

Abstract
This perspective presents a brief overview of the background of Gradient-free tuning for large language models competition, the championship scheme, as well as the challenges and future directions.
PROBLEM
Recent years have witnessed the rapid progress of self-supervised language models (LMs) [1], especially large language models (LLMs) [2]. LLMs not only achieved state-of-the-art performance on many natural language processing tasks, but also captured widespread attention from the public due to their great potential in a variety of real-world applications (e.g. chatbots, search engines, writing assistants, etc.) through providing general-purpose intelligent services. A few of the LLMs are becoming foundation models, an analogy to infrastructure, that empower hundreds of downstream applications. Currently, most competitive LLMs such as OpenAI’s GPT-3 [2] are released as services, allowing users to access these powerful models through black-box APIs. In such a scenario, termed language-model-as-a-service (LMaaS) [3], how to solve downstream tasks through black-box APIs is a challenging problem.
The challenge mainly lies in the invisibility of the model weights and their gradients, making conventional backpropagation-based training techniques infeasible. As an alternative, derivative-free optimization (DFO) does not depend on gradients but relies only on function values, i.e. the results returned by the black-box API. However, LLMs have tens or even hundreds of billions of parameters and DFO suffers from a slow convergence rate when the dimensionality of the search space is high. It has been demonstrated that combining parameter-efficient tuning and DFO methods can effectively drive LLMs through their black-box APIs to solve a variety of classification tasks under few-shot settings [3,4]. Despite their success, these methods, named black-box tuning, still lag behind backpropagation on some difficult tasks such as many-label classification tasks and entailment tasks in terms of accuracy and efficiency.
The 1st Competition for Gradient-Free Tuning of Large Language Models, organized within the Guangdong-Hong Kong-Macao Greater Bay Area International Algorithm Case Competition, is one of the first attempts to encourage the development of this promising line of research. The main objectives of the competition were as follows.
Invite the community to develop derivative-free optimization algorithms for large language models.
Invite the community to work on solutions that can effectively and efficiently use large language models deployed as services.
Provide the first opportunity for a standard and comprehensive evaluation on a common hardware platform and a shared set of tasks and metrics for a fair comparison.
The competition includes five public natural language understanding tasks: topic classification (DBPedia-14), sentiment classification (SST-2), textual entailment (SNLI), question matching (QQP) and question-answering matching (QNLI); see the online supplementary material for further details. The multi-label tasks (i.e. SNLI and DBPedia-14) are evaluated with the macro-F1 metric. The rest are binary classification tasks and are evaluated with accuracy.
ALGORITHM
Background
Prompt-based learning. Prompt-based learning is a new paradigm that converts downstream tasks into (masked) language modeling, reducing the gap between pre-training and downstream tasks [2,5]. For example, for a sentiment analysis sample, ‘A fantastic movie’, we can modify the input to ‘A fantastic movie. It was[MASK].’, and let the language model predict the masked word as ‘great’ or ‘terrible’.
Black-box tuning. Black-box tuning (BBT) [3] is a gradient-free framework that optimizes continuous prompt prepended to the input text merely by means of black-box inference APIs. In particular, it optimizes a low-dimensional vector using the covariance matrix adaptation evolution strategy (CMA ES) [6] and then projects it to a higher-dimensional space to obtain the final continuous prompt. BBT adopts a prompt-based learning paradigm that reuses the masked language modeling head of the pre-trained language model.
BBTv2. BBTv2 is an improved version of black-box tuning. Instead of prepending the continuous prompt merely to the input text, BBTv2 prepends to hidden states of every layer and proposes a divide-and-conquer algorithm [4] to alternately optimize the injected prompts from the bottom to the top. In addition, it uses normal distributions with model-related standard deviations to generate random projections, making the distribution of continuous prompts closer to that of the word embedding or hidden states of the model.
The proposed solution
In this section, we present the solution proposed by the champion team, which is based on BBTv2 with the following several improvements. The overall illustration of the proposed solution is shown in Fig. 1.
Figure 1.

Overview of the winning solution. Here hmask denotes the hidden states of the masked token, d and D refer to the dimensionality of the low-dimensional continuous prompt z and the hidden size of the language model, respectively.
Calibration. The predictions of pre-trained LMs are usually biased due to the word frequency of the pre-training corpus [7]. For example, given a template with an empty input ‘It was[MASK]’, LMs tend to predict with a higher probability ‘great’ rather than ‘terrible’ on the masked position. Therefore, we use a calibration module to calibrate the predicted probabilities over words so that the output probabilities of the words representing each label are approximately equal.
In particular, all training samples are formatted with prompt and then fed into the pre-trained LM. We average the output logits of the masked position across all the samples. The obtained result can be formulated into a diagonal matrix and inverted as
 |
(1) |
where N is the total number of samples, qi is the logits corresponding to sample i and λ is the scaling factor that scales the logits back to their original scale, i.e.
 |
(2) |
where K is the number of classes in the classification task. In this way, the calibrated probability distribution can be obtained by p1 = softmax(Wq).
Integrating with the feature-based method. In the scenario of LMaaS, a straightforward way to use the black-box model is to extract the features of the samples and train a local classifier with gradient descent. In this way, the pre-trained LM serves as a feature extractor and therefore the expensive backpropagation through the large LM can be avoided. However, despite its lower cost (one sample for one inference API), its performance is much lower than BBT [3] and BBTv2 [4]. In this solution, we combine the feature-based method and black-box tuning. On the one hand, we use BBTv2 to fine-tune a small portion of parameters of the model. On the other hand, we use the final hidden states of the [MASK] token as features to train a classifier:
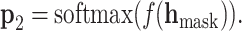 |
Here f is the local classifier optimized directly by gradient descent and hmask is the hidden states of the [MASK] token.
Furthermore, it was observed in the experiments that the two approaches are complementary and therefore we combine the two approaches and optimize them jointly as
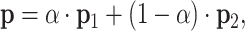 |
where α is a hyper-parameter to balance the two approaches. In practice, we set α = 0.5. By integrating the feature-based method, we achieved not only faster convergence but also improved accuracy. We also found in our experiments that the performance improvement of our method does not mainly come from the weighted output of the two approaches, but rather the two methods share the hidden states of the [MASK] token hmask, allowing hmask to learn a better semantic representation.
Training protocol. In the proposed solution, there are two groups of parameters to be optimized: (1) the low-dimensional continuous prompt z to be optimized by the CMA ES and (2) the local classifier fθ to be optimized by gradient descent. To handle the two optimization problems, we propose an alternating joint optimization (AJO) algorithm. As detailed in Algorithm 1 below, the local classifier f is first optimized using gradient descent, followed by CMA ES combined with the divide-and-conquer algorithm [4] to optimize the parameters zl corresponding to the low-dimensional prompt at layer l. We alternate the above process until convergence.
Algorithm 1.
AJO algorithm
|
|

EVALUATION
In this section, we show the results of the competition for this track in detail. Additionally, we discuss the champion’s method from innovation and application aspects.
Implementation details
The competition uses RoBERTa-Large as the base model and our learning rate η is set to 3 × 10−4; the training epoch E is set to 3. For SST-2 and DBPedia, the budget of API calls  is 3000; for QQP, QNLI and SNLI, the budget of API calls
is 3000; for QQP, QNLI and SNLI, the budget of API calls  is 8000.
is 8000.
Results
The results of the competition are reported in the online supplementary material; we consider BBTv2 [4] as a strong baseline. By comparison, the champion’s method consistently improves the results on all the datasets and achieves an average absolution gain of 6.6% in terms of accuracy. We can observe relatively large gains on the topic classification task (DBPedia, which has 14 classes) and hard entailment tasks (QQP, QNLI). However, for some of the more difficult tasks, such as SNLI, it can be seen that the improvement is not significant. In addition, we use the number of API calls to calculate the average speedup ratio. As a result, we find that the proposed method achieves a speedup ratio of about 1.3, which implies a lower training budget and a shorter training time.
Discussion
In this section we present the program committee’s discussion on the winning approach and the competition results.
Innovation. The proposed solution combines two promising approaches for LMaaS, namely, black-box tuning and feature-based methods, corresponding to zeroth-order and first-order optimization, respectively. Such a combination is demonstrated to be beneficial to both accuracy and efficiency. Furthermore, the winning solution incorporates a calibration module to mitigate the prediction bias, which further improves overall accuracy and the robustness of the prompt design.
Application. The winning approach significantly improves accuracy and reduces training costs when adapting large LMs to downstream tasks through black-box APIs. Such improvements naturally extend the scope of the applications of LMaaS.
FUTURE DIRECTIONS
The 1st Competition for Gradient-Free Tuning of Large Language Models held at Guangdong-Hong Kong-Macao Greater Bay Area International Algorithm Case Competition aims at promoting the development of gradient-free tuning for large LMs to expand the applications of LMaaS. The champion’s method improves the accuracy on all the datasets over the baseline model by combining calibration and integrating with the feature-based method, achieving a new state of the art. This method allows large LMs deployed on cloud servers to be efficiently adapted to a wide range of downstream tasks with only a small number of training samples. The method requires no access to the model weights and gradients and therefore enjoys great advantages on computation budget and security.
We summarize the current challenges and possible future directions as follows.
Accuracy and cost. The current approach has achieved comparable or even better accuracy than conventional backpropagation-based optimization methods. However, the performance of the current approach on more difficult tasks such as machine reading comprehension and information extraction is still under-explored. In addition to the accuracy, the training cost is another important metric to be considered. A single-minded focus on accuracy is undesirable and a composite metric should be designed to encourage the balance between accuracy and training cost.
Generation. Most of the current approaches focused on classification tasks, while generation tasks such as text summarization, machine translation and dialogue are still untouched. Considering the wide applications of the generation tasks, including some generation tasks in the next competition should be encouraged.
Compatibility. The current competition is limited to prompt-based tuning. All the tunable parameters are in the continuous prompt. We advocate the adoption of new gradient-free tuning frameworks that are compatible with more parameter-efficient tuning approaches such as Adapter [8] and BitFit [9].
Security. The large-scale use of model inference APIs poses several security issues, such as stealing model weights via API calls [10], and privacy issues of user data. The measurement and the approaches to mitigate such issues are worth exploring in the following competitions.
Supplementary Material
Contributor Information
Tingfeng Cao, School of Software Engineering, South China University of Technology, China.
Liang Chen, School of Software Engineering, South China University of Technology, China.
Dixiang Zhang, School of Software Engineering, South China University of Technology, China.
Tianxiang Sun, School of Computer Science, Fudan University, China.
Zhengfu He, School of Computer Science, Fudan University, China.
Xipeng Qiu, School of Computer Science, Fudan University, China.
Xing Xu, School of Computer Science and Engineering, University of Electronic Science and Technology of China, China; Pazhou Laboratory (Huangpu), China.
Hai Zhang, School of Mathematics, Northwest University, China; Pazhou Laboratory (Huangpu), China.
FUNDING
This work was supported by the National Natural Science Foundation of China (62236004 and 62022027).
Conflict of interest statement. None declared.
REFERENCES
- 1. Qiu X, Sun T, Xu Yet al. Sci China Technol Sci 2020; 63: 1872–97. 10.1007/s11431-020-1647-3 [DOI] [Google Scholar]
- 2. Brown TB, Mann B, Ryder Net al. Language models are few-shot learners. In: Larochelle H, Ranzato M, Hadsell R. et al (eds). Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates, 2020, 1877–901. 10.48550/arXiv.2005.14165 [DOI] [Google Scholar]
- 3. Sun T, Shao Y, Qian Het al. Black-box tuning for language-model-as-a-service. In: Chaudhuri K, Jegelka S, Song L. et al (eds). Proceedings of the 39th International Conference on Machine Learning. New York: PMLR, 2022, 20841–55. 10.48550/arXiv.2201.03514 [DOI] [Google Scholar]
- 4. Sun T, He Z, Qian Het al. BBTv2: towards a gradient-free future with large language models. In: Goldberg Y, Kozareva Z, Zhang Y (eds). Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, 3916–30. 10.48550/arXiv.2205.11200 [DOI] [Google Scholar]
- 5. Schick T, Schütze H. Exploiting cloze-questions for few-shot text classification and natural language inference. In: Merlo P, Tiedemann J, Tsarfaty R (eds). Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Stroudsburg, PA: Association for Computational Linguistics, 2021, 255–69. 10.18653/v1/2021.eacl-main.20 [DOI] [Google Scholar]
- 6. Hansen N, Müller SD, Koumoutsakos P. Evol Comput 2003; 11: 1–18. 10.1162/106365603321828970 [DOI] [PubMed] [Google Scholar]
- 7. Zhao Z, Wallace E, Feng Set al. Calibrate before use: Improving few-shot performance of language models. In: Meila M, Zhang T (eds). Proceedings of the 38th International Conference on Machine Learning. New York: PMLR, 2021, 12697–706. 10.48550/arXiv.2102.09690 [DOI] [Google Scholar]
- 8. Houlsby N, Giurgiu A, Jastrzebski Set al. Parameter-efficient transfer learning for NLP. In: Chaudhuri K, Salakhutdinov R (eds). Proceedings of the 36th International Conference on Machine Learning. New York: PMLR, 2019, 2790–9. 10.48550/arXiv.1902.00751 [DOI] [Google Scholar]
- 9. Zaken EB, Goldberg Y, Ravfogel S. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. In: Muresan S, Nakov P, Villavicencio A (eds). Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg PA: Association for Computational Linguistics, 2022, 1–9. 10.18653/v1/2022.acl-short.1 [DOI] [Google Scholar]
- 10. Krishna K, Tomar GS, Parikh APet al. Thieves on sesame street! Model extraction of bert-based APIs. In: 8th International Conference on Learning Representations, Addis Ababa, Ethiopia. OpenReview.net, 2020, https://openreview.net/forum?id=Byl5NREFDr. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.