

Abstract
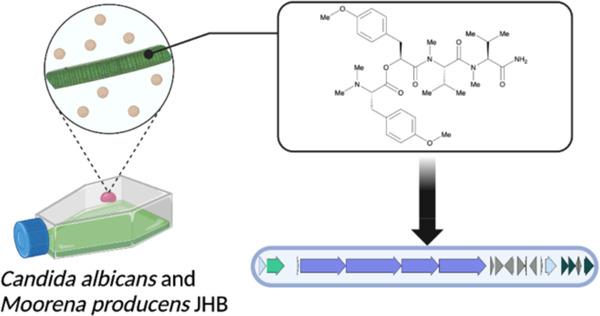
The tropical marine cyanobacterium Moorena producens JHB is a prolific source of secondary metabolites with potential biomedical utility. Previous studies of this strain led to the discovery of several novel compounds such as the hectochlorins and jamaicamides; however, bioinformatic analyses of its genome suggested that there were many more cryptic biosynthetic gene clusters yet to be characterized. To potentially stimulate the production of novel compounds from this strain, it was co-cultured with Candida albicans. From this experiment, we observed the increased production of a new compound that we characterize here as hectoramide B. Bioinformatic analysis of the M. producens JHB genome enabled the identification of a putative biosynthetic gene cluster responsible for hectoramide B biosynthesis. This work demonstrates that co-culture competition experiments can be a valuable method to facilitate the discovery of novel natural products from cyanobacteria.
Graphical Abstract
Introduction
Members of the cyanobacterial genus Moorena are tropical, filamentous, photosynthetic, non-diazotrophic, and generally reside in the marine benthic zone.1 Notably, they are also a prolific source of bioactive secondary metabolites such as apratoxin A, a cyclic depsipeptide isolated from Moorena bouillonii collected in Guam that is a potent inhibitor of protein synthesis.2–4 Comparative genomics of species of this genus have revealed their extensive biosynthetic potential (~18% of their genomes is dedicated to secondary metabolism) with the average number of biosynthetic gene clusters (BGCs) generally much higher than other cyanobacteria.5 Intriguingly, a significant number of these BGCs are silent or cryptic and have yet to be explored for their encoded products. Therefore, new approaches are needed to induce or increase the production levels of these natural products (NPs).
The tropical filamentous marine cyanobacterium Moorena producens JHB (formerly known as Lyngbya majuscula, hereinafter referred to as JHB) was obtained from a shallow marine environment in Hector’s Bay, Jamaica and has been continuously cultivated in seawater-BG11 (SWBG11) culture medium since its original collection.6 It is an abundant producer of diverse bioactive secondary metabolites, including the potent antifungal NPs hectochlorins A-D,6 sodium channel antagonists jamaicamides A-F,7,8 cryptomaldamide,9 and hectoramide A.7 Although this represents a large number of compounds isolated from a single cyanobacterium, genome analysis of this strain revealed that there are as many as 42 cryptic gene clusters yet to be investigated, 11 of which contain non-ribosomal peptide synthetase (NRPS)-related genes.5 Therefore, we sought to drive the expression of some of these previously uninvestigated BGCs through stimulation by a competing microorganism (Candida albicans), a method well known to upregulate the expression of NPs.10,11
Results and Discussion
Discovery from Co-culture Experiment
The biomass of the co- and mono-cultures of JHB with and without C. albicans were harvested, extracted, and analyzed, all in triplicate, by LCMS after 4 weeks of incubation. The peak areas of metabolites observed by LCMS were compared in order to identify metabolites with enhanced production in co-culture experiments as compared to the controls. We observed that the co-cultures had an antagonistic effect on the growth of the cyanobacteria, with biomass of co-cultured cyanobacteria greatly reduced compared to the mono-cultures after the same growth period. The production of hectoramide B (1) in the co-culture with JHB and C. albicans appeared increased relative to the mono-culture of JHB (Figure S14). This possible metabolic upregulation inspired interest in identifying and characterizing the structure, biosynthetic gene cluster, and bioactivity of this unique metabolite.
Structure Determination of Hectoramide B (1)
Hectoramide B (1) was isolated by VLC and HPLC to yield 1.7 mg of yellow oil from the co-culture experiments. Based on HRMS, (exact mass = 627.3750 m/z), a putative molecular formula for compound 1 was calculated as C34H50N4O7. The 12 degrees of unsaturation required for this molecular formula were deduced by interpretation of NMR data to result from two phenyl rings and four ester/amide-type carbonyls.
The 1H NMR spectrum of compound 1 was remarkably similar to that of the previously determined structure of hectoramide7 [here renamed hectoramide A (2)]. Moreover, analysis of the MS/MS fragmentation using GNPS molecular networking,12 also revealed that 1 was closely related to 2. However, its larger size suggested that it may have an additional amino acid residue in comparison with 2. Additional NMR signals in 1 that were not present in 2 included aromatic proton peaks, N- and O-methyl singlets, and a deshielded proton alpha to a heteroatom coupled to a mid-field methylene group, altogether suggesting this additional amino acid might be an N, N-dimethyl-O-methyl tyrosine moiety.
SMART-NMR13 analysis of the HSQC spectrum of 1 further suggested the presence of multiple valine residues as well as methylated tyrosine residues (Figure S7). HSQC, HMBC and COSY correlations confirmed the sections of compound 1 that were identical to compound 2, and also established the new residue as the proposed trimethyl-tyrosine residue (Figure 2a). This was also supported by analysis and comparison of the MS/MS fragmentation for 2 and 1, which revealed some shared MS2 peaks (Figure 2b). Previous determination of the absolute configuration of 27, combined with a bioinformatic analysis as detailed below, were used to infer the absolute configuration of 1. These analyses allowed deduction of the configurations of the tyrosine and both valine derivatives as l, and the Mppa moiety as S.
Figure 2.
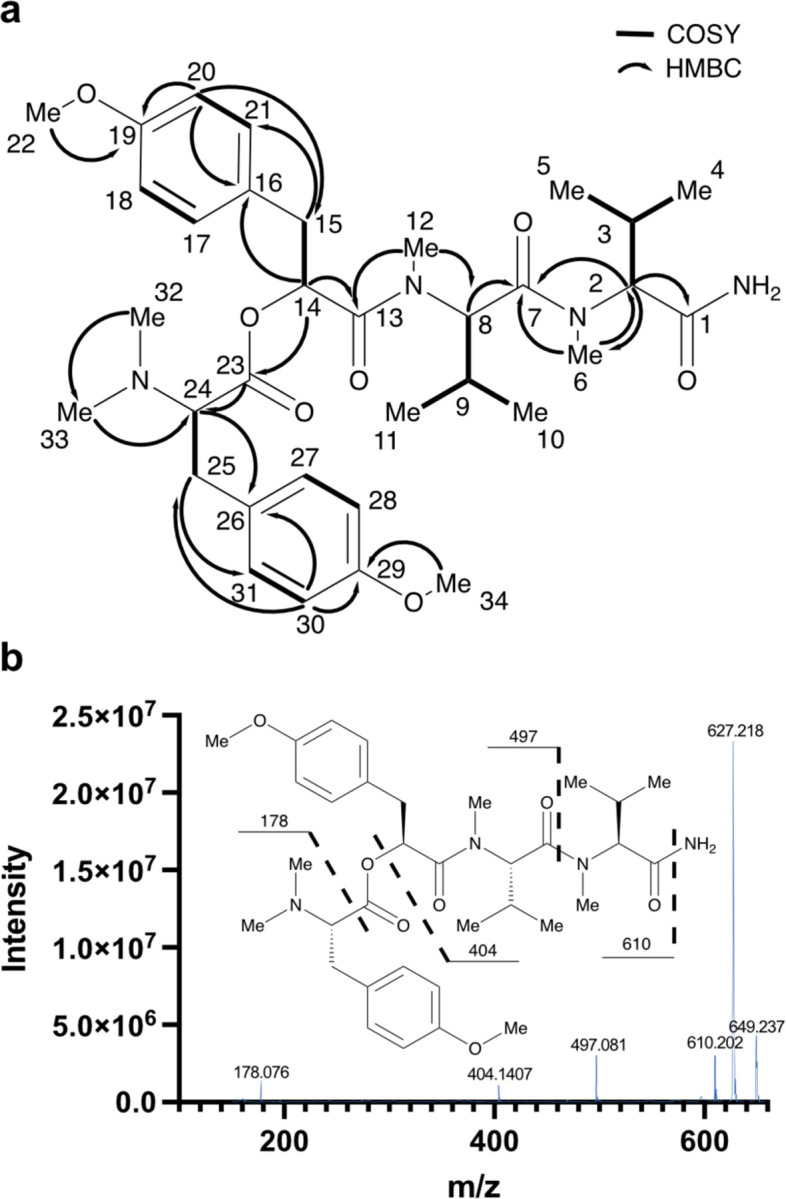
Structural assignment of hectoramide B. (a) Key COSY and HMBC correlations used in the structural determination of hectoramide B (1), All COSY and HMBC correlations are reported in Table S1. (b) Fragmentation pattern of 1 based on MS2 spectrum from the molecular ion (m/z 627.218)
Biosynthetic Gene Cluster Analysis
Non-ribosomal peptides are typically synthesized in a collinear manner where each module encodes for the incorporation of an amino or hydroxy acid residue and chain elongation occurs in the sequence that the modules are ordered.14
A retrobiosynthetic scheme for the probable hectoramide B biosynthetic gene cluster was developed based on its chemical structure, including modules consistent with a non-ribosomal peptide synthetase (NRPS) incorporation of amino or hydroxy acids, and tailoring enzymes for key structural modifications such as methyl groups on heteroatoms (Figure S8). We hypothesized that the initial module would be an NRPS that would contain an adenylation (A) domain specific for tyrosine incorporation, followed by methyltransferase domains that would catalyze the methylations of the tyrosine phenolic oxygen atom and nitrogen atom of the amine group. We predicted that module 2 would include a depsipeptide synthetase that would incorporate an α-keto acid version of tyrosine that is subsequently reduced to 2-hydroxy-3-(4-hydroxyphenyl) propanoic acid by a ketoreductase (KR) domain. This module should also include a methyltransferase domain that methylates the phenolic oxygen atom of this tyrosine-derived residue. Modules 3 and 4 are predicted to contain A domains that incorporate valine residues followed by methylation by an N-methyltransferase. A terminal amidation enzyme is predicted to be encoded at the distal end of module 4, possibly related to one observed in carmabin A10 and vatiamide E and F11 biosynthesis, completing the pathway.
Previous sequencing efforts of the JHB genome were conducted using Illumina MiSeq and assembled using a Moorena producens PAL reference assembly.5 We were unable to identify a candidate biosynthetic gene cluster after initial inspection of this assembly. Therefore, we sought to obtain an improved genome assembly of JHB by extracting high molecular weight DNA and obtaining long-reads with Nanopore PromethION sequencing. Previous sequencing data from Illumina MiSeq and the new sequencing data from Nanopore PromethION were assembled with different tools to obtain an improved assembly of the JHB genome (Table 1). The final assembly of the JHB genome resulted in a single circular scaffold of 9.6 Mbp, a GC content of 43.67%, and completeness of 99.22%. Therefore, we selected this assembly for BGC analysis using antiSMASH (GenBank Accession Number: CP017708.2).
Table 1.
Evaluation of the Quality of Genome Assembly Based on Quast and BUSCOa analysis.
| Assembly method | # of Contigs | N50 | Total length (bp) | Completea (%) |
|---|---|---|---|---|
| SPades | 3 | 9373345 | 9384763 | 98.84 |
| Unicycler long-read | 2 | 8738093 | 9632771 | 60.67 |
| Unicycler hybrid | 2 | 5885695 | 9639251 | 99.22 |
| Flye | 1 | 9645659 | 9645659 | 79.56 |
| Flye + Pilon | 1 | 9648534 | 9648534 | 99.22 |
Completeness was based on presence of complete single-copy orthologs in the BUSCO cyanobacteria_odb10 database
Putative Biosynthetic Gene Cluster for Hectoramide B
Inspection of the M. producens JHB genome revealed one candidate BGC that was consistent with the biosynthesis of hectoramide B (the hca pathway, MiBIG Accession: BGC0002754, GenBank Accession: OQ821997), the predicted retrobiosynthetic scheme, and the NMR and MS based structural assignment of hectoramide B (1) (Figure S8, Table S9). AntiSMASH annotations were integrated with protein family homology analysis, substrate selectivity predictions, and active site and motif identification. The hca pathway is composed of 4 core biosynthetic NRPS modules (hcaA-hcaD), flanked by putative regulatory genes, transport-related genes, and coding regions for hypothetical proteins, providing provisional boundaries to the biosynthetic cluster (Figure 3).
Figure 3.

Putative biosynthetic gene cluster for hectoramide B. (a) Purple arrows indicate core biosynthetic genes. Additional arrows indicate additional ORFs that provide provisional boundaries to the hca BGC. Their proposed functions can be found in Table S9. (b) There are four core biosynthetic modules organized in a colinear fashion in the hca pathway. C: condensation domain, A: adenylation domain, TYR: adenylation domain for tyrosine incorporation, OMT: oxygen methyltransferase domain, NMT: nitrogen methyl transferase domain, MPOPA: adenylation domain for the proposed 3-(4-methoxyphenyl)-2-oxopropanoic acid incorporation, CAL: co-enzyme A ligase domain, KR: ketoreductase domain, VAL: adenylation domain for valine incorporation, AMT: amidotransferase. PCP: peptidyl-carrier protein. Phosphopantathiene arms are symbolized by wavy lines.
Bioinformatic analysis of the hca gene cluster suggested that the initial core biosynthetic module, hcaA, encodes for a multienzyme that is responsible for incorporating a tyrosine residue. This module contains condensation (C), adenylation (A), O-methyltransferase (OMT) and N-methyltransferase (NMT) domains as well as a peptidyl carrier protein (PCP) domain. The presence of both an OMT and the NMT is consistent with the amino terminus structure of hectoramide B. However, initial AntiSMASH analysis predicted the presence of two NMT domains, and therefore a phylogenetic tree of OMT and NMT domains from cyanobacteria was generated to examine more carefully the specificities of each of the annotated methyltransferase domains in hcaA. This revealed that the first MT, HcaA-MT1 clades well with other OMT domains, such as the OMT in the VatN module of the vatiamide biosynthetic gene cluster15 (Figure S10). The vatiamide OMT is also predicted to methylate the phenolic oxygen atom of a tyrosine residue. The second MT, HcaA-MT2, clades well with other NMT domains, specifically those within the hca pathway and the NMT of the VatN module in the vatiamide pathway. Therefore, N, N-dimethyl-O-methyl-l-tyrosine serves as the first structural unit in the hca pathway.
The second module, hcaB, is predicted to encode for a protein that ultimately incorporates 2-hydroxy-3-(4-methoxyphenyl) propanoic acid (Mppa). In previous studies of cyanobacterial depsipeptide formation, the A domain initially selects for an α-keto acid substrate that is reduced in cis to an α-hydroxy acid by a ketoreductase (KR) domain before incorporation into the natural product scaffold.12 However, antiSMASH analysis of this module did not reach a consensus for substrate specificity, and there was no annotation for an OMT domain to install a methyl group on the phenolic oxygen atom. Therefore, a sequence and structural alignment of the HcaB-A domain with other NRPS A domains selecting for tyrosine and phenylalanine was generated to identify the specificity conferring residues of hcaB-A (Figure 4a). Interestingly, the proposed specificity conferring residues of HcaB-A did not coincide with previous patterns observed in α-keto acid selecting A domains. Typically, in keto-acid activating A domains the conserved Asp235 residue, which traditionally hydrogen bonds with the primary amine of amino acids, is substituted to an aliphatic residue while the remaining specificity conferring residues match those predicted for the corresponding amino acid.16 However, neither was the case for HcaB-A; Asp235 is still present, and the remaining proposed specificity conferring residues did not match those expected for tyrosine (Figure 4a). Furthermore, alignment of a predicted structural model constructed de novo with AlphaFold217 of HcaB-A and crystallography-derived structures of other NRPS A domains showed excellent congruence with the specificity conferring codes suggested by the sequence alignment described above (Figure 4b). Finally, as noted there was no annotated OMT domain in the hcaB gene. One possibility that is consistent with these features is that hcaB could be selecting for the α-keto acid form of O-methyl-tyrosine, 3-(4-methoxyphenyl)-2-oxopropanoic acid (MPOPA), rather than the α-keto acid form of tyrosine. An additional methyl group on the phenolic oxygen atom would require a significant alteration of the specificity binding pocket in order to accommodate this bulkier side chain.
Figure 4.
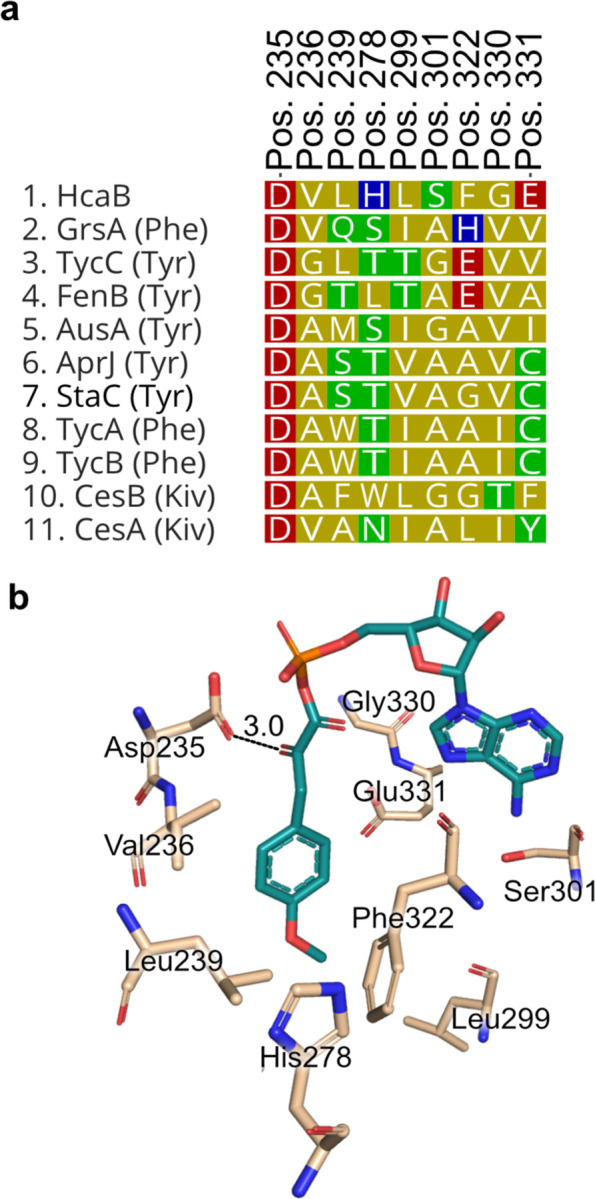
Sequence and structural alignment of hcaB adenylation domain reveals amino acids potentially conferring specificity. (a) Putative specificity conferring codes of HcaB-A compared with those from other adenylation domains from NRPS systems. (b) Three-dimensional model of hcaB-A domain generated using Alphafold2 bound to 3-(4-methoxypheny1)-2-oxopropanoic acid (MPOPA) adenylate. The α-keto group of the Mpopa (teal) potentially binds through an antiparallel carbonyl-carbonyl interaction with the carbonyl group of Asp235 (wheat). See Table S12 for compound identities and other information
α-Keto acids can also be selected for by an antiparallel carbonyl-carbonyl interaction between the α-keto group and the carbonyl of the peptide bond connecting Gly414 and Met415.18 This carbonyl-carbonyl interaction has a comparable strength to that of a hydrogen bond and is important to α-keto acid selection. However, based on the model of HcaB-A (Figure 4b), the only residue that is in close proximity to the α-keto group is Asp235 (3.0 Å) whereas the Gly-Met backbone carbonyl is far distant. The predicted antiparallel orientation of these two carbonyls suggests a basis for stabilizing the incorporation of this α-keto acid.
Another component of this module is the domain annotated as a coenzyme A ligase (CAL). CAL domains are predicted to have specificity for fatty acids; however, as there are no fatty acid moieties in hectoramide B, it may be non-functional. Interestingly, similar CAL domains are found in a number of other depsipeptide producing BGCs such as cryptophycin-327,19 hectochlorin,20 and didemnin B,21 and therefore could be playing another role in the production of depsipeptides, a hypothesis that warrants further investigation. Lastly, the KR domain in the HcaB module is predicted to have stereospecificity for an S product. We propose that after activation of MPOPA, the KR domain in this module reduces the α-keto acid to 2S-hydroxy-3-(4-methoxyphenyl) propanoic acid (MPPA) through an NADPH-dependent reaction. The C-domain then catalyzes the formation of the ester bond between the oxygen of the newly formed hydroxy function in this module 2 substrate and the carbonyl of the tethered trimethyl tyrosine residue in module 1.
Based on annotation by antiSMASH, HcaC is predicted to encode for the incorporation of an N-methyl valine into hectoramide B. The final module, HcaD, is also predicted to incorporate an N-methyl valine residue. However, it lacks a terminal thioesterase (TE) domain; instead, it possesses a domain closely related (83.5% identity, Table 2, Figure S13) to one found in the vatiamide pathway that is believed to catalyze offloading from the enzymatic pathway through terminal amidation. In the vatiamide pathway, this proposed enzymatic function is embedded in VatR, downstream of the PCP; the same domain organization is observed in the hectoramide B pathway15. Terminal amides resulting from an NRPS pathway have previously been found in several cyanobacterial natural products, including dragonamide A, B and E,22 carmabin A,23 and vatiamide E and F.15 Although the mechanism and enzymology of terminal amidation has not been studied, it is hypothesized that this motif catalyzes offloading through ammonolysis, mechanistically similar to the more typical hydrolysis of NRPS thioester linkages.
Table 2.
Sequence identity and similarity between terminating modules HcaD and VatR.
| Amino Acid Position | Predicted function | Identity/Similarity |
|---|---|---|
| 76–380 | Condensation | 23.0/43.0 |
| 555–952 | Adenylation | 88.2/95.0 |
| 1046–1267 | N-methyltransferase | 90.1/95.0 |
| 1477–1543 | Peptidyl carrier protein | 83.6/91.0 |
| 1544–1977 | Amidotransferase | 83.5/93.0 |
| Overall: | 72.0/86.7 |
In addition to the core domains in the hca gene cluster, an upstream regulatory gene, ORF 2, was identified (Table S9). This regulatory gene belongs to the Streptomyces Antibiotic Regulatory Protein (SARP) family, a group of transcriptional regulators commonly found in actinomycetes that regulates the biosynthesis of various antibiotic gene clusters.24,25 This discovery suggests that ORF 2 may play a pivotal role in controlling the production of hectoramide B. However, further analysis and investigation are necessary to fully understand its specific involvement and mechanism of action within the hca gene cluster. A PGAP1-like protein with hydrolase activity in ester bonds was identified in ORF1 and may also play a role in the biosynthesis of hectoramide A. It is plausible that after offloading of 1, ORF1 catalyzes the hydrolysis of the ester bond in 1, ultimately leading to the formation of 2.
Exploring the Bioactivity of Hectoramide B
To explore the potential antifungal properties of hectoramide B (1), a microbroth dilution method was employed. The original strain of C. albicans used in the co-culture experiments was no longer available, which prevented repeat testing with this strain. We therefore used Saccharomyces cerevisiae as a surrogate yeast strain. However, no antifungal activity was detected at a maximum test concentration of 200 μg/mL of hectoramide B. As a result, it remains uncertain whether hectoramide B (1) demonstrates any antifungal activity, and thus the underlying reason for its increased production in the co-culture experiment is yet unknown.
Conclusion
Genome sequencing projects of marine cyanobacteria have revealed that they, like many other bacteria, contain a large number of orphan gene clusters that encode for cryptic natural products. Antagonistic co-culture experiments have been successful in stimulating the expression of some of these natural product BGCs10, and we were interested to explore this concept with our marine cyanobacterial cultures. We found hectoramide B to be prominently upregulated in the co-culture experiment with C. albicans. The structure of hectoramide B (1) was determined from a careful analysis of its spectroscopic features, comparison to the co-metabolite hectoramide A (2), and a bioinformatic investigation of its biosynthetic gene cluster. Although anti-yeast activity to Saccharomyces cerevisiae was not detected, it is still possible that hectoramide B plays a role in protecting M. producens JHB from antagonism by C. albicans. The hca gene cluster and its encoded protein components show several interesting features, such as an unusual motif for α-hydroxy acid incorporation, the presence of a coenzyme A ligase (CAL) in depsipeptide formation, and pathway termination through a putative ammonolysis reaction. Further biochemical interrogation of the formation of these C-terminal amides is certainly warranted. This terminal amide moiety is a popular bioisostere for improving cellular permeability of carboxylic acids;26 understanding how marine cyanobacteria produce this structural feature may enable development of biocatalytic methods for its creation.
Methods
General considerations
NMR spectra were recorded using a JEOL ECZ 500 MHz NMR spectrometer (Akishima, Tokyo, Japan). Data for NMR spectra are reported as follows: shift (δ) in ppm; s, singlet; d, doublet; t, triplet; q, quartet; m, multiplet or unresolved; brs, broad signal; J, coupling constant(s) in Hz. NMR spectra were analyzed using MestreNova v. 14.3.0–30573 (Mestrelab, Santiago de Compostela, Spain). Mass spectrometry data were analyzed using Xcalibur Qual Browser v. 1.4 SR1 (Thermo Fisher Scientific, Inc.). LR-LCMS data were collected on a Thermo Finnigan Surveyor Autosampler/LC-Pump-Plus/PDA-Plus with a Thermo Finnigan Advantage Max mass spectrometer. HPLC purification was carried out with a Thermo Scientific Dionex Ultimate 3000 Pump/RS/Autosampler/RS Diode Array Detector/Automated Fraction Collector using Chromeleon software. An Agilent 6230 time-of-flight mass spectrometer (TOFMS) with Jet Stream electrospray ionization source (ESI) was used for high resolution mass spectrometry (HR-MS) analysis. The Jet Stream ESI source was operated under positive ion mode with the following parameters: VCap: 3500V; fragmentor voltage: 160 V; nozzle voltage: 500 V; drying gas temperature: 325 C, sheath gas temperature: 325 C, drying gas flow rate: 7.0 L/Min; sheath gas flow rate: 10 L/Min; nebulizer pressure: 40 psi. Solvents used for extraction, purification, and LC-MS/MS analysis were purchased from Fisher Chemical. All solvents were HPLC grade except H2O which was purified with a Millipore Milli-Q system before use. Deuterated solvents were purchased from Cambridge Isotope Laboratories.
Microbial strains and Culture conditions
As previously reported, M. producens JHB was collected from Hector’s Bay, Jamaica on August 22, 1996. The JHB culture has been continuously maintained in SWBG11 media in our laboratory at 26 ºC with a 16 h light/ 8 h dark regimen6 since its original collection. Candida albicans and Saccharomyces cerevisiae were stored in a −80ºC freezer in LB media with 20% glycerol and obtained from ATCC.
Growth of C. albicans in SWBG11 media
LB media and SWBG11 media were prepared separately according to standard protocols.27 Five combinations of LB-SWBG11 media were prepared at the following ratios of LB:SWBG11: 60:40%, 40:60, 20:80, 10:90 and 100% LB media to determine optimal ratio for growth of C. albicans in SWBG11 media. Each media type (30 mL) was aliquoted into a 50 mL Falcon tube. One mL of C. albicans seed culture in LB media was added to each tube and incubated for 24 h at 37°C. Each combination was prepared in triplicate. A small amount of C. albicans growth was clearly observed in the lowest ratio of 10:90 LB-SWBG11 media and this condition was used for subsequent co-culture experiments.
Co-culture of cyanobacteria with Candida albicans
Cyanobacteria were grown for four weeks in SWBG11 artificial seawater growth medium at 27ºC and 756 Lux in triplicate, with the following combinations: M. producens JHB alone and M. producens JHB + C. albicans. This light intensity was chosen because it was consistent with conditions that JHB culture was accustomed to in order to minimize changes to variables that might affect growth and productivity. Samples of M. producens JHB were prepared separately and added to 125 mL of SWBG11 media in a sterile, 250 mL plastic bottle. These bottles were inoculated with 5 mL of C. albicans from LB-SWBG11 media prepared above. Similarly, JHB in 125 mL of SWBG11 medium, were prepared as controls. The bottles were sealed and opened and gently aerated with swirling motion in a biosafety cabinet to facilitate adequate gas exchange.
Extraction and LC-MS of Co- and Mono-cultures
After the co- and mono-cultures were incubated for 30 days, the biomass was harvested from each sample through vacuum filtration. Each culture sample was extracted four times using 2:1 dichloromethane/methanol (DCM/MeOH) by sonication for 3 min followed by soaking for 15–20 min to obtain crude extracts. Each crude extract was diluted to a concentration between 0.5–4 mg/mL (Table S14). A 1 mg portion of the extract was subjected to filtration using a C18 SPE column, dried under N2, and redissolved in LC-MS grade MeOH for a final concentration 1 mg/mL. The samples of the extract and a blank of MeOH were analyzed by LR-LCMS using a Phenomenex Kinetex 5 μm C18 100 A 100 × 4.60 mm column at a flow rate of 0.6 mL/min. The mobile phase was comprised of solvent A, water + 0.1% formic acid (FA) and solvent B, acetonitrile (ACN). A 32-minute method was used starting with equilibration at 30% solvent B in solvent A for 2 minutes, followed by a linear 22-minute gradient to 99% solvent B, followed by a 4-minute washout phase at 99% solvent B, and a 4-minute re-equilibration period at 30% solvent B in solvent A. Data dependent acquisition (DDA) of MS/MS spectra was performed in the positive ion mode.
Extraction and LC-MS of hectoramide B (1)
A fresh laboratory culture sample of M. producens JHB was harvested through vacuum filtration resulting in 492.28 g of biomass (wet weight). It was extracted four times using 2:1 DCM/MeOH by sonication for 3 min followed by soaking for 15–20 min to afford 8.82 g of extract. A 1 mg portion of the extract was subjected to filtration using a C18 SPE column, dried under N2, and redissolved in LC-MS grade MeOH for a final concentration of 1 mg/mL. The samples of the extract and a blank of MeOH were subjected to LCMS and HR-MS analysis as described above.
VLC and HPLC purification
A 4.05 g portion of the crude extract was dissolved in 4 mL of 2:1 DCM/MeOH and mixed in a 500 mL round bottom flask with 16.2 g of TLC grade silica. The mixture was dried and loaded onto a 400 mL column for vacuum liquid chromatography (VLC). Fixed 300 mL volumes of hexanes, EtOAc, and MeOH solvents were used that progressively increased in polarity: (A) 100% hexanes, (B) 10% EtOAc/hexanes, (C) 20% EtOAc/hexanes (D) 40% EtOAc/hexanes, (E) 60% EtOAc/hexanes, (F) 80% EtOAc/hexanes, (G)100% EtOAc, (H) 25% MeOH/EtOAc, and (I) 100% MeOH. Fractions H and I contained hectoramide B (6) and were combined and solubilized in 100 mL of EtOAc for liquid-liquid extraction with H2O. Three iterations of liquid-liquid extraction were performed in a separatory funnel to remove salts, giving an organic layer of 0.5253 g for combined Fractions H+I. Fractions H+I was purified by HPLC using a Thermo Scientific Dionex Ultimate 3000 Pump/RS/Autosampler/RS Diode Array Detector/Automated Fraction Collector that yielded 6 subfractions. A Phenomenex Kinetex 5 μm C18 100 Å LC 150 × 21.2 mm column was used for reverse phase separation at a flow rate of 9 mL/ min. The mobile phase consisted of solvent A, water + 0.1% formic acid (FA), and solvent B, 100% ACN. A 32-minute method was used starting with equilibration at 20% solvent B in solvent A for 5 minutes, followed by a linear 20-minute gradient to 99% solvent B, followed by a 3-minute washout phase at 99% solvent B, and a 4-minute re-equilibration period at 20% solvent B in solvent A. The third subfraction from this separation of fractions H+I contained compound 1 and was purified further by HPLC using Phenomenex Kinetex 5 μm C18 100 Å LC 100 × 4.60 mm column at a flow rate of 1 mL/ min and gradient elution as described above. This purification procedure from the monoculture of M. producens JHB afforded 16.5 mg of 1.
DNA Extraction, Nanopore Sequencing of M. producens JHB, and Hybrid Assembly
DNA extraction was performed using a QIAGEN Bacterial Genomic DNA Extraction Kit using the standard kit protocol. The quality of the genomic DNA (gDNA) was evaluated by Nanodrop, 1% agarose gel electrophoresis, and Qubit.
Data generation was conducted using Oxford Nanopore PromethION sequencing platform by UC Davis Genomics Core. SQK-LSK110 and FLO-PRO002 were used for library construction and data generation. All data generation was conducted using the manufacturer’s protocols. Base-calling used Guppy v5.0.7 with dna_r9.4.1_450bps_hac model. A subset of the sequencing read data was generated with Filtlong v.0.2.128 with parameters Min_length=2000, keep-percent=90, and target_bases=1500000000 for read filtering.
Two long-read assembly tools (Unicycler v.0.5.029 and Flye v.2.9),30 which can conduct assembly using only Nanopore reads or with the addition of Illumina reads, were used for this study. Flye was used for assembly using only Nanopore reads with genome-size=9m as a parameter. Unicycler was used for assembly using only Nanopore reads and in combination with Illumina reads with default parameters for hybrid assembly and long-read only assembly. Unicycler utilizes SPades, Racon and Pilon as part of the workflow. Metagenome binning was conducted using Metabat2 v2.15.31 The bins were annotated using CheckM v.1.2.032 with taxonomy workflow, rank=phylum, and taxon=Cyanobacteria as the parameters. Bins that contained assemblies with ~43% GC content, and total contig length of ~9 Mbp were selected for genome polishing by Pilon.
Short reads from a previous Illumina sequencing effort were mapped to the assembly using bwa-mem2 v.0.7.1733 and polishing was conducted using Pilon v.1.2434 with default parameters. Three iterations of polishing were performed. The genome is deposited in Genbank with accession number CP017708.2.
For polished genome evaluation, BUSCO v.5.3.235 was used with the cyanobacteria_odb10 database. N50, number of contigs, and genome lengths were identified using Quast v.5.0.236 with default parameters. To assess BGC content, AntiSMASH v.6.037 was used on the web-based platform with settings detection=relaxed, and all extra features enabled. The resulting region that contained the putative hectoramide B biosynthetic gene cluster (BGC) was downloaded as a GenBank file and investigated further using Geneious Prime v.2022.1.1.
Sequence alignments and Phylogenetic Tree
Sequence alignments were generated using Clustal Omega v.1.2.3 on Geneious Prime software with default parameters. Methyltransferase domain and adenylation domain sequences were obtained from the NCBI and MiBIG databases.38 The phylogenetic tree was generated using Geneious Tree Builder with Jukes-Cantor model and default parameters. The methyltransferase (MT) domains used in the phylogenetic tree generation are listed in Table 1 of the Supporting Information. An oxygen methyltransferase from Tistrella mobilis KA091029–065 was used as the outgroup. Sequence alignment figures were generated by EsPript 3.0.39
Structural model and alignment
The model of the hcaB adenylation domain was built using AlphaFold217 with the ligand being placed by aligning to other known A domains in MOE. With the ligand placed into the predicted model of HcaB, the ligand placement was refined using a steepest descent energy minimization method followed by 10ns of low mode molecular dynamics (MD) to confirm the binding conformations of the sidechains. This final model was analyzed then in PyMol v.2.0.40 The model was superimposed onto other adenylation domains (A-domains) from the PDB database to obtain structural alignments (Table S12). The A-domain residues within 5 Angstroms of the binding pocket ligand in the hcaB model were evaluated as potential binding site residues by comparison with other A-domains.
Biological Assays
Minimum inhibitory concentrations (MIC) were determined using microtiter broth dilution in Yeast Peptone Dextrose (YPD) media. Frozen spore suspensions of Saccharomyces cerevisiae were grown on an overnight plate culture in YPD agar. Wells were inoculated to a final concentration of 1.5 × 105 cfu/mL. Plates were incubated at 30ºC for 20 hours and the MICs were defined as the lowest concentration of drug completely inhibiting visible growth. Cycloheximide and fluconazole were used as positive controls.
Supplementary Material
Figure 1.

Natural products isolated and characterized from Moorena producens JHB
ACKNOWLEDGMENT
The sequencing was carried out by the DNA Technologies and Expression Analysis Core at the UC Davis Genome Center, supported by NIH Shared Instrumentation Grant 1s10OD010786-01. We thank Sabine Ottilie (Calibr) for providing the protocol for the yeast assay, Brendan Duggan for help with the acquisition of the 600 MHz NMR data sets and Dr. Yongxuan Su for help with acquisition of the HRMS data set. We thank the Dickinson Foundation for purchase of the JEOL ECZ 500 MHz NMR Spectrometer.
ABBREVIATIONS
- A
adenylation
- ACN
acetonitrile
- AMT
amidotransferase
- BGC
biosynthetic gene cluster
- C
condensation
- CAL
co-enzyme A ligase
- COSY
correlated spectroscopy
- DCM
dichloromethane
- EtOAc
ethyl acetate
- FA
formic acid
- gDNA
genomic DNA
- GNPS
global natural products social molecular networking
- HMBC
heteronuclear multiple bond correlation
- HPLC
high performance liquid chromatography
- HSQC
heteronuclear single quantum coherence
- JHB
Moorena producens JHB
- KR
ketoreductase
- LC-MS
liquid chromatography mass spectrometry
- MeOH
methanol
- MIC
minimum inhibitory concentration
- Mpopa
3-(4-methoxyphenyl)-2-oxopropanoic acid
- Mppa
2-hydroxy-3-(4-methoxyphenyl) propanoic acid
- MT
methyltransferase
- NMR
nuclear magnetic resonance
- NMT
nitrogen-methyltransferase
- NRP
non-ribosomal peptide
- NRPS
non-ribosomal peptide synthetase
- OMT
oxygen-methyltransferase
- PCP
peptidyl-carrier protein
- SARP
streptomyces antibiotic regulatory protein
- TE
thioesterase
- VLC
vacuum liquid chromatography
Funding Statement
The research was supported by NIH grant 5R01GM107550-10 to W.H.G and L.G. K.LA. was funded by NIH/NCI T32 CA009523 and NIH T32 GM067550. C.B.N. was financially supported in part by NIH grant T32 CA009523. Research reported in this publication was supported in part by the National Center for Complementary and Integrative Health of the NIH under award number F32AT011475 to N.E.A. V,V,S. is financially supported by F32-GM145146
Footnotes
ASSOCIATED CONTENT
Supporting Information
The Supporting Information is available free of charge on the ACS Publications website.
Any additional relevant notes should be placed here.
REFERENCES
- (1).Engene N.; Rottacker E. C.; Kaštovský J.; Byrum T.; Choi H.; Ellisman M. H.; Komárek J.; Gerwick W. H. Y. 2012. Moorea Producens Gen. Nov., Sp. Nov. and Moorea Bouillonii Comb. Nov., Tropical Marine Cyanobacteria Rich in Bioactive Secondary Metabolites. International Journal of Systematic and Evolutionary Microbiology 62 (Pt_5), 1171–1178. 10.1099/ijs.0.033761-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (2).Liu Y.; Law B. K.; Luesch H. Apratoxin A Reversibly Inhibits the Secretory Pathway by Preventing Cotranslational Translocation. Mol Pharmacol 2009, 76 (1), 91–104. 10.1124/mol.109.056085. [DOI] [PubMed] [Google Scholar]
- (3).Luesch H.; Yoshida W. Y.; Moore R. E.; Paul V. J.; Corbett T. H. Total Structure Determination of Apratoxin A, a Potent Novel Cytotoxin from the Marine Cyanobacterium Lyngbya majuscula. J. Am. Chem. Soc. 2001, 123 (23), 5418–5423. 10.1021/ja010453j. [DOI] [PubMed] [Google Scholar]
- (4).Paatero A. O.; Kellosalo J.; Dunyak B. M.; Almaliti J.; Gestwicki J. E.; Gerwick W. H.; Taunton J.; Paavilainen V. O. Apratoxin Kills Cells by Direct Blockade of the Sec61 Protein Translocation Channel. Cell Chem Biol 2016, 23 (5), 561–566. 10.1016/j.chembiol.2016.04.008. [DOI] [PubMed] [Google Scholar]
- (5).Leao T.; Castelão G.; Korobeynikov A.; Monroe E. A.; Podell S.; Glukhov E.; Allen E. E.; Gerwick W. H.; Gerwick L. Comparative Genomics Uncovers the Prolific and Distinctive Metabolic Potential of the Cyanobacterial Genus Moorea. Proc Natl Acad Sci U S A 2017, 114 (12), 3198–3203. 10.1073/pnas.1618556114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (6).Marquez B. L.; Watts K. S.; Yokochi A.; Roberts M. A.; Verdier-Pinard P.; Jimenez J. I.; Hamel E.; Scheuer P. J.; Gerwick W. H. Structure and Absolute Stereochemistry of Hectochlorin, a Potent Stimulator of Actin Assembly. J. Nat. Prod. 2002, 65 (6), 866–871. 10.1021/np0106283. [DOI] [PubMed] [Google Scholar]
- (7).Boudreau P. D.; Monroe E. A.; Mehrotra S.; Desfor S.; Korobeynikov A.; Sherman D. H.; Murray T. F.; Gerwick L.; Dorrestein P. C.; Gerwick W. H. Expanding the Described Metabolome of the Marine Cyanobacterium Moorea Producens JHB through Orthogonal Natural Products Workflows. PLOS ONE 2015, 10 (7), e0133297. 10.1371/journal.pone.0133297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (8).Edwards D. J.; Marquez B. L.; Nogle L. M.; McPhail K.; Goeger D. E.; Roberts M. A.; Gerwick W. H. Structure and Biosynthesis of the Jamaicamides, New Mixed Polyketide-Peptide Neurotoxins from the Marine Cyanobacterium Lyngbya Majuscula. Chemistry & Biology 2004, 11 (6), 817–833. 10.1016/j.chembiol.2004.03.030. [DOI] [PubMed] [Google Scholar]
- (9).Kinnel R. B.; Esquenazi E.; Leao T.; Moss N.; Mevers E.; Pereira A. R.; Monroe E. A.; Korobeynikov A.; Murray T. F.; Sherman D.; Gerwick L.; Dorrestein P. C.; Gerwick W. H. A Maldiisotopic Approach to Discover Natural Products: Cryptomaldamide, a Hybrid Tripeptide from the Marine Cyanobacterium Moorea Producens. J. Nat. Prod. 2017, 80 (5), 1514–1521. 10.1021/acs.jnatprod.7b00019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (10).Dong-Chan Oh; Kauffman Christopher A.; Jensen Paul R., and; Fenical* Induced Production of Emericellamides A and B from the Marine-Derived Fungus Emericella sp. in Competing Co-culture. ACS Publications. 10.1021/np060381f. [DOI] [PubMed] [Google Scholar]
- (11).Wakefield J.; Hassan H. M.; Jaspars M.; Ebel R.; Rateb M. E. Dual Induction of New Microbial Secondary Metabolites by Fungal Bacterial Co-Cultivation. Frontiers in Microbiology 2017, 8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (12).Wang M.; Carver J. J.; Phelan V. V.; Sanchez L. M.; Garg N.; Peng Y.; Nguyen D. D.; Watrous J.; Kapono C. A.; Luzzatto-Knaan T.; Porto C.; Bouslimani A.; Melnik A. V.; Meehan M. J.; Liu W.-T.; Crüsemann M.; Boudreau P. D.; Esquenazi E.; Sandoval-Calderón M.; Kersten R. D.; Pace L. A.; Quinn R. A.; Duncan K. R.; Hsu C.-C.; Floros D. J.; Gavilan R. G.; Kleigrewe K.; Northen T.; Dutton R. J.; Parrot D.; Carlson E. E.; Aigle B.; Michelsen C. F.; Jelsbak L.; Sohlenkamp C.; Pevzner P.; Edlund A.; McLean J.; Piel J.; Murphy B. T.; Gerwick L.; Liaw C.-C.; Yang Y.-L.; Humpf H.-U.; Maansson M.; Keyzers R. A.; Sims A. C.; Johnson A. R.; Sidebottom A. M.; Sedio B. E.; Klitgaard A.; Larson C. B.; Boya P C. A.; Torres-Mendoza D.; Gonzalez D. J.; Silva D. B.; Marques L. M.; Demarque D. P.; Pociute E.; O’Neill E. C.; Briand E.; Helfrich E. J. N.; Granatosky E. A.; Glukhov E.; Ryffel F.; Houson H.; Mohimani H.; Kharbush J. J.; Zeng Y.; Vorholt J. A.; Kurita K. L.; Charusanti P.; McPhail K. L.; Nielsen K. F.; Vuong L.; Elfeki M.; Traxler M. F.; Engene N.; Koyama N.; Vining O. B.; Baric R.; Silva R. R.; Mascuch S. J.; Tomasi S.; Jenkins S.; Macherla V.; Hoffman T.; Agarwal V.; Williams P. G.; Dai J.; Neupane R.; Gurr J.; Rodríguez A. M. C.; Lamsa A.; Zhang C.; Dorrestein K.; Duggan B. M.; Almaliti J.; Allard P.-M.; Phapale P.; Nothias L.-F.; Alexandrov T.; Litaudon M.; Wolfender J.-L.; Kyle J. E.; Metz T. O.; Peryea T.; Nguyen D.-T.; VanLeer D.; Shinn P.; Jadhav A.; Müller R.; Waters K. M.; Shi W.; Liu X.; Zhang L.; Knight R.; Jensen P. R.; Palsson B. Ø.; Pogliano K.; Linington R. G.; Gutiérrez M.; Lopes N. P.; Gerwick W. H.; Moore B. S.; Dorrestein P. C.; Bandeira N. Sharing and Community Curation of Mass Spectrometry Data with Global Natural Products Social Molecular Networking. Nat Biotechnol 2016, 34 (8), 828–837. 10.1038/nbt.3597. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (13).Reher R.; Kim H. W.; Zhang C.; Mao H. H.; Wang M.; Nothias L.-F.; Caraballo-Rodriguez A. M.; Glukhov E.; Teke B.; Leao T.; Alexander K. L.; Duggan B. M.; Van Everbroeck E. L.; Dorrestein P. C.; Cottrell G. W.; Gerwick W. H. A Convolutional Neural Network-Based Approach for the Rapid Annotation of Molecularly Diverse Natural Products. J. Am. Chem. Soc. 2020, 142 (9), 4114–4120. 10.1021/jacs.9b13786. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (14).Süssmuth R. D.; Mainz A. Nonribosomal Peptide Synthesis—Principles and Prospects. Angewandte Chemie International Edition 2017, 56 (14), 3770–3821. 10.1002/anie.201609079. [DOI] [PubMed] [Google Scholar]
- (15).Moss N. A.; Seiler G.; Leão T. F.; Castro-Falcón G.; Gerwick L.; Hughes C. C.; Gerwick W. H. Nature’s Combinatorial Biosynthesis Produces Vatiamides A-F. Angew Chem Int Ed Engl 2019, 58 (27), 9027–9031. 10.1002/anie.201902571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (16).Alonzo D. A.; Schmeing T. M. Biosynthesis of Depsipeptides, or Depsi: The Peptides with Varied Generations. Protein Sci 2020, 29 (12), 2316–2347. 10.1002/pro.3979. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (17).Jumper J.; Evans R.; Pritzel A.; Green T.; Figurnov M.; Ronneberger O.; Tunyasuvunakool K.; Bates R.; Žídek A.; Potapenko A.; Bridgland A.; Meyer C.; Kohl S. A. A.; Ballard A. J.; Cowie A.; Romera-Paredes B.; Nikolov S.; Jain R.; Adler J.; Back T.; Petersen S.; Reiman D.; Clancy E.; Zielinski M.; Steinegger M.; Pacholska M.; Berghammer T.; Bodenstein S.; Silver D.; Vinyals O.; Senior A. W.; Kavukcuoglu K.; Kohli P.; Hassabis D. Highly Accurate Protein Structure Prediction with AlphaFold. Nature 2021, 596 (7873), 583–589. 10.1038/s41586-021-03819-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (18).Alonzo D. A.; Chiche-Lapierre C.; Tarry M. J.; Wang J.; Schmeing T. M. Structural Basis of Keto Acid Utilization in Nonribosomal Depsipeptide Synthesis. Nat Chem Biol 2020, 16 (5), 493–496. 10.1038/s41589-020-0481-5. [DOI] [PubMed] [Google Scholar]
- (19).Magarvey N. A.; Beck Z. Q.; Golakoti T.; Ding Y.; Huber U.; Hemscheidt T. K.; Abelson D.; Moore R. E.; Sherman D. H. Biosynthetic Characterization and Chemoenzymatic Assembly of the Cryptophycins. Potent Anticancer Agents from Cyanobionts. ACS Chem Biol 2006, 1 (12), 766–779. 10.1021/cb6004307. [DOI] [PubMed] [Google Scholar]
- (20).Ramaswamy A. V.; Sorrels C. M.; Gerwick W. H. Cloning and Biochemical Characterization of the Hectochlorin Biosynthetic Gene Cluster from the Marine Cyanobacterium Lyngbya Majuscula. J Nat Prod 2007, 70 (12), 1977–1986. 10.1021/np0704250. [DOI] [PubMed] [Google Scholar]
- (21).Bacterial Biosynthesis and Maturation of the Didemnin Anti-cancer Agents | Journal of the American Chemical Society. 10.1021/ja301735a (accessed 2023-05-09). [DOI] [PMC free article] [PubMed]
- (22).Balunas M. J.; Linington R. G.; Tidgewell K.; Fenner A. M.; Ureña L.-D.; Togna G. D.; Kyle D. E.; Gerwick W. H. Dragonamide E, a Modified Linear Lipopeptide from Lyngbya Majuscula with Antileishmanial Activity. J. Nat. Prod. 2010, 73 (1), 60–66. 10.1021/np900622m. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (23).Hooper G. J.; Orjala J.; Schatzman R. C.; Gerwick W. H. Carmabins A and B, New Lipopeptides from the Caribbean Cyanobacterium Lyngbya Majuscula. J. Nat. Prod. 1998, 61 (4), 529–533. 10.1021/np970443p. [DOI] [PubMed] [Google Scholar]
- (24).Hindra; Pak P.; Elliot M. A. Regulation of a Novel Gene Cluster Involved in Secondary Metabolite Production in Streptomyces Coelicolor. Journal of Bacteriology 2010, 192 (19), 4973–4982. 10.1128/JB.00681-10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (25).Krause J.; Handayani I.; Blin K.; Kulik A.; Mast Y. Disclosing the Potential of the SARP-Type Regulator PapR2 for the Activation of Antibiotic Gene Clusters in Streptomycetes. Front Microbiol 2020, 11, 225. 10.3389/fmicb.2020.00225. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (26).Ecker A. K.; Levorse D. A.; Victor D. A.; Mitcheltree M. J. Bioisostere Effects on the EPSA of Common Permeability-Limiting Groups. ACS Med. Chem. Lett. 2022, 13 (6), 964–971. 10.1021/acsmedchemlett.2c00114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (27).Moss N. A.; Leao T.; Glukhov E.; Gerwick L.; Gerwick W. H. Chapter One - Collection, Culturing, and Genome Analyses of Tropical Marine Filamentous Benthic Cyanobacteria. In Methods in Enzymology; Moore B. S., Ed.; Marine Enzymes and Specialized Metabolism - Part A; Academic Press, 2018; Vol. 604, pp 3–43. 10.1016/bs.mie.2018.02.014. [DOI] [PubMed] [Google Scholar]
- (28).Wick R. Rrwick/Filtlong, 2023. https://github.com/rrwick/Filtlong (accessed 2023-03-09).
- (29).Wick R. R.; Judd L. M.; Gorrie C. L.; Holt K. E. Unicycler: Resolving Bacterial Genome Assemblies from Short and Long Sequencing Reads. PLOS Computational Biology 2017, 13 (6), e1005595. 10.1371/journal.pcbi.1005595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (30).Kolmogorov M.; Yuan J.; Lin Y.; Pevzner P. A. Assembly of Long, Error-Prone Reads Using Repeat Graphs. Nat Biotechnol 2019, 37 (5), 540–546. 10.1038/s41587-019-0072-8. [DOI] [PubMed] [Google Scholar]
- (31).Kang D. D.; Li F.; Kirton E.; Thomas A.; Egan R.; An H.; Wang Z. MetaBAT 2: An Adaptive Binning Algorithm for Robust and Efficient Genome Reconstruction from Metagenome Assemblies. PeerJ 2019, 7, e7359. 10.7717/peerj.7359. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (32).Parks D. H.; Imelfort M.; Skennerton C. T.; Hugenholtz P.; Tyson G. W. CheckM: Assessing the Quality of Microbial Genomes Recovered from Isolates, Single Cells, and Metagenomes. Genome Res. 2015, 25 (7), 1043–1055. 10.1101/gr.186072.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (33).Li H. Aligning Sequence Reads, Clone Sequences and Assembly Con*gs with BWA-MEM. 2014. 10.6084/m9.figshare963153.v1. [DOI]
- (34).Walker B. J.; Abeel T.; Shea T.; Priest M.; Abouelliel A.; Sakthikumar S.; Cuomo C. A.; Zeng Q.; Wortman J.; Young S. K.; Earl A. M. Pilon: An Integrated Tool for Comprehensive Microbial Variant Detection and Genome Assembly Improvement. PLOS ONE 2014, 9 (11), e112963. 10.1371/journal.pone.0112963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (35).Manni M.; Berkeley M. R.; Seppey M.; Simão F. A.; Zdobnov E. M. BUSCO Update: Novel and Streamlined Workflows along with Broader and Deeper Phylogenetic Coverage for Scoring of Eukaryotic, Prokaryotic, and Viral Genomes. Molecular Biology and Evolution 2021, 38 (10), 4647–4654. 10.1093/molbev/msab199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (36).Gurevich A.; Saveliev V.; Vyahhi N.; Tesler G. QUAST: Quality Assessment Tool for Genome Assemblies. Bioinformatics 2013, 29 (8), 1072–1075. 10.1093/bioinformatics/btt086. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (37).Blin K.; Shaw S.; Kloosterman A. M.; Charlop-Powers Z.; van Wezel G. P.; Medema M. H.; Weber T. AntiSMASH 6.0: Improving Cluster Detection and Comparison Capabilities. Nucleic Acids Res 2021, 49 (W1), W29–W35. 10.1093/nar/gkab335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (38).Kautsar S. A.; Blin K.; Shaw S.; Navarro-Muñoz J. C.; Terlouw B. R.; van der Hooft J. J. J.; van Santen J. A.; Tracanna V.; Suarez Duran H. G.; Pascal Andreu V.; Selem-Mojica N.; Alanjary M.; Robinson S. L.; Lund G.; Epstein S. C.; Sisto A. C.; Charkoudian L. K.; Collemare J.; Linington R. G.; Weber T.; Medema M. H. MIBiG 2.0: A Repository for Biosynthetic Gene Clusters of Known Function. Nucleic Acids Research 2020, 48 (D1), D454–D458. 10.1093/nar/gkz882. [DOI] [PMC free article] [PubMed] [Google Scholar]
- (39).ESPript 3. ESPript 3. https://espript.ibcp.fr/ESPript/ESPript/ (accessed 2022-12-05).
- (40).Schrödinger LLC. The AxPyMOL Molecular Graphics Plugin for Microsoft PowerPoint, Version 1.8, 2015.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.