

Abstract
Imaging examination selection and protocoling are vital parts of the radiology workflow, ensuring that the most suitable exam is done for the clinical question while minimizing the patient’s radiation exposure. In this study, we aimed to develop an automated model for the revision of radiology examination requests using natural language processing techniques to improve the efficiency of pre-imaging radiology workflow. We extracted Musculoskeletal (MSK) magnetic resonance imaging (MRI) exam order from the radiology information system at Henry Ford Hospital in Detroit, Michigan. The pretrained transformer, "DistilBERT" was adjusted to create a vector representation of the free text within the orders while maintaining the meaning of the words. Then, a logistic regression-based classifier was trained to identify orders that required additional review. The model achieved 83% accuracy and had an area under the curve of 0.87.
1. Introduction
Over $100 Billion is spent on diagnostic imaging in the United States annually, but a growing body of evidence suggests that a substantial portion of this spending may be inappropriate; Flaherty et al. estimated that between 30-60% of MRIs are inappropriate, and there is a growing consensus that inappropriate diagnostic imaging represents a significant (and unnecessary) cost to the health system, more generally [1]. Many health systems have made an effort to reduce inappropriate imaging costs by integrating protocol review into the standard radiological workflow. More specifically, radiological imaging protocols must be “peer reviewed” before formal imaging takes place. While this mandatory review does reduce the number of inappropriate images captured, it also increases the task-burden on (already busy) clinicians. One potential solution to this problem is to (partially) automate the radiological review processing using Artificial Intelligence (AI) - this is the goal of our paper.
For many illnesses, radiological imaging is the first step of formal diagnosis (and subsequent, treatment). The radiological imaging workflow has three components: pre-imaging - where radiologists review patient clinical profiles and prescribe a set of imaging services needed by the patient (i.e. the “protocol”); imaging - where a radiographer generates the radiological images prescribed in the protocol and; post-imaging - where the images are interpreted by radiologists who then generate a report describing medical issues that may require further attention.
Pre-imaging protocoling is a vital part of the radiology workflow, and the most likely place for human errors to occur. Appropriate protocoling selects the most suitable radiological exam for a given clinical question while minimizing the patient’s exposure to unnecessary radiation. In contrast, errors in protocoling result in unsuitable exams that increase costs and reduce (or eliminate) imaging’s contribution to patient care [2]. An inappropriate imaging examination (e.g., an imaging protocol that solely targets the abdomen of a patient with pelvic pain) is of no benefit to the patient; but even if an imaging examination is appropriate given a patient’s profile, the imaging examination may still be incorrect due to more subtle errors such as suboptimal bolus timing, slice thickness, or planes of reconstruction that would not perfectly reveal the underlying issue [3]. In an effort to catch protocoling errors, institutions assign radiologists to review imaging requests before approval. However, the process of reviewing each request is time-consuming, inefficient, and itself prone to error [3].
Partial (or complete) automation of the radiological review process using recent advances in Artificial Intelligence generally, and Natural Language Processing (NLP) more specifically, may improve the quality and reduce the heavy burden of protocol review. The literature is full of successful applications of NLP to medical tasks including: illness detection [4], medical adverse effects prediction [5], ontology construction[6], and knowledge discovery [7]. However, relatively less work has explored the ability of NLP techniques for protocol selection and prioritization as a means to explicitly improve quality, safety, and value in radiology [2].
In this work, we demonstrate a model using artificial intelligence techniques to automate the process of approving the radiology Musculoskeletal (MSK) examinations from magnetic resonance imaging (MRI) requisitions. More specifically, we apply novel instantiations of advanced natural language processing (NLP) algorithms to autonomously evaluate which radiological protocols may need additional review by clinicians, and which can be automatically approved.
1.1. Literature Review
In recent years, NLP algorithms have been applied to a variety of pre-imaging workflow tasks such as protocol recommendation and radiological decision support [8]. The machine learning methods deployed include Support Vector Machine (SVM) [2], [9], [10], Random Forest (RF) [2], [10], Gradient Boosting Machine (GBM) [11] and K-Nearest Neighbors (KNN) [2], [10]. More recently, deep learning-based methods including Convolutional Neural Networks (CNN)[9], [10], [12] and Long Short Term Memory Networks (LSTM) [9] have shown promising results in automating protocol recommendations. In the literature review below, we provide a brief overview of several significant works in this domain, with a particular emphasis on works over the last 5 years. In Table 1, we summarize the results of earlier studies deploying NLP methods. The best performing of the reviewed methods were selected as baseline approaches for this work.
Tabel 1.
Summary of prior studies that applied NLP methods to radiology exam request data. (CNN: Convolutional Neural Networks, TF-IDF: Term Frequency Inverse Document Frequency, SVM: Support Vector Machines, RF: Random Forest, GBM: Gradient Boosting Machine, WA: Watson Algorithm, MRI: Magnetic Resonance Imaging, CT: Computerized Tomography, EMR: Electronic Medical Record)
| Ref. | Data Source /Institution | Features | Application | Best Performing Model Text representation method) | Performance (Accuracy) |
|---|---|---|---|---|---|
| [2] | 13,982 MRI brain examinations performed from January 1, 2013, to June 30, 2015, from St Michaels Hospital, Toronto, Ontario, Canada. | • Patient age • Patient gender • Study priority • Patient location • Ordering service • Examination type • Completion time • Ptudys clinical indication |
Task1: Protocol assignment (deciding between 13 available protocols) Task2: Contrast administration (deciding on whether an IV contrast should be administered) Task3: Prioritization (determining whether the examination needs to be performed within the next 24 hours) |
RF (TD) |
Task 1: 82.9% Task 2: 83.0% Task 3: 88.2% |
| [2], [11] | 7,487 MRI brain examinations performed during an 18-month period from January 1, 2014, to June 30, 2015 from St Michael’s Hospital Department of Medical Imaging. | Patient age, • Patient gender, • Location, • Ordering service |
Multilabel classification problem with 41 available protocols | GBM (TD) |
95.1% |
| [13] | 1,544 musculoskeletal MRI exams from a tertiary referral hospital. | • Clinical indication of study | Determining the use of intravenous contrast | WA | 83.2% |
| [12] | 6738 musculoskeletal MRI examinations were collected from the institution’s EMR between January and February 2017, from the Department of Radiology, Research Institute of Radiological Science, Yonsei University College of Medicine, South Korea. | • Referring department • Patient age • Patient gender |
Protocol assignment (Tumor versus routine protocol) | CNN (Word2Vec) |
92.10% |
| [10] | 22820 Deidentified order entry and protocol assignment for CT and MR collected from July 2016 to May 2019 from the US Department of Veterans Affairs, Washington, District of Columbia. | • Procedure name • Procedure modality • Procedure section • Procedure indication • Procedure history |
Protocol assignment (decide between 108 standard MR and CT protocols) | RF (TF-IDF) | 92 % |
| [9] | 700,000 CT and MRI radiology examination reports obtained during routine clinical use from ‘HealthTime medica (HT)’ private clinic | • Patient ID • Clinician’s request • Date • Hospital department • Part of the anatomy • Contrast status • Left or right • Protocol |
Task1: Protocol assignment (decide between 293 standard MRI or 88 CT protocols) Task2: Protocol Assignment (decide between 88 CT protocols) |
SVM (TF-IDF) |
Task 1: 82.0% Task 2: 86.0% |
1.1.1. Protocol Recommendation
Several studies have investigated the ability of NLP algorithms to recommend specific protocol types given medical data. In work by Lee (2018), musculoskeletal MRI exams were used to train a Deep-learning-based convolutional neural network that identifies whether the protocol is tumor or routine. Lee showed that the CNN embedded vector classifier using the Word2Vec Google news vectors was an effective tool for predicting musculoskeletal protocols [12].
In other work by Kalra et al. (2020), computerized tomography (CT) and MRI exams were used to develop NLP-based machine learning classification models that recommend a protocol, given the data [10]; they used a binary bag of words and Term Frequency-Inverse Document Frequency (TF-IDF) to represent the categorical and free-text features, respectively. Kalra et al. trained three different multi-class classification models: K-Nearest Neighbors (KNN), Random Forest (RF), and Deep Neural Network (DNN); they demonstrated that the resulting models could automatically assign protocols with high performance.
López-Úbeda et al. (2021) constructed a protocol classification system using natural language processing in order to automatically assign a protocol to each Radiological Request Form (RRF) suggested by reference physicians; they used two different corpora in Spanish, including CT and MRI exam reports. López-Úbeda et al. compared several models including traditional machine learning methods, neural networks, and transfer language techniques; they showed that an SVM model with a matrix of TF-IDF features had superior performance on protocol assignment on both CT and MRI datasets [9].
Brown and Marotta (2018) used NLP based models to automatically assign protocols given the patients’ demographics and clinical indications in unstructured text format. The authors used data from brain MRI orders to build three different models, including RF, SVM, and a Gradient Boosting Machine (GBM). Brown and Marotta demonstrate that GBM is able to automate the process of protocol assignment to MRI orders with higher performance [11].
1.1.2. Decision Support
Brown and Marotta (2017) built a model based on NLP to answer three different questions on protocoling an MRI brain study: (1) predicting the imaging protocol for a particular patient, (2) deciding whether an intravenous contrast should be administered, and (3) deciding if the test is time-sensitive and must be completed within the next 24 hours. They used the term-document matrix to represent text data. The authors used RF, SVM, and KNN classification algorithms and showed that machine learning-based NLP approaches could be successfully utilized as a decision support tool in order to facilitate the protocoling of imaging experiments [2].
Trivedi et al. (2018) investigated a machine learning-based NLP algorithm that is capable of deciding on the administration of intravenous contrast given a musculoskeletal MRI exam order; they showed that free-text clinical indication of the radiology study can be used to decide whether or not the study requires intravenous contrast [13].
1.2. Conclusions of the Literature Review
As the first step in developing support systems for automatic protocol selection or any decision making tasks, studies require applying natural language processing (NLP) techniques to extract and process relevant clinical text data in order to prepare a training dataset [8]. In the literature, traditional NLP techniques such as the TF-IDF and TD are frequently employed to represent text data [2], [9]–[11]. However, very few studies have focused on applying state-of-the-art techniques such as transformers [9]. Transformer-based techniques are revolutionizing the field of natural language processing with a concept known as “attention” [14]. Transformer-based language models integrate the capabilities of transformers, transfer learning, and self-supervised learning and are able to capture long-range relationships within a text. The Transformer is an encoder-decoder architecture that is able to track the relationships in sequential data using an attention mechanism; this allows the transformer to consider natural language context and more effectively model the meaning of text [14]. Transformers have increasingly been used as a core component of pretrained language models such as BERT [3], which have demonstrated significant success in most NLP tasks [15]; at their simplest, transformer models consist of two main layers: (1) an embedding layer and (2) transformer encoding layer. The embedding layer consists of three or more sub-layers; each sub-layer generates a vector of a particular embedding type (such as auxiliary information like position and segmentation) for the input tokens. The output of the sub-layers will be combined to obtain the final vector representation of tokens. The transformer encoder layer employs a self-attention mechanism to capture global contextual information for each token vector; it consists of a multi-head self-attention layer, followed by a feed-forward network. By applying a series of these transformer encoder layers to the input token vectors, the model is able to encode sophisticated linguistic information. Multi-head self-attention layer applies self-attention to each token in the input sequence; it updates the vector representation of each token to find how a token relates to other tokens.
1.3. Objective of Our Study
In this study, we aim to automate the process of reviewing the examination requests received from a reference physician. More specifically, we explore the potential of a novel fine-tuned transformer model that takes the request metadata and determines whether or not the request is prone to mistakes. If the request is determined to be incorrect, it will be sent to a radiologist for additional study. The next section discusses the data set and approach in full detail.
1. Materials and Methods
2.1. Data
All data for this study were collected from the radiology information system at Henry Ford Hospital in Detroit, Michigan, USA. The data consisted of 32,372 Musculoskeletal (MSK) magnetic resonance imaging (MRI) examination orders from 2015-2020.
2.1.1. Target Variable:
The target variable (i.e. output) for all modeling activities in this work was a binary variable indicating whether a given radiological exam order required revision (“flagged”, coded as 1) or not (“not flagged”, coded as 0)1. The Radiology exam orders consisted of 17 different Advanced MSK Examinations; the proportion of these exam orders in our dataset, and the conditional probability of an ordering being flagged given each exam type, are depicted in Table 2. In total, 1,820 (5.6%) of the total exam orders were flagged for revision.
Table 2.
Proportion of different radiology exam requests in the dataset. “flagged” indicates the radiological exam orders that required revision. “not flagged” indicates the exam orders that flow directly to the imaging process without requiring a revision by a radiologist.
| Exam | Proportion of orders (%) | p(flagged|Exam) (%) |
| MRI knee joint left without contrast | 21.60 | 0.36 |
| MRI knee joint right without contrast | 20.40 | 0.34 |
| MRI lumbar spine without contrast | 10.68 | 1.43 |
| MRI shoulder joint right without contrast | 9.41 | 0.21 |
| MRI shoulder joint left without contrast | 7.36 | 0.19 |
| MRI cervical spine without contrast | 4.71 | 0.69 |
| MRI ankle joint left without contrast | 3.43 | 0.06 |
| MRI ankle joint right without contrast | 3.35 | 0.07 |
| MRI arthrogram, shoulder, right | 3.21 | 0.21 |
| MRI hip right without contrast | 3.19 | 0.64 |
| MRI hip left without contrast | 2.89 | 0.59 |
| MRI arthrogram, shoulder, left | 2.28 | 0.15 |
| MRI foot left without contrast | 2.08 | 0.30 |
| MRI foot right without contrast | 2.02 | 0.27 |
| MRI pelvis without contrast body | 1.60 | 0.51 |
| MRI thoracic spine without contrast | 1.56 | 0.48 |
| MRI lumbar spine with and without contrast | 1.23 | 0.68 |
2.1.2. Model Features:
We also extracted a set of features that we hypothesized were relevant for predicting the value of the target variable. These features (i.e. inputs) included: patient demographics (age), International Classification of Diseases (ICD) codes, authorizing clinician license type and specialty, requested exam description, exam order history, and exam order comments.
The summary statistics of our selected features, partitioned by the target variable are shown in Table 3. The table shows that several of our selected features exhibit univariate differences with respect to the target variable. For example, when the authorizing clinician was an MD/PhD, the exam was nearly 4 times more likely to be erroneous; when the authorizing clinician specialty was Sports Medicine, the exam was half as likely to be erroneous. The table also indicates that exams associated with more common ICD codes were less likely to be erroneous.
Table 3.
Summary statistics of the dataset. “flagged” indicates the radiological exam orders that required revision. “not flagged” indicates the exam orders that flow directly to the imaging process without requiring a revision by a radiologist. The “Authorizing clinician” is the entity that reviews and approves the protocol.
| Categorical Features | not flagged (n=30,552) | flagged (n=1,820) | |
| Patient status (%) | |||
| Outpatient | 97.5% | 90.0% | |
| Inpatient | 1.5% | 6.6% | |
| Emergency Department | 1.0% | 3.3% | |
| Authorizing clinician license type (%) | |||
| MD | 84.6% | 74.3% | |
| MD, PhD | 4.2% | 16.5% | |
| DO | 7.1% | 6.0% | |
| DPM | 4.1% | 3.2% | |
| Authorizing clinician specialty (Top 5 most frequent in entire dataset) | |||
| Orthopedics | 45.5% | 48.2% | |
| Sports Medicine | 23.3% | 11.3% | |
| Family Medicine | 8.8% | 6.9% | |
| Internal Medicine | 7.1% | 11.1% | |
| Podiatry | 4.2% | 3.2% | |
| International Classification of Diseases (ICD) code and description (Top 5 most frequent) | |||
| G89.29 Other chronic pain | 12.3% | 9.5% | |
| M25.561, Pain in right knee | 6.9% | 1.4% | |
| M25.562, Pain in left knee | 6.7% | 1.5% | |
| M25.511, Pain in right shoulder | 4.9% | 2.7% | |
| M25.512, Pain in left shoulder | 3.6% | 1.9% | |
| Numeric Features | |||
| Age (mean ± std) | 48.47 ± 18.40 49.69 ± 20.19 | ||
| Text Features | |||
|
Exam order history
Exam order comment Requested exam description | |||
2.2. Preprocessing
Our preprocessing approach consisted of four steps: (1) removing incomplete records from our dataset, (2) converting diagnostic codes into a consistent format [i.e. ICD-10], (3) replacing diagnostic codes with a description to obtain text-type features, (5) Converting exam request descriptions to a single feature, and (6) dummy-coding of categorical data [with the most common category set as the reference group]. An overview of the preprocessing approach is illustrated in Figure 1, and we describe each of the steps below:
-
1.
Removing records with incomplete data: We removed all records with any missing exam orders, or feature values; this resulted in the removal of 2,909 records from our dataset.
-
2.
Converting ICD-9 codes to ICD-10 codes: The data included up to six ICD code diagnosis for each patient. These codes were in a mix of ICD-9 and ICD-10 diagnostic code format; To unify the ICD code formats, we converted all ICD-9 codes into their corresponding ICD-10 codes when an equivalent ICD-10 was available.
-
3.
Replacing ICD-10 code with description: We replaced the diagnostic codes with their corresponding descriptions to obtain a text-type feature.
-
4.
Concatenation of diagnostic text: Next, we concatenated the descriptions of all the diagnostics and treated it as a text-type feature.
-
5.
Concatenation of exam request description: A radiology exam request might include more than one type of exam for those orders. We combined the exam descriptions to create a new feature as a description of all exam orders separated by ";".
-
6.
Dummy encoding of (non-diagnostic) categorical variables: For each categorical feature, including patient status, authorizing clinician license type, authorizing clinician specialty, and modality, categories that fall into the lowest 20% occurrence were merged into a new category as "other". Then categorical features were encoded using dummy encoding, which is a simple and extensively used technique of encoding categorical features[16], [17] .
Figure 1.

Overview of preprocessing steps: 1) Removing records with incomplete data. 2) Converting ICD-9 codes to ICD-10 codes. 3) Replacing ICD-10 code with description. 4) Concatenation of diagnostic text. 5) Concatenation of diagnostic text 6) One-hot encoding of (non-diagnostic) categorical variables. Please see section 2.2 for a text accompaniment of this figure.
2.3. Method
2.3.2. Proposed Method
A fine-tuned DistilBERT transformer model was applied to build a vector representation of the concatenated diagnostic text (see section 2.2, step 4) within the orders while maintaining the semantic information. The text embeddings provided by the transformer model were appended to our selected numerical and dummy coded categorical features (see section 2.2, step 6) to create a 2,317dimensional feature vector for each radiological exam. Finally, an L2 regularized logistic regression model was trained to predict the probability of a flagged radiological exam (the target variable), given the feature vector. The overall methodology is shown in Figure 2. Below, we provide additional details on our approach:
Figure 2.

An illustration of our methodology. (1) Fine-tuning the transformer model, (2) applying the fine-tuned transformer to our text features and combining with categorical and numerical features, (3) exam order classification using logistic regression.
2.3.2.1. Using Transformer models to represent diagnostic text as a vector:
We employed DistilBERT, a general-purpose smaller and faster pre-trained version of BERT that retains 97% of the language understanding capabilities to represent free-text information from the radiology orders [18]. The DistilBERT transformer was fine-tuned to adjust the parameters of the model in order to fit the classification task. The transformer was applied to build a vector representation of the free text within the orders while maintaining the semantic information.
2.3.2.2. Fine-tuning the transformer model:
We combined all the text format features, including order history, order comments, exam descriptions, and diagnostic descriptions, into a single text input. Next, the inputs were tokenized using the DistilBERT tokenizer. Prepared inputs were fed to the DistilBERT transformer for fine tuning (hidden size of 768 and 12 self-attention heads,). The Adam optimizer was selected for fine-tuning as it has been shown to be effective for NLP data [9], [19]. After fine-tuning, the transformer was used to obtain the numeric representation of text data where each of the text columns was transformed into a 768-dimensional embedding vector.
2.3.2.3. Exam order classification using logistic regression:
The dummy encoding of our categorical features were combined with the embedding of textual and numeric features. The final feature vector was passed as an input into a logistic regression classifier with L2 regularization. The logistic regression model predicted the probability of an incorrect examination order (flag column), given our input features.
2.4. Baseline models for comparison
We compared the performance of our model against several other logistic regression models using other widely used NLP features in the literature, including (1) bag of words, (2) the word2vec and (3) the TF-IDF approach [20] and (4) a pretrained DistilBERT embeddings without fine tuning. We also compared our models against two models inspired by our literature review: (1) the most recent model by López-Úbeda et al. and (2) the best performing model by Brown and Marotta. Please see Table 1 more more details on these models.
2.5. Optimizing Prediction Thresholds for Practical Deployment
We derived the optimal classification threshold for our model by selecting a threshold that minimized the cost of protocol revision based on two metrics: clinician revision time and dollars. Additional details follow.
2.5.1. Time
In the process of pre-imaging protocoling, it is necessary for the radiologists to examine each exam order prior to giving their approval. The median time for a standard protocol review procedure at the radiology department of Henry Ford Hospital was one minute per protocol. By detecting protocols that do not require review, the model can eliminate this time requirement; that is, the radiologist would only be required to review orders that have been identified as true positives or false positives by the model.
2.5.2. Cost
In addition to the revision time, we have also compared the costs of the revision approaches in dollars. The total cost is calculated as the sum of the TP costs, FP costs, and FN costs of our model. The Bureau of Labor Statistics (BLS) of the United States estimates that the hourly wage of a radiologist is equivalent to 145 US dollars; given this estimate, we have determined the cost corresponding to each category as follows:
TP and FP Cost: If the model identifies the order as a “flagged” order, regardless of whether the model’s decision is valid or not, a radiologist will review the order. Therefore, for TP and FP instances, we have computed the total expense costs based on the average hourly wage of the radiologists and the time required to review an order.
TN Cost: If the order is correctly identified as “not flagged", the order will automatically be approved and sent to the imaging process; for this category, there are no costs.
FN Cost: If the order was incorrectly identified as “not flagged”, then in the worst scenario, the imaging should be repeated. For each of the instances that fall into this category, the cost of the correct imaging protocol is estimated based on the corresponding CPT code available at the federal government website managed by the U.S. Centers for Medicare & Medicaid Services (Centers for Medicare & Medicaid Services, 2022).
2. Results
3.1. Model Performance
All models were assessed according to their classification capabilities as measured by: accuracy, precision, recall, specificity, and AUROC. The generalizability of our models was assessed using 10-fold cross validation. That is, our model was trained 10 times, each time on a random 80% of the data and tested on the remaining 20% of the unseen data. The mean and standard deviation of the model’s performance across all ten folds on the test sets were reported.
In Table 4, we present the average performance of all models (our proposed approach, and the baselines) across the 10 test set folds; the table shows that our proposed approach (row 1), performs significantly better than all tested baseline approaches. Indeed, the AUC of the logistic regression model using the fine-tuned transformer features was higher than the next best approach (7% increase in AUC). This result provides evidence that the proposed model would provide added benefits when deployed as an automation system for exam order revision.
Table 4.
The comparison of the performance metrics for different text representations and two baseline models from literature; our proposed approach (Fine-tuned Transformer) is shown in the first row.
| Text Representation Method | Recall | Accuracy | Precision | Specificity | Area under the curve (AUC) |
| Fine-tuned Transformer | 76.94 ± 3.25 | 83.12 ± 1.22 | 21.86 ± 1.33 | 83.49 ± 1.38 | 0.87 ± 0.12 |
| Raw Transformer | 76.54 ± 3.57 | 77.88 ± 0.67 | 17.19 ± 0.84 | 77.96 ± 0.62 | 0.81 ± 0.02 |
| Word2Vec | 74.96 ± 2.22 | 72.97 ± 0.75 | 14.18 ± 0.56 | 72.86 ± 0.77 | 0.78 ± 0.13 |
| Bag of words | 67.14 ± 4.16 | 76.23 ± 0.82 | 14.74 ± 0.95 | 76.78 ± 0.84 | 0.76 ± 0.21 |
| TF-IDF | 61.23 ± 3.03 | 78.14 ± 0.63 | 14.94 ± 0.81 | 79.15 ± 0.61 | 0.74 ± 0.20 |
| López-Úbeda et al | 76.33 ± 3.91 | 71.58 ±1.65 | 13.75 ± 0.77 | 71.31 ± 1.89 | 0.73 ± 0.01 |
| Brown and Marotta | 48.59 ± 2.31 | 80.21 ±0.94 | 13.45 ± 0.59 | 82.02 ± 1.05 | 65.31 ± 01 |
Table 5 shows the performance of our proposed model (average across the ten test folds) at a classification threshold of 0.5; as illustrated in this table, the number of false negative samples (type 2 error); which serves as a significant indicator of model reliability, is low compared to the total number of samples (38 samples out of 2,946).
Table 5.
Average (across all 10 folds) confusion matrix of identifying "flagged" exam requests determined using logistic regression. FN: the number of “flagged” instances which are incorrectly classified as “not flagged”. FP: the number of “not flagged” instances that are incorrectly classified as “flagged”. TP: the number of “flagged” instances that are correctly classified as “flagged”. TN: the number of “not flagged” instances that are correctly classified as “not flagged”
| Actual Class | Predicted Class | |||
| “flagged” | “not flagged” | |||
| “flagged” | 128 (TP) |
38 (FN) |
Sensitivity TP/(TP+FN) |
|
| “not flagged” | 459 (FP) |
2,321 (TN) |
TN/(TN+FP) TN/(TN+FP) |
|
| Precision TP/(TP+FP) | Negative Predictive Value TN/TN+FN | Accuracy (TP+TN)/(TP+FN+FP+TN) | ||
3.2. Cost Savings
In Figure 3, we illustrate the optimal classification threshold for our model according to the anticipated savings of clinician time (right) and dollars (left); see section 2.6 for details of the cost computation methodology. At a threshold of 0, the model-assisted radiologist and the model-free radiologist spend the same amount of time reviewing the orders; this is because the model identifies all orders at this threshold for revision. As the threshold increases, the number of true negatives and false negatives will likewise increase, and therefore the review time will be decreased until the high end of the spectrum for the threshold where all the orders are approved without requiring the radiologist’s supervision. The comparison between the costs of a model-assisted radiologist and model-free radiologist for various threshold values are shown in figure 3 (left); the highlighted area indicates the saved costs when using the model. The cost asperity occurs at a threshold >=0.033. At the best threshold (0.025), the model-assisted radiologist was 4.5% more cost effective compared to the model-free radiologist. Given the optimal threshold implied by the cost, the corresponding revision time would be reduced from 49 to 43 hours (see Figure 3, left), a 12% improvement.
Figure 3.
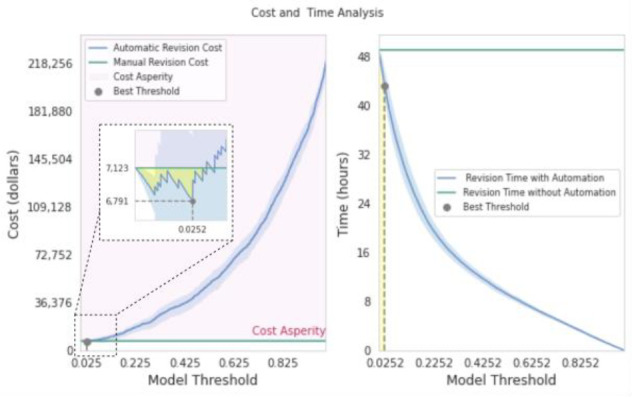
Comparison of the cost (left) and the time spent (right) for reviewing the orders manually (green line) and automatically (blue curve) depending on different thresholds. With the threshold set at 0.025, the model offers the most significant cost savings. At this point, the model saves 4.5 % of the cost and 12% of work time. The cost and time are averaged over all folds where blue highlights shows the error bar.
3.3. Approval Time
In this section, we have evaluated the time delay for the radiology exams in the radiology workflow. We assessed 2,946 MSK exam orders in terms of available time for approval and approved time. Based on this data, each exam stays in the queue for an average of 101 minutes until approval. Therefore, with an automated protocol approval system, the exam waiting time will be eliminated. Therefore, for the 2,946 exams, the total waiting time is 4,959 hours, and considering the 30-minute time slot for re-executing the false negative orders, the time penalty would be 19 hours.
4. Discussion
Protocoling is a critical component of the radiology pre-imaging workflow. Protocoling helps to ensure that the most suitable exam is conducted for a given clinical question, while reducing the patient’s exposure to unnecessary radiation. In recent years, machine learning techniques have shown high performance in enhancing radiology pre-imaging workflows, such as protocol selection. In this study, we have demonstrated a machine learning based NLP technique to automate the revision of radiology exam orders. While most of the methods in the literature focus on applying traditional NLP to deal with text data, herein, we employed a pre-trained transformer model (reusing a portion of an already trained neural network) to obtain a representation of text features prior to building the classification model. We have conducted comprehensive analysis to evaluate the performance of the proposed model. The results demonstrate that the model exhibits superior performance compared to other frequently used methods in the literature. Despite the highly imbalanced dataset, our model is able to correctly identify the requirement for revision with a 0.87 recall. The confusion matrix (Table 5) suggests that the number of orders requiring unnoticed revisions was low (38); this indicates that the model rarely misses the identification of the orders that require further revisions.
In addition to performance evaluation, we have conducted a cost and time analysis to assess the model’s performance compared to clinicians’ ongoing workflow. The results indicate that our model can assist radiologists with automatic revision of radiology exam orders by reducing the costs and time consumption. At the optimal threshold, the model saves 4.5% of the cost and 12% of the revision time.
While the model has shown high performance on the task, there are some limitations to this study which will direct future studies. We have implemented the model using a subset of available protocols in the musculoskeletal radiology system (17 protocols). The next step for this study is to extend the model to the complete protocol set and other types of imaging examinations such as computed tomography scans. One potential limitation is the generalizability of the model. This means that while the model may be effective in the specific context in which it was developed, it may not be as effective when applied to another context. One possible direction for future research would be to build an ontology-aware model for radiology domain; ontology-based model provides more structured and semantically rich representation of text data within radiology exam orders. Other potential limitation is that the cost analysis is solely based on economic feasibility that is not considering the costs associated with potential patient harm and delay in treatment due to a false negative. One important future direction for cost analysis would be to consider the potential costs associated with any adverse outcomes or complications.
5. Conclusion
In this work, we have proposed a model to automate the process of revision of advanced MSK radiology examination orders to identify erroneous orders. We have shown the application of NLP-based techniques has the potential to significantly reduce the time and cost spent on protocoling appropriate examinations. The results indicate that the proposed model can automate the assignment of orders for further revision. The low number of false negative instances suggests the reliability of the model. We have compared our approach to widely used NLP techniques in the literature. The results of the experimental analysis demonstrate the superiority of the proposed method in comparison to other methods.
Footnotes
The target variable was generated by clinical reviewers at (HFH).
Figures & Table
References
- [1].Flaherty S., Zepeda E. D., Mortele K., and G, Young J. “Magnitude and financial implications of inappropriate diagnostic imaging for three common clinical conditions,”. Int. J. Qual. Health Care. Nov. 2019;vol. 31(no. 9):691–697. doi: 10.1093/intqhc/mzy248. [DOI] [PubMed] [Google Scholar]
- [2].Brown A. D., Marotta T. R. “A Natural Language Processing-based Model to Automate MRI Brain Protocol Selection and Prioritization,”. Acad. Radiol. Feb. 2017;vol. 24(no. 2):160–166. doi: 10.1016/j.acra.2016.09.013. [DOI] [PubMed] [Google Scholar]
- [3].Boland G. W., Duszak Jr R., Kalra M. “Protocol design and optimization,”. J. Am. Coll. Radiol. May 2014;vol. 11(no. 5):440–441. doi: 10.1016/j.jacr.2014.01.021. [DOI] [PubMed] [Google Scholar]
- [4].Perlis R. H., et al. “Using electronic medical records to enable large-scale studies in psychiatry: treatment resistant depression as a model,”. Psychol. Med. Jan. 2012;vol. 42(no. 1):41–50. doi: 10.1017/S0033291711000997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Melton G. B., Hripcsak G. “Automated detection of adverse events using natural language processing of discharge summaries,”. J. Am. Med. Inform. Assoc. Jul. 2005;vol. 12(no. 4):448–457. doi: 10.1197/jamia.M1794. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Saha K., Sugar B., Torous J., Abrahao B., Kıcıman E., De Choudhury M. “A Social Media Study on the Effects of Psychiatric Medication Use,”. Proc Int AAAI Conf Weblogs Soc Media. Jun. 2019;vol. 13:440–451. [PMC free article] [PubMed] [Google Scholar]
- [7].Althoff T., Clark K., Leskovec J. “Large-scale Analysis of Counseling Conversations: An Application of Natural Language Processing to Mental Health,”. Trans Assoc Comput Linguist. 2016;vol. 4:463–476. [PMC free article] [PubMed] [Google Scholar]
- [8].Letourneau-Guillon L., Camirand D., Guilbert F., Forghani R. “Artificial Intelligence Applications for Workflow, Process Optimization and Predictive Analytics,”. Neuroimaging Clin. N. Am. Nov. 2020;vol. 30(no. 4):e1–e15. doi: 10.1016/j.nic.2020.08.008. [DOI] [PubMed] [Google Scholar]
- [9].López-Úbeda P., Díaz-Galiano M. C., Martín-Noguerol T., Luna A., Ureña-López L. A., Martín-Valdivia M. T. “Automatic medical protocol classification using machine learning approaches,”. Comput. Methods Programs Biomed. Mar. 2021;vol. 200:105939. doi: 10.1016/j.cmpb.2021.105939. [DOI] [PubMed] [Google Scholar]
- [10].Kalra A., Chakraborty A., Fine B., Reicher J. “Machine Learning for Automation of Radiology Protocols for Quality and Efficiency Improvement,”. J. Am. Coll. Radiol. Sep. 2020;vol. 17(no. 9):1149–1158. doi: 10.1016/j.jacr.2020.03.012. [DOI] [PubMed] [Google Scholar]
- [11].Brown A. D., Marotta T. R. “Using machine learning for sequence-level automated MRI protocol selection in neuroradiology,”. J. Am. Med. Inform. Assoc. May 2018;vol. 25(no. 5):568–571. doi: 10.1093/jamia/ocx125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Lee Y. H. “Efficiency Improvement in a Busy Radiology Practice: Determination of Musculoskeletal Magnetic Resonance Imaging Protocol Using Deep-Learning Convolutional Neural Networks,”. J. Digit. Imaging. Oct. 2018;vol. 31(no. 5):604–610. doi: 10.1007/s10278-018-0066-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Trivedi H., Mesterhazy J., Laguna B., Vu T., Sohn J.H. “Automatic Determination of the Need for Intravenous Contrast in Musculoskeletal MRI Examinations Using IBM Watson’s Natural Language Processing Algorithm,”. Journal of Digital Imaging. 2018;vol. 31(no. 2):245–251. doi: 10.1007/s10278-017-0021-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Shazeer, Parmar, Uszkoreit “Attention is all you need,”. neural information … [Google Scholar]
- [15].Kalyan K. S., Rajasekharan A., Sangeetha S. “AMMU: A survey of transformer-based biomedical pretrained language models,”. J. Biomed. Inform. Feb. 2022;vol. 126:103982. doi: 10.1016/j.jbi.2021.103982. [DOI] [PubMed] [Google Scholar]
- [16].Cerda P., Varoquaux G., Kégl B. “Similarity encoding for learning with dirty categorical variables,”. Mach. Learn. Sep. 2018;vol. 107(no. 8):1477–1494. [Google Scholar]
- [17].Hancock J. T., Khoshgoftaar T. M. “Survey on categorical data for neural networks,”. Journal of Big Data. Apr. 2020;vol. 7(no. 1):1–41. [Google Scholar]
- [18].Sanh V., Debut L., Chaumond J., Wolf T. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,”. arXiv [cs.CL] 02-Oct-2019 [Google Scholar]
- [19].Kingma D. P., Ba J. “Adam: A Method for Stochastic Optimization,”. arXiv [cs.LG] 22-Dec-2014 [Google Scholar]
- [20].Salton G., Buckley C. “Term-weighting approaches in automatic text retrieval,”. Inf. Process. Manag. Jan. 1988;vol. 24(no. 5):513–523. [Google Scholar]