

Abstract
Psoriasis is a chronic skin disease that affects millions of people worldwide. In 2014, psoriasis was recognized by the World Health Organization (WHO) as a serious non-communicable disease. In this study, a systems biology approach was used to investigate the underlying pathogenic mechanism of psoriasis and identify the potential drug targets for therapeutic treatment. The study involved the construction of a candidate genome-wide genetic and epigenetic network (GWGEN) through big data mining, followed by the identification of real GWGENs of psoriatic and non-psoriatic using system identification and system order detection methods. Core GWGENs were extracted from real GWGENs using the Principal Network Projection (PNP) method, and the corresponding core signaling pathways were annotated using the Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways. Comparing core signaling pathways of psoriasis and non-psoriasis and their downstream cellular dysfunctions, STAT3, CEBPB, NF-κB, and FOXO1 are identified as significant biomarkers of pathogenic mechanism and considered as drug targets for the therapeutic treatment of psoriasis. Then, a deep neural network (DNN)-based drug-target interaction (DTI) model was trained by the DTI dataset to predict candidate molecular drugs. By considering adequate regulatory ability, toxicity, and sensitivity as drug design specifications, Naringin, Butein, and Betulinic acid were selected from the candidate molecular drugs and combined into potential multi-molecule drugs for the treatment of psoriasis.
Keywords: pathogenic mechanism of psoriasis, systems biology method, core signaling pathways, DNN-based DTI model, drug design specifications, multi-molecule drug, bid data mining, DTI databases
1. Introduction
Psoriasis is a common chronic disease, which is an autoimmune disease. Its main symptoms are erythema, scales, dryness, and other lesions on the skin surface, usually affecting the scalp, elbows, knees, and back, and may be accompanied by pain and itching and other discomfort. Microscopically, psoriasis is characterized by markedly increased proliferation and incomplete differentiation of the epidermis, a marked increase in cutaneous blood flow, and leukocytic infiltration of the papillary dermis and the epidermis. In addition, psoriasis may also affect the nails and joints, causing symptoms such as deformed nails and joint pain. Psoriasis is a chronic disease, its symptoms may last for many years or lifelong, and it often presents a recurring state of incessant advances and retreats [1]. Psoriasis may also cause some psychologically related symptoms. Because the symptoms of psoriasis often appear on the skin, patients often feel distressed and insecure about their appearance, which in turn affects their mental health. Studies have shown that people with psoriasis may have higher levels of depression and anxiety and may even experience suicidal thoughts and behaviors [2]. Psoriasis is a global disease, and approximately 1% to 3% of the global population suffers from this disease, among which there are more patients in Europe and the United States and relatively few in Asia. It is estimated that approximately 125 million people worldwide currently suffer from psoriasis [3]. In 2014, World Health Organization (WHO) member states recognized psoriasis as a serious non-communicable disease and adopted resolution WHA 67.9, which called for multilateral efforts to raise awareness and combat stigma [4].
Psoriasis is an autoimmune disease, and its pathogenesis is not fully understood, but current research shows that a combination of factors may lead to the occurrence of psoriasis. First of all, genetic factors are one of the important causes of psoriasis. Research shows that family members with psoriasis are at higher risk than the general population [5]. There are specific gene variants that may be associated with the development of psoriasis, but no single gene mutation that is strongly associated with psoriasis has been found so far [6]. Secondly, environmental factors are also one of the causes of psoriasis. Environmental factors include stress, infection, smoking, alcohol abuse, overuse of certain drugs, overexposure to sunlight, etc. These factors may affect the function of the immune system, which can lead to the development of psoriasis [7]. In addition, psoriasis may also be related to abnormalities in the immune system. Under normal circumstances, the immune system attacks and destroys foreign bodies and abnormal cells to protect human health. However, in people with psoriasis, the immune system attacks the skin cells, causing them to overgrow and eventually form psoriatic plaques. In conclusion, psoriasis is an autoimmune disease, and its pathogenesis involves many factors, including genetic factors, environmental factors, and immune system abnormalities. Therefore, systematic genetic and epigenetic research, as well as genome-wide microarray data exploration and comparison of psoriasis and non-psoriasis, can help us better understand the etiology and treatment of psoriasis.
There is currently no complete cure for psoriasis, but there are a variety of medications that can help manage symptoms and improve the patient’s quality of life. The followings are common psoriasis medications: topical steroids suppress the immune system response and are widely used in the treatment of psoriasis. Topical steroids, including vitamin D analogs and topical corticosteroids, can reduce inflammation and control cell proliferation, reducing symptoms. However, long-term use of steroids increases the risk of side effects such as localized skin thinning and pigmentation [8]. Phototherapy is through ultraviolet B irradiation (UVB), narrow-wave ultraviolet B irradiation, and other methods. However, long-term side effects of UV exposure include pigmentary disorder, photoaging, cataracts, and carcinogenesis. Photodermatitis usually occurs in UV radiation as UV-induced DNA damage or mutation results in the activation of oncogenes or silencing of tumor-suppressor genes, which are closely related to the pathogenesis of skin squamous-cell carcinoma [9,10]. Immunosuppressants can suppress the immune system response and reduce inflammation and skin cell proliferation. These drugs are commonly used to treat severe psoriasis but can cause damage to the liver, kidneys, immune system, etc., and increase the risk of infection and disease [11]. Biological agents include TNF inhibitors, IL-23 inhibitors, etc. These medications are commonly used to treat severe psoriasis and can be effective in reducing symptoms and plaque size. However, biological agents affect the immune system to cause side effects, such as infection, fatigue, and approx. 30% of patients do not respond well to the therapy [12]. At present, there does not exist an effective medication to treat psoriasis. The approach is to combine systems medicine methods with some drug design specifications to improve the drug design discovery and design for the therapeutic treatment of psoriasis.
Drug discovery is a time- and resource-intensive process, often costing billions of dollars and over a decade [13]. Pharmaceutical companies spend significant resources conducting experiments to understand drug properties and their interactions with target molecules. Furthermore, drug efficacy and safety must also be considered, leading to extensive animal and clinical trials [14]. Despite these efforts, drug development failures are still common due to poor clinical outcomes [15]. Therefore, more efficient and systematic approaches to drug design are needed. Drug-target interaction (DTI) prediction is an important process in drug design and repurposing that can narrow down the list of drug candidates [16]. Traditional DTI prediction methods mainly include ligand-based methods and docking-based methods, which are used to predict interactions based on the similarity between proteins and ligands. In recent years, DTI prediction methods based on machine learning have developed rapidly [17,18,19,20]. Drug repurposing, which refers to the use of a drug for an indication other than its original approval, can yield a wealth of data for research and can also reduce the need for additional studies of pharmacokinetic properties and toxicity. A drug combination is a multi-molecule drug that can improve the efficacy of each molecular drug in the combination and reduce the toxicity, drug resistance, and side effects of patients [17]. DTI prediction for drug targets based on deep neural network (DNN) via the large DTI database can be applied to systemic drug design and discovery and to select adequate multi-molecule drugs for the treatment of various diseases from the perspective of drug repurposing and drug combination [18].
The goal of this study is to investigate core signaling pathways through the systems biology method, identify significant biomarkers for the pathogenic mechanism of psoriasis as drug targets, and employ a DNN-based DTI model to predict and design a multi-molecule drug for the treatment of psoriasis as shown in Figure 1. First, the genome-wide genetic and epigenetic networks (GWGENs) of psoriasis and non-psoriasis are constructed [19]. For the annotation of KEGG pathways, GWGENs of psoriasis and non-psoriasis are extracted by the principal network projection (PNP) method into two core GWGENs with 6000 significant nodes, as shown in Figure 2 and Figure 3, respectively. Then, two core GWGENs are annotated by KEGG pathways to core signaling pathways of psoriasis and non-psoriasis in Figure 4. Comparing core signaling pathways of psoriasis and non-psoriasis and their downstream cellular dysfunctions, the significant biomarkers for the pathogenic mechanism of psoriasis are identified as drug targets of therapeutic treatment. In order to improve the efficiency and success rate of drug discovery and design for the therapeutic treatment of psoriasis, a deep neural network (DNN)-based drug-target interaction (DTI) prediction model was proposed and trained by a large amount of DTI databases to predict candidate molecular drugs to target their significant biomarkers of psoriasis, as shown in Figure 5. The drug design specifications based on the regulation ability, toxicity, and sensitivity of drugs were employed for screening potential molecular drugs Naringin, Butein, and Betulinic acid, which can be combined as a multiple-molecule drug for the treatment of psoriasis.
Figure 1.

Flowchart of systems biology methods to identify significant biomarkers of pathogenic mechanism as drug targets of psoriasis and the outline of systematic drug discovery design of psoriasis. Candidate GWGEN is composed of a protein–protein interaction network (PPIN) and gene regulatory network (GRN), which are constructed by PPIN and GRN datasets. Real GWGENs were obtained by pruning false positives from candidate GWGENs by microarray data GSE117468 through system order detection and system identification. The core GWGENs were extracted from real GWGENs by the PNP method. Core GWGENs of psoriasis and non-psoriasis are annotated by KEGG pathways to obtain core signaling pathways of psoriasis and non-psoriasis, respectively. The pathogenic biomarkers were identified for the pathogenesis of psoriasis by comparing the core signaling pathways of psoriasis and non-psoriasis. Finally, the potential drugs were discovered by the prediction of the DNN-based DTI model and the screening of drug design specifications. Then, the screened molecular drugs were combined as a multi-molecule drug for the therapeutic treatment of psoriasis.
Figure 2.

(a) The real GWGEN of psoriasis; (b) the real GWGEN of non-psoriasis. The green lines represent the PPI, and the red lines represent the gene regulations. Numbers indicate the number of nodes.
Figure 3.

(a) The core GWGEN of psoriasis; (b) the core GWGEN of non-psoriasis. The green lines represent the PPI, and the red lines represent the gene regulations. Numbers indicate the number of nodes.
Figure 4.

The common and specific core signaling pathways and their downstream cellular dysfunctions between psoriasis and non-psoriasis. The figure shows the core genetic and epigenetic signaling pathways and pathogenic mechanisms of psoriasis. The left block contains the specific core signaling pathways of psoriasis. The middle block contains the overlapping core signaling pathways between psoriasis and non-psoriasis. The right block contains the specific core signaling pathways of non-psoriasis. The gene symbols in red or green font denote the selected significant biomarkers of the pathogenesis of psoriasis as drug targets of psoriasis.
Figure 5.

The flowchart of design and discovery of a multi-molecule drug for therapeutic treatment of psoriasis. Drug-target interaction data were obtained from drug-target interaction databases. Then, the drug and target feature vectors were pre-processed, including downsampling, standardization, and PCA, respectively. After data preprocessing, drug target feature vectors were divided into training data and testing data for training the DNN-based DTI model. The well-trained DNN-based DTI model was used to predict candidate drugs for these biomarkers (drug targets). The potential molecule drugs were selected from predicted candidate drugs according to the drug design specifications and combined as multi-molecule drugs for the therapeutic treatment of psoriasis.
The DNN-based DTI model method has significant advantages over traditional computational drug discovery methods [20]. It can learn the molecular features of drugs and targets and make predictions from a large number of drug and protein interactions [17]. As shown in the flowchart of multi-molecule drug design for psoriasis in Figure 5, the DNN-based DTI model will be trained using publicly available biological and chemical datasets to predict candidate drugs for biomarkers (drug targets) with accuracy and reliability. In addition to the development of single molecular drugs, drug repurposing and drug combinations are also the focus of our research. Drug repurposing can reduce the cost and time of drug development by harnessing the efficacy of existing molecular drugs to treat other diseases or conditions [17]. Molecular drug combinations can use more than one molecular drug to enhance the effect of treatment, thereby increasing the success rate of treatment and reducing side effects. Finally, our findings can provide a new perspective and approach for systems drug design and discovery, thereby opening up new possibilities for the systematic development and discovery of a multiple-molecular drug for therapeutic treatments of psoriasis and other diseases.
2. Results
2.1. An Overview of Systems Biology Approaches for the Study of Pathogenic Mechanisms and Systematic Drug Discovery and Design for the Treatment of Psoriasis
In this study, the goal is to investigate the pathogenic mechanism of psoriasis by systems biology methods in Section 4.3, Section 4.4 and Section 4.5 to identify significant biomarkers of pathogenesis as drugs targets of psoriasis and then use the drug-target interaction data to train DNN-based drug-target interaction (DTI) model to predict potential multi-molecule drug to target the significant biomarkers as shown in Figure 5. First, in order to realize the pathogenic mechanism to identify its significant biomarkers as drug targets for the therapeutic treatment of psoriasis, we constructed candidate GWGEN from the database (GSE117468) through the big data mining method. Candidate GWGEN is a binary matrix. The matrix will record 1 if there is an interaction between two proteins/genes and record 0 if two nodes have no interaction. The nodes of the candidate GWGEN are divided into several groups: proteins, receptors, transcription factors (TFs), genes, miRNAs, and lncRNAs. Then, candidate GWGENs are pruned to real GWGENs of psoriasis and non-psoriasis in Figure 2 using their corresponding microarray data by system identification in Equations (1)–(20) to trim off false positives in candidate GWGEN. Here, we utilize the Akaike information criteria (AIC) [21] in Equations (21)–(28) to perform the system order detection method to trim off the false-positive interactions and obtain real GWGENs of psoriasis and non-psoriasis. Although real GWGENs have been condensed, they are still too complex to be annotated by the KEGG pathways, which can only annotate 6000 molecules at most. Third, core GWGENs with 6000 nodes are extracted from real GWGENs. To investigate the significant pathways of psoriasis and non-psoriasis, we extract 6000 key nodes from real GWGENs and obtain core GWGENs in Figure 3 through the principal network projection (PNP) method in Equations (29)–(34). In the study, the top-ranked 6000 nodes of core GWGENs contain 85% network energy of real GWGENs. We plot the real and core GWGENs of psoriasis and non-psoriasis with the network visualization software Cytoscape in Figure 2 and Figure 3, respectively. The detail of nodes and edges in the candidate, real, and core GWGENs are given in Table 1. Fourth, based on the enrichment analysis of KEGG pathways in Table 2 and Table 3 for core GWGENs of psoriasis and non-psoriasis, respectively, we have established common and specific core signaling pathways for psoriasis and non-psoriasis and investigated the pathogenic mechanisms involved in the pathogenesis of psoriasis as shown in Figure 4. Important biomarkers of the pathogenesis of psoriasis were identified as drug targets based on the investigation of these core pathways and their targeted genes leading to downstream cellular dysfunctions of psoriasis. Fifth, for drug discovery and design, we proposed a DNN-based DTI model using the existing drug-target interaction (DTI) database as the training set in Equations (35)–(45) to predict candidate drugs for the drug targets of psoriasis as shown in Figure 5. Furthermore, we consider the regulation ability, sensitivity, and toxicity of candidate drugs as drug design specifications to select potential drugs to be combined as a multi-molecule drug for the therapeutic treatment of psoriasis. The flowchart in Figure 1 illustrates the process of establishing candidate, real, and core GWGENs, and then identifying core signaling pathways in psoriasis and non-psoriasis to investigate significant biomarkers of pathogenic mechanisms as drug targets and then predicting psoriasis. A more detailed description of the result will be given in the following subsections.
Table 1.
The statistics of the nodes and edges in real GWGENs of psoriasis and non-psoriasis.
| Nodes | Candidate GWGENs of Psoriasis |
Real GWGENs of Psoriasis |
Real GWGENs of Non-Psoriasis |
|---|---|---|---|
| Receptor | 2092 | 2081 | 2085 |
| TF | 1481 | 1472 | 1461 |
| Protein | 13,781 | 13,748 | 13,759 |
| miRNAs | 42 | 31 | 34 |
| LncRNAs | 436 | 416 | 420 |
| Total | 17,832 | 17,748 | 17,759 |
| Edges | Candidate GWGEN |
Real GWGEN
of psoriasis |
Real GWGEN
of non-psoriasis |
| PPIs | 3,872,294 | 1,711,359 | 1,712,333 |
| TF-Receptor | 14,159 | 5513 | 5517 |
| TF-TF | 11,808 | 4289 | 4439 |
| TF-Protein | 79,424 | 32,426 | 32,384 |
| TF-miRNA | 120 | 43 | 52 |
| TF-lncRNA | 583 | 359 | 356 |
| miRNA-Receptor | 694 | 7 | 8 |
| miRNA-TF | 579 | 4 | 9 |
| miRNA-Protein | 3969 | 63 | 73 |
| miRNA-miRNA | 3 | 1 | 1 |
| miRNA-lncRNA | 22 | 2 | 2 |
| lncRNA-Receptor | 719 | 84 | 74 |
| lncRNA-TF | 610 | 62 | 77 |
| lncRNA-Protein | 4259 | 852 | 821 |
| lncRNA-miRNA | 2 | 0 | 0 |
| lncRNA-lncRNA | 15 | 4 | 4 |
| Total edges | 3,989,260 | 1,755,068 | 1,756,150 |
Table 2.
KEGG pathways enrichment analysis of core GWGEN of psoriasis.
| Pathway | Gene Number | p-Value |
|---|---|---|
| Pathways in cancer | 251 | 1.2 × 10−12 |
| Cellular senescence | 92 | 3.6 × 10−11 |
| FoxO signaling pathway | 78 | 7.1 × 10−10 |
| Focal adhesion | 107 | 3 × 10−9 |
| Cell cycle | 74 | 7.6 × 10−9 |
Table 3.
KEGG pathways enrichment analysis of core GWGEN of non-psoriasis.
| Pathway | Gene Number | p-Value |
|---|---|---|
| FoxO signaling pathway | 76 | 3.1 × 10−10 |
| Colorectal cancer | 52 | 7.8 × 10−8 |
| Hippo signaling pathway | 82 | 9.2 × 10−8 |
| Cellular senescence | 80 | 3.6 × 10−7 |
| Endometrial cancer | 38 | 3.6 × 10−7 |
2.2. The Core Signaling Pathways and Their Downstream Cellular Dysfunctions to Investigate Molecular Pathogenesis of Psoriasis
In Figure 4, the common and specific core signaling pathways and their downstream cellular dysfunctions between psoriasis and non-psoriasis are given. Then, the specific core signaling pathways and their downstream cellular dysfunctions of psoriasis were investigated to identify biomarkers of the pathogenesis of psoriasis. The microenvironmental factor interleukin 6 (IL-6) is produced by keratinocytes and leukocytes. It is a cytokine that is a major mediator of the host response to tissue injury and infection. High expression of IL6 could directly cause psoriatic epidermal hyperplasia and affect the function of dermal inflammatory cells [22]. It plays a significant role in psoriasis by linking keratinocyte proliferation with immune activation and tissue inflammation. The receptor IL6R receives the microenvironment factor IL6 to activate JAK1 and STAT3 to upregulate TF STAT3 [23]. The Janus Kinase–Signal Transducer and Activator of Transcription (JAK–STAT) pathway plays a significant role in the intracellular signaling of cytokines of numerous cellular processes, which is important in both normal and pathological states of immune-mediated inflammatory diseases [24]. The transduction of STAT3 is involved in the maintenance of postnatal interactions between epithelial and mesenchymal compartments [25]. The upregulated TF STAT3 will overexpress target genes VEGF, COX-2, and BCL-XL [26]. The overexpression of VEGF induces angiogenesis in psoriasis [27,28]. BCL-XL is an anti-apoptotic gene. Overexpression of BCL-XL prevents apoptosis and thickens the epidermis [29,30]. COX-2 has been reported to be involved in acute inflammation [31].
In Figure 4, another microenvironment factor is IGF1. The pathogenesis of psoriasis is due to the activation of immune cells and their secretion of cytokines, chemokines, growth factors, and IGF-1, which may lead to psoriatic epidermal hyperplasia and therefore it is considered one of the causes of psoriasis [32]. The receptor IGF1R receives the IGF1 and activates the downstream pathways, P13K/AKT, and the well-known estrogen-mediated Ras/Raf/MEK/ERK pathway [33]. The phosphatidylinositol 3-kinase (PI3K) and protein kinase B (AKT) signaling pathway play a central role in multiple cellular functions, such as cell proliferation and survival. In psoriasis, the PI3K/AKT signaling pathway is crucial in regulating various cellular processes including cell survival and proliferation. One of its key effects is the inhibition of cell proliferation through the negative regulation of TF FOXO. In keratinocytes, PI3K signaling pathway promotes cell proliferation by activating AKT and other targets, and this is accomplished by decreasing the expression of FOXO [34]. TF FOXO affects two genes, BCL6 and IL7R. Genetic polymorphisms in IL7R are associated with susceptibility to various autoimmune diseases. Studies have suggested that IL7R is involved in the pathogenesis of psoriasis [35,36]. The inactivation of Foxo1 leads to the release of the target gene Bcl6 expression [37]. The B-cell lymphoma 6 (Bcl6) is selectively expressed by TFH cells, which affects the regulation of B-cell-mediated humoral immunity and thus affects the development of psoriatic disease [38,39].
In addition to affecting FOXO, AKT also phosphorylates the downstream protein IKBKB, which in turn phosphorylates the protein NFKBIA and causes its ubiquitination and degradation. After NFKBIA is phosphorylated, it initiates TF RELA to phosphorylate and transport to TF NF-kB. Nuclear factor kappa B (NF-κB) is a protein transcription factor that coordinates inflammation and other complex biological processes. It is a key regulatory element of multiple immune and inflammatory pathways, cell proliferation and differentiation, and apoptosis. Therefore, many studies believe that TF NF-κB is a key mediator involved in the pathogenesis of psoriasis [40,41]. TF NF-κB plays an important role in the inflammatory response, and it affects many target genes, including VEGF, IL6, CXCL, COX-2, TNF-α, and BCL-XL [42,43]. Interleukin 6 (IL-6) is a cytokine. Highly expressed IL-6 was reported to directly promote epidermal hyperplasia in psoriatic epithelial cells [22]. The target gene, Chemokine ligand (CXCL), is involved in the pathogenesis of psoriasis. Studies have demonstrated that CXCR3 and CXCL10 are present in keratinocytes and dermal infiltrates of active psoriatic plaques; effective treatment of active plaques reduces CXCL10 expression in plaques [44].
The third microenvironment factor is IL17A. In psoriasis, IL-17A mainly acts on non-hematopoietic cells, especially epithelial cells, and continues to participate in the protective immunity of marginal tissues. In the skin, IL-17A leads to increased proliferation and abnormal differentiation of keratinocytes and disrupts the skin barrier by downregulating the expression of molecules involved in keratinocyte differentiation, such as filaggrin [45,46]. IL-17A is received by the receptor IL-17RC to activate the signaling cascade ACT1/TRAF6/MAP3K7/IKBKB [47]. In addition, the signaling protein TRAF6 also upregulates TF CEBPB. CEBPB family members are involved in epidermal keratinocyte differentiation. The TF CEBPB is an additional transcriptional regulator of IL-17A. Both NF-κB and CEBPB binding sites are overexpressed in the promoters of target genes IL-17R in psoriasis [48]. After ACT1 ubiquitination traf6, TF CEBPB will regulate target genes IL6, CXCL, COX-2, and TNF-α. The target gene TNF-α has multiple effects ranging from inflammation to apoptosis. Microenvironment factor IL-17A induces miR-378a expression in primary keratinocytes through NF-κB and CEBPB. Induction of miR-378a leads to the suppression of TF NFKBIA/IκBα, which allows for activation of the NF-κB pathway, leading to further induction of inflammatory mediators, such as CXCL8 [49].
Another microenvironment factor is PGE2. Prostaglandin E 2 (PGE 2) is a major mediator of inflammatory disease and is produced by virtually all cells in the body. PGE2 is increased in the epidermis of psoriatic lesions and is associated with pruritus, and patients with psoriasis may experience pruritus secondary to PGE2 vasodilation and a decreased pruritus threshold [50,51,52]. After PGE2 is produced by the cell, the receptor EP1-4 receives it and begins to affect the protein Gby. It then affects both P13k/AKt/IKBKB/NF-κB signaling pathway and the MAPK signaling pathway Ras/Raf/MEK/ERK.
Tumor necrosis factor- α (TNF-α) is a pro-inflammatory cytokine that coordinates tissue homeostasis by regulating cytokine production, cell survival, and cell death. It is a key cytokine in the innate immune response and is increased in psoriatic lesions. Many studies considered it as the key cytokine to psoriasis [53,54,55]. The receptor TNFR1 receives signal TNF-α in the microenvironment and affects downstream protein RIP1, which is a key upstream regulator controlling the inflammatory signaling and the activation of multiple cell death signaling pathways, including apoptosis and necroptosis. RIP1 regulates the NF-κB-mediated inflammatory response along the signaling pathway MAP3K7/IKBKB in response to TNF stimulation [56]. In addition, TNF-α is also received by the EGF receptor (EGFR), which triggers the phosphorylation of downstream protein SRC and enters the P13K/AKT signaling pathway. In addition, EGFR also activates another signaling protein, GRb2, and enters the well-known estrogen-mediated Ras/Raf/MEK/ERK signaling pathway. Many experiments have established that mitogen-activated protein kinases p38 (p38 MAPKs) and extracellular signal-regulated kinase 1/2 (ERK1/2) are involved in the pathogenesis of psoriasis. They control several important cellular functions in cells, such as cell proliferation, differentiation, gene expression, and apoptosis [57,58,59]. Finally, TF ERK will regulate the target genes c-jun and VEGF. C-jun has been reported to be involved in proliferation, apoptosis, survival, tumorigenesis, and tissue morphogenesis. Furthermore, overexpression of TF ERK and gene c-jun are associated with hyperproliferation and abnormal differentiation of the psoriatic epidermis [60,61].
2.3. The Specific Molecular Pathogenesis of Non-Psoriasis
In tissues without psoriasis, we found that Wnt/β-catenin signaling regulated by the Hippo pathway plays an important role in anti-cell proliferation. Wnt ligands bind coreceptors of the Frizzled family and the LRP/arrow family. This binding activates intracellular Dishevelled (Dvl), which in turn regulates the activity of the serine-threonine protein kinase glycogen synthase kinase 3β (GSK-3β). The activation of Dvl inhibits GSK-3β in this complex, resulting in the stabilization and accumulation of β-catenin in the cytoplasm. After nuclear translocation, β-catenin interacts with members of the TCF/LEF family of DNA-binding molecules to affect target gene Axin2 expression [62,63]. Axin2 plays an important role in regulating β-catenin stability in the Wnt signaling pathway. The study pointed out that the expression of gene Axin2 in normal tissue was significantly higher than that of psoriasis tissue [64].
2.4. Using Systems Drug Discovery and Design to Identify Potential Molecular Drugs to Combine as Multi-Molecule Drug for Psoriasis by the Prediction of Deep Neural Network-Based Drug-Target Interaction Model and Drug Design Specifications
By investigating the significant pathogenic mechanism of psoriasis based on core signaling pathways and their downstream cellular dysfunctions in the previous section, we selected NF-κB, STAT3, FOXO1, CEBPB, and ERK1/2 in Table 4 as significant biomarkers of pathogenic mechanism for psoriasis. Then according to the pharmacological properties of the molecular drugs, including regulatory ability, sensitivity, and toxicity as a drug design specification, some suitable potential drugs are discovered and designed to reverse the expression level of significant biomarkers.
Table 4.
The selected potential molecular drugs based on their regulatory ability, toxicity, sensitivity, and their binding of drug targets for the therapeutic treatment of psoriasis.
| Target | FOXO1 | NF-kB | STAT3 | CEBPB | ERK1/2 | Toxicity (LC50) |
Sensitivity (PRISM) |
|
|---|---|---|---|---|---|---|---|---|
| Drug | ||||||||
| Betulinic acid | ● | ● | ● | 6.712 | −0.103441 | |||
| Butein | ● | ● | 5.776 | −0.054450 | ||||
| naringin | ● | ● | ● | 6.921 | 0.132488 | |||
| Chemical structure of multiple molecules drug | ||||||||
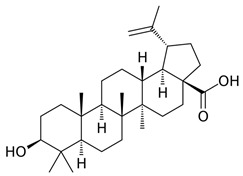
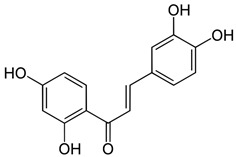
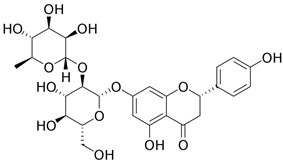
| Betulinic acid | Butein | naringin | ||||||
|
|
|
||||||
To develop a systematic drug design and discovery process, as shown in Figure 5, we first pre-trained a deep neural network (DNN)-based DTI model by DTI databases in Section 4.6 to predict potential molecular drugs to target the identified biomarkers (drug targets) of psoriasis. The trained DNN-based DTI model allowed us to efficiently estimate the probability of interaction between candidate drugs and identified drug targets (biomarkers) for psoriasis in Table 5. We then filtered the candidate drugs in Table 6 based on their pharmacological properties, such as regulatory ability, sensitivity, and toxicity as a drug design specification, to obtain potential molecular drugs in Table 4, which are combined to form a multi-molecule drug for the treatment of psoriasis.
Table 5.
Prediction performance of the DNN-based DTI model with five-fold cross-validation (early stopping at epoch 70).
| Validation Loss | Validation Accuracy | Testing Loss | Testing Accuracy | |
|---|---|---|---|---|
| 1 | 0.210332 | 0.933680 | 0.216158 | 0.979626 |
| 2 | 0.201320 | 0.927631 | 0.187810 | 0.983853 |
| 3 | 0.210199 | 0.925092 | 0.199039 | 0.982904 |
| 4 | 0.192665 | 0.928918 | 0.214739 | 0.982421 |
| 5 | 0.198525 | 0.929007 | 0.189671 | 0.982708 |
| average | 0.202608 | 0.928866 | 0.201483 | 0.982302 |
| Standard deviation | 0.006848 | 0.002792 | 0.012029 | 0.001422 |
Table 6.
The pharmacological information of candidate molecular drugs predicted by the DNN-based DTI model in Figure 5 for biomarkers of psoriasis. (+) means overexpression; (−) means low expression in psoriasis.
| STAT3 (+) | |||
|---|---|---|---|
| Drug | Regulation Ability (L1000) |
Sensitivity (PRISM) |
Toxicity (LC50, mol/kg) |
| CCT-018159 | −0.68150 | 0.068573 | 5.187 |
| Mofezolac | −0.34939 | 0.027005 | 5.684 |
| Eliprodil | −2.14303 | −0.00262 | 5.23 |
| Butein | −1.46898 | −0.05445 | 5.776 |
| LY-303511 | −0.57210 | −0.44921 | 5.075 |
| CEBPB (+) | |||
| Drug |
Regulation ability
(L1000) |
Sensitivity
(PRISM) |
Tox
icity
(LC50, mol/kg) |
| Limonin | −3.138645411 | −0.10563 | 6.726 |
| Mofezolac | −0.427841723 | 0.027005 | 5.684 |
| Betulinic-acid | −0.934850574 | −0.10344 | 6.712 |
| Tangeritin | −0.260343373 | −0.00037 | 5.488 |
| SB-415286 | −0.291000009 | 0.011518 | 6.282 |
| ERK1/2 (+) | |||
| Drug |
Regulation ability
(L1000) |
Sensitivity
(PRISM) |
Toxicity
(LC50, mol/kg) |
| Naringin | −0.12728 | 0.132488 | 6.921 |
| Mofezolac | −0.4780038 | 0.027005 | 5.684 |
| Betulinic-acid | −0.65759182 | −0.10344 | 6.712 |
| Quercetin | −0.297982544 | −0.03326 | 5.222 |
| BIBU-1361 | −0.908186227 | 0.155512 | 6.201 |
| NF-kB (+) | |||
| Drug |
Regulation ability
(L1000) |
Sensitivity
(PRISM) |
Toxicity
(LC50, mol/kg) |
| Naringin | −0.12728 | 0.132488 | 6.921 |
| Mofezolac | −1.00891 | 0.027005 | 5.684 |
| Butein | −1.46898 | −0.05445 | 5.776 |
| Ro-04-5595 | −0.2619 | −0.00387 | 5.443 |
| Flavoxate | −0.75315 | 0.107694 | 5.861 |
| FOXO1 (−) | |||
| Drug |
Regulation ability
(L1000) |
Sensitivity
(PRISM) |
Toxicity
(LC50, mol/kg) |
| Naringin | 0.579085 | 0.132488 | 6.921 |
| Mofezolac | 0.748792 | 0.027005 | 5.684 |
| Betulinic-acid | 0.756684 | −0.10344 | 6.712 |
| Penfluridol | 0.892637 | 0.144082 | 6.202 |
| Dexamethasone | 0.763925 | 0.122088 | 5.128 |
As shown in Figure 5, the training dataset consisted of 80,291 proven and 100,024 unproven drug-target interactions. To avoid imbalanced class distribution issues, we randomly selected an equal number of both types of interactions from the DTI database, as shown in Section 4.6. We also standardized the features in Equations (36) and (37) and reduced the dimensionality using principal component analysis (PCA) to obtain 996 of the 1359 features before training the DNN-based DTI model because the input layer of DNN we employed is only 996 nodes. The DNN-based DTI model consisted of an input layer with 996 nodes, four hidden layers with 512, 256, 128, and 64 neurons, and an output layer with one node, using ReLU activation for the neurons in hidden layers and sigmoid activation for the output layer. Dropout layers were also added to prevent overfitting. The learning curve of accuracy and loss during the DNN-based DTI model training process is shown in Figure 6 and Figure 7, respectively. The model achieved an average test accuracy of 98.2% with a standard deviation of 0.142% in five-fold cross-validation, as shown in Table 5. We also evaluated the model using ROC curves, with an AUC of 0.982, indicating significantly better performance than random prediction (AUC = 0.5), as shown in Figure 8. Finally, we used the best-performing DNN-based DTI model to predict candidate drugs based on the interaction probabilities with our identified drug targets in Table 6.
Figure 6.

The training and validation accuracy (five-fold cross-validation). ”-o-” line in different colors denotes the training accuracy, “-◊-” line in different colors denotes the validation accuracy.
Figure 7.

The training and validation loss (five-fold cross-validation).”-o-” line in different colors denotes the training loss, “-◊-” line in different colors denotes the validation loss.
Figure 8.

The prediction performance of the trained DNN-based DTI model has an AUC score of 0.982 for its receiver operating characteristic (ROC) curve.
In order to identify viable candidate drugs, we utilize predictions based on the likelihood of the candidate drug binding (docking) to the chosen biomarkers. However, it is important to maintain a balance between drug efficacy and potential adverse effects, as potent molecular drugs can often come with a higher risk of harm. To ensure the safety and efficacy of the candidate molecular drugs predicted by the DNN-based DTI model, we incorporated some pharmacological properties of drug design specifications, including regulation ability, sensitivity, and toxicity. To evaluate the molecular drug regulation ability, we used the LINCS L1000 Level 5 dataset, which contains data on 12,328 genes treated with 19,811 small molecule compounds across 76 different human cell lines [65,66]. Positive values in the accommodation ability data represent an increase in expression levels, while negative values represent a decrease in expression levels. We used this dataset to identify potential molecular drugs from the candidate drugs that can restore the drug targets (biomarkers) to their normal expression levels. For drug sensitivity, we utilized the primary PRISM repurposing dataset, which includes information on 4518 compounds across 578 human cell lines [67]. We selected compounds with sensitivity values close to zero, indicating that the cell line is insensitive to chemical perturbations. In addition, we considered drug toxicity (LC50) using the ADMETlab 2.0 tool [68]. A higher LC50 value indicates lower toxicity and fewer side effects. Table 6 presents several candidate drugs that were predicted by the DNN-based DTI model for the identified biomarkers, along with their pharmacological information on regulatory ability, toxicity, and sensitivity. Based on the drug design specifications of suitable regulation ability, less sensitivity close to 0, and low toxicity, potential molecular drugs such as Naringin, Butein, and Betulinic-acid were selected. These molecular drugs were then combined as a multiple-molecule drug for the therapeutic treatment of psoriasis, as shown in Table 4.
3. Discussion
In this study, we aimed to discover a potential multi-molecule drug for the therapeutic treatment of psoriasis. To achieve this, we utilized core GWGENs by genome microarray data via the system identification and PNP method and then employed KEGG annotations to construct the core signaling pathways and to identify the biomarkers of pathogenesis as drug targets for the therapeutic treatment of psoriasis. We then employed DNN-based DTI model prediction and drug design specification to find potential molecular drugs to combine as a multi-molecule drug that possesses the proper toxicity, sensitivity, and regulation ability. With these system medicine approaches, consequentially, we were able to predict Butein, Naringin, and Betulinic-acid to combine as a potential multi-molecule drug for the therapeutic treatment of psoriasis.
Betulinic acid, or 3β-hydroxy-lup-20(29)-en-28-oic acid, is a naturally occurring pentacyclic lupane-type triterpenoid widely distributed in plants [69]. Previous studies used various experimental models to demonstrate the anti-inflammatory activity of betulinic acid [70]. Betulinic acid can inhibit the expression of NF-κB by reducing the activation of IKKβ, which is an inhibitor of TF NF-κB, and by decreasing the phosphorylation of IκBα, another inhibitor of NF-κB [71]. Furthermore, Betulinic acid acts as a natural inhibitor of the CEBP family [72]. Betulinic acid has been reported to inhibit TF ERK1/2, affecting COX-2 expression [73]. In addition to the direct effects, other studies have reported that Betulinic acid can indirectly lower TF STAT3 and affect the regulation of gene VEGF [73]. For the treatment of psoriasis, although there are no clinical trials yet, the studies have confirmed that betulinic acid ameliorates psoriasis-like murine skin inflammation.
Butein (3,4,20,40-tetrahydroxychalcone) is present in numerous plants, including the stem-bark of cashews, herbs, such as caragana jubata, and rhus verniciflua, as well as the heartwood of Dalbergia odorifera. These plants have been used as herbal medicines for cancer treatment in many Asian countries, and the anti-cancer effects of these plant extracts are well-established [74]. Butein has been shown to exert various biological activities, such as antioxidant, anti-inflammatory, and anti-tumor activities [75]. For regulation on biomarkers, previous reports demonstrated that Butein induces anti-proliferative or pro-apoptotic effects in hepatic cells by downregulating signal transducer and activator of transcription-3 (STAT-3)-related gene expression and stimulating mitochondria-dependent caspase-3 activation [76]. In addition, studies have pointed out that in the human keratinocyte cell line, Butein inhibits TNF-α-induced expression of pro-inflammatory mediators by inhibiting NF-κB activation. In terms of treatment, Butein has immunomodulatory activity by inhibiting the expression of pro-inflammatory mediators in keratinocytes and is considered a therapeutic agent for the treatment of inflammatory skin diseases [77]. Butein has been shown to be a promising therapeutic agent for preventing adipose tissue inflammation and obesity-linked insulin resistance [78].
Naringin, chemically 4,5,7-trihydroxyflavanone-7-rhamnoglucoside, is a major flavanone glycoside obtained from tomatoes, grapefruits, and many other citrus fruits. A wide spectrum of beneficial effects has been attributed to Naringin, including cardiovascular, hypolipidemic, anti-inflammation, antidiabetic, neuroprotective, hepatoprotective, and anti-cancer activities [79,80]. For the regulation of biomarkers (drug targets), a previous study demonstrated that naringenin inhibits oxidative stress and inflammation, rescuing neuronal cell death. The mechanism was involved in the promotion of the SIRT1/FOXO1 signaling pathway. It has also been reported that Naringin stimulated the mitochondrial biogenesis pathway through regulation of the LKB1/AMPK/PGC-1α signaling pathway and upregulated FOXO1-mediated autophagy [81]. Naringin has been demonstrated to exert its anti-inflammatory effects by inhibiting the secretion, as well as inhibiting the phosphorylation of ERK1/2, JNK, and p38 MAPK, by blocking the activation of the NF-κB and MAPK signaling pathways [82]. In terms of therapeutic treatment, much research has demonstrated that Naringin exerts an anti-inflammatory effect on numerous chronic inflammatory diseases, including chronic bronchitis and inflammatory bowel disease [83]. In addition, Naringin combined with sericin significantly decreased the expression of mRNA and the production of all pro-inflammatory cytokines in hPBMCs from patients with psoriasis [84].
4. Materials and Methods
4.1. General Review of Constructing Core Genome-Wide Genetic and Epigenetic Networks (GWGENs) of Psoriasis and Non-Psoriasis
In order to construct the core genome-wide genetic and epigenetic networks (core GWGENs) for psoriasis and non-psoriasis, we first divided the data into a disease group and a healthy control group from the GSE117468 dataset. We then followed a four-step process, as shown in Figure 1. In the first step, we used a big database mining approach to construct a candidate PPIN (protein–protein interaction network) and a candidate GRN (gene regulatory network), which included the regulations of genes, miRNAs, and lncRNAs. In the second step, we identified the real GWGENs of psoriasis and non-psoriasis by using the microarray data of psoriasis and non-psoriasis to solve the constrained linear least squares estimation problems for the interaction parameters of PPIN and the regulation parameters of GRN using the system identification method. We pruned the false positives in the candidate GWGEN using the AIC method to obtain the real GWGENs of psoriasis and non-psoriasis [18]. In the third step, we extracted the core GWGENs by using the principal network projection PNP approach, which involves computing a projection value for each node in the real GWGENs to identify the top 6000 nodes, which is the largest number of nodes allowed for annotation by KEGG pathways with the higher projection values based on singular value to principal network structures with 85% energy of real GWGENs as the core GWGENs [85]. In the fourth step, we annotated the KEGG pathways of core GWGENs of psoriasis and non-psoriasis to construct their respective core signaling pathways. We then compared the upstream micro-environmental factors, core signaling pathways, and their corresponding downstream abnormal cellular functions of psoriasis and non-psoriasis to investigate the molecular mechanisms of carcinogenesis of psoriasis. Finally, we will identify significant biomarkers in core signaling pathways in response to cellular dysfunctions in pathogenic mechanism of psoriasis.
4.2. Data Preprocessing for Constructing the Candidate GWGEN
In this study, we obtained the dataset with accession number GSE117468 from NCBI, which contains microarray data of both psoriasis and non-psoriasis. We divided the microarray dataset into two groups: a disease group and a healthy control group. The dataset samples contain 128 samples of psoriasis and 128 samples of non-psoriasis. The dataset consists of mRNA, miRNA, and lncRNA data. To construct the candidate GWGEN, we used a binary matrix with a value of 1 assigned to nodes that showed interactions or regulation and a value of 0 assigned to nodes that did not. For the construction of the candidate PPIN, we referred to various databases, including DIP [86], IntAct [87], BioGRID [88], and MINT [89]. Similarly, we used several databases, such as HTRIdb [90], ITFP [91], TRANSFAC [92], CircuitDB [93], TargetScanHuman [94], and StarBase 2.0 [95] to construct the candidate GRN.
4.3. Building the Stochastic System Models of Candidate GWGEN to Identify Real GWGENs of Psoriasis and Non-Psoriasis
Based on the database and collected microarray data, we established candidate GWGEN. Next, we needed to identify the real GWGENs of psoriasis and non-psoriasis by their microarray data. Here, we constructed stochastic interaction and regulation models of candidate GWGEN, including protein–protein interactions, transcriptional regulations, miRNA and lncRNA regulations, as well as the basal level and stochastic noise due to model residuals and data measurement noise.
First, we established the following interaction equations between the a-th protein and its interacting proteins in the candidate PPIN of candidate GWGEN [96].
| (1) |
where pa [n] and pr[n] indicate the expression level of the a-th and the r-th protein in the n-th sample; τar represents the interaction ability between the a-th protein and the r-th protein; Ra stands for the total number of proteins interacting with the a-th protein; A is the total number of proteins in the candidate PPIN; N is the total number of the data samples (patients); represents the basal level of the a-th protein expression due to unknown interactions of histone modifications, such as phosphorylation and acetylation; [n] indicates the stochastic noise of the a-th protein in the n-th sample because of data measurement noise.
After the protein interaction equations are completed, we need to establish the gene regulation equations. For gene regulation, the expression levels of TFs, lncRNAs, and miRNAs all have a great impact. For the gene regulatory model, the transcriptional regulation of the b-th gene in the n-th sample is described by the following Equation:
| (2) |
where gb[n], th[n], li[n], and mj[n] denote the expression level of the b-th gene, the h-th TF, the i-th lncRNA, and the j-th miRNA for the n-th sample; and respectively indicate the transcriptional regulatory ability of the h-th TF and the i-th lncRNA on the b-th gene; > 0 is the post-transcriptional regulatory ability of the j-th miRNA to inhibit the b-th gene; , and represent the total binding number of TFs, lncRNAs and miRNAs of the regulation on the b-th gene, respectively; B is the total number of genes in candidate GRN; N is the total number of the data samples (patients); σb is the basal level of the b-th gene expression caused by unknown gene regulations, such as methylation; λb[n] is the stochastic noise of the b-th gene in the n-th sample owing to model uncertainty and data noise.
Next, we established the lncRNA regulation Equation. The expression levels of TFs, lncRNAs, and miRNAs all have a great impact on the expression level of lncRNA. For the lncRNA regulatory model, the transcriptional regulation of the c-th lncRNA in the n-th sample is described by the following Equation [17]:
| (3) |
where [n], th[n], li[n], and mj[n] denote the expression level of the c-th lncRNA, the h-th TF, the i-th lncRNA, and the j-th miRNA in the n-th sample, respectively; and separately indicate the transcriptional regulatory ability of the h-th TF and the i-th lncRNA on the c-th lncRNA; ≥ 0 is the post-transcriptional regulatory ability of the c-th miRNA to inhibit the c-th lncRNA; Hc, Ic, and Jc individually represent the total binding number of TFs, lncRNAs and miRNAs on the c-th lncRNA; C is the total number of lncRNA; N is the total number of the data samples (patients); σc is the basal level of the c-th lncRNA expression caused by unknown regulations, such as methylation; λc[n] is the stochastic noise of the c-th lncRNA in the n-th sample owing to model uncertainty and data noise.
Similarly, the expression levels of miRNAs are also regulated by TFs, lncRNAs, and other miRNAs. The regulatory model of miRNAs in candidate GWGEN is described in the following Equation:
| (4) |
where , th[n], li[n], and mj[n] denote the expression level of the d-th miRNA, the h-th TF, the i-th lncRNA and the j-th miRNA in the n-th sample, sequentially; xdh and ydi separately indicate the transcriptional regulatory ability of the h-th TF and the i-th lncRNA on the d-th lncRNA, respectively; zdj ≥ 0 is the post-transcriptional regulatory ability of the d-th miRNA to inhibit the d-th miRNA; Hd, Id, and Jd individually represent the total binding number of TFs, lncRNAs and miRNAs on the d-th miRNA; D is the total number of miRNA; N is the total number of the data samples (patients); σd is the basal level of the d-th lncRNA expression caused by unknown regulations; λd[n] is the stochastic noise of the d-th miRNA in the n-th sample owing to model uncertainty and data noise.
4.4. Using the System Identification Scheme and System Order Detection Method to Prune False Positives of the Candidate GWGEN and Identify Real GWGENs of Psoriasis and Non-Psoriasis
According to the stochastic interaction and regulatory model, we constructed four models for candidate GWGENs above, including the candidate PPI model [96], gene regulatory model, lncRNA regulatory model, and miRNA regulatory model in Equations (1)–(4), respectively. Then, we used system identification and system order detection method to prune the false positive interactions in candidate GWGENs and obtain the real GWGENs of psoriasis and non-psoriasis by their microarray data. To estimate the interactive and regulative parameters, we needed to rewrite Equations (1)–(4) into the following linear regression form [97]:
| (5) |
| (6) |
| (7) |
| (8) |
where ϕa[n], ϕb[n], ϕc[n], ϕd[n] are regression vectors of the expression data of the a-th protein, the b-th gene, the c-th lncRNA, and the d-th miRNA in the n-th sample, respectively; θa denotes the parameter vector of protein–protein interactions and the basal level of the a-th proteins; θb, θc, θd indicate the parameter vector of the transcriptional regulatory ability and basal level of the b-th gene, the c-th lncRNA, and the d-th miRNA, respectively; a[n],b[n],c[n],d[n] are the stochastic noise due to model residue and data noise of the a-th protein, the b-th gene, the c-th lncRNA, and the d-th miRNA for n samples, respectively.
Then, linear Equations (5)–(8) can be further rewritten with N microarray data samples as the following Equations:
| (9) |
| (10) |
| (11) |
| (12) |
The Equations (9)–(12) can be simply expressed as the following equations, respectively:
| (13) |
| (14) |
| (15) |
| (16) |
Then, we can estimate the parameter vectors a, b, c, d by their corresponding microarray data of N samples (patients). If the component number of the parameter vector of protein in PPIN and genes in GRN is larger than half (N/2) of the dataset samples, it may cause an overfitting problem in the parameter estimation. Therefore, we estimated the parameter vector by solving the constrained linear least-squares parameter estimation problem as follows [97]:
| (17) |
| (18) |
| (19) |
| (20) |
The constraints in Equations (18)–(20) ensure that the estimated post-transcriptional regulatory ability of miRNAs on genes, lncRNAs, and miRNAs is negative. Therefore, we can estimate the optimal vectors ,,, of the protein interaction, gene, lncRNA, and miRNA regulation by solving the constrained least squares parameter estimation problems in Equations (17)–(20) with the MATLAB Optimization Toolbox, respectively.
After solving the constrained least squares parameter estimation problems above, we obtained the parameters of interactive ability, regulatory ability, and basal level for each protein, gene, miRNA, and lncRNA in candidate GWGENs of psoriasis and non-psoriasis by their microarray data. Then, we pruned false positives in candidate GWGENs to obtain real GWGENs of psoriasis and non-psoriasis through the system order detection method via the Akaike Information Criterion (AIC) method. The AIC method for detecting the order of protein, gene, lncRNA, and miRNA in candidate GWGENs is given as follows [96]:
| (21) |
and ρa is the estimated residual error of the a-th protein, which was calculated from the least square estimated parameter in Equation (17). Ra is the number of protein interactions with the a-th protein.
| (22) |
and ρb is the estimated residual error of the b-th gene, which was calculated from the least square estimated parameter in the constrained estimation parameter problem Equation (18). Hb, Ib, and Jb are the number of regulations of genes, lncRNAs, and miRNAs on the b-th gene.
| (23) |
and ρc is the estimated residual error of the c-th lncRNA, which was calculated from the least square estimated parameter in the constrained estimation parameter problem Equation (19). Hc, Ic, and Jc are the number of regulations of genes, lncRNAs, and miRNAs on the c-th gene, respectively.
| (24) |
and ρd is the estimated residual error of the d-th miRNA, which be calculated from the least square estimated parameter in the constrained estimation parameter problem Equation (19). Hd, Id, and Jd are the number of regulations of genes, lncRNAs, and miRNAs on the d-th gene, respectively.
Akaike Information Criterion (AIC) is an index used to compare the pros and cons of different statistical models. The smaller the AIC value, the better the predictive ability of the model. To obtain the real GWGENs, we minimize the four AICs by equations as follows:
| (25) |
| (26) |
| (27) |
| (28) |
where R*a means the real number of protein interactions with the a-th protein. H*b, I*b, and J*b denote the real number of regulations of TFs, lncRNAs, and miRNAs on the b-th gene. H*c, I*c, and J*c denote the real number of regulations of TFs, lncRNAs, and miRNAs on the c-th lncRNA. H*d, I*d, and J*d denote the real number of regulations of TFs, lncRNAs, and miRNAs on the d-th miRNA. After solving the above AIC minimum problem, the false positives out of the real number of interactions and regulations must be removed from candidate GWGENs and obtain the real GWGENs of psoriasis and non-psoriasis in Figure 2.
4.5. Extracting the Core GWGENs from the Real GWGENs by the Principal Network Projection (PNP) Method
After system order detection and identification method by the corresponding microarray data, we successfully obtained real GWGENs of psoriasis and non-psoriasis in Figure 2. However, it is still too complicated to figure out the molecular mechanisms of psoriasis. Therefore, we needed to employ KEGG pathways to annotate signaling pathways of real GWGENs. However, at present, KEGG pathways can only annotate GWGENs with 6000 nodes at most. Therefore, we used the PNP method to extract 6000 nodes from real GWGENs of psoriasis and non-psoriasis for pathway annotation by KEGG. The PNP method is based on singular value decomposition (SVD) of real GWGENs in Figure 2 to extract k = 6000 important nodes in real GWGENs to construct core GWGENs in Figure 3. The procedure of the PNP method is given as follows: First, in order to employ the singular value decomposition technique, we constructed a network matrix W from real GWGENs.
| (29) |
where is a sub-matrix which records the estimated protein interaction abilities of PPIN. The bidirectional arrow means the protein interaction is bidirectional; the sub-network matrices , , and record the estimated transcriptional regulation abilities of TFs, lncRNAs, and miRNAs on genes, respectively; , , and indicate matrices of the estimated transcriptional regulation abilities of TFs, lncRNAs, and miRNAs on lncRNAs, respectively; , , are the matrices of the estimated transcriptional regulation abilities of TFs, lncRNAs and miRNAs on miRNAs, respectively. The following matrix is the detail on the network matrix of W of real GWGENs:
| (30) |
Then, we performed a singular value decomposition of the network matrix W as follows:
| (31) |
| (32) |
In order to extract the core GWEN from the real GWEN, we only retained the top K singular values of matrix Σ in Equation (32), which have at least 85% energy of real GWGENs. Similarly, the matrix U retains the top K rows, and VT retains the top-K columns to construct a significant network structure with at least 85% energy as follows [18,96]:
| (33) |
Next, we project each node of the real GWGENs (i.e., each row of network matrix W) separately to the top principal singular vectors and apply the 2-norm projection value of each node such as protein, gene,miRNA, and lncRNA in the real GWGENs of psoriasis and non-psoriasis to the top K principal singular vectors as follows:
| (34) |
where proj(a,b) denotes the projection value of the a-th node to the b-th principal singular vector; wa and vb are the a-th row of the W vector and the b-th principal singular vector. P(a) represents the 2-norm projection value of the a-th node to the top K singular vectors. The larger the P(a), the more influence the a-th node of real GWGENs is on the network structure. Conversely, if P(a) is very close to zero, then the a-th node of real GWGENs is almost independent of the significant network structure.
The core GWGENs of psoriasis and non-psoriasis were identified, as shown in Figure 3, by extracting the top 6000 significant nodes based on their projection values P(a) in Equation (34). These core GWGENs were then annotated by KEGG pathways, which allowed us to identify the core signaling pathways of psoriasis and non-psoriasis in Figure 4. We compared these two core signaling pathways in Figure 4 to gain insights into the pathogenesis underlying the development of psoriasis. Based on the investigated pathogenic mechanism in Figure 4, we selected essential biomarkers as potential drug targets for the therapeutic treatment of psoriasis.
4.6. Design and Discovery of Multi-Molecule Drug through the Prediction of DNN-Based DTI Model for Treatment of Psoriasis by DNN-Based DTI Model
After finding the essential biomarkers as drug targets for the pathogenesis of psoriasis, we needed to identify the corresponding candidate molecular drugs to target these essential biomarkers. DNN-based DTI model has been effectively employed to predict candidate drugs to interact with significant biomarkers (drug targets) [96].
To train a DNN-based DTI model to predict the interactions of drug candidates with significant biomarkers of psoriasis, we integrated multiple DTI databases, including STITCH, BIDD, UniProt, DrugBank, ChEMBL, PubChem, and KEGG [98,99,100,101,102,103], which provide information about molecular interactions, drug and target features. Drug features include structure, topology, geometric descriptors, and other molecular properties, while the sequence of the target protein is representative because the complete target protein information is usually encoded in the sequence. Target features are calculated from the structural and physicochemical features of proteins and peptides in amino acid sequences. After converting the properties of drugs and targets into features, we used the Python package PyBioMed under the Python 3.7 environment [104], and each drug-target pair was represented as a feature vector by concatenating the corresponding feature vectors. The feature vector of the drug-target pair is as follows [105]:
| (35) |
where xdrug-target refers to the feature vector for the drug-target pair, while D and T represent the feature vectors for the drug and target, respectively, dm and tn refer to the m-th drug feature and n-th target feature, respectively, where M and N indicate the total number of drug and target features, respectively.
Before using the drug-target vector in Equation (35) as training data for a deep neural network (DNN) as a DTI model to predict candidate molecular drugs for significant biomarkers (drug targets) of psoriasis, we needed to pre-process the data to make it suitable as an input to the DNN. Because there were more negative data with unknown interactions than positive data with known interactions, it was necessary to downsample the negative data to reduce the imbalance problem between the numbers of positive and negative data. The purpose of downsampling is to randomly reduce the amount of negative data to the same number as positive data, allowing the model to learn equally from both types of training data. Furthermore, since the variables of the feature vectors in Equation (35) in each drug-target pair are measured in different units, we need to normalize each feature vector to normalize the importance among the feature vectors. In other words, the purpose of preprocessing the training data is to enable DNN to better learn the model of drug-target interaction. The mathematical formulas for the normalization of the features of the drug and target are as follows:
| (36) |
| (37) |
where dm* represents the m-th drug feature represents the m-th drug feature after standardization, and dm represents the original m-th drug feature. Similarly, tn* represents the n-th target feature after standardization, and tn represents the original n-th target feature. The mean and standard deviation of each drug feature are represented by μm and σm, respectively. Likewise, the mean and standard deviation of each target feature is represented by μn and σn, respectively. Equations (36) and (37) refer to a standardization process for drug and target features, respectively.
Since the DNN, which is employed as a DTI model, has only 996 inputs, we needed to reduce the dimension of drug target features in the feature vectors in Equation (35) so that they could be input into the DNN. To reduce the input number of features to DNNs as the DTI model, we downsample the feature vectors of the drug-target pair to reduce their dimension using the principal component analysis (PCA) method. After data preprocessing, we use 75% of the data as training data and 25% of the data as testing data. The DNN-based DTI model in Figure 5 has four hidden layers containing 512, 256, 128, and 64 neurons, respectively. We used binary cross entropy as the loss function, the learning rate is 0.001, and we used the Adam algorithm as the optimizer. In addition, we set epochs to 100 and batch size to 100. Each hidden layer has a rectified linear unit (ReLU) activation function to avoid the vanishing gradient problem in deep learning. We also use the five-fold cross-validation method for learning data to check the stability and prediction performance of the DNN-based DTI model. We applied the early stopping approach to avoid the overfitting problem. The activation function of the output layer is a sigmoid function, which can limit the output value in the range of 0 to 1 as the probability predicted by the DNN-based DTI model. Because the drug-target interaction (DTI) is a binary classification issue, the cost function which we chose to calculate the model loss is the binary cross-entropy as follows [97]:
| (38) |
| (39) |
For the n-th sample, we have a true positive interaction probability pn and a predicted positive interaction probability , and a true negative interaction probability 1 − pn and a predicted negative interaction probability 1−. We use binary cross-entropy as the loss function to compute the total loss by averaging the loss L(w,b) per sample. w denotes the weighting vector; b indicates the bias vector of DNN. N is the total number of training data.
We utilized the backward propagation algorithm [106] to update the parameter vector θ of the weight vector w and bias vector b based on the cost function. This involves calculating the gradient to obtain the optimal parameter vector θ* for the DNN-based DTI model as follows:
| (40) |
| (41) |
| (42) |
and y means the y-th interaction of the learning process by training of the y-th drug-target feature vector; η is the learning rate which is set as 0.001 in this study; means the gradient of .
After training the DNN-based DTI model by feature vectors of drug-target pairs in Equation (35), we used the area under the curve (AUC) and receiver operating characteristic (ROC) curves in Figure 8 to evaluate the prediction performance of the model. For classification problems, this is one of the most useful evaluation metrics to visualize the performance of the DNN-based DTI model. The larger the area under the ROC curve, the higher the AUC and the higher the accuracy of the DNN-based DTI model in predicting true positive and true negative drug-target interactions. The mathematical formulas for AUC and ROC curves are as follows [96]:
| (43) |
| (44) |
| (45) |
where TP means the judgment is true and the fact is also true; TN means the judgment is false and real value is also false; FP means the judgment is true, but the real value is false; FN means the judgment is false, but the real value is true;
By using the DNN-based DTI model, we successfully obtained five candidate molecular drugs in Table 6, which can be pruned by drug design specifications to obtain potential molecular drugs for psoriasis. We screened out the potential molecular drugs from candidate molecular drugs in Table 6 based on some pharmacological properties such as adequate regulation ability, sensitivity, and toxicity as drug design specifications. Specifically, we referred to regulatory capacity data from the L1000 Level 5 dataset [65], from which molecular drugs were selected against selected biomarkers (drug targets). For example, if the gene expression of the selected biomarkers (drug targets) is abnormally upregulated, we will select the drug with a negative correlation. Conversely, if the gene expression of the selected biomarkers (drug targets) is abnormally downregulated, a drug with a positive correlation is selected. At the same time, we selected molecular drugs with sensitivity values close to zero corresponding datasets obtained from primary PRISM repurposing datasets [67]. A sensitivity value close to zero indicates that the cell is not sensitive to the molecular drug. In consideration of drug toxicity, we used the ADMETlab 2.0 tool to refer to the LC50 value and selected compounds with lower toxicity [68]. Finally, we screened out the potential molecular drugs of psoriasis following the above three drug design specifications and proposed three potential molecular drugs which are combined as a multi-molecule drug in Table 4. Overall, we have successfully selected a suitable combination of molecular drugs as a multi-molecule drug for the therapeutic treatment of psoriasis.
5. Conclusions
In this study, we first constructed candidate GWGENs via big data mining. Second, we used an AIC system order detection and system identification scheme to obtain the real GWGENs of psoriasis and non-psoriasis by their microarray data of 128 patients. Third, we extracted the core GWGENs of psoriasis and non-psoriasis by employing the PNP method. Afterward, core signaling pathways for psoriasis and health control were identified by KEGG pathways annotation of core GWGENs. After identifying the significant biomarkers for the pathogenesis of psoriasis as drug targets, with the help of the DNN-based DTI model trained by DTI databases, we could predict the candidate molecular drugs of the significant biomarkers. Finally, we selected potential molecular drugs to combine as a multi-molecule drug for the therapeutic treatment of psoriasis according to the drug design specifications of adequate regulatory ability, toxicity, and sensitivity between drugs and drug targets.
In this study, we identified NF-κB, FOXO1, CEBPB, STAT3, and ERK1/2 as the drug targets for the treatment of psoriasis. Then based on the prediction of the DNN-based DTI model and the proposed drug design specifications, Naringin, Butein, and Betulinic acid are selected and combined as the multiple-molecule drug to target multiple biomarkers of the pathogenesis of psoriasis. With more clinical and experimental verification, it is hoped that the multi-molecule drug proposed in this study can benefit patients with psoriasis. Finally, it is appealing to extend the novelty of this systems medicine approach in the search for new candidate molecules in the therapy of other diseases since, with the proposed work, the therapeutic expectations of the drugs thus identified are high.
Author Contributions
Conceptualization, Y.-P.Z. and B.-S.C.; methodology, Y.-P.Z. and B.-S.C.; software, Y.-P.Z. and B.-S.C.; validation, Y.-P.Z. and B.-S.C.; formal analysis, Y.-P.Z. and B.-S.C.; investigation, Y.-P.Z. and B.-S.C.; data curation, Y.-P.Z.; writing—original draft preparation, Y.-P.Z.; writing—review and editing, Y.-P.Z. and B.-S.C.; visualization, Y.-P.Z.; supervision, B.-S.C.; funding acquisition, B.-S.C. All authors have read and agreed to the published version of the manuscript.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw gene count datasets of human genes are integrated from GSE117468 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE117468, accessed on 15 November 2022). The drug regulation ability data are from Phase I L1000 Level 5 datasets (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE92742, accessed on 15 November 2022). The drug sensitivity datasets are from DepMapPRISM primary screen datasets (https://depmap.org/repurposing/, accessed on 15 November 2022). The code can be obtained from https://github.com/ZhanUPing/muti-molecular-drug-design, accessed on 15 November 2022.
Conflicts of Interest
The authors declare no conflict of interest.
Funding Statement
This research received no external funding.
Footnotes
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
References
- 1.Lowes M.A., Bowcock A.M., Krueger J.G.J. Pathogenesis and therapy of psoriasis. Nature. 2007;445:866–873. doi: 10.1038/nature05663. [DOI] [PubMed] [Google Scholar]
- 2.Magin P., Adams J., Heading G., Pond D., Smith W.J. The psychological sequelae of psoriasis: Results of a qualitative study. Psychol. Health Med. 2009;14:150–161. doi: 10.1080/13548500802512294. [DOI] [PubMed] [Google Scholar]
- 3.Michalek I., Loring B., John S.J. Venereology. A systematic review of worldwide epidemiology of psoriasis. J. Eur. Acad. Dermatol. Venereol. 2017;31:205–212. doi: 10.1111/jdv.13854. [DOI] [PubMed] [Google Scholar]
- 4.World Health Organization . World Health Organization Global Report on Psoriasis. World Health Organization; Geneva, Switzerland: 2016. [Google Scholar]
- 5.Bhalerao J., Bowcock A.M. The genetics of psoriasis: A complex disorder of the skin and immune system. Hum. Mol. Genet. 1998;7:1537–1545. doi: 10.1093/hmg/7.10.1537. [DOI] [PubMed] [Google Scholar]
- 6.Rendon A., Schäkel K. Psoriasis pathogenesis and treatment. Int. J. Mol. Sci. 2019;20:1475. doi: 10.3390/ijms20061475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hayes J., Koo J. Psoriasis: Depression, anxiety, smoking, and drinking habits. Dermatol. Ther. 2010;23:174–180. doi: 10.1111/j.1529-8019.2010.01312.x. [DOI] [PubMed] [Google Scholar]
- 8.Hengge U.R., Ruzicka T., Schwartz R.A., Cork M.J. Adverse effects of topical glucocorticosteroids. J. Am. Acad. Dermatol. 2006;54:1–15. doi: 10.1016/j.jaad.2005.01.010. [DOI] [PubMed] [Google Scholar]
- 9.Zhang P., Wu M.X. A clinical review of phototherapy for psoriasis. JAAD. 2018;33:173–180. doi: 10.1007/s10103-017-2360-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Seebode C., Lehmann J., Emmert S. Photocarcinogenesis and skin cancer prevention strategies. Anticancer Res. 2016;36:1371–1378. [PubMed] [Google Scholar]
- 11.Boffa M., Chalmers R.J.G. Methotrexate for psoriasis. Clin. Exp. Dermatol. 1996;21:399–408. doi: 10.1111/j.1365-2230.1996.tb00142.x. [DOI] [PubMed] [Google Scholar]
- 12.Honda H., Umezawa Y., Kikuchi S., Yanaba K., Fukuchi O., Ito T., Nobeyama Y., Asahina A., Nakagawa H. Switching of biologics in psoriasis: Reasons and results. Br. J. Dermatol. 2017;44:1015–1019. doi: 10.1111/1346-8138.13860. [DOI] [PubMed] [Google Scholar]
- 13.Hughes J.P., Rees S., Kalindjian S.B., Philpott K.L. Principles of early drug discovery. Br. J. Dermatol. 2011;162:1239–1249. doi: 10.1111/j.1476-5381.2010.01127.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Akhondzadeh S.J.A. The importance of clinical trials in drug development. Avicenna J. Med. Biotechnol. 2016;8:151. [PMC free article] [PubMed] [Google Scholar]
- 15.Weaver M.F., Hopper J.A., Gunderson E.W. Designer drugs 2015: Assessment and management. Addict. Sci. Clin. Pract. 2015;10:8. doi: 10.1186/s13722-015-0024-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Jain H., Bhat A.R., Dalvi H., Godugu C., Singh S.B., Srivastava S. Repurposing approved therapeutics for new indication: Addressing unmet needs in psoriasis treatment. Pharmacol. Res. 2021;2:100041. doi: 10.1016/j.crphar.2021.100041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Ting C.-T., Chen B.-S. Repurposing Multiple-Molecule Drugs for COVID-19-Associated Acute Respiratory Distress Syndrome and Non-Viral Acute Respiratory Distress Syndrome via a Systems Biology Approach and a DNN-DTI Model Based on Five Drug Design Specifications. Int. J. Mol. Sci. 2022;23:3649. doi: 10.3390/ijms23073649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Wang C.-G., Chen B.-S. Multiple-Molecule Drug Repositioning for Disrupting Progression of SARS-CoV-2 Infection by Utilizing the Systems Biology Method through Host-Pathogen-Interactive Time Profile Data and DNN-Based DTI Model with Drug Design Specifications. Stresses. 2022;2:405–436. doi: 10.3390/stresses2040029. [DOI] [Google Scholar]
- 19.Yeh S.-J., Chung Y.-C., Chen B.-S. Investigating the Role of Obesity in Prostate Cancer and Identifying Biomarkers for Drug Discovery: Systems Biology and Deep Learning Approaches. Molecules. 2022;27:900. doi: 10.3390/molecules27030900. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Yeh S.-J., Lin J.-F., Chen B.-S. Multiple-molecule drug design based on systems biology approaches and deep neural network to mitigate human skin aging. Molecules. 2021;26:3178. doi: 10.3390/molecules26113178. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Bozdogan H. Model selection and Akaike’s information criterion (AIC): The general theory and its analytical extensions. Psychometrika. 1987;52:345–370. doi: 10.1007/BF02294361. [DOI] [Google Scholar]
- 22.Grossman R.M., Krueger J., Yourish D., Granelli-Piperno A., Murphy D.P., May L.T., Kupper T.S., Sehgal P.B., Gottlieb A.B. Interleukin 6 is expressed in high levels in psoriatic skin and stimulates proliferation of cultured human keratinocytes. Proc. Natl. Acad. Sci. USA. 1989;86:6367–6371. doi: 10.1073/pnas.86.16.6367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Fiocco U., Accordi B., Martini V., Oliviero F., Facco M., Cabrelle A., Piva L., Molena B., Caso F., Costa L. JAK/STAT/PKCδ molecular pathways in synovial fluid T lymphocytes reflect the in vivo T helper-17 expansion in psoriatic arthritis. J. Immunol. Res. 2014;58:61–69. doi: 10.1007/s12026-013-8481-0. [DOI] [PubMed] [Google Scholar]
- 24.Nogueira M., Puig L., Torres T. JAK inhibitors for treatment of psoriasis: Focus on selective TYK2 inhibitors. Drugs. 2020;80:341–352. doi: 10.1007/s40265-020-01261-8. [DOI] [PubMed] [Google Scholar]
- 25.Levy D.E., Lee C.-k. What does Stat3 do? J. Clin. Investig. 2002;109:1143–1148. doi: 10.1172/JCI0215650. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ben-Bassat H., Klein B. Inhibitors of tyrosine kinases in the treatment of psoriasis. Curr. Pharm. Des. 2000;6:933–942. doi: 10.2174/1381612003400182. [DOI] [PubMed] [Google Scholar]
- 27.Canavese M., Altruda F., Ruzicka T., Schauber J. Vascular endothelial growth factor (VEGF) in the pathogenesis of psoriasis—A possible target for novel therapies? J. Dermatol. Sci. 2010;58:171–176. doi: 10.1016/j.jdermsci.2010.03.023. [DOI] [PubMed] [Google Scholar]
- 28.Marina M.E., Roman I.I., Constantin A.-M., Mihu C.M., Tătaru A.D. VEGF involvement in psoriasis. Clujul Med. J. 2015;88:247. doi: 10.15386/cjmed-494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Koçak M., Bozdoǧan Ö., Erkek E., Atasoy P., Birol A. Examination of Bcl-2, Bcl-X and bax protein expression in psoriasis. Int. J. Dermatol. 2003;42:789–793. doi: 10.1046/j.1365-4362.2003.01821.x. [DOI] [PubMed] [Google Scholar]
- 30.Wrone-Smith T., Johnson T., Nelson B., Boise L.H., Thompson C.B., Nunez G., Nickoloff B. Discordant expression of Bcl-x and Bcl-2 by keratinocytes in vitro and psoriatic keratinocytes in vivo. Am. J. Pathol. 1995;146:1079. [PMC free article] [PubMed] [Google Scholar]
- 31.Basu A., Das A.S., Sharma M., Pathak M.P., Chattopadhyay P., Biswas K., Mukhopadhyay R.J.B. STAT3 and NF-κB are common targets for kaempferol-mediated attenuation of COX-2 expression in IL-6-induced macrophages and carrageenan-induced mouse paw edema. Biochem. Biophys. Rep. 2017;12:54–61. doi: 10.1016/j.bbrep.2017.08.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.El-Komy M., Amin I., Zidan A., Kadry D., Zeid O., Shaker O. Venereology. Insulin-like growth factor-1 in psoriatic plaques treated with PUVA and methotrexate. J. Eur. Acad. Dermatol. Venereol. 2011;25:1288–1294. doi: 10.1111/j.1468-3083.2010.03966.x. [DOI] [PubMed] [Google Scholar]
- 33.Cheskis B.J., Greger J., Cooch N., McNally C., Mclarney S., Lam H.-S., Rutledge S., Mekonnen B., Hauze D., Nagpal S. MNAR plays an important role in ERa activation of Src/MAPK and PI3K/Akt signaling pathways. Steroids. 2008;73:901–905. doi: 10.1016/j.steroids.2007.12.028. [DOI] [PubMed] [Google Scholar]
- 34.Zhang M., Zhang X. The role of PI3K/AKT/FOXO signaling in psoriasis. Arch. Dermatol. Res. 2019;311:83–91. doi: 10.1007/s00403-018-1879-8. [DOI] [PubMed] [Google Scholar]
- 35.Chen W., Xie K., Liu X., Chen H. Identification of key pathways and genes in psoriasis via gene microarray analysis. Mol. Med. Rep. 2016;13:2327–2337. doi: 10.3892/mmr.2016.4790. [DOI] [PubMed] [Google Scholar]
- 36.Xie S., Chen Z., Wang Q., Song X., Zhang L. Comparisons of gene expression in normal, lesional, and non-lesional psoriatic skin using DNA microarray techniques. Int. J. Dermatol. 2014;53:1213–1220. doi: 10.1111/ijd.12476. [DOI] [PubMed] [Google Scholar]
- 37.Choi J., Crotty S. Bcl6-mediated transcriptional regulation of follicular helper T cells (TFH) Trends Immunol. 2021;42:336–349. doi: 10.1016/j.it.2021.02.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Nurieva R.I., Chung Y., Martinez G.J., Yang X.O., Tanaka S., Matskevitch T.D., Wang Y.-H., Dong C. Bcl6 mediates the development of T follicular helper cells. Science. 2009;325:1001–1005. doi: 10.1126/science.1176676. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Liu X., Wang J., Shen L., Wang R., Zhang L., Li C. Single-cell atlas reveals a high selection of IgA1-or IgG1-expressing plasma cells in patients with psoriasis. Mol. Immunol. 2023;153:85–93. doi: 10.1016/j.molimm.2022.11.015. [DOI] [PubMed] [Google Scholar]
- 40.Goldminz A., Au S., Kim N., Gottlieb A., Lizzul P. NF-κB: An essential transcription factor in psoriasis. J. Dermatol. Sci. 2013;69:89–94. doi: 10.1016/j.jdermsci.2012.11.002. [DOI] [PubMed] [Google Scholar]
- 41.Abdou A.G., Hanout H.M. Evaluation of survivin and NF-κB in psoriasis, an immunohistochemical study. J. Cutan. Pathol. 2008;35:445–451. doi: 10.1111/j.1600-0560.2007.00841.x. [DOI] [PubMed] [Google Scholar]
- 42.Wu Y., Chen X., Ge X., Xia H., Wang Y., Su S., Li W., Yang T., Wei M., Zhang H. Isoliquiritigenin prevents the progression of psoriasis-like symptoms by inhibiting NF-κB and proinflammatory cytokines. J. Mol. Med. 2016;94:195–206. doi: 10.1007/s00109-015-1338-3. [DOI] [PubMed] [Google Scholar]
- 43.Lin Z.C., Hsieh P.W., Hwang T.L., Chen C.Y., Sung C.T., Fang J. Topical application of anthranilate derivatives ameliorates psoriatic inflammation in a mouse model by inhibiting keratinocyte-derived chemokine expression and neutrophil infiltration. FASEB J. 2018;32:6783–6795. doi: 10.1096/fj.201800354. [DOI] [PubMed] [Google Scholar]
- 44.Ferrari S.M., Ruffilli I., Colaci M., Antonelli A., Ferri C., Fallahi P. CXCL10 in psoriasis. Adv. Med. Sci. 2015;60:349–354. doi: 10.1016/j.advms.2015.07.011. [DOI] [PubMed] [Google Scholar]
- 45.Martin D.A., Towne J.E., Kricorian G., Klekotka P., Gudjonsson J.E., Krueger J.G., Russell C.B. The emerging role of IL-17 in the pathogenesis of psoriasis: Preclinical and clinical findings. J. Invest. Dermatol. 2013;133:17–26. doi: 10.1038/jid.2012.194. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Lai Y., Li D., Li C., Muehleisen B., Radek K.A., Park H.J., Jiang Z., Li Z., Lei H., Quan Y. The antimicrobial protein REG3A regulates keratinocyte proliferation and differentiation after skin injury. Immunity. 2012;37:74–84. doi: 10.1016/j.immuni.2012.04.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Slivka P.F., Hsieh C.-L., Lipovsky A., Pratt S.D., Locklear J., Namovic M.T., McDonald H.A., Wetter J., Edelmayer R., Hu M. Small molecule and pooled CRISPR screens investigating IL17 signaling identify BRD2 as a novel contributor to keratinocyte inflammatory responses. ACS Chem. Biol. 2019;14:857–872. doi: 10.1021/acschembio.8b00260. [DOI] [PubMed] [Google Scholar]
- 48.Shen F., Hu Z., Goswami J., Gaffen S.L. Identification of common transcriptional regulatory elements in interleukin-17 target genes. J. Biol. Chem. 2006;281:24138–24148. doi: 10.1074/jbc.M604597200. [DOI] [PubMed] [Google Scholar]
- 49.Xia P., Pasquali L., Gao C., Srivastava A., Khera N., Freisenhausen J.C., Luo L., Rosén E., van Lierop A., Homey B. miR-378a regulates keratinocyte responsiveness to interleukin-17A in psoriasis. Br. J. Dermatol. 2022;187:211–222. doi: 10.1111/bjd.21232. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Hammarström S., Hamberg M., Samuelsson B., Duell E.A., Stawiski M., Voorhees J. Increased concentrations of nonesterified arachidonic acid, 12L-hydroxy-5, 8, 10, 14-eicosatetraenoic acid, prostaglandin E2, and prostaglandin F2alpha in epidermis of psoriasis. Proc. Natl. Acad. Sci. USA. 1975;72:5130–5134. doi: 10.1073/pnas.72.12.5130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Neisius U., Olssonb R., Rukwied R., Lischetzki G., Schmelz M. Prostaglandin E2 induces vasodilation and pruritus, but no protein extravasation in atopic dermatitis and controls. J. Invest. Dermatol. 2002;47:28–32. doi: 10.1067/mjd.2002.120462. [DOI] [PubMed] [Google Scholar]
- 52.Greaves M., Wall P. Pathophysiology of itching. Lancet. 1996;348:938–940. doi: 10.1016/S0140-6736(96)04328-0. [DOI] [PubMed] [Google Scholar]
- 53.Victor F.C., Gottlieb A.B. TNF-alpha and apoptosis: Implications for the pathogenesis and treatment of psoriasis. J. Drugs Dermatol. 2002;1:264–275. [PubMed] [Google Scholar]
- 54.Gottlieb A.B., Chamian F., Masud S., Cardinale I., Abello M.V., Lowes M.A., Chen F., Magliocco M., Krueger J. TNF inhibition rapidly down-regulates multiple proinflammatory pathways in psoriasis plaques. J. Immunol. 2005;175:2721–2729. doi: 10.4049/jimmunol.175.4.2721. [DOI] [PubMed] [Google Scholar]
- 55.Grine L., Dejager L., Libert C., Vandenbroucke R.E. An inflammatory triangle in psoriasis: TNF, type I IFNs and IL-17. Cytokine Growth Factor Rev. 2015;26:25–33. doi: 10.1016/j.cytogfr.2014.10.009. [DOI] [PubMed] [Google Scholar]
- 56.Ofengeim D., Yuan J. Regulation of RIP1 kinase signalling at the crossroads of inflammation and cell death. Nat. Rev. Mol. Cell Biol. 2013;14:727–736. doi: 10.1038/nrm3683. [DOI] [PubMed] [Google Scholar]
- 57.Johansen C., Kragballe K., Westergaard M., Henningsen J., Kristiansen K., Iversen L. The mitogen-activated protein kinases p38 and ERK1/2 are increased in lesional psoriatic skin. Br. J. Dermatol. 2005;152:37–42. doi: 10.1111/j.1365-2133.2004.06304.x. [DOI] [PubMed] [Google Scholar]
- 58.Yu X.-J., Li C.-Y., Dai H.-Y., Cai D.-X., Wang K.-Y., Xu Y.-H., Chen L.-M., Zhou C.-L. Expression and localization of the activated mitogen-activated protein kinase in lesional psoriatic skin. Exp. Mol. Pathol. 2007;83:413–418. doi: 10.1016/j.yexmp.2007.05.002. [DOI] [PubMed] [Google Scholar]
- 59.Wang S., Uchi H., Hayashida S., Urabe K., Moroi Y., Furue M. Differential expression of phosphorylated extracellular signal-regulated kinase 1/2, phosphorylated p38 mitogen-activated protein kinase and nuclear factor-κB p105/p50 in chronic inflammatory skin diseases. Br. J. Dermatol. 2009;36:534–540. doi: 10.1111/j.1346-8138.2009.00696.x. [DOI] [PubMed] [Google Scholar]
- 60.Takahashi H., Ibe M., Nakamura S., Ishida-Yamamoto A., Hashimoto Y., Iizuka H. Extracellular regulated kinase and c-Jun N-terminal kinase are activated in psoriatic involved epidermis. J. Dermatol. Sci. 2002;30:94–99. doi: 10.1016/S0923-1811(02)00064-6. [DOI] [PubMed] [Google Scholar]
- 61.Meng Q., Xia Y. c-Jun, at the crossroad of the signaling network. Protein Cell. 2011;2:889–898. doi: 10.1007/s13238-011-1113-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Kioussi C., Briata P., Baek S.H., Rose D.W., Hamblet N.S., Herman T., Ohgi K.A., Lin C., Gleiberman A., Wang J. Identification of a Wnt/Dvl/β-catenin→ Pitx2 pathway mediating cell-type-specific proliferation during development. Cell. 2002;111:673–685. doi: 10.1016/S0092-8674(02)01084-X. [DOI] [PubMed] [Google Scholar]
- 63.Malakou L.S., Gargalionis A.N., Piperi C., Papadavid E., Papavassiliou A.G., Basdra E.K. Molecular mechanisms of mechanotransduction in psoriasis. Ann. Transl. Med. 2018;6:245. doi: 10.21037/atm.2018.04.09. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Gudjonsson J.E., Johnston A., Stoll S.W., Riblett M.B., Xing X., Kochkodan J.J., Ding J., Nair R.P., Aphale A., Voorhees J. Evidence for altered Wnt signaling in psoriatic skin. J. Invest. Dermatol. 2010;130:1849–1859. doi: 10.1038/jid.2010.67. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Subramanian A., Narayan R., Corsello S.M., Peck D.D., Natoli T.E., Lu X., Gould J., Davis J.F., Tubelli A.A., Asiedu J. A next generation connectivity map: L1000 platform and the first 1,000,000 profiles. Cell. 2017;171:1437–1452.e17. doi: 10.1016/j.cell.2017.10.049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Seçilmiş D., Hillerton T., Morgan D., Tjärnberg A., Nelander S., Nordling T.E., Sonnhammer E.L. Uncovering cancer gene regulation by accurate regulatory network inference from uninformative data. NPJ 2D Mater. Appl. 2020;6:37. doi: 10.1038/s41540-020-00154-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Corsello S.M., Nagari R.T., Spangler R.D., Rossen J., Kocak M., Bryan J.G., Humeidi R., Peck D., Wu X., Tang A.A. Discovering the anticancer potential of non-oncology drugs by systematic viability profiling. Nat. Cancer. 2020;1:235–248. doi: 10.1038/s43018-019-0018-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Xiong G., Wu Z., Yi J., Fu L., Yang Z., Hsieh C., Yin M., Zeng X., Wu C., Lu A. ADMETlab 2.0: An integrated online platform for accurate and comprehensive predictions of ADMET properties. Nucleic Acids Res. 2021;49:W5–W14. doi: 10.1093/nar/gkab255. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Cichewicz R.H., Kouzi S.A. Chemistry, biological activity, and chemotherapeutic potential of betulinic acid for the prevention and treatment of cancer and HIV infection. Med. Res. Rev. 2004;24:90–114. doi: 10.1002/med.10053. [DOI] [PubMed] [Google Scholar]
- 70.Gautam R., Jachak S.M. Recent developments in anti-inflammatory natural products. Med. Res. Rev. 2009;29:767–820. doi: 10.1002/med.20156. [DOI] [PubMed] [Google Scholar]
- 71.Wan Y., Wu Y.-L., Lian L.-H., Xie W.-X., Li X., OuYang B.-Q., Bai T., Li Q., Yang N., Nan J.-X. The anti-fibrotic effect of betulinic acid is mediated through the inhibition of NF-κB nuclear protein translocation. Chem. Biol. Interact. 2012;195:215–223. doi: 10.1016/j.cbi.2012.01.002. [DOI] [PubMed] [Google Scholar]
- 72.Hollis A., Sperl B., Gräber M., Berg T. The natural product betulinic acid inhibits C/EBP family transcription factors. ChemBioChem. 2012;13:302–307. doi: 10.1002/cbic.201100652. [DOI] [PubMed] [Google Scholar]
- 73.Lin C.K., Tseng C.K., Chen K.H., Wu S.H., Liaw C.C., Lee J.C. Betulinic acid exerts anti-hepatitis C virus activity via the suppression of NF-κ B-and MAPK-ERK 1/2-mediated COX-2 expression. Br. J. Pharmacol. 2015;172:4481–4492. doi: 10.1111/bph.13233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Lee J.-C., Lee K.-Y., Kim J., Na C.-S., Jung N.-C., Chung G.-H., Jang Y.-S.J.F., Toxicology C. Extract from Rhus verniciflua Stokes is capable of inhibiting the growth of human lymphoma cells. Food Chem. Toxicol. 2004;42:1383–1388. doi: 10.1016/j.fct.2004.03.012. [DOI] [PubMed] [Google Scholar]
- 75.Lee S.H., Seo G.S., Sohn D.H. Inhibition of lipopolysaccharide-induced expression of inducible nitric oxide synthase by butein in RAW 264.7 cells. Biochem. Biophys. Res. Commun. 2004;323:125–132. doi: 10.1016/j.bbrc.2004.08.063. [DOI] [PubMed] [Google Scholar]
- 76.Pandey M.K., Sung B., Ahn K.S., Aggarwal B.B. Butein suppresses constitutive and inducible signal transducer and activator of transcription (STAT) 3 activation and STAT3-regulated gene products through the induction of a protein tyrosine phosphatase SHP-1. Mol. Pharmacol. 2009;75:525–533. doi: 10.1124/mol.108.052548. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Seo W.Y., Youn G.S., Choi S.Y., Park J. Butein, a tetrahydroxychalcone, suppresses pro-inflammatory responses in HaCaT keratinocytes. BMB Rep. 2015;48:495. doi: 10.5483/BMBRep.2015.48.9.259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Wang Z., Lee Y., Eun J.S., Bae E.J. Inhibition of adipocyte inflammation and macrophage chemotaxis by butein. Eur. J. Pharmacol. 2014;738:40–48. doi: 10.1016/j.ejphar.2014.05.031. [DOI] [PubMed] [Google Scholar]
- 79.Chanet A., Milenkovic D., Manach C., Mazur A., Morand C.J. Citrus flavanones: What is their role in cardiovascular protection? J. Agric. Food Chem. 2012;60:8809–8822. doi: 10.1021/jf300669s. [DOI] [PubMed] [Google Scholar]
- 80.Benavente-Garcia O., Castillo J. Update on uses and properties of citrus flavonoids: New findings in anticancer, cardiovascular, and anti-inflammatory activity. J. Agric. Food Chem. 2008;56:6185–6205. doi: 10.1021/jf8006568. [DOI] [PubMed] [Google Scholar]
- 81.Salama A.A., Yassen N.N., Mansour H.M. Naringin protects mice from D-galactose-induced lung aging and mitochondrial dysfunction: Implication of SIRT1 pathways. Life Sci. 2023;324:121471. doi: 10.1016/j.lfs.2023.121471. [DOI] [PubMed] [Google Scholar]
- 82.Liu Y., Su W.-W., Wang S., Li P.-B. Naringin inhibits chemokine production in an LPS-induced RAW 264.7 macrophage cell line. Mol. Med. Rep. 2012;6:1343–1350. doi: 10.3892/mmr.2012.1072. [DOI] [PubMed] [Google Scholar]
- 83.Amaro M.I., Rocha J., Vila-Real H., Eduardo-Figueira M., Mota-Filipe H., Sepodes B., Ribeiro M.H. Anti-inflammatory activity of naringin and the biosynthesised naringenin by naringinase immobilized in microstructured materials in a model of DSS-induced colitis in mice. Food Res. Int. 2009;42:1010–1017. doi: 10.1016/j.foodres.2009.04.016. [DOI] [Google Scholar]
- 84.Deenonpoe R., Prayong P., Thippamom N., Meephansan J., Na-Bangchang K. Anti-inflammatory effect of naringin and sericin combination on human peripheral blood mononuclear cells (hPBMCs) from patient with psoriasis. BMC Complement Altern. Med. 2019;19:168. doi: 10.1186/s12906-019-2535-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Yeh S.-J., Chen S.-W., Chen B.-S. Investigation of the genome-wide genetic and epigenetic networks for drug discovery based on systems biology approaches in colorectal cancer. Front. Genet. 2020;11:117. doi: 10.3389/fgene.2020.00117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Salwinski L., Miller C.S., Smith A.J., Pettit F.K., Bowie J.U., Eisenberg D.J. The database of interacting proteins: 2004 update. Nucleic Acids Res. 2004;32:D449–D451. doi: 10.1093/nar/gkh086. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Orchard S., Ammari M., Aranda B., Breuza L., Briganti L., Broackes-Carter F., Campbell N.H., Chavali G., Chen C., Del-Toro N. The MIntAct project—IntAct as a common curation platform for 11 molecular interaction databases. Nucleic Acids Res. 2014;42:D358–D363. doi: 10.1093/nar/gkt1115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Stark C., Breitkreutz B.-J., Reguly T., Boucher L., Breitkreutz A., Tyers M. BioGRID: A general repository for interaction datasets. Nucleic Acids Res. 2006;34:D535–D539. doi: 10.1093/nar/gkj109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Zanzoni A., Montecchi-Palazzi L., Quondam M., Ausiello G., Helmer-Citterich M., Cesareni G. MINT: A Molecular INTeraction database. FEBS Lett. 2002;513:135–140. doi: 10.1016/S0014-5793(01)03293-8. [DOI] [PubMed] [Google Scholar]
- 90.Bovolenta L., Acencio M., Lemke N. HTRIdb: An open-access database for experimentally verified human transcriptional regulation interactions. Nature. 2012;13:405. doi: 10.1186/1471-2164-13-405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Zheng G., Tu K., Yang Q., Xiong Y., Wei C., Xie L., Zhu Y., Li Y. ITFP: An integrated platform of mammalian transcription factors. Bioinformatics. 2008;24:2416–2417. doi: 10.1093/bioinformatics/btn439. [DOI] [PubMed] [Google Scholar]
- 92.Wingender E., Chen X., Hehl R., Karas H., Liebich I., Matys V., Meinhardt T., Prüß M., Reuter I., Schacherer F. TRANSFAC: An integrated system for gene expression regulation. Nucleic Acids Res. 2000;28:316–319. doi: 10.1093/nar/28.1.316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Friard O., Re A., Taverna D., De Bortoli M., Corá D. CircuitsDB: A database of mixed microRNA/transcription factor feed-forward regulatory circuits in human and mouse. BMC Bioinform. 2010;11:435. doi: 10.1186/1471-2105-11-435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Agarwal V., Bell G.W., Nam J.-W., Bartel D.P. Predicting effective microRNA target sites in mammalian mRNAs. elife. 2015;4:e05005. doi: 10.7554/eLife.05005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Li J.-H., Liu S., Zhou H., Qu L.-H., Yang J.-H. starBase v2. 0: Decoding miRNA-ceRNA, miRNA-ncRNA and protein–RNA interaction networks from large-scale CLIP-Seq data. Nucleic Acids Res. 2014;42:D92–D97. doi: 10.1093/nar/gkt1248. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96.Chen B.-S., Wu C.-C. Systems biology as an integrated platform for bioinformatics, systems synthetic biology, and systems metabolic engineering. Cell. 2013;2:635–688. doi: 10.3390/cells2040635. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Chang S., Wang L.H.-C., Chen B.-S. Investigating core signaling pathways of hepatitis b virus pathogenesis for biomarkers identification and drug discovery via systems biology and deep learning method. Biomedicines. 2020;8:320. doi: 10.3390/biomedicines8090320. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98.Kuhn M., von Mering C., Campillos M., Jensen L.J., Bork P. STITCH: Interaction networks of chemicals and proteins. Nucleic Acids Res. 2007;36:D684–D688. doi: 10.1093/nar/gkm795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Chen Y.Z. Bioinformatics and Drug Design Group at NUS. APBN. 2006;10:1478–1479. doi: 10.1142/S0219030306002229. [DOI] [Google Scholar]
- 100.research U.C. UniProt: A worldwide hub of protein knowledge. Nucleic Acids Res. 2019;47:D506–D515. doi: 10.1093/nar/gky1049. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 101.Knox C., Law V., Jewison T., Liu P., Ly S., Frolkis A., Pon A., Banco K., Mak C., Neveu V. DrugBank 3.0: A comprehensive resource for ‘omics’ research on drugs. Nucleic Acids Res. 2010;39:D1035–D1041. doi: 10.1093/nar/gkq1126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 102.Kim S., Thiessen P.A., Bolton E.E., Chen J., Fu G., Gindulyte A., Han L., He J., He S., Shoemaker B.A. PubChem substance and compound databases. Nucleic Acids Res. 2016;44:D1202–D1213. doi: 10.1093/nar/gkv951. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 103.Kanehisa M., Goto S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28:27–30. doi: 10.1093/nar/28.1.27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Dong J., Yao Z.-J., Zhang L., Luo F., Lin Q., Lu A.-P., Chen A.F., Cao D.-S. PyBioMed: A python library for various molecular representations of chemicals, proteins and DNAs and their interactions. J. Cheminform. 2018;10:16. doi: 10.1186/s13321-018-0270-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 105.Chang S., Chen J.-Y., Chuang Y.-J., Chen B.-S. Systems Approach to Pathogenic Mechanism of Type 2 Diabetes and Drug Discovery Design Based on Deep Learning and Drug Design Specifications. Int. J. Mol. Sci. 2020;22:166. doi: 10.3390/ijms22010166. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 106.Hecht-Nielsen R. Neural Networks for Perception. Elsevier; Amsterdam, The Netherlands: 1992. Theory of the backpropagation neural network; pp. 65–93. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The raw gene count datasets of human genes are integrated from GSE117468 (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE117468, accessed on 15 November 2022). The drug regulation ability data are from Phase I L1000 Level 5 datasets (https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE92742, accessed on 15 November 2022). The drug sensitivity datasets are from DepMapPRISM primary screen datasets (https://depmap.org/repurposing/, accessed on 15 November 2022). The code can be obtained from https://github.com/ZhanUPing/muti-molecular-drug-design, accessed on 15 November 2022.