (Curran Associates, Inc., 2021) pp. 25878–25890. [Google Scholar]
- [29].Chalk M, Marre O, and Tkacik G, Relevant sparse codes with variational information bottleneck, in Advances in Neural Information Processing Systems, Vol. 29, edited by Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Curran Associates, Inc., 2016) pp. 1957–1965. [Google Scholar]
- [30].Poole B, Ozair S, Van Den Oord A, Alemi A, and Tucker G, On Variational Bounds of Mutual Information, in Proceedings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 97, edited by Chaudhuri K and Salakhutdinov R (PMLR, 2019) pp. 5171–5180. [Google Scholar]
- [31].Nakkiran P, Kaplun G, Bansal Y, Yang T, Barak B, and Sutskever I, Deep Double Descent: Where Bigger Models and More Data Hurt, in International Conference on Learning Representations (2020). [Google Scholar]
- [32].d’Ascoli S, Sagun L, and Biroli G, Triple descent and the two kinds of overfitting: where & why do they appear?, in Advances in Neural Information Processing Systems, Vol. 33, edited by Larochelle H, Ranzato M, Hadsell R, Balcan M, and Lin H (Curran Associates, Inc., 2020) pp. 3058–3069. [Google Scholar]
- [33].Hastie T, Tibshirani R, and Friedman J, The Elements of Statistical Learning, 2nd ed. (Springer, 2009). [Google Scholar]
- [34].Sheng Y and Dobriban E, One-shot Distributed Ridge Regression in High Dimensions, in Proceedings of the 37th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 119, edited by D. H III and Singh A (PMLR, 2020) pp. 8763–8772. [Google Scholar]
- [35].Liu S and Dobriban E, Ridge Regression: Structure, Cross-Validation, and Sketching, in International Conference on Learning Representations (2020). [Google Scholar]
- [36].Chechik G, Globerson A, Tishby N, and Weiss Y, Information bottleneck for Gaussian variables, Journal of Machine Learning Research 6, 165 (2005). [Google Scholar]
- [37].Wu T and Fischer I, Phase Transitions for the Information Bottleneck in Representation Learning, in International Conference on Learning Representations (2020). [Google Scholar]
- [38].Ngampruetikorn V and Schwab DJ, Perturbation Theory for the Information Bottleneck, in Advances in Neural Information Processing Systems, Vol. 34, edited by Ranzato M, Beygelzimer A, Dauphin Y, Liang P, and Vaughan JW (Curran Associates, Inc., 2021) pp. 21008–21018. [PMC free article] [PubMed] [Google Scholar]
- [39].Cover TM and Thomas JA, Elements of Information Theory, 2nd ed. (Wiley-Interscience, 2006). [Google Scholar]
- [40].Dobriban E and Wager S, High-dimensional asymptotics of prediction: Ridge regression and classification, The Annals of Statistics 46, 247 (2018). [Google Scholar]
- [41].Hastie T, Montanari A, Rosset S, and Tibshirani RJ, Surprises in high-dimensional ridgeless least squares interpolation, The Annals of Statistics 50, 949 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Bartlett PL, Long PM, Lugosi G, and Tsigler A, Benign overfitting in linear regression, Proceedings of the National Academy of Sciences 117, 30063 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Emami M, Sahraee-Ardakan M, P Pandit S Rangan, and A. Fletcher, Generalization Error of Generalized Linear Models in High Dimensions, in Proceedings of the 37th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 119, edited by D. H III and Singh A (PMLR, 2020) pp. 2892–2901. [Google Scholar]
- [44].Li Z, Xie C, and Wang Q, Provable More Data Hurt in High Dimensional Least Squares Estimator (2020). [Google Scholar]
- [45].Wu D and Xu J, On the Optimal Weighted ℓ2 Regularization in Overparameterized Linear Regression, in Advances in Neural Information Processing Systems, Vol. 33, edited by Larochelle H, Ranzato M, Hadsell R, Balcan M, and Lin H (Curran Associates, Inc., 2020) pp. 10112–10123. [Google Scholar]
- [46].Mel G and Ganguli S, A theory of high dimensional regression with arbitrary correlations between input features and target functions: sample complexity, multiple descent curves and a hierarchy of phase transitions, in Proceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 139, edited by Meila M and Zhang T (PMLR, 2021) pp. 7578–7587. [Google Scholar]
- [47].Richards D, Mourtada J, and Rosasco L, Asymptotics of Ridge(less) Regression under General Source Condition, in Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, Vol. 130, edited by Banerjee A and Fukumizu K (PMLR, 2021) pp. 3889–3897. [Google Scholar]
- [48].Belkin M, Hsu D, Ma S, and Mandal S, Reconciling modern machine-learning practice and the classical bias-variance trade-off, Proceedings of the National Academy of Sciences 116, 15849 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [49].Marčenko VA and Pastur LA, Distribution of eigenvalues for some sets of random matrices, Mathematics of the USSR-Sbornik 1, 457 (1967). [Google Scholar]
- [50].Silverstein J, Strong Convergence of the Empirical Distribution of Eigenvalues of Large Dimensional Random Matrices, Journal of Multivariate Analysis 55, 331 (1995). [Google Scholar]
- [51].Silverstein J and Choi S, Analysis of the Limiting Spectral Distribution of Large Dimensional Random Matrices, Journal of Multivariate Analysis 54, 295 (1995). [Google Scholar]
- [52].Chen L, Min Y, Belkin M, and Karbasi A, Multiple Descent: Design Your Own Generalization Curve, in Advances in Neural Information Processing Systems, Vol. 34, edited by Ranzato M, Beygelzimer A, Dauphin Y, Liang P, and Vaughan JW (Curran Associates, Inc., 2021) pp. 8898–8912. [Google Scholar]