

Abstract
In a traditional pharmacokinetic (PK) bioequivalence (BE) study, a two‐way crossover study is conducted, PK parameters (namely the area under the time‐concentration curve [AUC] and the maximal concentration []) are obtained by noncompartmental analysis (NCA), and the BE analysis is performed using the two one‐sided test (TOST) method. For ophthalmic drugs, however, only one sample of aqueous humor, in one eye, per eye can be obtained in each patient, which precludes the traditional BE analysis. To circumvent this issue, the U.S. Food and Drug Administration (FDA) has proposed an approach coupling NCA with either parametric or nonparametric bootstrap (NCA bootstrap). The model‐based TOST (MB‐TOST) has previously been proposed and evaluated successfully for various settings of sparse PK BE studies. In this paper, we evaluate, via simulations, MB‐TOST in the specific setting of single sample PK BE study and compare its performance to NCA bootstrap. We performed BE study simulations using a published PK model and parameter values and evaluated multiple scenarios, including study design (parallel or crossover), sampling times (5 or 10 spread across the dosing interval), and geometric mean ratio (of 0.8, 0.9, 1, and 1.25). Using the simulated structural PK model, MB‐TOST performed similarly to NCA bootstrap for AUC. For , the latter tended to be conservative and less powerful. Our research suggests that MB‐TOST may be considered as an alternative BE approach for single sample PK studies, provided that the PK model is correctly specified and the test drug has the same structural model as the reference drug.
Study Highlights.
WHAT IS THE CURRENT KNOWLEDGE ON THE TOPIC?
In bioequivalence (BE) studies for generic drug development of ophthalmic products, one sample of aqueous humor is taken at a certain timepoint per eye for measurement of drug concentration. Currently, the U.S. Food and Drug Administration (FDA) recommends a nonparametric or parametric bootstrap noncompartmental (NCA) approach in the BE evaluation of these products. Recent research has focused on nonlinear mixed effect models which have been evaluated for sparse pharmacokinetic (PK) BE studies.
WHAT QUESTION DID THIS STUDY ADDRESS?
The present work compares a model‐based (MB) BE approach to the nonparametric NCA for PK BE studies with one sampling timepoint per subject and per occasion.
WHAT DOES THIS STUDY ADD TO OUR KNOWLEDGE?
Our simulations show that the MB BE approach controlled type I errors, and demonstrated a higher power for maximal concentration () compared to nonparametric NCA with parallel study designs.
HOW MIGHT THIS CHANGE DRUG DISCOVERY, DEVELOPMENT, AND/OR THERAPEUTICS?
Results of our research suggest that an MB approach may potentially serve as an alternative method to evaluate BE for generic ophthalmic drug products. However, further research and assessment are needed.
INTRODUCTION
Pharmacokinetic (PK) bioequivalence (BE) studies are key to the development of generic (or test) drugs. Traditionally, a two‐treatment, two‐sequence, two‐period (two‐way) crossover study is conducted and the two one‐sided test (TOST) is performed on estimates of the area under the concentration‐time curve (AUC) and the maximal concentration () obtained by noncompartmental analysis (NCA). In these BE studies, the AUC can be computed using the trapezoidal method and linear extrapolation, if sampling continues for at least three or more terminal elimination half‐lives of the drug and there are at least three sampling points after the peak. 1
In PK BE studies for ophthalmic drug products, typically only one single sample of aqueous humor is collected from one eye of each patient, at one assigned sampling timepoint, to measure drug exposure. Recommendations from the U.S. Food and Drug Administration (FDA) on BE study designs for ophthalmic drug products have been previously described. 2 , 3 A parallel design is typically used when only one sample is collected per patient. A crossover design may be used when using patients with bilateral disease (i.e., on both eyes), enabling the collection of two samples (i.e., one eye per period).
As such, PK BE studies of ophthalmic drug products present unique statistical challenges. Certainly, classical NCA is not feasible because it is not possible to calculate individual AUC values from a single concentration. To circumvent this issue, a nonparametric bootstrap NCA has been proposed by Shen et al. 4 This method involves resampling of the subjects, at each sampling time in both reference and test treatment groups, to generate nonparametric bootstrap datasets. Next, the arithmetic mean concentration is computed at each sampling time. 3 Then, AUC and are computed by NCA from the arithmetic mean concentration in each treatment group for each bootstrap data set to assess the relevant BE criteria. The product‐specific guidance (PSG) for ophthalmic drug products generally recommends to use this method or a parametric method for BE analysis in PK studies. 5
Nonlinear mixed effects modeling (NLMEM) is a powerful tool used to describe the PK properties of a drug and may be used to support a lower number of subjects or reduced sampling in PK studies. 6 In the last 15 years, NLMEM has been demonstrated to be a useful tool in the design and analysis of PK BE studies. 7 For example, Panhard and Mentré 8 proposed to perform a TOST on empirical Bayes estimates (EBEs) of individual AUC and or to analyze the data globally and perform two Wald tests on the model‐based treatment effect estimates (MB‐TOST). However, NLMEM requires specific estimation algorithms which may present certain challenges and concerns. For instance, Panhard and Mentré used the first‐order conditional estimates (FOCE) algorithm 9 which presents convergence issues that can be avoided with the more exact stochastic approximation expectation maximization (SAEM) algorithm. 10 Therefore, Dubois et al. 11 evaluated the tests on EBE using SAEM, exploring various scenarios, and found the latter are not recommended when the shrinkage is above 20%. Furthermore, they evaluated the MB‐TOST using SAEM and identified an inflation of the test type I error rate due to departure from the asymptotic conditions. 12 Consequently, Loingeville et al. 13 proposed alternative calculations of the standard errors (SEs) and showed that MB‐TOST using non‐asymptotic SE controls type I error rate on sparse PK BE studies with small sample sizes. In PK BE studies with large sample sizes, MB‐TOST using asymptotic SE derived from the observed Fisher information matrix (FIM) performed satisfactorily. 14 Yet, Möllenhoff et al. (2020) proposed the bioequivalence optimal test (BOT) which was shown to be more powerful while controlling type I error using either a model or NCA method to fit the concentrations. 15 Further, their simulation study highlighted the overly conservative type I error rate of the TOST method for drugs with large PK variability. Nonetheless, currently, the Agency recommends the reference‐scaled average BE approach for highly variable drugs. 1 , 16
Our objective in the present work is to compare an MB approach to the FDA recommended NCA nonparametric bootstrap approach for single point designs.
METHODS
Two one‐sided tests
For most drug products, BE studies are focused on the release of the drug substance from the drug product into the systemic circulation. In these BE studies, the rate and extent of drug absorption of the test (T) product is compared to the reference (R) product using AUC and metrics, respectively. For the drug exposure, one can estimate the AUC from time zero until the last sampling time () t last or the AUC from time zero until infinity ().
Let be the treatment effect (i.e., the difference between and []) the average means of the test and reference products for or , then the null hypothesis for BE testing is:
| (1) |
with a given threshold
The TOST relies on the decomposition of the null hypothesis stated in Equation 1 in two one‐sided hypotheses . 17 Thereby the null hypothesis is rejected if
| (2) |
where and are the estimate and its standard error, and is the quantile of a reference distribution.
This method is equivalent to constructing a ()‐confidence interval (CI) for and concluding BE if it is completely contained in the equivalence interval . In conventional BE analysis, regulatory authorities set the threshold and the significance level . 18 The BE acceptance criteria is for the 90% CI around the geometric mean ratio (GMR) of AUC or to be included in the [80–125]% interval.
Single point study design
In BE studies for generic drug development of ophthalmic drug products, one sample of aqueous humor is taken at a certain timepoint per eye for measurement of drug concentration. A parallel study design involves sampling from only one eye, whereas crossover study designs involve sampling from both eyes, with test product in one eye and reference product in the other eye.
In both treatment arms of parallel studies, the subjects will be assigned to each of several prespecified sampling times with . Let be the concentration of subject at the sampling time . The total number of samples is which is the same as the total number of subjects.
In the crossover studies, each subject with bilateral cataracts is randomly assigned for treatment with the test product in one eye and the reference product in the other eye.
A single sample of aqueous humor is collected from each eye at the same assigned sampling time . Let be the concentration of subject at the same assigned sampling time at each period/in each eye . So, the total number of samples in the study is for crossover. The total number of subjects .
MB‐TOST method
This approach uses NLMEM that account for the nonlinearity of the concentration versus time profile, as well as between‐ and within‐subject variability (BSV and WSV). 19
For crossover designs, the concentration is described by a nonlinear function depending on the vector of individual parameters of subject sampled at time for period/eye :
| (3) |
The element of the vector (i.e., the individual parameter where is the number of PK parameters) can be decomposed as in the following equation:
| (4) |
with the element of the vector of fixed effects for the covariate reference class. , , and are known vectors of treatment, period and sequence covariates, respectively. , , and are the vectors of coefficients of treatment, period and sequence effects, respectively, for the individual parameter. is the element of the vector of random effects for subject at time capturing the BSV. is the element of the vector of random effects for subject at time and period , capturing WSV.
The random effect vectors and are independently and normally distributed, with mean zero and variance–covariance matrix and , respectively, of size . Let and denote the diagonal element of and , corresponding to the BSVs and WSVs of the parameter, respectively.
The residual errors are independently and identically distributed according to a normal centered distribution of variance . The associated error model can be additive , proportional , or combined .
For parallel designs, both Equations 1 and 2 simplify as follows (i.e., no period or sequence effect because there is only one period/eye and one sequence per subject):
| (5) |
The full vector of parameters to be estimated in the NLMEM is or depending on the design. Let denote the asymptotic variance–covariance matrix of estimation, with the square root of its diagonal elements being the parameter asymptotic SEs. is derived as the inverse of the observed FIM.
The treatment effects on AUC and ( and , respectively) are functions of the reference effects and the treatment effects on the PK model parameters. The delta‐method is used to obtain estimates of and . 20 These estimates and their SE are used to calculate the TOST statistics stated in Equation 2 to be compared to the ‐quantile of a normal distribution.
In this approach, the exposure can be captured by and , both being different functions of the reference effects and the treatment effects on the PK model parameters.
Nonparametric bootstrap NCA
In recent years, the FDA has recommended parametric or nonparametric bootstrap NCA methods for the BE analysis of generic ophthalmic drug products. 3 , 4 , 5
For crossover designs, at each time , the mean of the concentrations are calculated, for each period k. Here, two versions of the nonparametric bootstrap NCA are evaluated (i) using the geometric mean of the concentrations or (ii) using the arithmetic mean of the concentrations. 3 In both versions, one value of and is derived from the (geometric or arithmetic) means at each timepoint, for each period (e.g., k = 1 for treatment T and 2 for treatment R).
Let be the product concentration of the subject and sampling timepoint , , , and . Let be the mean concentration of the product at the sampling timepoint, defined as follows:
| (6) |
Thus, the AUC of the product from the mean profile of drug concentration is calculated, using the trapezoidal rule, by:
| (7) |
is also obtained from the mean profile by:
| (8) |
Then, the ratios and are calculated and the 90% CIs around these ratio estimates are obtained using nonparametric bootstrap as follows.
Let us consider bootstrap samples. For each sampling time , the concentrations of the individuals at both occasions (i.e., for treatments R and T) are re‐sampled with replacement. For each bootstrap sample, at each time the geometric and arithmetic mean of the concentrations are calculated for each treatment group, before deriving the respective treatment , and the corresponding ratios. B ratio estimates and are obtained and the fifth and percentiles of these distributions are used as the lower and upper bounds of the 90% CIs, respectively. Then, BE is concluded if the latter intervals are included in the [80–125]% interval.
To calculate the 90% bootstrap CIs for parallel designs, the concentrations of the individuals are bootstrapped in each treatment group separately.
In this approach, the exposure is captured by (i.e., the trapezoidal rule is used to obtain the AUC and no extrapolation to infinity is made from the last sampling time). In the content of the following tables and figures, we refer to this approach as “NCA bootstrap Geometric and Arithmetic.”
Simulation study
Simulation settings
The PK data describing the PK of theophylline drug were simulated using the following one‐compartment PK model with first‐order absorption and elimination as in ref. 13, thereby assuming the test drug has the same PK structural model as the reference drug:
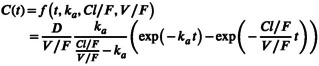 |
(9) |
where is the bioavailability, the dose, the distribution volume, the absorption rate constant, and the clearance of the drug. This PK model describes an exponential rise followed by a mono‐exponential decrease in the concentrations which would have fitted the data of the ophthalmic product described in ref. 4.
Parallel and two‐way crossover designs were considered, both with one sampling timepoint per subject. For each subject, the one sampling time was drawn from a rich or sparse set containing 10 or 5 sampling times, respectively, for selection. A total of 500 subjects was simulated with balanced sample sizes per sampling time and treatment group. For parallel designs, there were 25 subjects per sampling time in each treatment group for the rich set, and 50 subjects per sampling time in each treatment group for the sparse set. For crossover designs, there were 50 subjects per sampling time and per period/eye for the rich set, and 100 subjects per sampling time and period/eye for the sparse set.
The set of 10 sampling times was selected from: h, and the set of 5 was selected from: h. The latter was obtained by maximization of the determinant of the FIM with fixed sampling times at h. 8 For the two‐way crossover design, the same timepoint after drug administration is assumed in both periods/eyes within each individual.
Each subject received mg. The fixed effects for the reference treatment group of subjects were /h, L and mL/h. Diagonal matrices were used for both BSV and WSV (only used when crossover design) with for parallel designs, and and for crossover designs. We used a combined error model for the residual variance with mg/L and .
The limit of quantification (LOQ) for simulated concentrations was set at 0.2 mg/L. Simulated concentrations below 0.2 mg/L, including negative concentrations () and concentrations between 0 and 0.2 (0–0.2) mg/L were identified as below the limit of quantification (BLOQ). For MB‐TOST, BLOQ concentrations were handled in the likelihood calculations using the method described in ref. 21 (i.e., the likelihood for a BLOQ observation is taken to be the likelihood that it is between 0 and the LOQ, given the current model parameter estimates). For NCA bootstrap, the BLOQ data were set to LOQ/2 as in Ref. 4.
Evaluation
Both MB‐TOST and NCA bootstrap were evaluated for BE on and (and not on ) for the purpose of the comparison (see Supplementary Material S1 for the details of these metric calculations).
Despite the sparse sampling in our design, we used asymptotic SE for MB‐TOST due to the large sampling size evaluated (). Indeed, with ‐consistency for all PK parameters simulated and fitted with BSV (and WSV for crossover designs), we assumed asymptotic conditions were met.
For all approaches, the type I error was assessed under two different hypotheses by setting and , corresponding to a simulated GMR for and of 1.25 and 0.8, respectively (see Supplementary Material S1).
We simulated under two different hypotheses, first by setting and second by setting , corresponding to a simulated GMR for and of 1.111 and 1, respectively. In all scenarios, period and sequence effects were assumed to be null (i.e., ).
Therefore, we simulated 16 scenarios: two study designs (parallel or two‐way crossover) times two sets of possible sampling times (5 or 10) and four hypotheses (, , , ). Subsequently, our notation refers to the scenario with a crossover design, a set of 10 sampling times to choose from and a simulated treatment effect of .
Estimation errors (EEs; the differences between the estimates and the simulated value) were calculated for model‐based GMR and NCA bootstrap (geometric and arithmetic) mean ratio (MR) of AUC and . Similarly for all scenarios, we calculated the empirical 5th and 95th percentiles of the GMR for MB‐TOST (as the mean the standard deviation over all simulation estimates) and of the MR for the NCA bootstrap (geometric and arithmetic, as the 5th and 95th percentiles over all simulation estimates) to be compared to the distribution of the estimated 5th and 95th percentiles obtained on each simulated data sets, for AUC and .
For the MB approach, relative EE (REE), relative bias (Rbias) and relative root mean square error (RRMSE) were calculated for fixed effects, random effects, and error model parameters. 22 Because the treatment, sequence, and period effects were simulated at zero, we did not calculate REE, Rbias, and RRMSE for the latter but absolute values of the corresponding metrics.
MB‐TOST and NCA bootstrap were evaluated on 500 simulated data sets for each scenario. As NCA bootstrap runs faster, it was also evaluated on 10,000 simulated data sets for the challenging scenarios with 10 samples under one null and one alternative hypothesis: , , , and .
NCA bootstrap was evaluated with each of these scenarios, assuming there is no LOQ at 0.2 mg/L. Whereas MB‐TOST was evaluated on scenarios and with no LOQ at 0.2 mg/L. In the absence of a defined LOQ, concentrations simulated below zero were set to 0.0001.
MB‐TOST and NCA bootstrap were also evaluated on 500 simulated data sets for two parallel design scenarios with 10 possible sampling times and an increased residual variance at ( and ) and two crossover design scenarios with 10 possible sampling times and increased WSV and residual variance at and ( and ).
Implementation
For the NCA bootstrap method, bootstrap samples were performed in the R statistical software version 4.0.2.
For the model‐based approach, the Monolix 2018R2 software 23 was used which implements the SAEM algorithm for parameters. 24 Population parameters were estimated with 300 exploratory and 100 smoothing iterations, ensuring an appropriate convergence of SAEM visually assessed on a couple of data sets. Further, because there was only one observation per subject per occasion, 10 Markov chains were used to improve the precision of the estimation. This choice was motivated by a previous simulation study which already recommended to use 10 Markov chains with three sampling times per subject. 13 Initial values were set at the true value (i.e., the simulation value [see section simulation settings and Supplementary Material S2]) for all parameters except the treatment, period, and sequence effects all set to zero. Standard errors were computed using the stochastic approximation method. 25
BE tests were performed on GMR for MB‐TOST and MR for NCA bootstrap (geometric and arithmetic), of and in the R statistical software version 4.0.2.
RESULTS
Figure 1 represents a typical data set under the hypotheses of no BE ( top two lines) and equivalence ( bottom two lines) for scenarios with parallel (left column) and crossover (middle and right columns) designs and choosing the individual sample from a set of five or 10 possible times. As simulating corresponds to (see Supplementary Material S1), the test treatment curve appears above the reference treatment curve on plots A‐D of Figure 1. Consequently, simulating leads to the reference and test treatment curves being overlaid on plots E‐H of Figure 1. There were very few BLOQ data in our simulations, with 0.2% to 1.6% of simulated concentrations below 0.2 mg/L at 12 and 24 h post‐dose respectively, for scenario which simulates the lowest concentrations in the treatment group.
FIGURE 1.
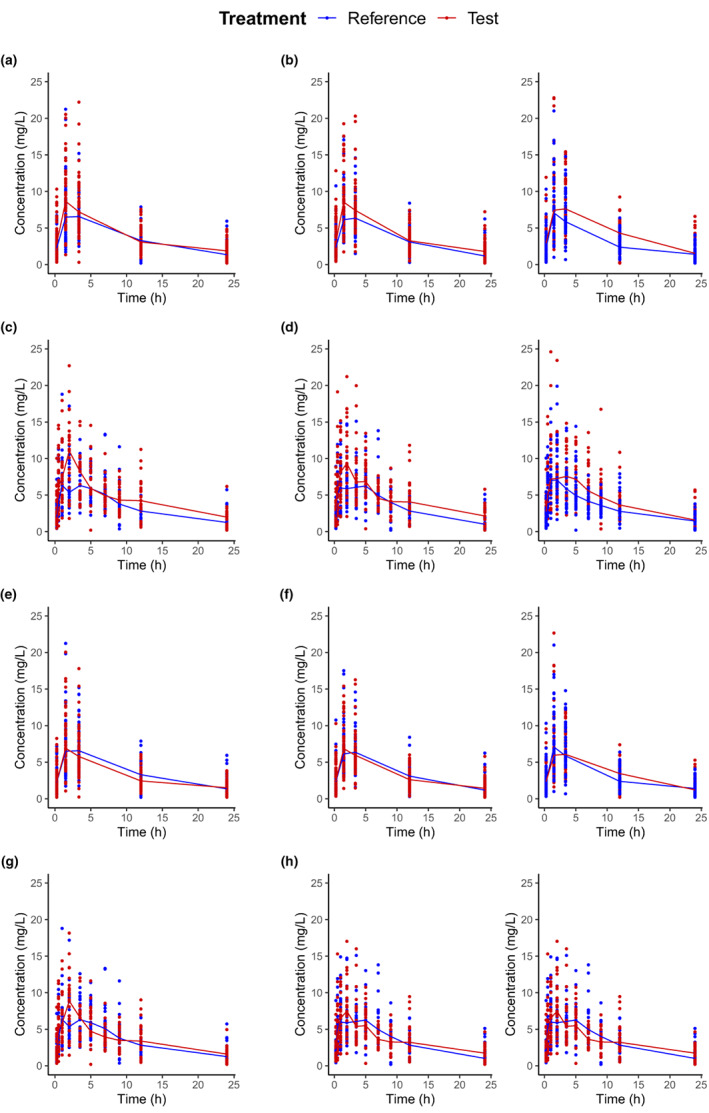
Concentrations versus time following the reference and test treatments for the first simulated clinical study for different simulation scenarios with parallel and two‐way crossover designs (period 1 on the left and period 2 on the right). The lines are connecting the median in each group successive timepoints. (a) ; (b) ; (c) ; (d) ; (e) ; (f) ; (g) ; and (h) .
Model‐based GMR and NCA bootstrap MR (geometric and arithmetic) for and were unbiased and precise (see Figures 2 and 3). These results validated the parameter estimation from both the model‐based and NCA approaches. The evaluation of the model parameter estimation is detailed in Supplementary Material S2.
FIGURE 2.
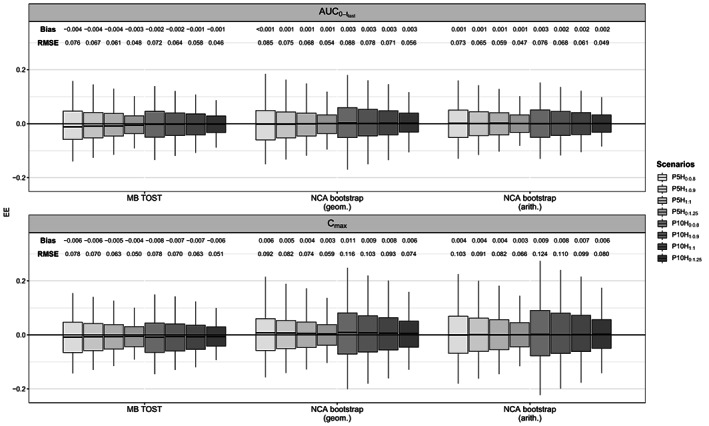
Boxplot (2.5th, 25th, 50th, 75th, and 97.5th percentiles) of estimation errors (EEs) of the geometric mean ratio (MB‐TOST) and the mean ratio (NCA bootstrap geometric and arithmetic) for and , for 500 simulated data sets with parallel designs. , area under the time‐concentration curve from time zero until the last sampling time; C max, maximum concentration; EEs, estimation errors; MB‐TOST, model‐based two one‐sided test; NCA, noncompartmental analysis.
FIGURE 3.
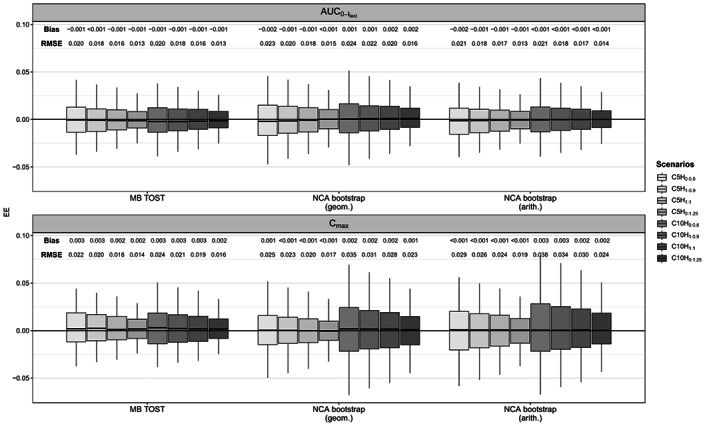
Boxplot (2.5th, 25th, 50th, 75th, and 97.5th percentiles) of EEs of the geometric mean ratio (MB‐TOST) and the mean ratio (NCA bootstrap geometric and arithmetic) for and , for 500 simulated data sets with two‐way crossover designs. , area under the time‐concentration curve from time zero until the last sampling time; C max, maximum concentration; EEs, estimation errors; MB‐TOST, model‐based two one‐sided test; NCA, noncompartmental analysis.
Compared to parallel studies, crossover studies resulted in smaller 90% CIs (see Figures S5 and S6) and consequently higher power estimates (see Table 1) close to 100%, as expected. The number of samples to choose from impacted only the percentiles of the NCA bootstrap MR for . Because the is an average over the concentrations, it is expected to be less sensitive to the design than which relies mostly on one measurement. Indeed, for designs with 10 rather than five samples to choose from, and consequently half of the sample size at each sampling time, the 90% CIs were significantly larger. This phenomenon led to 50% drops in power for parallel designs. For crossover designs, the drop in power was modest under the scenario with . Indeed, in crossover designs, we simulated a rather low WSV which resulted in small 90% CIs and consequently a power close to one. Of note, 90% CIs derived from the empirical percentiles were even smaller.
TABLE 1.
Study power [95% CI] using parallel and two‐way crossover study designs with 500 simulated data sets (estimates in brackets are obtained with 10,000 simulated data sets).
|
|
C max | ||||||
|---|---|---|---|---|---|---|---|
| MB‐TOST | NCA bootstrap | MB‐TOST | NCA bootstrap | ||||
| Geometric | Arithmetic | Geometric | Arithmetic | ||||
| P5H1:0.9 | 0.692 [0.649; 0.732] | 0.600 [0.556; 0.643] | 0.696 [0.654; 0.736] | 0.598 [0.554; 0.641] | 0.388 [0.345; 0.432] | 0.378 [0.335; 0.422] | |
| P10H1:0.9 | 0.696 [0.654; 0.736] | 0.554 [0.509; 0.598] (0.565 [0.555; 0.575]) | 0.676 [0.633; 0.717] (0.681 [0.672; 0.690]) | 0.588 [0.543; 0.632] | 0.194 [0.160; 0.231] (0.196 [0.188; 0.204]) | 0.170 [0.138; 0.206] (0.166 [0.159; 0.173]) | |
| P5H1:1 | 0.950 [0.927; 0.967] | 0.916 [0.888; 0.939] | 0.968 [0.949; 0.982] | 0.926 [0.899; 0.947] | 0.760 [0.720; 0.797] | 0.664 [0.621; 0.705] | |
| P10H1:1 | 0.968 [0.949; 0.982] | 0.884 [0.853; 0.911] | 0.970 [0.951; 0.983] | 0.896 [0.866; 0.921] | 0.370 [0.328; 0.414 | 0.294 [0.254; 0.336] | |
| C5H1:0.9 | 0.998 [0.989; 1.000] | 1 [0.993; 1.000] | 1 [0.993; 1.000] | 0.998 [0.989; 1.000] | 1 [0.993; 1.000] | 0.996 [0.986; 1.000] | |
| C10H1:0.9 | 0.998 [0.989; 1.000] | 1 [0.993; 1.000] (1 [1.000; 1.000]) | 1 [0.993; 1.000] (1 [1.000; 1.000]) | 0.998 [0.989; 1.000] | 0.972 [0.953; 0.985] (0.973 [0.970; 0.976]) | 0.932 [0.906; 0.952] (0.949 [0.944; 0.953]) | |
| C5H1:1 | 1 [0.993; 1.000] | 1 [0.993; 1.000] | 1 [0.993; 1.000] | 0.998 [0.989; 1.000] | 1 [0.993; 1.000] | 1 [0.993; 1.000] | |
| C10H1:1 | 1 [0.993; 1.000] | 1 [0.993; 1.000] | 1 [0.993; 1.000] | 0.998 [0.989; 1.000] | 1 [0.993; 1.000] | 1 [0.993; 1.000] | |
Note: The power estimates presented here are not corrected for the departure from the nominal level of the test.
Abbreviations: , area under the time‐concentration curve from time zero until the last sampling time; CI, confidence interval; C max, maximum concentration; MB‐TOST, model‐based two one‐sided test; NCA, noncompartmental analysis.
For AUC, both MB‐TOST and NCA bootstrap (geometric and arithmetic) obtained controlled type I error rates on 500 simulated data sets (see Table 2) with the exception of a slightly inflated estimate in scenario for NCA bootstrap geometric (0.076).
TABLE 2.
Type I error rates [95% CI] using parallel and two‐way crossover study designs with 500 simulated data sets (estimates in brackets are obtained with 10,000 simulated data sets).
|
|
C max | ||||||
|---|---|---|---|---|---|---|---|
| MB‐TOST | NCA bootstrap | MB‐TOST | NCA bootstrap | ||||
| Geometric | Arithmetic | Geometric | Arithmetic | ||||
| P5H0:0.8 | 0.068 [0.048; 0.094] | 0.058 [0.039; 0.082] | 0.064 [0.044; 0.089] | 0.054 [0.036; 0.078] | 0.026 [0.014; 0.044] | 0.034 [0.020; 0.054] | |
| P10H0:0.8 | 0.068 [0.048; 0.094] | 0.076 [0.054; 0.103] | 0.066 [0.046; 0.091] | 0.060 [0.041; 0.085] | 0.024 [0.012; 0.042] | 0.026 [0.014; 0.044] | |
| P5H0:1.25 | 0.038 [0.023; 0.059] | 0.058 [0.039; 0.082] | 0.052 [0.034; 0.075] | 0.038 [0.023; 0.059] | 0.028 [0.015; 0.047] | 0.040 [0.025; 0.061] | |
| P10H0:1.25 | 0.052 [0.034; 0.075] | 0.064 [0.044; 0.089] (0.056 [0.052; 0.061]) | 0.066 [0.046; 0.091] (0.057 [0.052; 0.061]) | 0.032 [0.018; 0.051] | 0.014 [0.006; 0.029] (0.020 [0.018; 0.023]) |
0.012 [0.004; 0.026] (0.020 [0.017; 0.023]) |
|
| C5H0:0.8 | 0.044 [0.028; 0.066] | 0.066 [0.046; 0.091] | 0.062 [0.043; 0.087] | 0.028 [0.015; 0.047] | 0.016 [0.007; 0.031] | 0.024 [0.012; 0.042] | |
| C10H0:0.8 | 0.048 [0.031; 0.071] | 0.052 [0.034; 0.075] | 0.056 [0.038; 0.080] | 0.026 [0.014; 0.044] | 0.014 [0.006; 0.029] | 0.014 [0.006; 0.029] | |
| C5H0:1.25 | 0.060 [0.041; 0.085] | 0.050 [0.033; 0.073] | 0.050 [0.033; 0.073] | 0.062 [0.043; 0.087] | 0.024 [0.012; 0.042] | 0.024 [0.012; 0.042] | |
| C10H0:1.25 | 0.052 [0.034; 0.075] | 0.068 [0.048; 0.094] (0.062 [0.057; 0.067]) | 0.070 [0.049; 0.096] (0.056 [0.052; 0.061]) | 0.060 [0.041; 0.085] | 0.010 [0.003; 0.023] (0.013 [0.011; 0.015]) | 0.014 [0.006; 0.029] (0.015 [0.013; 0.018]) | |
Abbreviations: , area under the time‐concentration curve from time zero until the last sampling time; CI, confidence interval; C max, maximum concentration; MB‐TOST, model‐based two one‐sided test; NCA, noncompartmental analysis.
In terms of power, MB‐TOST and NCA bootstrap arithmetic obtained similar mean estimates, whereas NCA bootstrap geometric power estimates were consistently lower in parallel designs.
For , the 90% CIs of all approaches were larger than the 90% CIs derived from the empirical percentiles. Further, the 90% CIs of the NCA bootstrap (geometric and arithmetic) MR was wider than that for the model‐based GMR. Consequently, type I error rates were significantly conservative, for NCA bootstrap in general with the exception of scenario when using arithmetic means and for scenarios and for MB‐TOST.
In terms of power, MB‐TOST had a similar power as NCA bootstrap in crossover designs, but higher power than NCA bootstrap in parallel designs. Of note for , conversely to AUC, NCA bootstrap geometric had slightly higher power than NCA bootstrap arithmetic in parallel studies, but the two were similar in crossover designs.
On the scenarios where we investigated NCA bootstrap on 10,000 simulated data sets, the type I error rates converged closer to the 5% target value and with narrower CIs compared with 500 simulated data sets (Supplementary Material S5). Other trends were similar to those observed in Tables 1 and 2. When we analyzed the data without a LOQ at 0.2 mg/L, the results were generally consistent (Supplementary Material S6) for AUC.
We observed no impact of inflating the simulated RUV on the type I error of MB‐TOST and NCA bootstrap for AUC or (Supplementary Material S4), in general. Inflating the simulated WSV only resulted in a slight inflation of the type I error of NCA bootstrap arithmetic for AUC in crossover designs. For a parallel design, the power estimate for AUC decreased by 28%, 21%, and 19% with MB‐TOST, NCA bootstrap geometric mean, and NCA bootstrap arithmetic, respectively, whereas on the crossover design they decreased by 8%, 17%, and 7%, respectively. Likewise, the power estimate for decreased by 26% and 21% with MB‐TOST using a parallel and crossover design, respectively, and decreased by more than 60% for both NCA bootstrap methods and designs.
Overall, MB‐TOST and NCA bootstrap performed similarly for AUC. For , NCA bootstrap tended to be conservative and less powerful for parallel designs compared to MB‐TOST, likely due to the more precise estimates of MB‐TOST when the PK model is correctly specified.
DISCUSSION
In this study, we used NLME tools to simulate PK BE studies for a generic ophthalmic drug product with one sampling timepoint per subject and per occasion. Consistent with our previous research, we estimated treatment effects on all model parameters 12 , 13 , 15 , 26 and evaluated various scenarios, including the study design (parallel or crossover), set of sampling times, and GMR. The aim was to evaluate and compare the performances of MB‐TOST 15 and the NCA bootstrap 4 using concentration geometric or arithmetic means.
All model parameters were well‐estimated except for the additive term of the combined error model, possibly due to the limitations of using a single sample per patient (see Tables S1–S8 in Supplementary Material S2). Whether a proportional error model or fixing the additive term would have solved that issue requires further evaluation. 27 It had, however, no impact on the estimation of the treatment, sequence, or period effects parameters as well as on the GMRs of AUC and .
Both MB‐TOST and the NCA bootstrap (geometric and arithmetic) performed similarly in terms of type I error rate for AUC. For , the NCA bootstrap approach almost always provided conservative type I error rates with values below 0.05. For parallel designs, NCA bootstrap, which does not need to specify the underlying PK model, led to noticeable lower power for as compared to MB‐TOST when the underlying PK model is correctly specified and the test drug has the same PK structural model as the reference drug. We used optimal design to choose the sampling times of the sparse set which did not include the according to the fixed effects. This may have favored MB‐TOST as NCA relies on observed sampling times to estimate . However, this advantage is difficult to appreciate as due to BSV all subjects had different . Power was also particularly impacted by the number of sampling timepoints. Indeed, with 10 sampling times to choose from, fewer subjects were allocated to informative timepoints, which reduced the informativeness of the design 28 and led to larger 90% CIs of the GMR and MR for . The simulation showed that estimates for were not as efficient as for AUC because is only based on one value whereas AUC is based on an average over the concentrations.
This work presents a notable limitation in the use of the simulated PK model structure, as well as the simulated values as initial guess for the parameters (except for the treatment effects which were fixed to 0) in the MB approach, whereas the model structure and parameter values are unknown in reality. In this paper, we did not test the performance of MB‐TOST if the underlying PK model is not correctly specified, which is likely with a limited number of sampling points. This is mitigated, however, by the fact that BE studies occur downstream of the drug development process when a non‐negligible knowledge has been accumulated on the PKs of the drug at least in the reference treatment arm. 6 Moreover, the model would be subjected to a thorough evaluation prior to its use for the BE analysis. 7 Nonetheless, using the true model and parameter estimates provided a favorable setup for MB‐TOST and challenging its robustness to departure from the simulated PK model and parameter values needs to be explored in the future.
Another limitation is only 500 datasets were simulated under each of the 16 scenarios due to the limitation of computation power, which can impact the precision of the evaluation of the performance (e.g., bias, type 1 error rate, and power). Computing times ranged in average from 15 min per data set for parallel designs to 45 min per data set for crossover designs, on a similar computing setup. Notably, it is the default number for simulation‐based goodness of fit plots in PsN, a recognized tool for NLMEM. 29 Additionally, the number of bootstraps for the NCA approaches could also have been increased from 5000 4 to 10,000.
In addition, the lowest concentration level in real studies is zero, but, in simulation, negative concentration levels can happen, which is a limitation of using simulation to generate concentration data. For those concentrations simulated below zero, they are imputed as 0.0001 when no LOQ is defined. When a LOQ is defined, the likelihood is taken to be between zero and the LOQ for all simulated BLOQ concentrations including those with 0 to LOQ (e.g., 0.2) values as well as negative (<0) concentration values for MB‐TOST. Likewise, for NCA bootstrap, LOQ/2 is imputed for both 0–0.2 mg/L values and negative (<0) concentration values. These are typically used methods to handle BLOQ values, however, for simulated concentration values below zero, these imputations may impact bias, type 1 error rate, and power. This limitation also contributes to the observed inflated type 1 error rate above 0.05 in certain scenarios, besides the limited simulation data sets (500).
In addition, we considered the same magnitude of BSV and WSV for , , and . Further, the initial 16 scenarios considered a residual variance at % and a WSV at 15%, which are rather low. We explored the impact of increasing both variances at 30% in four additional scenarios and found no impact on MB‐TOST and NCA bootstrap type I error rate and, as expected, a decrease in power although to a remarkable extent for with NCA bootstrap approaches on both parallel and crossover designs.
In conclusion, our simulations show that MB‐TOST demonstrates higher power and controlled type I error rate when compared to NCA‐TOST in single sample PK studies, provided that the underlying PK model is correctly specified, and the test drug has the same PK structural model as the reference drug. As such, MB‐TOST may potentially serve as an alternative approach to evaluate BE for generic ophthalmic drug products.
AUTHOR CONTRIBUTIONS
All authors wrote the manuscript. K.F., W.S., G.S., S.G., L.Z., L.F., F.M., and J.B. designed the research. C.T., F.L., and J.B. performed the research. C.T. analyzed the data.
FUNDING INFORMATION
This work was supported by the U.S. Food and Drug Administration, Silver Spring, MD 20993, USA, under FDA contract 75F40119C10111.
CONFLICT OF INTEREST STATEMENT
M.D., K.F., W.S., G.S., S.G., L.Z., and L.F. are employed by the U.S. Food and Drug Administration. As Editor‐in‐Chief of CPT:Pharmacometrics and Systems Pharmacology, F.M. was not involved in the review or decision process for this paper. The opinions expressed in this manuscript are those of the authors and should not be interpreted as the position of the U.S. Food and Drug Administration. All other authors declared no competing interests for this work.
Supporting information
Appendix S1
ACKNOWLEDGMENTS
The authors would like to acknowledge all their collaborators in the project “Evaluation of model‐based Bioequivalence (MBBE) statistical approaches for sparse design PK studies” under the FDA contract 75F40119C10111.
Tardivon C, Loingeville F, Donnelly M, et al. Evaluation of model‐based bioequivalence approach for single sample pharmacokinetic studies. CPT Pharmacometrics Syst Pharmacol. 2023;12:904‐915. doi: 10.1002/psp4.12960
REFERENCES
- 1. U.S. Food and Drug Administration . Bioequivalence studies with pharmacokinetic endpoints for drugs submitted under an ANDA guidance for industry. 2021. Accessed March 27, 2023. https://www.fda.gov/media/87219/download
- 2. Choi S, Lionberger RA. Clinical, pharmacokinetic, and in vitro studies to support bioequivalence of ophthalmic drug products. AAPS J. 2016;18:1032‐1038. [DOI] [PubMed] [Google Scholar]
- 3. FDA Office of Generic Drugs . Draft guidance on loteprednol etabonate. 2019. Accessed March 27, 2023. https://www.accessdata.fda.gov/drugsatfda_docs/psg/PSG_210565.pdf
- 4. Shen M, Machado SG. Bioequivalence evaluation of sparse sampling pharmacokinetics data using bootstrap resampling method. J Biopharm Stat. 2017;27(2):257‐264. [DOI] [PubMed] [Google Scholar]
- 5. FDA Office of Generic Drugs . Draft guidance on loteprednol etabonate; tobramycin. 2020. Accessed March 27, 2023. https://www.accessdata.fda.gov/drugsatfda_docs/psg/PSG_050804.pdf
- 6. Mould DR, Upton RN. Basic concepts in population modeling, simulation, and model‐based drug development. CPT Pharmacometrics Syst Pharmacol. 2012;1:e6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Seng Yue C, Ozdin D, Selber‐Hnatiw S, Ducharme MP. Opportunities and challenges related to the implementation of model‐based bioequivalence criteria. Clin Pharmacol Ther. 2019;105(2):350‐362. [DOI] [PubMed] [Google Scholar]
- 8. Panhard X, Mentré F. Evaluation by simulation of tests based on non‐linear mixed‐effects models in pharmacokinetic interaction and bioequivalence cross‐over trials. Stat Med. 2005;24(10):1509‐1524. [DOI] [PubMed] [Google Scholar]
- 9. Lindstrom ML, Bates DM. Nonlinear mixed effects models for repeated measures data. Biometrics. 1990;46(3):673‐687. [PubMed] [Google Scholar]
- 10. Delyon B, Lavielle M, Moulines E. Convergence of a stochastic approximation version of the EM algorithm. Ann Stat. 1999;27:94‐128. [Google Scholar]
- 11. Dubois A, Gsteiger S, Pigeolet E, Mentré F. Bioequivalence tests based on individual estimates using non‐compartmental or model‐based analyses: evaluation of estimates of sample means and type I error for different designs. Pharm Res. 2010;27(1):92‐104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Dubois A, Lavielle M, Gsteiger S, Pigeolet E, Mentré F. Model‐based analyses of bioequivalence crossover trials using the stochastic approximation expectation maximisation algorithm. Stat Med. 2011;30(21):2582‐2600. [DOI] [PubMed] [Google Scholar]
- 13. Loingeville F, Bertrand J, Nguyen TT, et al. New model–based bioequivalence statistical approaches for pharmacokinetic studies with sparse sampling. AAPS J. 2020;22(6):1‐8. [DOI] [PubMed] [Google Scholar]
- 14. Nie L. Convergence rate of MLE in generalized linear and nonlinear mixed‐effects models: theory and applications. J Stat Plan Infer. 2007;137:1787‐1804. [Google Scholar]
- 15. Möllenhoff K, Loingeville F, Bertrand J, et al. Efficient model‐based bioequivalence testing. Biostatistics. 2020;23:314‐327. doi: 10.1093/biostatistics/kxaa026 [DOI] [PubMed] [Google Scholar]
- 16. FDA Office of Generic Drugs . Draft Guidance on Progesterone. 2011. Accessed March 27, 2023. https://www.accessdata.fda.gov/drugsatfda_docs/psg/Progesterone_caps_19781_RC02‐11.pdf
- 17. Schuirmann DJ. A comparison of the two one‐sided tests procedure and the power approach for assessing the equivalence of average bioavailability. J Pharmacokinet Biopharm. 1987;15(6):657‐680. [DOI] [PubMed] [Google Scholar]
- 18. EMA . Guideline on the Investigation of Bioequivalence. 2014. Accessed March 27, 2023. https://www.ema.europa.eu/en/documents/scientific‐guideline/guideline‐investigation‐bioequivalence‐rev1_en.pdf
- 19. Lavielle M. Mixed Effects Models for the Population Approach: Models, Tasks, Methods and Tools. Chapman and Hall/CRC; 2014. [Google Scholar]
- 20. Oehlert GW. A note on the Delta method. Am Stat. 1992;46(1):27‐29. [Google Scholar]
- 21. Panhard X, Samson A, Mentré F. Extension of the SAEM algorithm to left‐censored data in nonlinear mixed‐effects model: application to HIV dynamics model. Comput Stat Data Anal. 2006;51(3):1562‐1574. [Google Scholar]
- 22. Savic R, Radojka M, Mentré F, Lavielle M. Implementation and evaluation of the SAEM algorithm for longitudinal ordered categorical data with an illustration in pharmacokinetics–pharmacodynamics. AAPS J. 2011;13(1):44‐53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Team Monolix, Lixoft . The Monolix Software 2018 ‐ R2. 2018.
- 24. Kuhn E, Lavielle M. Maximum likelihood estimation in nonlinear mixed effects models. Comput Stat Data Anal. 2005;49(4):1020‐1038. [Google Scholar]
- 25. Louis TA. Finding the observed information matrix when using EM algorithm. J R Stat Soc B. 1982;44:226‐233. [Google Scholar]
- 26. Guhl M, Mercier F, Hofmann C, et al. Impact of model misspecification on model‐based tests in PK studies with parallel design: real case and simulation studies. J Pharmacokinet Pharmacodyn. 2022;49(5):557‐577. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Plan EL, Maloney A, Mentré F, Karlsson MO, Bertrand J. Performance comparison of various maximum likelihood nonlinear mixed‐effects estimation methods for dose‐response models. AAPS J. 2012;14(3):420‐432. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Nyberg J, Bazzoli C, Ogungbenro K, et al. Methods and software tools for design evaluation in population pharmacokinetics‐pharmacodynamics studies. Br J Clin Pharmacol. 2015;79(1):6‐17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Keizer RJ, Karlsson MO, Hooker A. Modeling and simulation workbench for NONMEM: tutorial on Pirana, PsN, and Xpose. CPT Pharmacometrics Syst Pharmacol. 2013;2:e50. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendix S1