

Abstract
Background:
Relatively little is known about how communication changes as a function of depression severity and interpersonal closeness. We examined the linguistic features of outgoing text messages among individuals with depression and their close- and non-close contacts.
Methods:
419 participants were included in this 16-week-long observational study. Participants regularly completed the PHQ-8 and rated subjective closeness to their contacts. Text messages were processed to count frequencies of word usage in the LIWC 2015 libraries. A linear mixed modeling approach was used to estimate linguistic feature scores of outgoing text messages.
Results:
Regardless of closeness, people with higher PHQ-8 scores tended to use more differentiation words. When texting with close contacts, individuals with higher PHQ-8 scores used more first-person singular, filler, sexual, anger, and negative emotion words. When texting with non-close contacts these participants used more conjunctions, tentative, and sadness-related words and fewer first-person plural words.
Conclusion:
Word classes used in text messages, when combined with symptom severity and subjective social closeness data, may be indicative of underlying interpersonal processes. These data may hold promise as potential treatment targets to address interpersonal drivers of depression.
Keywords: affective disorders, digital phenotyping, personal sensing, smartphone, mood, language, social ties
1.0. INTRODUCTION
Depressive symptoms are moderated by social relationships and interactions (Nezlek et al., 1994; Taylor et al., 2015). There is accumulating evidence suggesting that people with depression have less intimate social relationships, report less enjoyment from social interactions, and experience more contentious interactions (Gotlib, 1992; Nezlek et al., 1994; Segrin & Abramson, 1994). Further, characteristics of social interactions may be linked with the course of depressive symptoms. For example, individuals who had more contentious interactions (e.g., criticism) with close others (e.g., family and friends) also had a tendency to experience a greater number of, and more severe, depressive symptoms in the past 12 months (Taylor et al., 2015). In contrast, individuals who had more emotional support from family networks (e.g., family members who spent time listening to an individual’s challenges), were found to have a reduced likelihood of depression (Lincoln et al., 2007).
One way of better understanding associations of social interactions with depression symptoms and course is through studying the social language of people experiencing depression symptoms. Emerging work has begun to explore social language use among individuals with depression, with findings suggesting that the nature of the relationship (e.g., closeness) may moderate the type of language depressed individuals employ. For instance, one recent study demonstrated that individuals with depression are more likely to use negative self-focused language when writing about romantic partners and friends but not family (Nalabandian & Ireland, 2019). Another study found that individuals with depression expressed more negative utterances (e.g., disagreement) in interactions with their friends than with strangers (Segrin & Flora, 1998).
Examining private data streams, such as text messages, may enhance existing research on how people with depression communicate, and how closeness moderates those communication styles. Text messaging, in the United States and messaging apps outside of the United States, have a number of advantages over social media language. They tend to be used in more intimate relationships relative to other data streams such as social networking sites (Liu & Yang, 2016); they are used more frequently than social media posts and can contain more personal communications that reflect daily interactions (Harari et al., 2020). Language feature scores extracted from text messages have been used to predict mental health conditions (e.g., Benoit et al., 2020; Nook et al., 2022; Stamatis, Meyerhoff, Liu, Hou, et al., 2022; Stamatis, Meyerhoff, Liu, Sherman, et al., 2022; Tlachac et al., 2022; Tlachac & Rundensteiner, 2020), including depression. For example, Tlachac et al. (2020) found that private text messages were more effective than social media language at predicting depression status. They also noted that language use among individuals with and without depression was differentiated. Specifically, individuals with depression used more domestic pet-focused language while individuals without depression used more words corresponding to leaders, air travel, exercise, among others (Tlachac & Rundensteiner, 2020). A follow-up study by Tlachac et al. (2022) examined the capability of different lexica to predict depression status. The authors found that a custom lexicon that included more colloquialisms demonstrated notably better prediction of depression in text messages than other established lexica. Tlachac et al. (2022) described that the most important features driving depression prediction status were vacation-related words that included the names of cities and US states. Additionally, Liu et al. (2021) found that language of negative emotions (e.g., sad, anger) and personal pronouns correlated with self-reported depression. Stamatis et al. (2022) found unique negative associations between depressive symptoms and several linguistic features including anticipation, trust, social processes, and affiliation words. Finally, Nook et al. (2022) examined text messages between clients and their therapists and found that linguistic distance, a derived construct comprising temporal distance (i.e., verbs in future and past tense, not present tense) and social distance (non-first-person pronouns), was found to be related to time in therapy as well as symptom reductions over time, though it remains unclear if linguistic language was mechanistic in symptom reductions over time. Together, these studies suggest that text message language provides a uniquely useful private data source that may be effective for understanding mechanisms of depression. However, since prior studies highlight the importance of social closeness (Nalabandian & Ireland, 2019; Segrin & Flora, 1998), in order to advance the literature on private day-to-day social language in depression, there is a need to consider how a person’s social closeness with their conversational partner may influence associations between the language used in text messages and depressive symptoms.
Little is known about whether and how individuals with depression communicate differently with interlocutors of varying degrees of closeness in private day-to-day digital media. Over the course of 16 weeks, we examined the linguistic features of outgoing text messages among 419 individuals with and without depression and their close- and non-close (i.e., more distant) contacts. We tested how individuals with varying degrees of depressive symptom severity communicate differently according to relationship closeness.
2.0. MATERIALS AND METHODS
2.1. Participants
A total of 673 participants were enrolled in this study over two waves of data collection. The first wave was recruited between February 2020 and April 2020 (n=384), spanning the beginning of the COVID-19 pandemic in the United States. The second wave was recruited between January 2021 and April (n=289), squarely during the COVID-19 pandemic in the United States. Participants were recruited via social media, online bulletin boards, the recruitment firm Focus Pointe Global, and digital recruitment registries including ResearchMatch (a national health volunteer registry supported by the National Institutes of Health as part of the Clinical Translational Science Award [CTSA] program), and an actively maintained registry within Northwestern University’s Center for Behavioral Intervention Technologies (CBITs). The CBITs registry includes individuals who have indicated an interest in participating in digital mental health trials and have completed pre-screening assessments that ensure effective targeting of recruitment calls (Lattie et al., 2018).
We oversampled participants such that approximately 50% of our sample experienced at least moderate depression symptoms (PHQ-8 ≥ 10; Kroenke et al., 2009). Participants were eligible for this study if they lived in the United States, were able to speak and read English at a level that enabled them to provide informed consent in English and participate in all study procedures and assessments, and used an Android smartphone with a data plan. Participants were not eligible to participate if they reported a diagnosis of bipolar disorder, schizophrenia, or other psychotic disorder, if they shared their smartphone with another person, or if they were not willing to share smartphone data necessary for sensor analyses. All participants were compensated for completing self-report online assessments and ecological momentary assessments (EMA), with a maximum possible compensation of $142. All study protocols and procedures were approved by Northwestern University’s Institutional Review Board (IRB), and prior to beginning study procedures, all participants provided informed consent.
2.2. Data Collection and Procedures
Following the enrollment period, participants downloaded the LifeSense app – a custom instantiation of an open-source development framework called Passive Data Kit (PDK)1 used for creating cross-platform passive data collection apps (Audacious Software, 2018). The LifeSense app passively and continuously collected internal sensor data (e.g., GPS markers, semantic location), phone use metadata (e.g., timestamped call logs, foreground app use), and processed raw-text messages into data aggregations such as Linguistic Inquiry and Word Count (LIWC; Pennebaker et al., 2015) word counts sums. Of note, raw text message language was not collected as part of this study, and instead we prioritized participant privacy by conducting text message data aggregations on participants’ devices before transmission to research servers (Figure 1). The observational study period lasted 16 weeks, during which participants completed periodic online assessments via research electronic data capture (REDCap) tools hosted at Northwestern University (Harris et al., 2009, 2019), as well as daily ecological momentary assessments (EMA) surveys within the LifeSense app (previous work with similar, or overlapping, datasets can be referenced here: Liu et al., 2021; Meyerhoff et al., 2021; Stamatis, Meyerhoff, Liu, Hou, et al., 2022; Stamatis, Meyerhoff, Liu, Sherman, et al., 20222).
Figure 1:
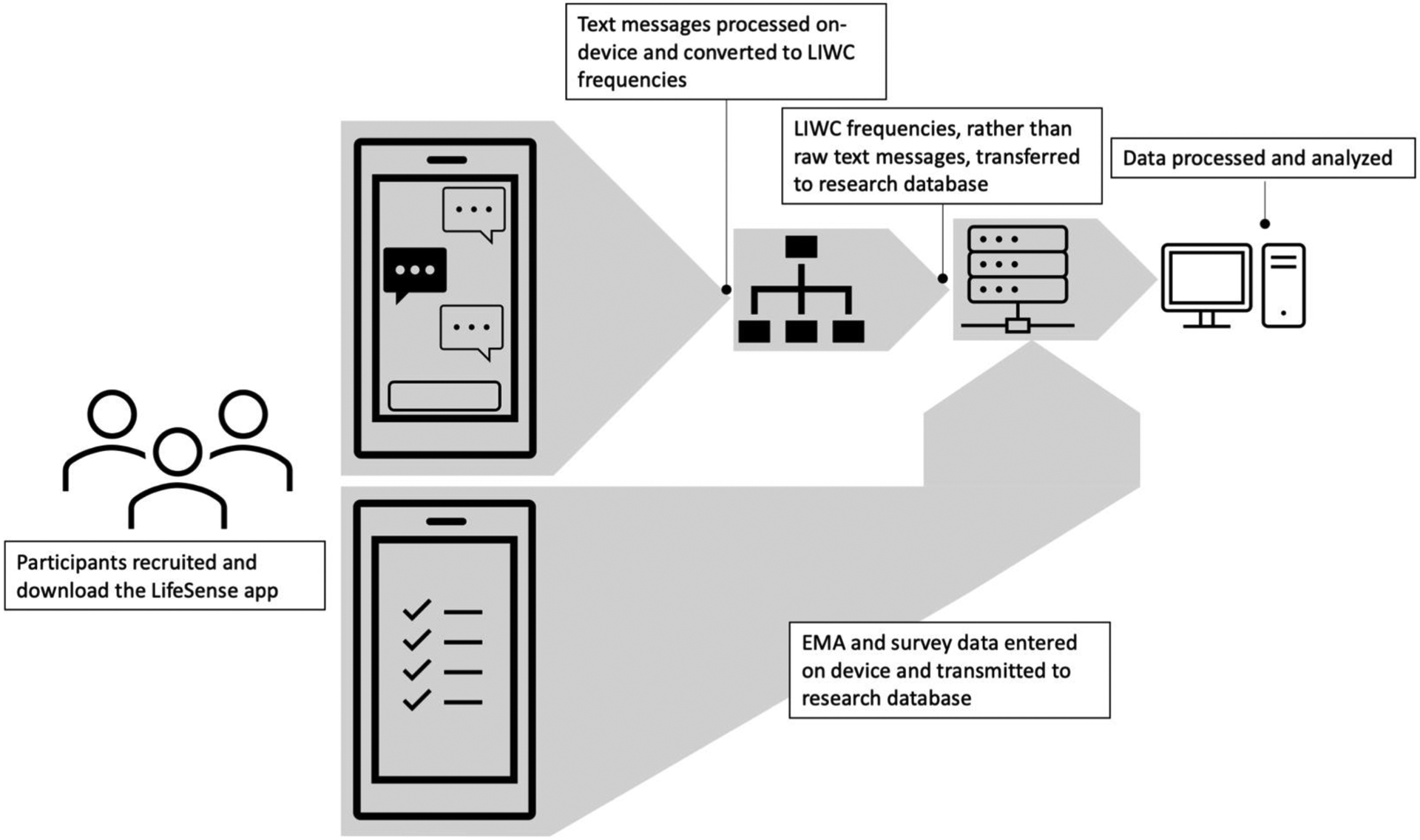
Schematic of data-collection and processing.
2.2.1. Depression Severity
Depression severity was measured using the PHQ-8 (Kroenke et al., 2009). The PHQ-8 was administered at baseline via REDCap and thereafter via the LifeSense app at the beginning and end of every third week starting in the first study week (i.e., weeks 1, 4, 7, 10, 13, 16). Severity scores were calculated as a single mean PHQ-8 score across the full 16-week study. We elected to examine participants’ mean PHQ-8 scores rather than dichotomized depression status to examine the full range of depression severity in this study. Prior work demonstrates that electronic administration of the PHQ-9, a similar measure that includes all the items of the PHQ-8 with an additional item assessing the frequency of self-injurious or suicidal thoughts (Wu et al., 2020), is acceptable (BinDhim et al., 2015) and has been successfully administered repeatedly in large remote trials (e.g., Arean et al., 2016).
2.2.2. Social Tie Strength
Each time participants communicated by phone call or text message with a new contact, the LifeSense app would launch a set of questions in the evening requesting that the participant characterize the nature of their relationship to that new contact (e.g., a friend, spouse/partner, family with whom the participant lives, family that lives apart from the participant, work colleague, acquaintance, a contact related to a task, or other). Participants were then asked a series of 5 questions (Marin & Hampton, 2007; Wiese et al., 2015) measuring different dimensions of how close a participant felt to that particular contact (i.e., “How much did you want to communicate with this person today?”, “How close do you feel to this person?”, “How much do you trust this person?”, etc.). Each of these questions was rated on a Likert scale ranging from 1 (not at all) to 7 (very), and these 5 items were summed to a total “closeness” score ranging from 5 to 35. We aggregated closeness ratings by contact type (Supplemental Figure 1) to examine patterns in overall closeness in an effort to reduce the dimensionality of the data. Based on overall closeness scores, it became apparent that two distinct groups were present with regard to contact types: The first group included spouse/partner, family with whom the participant lives, family that lives apart from the participant, friend; we considered these to be close contacts (mean closeness score = 25.94; SD=7.16). The second group included work colleagues, acquaintances, contacts related to a task (mean closeness score=18.06; SD=7.26); we considered these to be non-close contacts. To maximize data interpretability, we used a close/non-close dichotomization based on contact type to reduce the dimensionality of these data. An independent samples t-test demonstrated that these two categories differed significantly from one another (t=−38.025; p<0.001) on closeness ratings.
2.2.3. Linguistic Features
Linguistic feature scores were calculated using outgoing text messages passively processed on participants’ devices. The LifeSense app ran the LIWC 2015 (Pennebaker et al., 2015) dictionaries over all text messages participants sent during the study period. LIWC 2015 has demonstrated utility in previous studies of language use among individuals with depression (e.g., De Choudhury et al., 2013; Eichstaedt et al., 2018; Guntuku et al., 2019; Liu, Ungar, et al., 2022; Nguyen et al., 2014; Nook et al., 2022; Schwartz et al., 2014). Linguistic feature scores were calculated as a word count sum for each LIWC 2015 category. Feature scores were normalized by the total number of LIWC top-level category words used by each participant.
2.3. Data Analysis
Prior to analysis, participants who sent fewer than 100 text messages over the 16-week study were excluded from analyses to ensure sufficient data density for data analysis. Prior literature establishes a 500-word minimum threshold for reliable text-based analyses (Merchant et al., 2019). Since the median text message length in our sample was approximately 5–7 words, we used a 100-message threshold. Following filtering, 419/673 participants were included. We then examined a Linear Mixed Model (LMM) that predicted user-level linguistic feature scores of outgoing text messages as a function of depression severity, moderated by self-report ratings of contact tie strength (close contact or non-close contact):
Of note, for the purposes of model interpretation, tie-strength was binarized such that 0=non-close contact and 1=close contact and mean PHQ-8 score was standardized to make coefficients directly comparable. The predictor (1|participant-ID) means that a random intercept is estimated for each level of the participant, accounting for dependencies in the data due to repeated measures within person over time.
We used the coefficients estimated for this model to analyze relationships between depression severity and linguistic feature (i.e., LIWC category) usage, accounting for contact closeness. These coefficients can be understood by considering the reduced form of the regression equation under the possible values of the depression severity and tie-strength variables, as shown in Table 1. In Table 1, a indicates the average linguistic feature usage among individuals with a theoretical mean PHQ-8 score of 0 speaking with non-close contacts; β0 therefore represents, the change, relative to a, in average usage among non-depressed individuals when speaking with close contacts. Our two coefficients of interest, β1 and β2 , can be understood as follows: β1 gives the increase or decrease in estimated LIWC category usage with non-close contacts for a one-point increase in PHQ, while β2 gives the change in this slope relative to β1 when speaking with close contacts. β1+β2 is therefore the change in linguistic feature usage when speaking with close contacts.
Table 1:
Forms of regression equation under each possible variable setting.
| Mean standardized PHQ-8 = 0 | Mean standardized PHQ-8 > 0 | |
|---|---|---|
|
non-close contact
(binarized tie-strength=0) |
a | a + β1(mean standardized PHQ-8) |
|
close contact
(binarized tie-strength=1) |
a + β0 | a + β0 + (β1+β2)(mean standardized PHQ-8) |
We focus our investigation primarily on 37 LIWC categories associated with depression in the prior literature (out of a total of 73 LIWC categories; Eichstaedt et al., 2018; Liu et al., 2022; Schwartz et al., 2014). For each of these 37 categories (Supplemental Table 1 for full list) associated with depression in prior literature, we report Benjamini-Hochberg corrected p-values. As an additional exploratory piece, for the entire library of LIWC categories (Supplemental Table 1), we report the uncorrected p-values for model coefficients; we intend these uncorrected results to inform potential avenues for further investigation.
3.0. RESULTS
After filtering for individuals who sent at least 100 messages across the 16-week study period, 419 participants were included in analyses (n=233 from the first wave of recruitment and n=186 from the second wave of recruitment; reference Table 2 for participant demographics; reference Supplemental Figure 2 for distribution of mean PHQ-8 scores used in multilevel model). For each participant across the entire study period, the mean number of LIWC top-level words was 22,832.11 (SD: 29,423.97), while the mean per-message number of LIWC top-level words was 17.41 (SD: 23.31). Reference Supplemental Figures 3–5 for number of text message and LIWC words per participant as a function of social closeness.
Table 2:
Participant characteristics
| Variable | Statistic |
|---|---|
| Age in years, mean (sd) | 41.11 (12.44) |
| Sex (assigned at birth), n (%) | |
| • Female | 323 (77.1%) |
| • Male | 96 (22.9%) |
| Gender identity, n (%) | |
| • Cisgender Woman | 314 (75.7%) |
| • Cisgender Man | 95 (22.9%) |
| • Non-binary | 6 (1.4%) |
| • Transgender | 3 (0.7%) |
| • Genderqueer | 1 (0.2%) |
| Race, n (%) | |
| • White | 345 (82.3%) |
| • Black/African American | 48 (11.5%) |
| • Asian | 8 (1.9%) |
| • Native American/Alaskan Native | 2 (0.5%) |
| • More than one Race | 13 (3.1%) |
| • Prefer not to answer | 3 (0.7%) |
| Ethnicity, n (%) | |
| • Hispanic/Latinx | 24 (5.7%) |
| • Non-Hispanic/Non-Latinx | 394 (94%) |
| • Unknown/Prefer not to answer | 1 (0.2%) |
| Highest level education completed, n (%) | |
| • Some high school, no diploma | 4 (1%) |
| • High school/GED | 31 (7.4%) |
| • Some college, no degree | 102 (24.3%) |
| • Associate’s degree | 81 (19.3%) |
| • Bachelor’s degree | 125 (29.8%) |
| • Graduate degree | 76 (18.1%) |
| Marital status, n (%) | |
| • Single/never married | 135 (32.2%) |
| • Domestic partnership | 4 (1%) |
| • Married | 139 (33.2%) |
| • Separated | 13 (3.1%) |
| • Divorced | 66 (15.8%) |
| • Unknown/Prefer not to answer | 2 (0.5%) |
| Household income, n (%) | |
| • <$10,000 | 35 (8.4%) |
| • $10,000–19,999 | 41 (9.8%) |
| • $20,000–39,999 | 90 (21.5%) |
| • $40,000–59,999 | 82 (19.6%) |
| • $60,000–99,999 | 31 (21.7%) |
| • >$100,000 | 70 (16.7%) |
| • Unknown/Prefer not to answer | 10 (2.4%) |
| Employment, n (%) | |
| • Employed | 257 (61.3%) |
| • Unemployed | 59 (14.1%) |
| • Disability | 48 (11.5%) |
| • Retired | 15 (3.6%) |
| • Other | 38 (9.1%) |
| • Prefer not to answer | 2 (0.5%) |
| Overall PHQ-8, mean (sd) | 9.14 (4.99) |
| • Minimal (0–4), n (%) | 149 (35.6%) |
| • Mild (5–9), n (%) | 130 (31%) |
| • Moderate (10–14), n (%) | 68 (16.2%) |
| • Moderate-Severe (15–19), n (%) | 56 (13.4%) |
| • Severe (20–24), n (%) | 16 (3.8%) |
3.1. Depression effects
Our results indicate modest overlap with respect to linguistic features used, and the direction of effects, when texting both close and non-close contacts among people with varying depression symptom severity (Figure 2; Full model results in Supplemental Table 1). As is shown in Table 3 (where there are positive β1 and β1+β2 coefficients both with corrected p-values <0.05), after applying a Benjamini-Hochberg correction for multiple comparisons, in texts to both close and non-close contacts, people with more severe depression tended to use more differentiation words (reference Supplemental Figures 6 and 7 for visualization of model coefficient estimates by close or non-close contacts).
Figure 2:
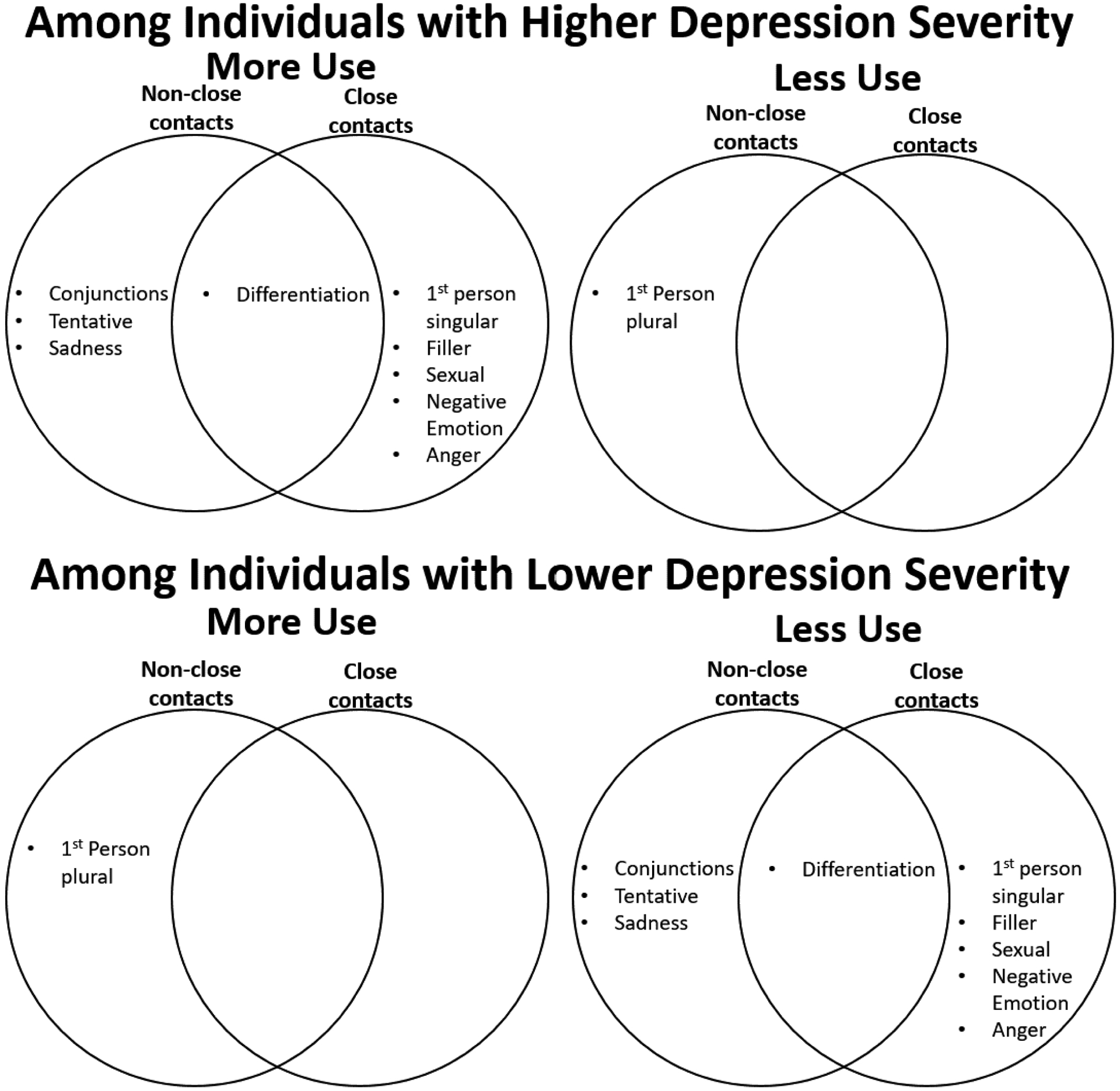
Linguistic feature frequency of use between close and non-close contacts among individuals with higher and lower depression severity
Table 3:
Regression coefficients for linguistic features used with close and non-close contacts
| Lexica | Non-close Contacts (β1) | Uncorrected p-value for β1 |
Corrected p-value for β1 |
Close Contacts (β1+β2) | Uncorrected p-value for β1+β2 |
Corrected p-value for β1+β2 |
|---|---|---|---|---|---|---|
| Total Function Words‡ | 0.000495 | 0.836 | 0.884 | 0.000507 | 0.415 | 0.465 |
| Common Adverbs | 0.000430 | 0.428 | 0.587 | 0.001001 | 0.031 | 0.094 |
| Conjunctions | 0.001452 | 0.004 | 0.042 | 0.000759 | 0.066 | 0.121 |
| Total Pronouns‡ | −0.001208 | 0.255 | 0.429 | 0.001692 | 0.053 | 0.121 |
| Personal Pronouns‡ | −0.001392 | 0.142 | 0.292 | 0.001747 | 0.031 | 0.094 |
| 1st Person Singular | 0.000646 | 0.361 | 0.534 | 0.001885 | 0.003 | 0.023 |
| 1st Person Plural | −0.000771 | <0.001 | 0.002 | −0.000341 | 0.044 | 0.108 |
| Affective Processes‡ | −0.000377 | 0.670 | -- | −0.000715 | 0.206 | -- |
| Negative Emotion | 0.000458 | 0.010 | 0.059 | 0.000613 | <0.001 | 0.004 |
| Anger | 0.000046 | 0.496 | 0.622 | 0.000244 | <0.001 | 0.004 |
| Sadness | 0.000428 | <0.001 | <0.001 | 0.000212 | 0.020 | 0.084 |
| Social Processes | −0.003344 | 0.002 | -- | −0.001000 | 0.176 | -- |
| Friend | −0.000206 | 0.080 | -- | −0.000261 | 0.012 | -- |
| Cognitive Processes | 0.001606 | 0.039 | 0.135 | 0.001743 | 0.012 | 0.061 |
| Discrepancy | 0.000712 | 0.040 | 0.135 | 0.000603 | 0.039 | 0.102 |
| Tentative | 0.000901 | 0.006 | 0.042 | 0.000339 | 0.145 | 0.244 |
| Differentiation | 0.001450 | <0.001 | <0.001 | 0.000924 | 0.004 | 0.023 |
| Perceptual Processes | 0.000893 | 0.008 | -- | −0.000154 | 0.321 | -- |
| See | 0.000754 | 0.010 | -- | −0.000194 | 0.250 | -- |
| Biological Processes‡ | 0.000291 | 0.258 | -- | 0.000358 | 0.079 | -- |
| Body | 0.000084 | 0.382 | 0.544 | 0.000190 | 0.023 | 0.084 |
| Sexual | 0.000152 | 0.020 | 0.092 | 0.000181 | 0.002 | 0.023 |
| Drives‡ | −0.002113 | 0.051 | 0.146 | −0.000792 | 0.228 | 0.336 |
| Affiliation | −0.001126 | 0.013 | 0.067 | −0.000682 | 0.063 | 0.121 |
| Time Orientation‡ | −0.000548 | 0.597 | -- | −0.000040 | 0.484 | -- |
| Past Focus | 0.000995 | 0.028 | 0.113 | 0.000896 | 0.022 | 0.084 |
| Informal Language‡ | 0.000335 | 0.921 | -- | 0.000857 | 0.398 | -- |
| Swear Words | 0.000141 | 0.097 | -- | 0.000298 | <0.001 | -- |
| Netspeak | 0.001179 | 0.091 | -- | 0.001312 | 0.028 | -- |
| Filler | 0.000052 | 0.072 | 0.178 | 0.000089 | <0.001 | 0.012 |
| Home | −0.000142 | 0.217 | -- | −0.000236 | 0.019 | -- |
| Death | 0.000014 | 0.606 | 0.701 | 0.000046 | 0.039 | 0.102 |
Sign of β1 or β1+β2 coefficients signals either a positive or negative association with increasing depression severity, while the p-value signals whether the relationship is significant.
Table includes uncorrected and Benjamini-Hochberg-corrected p-values, robust findings have a Benjamini-Hochberg-corrected p-value of <0.05. For example, a positive β1 coefficient with a significant corrected p-value indicates that individuals with greater depression severity used a particular linguistic feature more than individuals with lower depression severity when texting non-close contacts. Absence of a corrected p-value when an uncorrected p-value is also present signals that the category in question was not included as part of the 37 LIWC categories hypothesized to relate to depression based on prior literature.
Table has been truncated to include LIWC lexica categories (i.e., linguistic features) in which at least one of the β1 or β1+β2 coefficients have an uncorrected p-value <0.05.
Table also includes LIWC lexica super-categories that may not have any significant (p<0.05) associations. This is to illustrate the hierarchical nature of LIWC Lexica (super-categories marked with: ‡)
3.2. Depression and social closeness effects
Following the Benjamini-Hochberg correction, other linguistic features exhibited different relationships with depression severity when used among close contacts compared to non-close contacts (Figure 2). Among participants with more severe depression, when texting with close contacts, individuals tended to use more first-person singular words, filler, sexual, as well as negative emotions, including anger; the use of these linguistic features was, in contrast, not significantly associated with depression severity among non-close contacts (Table 3 where there are positive β1+β2 coefficients and corrected p-values <0.05, but non-significant β1 coefficients). Additionally, when texting non-close contacts, individuals with more severe depression tended to use more conjunctions, tentative, and sadness-related words (Table 3 where there are positive β1 coefficients and corrected p-values <0.05, but non-significant β1+β2 coefficients). When texting non-close contacts, participants with more severe depression used fewer first-person plural words (note: participants with less severe depression used this category more frequently; Table 3 where there are negative β1 coefficients with corrected p-values <0.05, but non-significant β1+β2 coefficients). For participants with more severe depression, there were no significant relationships indicating decreased use of particular linguistic categories when texting with close contacts.
3.3. Exploratory measures for further study
In the interest of supporting future research, the following section discusses exploratory findings. Because these findings did not survive a Benjamini-Hochberg correction, we provide a brief overview of these uncorrected findings exclusively to support future research and identify areas for further study. Table 3 includes all exploratory LIWC categories (of a possible 73) with an uncorrected β1 or β1+β2 p-value <0.05 as well as the associated corrected p-value, if applicable. Uncorrected findings are not robust enough to generate conclusions, but they may hold promise for future research.
When communicating with both close and non-close contacts, individuals with more severe depressive symptoms tended to use more cognitive processes (including discrepancy and differentiation), sexual, past focus, and negative emotion (including sadness) words (Table 3 where there are positive β1 and β1+β2 coefficients both with uncorrected p-values <0.05). Meanwhile, individuals with more severe depression tended to use fewer first-person plural words (note: individuals with lower depression severity used this linguistic category more frequently; Table 3 where there are negative β1 and β1+β2 coefficients both with uncorrected p-values <0.05).
There were also interactions between social closeness and depression severity. Specifically, when texting non-close contacts, individuals with more severe depression used more perceptual process (i.e., see), conjunction, and tentative words (Table 3 where there are positive β1 coefficients and uncorrected p-values <0.05, but non-significant β1+β2 coefficients). In contrast, when texting with non-close contacts, individuals with more severe depression tended to use less social process and affiliation words (note: participants with less severe depression used this category more frequently; Table 3 where there are negative β1 coefficients with uncorrected p-values <0.05, but non-significant β1+β2 coefficients). Meanwhile, when communicating with close contacts, individuals with more severe depression used more personal pronouns, first-person singular, adverb, filler, body, death, swear, anger, and netspeak words (Table 3 where there are positive β1+β2 coefficients and uncorrected p-values <0.05, but non-significant β1 coefficients). However, when texting close contacts, these same individuals used less friend and home words (note: participants with less severe depression used these words more frequently; Table 3 where there are negative β1+β2 coefficients and uncorrected p-values <0.05, but non-significant β1 coefficients).
4.0. DISCUSSION
4.1. Language use and depression
Our results highlight ways in which depression severity may be expressed through communication differences as a function of tie-strength in social networks. Here, we focus only on findings that were significant following a Benjamini-Hochberg correction based on 37 linguistic categories related to depression in previous literature (Eichstaedt et al., 2018; Liu, Giorgi, et al., 2022; Schwartz et al., 2014).3 Among individuals with higher depression severity, there is overlap in the linguistic features used across both close and non-close contacts, but there are also important differences. Those with greater depression severity tend to use more autobiographical (e.g., first-person singular), more hostile and more informal (e.g., filler, sexual, anger) language with close contacts, but more sadness and qualifying language (e.g., tentative, conjunctions) with non-close contacts. In contrast, we failed to find statistically significant evidence indicating that individuals with lower depression severity used any shared linguistic features more frequently (when texting both close and non-close contacts). Additionally, our analysis failed to detect any conspicuous patterns of differentiated language use by individuals with lower depression severity when messaging close contacts. Taken together, these results highlight that both depression severity and social closeness impact communication in text messages.
4.1.1. The moderating role of closeness.
These differences might be partially explained by the unique goals people have for engaging in self-disclosure with contacts of different tie strengths. Functional models of self-disclosure online illustrate that individuals engage in self-disclosure to achieve specific aims such as social validation, self-expression, relational development, identity clarification, and social control within the context of their online networks (Bazarova & Choi, 2014). Foundational work demonstrated that, in the context of Facebook, individuals used similar levels of positive language across both directed (i.e., private messages and wall posts) and undirected (i.e., status update) posts; however, Facebook users limited their use of negative sentiment only in status update posts – which are public broadcasts to a broad network (Bazarova et al., 2013). Bazarova et al.’s work (2013) highlights that individuals are highly responsive to their online audience, which may consist of a broader population and include non-close contacts, and moderate their use of language accordingly. Our results partially suggest a similar pattern of audience cognizance. While individuals with greater depression levels tended to use substantially more differentiated language when messaging either close contacts (e.g., first-person singular, filler, sexual, anger, etc.) or non-close contacts (e.g., conjunctions, tentative, sadness), for individuals with lower depression severity, we found relatively fewer indicators of differentiated language use when messaging with close or non-close contacts.
By considering depression severity as well as the role of social closeness, our findings build on the extant literature on differences in self-disclosure across types of digital media. A recent analysis of social media language demonstrated that language used on different social networking sites, which can be a rough proxy measure for different levels of social closeness, demonstrated that different networks lent themselves to varying amounts of self-disclosure. In the study, Facebook posts–which tend to be directed at audiences of real, personally known people–focused on topics of personal importance (e.g., family, friends, emotions) and generally included higher levels of personal self-disclosure than did posts made on Twitter – which tend to be directed at more public audiences or strangers (Jaidka et al., 2018). A similar study found that within the same individuals, language used on Facebook and language used in text messages differed such that text message language contained more autobiographical words, differentiation words, and discrepancy words (Liu, Giorgi, et al., 2022). These data may suggest that in text messages, which tend to be directed at specific people or small groups of closer contacts than audiences on social media, individuals are more focused on the self and may engage in more personal self-disclosure than when interacting with broader audiences. Extending this literature, our results suggest that when texting with contacts who are considered strong ties, individuals engage in more personal self-disclosure by way of increased first-person singular, sexual, and anger language when feeling more depressed. These same individuals do not engage in the same level of personal self-disclosure with non-close contacts and instead use more tentative and internalizing language. Moreover, these differentiated disclosure patterns do not appear to hold for individuals who have less severe depressive symptoms. In fact, individuals who were more depressed tended to use relatively less first-person plural words when texting with non-close others, and while this is first-person language, the plural form indicates a lower likelihood of self-disclosure than the singular form. This suggests that more hostile and negative self-disclosure may be a hallmark form of communication that is unique to individuals experiencing greater depression severity when communicating with close others.
4.1.2. Implications for models of social interaction in depression.
The differential patterns of day-to-day language use in the context of relationship closeness have implications for models of social interaction in depression. It is possible that individuals with elevated depression severity are more comfortable with their close contacts and subsequently express more self-related concerns (e.g., first-person singular words) and stigmatized negative emotions (e.g., anger) and less formal language than when communicating with their non-close contacts. Studies have repeatedly shown that certain linguistic features such as first-person language, pronoun use, cognitive processes, emotional language, and increased present-tense verbs, are associated to some extent with more severe depressive symptoms (Eichstaedt et al., 2018; Guntuku et al., 2017; Liu et al., 2021; Nook et al., 2022); however, recent work has attempted to identify whether there are certain contexts in which these language patterns are more or less salient. Our results suggest that one such contextual factor is interpersonal closeness. A recent study (Nalabandian & Ireland, 2019) found that individuals with depression tended to use more negative self-focused language when discussing romantic partners with whom they perceived a high degree of self-other overlap and with friends with whom they perceived a low self-other overlap; these same individuals did not appear to use negative self-focused language differentially when discussing family members. Our findings that individuals with more severe depression symptoms use more negative, aggressive, and self-focused language with close contacts, while using noticeably more differentiated language, replicates and extends the existing literature by showing that the nature of one’s relationship to others interacts with depressive symptoms and may moderate the language individuals use to communicate.
Our finding that depressed individuals communicate differently with close and non-close contacts also aligns with a growing literature on the importance of tie-strength in the use of text message data for depression classification. Classification of depression status from linguistic features has gained significant attention in recent years (Chancellor & De Choudhury, 2020). Previous work assessing algorithmic performance of depression classification from public tweets or private text messages found that private text messages offered a richer source of data and lent to better algorithmic classification than public tweets (Tlachac & Rundensteiner, 2020). Related work examined whether linguistic features derived from text messages differed with regard to classification performance if the features were derived from all an individual’s text messages or if they were derived from the messages to the top 25% of people an individual texted with most frequently. In their study, the authors found that features derived from the top 25% of contacts led to more accurate depression classifications than if features were derived from all contacts (Tlachac et al., 2019). Though these prior predictive results align with our findings that individuals have higher communication volume with close contacts (Supplemental Figure 3), an intuitive result, we find that there is still descriptive value in examining messages with both close and non-close contacts alike as they may have utility for understanding potential mechanisms in depression.
4.1.3. Interpersonal processes in depression.
Along with informing models of social interaction in depression, our results may offer insight into the interpersonal processes that can be both monitored and targeted in therapeutic interventions. Namely, the differences in communication with close and non-close contacts across the spectrum of depression severity sheds light on possible mechanisms by which social relationships strain and depressive symptoms worsen. One possibility is that expressed aggressive language (i.e., anger and sexual linguistic features) and more frequent use of autobiographical words and perspectives, may at once signal the presence of a close relationship as well as a risk factor for its straining. Close interpersonal relationships may afford an individual space to express their lived experience of their depressive symptoms and access needed emotional support. In fact, there is strong evidence that perceived emotional and instrumental support are protective against depressive symptoms (Santini et al., 2015), suggesting that for the individual with worsening symptoms, having close contacts who will listen, validate, and offer both material and emotional resources can be transformative and protective. However, it is also possible that emotional validation can shift into co-rumination, which has been linked to closer friendships, but worsening affective symptoms, and can paradoxically give rise to worsening depression (Keshishian et al., 2016). Another possible mechanism that should be explored in future work is that worsening depressive symptoms lead to the more aggressive and autobiographical language used in messages to close others which, over time, creates interpersonal distance and functionally reduces access to needed emotional support (Spendelow et al., 2017). At this stage, our results do not indicate causal structures around the interaction among social connection, language use, and depressive symptom severity; however, we are able to detect correlational signals in passively monitored text messages. Clinically, there is future potential for the integration of passive monitoring tools deployed on consenting individuals’ devices to monitor text message language use in a manner that preserves privacy. Such systems could help build awareness and alert individuals of shifting language used with close and non-close contacts that may indicate potential co-rumination, risk of worsening symptoms, and potential strains in important protective relationships.
4.2. Limitations
This study is not without limitations. First, raw text message content was not collected; prioritizing participant privacy. Consequently, we rely on derived text message linguistic features for our analysis. Thus, ground truth and underlying participant motivations remain uncertain, and we infer intent and meaning in a way that is limited to the linguistic features contained in the LIWC 2015 lexicon. Next, our analyses are associative and do not explain causal structures; future work may use more causal experimental designs to further explore hypotheses generated by our findings. Additionally, our static metric of tie-strength does not capture fluctuations in how close a contact is, which is likely to be a dynamic state. Further, interpretations of these results should be limited to understanding the nature of text message communications and cannot necessarily be generalized to face-to-face interactions. Another consideration is that our sample was limited to Android users, such that results may not generalize to the broader population of smartphone users. Finally, there is a potential that participation in this study led to altered text messaging behavior by regular prompting to complete online surveys and EMA prompts.
4.3. Conclusions
Overall, these data offer insight into the complex interrelated nature of depression symptom severity, social closeness, and language use. Certain word classes used in outgoing text messages, when combined with an individual’s subjective feeling of closeness to the recipient, may be indicative of underlying interpersonal processes which can be detected via passively and continuously monitored text message features. These data may hold promise as potential treatment targets that can be modified via DMHIs to address interpersonal drivers of depression.
Supplementary Material
Acknowledgements:
The authors thank Susan M. Kaiser, Nathan Winquist, Jessica Vergara, Olga Barnas, Nameyeh Alam, and Zara Mir of CBITs for their contributions to this work.
Funding Statement:
We acknowledge support from the National Institute of Mental Health (NIMH) [Grants: R01MH111610, T32MH115882, R34MH124960, K08MH128640], the National Institute on Alcohol Abuse (NIAA) [Grants: 1R01AA028032–01], as well as support from the Intramural Research Program of the National Institutes of Health (NIH), National Institute on Drug Abuse (NIDA) [Grants: ZIA DA000628]. Co-authors BC, TL, and GS are affiliated with NIDA and contributed to this manuscript by conducting analyses, interpreting data, writing contributions, and revisions. The NIMH and NIAA were not involved in the design, conduct, analysis, or writeup of this research.
Footnotes
Declaration of Competing Interests:
Jonah Meyerhoff has accepted consulting fees from Boehringer Ingelheim. David C. Mohr has accepted honoraria and consulting fees from Otsuka Pharmaceuticals, Optum Behavioral Health, Centerstone Research Institute, and the One Mind Foundation. He also receives royalties from Oxford University Press and has an ownership interest in Adaptive Health, Inc. No other co-authors report competing interests.
The Passive Data Kit open source repository can be accessed at https://github.com/audacious-software/PassiveDataKit-Android
Liu et al. (2021) examines text message linguistic features as a method of increasing the predictive accuracy of other networked smartphone sensors (e.g., GPS, app use, etc.). Meyerhoff et al. (2021) examines directional associations between different networked sensor features and depressive and anxiety symptom changes among individuals with heterogeneous symptom profiles. Stamatis, Meyerhoff, Liu, Hou, et al. (2022) examined language style matching to examine whether individuals who meet clinical thresholds for depressive or anxiety disorders engage in differentiated non-content-specific linguistic mirroring in dyadic conversations. Finally, Stamatis, Meyerhoff, Liu, Sherman, et al. (2022) examined the unique prospective linguistic associations of text message linguistic features with three different affective disorders, while controlling for effects of comorbidities. The present paper offers a unique contribution in that we focus on understanding how social closeness affects patterns of communication when closeness interacts with depressive symptoms.
We note that even though uncorrected exploratory results (Table 3; Supplemental Table 1) are not the primary focus of this Discussion, they may hold relevance for future research.
Data Availability Statement
Passively collected data are not publicly available due to the presence of potentially identifying information that could compromise participant privacy and consent, but de-identified self-report data (PHQ-8 and EMA) will be made available through the NIMH Data Archive at the conclusion of the study.
References:
- Arean PA, Hallgren KA, Jordan JT, Gazzaley A, Atkins DC, Heagerty PJ, & Anguera JA (2016). The Use and Effectiveness of Mobile Apps for Depression: Results From a Fully Remote Clinical Trial. Journal of Medical Internet Research, 18(12), e330. 10.2196/jmir.6482 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Audacious Software. (2018). Passive Data Kit. https://passivedatakit.org/ [Google Scholar]
- Bazarova NN, & Choi YH (2014). Self-Disclosure in Social Media: Extending the Functional Approach to Disclosure Motivations and Characteristics on Social Network Sites. Journal of Communication, 64(4), 635–657. 10.1111/jcom.12106 [DOI] [Google Scholar]
- Bazarova NN, Taft JG, Choi YH, & Cosley D (2013). Managing Impressions and Relationships on Facebook: Self-Presentational and Relational Concerns Revealed Through the Analysis of Language Style. Journal of Language and Social Psychology, 32(2), 121–141. 10.1177/0261927X12456384 [DOI] [Google Scholar]
- Benoit J, Onyeaka H, Keshavan M, & Torous J (2020). Systematic Review of Digital Phenotyping and Machine Learning in Psychosis Spectrum Illnesses. Harvard Review of Psychiatry, 28(5), 296–304. 10.1097/HRP.0000000000000268 [DOI] [PubMed] [Google Scholar]
- BinDhim NF, Shaman AM, Trevena L, Basyouni MH, Pont LG, & Alhawassi TM (2015). Depression screening via a smartphone app: Cross-country user characteristics and feasibility. Journal of the American Medical Informatics Association: JAMIA, 22(1), 29–34. 10.1136/amiajnl-2014-002840 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chancellor S, & De Choudhury M (2020). Methods in predictive techniques for mental health status on social media: A critical review. Npj Digital Medicine, 3(1), 1–11. 10.1038/s41746-020-0233-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Choudhury M, Gamon M, Counts S, & Horvitz E (2013). Predicting depression via social media. Seventh international AAAI conference on weblogs and social media. [Google Scholar]
- Eichstaedt JC, Smith RJ, Merchant RM, Ungar LH, Crutchley P, Preoţiuc-Pietro D, Asch DA, & Schwartz HA (2018). Facebook language predicts depression in medical records. Proceedings of the National Academy of Sciences, 115(44), 11203–11208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gotlib IH (1992). Interpersonal and Cognitive Aspects of Depression. Current Directions in Psychological Science, 1(5), 149–154. 10.1111/1467-8721.ep11510319 [DOI] [Google Scholar]
- Guntuku SC, Buffone A, Jaidka K, Eichstaedt JC, & Ungar LH (2019). Understanding and Measuring Psychological Stress Using Social Media. Proceedings of the International AAAI Conference on Web and Social Media, 13, 214–225. [Google Scholar]
- Guntuku SC, Yaden DB, Kern ML, Ungar LH, & Eichstaedt JC (2017). Detecting depression and mental illness on social media: An integrative review. Current Opinion in Behavioral Sciences, 18, 43–49. 10.1016/j.cobeha.2017.07.005 [DOI] [Google Scholar]
- Harari GM, Müller SR, Stachl C, Wang R, Wang W, Bühner M, Rentfrow PJ, Campbell AT, & Gosling SD (2020). Sensing sociability: Individual differences in young adults’ conversation, calling, texting, and app use behaviors in daily life. Journal of Personality and Social Psychology, 119(1), 204–228. 10.1037/pspp0000245 [DOI] [PubMed] [Google Scholar]
- Harris PA, Taylor R, Minor BL, Elliott V, Fernandez M, O’Neal L, McLeod L, Delacqua G, Delacqua F, Kirby J, & Duda SN (2019). The REDCap consortium: Building an international community of software platform partners. Journal of Biomedical Informatics, 95, 103208. 10.1016/j.jbi.2019.103208 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, & Conde JG (2009). Research electronic data capture (REDCap)—A metadata-driven methodology and workflow process for providing translational research informatics support. Journal of Biomedical Informatics, 42(2), 377–381. 10.1016/j.jbi.2008.08.010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jaidka K, Guntuku S, & Ungar L (2018). Facebook versus Twitter: Differences in Self-Disclosure and Trait Prediction. Proceedings of the International AAAI Conference on Web and Social Media, 12(1), Article 1. https://ojs.aaai.org/index.php/ICWSM/article/view/15026 [Google Scholar]
- Keshishian AC, Watkins MA, & Otto MW (2016). Clicking away at co-rumination: Co-rumination correlates across different modalities of communication. Cognitive Behaviour Therapy, 45(6), 473–478. 10.1080/16506073.2016.1201848 [DOI] [PubMed] [Google Scholar]
- Kroenke K, Strine TW, Spitzer RL, Williams JB, Berry JT, & Mokdad AH (2009). The PHQ-8 as a measure of current depression in the general population. Journal of Affective Disorders, 114(1–3), 163–173. [DOI] [PubMed] [Google Scholar]
- Lattie EG, Kaiser SM, Alam N, Tomasino KN, Sargent E, Rubanovich CK, Palac HL, & Mohr DC (2018). A Practical Do-It-Yourself Recruitment Framework for Concurrent eHealth Clinical Trials: Identification of Efficient and Cost-Effective Methods for Decision Making (Part 2). Journal of Medical Internet Research, 20(11), e11050. 10.2196/11050 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lincoln KD, Chatters LM, Taylor RJ, & Jackson JS (2007). Profiles of depressive symptoms among African Americans and Caribbean Blacks. Social Science & Medicine, 65(2), 200–213. 10.1016/j.socscimed.2007.02.038 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu D, & Yang C (2016). Media Niche of Electronic Communication Channels in Friendship: A Meta-Analysis. Journal of Computer-Mediated Communication, 21(6), 451–466. 10.1111/jcc4.12175 [DOI] [Google Scholar]
- Liu T, Giorgi S, Tao X, Bellew D, Curtis B, & Ungar L (2022). Cross-Platform Difference in Facebook and Text Messages Language Use: Illustrated by Depression Diagnosis. ArXiv:2202.01802 [Cs]. http://arxiv.org/abs/2202.01802 [Google Scholar]
- Liu T, Meyerhoff J, Eichstaedt JC, Karr CJ, Kaiser SM, Kording KP, Mohr DC, & Ungar LH (2021). The relationship between text message sentiment and self-reported depression. Journal of Affective Disorders. 10.1016/j.jad.2021.12.048 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu T, Ungar LH, Curtis B, Sherman G, Yadeta K, Tay L, Eichstaedt JC, & Guntuku SC (2022). Head versus heart: Social media reveals differential language of loneliness from depression. Npj Mental Health Research, 1(1), 1–8. 10.1038/s44184-022-00014-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marin A, & Hampton KN (2007). Simplifying the personal network name generator: Alternatives to traditional multiple and single name generators. Field Methods, 19(2), 163–193. 10.1177/1525822X06298588 [DOI] [Google Scholar]
- Merchant RM, Asch DA, Crutchley P, Ungar LH, Guntuku SC, Eichstaedt JC, Hill S, Padrez K, Smith RJ, & Schwartz HA (2019). Evaluating the predictability of medical conditions from social media posts. PLOS ONE, 14(6), e0215476. 10.1371/journal.pone.0215476 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meyerhoff J, Liu T, Kording KP, Ungar LH, Kaiser SM, Karr CJ, & Mohr DC (2021). Evaluation of Changes in Depression, Anxiety, and Social Anxiety Using Smartphone Sensor Features: Longitudinal Cohort Study. Journal of Medical Internet Research, 23(9), e22844. 10.2196/22844 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nalabandian T, & Ireland M (2019). Depressed Individuals Use Negative Self-Focused Language When Recalling Recent Interactions with Close Romantic Partners but Not Family or Friends. Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, 62–73. 10.18653/v1/W19-3008 [DOI] [Google Scholar]
- Nezlek JB, Imbrie M, & Shean GD (1994). Depression and everyday social interaction. Journal of Personality and Social Psychology, 67(6), 1101–1111. 10.1037/0022-3514.67.6.1101 [DOI] [PubMed] [Google Scholar]
- Nguyen T, Phung D, Dao B, Venkatesh S, & Berk M (2014). Affective and Content Analysis of Online Depression Communities. IEEE Transactions on Affective Computing, 5(3), 217–226. 10.1109/TAFFC.2014.2315623 [DOI] [Google Scholar]
- Nook EC, Hull TD, Nock MK, & Somerville LH (2022). Linguistic measures of psychological distance track symptom levels and treatment outcomes in a large set of psychotherapy transcripts. Proceedings of the National Academy of Sciences, 119(13), e2114737119. 10.1073/pnas.2114737119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pennebaker JW, Booth RJ, Boyd RL, & Francis ME (2015). Linguistic Inquiry and Word Count: LIWC2015, Operators Manual. Pennebaker Conglomerates. 10.4018/978-1-60960-741-8 [DOI] [Google Scholar]
- Santini ZI, Koyanagi A, Tyrovolas S, Mason C, & Haro JM (2015). The association between social relationships and depression: A systematic review. Journal of Affective Disorders, 175, 53–65. 10.1016/j.jad.2014.12.049 [DOI] [PubMed] [Google Scholar]
- Schwartz HA, Eichstaedt J, Kern ML, Park G, Sap M, Stillwell D, Kosinski M, & Ungar L (2014). Towards Assessing Changes in Degree of Depression through Facebook. Proceedings of the Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, 118–125. 10.3115/v1/W14-3214 [DOI] [Google Scholar]
- Segrin C, & Abramson LY (1994). Negative reactions to depressive behaviors: A communication theories analysis. Journal of Abnormal Psychology, 103(4), 655–668. 10.1037/0021-843X.103.4.655 [DOI] [PubMed] [Google Scholar]
- Segrin C, & Flora J (1998). Depression and Verbal Behavior in Conversations with Friends and Strangers. Journal of Language and Social Psychology, 17(4), 492–503. 10.1177/0261927X980174005 [DOI] [Google Scholar]
- Spendelow JS, Simonds LM, & Avery RE (2017). The Relationship between Co-rumination and Internalizing Problems: A Systematic Review and Meta-analysis. Clinical Psychology & Psychotherapy, 24(2), 512–527. 10.1002/cpp.2023 [DOI] [PubMed] [Google Scholar]
- Stamatis CA, Meyerhoff J, Liu T, Hou Z, Sherman G, Curtis BL, Ungar LH, & Mohr DC (2022). The association of language style matching in text messages with mood and anxiety symptoms. Procedia Computer Science, 206, 151–161. 10.1016/j.procs.2022.09.094 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stamatis CA, Meyerhoff J, Liu T, Sherman G, Wang H, Liu T, Curtis B, Ungar LH, & Mohr DC (2022). Prospective associations of text-message-based sentiment with symptoms of depression, generalized anxiety, and social anxiety. Depression and Anxiety. 10.1002/da.23286 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor RJ, Chae DH, Lincoln KD, & Chatters LM (2015). Extended Family and Friendship Support Networks are both Protective and Risk Factors for Major Depressive Disorder, and Depressive Symptoms Among African Americans and Black Caribbeans. The Journal of Nervous and Mental Disease, 203(2), 132–140. 10.1097/NMD.0000000000000249 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tlachac ML, & Rundensteiner E (2020). Screening For Depression With Retrospectively Harvested Private Versus Public Text. IEEE Journal of Biomedical and Health Informatics, 24(11), 3326–3332. 10.1109/JBHI.2020.2983035 [DOI] [PubMed] [Google Scholar]
- Tlachac M, Shrestha A, Shah M, Litterer B, & Rundensteiner EA (2022). Automated Construction of Lexicons to Improve Depression Screening with Text Messages. IEEE Journal of Biomedical and Health Informatics, 1–8. 10.1109/JBHI.2022.3203345 [DOI] [PubMed] [Google Scholar]
- Tlachac M, Toto E, & Rundensteiner E (2019). You’re Making Me Depressed: Leveraging Texts from Contact Subsets to Predict Depression. 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), 1–4. 10.1109/BHI.2019.883448132864624 [DOI] [Google Scholar]
- Wiese J, Min J-K, Hong JI, & Zimmerman J (2015). “You Never Call, You Never Write”: Call and SMS Logs Do Not Always Indicate Tie Strength. Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, 765–774. 10.1145/2675133.2675143 [DOI] [Google Scholar]
- Wu Y, Levis B, Riehm KE, Saadat N, Levis AW, Azar M, Rice DB, Boruff J, Cuijpers P, Gilbody S, Ioannidis JPA, Kloda LA, McMillan D, Patten SB, Shrier I, Ziegelstein RC, Akena DH, Arroll B, Ayalon L, … Thombs BD (2020). Equivalency of the diagnostic accuracy of the PHQ-8 and PHQ-9: A systematic review and individual participant data meta-analysis. Psychological Medicine, 50(8), 1368–1380. 10.1017/S0033291719001314 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Passively collected data are not publicly available due to the presence of potentially identifying information that could compromise participant privacy and consent, but de-identified self-report data (PHQ-8 and EMA) will be made available through the NIMH Data Archive at the conclusion of the study.