

Abstract
Background
The Fontan operation is associated with significant morbidity and premature mortality. Fontan cases cannot always be identified by International Classification of Diseases (ICD) codes, making it challenging to create large Fontan patient cohorts. We sought to develop natural language processing–based machine learning models to automatically detect Fontan cases from free texts in electronic health records, and compare their performances with ICD code–based classification.
Methods and Results
We included free‐text notes of 10 935 manually validated patients, 778 (7.1%) Fontan and 10 157 (92.9%) non‐Fontan, from 2 health care systems. Using 80% of the patient data, we trained and optimized multiple machine learning models, support vector machines and 2 versions of RoBERTa (a robustly optimized transformer‐based model for language understanding), for automatically identifying Fontan cases based on notes. For RoBERTa, we implemented a novel sliding window strategy to overcome its length limit. We evaluated the machine learning models and ICD code–based classification on 20% of the held‐out patient data using the F 1 score metric. The ICD classification model, support vector machine, and RoBERTa achieved F 1 scores of 0.81 (95% CI, 0.79–0.83), 0.95 (95% CI, 0.92–0.97), and 0.89 (95% CI, 0.88–0.85) for the positive (Fontan) class, respectively. Support vector machines obtained the best performance (P<0.05), and both natural language processing models outperformed ICD code–based classification (P<0.05). The sliding window strategy improved performance over the base model (P<0.05) but did not outperform support vector machines. ICD code–based classification produced more false positives.
Conclusions
Natural language processing models can automatically detect Fontan patients based on clinical notes with higher accuracy than ICD codes, and the former demonstrated the possibility of further improvement.
Keywords: congenital heart disease, Fontan, natural language processing, single ventricle
Subject Categories: Big Data and Data Standards, Machine Learning
Nonstandard Abbreviations and Acronyms
- AHS
adult health care system
- ML
machine learning
- PHS
pediatric health care system
- SVM
support vector machine
Clinical Perspective.
What Is New?
Native anatomy for Fontan cases varies and cannot always be identified by International Classification of Diseases (ICD) codes, making it challenging to create large Fontan patient cohorts.
Natural language processing and machine learning methods may detect evidence of Fontan operation from unstructured clinical notes.
A natural language processing–based supervised machine learning model detects Fontan cases with higher F 1 score than ICD codes.
What Are the Clinical Implications?
Data‐driven artificial intelligence methods can help to accurately identify Fontan patients.
The publicly available natural language processing and supervised machine learning methods can be used to create large Fontan cohorts for longitudinal studies.
The Fontan operation is typically performed in early childhood to palliate single‐ventricle congenital heart defects (CHDs), with heterogeneous native anatomy. Following the Fontan operation, the absence of a pulsatile pulmonary circulation and chronically elevated hepatic venous pressures lead to numerous comorbid complications with age, including arrhythmias, heart failure, hepatic fibrosis, renal disease, and other late complications. 1 The International Classification of Diseases, Ninth Revision, Clinical Modification (ICD‐9‐CM), and International Classification of Diseases, Tenth Revision, Clinical Modification (ICD‐10‐CM), diagnostic codes can be used to identify the categories of patients by their native anatomy and are commonly used in research for retrieving targeted cohort data. In addition, ICD‐9‐CM and ICD‐10 Procedure Coding System (PCS) procedural codes can be used to identify procedures a patient may have undergone. Although all Fontan patients have similar postsurgical anatomy and complications regardless of the native anatomy, 2 not all patients with the same native anatomy require a Fontan operation. Therefore, it is difficult to identify Fontan cases strictly by their ICD codes.
Text notes associated with the electronic health records (EHRs) of Fontan patients typically contain lexical cues indicative of the Fontan operation, recognizable by subject matter experts. However, manually reviewing notes in EHRs is time‐consuming, and the task is often impractical. Registry studies are an important mechanism to study rare cardiac conditions, and in countries with universal health care, these registries can track patients long‐term. 3 In the United States, registry studies are able to identify cohorts of Fontan patients, but linkage of registry data to medical record systems beyond the pediatric health care system can be challenging. Natural language processing (NLP) methods provide a potential complementary solution to automatically detect Fontan cases across medical record systems, and within medical record systems for which registry data are unavailable, for the purpose of conducting longitudinal cohort studies. NLP, a subdiscipline of computer science concerned with the use of computers to process information from human language, has been widely applied to clinical notes for creating health care applications. For example, studies have leveraged NLP of clinical notes for studying chronic diseases, 4 extracting critical HIV and cardiovascular risk information, 5 , 6 analyzing critical limb ischemia, 7 and extracting ad hoc concepts. 8 An effective NLP system, which can automatically identify Fontan cases from text notes in EHRs, will help improve the efficiency of creating Fontan cohorts, and hence, provide an additional method of conducting health‐related studies on Fontan cases.
In this article, we sought to train and evaluate NLP‐based supervised machine learning (ML) systems to identify Fontan cases based on unstructured clinical notes from 2 large health care systems. We used diverse text representation strategies and proposed a technological innovation to better model text using state‐of‐the‐art transformer‐based text representation methods.
METHODS
ML Classification Framework
The Python code associated with this article is available at https://github.com/yguo0102/Fontan_classification. The framework for the NLP‐based ML model training and evaluation is shown in Figure 1. The process includes 3 steps: (1) collecting clinical data, (2) manually annotating whether a patient has had a Fontan operation or not, and (3) training and evaluating supervised classification models. We provide further details in the following subsections.
Figure 1. The development framework of the Fontan patient identification system.
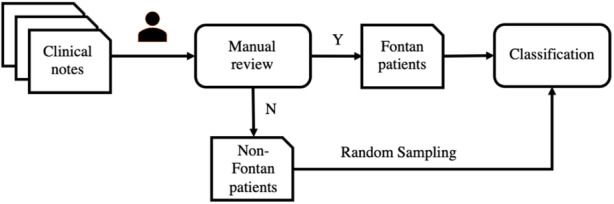
The clinical notes were manually annotated by clinical experts as Fontan or non‐Fontan patients. The non‐Fontan patients were randomly sampled and combined with the Fontan patients to develop the classification model. N indicates no; and Y, yes.
Study Population and Data Collection
This study used data on patients with at least one CHD ICD‐9‐CM or ICD‐10‐CM code (Table S1) documented in a health care encounter between January 1, 2010, and December 31, 2019, in databases for 2 statewide multihospital tertiary health care systems, 1 pediatric health care system (PHS) and 1 adult health care system (AHS). Data were collected under a cooperative agreement with the Centers for Disease Control and Prevention (CDC‐RFA‐DD19‐1902B). Emory University Institutional Review Board approved the study on August 26, 2020 (Institutional Review Board number STUDY00001030) and included a complete waiver of Health Insurance Portability and Accountability Act authorization as well as waiver of informed consent. Manually abstracted Fontan cases were collected and managed using Research Electronic Data Capture at Emory University, a secure, web‐based software platform designed to support data capture for research studies. 9 , 10
Case Validation
Fontan cases were confirmed in 1 of 4 ways: (1) Their Fontan operation was identified and noted by clinicians and trained abstractors during a manual abstraction and clinical review of health records for 1500 CHD cases of all types in the PHS and AHS. Interobserver and intraobserver reliability was measured by reabstracting 10% of cases to ensure reliability of the annotations, and exceeded 95%. (2) Their Fontan operation was documented in the pediatric Society of Thoracic Surgeons database, which includes data entered by trained research coordinators in the PHS and classification reviewed by a clinician. (3) The Fontan patient was included in an adult clinical Fontan tracking list created and maintained by clinicians to monitor clinical care for adult Fontan patients and verified by congenital cardiology clinicians. (4) An NLP‐driven search was conducted on all text notes available for patients with at least 1 select single‐ventricle diagnosis code or Fontan procedure code (Table 1) who were not already labeled as Fontan cases from 1 of the first 3 mechanisms. The NLP‐driven search performed inexact or fuzzy matching of the term “Fontan” within the text of the notes so that words similar to Fontan, including potential misspellings, were captured. All retrieved posts were manually reviewed, and Fontan cases were labeled. Reasons for false positives with NLP‐driven search were noted, as were reasons for false negatives with ICD code–based classification of single‐ventricle cases. Abstractors reviewed all false‐positive and false‐negative cases (as determined by NLP) to assess data quality. The chart abstractors played no role in model development and did not communicate at any point of the study with the investigators (Y.G., M.A.A.–G., and A.S.) involved in ML model development. This ensured that the model development was not biased by expert knowledge from the abstractors.
Table 1.
List of the ICD‐9‐CM and ICD‐10‐CM Diagnostic Codes for Single‐Ventricle Heart Defects and ICD‐9 and ICD‐10‐PCS Procedural Codes for Fontan Operation With Code Details
| Diagnostic codes for single‐ventricle heart defects | ||
|---|---|---|
| ICD‐9‐CM | ICD‐10‐CM | Code details |
| 745.3 | Q20.4 | Single ventricle or cor triloculare, double‐inlet left ventricle |
| 745.7 | … | Cor biloculare |
| 746.1 | Q22.4 | Tricuspid atresia, stenosis, or absence |
| … | Q22.6 | Hypoplastic right heart syndrome |
| 746.7 | Q23.4 | Hypoplastic left heart syndrome |
| ICD procedural codes for Fontan operation | |
|---|---|
| ICD‐9‐CM | Code details |
| 35.94 | Creation of conduit between atrium and pulmonary artery |
| ICD‐10‐PCS | Code details |
|---|---|
| 021608P | Bypass right atrium to pulmonary trunk with zooplastic tissue, open approach |
| 021608Q | Bypass right atrium to right pulmonary artery with zooplastic tissue, open approach |
| 021608R | Bypass right atrium to left pulmonary artery with zooplastic tissue, open approach |
| 021609P | Bypass right atrium to pulmonary trunk with autologous venous tissue, open approach |
| 021609Q | Bypass right atrium to right pulmonary artery with autologous venous tissue, open approach |
| 021609R | Bypass right atrium to left pulmonary artery with Autologous venous tissue, open approach |
| 02160AP | Bypass right atrium to pulmonary trunk with autologous arterial tissue, open approach |
| 02160AQ | Bypass right atrium to right pulmonary artery with autologous arterial tissue, open approach |
| 02160AR | Bypass right atrium to left pulmonary artery with autologous arterial tissue, open approach |
| 02160JP | Bypass right atrium to pulmonary trunk with synthetic substitute, open approach |
| 02160JQ | Bypass right atrium to right pulmonary artery with synthetic substitute, open approach |
| 02160JR | Bypass right atrium to left pulmonary artery with synthetic substitute, open approach |
| 02160KP | Bypass right atrium to pulmonary trunk with nonautologous tissue substitute, open approach |
| 02160KQ | Bypass right atrium to right pulmonary artery with nonautologous tissue substitute, open approach |
| 02160KR | Bypass right atrium to left pulmonary artery with nonautologous tissue substitute, open approach |
| 02160ZP | Bypass right atrium to pulmonary trunk, open approach |
| 02160ZQ | Bypass right atrium to right pulmonary artery, open approach |
| 02160ZR | Bypass right atrium to left pulmonary artery, open approach |
| 021648P | Bypass right atrium to pulmonary trunk with zooplastic tissue, percutaneous endoscopic approach |
| 021648Q | Bypass right atrium to right pulmonary artery with zooplastic tissue, percutaneous endoscopic approach |
| 021648R | Bypass right atrium to left pulmonary artery with zooplastic tissue, percutaneous endoscopic approach |
| 021649P | Bypass right atrium to pulmonary trunk with autologous venous tissue, percutaneous endoscopic approach |
| 021649Q | Bypass right atrium to right pulmonary artery with autologous venous tissue, percutaneous endoscopic approach |
| 021649R | Bypass right atrium to left pulmonary artery with autologous venous tissue, percutaneous endoscopic approach |
| 02164AP | Bypass right atrium to pulmonary trunk with autologous arterial tissue, percutaneous endoscopic approach |
| 02164AQ | Bypass right atrium to right pulmonary artery with autologous arterial tissue, percutaneous endoscopic approach |
| 02164AR | Bypass right atrium to left pulmonary artery with autologous arterial tissue, percutaneous endoscopic approach |
| 02164JP | Bypass right atrium to pulmonary trunk with synthetic substitute, percutaneous endoscopic approach |
| 02164JQ | Bypass right atrium to right pulmonary artery with synthetic substitute, percutaneous endoscopic approach |
| 02164JR | Bypass right atrium to left pulmonary artery with synthetic substitute, percutaneous endoscopic approach |
| 02164KP | Bypass right atrium to pulmonary trunk with nonautologous tissue substitute, percutaneous endoscopic approach |
| 02164KQ | Bypass right atrium to right pulmonary artery with nonautologous tissue substitute, percutaneous endoscopic approach |
| 02164KR | Bypass right atrium to left pulmonary artery with nonautologous tissue substitute, percutaneous endoscopic approach |
| 02164ZP | Bypass right atrium to pulmonary trunk, percutaneous endoscopic approach |
| 02164ZQ | Bypass right atrium to right pulmonary artery, percutaneous endoscopic approach |
| 02164ZR | Bypass right atrium to left pulmonary artery, percutaneous endoscopic approach |
For the ICD code–based classifier, all these codes were used. ICD indicates International Classification of Diseases; ICD‐9, International Classification of Diseases, Ninth Revision; ICD‐9‐CM, International Classification of Diseases, Ninth Revision, Clinical Modification; ICD‐10‐CM, International Classification of Diseases, Tenth Revision, Clinical Modification; and ICD‐10‐PCS, International Classification of Diseases, Tenth Revision, Procedure Coding System.
Classification Models
To automate the classification process and identify the best automatic classification strategy, we developed and evaluated multiple ML algorithms: support vector machines (SVMs) and a robustly optimized transformer‐based model for language understanding named RoBERTa (2 versions). Particularly, we compared what is an effective traditional text classification approach (SVM) with the latest and state‐of‐the‐art approach (RoBERTa) currently known, and also compared the performance of the ML models with the ICD code–based classification. For ML models, we divided our cohort into derivation and validation cohorts using stratified 80 to 20 random splits of data to ensure that the class distributions of the derivation and validation cohort remain the same. The derivation cohort data were used for training and optimization of models, and the validation cohort data were used for evaluating model performances. The model performances were measured by the precision (positive predictive value [PPV]), recall (sensitivity), and F 1 score (harmonic mean of PPV and sensitivity) over the positive class on the test sets. We chose F 1 score as the primary metric for comparison because it ensures that neither precision nor recall is optimized at the expense of the other. Equations for computing these metrics are shown in Equation 1. For each classification model, we computed the performance on the test set for the cases from the AHS, the cases from the PHS, and the cases from both databases. Bootstrap resampling was used to compute 95% CIs for the F 1 scores. 11 We performed significance testing for the F 1 scores using the assumption‐free randomization‐based method proposed by Yeh (2000). 12 , 13 The method computes a P value based on the predictions of 2 models. If the P<0.05, the difference in performance between the 2 models is significant. Further model‐specific details are provided below.
Equations 1:
SVM Model
SVMs 14 are popular choices when feature spaces are large, which is why they have been effective for text classification in the past and were chosen for this study. Term frequency–inverse document frequency for n‐grams was used to obtain the vectorized representations of text notes used as features. An n‐gram is a contiguous sequence of n words. In our setting, we used 1, 2, 3, and 4 grams. Term frequency–inverse document frequency is a numerical statistic used to measure the importance of a word in a document or set of documents. Term frequency refers to the number of times a word appears in a document (ie, a clinical note). Inverse document frequency refers to how rare the word is across the entire set of documents (ie, our entire training data set). Term frequency–inverse document frequency is used to weigh the importance of words in a document, with respect to the entire set of documents. The term frequency–inverse document frequency vectors thus have higher numerical values for n‐grams that are unique to each document and lower values for those occurring uniformly across all documents. During training, grid search was used to optimize 2 key hyperparameters, kernel function and , and obtain the optimal setting for the model. Five‐fold cross‐validation over the derivation cohort data was used to optimize the hyperparameters (ie, 4–fold used for training and 1 fold used for validation, over 5 iterations), and the hyperparameter combination with the best average performance across the 5 folds was used in the final model.
Transformer‐Based Model
Transformer‐based models are relatively recent and have achieved state‐of‐the‐art performances on many NLP tasks. 15 , 16 , 17 , 18 As a representative of transformer‐based models, we used RoBERTa, 18 a widely used pretrained transformer‐based model, for Fontan classification. Instead of extracting features from text or generating n‐grams, RoBERTa splits a clinical note into word pieces (ie, tokens), encodes each token into a vector, and combines them into a vector representation for the clinical narrative, as shown in Figure 2. Unlike n‐gram vectors, which are sparse in nature, the vectors generated by transformer‐based models are dense, and they also encode the context of each token (ie, the same token will have a different representation based on the context in which it appears). A key limitation of the RoBERTa model is that it is limited to 512 tokens when representing texts in vector format. We found that most of the clinical notes exceeded that length limitation. This meant that using the standard RoBERTa model results in suboptimal or incomplete representations of the clinical notes. To overcome this limitation, we used a sliding window strategy to split the long notes into multiple partial notes. The sliding window was of size 512 tokens, and when passed through the entire note, each unique 512‐token sequence in it was represented as an individual document. Thus, the model could be applied independently to each of the subdocuments represented by the window, and it could make independent predictions for each. In our approach, after the model predicted labels for each subdocument independently, the mode of the predictions over all the subsequences as the final prediction (ie, majority voting) was used. Like SVM, 5‐fold cross‐validation was used to optimize the model. Specific hyperparameters and technical details are presented in Table S2.
Figure 2. The process of how RoBERTa (a robustly optimized transformer‐based model for language understanding) converts a clinical narrative into a vector representation.

The input text is split into word pieces (ie, tokens) and encoded as vector representations. All the token representations are combined as a document vector representation.
ICD Code–Based Classification Model
We developed a classification model that used only the ICD codes in Table 1 associated with each health record to identify potential Fontan patients. ICD‐9‐CM and ICD‐10‐CM diagnostic codes for hypoplastic left heart syndrome (746.7/Q23.4), tricuspid atresia (746.1/Q22.4/Q22.6), and double‐inlet left ventricle/single ventricle (745.3/Q20.4) were included as individuals with these single‐ventricle heart defects typically undergoing Fontan palliation in childhood. ICD‐9‐CM and ICD‐10‐PCS procedural codes for the Fontan operation in Table 1 were also used to identify Fontan cases based on the presence of a Fontan operation procedural code associated with the case. 19 Depending on the severity of their specific heart defect, individuals with double‐outlet right ventricle, atrioventricular canal defect, pulmonary atresia intact ventricular septum, and other native anatomy may undergo Fontan palliation or 2‐ventricle repair. However ICD diagnostic codes do not capture severity of any given anatomic defect to differentiate those who would receive Fontan from those who undergo 2‐ventricle repair; ICD diagnostic codes for these defects were not used to identify Fontan cases in this classification scheme. If any code associated with a patient's record had at least 1 of the specific single‐ventricle codes included in Table 1 and/or the ICD‐10‐PCS Fontan operation codes noted in Table 1, the patient was classified as a Fontan case for this model. Different from the ML models, the ICD code classification was unsupervised, and there was no need to perform training‐testing data splitting. Therefore, we evaluated the ICD code–based classification model on the whole data set.
Postclassification Analyses
Learning Curve Analysis
To the best of our knowledge, no prior research effort has attempted to automate the task of building a Fontan cohort via supervised ML using the text data in their EHRs. Consequently, we had to annotate our own data. When annotating a sample of texts for a task like this, an important question arises about the amount of data needed to annotate. More specifically, at what number of annotations does the ML model start plateauing? To investigate this, the model performances were evaluated at different sizes of training data (20%, 40%, 60%, 80%, and 100%) while keeping the test set identical. We anticipated that this analysis may provide some insights about whether further increasing the training data size is necessary to improve the models' performances, or at what data size the model starts performing with sufficient accuracy.
Error Analysis
We manually analyzed the patient records that were misclassified by the ML models and summarized the common patterns. The differences between the characteristics of the clinical notes from the AHS and the PHS were also analyzed, because these could have affected the model performance. This analysis was performed particularly to identify the limitations of the model and any potential bias. Knowledge about the causes of errors may guide future directions of research to improve the model.
Model Generalizability Analysis
To assess the generalizability of our model, we attempted to assess its performance in particularly unfamiliar and difficult settings. Specifically, we conducted 2 additional classification experiments, by training on PHS data only and evaluating on AHS data and vice versa. Training data from the AHS was stratified via undersampling. Note that this experimental setting posed a particularly hard problem for the classifier because it could only learn from the pediatric or adult data to classify the other. In real‐life applications, the model trained on the combined data would be deployed. This setting, thus, provides us an estimate of the floor of the classifier performance (ie, its potential performance when applied to a vastly different cohort).
RESULTS
A total of 10 935 cases with available text notes, 778 validated Fontan and 10 157 non‐Fontan, were identified following deduplication and linked back to encounter‐level data and text notes from the EHR. Of these cases, 210 Fontan and 7400 non‐Fontan cases were from the AHS, and 568 Fontan and 2757 non‐Fontan cases were from the PHS. Cases that could not be linked back to text notes or without ICD codes available were excluded (n=25 066) from the data set for the NLP system development and evaluation. The average length of clinical notes from the AHS was 35 words, whereas that from the PHS was 1107 words. Interobserver and intraobserver reliability for abstracted cases exceeded 95%.
Classification Results
The classification results for the ML models and the ICD code–based classification model are shown in Table 2, including the precision, recall, F 1 score, and 95% CI for the F 1 score for each model. The exact P values of the significance tests for the difference in performance between pairs of models are shown in Table 3. For both AHS and PHS data combined, the ICD code classification model had a precision score of 0.74, a recall score of 0.90, and an F 1 score 0.81 (95% CI, 0.79–0.83). The ML models significantly outperformed the model using ICD codes (P<0.05). The model performance of RoBERTa with sliding window was better than that without sliding window (P<0.05), especially for the recall score (0.81 versus 0.51 in AHS and PHS combined). The results show that applying the sliding window strategy to RoBERTa can overcome the limitation of the default model and particularly improve the model's ability to find true positives. SVM significantly outperformed RoBERTa (P<0.05), demonstrating that the traditional model is better able to capture the meanings of the texts compared with the more recently proposed transformer‐based RoBERTa model that uses a pretrained language model. For both AHS and PHS data combined, precision for SVM was 0.97, recall was 0.95, and F1 score was 0.95 (95% CI, 0.92–0.97; Table 2). The confusion matrices for SVM and RoBERTa are shown in Figure 3 to visualize the high accuracy of SVM as the best‐performing model and the performance gap between SVM and RoBERTa.
Table 2.
Results of ICD Code Classifiers and ML Models
| Database | ICD code for single‐ventricle CHD* | SVM | RoBERTa with sliding window | RoBERTa without sliding window |
|---|---|---|---|---|
| AHS and PHS combined | 0.74/0.90/0.81 (0.79–0.83) | 0.97/0.94/0.95† (0.92–0.97) | 0.99/0.81/0.89 (0.88–0.95) | 0.85/0.51/0.67 (0.60–0.73) |
| AHS only | 0.58/0.92/0.71 (0.67–0.75) | 0.94/0.80/0.87† (0.77–0.93) | 0.95/0.46/0.62 (0.46–0.74) | 0.92/0.56/0.70 (0.55–0.81) |
| PHS only | 0.83/0.89/0.85 (0.83–0.88) | 0.97/0.99/0.98† (0.96–1.00) | 0.99/0.93/0.96 (0.93–0.98) | 1.00/0.49/0.65 (0.56–0.74) |
The model performances are presented as precision/recall/F1 score (95% bootstrap CI). AHS indicates adult health care system; CHD, congenital heart defect; ICD, International Classification of Diseases; ML, machine learning; PHS, pediatric health care system; RoBERTa, a robustly optimized transformer‐based model for language understanding; and SVM, support vector machine.
Codes used to identify “Fontan” are shown in Table 1.
The best model performance for each database.
Table 3.
Significance Testing for the Difference in Performance Between Pairs of ML Models
| Model 1 | Model 2 | P value |
|---|---|---|
| SVM | RoBERTa with sliding window | 0.0003 |
| SVM | RoBERTa without sliding window | 0.0001 |
| SVM | ICD code for single‐ventricle CHD | 0.0001 |
| RoBERTa with sliding window | RoBERTa without sliding window | 0.0001 |
| RoBERTa with sliding window | ICD code for single‐ventricle CHD | 0.0001 |
| RoBERTa without sliding window | ICD code for single‐ventricle CHD | 0.0001 |
The P value is computed using the assumption‐free randomization‐based method proposed by Yeh. 12 P<0.05 indicates that the difference in performance between 2 models is significant. CHD indicates congenital heart defect; ICD, International Classification of Diseases; ML, machine learning; RoBERTa, a robustly optimized transformer‐based model for language understanding; and SVM, support vector machine.
Figure 3. The confusion matrices for the support vector machine (SVM) (A) and RoBERTa (a robustly optimized transformer‐based model for language understanding) (B) classifiers evaluated on the test set of 2187 cases (20% of the total data).

For SVM, there are 147 true positives, 2025 true negatives, 6 false positives, and 9 false negatives. For RoBERTa, there are 126 true positives, 2029 true negatives, 2 false positives, and 30 false negatives.
Postclassification Analysis
Error Analysis of ML Models
The confusion matrices reveal that SVM predicted more true positives and fewer false negatives than RoBERTa. This may mean that SVM is better at detecting non‐Fontan cases compared with RoBERTa. RoBERTa with sliding window significantly underperformed compared with SVM on the cases from the AHS but achieved comparable results on the cases from the PHS. In contrast, RoBERTa without sliding window significantly underperformed compared with SVM on the cases from both sites. The performance gap can be attributed to the difference between the average lengths of the clinical notes from the 2 databases: the clinical notes from the PHS were substantially longer than those from the AHS in our data set. The results suggest that although applying the sliding window strategy can help the model performance for long texts, it might lead to suboptimal representation for short texts. Further work is required to explore how to address the challenge of long clinical notes.
Learning Curve
For RoBERTa (with sliding window) and SVM, we evaluated the model performances at different sizes of training data (20%, 40%, 60%, 80%, and 100%) on the same test set for which performance is reported in Table 2. Figure 4 presents the F 1 scores on the test set for different training set sizes. SVM consistently performed better than the RoBERTa model, although the latter showed greater improvement as more training data were added. This suggests that although the SVM classifier performs better with the data set currently available, it is possible that with more training data, the RoBERTa model may outperform it.
Figure 4. The model performance of support vector machine (SVM) and RoBERTa (a robustly optimized transformer‐based model for language understanding) using 20%, 40%, 60%, 80%, and all of the training data.

SVM outperformed RoBERTa at all sizes. Overall, the performances of both models were improved by increasing the size of training data.
Model Generalizability Analysis
Table 4 presents the results of the generalizability analysis experiments. Despite the difficulty imposed by the experimental setting, the models are able to achieve high F 1 scores on both data sets (0.88 and 0.83).
Table 4.
Classifier Performances for the Model Generalizability Analysis Experiments
| Model | Precision/PPV | Recall/sensitivity | F 1 score | 95% CI |
|---|---|---|---|---|
| Training on AHS and testing on PHS | ||||
| RoBERTa | 0.96 | 0.83 | 0.89 | 0.87–0.91 |
| SVM | 0.99 | 0.79 | 0.88 | 0.86–0.90 |
| Training on PHS and testing on AHS | ||||
| RoBERTa | 0.84 | 0.83 | 0.83 | 0.79–0.87 |
| SVM | 0.74 | 0.95 | 0.83 | 0.79–0.87 |
The metrics are precision, recall, and F 1 score for the positive class. For RoBERTa, the sliding window setting described in the article is used. The 95% CIs were computed via bootstrap resampling. AHS indicates adult health care system; PHS, pediatric health care system; PPV, positive predictive value; RoBERTa, a robustly optimized transformer‐based model for language understanding; and SVM, support vector machine.
DISCUSSION
Our experiments demonstrate that NLP‐based ML is a feasible, effective, and accurate mechanism for detecting Fontan cases based on the text notes of the EHRs. When analyzing the cases that were predicted as negative by the ICD code classifier but positive by the best‐performing SVM classifier, we found that most of these cases were true positives, illustrating that SVM is better at identifying Fontan cases than an ICD code–based classification. The high classification F 1 score of 0.95 suggests this is a reliable method to accurately classify Fontan cases in EHRs based on text notes. The learning curve analysis showed that despite the strong performance, there may be room for further improvement, particularly for transformer‐based models. The generalizability analysis showed that even when applied to a vastly different cohort, the models show high performance.
We chose to compare our NLP model with an ICD code–based classification system as ICD code–based classification is often used for population‐based cohort studies of patients who have undergone the Fontan procedure, 19 , 20 , 21 , 22 without determining the accuracy of these ICD codes. The ICD code–based classification has several limitations leading to both false positives and false negatives and may affect conclusions drawn from ICD‐based studies of Fontan populations. When using a combination of ICD‐9‐CM and ICD‐10‐CM/ICD‐10‐PCS diagnostic and procedural codes to identify Fontan cases, the PPV of ICD codes to detect Fontan cases was 58% in the AHS data set, 83% in the PHS data set, and 74% in the combined data set. ICD diagnostic codes classify cases by native anatomy, which can vary in severity not accounted for by ICD codes. Thus, although some patients may require a Fontan operation, others may not despite having the same anatomic CHD. Although there are ICD procedural codes for the Fontan operation, 19 these are typically only used at the time of the operation, limiting their usefulness for cases when the operation occurred outside of the surveillance period or outside of the data set. If the operation did not occur within the surveillance window and data set, the only code‐based indicators that may be used in follow‐up encounters to document prior Fontan operation are nonspecific diagnosis codes for “personal history of congenital heart surgery” (ie, V13.65 and Z87.74). Researchers may instead decide to identify Fontan patients using only ICD codes for hypoplastic left heart syndrome, tricuspid atresia, double‐inlet left ventricle, and single ventricle, because patients with these defects most likely have had a Fontan operation; however, individuals with other heart defects who may undergo Fontan operation, such as atrioventricular canal defect, unbalanced, or pulmonary atresia with intact ventricular septum, would be missed. Alternatively, including more ICD codes for these other heart defects to identify Fontan cases would result in false positives, because some of these cases may have 2‐ventricle repair in place of Fontan palliation, depending on the severity of their specific heart defect. Understanding longitudinal and late outcomes of Fontan patients with administrative data is limited by the poor PPV of ICD codes to identify the cohort. Although contemporary EHR systems developed in the past decade may allow identification of a cohort using the problem list, provider entries may vary, the Fontan operation may not be entered, and older legacy electronic record systems did not have this same functionality, thus limiting the identification of cases.
Although we did not directly compare NLP with CHD registries, registry studies, such as those performed with the Society for Thoracic Surgeons registry, are an important method for evaluating outcomes of individuals undergoing congenital heart disease surgery. 23 Registry data are typically verified and accurate, but are limited to those who had surgery at a participating institution, and may miss individuals in a health care system who had Fontan operation at a different health care system or had surgery before creation of the registry. NLP is a complementary method of identifying patients with prior Fontan operations who may be decades out from their surgery or have migrated into or out of a different health care system, and thus may be most helpful in looking at late outcomes. In addition, NLP could potentially be used to identify late Fontan‐related complications in patients identified through registries.
Applying NLP‐based ML models on the clinical notes can improve the precision of the system, reduce the risk of mistakenly detecting non‐Fontan patients, and capture Fontan cases missed by an ICD code–based approach. This work is an example of how NLP is more accurate than the ICD code–based approach for identifying individuals with single‐ventricle heart defects who have undergone Fontan palliation, allowing identification of more cases with greater accuracy. Individuals who have undergone Fontan palliation face complications that increase with time following Fontan operations. 24 Limited data are available to understand factors that contribute to these adverse outcomes. The NLP‐driven method that we have developed may improve longitudinal surveillance of individuals who have undergone Fontan palliation in childhood, allowing the incorporation of individuals who may be followed up outside of tertiary referral centers.
Strengths and Limitations
The primary strengths of our study are summarized below:
We are the first study to collect clinical notes, develop annotation guidelines, and create an annotated data set to develop NLP‐based supervised classification models for Fontan case detection.
We developed and evaluated 2 supervised classification models, SVM and RoBERTa, which can more effectively detect Fontan patients based on clinical notes with high F 1 score compared with ICD codes.
We proposed a strategy for improving the modeling of long texts by the RoBERTa classifier. The strategy uses a windowing method followed by majority voting to optimize the performance of the classifier.
We experimented with data from 2 diverse health systems, and our best‐performing model demonstrated relatively low variance across the data sets, suggesting that the NLP model is generalizable across sites.
The applicability of our study is limited by the requirement of availability of text notes in EHRs. Cases without available text notes could not be included in our cohort. Possible reasons for missing text notes include an earlier era of medical record systems, which may have contained scanned notes, or legacy medical records systems that lack access to older notes. However, as almost all health systems are currently electronic, NLP‐based methods for cohort creation will have high utility beyond the scope of this study. Although we are unable to share the data for this study, our code has been made publicly available, and researchers with annotated Fontan data from other health systems may adapt our code for their studies with relative ease.
NLP could be used as an adjunct to detect Fontan cases in a cohort initially identified by CHD ICD codes noted in Table S1. Although the accuracy of the NLP/ML model is close to perfect, it is not correct 100% of the time, so some false positives/false negatives are possible. It is also possible that the performance of the trained NLP model may be lower when applied to data from locations other than the 2 included in this study, although our generalizability analyses demonstrate that the models are fairly robust even when trained at 1 site. This is a relatively common scenario for NLP models when they are trained at 1 site and evaluated at a different site. In this study, the evaluation on data from 2 vastly different health systems illustrates that the automated method is portable, although future research is necessary to address some of the limitations of the state‐of‐the‐art NLP models, such as the length limitation.
CONCLUSIONS
We developed and evaluated 2 NLP‐based ML models, SVM and RoBERTa, which can more effectively detect Fontan patients based on clinical notes with higher accuracy than ICD codes. Our experiments suggested that because the sensitivity of ICD codes is high but PPV is low, it may be beneficial to apply ICD codes as a filter before applying NLP/ML to improve performance. Accurate identification of a Fontan cohort enables the development of large Fontan data sets to understand longitudinal outcomes in this population.
Sources of Funding
This work was supported by the Centers for Disease Control and Prevention Cooperative Agreement, Congenital Heart Defects Surveillance Across Time and Regions grant/award number CDC‐RFA‐DD19‐1902B.
Disclosures
None.
Supporting information
Tables S1–S2
Acknowledgments
Author contributions: Y. Guo: conceptualization, methods, investigation, data curation, writing original draft and review and editing, and analysis; Dr Al‐Garadi: conceptualization, methods, investigation, and data curation; Dr Book: conceptualization, methods, investigation, resources, data curation, writing original draft and review and editing, supervision, and funding acquisition; L. C. Ivey: methods, data curation, editing draft, and supervision; Dr Rodriguez: methods, data curation, editing draft, and supervision; C. L. Raskind‐Hood: conceptualization, methods, and draft editing; C. Robichaux: data curation; Abeed Sarker: conceptualization, methods, investigation, data curation, writing original draft and review and editing, preparation, supervision, and project administration.
Preprint posted on MedRxiv, March 6, 2023. doi: https://doi.org/10.1101/2023.03.01.23286659.
This article was sent to Tiffany M. Powell‐Wiley, MD, MPH, Associate Editor, for review by expert referees, editorial decision, and final disposition.
Supplemental Material is available at https://www.ahajournals.org/doi/suppl/10.1161/JAHA.123.030046
For Sources of Funding and Disclosures, see page 10.
REFERENCES
- 1. Clift P, Celermajer D. Managing adult Fontan patients: where do we stand? Eur Respir Rev. 2016;25:438–450. doi: 10.1183/16000617.0091-2016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Book WM, Gerardin J, Saraf A, Marie Valente A, Rodriguez F. Clinical phenotypes of Fontan failure: implications for management. Congenit Heart Dis. 2016;11:296–308. doi: 10.1111/chd.12368 [DOI] [PubMed] [Google Scholar]
- 3. Marshall KH, D'udekem Y, Winlaw DS, Dalziel K, Woolfenden SR, Zannino D, Costa DSJ, Bishop R, Celermajer DS, Sholler GF, et al. The Australian and New Zealand Fontan Registry Quality of Life Study: protocol for a population‐based assessment of quality of life among people with a Fontan circulation, their parents, and siblings. BMJ Open. 2022;12:e065726. doi: 10.1136/bmjopen-2022-065726 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Sheikhalishahi S, Miotto R, Dudley JT, Lavelli A, Rinaldi F, Osmani V. Natural language processing of clinical notes on chronic diseases: systematic review. JMIR Med Inf. 2019;7:e12239. doi: 10.2196/12239 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Feller DJ, Zucker J, Yin MT, Gordon P, Elhadad N. Using clinical notes and natural language processing for automated HIV risk assessment. J Acquir Immune Defic Syndr. 2018;77:160–166. doi: 10.1097/QAI.0000000000001580 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Khalifa A, Meystre S. Adapting existing natural language processing resources for cardiovascular risk factors identification in clinical notes. J Biomed Inform. 2015;58:S128–S132. doi: 10.1016/j.jbi.2015.08.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Afzal N, Mallipeddi VP, Sohn S, Liu H, Chaudhry R, Scott CG, Kullo IJ, Arruda‐Olson AM. Natural language processing of clinical notes for identification of critical limb ischemia. Int J Med Inform. 2018;111:83–89. doi: 10.1016/j.ijmedinf.2017.12.024 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Sarker A, Klein AZ, Mee J, Harik P, Gonzalez‐Hernandez G. An interpretable natural language processing system for written medical examination assessment. J Biomed Inform. 2019;98:103268. doi: 10.1016/j.jbi.2019.103268 [DOI] [PubMed] [Google Scholar]
- 9. Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG. Research electronic data capture (REDCap)‐a metadata‐driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009;42:377–381. doi: 10.1016/j.jbi.2008.08.010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Harris PA, Taylor R, Minor BL, Elliott V, Fernandez M, O'Neal L, McLeod L, Delacqua G, Delacqua F, Kirby J, et al. The REDCap consortium: building an international community of software platform partners. J Biomed Inform. 2019;95. doi: 10.1016/j.jbi.2019.103208 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Efron B. Another look at the jackknife. Ann Stat. 1979;7:1–26. doi: 10.1214/aos/1176344552 [DOI] [Google Scholar]
- 12. Yeh A. More accurate tests for the statistical significance of result differences. In: Proc COLING 2000: the 18th International Conference on Computational Linguistics. Volume 2. ACL ID: C00‐2137. Saarbrücken, Germany; 2000. Available at: https://aclanthology.org/C00‐2137. Accessed May 02, 2023. [Google Scholar]
- 13. Noreen EW. Computer‐intensive methods for testing hypotheses: an introduction. Am J Psychiatry. 1990;147:1373–1374. doi: 10.1176/ajp.147.10.1373-a [DOI] [Google Scholar]
- 14. Cortes C, Vapnik V. Support‐vector networks. Mach Learn. 1995;20:273–297. doi: 10.1007/BF00994018 [DOI] [Google Scholar]
- 15. Devlin J, Chang M‐WW, Lee K, Google KT, Language AI, Toutanova K. BERT: pre‐training of deep bidirectional transformers for language understanding. NAACL HLT 2019–2019 Conf North Am Chapter Assoc Comput Linguist Hum Lang Technol—Proc Conf . Paper presented at: NAACL‐HLT 2019, Minneapolis, MN 2019;1:4171–4186. Available at: https://aclanthology.org/N19‐1423.pdf. Accessed May 02, 2023.
- 16. Lo K, Beltagy I, Lo K, Cohan A. SciBERT: a pretrained language model for scientific text. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP‐IJCNLP). Paper presented at: 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP‐IJCNLP), Hong Kong, China. Association for Computational Linguistics; 2019:3615–3620. Available at: https://aclanthology.org/D19‐1371.pdf. Accessed May 02, 2023. [Google Scholar]
- 17. Lee J, Yoon W, Kim SS, Kim D, Kim SS, So CH, Kang J. BioBERT: a pre‐trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020;36:1234–1240. doi: 10.1093/bioinformatics/btz682 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, Levy O, Lewis M, Zettlemoyer L, Stoyanov V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv2019. doi: 10.48550/arXiv.1907.11692 [DOI]
- 19. Akintoye E, Miranda WR, Veldtman GR, Connolly HM, Egbe AC. National trends in Fontan operation and in‐hospital outcomes in the USA. Heart. 2019;105:708–714. doi: 10.1136/heartjnl-2018-313680 [DOI] [PubMed] [Google Scholar]
- 20. Duong SQ, Zaniletti I, Lopez L, Sutherland SM, Shin AY, Collins RT. Post‐operative morbidity and mortality after Fontan procedure in patients with heterotaxy and other situs anomalies. Pediatr Cardiol. 2022;43:952–959. doi: 10.1007/s00246-021-02804-w [DOI] [PubMed] [Google Scholar]
- 21. Zafar F, Allen P, Bryant R, Tweddell JS, Najm HK, Anderson BR, Karamlou T. A mapping algorithm for International Classification of Diseases 10th Revision codes for congenital heart surgery benchmark procedures. J Thorac Cardiovasc Surg. 2022;163:2232–2239. doi: 10.1016/j.jtcvs.2021.10.015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Bernardi A, Seckeler M, Moses S, Barber B, Witte M. Higher incidence of protein‐losing enteropathy in patients with single systemic right ventricle. Pediatrics. 2020;146:610. doi: 10.1542/peds.146.1MA7.610a [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Bedzra EKS, Adachi I, Peng DM, Amdani S, Jacobs JP, Koehl D, Cedars A, Morales DL, Maeda K, Naka Y, et al. Systemic ventricular assist device support of the Fontan circulation yields promising outcomes: an analysis of the Society of Thoracic Surgeons Pedimacs and Intermacs databases. J Thorac Cardiovasc Surg. 2022;164:353–364. doi: 10.1016/j.jtcvs.2021.11.054 [DOI] [PubMed] [Google Scholar]
- 24. Wilson TG, Shi WY, Iyengar AJ, Winlaw DS, Cordina RL, Wheaton GR, Bullock A, Gentles TL, Weintraub RG, Justo RN, et al. Twenty‐five year outcomes of the lateral tunnel Fontan procedure. Semin Thorac Cardiovasc Surg. 2017;29:347–353. doi: 10.1053/j.semtcvs.2017.06.002 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Tables S1–S2