

Abstract
An accurate and detailed account of patient medications, including medication changes within the patient timeline, is essential for healthcare providers to provide appropriate patient care. Healthcare providers or the patients themselves may initiate changes to patient medication. Medication changes take many forms, including prescribed medication and associated dosage modification. These changes provide information about the overall health of the patient and the rationale that led to the current care. Future care can then build on the resulting state of the patient. This work explores the automatic extraction of medication change information from free-text clinical notes. The Contextual Medication Event Dataset (CMED) is a corpus of clinical notes with annotations that characterize medication changes through multiple change-related attributes, including the type of change (start, stop, increase, etc.), initiator of the change, temporality, change likelihood, and negation. Using CMED, we identify medication mentions in clinical text and propose three novel high-performing BERT-based systems that resolve the annotated medication change characteristics. We demonstrate that our proposed systems improve medication change classification performance over the initial work exploring CMED.
Keywords: Medication information, Machine learning, Natural language processing, Information extraction
1. Introduction
An accurate and comprehensive medication history is key to guiding and directing appropriate medical care [1,2]. A comprehensive medication history is not limited to a list of medications the patient takes with the associated doses. It includes medications prescribed in the past, any over-the-counter medications, herbal supplements or alternative medicines, and patient adherence to prescribed medications. Knowledge of a patient’s past and current medications can help clinicians develop a differential diagnosis for active issues [3], inform their interpretation of certain tests (e.g. systemic corticosteroids can cause elevated glucose), direct future treatment options (e.g. avoid previously failed treatment, or unintended drug–drug interactions), and prevent prescription errors (e.g., restarting previously discontinued medications, omitting current medications, or prescribing at the wrong dose) [4].
Medication information is represented in the Electronic Health Record (EHR) through structured tabular data and unstructured clinical text (e.g. discharge summaries and treatment plans) [5]. The structured medication data capture medication prescription information like medication name, date, strength, and quantity. The free-text descriptions of medications in the clinical narrative include a more nuanced description of the patient medication history, which can complement the available structured medication data [6]. These descriptions can include non-prescription medications and information on patient adherence to the prescribed medications. Such details provide insight into clinical decision-making, including the rationale for medication changes and the description of alternative medication treatment options.
The use of medication information from clinical narratives in largescale or real-time secondary-use applications requires automatic extraction of the medication phenomena of interest. Natural language processing (NLP) and information extraction (IE) techniques can automatically identify and convert medication information into a structured form that can be incorporated into downstream secondary-use applications, including clinical research and clinical decision support [7]. There is a relatively large body of work exploring medication information extraction related to identifying and characterizing medication dosing [6,8], medication treatment names [9], adverse drug events (ADEs) [10,11], drug–drug interactions [12], and drug reviews [13]. This body of work includes the characterization of changes to patient medications in the clinical narratives [14–18]; however, due to the way medication changes are described in the clinical narratives, additional work is needed to create comprehensive representations that capture the context surrounding the medication changes in the patient timeline and answer key research questions related to medication prescription, medication adherence, and clinical decision-making.
In this work, we explore the extraction of changes to patient medications from clinical text using the Contextualized Medication Event Dataset (CMED) [19,20]. This data set includes annotations that characterize descriptions of patient medication changes across multiple dimensions, including the nature of the change (start, stop, increase, etc.); who initiated the change (patient or physician); temporality (past, present, or future); likelihood of change (certain, hypothetical, etc.); and negation. Within CMED and clinical notes more broadly, multiple medications are frequently described in close proximity (e.g. co-occur in the same sentence), and the description of the medication changes may be nuanced and interrelated. For example, a sentence may describe multiple medications, where the dosage of the current medication is increasing and a new medication may be started in the future if this increased dosage does not achieve the desired outcome. Our experimentation with CMED focuses on disambiguating the context used to describe medication changes to improve the interpretation of these nuanced descriptions. We propose high-performing Bidirectional Encoder Representations from Transformers (BERT) [21]-based architectures for extracting the CMED phenomena, including the identification of medication mentions and characterization of medication changes across five dimensions (which we refer to as events and attributes). We explore the synergies among the events and attributes by learning them jointly in a multi-task setting.
We implement a multi-step approach, where medication mentions are identified, and the change attributes are resolved for the identified medications. We identify medication mentions using a BERT-based sequence tagging approach, achieving very high performance at 0.959 F1. We resolve the medication change labels using a medication encoding approach, where identified medication mentions are marked with special tokens to allow the BERT model to infuse the relevant context throughout all model layers and learn individualized representations for each medication. Medication change attributes are predicted at 0.827 F1 using the gold standard medication mentions, and the end-to-end performance for medication identification and change attribute prediction is 0.803 F1. Relative to the original exploration of CMED, the presented approach improved performance by ; however, the largest gains are achieved for medications that co-occur in the same sentence and for medications that co-occur in the same sentence and have different change attribute labels .
2. Related work
There is a significant body of medication IE work related to a wide range of tasks, including medication administration, ADEs, drug–drug interactions, and drug reviews. Work in medication IE can be viewed as two higher-level tasks, medication mention extraction and medication characterization. In medication mention extraction, single and multi-word medication names (e.g. “Metformin”, “beta blocker”) are identified in text. In medication characterization, attributes associated with a medication mention are identified (e.g. dosage, frequency, or mode), or relations to other text-encoded phenomena are determined (e.g. drug side effects). Medication IE work includes the development of annotated data sets and data-driven extraction architectures. The 2009 [22] and 2018 [10] n2c2 challenge datasets are annotated with medication mentions, dosage, modes of administration, frequencies, durations, reasons for administration, and ADEs. Other datasets explore medication information in the context of ADEs [11], drug–drug interactions [12], and drug reviews [13].
Early work in medication IE primarily explored the 2009 i2b2 dataset using either rule-based systems with semantic and lexical information [23,24] or discrete machine learning approaches [8] with engineered features. More recent medication IE work leverages neural networks [25] and has utilized both the 2009 and 2018 n2c2 data sets. These n2c2 medication data sets are publicly available and frequently used to benchmark medication IE architectures. FABLE [26] used a semi-supervised approach with Conditional Random Fields (CRF) and leveraged unlabeled medication data leading to improved performance. Recurrent Neural Networks, including the bidirectional Long Short-Term Memory (BiLSTM) network and multi-layer BiLSTM-CRF models, were extensively used for medication and ADE extraction [27–30], providing improvements over discrete systems. Other works found architectural novelties on BiLSTM-based architectures, like attentive pooling, improved performance for medication information and relation extraction tasks [31], and drug–drug interaction [32].
Contemporary state-of-the-art medication IE work utilizes pre-trained language models, like BERT [21], which have gained prominence across a wide range of NLP tasks and biomedical applications. Much effort has gone into developing pre-trained models [33–36] specific to the clinical and biomedical domains with both mixed domain and in-domain pre-training techniques. Pre-trained language models have been utilized in several medication IE tasks, including extracting drug safety surveillance information using a combination of Embeddings from Language Models (ELMo) and a drug safety knowledge base [37], medication IE with the 2018 n2c2 dataset by embedding samples using hierarchical Long Short-term Memory (LSTM) network applied to BERT (without fine-tuning) embeddings [38], and exploring supervised and semi-supervised methods for medication IE [39] on the 2009 i2b2 dataset with BlueBERT [35].
Although previous medication IE work has studied the extraction of information related to patient medication changes [14–18], these works tend to focus on only specific aspects of medication changes depending on their particular use case. For example, Sohn et al. [15] explore medication status changes (e.g. ‘start’, ‘stop’ etc.) on clinical notes and utilize rule-based systems to classify the medication mentions. Medication status changes have also been studied for warfarin in the context of drug exposure modeling [40], dietary supplement use status [41], and heart failure medication status [42] using discrete machine learning models. CMED [19,20] attempts to create a more comprehensive characterization of medication change events considering the longitudinal and narrative nature of clinical documentation. CMED adds a new dimension to previous studies by capturing contextual information surrounding medication change events, including the type of change action, the initiator of the change (patient vs. clinician), negation, certainty (likelihood of medication change), and temporality.
Initial work [20] on CMED presents baseline data-driven IE systems that utilize tailor-made linguistic and semantic features and BERT-based deep learning architectures. While showing promising results, this initial exploration of CMED highlighted the challenges of characterizing medications when multiple medications are described in a single sentence. Within clinical narratives, multiple medications are frequently mentioned in the same sentence, and a majority of the sentences with medication changes in CMED contain multiple medication mentions. This work aims to address the accurate extraction of medication information even in these particularly challenging contexts. Our proposed methods combine pre-trained language models and multi-task learning with novel methods to achieve state-of-the-art results.
3. Methods
3.1. Data
This work used CMED to explore the automatic characterization of medication changes in the patient record. CMED consists of 500 clinical notes from the 2014 i2b2/UTHealth NLP shared task [43]. The CMED annotation scheme includes the identification of medication names, which we refer to as medication mentions, and the characterization of changes associated with each medication mention, which we refer to as medication change events. CMED captures the ‘what’, ‘who’, ‘when’, and ‘how’ of medication change events. Each medication mention is assigned one or more event labels from the classes {disposition, no disposition, undetermined}. Disposition indicates the presence of a change to the medication (e.g.“Start Plavix”), no disposition indicates no change to the medication (e.g. “pt is on Coumadin”), and undetermined indicates a medication change is not clear. Medication mentions that indicate a change event (event =disposition) are characterized through a set of five multi-class attributes: action, actor, negation, temporality, and certainty. Action specifies the nature of the medication change (e.g. start or stop). Actor indicates who initiated the change action (e.g. patient or physician). Negation indicates if the specified action is negated. Temporality indicates when the action is intended to occur (e.g. past, present, or future). Certainty characterizes the likelihood of the action taking place (e.g. certain, hypothetical, or conditional). The annotated event and attribute labels are summarized in Table 1. In the annotation scheme, all labels (event, action, negation, actor, temporality, and certainty ) are directly assigned to the medication mention, rather than the phrase(s) that resolves the event or attribute labels. In the example “Start Plavix”, the medication name, “Plavix”, is labeled as action = start, not the word “Start”. This dataset includes 9013 [19,20] annotated medication mentions, with 1746 change events (medications with event = disposition).
Table 1.
Label description for CMED event and attributes.
| Label | Definition | Classes |
|---|---|---|
| event | Is a medication change being discussed? | no disposition, disposition, undetermined |
| action | What is the change being discussed? | start, stop, increase, decrease, other change, unique dose, unknown |
| negation | Is the change being discussed negated? | negated, not negated |
| actor | Who initiated the change? | physician, patient, unknown |
| temporality | When is this change intended to occur? | past, present, future, unknown |
| certainty | How likely is this change to have occurred/will occur? | certain, hypothetical, conditional, unknown |
CMED includes a training set (400 notes with 7230 medication mentions) and a test set (100 notes with 1783 medication mentions). Training and test set assignments are made at the note level. Medication mentions are annotated with event and attribute labels. Table 2 describes the distribution of the event and attribute labels in CMED. There is an imbalance in the class distributions across the event and attribute label classes. A majority of the medication mentions are annotated with one event and a single set of attributes. However, some medication mentions are annotated with two events and two sets of attributes. In the example “…Treat with Keflex 500 qid × 7 days”., the medication mention Keflex is annotated with two events: (1) event = disposition, action = start, and temporality = present and (2) event = disposition, action = stop, and temporality = future. In this example, two sets of attributes are needed to capture the start of the medication in the present and the future cessation of the medication after seven days. However, medications with multiple event annotations are infrequent (≤ 90 instances in the training set).
Table 2.
Label distribution for the CMED training set.
| Task | Label | Count |
|---|---|---|
| event | disposition | 1,413 |
| no disposition | 5,260 | |
| undetermined | 557 | |
|
| ||
| action | decrease | 54 |
| increase | 129 | |
| other change | 1 | |
| start | 568 | |
| stop | 341 | |
| unique dose | 285 | |
| unknown | 35 | |
|
| ||
| negation | negated | 32 |
| not negated | 1,381 | |
|
| ||
| actor | patient | 107 |
| physician | 1,278 | |
| unknown | 28 | |
|
| ||
| certainty | certain | 1,177 |
| conditional | 100 | |
| hypothetical | 134 | |
| unknown | 2 | |
|
| ||
| temporality | future | 145 |
| past | 745 | |
| present | 494 | |
| unknown | 29 | |
Clinical notes often discuss multiple medications in the same sentence. Table 3 provides the distribution of medication mentions in the CMED training set based on their co-occurrence with other medication mentions in the same sentence. About 78% of the medication mentions occur in a sentence with at least one other medication mention. More than 50% of medication mentions co-occur with four or more other medication mentions. For these multi-medication sentences, the context may be common to all medication mentions, such that the event and attribute labels are the same for all the medication mentions. For example, the sentence, “Pain controlled in the ER with morphine and ibuprofen”. contains two medication mentions morphine and ibuprofen with similar context and the same event and attribute labels. Multi-medication sentences may also contain medication mentions with different contexts, such that medication mentions have different event and attribute labels. For example, the annotated sentence in Fig. 1 includes multiple medication mentions with differing contexts (i.e., different event and attribute labels). In Fig. 1, beta blocker will conditionally be started in the future if the patient’s ejection fraction (EF) is depressed, and a hypothetical reference to starting aldactone is made. Of sentences with multiple medication mentions, approximately 64% have a common context for all medication mentions (i.e. same event and attribute labels), and approximately 36% have differing context for medication mentions (i.e. different event and/or attribute labels).
Table 3.
Medication mention distribution based on their co-occurrence with other medication mentions sharing the same sentence in the CMED training set.
| # Meds/sentence | Medication mention count | Medication mention (%) |
|---|---|---|
| 1 | 1,591 | 22 |
| 2 | 1,002 | 14 |
| 3 | 462 | 6 |
| 4 | 360 | 5 |
| >= 5 | 3,815 | 53 |
|
| ||
| Total | 7,230 | 100 |
Fig. 1.
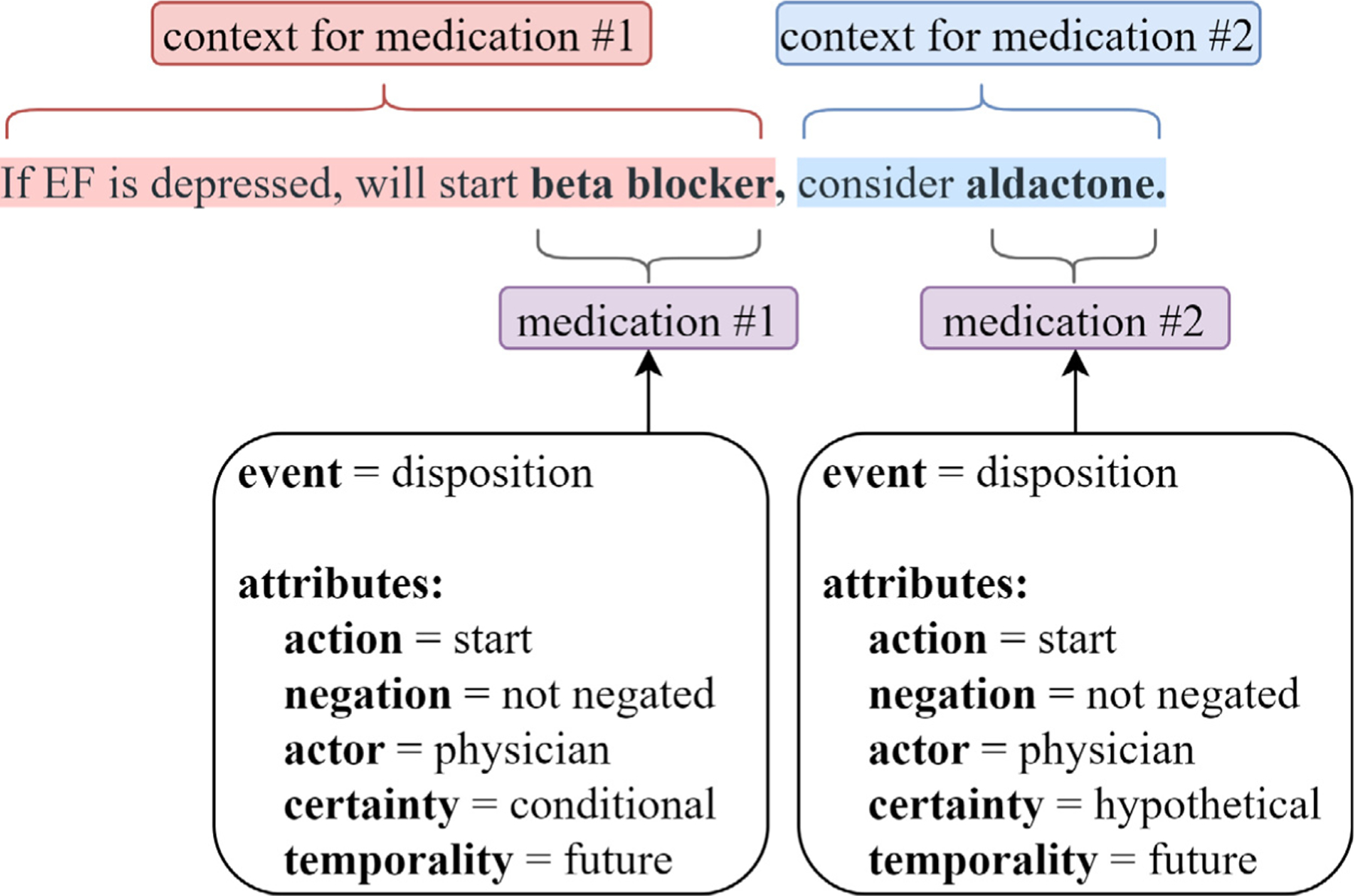
Sample sentence from CMED containing two medication mentions annotated with their respective event and attribute labels.
3.2. Medication information extraction
The CMED medication IE task can be conceptualized as two subtasks: (1) medication mention extraction - medication names are extracted as multi-word spans and (2) event and attribute classification - event and attribute labels are predicted for the medication mentions identified in the first task. The medication mention extraction task is well-studied [10,38] and can be performed with very high performance. The event and attribute classification task is less investigated and more challenging. The initial CMED experimentation explored the event and attribute classification task, using the gold medication mentions without performing medication mention extraction [19,20]. We differ from this initial CMED work by exploring the medication mention extraction task rather than using the gold medication spans. We develop classification models for event and attribute labels. Given the possible synergies among event and attribute, we study them in a multi-task setting. We aim to overcome key limitations of the initial work, including the classification of multiple medications that share a context but differ in their event and/or attribute labels. Most of our architecture development focuses on the event and attribute classification tasks.
3.2.1. Medication mention extraction
The medication mention extraction task identifies multi-word medication mention spans in free-text. We approach the medication mention extraction task as a sequence tagging task, using beginning-inside-outside (BIO) label prefixes. CMED medication spans tend to be short phrases, with more than 95% of the medication phrases containing three or fewer tokens. Medication mentions are extracted using BERT by adding a linear output layer to the BERT hidden state and fine-tuning the pre-trained BERT model. We explore several BERT variants that are pre-trained on clinical and biomedical domains, including BioBERT [34], Clinical BERT [33], PubMedBERT [36], and Blue BERT [35]. We compare the BERT-based models against well-studied medication extractors: CLAMP [30], a pre-trained LSTM-based medication recognizer, which we use in a zero-shot setting, and FABLE [26], which utilizes the CRF framework with semi-supervised learning. CLAMP was used without any adaptation or training, as there were no versions of CLAMP that could be adapted to our dataset. FABLE was adapted to CMED. We only tabulate the results from the FABLE with the BERT models in our results.
3.2.2. Event and attribute classification
The event and attribute classification task generates event and attribute predictions for the medication mentions extracted in the medication mention extraction task. The labels presented in Table 2 for the attributes (action, negation, actor, certainty, and temporality ) are only relevant if the event label for a medication mention is disposition. For attribute classification, we excluded the negation attribute since it did not have a meaningful sample size. For medication mentions where the event is no disposition or undetermined, we added a null label, none, to the attribute classes in Table 2. The event and attribute classification systems assumed gold standard medication mentions for model training and comparison. We also present end-to-end results for the event and attribute classification systems with gold standard and predicted medication mentions.
We present a sequence of extraction architectures, starting with the best-performing model from the initial CMED exploration [20], referred to here as MedSingleTask. We build on this initial work by exploring multi-task architectures that can take advantage of the synergies among event and attribute. We evaluate novel representations that can help disambiguate the context associated with medications that co-occur within a sentence. The architectures presented include MedSingleTask, MedMultiTask, MedSpan, MedIdentifiers, and MedIDTyped.
MedSingleTask encodes input sentences using BERT and generates predictions using a single output linear layer applied to the BERT pooled output state ( output vector). In this single task approach, a separate BERT model and output linear layer is trained to predict each event and attribute label (1 event label + 4 attribute labels = 5 total models). MedSingleTask generates sentence-level predictions for event and each attribute, without explicit knowledge or indication of the medication locations. The sentence-level predictions for event and each attribute are assigned to all medications within the sentence. Consequently, all medications in a sentence share a common set of event and attribute predictions, as the extraction architecture does not have the capacity to generate medication mention-specific predictions. Additionally, this single-task approach does not allow information to be shared across tasks (event and attributes), as each single-task model is only exposed to a single label type. The MedSingleTask model for event assigns a label to each sentence from {disposition, no disposition, or undetermined}. Separate MedSingleTask classification models are trained, which assign attribute labels for action, actor, certainty, and temporality. During evaluation, the MedSingleTask models for each event and attribute generate predictions for all samples in the withheld test set separately. MedSingleTask is the best performing event and attribute classification approach from the initial CMED work [20].
MedMultiTask encodes input sentences using a single BERT model and generates the event and attribute predictions using separate output linear layers (1 event layer + 4 attribute layers = 5 total output linear layers). Fig. 2 presents the MedMultiTask architecture. In this multitask approach, MedMultiTask has reduced computational complexity, relative to MedSingleTask, because all labels are predicted using a single model. The multitask objective function of MedMultiTask allows the model to learn dependencies between labels. Similar to MedSingleTask, this architecture generates a single set of event and attribute predictions for each sentence and is unable to generate medication mention-specific predictions.
Fig. 2.

MedMultiTask architecture.
MedSpan overcomes a key limitation of the MedSingleTask and MedMultiTask models, in that it can generate predictions specific to a target medication mention, allowing it to assign different event and attribute labels to medications within the same sentence. MedSpan encodes input sentences using BERT and generates event and attribute predictions using output linear layers applied to a medication mention span representation. Similar to MedMultiTask, MedSpan is a multi-task model with five output layers for predicting all event and attribute labels. The medication mention representation, , is defined as
where is the hidden state associated with the pooled output state token ( token), is the max pooling across the target medication mention span, is the th BERT hidden state, is the medication mention start, is the medication mention end, and denotes concatenation. Fig. 3 presents the MedSpan architecture. The pooled state vector provides sentence-level contextual information. The max pooling over the hidden states of the target medication mention span provides explicit knowledge of the target medication mention location. This type of span representation approach has been utilized in multiple span-based entity and relation extraction models, including the SpERT model [44].
Fig. 3.

The MedSpan Architecture. We utilize both the sentence-level and medication mention span representations to classify event and attributes.
MedIdentifiers uses the same multi-task architecture as MedMultiTask; however, the target medication mentions are encoded in the input to BERT using special tokens that indicate the target medication. Fig. 4 presents an input example, where the target medication “beta blocker” is encoded as “@ beta blocker $”. In this input encoding, the tokens “@” and “$” indicate the start and end of the target medication mention span. A unique encoding is created for each medication mention in the sentence. MedIdentifiers only encodes the target medication mention with special tokens and does not include special tokens for other (non-target) medication mentions within the sentence. By encoding the target medication mention with special tokens, MedIdentifiers is able to generate medication mention-specific predictions. The use of special tokens to identify target entities is a common approach in entity and relation extraction work [34].
Fig. 4.
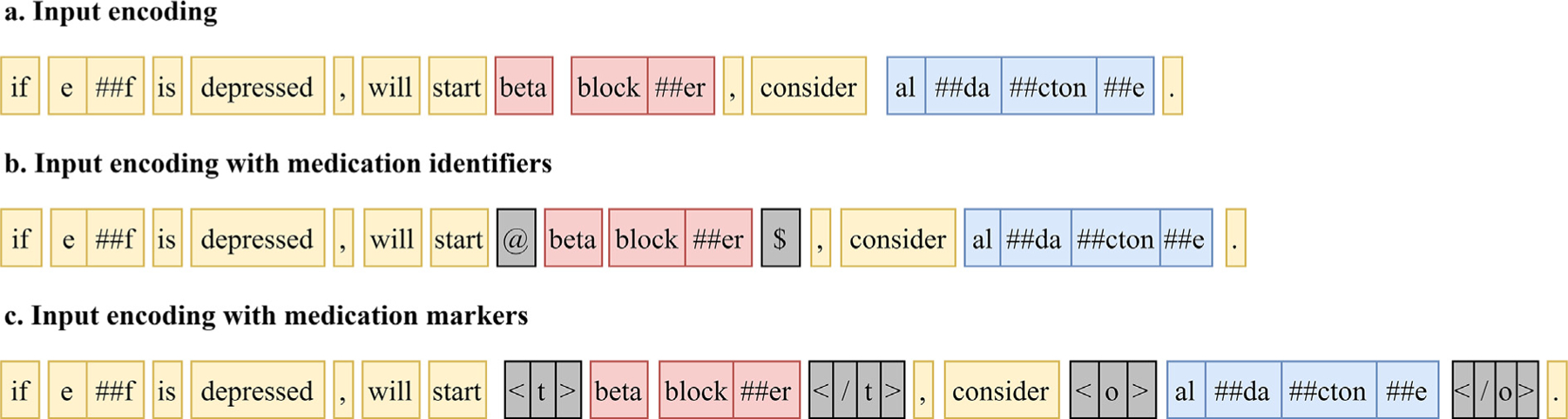
Input encodings for a sentence from the CMED using MedIdentifiers and MedIDTyped.
MedIDTyped uses a similar multi-task approach as MedIdentifiers, except that both target and non-target medication mentions are encoded in the BERT input using typed markers. The tokens “<t>” and “</t>” indicate the target medication mention and the tokens “<o>” and “</o>” indicate other (non-target) medication mentions. Fig. 4 presents an annotation example, where “beta blocker” is the target medication mention and “aldactone” is another (non-target) medication mention. This input encoding approach is included in experimentation to see if knowledge of non-target medication mentions informs the resolution of the target medication mention labels. These typed markers are similar to the entity markers introduced in Zhong, et al.’s entity and relation extraction work [45].
To summarize the model architectures, MedSingleTask involves using separate single-task models for event and each attribute, similar to the prior work with CMED [20]. All other models use a multitask approach, where all the event and attribute labels are generated by a single model. MedSingleTask and MedMultiTask do not explicitly incorporate any medication mention information and generate a common set of predictions for all medication mentions in a sentence and are ‘medication-agnostic’. The inability to disambiguate multiple medication mentions is a key limitation of the MedSingleTask and MedMultiTask approaches. MedSpan, MedIdentifiers, and MedIDTyped overcome this limitation by incorporating medication mentions location information (we refer to these models as ‘medication-aware’). MedSpan leverages medication mention location information by extracting the BERT hidden states associated with the target medication mention span and is our architecture-level solution to event-attribute classification. MedIdentifiers encodes medication mentions using special tokens to indicate the beginning and end of the target medication mention. MedIDTyped builds on MedIdentifiers by encoding both the target and non-target medication mentions in the model input. They are our data-level solutions to encode medication mention information to event-attribute classification.
3.3. Experimental setup
The systems were implemented in PyTorch using the HuggingFace transformers library [46] for the language models. We set aside 50 notes from the CMED training set as a validation set with no over-lapping patients between the new train and validation sets. We used a grid-search with discrete steps to tune hyperparameters for all the tasks. We tokenized the clinical notes using scispaCy [47] en_core_sci_md sentence tokenizer. The following configuration and parameters were common to all experimentation: optimizer= AdamW [48], dropout = 0.2, learning rate = 5e-5. The BERT-based medication mention extractors were trained on epochs = 4, maximum sequence length = 512, and batch size = 16. The event and attribute classifiers were trained on epochs = 20, and batch size = 32. The classifiers operated on sentences and the maximum sequence length (for event-attribute classification) was limited to 128 word-pieces. For sentences exceeding this maximum length, a 128 word-piece window was centered around the identified medication mention. A none label was marked wherever attributes are not applicable. For determining losses in multi-task settings, we used a simple average of the individual event and attribute cross-entropy losses.
3.4. Evaluation
For medication mention extraction, we evaluate systems using strict span-level exact match criteria and a token-level match. We report precision (P), recall (R), and F1 scores as was done previously in the 2009 i2b2 [22] medication extraction task and more recent work [26]. We evaluate the event and attribute classification systems using P, R, and F1 with macro- and micro-averages and report the overall unweighted average F1 score across both the event and attribute labels. We validate the effectiveness of the systems using a strict non-parametric (bootstrap) test [49]. We report end-to-end performance for the medication mention extraction as well as event and attribute classification on the CMED test set where we only count samples our systems correctly predicted both the medication mention with exact span-level match as well as the event or attribute labels correctly.
4. Results and discussion
4.1. Medication mention extraction
Table 4 presents the span-level (exact match) and token-level (partial match) medication mention extraction performance on the withheld CMED test set. We examined CLAMP, applied to the test set in a zero-shot setting, and FABLE, a semi-supervised model trained and adapted to CMED. CLAMP yielded a performance of 0.775 F1 at the span-level and 0.817 F1 at the token-level. We adapted FABLE to the CMED data and observed that FABLE yielded high precision of 0.961 but suffered from low recall at the token-level on the CMED test set. We compare the BERT models against FABLE as the baseline. The BERT models benefited from exposure to a larger vocabulary in pre-training and yielded higher performance (p< 0.05) at the span- and token-levels compared to FABLE. There was no significant difference in performance among the BERT models. Compared to the FABLE, the language models were better able to extract medication short forms and abbreviations (e.g., ‘ergo’ for ‘ergocalciferol’ or ‘tyl’ for ‘Tylenol’), recognize medication phrases that contain separators (e.g., ‘anti-hypertensives’ or ‘anti-platelet agent ’), and identify medication names with numeric text (e.g., ‘Humulin 70/30’). The hardest cases (< 10 occurrences) for all the systems, including the BERT models, were phrases where the medication mention was not followed by whitespace (e.g., the medication ‘Zofran’ in the phrase Zofran(No. Chemo)) and phrases where the medication names contained spelling errors (e.g., the medication ‘Ibuprofen’ in the phrase ‘DJD better takien only 1–2 ibuproens a day’).
Table 4.
Medication mention extraction performance on the CMED test set.
| Model | Span level |
Token level |
||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| FABLE | 0.874 | 0.950 | 0.910 | 0.961 | 0.861 | 0.909 |
| BioBERT | 0.952 | 0.951 | 0.951 | 0.960 | 0.958 | 0.959 † |
| Clinical BERT | 0.934 | 0.957 | 0.945 | 0.952 | 0.961 | 0.956† |
| BlueBERT | 0.925 | 0.938 | 0.931 | 0.951 | 0.947 | 0.949† |
| PubMedBERT | 0.925 | 0.958 | 0.941 | 0.941 | 0.963 | 0.952† |
The highest F1 is bolded.
indicates performance significance compared to FABLE. .
4.2. Event and attribute classification
Table 5 presents the results for event and attribute classification on the withheld CMED test set using the gold standard medication mentions. The Overall Average score in Table 5 is an unweighted average of the event and attribute label scores. We report the performance of five event and attribute classification systems, categorized into medication-agnostic (MedSingleTask and MedMultiTask) and medication-aware systems (MedSpan, MedIdentifiers, and MedIDTyped). We compare their micro-averaged F1 scores using bootstrap tests [49]. The MedSinglTask approach is the best-performing approach from prior CMED work [20]. Among medication-agnostic models, the MedMultiTask performed significantly better than the MedSingleTask in classifying the action and temporality attributes as well as overall performance (indicated by in Table 5). The MedMultiTask model’s significant performance gain over MedSingleTask indicates that the model benefits from the synergies among the event and attribute labels.
Table 5.
Event and attribute classification performance with gold standard medication mentions.
| Model | Metric | MedSingleTask |
MedMultiTask |
MedSpan |
MedIdentifiers |
MedIDTyped |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | ||
| event | P | 0.771 | 0.884 | 0.774 | 0.894 | 0.830 | 0.917 | 0.848 | 0.931 | 0.798 | 0.913 |
| R | 0.697 | 0.884 | 0.739 | 0.894 | 0.818 | 0.917 | 0.844 | 0.931 | 0.851 | 0.913 | |
| F1 | 0.729 | 0.884 | 0.755 | 0.894 | 0.824 | 0.917† | 0.846 | 0.931 ‡ | 0.815 | 0.913† | |
|
| |||||||||||
| action | P | 0.704 | 0.728 | 0.789 | 0.741 | 0.856 | 0.808 | 0.825 | 0.797 | 0.884 | 0.821 |
| R | 0.482 | 0.479 | 0.570 | 0.616 | 0.671 | 0.726 | 0.685 | 0.739 | 0.706 | 0.762 | |
| F1 | 0.568 | 0.578 | 0.646 | 0.673δ | 0.739 | 0.765† | 0.742 | 0.767† | 0.775 | 0.791 ‡ | |
|
| |||||||||||
| actor | P | 0.614 | 0.761 | 0.675 | 0.833 | 0.711 | 0.857 | 0.755 | 0.865 | 0.721 | 0.876 |
| R | 0.513 | 0.707 | 0.528 | 0.684 | 0.552 | 0.782 | 0.623 | 0.811 | 0.564 | 0.805 | |
| F1 | 0.554 | 0.733 | 0.592 | 0.751 | 0.611 | 0.818† | 0.677 | 0.837 † | 0.622 | 0.839† | |
|
| |||||||||||
| temporality | P | 0.707 | 0.729 | 0.768 | 0.802 | 0.727 | 0.785 | 0.724 | 0.804 | 0.743 | 0.812 |
| R | 0.570 | 0.622 | 0.592 | 0.645 | 0.631 | 0.691 | 0.655 | 0.749 | 0.651 | 0.746 | |
| F1 | 0.629 | 0.671 | 0.665 | 0.715δ | 0.675 | 0.735δ | 0.687 | 0.776† | 0.691 | 0.778 † | |
|
| |||||||||||
| certainty | P | 0.580 | 0.730 | 0.670 | 0.806 | 0.748 | 0.846 | 0.760 | 0.856 | 0.737 | 0.851 |
| R | 0.656 | 0.713 | 0.555 | 0.635 | 0.684 | 0.749 | 0.782 | 0.795 | 0.718 | 0.779 | |
| F1 | 0.611 | 0.722 | 0.598 | 0.710 | 0.701 | 0.795† | 0.766 | 0.824 † | 0.711 | 0.813† | |
|
| |||||||||||
| Overall* | P | 0.675 | 0.766 | 0.735 | 0.814 | 0.774 | 0.843 | 0.782 | 0.851 | 0.777 | 0.855 |
| R | 0.584 | 0.681 | 0.597 | 0.694 | 0.671 | 0.773 | 0.718 | 0.805 | 0.698 | 0.801 | |
| F1 | 0.618 | 0.718 | 0.651 | 0.748δ | 0.710 | 0.806† | 0.744 | 0.827 † | 0.723 | 0.827 † | |
Overall score is an unweighted average of the event and attribute scores.
indicates performance significance compared across all models.
indicates performance significance compared against MedSingleTask and MedMultiTask.
indicates performance significance over MedSingleTask.
The medication-aware models significantly outperformed the medication-agnostic models in terms of overall performance and also individual event and attribute performances, with the exception of MedSpan whose temporality classification performance was not significantly different from MedMultiTask. Among the medication-aware models, there was no significant difference in overall performance. However, MedIdentifiers outperformed all other systems in event classification performance with significance . MedIDTyped outperformed all the other systems in the classification of action with significance, demonstrating the benefits of utilizing both the target and non-target medication information to differentiate the context of multiple medications in the same sentence. The MedIdentifiers and MedIDTyped systems allow medication location information to be infused through all layers of the BERT architecture resulting in this gain. Our results align with the findings from earlier work [45] examining fusing entity information at the input to BERT.
To explore model performance in more detail, we analyzed the end-to-end performance on the entire withheld test set and various subsets of the test set. Table 6 presents the extraction performance (overall micro F1 score) for the models on partitions of the withheld test set: (1) the entire test set (“All”), (2) subset of the test set with sentences that contain at least two gold medication mentions (“Multiple medications”), and (3) subset of the test set with sentences that contain at least two gold medication mentions for which the event and/or attribute labels differ (“Multiple medications-different labels”). Table 6 includes the overall performance for event and attribute classification when the gold medication mentions are used (“Gold Med. Mentions” in the table) and when the predicted medication mentions are used (“End-to-End” in table). We use the Clinical BERT medication mention extractor (with span-level match) to extract medication mentions for the end-to-end systems. Readers may refer to Tables 7–9 in the Appendix for detailed end-to-end event and attribute classification results on the entire test set and its partitions.
Table 6.
End-to-end system micro F1 scores on the withheld CMED test and on two subsets of the test set with gold standard and predicted medication mentions. The Clinical BERT medication mention extractor was used for all the systems to extract medications.
| Model | All |
Multiple medications |
Multiple medications-different labels |
|||
|---|---|---|---|---|---|---|
| (n = 1755) |
(n = 1462) |
(n = 280) |
||||
| Gold Med. Mentions | End-to-End | Gold Med. Mentions | End-to-End | Gold Med. Mentions | End-to-End | |
| MedSingleTask | 0.718 | 0.693 | 0.685 | 0.667 | 0.614 | 0.594 |
| MedMultiTask | 0.748 | 0.725 | 0.728 | 0.711 | 0.605 | 0.586 |
| MedSpan | 0.806 | 0.787 | 0.815 | 0.799 | 0.806 | 0.785 |
| MedIdentifiers | 0.827 | 0.799 | 0.834 | 0.815 | 0.826 | 0.804 |
| MedIDTyped | 0.827 | 0.803 | 0.829 | 0.810 | 0.824 | 0.800 |
We achieved a high overall end-to-end performance of 0.803 F1 improving performance from prior work [20] by . We observe gains on subsets of the test set where medications co-occur in the same sentence and for medications that co-occur in the same sentence with different event and/or attribute labels from prior work indicating that our proposed medication-aware models are clearly better at disambiguating multiple medication change descriptions sharing the same sentence context.
In our error analysis, we describe different prediction error categories in the event and attribute classification and provide specific examples from the CMED test set for detailed understanding. We describe examples from error categories where the medication-agnostic models misclassify medication change descriptions and how our proposed medication-aware systems mitigate these errors. We also present examples from error categories that were challenging to all the classifiers and suggest possible directions to overcome them.
4.3. Error analysis
In earlier CMED work [19,20], errors were identified and classified into three major categories: (1) medication mentions with multiple annotations, (2) multiple medication mentions within the same sentence, and (3) medication mentions that require inter-sentence context. We explore and assess how the medication-agnostic and the medication-aware models handle specific examples of these error types. We observe that the medication-aware models effectively reduce the prediction errors under category (2) over the medication-agnostic models. The medication-aware models represent the medication context better for classifying sentences containing multiple medication descriptions. We analyzed the remaining errors and they may be classified under three additional error categories: (4) errors in longer sequences, (5) errors from models’ inability to draw inferences from clinical language (inferred meaning), and (6) errors due to inconsistent predictions.
Medication mentions with multiple annotations:
Some medication mentions are annotated with two sets of event and attribute labels, where event = disposition for both events with different attribute labels. For example, in “…Dispo: 14 day of inpatient IV antibiotics 8”., ‘antibiotics’ is annotated twice for a disposition event with temporality being present and future to account for the current start and future cessation of the antibiotics. The only explicit text indicating the start–stop action is ‘14 day.’ These type of multiple-annotated medication mentions mostly appear in isolation, often without other medications described in the same context. Our proposed systems are incapable of generating multiple sets of predictions for a given medication mention; however, medication mentions with multiple annotations are infrequent. Modifying the event and attribute classification architecture to accommodate multiple sets of predictions may negatively impact performance due to the additional degree of freedom. We believe these could be addressed by adding an additional start–stop class to the action label.
Multiple medication mentions within the same sentence:
When a sentence contains multiple medication mentions, these medication mentions may either have the same or different event and attribute labels. Earlier work explored this category of errors at a broad level. These errors have nuances that are effectively addressed by our proposed medication-aware architectures. Recall that our proposed models reported performance gains on the subset of the test set where medications co-occur in the same sentence and on medications that co-occur in the same sentence with different event or attribute labels as presented in Table 6. Consider the following two sentence examples:
In the first example sentence below, there are two medications described with equivalent event and attribute labels:
“At this point, his aspirin has been discontinued for a number of days and the Lopid was also discontinued apparently because of increased liver function tests”.
Both medications, aspirin and Lopid, have the same event and attribute labels: event = disposition, action = stop, temporality = past, certainty = certain, and actor = physician. These types of sentences were much more reliably classified by the medication-aware models compared to the medication-agnostic models.
For the second example, consider the sentence below, where multiple medications are described with different event and attribute labels:
“It is unclear to me why the warfarin was discontinued but given her stroke and the documentation of paroxysmal atrial fibrillation during her hospital stay, I think that she would benefit from anti-coagulation therapy”.
In this example, the medication warfarin was annotated for event = disposition, action = stop, actor = physician, temporality = past, and certainty = certain and the anti-coagulation treatment was annotated for event = disposition, action = start, actor = physician, temporality = present, and certainty = hypothetical. Medication-aware models performed better than medication-agnostic models on sentences that contained multiple medication mentions with different medication event and attribute labels. Medication-aware models were able to classify these multiple-medication sentences characterizing the descriptions with different event and attribute labels better than the medication-agnostic models.
We observed that all models found sentences containing multiple medication mentions that included a mix of all event labels (no disposition, disposition and undetermined) within a single sentence hard to classify. Some of these descriptions also contained coreferences of previously characterized medication mention annotated different labels. For example, in “Agree to methadone this time in light of Percocet shortage and possible preferability of methadone rx”., the first mention of the medication methadone is annotated as event = disposition, the second mention as event = no disposition, and the other medication Percocet is annotated as event = undetermined. Although the medication descriptions clearly indicate the disposition and no disposition events for methadone, the presence of an undetermined event for Percocet and the medication name methadone being annotated twice renders the sentence hard to operate on. The medication-aware models ended up predicting undetermined for the first instance methadone. These types of mixed-event (containing all event labels) sentence descriptions are difficult to classify because of the nuance of medication descriptions and the relatively low frequency (< 1% of test set) of these mixed-event descriptions in CMED.
Medication mentions that require inter-sentence context:
Some descriptions of medication changes span multiple sentences and need inter-sentence information to resolve the event and attribute labels. Sentence boundary detection errors contribute to this problem by creating artificially short sentences. This sentence boundary detection problem particularly affected sentences that contained only medication names and dosage information separated by line breaks. Below is an example:
“Started on IV heparin. Vanco and levo. Mucomyst x1 dose. ASA 325. Lopressor 25po”.
The sentence boundary detector separated the sentence into four separate spans- “Started on IV heparin”., “Vanco and levo”., “Mucomyst x1 dose”., “ASA 325. Lopressor 25po”. resulting in short sentences with only medication names and their dosage. Also, the phrase ‘Started on’ indicating the action = start appears much before the medication ASA that now appears with no context. Event classification of medication mentions for short phrases could be improved with better sentence tokenization and including cross-sentence contexts.
Longer sequences:
Shorter sentences with single medications have few event and attribute classification errors. However, medication-agnostic models contained more errors compared to the medication-aware models for longer sequences. Consider the example below:
“Vicente Aguilar is a 49 y/o male with cystic fibrosis, moderate to severe lung disease, colonized with mucoid-type Pseudomonas aeruginosa pancreatic insufficiency, CF related DM, HTN, renal insufficiency with proteinuria, recent h/o CVA, gout, cataracts who is currently experiencing a subacute exacerbation of his pulmonary disease requiring hospitalization to initiate IV antibiotics”
For the medication mention, ‘antibiotics’, the gold event is disposition and the medication-agnostic models predicted event = no disposition while the medication-aware predicted event = disposition. The medication-aware models have explicit knowledge of the medication mention locations and can better focus attention on the medication and its context, especially in longer sentences. For shorter sentences, this limitation may be less pronounced. As the sentence length increases, the medication-agnostic models have a more difficult time identifying the relevant aspects of the sentence (i.e., medication context).
Inferred meaning:
There are also sentences that did not contain phrases that clearly indicate a disposition event and a specific action. For example, in “…Although not certain to be successful, we have made a change to Bumex 1 mg po q. day today in the hopes that if Lasix is responsible for her rash this may resolve”. Lasix is annotated for action = stop and Bumex was annotated for action = start. The action to stop Lasix is inferred from the change to another medication (Bumex). However, there is no text explicitly indicating the stop action for Lasix. These cases are difficult to classify because of the required inference from the text. These cases may need a higher level of abstraction in the annotation of change events.
Inconsistent predictions:
Due to the hierarchical nature of annotations between events and attributes, a medication mention with event label of no disposition or undetermined should not have any applicable attribute labels. We added a null, none, attribute label for samples with an event label of no disposition or undetermined. The multitask architectures generated some inconsistent predictions, where either: (1) a medication with an event label of disposition was assigned one or more attribute labels of none or (2) a medication with an event label of no disposition or undetermined was assigned one or more attribute labels that were not none. E.g., in “…, last admission requiring lasix 80 IV TID to diurese 1–3L/day”. lasix was annotated as event = no disposition, and predicted correctly as event = no disposition, however, the action attribute was wrongly predicted as action = unique dose instead of none. These types of errors could be avoided by either implementing rules or architectures that take this dependency between event and attribute into account.
The improvements in performance using medication-aware models over medication-agnostic models and the analysis of errors show that creating medication mention-specific representations is important for medication change extraction in clinical text. Our work infusing medication information improves characterizing medication changes, including patient- and physician-initiated actions, temporality, and certainty of actions. The results of this work can support progress in monitoring medication errors, adherence and future diagnoses [50] and help build more accurate medication timelines [51,52].
Our work is limited by the annotated data set, which only utilizes data from the 2014 i2b2 dataset, specifically, data from a single data warehouse [20]. Our models may not generalize well to other institutions or clinical settings, and additional work with openly available data is needed to assess the generalizability of our systems. In working towards comprehensive clinical decision-support systems, our medication mention extraction model, as well as event and attribute classifiers, can be applied alongside other existing systems. For example, extracting medication changes in clinical notes could help inform systems that identify clinical recommendations and temporal reasoning [53].
5. Conclusions
We explore a novel medication information extraction task in which changes to medication disposition are characterized through a detailed representation. We approach this medication information extraction task using a two-step approach: (1) medication mention extraction and (2) event and attribute classification. For medication mention extraction, we discuss CLAMP in a zero-shot setting and compare FABLE with systems based on pre-trained BERT variants. The BERT variants outperform FABLE, achieving a performance of 0.951 F1 at the span-level.
For event and attribute classification, we explore several approaches for representing the medication mentions identified in the medication mention extraction step. Prior work in this task did not incorporate explicit knowledge of medication mentions, predicting a common set of event and attribute labels for all medications in the sentence. In this work, medication mentions are represented using a span extraction approach (MedSpan), where each medication is represented as the BERT hidden states associated with the medication mention span. Medication mentions are also represented using input identifiers in approaches MedIdentifiers and MedIDTyped, where each medication mention is encoded in the input to BERT using special tokens. These medication representation approaches allow the BERT model to focus the resolution of the event and attribute labels on individual medication mentions. Infusing information about medication mentions at both the architecture and data levels helps these medication-aware systems to perform better than the medication-agnostic systems.
We achieve new state-of-the-art performance in event classification with a micro-averaged F1 of 0.931 and an overall F1 of 0.827 over event and attributes using the MedIdentifiers, and MedIDTyped approaches that outperform prior CMED prior work with significance. We report a high end-to-end performance of 0.803 F1 combining medication mention extraction and event and attribute classification. On sentences containing co-occurring medications, we observe the medication-aware systems gain , and on sentences with co-occurring medications with different event or attribute labels, the medication-aware systems gain . The presented medication-aware architectures allow the models to focus on specific medication mentions and represent cases where multiple medication mentions appear in the same sentence with different events and attributes. With thorough error analysis, we discuss how the medication-aware architectures overcome key limitations from prior CMED work. The medication-aware models perform better for medication mentions in longer sentences than medication-agnostic systems. Additional performance gains may be achievable by improving sentence boundary detection, leveraging inter-sentence context, and incorporating a higher level of medication change abstraction. The improved performance and analyses indicate that infusing medication information through proposed systems implementing data-level and architecture-level solutions holds promise for improving performance in extracting medication change from clinical text. Including medication mention-specific representation will likely improve performance in identifying medication change with implications for enhancing clinical decision-support tools.
Acknowledgments
This work was supported in part by the National Institutes of Health, United States of America, National Library of Medicine (NLM), United States of America (Grant numbers T15LM007442, R01 CA248422-01A1, R15 LM013209). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Appendix
A.1. End-to-end event and attribute performance
Table 7.
Event and attribute classification performance with predicted medication mentions on the withheld CMED test set. We used the Clinical BERT model to extract the medications.
| Model | Metric | MedSingleTask |
MedMultiTask |
MedSpan |
MedIdentifiers |
MedIDTyped |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | ||
| event | P | 0.733 | 0.850 | 0.736 | 0.860 | 0.795 | 0.884 | 0.808 | 0.896 | 0.761 | 0.877 |
| R | 0.664 | 0.850 | 0.703 | 0.860 | 0.784 | 0.884 | 0.803 | 0.896 | 0.807 | 0.877 | |
| F1 | 0.693 | 0.850 | 0.718 | 0.860 | 0.789 | 0.884 | 0.805 | 0.896 | 0.776 | 0.877 | |
|
| |||||||||||
| action | P | 0.686 | 0.708 | 0.774 | 0.718 | 0.844 | 0.790 | 0.809 | 0.772 | 0.872 | 0.800 |
| R | 0.472 | 0.466 | 0.558 | 0.596 | 0.661 | 0.710 | 0.669 | 0.717 | 0.694 | 0.743 | |
| F1 | 0.555 | 0.562 | 0.632 | 0.651 | 0.728 | 0.748 | 0.727 | 0.743 | 0.763 | 0.770 | |
|
| |||||||||||
| actor | P | 0.600 | 0.733 | 0.665 | 0.813 | 0.702 | 0.839 | 0.741 | 0.837 | 0.708 | 0.851 |
| R | 0.499 | 0.681 | 0.520 | 0.668 | 0.544 | 0.765 | 0.609 | 0.785 | 0.552 | 0.782 | |
| F1 | 0.540 | 0.706 | 0.582 | 0.733 | 0.602 | 0.801 | 0.663 | 0.810 | 0.610 | 0.815 | |
|
| |||||||||||
| temporality | P | 0.687 | 0.702 | 0.745 | 0.773 | 0.716 | 0.770 | 0.704 | 0.776 | 0.727 | 0.791 |
| R | 0.553 | 0.599 | 0.575 | 0.622 | 0.621 | 0.678 | 0.636 | 0.723 | 0.636 | 0.726 | |
| F1 | 0.611 | 0.647 | 0.645 | 0.690 | 0.665 | 0.721 | 0.667 | 0.749 | 0.676 | 0.757 | |
|
| |||||||||||
| certainty | P | 0.572 | 0.710 | 0.662 | 0.785 | 0.742 | 0.831 | 0.748 | 0.828 | 0.730 | 0.833 |
| R | 0.648 | 0.694 | 0.548 | 0.619 | 0.679 | 0.736 | 0.772 | 0.769 | 0.711 | 0.762 | |
| F1 | 0.603 | 0.702 | 0.591 | 0.692 | 0.696 | 0.781 | 0.755 | 0.797 | 0.704 | 0.796 | |
|
| |||||||||||
| Overall | P | 0.655 | 0.741 | 0.716 | 0.790 | 0.760 | 0.823 | 0.762 | 0.822 | 0.760 | 0.830 |
| R | 0.567 | 0.658 | 0.581 | 0.673 | 0.658 | 0.755 | 0.698 | 0.778 | 0.680 | 0.778 | |
| F1 | 0.600 | 0.693 | 0.634 | 0.725 | 0.696 | 0.787 | 0.723 | 0.799 | 0.706 | 0.803 | |
Table 8.
Event and attribute classification performance with predicted medication mentions on medications that co-occur. We used the Clinical BERT model to extract the medications.
| Model | Metric | MedSingleTask |
MedMultiTask |
MedSpan |
MedIdentifiers |
MedIDTyped |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | ||
| event | P | 0.729 | 0.862 | 0.754 | 0.876 | 0.820 | 0.899 | 0.836 | 0.911 | 0.768 | 0.886 |
| R | 0.643 | 0.862 | 0.704 | 0.876 | 0.795 | 0.899 | 0.813 | 0.911 | 0.810 | 0.886 | |
| F1 | 0.679 | 0.862 | 0.727 | 0.876 | 0.807 | 0.899 | 0.824 | 0.911 | 0.780 | 0.886 | |
|
| |||||||||||
| action | P | 0.577 | 0.676 | 0.684 | 0.680 | 0.830 | 0.787 | 0.774 | 0.780 | 0.879 | 0.800 |
| R | 0.326 | 0.391 | 0.437 | 0.531 | 0.608 | 0.714 | 0.590 | 0.703 | 0.623 | 0.729 | |
| F1 | 0.401 | 0.495 | 0.506 | 0.596 | 0.667 | 0.749 | 0.655 | 0.740 | 0.704 | 0.763 | |
|
| |||||||||||
| actor | P | 0.873 | 0.747 | 0.515 | 0.810 | 0.587 | 0.832 | 0.602 | 0.861 | 0.430 | 0.851 |
| R | 0.371 | 0.615 | 0.374 | 0.620 | 0.457 | 0.776 | 0.457 | 0.776 | 0.407 | 0.771 | |
| F1 | 0.436 | 0.674 | 0.431 | 0.702 | 0.490 | 0.803 | 0.497 | 0.816 | 0.418 | 0.809 | |
|
| |||||||||||
| temporality | P | 0.748 | 0.709 | 0.839 | 0.824 | 0.819 | 0.810 | 0.794 | 0.832 | 0.836 | 0.822 |
| R | 0.531 | 0.557 | 0.562 | 0.609 | 0.671 | 0.708 | 0.702 | 0.750 | 0.673 | 0.745 | |
| F1 | 0.617 | 0.624 | 0.667 | 0.701 | 0.735 | 0.756 | 0.745 | 0.789 | 0.736 | 0.781 | |
|
| |||||||||||
| certainty | P | 0.624 | 0.704 | 0.704 | 0.812 | 0.787 | 0.841 | 0.796 | 0.861 | 0.764 | 0.851 |
| R | 0.611 | 0.656 | 0.537 | 0.583 | 0.701 | 0.745 | 0.798 | 0.776 | 0.728 | 0.771 | |
| F1 | 0.605 | 0.679 | 0.597 | 0.679 | 0.710 | 0.790 | 0.792 | 0.816 | 0.737 | 0.809 | |
|
| |||||||||||
| Overall Avg | P | 0.710 | 0.739 | 0.699 | 0.800 | 0.769 | 0.834 | 0.761 | 0.849 | 0.735 | 0.842 |
| R | 0.497 | 0.616 | 0.523 | 0.644 | 0.646 | 0.768 | 0.672 | 0.783 | 0.648 | 0.780 | |
| F1 | 0.548 | 0.667 | 0.586 | 0.711 | 0.682 | 0.799 | 0.703 | 0.815 | 0.675 | 0.810 | |
Table 9.
Event and attribute classification performance with predicted medication mentions on medications that co-occur with different event and/or attribute labels. We used the Clinical BERT model to extract the medications.
| Model | Metric | MedSingleTask |
MedMultiTask |
MedSpan |
MedIdentifiers |
MedIDTyped |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | Macro | Micro | ||
| event | P | 0.631 | 0.679 | 0.612 | 0.661 | 0.814 | 0.836 | 0.806 | 0.843 | 0.771 | 0.800 |
| R | 0.612 | 0.679 | 0.607 | 0.661 | 0.794 | 0.836 | 0.804 | 0.843 | 0.785 | 0.800 | |
| F1 | 0.613 | 0.679 | 0.608 | 0.661 | 0.802 | 0.836 | 0.803 | 0.843 | 0.770 | 0.800 | |
|
| |||||||||||
| action | P | 0.510 | 0.607 | 0.432 | 0.547 | 0.625 | 0.779 | 0.770 | 0.760 | 0.903 | 0.823 |
| R | 0.255 | 0.306 | 0.317 | 0.369 | 0.548 | 0.667 | 0.540 | 0.685 | 0.594 | 0.712 | |
| F1 | 0.329 | 0.407 | 0.361 | 0.441 | 0.578 | 0.718 | 0.607 | 0.720 | 0.674 | 0.763 | |
|
| |||||||||||
| actor | P | 0.919 | 0.840 | 0.496 | 0.756 | 0.603 | 0.857 | 0.620 | 0.890 | 0.462 | 0.905 |
| R | 0.370 | 0.568 | 0.365 | 0.559 | 0.499 | 0.811 | 0.495 | 0.802 | 0.413 | 0.775 | |
| F1 | 0.473 | 0.677 | 0.420 | 0.642 | 0.532 | 0.833 | 0.538 | 0.844 | 0.437 | 0.835 | |
|
| |||||||||||
| temporality | P | 0.743 | 0.696 | 0.793 | 0.770 | 0.801 | 0.813 | 0.789 | 0.840 | 0.854 | 0.853 |
| R | 0.483 | 0.495 | 0.496 | 0.514 | 0.652 | 0.703 | 0.693 | 0.757 | 0.660 | 0.730 | |
| F1 | 0.581 | 0.579 | 0.606 | 0.616 | 0.715 | 0.754 | 0.737 | 0.796 | 0.732 | 0.786 | |
|
| |||||||||||
| certainty | P | 0.607 | 0.667 | 0.661 | 0.732 | 0.772 | 0.844 | 0.806 | 0.869 | 0.812 | 0.884 |
| R | 0.548 | 0.595 | 0.479 | 0.468 | 0.694 | 0.730 | 0.801 | 0.775 | 0.764 | 0.757 | |
| F1 | 0.569 | 0.629 | 0.543 | 0.571 | 0.695 | 0.783 | 0.795 | 0.819 | 0.765 | 0.816 | |
|
| |||||||||||
| Overall | P | 0.682 | 0.698 | 0.599 | 0.693 | 0.723 | 0.826 | 0.758 | 0.840 | 0.761 | 0.853 |
| R | 0.453 | 0.529 | 0.453 | 0.514 | 0.637 | 0.749 | 0.666 | 0.772 | 0.643 | 0.755 | |
| F1 | 0.513 | 0.594 | 0.508 | 0.586 | 0.664 | 0.785 | 0.696 | 0.804 | 0.675 | 0.800 | |
Footnotes
CRediT authorship contribution statement
Giridhar Kaushik Ramachandran: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Resources, Writing – original draft, Visualization, Project administration. Kevin Lybarger: Conceptualization, Methodology, Software, Validation, Formal analysis, Investigation, Writing – review & editing, Visualization. Yaya Liu: Methodology, Software. Diwakar Mahajan: Data curation, Formal analysis, Writing – review & editing. Jennifer J. Liang: Data curation, Formal analysis, Writing – review & editing. Ching-Huei Tsou: Data curation, Formal analysis, Writing – review & editing. Meliha Yetisgen: Formal analysis, Writing – review & editing, Funding acquisition. Özlem Uzuner: Conceptualization, Methodology, Validation, Formal analysis, Investigation, Resources, Writing – review & editing, Supervision, Project administration, Funding acquisition.
Declaration of competing interest
The authors declare the following financial interests/personal relationships which may be considered as potential competing interests:
Diwakar Mahajan reports a relationship with IBM Thomas J. Watson Research Center that includes: employment.
Jennifer J Liang reports a relationship with IBM Thomas J. Watson Research Center that includes: employment.
Ching-Huei Tsou reports a relationship with IBM Thomas J. Watson Research Center that includes: employment.
Editors for this special issue of the journal are co-authors of this work—Özlem Uzuner, Meliha Yetisgen, Diwakar Mahajan.
References
- [1].Grahame-Smith DG, Aronson JK, Oxford Textbook of Clinical Pharmacology and Drug Therapy, Oxford University Press, 1992, 10.1002/hup.470070514. [DOI] [Google Scholar]
- [2].Fitzgerald RJ, Medication errors: the importance of an accurate drug history, Br. J. Clin. Pharmacol 67 (2009) 10.1111/j.1365-2125.2009.03424.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Balogh E, Miller B, Ball J, Improving Diagnosis in Health Care, 2015, URL https://www.ncbi.nlm.nih.gov/books/NBK338593/. [PubMed]
- [4].Lau HS, Florax C, Porsius AJ, De Boer A, The completeness of medication histories in hospital medical records of patients admitted to general internal medicine wards, Br. J. Clin. Pharmacol 49 (6) (2000) 597–603, 10.1046/j.1365-2125.2000.00204.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Casey J, Schwartz B, Stewart W, Adler N, Using electronic health records for population health research: A review of methods and applications, Annu. Rev. Public Health 37 (2016) 61–81, 10.1146/annurev-publhealth-032315-021353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Uzuner Ö, Solti I, Cadag E, Extracting medication information from clinical text, J. Am. Med. Inform. Assoc. JAMIA 17 (5) (2010) 514–518, 10.1136/jamia.2010.003947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Wang Y, Wang L, Rastegar-Mojarad M, Moon S, et al. , Clinical information extraction applications: A literature review, J. Biomed. Inform 77 (2018) 34–49, 10.1016/j.jbi.2017.11.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Patrick J, Li M, A cascade approach to extracting medication events, in: Proceedings of the Australasian Language Technology Association Workshop 2009, Sydney, Australia, 2009, pp. 99–103, URL https://aclanthology.org/U09-1014. [Google Scholar]
- [9].Uzuner Ö, South BR, Shen S, DuVall SL, 2010 I2b2/VA challenge on concepts, assertions, and relations in clinical text, J. Am. Med. Inform. Assoc. JAMIA 18 (5) (2011) 552–556, 10.1136/amiajnl-2011-000203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Uzuner Ö, Stubbs A, Lenert L, Advancing the state of the art in automatic extraction of adverse drug events from narratives, J. Am. Med. Inform. Assoc. JAMIA 27 (1) (2020) 10.1093/jamia/ocz206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Jagannatha A, Liu F, Liu W, Yu H, Overview of the first natural language processing challenge for extracting medication, indication, and adverse drug events from electronic health record notes(MADE 1.0), Drug Safety 42 (1) (2019) 99–111, 10.1007/s40264-018-0762-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Herrero-Zazo M, Segura-Bedmar I, Martínez P, Declerck T, The DDI corpus: An annotated corpus with pharmacological substances and drug–drug interactions, J. Biomed. Inform. X 46 (5) (2013) 914–920, 10.1016/j.jbi.2013.07.011. [DOI] [PubMed] [Google Scholar]
- [13].Gräßer F, Kallumadi S, Malberg H, Zaunseder S, Aspect-based sentiment analysis of drug reviews applying cross-domain and cross-data learning, in: Proceedings of the 2018 International Conference on Digital Health, DH ’18, Association for Computing Machinery, New York, NY, USA, 2018, pp. 121–125, 10.1145/3194658.3194677. [DOI] [Google Scholar]
- [14].Pakhomov S, Ruggieri A, Chute C, Maximum entropy modeling for mining patient medication status from free text, AMIA Annu Symp Proc (2002) 587–591, URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2244576/. [PMC free article] [PubMed]
- [15].Sohn S, Murphy S, Masanz J, Kocher J, Savova G, Classification of medication status change in clinical narratives, AMIA Annu Symp Proc 2010 (2010) 762–766, URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3041444/. [PMC free article] [PubMed] [Google Scholar]
- [16].Harkema H, Dowling J, Thornblade T, Chapman W, ConText: an algorithm for determining negation, experiencer, and temporal status from clinical reports, J. Biomed. Inform 42 (5) (2009) 839–851, 10.1016/j.jbi.2009.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Liu F, Pradhan R, Druhl E, Freund E, et al. , Learning to detect and understand drug discontinuation events from clinical narratives, J. Am. Med. Inform. Assoc. JAMIA 26 (10) (2019) 943–951, 10.1093/jamia/ocz048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Lerner I, Jouffroy J, Burgun A, Neuraz A, Learning the grammar of prescription: recurrent neural network grammars for medication information extraction in clinical texts, CoRR abs/2004.11622, 2020, URL https://arxiv.org/abs/2004.11622.
- [19].Mahajan D, Liang JJ, Tsou C-H, Towards understanding clinical context of medication change events in clinical narratives, 2021, arXiv, arXiv:2011.08835 [PMC free article] [PubMed] [Google Scholar]
- [20].Mahajan D, Liang JJ, Tsou C-H, Toward understanding clinical context of medication change events in clinical narratives, AMIA Annu. Symp. Proc 2021 (2021) 833–842, URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8861744/. [PMC free article] [PubMed] [Google Scholar]
- [21].Devlin J, Chang M, Lee K, Toutanova K, BERT: Pre-training of deep bidirectional transformers for language understanding, in: North American Chapter of the Association for Computational Linguistics, 2019, pp. 4171–4186, 10.18653/v1/N19-1423. [DOI] [Google Scholar]
- [22].Uzuner Ö, Solti I, Xia F, Cadag E, Community annotation experiment for ground truth generation for the i2B2 medication challenge, J. Am. Med. Inform. Assoc. JAMIA 17 (2010) 519–523, 10.1136/jamia.2010.004200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Xu H, Stenner S, J. K.B., et al. , MedEx: a medication information extraction system for clinical narratives, J. Am. Med. Inform. Assoc. JAMIA 17,1 (2010) 19–24, 10.1197/jamia.M3378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Hui Y, Automatic extraction of medication information from medical discharge summaries, J. Am. Med. Inform. Assoc. JAMIA 17,5 (2010) 545–548, 10.1136/jamia.2010.003863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Wang Y, Wang L, Rastegar-Mojarad M, Moon S, Shen F, Afzal N, Liu S, Zeng Y, Mehrabi S, Sohn S, Liu H, Clinical information extraction applications: A literature review, J. Biomed. Inform 77 (2018) 34–49, 10.1016/j.jbi.2017.11.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Tao C, Filannino M, Uzuner Ö, FABLE: A semi-supervised prescription information extraction system, AMIA Annu Symp Proc. 2018 (2018) 1534–1543, URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6371278/. [PMC free article] [PubMed] [Google Scholar]
- [27].Li F, Liu W, Yu H, Extraction of information related to adverse drug events from electronic health record notes: Design of an end-to-end model based on deep learning, JMIR Med. Inform 6 (4) (2018) 10.2196/12159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Munkhdalai T, Liu F, Yu H, Clinical relation extraction toward drug safety surveillance using electronic health record narratives: Classical learning versus deep learning, JMIR Public Health Surveill 4 (2) (2018) e29, 10.2196/publichealth.9361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Ju M, Nguyen NTH, Miwa M, Ananiadou S, An ensemble of neural models for nested adverse drug events and medication extraction with subwords, J. Am. Med. Inform. Assoc. JAMIA 27 (1) (2019) 22–30, 10.1093/jamia/ocz075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Soysal E, Wang J, et al. , CLAMP – a toolkit for efficiently building customized clinical natural language processing pipelines, J. Am. Med. Inform. Assoc. JAMIA 25 (3) (2017) 331–336, 10.1093/jamia/ocx132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [31].Alfattni G, Belousov M, Peek N, Nenadic G, Extracting drug names and associated attributes from discharge summaries: Text mining study, JMIR Med. Inform 2021 (9) (2021) 10.2196/24678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Sahu SK, Anand A, Drug-drug interaction extraction from biomedical texts using long short-term memory network, J. Biomed. Inform 86 (2018) 15–24, 10.1016/j.jbi.2018.08.005. [DOI] [PubMed] [Google Scholar]
- [33].Alsentzer E, Murphy J, Boag W, Weng W-H, Jin D, Naumann T, McDermott M, Publicly available clinical BERT embeddings, in: Clinical Natural Language Processing Workshop, 2019, pp. 72–78, 10.18653/v1/W19-1909. [DOI] [Google Scholar]
- [34].Lee J, Yoon W, Kim S, Kim D, Kim S, So CH, Kang J, BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics (2019) 10.1093/bioinformatics/btz682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Peng Y, Yan S, Lu Z, Transfer learning in biomedical natural language processing: An evaluation of BERT and ELMo on ten benchmarking datasets, 2019, arXiv:1906.05474 [Google Scholar]
- [36].Gu Y, Tinn R, Cheng H, Lucas M, Usuyama N, Liu X, Naumann T, Gao J, Poon H, Domain-specific language model pretraining for biomedical natural language processing, ACM Trans. Comput. Healthc 3 (1) (2022) 1–23, 10.1145/3458754. [DOI] [Google Scholar]
- [37].Dandala B, Joopudi V, Tsou C-H, Liang JJ, Suryanarayanan P, Extraction of information related to drug safety surveillance from electronic health record notes: Joint modeling of entities and relations using knowledge-aware neural attentive models, JMIR Med. Inform 8 (7) (2020) e18417, 10.2196/18417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Narayanan S, Mannam K, Achan P, Ramesh MV, Rangan PV, Rajan SP, A contextual multi-task neural approach to medication and adverse events identification from clinical text, J. Biomed. Inform 125 (2022) 103960, 10.1016/j.jbi.2021.103960. [DOI] [PubMed] [Google Scholar]
- [39].Kocabiyikoglu AC, Portet F, Qader R, Babouchkine J-M, Neural medication extraction: A comparison of recent models in supervised and semi-supervised learning settings, 2021, URL https://arxiv.org/abs/2110.10213. [Google Scholar]
- [40].Liu M, Jiang M, Kawai V, et al. , Modeling drug exposure data in electronic medical records: an application to warfarin, "AMIA Annu. Symp. Proc" (2018) 815–823, URL https://pubmed.ncbi.nlm.nih.gov/22195139/. [PMC free article] [PubMed] [Google Scholar]
- [41].Fan Y, Zhang R, Using natural language processing methods to classify use status of dietary supplements in clinical notes, BMC Med. Inform. Decis. Mak 18 (2018) 10.1186/s12911-018-0626-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Meystre S, Kim Y, Heavirland J, et al. , Heart failure medications detection and prescription status classification in clinical narrative documents, Stud. Health Technol. Inform (2015) URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5009609/. [PMC free article] [PubMed] [Google Scholar]
- [43].Kumar V, Stubbs A, Shaw S, Uzuner Ö, Creation of a new longitudinal corpus of clinical narratives, J. Biomed. Inform 58S (2015) 10.1016/j.jbi.2015.09.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [44].Eberts M, Ulges A, Span-based joint entity and relation extraction with transformer pre-training, in: Eur Conf on Artif Intell, 2020, pp. 2006–2013, URL https://ebooks.iospress.nl/volumearticle/55116. [Google Scholar]
- [45].Zhong Z, Chen D, A frustratingly easy approach for entity and relation extraction, in: Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, 2021, pp. 50–61, 10.18653/v1/2021.naacl-main.5, Online. [DOI] [Google Scholar]
- [46].Wolf T, Debut L, Sanh V, Chaumond J, Delangue C, Moi A, et al. , Transformers: State-of-the-art natural language processing, in: Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational Linguistics, 2020, pp. 38–45, Online. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6. [Google Scholar]
- [47].Neumann M, King D, Beltagy I, Ammar W, ScispaCy: Fast and robust models for biomedical natural language processing, in: Proceedings of the 18th BioNLP Workshop and Shared Task, Association for Computational Linguistics, 2019, 10.18653/v1/w19-5034. [DOI] [Google Scholar]
- [48].Loshchilov I, Hutter F, Fixing weight decay regularization in Adam, CoRR abs/1711.05101, 2017, URL http://arxiv.org/abs/1711.05101. [Google Scholar]
- [49].Berg-Kirkpatrick T, Burkett D, Klein D, An empirical investigation of statistical significance in NLP, in: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Association for Computational Linguistics, Jeju Island, Korea, 2012, pp. 995–1005, URL https://aclanthology.org/D12-1091. [Google Scholar]
- [50].Tariq R, Vashisht R, Sinha A, Scherbak Y, Medication Dispensing Errors And Prevention, StatPearls Publishing, 2022, URL https://www.ncbi.nlm.nih.gov/books/NBK519065/. [PubMed] [Google Scholar]
- [51].Plaisant C, Mushlin R, Snyder A, et al. , LifeLines: using visualization to enhance navigation and analysis of patient records, Proc. AMIA Symp (1998) 76–80, URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2232192/. [PMC free article] [PubMed]
- [52].Belden J, Wegier P, Patel J, et al. , Designing a medication timeline for patients and physicians, J. Am. Med. Inform. Assoc. JAMIA 26 (2) (2019) 95–105, 10.1093/jamia/ocy143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [53].Sun W, Rumshisky A, Uzuner Ö, Temporal reasoning over clinical text: the state of the art, J. Am. Med. Inform. Assoc. JAMIA 5 (2013) 814–819, 10.1136/amiajnl-2013-001760. [DOI] [PMC free article] [PubMed] [Google Scholar]