

Abstract
A solid-glass cannula serves as a micro-endoscope that can deliver excitation light deep inside tissue while also collecting emitted fluorescence. Then, we utilize deep neural networks to reconstruct images from the collected intensity distributions. By using a commercially available dual-cannula probe, and training a separate deep neural network for each cannula, we effectively double the field of view compared to prior work. We demonstrated ex vivo imaging of fluorescent beads and brain slices and in vivo imaging from whole brains. We clearly resolved 4 μm beads, with FOV from each cannula of 0.2 mm (diameter), and produced images from a depth of ~1.2 mm in the whole brain, currently limited primarily by the labeling. Since no scanning is required, fast widefield fluorescence imaging limited primarily by the brightness of the fluorophores, collection efficiency of our system, and the frame rate of the camera becomes possible.
1. Introduction
Widefield fluorescence microscopy can image with high specificity and resolution, but typically cannot image deep into tissue due to scattering and background fluorescence. Wavelengths where scattering and absorption are minimized (such as the shortwave infra-red) may mitigate some of these issues. However, imaging beyond several hundred micrometers below the surface is unlikely [1–6]. Two- and three-photon microscopy, on the other hand, can image deeper into tissue, however at the expense of requiring much higher laser power (with possibility of photo-toxicity), relatively slow speeds (due to scanning) and generally require more complex hardware [3,4,7–10]. Quoting the authors in Ref. [11] “even the deepest 3P imaging cannot penetrate a quarter of an adult mouse brain in vivo.” Although, the achievable imaging depth depends upon the nature and density of the fluorescent labeling, and the wavelength used for imaging, as noted above, the depth for non-invasive multi-photon imaging is practically limited to slightly larger than 1mm [1,2,6,7,12].
In order to access deeper regions, it is possible to implement either widefield/single-photon or multi-photon modalities in implantable micro-endoscopes (“probes”), with minimally-invasive surgery [5,13–20]. Such probes tend to have diameters larger than ~0.35mm, and typically utilize gradient-index (GRIN) lenses to relay the image through the probe. Aberrations inherent in such GRIN lenses limit the field-of-view (FOV) to a small fraction of the probe diameter (typically about a quarter radius). Previously, we showed that by replacing imaging via such GRIN lenses with computational image reconstruction enables FOV that is almost the same as the diameter of the probe [21,22]. We refer to this approach as computational-cannula microscopy (CCM), since we utilize a simple surgical cannula (which is a short-length multi-mode fiber) as the implanted probe. Furthermore, this approach is fast, since it requires no scanning. Previously, we demonstrated sub-10μm resolution with whole mouse brains [22]. Nevertheless, the FOV is limited by the diameter of the probe, and there is a need to enhance this FOV to address fundamental questions in neuroscience [8–10,23,24,25]. We propose to mitigate this limitation by parallelizing CCM, i.e., by using an array of cannulae, each one serving as an independent probe. Thereby, the main contribution of this paper is the experimental demonstration of parallel CCM with 2 cannulae, images from each one being recorded and reconstructed simultaneously to increase the total FOV.
In our experiments, the probe is a commercially available dual-cannula (Thorlabs CFM32L20), which was cut to 12mm in length, with 2mm beyond the holder. The core diameter of each cannula is 0.2mm. The center-to-center distance between the cannulae is 0.7mm. Each cannula acts as an independent computational microscope, thereby increasing the total FOV by a factor of 2 (in area) when compared to previous work [26–29]. Since, no scanning is required, there is no compromise in speed.
2. Experimental setup
Our setup is a modified version of an epi-fluorescence microscope (Fig. 1). The excitation light (λ = 561 nm, Gem 561, Laser Quantum) is coupled to the cannulae via an objective lens (Olympus PLN 10X, NA 0.25). During imaging, the cannulae are implanted inside tissue. A comprehensive analysis of imaging depth on imaging performance was reported earlier [28,30,31]. Each cannula transports excitation light to its distal end, which illuminates the tissue in its vicinity. Fluorescence is collected by each cannula and transported to its proximal end, which is then imaged by the same objective onto an EM-CCD camera (number of pixels = 512 × 512, Hamamatsu ImagEM X2). Reflected excitation light is rejected by a dichroic mirror and an additional long-pass filter (cut-on wavelength 568nm, 568 LP Edge Basic).
Fig. 1.
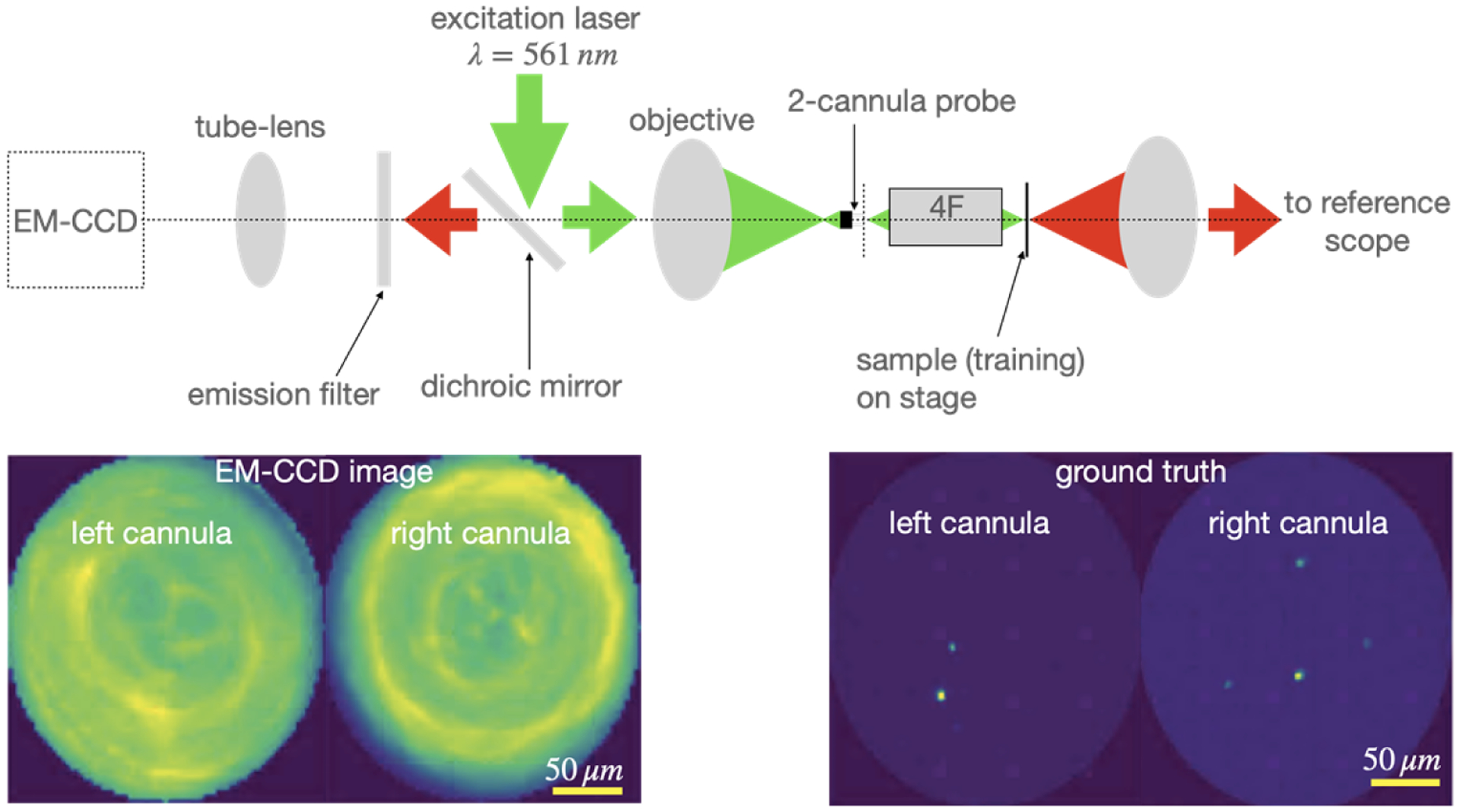
Schematic of microscope. In order to collect training data, a 4F system is used as image relay between the proximal end of the cannulae and image plane, and ground-truth images are collected by a reference scope in transmission. The image of the distal end of the cannulae is collected by the EM-CCD in a standard epi-fluorescence configuration. Green and red colors indicate excitation and fluorescence (emission) light, respectively. An example pair of EM-CCD frame and its corresponding ground-truth frame are shown below. Post-training, the 4F system and reference scope can be removed, and the cannulae are inserted into tissue.
Since we utilize deep learning to reconstruct images from the recorded frame, training with matched ground-truth images are necessary. In order to attain these, we make 3 modifications to the epi-fluorescence microscope described above. First, we use samples consisting of either fluorescent beads (diameter = 4μm) or glia cells dissected from adult mice brains, sandwiched between a glass slide (thickness = 1mm) and a coverslip (thickness = 0.08 to 0.13 mm) to obtain the training data. Second, an achromatic GRIN-lens-based 4F system is used to relay the image from the sample plane to the distal end of the cannula. This system ensures that training data can be obtained through the coverslip. Third, a conventional widefield fluorescence microscope is used to image the sample to provide ground-truth images (details are provided in the supplement). This reference scope is placed on the opposite side of the sample, and is therefore limited to transparent samples for training data.
In order to collect training data, the sample was mounted on a 3-axis stage, and then scanned over an approximately 2mm × 2mm area in steps of 0.02mm to generate CCM and ground-truth image-pairs, automatically. A total of 14,037 image-pairs of microbeads and 21,648 image-pairs of glia cells were recorded. From each set, 1000 image-pairs were set aside for testing, while 90% of the remaining were used for training (10% were used for validation). The two regions of interest (ROI) in the EMCCD frame corresponding to the positions of the 2 cannulae were aligned to the corresponding ROIs in the ground-truth frames. This was achieved by using the reference scope to image the distal faces of the cannulae without any sample. The sizes of each ROI were ~72 × 72 pixels for the EMCCD frame, and ~799 × 799 pixels for the ground-truth images.
3. Deep neural networks
Since the cannula is not an imaging element, there is no simple one-to-one mapping from each point in the sample plane to a corresponding point in the image. Rather, there is a space-variant response that maps each point in the sample plane to many points in the image plane. Typically, the spatial information from the sample plane is encoded into the intensity distribution within the entire image. Undoing such a space-variant transformation is possible using regularized inversion of the response matrix (or the space-variant point-spread-function) [30,31]. Recently, we and others showed that deep neural networks are efficient alternatives to linear-algebraic methods to achieve similar results [26,32]. Here, we train two distinct deep neural networks: first an auto-encoder called U-net (Fig. S3 in Supplement) [26–28,33,34], and next a coupled self-consistent cycle network called SC-net (Fig. S4 in Supplement) [28,35,36]. Details of each network have been described previously, and also included in the supplement for completeness (Section 2 in Supplement). All the images were resized to 128 × 128 pixels before being processed by the deep-neural networks. The U-net is a very common auto-encoder network used for image reconstructions. On the other hand, the SC-net incorporates two coupled networks: one predicting the forward problem (from the sample to the image), and the second predicting the inverse problem (from the image to the sample) [37,38]. The two generative adversarial networks associated with each problem (forward and inverse) within SC-net enforces simple forward-backward consistency (or cycle consistency) [28,35,36,39]. The networks ran on NVIDIA GeForce RTX 2080 Ti / Nvidia Tesla V100 GPU with 2 cluster nodes simultaneously to achieve fast results. The image reconstruction times were ~2ms and 22ms for the U-net and SC-Net, respectively.
Each network is trained separately for the two training datasets (beads and glial cells), and also for the two cannulae (note that there is no cross-talk between them). Finally, the performance of each network is quantified using both the structural similarity index (SSIM) and the mean absolute error (MAE) averaged over 1,000 test images (these were excluded during training, see Table 1).
Table 1.
Performance metrics for the deep neural networks
| Deep Neural Network | Sample | SSIM | MAE | ||
|---|---|---|---|---|---|
| Left Cannula | Right Cannula | Left Cannula | Right Cannula | ||
| U-Net | Microbead | 0.99 | 0.99 | 0.01 | 0.01 |
| SC-Net | 0.91 | 0.93 | 0.02 | 0.02 | |
| U-Net | Glia | 0.95 | 0.93 | 0.01 | 0.02 |
| SC-Net | 0.80 | 0.79 | 0.10 | 0.10 | |
4. Results and discussion
As mentioned earlier, we used 1000 images from the fluorescent beads and the glial-cells datasets for evaluating the performance of each network. Results from three exemplary images from each dataset and cannula are shown in Fig. 2. As the cannulae are not placed on the optical axis, the illumination is slightly different between the two, which can be observed in the images. The U-net is able to effectively reproduce the beads images (Figs. 2(a, b)). As expected, the glial cells are more challenging to reconstruct due to their increased complexity. Nevertheless, both networks are able to accurately locate the main cell bodies within the FOV of each cannula (Figs. 2(c, d)).
Fig. 2.
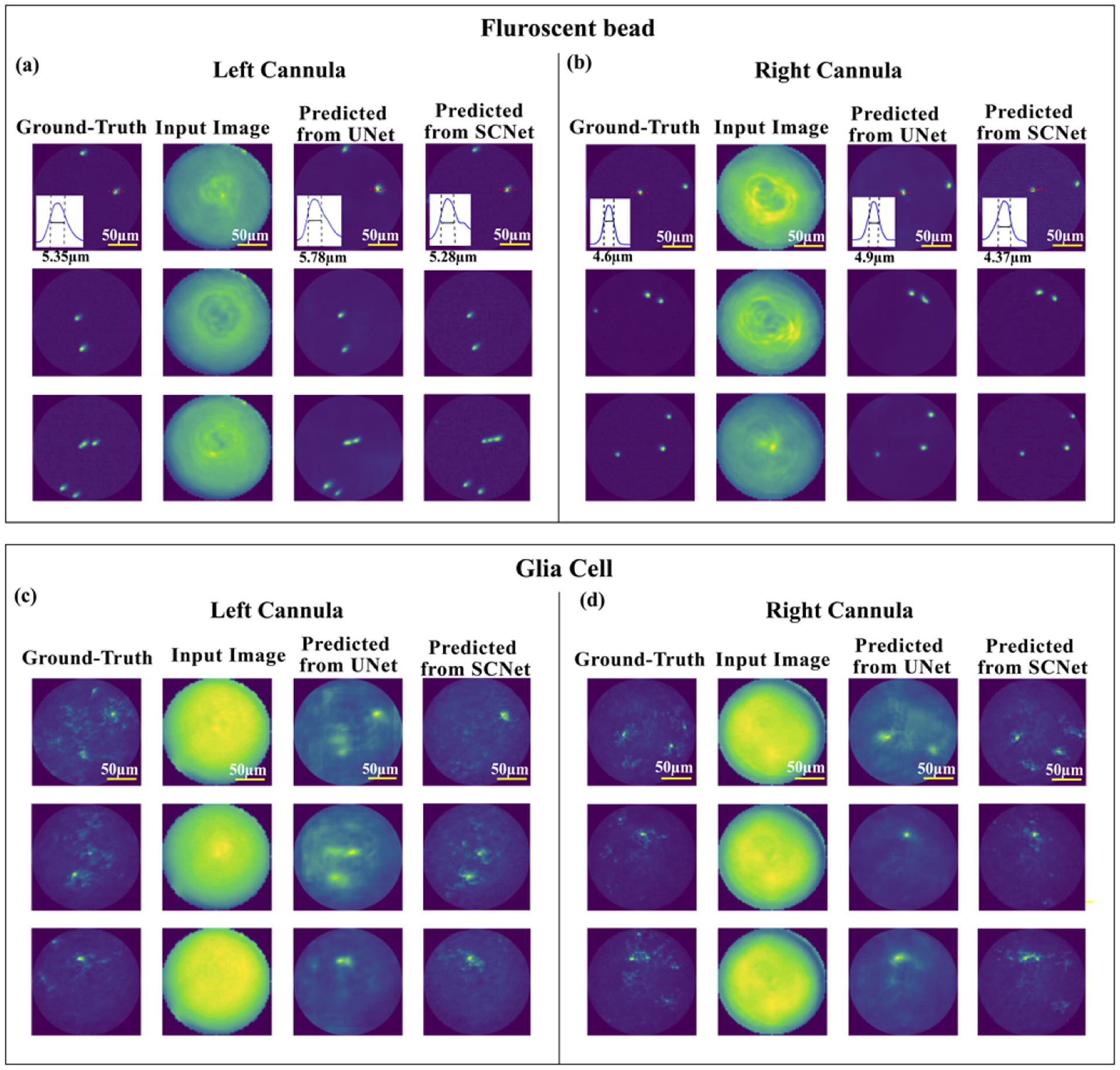
Example results from 3 images acquired using (a) left cannula, (b) right cannula using fluorescent-bead samples, and (c) left cannula and (d) right cannula using glial-cell samples. In each panel, columns from left to right are: ground-truth image from reference scope, input image to the deep neural network, predicted image from U-net, and predicted image from SC-net. In the inset of first row (a)-(b), the full-width at half-maximum (FWHM) through image of a single bead is shown as an estimate of system resolution.
To estimate system resolution, we identified an isolated bead within the FOV of each reconstructed image, and calculated its full width at half-maximum (FWHM) (insets in first row of Figs. 2(a,b)). The measured FWHM were 4.6μm, 4.9μm and 4.4μm in the ground-truth, U-net and SC-Net images, respectively. The U-net is able to reconstruct lower spatial frequency features well. The SC-net is able to reconstruct higher-spatial frequencies, but is also more prone to producing artefacts, lowering its average SSIM performance.
In order to investigate the potential for deep-tissue imaging, we prepared whole mouse brain samples [22,40]. Details of sample preparation are included in the supplement (Section 1.2). The dual-cannulae probe was inserted from the surface (depth = 0) to a maximum depth of 1.2 mm and images were acquired every 0.04 mm on the EMCCD camera. The step size was chosen so as to minimize the number of acquired images, while still observing variations (in the sensor frame) from one step to the next. We collected a total of 334 images. Since no ground truth images were available, we could not perform a quantitative SSIM and MAE analysis. Nevertheless, results from three exemplary images acquired using each cannula are summarized in Fig. 3. In each case, clear similarities between the predicted images from the two networks can be observed. In order to improve the generalization ability (since no ground truth is available), we averaged the predicted results from two networks (fourth column in Fig. 3) [28,33,35,36,41–44].
Fig. 3.
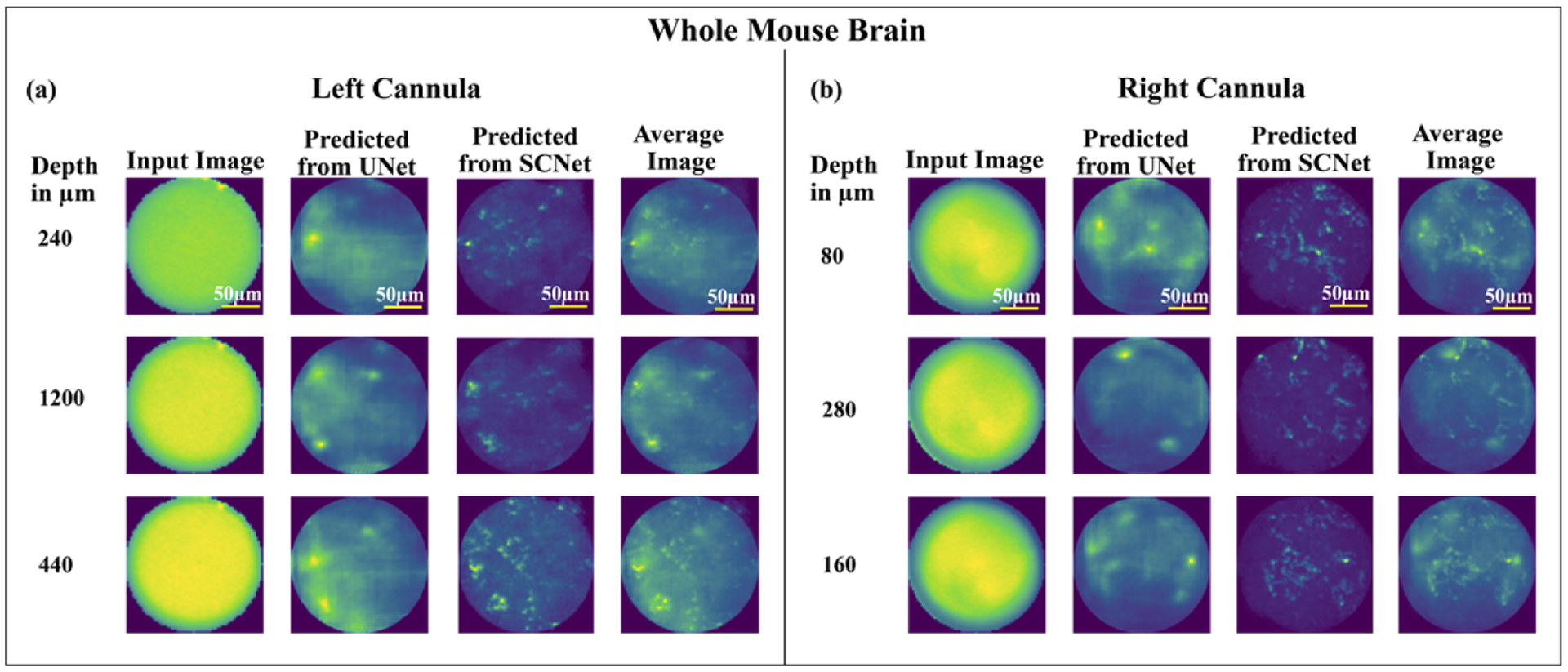
Example results from 3 images acquired using (a) left cannula, (b) right cannula using the whole mouse brain samples. In each panel, columns from left to right are: depth from surface in μm, input image to the deep neural network, predicted image from U-net, predicted image from SC-net, and the averaged using the two.
There were several constraints that limited our whole brain experiments. First, the brains tend to dry out within 2 hours. Since the fluorescent labels are randomly distributed throughout the sample, we have to test the cannula at many locations to find regions with sufficient emission signal. Furthermore, insertion of the cannula can cause inflammation of the sample, which was not controlled in our current experiments. We also successfully imaged using fixed brain samples (see section 5 of supplement), we were not successful in increasing the lifetime of the samples. These constraints can be addressed with an improved surgical protocol in the future. Additional challenges exist for insertion into deeper brain regions (>1 mm) [15,16]. First, the cannula may displace the tissue while inserting into brain, resulting in tissue compression between the working distance of the cannula and the focal plane. Therefore, we pursued a strategy of carefully inserting the cannula at a slow speed with multiple pauses into the brain to create a clear optical path for imaging. As second problem arises from the fact that the tissue between the two cannulae showed upward expansion. To avoid this deformation, the dual cannula was inserted with pressure slightly higher than that used for a single cannula. Using a guide cannula prior to dual-cannula insertion might overcome this problem. Finally, although we attempted to image regions deeper than 1.2 mm, the acquired raw signal levels were too low, which we hypothesize is due to the lack of fluorescent labels at those depths. Further work is required to clarify this observation. Finally, we had to attempt insertion in multiple regions of the brain to locate regions that provided sufficient fluorescence, since the cannula probe is being inserted blindly. In the future, we could perform non-invasive two-photon microscopy to identify promising locations for cannulae insertion. We further note that surgical insertion of electrode and optrode arrays have been studied in detail in the past [45,46]. Although the spacing between the cannulae in our probe is somewhat larger than those in the previous work, we expect to utilize the prior learnings.
5. Conclusion
We demonstrate the use of a commercial dual-cannula for widefield fluorescence imaging deep inside tissue. Since each cannula is only 0.225 mm thick and separated from each other by 0.7 mm, trauma during insertion can be minimized, and it enables relatively easy tissue displacement. The image from each cannula provides a field of view of ~0.2 mm diameter, which is far larger than achievable with a GRIN-based micro-endoscope. Since the images from both cannulae are acquired simultaneously, the overall field of view is double that of a single cannula. It is also noteworthy that the image reconstructions are extremely fast (as fast as ~2 ms/frame), limited primarily by fluorophore brightness and our collection efficiencies. We trained two neural networks (U-net and SC-net) separately for each cannula. We further used reconstructed images of isolated fluorescent beads to confirm full-width at half-maximum of ~4μm, which was limited by the diameter of the fluorescent beads. By using brain samples extricated from the animal, we showed imaging with peak depth of 1.2 mm, currently limited by the sample and not by our technique. By extending to a larger array of cannulae, and associating a deep neural network to each cannula in the array, we can perform widefield fluorescence imaging deep inside tissue with a much larger FOV and minimal trauma than is otherwise feasible. In this work, our experiments were performed on whole brains removed from the animal. But we note that the cannula probes are routinely used for animal studies with chronic implantation [47]. This will be investigated in the future.
Future work for improvements includes using weighted average [48] or model averaging on different networks to reduce variance and improve the prediction accuracy. Ensembling is an approach that considers the stochastic nature of different deep convolutional neural networks [43]. As the networks are trained using stochastic algorithms, they are sensitive to initial random weights and statistical noise in the training dataset. To reduce the variance in the predicted images, the generalizing ability of ensemble learning can be used as it has shown promising outcomes than a single learner [42–44].
Supplementary Material
Acknowledgements.
Useful discussions with Jason Sheperd and Steve Blair. We thank Steve Blair for use of the EMCCD camera.
Funding.
U.S. Department of Energy (55801063); National Institutes of Health (1R21EY030717-01).
Footnotes
Disclosures. The authors declare no conflicts of interest.
Supplemental document. See Supplement 1 for supporting content.
Data availability.
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.
References
- 1.Urban BE, Yi J, Chen S, Dong B, Zhu Y, DeVries SH, Backman V, and Zhang HF, “Super-resolution two-photon microscopy via scanning patterned illumination,” Phys. Rev. E 91(4), 042703 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Lee M, Kannan S, Muniraj G, Rosa V, Lu WF, Fuh JYH, Sriram G, and Cao T, “Two-photon fluorescence microscopy and applications in angiogenesis and related molecular events,” Tissue Eng., Part B 28(4), 926–937 (2022). [DOI] [PubMed] [Google Scholar]
- 3.Yeh CH and Chen SY, “Two-photon-based structured illumination microscopy applied for superresolution optical biopsy,” in Multiphoton Microscopy in the Biomedical Sciences XIII, 2013, vol. 8588: International Society for Optics and Photonics, p. 858826. [Google Scholar]
- 4.Chong DC, Yu Z, Brighton HE, Bear JE, and Bautch VL, “Tortuous microvessels contribute to wound healing via sprouting angiogenesis,” Arterioscler., Thromb., Vasc. Biol 37(10), 1903–1912 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Lin F, Zhang C, Zhao Y, Shen B, Hu R, Liu L, and Qu J, “In vivo two-photon fluorescence lifetime imaging microendoscopy based on fiber-bundle,” Opt. Lett 47(9), 2137–2140 (2022). [DOI] [PubMed] [Google Scholar]
- 6.Wang T, Ouzounov DG, Wu C, Horton NG, Zhang B, Wu C, Zhang Y, Schnitzer MJ, and Xu C, “Three-photon imaging of mouse brain structure and function through the intact skull,” Nat. Methods 15(10), 789–792 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Horton NG, Wang K, Kobat D, Clark CG, Wise FW, Schaffer CB, and Xu C, “In vivo three-photon microscopy of subcortical structures within an intact mouse brain,” Nat. Photonics 7(3), 205–209 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Bocarsly ME, Jiang W-C, Wang C, Dudman JT, Ji N, and Aponte Y, “Minimally invasive microendoscopy system for in vivo functional imaging of deep nuclei in the mouse brain,” Biomed. Opt. Express 6(11), 4546–4556 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Barretto RP and Schnitzer MJ, “In vivo microendoscopy of the hippocampus,” Cold Spring Harbor Protocols 2012(10), pdb.prot071472 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Meng G, Liang Y, Sarsfield S, Jiang W, Lu R, Dudman JT, Aponte Y, and Ji N, “High-throughput synapse-resolving two-photon fluorescence microendoscopy for deep-brain volumetric imaging in vivo,” eLife 8, e40805 (2019). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Wang T and Xu C, “Three-photon neuronal imaging in deep mouse brain,” Optica 7(8), 947–960 (2020). [Google Scholar]
- 12.Ouzounov DG, Wang T, Wang M, Feng DD, Horton NG, Cruz-Hernández JC, Cheng Y, Reimer J, Tolias AS, Nishimura N, and Xu C, “In vivo three-photon imaging of activity of GCaMP6-labeled neurons deep in intact mouse brain,” Nat. Methods 14(4), 388–390 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Erdogan AT, Al Abbas T, Finlayson N, Hopkinson C, Gyongy I, Almer O, Dutton NAW, and Henderson RK, “A high dynamic range 128 (120 3-D stacked CMOS SPAD image sensor SoC for fluorescence microendoscopy,” IEEE J. Solid-State Circuits 57(6), 1649–1660 (2022). [Google Scholar]
- 14.Accanto N, Blot FGC, Camara AL, Zampini V, Bui F, Tourain C, Badt N, Katz O, and Emiliani V, “A flexible two-photon endoscope for fast functional imaging and cell-precise optogenetic photo-stimulation of neurons in freely moving animals,” Proc. SPIE PC12144, PC1214404 (2022). [Google Scholar]
- 15.Urner TM, Inman A, Lapid B, and Jia S, “Three-dimensional light-field microendoscopy with a GRIN lens array,” Biomed. Opt. Express 13(2), 590–607 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Ali MJ and Naik MN, “First intraoperative experience with three-dimensional (3D) high-definition (HD) nasal endoscopy for lacrimal surgeries,” Arch. Oto-Rhino-Laryngol 274(5), 2161–2164 (2017). [DOI] [PubMed] [Google Scholar]
- 17.Vasudevan K, Saad H, and Oyesiku NM, “The role of three-dimensional endoscopy in pituitary adenoma surgery,” Neurosurgery Clinics of North America 30(4), 421–432 (2019). [DOI] [PubMed] [Google Scholar]
- 18.Nomura K, Kikuchi D, Kaise M, Iizuka T, Ochiai Y, Suzuki Y, Fukuma Y, Tanaka M, Okamoto Y, Yamashita S, Matsui A, Mitani T, and Hoteya S, “Comparison of 3D endoscopy and conventional 2D endoscopy in gastric endoscopic submucosal dissection: an ex vivo animal study,” Surg Endosc 33(12), 4164–4170 (2019). [DOI] [PubMed] [Google Scholar]
- 19.Zhang Q, Pan D, and Ji N, “High-resolution in vivo optical-sectioning widefield microendoscopy,” Optica 7(10), 1287–1290 (2020). [Google Scholar]
- 20.Taal AJ, Lee C, Choi J, Hellenkamp B, and Shepard KL, “Toward implantable devices for angle-sensitive, lens-less, multifluorescent, single-photon lifetime imaging in the brain using Fabry–Perot and absorptive color filters,” Light: Sci. Appl 11(1), 24 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Kim G and Menon R, “Numerical analysis of computational-cannula microscopy,” Appl. Opt 56(9), D1–D7 (2017). [DOI] [PubMed] [Google Scholar]
- 22.Kim G, Nagarajan N, Pastuzyn E, Jenks K, Capecchi M, Shepherd J, and Menon R, “Deep-brain imaging via epi-fluorescence computational cannula microscopy,” Sci. Rep 7(1), 44791 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Butiaeva LI and Kokoeva MV, “High-resolution intravital imaging of the murine hypothalamus using GRIN lenses and confocal microscopy,” STAR Protoc. 3(1), 101193 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Murray T and Levene M, “Singlet gradient index lens for deep in vivo multiphoton microscopy,” J. Biomed. Opt 17(2), 021106 (2012). [DOI] [PubMed] [Google Scholar]
- 25.Butiaeva LI, Slutzki T, Swick HE, Bourguignon C, Robins SC, Liu X, Storch K, and Kokoeva MV, “Leptin receptor-expressing pericytes mediate access of hypothalamic feeding centers to circulating leptin,” Cell Metab. 33(7), 1433–1448.e5 (2021). [DOI] [PubMed] [Google Scholar]
- 26.Guo R, Pan Z, Taibi A, Shepherd J, and Menon R, “3D computational cannula fluorescence microscopy enabled by artificial neural networks,” Opt. Express 28(22), 32342–32348 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Guo R, Pan Z, Taibi A, Shepherd J, and Menon R, “Computational cannula microscopy of neurons using neural networks,” Opt. Lett 45(7), 2111–2114 (2020). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Guo R, Nelson S, Regier M, Davis MW, Jorgensen EM, Shepherd J, and Menon R, “Scan-less machine-learning-enabled incoherent microscopy for minimally-invasive deep-brain imaging,” Opt. Express 30(2), 1546–1554 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Guo R, Nelson S, and Menon R, “Needle-based deep-neural-network camera,” Appl. Opt 60(10), B135–B140 (2021). [DOI] [PubMed] [Google Scholar]
- 30.Bertolotti J, van Putten EG, Blum C, Lagendijk A, Vos WL, and Mosk AP, “Non-invasive imaging through opaque scattering layers,” Nature 491(7423), 232 (2012). [DOI] [PubMed] [Google Scholar]
- 31.Katz O, Heidmann P, Fink M, and Gigan S, “Non-invasive single-shot imaging through scattering layers and around corners via speckle correlations,” Nat. Photonics 8(10), 784–790 (2014). [Google Scholar]
- 32.Rivenson Y, Göröcs Z, Günaydin H, Zhang Y, Wang H, and Ozcan A, “Deep learning microscopy,” Optica 4(11), 1437–1443 (2017). [Google Scholar]
- 33.Guo R, Nelson S, Mitra E, and Menon R, “Needle-based deep-neural-network imaging method,” in OSA Imaging and Applied Optics Congress 2021 (3D, COSI, DH, ISA, pcAOP) (Optica Publishing Group, 2021), paper ITh5D.3. [Google Scholar]
- 34.Ronneberger O, Fischer P, and Brox T, “U-net: convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 (Springer International Publishing, 2015), pp. 234–241. [Google Scholar]
- 35.Nelson S and Menon R, “Bijective-constrained cycle-consistent deep learning for optics-free imaging and classification,” Optica 9(1), 26–31 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Nelson S and Menon R, “Optics-free imaging using a self-consistent supervised deep neural network,” in OSA Optical Sensors and Sensing Congress 2021 (AIS, FTS, HISE, SENSORS, ES) (Optica Publishing Group, 2021), paper JTu5A.3. [Google Scholar]
- 37.Isola P, Zhu J, Zhou T, and Efros AA, “Image-to-image translation with conditional adversarial networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 21–26 July 2017 2017, pp. 5967–5976. [Google Scholar]
- 38.He K, Zhang X, Ren S, and Sun J, “Identity mappings in deep residual networks,” in Computer Vision – ECCV 2016 (Springer International Publishing, 2016), pp. 630–645. [Google Scholar]
- 39.Zhu J-Y, Park T, Isola P, and Efros AA, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” presented at the 2017 IEEE International Conference on Computer Vision (ICCV), 3, 2017. [Online]. Available: https://arxiv.org/abs/1703.10593v7. [Google Scholar]
- 40.Kim G, Nagarajan N, Capecchi MR, and Menon R, “Cannula-based computational fluorescence microscopy,” Appl. Phys. Lett 106(26), 261111 (2015). [Google Scholar]
- 41.Alippi C, Ntalampiras S, and Roveri M, “Model ensemble for an effective on-line reconstruction of missing data in sensor networks,” in the 2013 International Joint Conference on Neural Networks (IJCNN), 4–9 Aug. 2013, pp. 1–6. [Google Scholar]
- 42.Krogh A and Sollich P, “Statistical mechanics of ensemble learning,” Phys. Rev. E 55, 811(1997). [Google Scholar]
- 43.Wang Q and Kurz D, “Reconstructing Training Data from Diverse ML Models by Ensemble Inversion,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2909–2917. [Google Scholar]
- 44.Zhou Z-H, Ensemble Methods: Foundations and Algorithms, (CRC press, 2012). [Google Scholar]
- 45.Boutte RW, Merlin S, Yona G, Griffiths B, Angelucci A, Kahn I, Shoham S, and Blair S, “Utah optrode array customization using stereotactic brain atlases and 3-D CAD modeling for optogenetic neocortical interrogation in small rodents and nonhuman primates,” Neurophotonics 4(4), 041502 (2017). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Abaya TV, Diwekar M, Blair S, Tathireddy P, Rieth L, and Solzbacher F, “Deep-tissue light delivery via optrode arrays,” J. Biomed. Opt 19(1), 015006 (2014). [DOI] [PubMed] [Google Scholar]
- 47.Zong W, Obenhaus HA, Skytøen ER, Eneqvist H, de Jong NL, Vale R, Jorge MR, Moser M-B, and Moser EI, “Large-scale two-photon calcium imaging in freely moving mice,” Cell 185(7), 1240–1256.e30 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Izmailov P, Podoprikhin D, Garipov T, Vetrov D, and Wilson AG, “Averaging weights leads to wider optima and better generalization,” arXiv preprint arXiv:1803.05407, 2018. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Data underlying the results presented in this paper are not publicly available at this time but may be obtained from the authors upon reasonable request.